Abstract
We consider the problem of locating facilities and allocating servers on a congested network (LASCN). Demands for service that originate from the nodes are assumed to be Poisson distributed and the servers provide a service time that is exponentially distributed. The objective is to minimize the total cost of the system which includes a fixed installation cost, a variable server cost, a cost associated with travel time and a cost associated with the waiting time in the facility for all the customers. The problem is formulated using non-linear programming and subsequently analyzed. Results for exact and approximate solution approaches are reported. We also show that we can modify the approaches to solve the LASCN with constraints limiting both the travel time to the servers and the waiting time of customers.
1. Introduction
This paper belongs to the family of median-type location models on congested networks with fixed facilities. In median location problems the focus is on the average behavior of the system. Congestion occurs when requests for service are generated in a probabilistic fashion and when the capacity of the service facilities is limited. When facilities are fixed, customers travel to the closest facilities to obtain service.
CitationWang et al. (2002) studied the problem of locating facilities modeled as M/M/1 queuing systems. Their objective was to minimize the total cost of the system that consists of the travel cost and waiting time cost of customers subject to service level constraints on the maximum waiting time in all facilities. Customers were assumed to travel to the closest facility to obtain service. CitationBerman et al. (2006) considered a similar model. Their objective was to minimize the total number of facilities and they included an additional constraint on the demand that is lost due to congestion and insufficient coverage.
In a recent paper, CitationBerman and Drezner (2007) introduced a model in which they generalized the type of facilities considered by CitationWang et al. (2002) by modeling the facilities as M/M/k (k ≥ 1) queuing systems. Given p homogenous servers, the problem is to find locations for the service facilities and to allocate the p servers among them. It is assumed that there is a finite set of potential locations for the facilities (e.g., nodes) and customers travel to the closest facility to obtain service.
Given p facilities, the objective function in CitationWang et al. (2002) and in CitationBerman and Drezner (2007) is to minimize the sum of the travel cost and waiting time cost for all customers. In this paper, while the number of servers is also a decision variable, we consider a more realistic objective function which, in addition to travel and waiting time costs, also includes the fixed cost of opening facilities and the variable cost of the servers.
The new objective function introduces more trade-offs. With just the cost of travel and the cost of waiting, the trade-off is between the effect of pooling servers to reduce waiting time (for a discussion see CitationDrezner (1988)) and thus having fewer facilities with more servers in each, and the effect of travel which is reduced when locating more facilities in different locations. With the new objective function, there is also a trade-off between the fixed cost of facilities that gets smaller with fewer facilities, which also reduces the waiting time because of pooling and the variable cost of the servers that declines when we use fewer servers and thus more facilities which also reduces the cost of travel time.
A recent paper by CitationCastillo et al. (2002) considers a similar problem to the one discussed in this paper. The difference is that in CitationCastillo et al. (2002) there is a centralized assignment of customers to facilities and approximations are used for the probability of queuing delay, whereas in this paper customers are assigned to the closest facility and an exact queuing delay formula for the M/M/k is used. As a result the analysis is completely different from that in CitationCastillo et al. (2002).
This paper is different from CitationBerman and Drezner (2007) in that: (i) as mentioned earlier, in this paper the number of facilities is not limited and in the objective function the fixed cost of facilities and the variable cost of servers are also considered; (ii) whereas in CitationBerman and Drezner (2007) the focus in solving the problem is on heuristics, in this paper, following a detailed analysis of the model, we propose an exact solution approach that is shown to be quite efficient in our computational analysis; and (iii) the solution procedures introduced in this paper can be modified to solve an extended model with service level constraints.
Applications of the model introduced in this paper include location of bank branches where the number of teller stations at each branch is an important decision variable and the location of ATM machines where at each location one or more ATMs are built.
Finally, we note that in Aboolian, CitationBerman and Drezner (2006), a minimax-type model of the same problem as that discussed in CitationBerman and Drezner (2007) is introduced (i.e., the objective is to minimize the maximum sum of the travel cost and waiting time cost to customers).
Related location problems with congestion include: the median problem with mobile servers (see for example, CitationBerman et al. (1990)); covering-type models (see for example CitationMarianov and Serra (1998) and CitationMarianov and Rios (2000)); models where demand is a decreasing function of distance and possibly of waiting time (see for example CitationBerman and Drezner (2006)).
This paper is organized as follows. In the next section the problem is formulated. In Section 3 the problem of allocating servers given a facility location is discussed. In Section 4 we discuss solution procedures and in Section 5 computational results are reported. In the last section we conclude with a summary and suggestions for future research.
2. Problem formulation
Let G = (N,L) be a network with a set of nodes N (|N| = n) and a set of links L. We assume that demand is generated at the nodes at a rate of λ i per unit of time for each i ∈ N. The service rate for all servers is μ customers per unit of time. We also assume that the demand and service rates are both Poisson distributed. Let M⊂ N (|M| = m) be a set of potential locations for service facilities. We assume that there is no limit on the number of servers that can be allocated to each facility. Let d ij be the shortest distance between i, j ∈ N.
We will use S⊂ M to denote the set of facilities selected. We assume here that customers do not have any information on waiting times at the facilities and therefore they travel to the closest facility in S. For the time being we assume that there are no ties among closest facilities to a customer point. Later we show that with the exact algorithm we develop we can handle the situation when there are several facilities in S with closest equal distance to a customer point. In that case the demand in that point can be divided equally among the tying facilities. If a facility is located at site j, we call it facility j.
Define λ j (S) to be the arrival rate to facility j∈ S. Then (for simplicity of presentation we assume that there are no tying distances):
The expected waiting time for service at a facility is a function of the arrival rate, service rate and the number of servers at that facility. Let W q(λ, μ, k) be the expected waiting time spent at a facility with k servers each having a service rate of μ, when the arrival rate is λ . We denote by k j (S) the number of servers assigned to facility j∈ S and by vector K(S) = {k j (S) | j∈ S}, an assignment of servers to the facilities in S.
Let ƒ j be the fixed cost of installing servers in facility j∈ S, h be the variable server cost, g be the customer's traveling cost per unit of distance per unit of demand, and v be the customer's waiting cost per unit of time per unit of demand. Then, the problem is:
Consider the following decision variables
Note that each facility j∈ S acts as a M/M/k j (S) queuing system. Let γ j = ∑ i∈ N λ i y ij be the demand rate at facility j∈ M, and let W q(γ j ,μ,k j ) be the waiting time spent at facility j∈ M, which can be computed (see e.g., Winston (1994)), by the following equation:
Given the above definitions, the problem (LASCN) can be formulated as follows:
Constraints (3) forbid assigning a demand to a non-existent facility. Constraints (4) guarantee that each demand is assigned to a facility. Constraints (5) are to ensure that a customer will visit the facility with the smallest traveling time. In constraints (5), ℒ is a large-enough positive number (e.g., ℒ = max j∈ M, i∈ N {d ij }). In constraints (8) we ensure that the expected waiting time cannot be negative (it cannot be infinite because the objective function is a minimization). Note that (LASCN) is a highly non-linear integer program because of its objective function. To solve this problem we develop metaheuristics to find near-optimal solutions and a special purpose algorithm to find the optimal solution. In the next section, we show how to find the optimal assignment vector K*(S) = {k j *(S) | j∈ S} given S.
3. Optimal assignment of servers given a set of facilities
Given S, the objective function can be written as
The following property is a direct result of CitationDyer and Proll (1977).
Property 1. W q(λ j (S),μ,k j ) is decreasing and convex in k j , i.e., W q(λ j (S),μ,k j +1)−W q(λ j (S),μ,k j ) is increasing.
Define K*(S) to be the optimal server assignment vector given S and F(K*(S)) to be the minimum total cost of the waiting and server costs. For simplicity, throughout the paper we refer to F(K*(S)) as the server assignment cost and K as the server assignment vector.
We can find K*(S) and F(K*(S)) using the following result.
Lemma 1. F j (k j ) = hk j +vλ j (S)W q(λ j (S),μ,k j ) is convex in k j , and k j * (the number of servers which minimizes the cost function F j (k j )) can be found by
Proof. F j (k j ) is a sum of linear and convex functions and is thus convex.
We now introduce the following algorithm which finds an optimal assignment for a given set of server sites S.
Algorithm 1
-
Step 1. Follow Steps 1.1 through 1.5 ∀ j∈ S.
-
1.1. Find E j (S) the set of demand points in N such that facility j∈ S is the closest in S. Then set λ j (S) = ∑ i∈ E j (S)λ i .
-
1.2. Find k j = k j min = int[λ j (S)/μ] +1.
-
1.3. If F j (k j +1)−F j (k j ) ≥ 0 then go to Step 1.5.
-
1.4. Set k j = k j +1 and go to Step 1.3.
-
1.5. Set k j *(S) = k j and F j (k j *(S)) = hk j *(S)+v λ j (S)W q(λ j (S),μ,k j *(S)).
-
-
Step 2. Stop. K*(S) = {k j *(S)|j∈ S} is an optimal server assignment and F(K*(S)) = ∑ j∈ S F j (k j *(S)) is the optimal server assignment cost found by Algorithm 1.
4. Solution approaches
In this section we present several solution approaches, exact and approximate. First we present a special-purpose methodology which finds the optimal solution. This methodology is based on a location-allocation procedure where in each iteration the sum of the fixed cost of locating facilities and travel cost of customers is minimized to provide the location of facilities. Given the location of facilities, Algorithm 1 provides the optimal assignment cost by minimizing the sum of the variable cost of servers and waiting times of customers. We note that this general idea was also used recently in a competitive location problem (Aboolian, Sun and Koehler (2007)). However, the problem as well as the approaches used to solve the location and allocation problems in our paper and those in Aboolian, Sun and Koehler (2007) are completely different.
4.1. An exact solution approach
By ignoring the server assignment cost in the (LASCN), we immediately obtain the classical Uncapacitated Facility Location Problem (UFLP), for which many effective solution approaches are available even when the dimensionality is large (see e.g., CitationCornuejols et al. (1990)) and which is formulated as follows:
(UFLP)
Note that (UFLP) is a special case of (LASCN) where the server assignment cost is not considered. Consider Problem (UFLP(l)) as follows:
(UFLP(l))
Consider the following result.
Theorem 1. Define Z UFLP(l)* to be the optimal value for the objective function of (UFLP(l)). Then: (i) Z (UFLP(l))* is non-decreasing in l; and (ii) problem (UFLP(l)) provides the lth best solution of (UFLP).
Proof. We first prove that the role of constraints (13) in (UFLP(l)) is to avoid solutions S*(1), S*(2),…, and 𝒮*(l−1), without forcing any other solution to become infeasible. For any k = 1,2,¨,l−1; consider the following exhaustive cases:
-
Case 1. (∑ j∈S*(r) x j = |S*(r)|): In this case constraints (13) will result in ∑ j∈ M−S*(r) x j ≥ 1, which guarantees that the optimal server site location for (UFLP(l)) will never be S*(r).
-
Case 2. (∑ j∈S*(r) x j < |S*(r)|): In this case constraints (13) will lead to ∑ j∈ M−S*(r) x j ≥ a r , where a r = ∑ j∈S*(r) x j −|S*(r)|+1 ≤ 0, which guarantees that any solution other than S*(r) is feasible for (UFLP(l)) and from the condition of the case it is obvious that the optimal server site location for (UFLP(l)) will never be S*(r).
Therefore, we conclude that for any positive integer values p and q where 1 ≤ p < q, the feasible region of (UFLP(q)) is a subset of the feasible region of (UFLP(p)), and since both of these problems have identical values of the objective function, we obtain Z UFLP(p)* ≤ Z UFLP(q)* and S*(l) is the lth best solution of (UFLP) and Z*UFLP(l) is its value. Hence, the proof is complete.
We note that by Theorem 1, we can define Z UFLP(l)* to be the lth best solution for the (UFLP), which can be found solving (UFLP(l)).
We note that for a given S*(l) (the optimal set of server sites in (UFLP(l))), we can use Algorithm 1 to find K*(S*(l)) = {k j *(S*(l)) | j∈S*(l)} the optimal server assignment and F(K*(S*(l))) = ∑ j∈ S hk j *(S*(l))+vλ j (S*(l))W q(λ j (S*(l)),μ,k j *(S*(l))), the optimal server assignment cost given S*(l). Note that λ j (S*(l)) = ∑ i∈ E j (S*(l))λ i .
Denote F min to be the minimum server assignment cost, such that F min ≤ F(K*(S)) for any S⊂eqN. To find F min consider the following results.
Lemma 2. If ρ = γ/μ k, ![]() =
= ![]() /μ
/μ ![]() , ρ ≤
, ρ ≤ ![]() and
and ![]() < k, then P(γ,μ,k) < P(
< k, then P(γ,μ,k) < P(![]() ,μ,
,μ,![]() ).
).
Proof. From Equation (Equation2) we have:
Thus, the proof is complete.
Lemma 3. If ρ = γ/μ k, ![]() =
= ![]() /μ
/μ ![]() , ρ ≤
, ρ ≤ ![]() and
and ![]() < k, then γ W
q(γ,μ,k) <
< k, then γ W
q(γ,μ,k) < ![]() W
q(
W
q(![]() ,μ,
,μ,![]() ).
).
Proof. From Lemma 2 we have P(γ,μ,k) < P(![]() ,μ,
,μ, ![]() ). Since 0 < ρ ≤
). Since 0 < ρ ≤ ![]() , then:
, then:
Thus, the proof is complete.
Theorem 2. Suppose for a given S, we have γ = ∑
j∈ S
λ
j
(S) and ![]() = ∑
j∈ S
k
j
. Then:
= ∑
j∈ S
k
j
. Then:
Proof. Let ρ = γ/μ ![]() and ρ
j
= λ
j
(S)/μ k
j
, ∀ j∈ S. Consider the following exhaustive cases:
and ρ
j
= λ
j
(S)/μ k
j
, ∀ j∈ S. Consider the following exhaustive cases:
-
Case 1. (|S| = 1): In this case γ = λ j (S) and
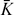 = k
j
, therefore γ W
q(γ, μ, ) = λ
j
(S) W
q(λ
j
(S), μ, k
j
).
= k
j
, therefore γ W
q(γ, μ, ) = λ
j
(S) W
q(λ
j
(S), μ, k
j
). -
Case 2. (|S| > 1 and ρ > ρ j ∀ j∈ S): By definition
= γ/μ ρ = (∑
j∈ S
λ
j
(S))/μ ρ = ∑
j∈ S
(λ
j
(S)/μ ρ) < ∑
j∈ S
(λ
j
(S)/μ ρ
j
) = ∑
j∈ S
k
j
· This contradicts = ∑
j∈ S
k
j
, therefore this case is impossible. -
Case 3. (|S| > 1 and ∃ r∈ S: such that ρ ≤ ρ r ): Since ρ ≤ ρ r and
> k
r
then from Lemma 3, we have γ W
q(γ,μ,) < λ
r
(S)W
q(λ
r
(S),μ,k
r
), therefore γ W
q(γ,μ,) < ∑
j∈ S
λ
j
(S)W
q(λ
j
(S),μ,k
j
).
This concludes the proof.
Theorem 3. Define γ = ∑ i∈ N λ i , and k** = arg min k ≥ int[γ/μ]+1{hk+vγ W q(γ,μ,k)}. Then:
Proof. For a given S, we have γ = ∑ i∈ N λ i = ∑ j∈ S λ j (S). We also have F(K*(S)) = h∑ j∈ S k j *(S)+v∑ j∈ S λ j (S)W q(λ j (S),μ,k j *(S)) ≥ h∑ j∈ S k j *(S)+vγ W q (γ,μ,∑ j∈ S k j *(S)) ≥ hk**+vγ W q(γ,μ,k**) = F min. The first inequality is from Theorem 2, and the second inequality is from the definition of k**. Hence, the proof is complete.
Notice that F min is the sever assignment cost when S is a singleton.
Theorem 4. Denote 𝒵 LASCN* to be the optimal total cost for the (LASCN). Then Z UFLP(1)*+ F min is a lower bound for 𝒵 LASCN* such that 𝒵 LASCN* ≥ Z UFLP(1)*+ F min.
Proof. Z*UFLP(l) is the minimum of the sum of the travel cost and fixed cost, and F min is the minimum of the sum of the waiting cost and variable cost. Therefore, Z*UFLP(l)+ F min is a lower bound for the problem.
Now we present the exact algorithm.
Algorithm 2
-
Step 0. Set l = 1, and Z A = ∞. Find F min using Theorem 3.
-
Step 1. Solve (UFLP(l)) and find S*(l), the optimal set of server sites in problem (UFLP(l)), and set Z UFLP(l)* = ∑ j∈S*(l)(ƒ j +g∑ i∈ E j (S*(l))λ i d ij ). If Z A < Z UFLP(l)*+F min then go to Step 4. Otherwise, go to Step 2.
-
Step 2. ∀ j∈S*(l), find K*(S*(l)) = {k j *(S*(l))|j∈S*(l)} using Algorithm 1. Set F(K*(S*(l)) = h∑ j∈S*(l) k j *(S*(l))+v∑ j∈S*(l)λ j (S*(l))W q(λ j (S*(l)),μ,k j * (S*(l))).
-
Step 3. If Z A > Z UFLP(l)*+F(K*(S*(l)), then set Z A = Z UFLP(l)*+F(K*(S*(l)), S A = S*(l), K A = K*(S*(l)). To find the next best solution for problem (UFLP), set l = l+1 and go to Step 1.
-
Step 4. Stop. Output location set is S A, output allocation set is K A = K*(S A) = {k j *(S A) | j∈S A}, and the objective function value is Z A.
Intuitively, Algorithm 2 starts solving (UFLP(l)) (for l = 1) to find 𝒮*(l), the lth best location for server sites, ignoring the server assignment cost. In Step 1 it also checks to see if this solution may be possibly improved over the current best solution. If it does not, then it stops the algorithm going to Step 4. Otherwise, in Step 2, using Algorithm 1, it finds the optimal server assignment given S*(l). In Step 3, if the total cost of the new solution (including installation, traveling and server assignment costs) is less than the total cost of the current best solution, then the new solution is assumed to be the current best solution. Next, Algorithm 2 looks for the next best solution for (UFLP) (this is done by solving (UFLP(l+1)) in Step 1). This continues until Algorithm 2 reaches a solution in Step 1, for which Z A ≤ Z UFLP(l)*+F min.
Note that the S*(l) and Z*UFLP(l) found when solving (UFLP(l)) will not change whether or not (UFLP(l)) assigns a customer's demand to a single facility or fractions of it to several facilities with equal distances. Therefore, when there are two or more facilities closest to a demand point we can divide the demand equally among the tying facilities in Step 1.1 of Algorithm 1. Therefore, Algorithm 2 can handle the situation when such ties exist.
The following results proves the exactness of Algorithm 2.
Theorem 5. Let Z A be the objective function value produced by Algorithm 2. Then Z A ≤ Z UFLP(l)*+F(K*(S*(l)) for l ≥ 1.
Proof. Define ![]() = arg min {Z
A ≤ Z
UFLP(l)*+F
min} to be the value of l, when Algorithm 2 stops. Consider the following exhaustive cases.
= arg min {Z
A ≤ Z
UFLP(l)*+F
min} to be the value of l, when Algorithm 2 stops. Consider the following exhaustive cases.
-
Case 1. (l <
 ): In this case by the definition of Step 3 in Algorithm 2 we obtain Z
UFLP(l)*+ F(K*(S*(l))) ≥ Z
A.
): In this case by the definition of Step 3 in Algorithm 2 we obtain Z
UFLP(l)*+ F(K*(S*(l))) ≥ Z
A. -
Case 2. (l ≥
): In this case by definition of and F
min, we obtain Z
UFLP(l)*+F(K*(S*(l)) ≥ Z
UFLP(l)*+F
min ≥ Z
UFLP()*+F
min ≥ Z
A. This concludes the proof.
Theorem 6. Let Z A be the objective function value produced by Algorithm 2. Let Z*be the optimal objective function value for problem(LASCN). Then Z A = Z*.
Proof. Note that given the definition of problem (UFLP(l)), it is easy to verify that ∀ S ⊂eqM, ∃ l integer such that S = S* (l). Now, Theorem 6 follows directly from Theorem 5.
Next we present heuristic algorithms to find approximate solutions for larger problems.
4.2. Approximate approaches
The heuristic approaches are based on the observation that once the set S is selected, the number of servers assigned to each node in S can be found by Algorithm 1. Consequently, the problem is converted to finding the best set S. The proposed metaheuristic approaches are similar to those suggested in CitationBerman and Drezner (2007).
4.2.1. The descent approach
We first define the neighborhood of a set S. Since the cardinality of S is not fixed, we consider in the neighborhood of S: (i) subsets with an additional node; (ii) subsets with one node removed from S; and (iii) adding a node to S and removing another node from S (exchange of nodes). The cardinality of the neighborhood is n+|S|(n−|S|) where |S| is the cardinality of S. Once the neighborhood is well defined, the descent algorithm is straightforward: randomly generate a starting subset S; evaluate the change in the value of the objective function for all the subsets in the neighborhood; if an improved subset exists in the neighborhood, move the search to the best subset in the neighborhood. Repeat the process with the new subset until no improved subset exists in the neighborhood. The last subset is the solution.
Note that adding and removing a node from S can be calculated in two steps, first adding a node and then removing a node. The calculation can be streamlined by evaluating the value of the objective function by adding nodes not in S in order. The value of the objective function for the subset S′ (including an extra node) is calculated. The subset S′ is in the neighborhood. As a second phase, a removal of all the nodes in S from S′ are evaluated. The evaluation of the value of the objective function for subsets with one node from S removed, completes the evaluation of all the subsets in the neighborhood.
4.2.2. Simulated annealing
The simulated annealing approach (CitationKirkpatrick et al., 1983) simulates the cooling process of melted metals. The variant used in this paper depends on three parameters: the starting temperature T 0; the number of iterations iter; and the factor α < 1 by which the temperature is reduced every iteration.
Algorithm 3: Simulated annealing
-
Step 1. Start with a randomly generated S and calculate F(S). Set the temperature T to T 0.
-
Step 2. Select randomly a move in the neighborhood of S. The move defines S′.
-
Step 3. Calculate F(S′).
-
Step 4. If F(S′) < F(S) change S to S′ and go to Step 6.
-
Step 5. Otherwise,
• Calculate δ = (F(S′)−F(S))/T.
• Change S to S′ with probability e−δ.
-
Step 6. Set T = α T and go to Step 2 unless the predetermined number of iterations is reached.
-
Step 7. The best encountered solution throughout the process is the resulting solution.
For our test problems the following parameters were used following extensive experimentations: T 0 = 1000, iter = 2000n, and α = 1− (5/iter).
5. (LASCN) with maximum traveling and waiting time constraints
In practice we may want to limit the customer traveling times to the server sites and the waiting time at a server site. Including the waiting time and traveling time constraints in (LASCN) will result in the following mathematical formulation:
(LASCN2)
In this section we show that all methodologies developed in Section 4 can be simply modified to handle constraints (16) and (17). Because of constraints (17), the value of k j min (the minimum number of servers required to serve the demand λ j (S)) is now computed by
The exact approach for (LASCN) with maximum traveling and waiting time constraints is similar to the one presented in Section 4.1 with the following modifications.
| 1. | In (UFLP(l)) when y ij d ij > α, replace d ij with a very large number to ensure that y ij * = 0 when solving (UFLP(l)). | ||||
| 2. | Solving Algorithm 1 to find K*(S*(l)) and F(K*(S*(l)), k j min is found using Equation (Equation18). | ||||
The approximate approaches for (LASCN) with maximum traveling and waiting time constraints is similar to the approach in Section 4.2 with the following modifications.
| 1. | When searching for a given set of server sites, S, accept only those assignments which are feasible considering constraints (16). | ||||
| 2. | Solving Algorithm 1 to find K*(S) and F(K*(S), k j min is found using Equation (Equation18). | ||||
6. Computational results
We tested the algorithms on the set of 40 Beasley problems which are networks designed for the solution of the p-median problems (CitationBeasley, 1990). The parameters used are: ƒ j = 1000, ∀ j; λ i = 1, ∀ i; μ = n/p; v = 1; and h = 50. Two values of g were tested g = 1 and g = 3.
The exact algorithm was coded in C++ and we used CPLEX LP/IP Version 9.0 to solve (UFLP(l)). The program was run on a 2.8 GHz laptop computer with a 256 MB RAM. The descent and simulated annealing algorithms were coded in Fortran, compiled by Intel Fortran 9.0, and run also on a 2.8 GHz laptop computer with a 256 MB RAM.
6.1. Experiments with the exact algorithm
The results for the exact algorithm are summarized in . The third (the seventh) column of the table is the lower bound Z*UFLP(1)+ F min for g = 1 (g = 3). The Best Found Solution (BFS), percent of BFS over the lower bound when the BFS is not known to be optimal and the CPU time are given respectively in the fourth, fifth and sixth columns (eighth, ninth and tenth) for g = 1 (g = 3). Recall that each iteration of the algorithm consists of one set of (UFLP) and the server cost assignment associated with it. We limited the time of an iteration to 30 minutes. Therefore, once a completed iteration took more than 30 minutes the test was terminated and the BFS (which is not known to be optimal) is recorded.
Table 1 Results for the 40 Beasley problems obtained using the optimal algorithm
The following conclusions are drawn from the table.
| 1. | When n ≤ 300 and g = 1 (n ≤ 200 and g = 3) the exact algorithm was able to find the optimal solution in a reasonable time for all problems. | ||||
| 2. | When n ≥ 700 and g = 1 (n ≥ 400 and g = 3) the algorithm failed to find an optimal solution in a reasonable time for all problems. | ||||
| 3. | Even when the optimal solution is not found the best solution is very close to the lower bound (results in columns 5 and 9 are less then 1% away from the lower bound). | ||||
| 4. | When n = 900 for all problems, CPLEX ran out of memory and even the first iteration could not be computed. | ||||
We also performed sensitivity analysis on the parameters of the problem. In , for the first Beasley problem with n = 100 and p = 5 we let μ, h, v, g, ƒ j and λ i change respectively in rows 1–4, 5–9, 10–14, 15–19, 20–24 and 25–28.
Table 2 Varying parameters for the first Beasley problem (n = 100, p = 5)
We make the following observations.
| 1. | The computational time is a decreasing function in μ. | ||||
| 2. | The computation time is a non-increasing function in ƒ j (looks convex), in fact when ƒ j ≤ 250, the optimal solution is not attainable in a reasonable amount of time. Note that this is for n = 100, the smallest size problem in Beasley's samples. | ||||
| 3. | The computational time is a non-decreasing function in v (looks concave). | ||||
| 4. | The exact method's computational time is a non-decreasing function (looks convex) in g and λ. In fact when g ≥ 5 or λ i ≥ 4, the optimal solution is not attainable in a reasonable amount of time. | ||||
| 5. | The exact method's computational time is independent of h. | ||||
6.2. Experiments with the heuristic algorithms
The results of the heuristic algorithms are listed in and . The descent algorithm was repeated 1000 times from 1000 randomly generated starting solutions. The simulated annealing was repeated ten times for each instance so as to require a comparable run time. The BFS (including all known optimal solutions) were found by the descent algorithm and simulated annealing for all problems.
Table 3 Results for the 40 Beasley problems for g = 1 using the heuristic algorithms
Table 4 Results for the 40 Beasley problems for g = 3 using the heuristic algorithms
For g = 1 () we draw the following conclusions.
| 1. | The descent algorithm found the BFS at least 165 times out of 1000 replications for each problem. | ||||
| 2. | It found the BFS in all 1000 replications for 28 of the 40 problems. | ||||
| 3. | It found the BFS in 87.7% of the runs and the average solution was 0.024% over the BFS. | ||||
| 4. | The simulated annealing found the BFS at least four times out of ten replications. | ||||
| 5. | It found the BFS in all ten runs for 30 of the 40 problems. | ||||
| 6. | It found the BFS in 91% of the runs and the average solution was only 0.015% over the BFS. | ||||
For g = 3 () we draw the following conclusions:
| 1. | The descent algorithm found the BFS at least 137 times out of 1000 replications for each problem. | ||||
| 2. | It found the BFS in all 1000 replications for 13 of the 40 problems. | ||||
| 3. | It found the BFS in 73.17% of the runs and the average solution was 0.038% over the BFS. | ||||
| 4. | The simulated annealing found the BFS at least twice out of ten replications. | ||||
| 5. | It found the BFS in all ten runs for 18 of the 40 problems. | ||||
| 6. | It found the BFS in 81.5% of the runs and the average solution was only 0.022% over the BFS. | ||||
Both heuristic algorithms performed extremely well. The g = 3 problems are somewhat harder to solve by the heuristic algorithms compared to the case when g = 1.
7. Conclusions and future research
In this paper we discussed the problem of locating facilities and allocating p servers to the facilities where the facilities behave as M/M/k queueing systems. The objective is to minimize the total cost of the system that is comprised of the fixed cost of opening facilities, the variable cost of servers, the travel cost and the waiting cost of customers.
The paper includes an exact algorithm and heuristics to solve the problem. The exact algorithm is a location allocation procedure. Given a set of facilities the problem of minimizing the server assignment costs is easy since it is proved that the server assignment cost for each facility is convex in the number of servers. Ignoring the server assignment cost the problem is a (UFLP). The overall algorithm is to solve in each iteration a (UFLP) that provides the facilities locations and for each set of locations Algorithm 1 is used to minimize the server assignment cost.
Two heuristic approaches are suggested in the paper: the descent approach and simulated annealing. Both heuristics performed very well (better for a small travel cost) in terms of CPU time and solution quality.
The exact algorithm performs well in terms of CPU time for medium (small) sized problems when the cost of travel is not large (large) and therefore not many (relatively many) facilities are required. The solution quality of the exact algorithm when the time for iterations is limited to 30 minutes is very good. Also, the exact algorithm becomes less efficient when the (waiting cost + variable cost) is not a small portion of the total cost. We see this point in , where it takes much more time to solve the problem when the fixed cost is small (100 and 250). Therefore, we suggest for future research to develop an exact algorithm to solve the problems more efficiently when the total waiting and variable cost is a significant part of the total cost. We believe that a promising direction is to obtain a tighter lower bound. We know that F min, the lower bound for server assignment cost, is based on the case when |S| = 1. Note that we can get tighter lower bounds based on |S| > 1 but finding those values seems to be quite hard. If we can come up with some theoretically sound lower bounds based on any given |S| (and note that as |S| gets larger, the bounds get tighter), we would be able to avoid a lot of solutions for (UFLP(l)) by enforcing the flowing constraint:
Other suggestions for future research are:
| i. | to study the problem discussed in the paper when there are bounds on the number of servers and on the number of facilities; | ||||
| ii. | to study the problem discussed in the paper when locating facilities on the plane; and | ||||
| iii. | to extend the problem to consider also finding optimal pricing for a monopolist when customer demand is a function of price, distance and waiting times. | ||||
Biographies
Robert Aboolian is an Assistant Professor of Operations and Supply Chain Management at the College of Business at the California State University San Marcos. He received his PhD (2002) in Operations Management from the Joseph L. Rotman School of Management at the University of Toronto. His main research interests include location theory, supply chain management and discrete optimization. He has published several articles in refereed journals such as European Journal of Operational Research, Annals of Operations Research, and Journal of Operational Research Society.
Oded Berman is the endowed Sydney Cooper Chair in Business and Technology and the former Associate Dean of Programs at the Joseph L. Rotman School of Management at the University of Toronto. He received his PhD (1978) in Operations Research from the Massachusetts Institute of Technology. He had been with the Electronic Systems Lab at MIT, the University of Calgary, and the University of Massachusetts at Boston, where he was also the Chairman of the Department of Management Science. He has published over 170 articles and has contributed to several books in his field. His main research interests include operations management in the service industry, location theory, network models, and software reliability. He is an Associate Editor for Management Science and Transportation Science, and a member of the Editorial Board for Computers and Operations Research.
Zvi Drezner is a Professor of Information Systems and Decision Sciences at California State University, Fullerton. He received his BSc in Mathematics and PhD in Computer Science from the Technion, Israel Institute of Technology. His research interests are in location theory, metaheuristics and computational statistics. He edited two books and published over 200 articles in refereed journals such as Operations Research, Management Science, IIE Transactions, Naval Research Logistics and others.
Acknowledgements
This paper was partially supported by a NSERC grant awarded to the second author. We would like to thank the referees and associate editor for valuable comments.
Notes
*Optimal.
†The BFS (or optimal solution).
‡Percent of BFS over the lower bound.
#Time in seconds.
*Optimal.
†Number of times BFS found (out of 1000 replications).
#Time in seconds (for all 1000 runs for descent).
*Optimal.
$Lower bound by solving the continuous (UFLP).
†Number of times BFS found (out of 1000 for Descent, ten for simulated annealing).
‡Percent of average solution over the BFS.
#Total time in seconds for all runs.
*Optimal.
$Lower bound by solving the continuous (UFLP).
†Number of times BFS found (out of 1000 for Descent, ten for simulated annealing).
‡Percent of average solution over the BFS.
# Total time in seconds for all runs.
References
- Aboolian , R. , Berman , O. and Drezner , Z. 2006 . “ The multiple server center location problem ” . In Annals of Operations Research (forthcoming)
- Aboolian , R. , Sun , Y. and Koehler , G. 2007 . A location-allocation problem for a web service provider in a competitive market . European Journal of Operational Research , doi: 10/1016/j.ejor.2007.11.057
- Beasley , J. E. 1990 . OR Library-distruting test problems by electronic mail . Journal of the Operational Research Society , 41 : 1069 – 1072 .
- Berman , O. , Chu , S. , Larson , R. C. , Odoni , A. and Batta , R. 1990 . “ Location of mobile servicers in a stochastic environment ” . In Discrete Location Theory , Edited by: Mirchandani , P. B. and Francis , R. L. 503 – 549 . New York, NY : Wiley .
- Berman , O. and Drezner , Z. 2007 . The multiple server location problem . Journal of the Operational Research Society , 58 : 91 – 99 .
- Berman , O. and Drezner , Z. 2006 . Location of congested capacitated facilities with distance sensitive demand . IIE Transactions , 38 : 213 – 221 .
- Berman , O. , Krass , D. and Wang , J. 2006 . Locating service facilities to reduce lost demand . IIE Transactions , 38 : 933 – 946 .
- Castillo , I. , Ingolfsson , A. and Sim , T. 2002 . Socially optimal location of facilities with fixed servers, stochastic demand and congestion , Edmonton, , Canada : University of Alberta School of Business . Management Science Working Paper 02-4
- Cornuejols , M. L. , Nemhauser , G. L. and Wolsey , L. A. 1990 . “ The uncapacitated facility location problem ” . In Discrete Location Theory , Edited by: Francis , R. L. and Mirchandani , P. 119 – 171 . New York, NY : Wiley .
- Drezner , Z. 1988 . On the pooling of services . Interfaces , 18 : 108 – 110 .
- Dyer , M. E. and Proll , L. G. 1977 . On the validity of marginal analysis for allocating servers in M/M/c queues . Management Science , 23 : 1019 – 1022 .
- Kirkpatrick , S. , Gelat , C. D. and Vecchi , M. P. 1983 . Optimization by simulated annealing . Science , 220 : 671 – 680 .
- Marianov , V. and Rios , M. 2000 . A probabilistic quality of service constraint for a location model of switches in ATM communications networks . Annals of Operations Research , 96 : 237 – 243 .
- Marianov , V. and Serra , D. 1998 . Probabilistic maximal covering location—allocation for congested systems . Journal of Regional Science , 38 : 401 – 424 .
- Pasternack , B. A. and Drezner , Z. 1998 . A note on calculating steady state results for an M/M/k queuing system when the ratio of the arrival rate to the service rate is large . Journal of Applied Mathematics and Decision Sciences , 2 : 133 – 135 .
- Wang , Q. , Batta , R. and Rump , C. M. 2002 . “ Algorithms for a facility location problem with stochastic customer demand and immobile servers ” . In Recent Developments in the Theory and Applications of Location Models Part II, Annals of Operations Research , Edited by: Berman , O. and Krass , D. 17 – 34 . Kluwer .
- Winston , W. L. 1994 . Operations Research: Applications and Algorithms, , third edn , Belmonth, CA : Duxbury Press .