
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose Robust Narrowest Significance Pursuit (RNSP), a methodology for detecting localized regions in data sequences which each must contain a change-point in the median, at a prescribed global significance level. RNSP works by fitting the postulated constant model over many regions of the data using a new sign-multiresolution sup-norm-type loss, and greedily identifying the shortest intervals on which the constancy is significantly violated. By working with the signs of the data around fitted model candidates, RNSP fulfils its coverage promises under minimal assumptions, requiring only sign-symmetry and serial independence of the signs of the true residuals. In particular, it permits their heterogeneity and arbitrarily heavy tails. The intervals of significance returned by RNSP have a finite-sample character, are unconditional in nature and do not rely on any assumptions on the true signal. Code implementing RNSP is available at https://github.com/pfryz/nsp.
1 Introduction
The problem of uncertainty quantification for possibly multiple parameter changes in time- or space-ordered data is motivated by the practical question of whether any suspected changes reflect real structural changes in the underlying stochastic model, or are due to random fluctuations. Approaches to this problem include confidence sets associated with simultaneous multiscale change-point estimation (Frick, Munk, and Sieling Citation2014; Pein, Sieling, and Munk Citation2017; Vanegas, Behr, and Munk Citation2022), post-selection inference (Hyun, G’Sell, and Tibshirani Citation2018; Duy et al. Citation2020; Hyun et al. Citation2021; Jewell, Fearnhead, and Witten Citation2022), inference without selection and post-inference selection via Narrowest Significance Pursuit (Fryzlewicz Citation2024), asymptotic confidence intervals conditional on the estimated change-point locations (Bai and Perron Citation1998; Eichinger and Kirch Citation2018; Cho and Kirch Citation2022), False Discovery Rate (Hao, Niu, and Zhang Citation2013; Li and Munk Citation2016; Cheng, He, and Schwartzman Citation2020), and Bayesian inference (Lavielle and Lebarbier Citation2001; Fearnhead Citation2006). These approaches go beyond mere change-point detection and offer statistical significance statements regarding the existence and locations of change-points in the statistical model underlying the data.
In this article, we are concerned with the following problem: given a sequence of noisy observations, automatically determine localized regions of the data which each must contain a change-point in the median, at a prescribed global significance level α. The methodology we introduce, referred to as Robust Narrowest Significance Pursuit (RNSP), achieves this for the piecewise-constant median model, capturing changes in the level of the median. By its algorithmic construction, RNSP offers exact finite-sample coverage guarantees with practically no distributional assumptions on the data, other than serial independence of the signs of the true residuals and their sign-symmetry, a weak requirement which is immaterial for continuous distributions (as all, even non-symmetric, continuous distributions are sign-symmetric). In contrast to the existing literature, RNSP requires no knowledge of the distribution on the part of the user, and permits arbitrarily heavy tails, heterogeneity over time and/or lack of symmetry. In addition, RNSP is able to handle distributions that are continuous, continuous with mass points, or discrete, where these properties may also vary over the signal. The execution of RNSP does not rely on having an estimate of the number or locations of change-points. Critical values needed by RNSP do not depend on the noise distribution, and can be accurately approximated analytically. RNSP explicitly targets the shortest possible intervals of significance. It is worth noting, however, that our large-sample consistency result for RNSP, shown in Section 4, relies on stronger assumptions than its finite-sample coverage properties, discussed in Sections 2 and 3. We now situate RNSP in the context of the existing literature.
Heterogeneous Simultaneous Multiscale Change Point Estimator, abbreviated as H-SMUCE (Pein, Sieling, and Munk Citation2017), an extension of SMUCE (Frick, Munk, and Sieling Citation2014), is a change-point detector in the heterogeneous Gaussian piecewise-constant model , where fi
is a piecewise-constant signal,
are iid N(0, 1) variables, and σi
can only change when fi
does. In Section A.1 of their work, the authors provide an algorithmic construction of confidence intervals for the locations of the change-points in fi
, which involves screening the data for short intervals over which a constant signal fit is unsuitable and they must therefore contain change-points. Crucially, this algorithmic construction relies on the knowledge of scale-dependent critical values (for measuring the unsuitability of a locally constant fit), which are not available analytically but only by simulation, and therefore the method does not extend automatically to unknown noise distributions (as the analyst needs to know what distribution to sample from). In Section 5, we show that H-SMUCE suffers from inflated Type I error rates in the sense that the thus-constructed confidence intervals, in the examples of Gaussian models shown, do not all contain at least one true change-point each in more than
of the cases, contrary to what this algorithmic construction sets out to do. H-SMUCE is also prone to failing if the model is mis-specified, for example if the distribution of the data has a mass point (which is unsurprising in view of its assumption of Gaussianity).
Multiscale Quantile Segmentation (Vanegas, Behr, and Munk Citation2022, MQS), another extension of SMUCE, is a procedure for detecting possibly multiple changes in a given piecewise-constant quantile of the input data sequence, which includes the median as a special case. MQS estimates the number of change-points in the quantile function as the minimum among those candidate fits for which the empirical residuals pass a certain multiscale test at level α, where the empirical residuals are defined as binary exceedance sequences of the data over the level defined by each candidate fit. Working with such binary exceedance sequences means that MQS makes no distributional assumptions on the data other than their serial independence. Like SMUCE and H-SMUCE, MQS then defines a confidence set around the estimated signals as a set of all feasible (in the same sense) signal fits at level α. This then enables the conceptual and algorithmic construction of asymptotic simultaneous confidence intervals for the change-point locations, which are guaranteed to (each) contain a change-point with probability . Chen, Shah, and Samworth (Citation2014) provide a critique of SMUCE from the inferential point of view, which also applies to H-SMUCE and MQS. In Section 5, we illustrate the advantages and disadvantages of MQS, as implemented in the R package mqs. In contrast to MQS, the coverage guarantees offered by RNSP are wholly based on exact inequalities and therefore hold for any sample size, which is reflected in its performance shown in Section 5.
The (non-robust) Narrowest Significance Pursuit (NSP; Fryzlewicz, Citation2024) is able to handle heterogeneous data in a variety of models, including the piecewise-constant signal plus independent noise model. However, NSP requires that the noise, if heterogeneous, is within the domain of attraction of the normal distribution and is symmetric, neither of which is assumed in RNSP. The self-normalized statistic used in NSP includes a term resembling an estimate of the local variance of the noise which, however, is only unbiased under the null hypothesis of no change-point being present locally. The fact that the same term over-estimates the variance under the alternative hypothesis, reduces the power of the detection statistic, which leads to typically long intervals of significance. We illustrate this issue in Section 5 and show that RNSP offers a significant improvement.
Bai and Perron (Citation1998, 2003), working with least-squares estimation of multiple change-points in regression models under possible heterogeneity of the errors, describe a procedure for computing confidence intervals conditional on detection, with asymptotic validity guarantees. Crucially, it does not take into the account the uncertainty associated with detection, which can be considerable especially for the more difficult problems (e.g., see the “US ex-post real interest rate” case study in Bai and Perron (2003), where there is genuine uncertainty between models with 2 and 3 change-points; we revisit this example in Section 6.1). By contrast, RNSP produces intervals of significant change in the median that are not conditional on detection and have a finite-sample nature.
The article is organized as follows. Section 2 motivates RNSP and sets out its general algorithmic framework. Section 3 describes how RNSP measures the local deviation from model constancy and gives finite-sample theoretical performance guarantees for RNSP. Section 4 quantifies the large-sample behavior of RNSP. Section 5 contains numerical examples and comparisons. Section 6 includes examples showing the practical usefulness of RNSP. Section 7 concludes with a brief discussion. Software implementing RNSP is available at https://github.com/pfryz/nsp.
2 Motivation and Review of RNSP Algorithmic Setting
2.1 RNSP: Context and Modus Operandi
RNSP discovers regions in the data in which the median departs from constancy, at a certain global significance level. This is in contrast to NSP (Fryzlewicz Citation2024), which targets the mean. RNSP does not make moment assumptions about the data, and therefore the median is a natural measure of data centrality. We now review the components of the algorithmic framework that are shared between NSP and RNSP, with the generic measurement of local deviation from the constant model as one of its building blocks. In Section 3, we introduce the particular way in which local deviation from the constant model is measured in RNSP, which is appropriate for the median and hence fundamentally different from NSP.
RNSP operates in the signal plus noise model
(1)
(1)
in which the signal
and the variables
satisfy the assumptions below. Define
, where
is the indicator function.
Assumption 2.1.
In (1), ft
is a piecewise-constant vector with an unknown number N and locations of change-points. (The location ηj
is a change-point if
.)
Assumption 2.2.
, where M is the median operator. (If the median is nonunique, we require
The variables
The variables
While Assumption 2.1 holds throughout the article, Assumption 2.2 is not formally needed until Section 3.2. Section 4 provides additional results under extra assumptions.
do not have to be identically distributed, and can have arbitrary mass atoms, or none, as long as their distributions satisfy Assumption 2.2. The distribution(s) of
can be unknown to the analyst, and we do not impose moment assumptions. Any zero-median continuous distribution (even one with an asymmetric density function) is sign-symmetric. The requirement of the independence of
is weaker than that of the independence of
itself: for example if Zt
is a (G)ARCH process driven by symmetric, independent innovations, then
is serially independent, while Zt
is not. While the results of Section 3 require the independence of
, those in Section 4 require the independence of Zt
; see Section 4 for details.
RNSP achieves the high level of generality in terms of the permitted distributions of Zt
thanks to its use of the sign transformation. The use of 0 in is critical for RNSP’s objective to provide exact finite-sample coverage guarantees also for discrete distributions and continuous distributions with mass points, an aspect we discuss in Section 3.1.1. The sign function is a critical building block of various procedures for nonparametric change-point testing and estimation; key references include Bhattacharyya and Johnson (Citation1968), Carlstein (Citation1988), and Dümbgen (Citation1991).
2.2 (R)NSP: Generic Algorithm
The generic algorithmic framework underlying both RNSP and the non-robust NSP in Fryzlewicz (Citation2024) is the same and is based on recursively searching for the shortest sub-samples in the data with globally significant deviations from the baseline model. In this section, we introduce this shared generic framework. In the following sections, we show how RNSP diverges from NSP through its use of a robust measure of deviation from the baseline model, suitable for the broad class of distributions specified in Assumption 2.2.
We start with a pseudocode definition of the RNSP algorithm, in the form of a recursively defined function RNSP. In its arguments, is the current interval under consideration and at the start of the procedure, we have
; Y (of length T) is as in the model formula (1); M is the minimum guaranteed number of sub-intervals of
drawn (unless the number of all sub-intervals of
is less than M, in which case drawing M sub-intervals would mean repetition);
is the threshold corresponding to the global significance level α (typical values for α would be 0.05 or 0.1) and τL
(respectively τR
) is a functional parameter used to specify the maximum extent of overlap of the left (respectively right) sub-interval of
searched next after having identified a region of significance within
, if any. The no-overlap case would correspond to
. In each recursive call on a generic interval
, RNSP adds to the set
any globally significant local regions (intervals) of the data identified within
on which Y is deemed to depart significantly (at global level α) from the baseline constant model. We provide more details underneath the pseudocode below. In the remainder of the article, the subscript
relates to a constant indexed by the interval
whose value will be clear from the context.
function RNSP(s, e, Y, M,
if
STOP
end if
if
draw all intervals
else
draw a representative (see description below) sample of intervals
end if
for
end for
if
STOP
end if
add
RNSP
RNSP
end function
The RNSP algorithm is launched by the pair of calls: ; RNSP
. On completion, the output of RNSP is in the set
; when the context requires it, we write the output as
. We now comment on the RNSP function line by line. In lines 2–4, execution is terminated for intervals that are too short. In lines 5–10, a check is performed to see if M is at least as large as the number of all sub-intervals of
. If so, then M is adjusted accordingly, and all sub-intervals are stored in
. Otherwise, a sample of M sub-intervals
is drawn in which sm
and em
are all possible pairs from an (approximately) equispaced grid on
which permits at least M such sub-intervals. The ability to adjust the M parameter offers the users a choice between a faster but less thorough procedure (for lower values of M) and a slower but more accurate one (for higher values of M). The reason for not necessarily using the maximum possible number of intervals is that this may increase the computation time beyond what is acceptable to the user. All examples in the article use M = 1000.
In lines 11–13, each sub-interval is checked to see to what extent the response on this sub-interval (denoted by
) deviates from the baseline constant model. This core step of the RNSP algorithm will be described in more detail in Section 3.
In line 14, the measures of deviation obtained in line 12 are tested against threshold , chosen to guarantee the global significance level α. How to choose
is independent of the distribution of Zt
if it is continuous, and there is also a simple distribution-independent choice of
for discrete distributions and continuous distributions with probability masses; see Section 3.2. The shortest sub-interval(s)
for which the test rejects the baseline model at global level α are collected in set
. In lines 15–17, if
is empty, then the procedure decides that it has not found regions of significant deviations from the constant model on
, and stops on this interval as a consequence. Otherwise, in line 18, the procedure continues by choosing the sub-interval, from among the shortest significant ones, on which the deviation from the baseline constant model has been the largest. The chosen interval is denoted by
.
In line 19, is searched for the shortest sub-interval on which the hypothesis of the baseline model is rejected locally at a global level α. Such a sub-interval certainly exists, as
itself has this property. The structure of this search again follows the workflow of the RNSP procedure; it proceeds by executing lines 2–18 of RNSP, but with
in place of s, e. The chosen interval is denoted by
. This second-stage search is important to RNSP’s pursuit to produce short intervals: indeed, if the sample of intervals
contained insufficiently short intervals (perhaps because an insufficiently large M was chosen), then, without the second-stage search in line 19, the intervals of significance returned by RNSP might be overly long. The second-stage search in line 19 can be seen as a guard against a small M, or in other words against an insufficiently fine original grid of interval endpoints. In line 20, the selected interval
is added to the output set
.
Because of the second-stage search in line 19, pre-drawing the intervals prior to launching the RNSP procedure (rather than drawing them recursively on each current interval as it done in the algorithm) is not an option for RNSP. Indeed, in the presence of the second-stage search, the selected interval of significance
may be misaligned with the initial grid of intervals drawn, in which case the grid of intervals to the left and to the right of
must be redrawn to avoid leaving un-examined gaps in the data.
In lines 21–22, RNSP is executed recursively to the left and to the right of the detected interval . However, we optionally allow for some overlap with
. The overlap, if present, is a function of
and, if it involves detection of the location of a change-point within
, then it is also a function of Y. An example of the relevance of this is given in Section 6.1.
3 Robust NSP: Measuring Deviation from the Constant Model
3.1 Deviation Measure: Motivation, Definition, and Properties
The main structure of the DeviationFromConstantModel
operation is as follows: (a) Fit the best, in the sense described precisely later, constant model to
. (b) Examine the signs of the empirical residuals from this fit. If their distribution is deemed to contain a change-point (which indicates that the constant model fit is unsatisfactory on
and therefore the model contains a change-point on that interval), the value returned by DeviationFromConstantModel
should be large; otherwise small.
A key ingredient of our measure of deviation is a multiresolution sup-norm introduced below, used on the signs of the input rather than in the original data domain. Its basic building block is a scaled partial sum statistic, defined for an arbitrary input sequence by
. We define the multiresolution sup-norm (Nemirovski Citation1986; Li Citation2016) of an input vector x (of length T) with respect to the interval set
as
. The set
used in RNSP contains intervals at a range of scales and locations. A canonical example of a suitable interval set
is the set
of all subintervals of
. We will use
in defining the largest acceptable global probability of spurious detection. However, for computational reasons, DeviationFromConstantModel will use a smaller interval set (we give the details later). This will not affect the exactness of our coverage guarantees, because, naturally, if
, then
. We also define the restriction of
to an arbitrary interval
as
. Note the trivial inequality
(2)
(2)
for any
. When the above multiresolution sup-norm is applied to the signs of the input, as is done in this work, rather than the original input, we refer to it as the sign-multiresolution sup-norm. When applied to the empirical residuals from a candidate constant fit on an interval, it can be viewed as a simple robust multiscale measure of data fidelity of the given candidate fit on all time scales up to the length of the interval.
We now define the deviation measure DeviationFromConstantModel
, which satisfies the property that if there is no change-point on the interval
, then it is guaranteed that
(3)
(3)
The discussion below assumes that there is no change-point in . For the true constant signal
, denote
. There are only at most
different possible constants
leading to different sequences
. To see this, sort the values of
in nondecreasing order to create
. Take candidate constants
, defined as follows.
(4)
(4)
We have the following simple result; the proof is trivial and we omit it.
Proposition 3.1.
Under Assumption 2.1, assume no change-point in and denote
. Let the constants
be defined as in (4). There exists a
such that
(5)
(5)
We now define our measure of deviation , and prove its key property as a corollary to Proposition 3.1.
Definition 3.1.
Let the constants be defined as in (4). We define
(6)
(6)
tries all possible baseline constant model fits on
and chooses the one that minimizes the sign-multiresolution norm of the residuals, to ensure that the finite-sample coverage guarantees hold, as we will see below.
Corollary 3.1.
Under Assumption 2.1, for any interval on which there is no change-point, we have
(7)
(7)
In other words, the deviation measure defined in (6) satisfies the desired property (3).
Proof.
Let the index j0 be as in the statement of Proposition 3.1. We have
□
This leads to the following guarantee for the RNSP algorithm.
Theorem 3.1.
Let Assumption 2.1 hold, and let be the set of intervals returned by the RNSP algorithm. We have
.
Proof.
On the set , each interval Si
must contain a change-point as if it did not, then by Corollary 3.1 and inequality (2), we would have to have
(8)
(8)
However, the fact that Si
was returned by RNSP means, by line 14 of the RNSP algorithm, that , which contradicts (8). This completes the proof. □
Theorem 3.1 should be read as follows. Let . For a set of intervals returned by RNSP, we are guaranteed, with probability of at least
, that there is at least one change-point in each of these intervals. Therefore,
can be interpreted as an automatically chosen set of regions (intervals) of significance in the data. In the no-change-point case (N = 0), the probability of obtaining one of more intervals of significance (
) is bounded from above by
. Theorem 3.1 is of a finite-sample character and holds exactly and for any sample size. Moreover, it is independent of the form of the innovations Z. Assumptions on Z will only be needed in controlling the term
; we defer this to Section 3.2.
We emphasize that Theorem 3.1 does not promise to detect all the change-points, or to do so asymptotically as the sample size gets larger: this would be impossible without assumptions on the strength of the change-points (involving spacing between neighboring change-points and the sizes of the jumps). This aspect of RNSP is investigated in Section 4. Instead, Theorem 3.1 promises that every interval of significance returned by RNSP must contain at least one change-point each, with a certain global probability adjustable by the user. Therefore, one particular implication of Theorem 3.1 is that we must have
(9)
(9)
The intervals of significance returned by RNSP have an “unconditional confidence interval” interpretation: they are not conditional on any prior detection event, but indicate regions in the data each of which must unconditionally contain at least one change in the underlying signal ft
, with a global probability of at least . Therefore, as in NSP (Fryzlewicz Citation2024), RNSP can be viewed as performing “inference without selection” (where “inference” refers to producing the RNSP intervals of significance and “selection” to the estimation of change-point locations, absent from RNSP). This viewpoint also enables “post-inference selection” or “in-inference selection” if the exact change-point locations (if any) are to be estimated within the RNSP intervals of significance after or during the execution of RNSP.
3.1.1 Deviation Measure: Discussion
Achieving computational savings without affecting coverage guarantees
The operation of trying each constant in (6) is fast, but in order to accelerate it further, we introduce the two computational savings below, which do not increase
and therefore respect the inequality (7) and hence also our coverage guarantees in Theorem 3.1.
Reducing the set . To accelerate the computation of (6), we replace the set
in
with the set
(with l and r standing for left and right, respectively), where
and
. This reduces the cardinality of the set of intervals included in
from
to
. As
and hence
, the results of Corollary 3.1 and Theorem 3.1 remain unchanged for the thus-reduced
. On the other hand,
has been defined in this particular way so as not to compromise the detection power in the piecewise-constant signal model. To see this, consider the following illustrative example. Suppose Y t
= ft
(noiseless case) and ft
= 0 for
and ft
= 1 for
. On
, the baseline constant signal level fitted is
and we have
for
;
for
. In this setting, the two multiresolution sup-norms:
and
are identical, equal to
and achieve this value for the intervals
and
, members of both
and
. This simple example illustrates the wider phenomenon that if there is a single change-point in ft
on a generic interval
under consideration, then in the noiseless case the multiresolution norm over the set
is maximized at one of the “left” or “right” intervals in
, and we are happy to sacrifice potential negligible differences in the noisy case in exchange for the substantial computational savings.
Limiting interval lengths. In practice, the analyst may not be interested in excessively long RNSP intervals of significance and may therefore wish to ignore intervals for which for a user-specified maximum length L.
Validity for non-continuously distributed data
The following three aspects of RNSP ensure the validity of its coverage guarantees in the presence of mass points in Zt
or if the distribution of Zt
is discrete: (a) the fact that the sign function defined in Section 2.1 returns zero if its argument is zero, (b) the fact that the test levels (definition (4)) are placed at data points, and (c) the fact that these test levels are placed in between the sorted data points. Indeed, in the absence of (a), (b), or (c), it is easy to construct simple discrete distributions of Zt
for which
would be spuriously large in the absence of change-points on
.
3.2 Evaluation and Bounds for
To make Theorem 3.1 operational, we need to obtain an understanding of the distribution of so we are able to choose
such that
(or approximately so) for a desired global significance level α.
Initially we consider Zt
such that (the general case
is covered in the next paragraph). One simple way of determining the distribution of
for any finite T is by simulation; this would only need to be done once for every T and the quantiles stored for fast access. Another approach is asymptotic and proceeds as follows. From Theorem 1.1 in Kabluchko and Wang (Citation2014) (which applies to sequences of serially independent symmetric Bernoulli variables as explained in Section 1.5.1 of that work; our Assumption 2.2 means that result is applicable in our context), we have
(10)
(10)
where
and Λ is a constant. As the theoretical calculation of Λ in Kabluchko and Wang (Citation2014) contains an error, we use simulation over a range of values of T and τ to determine a suitable value of Λ as 0.274. The practical choice of the significance threshold
then proceed as follows: (a) fix α to the desired level, for example 0.05 or 0.1; (b) obtain the value of τ by equating
; (c) obtain
. While this approach is asymptotic in nature (note the limit as
in (10)), we observe that the finite-sample agreement of
with its limit in (10) is excellent even for small sample sizes. If the user chooses to pursue this route of obtaining
, this will be the only asymptotic component of RNSP.
Suppose now that ; note that the sign-symmetry Assumption 2.2(b) implies
. Construct the variable
. As
, the limiting statement (10) applies to
. However, we have the double inequality
(11)
(11)
with
, where
. The first inequality in (11) holds because every constituent partial sum of
has a corresponding larger or equal in magnitude partial sum in
constructed by removing the zeros from its numerator and decreasing (or not increasing) its denominator as it contains fewer (or the same number of) terms. As an illustrative example, suppose the sequence of
starts
. The absolute partial sum
, a constituent of
, is majorized by the absolute partial sum
, a constituent of
, where the latter sum has been constructed by removing the 0 from
and adjusting for the number of terms (now 3 instead of 4). The second inequality in (11) holds simply because
. The implication of (11) is that
for
is majorized by
for
, the case handled by (10). Therefore, the threshold
obtained as a consequence of (10) can also meaningfully be applied in the general case
.
4 Detection Consistency and Lengths of RNSP Intervals
This section shows the large-sample consistency of RNSP in detecting change-points, and the rates at which the lengths of the RNSP intervals contract (relative to T), as T increases. To simplify our technical arguments, we consider a version of the RNSP algorithm that considers all subintervals of . Our focus on iid Zt
’s in this section is mainly due to our ability to rely on the Dvoretzky-Kiefer-Wolfowitz inequality in the proof of Corollary 4.1; however, note that the finite-sample result of Theorem 4.1 holds regardless of the dependence structure of Zt
. We focus on continuously-distributed Zt
’s as this results in notationally much less involved arguments regarding the minimum signal strength required. We first introduce some essential notation, and then state our assumption and the result. For each change-point ηj
, define
(12)
(12)
(13)
(13)
In addition, for any process Vt
, define .
Assumption 4.1.
The variables
The variables
The distribution of Z1 is continuous.
With the notation
Our first result below is of a finite-sample nature.
Theorem 4.1.
Let Assumptions 2.1, 2.2(a) and 4.1(b),(c),(d) hold. On the set defined by the intersection of the events and
, a version of the RNSP algorithm that considers all intervals, executed with no overlaps and with threshold
, returns exactly N intervals of significance
such that
and
for
.
Theorem 4.1 leads to the following corollary giving a large-sample consistency result.
Corollary 4.
1. Let the assumptions of Theorem 4.1 and Assumption 4.1(a) hold. Let and
, for any
. Let
denote the set of intervals of significance
returned by RNSP algorithm that considers all intervals, executed with no overlaps and with threshold
. We have
as
.
This and Corollary 4.2 below are the only large-sample results of the article; the others are of a finite-sample character. Setting and
, for any
, causes the probabilities of the events
and
in Theorem 4.1 (respectively) to converge to one. Note that here,
does not depend on α and is of a higher order of magnitude than the (α-dependent)
of Section 3.2. Paraphrasing, this is to say that we need the global significance level α to tend to zero with T in order to obtain large-sample consistency; a result in line with analogous results in Pein, Sieling, and Munk (Citation2017) and Vanegas, Behr, and Munk (Citation2022).
We briefly comment on what the result of Corollary 4.1 means for the minimum signal strength Assumption 4.1(iii), and for the localization rates of the RNSP algorithm in detecting the change-points. If the distribution of Zt
does not vary with T (this section already assumes that it does not vary with t), and if the jump sizes are bounded from below by a positive constant independent of j and T, then Δj
(formula (12)) is also bounded from below by a positive constant independent of j and T. By formula (13), the assumptions on
in Corollary 4.1 then imply
(where Θ should be read “of the exact order”). Assumption 4.1(iii) then requires that the spacings between the change-points be at least of order
. Corollary 4.1 states that the length of each RNSP interval of significance,
, is, with global probability approaching 1, at most of order
. These minimum-spacing assumptions and the implied lengths of the localization intervals are near-optimal and the same as those in the non-robust literature, see for example Theorem 1 in Baranowski, Chen, and Fryzlewicz (Citation2019) and Corollary 4 in Fryzlewicz (Citation2024), as well as the associated discussions. However, the results of this section also permit
with T, which will, naturally, affect the above minimum-spacing requirements and localization rates as stipulated by formulas (12) and (13) and Assumption 4.1(iii).
The consistency of RNSP in the sense of Corollary 4.1 implies the consistency of any pointwise estimators contained within the RNSP intervals of significance
, with the localization rate of
bounded from above by the length of the interval
. In particular, the near-optimality of the lengths of the RNSP intervals
(as discussed in the preceding paragraph) automatically implies the near-optimality of the localization rate of
. Indeed, since by Corollary 4.1,
is guaranteed to contain ηj
(on an event of high probability), for any estimator
, we must have
(on the same event). In other words, the rate with which
contract (relative to T) is inherited by any estimator
; this applies even to naive estimators constructed for example as the middle points of their corresponding RNSP intervals
, that is
. More refined estimators, for example one based on the CUSUM maximization of the signs of the data around their median (Sen and Srivastava Citation1975) within each RNSP interval, can also be used and will also automatically inherit the consistency and rate. Sections 5 and 6 illustrate both of these estimators. Trivially, in light of Corollary 4.1, the set of estimated change-points
is consistent in the Hausdorff measure for
, the set of true change-points in ft
.
Yet another implication of Theorem 4.1 appears below.
Corollary 4.2.
Let the assumptions of Corollary 4.1 hold. Let be such that
and let
, for any
. Let
denote the set of intervals of significance
returned by RNSP algorithm that considers all intervals, executed with no overlaps and with threshold
. We then have
The computation of the deviation measure for all subintervals
of
, as the results of this section require, is a
operation. The cubic complexity should not surprise in the context of a robust method that considers all intervals, as there are
intervals to consider and O(T) binary exceedance levels within each interval. In practice, we use three devices to reduce the computational complexity of RNSP: (a) using a fixed (i.e., unchanging with T) value of M, (b) restricting the length of intervals under consideration to
, and (c) reducing the set
. Items (b) and (c) are described in more detail in Section 3.1.1.
5 Numerical Illustrations
In this section, we demonstrate numerically that the guarantee offered by Theorem 3.1 holds for RNSP in practice over a variety of homogeneous and heterogeneous models for which the variables Zt
satisfy Assumption 2.2. We also investigate the circumstances under which similar guarantees are not offered by H-SMUCE (Pein, Sieling, and Munk Citation2017), MQS (Vanegas, Behr, and Munk Citation2022) or the self-normalized version of NSP (SN-NSP), suitable for heterogeneous data (Fryzlewicz Citation2024). In this section, we use the acronyms RNSP and SN-NSP to denote the versions of these respective procedures with no interval overlaps, that is . Later in this section, we introduce notation for versions with overlaps. Both RNSP and SN-NSP use M = 1000 intervals, the default setting. For H-SMUCE, the function call we use is stepR::stepFit(x, alpha = 0.1, family="hsmuce", confband = TRUE). The type parameter in MQS specifies the loss function for their final estimate with multiscale constraints; we denote by MQS-R the result of mqs::mqse(x, alpha = 0.1, conf = TRUE, type="runs") and by MQS-K the result of mqs::mqse(x, alpha = 0.1, conf = TRUE, type="koenker"). We use the following package versions: mqs v1.0, stepR v2.1-8, nsp v1.0.0.
We begin with null models, by which we mean models (1) for which ft
is constant throughout, that is N = 0. For null models, Theorem 3.1 promises that RNSP at level α returns no intervals of significance with probability at least . In this section, we use
. There are analogous parameters in H-SMUCE, MQS and SN-NSP, and they are also set to 0.1. However, while in both RNSP and SN-NSP, the parameter α is responsible for finite-sample coverage guarantees (for both null and non-null models), in MQS and H-SMUCE it is responsible for similar but only asymptotic coverage guarantees, as
. For H-SMUCE, this latter point is clarified (jointly) in Theorem 5 of Pein, Sieling, and Munk (Citation2017) and in Section A.1 of the online supplement to that work, and for MQS–in Theorem 2.3 of Vanegas, Behr, and Munk (Citation2022) and in Section S.4 of the online supplement to that work.
The null models used are listed in , and shows the associated results. RNSP, MQS-R and MQS-K keep the nominal size well across all the models considered, returning no intervals of significance at least 95% of the time in all situations. H-SMUCE behaves correctly for the three Gaussian models, but fails for the discrete distributions and model Mix 1, which contains mass points. It is unexpectedly successful in the Plain Cauchy model, but this is perhaps because it has very limited detection power in the Cauchy model with change-points (more on this model below). It also underperforms slightly for model Mix 2, which is continuous (and within the domain of attraction of the Gaussian distribution) but multimodal. SN-NSP fails for the discrete distributions, which is a consequence of the (asymptotically guaranteed) closeness of the self-normalized deviation measure to the appropriate functional of the Wiener process not kicking in in these instances (due to the relatively small sample sizes).
Table 1 Null models for the comparative simulation study in Section 5.
Table 2 Percentage of times, out of 200 simulated sample paths of each null model, that the respective method indicates no intervals of significance at level (nominal coverage = 90%).
We now discuss performance for signals with change-points (N > 0). defines our models; the model labeled MQS.easy is taken from https://github.com/ljvanegas/mqs/blob/master/mqs.ipynb and MQS.hard and MQS.vhard are its lower signal-to-noise versions. Theorem 3.1 promises that any intervals of significance returned by RNSP at levels α are such that, with probability at least , they each contain at least one true change-point. In addition to RNSP, H-SMUCE, MQS-R, MQS-K, and SN-NSP, we also test versions of RNSP and SN-NSP with the following overlap functions:
(14)
(14)
Table 3 Non-null models for the comparative simulation study in Section 5.
This setting means that upon detecting a generic interval of significance within
, the RNSP and SN-NSP algorithms continue on the left interval
and the right interval
(recall that the no-overlap case results uses the left interval
and the right interval
). We denote the versions of the two procedures with the overlaps as above by RNSP-O and SN-NSP-O, respectively. As before, we set
for all methods tested.
For each model and method tested, we evaluate the following metrics, which collectively promote the detection of genuine, and the non-detection of spurious, intervals of significance: [coverage] the empirical coverage (i.e., whether at least of the simulated sample paths are such that any intervals of significance returned contain at least one true change-point each); [prop. gen. int.] if any intervals are returned, the proportion of those that are genuine (i.e., the proportion of those intervals returned that contain at least one true change-point); [no. gen. int.] the number of genuine intervals (i.e., the number of those intervals returned that contain at least one true change-point); and [av. gen. int. len.] the average length of genuine intervals (i.e., the average length of those intervals returned that contain at least one true change-point). No single measure describes the performance of (any) method accurately, but the four measures in conjunction provide a clear picture. As a cartoon illustration of how naive solutions are able to skew some of these measures but not the others, consider a putative interval estimator that always returns the longest possible interval of
. For a model with
change-points, “coverage” and “prop. gen. int” will return 100 and 1, respectively. However, this naive solution will be penalized by the next two measures, “no. gen. int.” and “av. gen. int. len.”. For models with a single change-point, the
solution will return an interval that in most cases will be unreasonably long, and this will be picked up by the “av. gen. int. len.” measure. In addition, for models with more than one change-point, “no. gen. int.” (equal to one) will be inaccurate.
For completeness, we also show the Mean-Square Errors (MSEs) between the reconstructed signal and the truth ft
. Given an increasingly sorted set
of pointwise change-point estimators (for any method), and defining in addition
, a natural estimate of the signal ft
is a piecewise-constant vector
such that
for
, where med is the empirical median operator. HSMUCE comes with its own pointwise change-point estimates. MQS, NSP or RNSP do not automatically provide pointwise location estimates. For these three methods, we use two different approaches to producing pointwise change-point location estimates within each interval of significance: (a) we take the mid-points of the respective intervals of significance and (b) we take the argument-maximum of the absolute value of the CUSUM statistic of the signs of the data around the empirical median within each interval of significance. (Midpoints of RNSP intervals of significance, while seemingly appearing ad hoc as pointwise estimates of change-point location, often behave well empirically, which may be due to the fact that RNSP pursues short intervals, and those tend to be symmetric around the true change-points as this offers the same amount of evidence on either side of the change-points—hence the frequent empirical closeness of RNSP interval midpoints to the truth.)
shows the results. H-SMUCE does not perform well in any scenario, not even in the Blocks model, an instance of the homogeneous Gaussian model, a simple sub-class of the heterogeneous Gaussian model class for which it was specifically designed (where it achieves the coverage of 30, well short of the expected 90). Its coverage of 100 in the Cauchy model is an artifact of the fact that it does not achieve almost any detections over the 100 simulated sample paths (so there are also no spurious detections).
Table 4 Results for each model + method combination, out of 200 simulated sample paths: “coverage” is the percentage of times that the respective model + method combination did not return a spurious interval of significance; “prop. gen. int.” is the average proportion of genuine intervals out of all intervals returned, if any (if none are returned, the corresponding 0/0 ratio is ignored in the average); “no. gen. int.” is the average number of genuine intervals returned; “av. gen. int. len.” is the average length of a genuine interval returned in the respective model + method combination; “MSE ()” is the MSE of
constructed as described in the text, with the respective pointwise change-point estimation in brackets.
With the exception of MQS.easy, the least challenging model, MQS frequently produces spurious intervals in signals with change-points: the coverage figures for MQS are well short of 90% in all but one models tested. On the upside, in MQS.easy (the only set-up in which MQS achieves the correct coverage), the average length of genuine intervals is around 20% below that of RNSP.
RNSP and RNSP-O significantly outperform SN-NSP and SN-NSP-O in five out of the seven scenarios tested, the only exception being Bursts and MQS.vhard. In Blocks and Cauchy, the RNSP methods achieve more detections and shorter intervals of significance (so better localization). In Poisson, in addition, they achieve much better coverage (the SN-NSP methods are misled by the discrete nature of this relatively low-intensity Poisson dataset, for which their required asymptotics do not kick in, which results in a very large number of spurious detections). However, the SN-NSP methods work better for the Bursts data in the sense that they lead to more detections. The underlying reason is that the signal level in this model is linearly proportional to the standard deviation of the noise, which particularly suits the self-normalized SN-NSP methods. The RNSP methods are the clear winners for the MQS.easy and MQS.hard models. No method performs particularly well for the MQS.vhard model, but the SN-NSP methods achieve more detections than RNSP there, although at the price of the intervals being much longer.
With regards to the MSE (midpoint) and MSE (CUSUM) measures, the clear overall winner is the RNSP-O method with sign-CUSUM localization; however, all four versions of the RNSP approach offer competitive performance.
6 Data Examples
6.1 The U.S. Real Interest Rates
We first reanalyze the time series of U.S. ex-post real interest rate (the three-month treasury bill rate deflated by the CPI inflation rate) considered in Garcia and Perron (Citation1996), Bai and Perron (2003), and Fryzlewicz (Citation2024). The dataset is available at http://qed.econ.queensu.ca/jae/datasets/bai001/. The time series, shown in the left plot of , is quarterly and the range is 1961:1–1986:3, so .
Fig. 1 Left: The U.S. 3-month ex-post real interest rate time series (black); intervals of significance returned by RNSP (transparent pink); their midpoints (red); argument-maxima of absolute CUSUMs of signs of the data around the median in each interval of significance (blue). See Section 6.1 for a detailed description. Right: The U.S. 1-month real interest rate time series (black); intervals of significance returned by RNSP (transparent pink); their midpoints (red); argument-maxima of absolute CUSUMs of signs of the data around the median in each interval of significance (blue). Superimposed on the bottom of the graph is the probability of recession time series (purple), on the scale of 0 (bottom purple dashed line) to 1 (top purple dashed line). RNSP significance level . See Section 6.1 for a detailed description.
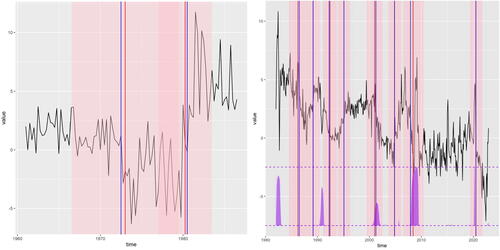
RNSP appears to be an appropriate tool here, as the data displays heterogeneity and possibly some heavy-tailed movements toward the latter part. We run the RNSP algorithm with the default setting of M = 1000, with and with overlaps as defined in (14). The procedure returns two intervals of significance:
and
. These are shown in the left plot of , together with their midpoints as well as the maximizers of absolute CUSUMs of signs of the data around the median in each interval of significance. As with any RNSP execution with nonzero overlaps, one question that may be asked is whether the two intervals may be indicating the same change-point, but this, visually, is unlikely here (the reason for using nonzero overlaps is simply to provide larger samples for RNSP following the detection of the first interval; using zero overlaps means the samples are too short and RNSP with zero overlaps does not pick up the second change-point). Therefore, the solution points to a model with at least two change-points. This is consistent, or at least not inconsistent, with both Garcia and Perron (Citation1996), who also settle on a model with two change-points, and Bai and Perron (2003), who prefer a three-change-point model, not excluded by RNSP here.
The difference between those two earlier analyses and ours is that those two (a) were based on asymptotic arguments (and therefore valid asymptotically, for unspecified large samples) and (b) were conditional in the sense that the confidence regions for change-point locations in those two works were conditional on the detection event. By contrast, our analysis via RNSP has a finite-sample nature and the intervals of significance have an unconditional character. Importantly, we do not make any distributional assumptions besides independence and sign-symmetry, both of which are likely to be acceptable for this dataset. The analysis via RNSP is unaffected by the likely heterogeneity in the data.
To illustrate RNSP on a more recent dataset of a similar nature, we examine the 1-month U.S. real interest rate, available from https://fred.stlouisfed.org/series/REAINTRATREARAT1MO. The time series, shown in the right plot of , is monthly and runs from January 1982 to February 2023. We run RNSP with M = 1000, and no overlaps. The intervals of significance returned by RNSP appear visually plausible and it is interesting (albeit not unexpected) to observe that the periods of peaking probabilities of recession (data available from: https://fred.stlouisfed.org/series/RECPROUSM156N) from year 2000 onwards are wholly contained within RNSP intervals of significance, indicating declines in the 1-month real interest rate. The period of high probability of recession in 1982 does not appear supported in the 1-month real rate data in a way detectable to RNSP. Finally, the period of high probability of recession in 1990 appears to coincide with a falling 1-month rate but RNSP has, in this case, a visually justifiable preference for intervals just before and just after this likely recession period.
6.2 Interest in the Search Term “Data Science”
We analyze the weekly interest in the search term “data science” from Google Trends, in the U.S. state of California. The link to obtain the data was https://trends.google.com/trends/explore?date=today%205-y&geo=US-CA&q=data%20science. Google Trends describe the data as follows. “Numbers represent search interest relative to the highest point on the chart for the given region and time. A value of 100 is the peak popularity for the term. A value of 50 means that the term is half as popular. A score of 0 means there was not enough data for this term.” Weeks in this data series start on Sundays and the dataset spans the weeks from w/c 28th August 2016 to w/c 15th August 2021 (so almost five years’ worth of data). The observations are discrete (integers from 22 to 100), which would likely pose difficulties for the competing methods as outlined earlier.
We execute the RNSP procedure with the default setting of M = 1000 and with , with no overlaps, which returns the three intervals of significance shown in . The intervals are: w/c 23 April 2017–w/c 10 June 2018 (interval 1), w/c 24 June 2018–w/c 17 November 2019 (interval 2), w/c 3 May 2020–w/c 14 March 2021 (interval 3). While intervals 1 and 2 correspond to likely increases in the median interest, interval 3 clearly corresponds to a likely decrease, and the midpoint of interval 3 (w/c 4 October 2020) visually aligns well with what seems to be a rather sudden drop of interest.
Fig. 2 Weekly relative interest (top = 100) in the search term “data science” in California in weeks from w/c 28 August 2016 to 15 August 2021 (black); intervals of significance returned by RNSP (transparent pink); their midpoints (red); argument-maxima of absolute CUSUMs of signs of the data around the median in each interval of significance (blue). RNSP significance level . See Section 6.2 for a detailed description.
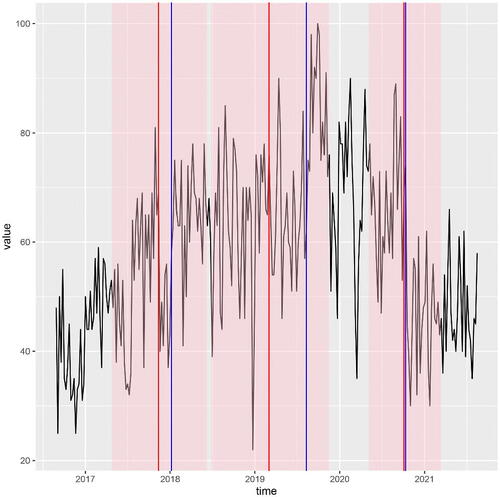
It is difficult to speculate as to possible reasons for this drop of interest. A blog post on the popular website https://towardsdatascience.com (https://bit.ly/3kqwDWO) reports that “2020 was the first year since 2016, Data Scientist was not the number one job in America, according to Glassdoor’s annual ranking. That title would belong to Front End Engineer, followed by Java Developer, followed by Data Scientist.” However, visually, a similar decline in interest is observed for example in the analogous Google Trends series for the term “Java” (not shown).
7 Discussion
Other quantiles. Note that Corollary 3.1, crucial to the success of RNSP, can be rewritten as
(15)
(15)
where
is the population q-quantile. However, the left-hand side of (15) was not specifically constructed with q = 1/2 in mind and therefore the inequality
is true for any
. This shows that RNSP can equally be used for significant change detection in any quantile, and not just the median. However, for
, the challenge is to obtain the null distribution of
. Even if this challenge is overcome (e.g., by simulation), RNSP as defined in this work may not be effective for change detection in quantiles “far” from the median, due to the particular way in which
is constructed (involving minimization over all levels). For RNSP to be a successful device for change detection in other quantiles, the definition of
would have to be modified to only minimize over ‘realistic’ candidate levels not far from the population q-quantile under the local null.
Set of feasible signals. It is convenient to define the set of feasible signals at level α with respect to the algorithmic execution
by
, where
is such that
. That is,
is the set of postulated signals f0 such that, on fitting f0 to the data and obtaining the empirical residuals, RNSP cannot distinguish (at level α) the empirical residuals from white noise. For any candidate fit f0, it is straightforward to check whether or not it is a member of
by executing
.
Supplementary Materials
R code to accompany the paper appears at https://github.com/pfryz/nsp.
Disclosure Statement
There are no competing interests to declare.
Additional information
Funding
References
- Bai, J., and Perron, P. (1998), “Estimating and Testing Linear Models with Multiple Structural Changes,” Econometrica, 66, 47–78. DOI: 10.2307/2998540.
- ———(2003), “Computation and Analysis of Multiple Structural Change Models,” Journal of Applied Econometrics, 18, 1–22.
- Baranowski, R., Chen, Y., and Fryzlewicz, P. (2019), “Narrowest-Over-Threshold Detection of Multiple Change-Points and Change-Point-Like Features,” Journal of the Royal Statistical Society, Series B, 81, 649–672. DOI: 10.1111/rssb.12322.
- Bhattacharyya, G., and Johnson, R. (1968), “Nonparametric Tests for Shift at an Unknown Time Point,” The Annals of Mathematical Statistics, 39, 1731–1743. DOI: 10.1214/aoms/1177698156.
- Carlstein, E. (1988), “Nonparametric Change-Point Estimation,” Annals of Statistics, 16, 188–197.
- Chen, Y., Shah, R., and Samworth, R. (2014), “Discussion of ‘Multiscale Change Point Inference’ by Frick, Munk and Sieling,” Journal of the Royal Statistical Society, Series B, 76, 544–546.
- Cheng, D., He, Z., and Schwartzman, A. (2020), “Multiple Testing of Local Extrema for Detection of Change Points,” Electronic Journal of Statistics, 14, 3705–3729. DOI: 10.1214/20-EJS1751.
- Cho, H., and Kirch, C. (2022), “Bootstrap Confidence Intervals for Multiple Change Points based on Moving Sum Procedures,” Computational Statistics and Data Analysis, 175, Article no. 107552. DOI: 10.1016/j.csda.2022.107552.
- Dümbgen, L. (1991), “The Asymptotic Behavior of Some Nonparametric Change-Point Estimators,” Annals of Statistics, 19, 1471–1495.
- Duy, V. N. L., Toda, H., Sugiyama, R., and Takeuchi, I. (2020), “Computing Valid p-value for Optimal Changepoint by Selective Inference Using Dynaming Programming,” in Advances in Neural Information Processing Systems, (Vol. 33), pp. 11356–11367.
- Eichinger, B., and Kirch, C. (2018), “A MOSUM Procedure for the Estimation of Multiple Random Change Points,” Bernoulli, 24, 526–564. DOI: 10.3150/16-BEJ887.
- Fearnhead, P. (2006), “Exact and Efficient Bayesian Inference for Multiple Changepoint Problems,” Statistics and Computing, 16, 203–213. DOI: 10.1007/s11222-006-8450-8.
- Frick, K., Munk, A., and Sieling, H. (2014), “Multiscale Change-Point Inference,” (with Discussion), Journal of the Royal Statistical Society, Series B, 76, 495–580. DOI: 10.1111/rssb.12047.
- Fryzlewicz, P. (2024), “Narrowest Significance Pursuit: Inference for Multiple Change-Points in Linear Models,” Journal of the American Statistical Association, to appear.
- Garcia, R., and Perron, P. (1996), “An Analysis of the Real Interest Rate under Regime Shifts,” Review of Economics and Statistics, 78, 111–125. DOI: 10.2307/2109851.
- Hao, N., Niu, Y., and Zhang, H. (2013), “Multiple Change-Point Detection via a Screening and Ranking Algorithm,” Statistica Sinica, 23, 1553–1572. DOI: 10.5705/ss.2012.018s.
- Hyun, S., G’Sell, M., and Tibshirani, R. (2018), “Exact Post-Selection Inference for the Generalized Lasso Path,” Electronic Journal of Statistics, 12, 1053–1097. DOI: 10.1214/17-EJS1363.
- Hyun, S., Lin, K., G’Sell, M., and Tibshirani, R. (2021), “Post-Selection Inference for Changepoint Detection Algorithms with Application to Copy Number Variation Data,” Biometrics, 77, 1037–1049. DOI: 10.1111/biom.13422.
- Jewell, S., Fearnhead, P., and Witten, D. (2022), “Testing for a Change in Mean After Changepoint Detection,” Journal of the Royal Statistical Society, Series B, 84, 1082–1104. DOI: 10.1111/rssb.12501.
- Kabluchko, Z., and Wang, Y. (2014), “Limiting Distribution for the Maximal Standardized Increment of a Random Walk,” Stochastic Processes and their Applications, 124, 2824–2867. DOI: 10.1016/j.spa.2014.03.015.
- Lavielle, M., and Lebarbier, E. (2001), “An Application of MCMC Methods for the Multiple Change-Points Problem,” Signal Processing, 81, 39–53. DOI: 10.1016/S0165-1684(00)00189-4.
- Li, H. (2016), “Variational Estimators in Statistical Multiscale Analysis,” PhD thesis, Georg August University of Göttingen.
- Li, H., and Munk, A. (2016). “FDR-Control in Multiscale Change-Point Segmentation,” Electronic Journal of Statistics, 10, 918–959. DOI: 10.1214/16-EJS1131.
- Massart, P. (1990), “The Tight Constant in the Dvoretzky-Kiefer-Wolfowitz Inequality,” The Annals of Probability, 18, 1269–1283. DOI: 10.1214/aop/1176990746.
- Nemirovski, A. (1986), “Nonparametric Estimation of Smooth Regression Functions,” Journal of Computer and System Sciences, 23, 1–11.
- Pein, F., Sieling, H., and Munk, A. (2017), “Heterogeneous Change Point Inference,” Journal of the Royal Statistical Society, Series B, 79, 1207–1227. DOI: 10.1111/rssb.12202.
- Sen, A., and Srivastava, M. S. (1975), “On Tests for Detecting Change in Mean,” The Annals of Statistics, 3, 98–108. DOI: 10.1214/aos/1176343001.
- Shao, Q.-M. (1995), “On a Conjecture of Révész,” Proceedings of the American Mathematical Society, 123, 575–582. DOI: 10.2307/2160916.
- Vanegas, L., Behr, M., and Munk, A. (2022), “Multiscale Quantile Segmentation,” Journal of the American Statistical Association, 117, 1384–1397. DOI: 10.1080/01621459.2020.1859380.
Appendix A:
Proofs
Proof of Theorem 4.1.
Consider initially the case of a single change-point η1. RNSP will, among others, consider intervals symmetric about the true change-point, that is , for all appropriate d. Take a constant candidate fit w on the interval
and define
(the latter equality holds due to the continuity of the distribution of Zt
). Assume wlog
. We have
(16)
(16)
Now note
Continuing from (16), this implies
(17)
(17)
The infimum over w will be achieved if both elements of the maximum are the same (or otherwise it would be possible to alter w slightly to decrease the larger of the two moduli). But this is only possible if and hence, bearing in mind that Zt
is median-zero, we have
Let w0 be such that . Since
=
, then either
or
. Therefore,
Continuing from (17), we therefore have
(18)
(18)
But from the definition of the RNSP algorithm (line 14), detection on an interval will occur if
. Therefore, from (18), detection on
will occur if
(19)
(19)
As RNSP looks for the shortest intervals of significance, the length of the RNSP interval will not exceed that of , which is 2d. From (19), its length will therefore be bounded from above by
. We now turn our attention to the multiple change-point case. Note that even though the RNSP interval of significance around ηj
is guaranteed to be of length at most
, it will not necessarily be a sub-interval of
. Therefore, in order that an interval detection around ηj
does not interfere with detections around
or
, the distances
and
must be suitably long, but this is guaranteed by Assumption 4.1(iii). This completes the proof. □
Proof of Corollary 4.1.
The fact that as
is a simple consequence of Corollary 1 in Shao (Citation1995). We next assess and bound the magnitude of
. The Dvoretzky-Kiefer-Wolfowitz inequality (with Massart’s optimal constant, see (Massart Citation1990)) implies
This leads to a uniform bound via Bonferroni’s correction.
For , the above tends to zero if
. This completes the proof. □
Proof of Corollary 4.2.
As in the proof of Corollary 4.1, setting α at this level means that
as
, and therefore
Theorem 4.1 implies the result. □