
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
While venture capital firms are increasingly relying on recommendation models in investment decisions, existing startup recommendation models fail to consider the uniqueness of venture capital context, including two-sided matching between investing and investee firms and a lack of information disclosure requirements on startups. Following the design science research paradigm and guided by the proximity principle from social psychology, we develop a novel framework called SocioLink by depicting and analyzing various relations in a knowledge graph via machine learning. Our experimental results show that SocioLink significantly outperforms state-of-the-art startup recommendation methods in both accuracy and quality. This improvement is driven by not only the inclusion of social relations but also the superiority of modelling relations via knowledge graph. We also develop a web-based prototype to demonstrate explainable artificial intelligence. This work contributes to the FinTech literature by adding an innovative design artifact—SocioLink—for decision support in the investment context.
Introduction
Venture capitalists (VCs) invest in new companies with high-growth potential in exchange for an equity stake. According to a survey with VCs around the globe, selecting the right investments is considered to be the most important step in value creation [Citation19]. A recent article in the chief information officer (CIO) Journal column of Wall Street Journal reports that venture capital firms are now applying artificial intelligence (AI) algorithms to help with their own investment decisions [Citation62]. VCs are changing their investing strategy away from relying on experience and instinct to a quantitative process based on data and analytics. Consequently, startup recommendation models have attracted increasing attention in both academia and industry in recent years.
The existing startup recommendation models such as item-based collaborative filtering [Citation55], matrix factorization [Citation67], and startup success prediction model [Citation50] provide recommendations mainly based on preferences of investors but not that of startups (i.e., one-sided recommendation), which is similar to product recommendations in transactional markets [Citation17, Citation24, Citation43]. However, startup recommendations for venture capitalists are significantly different from the traditional recommendation tasks (e.g., product/stock/job/dating partner recommendations) due to the uniqueness of venture capital in three aspects. First, in contrast with transactional markets (e.g., e-commerce), venture capital is a two-sided matching market, in which an investment deal is a mutual decision that requires the consent of both the investor and the startup [Citation53]. In other words, business partnership between a VC and a startup can be established only when the VC makes an offer and the startup accepts it at the same time [Citation10]. A startup may turn down offers from VCs, especially when faced with multiple offers [Citation31]. Second, information asymmetry between investors and investees is higher in venture capital than in public stock markets. Private firms in the United States are not required by financial regulations to disclose information on their operations and financial performance [Citation20]. Moreover, for early-stage ventures including newly founded companies, information on past funding rounds is often limited. Therefore, VCs typically face great uncertainty about the future financial returns of startups [Citation19]. To assess the quality of startups, VCs generally rely on private information collected from personal and organizational networks, business plans submitted by entrepreneurs, and venture capital and entrepreneur conferences [Citation10]. Third, venture capital is essentially an inter-organizational trading market, as the two parties participating in investment deals are both organizations. In contrast, the two parties in online dating are both individuals, while those in the online labor market are organizations and individuals, respectively. On the one hand, the decision-making process within organizations is more complicated than that of a single person; on the other hand, collecting preference information of two organizations are more costly than individuals. Notably, existing recommendation models are not well suited for addressing the investment selection problem in venture capital, because they fail to account for the unique attributes of this context. Significant research gaps exist in the current state of research in this area due to context differences.
To fill this gap, we propose to leverage information on various relations among different players in the venture capital industry, in particular individuals’ social connections, and develop a novel startup recommendation framework called SocioLink following the design science paradigm [Citation23, Citation29, Citation45]. The advantages of SocioLink include (1) relational closeness can capture the extent of matching as well as communication effectiveness between two organizations, thus facilitating mutual screening between VCs and startups; (2) relational connections (e.g., employment affiliation overlap, ethnic or educational connection, or physical distance) can alleviate information asymmetry by lowering the cost of VCs in gathering private information of startup companies; (3) relational data in the VC industry is publicly available—collecting such data is feasible and not so costly.
Our optimism is premised on theoretical and empirical research findings that various forms of relations have a significant impact on the formation of business partnerships (e.g., [Citation9, Citation27, Citation48]). The findings in finance and management literature extend the proximity principle originated in social psychology [Citation39], which emphasizes the tendency of individuals to form connections with close (or similar) parties, in several ways. First, socially connected individuals are more likely to collaborate with each other because they not only have a higher level of trust [Citation4, Citation9, Citation21], but also are more homophilous in social norms, interests, or culture than unconnected ones, and communication between parties is more effective when the two parties are more alike [Citation12, Citation27, Citation48, Citation51]. Second, geographically proximate firms are more likely to form business partnerships than distant ones due to lower cost of information collection and face-to-face communication [Citation10, Citation35]. Third, VCs (especially corporate VCs) tend to limit investments to industries they are familiar with [Citation36, Citation51, Citation54]. To synthesize the findings documented in the literature, we model three categories of relationships between VCs and startups in a knowledge graph (KG) [Citation7, Citation59]: social connections between the employees of two firms (i.e., overlap in employment affiliation, educational background, or ethnicity), geographic proximity, and industry relatedness. Our study applies the proximity principle innovatively to the task of venture recommendations and demonstrates the effect of individual relations affecting organization matching—Individual-Driven Organizational Proximity, thus extending its theoretical depth in a new business domain.
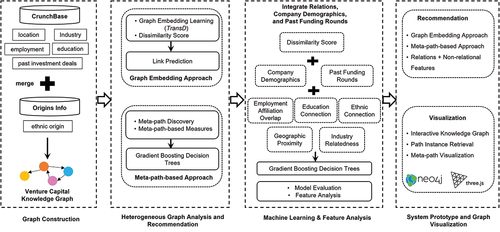
summarizes our framework of relation-based recommendations, which we refer to as SocioLink. We first construct a venture capital KG to depict various connections among VCs, startups, persons, ethnicities, educational institutions, cities, and industries. To model the multi-relational data in the graph for recommendations, we adopt two different approaches, namely graph embedding approach and meta-path-based approach. The graph embedding approach models all entities and relations in the graph through low-dimensional vectors [Citation6]. We define a dissimilarity score between a VC and a startup, which indicates the probability of one entity having a specific type of relation with another given the observed connectivity patterns in the KG. In this study, we adopt an advanced graph embedding approach called TransD because of its superior performance and efficiency [Citation34]. The meta-path-based approach describes different connectivity patterns between two entities using structural paths (i.e., meta-paths) [Citation57]. We first define a set of meta-paths starting from a VC and ending with a startup to represent different types of relations including employment affiliation overlap, educational and ethnic connections, geographic proximity, and industry relatedness. Then, we count the number of occurrences of each meta-path between two entities, which is referred to as path count and indicates the level of closeness in a specific relation. In addition, we also develop a feature-based machine learning model to integrate relational information and commonly used non-relational information for prediction. Specifically, the features that we include in the model are dissimilarity score computed from TransD, path counts for different meta-paths, and non-relational features constructed from company demographics and past funding rounds [Citation50, Citation63].
Figure 1. SocioLink: Relation-based recommendation framework.
To evaluate the performance of our SocioLink framework, we conduct computational experiments on the CrunchBase dataset. We apply four representative recommendation models adapted from prior studies as benchmarks, including the weighted regularized matrix factorization (WR-MF) [Citation32], a hybrid model combining item-based K-nearest neighbour (KNN) collaborative filtering and item-based KNN attribute (Item KNN: CF+Attribute) [Citation55], a feature-based model using data on company demographics and past funding rounds (Non-relational Features) [Citation50, Citation63], and a feature-based model combining Non-relational Features with geographic proximity and industry relatedness between investors and startups (Non-relational Features+Geo+Industry) [Citation64, Citation67]. Our results show that the SocioLink method (DissimilarityScore+Meta-paths+Non-relational Features) has achieved significantly better recommendation accuracy over the four benchmarks, revealing the unique power of utilizing the novel information on social relationships for startup recommendations. We further examine the relative importance of relation-based features in our SocioLink method. Employment affiliation overlap, ethnic connection in the employees of VC and startup, and industry relatedness between VC’s past investees and startup provide the largest contribution to the matching of VCs and startups among all meta-paths, while geographic proximity, educational connection, and industry relatedness between VC and startup are, relatively speaking, less important.
Next, to demonstrate the superiority of modeling relations via KG, we compare the performances of SocioLink and two modified benchmark methods that also take social relations information into consideration, despite that no prior design science study in this area has considered social relations. Specifically, the first modified benchmark is to integrate each of the five relations (employment affiliation overlap, educational connection, ethnic connection, geographic proximity, and industry relatedness) or all of them together into the matrix factorization method; the second is to add the three social relations to the feature-based Non-relational Features+Geo+Industry method. We find that the SocioLink method again outperforms these two modified benchmarks that also leverage both non-relational and relational information. This result illustrates the superiority of our innovative approaches based on graph embeddings and meta-paths for modeling relations.
To further demonstrate the practical value of relation-based models, we first conduct additional experiments to show that our SocioLink method can find more successful actual investment targets than all the benchmark methods, suggesting that by using our method investors can not only save a lot of time and efforts in searching for startups but also can make more financial gains. Second, we develop a web-based prototype for startup recommendations based on the SocioLink framework. We implement three relation-based models (including graph embedding approach, meta-path-based approach, and DissimilarityScore+Meta-paths+Non-relational Features) in the system. After a user specifies the name of a VC, the system can produce a list of promising startup candidates for the VC to facilitate investment selection. Moreover, we integrate a visualization module in the system to present all meta-paths starting from the VC and ending with each recommended startup. Users can also explore the KG with any entity selected as the center. The purpose of these visualizations is to help investors better understand the underlying logic behind each recommendation as well as their connections with other entities.
Our study makes the following contributions to the information systems (IS) literature and financial technology (FinTech) practice. First, our study advances the literature on startup recommendation models by developing a new two-sided recommendation method. Most prior studies in this literature treat startup recommendations as a one-sided recommendation problem. Our finding reveals that two-sided recommendations can retrieve more successful actual investment targets than one-sided recommendations. This indicates that considering mutual screening between the two sides is critical for making high-quality recommendations in the venture capital context. In addition, compared to existing two-sided recommendation methods, the SocioLink framework we propose utilizes publicly available relational data, especially individuals’ social relations, instead of explicit preference information solicited from both sides, which can lead to a new paradigm of recommendation methods in new contexts where individual relations affect organizational matching—a new concept we refer to as Individual-Driven Organizational Proximity, as in the cases of venture capital investment and Mergers & Acquisitions.
Second, our study falls under the realm of design science research paradigm that focuses on creating and evaluating analytics solutions to solve important organizational problems [Citation29]. We design a novel recommendation framework to facilitate investment decisions, which serves as the information technology (IT) artifact. In addition, the design of SocioLink is motivated and guided by the proximity principle [Citation39] in social psychology and its extensions in management and finance, which serves as the kernel theory [Citation23]. Our study contributes to the IS knowledge base by providing generalized guidelines for theory-informed design for decision support in the investment context.
Third, this study provides a new and successful application of KG in the FinTech industry. Prior studies have applied KG for investment behavior prediction in crowdfunding [Citation64] and stock price prediction [Citation38], to name a few. Our proposed framework distinguishes from these prior studies in two aspects: (1) SocioLink synthesizes various social relations in a KG and then leverages such novel information for two-sided recommendations; and (2) SocioLink models complex relations by integrating KG embedding approach, meta-path-based approach, machine learning, and graph visualization, which improves both recommendation accuracy and interpretability. A growing number of FinTech studies have emerged in IS in recent years (e.g., [Citation8, Citation58, Citation66]) due to the increasing impact of IT on financial practices [Citation28]. Our study advances this literature by adding a viable FinTech solution in a new business domain (i.e., venture capital).
Literature review
Startup recommendation models
We review three well-known techniques for startup recommendations, namely Latent Factor Model, ItemKNN, and Feature-based Model, as the base models for our study.
Latent factor model aims to derive a low-dimensional representation of users and items in the latent feature space from user-item matrix (e.g., ratings, purchases) [Citation16]. In the latent feature space, underlying interactions between users and items—users’ overall interest in item characteristics, can be more easily identified, compared with the user-item matrix [Citation32]. Prior studies (e.g., [Citation67]) have applied the latent factor model in startup recommendations, where VCs, startups, and VCs’ past investment choices correspond to users, items, and user-item matrix, respectively.
Item-based K-nearest neighbour (ItemKNN) recommends items that are most similar to a user’s previously selected items [Citation11, Citation44]. To calculate the similarity between items, two different approaches can be adopted by applying a similarity computation technique (e.g., cosine-based similarity). The first approach utilizes historical information about user-item interactions and measures to what extent two items are selected by the same users before. This approach is referred to as item-based KNN collaborative filtering in prior literature [Citation26, Citation49]. The second approach uses content-based information and measures the similarity between two items in terms of attributes (e.g., category) or descriptions. This approach is used to solve the cold-start problem when no prior events (e.g., ratings or purchases) are observed for certain items [Citation15]. Stone et al. [Citation55] apply ItemKNN to the task of top-N investment opportunity recommendations in venture capital. They develop a startup recommendation model to find new investment opportunities that are most similar to a VC’s previously invested startups. Their proposed model combines the two different approaches mentioned above using the linear ensemble method. Results show that the hybrid model achieves superior performance over the traditional item-based KNN collaborative filtering approach.
Feature-based model aims to learn patterns on how constructed features affect an outcome from historical data. To predict whether a startup that has already secured the initial (seed or angel) funding will attract a further round of investment, Sharchilev et al. [Citation50] construct various features using data collected from CrunchBase and LinkedIn. Their features cover company demographics, information on historical funding rounds (e.g., number and types of previously secured funding rounds, number of investments made by each company), information on founders/employees (e.g., number of founders, tenure of employment), and news articles (e.g., number of mentions, topics). For model training, different machine learning algorithms, including logistic regression, naïve Bayes, support vector machine, neural network, and gradient boosting decision trees (GBDT), can be adopted [Citation63].
Knowledge graph embedding approaches and applications
A KG is a multi-relational graph comprising various entities and different types of relations among entities. Each entity is represented by a node in the graph, and each edge takes the form of a triplet (head entity, relation, tail entity) to record a fact about the presence of a certain relation between two nodes. To effectively model relational data in a KG and facilitate the use of its rich information for analysis in relevant applications (e.g., making KG compatible with machine learning models), a series of embedding approaches have been developed in recent years [Citation7]. The key idea of KG embedding is to represent both entities and relations in a graph in continuous vector spaces and then model the interactions between them to maximize the plausibility or validity of all observed facts (i.e., relations among entities). In prior studies, KG embedding approach has been applied in stock price prediction [Citation38] and product recommendations [Citation59], to name a few.
Meta-path-based approaches
Meta-path, which refers to a path consisting of a sequence of relations defined between different entity types, is a concept defined in a heterogeneous information network [Citation57]. A meta-path can describe more sophisticated relations than a single edge, and different meta-paths indicate various semantic meanings. To define a set of meta-paths in a specific context, users can explicitly specify the meta-paths based on domain knowledge [Citation57], choose the best paths using experimental trials [Citation64], or apply a greedy algorithm to learn the meta-paths from training examples [Citation40]. Based on the identified meta-paths, different similarity measures can be defined to assess the level of closeness between two network nodes, such as path count [Citation56] and PathSim [Citation57]. These similarity measures have been used for similarity search [Citation57] and investment behavior prediction in crowdfunding [Citation64], to name a few applications. Different from prior studies, we apply the meta-path-based measures in the context of venture capital and incorporate a wide range of social relationships guided by the theoretical and empirical findings in sociology, management, and finance literature. Moreover, we employ the concept of meta-path to visualize the connectivity patterns between a VC and a startup to help explain the underlying rationale of different relation-based recommendation models.
Theoretical foundation
Organizations are embedded in heterogeneous networks consisting of many different kinds of nodes (e.g., people, companies, industries) and relations [Citation52]. A growing body of literature in management and finance has studied the influence of different relations on the formation of business partnerships and economic performance, substantiating the proximity principle originated in social psychology [Citation39]. Online Supplemental Appendix 1 presents a summary of these prior studies. The types of relations between two firms examined in related prior literature can be categorized as social connections, geographic proximity, and industry relatedness.
Social connections
Social connections refer to the interpersonal relationships between employees across two organizations in terms of career background, educational background, or ethnicity. Prior studies document that socially proximate organizations are more likely to form a business partnership [Citation4, Citation9, Citation12, Citation25, Citation27]. There are two primary reasons underlying the empirical finding. First, interpersonal relationships among organizational employees can generate trust and facilitate information exchange across organizational boundaries—advantages in information collection [Citation33]. Organizations can access private information at a lower cost through the colleague network [Citation21, Citation48], education network [Citation9, Citation21], or ethnic network [Citation1, Citation4, Citation27]. Second, communication between two socially connected individuals is more effective because of shared language or mutual understanding of the significance of products, markets, and opportunities—communication advantage; the communication advantage can facilitate mutual screening [Citation27, Citation39].
Geographic proximity
Geographic proximity refers to the closeness of physical locations. Physical distance is one of the most important determinants of VCs’ investment decisions and can affect the cost of information collection and face-to-face communication. Empirical evidence in prior literature shows that VCs generally are more likely to invest in local ventures [Citation10, Citation35, Citation54].
Industry relatedness
Industry relatedness has different definitions in prior literature. First, industry relatedness may denote whether two organizations operate in the same industry sector. Generally, VC-company pairs have a higher level of industry relatedness than random pairs, as VCs tend to limit investments to areas, with which they are familiar [Citation51]. Moreover, corporate VCs, whose strategic goals are new technology nurturing and market expansion, are more likely to invest in firms with similar products or services and in overlapping industries [Citation36]. Second, industry relatedness can also be defined as similarity between the industry of the VC’s prior investees and industry of the target startup [Citation54]. VCs often communicate with entrepreneurs of their prior investees and other contacts in their target industries to collect information for new investment opportunities.
In summary, personal and organizational relationships have a significant influence on VCs’ investment decision; relational connections are not only the important sources for VCs to collect private information of startups but also are indicative of the extent of matching between VCs and startups in terms of social norms, culture, and expertise. Therefore, we propose that startup recommendation models incorporating relational information can outperform traditional one-sided recommendation models in matching (H1).
Moreover, prior literature show that social proximity is positively related with performance in venture capital investment because of superior communication and coordination between investors and investees after the investment [Citation27]. Since geographic distance can affect the ability of VCs to closely monitor entrepreneurs, local ventures on average perform better than distant ventures [Citation10]. In addition, industry relatedness is also shown to have positive association with post-investment performance [Citation27, Citation54]. Thus, we propose that startup recommendation models incorporating relational information can retrieve more successful actual investment targets than traditional one-sided recommendation models (H2).
Relation-based recommendation
To utilize relational information for startup recommendations, we propose a novel relation-based framework called SocioLink, as illustrated in . The major challenges of relation-based recommendation are first to integrate many different types of relations and model such heterogeneous information for startup recommendations and second to understand how the recommendation models work in order to interpret the recommendation results. To tackle such challenges, our framework relies on multiple methods, including KG embedding, meta-path analysis, machine learning, and graph visualization. The framework consists of four components, namely graph construction, heterogeneous graph analysis and recommendation, machine learning and feature analysis, and system prototype and graph visualization. First, we merge the startup ecosystem data from CrunchBase (https://www.crunchbase.com/) and ethnicity data from OriginsInfo (https://www.originsinfo.com.au/) to construct a venture capital KG. Then, we implement the graph embedding approach and meta-path-based approach to model multi-relational data for startup recommendations. We also apply a machine learning algorithm to integrate the new relation-based features with non-relational information commonly used by existing models such as company demographics and past funding rounds. Next, we evaluate the performance of the proposed framework by conducting computational experiments. We then conduct feature analysis to uncover the relative importance of different relation-based features. Finally, we develop a SocioLink prototype that contains both recommendation and graph visualization modules.
Venture capital knowledge graph
We first build a venture capital KG that systematically describes a wide range of interactions among major participants in venture capital activities. describes the schema for the venture capital KG. To design the graph, we first identify major actors participating in venture capital activities, namely VCs, persons, and startup companies. These actors are represented by entities in the graph. From the relationships between a person and a company (either VC or startup), we can identify the connections associated with employment affiliation. Additionally, we also create entities to represent specific attributes of both persons and companies, including educational institution, ethnicity, city, and industry. It is important to note that only categorical attributes are modelled as entities in the graph. Our choice of attributes is based on the theoretical arguments about the impact of relations on investment decision and performance discussed in the section of theoretical foundation. Modelling the aforementioned four attributes as entities enables us to describe the connections between VCs and startups in terms of education background, ethnicity, location, and industry.
Figure 2. Venture capital knowledge graph schema.
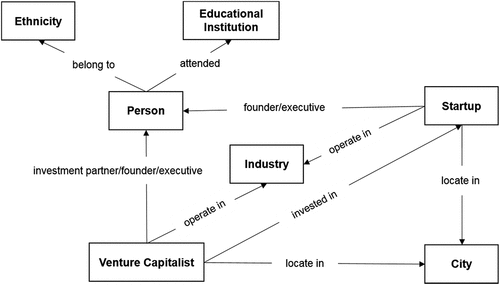
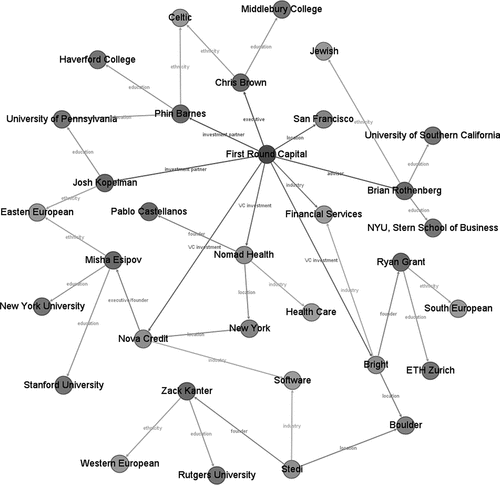
In total, we have identified six different types of connections among the specified entities, including venture capital investment, employment affiliation (i.e., founder/co-founder, executive, board member, advisor, board observer, and investment partner), educational attainment, ethnicity assignment, location, and industry assignment. is an instantiation of the venture capital KG. Nodes in different colors denote different types of entities. The constructed graph is able to depict different connectivity patterns between VCs and startups, and our analysis later will show such information is useful for startup recommendations.
Figure 3. Instantiation of the venture capital knowledge graph.
Graph embedding approach
Feature engineering and model building based on graphs are difficult due to the complexity in connectivity patterns and the symbolic nature of triplets (e.g., (New Science Ventures, locate in, New York)). To tackle this issue, a new research direction known as knowledge graph embedding was proposed and quickly gained broad attention [Citation7]. Graph embedding approaches aim to characterize different types of entities and relations using low-dimensional vectors while preserving the structural information and graph properties. Those entity and relation embeddings can be further utilized in many tasks such as entity classification, entity resolution, link prediction, and triplet classification.
Translation distance models are one of the most popular graph embedding approaches. These models employ distance-based scoring functions. They measure the plausibility of a fact, which is represented in the form of a triplet, (head, relation, tail), as the distance between the two entity embeddings plus some vector that depends on a relationship [Citation6]. The basic assumption is that an entity’s embedding is more similar to the embedding of connected entities than that of any other unconnected entities in terms of a specific relationship [Citation7]. We employ an advanced model called TransD proposed by Ji et al. [Citation34] for our startup recommendation application. The main advantage of TransD is that it considers the diversity (i.e., various types and attributes) of entities and relations simultaneously. Another advantage is that it has a small number of hyperparameters and does not require matrix-vector multiplication, which makes it easy to be applied on large scale graphs. Experimental results in prior literature show that TransD outperforms other translation distance models such as TransE [Citation6], TransH [Citation60], and TransR [Citation37] in link prediction tasks.
We employ TransD to learn the embeddings for entities and relations in the graph using historical data. The technical details of TransD are provided in Online Supplemental Appendix 2. Then, we can compute the distance scores for all the (VC, invested in, startup) triplets in the dataset based on entity and relation embeddings. The score reveals the probability of whether a triplet is correct or not, and a lower score indicates a higher probability. In this study, we call it “dissimilarity score.” Therefore, we can obtain top N recommendations for each VC by sorting the scores of triplets in the test dataset in an ascending order.
Meta-path-based approach
Although graph embedding approach is effective and efficient in modelling multi-relational data, the connectivity patterns between VCs and startups are implicitly hidden in the entity and relation embeddings. To explicitly represent different connectivity patterns between two firms and develop a more interpretable recommendation model, we adopt the meta-path-based approach proposed by Sun et al. [Citation57]. Meta-path is a concept defined in a heterogeneous information network, which refers to a path consisting of a sequence of relations between different entity types. A meta path P is denoted in the form of , which defines a composite relation
between entity types
and
, where
denotes the composition operator on relations. The length of P is the number of relations in P. For instance,
is a meta-path between VC and startup, indicating that the two organizations locate in the same city, where locate in−1 is a reverse relation of locate in. The length of this meta-path is two. Meta-paths can explain sophisticated relationships among entities that cannot be explained by a single edge.
We manually identify a set of meta-paths starting from a VC and ending with a startup to describe different relations that are shown to have a significant influence on the formation of business partnerships in prior management and finance literature. The types of relations we consider include employment affiliation overlap between VCs and startups, educational and ethnic connections between the employees of VCs and startups, geographic proximity, and industry relatedness. In total, we have identified seven different meta-paths as summarized in . Path 1 and Path 2 describe the relations between VCs and startups in terms of employment affiliation. Specifically, Path 1 describes whether the target startup and the VC employs/employed the same person [Citation51]. Path 2 denotes whether the target startup employs/employed a person who have worked for an existing portfolio company of the VC [Citation25]. Path 3 and 4 describe the education connection and ethnic matching between the employees of the VC and the target startup, respectively [Citation9, Citation27, Citation48]. Path 5 indicates whether the VC and the target startup locate in the same city [Citation10]. Path 6 indicates whether the VC and the target startup operate in the same industry [Citation36, Citation51], and Path 7 measures the similarity between the industry of VC’s past investees and the industry of the target startup [Citation54].
Table 1. Meta-path design.
PathCount refers to the number of path instances p between two entities following a specific meta-path P and can measure the level of closeness between two entities in a certain relation. For each meta-path, we calculate a PathCount between two entities following the path and use it as a feature. The details of how to compute PathCount are available in Online Supplemental Appendix 3. Then, we employ GBDT as the learning algorithm to build the model. The algorithm aims to learn patterns on how different features influence the investment choices of VCs from historical data. The reasons why we choose GBDT include the following: first, decision tree is advantageous in handling missing data and detecting non-linear effects and possible interactions among features; second, GBDT is an ensemble model of decision trees, where several decision trees are built sequentially [Citation13]. For each new iteration in the sequential process, the decision tree focuses on correcting the errors of previous trees. Thus, in a stage-wise fashion GBDT produces a stronger prediction model and can achieve the best performance among traditional machine learning algorithms [Citation47, Citation50].
Integration of relations, company demographics, and past funding rounds
We also develop a feature-based model to evaluate whether integrating relational information with the non-relational information such as company demographics and past funding rounds can help further improve the recommendation performance. First, we construct 32 non-relational features adapted from Xiang et al. [Citation63] and Sharchilev et al. [Citation50] using company demographics (e.g., firm age, firm size, industry, competitor count) and information on past funding rounds (e.g., number of prior VCs, amount of investment per funding round, own investment count). The definitions of these features are presented in Online Supplemental Appendix 4. Then, we incorporate the dissimilarity score from TransD and path counts for seven different meta-paths into the feature set. Finally, we also employ GBDT as the learning algorithm to build the model.
Empirical validation
In design science research, it is important to provide evidence that the proposed artifact is effective [Citation23, Citation45]. Therefore, we conduct a series of computational experiments to compare the performance of relation-based recommendation methods with well-established benchmarks [Citation46]. The main objective in this section is to test the two hypotheses: whether our proposed relation-based models can outperform all existing models in finding actual investment targets and whether recommendations provided by our proposed models include more successful actual investment targets of a VC compared with those from existing models.
Data
The main data source for our analysis is CrunchBase, which is one of the most popular databases for the entrepreneurial ecosystem. We subscribe to the CrunchBase Enterprise solution, which offers API access and bulk exports and thus enables us to obtain a complete snapshot of the dataset at a chosen time point. The CrunchBase dataset provides detailed information of VCs, startups, founders, employees, VC partners, and funding rounds. Since CrunchBase does not include information about ethnic origin, we identify the ethnicity of a person based on his/her family name and given name following the prior literature [Citation27, Citation61]. Such data is acquired from OriginsInfo Ltd., a commercial vendor of name-based classification services for ethnically targeted marketing campaigns. We restrict our sample to U.S.-based VCs and startups. For the recommendation task, we only focus on initial (i.e., first-time) investment transactions between VCs and startups.
Evaluation procedures
Training, validation, and test sets
For our experiment, we use initial venture capital investment deals announced in 2014, 2015, and 2016 as the training set, initial investment deals announced in 2017 as the validation set, and those announced in 2018 as the test set. We do not use the most recent full year because a few years is required to observe the performance of each investment deal [Citation30]. In addition, we only consider VCs that have participated in at least 5 deals in each year. Having such a constraint is to ensure that the number of actual investments per VC is large enough to better differentiate the performances of different models in evaluation [Citation5]. The summary statistics of the training, validation and test sets are shown in . In the training set, there are 652 unique VCs, who have participated in 13,282 initial investment deals. In the validation set, there are 387 VCs and 4,101 initial investment deals; each investor has participated in 10.6 deals on average. The test set includes 364 VCs participating in 3,736 deals, and each VC invests in 10.3 deals on average. Following common practice, the validation set is used to fine-tune hyperparameters in the learning process for all recommendation models, and the test set is used to compare their out-of-sample performances [Citation14]. Next, we construct a sample of VC-startup pairs—both actual, for which the investment did occur, and counterfactual, for which investment could have occurred but did not. We consider all startups that have been funded within a certain year as the consideration set, because these startups are actively seeking for funding in that period.
Table 2. Summary of training, validation, and test sets.
Benchmark models
We apply four recommendation models adapted from prior studies for startup recommendations, namely the weighted regularized matrix factorization (WR-MF) [Citation32], a hybrid model combining item-based KNN collaborative filtering and item-based KNN attribute (ItemKNN: CF+Attribute) [Citation55], a feature-based model using information on company demographics and past funding rounds (Non-relational Features) [Citation50, Citation63], and a feature-based model combining non-relational features with geographic proximity and industry relatedness (Non-relational Features+Geo+Industry) [Citation64, Citation67]. The learning algorithm adopted in the feature-based models is GBDT. The hyperparameter tuning for all models is illustrated in Online Supplemental Appendix 5. It is important to note that all these benchmarks based on prior literature do not consider any social relations information. More specifically, the first three benchmarks do not utilize any relational information, while the fourth benchmark incorporates non-social relations such as geographic proximity and industry relatedness.
Evaluation metrics
For each method, we first obtain a list of recommended investees for each VC and then compare this list with the actual investment decisions made by each investor in the validation or test set. Companies are deemed as correct recommendations if they appear in the actual investment list of the investor, and incorrect ones otherwise. We use mean average precision (MAP), mean reciprocal rank (MRR), and recall among the top N recommendations (N is set to be 50, 100, 200, or 300) for model evaluation. Mean average precision is a widely adopted metric in measuring the performance of recommendation systems. MAP provides the highest score when all actual investees precede those that have not been invested. MAP is defined in terms of precision and average precision. Precision measures what percentage of the list of recommended startups are actual investees. Average precision calculates precision at each point where an actual investee is found:
where is the precision at the rank position of actual investee i in the recommendation results (i.e.,
;
is the set of actual investees of a VC;
is the total number of actual investees for the VC. MAP is then defined as the average of all average precisions across a set of test VCs. The second measure, mean reciprocal rank, assesses how far from the top appears the first actual investee, which is defined as follows:
where is the position of the first actual investee in the recommendation result for VC i;
is the total number of VCs in the validation/test set. Lastly, Recall@N refers to the proportion of actual investees within the top N results among all actual ones.
Construction of venture capital knowledge graph
To implement the relation-based recommendation framework, we need to first construct venture capital KGs. To avoid data leakage, for both training and evaluation we only use the information over previous years in the construction of KGs. For this reason, we construct yearly KGs; more specifically, we construct three graphs (i.e., 2014, 2015, and 2016) for training, one graph (2017) for validation, and one graph (2018) for testing. We restrict the scope of the graph to include VCs and startups in the United States only but include all relations of these U.S. companies. That means educational attainment and ethnic origins around the globe are included. For edges (or relations), we first only include venture capital investment deals announced since 2000, because information on investment deals prior to 2000 are very sparse in the CrunchBase database. For employment affiliation relations, we do not set any time constraint on founders and co-founders; we consider investment partner relations starting from 2000 because they are associated with the investment deals data; all the other remaining employment affiliations are restricted to the years between 1970 and the year prior to the prediction year because employment data prior to 1970 are also very sparse in Crunchbase. As an example, we present the summary statistics of the venture capital KG that utilizes information before 2018 (i.e., for the test set) in . The total numbers of entities and relations in the graph are 107,507 and 376,115, respectively.
Table 3. Summary statistics of the venture capital knowledge graph before 2018.
Results
Recommendation accuracy
presents the comparisons among different methods in terms of MAP, MRR, and Recall@N on the test set. To examine the value of relational information in startup recommendations, we first compare the performances of our proposed methods using solely relational information with those of the three benchmarks using solely non-relational information, including Non-relational Features, WR-MF, and ItemKNN: CF+Attribute. shows that the graph embedding approach (DissimilarityScore) and the meta-path-based approach (Meta-paths) both achieve superior performance over the three benchmark methods. It is very encouraging to find that these two approaches, which contain only one and seven relation-based features, respectively, can significantly outperform the Non-relational Features method, which includes a relatively larger set of 32 features using information on company demographics and past funding rounds. Our methods also beat the other two more sophisticated benchmark methods (WR-MF and ItemKNN: CF+Attribute), which are shown to achieve wide success in academia and practice [Citation11, Citation32, Citation55]. When comparing with the fourth benchmark (Non-relational Features+Geo+Industry) that leverages non-social relations such as geographic proximity and industry relatedness, the graph embedding approach with one feature only (DissimilarityScore) slightly underperforms, but the other two proposed methods (Meta-paths and DissimilarityScore+Meta-paths) significantly outperform in almost all evaluation metrics (except for Recall@200 and Recall@300 of Meta-paths).These results validate the value of leveraging social relations information for startup recommendations.
Table 4. Performance in recommending startups to VCs on the test set.
Then, we examine the incremental contribution of incorporating the relational information into the recommendation task by comparing the performances of the SocioLink method (DissimilarityScore+Meta-paths+Non-realtional Features) and the benchmarks. The SocioLink method yields a MAP of 0.051, a MRR of 0.197, and Recall@N values of between 14.08 percent and 34.88 percent. SocioLink outperforms the best benchmark among the three non-relational approaches (i.e., ItemKNN: CF+Attribute) by 0.038 in terms of MAP, by 0.147 in MRR, and by over 9.41 percent in Recall@N; it outperforms the Non-relational Features+Geo+Industry method that includes non-social relations by 0.025 in terms of MAP, by 0.117 in MRR, and by over 5.92 percent in Recall@N. These accuracy numbers may appear low, but they are largely consistent with prior recommendation studies with very sparse datasets [e.g., 24, 26, 43). The problem of startup recommendations is a very challenging one, because the transactional data (i.e., investment deals) are very sparse—in our context, density, which is defined as the average number of unique deals per VC divided by the number of startups seeking for funding in a specific year, is only 0.2 percent, 0.3 percent, and 0.3 percent in our training, validation, and test sets, respectively. Due to the sparsity issue of startup recommendations, the value of performance metrics for both benchmarks and our methods is low. Nevertheless, our model has achieved large improvements over all the benchmark methods. We conduct a t-test to examine the significance level of performance difference between SocioLink and each benchmark. The t-statistics show that the improvements achieved by the SocioLink method are all significant at p < 0.01. These results strongly support our argument that relations provide valuable novel information that are not available in the non-relational data used by existing recommendation models and that incorporating such additional information can significantly improve the prediction of business partnerships. Therefore, H1 is supported. Furthermore, the comparison between SocioLink and Non-relational Features+Geo+Industry further illustrates that a significant part of the boost in accuracy for SocioLink is attributed to the addition of social relations.
In addition, SocioLink is innovative not only in utilizing individuals’ social relations for matching between two organizations, but also in modelling complex relations via KG. To demonstrate the superiority of our relational modelling approaches, we modify the benchmarks by incorporating social relations using simple approaches and then compare them with our SocioLink method. In particular, we first integrate each of the five relations (employment affiliation overlap, education connection, ethnic connection, geographic proximity, and industry relatedness) or all of them into the matrix factorization method; we then also construct relational dummies to capture the five relations and add them to the Non-relational Features method. Results in show that our method continues to outperform these two sets of modified benchmarks, exhibiting the advantage of modelling relations with graph embeddings and meta-paths.
Table 5. Performance of different relational modelling approaches on the test set.
In an attempt to explore whether feature fusion between non-relational and relational features can deliver further performance improvement, we experiment with three common early feature fusion strategies [Citation2, Citation3], including simple concatenation, fusion based on principal component analysis, and neural network-based joint representations, and three widely applied late fusion strategies, namely score fusion based on the sum rule, score fusion based on the product rule, and a secondary classifier (i.e., logit model). We find that feature fusion based on simple concatenation, which is implemented in the SocioLink method, performs sufficiently well in our context. The detailed procedures and results are available in the Online Supplemental Appendix 6.
Feature importance analysis
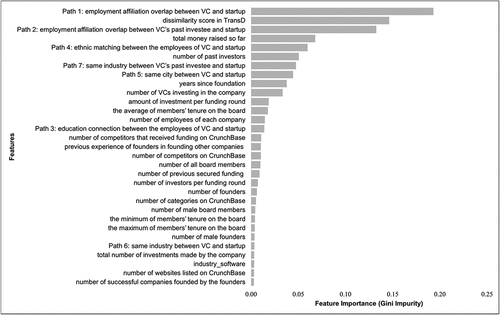
To understand the relative importance of different relation-based features for recommendation accuracy, we examine the feature importance defined by Gini impurity for all features in the SocioLink (i.e., DissimilarityScore+Meta-paths+Non-relational Features) model. The Gini importance (i.e., mean decrease in Gini impurity) is a well-known variable importance metric for classification trees (e.g., random forest, GBDT) [Citation13, Citation65]. A higher Gini importance score indicates a higher feature importance in tree-based methods. In , we present features with Gini importance scores larger than 0.003 and sort these features in a descending order by Gini score. Among the top ten features ranked by Gini score, more than half of them are relation-based features including Path 1 (employment affiliation overlap between VC and startup), dissimilarity score, Path 2 (employment affiliation overlap between VC’s past investee and startup), Path 4 (ethnic connection), Path 7 (same industry between VC’s past investee and startup), and Path 5 (same city between VC and startup). Path 1 (employment affiliation overlap between a VC and a startup) has the highest Gini importance score, suggesting that prior employment contact is the strongest relation among all relations defined by the seven meta-paths in facilitating communication and collaboration between two parties. The dissimilarity score in TransD has the second highest Gini score. This feature is computed based on both entity and relation embeddings, which contain information of connectivity patterns across heterogenous relationships. The high feature importance of dissimilarity score validates our proposition that synthesizing multiple kinds of relations is instrumental in predicting the business partnerships between VCs and startups. In a nutshell, the five categories of relations are ranked by feature importance as follows: employment affiliation overlap > ethnic connection > industry relatedness > geographic proximity > educational connection. These new insights extend prior work in the finance and management literature and help us understand the differential roles of various relations on business partnership formation.
Figure 4. Feature importance analysis.
Recommendation quality
What VCs care the most when making investment decisions is whether they can earn high financial returns from the investment deals [Citation19]. We conducted an additional experiment to examine whether the relation-based models can retrieve more successful actual targets for each VC compared with existing ones. In this experiment, we only focus on successful investment deals. Following prior studies [Citation27, Citation30], we measure investment success using companies’ successful exits via IPOs and acquisitions by 2021. VCs earn high average returns through exit channels. In the absence of data on return on investment, successful exits are the clearest available signal of investment success. For the experiment, we reconstruct training, validation, and test sets by removing VCs that do not have any successful investment deals by 2021 from the sample used in the main experiment (see ). The summary statistics of the new training, validation, and test sets are shown in Online Supplemental Appendix 7.
presents the performance comparisons among all the methods. The results show that our SocioLink method gives the best performance in term of MAP, MRR, and Recall@N compared with all the other models. On average, SocioLink can retrieve 35.3 percent of all successful actual targets for each VC at top 300 recommendations, while the best benchmark method that does not include any relational information (ItemKNN: CF+Attribute) can only retrieve 18.26 percent and the Non-relational Features+Geo+Industry method can retrieve 25.83 percent. Therefore, our H2 is also supported. The additional experimental results imply that investors can earn more financial returns by using our method than using existing methods. An alternative measure of startup success is whether the company will attract a further round of investment in a given period of time [Citation30, Citation50]. For a robustness check, we adopt this success measure and reconduct the experiment following the same procedures. The results in Online Supplemental Appendix 8 show that our SocioLink method significantly outperforms all the other models across the three performance measures.
Table 6. Performance in recommending successful startups to VCs on the test set.
System prototype
To demonstrate the practical value of SocioLink, we build a proof-of-concept prototype to provide startup recommendations for VCs and explain the underlying logic by illustrating the connectivity patterns between a VC and each recommended startup [Citation42]. The SocioLink prototype contains two modules: recommendation and visualization. The recommendation module incorporates three models—graph embedding approach, meta-path-based approach, and DissimilarityScore+Meta-paths+Non-relational Features. For each model, the learning phase and recommendation phase are deployed offline. Since the model parameters, company demographics, past funding rounds, and relations are relatively stable within a given time period, they can be updated periodically (e.g., every week). This design enables fast recommendations in the system as it only involves searching the name of a VC and then retrieving its recommendation results stored in the database. The visualization module allows the exploration of an interactive KG centered on a chosen entity (e.g., VC, startup, person) as well as all the meta-paths starting from a VC and ending with a startup. We use Neo4j (https://neo4j.com/) to store and process the graph data and leverage the three.js (https://threejs.org) library for graph visualization. The path instances of seven different meta-paths between every pair of VC and startup are generated offline and then stored in the database. The procedures of finding all path instances between VC-startup pairs in a large KG are elaborated in the Online Supplemental Appendix 9. The detailed description of the prototype is also presented in the Online Supplemental Appendix 10.
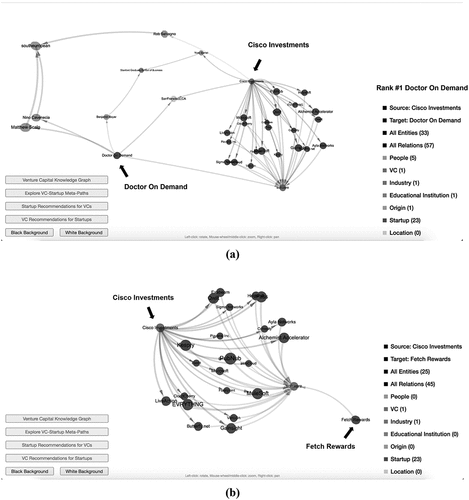
The visualization of KG and meta-paths in SocioLink can help investors better understand the recommendation results and the connections between various entities. Take the startup recommendations for Cisco Investments as an example. The first startup recommended for Cisco Investments using the graph embedding approach (i.e., DissimilarityScore) is Doctor On Demand, while startups with a relatively high dissimilarity score (i.e., low probability in forming a business partnership) inferred by TransD is Fetch Rewards (Rank #502). show the meta-paths between Cisco Investments and each of the two startups, respectively. Generally, higher ranked startups are more closely-connected. By examining the meta-paths, an investor can quickly understand how it connects with each startup. For instance, shows that Cisco Investments and Doctor On Demand are connected by different paths. First, Cisco Investments previously invested in many startups operating in the same industry sector (i.e., software) as Doctor On Demand. Second, Doctor on Demand and Cisco Investments locate in the same city, San Francisco, CA, USA. Third, one of top executives of Cisco Investments and the board observer of Doctor On Demand both graduated from Stanford Graduate School of Business. Fourth, both Cisco Investments and Doctor On Demand have top executives who are South European. By comparison, as shown in , there is only one type of meta-path between Cisco Investments and Fetch Rewards. Cisco Investments previously invested in many startups, which operates in the same industry as Fetch Rewards. More visualization examples are available in Online Supplemental Appendix 10.
Figure 5. Illustrations of meta-paths between Cisco investments and startups ranked differently by the graph embedding approach.
Conclusion
Our study is among the first to propose and validate that relational information, especially individuals’ social relations, which are often publicly available in many industries, is valuable for designing a two-sided recommendation model. We develop a novel two-sided recommendation framework called SocioLink for the venture capital context. Through a KG, three different types of relations, namely social connections, geographic proximity, and industry relatedness, are integrated with company demographics and data on past investment deals. Using data collected from CrunchBase, we demonstrate that the performance of the SocioLink framework improves over several state-of-the-art startup recommendation models.
Our study offers two important managerial implications for financial technology businesses. First, although prior studies have shown that individual relations affect organization decisions in the investment context, the SocioLink framework exhibits the power of synthesizing many different types of relations, especially social relations, in predicting business partnerships from a design science perspective. Considering the wide adoption of AI-enabled models for decision making in the near future [Citation18, Citation22, Citation41], collecting data on various relations and incorporating them in recommendation models can bring substantial financial gains and improved operational efficiency for VCs. Second, the SocioLink framework can be applied in other investment domains, where relations play an important role. For example, our framework can also be implemented in Mergers and Acquisitions (M&A) prediction, in which a KG is first constructed to describe different relations among acquirer, acquiree, person, location, industry, and so on. Different meta-paths can be specified to illustrate the extent of matching between acquirers and potential targets. Then, the relation-based models we propose, such as the DissimilarityScore+Meta-paths+Non-relational Features approach, can be easily adapted for target recommendations in M&A.
There are several limitations with our study that warrant future research. First, personal relationships on social media platforms (e.g., Facebook, Twitter, or LinkedIn) are also an important data source of social relations. However, we have not included online relationships in our venture capital KG because such data are not available in our dataset. A promising future research direction is to examine the value of online social relationships in the prediction of business partnerships. Second, in the meta-path-based approach, we manually identify seven different meta-paths based on the graph schema to describe the relations that have been examined by prior studies in management and finance. As the graph becomes more complex and larger (e.g., by adding online relationships), retrieving meta-paths manually can be tedious and difficult. Future research can develop algorithms to learn the most relevant meta-paths for large and complex KGs.
Supplemental Material
Download MS Word (1.1 MB)Supplementary Material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/07421222.2023.2196771
Disclosure statement
The authors have no conflicts of interest to disclose.
Additional information
Funding
Notes on contributors
Ruiyun Xu
Ruiyun Xu [email protected] is an Assistant Professor at the Department of Information Systems and Analytics, Farmer School of Business, Miami University. She received her Ph.D. in Information Systems from City University of Hong Kong. Dr. Xu’s research focuses on artificial intelligence, financial technology, knowledge graph, venture capital, and blockchain.
Hailiang Chen
Hailiang Chen [email protected] corresponding author) is an Associate Professor at the Faculty of Business and Economics, University of Hong Kong. He is interested in the research areas of financial technology, social media, mobile commerce, business analytics, economics of information systems, and design science. Dr. Chen’s research has been published in elite business journals in information systems, finance, and management, including Information Systems Research, Journal of Financial Economics, Journal of Management Information Systems, Management Science, Review of Financial Studies, and Strategic Management Journal. His research has received media coverage in such publications as Wall Street Journal, Forbes, Reuters, Seeking Alpha, TechSpot, and others.
J. Leon Zhao
J. Leon Zhao [email protected] is Presidential Chair Professor of Information Systems, Director of Center on Blockchain and Intelligent Technology, Co-head of Information Systems and Operations Management, School of Management and Economics, Chinese University of Hong Kong, Shenzhen. He holds a Ph.D. from Haas School of Business, University of California at Berkeley. Dr. Zhao’s research focuses on blockchain, business intelligence, and FinTech. He has published over three hundred research papers in journals and conference proceedings, including such journals as Management Science, Information Systems Research, Journal of Management Information Systems, MIS Quarterly, and IEEE and ACM Transactions. He is co-editor of Financial Innovation, a Springer OpenAccess journal and has co-edited over 30 special issues for academic journals including MIS Quarterly, Information Systems Research, and Decision Support Systems. Dr. Zhao has chaired about 30 conferences covering Information Systems, Service Sciences, FinTech, and Blockchain.
References
- Agrawal, A.; Kapur, D.; and McHale, J. How do spatial and social proximity influence knowledge flows? Evidence from patent data. Journal of Urban Economics, 64, 2 (2008), 258–269.
- Alghowinem, S.; Goecke, R.; Wagner, M.; Epps, J.; Hyett, M.; Parker, G.; and Breakspear, M. Multimodal depression detection: Fusion analysis of paralinguistic, head pose and eye gaze behaviors. IEEE Transactions on Affective Computing, 9, 4 (2016), 478–490.
- Baltrušaitis, T.; Ahuja, C.; and Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41, 2 (2018), 423–443.
- Bengtsson, O.; and Hsu, D.H. Ethnic matching in the U.S. venture capital market. Journal of Business Venturing, 30, 2 (2015), 338–354.
- Bethard, S., and Jurafsky, D. Who should I cite: learning literature search models from citation behaviour. In The 19th ACM International Conference on Information and Knowledge Management. Toronto, Ontario, Canada: Association for Computing Machinery (ACM), 2010, pp. 609–618.
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and Yakhnenko, O. Translating embeddings for modeling multi-relational data. Advances in Neural Information Processing Systems, 2013, pp. 2787–2795.
- Cai, H.; Zheng, V.W.; and Chang, K.C.C. A comprehensive survey of graph embedding: problems, techniques, and applications. In IEEE Transactions on Knowledge and Data Engineering, 30, 9 (2018), pp. 1616–1637.
- Clarke, J.; Chen, H.; Du, D.; and Hu, Y.J. Fake news, investor attention, and market reaction. Information Systems Research, 32, 1 (2020), 35–52.
- Cohen, L.; Frazzini, A.; and Malloy, C. The small world of investing: Board connections and mutual fund returns. Journal of Political Economy, 116, 5 (2008), 951–979.
- Cumming, D.; and Dai, N. Local bias in venture capital investments. Journal of Empirical Finance, 17, 3 (2010), 362–380.
- Deshpande, M.; and Karypis, G. Item-based top-N recommendation algorithms. ACM Transactions on Information Systems, 22, 1 (2004), 143–177.
- Franke, N.; Gruber, M.; Harhoff, D.; and Henkel, J. What you are is what you like—similarity biases in venture capitalists’ evaluations of start-up teams. Journal of Business Venturing, 21, 6 (2006), 802–826.
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29, 5 (2001), 1189–1232.
- Friedman, J.; Hastie, T.; and Tibshirani, R. The Elements of Statistical Learning, Berlin: Springer, 2001.
- Gantner, Z.; Drumond, L.; Freudenthaler, C.; Rendle, S., and Schmidt-Thieme, L. Learning attribute-to-feature mappings for cold-start recommendations. In IEEE International Conference on Data Mining. Sydney, NSW, Australia: IEEE, 2010, pp. 176–185.
- Ghoshal, A.; Menon, S.; and Sarkar, S. Recommendations using information from multiple association rules: A probabilistic approach. Information Systems Research, 26, 3 (2015), 532–551.
- Ghoshal, A.; Mookerjee, V.S.; and Sarkar, S. Recommendations and cross-selling: pricing strategies when personalizing firms cross-sell. Journal of Management Information Systems, 38, 2 (2021), 430–456.
- Gomber, P.; Kauffman, R.J.; Parker, C.; and Weber, B.W. On the fintech revolution: Interpreting the forces of innovation, disruption, and transformation in financial services. Journal of Management Information Systems 35, 1 (2018), 220–265.
- Gompers, P.A.; Gornall, W.; Kaplan, S.N.; and Strebulaev, I.A. How do venture capitalists make decisions? Journal of Financial Economics, 135, 1 (2020), 169–190.
- Gompers, P.A.; and Lerner, J. The Venture Capital Cycle. Cambridge, MA: MIT Press, 1999.
- Gompers, P.A.; Mukharlyamov, V.; and Xuan, Y. The cost of friendship. Journal of Financial Economics, 119, 3 (2016), 626–644.
- Gozman, D.; Liebenau, J.; and Mangan, J. The innovation mechanisms of fintech start-ups: insights from SWIFT’s innotribe competition. Journal of Management Information Systems, 35, 1 (2018), 145–179.
- Gregor, S.; and Hevner, A.R. Positioning and presenting design science research for maximum impact. MIS Quarterly, 37, 2 (2013), 337–355.
- Guo, J.; Zhang, W.; Fan, W.; and Li, W. Combining geographical and social influences with deep learning for personalized point-of-interest recommendation. Journal of Management Information Systems, 35, 4 (2018), 1121–1153.
- Hallen, B.L. The causes and consequences of the initial network positions of new organizations: From whom do entrepreneurs receive investments? Administrative Science Quarterly, 53, 4 (2008), 685–718.
- He, J.; Fang, X.; Liu, H.; and Li, X. Mobile app recommendation: an involvement-enhanced approach. MIS Quarterly, 43, 3 (2019), 827–849.
- Hegde, D.; and Tumlinson, J. Does social proximity enhance business partnerships? Theory and evidence from ethnicity’s role in U.S. venture capital. Management Science, 60, 9 (2014), 2355–2380.
- Hendershott, T.; Zhang, X.; Zhao, J.L.; and Zheng, Z. FinTech as a game changer: Overview of research frontiers. Information Systems Research, 32, 1 (2021), 1–17.
- Hevner, A.R.; March, S.T.; Park, J.; and Ram, S. Design science in information systems research. MIS Quarterly, 28, 1 (2004), 75–105.
- Hochberg, Y.; Ljungqvist,A.; and Lu, Y. Whom you know matters: Venture capital networks and investment performance. Journal of Finance, 62,1 (2007), 266–301.
- Hsu, D. What do entrepreneurs pay for venture capital affiliation? Journal of Finance, 59, 4 (2004), 1805–1844.
- Hu, Y.; Koren, Y., and Volinsky, C. Collaborative filtering for implicit feedback datasets. In The Eighth IEEE International Conference on Data Mining. Sydney, NSW, Australia: IEEE, 2008, pp. 263–272.
- Ingram, P.; and Roberts, P.W. Friendships among competitors in the Sydney hotel industry. American Journal of Sociology, 106, 2 (2000), 387–423.
- Ji, G.; He, S.; Xu, L.; Liu, K., and Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: Association for Computational Linguistics, 2015, pp. 687–696.
- Lerner, J. Venture capitalists and the oversight of private firms. Journal of Finance, 50, 1 (1995), 301–318.
- Lerner J. Corporate venturing. Harvard Business Review, 91, 10, (2013), 86–94.
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y., and Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In The Twenty-ninth AAAI Conference on Artificial Intelligence. Austin, Texas: Association for the Advancement of Artificial Intelligence, 29, 1 (2015), pp. 2181–2187.
- Long, J.; Chen, Z.; He, W.; Wu, T.; and Ren, J. An integrated framework of deep learning and knowledge graph for prediction of stock price trend: An application in Chinese stock exchange market. Applied Soft Computing, 91 (2020), 106–205.
- McPherson, M.; Smith-Lovin, L.; and Cook, J. M. Birds of a feather: Homophily in social networks. Annual Review of Sociology, 27, 1 (2001), 415–444.
- Meng, C.; Cheng, R.; Maniu, S.; Senellart, P., and Zhang, W. Discovering meta-paths in large heterogeneous information networks. In The 24th International Conference on World Wide Web. Florence, Italy: Association for Computing Machinery (ACM), 2015, pp. 754–764.
- Müller, O.; Fay, M.; and vom Brocke, J. The effect of big data and analytics on firm performance: An econometric analysis considering industry characteristics. Journal of Management Information Systems, 35, 2 (2018), 488–509.
- Nunamaker Jr, J.F.; Briggs, R.O.; Derrick, D.C.; and Schwabe, G. The last research mile: Achieving both rigor and relevance in information systems research. Journal of Management Information Systems, 32, 3 (2015), 10–47.
- Pan, Y.; and Wu, D. A novel recommendation model for online-to-offline service based on the customer network and service location. Journal of Management Information Systems, 37, 2 (2020), 563–593.
- Pathak, B.; Garfinkel, R.; Gopal, R.D.; Venkatesan, R.; and Yin, F. Empirical analysis of the impact of recommender systems on sales. Journal of Management Information Systems, 27, 2 (2010), 159–188.
- Peffers, K.; Tuunanen, T.; Rothenberger, M.A.; and Chatterjee, S. A design science research methodology for information systems research. Journal of Management Information Systems, 24, 3 (2007), 45–77.
- Prat, N.; Comyn-Wattiau, I.; and Akoka, J. A taxonomy of evaluation methods for information systems artifacts. Journal of Management Information Systems, 32, 3 (2015), 229–267.
- Richardson, M.; Dominowska, E., and Ragno, R. Predicting clicks: Estimating the click-through rate for new Ads. In The 16th International Conference on World Wide Web. New York, NY: Association for Computing Machinery (ACM), 2007, pp. 521–530.
- Rider, C.I. How Employees’ prior affiliations constrain organizational network change: A study of US venture capital and private equity. Administrative Science Quarterly, 57, 3 (2012), 453–483.
- Sarwar, B.; Karypis, G.; Konstan, J., and Riedl, J. Item-based collaborative filtering recommendation algorithms. In The 10th International Conference on World Wide Web. Hong Kong: Association for Computing Machinery (ACM), 2001, pp. 285–295.
- Sharchilev, B.; Roizner, M.; Rumyantsev, A.; Ozornin, D.; Serdyukov, P., and de Rijke, M. Web-based startup success prediction. In The 27th ACM International Conference on Information and Knowledge Management. Torino, Italy: Association for Computing Machinery (ACM), 2018, pp. 2283–2291.
- Shi, Z.; Lee, G.M.; and Whinston, A.B. Toward a better measure of business proximity: Topic modeling for industry intelligence. MIS Quarterly, 40, 4 (2016), 1035–1056.
- Shipilov, A.; Gulati, R.; Kilduff, M.; Li, S.; and Tsai, W. Relational pluralism within and between organizations. Academy of Management Journal, 57, 2 (2014), 449–459.
- Sørensen, M. How Smart is Smart Money? A two-sided matching model of venture capital. The Journal of Finance, 62, 6 (2007), 2725–2762.
- Sorenson, O.; and Stuart, T.E. Syndication networks and the spatial distribution of venture capital investments. American Journal of Sociology, 106, 6 (2001), 1546–1588.
- Stone, T.; Zhang, W., and Zhao, X. An empirical study of top-N recommendation for venture finance. In The 22nd ACM International Conference on Information & Knowledge Management. San Francisco, California: Association for Computing Machinery (ACM), 2013, pp. 1865–1868.
- Sun, Y.; Barber, R.; Gupta, M.; Aggarwal, C.C., and Han, J. Co-author relationship prediction in heterogeneous bibliographic networks. In The International Conference on Advances in Social Networks Analysis and Mining. Kaohsiung, Taiwan: IEEE, (2011), pp. 121–128.
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; and Wu, T. PathSim: meta path-based top-k similarity search in heterogeneous information networks. The VLDB Endowment, 4, 11 (2011), 992–1003.
- Sun Yin, H.H.; Langenheldt, K.; Harlev, M.; Mukkamala, R.R.; and Vatrapu, R. Regulating cryptocurrencies: a supervised machine learning approach to de-anonymizing the bitcoin blockchain. Journal of Management Information Systems, 36, 1 (2019) 37–73.
- Wang, J.; Huang, P.; Zhao, H.; Zhang, Z.; Zhao, B., and Lee, D.L. Billion-scale commodity embedding for e-commerce recommendation in Alibaba. In The 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London: Association for Computing Machinery (ACM), 2018, pp. 839–848.
- Wang, Z.; Zhang, J.; Feng, J., and Chen, Z. Knowledge graph embedding by translating on hyperplanes. In The Twenty-Eighth AAAI Conference on Artificial Intelligence. Québec, Canada: Association for the Advancement of Artificial Intelligence, 2014, pp. 1112–1119.
- Webber R. 2007. Using names to segment customers by cultural, ethnic or religious origin. Journal of Direct Data Digital Marketing Practice, 8, 3 ( 2014), 226–242.
- WSJ. 2021. VC Firms Have Long Backed AI. Now, They Are Using It. https://www.wsj.com/articles/vc-firms-have-long-backed-ai-now-they-are-using-it-11616670000 (accessed on April 7, 2023).
- Xiang, G.; Zheng, Z.; Wen, M.; Hong, J.I.; Rosé, C.P., and Liu, C. A supervised approach to predict company acquisition with factual and topic features using profiles and news articles on TechCrunch. In The Sixth International AAAI Conference on Weblogs and Social Media. Dublin, Ireland: Association for the Advancement of Artificial Intelligence, 2012, pp. 607–610.
- Zeng, X.; Li, Y.; Leung, S.C.; Lin, Z.; and Liu, X. Investment behavior prediction in heterogeneous information network. Neurocomputing, 217 (2016), 125–132.
- Zhang, W.; and Ram, S. A comprehensive analysis of triggers and risk factors for asthma based on machine learning and large heterogeneous data sources. MIS Quarterly, 44, 1 (2020), 305–350.
- Zhang, W.; Wei, C.P.; Jiang, Q.; Peng, C.H.; and Zhao, J.L. Beyond the block: A novel blockchain-based technical model for long-term care insurance. Journal of Management Information Systems, 38, 2 (2021), 374–400.
- Zhong, H.; Liu, C.; Zhong, J.; and Xiong, H. Which startup to invest in: A personalized portfolio strategy. Annals of Operations Research, 263, 1–2 (2018), 339–360.