
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This article presents new estimation algorithms for three types of dynamic panel data models with latent variables: factor models, discrete choice models, and persistent-transitory quantile processes. The new methods combine the parameter expansion (PX) ideas of Liu, Rubin, and Wu with the stochastic expectation-maximization (SEM) algorithm in likelihood and moment-based contexts. The goal is to facilitate convergence in models with a large space of latent variables by improving algorithmic efficiency. This is achieved by specifying expanded models within the M step. Effectively, we are proposing new estimators for the pseudo-data within iterations that take into account the fact that the model of interest is misspecified for draws based on parameter values far from the truth. We establish the asymptotic equivalence of the likelihood-based PX-SEM to an alternative SEM algorithm with a smaller expected fraction of missing information compared to the standard SEM based on the original model, implying a faster global convergence rate. Finally, in simulations we show that the new algorithms significantly improve the convergence speed relative to standard SEM algorithms, sometimes dramatically so, by reducing the total computing time from hours to a few minutes.
1 Introduction
This article presents new estimation algorithms for dynamic panel data models with latent variables. Dynamic panel data models are widely used in applied work today. They tend to exhibit many latent variables over multiple periods (e.g., time-invariant, persistent, and transitory components), which are important to capture unobserved heterogeneity and dynamic responses (Arellano and Bonhomme 2017). However, the presence of latent variables brings challenges to the estimation.
Iterative methods like the stochastic expectation-maximization (SEM) algorithm can be useful tools for estimating models with latent variables (Diebolt and Celeux Citation1993).Footnote1 Specifically, as a simulated version of the Expectation-Maximization (EM) algorithm (Dempster, Laird, and Rubin Citation1977), SEM iterates through an E-step where we draw latent variables from the posterior distribution of the model of interests given observables, and an M-step where we estimate the model as if the draws were observables until the parameters converge to the stationary distribution. It simplifies the estimation as it replaces the complex optimization problem, which involves multiple integrals due to latent variables, with a series of much simpler optimization problems under pseudo-complete data.
However, the slow convergence, an often voiced criticism of EM and its variants, tends to diminish its practical appeal. Indeed, the slow convergence issue in practice is even more pronounced: researchers often need to run the algorithms multiple times with different initial guesses and select the result based on criteria such as the likelihood value, to mitigate the negative effects of a “bad” initial guess and to address the possibility of the algorithm converging to a local maximum. Recent research has explored alternative samplers for latent variables when performing the E-step to improve sampling efficiency and stability.Footnote2 In contrast, this article focuses on the potential improvement in the M-step.
In this article, we develop a new estimation method, the PX-SEM algorithm, by combining the parameter expansion ideas in Liu, Rubin, and Wu (Citation1998) with the SEM algorithm. The goal is to facilitate convergence in models with a large space of latent variables by improving algorithmic efficiency. Even though the general concept of the PX-SEM algorithm applies to various models, we focus on three types of dynamic panel data models containing rich latent variable structures, where slow convergence issues are exacerbated, with the expectation that it can be particularly fruitful: (a) dynamic factor models, (b) random effects discrete choice models with persistent and transitory components, and (c) persistent-transitory dynamic quantile models with individual effects.Footnote3
The PX-SEM algorithm consists of two steps: an E-step, where we draw values of latent variables from the posterior distribution, and a PX-M-step, where we update parameters. Having the same E-step as the SEM algorithm, PX-SEM replaces the SEM M-step estimator with a more robust one, taking into account the possibility that E-step draws could violate model assumptions when parameter guesses are far from the true value. The PX-M step estimator is able to leverage additional information from the model itself, effectively “correcting” the M step updates in progressing to more accurate ones.
To implement the PX-SEM algorithm, one must construct an expanded model, the L model, which needs to satisfy two conditions. First, the L model must nest the original model, the O model. Second, there must exist a reduction function, a mapping from the L model parameters to the O model parameters, keeping the observed-data likelihood unchanged. After constructing a suitable L model, we can iterate between the E step and the PX-M step, which involves (a) estimating the L model and (b) mapping back to the O model parameters through the reduction function.
There are different ways to construct L models. All else being equal, a more flexible L model should improve the convergence rate. However, since our ultimate goal is to reduce the total computing time, we also need to consider the time spent in each iteration for estimating the L model and converting it to the O model. Therefore, taking these two factors into account, this article proposes a method to expand the model linearly. Linear expansion addresses the potential violation of zero-correlation assumptions.
In terms of statistical properties, Liu, Rubin, and Wu (Citation1998) proves the monotone convergence of the parameter-expanded EM algorithm and its superior rate of convergence relative to its parent EM. By combining the results of Nielsen (Citation2000) and Arellano and Bonhomme (Citation2016), this article establishes the asymptotic equivalence of the likelihood-based PX-SEM to an alternative SEM algorithm with a smaller expected fraction of missing information compared to the standard O model based SEM, implying a faster global convergence rate and a smaller variance for the limiting stationary distribution. Finally, in the simulations, we show that PX-SEM can significantly improve algorithmic efficiency compared to the standard SEM algorithm, sometimes dramatically so. For example, in our numerical calculations for discrete choice and quantile models, SEM has still not converged even after running for 50–80 min whereas PX-SEM converges within 2–3 min.
This article belongs to an expanding literature that considers the application of the EM algorithm (Dempster, Laird, and Rubin Citation1977) and its variants in estimating latent variable models (Diebolt and Celeux Citation1993; Liu, Rubin, and Wu Citation1998; Arcidiacono and Jones Citation2003; Pastorello, Patilea, and Renault Citation2003; Arellano and Bonhomme Citation2016; Chen Citation2016; Arellano et al. Citation2023, among others). This article contributes to this literature in two ways. First, by developing a new estimation method, PX-SEM, which combines the parameter expansion idea with the SEM algorithm.Footnote4 The method offers appealing theoretical properties and the potential to enhance algorithmic efficiency, which is particularly valuable for complex models such as nonlinear panel data models, where SEM may encounter slow convergence issues. Second, the article proposes a specific class of linear expansions for implementing PX-SEM and develops new estimation algorithms for three types of latent-variable panel data models with enhanced algorithmic efficiency.
The article proceeds as follows. Section 2 illustrates the difference between the standard stochastic EM algorithm and the parameter-expanded stochastic EM algorithm using a simple toy model. In Section 3, a formal definition of PX-SEM is provided, along with a discussion of its statistical properties and implementation based on linear expansions. Sections 4–6 develop PX-SEM methods for three types of latent-variable panel data models: dynamic factor models, discrete choice models, and persistent-transitory dynamic quantile models, respectively. Finally, Section 7 concludes.
2 Toy Model
Based on a simple toy model, this section compares the parameter-expanded stochastic EM (PX-SEM) algorithm with the standard stochastic EM (SEM) algorithm and provides intuitions behind PX-SEM.
Consider the following model we want to estimate, denoted as the O model:
The observed outcomes are , and the latent variables whose distribution is of interest are
. The only unknown parameter is the standard deviation σ.
SEM
To implement the SEM algorithm, we need to start with an initial guess of the unknown parameter , and then iterate the following two steps for
until the convergence of
to the stationary distribution:
1. Stochastic E step: Draw from the posterior distribution
2. M step: Estimate the O model and update , that is
where
is the density function of O model. The final estimator is the average of the last S0 iterations
.
The nonstochastic version, the EM algorithm, is effective because it improves the observed-data likelihood in each iteration:
(1)
(1) where
.Footnote5
PX-SEM
Now we introduce the PX-SEM algorithm. Like SEM, PX-SEM comprises an E step for draws of latent variables and an M step for updating parameters. While sharing the same E-step as SEM, PX-SEM’s M step involves (a) estimating an expanded model, the L model, and (b) mapping L model parameters to the O model parameters.
For this toy model, we propose the following L model:
(L Model)
In addition to σ, the L model also contains an auxiliary parameter k. It is easy to verify that when k = 1, the two models coincide, that is ; and when
, L model expands the O model by allowing for a nonzero correlation between
and ϵi, as
. Moreover, the L model is unidentified with observables: for any L model with parameter values σL and kL, the O model with parameter value
has the same observed data likelihood, that is
.Footnote6
To implement PX-SEM, we begin with an initial guess of the unknown parameter , and then iterate the following two steps for
until the convergence of
to the stationary distribution:
Stochastic E step: Draw
from the posterior distribution
PX-M step: Update parameters by
Estimate the L model:
Reduction: mapping from
The final estimator is the average of the last S0 iterations: . As we see, the difference between the two methods lies in the estimators of the M step: the PX-SEM estimator is adjusted by
.
illustrates how PX-SEM has the potential to enhance algorithmic efficiency through the utilization of the auxiliary parameter k. Specifically, depicts a scatterplot of simulations generated by the data generating process (DGP), the O model with a true value of σ = 2. The X-axis and Y-axis display and ϵi, respectively, but only their sum
is used for estimation.
Fig. 1 Data and E-step draws under different guess values of σ.
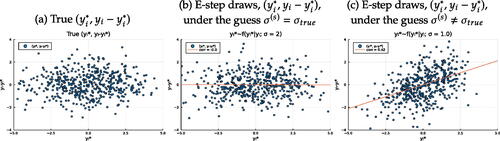
is the scatterplot of where
is the E-step draws under the true value, that is
, and is the scatterplot of
where
is the E-step draws under an incorrect value σ = 1, that is
. Contrary to the case of , where E-step draws are generated under correct guess, and there is no significant correlation between
and
, presents a significant positive correlation between E-step draws
and
, which is assumed to be zero by the O model. This “false” positive correlation arises because the draws are taken under a wrong condition that the variance of
should not deviate significantly from one.
As a consequence, for the E-step draws in , both M-step and PX-M step estimators are consistent: the SEM one is under a correct constraint k = 1. However, in the case of , the M-step of SEM ignores the violation of the zero-correlation assumption at the current draws, while PX-SEM takes into account the “false” correlation by adding the parameter k. By construction, the extra flexibility induced by k leads to a better model fit of the PX-M step for the current draws and thus, a larger pseudo complete data likelihood. As we will show in Section 3, similar to EM, the PX-EM can improve observed-data likelihood in each iteration by transmitting gains from pseudo-complete data likelihood. Therefore, improving model fit as in the PX-M step essentially equates to improving the lower bound of the inequality in (1). Finally, by mapping the L model parameters to the O model parameters keeping the observed-data likelihood unchanged, we preserve the “gains” in likelihood. Intuitively, PX-SEM replaces the SEM M-step with a more robust estimator that leverages additional model information, namely, there is a linear correlation between the E-step draws and
, even though there should not be. Appendix A provides more explanation with illustrative figures.
Regarding the choice of the L model, there are many different ways of expanding the O model. Flexible expansion should help increase the convergence rate. Appendix A compares different L models and PX-M step estimators using the toy model. However, in practice, when we estimate more complex models, we must consider how easily we can estimate the L model and reduce it to the O model to avoid spending too much time in each iteration and increasing the total computing time. With this consideration in mind, we propose a linear expansion method in Session 3 and discuss its applications in Sessions 4–6.
As a final comment, the PX-SEM algorithm aims to enhance algorithm efficiency, even when E-step draws are appropriately obtained. For instance, as demonstrated in Appendix A, PX-SEM improves the convergence rate when the E-step draws are based on direct sampling. In more complex models where direct sampling is not feasible, and methods such as MCMC are required, the PX-SEM algorithm demonstrates lower sensitivity to poorly generated E-step draws. This can be justified if one of the ways that “bad” draws manifest themselves is through violations of model assumptions. Moreover, an MCMC-based E-step generally requires more time for each iteration, so reducing the iterations needed for convergence can significantly reduce the total computing time. For example, as shown in Sections 5 and 6, while SEM can take more than 3000 sec without showing signs of convergence, PX-SEM converges within a couple of minutes.
3 Parameter Expanded Stochastic EM Algorithm
The section begins by defining the PX-SEM algorithm. Following that, we discuss its statistical properties and explore the reasons behind its potential to enhance algorithmic efficiency. Specifically, we establish the asymptotic equivalence between PX-SEM and an alternative SEM with a reduced expected fraction of missing information. Finally, we propose a general approach, the linear expansion method, for the implementation.
3.1 Definition of PX-SEM Algorithm
Setup
Let for
be iid random variables following the distribution of the O model, denoted as
. Here
represents the observable vector,
is the latent-variable vector, and θ is the unknown parameter vector to be estimated. The true value,
, satisfies the equation
, where
represents the score function of the complete O model in the case of the likelihood-based PX-SEM algorithm and moment restrictions in the case of the moment-based one. The law of iterated expectations implies that the true value
also satisfies the equation:
(2)
(2)
Define as the solution of the integrated moment restrictions of the original O model,
, a sample analogy to (2). In the case of a likelihood-based algorithm, we know that
is the MLE.
Denote the expanded model, the L model, as , where K represents the auxiliary parameter vector. The expanded L model needs to satisfy two conditions: (a) The L model nests the O model: There exists K = K0 such that
, and (b) Existence of reduction function: There exists a mapping from the L model parameters to the O model parameters, the reduction function
, such that the observed-data likelihood is preserved:
.
Let denote the score function of the L model with respect to θ in the case of the likelihood-based PX-SEM algorithm and the same moment restrictions as
in the case of the moment-based one. Under condition (a), we have
, and thus
. Additionally, assuming that K is identified when we observe
, meaning that there exists
such that
, we then have
, where
. By the law of iterated expectations, this implies:Footnote7
(3)
(3)
Definition of the PX-SEM algorithm
Before we outline the general steps of PX-SEM, let us take a look at the SEM algorithm for comparison. SEM is an iterative algorithm where, in the E step, we make draws of latent variables from the posterior distribution
under the parameter guess
, and in the M step, we update it to
, which satisfies
. This stochastic version differs from the original EM algorithm as it replaces the integral in (2) with latent draws.
In contrast, the PX-SEM algorithm proposes iterations that are better linked to (3): while we still make draws of latent variables from the posterior distribution
under the parameter guess
, we use the expanded model to update the parameter to
, satisfying
, where
.
The general steps are as follows: starting with an initial guess , we iterate the following two steps for
until
converges to the stationary distribution:
Stochastic E step: Draw
PX-M step: Update parameters by
Estimate L model:
Reduction:
Reduction function
In practice, one of the challenges in implementing the PX-SEM algorithm is to find the reduction function associated with the L model. However, if we construct the L model such that the auxiliary parameter K does not affect the observed-data likelihood, that is , then immediately, the reduction function becomes
. As a result, PX-SEM can be simplified as follows:
Stochastic E step: Draw
PX-M step: Update parameters by solving
Comparing the PX-M and M steps, we find that the M-step estimator is a constrained version of the PX-M-step estimator with the constraint K = K0. Intuitively, when the E-step draws are generated under a guess
close enough to the true value, the M-step estimator is under the correct restriction, leading both the M-step and PX-M-step estimators to be consistent at that iteration, as indicated by (2) and (3).
However, when the guess deviates significantly from the true value, causing the draws
to violate certain model assumptions, we would expect the PX-SEM estimator to exhibit greater “robustness” due to extra flexibility brought by auxiliary parameter K. As shown in the following section, the likelihood-based PX-M step can achieve a larger pseudo-complete data likelihood improvement, which could further lead to a greater observed-data likelihood improvement compared to the M step.
3.2 Statistical Properties
This section focuses on the statistical properties of likelihood-based algorithms. We will first show that the parameter-expanded EM algorithm exhibits nonnegative improvement in the observed-data log-likelihood at each iteration. Next, for the stochastic version, PX-SEM, we will establish its asymptotic equivalence to an alternative SEM algorithm with a smaller expected fraction of missing information compared to the standard O model based SEM, which implies a faster global convergence rate and a smaller variance for the limiting stationary distribution in a semipositive definite order.
Convergence
Following Liu, Rubin, and Wu (Citation1998), we now prove that PX-EM algorithm increases the observed-data likelihood in each iteration. The change in the observed-data log-likelihood between iterations equals
where
.
The equality holds because of both condition (a): When K = K0, two models coincide, meaning , and condition (b): The reduction function exists, and thus by construction
. We then apply Gibbs’ inequality. Finally, the definition of
, which is
, leads to a nonnegative change in observed-data likelihood. Notably, the result also implies that
is a fixed point of PX-EM, where
represents the MLE.Footnote8
As a final remark, the L model nesting the O model implies the following inequality:
where
. Therefore, the parameter expansion technique can be intuitively interpreted as a way to improve the lower bound of the log-likelihood increment compared to the EM algorithm.
Asymptotic properties
We first characterize the dynamics of PX-SEM updates. Define Θ as the joint set of auxiliary and O model parameters, . Accordingly,
represents the vector of true values, and
represents the MLE of the O model. Given any estimate
in the iteration s, PX-SEM generates the next update from a Markov process:
, where
.Footnote9Footnote10 Expanding around
and considering
, as shown in detail in Appendix B, we have
(4)
(4) where, under the correct specification,
is the L model-based complete-data information matrix,
is the L model-based observed-data information matrix,
is the expected fraction of missing information, and
.
The SEM iterations can be characterized in the same way:
(5)
(5) where
represents the O model-based complete-data information matrix,
represents the O model-based observed-data information matrix,
is the expected fraction of missing information, and
. Moreover, PX-SEM and SEM dynamics are closely connected:
where
and
.
We now present the main results of the asymptotic properties, building on Liu, Rubin, and Wu (Citation1998) and Nielsen (Citation2000), with detailed discussions provided in Appendix B.
Theorem 1.
The PX-SEM iteration of is asymptotically equivalent to SEM iteration with observed-data information matrix
and complete-data information matrix
.
Proof.
Let H denote the inverse of matrix A, that is
where, by design,
. Then the coefficient matrix
and the asymptotic variance of the innovation term
in (4) become:
It becomes evident that the PX-SEM process of is asymptotically equivalent to an alternative SEM dynamics, described by (6), which shares the same observed-data information matrix
as the standard SEM in (5), but replaces the original complete-data information matrix
by
.
(6)
(6)
where , and
is the expected fraction of missing information.Footnote11□
Since , under the condition that A is positive definite,
in a semipositive definite order, implying the largest eigenvalue of FPX is no greater than the largest eigenvalue of FSEM. Applying Theorem 1, this comparison in the expected fraction of missing information matrix between PX-SEM and SEM immediately implies the dominance of PX-SEM in convergence rate, as stated in Corollary 1.
Corollary 1.
PX-SEM dominates SEM in global rate of convergence.
Proof.
In Appendix B.2. □
Moreover, Nielsen (Citation2000) provides conditions under which the SEM update is ergodic and characterizes the limiting stationary distribution, based on which Corollary 2 describes the limiting stationary distribution of PX-SEM and compares it with SEM.Footnote12
Corollary 2.
The limiting stationary distribution of PX-SEM updates , conditional on Wi, is
, and unconditionally, is
, with its variances being less than or equal to those of the standard O model-based SEM, that is,
in semipositive definite order.
Proof.
In Appendix B.2. □
Corollary 2 implies that PX-SEM updates exhibit smaller fluctuation along iterations in large samples. Moreover, since the final estimator is the average of the last S0 iterations after convergence, , which converges to the MLE as the number of iterations increases, PX-SEM and SEM estimators share the same asymptotic variance.Footnote13
When the M-step is moment-based, in general, convergence is not guaranteed. Under convergence, the speed does not necessarily dominate SEM. Indeed, Appendix A shows an example where moment-based PX-SEM underperforms SEM for some initial guesses.
However, moment-based PX-SEM may be the preferred choice in practice for at least two crucial reasons. First, in some cases, obtaining GMM estimators is much easier, such as in the quantile model discussed in Section 6. Since our final target is to reduce the computing time, we should consider not only the number of iterations but also the time spent in each iteration. Second, even if obtaining the MLE of the O model is feasible, restricting ourselves to a tractable MLE in the PX-M step can limit the flexibility in building the L model, negatively impacting the convergence rate. Appendix A shows an example of the toy model where the moment-based PX-SEM with a more flexible L model outperforms the likelihood-based PX-SEM, which uses a less flexible L model.
3.3 Implementation based on Linear Expansions
So far, we have shown that a new estimation method, PX-SEM, which combines the parameter expansion technique with the SEM algorithm, has attractive theoretical properties relative to ordinary SEM and the potential to achieve large computational gains.
However, the parameter expansion technique itself does not speak of the selection of the L model. On the one hand, all else being equal, a more flexible L model should improve the convergence rate. On the other hand, we also need to consider the time spent in each iteration to estimate the L model and convert it to the O model since our ultimate goal is to reduce the total computing time. Therefore, another contribution of this article is to propose a specific class of linear expansions, targeting the potential violation of zero-correlation assumptions, which can be generally applied to a wide range of models.
Considering an O model of the form: , where both
and
are known parametric functions up to unknown parameter θ, we propose the following linear expansion to
Footnote14
(L Model)where the auxiliary parameter is given by
.Footnote15
The expansion is straightforward. We assume that the latent variable follows the same distribution as the O model counterpart. However, the E-step draws
, which directly contribute to the measurement equation and observable Yi, result from an affine transformation applied to
. It is easy to check that when A = I, the L model coincides with the O model, whereas when
, it allows us to introduce linear correlations among elements of
. The constraint ensures that the auxiliary parameters do not affect the observed-data likelihood, simplifying the reduction function to
.Footnote16
To implement the PX-SEM algorithm, in the E-step, we draw from the O model based posterior distribution as discussed before. In the PX-M step, we leverage moment constraints or the distribution of
to pin down A and θ.
This method has the advantage that, despite the model of interest being nonlinear, the expansion is linear in latent variables, which are drawn from the E-step and treated as observables in the PX-M step. Thus, we can identify the auxiliary parameters separately through a relatively simple linear model, regardless of the specific form of .
In the following sections, we discuss three applications: (a) dynamic factor models, (b) discrete choice models, and (c) quantile models, for which we propose PX-SEM algorithms based on linearly expanded models.
4 Dynamic Factor Models
The first type of model we discuss is the dynamic factor model (Geweke Citation1977). The appeal of this class of models is their ability to explain variation across multiple dimensions using fewer latent common factors. Applications span multiple fields, including topics in macroeconomics and finance, among others (Bai and Ng Citation2008; Stock and Watson Citation2006, 2011). While we will focus on a specific single-factor O model, it is worth noting that the same approach for implementing the PX-SEM algorithm can be applied to models with multiple latent factors. The O model to be estimated is as follows:
(O Model)where
, and ut is independent of ϵit.
The model contains a latent common factor νt that follows a Gaussian random walk. We observe N different measures, yi, where , over a total of T periods, with each measure associated with a distinct factor loading λi. The set of unknown parameters is denoted as
.Footnote17
SEM
We first explain the SEM procedure. Let . Starting with an initial guess
, we iterate through the E-step and the M-step for
until the convergence of
to the stationary distribution:
Stochastic E step: Draw ν from the posterior distribution
M step: Update
PX-SEM
To implement PX-SEM, we construct a simple L model as follows:
(L Model)where
, and ut is independent of ϵit.
This L model expands the O model by introducing an auxiliary parameter, k, allowing the variance of the persistent shock ut to deviate from 1. Since k can always take the value of 1, making the two models coincide, the L model satisfies condition (a). Moreover, it is easy to verify that reduction function satisfies condition (b), that is
.
With the L model specified and an initial guess , we iterate through the E-step and the PX-M step for
until the convergence of
to the stationary distribution:
Stochastic E step: Draw ν from the posterior distribution
PX-M step:
L model estimation:
Reduction:
The PX-M step estimation of the auxiliary parameter k is straightforward due to the separability of the log-likelihood function. Compared to SEM, the PX-SEM update takes into account potential deviations from the assumption
in the O model. When the guess
is sufficiently close to the true value, we expect
to be close to 1, resulting in similar SEM and PX-SEM updates
. However, when the guess
deviates significantly from the true value, leading to a violation of the assumption
in the E-step draws, PX-SEM adjusts the estimate accordingly. For instance, if
is greater than 1, it suggests scaling down the latent draws ν by a factor of k to ensure
and scaling up λi by the same factor k to maintain the same log-likelihood for observed data.
Remark.
It is easier to see the connection to the proposed linear expansion method after reparameterizing the L model. As detailed in Appendix C, we obtain an alternative expanded model with the reduction function , that is,
, where
, u, and
follow identical distributions to the O model counterparts. Thus, it is evident that the proposed L model belongs to the linear expansions with a specific constraint on matrix Ai: only contemporaneous correlations between
and
are allowed. Despite its advantage of the easy adaptation for various models and a negligible increase in computational burden due to the likelihood separability, in the other two applications, we will explore more flexible L models by relaxing constraints in the matrix A, such as allowing for correlations across periods, to achieve faster convergence.
Simulation Results
presents simulation results for a DGP where and
with N = 3 and T = 200. The x-axis represents the number of iterations
, and the y-axis represents the M-step update
. The blue line depicts the SEM trajectory, whereas the orange line depicts the PX-SEM trajectory. The horizontal green dashed line represents the true value. Starting from a randomly chosen initial guess
, both SEM and PX-SEM updates move toward the true value and stabilize after several iterations. We use the average of the last 500 updates as the final estimate.
Fig. 2 SEM and PX-SEM iterations of from a random initial guess.
NOTE: Iterations of SEM (blue line) and PX-SEM (orange line) based on direct sampling, compared with the true value (green dashed line). SEM estimates (blue diamond) and PX-SEM estimates (orange star) are calculated as the average of the last 500 iterations. Random initial guess generated from a lognormal distribution. .
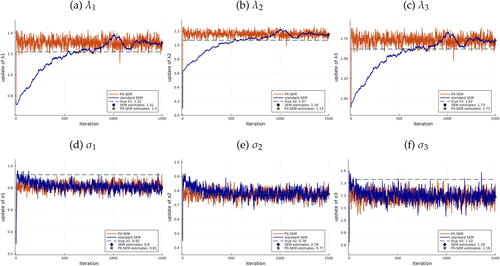
As shown in , for all the parameters, PX-SEM converges almost immediately. However, for SEM, although it also converges relatively fast for , a notable difference is observed in the case of
: it does not converge until 500 iterations.
Regarding volatilities of updates across iterations, Appendix D presents figures with longer trajectories, where we can observe that PX-SEM exhibits smaller volatilities. Appendix D also includes results for larger sample sizes and additional figures plotting cumulative computing time, revealing significant gains, especially for larger samples.
5 Discrete Choice Models
The second type of model we discuss is the random effects discrete choice model with persistent and transitory components. Discrete choice models are widely used in empirical research on various topics, including labor supply (Hyslop Citation1999) and consumer demand (Keane et al. 2013), among others. Distinguishing heterogeneity from persistence is of interest for many reasons, but the nonlinearity and the presence of latent variables complicate the estimation process.Footnote18
In this section, we develop PX-SEM algorithms for a group of discrete choice models with rich latent-variable structures, including time-invariant, persistent, and transitory components. Specifically, the O model is as follows:
where
; and μi, uit, ϵit are mutually independent.Footnote19
For each individual at period
, we observe a vector of independent variable xit of dimension J and a binary (0-1) discrete dependent variable yit, whereas zit, individual effect μi, persistent component νit, and transitory component ϵit are latent. We denote the set of unknown parameters as θ, where
.
SEM
Let . From an initial guess
, we iterate through E-step and M-step for
until
converges to the stationary distribution:
Stochastic E step: Draw
M step: Update
PX-SEM
One option for building the L model is to expand the O model to include only contemporaneous correlations, similar to the dynamic factor model in Section 4. Its advantage lies in the MLE being readily obtained in the PX-M step due to a separable likelihood. Appendix E provides the detailed steps and results of this approach. However, to achieve faster convergence, we now propose a more flexible L model.
Let us define , and
. We construct the following L model:
where
, and
, uit,
are mutually independent; and subject to
, and
, where
and A is a lower triangular matrix with positive diagonal entries. Alongside θ from the O model, the L model contains a vector of auxiliary parameters
.
Following the linear expansion method, we introduce latent variables , and
, which follow the same distributions as their O model counterparts. However, the E-step draws for
, given xi, can result from an affine transformation applied to
, allowing for linear correlations among μi, νi, ϵi, and dependence on xi. The scalar p permits scaling zit and thus the deviation of
from the value of 1. Hence, the L model satisfies condition (a): when
, the two models coincide
.
The L model has two key constraints: and
. Beyond addressing identification, these constraints simplify the reduction function. Specifically, under these constraints, the L model can be written as
, implying no effect of auxiliary parameters p, A, and B on the conditional distribution of yit given xit. Therefore, regarding condition (b), we find a reduction function,
, satisfying
.
Finally, with the L model specified and an initial guess , we iterate through the following two steps for
until
converges to the stationary distribution:
Stochastic E step: Draw
PX-M step:
L model estimation:
Reduction:
where
Simulation Results
We conduct simulations to compare SEM and PX-SEM from a DGP with true parameter values: , and
.
The initial guess is determined as follows: (a) is the Probit regression coefficients of yit on xit, (b) Impose
, and the rest of the parameters are estimates of the linearly approximated model.Footnote20 In the E-step, we employ a random-walk Metropolis-Hastings sampler with an acceptance rate controlled between 20% and 40%.
presents the estimation results of one simulation with N = 5000 and T = 8. Specifically, we plot the M-step updates for 1000 iterations (S = 1000). The blue line depicts each update of SEM, while the orange one represents the PX-SEM updates. In this example, we might be interested in switching to SEM, which is likelihood-based, treating the PX-SEM estimate as an initial guess. Hence, we also present the results of a combined approach, where we run PX-SEM for 500 iterations and then continue with SEM for another 500 iterations, using the average of the last 250 PX-SEM iterations as the initial guess, as shown by the gray line.Footnote21 The green dashed line indicates the true value. The final estimates are the average of the last 250 iterations (
), represented by the blue diamond for SEM, the orange star for PX-SEM, and the gray circle for PX-SEM + SEM.
Fig. 3 SEM and PX-SEM iterations of from an informed guess.
NOTE: Iterations of SEM (blue line), PX-SEM (orange line), and PX-SEM + SEM (gray line) based on 100 MH draws, compared with the true value (green dashed line). Estimates of SEM (blue diamond), PX-SEM (orange star), and PX-SEM + SEM (gray circle) are the average of the last 250 iterations. Informed initial guess.
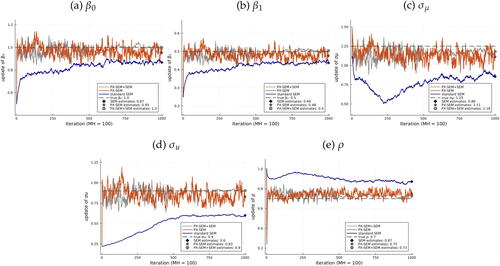
From this comparison, it is clear that starting from the same initial guess, PX-SEM converges almost immediately (within 100 iterations). In contrast, SEM progresses much slower, especially for , and
, and does not converge within 1000 iterations. In terms of the combined approach, the variation across iterations significantly decreases after transitioning to SEM. However, since the final estimates are the average of the last 250 updates, the difference between PX-SEM and PX-SEM + SEM is small.Footnote22
Appendix L provides additional figures where the x-axis is the cumulative computing time. The gain is significant: SEM takes approximately 3000 sec to run 1000 iterations without converging, while PX-SEM converges almost immediately.Footnote23
Appendix H compares algorithms based on random initial guesses. Researchers often run SEM algorithms from various initial guesses and choose one based on specific criteria (e.g., the likelihood value) to avoid obtaining a local maximum, given that getting a “good” initial guess can be challenging. Appendix H shows that the dominance of PX-SEM in convergence rate remains under random initial guesses. Given that this type of exercise is often performed repeatedly in practice, the time saved could be substantial.Footnote24
Finally, Appendix M provides the overall trajectories of SEM and PX-SEM over iterations. Specifically, we conduct 40 simulations using the same DGP, each estimated under a different set of initial guesses shared by both SEM and PX-SEM. For each parameter, we examine the distribution of updates across 40 trajectories at each specific iteration and how this distribution evolves over the iterations for SEM and PX-SEM, respectively. We reach the same conclusion: PX-SEM significantly improves algorithmic efficiency.
6 Quantile Models
The final type of model for which we consider a PX-SEM approach is the persistent-transitory dynamic quantile models with individual effects, as proposed by Arellano, Blundell, and Bonhomme (Citation2017) (referred to as ABB hereafter). The ABB model does not impose functional-form restrictions on the distributions of individual effects, transitory shocks, or conditional distributions of the persistent component. Indeed, the flexible dynamics of the persistent component allow for attractive features such as nonlinear persistence, meaning that the persistence could vary with the size of shocks and accumulated history, which is shown to be empirically prominent in earning dynamics. The model has also been applied to other topics including firm and health dynamics.
Specifically, we focus on the ABB baseline model with an additive fixed effect, discussed in their Appendix.Footnote25 Denote the τth conditional quantile of νit given as
for each
. The O model to be estimated is as follows:
(O Model)where ϵit has zero mean, iid over time, and independent of
and μi. Individual effect μi is assumed to be independent of
and νi.
To estimate this model, we follow Arellano, Blundell, and Bonhomme (Citation2017) and empirically specify the quantile function of νit given , the quantile function of ϵit,
, the quantile function of
, and the quantile function of μi,
, as follows:
where
is Hermite polynomials of order h and
are functions to be estimated.
Arellano, Blundell, and Bonhomme (Citation2017) exploit a variation of SEM for estimation, where the M-step involves a series of quantile regressions instead of likelihood optimization for computational convenience. We first explain their procedures. Let θ denote the set of unknown parameters, including , and
.Footnote26 With an initial guess
, we iterate through the following two steps until
converges to the stationary distribution:
Stochastic E step: Draw μi and νi from the posterior distribution
M step: Update parameters by computing a series of quantile regressions:
where
PX-SEM
We expand the O model linearly targeting the correlations among μi, νi, and ϵi. Define . We build the following L model:
(L Model)subject to
, where
. Similarly, we assume that
has zero mean, iid over time, and independent of
and
, and
is independent of
. The L model contains a vector of auxiliary parameters
.
Consistent with the linear expansion method, E-step draws are assumed to be outcomes of affine transformations through matrix A of
, which follow identical distributions as their O model counterparts. When
, two models coincide, satisfying condition (a). Moreover, with the constraint
, the L model becomes
, implying no effect of K on the observed-data likelihood. Thus, regarding condition (b), the reduction function is
.
Finally, with this L model and an initial guess , we iterate through the following two steps for
until
converges to the stationary distribution:
Stochastic E step: Draw μi and νi from posterior distribution
PX-M step:
L model estimation:
Reduction:
where
The inclusion of matrix A adds complexity to joint estimation due to infeasible separate quantile regressions as in the SEM M-step and the involvement of many more parameters.Footnote27 Thus, we employ two strategies: adding extra constraints on the entries of matrix A and sequential estimation.
Regarding the extra constraints, we assume that ϵit is orthogonal to ,…,
, for
, and the coefficient of
with respect to ϵit is homogenous across all periods. The advantage of doing so is that, by exploiting moment conditions including zero correlation among
, and
, and
following the first-order Markov process as well as
being iid, we can separately estimate matrix A through constrained GMM while restricting the number of unknowns to only two. This further facilitates the sequential estimation strategy. Once obtaining
, we estimate θ through the same series of quantile regressions as in SEM using
. Appendix I provides a detailed discussion of the estimation process.Footnote28
Simulation Results
We simulate from the following DGP ():
(7)
(7) where
, and μi,
, vit, ϵit are mutually independent.
We present results for a persistent-transitory process without time-invariant heterogeneity and heteroscedasticity in the persistent shock by imposing and
. The other parameter values are
. Appendix J provides simulation results for a DGP with time-invariant heterogeneity and heteroscedasticity and another DGP, which is based on a flexible quantile model.
With the simulated data, we estimate the quantile model with time-invariant heterogeneity, as specified previously (the O model), assuming no knowledge of the distribution family. We set the initial guess by estimating the canonical random-walk permanent-transitory model, with details explained in Appendix J. Finally, the highest order of Hermite polynomials for the empirical specification of the νit dynamics, H, is set to two.
presents the results. To provide clearer visualization, instead of plotting the updates of raw parameters in the quantile model directly (due to their large quantity), we plot the iterations of estimated parameter values in the parametric model, (7). Specifically, in each iteration, we estimate the parametric model using E-step draws (μ, ν, and ϵ) for SEM and” corrected” draws (, and
) for PX-SEM. Importantly, these estimates are only for visualizing convergence and are not directly involved in the algorithm updating procedure. Consistent with previous exercises, PX-SEM exhibits rapid convergence for all parameters, whereas SEM converges much more slowly.
Fig. 4 SEM and PX-SEM iterations, .
NOTE: Iterations of SEM (blue solid line) and PX-SEM (orange solid line) based on 100 MH draws, compared with the true value (green dashed line). In each iteration, we estimate the parametric model, (7), using E-step draws μ, ν, ϵ for SEM and “corrected” draws ,
for PX-SEM. These estimates are only used for visualizing the convergence and are not directly involved in any algorithm. SEM estimates (blue diamond) and PX-SEM estimates (orange star) are both calculated as the average of the last 100 iterations. Informed initial guess.
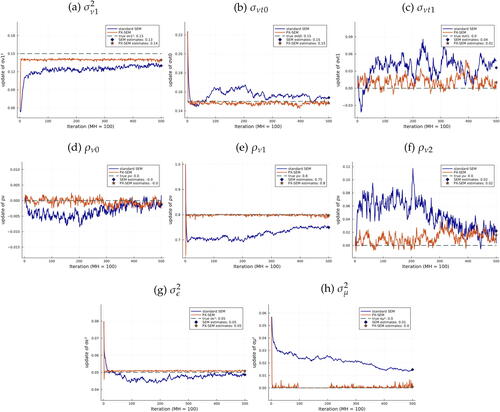
Appendix L provides complementary figures to , with cumulative computing time as the x-axis, showing significant time gain: SEM takes over 5500 sec for 500 iterations without clear convergence, whereas PX-SEM converges almost immediately.Footnote29 Appendix M presents the overall trajectories of 40 iterations. Finally, Appendix K shows simulation results for different sample sizes.
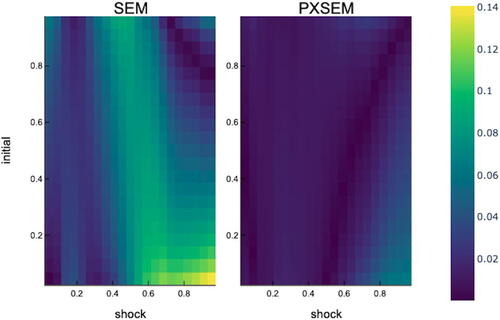
After 500 iterations, averaging the last 100 updates as temporary estimates, we simulate from the estimated models and compare the model fit, focusing on the persistence of the νit dynamics, , one of the characteristics of interest (Arellano, Blundell, and Bonhomme Citation2017). displays heatmaps showing the absolute distance between the estimated persistence and true persistence at different levels of the shock τ and
for SEM and PX-SEM, respectively. Overall, PX-SEM shows a better model fit.
Fig. 5 Distance between estimated persistence and true persistence, . NOTE: The absolute distance between the estimated νt persistence (based on the average of the last 100 iterations) and true persistence for each level of the shock τ and
.
7 Conclusions
This article introduces new estimation algorithms for dynamic panel data models with latent variables. By combining the parameter expansion ideas with the SEM algorithm, we develop the PX-SEM algorithm, which could facilitate convergence in models with a large space of latent variables by improving algorithmic efficiency.
Sharing the same E-step as SEM, PX-SEM differs in the M-step. Instead of estimating the original model (the O model), the M-step of PX-SEM requires estimating an expanded model (the L model). Effectively, we propose new estimators for the pseudo-data within iterations, accounting for the misspecification of the O model for draws based on parameter values far from the truth. Thus, PX-SEM can leverage additional model information to effectively” correct” the M-step updates in progressing to more accurate ones.
Moreover, the article proposes a method for constructing the L model through linear expansion and presents new PX-SEM-based estimation algorithms for three types of dynamic panel data models: factor models, discrete choice models, and quantile models.
Regarding statistical properties, we establish the asymptotic equivalence of the likelihood-based PX-SEM to an alternative SEM with a smaller expected fraction of missing information compared to the standard O model based SEM, implying a faster global convergence rate and a smaller variance for the limiting stationary distribution. Finally, simulations show that PX-SEM can significantly improve the algorithmic efficiency relative to SEM.
Supplementary Materials
The online supplement consists of the following appendices. Appendix A presents illustrative figures for the intuition behind PX-SEM and comparisons among different L models and M-step estimators using the toy model. Appendix B provides a detailed proof for Section 3. Appendix C explains the equivalence through reparameterization among L models. Appendices E, F, and G discuss alternative L models, detailed L model estimation procedures, and PX-SEM methods applied to two extensions for the discrete choice model in Section 5. Appendix I provides detailed L model estimation procedures for the quantile model in Section 6. Appendices D, H, J–M present more simulation results for the three types of models discussed in Sections 4-6, with more iterations, different sample sizes, cumulative computing time, different initial guesses, and overall trajectories.
Supplementary_Materials_for_Review (20).zip
Download Zip (8.3 MB)Acknowledgments
This work is based on Chapter 2 of my PhD thesis at CEMFI, which received the Enrique Fuentes Quintana Funcas Award in Economics, Finance and Business 2021-2022. I am deeply grateful to Manuel Arellano for his invaluable support and advice. I also thank Martin Almuzara, Dante Amengual, Dmitry Arkhangelsky, Orazio Attanasio, Richard Blundell, Stéphane Bonhomme, Micole De Vera, Jose Gutierrez, Pedro Mira, Josep Pijoan-Mas, Enrique Sentana, Liyang Sun, and seminar participants at IE university, CEMFI, International Panel Data Conference, EEA-ESEM, and SAEe meetings for valuable comments and suggestions. Two anonymous referees and an Associate Editor have helped greatly improve the article. All errors are my sole responsibility.
Disclosure Statement
The author reports there are no competing interests to declare.
Additional information
Funding
Notes
1 Arellano and Bonhomme (2017) discusses the potentials of SEM in nonlinear panel data analysis.
2 For instance, Arellano et al. (Citation2023) develops a Sequential Monte Carlo sampler for the E step.
3 Wei (Citation2022) applies the algorithms developed in this article to a substantive analysis of the earnings and employment dynamics of older workers, which brings together elements of the three types of panel models considered here.
4 Liu, Rubin, and Wu (Citation1998) is based on the EM algorithm; Liu and Wu (Citation1999) applies the parameter expansion technique to Bayesian inference; Lavielle and Meza (Citation2007) combines the parameter expansion technique with Monte Carlo EM (Wei and Tanner Citation1990).
5 See Wu (Citation1983) for more discussions.
6 Since k does not affect the L model observed data likelihood,
7 Note that the reduction function satisfies .
8 In the moment-based PX-EM case, if the fixed point with K = K0 exists, then it will satisfy .
9 Note that the E-step draws of PX-SEM are based on the O model under the guess . This is equivalent to making draws from the L model under the guess
, due to condition (a).
10 Appendix B shows that for any L model, an alternative L model can be found by reparameterization, which yields identical updates of θ with the reduction function .
11 That A–V being positive definite implies being positive definite.
12 The author thanks an anonymous referee for his/her encouragement to develop this result.
13 With a fixed S0, the PX-SEM and SEM estimators will in general give rise to different asymptotic variances. Expressions for these variances are provided in Appendix B.
14 In this expression, also includes error terms in the measure equation
.
15 Extensions include unit-specific matrix A (Section 4) and adding exogenous regressor Xi (Section 5).
16 The constraint might not be necessary in applications where reduction functions are easy to find.
17 The method can be easily adapted to models with (a) unknown persistence in the νt process, (b) multiple latent factors, (c) ϵit following an MA process, etc.
18 Chen (Citation2016) proposes a fixed effects EM estimator for a class of nonlinear panel data models.
19 Appendix G presents two extensions: (a) Allowing for the dependence of μi and on
, and (b) Logit (with strategies for the quantile model in the next section).
20 We approximate the model as follows .
21 We could also endogenize the switching procedure by using metrics like the distance between and K0 or the likelihood difference between the L model and the O model to guide our transition to SEM.
22 Whether PX-SEM requires more iterations in this example due to its higher volatility, impacting total computing time, is beyond this article’s scope, especially considering the PX-SEM + SEM option.
23 The results are obtained using a Mac Mini (M1, 2020) with a single processor core. We apply the Metropolis-Hastings algorithm for the E-step, with the first 100 iterations designated as a burn-in phase.
24 Appendix H also presents simulation results with more iterations and different sample sizes.
25 In practice, standard SEM generally performs well in estimating the ABB baseline model without the fixed effect. But it is challenging when a fixed effect is included. We also remove age effects.
26 Unknown parameters also include tail parameters. Functions are piecewise-polynomial interpolating splines on a grid
,…,
. And the tails on
and
are modeled using a parametric model. Please refer to Appendix B in Arellano, Blundell, and Bonhomme (Citation2017) for more details.
27 In the discrete choice model, the matrix A and other auxiliary parameters can be easily estimated in the PX-M step by focusing solely on the first two moments due to the normality assumption.
28 Similar strategies are used to estimate a Logit model in Appendix G.
29 The results are obtained using a Mac Mini (M1, 2020) with a single processor core. We apply the Metropolis-Hastings algorithm for the E-step, with the first 100 iterations designated as a burn-in phase.
References
- Arcidiacono, P., and Jones, J. B. (2003), “Finite Mixture Distributions, Sequential Likelihood and the EM Algorithm,” Econometrica, 71, 933–946. DOI: 10.1111/1468-0262.00431.
- Arellano, M., Blundell, R., and Bonhomme, S. (2017), “Earnings and Consumption Dynamics: A Nonlinear Panel Data Framework,” Econometrica, 85, 693–734. DOI: 10.3982/ECTA13795.
- Arellano, M., Blundell, R., Bonhomme, S., and Light, J. (2023), “Heterogeneity of Consumption Responses to Income Shocks in the Presence of Nonlinear Persistence,” Journal of Econometrics, 240, 105449. DOI: 10.1016/j.jeconom.2023.04.001.
- Arellano, M., and Bonhomme, S. (2016), “Nonlinear Panel Data Estimation via Quantile Regressions,” The Econometrics Journal, 19, C61–C94. DOI: 10.1111/ectj.12062.
- ———(2017), “Nonlinear Panel Data Methods for Dynamic Heterogeneous Agent Models,” Annual Review of Economics, 9, 471–496.
- Bai, J., and Ng, S. (2008), Large Dimensional Factor Analysis. Foundations and Trends[textregistered] in Econometrics (Vol. 3), pp. 89–163, Hanover, MA: Now Publishers. DOI: 10.1561/0800000002.
- Chen, M. (2016), “Estimation of Nonlinear Panel Models with Multiple Unobserved Effects,” Working Paper, Department of Economics, University of Warwick.
- Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977), “Maximum Likelihood from Incomplete Data via the EM Algorithm,” Journal of the Royal Statistical Society, Series B, 39, 1–22. DOI: 10.1111/j.2517-6161.1977.tb01600.x.
- Diebolt, J., and Celeux, G. (1993), “Asymptotic Properties of a Stochastic EM Algorithm for Estimating Mixing Proportions,” Stochastic Models, 9, 599–613. DOI: 10.1080/15326349308807283.
- Geweke, J. (1977), “The Dynamic Factor Analysis of Economic Time Series,” in Latent Variables in Socio-Economic Models, eds. D. J. Aigner and A. S. Goldberger, Amsterdam: North-Holland.
- Hyslop, D. R. (1999), “State Dependence, Serial Correlation and Heterogeneity in Intertemporal Labor Force Participation of Married Women,” Econometrica, 67, 1255–1294. DOI: 10.1111/1468-0262.00080.
- Keane, M. P. (2013), “Panel Data Discrete Choice Models of Consumer Demand,” in The Oxford Handbook of Panel Data, ed. B. H. Baltagi, pp. 548–582, Oxford: Oxford University Press.
- Lavielle, M., and Meza, C. (2007), “A Parameter Expansion Version of the SAEM Algorithm,” Statistics and Computing, 17, 121–130. DOI: 10.1007/s11222-006-9007-6.
- Liu, C., Rubin, D. B., and Wu, Y. N. (1998), “Parameter Expansion to Accelerate EM: The px-em Algorithm,” Biometrika, 85, 755–770. DOI: 10.1093/biomet/85.4.755.
- Liu, J. S., and Wu, Y. N. (1999), “Parameter Expansion for Data Augmentation,” Journal of the American Statistical Association, 94, 1264–1274. DOI: 10.1080/01621459.1999.10473879.
- Nielsen, S. F. (2000), “The Stochastic EM Algorithm: Estimation and Asymptotic Results,” Bernoulli, 6, 457–489. DOI: 10.2307/3318671.
- Pastorello, S., Patilea, V., and Renault, E. (2003), “Iterative and Recursive Estimation in Structural Nonadaptive Models,” Journal of Business & Economic Statistics, 21, 449–509. DOI: 10.1198/073500103288619124.
- Stock, J. H., and Watson, M. W. (2006), “Forecasting with Many Predictors,” Handbook of Economic Forecasting, 1, 515–554.
- ———(2011), “Dynamic Factor Models,” in Oxford Handbook of Economic Forecasting, eds. Michael P. Clements and David F. Hendry, Oxford: Oxford University Press.
- Wei, G. C., and Tanner, M. A. (1990), “A Monte Carlo Implementation of the EM Algorithm and the Poor Man’s Data Augmentation Algorithms,” Journal of the American statistical Association, 85, 699–704. DOI: 10.1080/01621459.1990.10474930.
- Wei, S. (2022), “Income, Employment and Health Risks of Older Workers,” Documentos de Trabajo (CEMFI), (5), 1.
- Wu, C. J. (1983), “On the Convergence Properties of the EM Algorithm,” The Annals of Statistics, 11, 95–103. DOI: 10.1214/aos/1176346060.