Abstract
Analytical models of multi-product manufacturing systems operating under CONWIP control are composed of closed queuing networks with synchronization stations. Under general assumptions, these queuing networks are hard to analyze exactly and therefore approximation methods must be used for performance evaluation. This research proposes a new approach based on parametric decomposition. Two-moment approximations are used to estimate the performance measures at individual stations. Subsequently, the traffic process parameters at the different stations are linked using stochastic transformation equations. The resulting set of non-linear equations is solved using an iterative algorithm to obtain estimates of key performance measures such as throughput, and mean queue lengths. Numerical studies indicate that the proposed method is computationally efficient and yields fairly accurate results when compared to simulation.
1. Background and literature review
Manufacturing industries are under increasing pressure to offer a large variety of products to their customers with shorter lead times and at reduced costs. This has led to a significant interest in pull-type material control systems and their ability to improve factory efficiencies. The CONWIP system proposed by CitationSpearman et al. (1990) is one of the simplest ways to implement pull control. Unlike traditional kanban systems that impose limits on inventory at each manufacturing stage, the CONWIP system uses kanban cards to solely limit the overall inventory in the system (Work In Process (WIP) as well as finished goods inventory). The superiority of the CONWIP system over traditional kanban systems has been argued in several papers including CitationSpearman (1992) and CitationSpearman and Zazanis (1992). Performance comparisons of CONWIP with other systems have been reported in CitationBuzacott and Shanthikumar (1993) and CitationBonvik et al. (2000). A majority of these efforts focus on manufacturing systems with a single product. Recently, there has been significant interest in understanding the impact of WIP limits in multi-product CONWIP systems. Studies such as CitationDuenyas (1994). CitationRyan et al. (2000) and CitationRyan and Vorasayan (2005) argue that when product characteristics (such as routing and processing time requirements) are different, imposing product-specific WIP limits (using dedicated kanbans to individual products) is better than imposing an overall WIP limit (using shared kanbans). However, determining the WIP limits appropriate for individual products requires understanding the complex dynamics of manufacturing systems. The queuing models described in this paper can be used to analyze the impact of WIP limits on performance measures such as throughput, inventory and backorders.
Queuing network models of multi-product manufacturing systems operating under CONWIP control are comprised of multi-class closed networks with fork/join synchronization stations. When the manufacturing system has fairly general characteristics (such as product-specific routings and distinct processing times for each product at the different stations), exact analysis of the underlying queuing network can be very hard. Consequently approximation methods have been used for performance evaluation. CitationRyan and Choobineh (2003) and CitationRyan and Vorasayan (2005) use non-linear programming formulations to determine WIP limits that guarantee desired throughput levels for individual products. CitationHopp and Roof (1998) use statistical throughput control to analyze CONWIP systems, and CitationBaynat and Dallery (1996) use product-form approximations to estimate the performance measures of interest.
This paper proposes a new approach based on parametric decomposition. The approach is based on characterizing the traffic processes (arrival and departure) in the network using mean and variability parameters. Two-moment approximations are used to estimate the performance measures at individual stations, and the traffic process parameters at the different stations are linked using suitable stochastic transformation equations. These result in a set of non-linear equations that is solved to estimate the performance measures of interest. Although the parametric decomposition technique has been extensively used for the analysis of open queuing networks (see Whitt (Citation1983, Citation1994) and CitationBitran and Tirupati (1988) and the references therein), its use in the analysis of closed queuing networks has been limited. CitationKamath et al. (1988) use a parametric-decomposition-based approach to analyze a single-class cyclic network, while more recently, CitationKrishnamurthy and Suri (2006) use a parametric-decomposition-based approach to analyze single-class closed networks with synchronization stations. The key challenge in extending the approach to multi-class networks, is to efficiently model the interactions of the multiple classes while determining performance measures for each class of customers. In this paper, new approximations are derived for the mean waiting times of customers of individual classes at the different stations of the network. These approximations are subsequently used in an iterative procedure that yields the key performance measures of interest. A key feature of this approach is that it can be easily used to study of the effects of variability in multi-product CONWIP systems.
The rest of the paper is organized as follows. Section 2 describes the queuing model of the multi-product system operating under CONWIP control. Section 3 describes the approach used for the analysis of the network. The details of the analysis are discussed in individual subsections. Section 4 summarizes the results of the numerical studies conducted to test the approach, and Section 5 summarizes the conclusions and possible extensions of this research.
2. System model
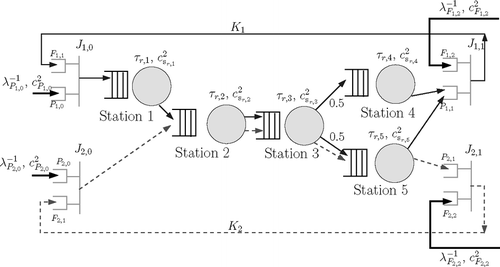
This section describes the queuing network model of a multi-product system with R products (labeled r = 1, …, R) and M manufacturing stations (labeled m = 1, …, M) operating under CONWIP control. It is assumed that the kanban cards are specific to each product, and that there are K r cards for product r. Each manufacturing station is modeled as a single server queue operating under a first-come first-served service discipline. The service time distribution of a product r at a manufacturing station m is described by two parameters: the mean, τ r,m , and the Squared Coefficient of Variation (SCV), c r,m 2. Note that a mean service time of τ r,m implies that the service rate, μ r,m for product r at station m is equal to τ−1 r,m . Fork/join stations are used to model synchronization constraints between: (i) raw materials and CONWIP cards; and (ii) finished goods and customer demands respectively. Each product route has two fork/join stations, J r,i , i = 0, 1 and each fork/join station, J r,i , has two input buffers, P r,i and F r,i+1. illustrates a system with M = 5 and R = 2. The system operates as follows.
Raw materials of product r arrive at buffer P r,0 of the fork/join station J r,0. The raw material arrival process is described by two parameters, namely the mean, λ P r,0 −1, and the SCV, c P r,0 2, of the inter-arrival times. It is assumed that at most K r,0 units of raw materials of product r can queue in buffer P r,0 at any point in time. Free CONWIP cards corresponding to product r queue at the buffer F r,1 of the fork/join station J r,0. When there is at least one unit of raw material in the buffer P r,0 and one free CONWIP card in the buffer F r,1, one entity from each buffer is removed and “joined” to form a combined entity. This combined entity is released to the first manufacturing station in the product's routing.
In the manufacturing system, product r undergoes processing at each station in its routing. The routing for each product r is defined by its routing matrix B r , whose elements b r i,j denote the probability that product r visits station j upon completion of service at station i. B r is a (M+2)× (M+2) matrix, with the indices i = 0 and i = M+1 in b r i,j denoting the upstream fork/join station J r,0, and the downstream fork/join station J r,1, respectively. For simplicity of exposition, it is assumed that the elements b r i,j are such that each product undergoes processing at a manufacturing station at most once, and that b r 0,j = 1 and b r i,M+1 = 1 for some j and i respectively. The method described here can be extended to the case where these assumptions on the routing are relaxed. Note that the routing matrices can be used to define a set V r comprised of the indexes of the manufacturing stations visited by product r, and a set E m comprised of the indices of the products processed at manufacturing station m.
After completing processing at the last manufacturing station in its route, product r is routed to fork/join station J r,1 where it queues in the finished goods buffer, P r,1 to get matched with a customer demand for that product. Customer demands for product r arrive to buffer F r,2 of station J r,1. The demand arrival process of product r is described by two parameters, namely the mean, λ F r,2 −1, and SCV, c F r,2 2, of the demand inter-arrival times. Furthermore, it is assumed that at most K r,1 customer demands for product r can queue in buffer F r,2 at any point in time. At the station J r,1, customer demands in buffer F r,2 and finished products in buffer P r,1 “join” together and exit the system. At the same instant, the CONWIP card attached to the finished product is released and “forks” back to buffer F r,1 to enable the release of another unit of product r into the system. Note that customer demands waiting in buffer F r,2 and products waiting in buffer P r,1 correspond to backorders and finished goods inventory, respectively. In , product 1 has a probabilistic routing described by b 10,1 = b 11,2 = b 12,3 = b 14,6 = b 15,6 = 1 and b 13,4 = b 13,5 = 0.5, while product 2 has a deterministic routing described by b 20,2 = b 22,3 = b 23,5 = b 15,6 = 1. For this network E 1 = (1), E 2 = (1,2), E 3 = (1,2), E 4 = (1), E 5 = (1,2) and V 1 = (1,2,3,4,5), V 1 = (2,3,5).
Fig. 1 Queuing model of multi-product CONWIP system.
3. Overall approach and analysis details
The overall approach is based on parametric decomposition. It has two main features. First, it approximates the traffic processes (arrival and departure processes at the different stations) in the network by renewal processes, and second, it characterizes the distribution of the inter-renewal times of the renewal processes by two parameters, namely the mean and the SCV. In reality, the arrival and departure processes in the network are not renewal. Therefore, the two-parameter characterization is an approximate representation of these traffic processes by “equivalent” renewal processes. The first parameter, corresponding to the mean, is equal to the mean of the corresponding inter-arrival or inter-departure times. The role of the second parameter, corresponding to the SCV of the equivalent renewal process is to account for the complex structure of the arrival and departure processes in an aggregate way. When applied to the analysis of closed queuing networks such as that shown in , the approach consists of four steps.
| 1. | Decomposition. Decomposition of the network yields M manufacturing stations and 2R synchronization stations. Note that, each manufacturing station, m (m = 1,…, M), could serve multiple products, but each synchronization station, J r,i , i = 0,1, is dedicated to product r. | ||||
| 2. | Characterization. Each station obtained from decomposition is analyzed under the assumption that the arrival and service processes at the station are renewal processes characterized by two parameters, the mean and SCV of the inter-renewal times. While the parameters characterizing the service process at the manufacturing station m, and external raw material (at J r,0) and demand arrival processes (at J r,1) are known inputs for the analysis, the parameters characterizing the internal traffic processes in the network are not known. In the characterization step, it is assumed that the two parameters characterizing the arrival process at each station are also known. Using this information, each station is analyzed in isolation to obtain two-moment approximations that describe the departure process and the performance measures at the station. For details see Section 3.1 and 3.2. | ||||
| 3. | Linkage. In this step, the traffic processes at the individual stations are linked together using two key features of the closed queuing network. First, with respect to station m, it is noted that the arrival process is the superposition of the departure process of different products from the preceding station. Second, with respect to product r, it is noted that the sum of the mean queue lengths at the different manufacturing stations and the synchronization stations J r,i in its route for each product r must be equal to its population constraint, K r . Using these facts, expressions that link the mean and SCV parameters of the arrival and departure processes at the different stations are derived. This results in a system of non-linear equations. For details see Section 3.3. | ||||
| 4. | Solution. The system of non-linear equations is solved using an iterative algorithm to determine the unknown parameters characterizing the internal traffic processes. Once these parameters are obtained, the network performance measures such as the system throughput and mean queue lengths at the different stations can be easily computed. For details see Section 34. | ||||
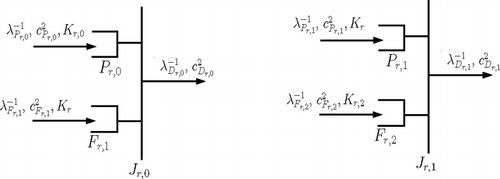
3.1. Characterization of fork/join synchronization stations J r,i .
shows the fork/join synchronization stations, J
r,0 and J
r,1, obtained from the decomposition step. Raw material arrivals to buffer P
r,0 at J
r,0 are characterized in terms of the mean and SCV (λ
P
r,0
−1 and c
P
r,0
2) of the inter-arrival times, and K
r,0, the maximum number of raw material units permitted to queue at P
r,0. Similarly, arrivals of free cards to buffer F
r,1 at J
r,0 are characterized in terms of the mean and SCV of the inter-arrival times (λ
F
r,1
−1 and c
F
r,1
2) and K
r
, the number of kanban cards for product r. The arrival process of free cards from the rest of the network to buffer F
r,1 shuts down when all K
r
cards are in the buffer. This implies that the input to the station J
r,0 is characterized by the parameter six-tuple (λ
P
r,0
, c
P
r,0
2, K
r,0,λ
F
r,1
, c
F
r,1
2, K
r
). Similarly, the input to the station J
r,1 is characterized by the parameter six-tuple (λ
P
r,1
, c
P
r,1
2, K
r
,λ
F
r,2
, c
F
r,2
2, K
r,2). CitationKrishnamurthy et al. (2003) and CitationKrishnamurthy and Suri (2006) analyze fork/join stations characterized by the input tuple (λ
P
r,i
, c
P
r,i
2, K
r,i
,λ
F
r,i+1
, c
F
r,i+1
2, K
r,i+1) and derive expressions for the mean (λ−1
D
r,i
) and SCV (c
D
r,i
2) of the inter-departure times, and the mean queue lengths (![]() P
r,i
and
P
r,i
and ![]() F
r,i+1
) at the buffers (P
r,i
and F
r,i+1). Those results are used as characterization equations for the fork/join stations. For notational simplicity, the following parameters are defined:
F
r,i+1
) at the buffers (P
r,i
and F
r,i+1). Those results are used as characterization equations for the fork/join stations. For notational simplicity, the following parameters are defined:
The expressions for the performance measures are if w r,i ≠1:
Fig. 2 Characterization of fork/join synchronization stations J r,i .
if w r,i = 1
For the system discussed in this paper, the characterization equations for upstream fork/join station J r,0 are obtained by setting i = 0, and K r,1 = K r in the above equations. Similarly, setting i = 1, and K r,1 = K r yields the equations for downstream fork/join station J r,1.
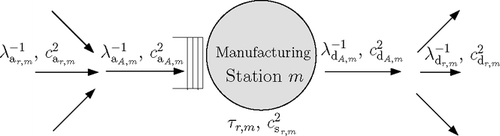
3.2. Characterization of manufacturing stations
shows a manufacturing station m obtained from the decomposition step. It is assumed that the inter-arrival times of product r at station m are characterized by their mean and SCV (λa
r,m
−1 and c
a
r,m
2). Similarly, the service times for product r at station m are characterized by their mean and SCV (τ
r,m
and c
s
r,m
2). In the characterization step, expressions for the mean and SCV (λd
r,m
−1 and c
d
r,m
2) of the inter-departure times and mean queue length (![]() r,m
) are written. The details are presented in the following subsections.
r,m
) are written. The details are presented in the following subsections.
Fig. 3 Characterization of manufacturing station m.
3.2.1. Analysis of departure process
Note that the arrivals to a manufacturing station m is actually the superposition of the arrival processes of the products routed through the station. First, using superposition arguments an aggregate product is defined at station m. Then, the departure process at station m is characterized using the mean and SCV parameters (λa A,m −1, c a A,m 2) of the inter-arrival times, and the mean and SCV parameters (τ A,m and c s A,m 2) of the service time of this aggregate product. (Note that throughout this discussion, the subscript A is introduced to emphasize parameters of the aggregate product.) The analysis in CitationWhitt (1983) and CitationBitran and Tirupati (1988) yield Equations (13)–(16) for these parameters. In particular:
3.2.2. Analysis of mean queue length
Let ![]() q
r,m
denote the mean waiting time in queue at a manufacturing station m for product r. Expressions for the mean queue length,
q
r,m
denote the mean waiting time in queue at a manufacturing station m for product r. Expressions for the mean queue length, ![]() r,m
, of a product r, and the overall mean queue length,
r,m
, of a product r, and the overall mean queue length, ![]() m
, can be written as
m
, can be written as
3.2.3. Determination of f r,m
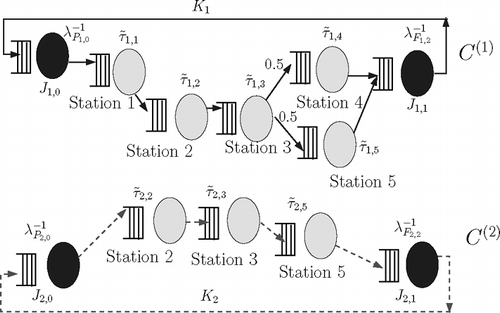
To determine the f r,m , corresponding to each class in the original multi-class closed queuing network, R single-class product-form closed queuing networks, C (r), r = 1, …, R are defined. The stations in C (r) correspond to the manufacturing stations and the fork/join stations, J r,0 and J r,1, in the routing for product r. Product r is routed through stations in C (r) according to its routing matrix B r . To ensure that C (r) has a product-form solution, the following two assumptions are made: one with respect to manufacturing stations, and the other with respect to the fork/join stations.
With respect to the manufacturing stations in C
(r), it is assumed that the service times are exponentially distributed. Additionally, the effect of the other products, r′ ≠ r, are accounted for in an aggregate way using the following argument. From the perspective of a unit of product r waiting in the queue at station m, it is assumed that the station is temporarily unavailable whenever it is processing products of type r′≠ r that are ahead of it in the queue. The effect of server unavailability on product r is accounted for by artificially inflating the mean service times, ![]() r,m
of product r at station m in the network C
(r) by a suitable factor. Since the proportion of time that station m is unavailable for product r is ∑
k∈ E
m
, k≠ r
ρ
k,m
, the mean service time
r,m
of product r at station m in the network C
(r) by a suitable factor. Since the proportion of time that station m is unavailable for product r is ∑
k∈ E
m
, k≠ r
ρ
k,m
, the mean service time ![]() r,m
, is given by
r,m
, is given by
Corresponding to the fork/join stations, J
r,0 and J
r,1, in the original network, two stations with exponential service times are defined. These stations are defined such that the mean queue length of kanbans (the customers in the closed network) at these stations in C
(r) are approximately equal to the mean queue lengths at the corresponding buffers of the fork/join stations in the original network. At station J
r,0, if w
r,0 = 1 it is replaced by a station with infinite servers, with each server having a mean service time of λ−1
D
r,0(K
r,1/2) (K
r,1+1)/(![]() r,0+1). Note that Equation (Equation12) implies that when w
r,0 = 1, the mean queue length at this infinite server station in C
(r) would be exactly equal to the mean queue length at buffer F
r,1 in the original network. If w
r,0≠ 1, it could be argued that free kanbans primarily wait for raw materials and therefore, the fork/join station J
r,0 is replaced by a single exponential server station with mean service time, λ
P
r,0
−1. Similarly, at station J
r,1, if w
r,1 = 1 it is replaced by a station with infinite servers, with each server having a mean service time of λ−1
D
r,1(K
r,1/2) (K
r,1+1)/(
r,0+1). Note that Equation (Equation12) implies that when w
r,0 = 1, the mean queue length at this infinite server station in C
(r) would be exactly equal to the mean queue length at buffer F
r,1 in the original network. If w
r,0≠ 1, it could be argued that free kanbans primarily wait for raw materials and therefore, the fork/join station J
r,0 is replaced by a single exponential server station with mean service time, λ
P
r,0
−1. Similarly, at station J
r,1, if w
r,1 = 1 it is replaced by a station with infinite servers, with each server having a mean service time of λ−1
D
r,1(K
r,1/2) (K
r,1+1)/(![]() r,1+1). Again, Equation (Equation11) implies that the mean queue length at this infinite server station in C
(r) would be exactly equal to the mean queue length at buffer P
r,1 in the original network. When w
r,1≠ 1 the fork/join station J
r,1 is replaced by a single exponential server with mean service time, λ
F
r,2
−1. The equivalent single-class networks are shown in .
r,1+1). Again, Equation (Equation11) implies that the mean queue length at this infinite server station in C
(r) would be exactly equal to the mean queue length at buffer P
r,1 in the original network. When w
r,1≠ 1 the fork/join station J
r,1 is replaced by a single exponential server with mean service time, λ
F
r,2
−1. The equivalent single-class networks are shown in .
Fig. 4 Equivalent single-class networks defined for determination of f r,m .
Under these assumptions, network C
(r) has a product form solution that can be obtained using a suitable method such as a convolution algorithm or Mean Value Analysis to determine performance measures such as the throughput, ![]() r,m
, and the mean waiting time, [Wtilde]
C(r)
q
r,m
, at each station m in C
(r). Next, consider an M/M/1 queue with arrival rate equal to the throughput of the network C
(r),
r,m
, and the mean waiting time, [Wtilde]
C(r)
q
r,m
, at each station m in C
(r). Next, consider an M/M/1 queue with arrival rate equal to the throughput of the network C
(r), ![]() r,m
and exponential service times with mean,
r,m
and exponential service times with mean, ![]() r,m
. Let [Wtilde]
O
q
r,m
be the mean waiting time in this M/M/1 queue. Then, f
r,m
is defined as the ratio of the mean waiting time in C
(r) to the mean waiting time in the M/M/1 queue. Therefore, f
r,m
is written as
r,m
. Let [Wtilde]
O
q
r,m
be the mean waiting time in this M/M/1 queue. Then, f
r,m
is defined as the ratio of the mean waiting time in C
(r) to the mean waiting time in the M/M/1 queue. Therefore, f
r,m
is written as
3.3. Linkage
In the characterization step, the parameters describing the inputs at manufacturing and synchronization stations were assumed to be given, when in fact the parameters characterizing the internal traffic flows need to be determined. This section describes how the equations used to determine these parameters are established for each product r.
Note that the station preceding a manufacturing station j, j ∈ V r , could be either the fork/join station J r,0 (if station j is the first station in the routing for product r) or another manufacturing station i. If station j is preceded by a fork/join station then the departure process parameters at J r,0, (λ D r,0 ,c D r,0 2) are equated to the arrival process parameters (λa r,j ,c a r,j 2) at station j. If station j is preceded by other manufacturing stations i, i ∈ V r , then the departure process parameters (λd r,i ,c d r,i 2) at station i are related to the arrival process parameters (λa r,j ,c a r,j 2) at station j using the routing probabilities, b r i,j . Since the specific linking equations are identical to those specified in Krishnamurthy and Suri (Citation2006, Section 4.3) and Whitt (Citation1983, Section 4.4), the details of these equations are omitted here.
Next, consider arrivals to fork/join stations J r,0 and J r,1 in the routing for product r. Note that, in the routing for product r, station J r,0 is preceded by station J r,1. Therefore, the parameters describing the departure process of free cards at J r,1 (i.e., λ D r,1 , c D r,1 2) need to be related to the parameters describing the arrival process of free cards at buffer F r,1 (i.e., λ a r,j , c a r,j 2) at station J r,0. Unlike station J r,0, station J r,1 is preceded by a manufacturing station (say station i). This implies that the linking equations need to relate the parameters describing the departure process of product r at station i (i.e., λd r,i , c d r,i 2) to the parameters describing the arrival process of product r at buffer P r,1 (i.e., λ P r,1 , c P r,1 2) at station J r,1. The specific linking equations are identical to those specified in Krishnamurthy and Suri (Citation2006, Section 4.3) and the details of these equations are omitted here.
Finally, it is noted that since the system operates under CONWIP control, for each product r, the queue lengths at individual stations should sum up to K r , implying that the following relationship must hold:
The above linking relationships yield a system of non-linear equations in terms of the mean and SCV parameters characterizing the internal traffic processes of each product r. The solution algorithm described in the next section solves this system of equations.
3.4. Solution
The solution algorithm begins with an initial vector, Λ (0) = (λ1,…, λ R ) of throughput estimates and progressively updates the estimates of throughput and different traffic process parameters until they converge (within a user-specified tolerance limit) and are consistent with the input parameters. To improve the efficiency of the algorithm, the search for each λ r is restricted to be between lower and upper bounds, λ r LB and λ r UB. The lower bound, λ r LB, is set equal to zero. The upper bound, λ r UB, is set noting that the throughput, λ r , for each product r in the closed queuing network must be less than min m ∈ V(r)(λ P r,0 , μ r,m , λ F r,2 ). The other inputs to the algorithm are the product routing matrices B r , service time parameters μ r,m , c 2 s r,m , ∀ r ∈ V r , and the population limits K r , K r,0 and K r,2 respectively. The details of the algorithm are provided below. The description assumes that all products are routed sequentially through all M stations. The procedure only requires minor modifications if this is not the case.
In Step 1, the algorithm sets the initial throughput estimates to be equal to the lower bounds. The iterative procedure starts by equating the initial throughput estimate, λ r , to the arrival rate, λa r,1 , at station 1 for each product r. To completely specify the arrival process at station 1, an initial choice of c a r,i 2 is also made. However, the initial choice of λa r,1 and c a r,1 2 might not be consistent with each other. Therefore, in Step 2, the algorithm updates the initial estimate of c a r,1 2 till it is consistent with the current choice of λa r,1 . To update the estimate of c a r,1 2, the algorithm uses the linking and characterization equations derived in the previous sections successively at each station in the routing for product r. Subsequently, the departure process parameters at J r,1 and J r,0 are estimated. Since departures from J r,0 form arrivals to station 1, a new estimate of c a r,1 2 is obtained. If the old and the new estimates of c a r,1 2 are not within a pre-defined tolerance limit, the procedure is repeated for each product r with the new estimate of c a r,1 2. Once the algorithm obtains a value of c a r,1 2 which is consistent with the choice of λa r,1 , in Step 3 the algorithm verifies whether the values of λa r,1 and c a r,1 2 are consistent with the other input parameters of the network. In particular, the algorithm verifies whether the sum of the mean queue lengths at stations in V r sums up to K r for each product r (Equation (Equation28)). If Equation (Equation28) is satisfied within some user-specified tolerance limit, the algorithm terminates. Otherwise in Step 4, the choice of (λ1,…, λ R ) must be updated. Broyden's method (CitationBroyden, 1965) is used to determine a new estimate Λ(new) = (λ(new) 1,…, λ(new) R ). Using this new vector, Steps 2 and 3 are repeated.
Solution algorithm
Given: K r , K r,0, K r,2, μ r,m , c s r,m 2, ∀ r, m
Define: Δ
r
= |![]() r
−K
r
| and Δ = max
r
(Δ
r
); calculate the λ
r
LB, λ
r
UB
r
−K
r
| and Δ = max
r
(Δ
r
); calculate the λ
r
LB, λ
r
UB
Step 1. Initialize: Λ(0) = (λ1 LB , …,λ R LB ), Δ = 1.0 Step 2. While |Δ| > ε1 do 2.1 Initialize c a r,1 2 = min m (c s r,m 2)∀ r, δ = 1 2.2 While |δ| > ε2 do Compute c d r,m 2, c a r,m 2, c D r,0 2, c D r,1 2 ∀, r, m from characterization and linkage equations, compute δ = max r |c a r,1 2−c dr,M 2| and set c a r,1 2 = c d r,M 2∀ r | |||||
Step 3. Compute mean queue lengths | |||||
Step 4. Calculate new estimates of Λ (new) = (λ1 (new), …, λ R (new)) using Broyden's method. | |||||
4. Numerical results
To check the numerical accuracy of the proposed method, the algorithm was implemented in MATLAB (Rev 6.5.1) and executed on an Intel Pentium IV PC. The algorithm converged to yield performance estimates in less than a minute for each scenario (when ε1 = ε2 = 0.01). The results from the analytical model were compared with those obtained from a simulation model built using ProModel (www.promodel.com) and executed on the same PC. The simulation experiment for each scenario took 10 minutes on average. The simulation results were recorded based on five independent simulation runs with a 95% confidence interval. This ensured that the standard deviation of the throughput value from different replications is within ± 0.5 % of the mean. Each run represented the production of at least 200 000 parts. The statistics corresponding to first 50 000 parts were discarded to account for the transient start-up effects. In all the simulation experiments, the random variables corresponding to service times, raw material and demand inter-arrival times were generated using samples from a two-phase Coxian distribution with balanced means. The main performance measures recorded in all experiments were the throughput (λ
r
) and the mean queue lengths at the manufacturing and fork/join stations (![]() r,m
,
r,m
, ![]() F
r,i
and
F
r,i
and ![]() P
r,i
) for each product. To determine the numerical accuracy of the proposed analytical approach, percentage errors between the analytical estimate (A) and the simulation estimate (S) of the performance measures were computed. The percentage errors in throughput and mean queue lengths are computed as
P
r,i
) for each product. To determine the numerical accuracy of the proposed analytical approach, percentage errors between the analytical estimate (A) and the simulation estimate (S) of the performance measures were computed. The percentage errors in throughput and mean queue lengths are computed as
The error in the queue length was computed as a percentage of the total number of customers for product r to avoid the potential problems that might arise when the average queue length itself is small. Next, results from three sets of experiments are reported.
4.1. Experiment 1
In this experiment, the performance of a network with R = 3 products and M = 3 manufacturing stations is analyzed. The products have identical routing, and each product r visits manufacturing stations m = 1, 2 and 3 sequentially. shows the input settings and corresponding outputs for eight different cases (labeled 1–8). In all cases μ
r,m
= 6 for all r,m; λ
P
r,0
= 6 and K
r,0 = K
r,2 = 4 for all r. The results for the eight cases provide insights regarding the impact of different input parameters such as card limits (K
r
), demand arrival rates (λ
F
r,2
) and SCVs (c
P
r,0
2, c
F
r,2
2, c
s
r,m
2) on important performance measures such as throughput (λ
r
), mean queue lengths (![]() r,m
) and average backorders (
r,m
) and average backorders (![]() F
r,2
) for each product.
F
r,2
) for each product.
Table 1 Results for Experiment 1: results are shown for the case where μ r,m = 6, ∀ r,m; K r,0 = K r,2 = 4; λ P r,0 = 6
As seen in , the estimates of throughput (mean queue lengths) are within 6% (8%) of the simulation estimates. The results also provide several design and performance insights for CONWIP systems. Comparing results for case 1 and case 2, respectively, it is observed that an increase in the SCVs results in a decrease in throughput and increase in mean queue lengths (WIP inventory) for each product. Since the total number of cards for each product is constant (and equal to four) in both cases, the increase in mean queue lengths is compensated by a corresponding decrease in the mean queue length of free kanban cards and finished goods inventory at buffers F r,1 and P r,1, respectively. It is also observed that the increase in SCVs results in an increase in the average backorders for each product. A similar effect of SCVs on throughput, WIP and backorders is observed when the results for case 3 and case 4 are compared. Comparison of the results of case 2 and case 4, indicates that as expected in a pull system, throughput increases with demand rates as long as the demand rates are less than the maximum throughput capacity of the system. This increase in throughput is accompanied by a corresponding increase in queue lengths or WIP inventory. Case 5 and case 6 illustrate the impact of card setting on various performance measures. In case 5, K r = 4 for all products, r = 1, 2, 3, while in case 6, K 1 = 4, K 2 = 6, K 3 = 5. Increase in K 2 and K 3 results in an increase in throughput for products 2 and 3. However, as products share capacity of the manufacturing stations, the throughput for product 1 decreases even though K 1 = 4 in both cases. Both the results from simulation and analytical method indicate that the relative increase in throughput is more for product 2 than for product 3. Furthermore, the increase (or decrease) in throughput for a product is accompanied by a corresponding increase (or decrease) in mean queue lengths and average backorders. Similar insights are obtained on comparing results from case 7 and case 8 respectively. Results of case 4 and case 7 also indicate the impact of demand arrival rates on performance measures. Although throughput increases with demand arrival rate, the high rate of demand arrivals also results in a significant increase in backorders.
plots the impact of SCV and card settings on system throughput (sum of the throughputs for the individual products) and mean queue lengths. As before M = R = 3 and all products are sequentially routed through each station. Furthermore, μ r,m = λ P r,0 = λ F r,2 = 6, and K r,0 = K r,1 = 4. Five WIP card settings are considered corresponding to (K 1,K 2,K 3) = (3, 3, 3), (4, 4, 4), (4, 6, 5), (6, 6, 6) and (6, 8, 9) respectively. The system throughput graphs correspond to the cases where c 2 s r,m (= c 2 P r,0 = c 2 F r,2 ) are equal to 0.7 and 2 respectively. It is observed that an increase in the SCVs leads to a decrease in system throughput. The graphs also show that the accuracy in throughput estimates is marginally better for systems with a larger number of cards, and smaller SCV. also plots mean queue length for product 1 and product 3 at station 2 for the case where c 2 s r,m (= c 2 P r,0 = c 2 F r,2 ) is equal to two. It is observed that the algorithm yields reasonably accurate estimates of mean queue lengths at the station.
Fig. 5 Performance insights using the analytical method.
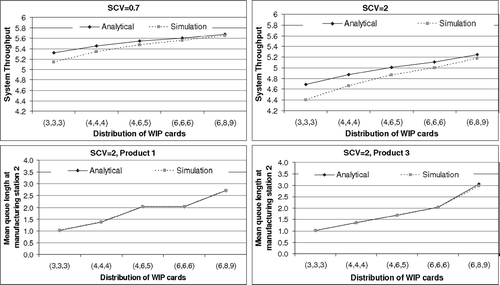
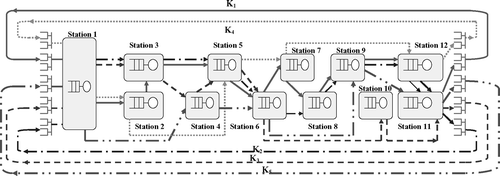
Fig. 6 Queuing network model for system in Experiment 2 with 12 machines and five products.
4.2. Experiment 2
This experiment investigates the performance of the parametric-decomposition-based approach on a larger network. In particular, a system with five products (R = 5) and 12 manufacturing stations (M = 12) is considered. shows the queuing model of the system considered in this experiment, and indicates the product routing and service process parameters (μ r,m and c 2 s r,m ) for each product at each station. The example is similar to Example 3 in CitationBaynat and Dallery (1996), with modifications made in order to explicitly model demand and raw material arrivals for each product. reports performance results corresponding to three different system configurations, namely:
Case 1. λ P r,0 = 6, ∀ r; λ F 1,2 = 0.2, λ F 2,2 = 0.25, λ F 3,2 = 0.3, λ F 4,2 = 0.30, λ F 5,2 = 0.35, K 1 = 6, K 2 = 8, K 3 = 10, K 4 = 7, K 5 = 9. | |||||
Case 2. λ P r,0 = 6, ∀ r; λ F 1,2 = 0.2, λ F 2,2 = 0.25, λ F 3,2 = 0.3, λ F 4,2 = 0.30, λ F 5,2 = 0.35, K 1 = 12, K 2 = 15, K 3 = 11, K 4 = 13, K 5 = 10. | |||||
Case 3. λ P r,0 = 6, ∀ r; λ F 1,2 = 0.25, λ F 2,2 = 0.25, λ F 3,2 = 0.35, λ F 4,2 = 0.40, λ F 5,2 = 0.45, K 1 = 16, K 2 = 20, K 3 = 18, K 4 = 14, K 5 = 19. | |||||
Table 2 Routing and service process parameters for network in Experiment 2
Table 3 Performance results for Experiment 2
In all three cases, c 2 P r,0 = c 2 F r,2 = 1, K r,0 = 8, K r,2 = 4, ∀ r. The results indicate that the throughput estimates for the larger network are within 10% of the simulation estimates for most cases. While the error in estimates appears to increase with network complexity, such trends are observed with other approaches discussed in the literature as well. The next experiment compares the performance of the parametric-decomposition-based approach with two different approaches reported in literature.
4.3. Experiment 3
This section compares the performance of the parametric-decomposition-based approach with the product-form approximation approach proposed by CitationBaynat and Dallery (1996) (Experiment 3.1) and the approach proposed by CitationRyan and Choobineh (2003) (Experiment 3.2). In Experiment 3.1, a network with five products (R = 5) and 12 manufacturing stations (M = 12) is considered. The products have probabilistic routing and the network configuration is same as that considered in Example 3 in CitationBaynat and Dallery (1996). summarizes the results of the comparison. From this experiment, it appears that the error levels in the estimation of throughput using the parametric decomposition method are comparable to those obtained using the product-form approximation approach of CitationBaynat and Dallery (1996) on the same network. Experiment 3.2 considers a network with two products (R = 2) and six manufacturing stations (M = 6). The network configuration is the same as that considered in Example 1 in CitationRyan et al. (2000). summarizes the results of the comparison. From the comparison experiments it appears that the parametric-decomposition-based method yields marginally better estimates of throughput as compared to those reported in CitationRyan et al. (2000).
Table 4 Performance results for Experiment 3.1: comparison with Baynat and Dallery (Baynat and Dallery, 1966)
Table 5 Performance results for Experiment 3.2: comparison with CitationRyan et al. (2000)
5. Conclusions
This paper proposes a parametric-decomposition-based approach for performance evaluation of queuing network models of multi-product systems with CONWIP control. Two-moment approximations are first used to characterize the performance measures at fork/join stations and manufacturing stations in the network. Subsequently, stochastic transformation equations are used to link the traffic processes at the different stations in the network, and the resulting set of non-linear equations is solved using an iterative algorithm to obtain the performance measures of interest.
The approach presented has some qualitative advantages over previous approaches for analysis of closed queuing network models of multi-product CONWIP systems, such as CitationBaynat and Dallery (1996) and CitationRyan and Choobineh (2003). In the product-form approximations used by CitationBaynat and Dallery (1996) the number of unknown parameters (namely the load-dependent arrival and service rates at the different stations) grows with the network population. In contrast, in the parametric-decomposition-based approach, the number of unknown parameters (mean and variability parameters of the traffic processes) is independent of the network population. CitationRyan and Choobineh (2003) use a non-linear programming-based approach to analyze multi-product CONWIP systems. Their approach is tested for several systems operating under exponential service time assumptions and some sensitivity analysis is done using simulation to test the impact of other service time distributions. The approach proposed in this paper, provides a more elaborate model of variability. In particular, the approach explicitly models variability in the arrival processes of raw materials, demand and processing times at the manufacturing stations. Therefore, the effects of different types of variability on system performance can be directly studied.
In terms of numerical accuracy, the approach yields throughput and mean queue length estimates that are comparable to that of the product-form approximation approach in CitationBaynat and Dallery (1996), and marginally better than than obtained using the approach reported in CitationRyan et al. (2000). Although a more exhaustive study of the different approaches is required to provide more conclusive comparison results, it does appear that the parametric decomposition approach provides an alternative method for performance evaluation that avoids the need to compute multiple load-dependent arrival and service rates, and yet provides performance estimates with comparable accuracy. Finally, the approach can be used to develop efficient decomposition-based approaches for multi-stage multi-product systems under pull-type controls with batch size and set up constraints. Parametric decomposition approaches based on two-moment approximations closely lend themselves to the analysis of such systems without significant increase in computational complexity (CitationVandaele et al., 2002; CitationSatyam and Krishnamurthy, 2006). These extensions are currently being investigated.
Biographies
Kumar Satyam is a Ph.D. candidate in the Department of Decision Sciences and Engineering Systems at Rensselaer Polytechnic Institute (RPI), located in Troy, NY, USA. He holds a Master's degree (M.S.) in Industrial and Management Engineering from RPI, and a Bachelor's degree (B.Tech) in Industrial Engineering from the Indian Institute of Technology (IIT), Roorkee, India. His current research focuses on performance evaluation of multi-product systems operating under various forms of pull-control strategies. He is a member of INFORMS and IIE.
Ananth Krishnamurthy is an Assistant Professor in the Department of Decision Sciences and Engineering Systems at Rensselaer Polytechnic Institute (RPI), located in Troy, NY, USA. He obtained his Ph.D. from the University of Wisconsin-Madison in 2002. His research focuses on topics including production inventory control, assembly operations, material handling and warehouse systems, product variety, customization, lead time reduction and quick response manufacturing. He is a member of INFORMS, IIE, SME and APICS.
References
- Baynat , B. and Dallery , Y. 1996 . A product-form approximation method for general closed queuing networks with several classes of customers . Performance Evaluation , 24 : 165 – 188 .
- Bitran , G. R. and Tirupati , D. 1988 . Multiproduct queuing networks with deterministic routing: decomposition approach and the notion of interference . Management Science , 34 ( 1 ) : 75 – 100 .
- Bonvik , A. M. , Dallery , Y. and Gershwin , S. B. 2000 . Approximate analysis of production systems operated by a CONWIP/finite buffer hybrid control policy . International Journal of Production Research , 38 ( 13 ) : 2845 – 2869 .
- Broyden , C. G. 1965 . A class of methods for solving non-linear simultaneous equations . Mathematics of Computation , 19 : 577 – 593 .
- Buzacott , J. A. and Shantikumar , J. G. 1993 . Stochastic Models of Manufacturing Systems , Englewood Cliffs , NJ : Prentice Hall .
- Duenyas , I. 1994 . A simple release policy for networks of queues with controllable inputs . Operations Research , 42 : 1162 – 1171 .
- Hopp , W. and Roof , M. 1998 . Setting WIP levels with statistical throughput control (STC) in CONWIP production lines . International Journal of Production Research , 36 : 867 – 882 .
- Kamath , M. , Suri , R. and Sanders , J. L. 1988 . Analytical performance models for closed-loop flexible assembly systems . The International Journal of Flexible Manufacturing Systems , 1 ( 1 ) : 51 – 84 .
- Krishnamurthy , A. and Suri , R. 2006 . Performance analysis of single stage kanban controlled production systems using parametric decomposition . Queuing Systems: Theory and Applications , 54 : 141 – 162 .
- Krishnamurthy , A. , Suri , R. and Vernon , M. 2003 . “ Two-moment approximations for throughput and mean queue length of a fork/join station with general input processes ” . In Stochastic Modeling and Optimization of Manufacturing Systems and Supply Chains , Edited by: Shantikumar , J. G. , Yao , D. D. and Zijm , W. H.M. 87 – 126 . Kluwer .
- Ryan , S. M. , Baynat , B. and Choobineh , F. 2000 . Determining inventory levels in a CONWIP controlled job shop . IIE Transactions , 32 : 105 – 114 .
- Ryan , S. M. and Choobineh , F. 2003 . Total WIP and WIP mix for a CONWIP controlled job shop . IIE Transactions , 35 ( 3 ) : 405 – 418 .
- Ryan , S. M. and Vorasayan , J. 2005 . Allocating work in process in multi-product CONWIP system with lost sales . International Journal of Production Research , 43 : 223 – 246 .
- Satyam , K. and Krishnamurthy , A. Analytical models for multi-product pull systems with batch sizes . Presented at the Industrial Engineering Research Conference . Orlando , FL .
- Spearman , M. 1992 . Customer service in pull production systems . Operations Research , 40 : 948 – 958 .
- Spearman , M. , Woodruff , D. and Hopp , W. 1990 . CONWIP: A pull alternative to kanban . International Journal of Production Research , 28 : 879 – 894 .
- Spearman , M. and Zazanis , M. 1992 . Push and pull production systems: Issues and comparisons . Operations Research , 40 : 521 – 532 .
- Vandaele , N. , Boeck , L. D. and Callewier , D. 2002 . An open queuing network for lead time analysis . IIE Transactions , 34 : 1 – 9 .
- Whitt , W. 1983 . The queuing network analyzer . The Bell System Technical Journal , 62 ( 9 ) : 2779 – 2815 .
- Whitt , W. 1994 . Towards better multi-class parametric decomposition approximations for open queuing networks . Annals of Operations Research , 48 : 221 – 248 .