

Abstract
Judicial experience is considered essential for the proper functioning of the sentencing system. We investigate how it influences judicial decisions and its role in reducing sentencing disparity. To do so, we analyze all Czech criminal decisions imposed in 2007–2017 using data that includes judge identifiers. This unique feature of our data enables us to measure judges’ experience directly, as the number of criminal cases processed, and to assess patterns in between-judge disparities longitudinally over the course of judges’ careers. We find that experienced judges impose more prison sentences, decide fewer cases via shortened procedure and find fewer defendants guilty. In addition, as judges become more experienced, between-judge disparities reduce across all the outcomes considered. Experience is thus an instrumental factor affecting judicial decisions throughout the criminal process, and one that contributes to greater consistency.
Disclosure statement
No potential conflict of interest was reported by the authors.
Methodological Appendix A
Measurement Appendix
In this Measurement Appendix we expand our justification for using the number of cases processed as a measure of issue-specific judicial experience and we provide further insights into it how this variable was calculated and how it compares with similar proxies considered in the literature, such as time on bench and judge’s age.
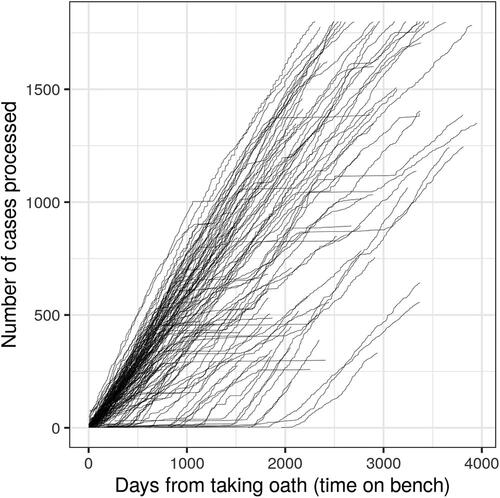
Measuring Judicial Experience
One of the important contributions of our study is the distinction between issue-specific judicial experience (represented by the number of processed criminal cases) and general judicial experience (represented by time on bench). The main advantage of issue-specific judicial experience over general judicial experience consists in better recognizing specific judicial activities. The displays the relationship between time on bench and the number of processed cases for the judges captured in our sample across our window of observation.Footnote6 Each line represents an individual judge; the figure reveals that many judges began deciding criminal cases years after taking their oath, and thus that their experience would not be accurately reflected by the time on bench measure. Time on bench would also not reflect the fact that some judges sentence more cases over a given period of time than others. There are various reasons behind these disparities in the frequency of cases processed, such as work on civil or administrative cases (not criminal ones), career gaps as a result of parental leave, pursuing further education, or similar. Using the total number of criminal cases tried overcomes both of this limitations, although it is still not a perfect measure of experience. In particular, the number of cases processed places all its emphasis on the quantity of the experience gained from processing cases, and fails to consider the quality of that experience. If the criminal justice system allows it, certain judges might be given fewer, yet harder and longer-lasting cases or might specialize in a particular type of criminality, which might shape their decision-making differently.
While there are obvious issues with general judicial experience, it can, however, provide a crude insight into how judicial experience influences judges. While issue-specific experience and general judicial experience differ, the correlation between them is still high (Pearson’s of 0.816, Sample 1). This is not true for age as the correlation between age and both the issue-specific experience and general judicial experience is low (Pearson’s
of 0.35 and 0.44, Sample 1). As a result, age should not be used as a proxy of judicial experience.
Figure A1. Experience measured as time on bench and as number of cases processed (Czech judges who took their oaths in 2007–2017).
Note. Each line captures the trajectory of an individual judge over time on bench. N = 93,374, Njudges = 149.
Moreover, we are aware that our measure of issue-specific experience might be affected by missing judge identifiers. In we report the number of cases in which we were not able to acquire the name of the judge deciding the case. We do not consider this missing data to be a substantial issue for our study as judge identifiers were missing only for a small share of cases. As we explain in the main text, there are a number of potential explanations to this missing data, such as a detected technical error experienced by three district courts in 2016 and 2017.
Table A1. Share of cases for which we lack information about the deciding judge, 2007–2017.
Analytical Appendix
In this appendix, we provide further details of our modelling strategy and additional robustness checks. Between-judge variability has often been ignored in sentencing research, due to the common absence of judge identifiers in official sentencing data (Pina-Sánchez et al., Citation2019). When accounted for, it is always assumed to be uniform across time, despite overwhelming evidence from life-course literature that it is safer to assume that individual differences do change across time (Fine & Cauffman, Citation2015; Penn & Silverstein, Citation2012). Again, we probably owe this assumption to the limitations of previously available sentencing data. Methodologically, failing to account for this variability affects a model’s measures of uncertainty (Dhami & Belton, Citation2016; Johnson, Citation2006). Importantly, there are also substantive implications to be considered. If we ignore the longitudinal dimension in sentencing data, we cannot reliably estimate the true extent of between-judge disparities or examine how these change as judges gain experience.
We specify the unique longitudinal component available in our sentencing dataset using growth curve models. The various elements that make up a growth curve model can be visualized by considering a typical linear regression model where sentence length, denoted as Y, is regressed upon a list of k case characteristics,
with
representing the model’s intercept, the average sentence length after controlling for each of the k case characteristics included in the model;
represents the effect of each of those case characteristics on sentence length; and
represents the residual term, capturing differences in sentence length that cannot be explained by the case characteristics included in the model, which are assumed to be independent and normally distributed, with mean 0 and constant variance
If the model is well specified in the sense that most of the legally relevant characteristics of the case are accounted for, then this residual term can be taken as an estimate of the extent of unwarranted sentencing disparities present in the system (Pina-Sánchez & Linacre, Citation2014). Notice as well that two subscripts t and i are included in each of the variables and the residual term. This is to denote that cases, t, are clustered within judges, i.
This standard model can be extended by including a covariate capturing the order in which the sentences were imposed by each judge, denoted here as The regression coefficient associated with that covariate,
can then be used to estimate the average association between
and Y. For example, if
and statistically significant, this indicates that judges increase the severity of their sentences as they become more experienced. To consider not just the average effect of experience, but also each judge’s individual trajectory, the model can be further extended by including a random intercept term,
and a random slopes term,
These two random terms allow the intercept and the effect of experience to vary by judge as follows
and
which is why they are now presented with their own subscript i. This linear growth curve model can be presented in the following form, which is similar to the random slopes models commonly used in sentencing research to examine disparities between judges or courts in the use of certain case characteristics (Anderson & Spohn, Citation2010; Johnson, Citation2005):
The addition of these two random effects implies invoking further assumptions, namely that each of these judge-level residuals is distributed independently as a normal variable with mean 0 and a given variance,
and is independent from the case level residuals, represented as
However, we do not assume that
and
are independent of each other; indeed, the covariance between the two random effects,
will be used to examine any potential changes in unobserved between-judge disparities as judges progress in their careers. For example, if
are statistically significant, this may indicate that between-judge disparities in sentence length increase as judges become more experienced.
The growth curve model represented above is of a linear type, as is the model we use to examine differences in the lengths of the custodial sentences imposed – we call this Model 2 (sentence length is log-transformed to adjust for the right-skewness observed in its distribution). For Model 1 and Models 3 and 4, where we explore the probabilities of incarceration, guilt adjudication and penal order procedures, we extend the model defined above using a binary logit growth curve specification. All our models are estimated using MLwiN (v. 3.0) and R (v. 3.6.3) connected by the package R2MlwiN (v. 0.8-6).
Robustness Checks
We have undertaken robustness checks to assess the sensitivity of our findings to a series of assumptions. We tested whether the effect that we have attributed to judicial experience could be biased by exploring the association between the number of cases processed with changes in the Czech criminal justice system across the window of observation considered, or with the types of cases judges are assigned throughout their careers. There is little evidence of such potential confounding effects. The correlation between issue-specific experience (the number of cases processed by a given judge) and time (measured as the number of days elapsed from January 1st 2007) is relatively weak (Pearson’s of 0.37, Sample 1), as is the correlation between the number of cases processed and the age of the judge (Pearson’s
of 0.35, Sample 1). Since the judges in our sample joined the judiciary gradually, any trend (changes in the criminal justice system) would need to be stable across the entire examined period as there is no unusually large wave of judges entering the system at any point, which could give rise to a linear effect starting from such a point. To control for such a possible trend, we also estimate models 1–4 substituting the yearly dummy variables with a continuous variable capturing the time since the onset of our window of observation. This change did not affect our main findings, namely the fixed and random estimates associated with experience.
In addition, as shown in , our explanatory variables do not change substantially over time, which suggests an absence of significant changes in the Czech criminal justice system, or in the assignment of cases correlated with judicial experience. The only exception being a positive association between number of cases processed and the age of defendants, but this only amounts to one year of age over 1800 decisions, plus defendant’s age is one of the variables controlled for in our models.
Figure A2. Relationship between number of cases processed and case characteristics (Sample 1).
Note. The presented characteristics refer to average values across cases processed at specific points in judicial careers. The average value is calculated across cases decided by all judges at given numbers of cases processed. Non-continuous variables were rounded to hundreds of processed cases; the geom_smooth function in R was used to capture the trend.
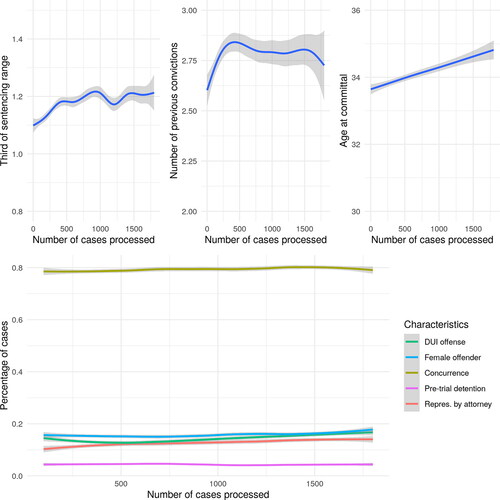
To test the quasi random allocation of cases to judges within the Czech criminal justice system, we employ a model in which the response variable is the judge decision number and the explanatory variables are all the case characteristics recorded in our dataset (sentencing range, previous convictions, offense type, offender age and sex, type of criminal code, concurrence, pre-trial detention, manner of beginning procedure and representation by an attorney). The results are reported in . We explicitly removed year dummies as year is inherently correlated with the judge decision number. While approximately half of the explanatory variables are statistically significant, there is no substantively significant pattern of case-composition across cases assigned to novice or experienced judges (e.g. fewer DUI offenses, more serious offenses, more pre-trial detentions). The standardized coefficients are very small with the largest (after the criminal code, which is time-dependent and inherently correlated with the judge decision number) being representation by an attorney pushing standard deviation by 3.3%; this is likely explained by the increasing wealth of the Czech population between 2007 and 2017. Hence, we can conclude, that cases are not assigned in a particular pattern across time, at least not based on the case characteristics that we were able to observe.
Table A2. Results of model with judge decision number as response variable (Sample 1).
Notes
1 Specializations might include e.g. traffic offenses or whether the case began via a shortened procedure or not. Cases are usually successively assigned to individual judges using a wheel (one-by-one in a fixed order; algorithm-like random case assignment is rare). In many ways, the differences between specializations should be captured by the variables we are using, such as the type or seriousness of the offense and the type of criminal proceedings initially chosen. This is further discussed in the Analytical Appendix, where we show that, on where the observable characteristics are concerned, the cases dealt with by novice and experienced judges did not differ substantially.
2 The vast majority of female Czech last names end with the suffix “-ová” or “-á”. For those few judges whose sex could not be identified from their last names (such as those ending with -ů or -í), their sex was deducted from their first names (the vast majority of which are also sex-specific). Judges’ sex was coded manually.
3 For young offenders, offenders in pre-trial detention, offense categories with a sentencing maximum of at least 5 years and other relatively infrequent cases; s. 36-36b of the Code of Criminal Procedure.
4 District judges deal with the vast majority (98%) of criminal cases; only the most serious cases are tried by regional judges.
5 We are happy to provide the results of these and other models that are not reported in the paper upon request.
6 We only consider district court cases. That is, cases that judges may have been involved in when on secondment to higher courts are not counted.
Additional information
Funding
Notes on contributors
Jakub Drápal
Jakub Drápal is a researcher at the Institute of State and Law of the Czech Academy of Sciences and at the Faculty of Law, Charles University.
Jose Pina-Sánchez
José Pina-Sánchez is an Associate Professor in Quantitative Criminology at the School of Law of the University of Leeds.