
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose a novel class of Markov processes for dealing with continuous positive time series data, which is constructed based on a latent gamma effect and named gamma-driven (GD) models. The GD processes possess desirable properties and features: (i) it can produce any desirable invariant distribution with support on , (ii) it is time-reversible, and (iii) it has the transition density function given in an explicit form. Estimation of parameters is performed through the maximum likelihood method combined with a Gauss Laguerre quadrature to approximate the likelihood function. The evaluation of the estimators and also confidence intervals of parameters are explored via Monte Carlo simulation studies. Two generalizations of the GD processes are also proposed to handle nonstationary and long-memory time series. We apply the proposed methodologies to analyze the daily realized volatility of the FTSE 100 equity index.
1 Introduction
In stochastic process theory and application, there is extensive literature about the construction of Markov processes. More than being well adjustable to the data, desirable properties like stationarity and reversibility in time are sometimes required. In time series, there is solid literature on this type of construction. The classic AR(1) model is one of the most famous and defined by a sequence of random variables satisfying
where
are independent and identically distributed random variables (iid) with zero mean and variance
and independent of
and
.
Outside the scenario where normality is assumed, establishing the distribution of such that the strict stationarity of
is guaranteed is a challenging task. Some authors fixed this issue by dealing directly with the marginal of the model, ensuring that the results of interest were satisfied. Jacobs and Lewis (Citation1977) and Lawrance and Lewis (Citation1977) proposed the construction of first-order autoregressive processes with exponential marginals. Gaver and Lewis (Citation1980), in turn, explored the properties of first-order autoregressive processes whose marginal followed a gamma distribution (for
).
Joe (Citation1980) made significant advances by proposing time series models with the distribution of the response variable Xt belonging to an infinitely divisible class closed by convolution. The class includes the Poisson, negative binomial (with fixed probability parameter), gamma (with fixed scale parameter), Generalized Poisson (with one fixed parameter), inverse-Gaussian (with one fixed parameter), and normal distributions. Among the models proposed by Joe (Citation1980), there is a stationary and time-reversible AR(1) Markov model. There is vast literature about Markov process constructions with discrete marginal. For example, the integer-valued autoregressive (INAR) processes introduced by McKenzie (Citation1985) and Al-Osh and Alzaid (Citation1987).
Pitt, Chatfield, and Walker (Citation2002) introduce an alternative way to the ones mentioned above to build first-order autoregressive models. The construction of the process is done by specifying the joint density of , or equivalently, specifying the marginal distribution of Xt and the conditional (transition) of
. Mena and Walker (Citation2005) proposed the construction of a Markov process with a nonparametric approach to model the transition density with desirable stationary densities. A generalization of this nonparametric approach with a focus on the discrete case was considered by Contreras-Cristán, Mena, and Walker (Citation2009).
Following this same line of construction, Anzarut et al. (Citation2018) proposed a method for constructing strictly stationary Markov models, which have a similar structure to the models by Pitt, Chatfield, and Walker (Citation2002) and Mena and Walker (Citation2005). Their processes are driven by a Poisson transformation, which modulates their dependency structure. The construction allows for time-reversibility and stationarity with the desirable invariant distribution of interest. Further, the authors considered a Bayesian approach to make inference. Leisen et al. (Citation2019) proposed construction of stationary Markov models having negative binomial marginals. They showed that choosing the negative binomial distribution as marginal leads them to find analytical conditions that satisfy the Chapman-Kolmogorov equations leading to a rich class of continuous-time Markov chains. Using their conditional probability structure, Palma and Mena (Citation2021) proposed a dual continuous-time Markov process.
Our chief aim in this article is to propose a novel way to construct stationary Markov processes having any desirable positive continuous distribution in the marginals. To do that, we introduce a weighted gamma density function, which will control the dependence structure within our class of time series models. We call our class the gamma-driven (GD) Markov processes. We show that simple expressions can be found for the transition densities and autocorrelation. The GD models can be seen as an alternative to the Poisson-driven (PD) models by Anzarut et al. (Citation2018). In particular, we show through an empirical illustration that our GD processes can have a better predictive power than PD processes for modeling realized volatility. Another key contribution of our article is the proposal of two generalizations of GD models to handle nonstationary and long-memory time series.
We apply the proposed gamma-driven models to analyze the daily realized volatility of FTSE 100 equity index log-returns computed every 10 min from October 31st, 2003, to May 31st, 2007. In an initial study under this “short” period of time, we compare our GD models with the Poisson-driven approach through out-of-sample prediction exercises. Our findings show that our models produce better predictions than Poisson-driven models for the realized volatility considered. In a second study, we consider the daily realized volatility of FTSE 100 for a longer period of time, from January 2nd, 2004 to December 4th, 2017. To handle this problem, an extension of the GD processes is developed to accommodate long memory, which is a feature commonly observed in the analysis of realized volatility. Our results reveal that such an extension is needed and yields better predictions when compared to the Markovian GD models.
The article is organized as follows. Section 2 deals with the construction of the gamma-driven (GD) Markov processes. Some properties of the GD models are established, such as time-reversibility and stationarity. Further, the cases where the marginals are gamma and inverse-Gaussian distributed are explored in more detail. Section 3 deals with maximum likelihood estimation combined with Gauss Laguerre quadrature to approximate the log-likelihood function. Furthermore, Monte Carlo simulations are presented to evaluate the performance of the proposed estimation procedure. We propose two generalizations of the GD processes to handle nonstationary and long-memory time series in Section 4. Section 5 illustrates the usefulness of our methodology, where the daily realized volatility of the FTSE 100 index log-returns is analyzed. Concluding remarks and possible future research are provided in Section 6. This article contains supplementary materials.
2 Gamma-Driven Markov Processes
We introduce the weighted gamma density function, which will play an important role in constructing the stationary gamma-driven Markov processes. A random variable Z following a gamma distribution with shape and scale parameters and
, respectively, is denoted by
and has density function given by
, for z > 0.
Definition 2.1.
(Weighted gamma density) Let X be a positive continuous random variable with density function f, and assume that Y is a random variable such that , for
. The weighted gamma density function is defined as the conditional density of
, which assumes the form
(1)
(1)
where is the normalization constant
(2)
(2)
If has a conditional probability density function given in (1), the associated rth moment and Laplace transform are respectively given by
(3)
(3)
Let be a stationary stochastic process with arbitrary marginal density f with support on
. Using the idea on weighted gamma densities above, we consider a latent stochastic process
such that
and then
has a gamma weighted density function given in (1), for
. Under the above construction, we obtain that the conditional density function of Xt given
(transition density) is
(4)
(4)
Definition 2.1. We say that a stochastic process in discrete-time is a stationary gamma-driven (GD) Markov process if its density transitions are given by (4), for some density function f with support on
.
We now show that a GD process is stationary and time-reversible. Therefore, the above method gives us one way to construct stationary Markov processes with any desirable positive continuous distribution in the marginals.
Proposition 2.2.
The gamma-driven processes are stationary and time-reversible.
Proof.
Let be a GD process. From (4), we have that
(5)
(5) for all
. In other words, the process satisfies the detailed balance equation and is therefore time-reversible. Using (4) again, it follows that
(6)
(6)
Hence, is a stationary process with marginal densities f. □
We now provide an expression for the conditional moments of the GD processes. These moments will be used to obtain the lag-1 autocorrelation of our Markov models.
Proposition 2.3.
Let be a GD process. For
, the rth conditional moment of Xt given
can be expressed by
(7)
(7)
Proof.
For and using (3) and (4), we obtain that rth conditional moment Xt given
is given by
□
If the density function f is square integrable, we can use the above result to get that the lag-1 autocorrelation of a GD process can be expressed by
(8)
(8) where
and
are respectively the mean and variance associated with the density f. The parameter ϕ controls the model dependence. This will be illustrated in the next sections, where we explore two special cases of the GD models.
2.1 Generalized Inverse-Gaussian GD Process
In this section, we consider the GD model having generalized inverse-Gaussian marginals (in short, GIG-GD). A random variable X following a GIG distribution with parameters and
is denoted by
and has probability density function given by
(9)
(9) where
is the modified Bessel function of the third kind with index β; for instance, see Abramowitz and Stegun (Citation1974).
By identifying a GIG kernel density, it can be shown that the normalized constant in (2) is
(10)
(10)
Hence, using expression (10) and considering f a density function as in (9), we obtain that the weighted gamma density function assumes the form
(11)
(11)
Note that the conditional distribution associated with the density in (11) is . Let
be a GIG-GD process. Then, its transition densities can be expressed as
for
and
. The conditional expectation of Xt given
is of interest to perform prediction or forecasting. From (7), we obtain that
(12)
(12)
An expression for the 1-lag autocorrelation of the GIG-GD process can also be obtained by using (8) as follows:
(13)
(13)
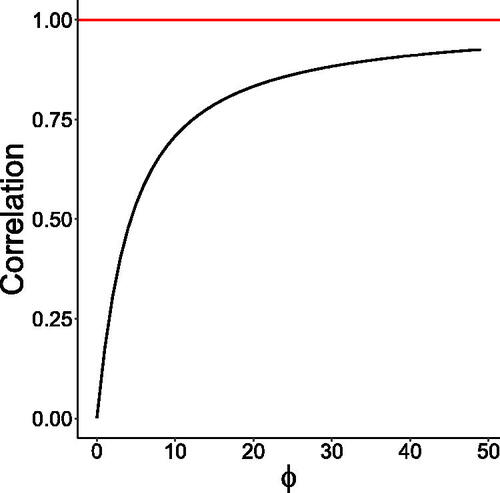
shows a plot of the lag-1 autocorrelation (13) as a function of ϕ for the GD model with marginals distributed. The correlation between Xt and
increases as ϕ increases and goes to zero when ϕ approaches zero.
Fig. 1 Plot of the lag-1 autocorrelation (13) as a function of ϕ for β = 1, δ = 2, and γ = 3.
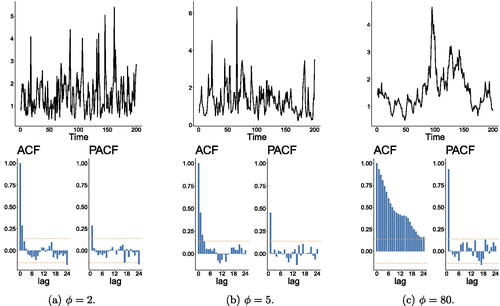
In , we provide plots of simulated trajectories of the GIG-GD model with sample size n = 200 and their associated autocorrelation function (ACF) and partial autocorrelation function (PACF) plots for and some values of ϕ. We can observe that the model seems to behave nonstationary when ϕ is large.
Fig. 2 Simulated trajectories of the GIG-GD process with marginals distributed and their associated ACF and PACF plots for
and 80 and sample size 200.
2.2 Gamma GD Process
We now discuss the special case when the GD process has marginals, where a > 0 and b > 0 are shape and scale parameters from a gamma distribution, respectively. The normalizing constant (2) is obtained for the gamma case by identifying a gamma kernel. More specifically, we have that
It can be checked that the associated weighted gamma density is distributed. Let
be a GD process with
marginals. Then, its transition densities assume
(14)
(14)
The conditional expectation and the lag-1 autocorrelation for the Gamma-GD process are given, respectively, by
(15)
(15)
and
(16)
(16)
Note that we obtain an explicit and simple expression for the lag-1 autocorrelation. This also happens with the gamma Poisson-driven process by Anzarut et al. (Citation2018). Another remarkable point is that the autocorrelation in our gamma model is by ϕ and also by the parameter a, related to the marginal distribution. For the gamma model by Anzarut et al. (Citation2018), the lag-1 autocorrelation is just controlled by the parameter related to the latent Poisson variable.
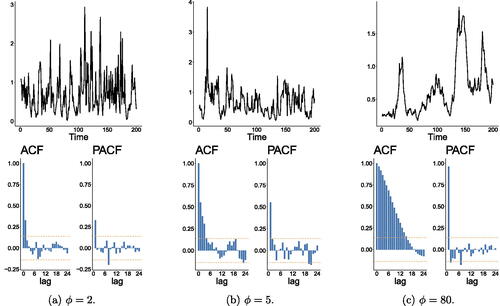
The autocorrelation (16) goes to 0 and 1 when ϕ tends to 0 and , respectively. shows a plot of this function. We present plots of simulated trajectories, ACF, and PACF for the Gamma-GD process in . Similarly, as in the GIG case, the simulated trajectory for the gamma case with
behaves like a nonstationary time series, which is suitable since
tends to 1 when
.
Fig. 3 Plot of the lag-1 autocorrelation (16) as a function of ϕ for a = 2.
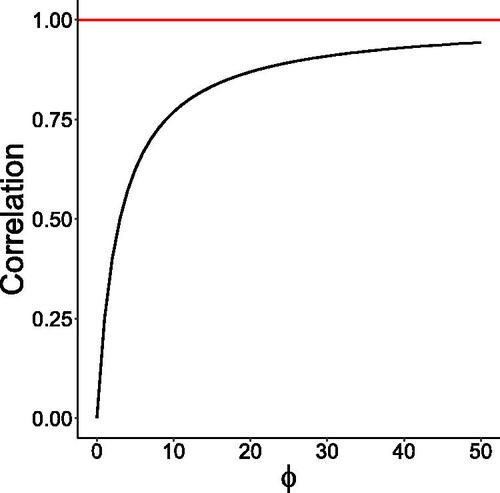
Fig. 4 Simulated trajectories of the Gamma-GD process with marginals distributed and their associated ACF and PACF plots for
, and 80 and sample size 200.
3 Parameter Estimation
We develop an estimation of the parameters of the GD processes through maximum likelihood estimation (MLE). We discuss the special cases where the marginals are gamma and GIG distributed. Denote by an observed trajectory, and
and
the vectors of parameters associated to the GIG-GD and Gamma-GD processes, respectively. The log-likelihood functions of the GIG and gamma cases are respectively given by
(17)
(17)
and
(18)
(18)
The maximum likelihood estimators of the GIG-GD and Gamma-GD models are obtained by maximizing the log-likelihood functions (17) and (18), respectively. In both cases, we need to handle integrals. To tackle this problem, we propose an approximation for the integral through the numerical quadrature of Gauss Laguerre presented in Kahaner, Moler, and Nash (Citation1989). The authors claim that certain functions usually appear as part of the integrand in infinite intervals and point out that two common cases are the functions and
. The method presented by the authors is based on the technique of weight functions. In particular, we have that approximation
where
is some function defined on the interval (c, d), the limits c and d can be finite or infinite, the points xk are called nodes, while wk are the weights associated with the nodes, and Rn denotes the rest; for more detail, please see Kahaner, Moler, and Nash (Citation1989).
To approximate the integrals involved in the log-likelihood function, we use the gaussLaguerre function of the R package pracma with 17 weights and 17 nodes of the Gauss Laguerre Quadrature. The approximations to the integrals involved in the log-likelihoods (17) and (18) using Gauss Laguerre quadrature are
(19)
(19)
and
(20)
(20)
Remark 3.1.
In preliminary studies, we have evaluated the estimation of parameter via maximum likelihood method with the approximated likelihood for different values of nodes. From these studies, we noticed that 17 nodes were enough to produce accurate results in terms of point estimation and accuracy of standard errors for both GIG and gamma GD processes, as it will be demonstrated in our numerical experiments in what follows. In Section 2 of the supplementary materials, we show a simple example that illustrate the accuracy of the Gauss-Laguerre quadrature to approximate the integral involved in the gamma case.
We now present some Monte Carlo studies to evaluate the estimation method based on maximum likelihood with Gauss Laguerre Quadrature approximation for the log-likelihood function. All the implementations in this article are in R. We consider N = 1000 Monte Carlo replications and samples of sizes and 5000. Regarding the setting of parameters, we set ϕ = 2 and ϕ = 5. Further, we take
and
for GIG and gamma models, respectively. The maximization of the approximated log-likelihood is done through the R function optim with the optimization method Nelder-Mead. For the initial values for the optimization, we consider
and the MLEs of the marginals (assuming iid sample) for the remaining parameters. In the GIG case, we used the gigFit function from the package GeneralizedHyperbolic for getting the initial guesses. For the gamma case, we used a vector of ones as initial guesses (corresponding to an exponential distribution with mean 1), which worked well without numerical issues.
We generate time series trajectories from the GIG-GD process and compute their maximum likelihood estimates. provides the empirical means and the root mean squared error (RMSE) of the parameter estimates for the GIG model. The results for the gamma model are presented in . From these tables, we can observe that the parameters are well-estimated and that the bias and RMSE decrease as the sample size increases. We also provide boxplots, histograms, and qq-plots of the MLEs in from supplementary materials, which reveals that a normal approximation is adequate for the scenarios considered in this section.
Fig. 5 Plots of the daily realized volatility with its associated ACF and PACF.
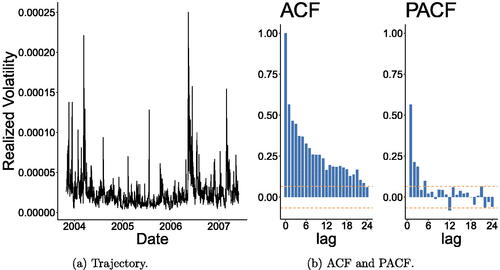
Fig. 6 One-step ahead prediction of the daily realized volatility of the FTSE 100 log-returns under the gamma-driven (left) and Poisson-driven (right) models with GIG marginals.
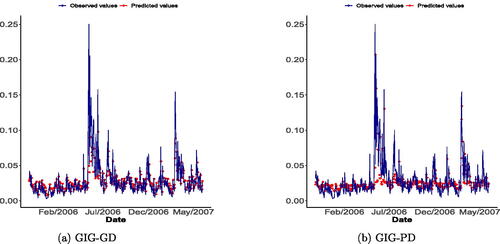
Table 1 Empirical means and RMSE (in parenthesis) of the maximum likelihood estimates for the GIG-GD process with , n = 500, 1000, 5000, and
.
Table 2 Empirical means and RMSE (in parenthesis) of the maximum likelihood estimates for the Gamma-GD process with , n = 500, 1000, 5000, and
.
To get the standard errors of the maximum likelihood estimates, we propose using the Hessian matrix associated with the approximated log-likelihoods. To evaluate the performance of this approach, we perform Monte Carlo simulations where time series trajectories are generated from the GIG and gamma models, and confidence intervals are constructed for the parameters based on asymptotic normality and standard errors obtained via the Hessian matrix. If the standard errors are accurately estimated, the empirical coverages of the confidence intervals will be close from the nominal coverages. We consider 1000 Monte Carlo replications and parameter settings as before. and provide the empirical coverages for the 90%, 95%, and 99% confidence intervals under the GIG and gamma cases, respectively. The empirical coverages are obtained as the proportion of times that the confidence intervals constructed in the Monte Carlo simulation contain the true value of the parameter. Looking at these tables, we can see that the proposed approach for getting standard errors and constructing confidence intervals for the parameters is working quite well since the empirical coverages are close to the desired ones for all cases considered. It is worth mentioning that in general Hessian matrix can be unstable and produce numerical issues, which cause problems to obtain standard errors based on it, but not in our case. Note that the complicated term of the log-likelihood function, the non-closed form integral, is replaced by a simple function via the Gauss-Laguerre expansion. This simplicity and the fact that such an approximation is accurate, explains why we did not experience issues with the Hessian matrix.
Table 3 Empirical coverages of confidence intervals for the parameters under the GIG-GD process with n = 500, 1000, 5000 when trajectories are generated from GIG-GD process.
Table 4 Empirical coverages of confidence intervals for the parameters under the Gamma-GD process with n = 500, 1000, 5000 when trajectories are generated from Ga-GD process.
4 Generalizations
In this section we propose two generalizations of the gamma GD process to account for stylized features from realized volatility. We here consider a reparameterization of the gamma distribution in terms of mean and dispersion parameters for the marginals of the GD process addressed in this section. A random variable X following a gamma distribution with mean and dispersion
has density function given by
, for x > 0. In this case,
and
. This reparameterization can be obtained from
distribution by setting
and
.
Remark 4.1.
Although we will be presenting such extensions for the gamma model, this can be easily be done for other distributions. For example, one could consider the inverse-Gaussian (IG) distribution (special case from the GIG model with ) with parameterization in terms of the mean
and variance
, where κ is a dispersion parameter. The inclusion of covariates and long-memory extension for the IG model follow exactly as in the gamma case in what follows. An application of the IG long-memory model to a realized volatility data will be discussed in Section 5.2.
4.1 Inclusion of Covariates
We now define a nonstationary gamma GD process by assuming that its transition densities have the form (14) with κ and
replacing a and b, respectively, and
, where Wt is a matrix composed of
time-varying covariates and ψ is a
vector of associated regression coefficients to be estimated. Under this formulation, we have that
, and
, for
. Therefore, the model allows for nonstationary positive time series and covariates can be included in the model through the mean as in generalized linear models. Let us denote this model by Ga-GLMGD.
The maximum likelihood estimation (MLE) of parameters is performed similarly as in the stationary case discussed previously, with the log-likelihood function assuming a similar form as (18) with a and b replaced by κ and (note that one of the parameters now is time-varying), respectively. The parameter vector here is
and we estimate it via maximum likelihood.
We now present a small Monte Carlo simulation to check the performance of the MLEs. We generate a covariate time series Wt through a logit transformation of a realization of a first-order autoregressive process, say Zt (with autoregressive coefficient 0.5 and variance noise equal to 1), that is , for
. The idea here is to mimic a bounded time series covariate on the interval (0, 1) that is important to explain the response time series. The following settings are assumed for this Monte Carlo simulation (with 1000 replications): n = 500, 1000, ϕ = 5, κ = 3,
(intercept) and
. provides the empirical means and RMSE of the maximum likelihood estimates obtained in the Monte Carlo simulation. We can notice that the estimation of the parameters via MLE is working well.
Table 5 Empirical means and RMSE (in parentheses) of the maximum likelihood estimates for the Ga-GLMGD process with ϕ = 5, κ = 3, , and sample sizes n = 500, 1000.
4.2 Long-Memory Modeling
Inspired by the work by Corsi (Citation2009), we now extend the GD processes to handle long-memory time series, which is an important feature to be considered when modelling realized volatility for many years. Let be a stochastic process and denote
, that is, the σ-algebra generated by
. We define a gamma long-memory GD process by assuming that its transition densities have the form (14) with κ and
replacing a and b, respectively, and
given by
(21)
(21) where
, and
are parameters to be estimated,
is a medium-term investors who rebalance weekly and
is a long-term investors who rebalance their positions after one or more months; for instance, see Pascalau and Poirier (Citation2023). Note that the short-term traders with a daily, or shorter rebalance frequency, in other words, the dependence on
enters the model via the conditional expectation μt (see EquationEquation (21)
(21)
(21) ) and also through the latent gamma process
introduced in Section 2.
Remark 4.2.
It is worth mentioning that the nomenclature long-memory GD processes refers to the ability of such models to provide a good approximation for handling positive continuous long-memory time series and not to its theoretical property since in theory these models are short-memory like Corsi’s (Citation2009) model.
As in the model introduced in Section 4.1, the log-likelihood function for the long-memory GD process has the form (18) with a and b replaced by κ and , with μt given by (21). The standard maximum likelihood method can be applied to obtain parameter estimates and to perform inference as well. The gamma long-memory GD model (in short Ga-LMGD) will be applied to a realized volatility data in Section 5.2.
5 Realized Volatility Data Analysis
In this section, we apply the gamma-driven models to the daily realized volatility of FTSE 100 equity index log-returns computed every 10 min from October 31st, 2003, to May 31st, 2007. We will initially analyze this realized volatility for this “short” period of time but in Section 5.2 a longer period will be considered, which requires a more complex modeling where long-memory can be accommodated. These data can be found at Heber et al. (Citation2020) and consist of 939 observations. There are 38 missing observations (corresponding to holidays and weekends) and one outlier (corresponding to an isolated fact that occurred in London). The missing observations were not considered, and the outlier was replaced by a missing value (NA) and then imputed using the R package mice. These data have also been considered and analyzed by Anzarut et al. (Citation2018), where a similar treatment for missing values and imputation was considered. After the data cleaning, we end up with 901 observations. For other recent works dealing with realized volatility, for instance, see Chen et al. (Citation2018), Chen, Watanabe, and Lin (2021), and Takahashi, Watanabe, and Omori (in press).
presents some descriptive statistics for the daily realized volatilities. shows the realized volatility and its associated ACF and PACF plots. These plots indicate a stationary behavior of the time series data.
Table 6 Descriptive statistics for the daily realized volatility of the FTSE 100 equity index log-returns computed every 10 min from October 31st, 2003, to May 31st, 2007.
We fit the GD processes to the realized volatilities multiplied by 1000. Then, we consider the maximum likelihood approach combined with the Gauss Laguerre quadrature to estimate the parameters under the GIG and gamma GD models. The maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the GIG and gamma assumptions are provided in and , respectively.
Table 7 Maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the GIG-GD process.
Table 8 Maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the Gamma-GD process.
We check if the GIG and gamma GD models are fitting well the daily realized volatility considered here. To do that, we consider residual analyses with simulated envelopes and a probability integral transform approach. To save space in the article, all the results are presented in Section 3 of the supplementary materials. In summary, the goodness-of-fit analyses showed that both models are well-fitted to the data.
In what follows, we investigate whether the GIG and gamma GD models provide a suitable fit to the realized volatility and perform an out-of-sample prediction exercise. A comparison with a discrete-time Poisson-driven model by Anzarut et al. (Citation2018) will also be presented.
5.1 Out-of-Sample Prediction
To assess the performance of the models in terms of forecasting, an out-of-sample prediction exercise is considered as done, for instance, in Agosto et al. (Citation2016). This method divides the sample of size T into two parts. The first with size is used to for the initial model estimation, and the remaining observations, of size
, are used to the forecasting exercise. Given the parameter estimate using just the information until the time t, the corresponding one-step ahead forecast of
is calculated as
. This exercise is repeated for
, thus, providing a sequence of one-step ahead predictions
. To evaluate the predictive power of the models, we consider the mean square forecasting error (MSFE)
and the forecasting score (FS)
For sake of comparison, we also consider here the discrete-time Poisson-driven model with GIG marginals (GIG-PD) by Anzarut et al. (Citation2018). We performed maximum likelihood estimation of parameters and a summary is provided in (using all the data); the parameter ϕ here is related to the latent Poisson variable from Anzarut et al.’s (2018) model.
Table 9 Maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the GIG-PG process.
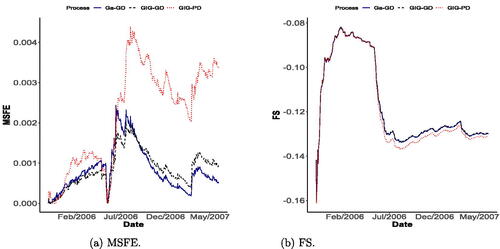
The prediction exercise was performed to the realized volatility with , and initial 401 observations were used for the initial estimation of the model. shows the observed times series and one-ahead forecasts according to GIG-GD and GIG-PD models. We do not present the plot for the GD-Ga model to save space in the article since it was quite similar to the GIG-GD one. This plot reveals that our method is providing better predictions than the GIG-PD approach. This can be also be noticed from , which provides the MSFE and FS plots for the fitted Ga-GD, GIG-GD, and GIG-PD processes. The smallest MSFEs are produced by the gamma-driven models, which are performing better than the Poisson-driven model. Regarding the FS (the higher, the better the model), Ga-GD and GIG-GD model performances are almost indistinguishable and still provide better results than the GIG-PD model.
Fig. 7 MSFE (on the left) and FS (to the left) plots for the fitted Ga-GD, GIG-GD, and GIG-PD processes.
5.2 Long-Memory Analysis
We now consider the realized volatility of FTSE 100 for a longer period, from January 2nd, 2004 to December 4th, 2017. In this case, the gamma driven and Poisson-driven Markov processes are not suitable for analyzing this data and a more complex model is necessary. As pointed out by one of the Referees, even for a shorter period of time, these models might not enough capture key features and this is reflected by some large standard errors of estimates; for instance, see and . That is our motivation for proposing the long-memory extension of our GD processes in Section 4.2 inspired by the work by Corsi (Citation2009), as suggested by the AE. After cleaning the data (following the same procedures as at the beginning of the section), we end up with n = 3508 observations, which are multiplied by 1000 (as before). provides a descriptive analysis, while shows plots of the realized volatility of FTSE 100 and its associated ACF and PACF.
Fig. 8 Plots of the realized volatility of FTSE 100 (multiplied by 1000) from January 2, 2004 to December 4, 2017 and its associated ACF and PACF.
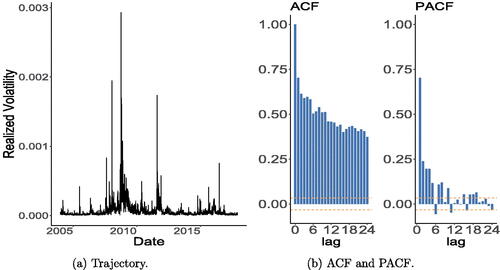
Table 10 Descriptive statistics for the daily realized volatility of the FTSE 100 equity index log-returns computed every 10 min from January 2nd, 2004 to December 4th, 2017.
The summary fits of Ga-LMGD and IG-LMGD are respectively presented in and , respectively. From these tables, we can observe relatively small standard errors and parameter estimates “far from zero,” which is an indication that the components included in the model are significant. In particular, an interesting fact is that the nonlinear incorporation of to explain Xt seems to be significant under both gamma and IG models. Of course, the null hypothesis
belongs to the boundary of the parameter space and this should be tested adequately; a likelihood ratio test can be used and the asymptotic distribution is not longer Chi-squared distributed, but a 50%–50% mixture between a Chi-square distribution and a degenerated distribution at 0. Anyway, the estimate of ϕ is not close to zero and the standard error is small, which gives us evidence that this nonlinearity is important to be considered through our proposed gamma-driven approach. Also, note that
and
also seem to be significant to be included in the gamma LMGD process to explain the conditional mean (in a linear way). On the other hand,
seems to be not significant to explain the conditional mean (in a linear way) under the inverse-Gaussian LMGD model. These results show the importance of considering a nonlinear relationship between Xt and
in the analysis of realized volatility, which is a relevant finding of this article.
Table 11 Maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the gamma long-memory GD process.
Table 12 Maximum likelihood estimates, standard errors, and 95% confidence intervals for the parameters under the inverse-Gaussian long-memory GD process.
To conclude the realized volatility analysis, we evaluate the forecast power of our long-memory models by performing an out-of-sample prediction exercise as described in Section 5.1 with . For sake of comparison, we consider the performance of the GIG and gamma GD processes. We additionally include Corsi’s model that serves as an interesting benchmark, where we have used least squares method to estimate its parameters.
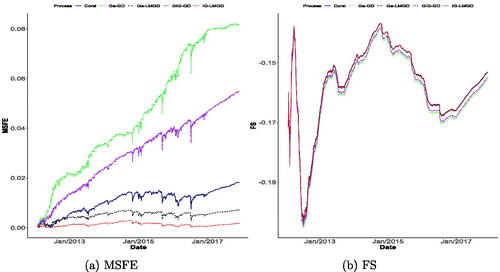
The MSFE and FS plots are displayed in , which reveals the superior performance of the long-memory models over the Markovian ones, as expected, especially in terms of MSFE. Among those models that can capture long-memory, we notice that our long-memory processes perform better than Corsi’s model, which is already expected since they are designed to handle continuous positive time series, while Corsi’s model is -valued. It is worth mentioning again that these models are in theory short-memory, but they are capable of handling long-memory time series well, as discussed in Remark 4.2.
Fig. 9 MSFE (on the left) and FS (to the left) plots based on Ga-LMGD, IG-LMGD, Corsi, Ga-GD, and GIG-GD models.
6 Concluding Remarks
We proposed a novel method to construct a Markovian model with desirable marginals based on a gamma latent variable. Properties of our gamma-driven (GD) models were explored, in particular, its time-reversibility, and explicit form for the transition densities. The likelihood function of GD models depend on integrals without closed form, which makes inference more challenging. To overcome this issue, we approximated such integrals via Gauss Laguerre quadrature. Then, we proposed estimation of parameters through maximum likelihood using the approximated likelihood function. Extensive simulated results gave us evidence that the proposed estimation procedure produces accurate estimates and reliable standard errors obtained via the resulting approximated Hessian matrix. Two generalizations of GD processes for dealing with nonstationary and long-memory time series were proposed. Applications of our methodologies to the daily realized volatility of FTSE 100 equity index log-returns were presented and compared to the discrete-time Poisson-driven (PD) models by Anzarut et al. (Citation2018). These empirical applications showed that GD processes and their generalizations can be produce better results in terms of prediction over PD models. provides the computational time (in seconds) to fit a GD process or one of its generalizations for the simulated (one replica) or real datasets (n denotes the sample size) considered in this article, which gives an idea about the scalability of our approches. As can be seen, the models requiring more computational efforts are the gamma and inverse-Gaussian long-memory GD processes for the realized volatility data analysis consisting of n = 3508 observations. Anyway, less than 1 min is needed to fit such a data under both models.
Table 13 Computational time in seconds to fit GD processes and their generalizations for simulated and real data considered in this article; n here denotes the sample size.
We believe that there are many points deserving further investigation. The generalizations we proposed for GD processes allowing for inclusion of covariates and to handle long-memory time series can also be adapted to extend the Poisson-driven models by Anzarut et al. (Citation2018). One of the Referees suggested us to extend our GD approach to the continuous time as done by Anzarut et al. (Citation2018). In order to obtain such an extension we need to prove that the transition densities of GD Markov process satisfy the Chapman-Kolmogorov equations. Under our approach, such an extension seems to be complicated since it involves a functional equation that we are not able to solve. Whereas, in the case of the Poisson-driven model by Anzarut et al. (Citation2018), it arises the well-known Cauchy’s exponential functional equation. Another point to be investigated in future research are the long-memory GD models introduced in Section 4.2. The application of such models to realized volatility, say , indicates that is important to include
in both nonlinear and linear ways in the models to explain Xt. A formal hypotheses testing in this case is more challenge since the null hypothesis belongs to the boundary of the parameter space. We believe that the restricted bootstrap by Cavaliere, Nielsen, and Rahbek (Citation2016) is a great tool to cope this problem and we hope to report results on that soon in a future paper. Finally, other extensions of the GD processes by incorporating stylized features such as unobserved components and jumps with stochastic (possibly self-exciting) intensity (for instance, see Li and Zinna (Citation2018)) are worth investigation.
The supplementary material contains additional numerical results from simulated and real data and an evaluation of the Gaussian Laguerre quadrature for a simple example.
Supplement.pdf
Download PDF (1.7 MB)Acknowledgments
We thank the Editor Prof. Atsushi Inoue, AE and two anonymous Referees for their constructive criticisms that led the article to a substantial improvement.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Abramowitz, M., and Stegun, I. A. (1974), Handbook of Mathematical Functions, With Formulas, Graphs, and Mathematical Tables, New York: Dover Publications, Inc.
- Agosto, A., Cavaliere, G., Kristensen, D., and Rahbek, A. (2016), “Modeling Corporate Defaults: Poisson Autoregressions with Exogenous Covariates (PARX),” Journal of Empirical Finance, 38, 640–663. DOI: 10.1016/j.jempfin.2016.02.007.
- Al-Osh, M. A., and Alzaid, A. A. (1987), “First-Order Integer-Valued Autoregressive (INAR(1)) Process,” Journal of Time Series Analysis, 8, 261–275. DOI: 10.1111/j.1467-9892.1987.tb00438.x.
- Anzarut, M., Mena, R. H., Nava, C. R., and Prünster, I. (2018), “Poisson-Driven Stationary Markov Models,” Journal of Business and Economic Statistics, 36, 684–694. DOI: 10.1080/07350015.2016.1251441.
- Cavaliere, G., Nielsen, H., and Rahbek, A. (2016), “On the Consistency of Bootstrap Testing for a Parameter on the Boundary of the Parameter Space,” Journal of Time Series Analysis, 38, 513–534. DOI: 10.1111/jtsa.12214.
- Corsi, F. (2009), “A Simple Approximate Long-Memory Model of Realized Volatility,” Journal of Financial Econometrics, 7, 174–196. DOI: 10.1093/jjfinec/nbp001.
- Chen, X. B., Gao, J. H., Li, D., and Silvapulle, P. (2018), “Nonparametric Estimation and Forecasting for Time-Varying Coefficient Realized Volatility Models,” Journal of Business and Economic Statistics, 36, 88–100. DOI: 10.1080/07350015.2016.1138118.
- Chen, X. B., Watanabe, T., and Lin, E. (2023), “Bayesian Estimation of Realized GARCH-Type Models with Application to Financial Tail Risk Management,” Econometrics and Statistics, 28, 30–46. DOI: 10.1016/j.ecosta.2021.03.006.
- Contreras-Cristán, A., Mena, R. H., and Walker, S. G. (2009), “On the Construction of Stationary AR(1) Models via Random Distributions,” Statistics, 43, 227–240. DOI: 10.1080/02331880802259391.
- Gaver, D. P., and Lewis, P. A. W. (1980), “First-Order Autoregressive Gamma Sequences and Point Processes,” Advances in Applied Probability, 12, 727–745. DOI: 10.2307/1426429.
- Heber, G., Shephard, N., Sheppard, K., Lunde, A., Sharp, J., Hendricks, D., and Pesch, D. (2020), “Oxford-Man Institute’s Realized Library, version 0.3,” https://realized.oxford-man.ox.ac.uk/data.
- Jacobs, P. A., and Lewis, P. A. W. (1977), “A Mixed Autoregressive-Moving Average Exponential Sequence and Point Process (EARMA 1,1),” Advances in Applied Probability, 9, 87–104. DOI: 10.2307/1425818.
- Jacobs, P. A., and Lewis, P. A. W. (1978), “Discrete Time Series Generated by Mixtures II: Asymptotic Properties,” Journal of the Royal Statistical Society, Series B, 40, 222–228. DOI: 10.1111/j.2517-6161.1978.tb01667.x.
- Joe, H. (1980), “Time Series Models with Univariate Margins in the Convolution-Closed Infinitely Divisible Class,” Journal of Applied Probability, 33, 664–677. DOI: 10.2307/3215348.
- Kahaner, D., Moler, C., and Nash, S. (1989), Numerical Methods and Software, Upper Saddle River, NJ: Prentice Hall.
- Lawrance, A. J., and Lewis, P. A. W. (1977), “An Exponential Moving-Average Sequence and Point Process (EMA1),” Journal of Applied Probability, 14, 98–113. DOI: 10.2307/3213263.
- Leisen, F., Mena, R., Palma, F., and Rossini, L. (2019), “On a Flexible Construction of a Negative Binomial Model, Statistics and Probability Letters, 152, 1–8. DOI: 10.1016/j.spl.2019.04.004.
- Li, J., and Zinna, G. (2018), “The Variance Risk Premium: Components, Term Structures and Stock Return Predictability,” Journal of Business and Economic Statistics, 36, 411–425. DOI: 10.1080/07350015.2016.1191502.
- McKenzie, E. (1985), “Some Simple Models For Discrete Variate Time Series,” Journal of the American Water Resources Association, 21, 645–650. DOI: 10.1111/j.1752-1688.1985.tb05379.x.
- Mena, R. H., and Walker, S. G. (2005), “Stationary Autoregressive Models via a Bayesian Nonparametric Approach,” Journal of Time Series Analysis, 26, 789–805. DOI: 10.1111/j.1467-9892.2005.00429.x.
- Palma, F. & Mena, R.H. (2021). Duality for a class of continuous-time reversible Markov models, Statistics 55, 231–242. DOI: 10.1080/02331888.2021.1881098.
- Pascalau, R., and Poirier, R. (2023), “Increasing the Information Content of Realized Volatility Forecasts, Journal of Financial Econometrics, 21, 1064–1098. DOI: 10.1093/jjfinec/nbab028.
- Pitt, M. K., Chatfield, C., and Walker, S. G. (2002), “Constructing First Order Stationary Autoregressive Models via Latent Processes,” Scandinavian Journal of Statistics, 29, 657–663. DOI: 10.1111/1467-9469.00311.
- Takahashi, M., Watanabe, T., and Omori, Y. (in press), “Forecasting Daily Volatility of Stock Price Index Using Daily Returns and Realized Volatility,” Econometrics and Statistics. DOI: 10.1016/j.ecosta.2021.08.002.