
Abstract
It is well-known that children with expressive communication difficulties have the right to communicate, but they should also have the right to do so in whichever language they choose, with a voice that closely matches their age, gender, and dialect. This study aimed to develop naturalistic synthetic child speech, matching the vocal identity of three children with expressive communication difficulties, using Tacotron 2, for three under-resourced South African languages, namely South African English (SAE), Afrikaans, and isiXhosa. Due to the scarcity of child speech corpora, 2 hours of child speech data per child was collected from three 11- to 12-year-old children. Two adult models were used to “warm start” the child speech synthesis. To determine the naturalness of the synthetic voices, 124 listeners participated in a mean opinion score survey (Likert Score) and optionally gave qualitative feedback. Despite limited training data used in this study, we successfully developed a synthesized child voice of adequate quality in each language. This study highlights that with recent technological advancements, it is possible to develop synthetic child speech that matches the vocal identity of a child with expressive communication difficulties in different under-resourced languages.
Research in augmentative and alternative communication (AAC) has often discussed an individual’s right to communicate, but the rights of individuals using AAC to communicate in whichever language they choose, particularly languages spoken in low- and middle-income countries, has not been equally prioritized (Tönsing et al., Citation2019). High-income, English-speaking countries often dominate AAC research and development (Tönsing et al., Citation2019). As a result, American English is most commonly found on speech-generating devices (Terblanche et al., Citation2022). Languages and dialects from low- and middle-income countries, such as South Africa, are often underrepresented (Sefara et al., Citation2019). This means that the speech output available on high-tech AAC devices, given to children with expressive communication difficulties to assist with functional communication in low- and-middle income countries, is often not reflective of the child’s natural voice, and there is regularly an age, gender, language and/or dialectal-mismatch on these devices (Jreige et al., Citation2009; Mills et al., Citation2014). Although South Africa is well-known for its multilingualism, as there are 12 official languages, including sign language, and many unofficial languages and dialects, this linguistic and cultural diversity is not well-represented on South African AAC devices (Sefara et al., Citation2019), as many of these official languages are considered under-resourced. Languages are considered under-resourced when they have a limited online presence, there is a lack of linguistic expertise on the language, there are limited data for speech and language processing, reduced transcribed speech corpora and pronunciation dictionaries, as well as limited resources for speech, language, and literacy development (Besacier et al., Citation2014). Despite under-resourced languages having limiting expertise and resources, they are not necessarily the minority languages in the country (Besacier et al., Citation2014), and there is often a substantial user base. For instance, according to Statistics SA (Citation2011), more South Africans speak Afrikaans (6.8 million), isiXhosa (8.15 million) and isiZulu (11.58 million) as their home language than South African English (4.89 million).
Limited access to devices that incorporate their home languages may further marginalize children who rely on AAC to communicate. Children using a speech-generating device in low- and middle-income countries are likely using their second or third language to communicate (Tönsing et al., Citation2019), with many sharing the same synthetic voice (e.g., adult US-English male) as all the other children with expressive communication difficulties in the classroom (Mills et al., Citation2014). Due to the dearth of contextually relevant resources in low- and middle-income countries, such as South Africa (Pascoe & Norman, Citation2011), the lack of African AAC resources, including applicable child voices in African languages, results in African AAC users being underserved. Creating linguistically and culturally appropriate synthetic speech in low- and middle-income countries begins to address the historical linguistic imbalance and discrimination imposed onto under-resourced and indigenous languages (Sefara et al., Citation2019). In Tönsing et al. (Citation2019) study, South African participants with expressive communication difficulties shared that they could not express themselves in all the languages that they understood and were exposed to and were mostly limited to English. These participants viewed their ability to express themselves in certain languages as part of their identity. They therefore expressed a desire for the development of appropriate AAC systems and interventions in different languages, as well as increased literacy learning opportunities (Tönsing et al., Citation2019). In addition, it has been found that using a specific language in a multilingual setting allows one to show respect, promote group cohesion and align or distance oneself from communication partners (Ndlangamandla, Citation2010). According to the South African Constitution (South African Government, Citation1996), every citizen has the right to use whichever language they choose. This basic right should not be overlooked for individuals with expressive communication difficulties who are not given access to speech generating devices that feature their home language. Until AAC applications can meet the communication needs of children with expressive communication difficulties, AAC use, particularly in low- and middle-income countries, will likely remain limited, resulting in fewer opportunities for participation, interaction, and academic growth for individuals with expressive communication difficulties.
As an individual’s voice is an indicator of their personality, age, sex, social background, and cultural identity (Jreige et al., Citation2009; Mills et al., Citation2014; Sutton et al., Citation2019), the voice used on speech generating devices for children, should, if possible, at least approximate the child’s voice and linguistic background. The development of child voices in under-resourced languages is therefore an important task. However, due to the scarcity of child speech corpora, generating natural child speech synthesis is a difficult task. There are several challenges associated with the collection of child speech data for the creation of a synthetic voice. For example, children’s read speech is generally less fluent as compared to adult speech, particularly if children have reduced literacy skills in their home languages. Children’s speech includes articulatory inaccuracies, and often presents with typical disfluencies and hesitations. Moreover, child speech recordings are typically conducted in insufficient recording environments, and as a result background noise is a common occurrence (Govender et al., Citation2015). However, in instances when the available data is limited, implementing a warm start has been proven useful (Phuong et al., Citation2021). Essentially, transfer learning is a specific example of warm starting, where the weights of one model are used as the initialization point for training another model, i.e., established synthetic speech models act as a skeleton for newer models. In other words, using more widely available adult data as a skeleton to create a child’s voice. There are documented benefits to implementing a warm start. First, using a warm start can greatly reduce the model’s training time (Barnekow et al., Citation2021; Cooper et al., Citation2020; Zhu, Citation2020). Second, using a pre-trained English model to warm start models in other languages, has proven to be very effective (Phuong et al., Citation2021; Saam & Cabral, Citation2021; Zhu, Citation2020). This is due to the fact that the preexisting model’s voice is erased, but the speaker-general characteristics, which can be transferred to other speakers and languages, remain intact, thereby reducing the overall iteration and/or training time of the new model (Barnekow et al., Citation2021). For example, Phuong et al. (Citation2021) used an English pre-trained model with 1 hour of Vietnamese data and found that the quality of the resultant speech output was as good as training a model without a warm start, with 5 hr of Vietnamese data. When child speech data is available, there are various freely available speech synthesis systems that can be used to develop synthetic voices. One open-source speech synthesis system that produces synthetic speech with high naturalness and good perceptual similarity to target speakers/donor voices is known as Tacotron 2 (Shen et al., Citation2018; Wang et al., Citation2020). Tacotron 2 is an end-to-end neural network-based text-to-speech (TTS) system that can be trained on text-to-audio pairs, without substantial phonetic annotation. These technical advances mean that data from well-resourced languages can now be recruited much more effectively than previously possible to develop synthetic voices for under-resourced languages.
Due to these recent advancements in accessible text-to-speech technology, this study aims to accurately develop synthetic child speech in three different under-resourced languages that match the vocal identity of three target children with expressive communication difficulties. This paper is therefore primarily a description of practice and intervention development. First, we set out to determine if it is feasible to develop naturalistic child speech synthesis for three under-resourced South African languages, namely Afrikaans, isiXhosa, and South African English (SAE), using Tacotron 2, an open-source speech synthesis system. Second, we solicited feedback from first-language speakers in terms of the naturalness of the synthetic voices we developed.
Method
This project involved two phases. In Phase 1, child speech data for each of the three languages was collected. Following this, we used open-source adult speech corpora to develop synthetic adult speech in SAE, Afrikaans, and isiXhosa (Louw & Schlünz, Citation2016a, Citation2016b, Citation2016c). We incorporated these adult models, along with the collected child speech data, to develop child speech synthesis in each language. The synthetic child speech was created for three specific children with expressive communication difficulties who attend different schools for learners with special education needs, in Cape Town. In Phase 2, we evaluated the synthetic speech. The subjective mean opinion score (MOS) method was used to gather listeners’ perceptions of the naturalness of the synthetic voices. Additionally, participants were able to optionally provide a qualitative description of their impression of the synthetic speech in response to an open-ended question, “Is there anything else you wish to share about the voices?”
Phase 1: Development of the synthetic child speech
Participants
Spontaneous (5 min) and read speech (5 min) samples from 98 children who were typically developing were obtained in a classroom repurposed as a storeroom at one mainstream English school in Cape Town. The repurposed classroom had carpets, few windows, and the additional books and furniture were helpful to reduce reverberation and background noise. Based on the similarity of the children who were typically developing to the three children with expressive communication difficulties, for whom the synthetic child speech was intended (i.e., age, gender, home language, demographic group), as well as their performance in the picture description and reading tasks, only three of those 98 children who were typically developing were selected to further participate in the study. Two 12-year-old children who were typically developing (one male and one female) and one 11-year-old male child who was typically developing were recruited to each record a total of 2 hr of read speech. A purposive sampling method was used to collect the speech samples from the children. In this method, the researcher intentionally selects participants based on their particular qualities, specifically their similarity to the three children with expressive communication difficulties for whom the voices were being developed. Although purposive sampling is subjective, Taherdoost (Citation2016) states that this method is convenient, low cost, less time consuming and ideal for exploratory research. All required approvals for collecting the children’s speech data were obtained; guidelines outlined in the Helsinki Declaration of 2013 were followed (World Medical Association, Citation2013). The provincial education department and the relevant school principals gave permission to access the schools. All the children and their caregivers gave informed consent to audio record and use the speech data for this research.
Materials and measures
To select suitable child participants who were typically developing, a picture description task (The School Aged Language Assessment Measures/SLAM) was used. SLAM’s Ball Mystery Story (Crowley, Citation2019) includes picture cards and questions to elicit connected speech for children aged between 9-15 years old. In addition, various age-appropriate library books were offered to the children for the reading task, and based on their interests, the children selected their preferred books to read in their home languages. A Zoom H1 Handy recorderFootnote1 was used to collect the children’s speech data.
As the child speech data was limited, this study also included various freely available adult models and corpora. First, the creators of Tacotron 2 published a pre-trained Tacotron 2 model from NVIDIAFootnote2. This established model was used in this study. The LJ dataset (Ito & Johnson, Citation2017) was used to train the Tacotron 2 model, and it is extensive, with approximately 24 hr of short recordings from one female adult North American English (NAE) speaker (Ito & Johnson, Citation2017). Second, the Afrikaans (Louw & Schlünz, Citation2016a), isiXhosa, (Louw & Schlünz, Citation2016c) and the SAE Lwazi III text-to-speech datasets (Louw & Schlünz, Citation2016b) were also used. Each Lwazi III dataset is made up of short and long audio clips from one female adult speaker per language. Each language has approximately 6-7 hr of data. Although each Lwazi III dataset contains mostly one language, there are also small amounts of additional language data, which provides phone coverage of other languages (Louw & Schlünz, Citation2016b). For example, the isiXhosa Lwazi III dataset contains 5 hr and 53 min of isiXhosa but also includes SAE (32 min), Afrikaans (3 min), isiZulu (5 min), Sependi (7 min), and Setswana (4 min) data. It was hypothesized that the inclusion of additional phone coverage might improve the model’s pronunciation of non-English names and surnames. It was also suspected that the additional language data may improve the pronunciation of loan words, which are frequently exchanged between languages. To develop the synthetic adult voices, Tacotron 2 (Wang et al., Citation2017) was used. Tacotron 2 is a state-of-the-art, open-source speech synthesis system that generates synthesized speech directly from graphemes and consists of a recurrent sequence-to-sequence mel-spectrogram prediction network (Wang et al., Citation2017).
The published pre-trained Tacotron 2 model from NVIDIA1 was one of the models used to warm start the child speech synthesis (warm start A). The pretrained adult models in each language were also used as an alternative warm start for the child speech synthesis (warm start B). Tacotron 2 (Wang et al., Citation2017) was also used to develop the synthetic child speech, and a Titan V GPU from NVIDIAFootnote3 was used for all training.
Procedures
The synthetic child voices were developed in three stages. gives an outline of the process used to generate the synthetic child speech in Part 1. First, the speech data from three children who were typically developing was collected (the left-most component in ). The three children who were typically developing were asked to read in their home languages, namely Afrikaans, isiXhosa, and SAE. Recording sessions lasted 30 min, and the children were given breaks of approximately 5 min every 10-15 min. Using a Zoom H1 Handy recorder (44100 Hz, 16 bit)3, the recordings were collected in a repurposed classroom. Tacotron 2 has a shorter training time when audio files are ≤13 sec. Thus, the data were segmented into short utterance chunks of ≤13 sec. As fluent speech is preferred for speech synthesis, all false starts, disfluencies, and misarticulations were manually removed from the data. After data cleaning, approximately 15-30 min of data per child were lost, leaving 108.7 min for Afrikaans, 101.9 min for isiXhosa, and 113.7 min for SAE. The sound files were split by manually marking utterances using Praat TextGrids. Individual single-channel files were extracted from each of the marked-up utterances and downsampled to 22050 Hz. The data were then randomly divided into training (90%) and validation files (10%).
Figure 1. Overview of the Process to Generate Synthetic Child Speech for Each South African Language Using Tacotron 2.
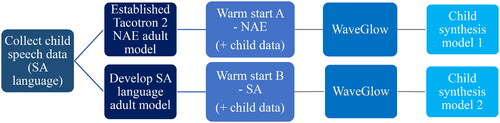
Second, as adult models were required to warm start the child speech synthesis, adult models first had to be developed (the second component in ). Using Tacotron 2’s (Wang et al., Citation2017) default architecture, the three adult models were trained on cleaned, resampled (22050 Hz) Afrikaans (Louw & Schlünz, Citation2016a), isiXhosa, (Louw & Schlünz, Citation2016c) and SAE Lwazi III text-to-speech datasets (Louw & Schlünz, Citation2016b) (see supplementary Table 1 for further information). Due to Lwazi III’s relatively restricted datasets, a warm start training procedure was implemented for all three languages, using the published pre-trained Tacotron 2 model from NVIDIA1, trained on the LJ dataset (Ito & Johnson, Citation2017). As transfer learning allows the speaker-general characteristics from the preexisting model to be transferred to other speakers and languages, the model’s training time is reduced (Barnekow et al., Citation2021; Cooper et al., Citation2020). This technique is useful when there is limited data, such as with under-resourced languages. During training, each language’s full Lwazi III dataset, including the additional language data, were used. After minimal cleaning and segmenting of the Afrikaans and English datasets, training took approximately 5 days per language. However, the isiXhosa audio files were longer and therefore, the batch settings had to be significantly reduced to reduce GPU memory constraints, which resulted in an increased training time of 13 days. Using the generated mel-scale spectrograms from Tacotron 2, a pretrained, publicly available WaveGlow (Prenger et al., Citation2019) model was used as a vocoder to synthesize time-domain waveforms. WaveGlow is a flow-based generative speech synthesis program (Prenger et al., Citation2019). Some undesirable artifacts and unwanted background noise were removed by using the denoising code from the WaveGlow repository.
Third, due to the limited child speech data collected, two distinct warm start models, using the adult speech data, were used during the creation of the child speech synthesis (the third component in ). In warm start A, the child models were trained on the published pre-trained Tacotron 2 model from NVIDIA1. For warm start B, each child model was trained on the respective South African adult model, using the Lwazi III datasets (see supplementary Table 2 for further information). Training for the child speech synthesis took approximately 72 hr for each language, no matter the warm start training procedure utilized. WaveGlow (Prenger et al., Citation2019) was used as the vocoder to synthesize time-domain waveforms and the denoising code from the WaveGlow repository was implemented (the fourth component in ).
Phase 2: Evaluation of the synthetic speech via listener perception tests
Participants
In Phase 2, 124 South African participants who spoke the language/s rated the naturalness of the synthetic voices. Snowball sampling was used as colleagues and friends were initially recruited via social media to give their opinions on the voices, and they were encouraged to share the anonymous MOS survey link with others. The survey was therefore shared nationwide, and any South Africans over the age of 18 were eligible to participate. One participant was excluded as they were not South African, leaving 123 participants. The age range of the participants was 18-71 years old (x̅= 32 years old). There were 103 females, 19 males, and 1 participant who identified as ‘other’. Participants indicated which language/s they spoke and were only presented with stimuli in all the languages applicable to them. Overall, there were 60 Afrikaans listeners, 111 South African? English listeners and 19 isiXhosa listeners who participated (some participants spoke more than one language). As Phase 2 involved an online MOS survey, participants conducted the survey from the comfort of their homes or places of work.
Materials and measures
In Phase 2, jsPsych (de Leeuw et al., Citation2023), a JavaScript framework for creating behavioral experiments that run in a web browser, was used to run the online MOS survey. MOS is often used to judge the quality of synthetic voices (Govender & de Wet, Citation2016; Jain et al., Citation2022).
Research design
In Phase 2, a non-experimental quantitative descriptive design was used to evaluate the naturalness of the synthetic voices using MOS. With a quantitative descriptive design, researchers aim to systematically investigate phenomenon through the collection of numerical data, obtained either via surveys or observation, and undertake statistical techniques to analyze the data (Mertler, Citation2016). All required approvals were received from the appropriate ethics committee; guidelines outlined in the Helsinki Declaration of 2013 were followed (World Medical Association, Citation2013). Each participant provided informed consent before beginning the MOS survey.
Procedures
In Phase 2, participants were asked to rate the naturalness of the synthetic adult and child speech using a 5-point Likert Scale, from 0 (completely unnatural) to 4 (completely natural). Speech naturalness can be described as how well the speech matches a listener’s standards of rate, rhythm, intonation, and stress, hence determining how natural the synthetic speech sounds as compared to spoken speech (Sefara et al., Citation2019). In addition, at the end of the MOS survey, participants were able to optionally provide a qualitative description of their impression of the synthetic speech. The online MOS survey was open for three weeks and participants listened to both synthetic child and adult speech. Listeners were asked to listen to audio clips of words and semantically predictable sentences of differing syllable lengths. For instance, the audio was regarded as short for words of approximately three syllables. The audio was regarded as medium length when sentences had approximately eight syllables, while audio was regarded as long when sentences had approximately 15 to 23 syllables. Research on child speech synthesis has shown that children’s speech is difficult to interpret using semantically unpredictable sentences, which is generally used during conventional listening tests (Govender & de Wet, Citation2016). Therefore, semantically predictable sentences were used during these listening tests. Words and sentences were randomly presented to the listeners and participants were able to listen to the audio as often as they liked before moving on to the next audio clip. Participants first rated the child voice and then the adult voice in one language, before moving on to the next language, if applicable.
Each participant made 18 MOS ratings per language: five MOS ratings for the synthetic child speech implementing warm start A, five MOS ratings for the synthetic child speech implementing warm start B, and eight MOS ratings for the synthetic adult speech. There were 1080 Afrikaans responses, 1998 English responses, and 342 isiXhosa responses. Using R (R Core Team, Citation2019), both descriptive and inferential statistics were conducted on the MOS data. Considering the inferential statistics, we use an ordinal mixed-effects regression model. Individual Likert-type questions are generally considered ordinal data because the items have clear rank order, but don’t have an even distribution, and a mixed effects model is a statistical test used to predict a single variable using two or more other variables. It is also used to determine the numerical relationship between one variable and others. The predictors for the ordinal mixed-effects regression model are overall ratings, the speaker (adult vs. child speech), the language (SAE vs. Afrikaans vs. isiXhosa), the warm start type (warm start A vs warm start B), as well as the amount of child speech training data required for improved quality. The model also makes use of random effects, which include the participants and the audio stimuli.
Results
The results section considers the MOS results and the qualitative feedback that some of the listeners provided. This section compares the overall ratings, the speaker, the language, the warm start type, as well as the amount of child speech training data required.
Overall ratings
Encouragingly, we were able to develop both a synthesized child voice and a synthesized adult voice, in each language. It is important to note that carefully cleaned speech data was preferrable over dirty speech data (e.g., data with false starts). For instance, the synthetic child voices with clean training data were impressionistically less noisy, with improved accuracy. Although the child speech was trained over a different adult model, the accent, language, and vocal acoustics are comparable to the South African child donor, rather than the adult voice. One participant said, “The [English] child’s voice was clearly a Western Cape accent. Initially difficult to understand (culturally) but then got more used to it and it sounded natural”.
The MOS results gave further insight into the naturalness of the voices. The average naturalness rating across all voices was 2.72. illustrates the average MOS, categorized by speaker, language, and warm start type. To test the statistically significant effects, an ordinal mixed-effects regression model was implemented with the ordinal package (Christensen, Citation2022) in R (R Core Team, Citation2019), with the results presented in and .
Figure 2. MOS Responses, with Reference to Speaker, Language, and Warm Start Type.
Note. This figure presents MOS responses categorized by speaker type (adult and child), language (Afrikaans/AFR, South African English/SAE, and isiXhosa/XHO), and warm start type (North American English/NAE, and South African/SA). The vertical axis represents MOS responses from 0 (completely unnatural) to 4 (completely natural), while the horizontal axis denotes the different languages. Each language corresponds to a specific combination of speaker and warm start type, providing a comprehensive overview of the perceived speech synthesis quality across these dimensions.
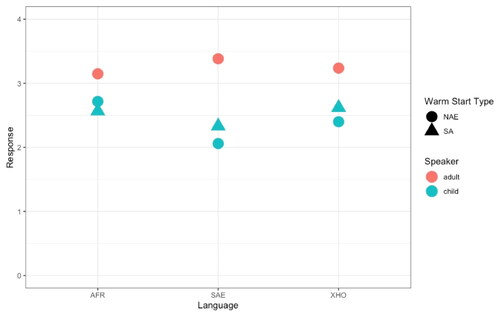
Table 1. Fixed effects coefficients of all the voices.
Table 2. Fixed effects coefficients of the child voices.
Speaker
The average natural rating across all the adult voices was 3.25, while the average natural rating across all the child voices was 2.45. An ordinal mixed-effects regression model predicting mean opinion score as a function of language, speaker, and syllable length, was run (formula: Response ∼ Language + Speaker + Syllables). The model’s intercept corresponds to Language = Afrikaans, Speaker = Adult. highlights the fixed effects coefficients for all the voices. displays the estimated coefficients, standard errors (SE), z-scores (z), and p-values (p) for each fixed effect in the regression model. The coefficients represent the estimated change in the dependent variable associated with each predictor variable while holding other variables constant. Statistically significant coefficients are denoted by p-values less than .01.
There was a statistically significant effect between adult and child voices, with the adult voices consistently rated as more natural as compared to the child voices. This effect is illustrated in , as the MOS responses corresponding to the adult voices are higher than the child voices, indicating greater naturalness ratings for the adult voices. Moreover, one participant expressed their opinion well by saying, “I feel that the adult voices are definitely more clear, and natural, but I really enjoy the children’s voices, especially if it’s for a child- it makes them feel like they can be who they are supposed to be!”
Additionally, shows that there is not a statistically significant difference in naturalness between synthetic sentences of differing syllable lengths for either the child or adult voices. Similarly to findings from Jain et al. (Citation2022), the first and last words in the synthetic child speech were more likely subject to distortions and artifacts, as compared to the middle of the phrase. As typical children’s speech is less fluent when compared to adults (Jain et al., Citation2022), any articulatory inaccuracies consistently produced, were also present in the synthetic child voice. This was observed in all three languages. For example, in SAE, the child donor had a nonstandard pronunciation of/ld/, such as in world and child and in isiXhosa, the child donor simplified the isiXhosa click sound/ǃ/, used in words such as ugqirha (doctor) and umnqwazi (hat). This inconsistency was noted by one isiXhosa listener who said that “[the isiXhosa child] is not pronouncing the clicks correctly,” Conversely, audio of the donor’s breathing remained in the training data, which transferred to the synthetic models, making them appear more realistic, according to listeners.
Language
In , we can see that the Afrikaans adult voice was rated least natural, while the Afrikaans child voice was rated as most natural. Conversely, the English adult voice was rated as most natural, while the English child voice was rated as least natural. No statistically significant effect was found between any of the adult voices. It should be noted that the additional mixed-language data used in the adult synthesis did not improve the pronunciation of non-English names and loan words to a great degree. Regarding the synthetic child voices, a model of mean opinion score as predicted by language and warm start type is shown in (formula: Response ∼ Language + Start). The model’s intercept corresponds to Language = Afrikaans child, Start = Warm start A. displays the estimated coefficients, standard errors (SE), z-scores (z), and p-values (p) for each fixed effect in the regression model related to the child voices. The coefficients represent the estimated change in the dependent variable associated with each predictor variable while holding other variables constant. Statistically significant coefficients are denoted by p-values less than .01.
There was a statistically significant effect between the Afrikaans child voice and the SAE child voice. The SAE child voice was considered less natural than the Afrikaans and isiXhosa child voices by listeners. Additionally, as the isiXhosa child donor’s language of learning and teaching was English, her isiXhosa literacy skills were reduced in comparison to her English literacy skills, which resulted in a slower reading rate, thereby affecting the pacing of the isiXhosa synthetic child speech. This was also observed by an isiXhosa participant who shared that, “[The isiXhosa child] sounds like it’s an American learning to speak isiXhosa, it was like listening to the audio of Wakanda. [The isiXhosa adult] is audible and sounds natural.”
Warm start type
also highlights that child voices created by implementing warm start B (South African/SA adult voices) were not significantly different from warm start A (North American English/NAE voice). Although not statistically significant, suggests that listeners appear to prefer the SAE and isiXhosa child models when warm start B (SA speaker) was used. In , MOS responses for warm start B are higher than warm start A for the SAE and isiXhosa child voices, indicating greater naturalness for warm start B. The opposite can be observed when looking at the Afrikaans child voice, as Afrikaans listeners appear to prefer the Afrikaans model when warm start A (NAE speaker) was used. This preferential pattern is also observed when comparing the consistency of each model’s speech output (see supplementary Figure 1). It appears that the SAE and isiXhosa child models are more consistent when warm start B (SA speaker) is used, while the Afrikaans child model is more consistent with warm start A (NAE speaker).
Child speech training data
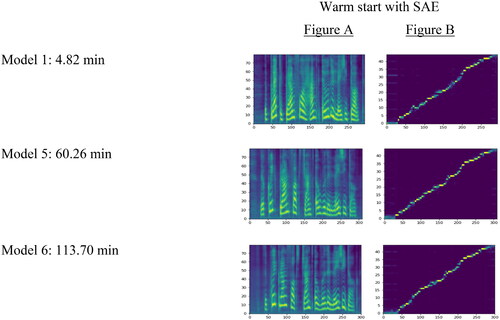
Using the SAE child speech data, six models with increasing training length were run to determine how much data would be needed to develop child speech synthesis in SAE. Warm start B was used for each model, and models were run with 5 min, 10 min, 20 min, 30 min, 60 min, and the full 113 min of SAE child speech data. depicts the mel-spectrograms (Figure A) and alignment plots (Figure B) for some of the SAE child models. Mel-spectrograms (Figure A) allow us to examine how accurately the model captures the nuances of the child donor’s speech, such as higher pitch, shorter durations, and different phonetic patterns compared to adult speech. In contrast to Model 6, which displays clear and well-defined spectral patterns, Model 1 shows less distinct spectral characteristics due to the presence of additional noise in the synthetic speech. Moreover, each point on the alignment plot (Figure B) represents a pair of corresponding elements, i.e., the synthesized speech and the donor speech. Figure B shows that our child synthesis model aligns well with the donor speech with regards to intonation, rhythm, and specific phonetic features, which is particularly observed in Model 6. Based on impressionistic listening, the mel-spectrograms and alignment plots, as little as 5 min of training data can produce a speech-like output. However, the speech output for 5-10 min of training data did not consistently match the text, which is not ideal for a text-to-speech voice in the real world. As expected, more training data improves the accuracy and the quality of the child speech output, as real gains were perceptually achieved after 60 min of training data. Despite the occasional pronunciation and prosodic irregularity, adequate quality child speech synthesis was developed with fairly little child speech data (only 113 min), using preexisting models (adult-child), to warm start the training.
Figure 3. Tacotron 2 Mel-Spectrogram (a) and Alignment (b) Plots of Synthesized Speech: “The Quick Brown Fox Jumped Over the Lazy Dog”.
Note. The mel-spectrogram is a spectrogram with the mel scale as its y-axis. It is a good indicator of the signal strength at various frequencies in the waveform. The alignment plot is a quick way to visualize a model’s success. A straight diagonal line from the bottom left to the top right is a good indicator that the model is producing something similar to speech.
Discussion
This study addressed the feasibility of creating synthetic child speech for children with expressive communication difficulties, using a limited training data scenario for under-resourced languages, namely Afrikaans, isiXhosa and South African English/SAE. Less than 2 hr of child speech data was used with adult speech corpora (approximately 30 hr) to pre-train a Tacotron 2 model.
Speaker
A higher naturalness rating was anticipated for the adult speech synthesis due to the quality and quantity of the adult speech data used. Adult speech corpora of high quality are often more accessible than child speech corpora and the child speech data used in the current study was limited and recorded in a sub-optimal recording environment, which in part resulted in the child speech synthesis’ decreased quality. Additionally, child speech differs quite substantially from adult speech, not only in terms of fundamental frequency, but also prosodic features. An adult’s speech is often more fluent while a child’s speech patterns are more inarticulate and vary significantly with regards to volume, pacing and emotional expressivity (Govender & de Wet, Citation2016; Jain et al., Citation2022). Although a MOS experiment is one of the traditional evaluation methods proposed by researchers (Govender & de Wet, Citation2016; Jain et al., Citation2022), the difference between adult and child speech may have also resulted in a lower naturalness rating for the child speech as naturalness is expressed differently between these speakers. It is fairly typical for a child to hesitate with new words, take breaks mid-sentence, mispronounce words and sounds, and wander off toward the end of sentences (Jain et al., Citation2022). It was hypothesized that listeners may have noted this distinctive child speech and prosodic characteristics and thought that the synthetic child voices were less natural as a result, likely due to different quality expectations for synthetic voices. Despite this, if the synthetic child voice on a speech-generating device is intelligible but still presents with minor mispronunciations or articulatory idiosyncrasies transferred from a donor child’s speech, it may be more relatable for children who will be using the synthetic speech to communicate, as opposed to using adult speech. Research from Begnum et al. (Citation2012) shows that children with expressive communication difficulties want voices that match their vocal identity, but not at the cost of intelligibility, as listeners must be able to understand them.
Similarly, researchers outlined that communication partners of children with expressive communication difficulties often prioritize intelligibility of the synthetic speech output, over similarity to the child’s natural voice (Baxter et al., Citation2012; Begnum et al., Citation2012). Although the vocal identity of the child is still incredibly important to children’s communication partners, it has been found that the synthetic child voice must be functional in various demanding environments, such as classrooms (Begnum et al., Citation2012). In addition, Drager et al. (Citation2010) found that shorter sentences and single-word utterances produced with synthetic speech, are often less intelligible to listeners. Although our research has shown that listeners did not experience a significant difference in naturalness between sentences of differing lengths when modern speech synthesis was used, intelligibility may however still be affected, as this was not independently tested in the current study. Practically, using a single-word AAC device is very common for new AAC users, which suggests that communication partners may find it difficult to easily understand the synthesized speech output on entry-level speech-generating devices used by children unless the context is given (Drager et al., Citation2010; Terblanche et al., Citation2022).
Although synthesized SAE is likely new to listeners, listeners have probably heard synthetic adult US-English speech before via the internet and on popular social media sites. The SAE adult voice had a standard SAE dialect, which listeners may have been expecting, while the SAE child voice had a nonstandard dialect. Despite the SAE child voice presenting with minor distortions and some noise, it is hypothesized that the English child voice was rated more harshly by listeners due to the child donor’s unusual prosodic patterns and strong dialectal influence, which may have impaired the comprehensibility of the voice to unfamiliar listeners. On the other hand, Afrikaans and isiXhosa synthetic speech are not as freely available, so listeners likely did not have any predetermined expectations. As listeners aren’t used to hearing synthetic speech in these languages, and even though dialectal variations were present, the child voices were not judged as harshly as the SAE. Results from the current study highlight that open-source software, such as Tacotron 2, opens the door for researchers to develop culturally, linguistically and age- appropriate voices in under-resourced languages and dialects, particularly for children with expressive communication difficulties.
Language
Despite the need for synthetic child voices, generating a synthetic child voice in under-resourced languages can be complicated, particularly when children’s literacy skills are reduced. African home languages are mainly spoken, rather than written. Thus, children’s literacy skills in African languages are often limited, due to the large language and literacy disparities in South African schools (Coetzee-Van Rooy, Citation2012). To account for this mismatch, spontaneous speech samples are often collected as an alternative. However, it is generally known that there is more variation, both acoustically and linguistically, with spontaneous speech as compared to read speech (Tucker & Mukai, Citation2023). In our study, although the isiXhosa child’s speaking rate increased during the spontaneous speech sample, the sample was filled with partial words and repairs, resulting in less precise pronunciation. She also presented with a greater degree of code-switching during spontaneous speech than?. Ultimately, the data from the read speech was preferred for all three of the language models. Due to the challenges associated with collecting usable child speech data and the lack of applicable child speech corpora in different languages (Jain et al., Citation2022), it is not surprising that text-to-speech for child voices, particularly in under-resourced languages, are currently limited.
However, after the collection of child speech data and due to cross-lingual transfer learning, limited modifications are required for each language when using the default Tacotron 2 architecture. Transfer learning is an approach where a model trained on a source domain (i.e., English speech data) is used to improve the generalizability of a target domain (i.e., isiXhosa speech data) (Wang & Zheng, Citation2015). This is incredibly encouraging for the multilingual South African population. Non-English children with expressive communication difficulties often have to use English AAC devices (Tönsing et al., Citation2018). However, when there is a language mismatch between the language used on the AAC device at school and the language used at home, caregivers are less likely to use speech-generating devices (Tönsing et al., Citation2018). This language mismatch ultimately causes reduced buy-in from caregivers, modeling opportunities and consistent AAC use. Our study highlights that researchers will be able to either collect residual speech from children with expressive communication difficulties, with various home languages, and incorporate it into a training model, or if speech is severely impaired, they will be able to use an age-matched child’s voice to develop synthetic child speech in under-resourced languages.
Warm start type
By implementing a warm start using available adult speech data, with Tacotron 2 (Wang et al., Citation2017), age, language, dialect, and gender mismatch are no longer limiting factors for the creation of suitable synthetic speech for children with expressive communication difficulties. For example, the final output of the SAE and Afrikaans child voices were male, while the training data used in the warm start was that of an adult female. When there are limited training data, which often occurs with child speech data, along with possible computational resource constraints, incorporating a warm start, with an established adult model of high quality, can improve the quality of the synthesized child speech output. The results from the current study support Phuong et al. (Citation2021) findings, as the model’s training time was reduced, and each model’s quality improved dramatically after initializing a warm start.
It was anticipated, however, that including a warm start procedure twice, may result in the child model underperforming. For instance, the established Tacotron 2 model was used to warm start the different South African adult models. The South African adult models (warm start B) were then utilized to warm start the respective child synthesis, in each language. Interestingly, the child models performed equally well with warm start B as with warm start A. This suggests that more than one warm start does not necessarily affect performance. Rather, the naturalness of the child model is directly proportional to the quality and the quantity of the adaptation data used. Although both warm start procedures produced adequate quality child speech synthesis, if one were to use the voices for AAC purposes, it would be sensible to choose the model that produces synthetic speech with the greatest consistency. As Tacotron 2 (Wang et al., Citation2017) is open-source and produces naturalistic synthetic speech, the lack of extensive speech data should no longer limit the development of appropriate child voices.
Child speech training data
Shivakumar and Georgiou’s (Citation2020) study showed that any amount of child speech data were helpful, but 35 min of child speech data were able to give improvements of up to 9.1% over their adult model. Our results support Shivakumar and Georgiou’s conclusions. Even though our study suggests that as little as 5 min of clean training data can produce a speech-like output when using a warm start procedure, the quality and accuracy of the synthetic speech systematically improve with over 1 hour of speech data. It is clear that the more high-quality speech data you have for training and adaptation, as seen with our adult South African voices, the more successful the model will be, which is supported by numerous researchers (Hasija et al., Citation2021; Kumar & Surendra, Citation2011; Shivakumar & Georgiou, Citation2020). Additionally, if the donor child’s speech were to be recorded in a sound-attenuated room, one would get improved child speech synthesis results. Moreover, a scoping review by Terblanche et al. (Citation2022) highlighted that the best synthesis results are usually found when data is carefully selected, rather than through blind selection. Similarly, in the present study, it was found that training Tacotron 2 with clean data (minimal disfluencies and errors etc.) provided a cleaner voice output. In other words, even if there were child speech corpora in under-resourced languages, researchers would need to spend time carefully selecting and cleaning the data, otherwise the articulatory errors, incomplete sentences, disfluencies, and hesitations that typically present in child speech would also appear in the synthetic speech output (Kumar & Surendra, Citation2011). Although cleaning the data has traditionally been considered a tedious task, our study shows that we no longer need over 24 hr of speech data to develop synthetic speech of adequate quality, due to the implementation of a warm start. Thus, reducing the amount of speech data needed also reduces the time spent cleaning the data. Our hope is that researchers will consider including a warm start method to develop synthetic child speech in other under-resourced languages.
Implications
Using this technology, and incorporating a warm start procedure, has the potential to support marginalized AAC communities and develop much-needed resources in low- and middle-income countries, especially where child speech data in under-resourced languages is restricted. This study showed that it is possible for children with expressive communication difficulties to have linguistically, culturally, and age-appropriate synthetic voices.
Limitations and future directions
It could be argued that using the established Tacotron 2 architecture is not in itself a novel approach to speech synthesis; however using modern text-to-speech technologies to generate text-to-speech resources in under-resourced languages for children with expressive communication difficulties, who live in low- and middle-income countries, has not received sufficient attention in the literature (Govender & de Wet, Citation2016; Hasija et al., Citation2021). We hope that this contribution can provide a model for others interested in creating synthetic child voices in under-resourced languages. Second, there are some limitations to the subjective quality assessments used. For instance, as the listening test was conducted online, some participants may have experienced technical difficulties, such as an increased lag time, which may have influenced their MOS rating. In addition, due to limited synthetic speech in under-resourced languages, fluent speakers have had few opportunities, if any, to hear synthetic speech in their home languages and dialects. Feedback from first language speakers is therefore particularly intriguing when considering future speech synthesis development in low- and middle-income countries. However, as only 124 listeners participated in the subjective MOS survey, with only 19 isiXhosa listeners, results are not necessarily generalizable to the entire population.
As an additional limitation, there are limited AAC devices/apps that are currently equipped to load the African synthetic voices we developed. Because the syntax and morphology of these languages differ greatly from English, researchers and clinicians will need to develop core vocabulary for each of these languages. Using a new or established device or app, this core vocabulary can then be paired with the synthetic speech in each language, to form a functioning speech-generating system. Along with the core vocabulary, one would need to incorporate graphic symbols with cross-cultural readability into a system to support children who are illiterate, or one could simply utilize a simple text-to-speech system in each language. However, using a system without symbols may limit its efficacy for many of the South African children with special needs, due to the low literacy levels amongst this population. Future research could incorporate the speech of children with expressive communication difficulties into the training procedure, so that synthetic voices can be even more individualized for specific children (Mills et al., Citation2014). In addition, obtaining feedback from children who make use of speech-generating devices about their preferred synthetic voice (i.e., an adult, a child, or a child voice that includes some of their own speech) would be an important next step. It may be worthwhile for researchers to explore code-switching in speech synthesis, and to include more data to improve the pronunciation of names. If a high-quality child model is available, it may also be interesting to pre-train a model with child data rather than adult data. Lastly, it would be beneficial to gather in-depth feedback about the quality and intelligibility of the synthetic voices from caregivers, teachers, and speech and language therapists who have or work with children who have expressive communication difficulties.
Conclusion
This paper addressed the feasibility of creating synthetic child speech, using a limited training data scenario for three under-resourced South African languages, namely Afrikaans, isiXhosa and SAE. A small amount of child speech data was collected, and together with adult speech corpora, was used to pre-train a Tacotron 2 model. Despite limited child speech data, we were able to develop child voices that listeners rated as more natural than not. In addition, although the synthetic adult voices developed in this study appear more natural than the synthetic child voices, likely due to the quality and quantity of the adult data used, the child voices do match the voices of the South African donor children. In conclusion, this study highlights that due to recent technological advances, it is possible to accurately develop synthetic child speech with limited training data. This means that it is feasible to develop synthetic child voices in under-resourced languages for children with expressive communication difficulties, living in low- and middle-income countries, who may wish to speak in a language other than American or British English.
The financial assistance of the National Research Foundation (NRF) of South Africa (DSI-NRF Reference Number: MND200619533947) is hereby acknowledged. This work was supported by Mitacs through the Mitacs Globalink Research Award Program. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan V GPU used for this research. This is a student paper based on the doctoral research of the first author.
2023_0083_Supplemental_Material.docx
Download MS Word (400.7 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1 The pre-trained Tacotron 2 model (tacotron2_statedict.pt) from NVIDIA Deep Learning Examples. California, United States.
2 Titan V GPU © is a product of NVIDIA. California, United States.
3 Zoom H1 Handy recorder © is a product of the Zoom corporation, Hauppauge, New York.
References
- Barnekow, V., Binder, D., Kromrey, N., Munaretto, P., Schaad, A., & Schmieder, F. (2021, December). Creation and Detection of German Voice Deepfakes. In International Symposium on Foundations and Practice of Security (pp. 355–364). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-031-08147-7_24
- Baxter, S., Enderby, P., Evans, P., & Judge, S. (2012). Barriers and facilitators to the use of high-technology augmentative and alternative communication devices: A systematic review and qualitative synthesis. International Journal of Language & Communication Disorders, 47(2), 115–129. https://doi.org/10.1111/j.1460-6984.2011.00090.x
- Begnum, M., Flatebø Hoelseth, S., Johnsen, B., & Hansen, F. (2012). A child’s voice [Paper presentation]. Norsk Informatikkonferanse (NIK) Conference (9–12 November), 165–176.
- Besacier, L., Barnard, E., Karpov, A., & Schultz, T. (2014). Automatic speech recognition for under-resourced languages: A survey. Speech Communication, 56, 85–100. https://doi.org/10.1016/j.specom.2013.07.008
- Christensen, R. H. B. (2022). Ordinal—Regression models for ordinal data [R package version 2022.11-16]. https://CRAN.R-project.org/package=ordinal
- Coetzee-Van Rooy, S. (2012). Flourishing functional multilingualism: Evidence from language repertoires in the Vaal Triangle region. International Journal of the Sociology of Language, 2012(218), 87–119. https://doi.org/10.1515/ijsl-2012-0060
- Cooper, E., Lai, C. I., Yasuda, Y., Fang, F., Wang, X., Chen, N., & Yamagishi, J. (2020, May). Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6184–6188). IEEE. https://doi.org/10.1109/ICASSP40776.2020.9054535
- Crowley, C. (2019). School-age language assessment measures: The ball mystery. Leadersproject.Org. https://www.leadersproject.org/2021/05/26/slam-the-ball-mystery/
- de Leeuw, J., Gilbert, R., & Luchterhandt, B. (2023). jsPsych: Enabling an open-source collaborative ecosystem of behavioral experiments. Journal of Open Source Software, 8(85), 5351. https://joss.theoj.org/papers/10.21105/joss.05351 https://doi.org/10.21105/joss.05351
- Drager, K., Reichle, J., & Pinkoski, C. (2010). Synthesized speech output and children: A scoping review. American Journal of Speech-Language Pathology, 19(3), 259–273. https://doi.org/10.1044/1058-0360(2010/09-0024)
- Govender, A., & de Wet, F. (2016). Objective measures to improve the selection of training speakers in HMM-based child speech synthesis [Paper presentation]. Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech).
- Govender, A., Nouhou, B., & De Wet, F. (2015). HMM Adaptation for child speech synthesis using ASR data [Paper presentation]. 2015 Pattern Recognition Association of South Africa and Robotics and Mechatronics International Conference (PRASA-RobMech), Port Elizabeth, South Africa. https://doi.org/10.1109/RoboMech.2015.7359519
- Hasija, T., Kadyan, V., & Guleria, K. (2021). Out domain data augmentation on Punjabi children speech recognition using Tacotron. Journal of Physics: Conference Series, 1950(1), 012044. https://doi.org/10.1088/1742-6596/1950/1/012044
- Ito, K., Johnson, L. (2017). The LJ speech dataset. https://keithito.com/LJ-Speech-Dataset/
- Jain, R., Yiwere, M. Y., Bigioi, D., Corcoran, P., & Cucu, H. (2022). A text-to-speech pipeline, evaluation methodology, and initial fine-tuning results for child speech synthesis. IEEE Access, 10, 47628–47642. https://doi.org/10.1109/ACCESS.2022.3170836
- Jreige, C., Patel, R., & Bunnell, H. T. (2009). VocaliD: Personalizing text-to-speech synthesis for individuals with severe speech impairment [Paper presentation]. 11th International ACM SIGACCESS Conference on Computers and Accessibility (Assets '09), 259–260. https://doi.org/10.1145/1639642.1639704
- Kumar, J. V., & Surendra, A. K. (2011). Statistical parametric approach for child speech synthesis using HMM-based system. International Journal of Computer Science & Technology, 2(1), 149–152.
- Louw, A., & Schlünz, G. (2016a). Lwazi III Afrikaans TTS Corpus (ISLRN 605-808-477-011-9; 1st ed.) [dataset]. Meraka Institute, CSIR. https://hdl.handle.net/20.500.12185/266
- Louw, A., & Schlünz, G. (2016b). Lwazi III English TTS Corpus (ISLRN 266-833-874-480-1; Vol. 1) [dataset]. Meraka Institute, CSIR. https://hdl.handle.net/20.500.12185/267
- Louw, A., & Schlünz, G. (2016c). Lwazi III isiXhosa TTS Corpus (ISLRN 038-391-782-117-6; Vol. 1) [dataset]. Meraka Institute, CSIR. https://hdl.handle.net/20.500.12185/268
- Mertler, C. (2016). Quantitative Research Methods. In Introduction to Educational Research. SAGE Publications, Inc.
- Mills, T., Bunnell, T., & Patel, R. (2014). Towards personalized speech synthesis for augmentative and alternative communication. Augmentative and Alternative Communication (Baltimore, Md.: 1985), 30(3), 226–236. https://doi.org/10.3109/07434618.2014.924026
- Ndlangamandla, S. C. (2010). Multilingualism in desegregated schools: Learners’ use of and views towards African languages. Southern African Linguistics and Applied Language Studies, 28(1), 61–73. https://doi.org/10.2989/16073614.2010.488444
- Pascoe, M., & Norman, V. (2011). Contextually relevant resources in speech-language therapy and audiology in South Africa – Are there any?. The South African Journal of Communication Disorders = Die Suid-Afrikaanse Tydskrif Vir Kommunikasieafwykings, 58(1), 2–5. https://doi.org/10.4102/sajcd.v58i1.35
- Phuong, P. N., Quang, C. T., Do, Q. T., & Luong, M. C. (2021). A study on neural-network-based text-to-speech adaptation techniques for Vietnamese [Paper presentation]. 24th Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques.
- Prenger, R., Valle, R., & Catanzaro, B. (2019, May). Waveglow: A flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 3617–3621). IEEE. https://doi.org/10.1109/ICASSP.2019.8683143
- R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing [Computer software]. https://www.R-project.org/
- Saam, C., & Cabral, J. P. (2021). Using multi-speaker models for single speaker Spanish synthesis in the Blizzard 2021 [Paper presentation]. FestVox. The Blizzard Challenge 2021. https://doi.org/10.21437/Blizzard.2021-7
- Sefara, T. J., Mokgonyane, T. B., Manamela, M. J., & Modipa, T. I. (2019). HMM-based speech synthesis system incorporated with language identification for low-resourced languages [Paper presentation]. International Conference on Advances in Big Data, Computing and Data Communication Systems (IcABCD). https://doi.org/10.1109/ICABCD.2019.8851055
- Shen, J., Pang, R., Weiss, R. J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y., Wang, Y., Skerrv-Ryan, R., &., et al. (2018). Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions [Paper presentation]. International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 47792–4783. https://doi.org/10.48550/arXiv.1712.05884
- Shivakumar, P. G., & Georgiou, P. (2020). Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations. Computer Speech & Language, 63(8), 1–46. https://doi.org/10.1016/j.csl.2020.101077
- South African Government. (1996). The Constitution of the Republic of South Africa. https://www.gov.za/documents/constitution/constitution-republic-south-africa-1996-1
- Statistics SA. (2011). South African National Census of 2011. https://www.statssa.gov.za/census/census_2011/census_products/Census_2011_Census_in_brief.pdf
- Sutton, S., Foulkes, P., Kirk, D., & Lawson, S. (2019). Voice as a design material: Sociophonetic inspired design strategies in Human-Computer Interaction [Paper presentation]. CHI Conference on Human Factors in Computing Systems Proceedings (CHI 2019). https://doi.org/10.1145/3290605.3300833
- Taherdoost, H. (2016). Sampling methods in research methodology: How to choose a sampling technique for research. International Journal of Academic Research in Management, 5, 18–27. https://doi.org/10.2139/ssrn.3205035
- Terblanche, C., Harty, M., Pascoe, M., & Tucker, B. V. (2022). A situational analysis of current speech-synthesis systems for child voices: A scoping review of qualitative and quantitative evidence. Applied Sciences, 12(11), 5623. https://doi.org/10.3390/app12115623
- Tönsing, K., Van Niekerk, K., Schlünz, G. I., & Wilken, I. (2018). AAC services for multilingual populations: South African service provider perspectives. Journal of Communication Disorders, 73, 62–76. https://doi.org/10.1016/j.jcomdis.2018.04.002
- Tönsing, K., van Niekerk, K., Schlünz, G., & Wilken, I. (2019). Multilingualism and augmentative and alternative communication in South Africa – Exploring the views of persons with complex communication needs. African Journal of Disability, 8(0), 507. https://doi.org/10.4102/ajod.v8i0.507
- Tucker, B. V., & Mukai, Y. (2023). Spontaneous speech. Cambridge University Press. https://doi.org/10.1017/9781108943024
- Wang, D., & Zheng, F. (2015). Transfer learning for speech and language processing [Paper presentation]. Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA) (16-19 December 2015), Hong Kong, China. https://doi.org/10.1109/APSIPA.2015.7415532
- Wang, X., Yamagishi, J., Todisco, M., Delgado, H., Nautsch, A., Evans, N., … & Ling, Z. H. (2020). ASVspoof 2019: A large-scale public database of synthesized, converted and replayed speech. Computer Speech & Language, 64, 101114. https://doi.org/10.1016/j.csl.2020.101114
- Wang, Y., Skerrv-Ryan, R., Stanton, D., Wu, Y., Weiss, R. J., Jaitly, N., Yang, Z., Xiao, Y., Chen, Z., Bengio, S., Le, Q., Agiomyrgiannakis, Y., Clark, R., & Saurous, R. (2017). Tacotron: Towards end-to-end speech synthesis. ArXiv preprint arXiv:1703.10135. https://doi.org/10.48550/arXiv.1703.10135
- World Medical Association. (2013). World Medical Association declaration of Helsinki: Ethical principles for medical research involving human subjects. Clinical Review & Education, 310(20), 2191–2194.
- Zhu, J. (2020). Probing the phonetic and phonological knowledge of tones in Mandarin TTS models [Paper presentation]. Proc. Speech Prosody 2020, 930–934. https://doi.org/10.21437/SpeechProsody.2020-190