Abstract
The recent trends in manufacturing toward modularity and flexibility result in complex multistage manufacturing processes that consist of many interrelated workstations. In such processes, it is highly desirable to differentiate between local and propagated variations, and implement process variability monitoring and reduction. In this paper, attention is focused on the properties of a widely used regression-adjustment-based method in the monitoring of variation propagation in multistage manufacturing processes. Particularly, the impacts of measurement errors and regressor selection on the monitoring scheme are investigated, and conclusions which can help guide the use of this method are summarized. Numerical examples are also presented to validate the analysis.
1. Introduction
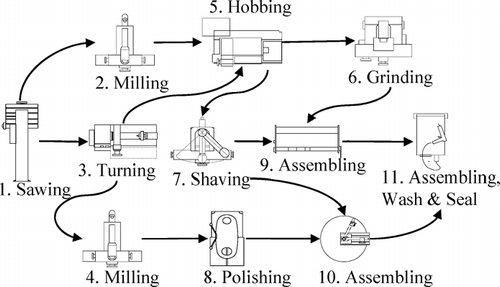
The growing demand for products with both an improved functionality and a shorter time to market in order to be successful in today's fiercely competitive marketplace places an enormous strain on production systems. Manufacturing paradigms such as modular production systems (CitationRogers and Bottaci, 1997), cellular manufacturing (CitationHyer and Wemmerlov, 2002) and reconfigurable manufacturing (CitationKoren et al., 1999) have been developed and adopted in recent years and they are able to achieve unprecedented levels of flexibility and responsiveness. As a result, it is increasingly common to find many complex and modularized workstations linked together to create the final product in a manufacturing environment. illustrates a manufacturing system consisting of 11 stations and capable of producing five different types of motor reducers. Because fabrication errors are carried by the product from one station to the next station, the outgoing product quality at a particular station is determined not only by various local disturbances at that station, such as thermal error cutting-force induced error and machine geometric error, but also by the propagated variations from previous stations such as the datum error due to preceding cutting operations. The final product variation is the accumulation of variations from all manufacturing stations.
Fig. 1 A multistage process for motor reducers.
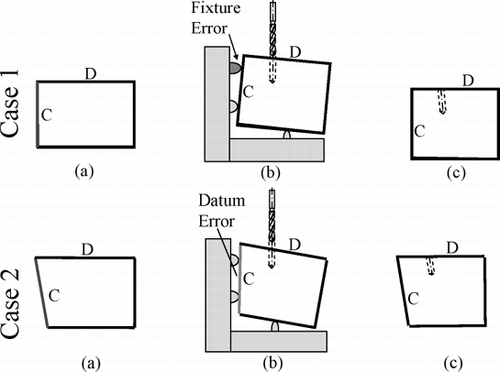
The local and propagated quality variations can be illustrated by a simple two-step machining example, as shown in . The workpiece is a cube of metal (the front view is shown). Surface C of the workpiece is milled in the first step (). A hole is drilled on surface D using surface C as the primary datum () in the second step. Clearly, the resulting hole is not perpendicular to surface D (). In case 1 illustrated in , the geometric error associated with the hole is caused by the local fixture error in the drilling operation. However, in case 2, the error associated with the hole is not caused by the drilling operation, but by the propagated error from the milling operation in the first step. In general, the Quality Characteristics (QCs) at a certain stage can be influenced not only by the errors at the current stage, but also by its preceding QCs in a multistage manufacturing process. One can imagine that process variation will propagate along the physical process topology and form a network of variation flow.
Fig. 2 A two-step maching process: (a) front view of the workpiece; (b) drilling of the hole; and (c) non-perpendicular nature of the hole.
The variation propagation poses significant new challenges for process variability monitoring and reduction. Without considering the variation propagation conventional statistical monitoring methods are not able to differentiate between local and propagated variations. Thus, a significant number of false alarms can be generated at a given stage, i.e., the monitoring scheme can mistake the propagated variation as a local variation and then generate an alarm that is due to other stages. An effective statistical monitoring scheme for variability monitoring and reduction should be able to pinpoint the variation sources to a particular stage.
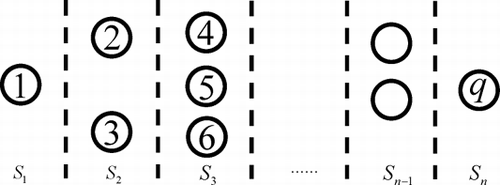
Due to rapid developments in information and sensing technologies, an abundance of data is now readily available in manufacturing processes. Total inspection for discrete processes at each intermediate operation and very high sampling rates are no longer rare in practice. For example, in autobody assembly processes, 100% dimensional inspection has been achieved through in-line optical coordinate measurement machines (CitationCeglarek and Shi, 1995). With these measurements at intermediate stages, if we define the QCs as nodes, a general multistage manufacturing process has a physical layout as shown in , where q QCs, Q j , j = 1, 2, …, q, are distributed at n stages.
Fig. 3 Layout of a general multistage process.
This profusion of process/product measurement data provides an opportunity for effective process control of multistage manufacturing processes. In fact, some research efforts have already been made to conquer this problem. These methods can be roughly classified as being either analytical methods, those based on an off-line physical model of the process, or as data-driven techniques, those based on the statistical analysis of historical process data. The analytical method approach is represented by the recently developed “stream of variation” methodologies which focus on dimensional variation analysis of sequential discrete machining (e.g., CitationHuang et al. (2000), CitationDjurdjanovic and Ni (2001) and CitationZhou et al. (2003)) and assembly processes (e.g., CitationDing et al. (2000) and CitationJin and Shi (1999)). They are effective in describing the interactions between different units but require a thorough physical understanding of the process that might not be generally available. The existing data-driven techniques include the regression control chart of CitationMandel (1969) and its updated version, the cause-selecting control chart (CitationZhang, 1985; CitationWade and Woodall, 1993), where the outgoing quality is monitored after adjustment for the effect of the incoming quality. As an extension, Hawkins (Citation1991, Citation1993) proposed the methodology and studied the design of the related procedures for monitoring correlated QCs based on regression adjustment in cascade processes. It was suggested that every QC is monitored by a corresponding regression-adjusted chart which is built based on the (standardized) residual, Z j = Q j − Q j , j = 1, …, q, called regression-adjusted variables, which occur when Q j is regressed on all its preceding QCs. Then Z j being out of control can be directly interpreted as faults occurring on QC j. The idea of regression adjustment has been widely accepted as a good way to deal with multistage quality control problems and is the basis of several papers in the literature. For example, CitationZantek et al. (2002) measured the impact of each stage's performance on the variation in intermediate and final product quality. CitationHauck et al. (1999) considered process monitoring and diagnosis based on regression adjustment in multivariate cases, and CitationFong and Lawless (1998), CitationAgrawal et al. (1999) and CitationLawless et al. (1999), analyzed the variation transmission in key characteristics as discrete parts move through a multistage production process.
Despite the general effectiveness of the regression-adjustment-based method shown in the existing studies, its properties in the monitoring of variability in practice are not comprehensively studied. There are two potential issues involved.
| 1. | In most of the data-driven methods, the QCs Q j , j = 1, …, q, are often assumed to be directly observable. However, in practice, the QCs can never be measured exactly and thus the observed value, X j , is actually a combination of Q j and a non-zero measurement error ε j . It has been pointed out that the least squares estimate in the presence of measurement errors is inconsistent (CitationFuller, 1987). As a result, the diagnostic capability of the quality control procedures based on least squares regression may be degraded by the bias of estimation. Actually the existence of measurement errors has been highlighted in the literature (CitationAgrawal et al., 1999; CitationLawless et al., 1999), but the influence of these errors on the monitoring of QCs in multistage manufacturing processes has not been explored. | ||||
| 2. | For a complex process consisting of many QCs, regressor selection and its impact on the monitoring scheme are also very important issues. However, little work has been reported on this topic. In most cases, for every QC j, people just monitor its residual that is resulted from the adjustment of all its preceding QCs (e.g., CitationHawkins (1993) and CitationZantek et al. (2006)) without the pre-examination of the subset of QCs that really influences j. Thus, it is necessary to investigate the possible advantages or disadvantages if a regressor selection procedure, which is usually an indispensable part in the application of regression, is added into the regression adjustment method. | ||||
This article focuses on the properties of a regression-adjustment-based method in the monitoring of variability in multistage manufacturing processes. Particularly, we investigate the impacts of measurement errors and regressor selection on the existing monitoring scheme. It is found that with the measurement errors, the regression-adjusted control chart of every QC responds not only to the change of its local variation, but also to that of its preceding local variations. As a result, the preceding local variations become sources of false alarms and misdetection of the monitoring scheme. Furthermore, we find that the impacts of measurement errors and regressor selection are actually mingled together in that without measurement errors, regressor selection (either with or without) will not affect the monitoring procedure. However, when measurement errors exist, regressor selection will come into play and influence the performance of the monitoring scheme. We compare the performances of two adjustment methods, that is, adjustment for all preceding QCs and that for only the subset identified through some regressor selection procedures (called the “all-adjustment” method and “subset-adjustment” method respectively). It is shown that the monitoring procedure using the subset-adjustment procedure corresponds with fewer false alarm sources, whereas the all-adjustment procedure potentially has a lower misdetection rate. Some conclusions are drawn based on the comparison, which can be used to guide the application of regression-adjustment monitoring procedures.
The reminder of the paper is organized as follows. Section 2 introduces the conventional variability monitoring procedure based on regression adjustment. Section 3 points out the impact of measurement errors in general and compares such impacts when the all-adjustment procedure and subset-adjustment procedure are used. In Section 4, two numerical examples are used to demonstrate the analysis in Section 3. The paper concludes in Section 5.
2. Variability monitoring procedure based on regression adjustment
2.1. Process model and assumptions
For j = 1, …, q, define ![]() j
= {1, 2, …, p} as the set of QCs in the preceding stages of QC j. For example, in , P
5 is {1, 2, 3}, while
j
= {1, 2, …, p} as the set of QCs in the preceding stages of QC j. For example, in , P
5 is {1, 2, 3}, while ![]() q
includes all the QCs except q. In our study, we assume that QC j can be influenced by the QCs in
j
. Also, let U
j
and U
i
, i ∈
j
, be the local variation sources of QC j and QC i respectively. The local variation sources represent the quantities which are related to a specific QC and are often not directly observable. They have different physical meanings in different processes. For example, in the simple machining process shown in , they denote the local fixture errors. For the sake of simplicity, we assume that every QC in the process has a different local variation source in this paper. However, the conclusions we get here are feasible for more general cases where the QCs at the same stage could share the same local variation sources. The linear model between Q
j
and Q
i
, i ∈
q
includes all the QCs except q. In our study, we assume that QC j can be influenced by the QCs in
j
. Also, let U
j
and U
i
, i ∈
j
, be the local variation sources of QC j and QC i respectively. The local variation sources represent the quantities which are related to a specific QC and are often not directly observable. They have different physical meanings in different processes. For example, in the simple machining process shown in , they denote the local fixture errors. For the sake of simplicity, we assume that every QC in the process has a different local variation source in this paper. However, the conclusions we get here are feasible for more general cases where the QCs at the same stage could share the same local variation sources. The linear model between Q
j
and Q
i
, i ∈![]() j
, is
j
, is
Because of measurement errors, the observed quantities are (Y, X) which satisfy:
The following assumptions can be made based on the characteristics of most manufacturing processes.
| 1. | All local variation sources and measurement errors follow a normal distribution. Due to the existence of various disturbances, the variation sources and measurement errors are often a result of combined random disturbances. Thus, a normal distribution is often a reasonable assumption due to the central limit theorem. Furthermore, in this article, we focus on the detection of variance change instead of mean shift. For the sake of simplicity, we also assume that the local variation sources and the measurement errors have zero means. | ||||
| 2. | All local variation sources and measurement errors are independent of one another. Because the variation sources are in the process and measurement errors are in the measurement systems that are physically independent of the process, it is natural to assume that the variation sources are independent of the measurement errors. Furthermore, the local variation sources are often the result of different physical root causes and/or different manufacturing stages, so it is also reasonable to assume that they are independent of one another. Based on this assumption, the variance-covariance matrix of U, Σ U , and that of ε , Σ ε , are diagonal, i.e., Σ U = diag(σ U i 2,i = 1, …,p) and Σ ε = diag(σε i 2,i = 1,…,p), where σ U i 2 and σε i 2 are the variances of U i and ε i respectively. | ||||
| 3. | The process is stable, meaning that β, D, σ
e
2 and σε
i
2, i ∈ | ||||
It should be highlighted that the model described by Equations (Equation1),(Equation2), (Equation3),(Equation4) and assumptions 1–3 are consistent with the analytical models developed for multistage manufacturing processes (e.g., CitationZhou et al. (2003)) and have been adopted as the basis for several recently developed variability monitoring and diagnosis methodologies (e.g., CitationApley and Shi (2001) and CitationZhou et al. (2003)). In this article, we focus on the following problem: knowing Y and X and the model structures (the model parameters are unknown), how do we develop an effective statistical monitoring scheme to detect the local variation change? Before answering this question we briefly review the conventional regression-adjusted variability monitoring procedure.
2.2. The regression-adjusted variability monitoring procedure
The variability monitoring procedure based on regression adjustment has two steps.
Phase I analysis: Assume that the historical data set includes m subgroup samples, each consisting of n (p + 1)-dimensional multivariate observations. The data of the hth, h = 1, 2, …, m, subgroup are denoted by (y h , χ h ), where y h = [y h1, y h2, …, y hn ]′ is an n-dimensional vector in which y ht , t = 1,2, …, n, represents the tth observation of Y and χ h = [x h1,x h2, …, x hn ]′ is an n × p matrix in which x ht represents the tth observation of X. The following needs to be done in sequence:
Step 1. Obtain the least squares estimate of the coefficient β by | |||||
Step 2. Calculate the residuals and their standard deviations for each subgroup sample. For the hth subgroup, the residuals and corresponding standard deviation are | |||||
Step 3. Calculate the control limits for the S chart of the residuals: | |||||
Phase II analysis: When a new subgroup sample, (y 0, χ0), is obtained, the residuals using the estimate from Equation (Equation5) are calculated by
The two-step analysis above will be conducted iteratively for j = 1, 2., q. In this way, we can find the root causes of the variability change in the process.
It should be highlighted that the chart we used here is different from that used by CitationZhang (1985), Hawkins (Citation1991, Citation1993) and CitationZantek et al. (2006). They respectively used a ![]() chart, a CUSUM chart and a T2 chart to monitor the residuals because they were mainly interested in mean shifts, whereas in our study we select the S chart for the purpose of monitoring variability/variance changes. Later, we focus on the impacts of measurement errors and regressor selection on the monitoring performance. Although the simple S chart is used here, the conclusions should generally hold for any variability monitoring chart.
chart, a CUSUM chart and a T2 chart to monitor the residuals because they were mainly interested in mean shifts, whereas in our study we select the S chart for the purpose of monitoring variability/variance changes. Later, we focus on the impacts of measurement errors and regressor selection on the monitoring performance. Although the simple S chart is used here, the conclusions should generally hold for any variability monitoring chart.
3. Impacts of measurement errors and regressor selection
3.1. Impact of measurement errors
Under assumptions (1–3), when the sample size (say, mn in the procedure) is large, the least squares estimate β → ( Σ X )− 1 Σ X Y , where Σ X denotes the (variance-) covariance matrix of X, while Σ X Y denotes that between X and Y (CitationWhittaker, 1990). According to Equations (Equation1), (Equation3) and (Equation4), Σ X = Σ Q + Σ ε and Σ X Y = cov(Q, β ′Q) = Σ Q β , where Σ Q is the covariance matrix of Q. Consequently,
Let (Y 0, X 0) be the new measurement in Phase II analysis, then the residual based on least squares estimate in Phase I analysis is Z 0 = Y 0− β ′ X 0, which is essentially the prediction error of the model built on the estimate. By substituting into Equations (Equation1)(Equation2),(Equation3),(Equation4), we can get:
According to Equation (Equation11), if there is no measurement error or it is negligible, i.e.,
Σ
ε
≈0
p× p
, by Equation (Equation9),
β
− ![]() ≈0
p
and consequently var(Z
0) ≈ σ
U
0j
2 + σ
e
2, where 0
p
denotes the p-dimensional empty vector. Since σ
e
2 is assumed to be fixed (by assumption 3), var(Z
0) is only determined by σ
U
0j
2 and so if σ
U
0j
2 changes it can be detected using the monitoring procedure introduced in Section 2.2. In fact, this is what makes regression adjustment an effective way to monitor the local variations.
≈0
p
and consequently var(Z
0) ≈ σ
U
0j
2 + σ
e
2, where 0
p
denotes the p-dimensional empty vector. Since σ
e
2 is assumed to be fixed (by assumption 3), var(Z
0) is only determined by σ
U
0j
2 and so if σ
U
0j
2 changes it can be detected using the monitoring procedure introduced in Section 2.2. In fact, this is what makes regression adjustment an effective way to monitor the local variations.
However, if the measurement error is not negligible, by Equation (Equation11), var(Z 0) is related not only with σ U 0j 2, but also with Σ U 0 , or more specifically, σ U 01 2, σ U 02 2, …, σ U 0p 2. Consequently, two detrimental effects would occur.
| 1. | The False Alarm Rate (FAR) or the Type I error probability of the monitoring procedure will increase. Here, FAR is defined as the probability that σ U 0j 2 is declared to be out of control when in truth it is in control. This point is easy to understand: since the change of var(Z 0) in Equation (Equation11) may be not from σ U 0j 2, but from some σ U 0i 2, i ∈ j , σ U 0j 2 may be declared to be out of control when it actually experiences no change. | ||||
| 2. | Likewise, the misdetection rate (MDR), or the Type II error probability, which is defined as the probability that σ U 0j 2 is declared to be in control when in truth it is out of control, will also increase. In the presence of σ U 0i 2, the proportion between the change of σ U 0j 2 and var (Z 0) will decrease and thus the monitoring procedure will have a larger Type II error probability as illustrated by the operation characteristic curves of a typical S chart (CitationMontgomery, 2001). | ||||
In other words, the diagnostic capability of the monitoring procedure will degrade in the presence of measurement errors.
To provide more insight on the impact of measurement errors, we will use a two-stage process as an example to get a specific expression of Equation (Equation11). Assume there is one QC in each stage and the true model of the QCs are Q 1 = U 1 and Q 2 = β Q 1 + U 2, while the measurements are X 1 = Q 1 + ε andY = Q 2 + e. Also assume that σ U 1 2 = σ U 2 2, σ ε 2 = σ e 2 and the Phase I signal-to-noise ratio σ U 1 2/σε 2 = κ. Then by Equation (Equation9), we can get:
3.2. Impact of regressor selection
In regression model building, the set of regressors can be often reduced through a selection of relevant factors in the model. Accordingly, there are two ways to conduct regression adjustment, namely, the all-adjustment procedure that regresses Y on all the preceding QCs and the subset-adjustment procedure that regresses Y on only a selected subset of the preceding QCs. In this section, these two adjustment methods are compared. Firstly, a graph representation of regressor selection results is introduced.
3.2.1. Graph representation of regressor selection results
For ease of comparison of the two regression adjustment methods, a graph can be constructed as shown in , to show the interactions among the QCs in a process. In this graph, if there is a directed line from QC i to QC j, it means that the coefficient of i is non-zero in the multiple regression of j, i.e., β i ≠ 0 in Equation (Equation1). This selection can be done through physical analyses of the process or data-driven statistical selection procedures. For example, if we can identify that i is physically independent of j, then there should not be a line between i and j. For a simple process, physical analysis might be a viable way to establish such a graph. However, for a complex process involving many QCs, data-driven methods have to be used. The data-driven techniques to build such graphs include both the conventional model selection techniques (CitationSeber and Lee, 2003) and the recent statistical testing methods based on graphical models (CitationDrton and Perlman, 2005; CitationZeng and Zhou, 2006). In this article, however, we will not investigate the model building technique; instead, we assume that a graphical model is given.
Fig. 4 The graph representation of regressor selection results.
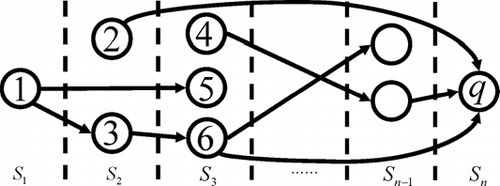
Based on this graph, ![]() j
can be divided into two subsets,
j
can be divided into two subsets, ![]() j1 and
j1 and ![]() j2, such that for every i ∈
j2, such that for every i ∈![]() j1, β
i
≠ 0 there is a directed line from i to j, and for every i ∈
j1, β
i
≠ 0 there is a directed line from i to j, and for every i ∈![]() j2, β
i
= 0 or there is no line between i and j. For example, in , let j = 5, then
j2, β
i
= 0 or there is no line between i and j. For example, in , let j = 5, then ![]() 51 = {1} and
51 = {1} and ![]() 52 = {2, 3}. Correspondingly, the regressors and parameters in Equations (Equation1) (Equation2), (Equation3),(Equation4) can be divided into two parts, that is, Q = [Q′I,Q′II]′, X = [X′I,X′II]′,
ε
= [
ε
′I,
ε
′II]′, β = [
β
′I,
β
′II]′ and D = [D′I, D′
II]′, where the quantities with subscript “I” are related with QCs in
52 = {2, 3}. Correspondingly, the regressors and parameters in Equations (Equation1) (Equation2), (Equation3),(Equation4) can be divided into two parts, that is, Q = [Q′I,Q′II]′, X = [X′I,X′II]′,
ε
= [
ε
′I,
ε
′II]′, β = [
β
′I,
β
′II]′ and D = [D′I, D′
II]′, where the quantities with subscript “I” are related with QCs in ![]() j1 and those with subscript “II” are related with QCs in
j1 and those with subscript “II” are related with QCs in ![]() j2. Then model (1) becomes.
j2. Then model (1) becomes.
In later discussion, subset adjustment means that Y is regressed on X I, while all adjustment means that Y is regressed on X. The two sets of regressors can be easily identified from . For example, for j = 5, the regressor is X 1 in subset adjustment and they include X 1, X 2 and X 3 in all adjustment.
3.2.2. Subset adjustment compared to all adjustment
The two adjustment methods can be compared in terms of the FAR and MDR of the procedure resulted when they are used respectively.
3.2.2. FAR comparison If the subset-adjustment procedure is used, by Equation (Equation8), the least squares estimate:
Instead, if the all-adjustment procedure is used, the estimate:
According to Equations (Equation20)(Equation21)(Equation22)(Equation23), the coefficients of σ U 0i 2, f i s and f i a, are all non-negative and can be viewed as the measures of the influence of σ U 0i 2 on the monitored quantity in subset-adjustment and all-adjustment methods, respectively. The larger this measure, the larger the FAR resulting from a certain change of σ U 0i 2. In other words, if f i s > f i a, such an influence is larger in subset adjustment than in all adjustment and thus the latter is a better choice in terms of reducing the effect of σ U 0i 2; and vice versa.
Considering the general assumptions in our study, it is difficult to further simplify Equations (Equation22) and (Equation20). However, the following facts can be drawn about the comparison between f
i
s and f
i
a: Fact 1: If Q
I and Q
II are independent, then f
i
s = f
i
a for all i ∈![]() j
.
j
.
This is a direct result. If Q
I and Q
II are independent, C = D
IΣ
U
D′II =
Σ
Q
I
Q
II
= 0
p
1 × p
2
, where p
1 and p
2 are the numbers of QCs in ![]() j1 and
j1 and ![]() j2 respectively,
Σ
Q
I
Q
II
is the covariance matrix between Q
I and Q
II. Thus, by Equations (Equation22) and (Equation22), f
i
s = f
i
a = (β ′I
Σ
ε
I
A
− 1
d
1i
)2, meaning that the influence of σ
U
0i
2 is the same in both methods.
j2 respectively,
Σ
Q
I
Q
II
is the covariance matrix between Q
I and Q
II. Thus, by Equations (Equation22) and (Equation22), f
i
s = f
i
a = (β ′I
Σ
ε
I
A
− 1
d
1i
)2, meaning that the influence of σ
U
0i
2 is the same in both methods.
Fact 2: For those i ∈![]() j
such that d
1i
= 0
p
1
, f
i
s = 0 and f
i
a ≥ 0.
j
such that d
1i
= 0
p
1
, f
i
s = 0 and f
i
a ≥ 0.
This is also direct from Equations (Equation22) and (Equation23). It means that for the preceding local variations satisfying this condition, their changes will not influence the monitored quantity at all if subset adjustment is used, but may have influence if all adjustment is used.
Fact 3: In general, the magnitudes of f i s and f i a depend on D and the values of the local variations and measurement errors. For some i, f i s > f i a, and for others, f i s ≤ f i a. In other words, there is no uniform conclusion in general cases.
Fact 3 tells us that the subset-adjustment method and the all-adjustment method are not uniformly better than the other. This point can be shown specifically by the three-stage example represented by .
Fig. 5 A three-stage process.
In this example, assume the true model is Q 1 = U 1, Q 2 = b 1 Q 1 + U 2 and Q 3 = β2 Q 2 + U 3, where b 1, β2≠ 0. The measurements are X 1 = Q 1 + ε1, X 2 = Q 2 + ε2 and Y = Q 3 + e. So the matrix D can be written as
Considering a special case where σ U 1 2 = σ U 2 2, σε1 2 = σε2 2 and σ U 1 2/σε1 2 = κ, it can be shown that.
From the three facts, we can see that when the QCs in ![]() j1and
j1and ![]() j2 are independent, there is no difference between the two adjustments since the monitoring procedures using them will suffer the same influences from the preceding local variations. When the QCs in the two sets are correlated, depending on the correlation structure between them and the specific local variation, the performances of the subset-adjustment and all-adjustment methods are different. For the local variations which satisfy the condition in fact 2, subset adjustment can completely eliminate their influences on the monitoring procedure, but all adjustment may not do so.
j2 are independent, there is no difference between the two adjustments since the monitoring procedures using them will suffer the same influences from the preceding local variations. When the QCs in the two sets are correlated, depending on the correlation structure between them and the specific local variation, the performances of the subset-adjustment and all-adjustment methods are different. For the local variations which satisfy the condition in fact 2, subset adjustment can completely eliminate their influences on the monitoring procedure, but all adjustment may not do so.
3.2.2.2. MDR comparison In this part, we consider those cases where all preceding local variations are kept in normal status, i.e., σ U 0i 2 = σ U i 2 for i ∈ j , and only the local variation of QC j increases. MDR is the probability that the change in σ U 0j 2 is missed by the monitoring scheme.
Consider Phase I analysis of the monitoring procedure in Section 2.2. According to the linear least square theory, the variance of Y can be decomposed into that of Y, the predictor, and that of Y − Y, the residual (CitationWhittaker, 1990, Proposition 5.3.4). Consequently, we have that:
We now perform the Phase II analysis. Assume the local variation of QC j increases by δ j , i.e., σ U 0j 2 − σ U j 2 = δ j . According to Equations (Equation17) and (Equation19), var(Z 0 s) = var(Z s) + δ j and var(Z 0 a) = var(Z a) +δ j . Thus, the ratios between the variation change, δ j , and the background variations are
Fact 5: Generally, r s < r a, meaning that the subset-adjustment method is less sensitive to the change of j's local variation than the all-adjustment method and thus it will yield a higher MDR.
3.2.3. Summary of the impact of regressor selection
Using the five facts obtained from the comparison, some conclusions that are helpful in the use of a regression-adjusted monitoring procedure can be summarized as follows.
| 1. | By fact 1 and fact 4, all the QCs in | ||||
| 2. | As far as the FAR is concerned, by fact 3, there is no clear advantage to using either the subset-adjustment method or the all-adjustment method. Generally they depend on the correlation structure of the QCs in the process and specific local variations. However, we can safely conclude that procedures using the all-adjustment method will suffer the influences from all preceding local variations, whereas those using the subset-adjustment method can eliminate the influences from some local variations satisfying the condition in fact 2. In other words, the subset-adjustment method corresponds with fewer false alarm sources. | ||||
| 3. | In terms of reducing the MDR, by fact 4 and fact 5, the all-adjustment method is a better choice or at least performs as well as the subset-adjustment method. | ||||
As such, there is generally no uniform priority between these two adjustment methods. In practice, which one to choose depends on the specific situation and people's preference on FAR and MDR. If a low FAR is important, then the subset-adjustment method should be seriously considered, whereas if MDR is critical, the all-adjustment method should be used.
4. Numerical study
4.1.4. A two-stage process to illustrate the impact of measurement errors
In this example, we apply the monitoring procedure in Section 2.2 on the two-stage process as described in Section 3.1. In Phase I analysis, assume σ U 1 2 = σ U 2 2 = 1, m = 200 and n = 25. Three-sigma limits are used to construct the S chart. In phase II analysis (the sample size is again 25), we consider two scenarios: in scenario 1, β is fixed at 2, while κ can be 5, 7, 10 or 20, and in scenario 2, κ is fixed at 10, while β can be 1, 2, 3 or 6. The FAR and MDR values of the procedure in these two scenarios are calculated by changing the two ratios, σ U 01 2/σ U 1 2 and σ U 02 2/σ U 2 2, respectively.
and list the Phase I analysis results including ![]() β and estimated control limits in scenarios 1 and 2 respectively. It is clearly seen that, as indicated by Equation (Equation12), the difference between β and β becomes larger when κ is smaller or β is larger. FAR against σ
U
01
2/σ
U
1
2 and MDR against σ
U
02
2/σ
U
2
2 in scenario 1 are shown in , and those in scenario 2 are in , where every result is obtained through 20 000 Monte Carlo simulations. According to , we know that, as indicated by Equation (Equation13):
β and estimated control limits in scenarios 1 and 2 respectively. It is clearly seen that, as indicated by Equation (Equation12), the difference between β and β becomes larger when κ is smaller or β is larger. FAR against σ
U
01
2/σ
U
1
2 and MDR against σ
U
02
2/σ
U
2
2 in scenario 1 are shown in , and those in scenario 2 are in , where every result is obtained through 20 000 Monte Carlo simulations. According to , we know that, as indicated by Equation (Equation13):
| 1. | A larger σ U 01 2 or smaller κ corresponds with a larger FAR. We can also note that the value of κ is a very important factor in that FAR is almost unchanged and also very small when κ is large (e.g., > 20). | ||||
| 2. | A smaller σ U 02 2 or smaller κ corresponds with a larger MDR. Moreover, as σ U 02 2 becomes very large, MDRquickly reduces to around zero. This suggests that MDR is influenced by measurement errors especially when the change of σ U 02 2, which is supposed to be detected by the monitoring procedure, is small. Also, the impact of measurement errors becomes larger when β increases, as shown in . | ||||
Fig. 6 (a) FAR for different values of κ; and (b) MDR for different values of κ.
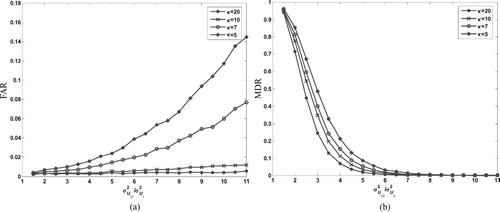
Fig. 7 (a) FAR for different values of β; and (b) MDR for different values of β.
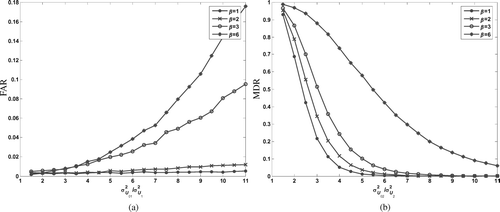
Table 1 Phase I analysis results under different values of κ β= 2)
Table 2 Phase I analysis results under different values of β (κ = 10)
4.2. A four-stage process to illustrate the impact of regressor selection
In this example, consider the monitoring of QC 5. Assume we have obtained the graph representing the interactions in the process, which is exactly as shown in , using a regressor selection technique. Accordingly, assume the true relationships are Q 1 = U 1, Q 2 = b 12 Q 1 + U 2, Q 3 = U 3, Q 4 = b 24 Q 2 + U 4 and Q 5 = β2 Q 2 + U 5, while the measurements are X 1 = Q 1 + ε1, X 2 = Q 2 + ε2, X 3 = Q 3 + ε3, X 4 = Q 4 + ε4 and Y = Q 5 + e. In the simulation, let b 12 = 1, b 24 = 2, β2 = 5, κ = 10. In Phase I analysis, σ U 1 2 = σ U 2 2 = σ U 3 2 = σ U 4 2 = σ U 5 2 = 1, m = 200 and n = 25. The sample size in Phase II is also 25. lists the Phase I analysis results when subset adjustment, Y∼ X 2, and all adjustment, Y∼ X 1+ X 2+ X 3+ X 4, are used. The FAR against σ U 01 2/σ U 1 2, σ U 02 2/σ U 2 2, σ U 03 2/σ U 3 2 and σ U 04 2/σ U 4 2 are shown in , , and respectively, where the two lines in each figure denote the results obtained in these two adjustments.
Fig. 8 A four-stage process.
Fig. 9 FAR for the two considered adjustments: (a) FAR plotted against σ U 01 2/σ U 1 2; (b) FAR against σ U 02 2/σ U 2 2; (c) FAR against σ U 03 2/σ U 3 2; and (d) FAR against σ U 04 2/σ U 4 2.
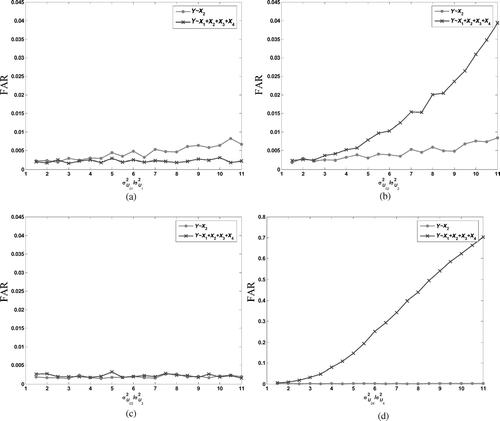
Table 3 Phase I analysis results for the two adjustment methods
It's easy to find that QC 3 is independent of QC 2. Thus, by fact 1, the influences of σ U 03 2 in subset adjustment and all adjustment are the same, as validated by . Also, we can find that d14 = 0, and consequently, by fact 2, the change of σ U 04 2 will not cause a false alarm when the subset-adjustment method is used. This is shown by , where the FDR resulting from the change of σ U 04 2 is very high (> 0.5) in all adjustment, but around zero in subset adjustment. So subset adjustment is, as expected, a quite advantageous choice to eliminate the possible serious FAR caused by σ U 04 2. indicates that the influence of σ U 01 2 using all adjustment is smaller than that using subset adjustment, whereas gives the contrary conclusion. This is as suggested by Equation (Equation25).
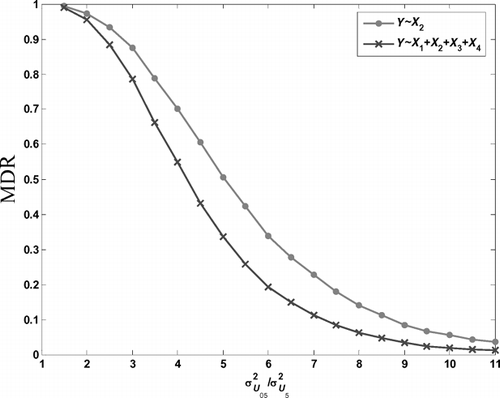
shows the MDR against σ U 05 2/σ U 5 2 for the two adjustment methods when the FAR is maintained at around 0.0027. As expected, the all-adjustment method has a lower MDR and as the change in σ U 05 2 becomes large, the MDR for both methods quickly reduces to zero.
Fig. 10 MDR for the two adjustment methods.
5. Summary and discussion
This paper investigates the impacts of measurement errors and regressor selection on the regression-adjustment-based monitoring scheme of variability in multistage processes. It is shown that the existence of measurement errors will result in higher FAR and MDR levels, and the complexity of the impact of regressor selection is actually a byproduct of the measurement error impact. We also compare the performances of the subset-adjustment method and all-adjustment method and find that the monitoring procedure using the subset-adjustment method is more robust to the change of some preceding local variations than that using the all-adjustment method, however the all-adjustment method has a lower MDR. Thus, the choice of which of these methods to use is dependent on the characteristics of the process and preference about the FAR and MDR of the monitoring procedure.
In the analysis, asymptotical performances under large sample conditions are considered. However, similar results can be verified through further numerical studies when sample sizes are much smaller. Thus, the results of this study can be viewed as a general reflection of multistage manufacturing processes where a large number of samples are often readily available due to advances in sensing and information technologies. Consequently, the conclusions summarized in this paper possess wide applicability in practice. Another point worth mentioning is that the detrimental influences of measurement errors in regression-adjusted methods can be optimally reduced if we replace the ordinary least squares regression with a modeling technique which is known as Total Least Squares (TLS) in computational mathematics and engineering, or as Errors-In-Variables (EIV) modeling in statistics (CitationVan Huffel and Lemmerling, 2002). By TLS/EIV, a consistent estimate ![]() can be obtained and thus the influence of measurement errors is minimized. However, these techniques are computational intense and are not easy to apply in practice. Moreover, one of the four conditions (i) σ
e
2/σ ε
i
2 is known; (ii) σ
e
2 is known; (iii) σε
i
2 is known; (iv) both of σ
e
2 and σε
i
2 are known, is required to get the solution (CitationVan Huffel, 2004), which sets another obstacle for TLS/EIV techniques to be applied widely. Thus, in many practical cases, least squares regression is still an efficient choice.
can be obtained and thus the influence of measurement errors is minimized. However, these techniques are computational intense and are not easy to apply in practice. Moreover, one of the four conditions (i) σ
e
2/σ ε
i
2 is known; (ii) σ
e
2 is known; (iii) σε
i
2 is known; (iv) both of σ
e
2 and σε
i
2 are known, is required to get the solution (CitationVan Huffel, 2004), which sets another obstacle for TLS/EIV techniques to be applied widely. Thus, in many practical cases, least squares regression is still an efficient choice.
Appendices
Appendix 1. Proof of Equations (Equation22) and (Equation23)
According to Equation (Equation9):
Substituting Equation (EquationA4) into Equation (EquationA2) yields:
Appendix 2. Proof of Equation (Equation25)
Let σ U 1 2 = σ U 2 2 = κ σε1 2 = κ σε2 2, κ > 0, substituting them into Equation (Equation24) yields:
Appendix 3. Proof of Equations (Equation28) and (Equation29)
By the additivity of the explained variation (CitationWhittaker, 1990, Proposition 5.6.1):
By Proposition 5.5.1 in CitationWhittaker (1990):
Another important fact is that according to Proposition 10.5.1 in CitationWhittaker (1990), βII = 0 in Equation (Equation14) is equivalent to cov(Q j ,Q II|Q I) = 0.
Thus, comparing Equations (EquationA11), (EquationA12) and (EquationA15), we can get:
| 1. | If Q I and Q II are independent, i.e., cov(Q I,Q II) = 0, cov (Y,X II|X I) = cov(Q j ,Q II|Q I) = 0, and consequently: | ||||
| 2. | Generally, since var εI) ≠0, cov(Y,X II|X I) ≠cov(Q j , Q II|Q I) and thus cov(Y,X II|X I) ≠0. Consequently: | ||||
Biographies
Li Zeng is a Ph.D. student in the Department of Industrial and Systems Engineering at the University of Wisconsin-Madison. Her research interests are statistical modeling and variation source diagnosis in large complex systems.
Shiyu Zhou is an Associate Professor in the Department of Industrial and Systems Engineering at the University of Wisconsin-Madison. He was awarded his B.S. and M.S. degrees in Mechanical Engineering by the University of Science and Technology of China in 1993 and 1996 respectively. He received his Master's degree in Industrial Engineering and Ph.D. in Mechanical Engineering at the University of Michigan in 2000. His research focus is on creating in-process quality and productivity improvement methodologies by integrating statistics, system and control theory, and engineering knowledge. The objective is to achieve automatic process monitoring, diagnosis, compensation, and their implementation in various manufacturing processes. His research is sponsored by National Science Foundation, Department of Energy, NIST-ATP, and industries. He is a recipient of the CAREER Award from the National Science Foundation in 2006. He is a member of IIE, INFORMS, ASME and SME.
Acknowledgements
The financial support of this work is provided by NSF grant CMMI-0545600. The authors gratefully appreciate the editor and the referees for their valuable comments and suggestions.
References
- Agrawal , R. , Lawless , J. F. and Mackay , R. J. 1999 . Analysis of variation transmission in manufacturing processes—part II . Journal of Quality Technology , 31 ( 2 ) : 143 – 154 .
- Apley , D. W. and Shi , J. 2001 . A factor-analysis method for diagnosing variability in multivariate manufacturing processes . Technometrics , 43 ( 1 ) : 84 – 95 .
- Ceglarek , D. and Shi , J. 1995 . Dimensional variation reduction for automotive body assembly . Journal of Manufacturing Review , 8 : 139 – 154 .
- Ding , Y. , Ceglarek , D. and Shi , J. Model and diagnosis of multistage manufacturing processes: part I state space model . Proceedings of the 2000 Japan/USA Symposium on Flexible Automation . Ann Arbor , MI . 2000JUSFA-13146
- Djurdjanovic , D. and Ni , J. 2001 . Linear state space model of dimensional machining errors . Transactions of NAMRI/SME , 29 : 541 – 548 .
- Drton , M. and Perlman , M. D. 2005 . A sinful approach to Gaussian graphical model selection . Journal of Statistical Planning and Interference , (in press)
- Fong , D. Y.T. and Lawless , J. F. 1998 . The analysis of process variation transmission with multivariate measurements . Statistica Sinica , 8 : 151 – 164 .
- Fuller , W. A. 1987 . Measurement Error Models , New York , NY : Wiley .
- Hauck , D. J. , Runger , G. C. and Montgomery , D. C. 1999 . Multivariate statistical process monitoring and diagnosis with grouped regression-adjusted variables . Communications in Statistics. Simulation and Computation , 28 ( 2 ) : 309 – 328 .
- Hawkins , D. M. 1991 . Multivariate quality control based on regression-adjusted variables . Technometrics , 33 ( 1 ) : 61 – 75 .
- Hawkins , D. M. 1993 . Regression adjustment for variables in multivariate quality control . Journal of Quality Technology , 25 ( 3 ) : 170 – 182 .
- Huang , Q. , Zhou , N. and Shi , J. Stream of variation modeling and diagnosis of multi-station machining processes . Proceedings of the 2000 ASME International Mechanical Engineering Congress and Exposition . pp. 81 – 88 .
- Hyer , N and Wemmerlov , U . 2002 . Reorganizing the Factory: Competing Through Cellular Manufacturing , Portland , OR : Productivity Press .
- Jin , J. and Shi , J. 1999 . State space model of sheet metal assembly for dimensional control . ASME Transactions, Journal of Manufacturing Science and Engineering , 121 : 756 – 762 .
- Koren , K. , Heisel , U. , Jovane , F. , Moriwaki , T. , Pritschow , G. , Ulsoy , G. and Van Brussel , H. 1999 . Reconfigurable manufacturing systems . Annals of the CIRP , 48 : 1 – 14 .
- Lawless , J. F. , Mackay , R. J. and Robinson , J. A. 1999 . Analysis of variation transmission in manufacturing processes-part I . Journal of Quality Technology , 31 ( 2 ) : 131 – 142 .
- Mandel , B. J. 1969 . The regression control chart . Journal of Quality Technology , 1 ( 1 ) : 1 – 9 .
- Montgomery , D. C. 2001 . Introduction to Statistical Quality Control, , fourth edn , New York , NY : Wiley .
- Rogers , G. G. and Bottaci , L. 1997 . Modular production systems: A new manufacturing paradigm . Journal of Intelligent Manufacturing , 8 : 147 – 156 .
- Seber , G. A.F. and Lee , A. J. 2003 . Linear Regression Analysis, , Second edn. , Hoboken , NJ : Wiley .
- Van Huffel , S. Total least squares and errors-in-variables modeling: bridging the gap between statistics, in computational mathematics and engineering . Compstat Proceedings in Computational Statistics . pp. 539 – 555 .
- Van Huffel , S. and Lemmerling , P. , eds. 2002 . Total Least Squares and Errors-in-Variables Modeling: Analysis, Algorithms and Applications , Dordrecht , , The Netherlands : Kluwer .
- Wade , M. R. and Woodall , W. H. 1993 . A review and analysis of cause-selecting control charts . Journal of Quality Technology , 25 ( 3 ) : 161 – 169 .
- Whittaker , J. 1990 . Graphical Models in Applied Multivariate Statistics , Chichester , , UK : Wiley .
- Zantek , P. F. , Wright , G. P. and Plante , R. D. 2002 . Process and product improvement in manufacturing systems with correlated stages . Management Science , 48 ( 5 ) : 591 – 606 .
- Zantek , P. F. , Wright , G. P. and Plante , R. D. 2006 . A self-starting procedure for monitoring process quality in multistage manufacturing systems . IIE Transactions , 38 ( 4 ) : 293 – 308 .
- Zeng , L. and Zhou , S. 2006 . Inferring the interactions in complex manufacturing processes using graphical models . Technometrics , (in press)
- Zhang , G. 1985 . Cause-selecting control charts: A new type of quality control chart . The QR Journal , 12 : 221 – 225 .
- Zhou , S. , Huang , Q. and Shi , J. 2003 . State space model of dimensional variation propagation in multistage machining process using differential motion vectors . IEEE Transactions on Robotics and Automation , 19 ( 2 ) : 296 – 309 .