
ABSTRACT
We describe stationarity and ergodicity (SE) regions for a recently proposed class of score driven dynamic correlation models. These models have important applications in empirical work. The regions are derived from sufficiency conditions in Bougerol (Citation1993) and take a nonstandard form. We show that the nonstandard shape of the sufficiency regions cannot be avoided by reparameterizing the model or by rescaling the score steps in the transition equation for the correlation parameter. This makes the result markedly different from the volatility case. Observationally equivalent decompositions of the stochastic recurrence equation yield regions with different shapes and sizes. We use these results to establish the consistency and asymptotic normality of the maximum likelihood estimator. We illustrate our results with an analysis of time-varying correlations between U.K. and Greek equity indices. We find that also in empirical applications different decompositions can give rise to different conclusions regarding the stability of the estimated model.
1. Introduction
Time-variation in correlations is an important feature of economic and financial data and a crucial ingredient of empirical analyses, such as the assessment of risk and the construction of investment portfolios. Available models for capturing the time-variation in correlations include, amongst many others, the Baba-Engle-Kraft-Kroner (BEKK) model of Engle and Kroner (Citation1995), the switching correlation models of Pelletier (Citation2006), the dynamic conditional correlation (DCC) model of Engle (Citation2002) with its adaptation by Aielli (Citation2013), the dynamic equicorrelation (DECO) model of Engle and Kelly (Citation2012), the dynamic copula models of Patton (Citation2009) and Oh and Patton (Citation2012), and the score driven models of Creal et al. (Citation2011, Citation2013) and Harvey (Citation2013); see also the overviews of Bauwens et al. (Citation2006) and Silvennoinen and Teräsvirta (Citation2009).
We focus on the stochastic properties of the recently proposed score driven models of Creal et al. (Citation2011, Citation2013) and Harvey (Citation2013), which we refer to as generalized autoregressive score (GAS) models. These models have proved particularly useful when modeling fat-tailed or skewed data, such as often encountered in empirical finance; see for example Janus et al. (Citation2014), Harvey and Luati (Citation2014), and Lucas et al. (Citation2014). The dynamics of correlations and volatilities in these models are driven by the score of the predictive conditional distribution. If the latter is fat-tailed, the score driven dynamics automatically correct for influential observations, see Creal et al. (Citation2011). In this way, they share some similarities with models from the robust generalized autoregressive conditional heteroskedasticity (GARCH) literature; see for example Boudt et al. (Citation2013). The score driven approach used in the construction of GAS models, however, provides a much more general and unified framework for parameter dynamics that is applicable far beyond the volatility and correlation context; see Creal et al. (Citation2013, Citation2014) for a range of other examples. In addition, from a forecasting perspective GAS models often have a similar performance to correctly specified state-space models, see Koopman et al. (Citation2012).
Despite their proven empirical usefulness, the theoretical properties of GAS models are less well developed. The complication lies in the highly nonlinear transition dynamics of the time-varying parameter in typical GAS models. In this article, we contribute to our understanding of the stochastic properties of GAS models for dynamic correlations. The fundamental question is to understand which parameterizations, and parameter values generate stationary and ergodic (abbreviated as SE from now on) time series processes. This offers an important characterization of the stochastic properties of GAS models. SE properties can be combined with the existence of unconditional moments for the objective function to establish proofs of consistency and asymptotic normality of extremum estimators; see, e.g., Straumann and Mikosch (Citation2006) for maximum likelihood estimation of nonlinear conditional volatility models, Francq and Zakoian (Citation2011) and Boussama et al. (Citation2011) for the case of multivariate GARCH models, and Harvey (Citation2013) for GAS volatility models. For each correlation model we consider, we identify the parameter values that ensure the SE property and call this the “SE region” of the parameter space. To establish SE regions, we follow the classical average contraction argument for stochastic recurrence relations as laid out in the sufficient conditions formulated by Bougerol (Citation1993). Given these conditions, we compute numerically the SE regions for a range of empirically relevant models.
We have four contributions. First, we are the first to derive SE regions for the class of score driven correlation models that have been suggested recently in the literature. We show that the SE sufficiency regions take a highly nonstandard form, dissimilar to the familiar triangle and curved triangular shapes for the GARCH model; see Nelson (Citation1990). In an empirical example, we demonstrate that the conditions for nonlinear recurrence equations can be used to ensure stationarity of concrete models, applied on real data. This also extends the results in Blasques et al. (Citation2014b) for volatility and tail index models with univariate observations to the case of time-varying parameters and multivariate observations.
Second, we show that the shape and size of the SE sufficiency region as derived from the conditions of Bougerol (Citation1993) depends on the way the stochastic recurrence equation for the correlation is constructed from bivariate uncorrelated noise. In particular, we show that the choice of the square root of the correlation matrix in this construction has a nontrivial effect on the size of the SE sufficiency region.
Third, we show analytically why the correlation case is markedly different from the volatility case. For the volatility case, Harvey (Citation2013) shows that modeling the log-volatility renders the information matrix independent of the time-varying volatility. The resulting stochastic recurrence equation becomes linear, and we can use linear process theory to study the SE properties. A similar feature is generally not available for the dynamic correlation model: neither a reparameterization of the correlation nor a scaling of the score steps makes the stochastic recurrence equation a linear process. The reason is that unlike in the volatility case, the GAS steps for the correlation model consist of two separate terms with different nonlinearities in the correlation parameter.
Fourth, we use our SE results to establish the consistency and asymptotic normality of the ML estimator.
The remainder of this article is organized as follows. In Section 2, we introduce our model for dynamic bivariate correlations. In Section 3, we state the conditions for the SE sufficiency regions. In Section 4, we establish model invertibility as well as the consistency and asymptotic normality of the ML estimator. In Section 5, we determine the SE regions numerically for a number of different models and provide an empirical illustration for U.K. and Greek equity indices. We conclude in Section 6. The Appendix gathers the more technical results and derivations.
2. Score models for correlations
Consider a real-valued bivariate stochastic sequence of observations {yt}t∈ℕ generated by a zero mean elliptical conditional distribution with time-varying correlation matrix R(ft)
The formulation in (1) can also be interpreted as a copula model, see the discussion in Patton (Citation2009). Under the assumptions of stationary marginals and no volatility spillovers, stability conditions for the copula then lead to stability of the whole model. The class of elliptical models is also economically interesting, as it enables an analytic characterization of the resulting portfolio returns and the risk-return trade-off; see for example Chamberlain (Citation1983), Owen and Rabinovitch (Citation1983), and Hamada and Valdez (Citation2008).
Following Creal et al. (Citation2011, Citation2013), the GAS dynamics for the time-varying parameter ft in (1) take the form
Each choice for the scaling function S in (3) gives rise to a new GAS model. An often used choice of S relates to the local curvature of the score as measured by the information matrix, for example
The parameter dynamics in (2) and (3) are intuitive. The time-varying parameter ft is updated in the (scaled) direction of steepest ascent as measured by the scaled conditional log observation density at time t. For example, standard GARCH and BEKK models are special cases of the GAS framework under normality, see Creal et al. (Citation2013). The GAS setup is very general and can also easily be applied outside the correlation context as long as a conditional observation density is available. For other examples, including many new models, we again refer to Creal et al. (Citation2013, Citation2014).
3. Conditions for stationarity and ergodicity
We follow the approach of Blasques et al. (Citation2014b), who consider a treatment of univariate GAS models. Our SE results build on the stochastic recurrence relations or iterated random functions approach; see Diaconis and Freedman (Citation1999) and Wu and Shao (Citation2004). In particular, we use the sufficient conditions of Bougerol (Citation1993) and results in Straumann and Mikosch (Citation2006) to establish, for any fixed initial condition f1 ∈ ℱ, exponentially fast almost sure convergence of the time series {yt, ft(θ, f1)}t∈ℕ generated by (1)–(3) to a unique SE solution {yt, ft(θ)}t∈ℤ.
Let ℱ ⊆ ℝ and 𝒴 ⊆ ℝ2 denote the domains of ft and yt, respectively. We have that ρ: ℱ → (− δ, δ) for 0 < δ ≤1 and s: ℱ × 𝒴 × Θ → ℝ is almost surely (a.s.) smooth in all its arguments and Lipschitz in f ∈ ℱ. Using the model as specified in (1)–(4), we analyze the stochastic properties of yt and ft via the stochastic recurrence equation
Continuity of φt in ut for every t can be used to ensure that {φt} is an i.i.d. sequence of functions. Together with Eq. (6), it then follows directly from Bougerol (Citation1993) and Straumann and Mikosch (Citation2006) that there is a unique SE solution to (1)–(3) if φt is contracting on average, i.e., if the Lyapunov exponent of the mapping is negative. In particular, we obtain the desired SE result if
For the score driven dynamic correlation model of Section 2, we prove the following result in the Appendix.
Lemma 1
Let Ψ be a class of functions such that for every ψ ∈ Ψ, ψ ∈ 𝒞1([ − δ, δ], ℝ) with . Assume that
for i, j ∈ {1, 2}, with ut = (u1, t, u2, t)⊤. For any fixed initial condition f1 ∈ ℱ, the process {ft(θ, f1)}t∈ℕ generated by the dynamic correlation model (1)–(4) converges exponentially fast almost surelyFootnote1 (e.a.s.) to a unique stationary and ergodic solution {ft(θ)}t∈ℤ if
ġ(ρ) = ∂g(ρ)/ρ, c2ψ(ρ) = cos (2ψ(ρ)), and s2ψ(ρ) = sin (2ψ(ρ)).
We note several features of the result stated in Lemma 1. First, the SE region only depends directly on the parameters α and β, on the functional forms of S(f) and q(h(f)ut, f), and on the density of ut. The dependence on the latter enters in two ways, namely through the expectations operator in (8) and through the functional form of k(ut) in (10). Also note that the expectations operator in (8) does not necessarily require the second moments of ut to exist. Instead, we only require the expectation of for i, j ∈ {1, 2} to exist. This condition is much weaker, particularly for fat-tailed elliptical densities. For example, it is easily satisfied for the bivariate Cauchy distribution, even though neither the second nor the first moment exists for this distribution. The continuity and boundedness properties of s can be verified immediately for parametric distributional forms, notably for the Student's t density in Section 5.1.Footnote2 Therefore, condition (8) effectively forms a sufficient condition for the SE property of the model.
Second, Eq. (8) directly reveals that the correlation case is markedly different from the volatility case. For the volatility case, it is shown in Harvey (Citation2013) and Blasques et al. (Citation2014b) that through a clever choice of parameterization h or scaling S the scaled score in recurrence relation (6) can be made independent of ft. The SE condition then reduces to the requirement that |β| <1. In the volatility case the analogue of the function g(ρ) in (9) is scalar valued. In the correlation case, Eq. (8) shows that through the trivariate nature of the functions g(ρ) and ġ(ρ) the contraction condition consists of a number of different terms, each with a different nonlinear dependence on f. It is impossible to offset all of these simultaneously by a single choice of scaling function or parameterization. This makes the correlation model theoretically more interesting in its own right.
Third, the SE sufficient condition in Eq. (8) has an additional degree of flexibility provided by the choice of ψ. As follows from the proof of Lemma 1, the function ψ determines which square root h(f) is used for the correlation matrix R(f). For the purpose of guaranteeing a proper correlation matrix, define ξ(ρ) = arcsin (ρ) − ψ(ρ), and
Fourth, condition (8) simplifies for particular choices of parameterizations and scale functions. For example, if we use the familiar Fisher transformation ρ(f) = tanh (ft), we have and the entire middle term in (8) vanishes. For this particular parameterization and fixing the scaling function to S(f) ≡ 1, we can even provide further analytical results relating to the optimal choice of the function ψ. Using a Jensen, triangle, and Cauchy–Schwarz inequality, we obtain a stricter sufficient condition for SE from (8) as
Lemma 2
Under the assumptions stated in Lemma 1, setting ψ(ρ) = kψarcsin (ρ) with kψ = 1/2 reaches the functional lower bound for the sufficient condition stated in either Eq. (12) or (13). The condition then reduces to |β| + |α| 𝔼‖k(ut)‖ <1 \ for condition (12) and |β| + |α| 𝔼|k1(ut)| <1 for condition (13), respectively, where k1(ut) is the first element of k(ut). The link function becomes the symmetric matrix root
The result in Lemma 2 shows that we uniformly obtain the largest SE region for the stricter conditions (12) or (13) for the symmetric matrix root h in (6). The choice of h in setting up the dynamic Eq. (6) is thus far from innocuous and directly influences the size and shape of the SE region.
4. Asymptotic properties of ML estimator
In this section we establish the invertibility of the GAS model, as well as the consistency and asymptotic normality of the maximum likelihood estimator (MLE) for the static parameters θ.
Model invertibility is a critical element in the proof of consistency and asymptotic normality of the MLE since the filter (2) enters the likelihood function and thus must be ensured to have appropriate stochastic properties. Similarly to Straumann and Mikosch (Citation2006), this section uses the contraction condition of Bougerol (Citation1993) in order to ensure model invertibility and bounded moments for the filtering sequence. This is crucial for the asymptotic properties of the MLE since the initialized time-varying parameter and its derivatives enter the likelihood function and its derivatives. The following result builds on the SE nature of the data {yt}t∈ℤ which follows easily from the SE nature of the true time-varying parameter {ft}t∈ℤ established in the previous section.
Lemma 3 (Model Invertibility)
Let Θ be compact, let {yt}t∈ℤ generated by (1)–(3) be SE, let the scaled score s be smooth in all arguments and Lipschitz in f ∈ ℱ, and assume that there exists a nonrandom f1 such that the following statements hold:
𝔼log +|S(f1)q(f1, yt)| < ∞;
𝔼log sup θ∈Θsup f*|α(Ṡ(f*)q(f*, yt) + S(f*)
(f*, yt)) + β| <1.
Here, log +x ≡ max (log x, 0) for x ∈ ℝ+ and q(ft, yt) is the score expression in (4). Then the GAS recursion {ft(θ, f1)}t∈ℕ defined in (2) converges e.a.s. to a unique limit SE process {ft(θ)}t∈ℤ that admits the representation ft(θ) = Φ(yt−1, yt−2,...) for every t and some measurable function Φ.
Note that the contraction condition (ii) in Lemma 3 is different from the one studied in Lemma 1 since it refers to the filtering equation that takes the data yt as given. By contrast, the contraction property in Lemma 1 looks at the GAS model as a data generating process, and hence defines the data yt in terms of the true unknown parameter ft and the innovations ut. The invertibility condition above is in particular required in order to make dependence on the fixed initial value f1 vanish in the GAS recursion and therefore in the objective function. To make this transparent, let ℓt(θ, f1) denote the time t log-likelihood contribution for the vector of static parameters θ, and
Define ℒT(θ) and ℓt(θ) similar to (14), but with the limiting process ft(θ) replacing ft(θ, f1).
Theorem 1 establishes the strong consistency of the MLE assuming the identification of the true parameter vector θ0 ∈ Θ. The strong consistency result holds for every initialization of the filter satisfying the conditions of Lemma 3.
Theorem 1 (Consistency)
Let (Θ, 𝔅(Θ)) be a compact measurable space, and let the conditions of Lemmas 1 and 3 hold. Furthermore, assume that 𝔼sup θ∈Θ|ℓt(θ)| < ∞ and that θ0 ∈ Θ is the unique maximizer of ℒ∞(θ) ≡ 𝔼ℓt(θ). Then, for every f1 ∈ ℱ, the MLE, defined as satisfies
as T → ∞.
Theorem 2 establishes the asymptotic normality of the MLE. In this theorem, we let denote the Fisher information matrix and
is the expected outer product of gradients, with
and
denoting first and second order derivatives of ℓt(θ) with respect to θ, respectively.
Theorem 2 (Asymptotic Normality)
Let the conditions of Theorem 1 hold, and let θ0 be a point in the interior of Θ. Furthermore, let the first and second derivatives of the log likelihood contributions ℓt(θ) be asymptotically SE and satisfy and
. Then, for every f1 ∈ ℱ, the ML estimator
satisfies
The theoretical results in the previous two theorems are supported by unreported simulation experiments. We find that increasing the sample size brings the ML estimates over repeated Monte Carlo replications closer to their true values in a controlled setting. Moreover, we also find that the distribution of the estimator approaches the normal distribution for increasing sample sizes.
Theorems 1 and 2 rely on high-level conditions and are applicable to the generic setting. For particular models, however, the statements can be further particularized into more transparent low-level conditions. Corollaries 1 and 2 provide such primitive conditions for the consistency and asymptotic normality of the MLE for the parameters of two bivariate models based on the normal and Student's t distribution, respectively. We use unit scaling and a parameterization given by ρt = δ·tanh (ft). This automatically bounds the correlation to the interval (− δ, δ) to render the correlation matrix positive definite. The practitioner can choose a value of δ arbitrarily close to unity to obtain the contraction conditions in Lemmas 1–3. Proofs of these corollaries can be found in Section D of the Supplementary Appendix.
Corollary 1
There exists a compact parameter space Θ satisfying 0 < δ <1 and α ≠ 0, where the MLE for the parameters of the bivariate Gaussian model with δ·tanh link function and unit scaling is consistent and asymptotically normal.
Corollary 2
There exists a compact parameter space Θ satisfying 0 < δ <1, α ≠ 0, and 2 < ν, where the MLE for the parameters of the bivariate Student's t model with δ·tanh link function and unit scaling is consistent and asymptotically normal.
The implied parameter space Θ, constrained by the above conditions, depends not only on α and β, but also on distributional and parametrization choices. The shapes and sizes of the contraction regions are further analyzed in Section 5. Further analytical and numerical details are developed in Sections C and D in the Supplemental Appendix.
5. Numerical and empirical results
5.1. Numerical results
Alternative choices for the error density generator p, the scaling function S, the parameterization ρ, and the matrix square root h give rise to different models with different SE regions. For a number of these choices, we check for every pair (α, β) whether the sufficient condition (8) is satisfied. We plot the SE region in the (α, β)-plane by numerically identifying, for every fixed β, the corresponding maximum and minimum values of α that satisfy (8).
To fix ideas, consider the class of Student's t densities for ut as in Creal et al. (Citation2011). The Fisher transformation ρ(ft) = tanh (ft) ensures proper value for the correlation parameter. As indicated in Section 3, this also simplifies the evaluation of the SE condition in Lemma 1. For the scaling function S, we adopt the three choices based on the information matrix as presented in Eq. (5).
Next, we investigate the sensitivity of the SE region to the choice of matrix root h(·). For this, we consider two prominent alternatives, both described by ψ(ρ) = kψarcsin (ρ) for kψ ∈ ℝ. The first alternative is the symmetric matrix root of Lemma 2 with kψ = 1/2. The second is the familiar (lower triangular) Cholesky decomposition, which is obtained by setting kψ = 1.
To numerically evaluate the sufficient SE condition (8), we need to solve an optimization problem within an integration procedure. As the state equation is univariate, the integral can be evaluated via a quadrature rule. We can gain further numerical efficiency for the inner optimization problem by storing maximum and minimum values of S(f) q(h(f)ut, f) for each point ut and recycling these for evaluation at different points in the (α, β)-plane. Local optima are avoided by evaluating the function over a wide grid and by noting that for the Student's t distribution (∂/∂f)is(f, yt) → 0 as |f| → ∞ for all i > 1. We can further halve the computation time by noting that in our setting |∂φt(f; θ)/∂f| = |∂φt(f; − θ)/∂f|.
In panel (a) of Fig. , we present the results for the normal distribution and the symmetric root h(f), i.e., kψ = 1/2. The figure contains three different regions, each one corresponding to a different form of scaling in Eq. (5). Points inside each region are combinations of (α, β) for which the sufficient condition (8) is met. The shape of the sufficient SE region is antisymmetric around the origin due to the absolute signs in (8), such that we only plot its upper half. The region also shows a nonmonotonic curvature, particularly in the second quadrant. This feature is due to the use of absolute values, the change in the location of the supremum in (8) in the second quadrant, and a shift in the relevant region of integration if the derivative of S(f)q(h(f)ut, f) changes sign.
Figure 1 Stationarity and ergodicity sufficiency regions for the normal distribution and different scaling choices S(f) = (ℐt(f))−a for a ∈ {0, 1/2, 1}. The two panels contain different regions obtained by parameterizing the matrix roots h(f) with ψ(ρ) = kψarcsin (ρ). Panel (a) contains the results for the symmetric matrix root (kψ = 1/2), and panel (b) corresponds to the Cholesky decomposition (kψ = 1).
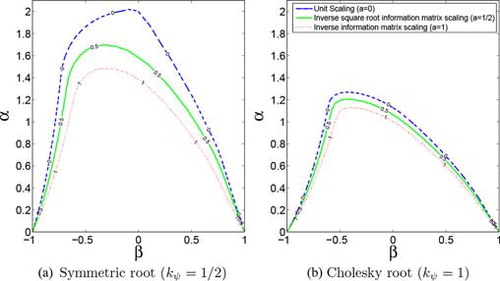
An interesting feature in Fig. is the behavior of the region for square root inverse information matrix scaling, a = 1/2 in (5). First note that a = 1/2 has the property that the update via s(ft, yt) is invariant with respect to reparametrizations of ft. Furthermore, under correct specification the steps S(f)q(yt, f) in (4) are by construction martingale differences with unit variance; see also Creal et al. (Citation2013). This implies that {ft}t∈ℕ converges to a covariance stationary process as long as |β| <1. The region in Fig. shows that |β| <1 is necessary, but not sufficient for (8) to be satisfied. This relates directly to discussions in the GARCH literature, where in the univariate setting covariance stationarity is a more restrictive condition than strict stationarity, but the relation between the two remains an open question in a multivariate context; see for example Boussama et al. (Citation2011).
Panel (b) in Fig. shows the different SE regions for a different choice of matrix root h(f), namely the Cholesky decomposition. It is clear that the sufficiency regions in the (α, β)-plane are smaller than the corresponding regions for the symmetric root. As models constructed with a symmetric root and a Cholesky root are observationally equivalent, we can take the larger regions as sufficient regions for SE to hold; see also Lemma 2. The differences make clear that the choice of matrix root is important for determining the size of the region either analytically or numerically.
We provide more SE regions in the Supplemental Appendix, including regions based on the further inequalities used to establish Lemma 2. In particular, we show that the SE regions for the Student's t distribution under square root information matrix scaling (a = 1/2) are smaller for fatter tails if the Cholesky decomposition is used (kψ = 1), while the converse holds if we use the symmetric root decomposition (kψ = 1/2). In Section 5.2, we document how this wedge may also become empirically relevant.
5.2. Empirical illustration
In this section, we study the time-varying correlation between the London and Athens stock exchange indexes. We take daily returns of the Financial Times Stock Exchange (FTSE) 100 and the Athex Composite over the period January 1, 2002 to March 2, 2013. We are particularly interested in whether there are indications that the correlation between these two markets changed over the course of the European sovereign debt crisis.
To focus on the correlation part of the model, we first filter both series using AR-GARCH type models; see also Patton (Citation2009). The mean of both series is modeled by a first order autoregressive progress. We find a strong leverage effects in both series and capture these by a GJR(1,2) model of Glosten et al. (Citation1993) for the FTSE index, and an EGARCH(1,2) specification of Nelson (Citation1991) for the Athens index, respectively.Footnote3 We test the null hypothesis of constant and zero residual correlation against time-varying alternatives using a Nyblom test of the form
Figure 2 Empirical results. Panel (a) shows 60-day rolling correlations and the filtered correlations between the FTSE 100 (U.K.) and Athex Composite (Greece) equity index returns. The right panel puts the empirical estimates obtained by unconstrained estimation into the zoomed stationarity and ergodicity region perspective.
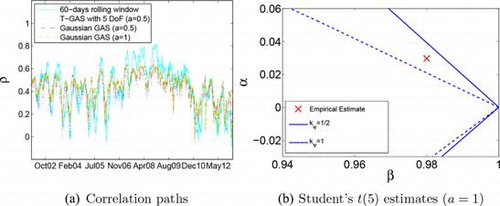
Table 1 Estimation results.
Panel (a) in Fig. shows the dynamic correlations between the filtered series. As a nonparametric benchmark, we plot simple 60-day rolling window correlations. The rolling window estimates suggest that correlations exhibit clear signs of time variation. Correlations lie around 0.4 up to about 2006, then increase to about 0.6, and come down substantially to around 0.2 during the sovereign debt crisis. On top of this slow variation, there are also substantial dynamic patters at higher frequencies.
The possibly lower correlations between the U.K. and Greek stock indices are interesting economically, particularly given the stable correlation pattern between the two series during almost the whole of the prelude, height, and aftermath of the preceding financial crisis (2007–2009). The financial crisis, apparently, did not substantially alter the real economic linkages between the two economies as evidenced by the stable dynamic of the correlations between between the two stock markets. It is only after the announcement of the record Greek deficit late 2009 and the subsequent actions that gave rise to the European sovereign debt crisis, that the link between the euro-denominated Greek stock market and the sterling-denominated FTSE is broken. The correlations remain at low levels even after the nonstandard monetary policy actions by the European Central Bank.
Table provides the parameter estimates of the GAS models. We provide a benchmark by estimating a simple exponentially weighted moving average (EWMA) scheme for the correlation based on the recursion ρt = tanh (ft) and
We see that the GAS model is empirically useful both in terms of in-sample likelihood fit and improving the diagnostics for time-varying correlation. All models indicate that the correlation parameter is highly persistent: the estimated values of β all lie very close to 1. The scaling function for the score only has a mild effect on the model's fit: the likelihood values are similar for a = 0, 1/2, 1. The degrees of freedom parameter λ is estimated around 9. This is substantially fatter-tailed than the normal, but also substantially lighter-tailed than the Student's t distribution with the degrees of freedom fixed at 5. The differences in likelihood values, as well as Akaike (AIC) and Bayes (BIC) information criteria indicate that estimating the degrees of freedom improves the fit of the model substantially. Furthermore, the estimation of the tail parameter λ also improves the fit in terms of model diagnostics: only the GAS model with estimated degrees of freedom passes the Nyblom tests for remaining time-variation in the residual cross-correlations.
We plot the SE region boundaries for the Cholesky and the symmetric root decomposition in panel (b) of Fig. . The estimated values of α and β for the t(λ)-GAS specification are indicated by the cross mark. The results clearly confirm the importance of the choice of ψ in verifying the SE properties. For the symmetric root-based region, we obtain stationarity and ergodicity at the estimated parameter values. For the Cholesky decomposition, by contrast, we fail to obtain this result. As condition (8) takes the infimum over ψ and thus the widest region in panel (b) over all admissible decompositions h(ft), the Cholesky decomposition is in this setting less powerful to discriminate SE from non-SE regions of the parameter space. We stress again that all of these regions are only based on sufficient conditions, and that the actual regions may be wider.
For all models considered, the bottom lines in Table indicate whether the estimated parameters lie inside the SE region. For the Gaussian models with unit (a = 0) and inverse square root information matrix scaling (a = 1/2) the choice of matrix decomposition does not have an impact. Both the symmetric root (kψ = 1/2 in (11)) and Cholesky root (kψ = 1 in (11)) indicate that the estimated parameters are inside the SE region and satisfy the average contraction condition. For inverse information matrix scaling, however, and for the Student's t based models, we find a similar difference as in panel (b) of Fig. : we cannot ensure SE properties based on the Cholesky decomposition, whereas we can do so for the symmetric root. This again highlights that the use of different constructive devices such as different matrix decompositions is empirically relevant for the verification of sufficient SE conditions in a multivariate setting.
6. Concluding remarks
We have derived sufficient regions for stationarity and ergodicity for a new class of score driven dynamic correlation models. The regions exhibit a highly nonstandard shape. Moreover, we have shown that the shape and size of the SE regions depends on the type of matrix root that is chosen in checking the sufficient conditions of Bougerol (Citation1993). Furthermore, we have seen how the stationarity conditions can be used in establishing results for consistency and asymptotic normality of the maximum likelihood estimator. The numerical stability conditions were supported by an empirical investigation of the time varying correlation between U.K. and Greek stock markets. We found a substantial drop in the linkages between the sterling-denominated U.K. market and the euro denominated Greek market over the course of the European sovereign debt crisis. Such a break in dependence between markets, however, was absent during the preceding global financial crisis.
An interesting possible extension of our current results concerns a generalization to the fully multivariate (rather than bivariate) setting of score driven correlation models proposed in Creal et al. (Citation2011). The challenge here is to limit the number of parameters describing the dynamics of time-varying volatilities and correlations. We leave this for future work.
lecr_a_1139821_sm3694.pdf
Download PDF (197.4 KB)Acknowledgments
A previous version of this article was circulated under the title “Stationarity and Ergodicity Regions for Score Driven Dynamic Correlation Models.” We thank Peter Boswijk and Andrew Harvey for helpful discussions. We also thank participants of the Amsterdam–Cambridge Conference on Score Driven Models (2013) and participants of 7th International Conference on Computational and Financial Econometrics (CFE 2013) for comments.
Notes
A sequence {xt} converges exponentially fast almost surely to a sequence if for some constant c > 1 we have
for t → ∞.
The functional forms for the updating equation for the particular case of the Student's t distribution are presented in the Supplemental Appendix accompanying this article.
Further robustness results for alternative specifications for the marginals can be found in Section E of the Supplemental Appendix.
Critical values of the test are simulated by discretizing the processes B(·) and Bb(·) and can also be found in Hansen (Citation1992).
Related Research Data
References
- Aielli, G. P. (2013). Dynamic conditional correlation: on properties and estimation. Journal of Business & Economic Statistics 31(3):282–299.
- Bauwens, L., Laurent, S., Rombouts, J. V. K. (2006). Multivariate GARCH models: a survey. Journal of Applied Econometrics 21(1):79–109.
- Billingsley, P. (1961). The lindeberg-levy theorem for martingales. Proceedings of the American Mathematical Society 12(5):788–792.
- Billingsley, P. (1995). Probability and Measure. Wiley Series in Probability and Mathematical Statistics. New York: Wiley.
- Blasques, F., Koopman, S. J., Lucas, A. (2014a). Maximum likelihood estimation for generalized autoregressive score models. Tinbergen Institute Discussion Papers 14-029/III.
- Blasques, F., Koopman, S. J., Lucas, A. (2014b). Stationarity and ergodicity of univariate Generalized Autoregressive Score processes. Electronic Journal of Statistics 8:1088–1112.
- Boudt, K., Danielsson, J., Laurent, S. (2013). Robust forecasting of dynamic conditional correlation garch models. International Journal of Forecasting 29(2):244–257.
- Bougerol, P. (1993). Kalman filtering with random coefficients and contractions. SIAM Journal on Control and Optimization 31(4):942–959.
- Boussama, F., Fuchs, F., Stelzer, R. (2011). Stationarity and geometric ergodicity of BEKK multivariate GARCH models. Stochastic Processes and their Applications 121(10):2331–2360.
- Chamberlain, G. (1983). A characterization of the distributions that imply mean–variance utility functions. Journal of Economic Theory 29(1):185–201.
- Creal, D., Koopman, S. J., Lucas, A. (2011). A dynamic multivariate heavy-tailed model for time-varying volatilities and correlations. Journal of Business and Economic Statistics 29(4):552–563.
- Creal, D., Koopman, S. J., Lucas, A. (2013). Generalized autoregressive score models with applications. Journal of Applied Econometrics 28(5):777–795.
- Creal, D., Koopman, S. J., Lucas, A., Schwaab, B. (2014). Observation-driven mixed measurement dynamic factor models. Review of Economics and Statistics. 96(5):898–915.
- Diaconis, P., Freedman, D. (1999). Iterated random functions. SIAM Review 41(1):45–76.
- Engle, R. (2002). New frontiers for ARCH models. Journal of Applied Econometrics 17(5):425–446.
- Engle, R. F., Kelly, B. (2012). Dynamic equicorrelation. Journal of Business and Economic Statistics 30:212–228.
- Engle, R. F., Kroner, K. F. (1995). Multivariate simultaneous generalized arch. Econometric theory 11(01):122–150.
- Francq, C., Zakoian, J. (2011). GARCH Models: Structure, Statistical Inference and Financial Applications. New York: Wiley.
- Glosten, L. R., Jagannathan, R., Runkle, D. E. (1993). On the relation between the expected value and the volatility of the nominal excess return on stocks. The Journal of Finance 48(5):1779–1801.
- Hamada, M., Valdez, E. A. (2008). Capm and option pricing with elliptically contoured distributions. Journal of Risk and Insurance 75(2):387–409.
- Hansen, B. E. (1992). Testing for parameter instability in linear models. Journal of Policy Modeling 14(4):517–533.
- Harvey, A. C. (2013). Dynamic Models for Volatility and Heavy Tails. Cambridge: Cambridge University Press.
- Harvey, A. C., Luati, A. (2014). Filtering with heavy tails. Journal of the American Statistical Association. 109(507):1112–1122.
- Janus, P., Koopan, S. J., Lucas, A. (2014). Long memory dynamics for multivariate dependence under heavy tails. Journal of Empirical Finance. 29:187–206.
- Koopman, S. J., Lucas, A., Scharth, M. (2012). Predicting time-varying parameters with parameter-driven and observation-driven models. Tinbergen Institute Discussion Papers 12-020/4.
- Krengel, U. (1985). Ergodic Theorems. Berlin: De Gruyter Studies in Mathematics.
- Lucas, A., Schwaab, B., Zhang, X. (2014). Conditional euro area sovereign default risk. Journal of Business and Economic Statistics 32(2):271–284.
- Nelson, D. B. (1990). Stationarity and persistence in the GARCH (1, 1) model. Econometric Theory 6(03):318–334.
- Nelson, D. B. (1991). Conditional heteroskedasticity in asset returns: A new approach. Econometrica 59(2):347–370.
- Oh, D. H., Patton, A. J. (2012). Modelling dependence in high dimensions with factor copulas. Manuscript, Duke University.
- Owen, J., Rabinovitch, R. (1983). On the class of elliptical distributions and their applications to the theory of portfolio choice. The Journal of Finance 38(3):745–752.
- Patton, A. J. (2006). Modelling asymmetric exchange rate dependence. International economic review 47(2):527–556.
- Patton, A. J. (2009). Copula–based models for financial time series. In: Handbook of Financial Time Series, Berlin Heidelberg: Springer, pp. 767–785.
- Pelletier, D. (2006). Regime switching for dynamic correlations. Journal of Econometrics 131(1):445–473.
- Silvennoinen, A., Teräsvirta, T. (2009). Multivariate GARCH models. In: Handbook of Financial Time Series, Berlin Heidelberg: Springer, pp. 201–229. Springer.
- Straumann, D., Mikosch, T. (2006). Quasi-maximum-likelihood estimation in conditionally heteroeskedastic time series: A stochastic recurrence equations approach. The Annals of Statistics 34(5):2449–2495.
- van der Vaart, A. W. (2000). Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge: Cambridge University Press.
- White, H. (1994). Estimation, Inference and Specification Analysis. Cambridge Books. Cambridge: Cambridge University Press.
- Wu, W., Shao, X. (2004). Limit theorems for iterated random functions. Journal of Applied Probability 41(2):425–436.
Appendix A: Proofs
We first state Theorem 3.1 of Bougerol (Citation1993). Denote by log Λ(φ0) the term inside the expectation on the left-hand side of (7).
Theorem 3 (Bougerol, 1993, Theorem 3.1)
Let {φt} be a stationary and ergodic sequence of endomorphic Lipschitz maps. Assume as follows:
There exists a f ∈ ℱ and distance measure d such that 𝔼[log +d(φ0(f), f)] < ∞;
𝔼[log +Λ(φ0)] < ∞;
Then the stochastic recurrence Eq. (6) admits a stationary ergodic solution {ft}.
Proof of Lemma 1
The SE property of {ft} follows from the measurability with respect to {ut}. The Lipschitz property is obtained from the boundedness of the terms in Eq. (A6) below. Condition 3 is then ensured by the definition of the GAS transition equation and the assumed moments in Lemma 1, as we can write 𝔼[log +d(φ0(f), f)] ≤ 𝔼|φ0(f) − f| = 𝔼|ω + (β −1)f + αS(f)q(h(f)u0, f)| ≤ |ω| + |(β −1)f| + α𝔼|S(f)q(h(f)u0, f)|. As requirement 3 is implied by 3, we can now turn our main interest towards the study of the latter, nontrivial, condition 3.
We write ξ and ψ for ξ(ρ) and ψ(ρ), respectively. Define the shorthand notation cw = cw(ρ) = cos (w(ρ)) with w: [ − δ, δ] → ℝ, and similarly sw = sw(ρ) = sin (w(ρ)). Each matrix root h of the correlation matrix can be written as
Using (A1), we obtain
Using yt = h(f)ut, we can rewrite (4) as
The definitions in (6) and (A2) then imply that (7) can be written as
Proof of Lemma 2
Using (A4), we can rewrite ‖ġ(ρ)‖2 as
For ψ(ρ) = arcsin (ρ)/2, the second term vanishes, and we obtain the functional lower bound (1 − ρ2)·‖ġ(ρ)‖2 = 1 − ρ2, which reaches its supremum of 1 at ρ = 0. The rest of the result follows directly from the definition of ξ(ρ) = arcsin (ρ) − ψ(ρ) = arcsin (ρ)/2. For computational reasons, it may be useful to note that
An analogous line of reasoning holds for condition (13) based on applying the triangle inequality twice.
Proof of Lemma 3
The proof follows immediately from Theorem 2.8 in Straumann and Mikosch (Citation2006) by noting that our conditions (i) and (ii) imply conditions S.1 and S.2 in their theorem.
Proof of Theorem 1
We follow Blasques et al. (Citation2014a) and appeal to Theorem 3.4 of White (Citation1994), and obtain from the uniform convergence of the criterion function and the identifiable uniqueness of the maximizer θ0 ∈ Θ defined, e.g., in White (Citation1994).
Existence. Note that ℒT(θ, f1) is a.s. continuous in θ ∈ Θ if each likelihood contribution is. This is obtained by the smoothness of the scaled score s: ℱ × 𝒴 × Θ → ℝ and the resulting continuity of ft in θ as a composition of t continuous maps. Due to the compactness of Θ, by Weierstraß\ theorem, the arg max set of the likelihood is nonempty a.s., and hence exists.
Uniform Convergence. By an application of the triangle inequality, we have
The first term in (A7) vanishes by the convergence of ft(y1: t−1, θ, f1) to ft(yt−1, θ) which is established in Lemma 3. The maintained smoothness assumption on the scaled score ensures that ℓt(·, f1) = ℓ(ft(y1: t−1, ·, f1), yt, ·) is continuous in (ft(y1: t−1, ·, f1), yt). There thus exists a unique SE sequence {ft(y1: t−1, ·)}t∈ℤ satisfying ∀ f1 ∈ ℱ. It thus follows that
as t → ∞ by application of the continuous mapping theorem (see also Theorem 2.3[i] in van der Vaart, Citation2000) for ℓ: ℂ(Θ, ℱ) × 𝒴 × Θ → ℝ.
The second term in (A7) vanishes by an application of the ergodic theorem for separable Banach spaces (Theorem 2.7 in Straumann and Mikosch, Citation2006) to the sequence {ℒT(·)} with elements taking values in ℂ(Θ), so that as T → ∞. This is obtained under the moment assumption 𝔼sup θ∈Θ|ℓt(θ)| < ∞, by the SE nature of the sequence {ℓt}t∈ℤ, which is implied by continuity of ℓ on the SE sequence {(ft(yt−1, ·), yt)}t∈ℤ, which is SE using Lemmas 1 and 3 and Proposition 4.3 in Krengel (Citation1985).
Identifiable Uniqueness. Identifiable uniqueness of θ0 ∈ Θ, i.e., sup θ: ‖θ−θ0‖ > εℓ∞(θ) < ℓ∞(θ0) for all ε > 0, follows by the assumed uniqueness of θ0, the compactness of the parameter space Θ, and the continuity of 𝔼ℓt(θ) in θ ∈ Θ, which is implied by the continuity of ℒT in θ ∈ Θ and the uniform convergence of the objective function proved above; see, e.g., White (Citation1994).
Proof of Theorem 2
We make use of the asymptotic normality conditions found, e.g., in Theorem 6.2 of White (Citation1994). These conditions are as follows: (i) the strong consistency of ; (ii) the a.s. twice continuous differentiability of ℒT(θ, f1) in θ ∈ Θ; (iii) the asymptotic normality of the score
Weak Convergence of the Score. The score sequence depends not only on the data {yt} and the initialized process {ft(θ, f1)} but also on the derivative processes
. As such, the limit SE nature of the score and its smoothness properties imply that
is a continuous function of the limit SE process
and thus SE by Theorem 36.4 in Billingsley (Citation1995). Note that the data {yt} is SE under the conditions of Lemma 1, and the process {ft(θ, f1)} and its derivative
both converge e.a.s. to an SE limit under the conditions of Lemma 3 since it is easy to show that the contraction condition in (ii) of Lemma 3 for {ft(θ, f1)} is also the relevant contraction condition for any derivative process
of any order; see Blasques et al. (Citation2014a).
The remainder of the proof now follows along similar lines as in Blasques et al. (Citation2014a, Theorem 4). As a continuous function of the SE process , the score sequence
is also SE, and we can apply the central limit theorem (CLT) for SE martingales in Billingsley (Citation1961) to obtain
As a result, we can also conclude by Theorem 18.10\small[iv] in van der Vaart (Citation2000) that
To establish the e.a.s. convergence in (A10), we use the e.a.s. convergence and
, as implied by the conditions of Lemma 3. From the differentiability of
in
and the convexity of ℱ, we use the mean-value theorem to obtain
Uniform Convergence of Second Derivatives. We use the triangle inequality to write
The first term vanishes a.s. with T → ∞ by application of a continuous mapping theorem because the maintained smoothness assumptions ensure that is continuous in its arguments
and the invertibility conditions of Lemma 3 guarantee that there exists a unique SE sequence
such that
. The second term in (A11) converges under a uniform law of large numbers by the maintained assumption that
and the SE nature of
.
Finally, the nonsingularity of the limit in (v) is implied by the uniqueness of θ0 as a maximizer of
in Θ.