
ABSTRACT
We study the invariance properties of various test criteria which have been proposed for hypothesis testing in the context of incompletely specified models, such as models which are formulated in terms of estimating functions (Godambe, 1960) or moment conditions and are estimated by generalized method of moments (GMM) procedures (Hansen, 1982), and models estimated by pseudo-likelihood (Gouriéroux, Monfort, and Trognon, 1984b,c) and M-estimation methods. The invariance properties considered include invariance to (possibly nonlinear) hypothesis reformulations and reparameterizations. The test statistics examined include Wald-type, LR-type, LM-type, score-type, and C(α)−type criteria. Extending the approach used in Dagenais and Dufour (1991), we show first that all these test statistics except the Wald-type ones are invariant to equivalent hypothesis reformulations (under usual regularity conditions), but all five of them are not generally invariant to model reparameterizations, including measurement unit changes in nonlinear models. In other words, testing two equivalent hypotheses in the context of equivalent models may lead to completely different inferences. For example, this may occur after an apparently innocuous rescaling of some model variables. Then, in view of avoiding such undesirable properties, we study restrictions that can be imposed on the objective functions used for pseudo-likelihood (or M-estimation) as well as the structure of the test criteria used with estimating functions and generalized method of moments (GMM) procedures to obtain invariant tests. In particular, we show that using linear exponential pseudo-likelihood functions allows one to obtain invariant score-type and C(α)−type test criteria, while in the context of estimating function (or GMM) procedures it is possible to modify a LR-type statistic proposed by Newey and West (1987) to obtain a test statistic that is invariant to general reparameterizations. The invariance associated with linear exponential pseudo-likelihood functions is interpreted as a strong argument for using such pseudo-likelihood functions in empirical work.
1. Introduction
Model and hypothesis formulation in econometrics and statistics typically involve a number of arbitrary choices, such as the labelling of independent and identically distributed (i.i.d.) observations or the selection of measurement units. Further, in hypothesis testing, these choices often do not affect the interpretation of the null and the alternative hypotheses. When this is the case, it appears desirable that statistical inference remain invariant to such choices; see Hotelling (Citation1936), Pitman (Citation1939), Lehmann (Citation1983, Chapter 3), Lehmann (Citation1986, Chapter 6), and Ferguson (Citation1967). Among other things, when the way a null hypothesis is written has no particular interest or when the parameterization of a model is largely arbitrary, it is natural to require that the results of test procedures do not depend on such choices. This holds, for example, for standard t and F tests in linear regressions under linear hypothesis reformulations and reparameterizations. In nonlinear models, however, the situation is more complex.
It is well known that Wald-type tests are not invariant to equivalent hypothesis reformulations and reparameterizations; see Cox and Hinkley (Citation1974, p. 302), Burguete et al. (Citation1982, p. 185), Gregory and Veall (Citation1985), Vaeth (Citation1985), Lafontaine and White (Citation1986), Breusch and Schmidt (Citation1988), Phillips and Park (Citation1988), and Dagenais and Dufour (Citation1991). For general possibly nonlinear likelihood models (which are treated as correctly specified), we showed in previous work (Dagenais and Dufour, Citation1991, Citation1992; Dufour and Dagenais, Citation1992) that very few test procedures are invariant to general hypothesis reformulations and reparameterizations. The invariant procedures essentially reduce to likelihood ratio (LR) tests and certain variants of score [or Lagrange multiplier (LM)] tests where the information matrix is estimated with either an exact formula for the (expected) information matrix or an outer product form evaluated at the restricted maximum likelihood (ML) estimator. In particular, score tests are not invariant to reparameterizations when the information matrix is estimated using the Hessian matrix of the log-likelihood function evaluated at the restricted ML estimator. Further, C(α) tests are not generally invariant to reparameterizations unless special equivariance properties are imposed on the restricted estimators used to implement them. Among other things, this means that measurement unit changes with no incidence on the null hypothesis tested may induce dramatic changes in the conclusions obtained from the tests and suggests that invariant test procedures should play a privileged role in statistical inference.
In this article, we study the invariance properties of various test criteria which have been proposed for hypothesis testing in the context of incompletely specified models, such as models which are formulated in terms of estimating functions (Godambe, Citation1960)—or moment conditions—and are estimated by generalized method of moments (GMM) procedures (Hansen, Citation1982), and models estimated by M-estimation (Huber, Citation1981) or pseudo-likelihood methods (Gouriéroux et al., Citation1984b,c; Gouriéroux and Monfort, Citation1993). For general discussions of inference in such models, the reader may consult White (Citation1982), Newey (Citation1985), Gallant (Citation1987), Newey and West (Citation1987), Gallant and White (Citation1988), Gouriéroux and Monfort (Citation1989, Citation1995), Godambe (Citation1991), Davidson and MacKinnon (Citation1993), Newey and McFadden (Citation1994), Hall (Citation1999), and Mátyás (Citation1999); for studies of the performance of some test procedures based on GMM estimators, see also Burnside and Eichenbaum (Citation1996) and Podivinsky (Citation1999).
The invariance properties we consider include invariance to (possibly nonlinear) hypothesis reformulations and reparameterizations. The test statistics examined include Wald-type, LR-type, LM-type, score-type, and C(α)-type criteria. Extending the approach used in Dagenais and Dufour (Citation1991) and Dufour and Dagenais (Citation1992) for likelihood models, we show first that all these test statistics except the Wald-type ones are invariant to equivalent hypothesis reformulations (under usual regularity conditions), but all five of them are not generally invariant to model reparameterizations, including measurement unit changes in nonlinear models. In other words, testing two equivalent hypotheses in the context of equivalent models may lead to completely different inferences. For example, this may occur after an apparently innocuous rescaling of some model variables.
In view of avoiding such undesirable properties, we study restrictions that can be imposed on the objective functions used for pseudo-likelihood (or M-estimation) as well as the structure of the test criteria used with estimating functions and GMM procedures to obtain invariant tests. In particular, we show that using linear exponential pseudo-likelihood functions allows one to obtain invariant score-type and C(α)-type test criteria, while in the context of estimating function (or GMM) procedures it is possible to modify a LR-type statistic proposed by Newey and West (Citation1987) to obtain a test statistic that is invariant to general reparameterizations. The invariance associated with linear exponential pseudo-likelihood functions can be viewed as a strong argument for using such pseudo-likelihood functions in empirical work. Of course, the fact that Wald-type tests are not invariant to both hypothesis reformulations and reparameterizations is by itself a strong argument to avoid using this type of procedure (when they are not equivalent to other procedures) and suggest as well that Wald-type tests can be quite unreliable in finite samples; for further arguments going in the same direction, see Burnside and Eichenbaum (Citation1996), Dufour (Citation1997), and Dufour and Jasiak (Citation2001).
In Section 2, we describe the general setup considered, while the test statistics studied are defined in Section 3. The invariance properties of the available test statistics are studied in Section 4. In Section 5, we make suggestions for obtaining tests that are invariant to general hypothesis reformulations and reparameterizations. Numerical illustrations of the invariance (and noninvariance) properties discussed are provided in Section 6. In Section 7, we consider linear stochastic discount factor model as an empirical example and show that noninvariant procedures may yield drastically different outcomes depending on the identifying restrictions imposed. We conclude in Section 8.
2. Framework
We consider an inference problem about a parameter of interest 𝜃∈Θ⊆ℝp. This parameter appears in a model which is not fully specified. In order to identify 𝜃, we assume there exist a m×1 vector score-type function where
is a n×k stochastic matrix such that
is a mapping from Θ onto ℝm such that
Typically, such a model is estimated by minimizing with respect to 𝜃 an expression of the form
,
; see Gouriéroux and Monfort (Citation1995, Ch. 9). Note also that “asymptotic estimation efficiency” arguments suggest one to use
as weighting matrix, where In is consistent estimator of I0.Footnote1
If we assume that the number of equations is equal to the number of parameters (m = p), a general method for estimating 𝜃 also consists in finding an estimator which satisfies the equation
Typically, in such cases, is the derivative of an objective function
which is maximized (or minimized) to obtain
so that
In this case, is asymptotically normal with zero mean and asymptotic variance
Obviously, condition (2.8) is entailed by the minimization of Mn(𝜃) when m = p. It is also interesting to note that problems with m>p can be reduced to cases with m = p through an appropriate redefinition of the score-type function , so that the characterization (2.8) also covers most classical asymptotic estimation methods. A typical list of methods is the following one.
ML. In this case, the model is fully specified with log-likelihood function
and score function
GMM. 𝜃 is identified through a m×1 vector of conditions of the form:
and the quadratic formwhere Wn is a symmetric positive definite matrix. In this case, the score-type function isM-estimator.
The score function has the following form:
3. Test statistics
Consider now the problem of testing
At this stage, it is not necessary to specify closely the way the matrices I(𝜃0) and J(𝜃0) are estimated. We will denote by and
or by
and
the corresponding estimated matrices depending on whether they are obtained with or without the restriction ψ(𝜃) = 0. In particular, if
For , other estimators are also widely used. Here, we shall consider general estimators of the form
For example, a “mean corrected” version of may be obtained on taking
where In is the identity matrix of order n and
which yields
For further discussion of such estimators, the reader may consult Newey and West (Citation1987), Andrews (Citation1991), Andrews and Monahan (Citation1992), Hansen (Citation1992), and Cushing and McGarvey (Citation1999).
In this context, analogues of the Wald, LM, score, and C(α) test statistics can be shown to have asymptotic null distributions without nuisance parameters, namely distributions. On assuming that the referenced inverse matrices do exist, these test criteria can be defined as follows:
(a) The Wald-type statistic,
(b) The score-type statistic,
(c) The LM-type statistic,
(d) The C(α)-type statistic,
The above Wald-type and score-type statistics were discussed by Newey and West (Citation1987) in the context of GMM estimation, and for pseudo-maximum likelihood estimation by Trognon (Citation1984). The C(α)-type statistic is given by Davidson and MacKinnon (Citation1993, p. 619). Of course, LR-type statistics based on the difference of the maxima of the objective function have also been considered in such contexts:
It is well known that, in general, this difference is distributed as a mixture of independent chi-square with coefficients depending upon nuisance parameters; see, for example, Trognon (Citation1984) and Vuong (Citation1989). Nevertheless, there is one LR-type test statistic whose distribution is asymptotically pivotal with a chi-square distribution, namely the D statistic suggested by Newey and West (Citation1987):
is a consistent estimator of I(𝜃0),
minimizes
without restriction, and
minimizes
under the restriction ψ(𝜃) = 0. Note, however, that this LR-type statistic is more accurately viewed as a score-type statistic: if Dn is the derivative of some other objective function (e.g., a log-likelihood function), the latter is not used as the objective function but replaced by a quadratic function of the “score” Dn.
Using the constrained minimization condition,
and Wn is a symmetric positive definite (possibly random) m×m matrix such that
Under standard regularity conditions, we have
In particular, this will be the case if is the derivative vector of a (pseudo) log-likelihood function. Finally, for m≥p, when
is obtained by minimizing
subject to ψ(𝜃) = 0, we can write
and
ψ,Wn) is identical to the score (or LM)-type statistic suggested by Newey and West (Citation1987). Since the statistic
ψ,Wn) is quite comprehensive, it will be convenient for establishing general invariance results.
4. Invariance
Following Dagenais and Dufour (Citation1991), we will consider two types of invariance properties: (1) invariance with respect to the formulation of the null hypothesis, and (2) invariance with respect to reparameterizations.
4.1. Hypothesis reformulation
Let
A test statistic is invariant with respect to Ψ if it is the same for all ψ∈Ψ. It is obvious the LR-type statistics LR(ψ) and DNW(ψ) (when applicable) are invariant to such hypothesis reformulations because the optimal values of the objective function (restricted or unrestricted) do not depend on the way the restrictions are written. Now, a reformulation does not affect , and
The same holds for
and
provided the restricted estimator
used with C(α) tests does not depend on which function ψ∈Ψ is used to obtain it. However,
, and
change. Following Dagenais and Dufour (Citation1991), if
we have
Proposition 4.1 (Invariance to Hypothesis Reformulations).
Let Ψ be a family of p1×1 continuously differentiable functions of 𝜃 such that has full row rank when ψ(𝜃) = 0 (1≤p1≤p), and
Then, where T stands for any one of the test statistics S(ψ), LM(ψ),
ψ), LR(ψ), DNW(ψ), and
ψ,Wn) defined in (3.11)–(3.15) and (3.24).
Note that the invariance of the S(ψ), LM(ψ), LR(ψ), and DNW(ψ) statistics to hypothesis reformulations has been pointed out by Gouriéroux and Monfort (Citation1989) for mixed-form hypotheses.
4.2. Reparameterization
Let ḡ be a one-to-one differentiable transformation from Θ⊆ℝp to . ḡ represents a reparameterization of the parameter vector 𝜃 to a new one, 𝜃∗. The latter is often determined by a one-to-one transformation of the data
as occurs for example when variables are rescaled (measurement unit changes). But it may also represent a reparameterization without any variable transformation. Let k = ḡ−1 be the inverse function associated with ḡ:
Set
Since k[ḡ(𝜃)] = 𝜃 and we have by the chain rule of differentiation
Let
Clearly,
By the invariance property of Proposition 4.1, it will be sufficient for our purpose to study invariance to reparameterizations for any given reformulation of the null hypothesis in terms of 𝜃∗. From the above definition of it follows that
We need to make an assumption on the way the score-type function changes under a given reparameterization. We will consider two cases. The first one consists in assuming that
as in (3.3) where the values of the scores are unaffected by the reparameterization, but are simply reexpressed in terms of 𝜃∗ and zt∗ (invariant scores)
Under condition (4.11), we see easily that
Further the functions and
in (3.4) are then transformed in the following way:
If and
are defined as in (3.4), if
and if
is equivariant with respect to ḡ [i.e.,
], it is easy to check that the generalized C(α) statistic defined in (3.24) is invariant to the reparameterization 𝜃∗ = ḡ(𝜃). This suggests the following general sufficient condition for the invariance of C(α) statistics.
Proposition 4.2 (C(α) Canonical Invariance to Reparameterizations: Invariant Score Case).
Let and suppose the following conditions hold:
Here
, and Wn are defined as in (3.24), and
is invertible. Then
It is clear that the estimators and
satisfy the equivariance condition, i.e.,
and
Consequently, the above invariance result also applies to score (or LM) statistics. It is also interesting to observe that
This holds, however, only for the special reformulation
not for all equivalent reformulations
On applying Proposition 4.1, this type of invariance holds for the other test statistics. These observations are summarized in the following proposition.
Theorem 4.3 (Test Invariance to Reparameterizations and General Hypothesis Reformulations: Invariant Score Case).
Let be any continuously differentiable function of
such that ψ∗(ḡ(𝜃)) = 0⇔ψ(𝜃) = 0, let m = p, and suppose:
Here Then, provided the relevant matrices are invertible, we have
If the Wald statistic is invariant:
Cases where (4.12) holds only have limited interest because they do not cover problems where Dn is the derivative of an objective function, as occurs for example when M-estimators or (pseudo) maximum likelihood methods are used
In such cases, one would typically have
From (2.3) and (4.17), it then follows that
Further,
By a set of arguments analogous to those used in Dagenais and Dufour (Citation1991), it appears that all the statistics (except the LR-type statistic) are based upon Hn and so they are sensitive to a reparameterization, unless some specific estimator of J is used. At this level of generality, the following results can be presented using the following notations : are the estimated matrices for a parameterization in 𝜃 and
are the estimated matrices for a parameterization in 𝜃∗. The first proposition below provides an auxiliary result on the invariance of generalized C(α) statistics for the canonical reformulation
while the following one provides the invariance property for all the statistics considered and general equivalent reparameterizations and hypothesis reformulations.
Proposition 4.4 (C(α) Canonical Invariance to Reparameterizations).
Let , and suppose the following conditions hold:
Here
, and Wn are defined as in (3.24), and
Then, provided the relevant matrices are invertible,
Theorem 4.5 (Test Invariance to Reparameterizations and General Equivalent Hypothesis Reformulations).
Let be any continuously differentiable function of
such that ψ∗[ḡ(𝜃)] = 0⇔ψ(𝜃) = 0, let m = p, and suppose:
Here Then, provided the relevant matrices are invertible, we have
and, in the case where
It is of interest to note here that condition (a) and (b) of the latter theorem will be satisfied if and each individual “score” gets transformed after reparameterization according to the equation
Despite the apparent “positive nature” of the invariance results presented in this section, the main conclusion is that none of the proposed test statistics is invariant to general reparameterizations, especially when the score-type function is derived from an objective function. This is due, in particular, to the behavior of moment (or estimating function) derivatives under nonlinear reparameterizations. As shown in Dagenais and Dufour (Citation1991), this type of problem is already apparent in fully-specified likelihood models where LM statistics are not invariant to general reparameterizations when the covariance matrix is estimated through the Hessian of the log-likelihood function (i.e., derivatives of the score function). When the true likelihood is not available, test statistics must be modified to control the asymptotic level of the test. Reparameterizations involve derivatives of score-type function (or pseudo-likelihood second derivatives), even in the case of LR-type statistics (see Theorem 4.5). In other words, the adjustments required to deal with an incompletely specified model (no likelihood function) make invariance more difficult to achieve, and building valid invariant test procedures becomes a challenge.
5. Invariant test criteria
In this section, we propose two ways of building invariant test statistics. The first one is based on modifying the LR-type statistics proposed by Newey and West (Citation1987) for GMM setups, while the second one exploits special properties of the linear exponential family in pseudo-maximum likelihood models.Footnote4
5.1. Modified Newey–West LR-type statistic
Consider the LR-type statistic
However, there is a simple way of creating the appropriate invariance as soon as the function is a reasonably smooth function of 𝜃. Instead of estimating 𝜃 by minimizing
estimate 𝜃 by minimizing
For example, such an estimation method was studied by Hansen et al. (Citation1996). When the score vector Dn and the parameter vector 𝜃 have the same dimension (m = p), the unrestricted objective function will typically be zero
Zn) = 0], so the statistic reduces to
When m>p, this will typically not be the case.
Suppose now the following conditions hold:
Then, for 𝜃∗ = ḡ(𝜃),
Consequently, the unrestricted minimal value
and the restricted one
so obtained will remain unchanged under the new parameterization, and the corresponding J and the LR-type statistics, i.e.,
are invariant to reparameterizations of the type considered in (4.17)–(4.19). Under standard regularity conditions on the convergence of and
as n→∞ (continuity, uniform convergence), it is easy to see that D and DNW are asymptotically equivalent (at least under the null hypothesis) and so have the same asymptotic
distribution.Footnote5
5.2. Pseudo-maximum likelihood (PML) methods
PML methods
Consider the problem of making inference on the parameter which appears in the mean of an endogenous G×1 random vector yt conditional on an exogenous random vector xt
Irrespective of the true data generating process, a consistent and asymptotically normal estimator of 𝜃 can be obtained by maximizing
or equivalently through the following equivalent program:
The class of linear exponential distributions contains most of the classical statistical models, such as the Gaussian model, the Poisson model, the Binomial model, the Gamma model, the negative Binomial model, etc. The constraint in the program (5.9) ensures that the expectation of the linear exponential pseudo-distribution is μ. The pseudo-likelihood equations have an orthogonal condition form
The PML estimator solution of these first order conditions is consistent and asymptotically normal and we can write
These matrices can be estimated by
Since and
are invariant to reparameterizations,
and
are modified only through
Further,
and
The Lagrange multiplier, score and C(α)-type pseudo-asymptotic tests are then invariant to a reparameterization, though of course Wald tests will not be generally invariant to hypothesis reformulations. Consequently, this provides a strong argument for using pseudo true densities in the linear exponential family (instead of other types of densities) as a basis for estimating parameters of conditional means when the error distribution has unknown type.
The estimation of the J matrix could be obtained through direct second derivative calculus of the objective function. For example, when yt is univariate (G = 1), we have
The first two terms of this estimator behave after reparameterization as , but the last term is based on second derivatives of ft(𝜃) and so leads to noninvariance problems [see (3.4) and (4.20)]. The two last terms of J vanish asymptotically, and they can be dropped as in the estimation method proposed by Gouriéroux et al. (Citation1984c). For the invariance purpose, to discard the last term is the correct way to proceed.
Quasi generalized PML (QGPML) methods
Gouriéroux et al. (Citation1984c) pointed out that some lower efficiency bound can be achieved by a two-step estimation procedure, when the functional form of the true conditional second order moment of yt given xt is known:
The method is based on various classical exponential families (negative-binomial, gamma, normal) which depend on an additional parameter η linked with the second order moment of the pseudo-distribution. If μ and Σ are the expectation and the variance-covariance matrix of this pseudo-distribution: η = Ψ(μ, Σ), where Ψ defines for any μ, a one-to-one relationship between η and Σ.
The class of linear exponential distributions depending upon the extra parameter η is of the following form:
If we consider the negative binomial pseudo distribution and C(μ,η) = ln(μ∕(η+μ)); if otherwise we use the Gamma pseudo distribution: A(μ,η) = −ηln(μ) and
. In the former case,
, and in the latter
With preliminary consistent estimators ,
of α, 𝜃 where
and
are equivariant with respect to ḡ, computed for example as in Trognon (Citation1984), the QGPML estimator of 𝜃 is obtained by solving a problem of the type
The QGPML estimator of 𝜃 is strongly consistent and asymptotically normal:
with
I0 and J0 can be consistently estimated by
Since , and
are invariant to reparameterizations if
and
are equivariant, we face the same favorable case as before
Furthermore the quasi-generalized LR statistic (QGLR) is invariant provided, the first-step estimators and
are equivariant under reparameterization. And as shown in Trognon (Citation1984), the QGLR statistic is asymptotically equivalent to the other pseudo-asymptotic statistic under the null and under local alternatives.
6. Numerical results
In order to illustrate numerically the (non)invariance problems discussed above, we consider the model derived from the following equations:
The log-likelihood associated with this model is
It is easy to see that changing the measurement units on x1t and x2t leaves the form of model (6.1) and the null hypothesis invariant. For example, if both x1t and x2t are multiplied by a positive constant k, i.e.,
Table 1. Test statistics for H0:λ = 1 for different measurement units five moment model.
On interpreting model (6.1) as a pseudo-model and (6.3) as a pseudo-likelihood, we will examine the effect of rescaling on GMM-based and pseudo-likelihood tests. Moment equations can be derived from the above model by differentiating the log-likelihood with respect to model parameters and equating the expectation to zero. This yields the following five moment conditions:
These equations provide an exactly identified system of equations. To get a system with six-moment equations (hence overidentified), we add the equation
To get data, we considered the sample size n = 200 and generated yt according to Eq. (6.1) with the parameter values γ = 10, β1 = 1.0, β2 = 1.0, λ = −1.0, and σ2 = 0.85. The values of the regressors x1t and x2t were selected by transforming the values used in Dagenais and Dufour (Citation1991).Footnote7
Numerical values of the GMM-based test statistics for a number of rescalings are reported in Table for the five moment system (6.8)–(6.9) and in Table for the six-moment system (6.8)–(6.10). Results for the pseudo-likelihood tests appear in Table . Graphs of the noninvariant test statistics are also presented in Figs – . In these calculations, the first-step estimator of the two-step GMM tests is obtained by minimizing in (2.5) with
(equal weights), while the second step uses the weight matrix defined in (3.4). No correction for serial correlation is applied (although this could also be studied).
Table 2. Test statistics for H0:λ = 1 for different measurement units six moment models.
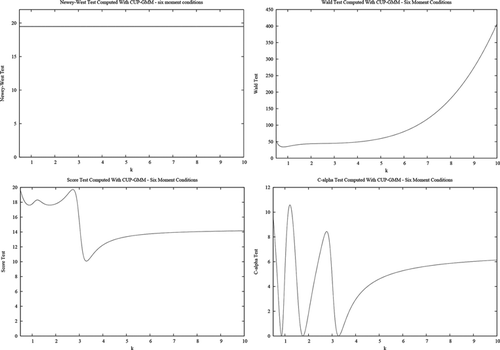
These results confirm the theoretical expectations of the theory presented in the previous sections. Namely, the GMM-based test statistics [D(ψ), Wald, score, C(α)] are not invariant to measurement unit changes and, indeed, can change substantially (even if both the null and the alternative hypotheses remain the same under the rescaling considered here). Noninvariance is especially strong for the overidentified system (six equations). In contrast, the D(ψ) and score tests based on the continuously updated GMM criterion are invariant. The same holds for the LR and adjusted score criteria based on linear exponential pseudo likelihoods.
Figure 1. Two-step GMM tests based on five moment conditions.
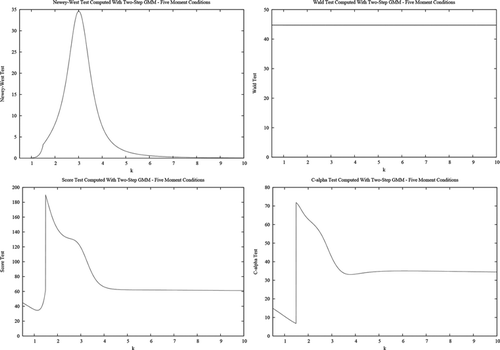
Figure 2. Two-step GMM tests based on six moment conditions.
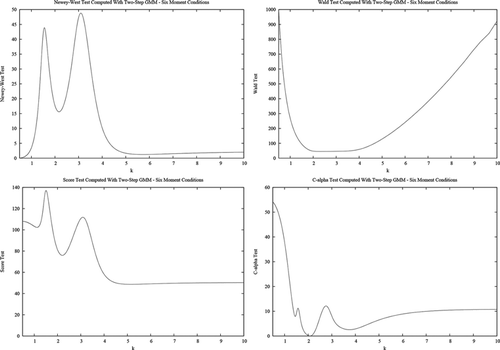
Figure 3. CUP GMM tests based on six moment conditions.
7. Empirical illustration: Linear stochastic discount factor models
In the context of linear stochastic discount factor model, it is shown that procedures based on noninvariant test statistics could lead to drastically different results depending on the form of identifying restrictions imposed. While an in-depth analysis of this problem is provided by Burnside (Citation2010) from the perspective of model misspecification and identification, we aim to shed light on this issue from invariance considerations. The linear stochastic discount factor model is described by the following two equations:
Since the unknowns a and b are not identified individually, we consider the following two normalizations (see Burnside, Citation2010; Cochrane, Citation2005):
By applying the normalizations to (7.3), we have
It is clear that the sample moments satisfy
Therefore, by virtue of Eq. (5.3), the continuously updated GMM (CUP-GMM) objective function and the statistic D are invariant to affine transformation of ft, i.e., they are not affected by the form of normalization employed. The model is estimated using the observed returns on five stocks: Weis Markets (WMK), Unisys Corporation (UIS), Orbital Sciences Corporation (ORB), Mattel (MAT) and Abaxis (ABAX), and the three factors Rm-Rf, Small [market capitalization] Minus Big (SMB), and High [book-to-market ratio] Minus Low (HML), from the Fama–French data set over the period from January 5th, 1993–March 16th, 1993. All calculations were carried out in R Version 3.0.2 (R Development Core Team (Citation2013)) using the package gmm developed by Pierre Chaussé (Chaussé, Citation2010). The data we use are readily available in the Finance data set contained in gmm. The estimation methods are two-step GMM and CUP-GMM with covariance matrix estimated with Bartlett and Quadratic Spectral (QS) kernels. Table reports the values of J statistic for testing the validity of the restrictions (7.4). For the two-step GMM, it is clear that the values of test statistics differ greatly across the normalizations, and are sensitive to the choice of kernels. Furthermore, the test rejects the null of correct specification under Normalization 2 with QS kernel, but the conclusion is reversed under Normalization 1. In the case of CUP-GMM with Bartlett kernel, though there is a small incongruity in the values of test statistics (possibly due to an optimization error), the model is not rejected under both normalizations. The difference between test statistics under the CUP-GMM with QS kernel may be attributed to the noninvariance of the objective function with QS kernel. The main message of this exercise is that procedures based on noninvariant test statistics can be quite sensitive to the identifying restrictions employed and may result in conflicting conclusions. For a thorough discussion on the effect of normalizations on estimation and inferences, we refer the reader to Hamilton et al. (Citation2007).
Table 3. J statistic for the validity of (7.4) under different identifying restrictions (p-values in parentheses).
8. Conclusion
In this article, we have studied the invariance properties of hypothesis tests applicable in the context of incompletely specified models, such as models formulated in terms of estimating functions and moment conditions, which are usually estimated by GMM procedures, or models estimated by pseudo-likelihood and M-estimation methods. The test statistics examined include Wald-type, LR-type, LM-type, score-type, and C(α)-type criteria. We found that all these procedures are not generally invariant to (possibly nonlinear) hypothesis reformulations and reparameterizations, such as those induced by measurement unit changes. This means that testing two equivalent hypotheses in the context of equivalent models may lead to completely different inferences. For example, this may occur after an apparently innocuous rescaling of some model variables.
In view of avoiding such undesirable properties, we studied restrictions that can be imposed on the objective functions used for pseudo-likelihood (or M-estimation) as well as the structure of the test criteria used with estimating functions and GMM procedures to obtain invariant tests. In particular, we showed that using linear exponential pseudo-likelihood functions allows one to obtain invariant score-type and C(α)-type test criteria, while in the context of estimating function (or GMM) procedures it is possible to modify a LR-type statistic proposed by Newey and West (Citation1987) to obtain a test statistic that is invariant to general reparameterizations. The invariance associated with linear exponential pseudo-likelihood functions is interpreted as a strong argument for using such pseudo-likelihood functions in empirical work. Furthermore, the LR-type statistic is the one associated with using continuously updated GMM estimators based on appropriately restricted weight matrices. Of course, this provides an extra argument for such GMM estimators.
Acknowledgements
The authors thank Marine Carrasco, Jean-Pierre Cotton, Russell Davidson, Abdeljelil Farhat, V. P. Godambe, Christian Gouriéroux, Stéphane Grégoir, Hervé Mignon, Denis Pelletier, Mohamed Taamouti, Pascale Valéry, three anonymous referees, and the Editor Esfandiar Maasoumi for several useful comments.
Notes
1This “optimal” choice may be infeasible (or far from “efficient”) in finite samples when I0 (or In) is not invertible or “ill-conditioned” (close to noninvertibility). For this reason, we consider here the general formulation in (2.5), though the weighting matrix is allowed as a special case. Note also that “efficiency” from the estimation viewpoint is not in general equivalent to efficiency from the testing viewpoint (in terms of power), so it is not clear
is an optimal choice for the purpose of hypothesis testing.
2The regularity conditions and a rigorous proof of the latter assertion appear in the working paper version of this article Dufour et al. (Citation2013); see also Dufour et al. (Citation2015).
3For further discussion of C(α) tests, the reader may consult Bernshtein (Citation1981), Basawa (Citation1985), Ronchetti (Citation1987), Smith (Citation1987), Berger and Wallenstein (Citation1989), Dagenais and Dufour (Citation1991), Davidson and MacKinnon (Citation1991, Citation1993), Kocherlakota and Kocherlakota (Citation1991), Bera and Bilias (Citation2001), and Dufour and Valéry (Citation2009).
4The reader may note that further insight can be gained on the invariance properties of test statistics by using differential geometry arguments; for some applications to statistical problems, see Bates and Watts (Citation1980), Amari (Citation1990), Kass and Vos (Citation1997), and Marriott and Salmon (Citation2000). Such arguments may allow one to propose reparameterizations and “invariant Wald tests”; see, for example, Bates and Watts (Citation1981), Hougaard (Citation1982), Le Cam (Citation1990), Critchley et al. (Citation1996), and Larsen and Jupp (Citation2003) in likelihood models. As of now, such procedures tend to be quite difficult to design and implement, and GMM setups have not been considered. Even though this is an interesting avenue for future research, simplicity and generality considerations have led us to focus on procedures which do not require adopting a specific parameterization.
5The regularity conditions and a proof of the asymptotic distribution are given in our working paper (Dufour et al., Citation2013).
6For further discussion of such methods, the reader may consult: Gong and Samaniego (Citation1981), Gouriéroux et al. (Citation1984a), Trognon (Citation1984), Bourlange and Doz (Citation1988), Trognon and Gouriéroux (Citation1988), Gouriéroux and Monfort (Citation1993), Crépon and Duguet (Citation1997), and Jorgensen (Citation1997).
7The numerical values of x1t, x1t, and yt used are available from the authors upon request. It is important to note that this is not a simulation exercise aimed at studying the statistical properties of the tests, but only an illustration of the numerical properties of the test statistics considered.
References
- Amari, S.-I. (1990). Diffrential-Geometrical Methods in Statistics. Lecture Notes in Statistics, Vol. 28. Berlin: Springer-Verlag.
- Andrews, D. W. K. (1991). Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econometrica 59:817–858.
- Andrews, D. W. K., Monahan, J. C. (1992). An improved heteroskedasticity and autocorrelation consistent covariance matrix estimator. Econometrica 60:953–966.
- Basawa, I. V. (1985). Neyman-Le Cam tests based on estimating functions. In: Le Cam, L., Olshen, R. A., eds, Berkeley Conference in Honor of Jerzy Neyman and Jack Kiefer. CA: Wadsworth, Belmont, pp. 811–825.
- Basawa, I. V., Godambe, V. P., Taylor, R. L., eds., (1997). Selected Proceedings of the Symposium on Estimating Functions. IMS Lecture Notes Monograph Series, Vol. 32. Hayward, CA: Institute of Mathematical Statistics.
- Bates, D. M., Watts, D. G. (1980). Relative curvature measures of nonlinearity. Journal of the Royal Statistical Society, Series B 42:1–25.
- Bates, D. M., Watts, D. G. (1981). Parameter transformations for improved approximate confidence regions in nonlinear least squares. The Annals of Statistics 9:1152–1167.
- Bera, A., Bilias, Y. (2001). Rao’s score, Neyman’s C(α) and Silvey’s LM tests: an essay on historical developments and some new results. Journal of Statistical Planning and Inference 97:9–44.
- Berger, A., Wallenstein, S. (1989). On the theory of Cα-tests. Statistics and Probability Letters 7:419–424.
- Bernshtein, A. V. (1981). Asymptotically similar criteria. Journal of Soviet Mathematics 17(3):1825–1857.
- Bourlange, D., Doz, C. (1988). Pseudo-maximum de vraisemblance: expériences de simulations dans le cadre de modèle de Poisson. Annales d’Économie et de Statistique 10:139–178.
- Breusch, T. S., Schmidt, P. (1988). Alternative forms of the Wald test: How long is a piece of string? Communications in Statistics, Theory and Methods 17:2789–2795.
- Burguete, W. J., Gallant, A. R., Souza, G. (1982). On unification of the asymptotic theory of nonlinear econometric models. Econometric Reviews 1:151–211 (with comments).
- Burnside, C. (2010). Identification and inference in linear stochastic discount factor models, Technical report. NBER WP 16634.
- Burnside, C., Eichenbaum, M. S. (1996). Small-sample properties of GMM-based Wald tests. Journal of Business and Economic Statistics 14:294–308.
- Chaussé, P. (2010). Computing generalized method of moments and generalized empirical likelihood with r. Journal of Statistical Software 34(11):1–35.
- Cochrane, J. H. (2005). Asset Pricing. Princeton, NJ: Princeton University Press.
- Cox, D. R., Hinkley, D. V. (1974). Theoretical Statistics. London: Chapman & Hall.
- Crépon, B., Duguet, E. (1997). Research and development, competition and innovation: Pseudo maximum likelihood and simulated maximum likelihood applied to count data models with heterogeneity. Journal of Econometrics 79:355–378.
- Critchley, F., Marriott, P., Salmon, M. (1996). On the differential geometry of the Wald test with nonlinear restrictions. Econometrica 64:1213–1222.
- Cushing, M. J., McGarvey, M. G. (1999). Covariance matrix estimation. In: (Mátyás 1999), Chapter 3, pp. 63–95.
- Dagenais, M. G., Dufour, J.-M. (1991). Invariance, nonlinear models and asymptotic tests. Econometrica 59:1601–1615.
- Dagenais, M. G., Dufour, J.-M. (1992). On the lack of invariance of some asymptotic tests to rescaling. Economics Letters 38:251–257.
- Davidson, R., MacKinnon, J. G. (1991). Artificial regressions and C(α) tests. Economics Letters 35:149–153.
- Davidson, R., MacKinnon, J. G. (1993). Estimation and Inference in Econometrics. New York: Oxford University Press.
- Dufour, J.-M. (1997). Some impossibility theorems in econometrics, with applications to structural and dynamic models. Econometrica 65:1365–1389.
- Dufour, J.-M., Dagenais, M. G. (1992). Nonlinear models, rescaling and test invariance. Journal of Statistical Planning and Inference 32:111–135.
- Dufour, J.-M., Jasiak, J. (2001). Finite sample limited information inference methods for structural equations and models with generated regressors. International Economic Review 42:815–843.
- Dufour, J.-M., Trognon, A., Tuvaandorj, P. (2013). Invariant tests based on M-estimators, estimating functions, and the generalized method of moments, Technical report, Department of Economics, McGill University. http://www.jeanmariedufour.com. [Accessed: 12 May 2016].
- Dufour, J.-M., Trognon, A., Tuvaandorj, P. (2015). Generalized C(α) tests for estimating functions with serial dependence, Technical report, McGill University and CREST-ENSAE Paris. http://www.jeanmariedufour.com. Accessed: 12 May 2016.
- Dufour, J.-M., Valéry, P. (2009). Exact and asymptotic tests for possibly non-regular hypotheses on stochastic volatility models. Journal of Econometrics 150:193–206.
- Durbin, J. (1960). Estimation of parameters in time series regression models. Journal of the Royal Statistical Society, Series A 22:139–153.
- Ferguson, T. S. (1967). Mathematical Statistics: A Decision Theoretic Approach. New York: Academic Press.
- Gallant, A. R. (1987). Nonlinear Statistical Models. New York: John Wiley & Sons.
- Gallant, A. R., White, H. (1988). Estimation and Inference for Nonlinear Dynamic Models. New York: Blackwell.
- Godambe, V. P. (1960). An optimum property of regular maximum likelihood estimation. The Annals of Mathematical Statistics 31:1208–1212. Ackowledgement 32:1343.
- Godambe, V. P., ed., (1991). Estimating Functions. Oxford, U.K.: Clarendon Press.
- Gong, G., Samaniego, F. J. (1981). Pseudo maximum likelihood estimation: Theory and applications. The Annals of Statistics 13:861–869.
- Gouriéroux, C., Monfort, A. (1989). A general framework for testing a null hypothesis in a ‘mixed’ form. Econometric Theory 5:63–82.
- Gouriéroux, C., Monfort, A. (1993). Pseudo-likelihood methods. In: Maddala, G. S., Rao, C. R., Vinod, H. D., eds. Handbook of Statistics 11: Econometrics, Chapter 12. Amsterdam: North-Holland, pp. 335–362.
- Gouriéroux, C., Monfort, A. (1995). Statistics and Econometric Models, Volumes One and Two. Cambridge, U.K.: Cambridge University Press, Translated by Quang Vuong.
- Gouriéroux, C., Monfort, A., Trognon, A. (1984a). Estimation and test in probit models with serial correlation. In: Florens, J. P., Mouchart, M., Roualt, J. P., Simar, L., eds. Alternative Approaches to Time Series Analysis. Facultes Universitaires Saint-Louis, Bruxelles, Belgium, pp. 169–209.
- Gouriéroux, C., Monfort, A., Trognon, A. (1984b). Pseudo maximum likelihood methods: Applications to Poisson models. Econometrica 52:701–720.
- Gouriéroux, C., Monfort, A., Trognon, A. (1984c). Pseudo maximum likelihood methods: Theory. Econometrica 52:681–700.
- Gregory, A., Veall, M. (1985). Formulating Wald tests of nonlinear restrictions. Econometrica 53:1465–1468.
- Hall, A. R. (1999). Hypothesis testing in models estimated by GMM. In: Generalized Method of Moments Estimation, Chapter 4. Cambridge, U.K.: Cambridge University Press, pp. 96–127.
- Hall, A. R. (2004). Generalized Method of Moments. Advanced Texts in Econometrics. Oxford, U.K.: Oxford University Press.
- Hamilton, J. D., Waggoner, D. F., Zha, T. (2007). Normalization in econometrics. Econometric Reviews 26:221–252.
- Hansen, B. E. (1992). Consistent covariance matrix estimation for dependent heterogeneous processes. Econometrica 60:967–972.
- Hansen, L. (1982). Large sample properties of generalized method of moments estimators. Econometrica 50:1029–1054.
- Hansen, L. P., Heaton, J., Yaron, A. (1996). Finite-sample properties of some alternative GMM estimators. Journal of Business and Economic Statistics 14:262–280.
- Hotelling, H. (1936). Relations between two sets of variables. Biometrika 28:321–377.
- Hougaard, P. (1982). Parameterisations of nonlinear models. Journal of the Royal Statistical Society, Series B 44:244–252.
- Huber, P. J. (1981). Robust Statistics. New York: John Wiley & Sons.
- Jorgensen, B. (1997). The Theory of Dispersion Models. London, U.K.: Chapman & Hall.
- Kass, R. E., Vos, P. W. (1997). Geometrical Foundations of Asymptotic Inference. New York: John Wiley & Sons.
- Kocherlakota, S., Kocherlakota, K. (1991). Neyman’s C(α) test and Rao’s efficient score test for composite hypotheses. Statistics and Probability Letters 11:491–493.
- Lafontaine, F., White, K. J. (1986). Obtaining any Wald statistic you want. Economics Letters 21:35–40.
- Larsen, P. V., Jupp, P. E. (2003). Parametrization-invariant Wald tests. Bernoulli 9(1):167–182.
- Le Cam, L. (1990). On the standard asymptotic confidence ellipsoids of Wald. International Statistical Review 58:129–152.
- Lehmann, E. L. (1983). Theory of Point Estimation. New York: John Wiley & Sons.
- Lehmann, E. L. (1986). Testing Statistical Hypotheses. 2nd ed. New York: John Wiley & Sons.
- Marriott, P., Salmon, M., eds, (2000). Applications of Differential Geometry to Econometrics. Cambridge, U.K.: Cambridge University Press.
- Mátyás, L., ed., (1999). Generalized Method of Moments Estimation. Cambridge, U.K.: Cambridge University Press.
- Newey, W. K. (1985). GMM specification testing. Jornal of Econometrics 29:229–256.
- Newey, W. K., McFadden, D. (1994). Large sample estimation and hypothesis testing. In: Engle, R. F., McFadden, D. L., eds. Handbook of Econometrics, Volume 4, Chapter 36. Amsterdam: North-Holland, pp. 2111–2245.
- Newey, W. K., West, K. D. (1987). Hypothesis testing with efficient method of moments estimators. International Economic Review 28:777–787.
- Neyman, J. (1959). Optimal asymptotic tests of composite statistical hypotheses. In: Grenander, U., ed. Probability and Statistics, the Harald Cramér Volume. Uppsala, Sweden: Almqvist and Wiksell, pp. 213–234.
- Phillips, P. C. B., Park, J. Y. (1988). On the formulation of Wald tests of nonlinear restrictions. Econometrica 56:1065–1083.
- Pitman, E. J. G. (1939). Tests of hypotheses concerning location and scale parameters. Biometrika 31:200–215.
- Podivinsky, J. M. (1999). Finite sample properties of GMM estimators and tests. In: Generalized Method of Moments Estimation. Chapter 5. Cambridge, U.K.: Cambridge University Press, pp. 128–148.
- R Development Core Team, (2013). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0. Available at http://www.R-project.org. Accessed: 12 May 2016.
- Ronchetti, E. (1987). Robust C(α)-type tests for linear models. Sankhyā Series A 49:1–16.
- Smith, R. J. (1987). Alternative asymptotically optimal tests and their application to dynamic specification. Review of Economic Studies LIV:665–680.
- Trognon, A. (1984). Généralisation des tests asymptotiques au cas où le modèle est incomplètement spécifié. Cahiers du Séminaire d’Économétrie 26:93–109.
- Trognon, A., Gouriéroux, C. (1988). Une note sur l’efficacité des procédures d’estimation en deux étapes. In: Champsaur, P., Deleau, M., Grandmont, J.-M., Henry, C., Laffont, J.-J., Laroque, G., Mairesse, J., Monfort, A., Younès, Y., eds. Mélanges économiques. Essais en l’honneur de Edmond Malinvaud. Paris: Economica, pp. 1056–1074.
- Vaeth, M. (1985). On the use of Wald’s test in exponential families. International Statistical Review 53:199–214.
- Vuong, Q. (1989). Likelihood ratio tests for model selection and non-nested hypotheses. Econometrica 57:307–333.
- White, H. (1982). Maximum likelihood estimation of misspecified models. Econometrica 50:1–25.