Abstract
We propose an approximate evaluation procedure for a kanban-controlled production system with two stages and multiple products. In the first stage, single-product manufacturing facilities produce items that are the input material for a single multi-product manufacturing facility in the second stage. Each manufacturing facility is controlled by a distinct kanban loop with a fixed number of kanbans. Processing and setup times are exponentially distributed, demand arrivals at the output store of the second stage are Poisson and independent for each product. If a customer's demand cannot be met from stock, the customer either waits or leaves the system, depending on the admissible number of backorders and the current number of waiting customers (partial backordering). We describe a new decomposition-based approximation method for the evaluation of such systems in steady state. We focus on the performance measures average fill rate, average fraction of served demand, and average inventory level. We report the results of several numerical tests. The results indicate that the approximation is sufficiently accurate for a large variety of systems. We also illustrate the effects of increasing the maximum number of backorders on the performance of the system.
1. Introduction
Several empirical studies document that kanban control bears great potential to significantly improve operations (e.g., CitationWhite et al. (1999), CitationFullerton and McWatters (2001) and CitationWhite and Prybutok (2001)). The main advantage of a kanban control system is its simplicity. Although there is not the kanban system, one principle is common to all variants: production, or some other kind of operation, may only take place if there is a deficit, that is, if less containers with processed items are at hand than desired.
In the classic kanban system, the number of full containers that should be on stock determines the number of cards, or “kanbans”, that circulate in the system (e.g., CitationMonden (1998)). Since full containers must always have a kanban attached to them and since those kanbans must be removed when a container is depleted, the number of free, or “active”, kanbans signals the current deficit. Active kanbans are usually collected at one place (for example, a scheduling board) that is close to the person responsible for the operation. As a result, that person always has all the information necessary to decide whether to continue processing without the need to receive explicit orders from a planning department and without running the risk of producing unwanted surplus. In the literature many different versions of kanban systems or pull control policies are described (e.g., CitationBuzacott and Shanthikumar (1993), CitationGershwin (2000) and CitationDallery and Liberopoulos (2000)). However, most of them are very similar and only differ in their details.
Determining the appropriate number of kanbans is crucial for the performance of the system. If this number cannot be found by trial and error during the first days of operation, then procedures are needed to evaluate the performance of the system for any number of cards that might be optimal. Simulation models could be used to determine the system's performance, but optimizing a system using a simulation model as the evaluation tool is cumbersome. Fast analytical procedures are needed, even if they may only be able to approximate the true performance of the system.
A number of analytical procedures have been proposed for single- and multi-stage kanban systems with one type of product (single-stage: CitationJordan (1988), Wang and Wang (Citation1990, Citation1991), CitationDi Mascolo (1996), CitationKim and Tang (1997), CitationNori and Sarker (1998) and CitationSeki and Hoshino, 1999; multi-stage: CitationSo and Pinault (1988), CitationDeleersnyder et al. (1989), CitationKarmarkar and Kekre (1989), Berkley (Citation1990, Citation1991, Citation1992), Mitra and Mitrani (Citation1990, Citation1991), Di Mascolo et al. (Citation1992, Citation1996), CitationBuzacott and Shanthikumar (1993), CitationDe Araújo et al. (1993), CitationDi Mascolo et al. (1993), CitationTayur (1993), CitationSchmidbauer and Röesch (1994), CitationSiha (1994), CitationAlbino et al. (1995), CitationGstettner and Kuhn (1996), CitationFujiwara et al. (1998), CitationBonvik et al. (2000) and CitationBaynat et al. (2001)).
Some approaches are available for single-stage multi-product kanban systems (CitationAskin et al. 1993; CitationKrieg and Kuhn, 2002, Citation2004). In the context of stochastic lot scheduling problems, CitationFedergruen and Katalan (1996) and CitationMarkowitz et al. (2000) analyze systems very similar to the single-stage multi-product kanban systems studied by CitationKrieg and Kuhn (2002). Altiok and Shiue (Citation1994, Citation1995, Citation2000) analyze stochastic “multi-product pull-type production/ inventory systems,” which are equivalent to single-stage multi-product kanban systems with a shared manufacturing facility (see also CitationAltiok, 1997).
In this paper, we extend the procedure given in CitationKrieg and Kuhn (2004) for the analysis of single-stage multi-product kanban systems to kanban-controlled systems with multiple products and two stages. We also consider the possibility of partial backordering. In future research, the new procedure proposed here is also expected to prove instrumental as a building block for the analysis of multi-product kanban systems with an arbitrary number of stages.
The rest of this paper is organized as follows. In Section 2, we give a detailed description of the considered system. In Section 3, we show that although the system could be modeled exactly by a continuous-time Markov chain, the size of the state space prohibits the construction and solution of the exact model for most system sizes. We then develop a decomposition-based procedure to approximate the performance of the system in steady state (Section 4). We focus on the performance measures average fill rate, average fraction of served demand and average inventory level. The accuracy of the approximation is indicated in Sections 5 and 6 via comparisons with results from exact analysis and simulation. In Section 7, we illustrate the effects of increasing the maximum number of backorders on the performance of the system. We conclude with a short summary and suggestions for future research.
2. Description of the system
In this paper, we consider a production system with two stages. In stage 1, r single-product manufacturing facilities process items of r different products (one product per manufacturing facility). These items are processed further in a single multi-product manufacturing facility in stage 2 (:model_Mitra_Mitrani_like depicts such a system with three different products). Each manufacturing facility is controlled by a distinct kanban loop with a fixed number of kanbans, K i (1) and K i (2), i = 1,…,r (in , the kanban loops are indicated by dashed lines). Processed items of both stages are carried, stored and requested in standard containers with a fixed, product-specific filling quantity (in , the flow of products is indicated by arrows with regular lines). The filling quantity is the minimum manufacturing lot size for a product, and any other lot size is an integer multiple of this filling quantity.
Fig. 1 Model of a kanban system with two stages and three different products (adapted from Mitra and Mitrani (Citation1990, )).
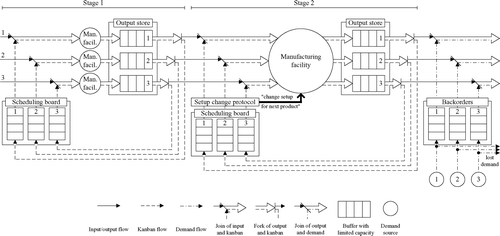
Customers arrive to the output store of stage 2 according to Poisson processes with rate λ i , i = 1,…,r (in , the demand sources are depicted by the numbered circles in the bottom right-hand corner, the demand flow is indicated by arrows with alternately dashed and dotted lines). Each customer demands one container of a single product. Should no full container be available to fill the customer's demand, then this demand is backordered (in , backordered demand accumulates in the buffers on the right-hand side). For each product i, the maximum number of backorders is restricted by B i max. A customer who arrives at the system when the maximum number of backorders is reached leaves the system immediately and satisfies his or her demand elsewhere.
Input material for the first stage is always available in the required quantities. After a container in stage 1 has been filled, it is transferred to the output store of the stage. Each manufacturing facility in stage 1 can only process items of one specific product. We define that manufacturing facility i always produces items of product i. No setup activities are required in stage 1. The time to fill a container in stage 1 is exponentially distributed with mean 1/μ i (1), i = 1,…,r.
The items processed in stage 1 are the input material for stage 2. Just before the manufacturing facility of stage 2 starts processing items, it removes the required input material from the output store of stage 1. The time to fill a container in stage 2 is exponentially distributed with mean 1/μ i (2), i = 1,…,r. The time to set up the manufacturing facility in stage 2 for product i is exponentially distributed with mean s i (2), i = 1,…,r.
The condition for a setup is that at least one active kanban and one container with input material must be available. Once the manufacturing facility in stage 2 has been set up for a product, it processes items of this product until either the number of active kanbans is zero, that is, all empty containers for the product are filled, or the number of containers with input material is zero (exhaustive processing with limited input material). Then the manufacturing facility is being set up for the next product that meets the setup condition. The order in which products are considered for production is stipulated by a predetermined fixed setup sequence. For ease of presentation, we only consider setup sequences that result from a rotation cycle, that is, a setup cycle with one setup change per product. Without loss of generality, we use the setup cycle (1, 2, …, r).
Should no product meet the setup condition at the end of a production run, then the manufacturing facility idles until there is at least one active kanban and one container with input material for a product. During an idle period the current setup of the manufacturing facility is preserved, that is, if the first product to meet the setup condition is the same product that was manufactured last, then no additional setup activities are required and production can resume instantly.
3. Exact model
The pieces of information that must be represented in an exact model of this system are the current state of the manufacturing facility in stage 2 and, for each product, the number of full containers in the output store of stage 1 and the number of active kanbans and backorders in stage 2. It is not necessary to explicitly represent the number of active kanbans for a product in stage 1 because this number can be derived directly from the number of full containers and the total number of kanbans in stage 1. It is also not necessary to explicitly represent the number of full containers in the output store of stage 2 because this number can be derived directly from the number of active kanbans and the total number of kanbans in stage 2. Lastly, it is also not necessary to explicitly represent the current state of each manufacturing facility in stage 1 because this state can be derived directly from the number of kanbans for the respective product in stage 1. If this number is greater than zero, then the facility is busy, otherwise, it idles.
A Continuous-Time Markov Chain (CTMC) can be constructed to accurately model the considered system. We did this to obtain reference values for the small systems evaluated during the numerical tests described in Section 5 and Section 6. The state vector of this CTMC contains two elements for each product (the number of full containers in stage 1 and the number of active kanbans and backorders in stage 2) and one element for the current state of the manufacturing facility in stage 2. After the state vector has been defined, the formulation of the balance equations of this CTMC is time consuming, but straightforward. We therefore omit a detailed description of the balance equations.
Unfortunately, the size of the state space grows so rapidly with increasing number of products and kanbans that this modeling approach is impractical for most system sizes. If ![]() denotes the state space of the CTMC and |
denotes the state space of the CTMC and |![]() | the number of elements in this set, then the number of states is
| the number of elements in this set, then the number of states is
For a system with three different products and five kanbans for each product in each of the two stages, the CTMC consists of 217 833 states. For a system with three different products and ten kanbans each, the number of states is 9 251 613. Because of this state space explosion, construction and analysis of the CTMC is mathematically intractable for most system sizes. We therefore propose a decomposition-based approximation method that generates sufficiently accurate values for the performance measures of interest for systems of practically any size. A general approach to developing decomposition-based methods can be found in CitationGershwin (1994).
4. Decomposition into subsystems
The explosive growth of the state space of the exact model stems from the necessity to increase the state vector by two elements for each additional product. Therefore, we decompose the original system into single-product subsystems for which the state vector always, that is, for any number of products, consists of only three elements: one for the number of active kanbans and backorders in stage 2, n (2)+b, one for the number of full containers in the output store of stage 1, y (1), and one for the current state of the manufacturing facility in stage 2, z. The different states of this manufacturing facility in a subsystem will be discussed in the following subsection.
4.1. Description of a subsystem
In each subsystem, only one product, for example, product i in subsystem i, is considered explicitly. The other products, however, must also be included in some way because they also determine the behavior of the manufacturing facility in stage 2. We propose the use of server vacation phases to solve this problem. This approach will be explained in detail in the following paragraphs.
A queueing model of subsystem i is given in . The join symbol on the left-hand side of the manufacturing facility with vacations (depicted by the right circle) represents that at least one container with input material (manufactured in stage 1) and one active kanban for stage 2 must be present before production may start in stage 2. To correctly capture the kanban control mechanism in stage 1, the size of the queue following the first manufacturing facility is set equal to the number of kanbans for product i in stage 1, K i (1), and it is assumed that production stops in stage 1 as soon as the queue is filled to capacity (blocking before service). Alternatively, the assumption blocking after service could be used here as well. Then, however, the queue size would have to be set equal to K i (1)−1.
Fig. 2 Queueing model of subsystem i (product i); BBS = Blocking Before Service.
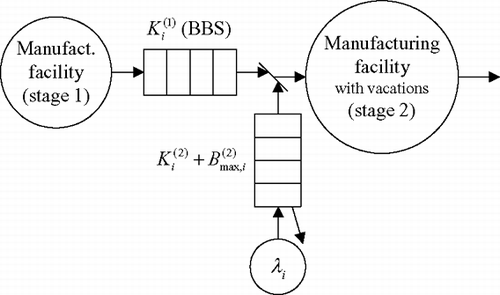
From the start of the setup activities until the end of the busy period for product i, that is, when either all active kanbans or all containers with input material have been fully depleted, the behavior of the manufacturing facility in stage 2 depends only on product i. Therefore, these time periods can be captured exactly in the model of the single-product subsystem for product i. At the end of the busy period, however, the complete state of the system, that is, the number of active kanbans and containers with input material for the other products, too, must be known to decide whether the manufacturing facility in stage 2 will idle or be set up for one of the other products. If the manufacturing facility in stage 2 turns its attention to a different product, then the time until its return to product ialso depends on the other products. Thus, in a model of subsystem i, the length of the period in which the manufacturing facility in stage 2 attends to some product j (j≠ i) must be based on information derived from subsystem j.
Even if products may be skipped in a specific cycle, thus causing a sojourn time of zero for some states, the general sequence of states of the manufacturing facility in stage 2 is always identical (). For each of these states, there is a long-run average time length. These averages can be used in the model of a subsystem to represent the lengths of the time periods when the manufacturing facility in stage 2 is not available for the explicitly modeled product without knowing the current status of the other products.
Fig. 3 States of the manufacturing facility in stage 2 in the original system and in subsystem i.
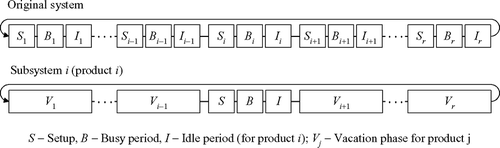
We use one state for each of the products that are not explicitly modeled in a subsystem and determine the long-run average length of each of these states by analyzing the model of the subsystem that explicitly considers the respective product (the details will be given in Section 4.6). Following classical queueing theory, we call the time period when the manufacturing facility in stage 2 is not available for product i in subsystem i during a cycle a “vacation”. In addition, we call the time period when the manufacturing facility in stage 2 is not available for product i (because it is being set up for processing, or being idle after processing product j) a “vacation phase for product j”. Thus, a vacation in subsystem i consists of r−1 vacation phases, one vacation phase for each product j, j = 1,…,r; j≠ i (). In summary, we have 3+(r−1) different states of the manufacturing facility in stage 2 in the model of each subsystem. For subsystem i, these states are: setup (S), busy period (B), and idle period (I) for product i and one vacation phase (V j ) for each product j, j = 1,…,r; j≠ i.
4.2. Definition of stochastic processes
For each subsystem, we define three elementary stochastic processes. To simplify the notation, we use n instead of n (2)+b to denote the number of active kanbans and backorders in stage 2, y instead ofy (1) to denote the number of full containers in the output store of stage 1, and z instead of z (2) to denote the state of the manufacturing facility in stage 2.
Let N (i)(t) denote the number of active kanbans and backorders in stage 2 in subsystem i at time t (i = 1,…,r; t ≥ 0). Then {N (i)(t), t ≥ 0} is a stochastic process over state space {0,…,K i (2)+B i max}, where K i (2) is the number of kanbans for product i in stage 2 and B i max is the maximum number of backorders for product i.
Let Y (i)(t) denote the number of full containers in the output store of stage 1 in subsystem i at time t. Then {Y (i)(t), t ≥ 0} is a stochastic process over state space {0,…,K i (1)}, where K i (1) is the number of kanbans for product i in stage 1. Note that due to the rules in a kanban system, the number of kanbans for a product in a stage defines the maximum number of full containers for this product in the output store of this stage.
Let Z
(i)(t) denote the state of the manufacturing facility in stage 2 in subsystem i at time t. We abbreviate the possible states of the manufacturing facility by S (setup), B (busy period), I (idle period), and V
j
, j = 1, …, r; j ≠ i (vacation phase for product j). Then {Z
(i)(t), t ≥ 0} is a stochastic process over state space ![]() (i) = {S;B;I;V
j
, j = 1,…,r;j≠ i }.
(i) = {S;B;I;V
j
, j = 1,…,r;j≠ i }.
4.3. Approximate model of a subsystem
The triple [N
(i)(t), Y
(i)(t), Z
(i)(t)]completely defines the state of subsystem i at time t. Unfortunately, the combined stochastic process {[N
(i)(t), Y
(i)(t), Z
(i)(t)], t ≥ 0 } is not a Markov process because the length of a vacation phase is generally not exponentially distributed. To make it a Markov process, we substitute an exponential distribution with parameter t
SBI
(j) for the (unknown) true distribution of the length of vacation phase V
j
, j = 1,…,r; j≠ i (an equation for parameter t
SBI
(j) will be developed in Section 4.6). If, for example, {Ñ(i)(t), t ≥ 0} is defined analogously to {N
(i)(t), t ≥ 0} for the resulting approximate model of subsystem i, then the combined stochastic process {Ñ(i)(t), Ỹ(i)(t), [Ztilde](i)(t)],t ≥ 0} is a CTMC on state space ![]() (i) = {(n,y,S), n = 1,…,K
i
(2)+B
i
max;y = 1,…,K
i
(1); (n,y,B),n = 1,…,K
i
(2)+B
i
max; y = 0,…,K
i
(1);(0,y,I), y = 0,…,K
i
(1); (n,0,I),n = 1,…,K
i
(2)+B
i
max; n,y,V
j
),n = 0,…,K
i
(2)+B
i
max; y = 0,…,K
i
(1);j = 1,…,r; j ≠ i }.
(i) = {(n,y,S), n = 1,…,K
i
(2)+B
i
max;y = 1,…,K
i
(1); (n,y,B),n = 1,…,K
i
(2)+B
i
max; y = 0,…,K
i
(1);(0,y,I), y = 0,…,K
i
(1); (n,0,I),n = 1,…,K
i
(2)+B
i
max; n,y,V
j
),n = 0,…,K
i
(2)+B
i
max; y = 0,…,K
i
(1);j = 1,…,r; j ≠ i }.
and show the main part of a generalized state-transition rate diagram of this CTMC (divided into two layers to improve readability). To simplify the notation in these figures, we substitute Y i for K i (1), the number of kanbans for product i in stage 1, and K i for K i (2)+B i max, the number of kanbans plus the maximum number of backorders for product i in stage 2. Symbol Y i may be read as the maximum number of full containers with items of product i in the output store of stage 1. The significance of transition rates μ′ i , μ” i and Λ i will be explained in Sections 4.7 and 4.9.
Fig. 4 State-transition rate diagram of the CTMC for subsystem i (product i): layer 1.
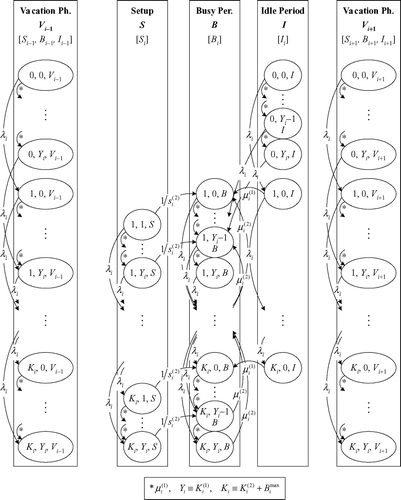
Fig. 5 State-transition rate diagram of the CTMC for subsystem i (product i): layer 2.
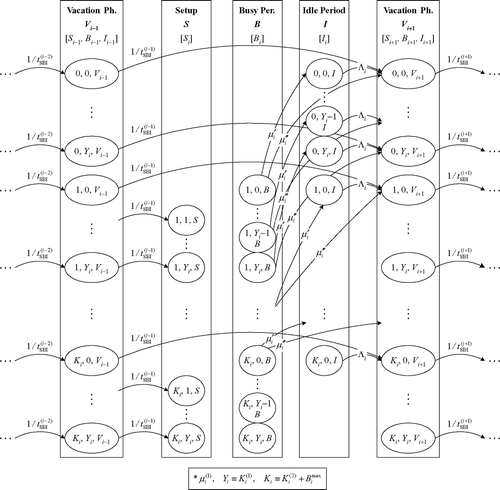
A decomposition approach can only be successful if it is possible to quickly analyze the subsystems. For Markov chains, the size of the state space is the critical factor for the computation time. The number of states of the CTMC for any subsystem i is
4.4. Steady-state probability distributions
Next, we define steady-state probability distributions for the stochastic processes {Ñ(i)(t), t ≥ 0}, {Ỹ(i)(t), t ≥ 0}, and {[Ztilde](i)(t), t ≥ 0}, and for several combined stochastic processes. We also give equations for computing the values of these distributions.
Let [Ptilde](i)(n) = lim t→∞ P[Ñ(i)(t) = n], n = 0,…,K i (2)+B i max, be the steady-state probability distribution of {Ñ(i)(t), t ≥ 0}.
Let [Ktilde](i)(y) = lim t→∞ P[Ỹ(i)(t) = y], y = 0, …, K i (1), be the steady-state probability distribution of {Ỹ(i)(t), t ≥ 0}.
Let [gtilde](i)(z) = lim
t→∞
P[[Ztilde](i)(t) = z], z ∈ ![]() (i), be the steady-state probability distribution of {[ztilde](i)(t), t ≥ 0}.
(i), be the steady-state probability distribution of {[ztilde](i)(t), t ≥ 0}.
Let [Gtilde](i)(n,z) = lim t→∞ PÑ(i)(t) = n,[Ztilde](i)(t) = z], (n,z)∈ {[(n,S), (n,B)], n = 1,…,K i (2)+B i max; [(n,I), (n,V j )], n = 0,…,K i (2)+B i max; j = 1,…,r; j ≠ i }, be the steady-state probability distribution of{Ñ(i)(t),[Ztilde](i)(t)], t ≥ 0}.
Let [htilde](i)(y,z) = lim t→∞ P[ỹ(i)(t) = y,[Ztilde](i)(t) = z], (y,z)∈ {(y,S), y = 1,…,K i (1); [(y,B),(y,I),(y,V j )],y = 0,…,K i (1); j = 1,…,r; j ≠ i }, be the steady-state probability distribution of {[Ỹ(i)(t),[Ztilde](i)(t)], t ≥ 0}.
Let õ(i)(n,y,z) = lim
t→∞
P[Ñ(i)(t) = n,Ỹ(i)(t) = y, [Ztilde](i)(t) = z], (n,y,z)∈ ![]() (i), be the steady-state probability distribution of {[Ñ(i)(t),Ỹ(i)(t),[Ztilde](i)(t)], t ≥ 0}.
(i), be the steady-state probability distribution of {[Ñ(i)(t),Ỹ(i)(t),[Ztilde](i)(t)], t ≥ 0}.
We can determine distribution õ(i) by solving the balance equations for the rate of probability inflows and outflows of each state of the CTMC. Using distribution õ(i), we can then calculate distribution [qtilde](i),
Distributions [Ptilde](i) and [gtilde](i) can be derived from distribution [qtilde](i),
4.5. Performance measures
The steady-state probability distributions defined above can be employed to determine performance measures for the approximate model of subsystem i. These values can then be used as estimates for the respective performance measures of the original system.
The fill rate is a measure of the service level of a system. It is the fraction of demand that is filled immediately (off-the-shelf service, type-1 service). An estimate for the long-run average fill rate of product i in the original system is
If demands may be backordered, then the fraction of served demand (backordered and immediately served demand) is another measure of the service level. An estimate for the long-run average fraction of served demand of product i in the original system is ![]() SD,i
= 1−ᵱ(i)(K
i
(2)+B
i
max).
SD,i
= 1−ᵱ(i)(K
i
(2)+B
i
max).
If we measure the inventory level of a product in a stage by the number of full containers in the output store of that stage, then ![]() i
(1) = ∑
y = 1
K
i
(1)
y × [Ktilde](i)(y)is an estimate for the long-run average inventory level of product iin stage 1 in the original system and
i
(1) = ∑
y = 1
K
i
(1)
y × [Ktilde](i)(y)is an estimate for the long-run average inventory level of product iin stage 1 in the original system and ![]() i
(2) = ∑
n = 0
K
i
(2)−1(K
i
(2)−n)ᵱ(i)(n)is an estimate for the long-run average inventory level of product i in stage 2 in the original system.
i
(2) = ∑
n = 0
K
i
(2)−1(K
i
(2)−n)ᵱ(i)(n)is an estimate for the long-run average inventory level of product i in stage 2 in the original system.
4.6. Equation for parameter t SBI (i)
Let t S (i) (t B (i), t I (i)) be the long-run average amount of time that the manufacturing facility in the model of subsystem ispends in state S (B, I) between two vacations. Also, let t SBI (i) be the long-run average total amount of time between two vacations in the model of subsystem i. Since the manufacturing facility of a subsystem can only be in states S, B, or I between two vacations, we know that t SBI (i) = t S (i)+t B (i)+t I (i) (CitationKrieg and Kuhn, 2004).
We define T (i) as the long-run average amount of time from the end of a vacation until the end of the next vacation in subsystem i. If t V (i) denotes the long-run average length of a vacation in the model of subsystem i, then T (i) = t SBI (i)+ t V (i). Note thatt V (i) = ∑ j = 1;j≠ i r t SBI (j).
From distribution [gtilde](i), we get the long-run average fraction of time of a vacation in the model of subsystem i: [gtilde] V (i) = ∑ j = 1;j≠ i r [gtilde](i)(V j ). Since[gtilde] V (i) T (i) = t V (i), we can now calculate T (i)with T (i) = t V (i)/[gtilde] V (i).Finally, we can determine t SBI (i) with t SBI (i) = T (i)−t V (i).
At the beginning of the algorithm of the proposed decomposition method (Section 4.10), we need rough estimates for t S (i), t B (i), i = 1,…,r, and for t SBI (i), i = 1,…,r; i ≠ 2. A rough estimate for t SBI (2) is not required because the algorithm starts with the analysis of the CTMC for subsystem 2 and this CTMC does not contain transition rate t SBI (2). Simplifying greatly, we pretend that the sequence of states of the manufacturing facility in the original system is S 1, B 1, S 2, B 2, …, S r , B r , S 1, B 1, S 2, B 2, …, S r , B r , …, that is, always at least one active kanban and one container with input material for the product that is to be produced next, so that no setup of the setup sequence is skipped and the manufacturing facility never idles. Based on this scenario, rough estimates for t S (i) and t I (i) are t S i:est = s i (2) and t I i:est = 0.
The number of active kanbans and backorders at the beginning of a busy period, say B i , must be between one and the sum of the total number of kanbans and the maximum number of backorders for product i in stage 2, K i (2)+B i max. Thus, the long-run average number of active kanbans at the beginning of B i may be (very) roughly estimated as (K i (2)+B i max)/2. A busy period ends when either the number of active kanbans or the number of containers with input material is down to zero. We estimate the long-run average time to reduce the number of active kanbans in subsystem i by one unit as (μ i (2)−λeff, i M/M/1/N )−1, where λeff,i M/M/1/N is the effective arrival rate in an M/M/1/N queueing system with λ = λ i , μ = μ i (2) and N = K i (2)+B i max (N = system capacity including service position). Assuming that input material is always available, we get as a rough estimate for t B (i): t B i:est = (K i (2)+B i max)/2 × (μ i (2)−λeff, i M/M/1/N )−1, where, with ρ i = λ i /μ i (2):
4.7. Equations for transition rates μ′ i and μ″; i
Transition rates μ i ′ and μ i ″ result from splitting transition rate μ i (2), the average processing rate for product i containers in stage 2. At the end of the busy period, the manufacturing facility in stage 2 either switches into the idle state or it starts a vacation (). If no product meets the setup condition in stage 2, that is, if there is not at least one active kanban and one container with input material for any product, then the manufacturing facility in stage 2idles. If E i denotes the event that no product meets the setup condition at the end of a busy period in stage 2 of subsystem i and P(E i ) denotes the probability of this event, then μ′ i = P(E i )μ i (2)and μ” i = [1−P(E i )]μ i (2).
4.8. Approximation of probability P(E i )
The probability that no product meets the setup condition at the end of a busy period in stage 2 of subsystem i, P(E i ), depends on the individual probabilities that each of the products does not meet the setup condition at this point in time. Let P(E ij ) denote the probability that product j, j = 1,…,r, does not meet the setup condition at the end of a busy period for product i in stage 2. If it is true that all events E ij for the same value of i are mutually independent, then P(E i ) = ∏ j = 1 r P(E ij ).
There is no reason to believe that the events E ij for a fixed i and j = 1,…,r are stochastically dependent. The demand arrival processes that determine the availability of active kanbans for all products j = 1,…,r run independently, and the same is true for the product-specific manufacturing facilities in stage 1 that determine the availability of containers with input material for stage 2. Hence, the fact that some product j does not meet the setup condition at the end of a production run for product i in stage 2 does not contain any information about the availability of active kanbans and input material for the other products.
It remains to determine the probabilities P(E ij ). Clearly, the probability that product i does not meet the setup condition at the end of a busy period for product i in stage 2 is one because the busy period is terminated as soon as the setup condition is breached. That is, P(E ii ) = 1. To approximate probability P(E ij ) for all j = 1,…,r; j≠ i, note that P(E ij ) = P(E ij n j = 0 ∨ y j = 0) = P(E ij n j = 0 ∧ y j > 0) + P(E ij n j > 0 ∧ y j = 0) + P(E ij n j = 0 ∧ y j = 0), if n j denotes the number of active kanbans and backorders for product j in stage 2, y j denotes the number of full containers in the output store of stage 1 for product j, E ij n j = 0 ∨ y j = 0 denotes the event that n j = 0 or y j = 0 (inclusive or) at the end of a busy period for product i and, for example, E ij n j = 0 ∧ y j > 0 denotes the event that n j = 0 and y j > 0 at the end of a busy period for product i. To simplify the notation, we substitute P(E ij n ), P(E ij y ) and P(E ij n,y ) for P(E ij n j = 0 ∧ y j > 0), P(E ij n j > 0 ∧ y j = 0) and P(E ij n j = 0 ∧ y j = 0).
Consider probability P(E ij n ). The conditional probability that input material is available, but no kanban is active for product j given that the manufacturing facility is dedicated to product i, may serve as an approximation for the probability that both conditions are met at the end of a busy period for product i. This conditional probability for the approximate model of subsystem i is equal to [[qtilde](j)(0,V i )−õ(j)(0,0,V i )]/[gtilde](j)(V i ). Hence, P(E ij n ) ≈ [[qtilde](j)(0,V i )−õ(j)(0,0,V i )]/[gtilde](j)(V i ).
Equivalently, P(E ij y )≈ [[htilde](j)(0,V i )−õ(j)(0,0,V i )]/[gtilde](j)(V i )andP(E ij n,y )≈ õ(j)(0,0,V i )/[gtilde](j)(V i ).
Since no values are available for the steady-state probability distributions for the model of subsystem j until after the first analysis of subsystem j, different approximations are required for probabilities P(E ij n ), P(E ij y ) and P(E ij n,y )at the beginning of the algorithm.
If P(E ij n j = 0) denotes the probability that no kanban is active for product j at the end of the busy period for product i (regardless of the number of containers with input material) and if t ji is an estimate for the long-run average time from the last busy period for product j until the end of the busy period for product i, then, assuming that n j was zero at the end of the last busy period for product j, a (very rough) estimate for P(E ij n j = 0) is P est(E ij n j = 0) = e−λ j t ji , where
4.9. Equation for transition rate Λ i
The idle period in subsystem i ends as soon as one product meets the setup condition. If this product is product i, then the manufacturing facility immediately resumes production, that is, the manufacturing facility switches back into state B. If, however, the first product that satisfies the setup condition in one of the other products, then a vacation starts, that is, the manufacturing facility switches into state V i+1.
The transition rate for transitions (0,y,I)→ (0,y,V i+1), y = 0,…,Y i , and transitions (n,0,I) → (n,0,V i+1), n = 1,…,K i , must be the reciprocal of the mean of an exponentially distributed random variable that stands for the time from the beginning of the idle period until the first of the other products meets the setup condition. We denote this reciprocal by Λ i . Ifl ij denotes the long-run average time from the beginning of the idle period after processing items of product i until product j meets the setup condition and if the actual time followed an exponential distribution, then Λ i = ∑ j = 1;j≠ i r 1/l ij , since the minimum of independent exponential random variables is an exponential random variable, and the parameter of this random variable is the sum of the parameters of the individual random variables.
The averages l ij can only be approximated since no information is available in the model of subsystem i on the number of active kanbans and full containers with input material for product j, j = 1,…,r;j≠ i. It is known that product j needs an average of 1/λ j time units to meet the setup condition if input material is available in the output store of stage 1, but no kanban is active (n j = 0). It is also known that product j needs an average of 1/μ j (1) time units to meet the setup condition if the number of active kanbans is greater than zero, but no input material is available in the output store of stage 1 (y j = 0). Finally, it is known that product j needs an average of 1/λ j +1/μ j (1)−1/(λ j +μ j (1)) time units to meet the setup condition if the number of active kanbans and the number of containers with input material are both zero. The average time needed in this last case is equal to the average value of the maximum of the two exponential random variables that stand for the time until a container of input material is filled in stage 1 and the time until a kanban is activated in stage 2. Weighting these three average times with the (approximate) probabilities that each of the three different situations prevails at the beginning of the idle period after processing items of product i, we get
4.10. Algorithm
The algorithm consists of two parts. In the first part (Steps 1–3), initial values are determined, in the second part (Steps 4–6), the models of subsystems 1 through r are analyzed one by one repeatedly until the performance measures change by less than 100ε percent.
Algorithm of the decomposition method
(Initialization)
Step 1. Compute t S i:est and t B i:est for all i = 1,…,r. | |||||||||||||||||||||||||||||||||||||||||
Step 2. Compute t SBI i:est for all i = 1,…,r; i ≠ 2. | |||||||||||||||||||||||||||||||||||||||||
Step 3. (The “zeroth” rotation, starting with i = 2) For i = 2 to r
| |||||||||||||||||||||||||||||||||||||||||
Step 4. Set k = 1. | |||||||||||||||||||||||||||||||||||||||||
Step 5. (The kth rotation) For i = 1 to r
| |||||||||||||||||||||||||||||||||||||||||
Step 6. Set k = k+1. Go to Step 5. | |||||||||||||||||||||||||||||||||||||||||
5. Tests without backorders
We conducted a series of test sets to determine the accuracy of the proposed approach (). In each test set, one characteristic of the base system () was systematically increased by a given increment (the traffic intensity for manufacturing facility i in stage 1 was defined as ρ i (1) = λ i /μ i (1), the total traffic intensity for stage 2 was defined as ρ(2) = ∑ i = 1 r ρ i (2) = ∑ i = 1 r λ i /μ i (2) and the parameter values for products 2,…,r−1 were chosen to obtain equal differences between the parameter values of consecutive products, for example, s 2−s 1 = s 3−s 2 = … = s r −s r−1). This experimental design was chosen to detect critical system properties that may significantly impact the approximation quality of the decomposition method.
Table 1 Test sets (tests without backorders)
Table 2 Parameter values and ratios of the base system
As basis for comparison, we took either the results of the exact model (for small systems) or the results of a discrete-event simulation. Simulation results were gathered with the replication/deletion approach (e.g., CitationLaw and Kelton (2000)). Warmup periods and observation periods (replication length−warmup period) were generally set generously to obtain observations representative of steady-state behavior (warmup periods:200 000 or 300 000 time units, observation periods: from 3000 000 up to 6000 000 time units). We selected a maximum relative error of 0.1% for each point estimate at an individual confidence level of (approximately) 99%. When the point estimates did not satisfy this condition after 25 replications, additional replications were performed until either the maximum relative errors of the point estimates were satisfactory, or 80 replications had been performed. For some performance measures, the maximum relative error still exceeded the desired relative precision after 80 replications (test set 1b, ρ
i
(1) = 1.00, y
1
(1): max. rel.error 0.102%, ![]() 2
(1): 0.123%,
2
(1): 0.123%, ![]() 3
(1): 0.125%; 1c, ρ
i
(1) = 0.90,
3
(1): 0.125%; 1c, ρ
i
(1) = 0.90, ![]() 2
(1): 0.127%, y
3
(1): 0.123%; 1c, ρ
i
(1) = 1.00,
2
(1): 0.127%, y
3
(1): 0.123%; 1c, ρ
i
(1) = 1.00, ![]() 1
(1): 0.213%,
1
(1): 0.213%, ![]() 2
(1): 0.261%,
2
(1): 0.261%, ![]() 3
(1): 0.276%
3
(1): 0.276%![]() 2
(2): 0.111%,
2
(2): 0.111%,![]() 3
(2): 0.112%; 2a, ρ1
(2)/ρ
r
(2) = 12,
3
(2): 0.112%; 2a, ρ1
(2)/ρ
r
(2) = 12, ![]() 3
(1): 0.111%; 2a, ρ1
(2)/ρ
r
(2) = 14,
3
(1): 0.111%; 2a, ρ1
(2)/ρ
r
(2) = 14, ![]() 3
(1): 0.104%; 2a, ρ1
(2)/ρ
r
(2) = 16,
3
(1): 0.104%; 2a, ρ1
(2)/ρ
r
(2) = 16, ![]() 3
(1): 0.129%; 2a, ρ1
(2)/ρ
r
(2) = 18,
3
(1): 0.129%; 2a, ρ1
(2)/ρ
r
(2) = 18, ![]() 3
(1): 0.127%; 2a, ρ1
(2)/ρ
r
(2) = 20,
3
(1): 0.127%; 2a, ρ1
(2)/ρ
r
(2) = 20, ![]() 3
(1): 0.170%).
3
(1): 0.170%).
The proposed evaluation algorithm was implemented with Visual Basic 5.0 and run on a PC with a Pentium III processor at 733 MHz. It converged for all test instances. We report for each test instance the number of rotations and the computation time (ε = 10−4). For many test instances the number of rotations is non-integer. This indicates that for these test instances the stopping criterion was met before the last rotation was completed.
Instead of reporting every single relative approximation error we reduced the amount of data by calculating for each stage and performance measure the Mean Absolute relative Deviation (MAD) and the Maximum relative Deviation (MaxD) of the estimates over all products. Let the relative Deviation (D) of an estimate be D = (estimate−exact value)/exact value. Then,
Note that if MaxD is negative (positive), then the decomposition method underestimated (overestimated) the true performance measure.
In test sets 1a–1c, we varied the total traffic intensity for stage 2 and the traffic intensity for each product in stage 1, respectively. As for all other test sets, the kanban configuration for each test instance, that is, the number of kanbans for each product in stages 1 and 2, was determined with a heuristic optimization procedure very similar to the one described in CitationKrieg and Kuhn (2001). In this optimization procedure, a kanban configuration is considered optimal if there is no other kanban configuration that achieves given average fill rates with less average total inventory holding cost per unit of time. Out of pocket costs for setup changes are assumed to be negligible and identical inventory holding costs per container and unit of time are used for both stages and all products.
The results for test sets 1a–1c (, , ) indicate that the approximation is only moderately sensitive to changes in the (total) traffic intensity. It appears that the estimation errors tend to increase for higher traffic intensities.
Table 3 Test set 1a
Table 4 Test set 1b
Table 5 Test set 1c
In test sets 2a–2c (,, ), the test instances were increasingly unbalanced with respect to the per product traffic intensities in stage 2 (test sets 2a, 2b) and in stage 1 (test set 2c). For that purpose, the ratio of the traffic intensity of the first product and the traffic intensity of the third product in stage 2 was systematically enlarged (the mean of the resulting intensities was used for product 2). For test set 2c, the traffic intensity of product 2 in stage 1, ρ2 (1) = λ2/μ2 (1), was fixed at 0.50 and the spread of the traffic intensities for products 1 and 3 was systematically increased (while ρ1 (1) ≥ ρ3 (1) and ρ1 (1)−ρ2 (1) = ρ2 (1)−ρ3 (1)). The results of these test sets suggest that the approximation is insensitive to changes of the traffic intensity ratio in stage 2 and moderately sensitive to drastically different average processing rates for the products in stage 1. Note that in the last instance of set 2c μ1 (1) = 0.69 and μ3 (1) = 9.12.
Table 6 Test set 2a
Table 7 Test set 2b
Table 8 Test set 2c
In test sets 3 and 4 ( and ), the setup times were changed. First, they were simultaneously enlarged for all products, then, the ratio of the setup times for product 1 and 3 was varied (s 2 (2) = (s 3 (2)−s 1 (2))/2). The results indicate a relatively high sensitivity of the approximation to changes in the setup times. The errors are most pronounced for the estimates of the average inventory levels in stage 2.
Table 9 Test set 3
Table 10 Test set 4
Finally, the number of products was systematically increased from three to ten (test set 5, shown in ). The results show no significant changes in the approximation quality when more products are added to the system.
Table 11 Test set 5
6. Tests with backorders
In this section, we give results of tests in which the maximum number of backorders, B
i
max, is greater than zero (partial backordering). All reference values, except for the two instances of the first test set, were obtained from simulation. In the simulation experiments for the first test set (warmup periods: 300 000 time units, observation periods: 6000 000 time units), additional replications were made until each point estimate had a relative error of at most 0.1% at an individual confidence level of (approximately) 99%. In the simulation experiments for the second test set (warmup periods: 400 000 time units, observation periods: 8000 000 time units), additional replications were made until each point estimate had a relative error of at most 0.2% at an individual confidence level of (approximately) 99%. Only for B
i
max = 18, did the maximum relative errors of the estimates for the average inventory levels in stage 2 for products 1 and 2 still exceed this value after 80 replications ![]() 1
(2): 0.205%,
1
(2): 0.205%, ![]() 2
(2): 0.205%).
2
(2): 0.205%).
First, we ran test set 1a with B i max = 1 for all i = 1,…,r to determine if increasing the total traffic intensity in stage 2 has the same effect on the approximation quality when B i max > 0, that is, larger errors for ρ(2) > 0.70.
The results () are almost identical to the ones for B i max = 0 (). Only for total traffic intensities above 0.70, do the relative errors appear to increase systematically. The relative errors, however, are still very moderate, even for ρ(2) = 0.90.
Table 12 Test set 1a with backorders
We also investigated if increasing the maximum number of backorders has any effect on the accuracy of the approximation (test set 6). For that purpose, we used a completely balanced system with three products and ρ(2) = 0.80, ρ i (1) = 0.80 and s i (2)μ i (2) = 2, i = 1,2,3 (μ i (2) = 2, λ i = 0.53, s i (2) = 1 and μ i (1) = 0.67). We set the number of kanbans to K i (1) = 7 and K i (2) = 9 to yield average fill rates of about 0.90 for B i max = 0. Then B i max was increased from zero to 18 in increments of two ().
Table 13 Test set 6
In this example, increasing the maximum number of backorders leads to a very moderate rise of the relative approximation errors of the average inventory levels in stage 1 and the average fractions of served demand. The increase of the relative errors of the average fill rates and the average inventory levels in stage 2, however, is more pronounced. Starting at under 1% the values rise to almost 10% for B i max = 18.
7. Analysis of system behavior
For a completely balanced two-stage kanban system with three products and no or a limited number of backorders (λ i = 0.53, μ i (2) = 2, s i = 1, i = 1,2,3; ρ(2) = 0.80), we explored the effects of increasing the maximum number of backorders on the performance measures average fraction of served demand, average fraction of immediately served demand (average fill rate) and average inventory level, first, when stage 1 is the bottleneck of the system (μ i (1) = 0.67, hence, ρ i (1) = 0.80), and, second, when stage 1 is not the bottleneck (μ i (1) = 5.3, hence, ρ i (1) = 0.10). Since the performance measures are identical for all three products, we only report the values for product 1.
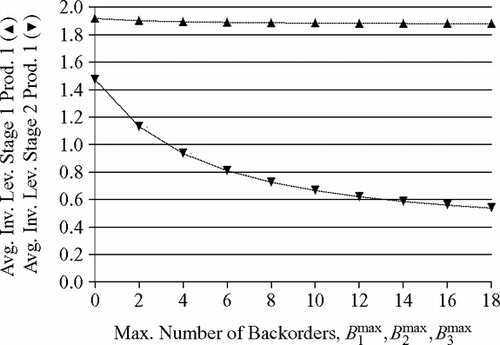
For the first experiment, the approximations are depicted in and . We increased the maximum number of backorders simultaneously for each product from zero to 18 in increments of two, while we kept the number of kanbans in stages 1 and 2 constant at K 1 (1) = K 2 (1) = K 3 (1) = 3 and K 1 (2) = K 2 (2) = K 3 (2) = 4, respectively, to yield average fill rates of about 0.70 forB 1 max = B 2 max = B 3 max = 0. The results depicted in indicate that the average fraction of served demand hardly changes, whereas the average fraction of immediately served demand (average fill rate) drops sharply. At the same time, the average inventory level in stage 1 remains almost constant, while the average inventory level in stage 2 falls drastically ().
Fig. 6 Increasing the maximum number of backorders when stage 1 is the bottleneck (ρ(1) = 0.80, ρ(2) = 0.80); • = average fraction of served demand for product 1, ▪ = average fraction of immediately served demand for product 1 (average fill rate).
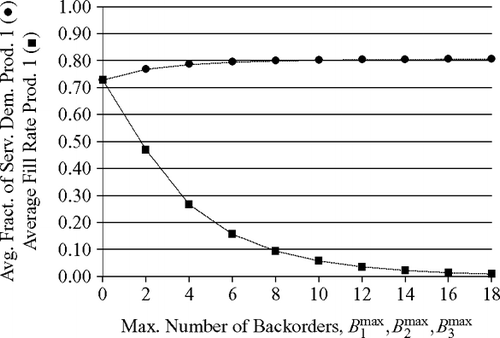
Fig. 7 Increasing the maximum number of backorders when stage 1 is the bottleneck(ρ(1) = 0.80, ρ(2) = 0.80); ▵ = average inventory level in stage 1 for product 1, ▪ = average inventory level in stage 2 for product 1.
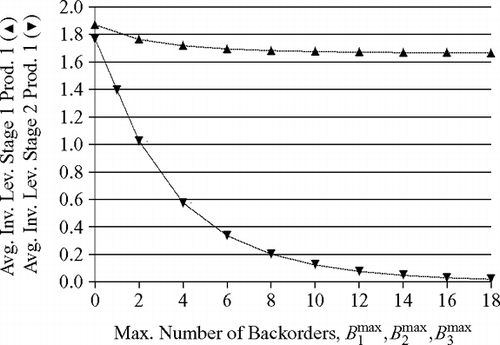
One would expect the average fraction of served demand to rise faster when the maximum number of backorders is increased. The production runs in stage 2 should become longer because more orders may accumulate between production runs since the maximum number of orders at the start of a production run is K i (2)+B i max,2 for product i. Longer production runs mean that the fraction of time that the manufacturing facility in stage 2 actually produces items increases and a smaller fraction of time is used for changing the setup. Consequently, the average production rates for each product should increase, which would then translate directly into larger fractions of served demand. In this example, however, stage 1, which is clearly the bottleneck of the system, sabotages the described mechanism. Production runs in stage 2 must be terminated before all production orders have been processed because stage 1 cannot keep up with the production of the input material for stage 2. As a consequence, the production runs in stage 2 hardly expand when the number of backorders is raised. Average inventory levels in the output store of stage 2 drop sharply because filled containers are often withdrawn instantly to satisfy accumulated backorders.
For comparison, we conducted a second experiment in which stage 1 was not the bottleneck of the system. Again, we increased the maximum number of backorders for each product simultaneously from zero to 18 in increments of two. We held the number of kanbans constant at K 1 (1) = K 2 (1) = K 3 (1) = 2 and K 1 (2) = K 2 (2) = K 3 (2) = 3 to yield average fill rates of about 0.70 for B 1 max = B 2 max = B 3 max = 0. illustrates that in this experiment the average fraction of served demand increases much faster and the average fill rate falls significantly slower. Moreover, the average inventory levels in both stages clearly decrease at a lower pace ().
Fig. 8 Increasing the maximum number of backorders when stage 1 is not the bottleneck (ρ(1) = 0.10, ρ(2) = 0.80); • = average fraction of served demand for product 1,▪ = average fraction of immediately served demand for product 1 (average fill rate).
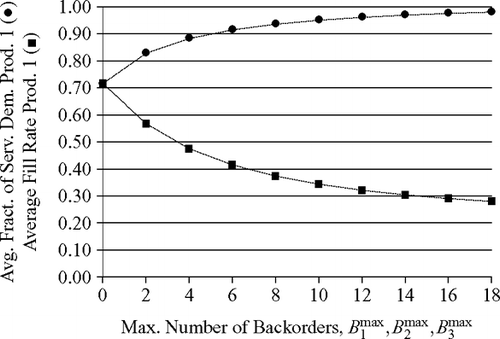
Fig. 9 Increasing the maximum number of backorders when stage 1 is not the bottleneck (ρ(1) = 0.10, ρ(2) = 0.80); ▵ = average inventory level in stage 1 for product 1, ▪ = average inventory level in stage 2 for product 1.
8. Conclusions
In this paper, we have presented a decomposition method for the evaluation of two-stage multi-product kanban systems. The proposed procedure is an extension of the decomposition method described in CitationKrieg and Kuhn (2004). The general principle used is the decomposition of a system with r products into r single-product subsystems. The results of several test sets suggest that the approximation is sufficiently accurate for a large variety of systems.
In future research, an approach should be developed for the evaluation of multi-product kanban systems with an arbitrary number of stages in series. The decomposition method presented here is expected to be an important building block in the construction of a suitable and effective procedure.
Biographies
Georg N. Krieg received his Ph.D. in Business Administration from the Catholic University of Eichstaett-Ingolstadt, Germany. He holds a degree in Business Administration from the University of Cologne, Germany, and an M.B.A. from Eastern Illinois University, Charleston, IL, USA. He was an Assistant Professor at the Chair of Production and Operations Management of the Catholic University of Eichstaett-Ingolstadt (2003–2006). Before that, he was a Teaching and Research Assistant at the same chair (1998–2003). He is the author of the research monograph Kanban-Controlled Manufacturing Systems published by Springer (Berlin, 2005).
Heinrich Kuhn is a Full Professor of Production and Operations Management at the Catholic University of Eichstaett-Ingolstadt, Germany and a Contract Professor for Production and Logistics at the Free University of Bozen, Italy in the Faculty of Business Administration and Economics. Before that, he was an Assistant Professor at the University of Cologne, Germany (1994–1997) and a Teaching and Research Assistant at the Technical University of Brunswick, Germany (1990–1994). He received his Ph.D. (1990) in Industrial Engineering from the Technical University of Darmstadt, Germany, and the degree of Habilitation (1997) in Business Administration from the University of Cologne, Germany. He is a co-author of the textbook Flexible Manufacturing Systems – Decision Support for Design and Operation, published by Wiley (New York, NY, 1993). His research interest are in operations management, logistics, lot sizing, scheduling and stochastic models.
Acknowledgements
We are grateful for the helpful comments of the editor, Dr. Stanley B. Gershwin, and two anonymous reviewers.
Notes
eComparison based on exact values.
eComparison based on exact values.
eComparison based on exact values.
eComparison based on exact values.
References
- Albino , V. , Dassisti , M. and Okogbaa , G. O. 1995 . Approximation approach for the performance analysis of production lines under a kanban discipline . International Journal of Production Economics , 40 ( 1 ) : 197 – 207 .
- Altiok , T. 1997 . Performance Analysis of Manufacturing Systems , New York , NY : Springer . ch. 7
- Altiok , T. and Shiue , G. A. 1994 . Single-stage, multi-product production/inventory systems with backorders . IIE Transactions , 26 ( 2 ) : 52 – 61 .
- Altiok , T. and Shiue , G. A. 1995 . Single-stage, multi-product production/inventory systems with lost sales . Naval Research Logistics , 42 : 889 – 913 .
- Altiok , T. and Shiue , G. A. 2000 . Pull-type manufacturing systems with multiple product types . IIE Transactions , 32 ( 2 ) : 115 – 124 .
- Askin , R. G. , Mitwasi , M. G. and Goldberg , J. B. 1993 . Determining the number of kanbans in multi-item just-in-time systems . IIE Transactions , 25 ( 1 ) : 89 – 98 .
- Baynat , B. , Dallery , Y. , Di Mascolo , M. and Frein , Y. 2001 . A multi-class approximation technique for the analysis of kanban-like control systems . International Journal of Production Research , 39 ( 2 ) : 307 – 328 .
- Berkley , B. J. 1990 . Analysis and approximation of a JIT production line: a comment . Decision Sciences , 21 ( 3 ) : 660 – 669 .
- Berkley , B. J. 1991 . Tandem queues and kanban-controlled lines . International Journal of Production Research , 29 ( 10 ) : 2057 – 2081 .
- Berkley , B. J. 1992 . A decomposition approximation for periodic kanban-controlled flow shops . Decision Sciences , 23 ( 2 ) : 291 – 311 .
- Bonvik , A. M. , Dallery , Y. and Gershwin , S. B. 2000 . Approximate analysis of production systems operated by a CONWIP/finite buffer hybrid control policy . International Journal of Production Research , 38 ( 13 ) : 2845 – 2869 .
- Buzacott , J. A. and Shanthikumar , J. G. 1993 . Stochastic Models of Manufacturing Systems , Englewood Cliffs , NJ : Prentice-Hall .
- Dallery , Y. and Liberopoulos , G. 2000 . Extended kanban control system: combining kanban and base stock . IIE Transactions , 32 ( 4 ) : 369 – 386 .
- De Araújo , S. L. , Di Mascolo , M. and Frein , Y. Performance evaluation of kanban controlled production systems with multiple consumers and multiple suppliers . International Conference on Industrial Engineering and Production Management (IEPM1993) . June 2–4 1993 , Mons , Belgium.
- Deleersnyder , J. L. , Hodgson , T. J. , Muller (-Malek) , H. and O'Grady , P. J. 1989 . Kanban controlled pull systems: an analytic approach . Management Science , 35 ( 9 ) : 1079 – 1091 .
- Di Mascolo , M. 1996 . Analysis of a synchronization station for the performance evaluation of a kanban system with a general arrival process of demands . European Journal of Operational Research , 89 ( 1 ) : 147 – 163 .
- Di Mascolo , M. , Frein , Y. , Baynat , B. and Dallery , Y. Queueing network modeling and analysis of generalized kanban systems . Proceedings of the Second European Control Conference (ECC1993) . Edited by: Nieuwenhuis , J. W. pp. 170 – 175 .
- Di Mascolo , M. , Frein , Y. and Dallery , I. Queueing network modeling and analysis of kanban systems . Proceedings of the Third International Conference on Computer Integrated Manufacturing . pp. 202 – 211 . Troy , NY : IEEE Computer Society Press .
- Di Mascolo , M. , Frein , Y. and Dallery , Y. 1996 . An analytical method for performance evaluation of kanban controlled production systems . Operations Research , 44 ( 1 ) : 50 – 64 .
- Federgruen , A. and Katalan , Z. 1996 . The stochastic economic lot scheduling problem: cyclical base-stock policies with idle times . Management Science , 42 ( 5 ) : 783 – 796 .
- Fujiwara , O. , Yue , X. , Sangaradas , K. and Luong , H. T. 1998 . Evaluation of performance measures for multi-part, single-product kanban controlled assembly systems with stochastic acquisition and production lead times . International Journal of Production Research , 36 ( 5 ) : 1427 – 1444 .
- Fullerton , R. R. and McWatters , C. S. 2001 . The production performance benefits from JIT implementation . Journal of Operations Management , 19 : 81 – 96 .
- Gershwin , S. B. 1994 . Manufacturing Systems Engineering , Englewood Cliffs , NJ : Prentice Hall .
- Gershwin , S. B. 2000 . Design and operation of manufacturing systems: the control-point policy . IIE Transactions , 32 : 891 – 906 .
- Gstettner , S. and Kuhn , H. 1996 . Analysis of production control systems kanban and CONWIP . International Journal of Production Research , 34 ( 11 ) : 3253 – 3273 .
- Jordan , S. 1988 . Analysis and approximation of a JIT production line . Decision Sciences , 19 ( 3 ) : 672 – 681 .
- Karmarkar , U. S. and Kekre , S. 1989 . Batching policy in kanban systems . Journal of Manufacturing Systems , 8 ( 4 ) : 317 – 328 .
- Kim , I. and Tang , C. S. 1997 . Lead time and response time in a pull production control system . European Journal of Operational Research , 101 : 474 – 485 .
- Krieg , G. N. and Kuhn , H. Production planning of multi-product kanban systems with significant setup times . Operations Research Proceedings 2000 . Edited by: Fleischmann , B. , Lasch , R. , Derigs , U. , Domschke , W. and Rieder , U. pp. 316 – 321 . Berlin : Springer .
- Krieg , G. N. and Kuhn , H. 2002 . A decomposition method for multi-product kanban systems with setup times and lost sales . IIE Transactions , 34 ( 7 ) : 613 – 625 .
- Krieg , G. N. and Kuhn , H. 2004 . Analysis of multi-product kanban systems with state-dependent setups and lost sales . Annals of Operations Research , 125 ( 1–4 ) : 141 – 166 .
- Law , A. M. and Kelton , W. D. 2000 . Simulation Modeling and Analysis, , third edn. , New York , NY : McGraw-Hill . ch. 9
- Markowitz , D. M. , Reiman , M. I. and Wein , L. M. 2000 . The stochastic economic lot scheduling problem: heavy traffic analysis of dynamic cyclic policies . Operations Research , 48 ( 1 ) : 136 – 154 .
- Mitra , D. and Mitrani , I. 1990 . Analysis of a kanban discipline for cell coordination in production lines. I . Management Science , 36 ( 12 ) : 1548 – 1566 .
- Mitra , D. and Mitrani , I. 1991 . Analysis of a kanban discipline for cell coordination in production lines, II: stochastic demands . Operations Research , 39 ( 5 ) : 807 – 823 .
- Monden , Y. 1998 . Toyota Production System: An Integrated Approach to Just-In-Time, , third edn. , Norcross , GA : Engineering & Management Press .
- Nori , V. S. and Sarker , B. R. 1998 . Optimum number of kanbans between two adjacent stations . Production Planning & Control , 9 ( 1 ) : 60 – 65 .
- Schmidbauer , H. and Rösch , A. 1994 . A stochastic model of an unreliable kanban production system . OR Spektrum , 16 : 155 – 160 .
- Seki , Y. and Hoshino , N. 1999 . Transient behavior of a single-stage kanban system based on the queueing model . International Journal of Production Economics , 60–61 : 369 – 374 .
- Siha , S. 1994 . The pull production system: modelling and characteristics . International Journal of Production Research , 32 ( 4 ) : 933 – 949 .
- So , K. C. and Pinault , S. C. 1988 . Allocating buffer storages in a pull system . International Journal of Production Research , 26 ( 12 ) : 1959 – 1980 .
- Tayur , S. R. 1993 . Structural properties and a heuristic for kanban-controlled serial lines . Management Science , 39 ( 11 ) : 1347 – 1367 .
- Wang , H. and Wang , H. P.B. 1990 . Determining the number of kanbans: a step toward nonstock-production . International Journal of Production Research , 28 ( 11 ) : 2101 – 2115 .
- Wang , H. and Wang , H. P.B. 1991 . Optimum number of kanbans between two adjacent workstations in a JIT system . International Journal of Production Economics , 22 : 179 – 188 .
- White , R. E. , Pearson , J. N. and Wilson , J. R. 1999 . JIT manufacturing: a survey of implementations in small and large U.S. manufacturers . Management Science , 45 ( 1 ) : 1 – 15 .
- White , R. E. and Prybutok , V. 2001 . The relationship between JIT practices and type of production system . Omega , 29 : 113 – 124 .