
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Background
The endoscopic Hill classification of the gastroesophageal flap valve (GEFV) is of great importance for understanding the functional status of the esophagogastric junction (EGJ). Deep learning (DL) methods have been extensively employed in the area of digestive endoscopy. To improve the efficiency and accuracy of the endoscopist’s Hill classification and assist in incorporating it into routine endoscopy reports and GERD assessment examinations, this study first employed DL to establish a four-category model based on the Hill classification.
Materials and Methods
A dataset consisting of 3256 GEFV endoscopic images has been constructed for training and evaluation. Furthermore, a new attention mechanism module has been provided to improve the performance of the DL model. Combined with the attention mechanism module, numerous experiments were conducted on the GEFV endoscopic image dataset, and 12 mainstream DL models were tested and evaluated. The classification accuracy of the DL model and endoscopists with different experience levels was compared.
Results
12 mainstream backbone networks were trained and tested, and four outstanding feature extraction backbone networks (ResNet-50, VGG-16, VGG-19, and Xception) were selected for further DL model development. The ResNet-50 showed the best Hill classification performance; its area under the curve (AUC) reached 0.989, and the classification accuracy (93.39%) was significantly higher than that of junior (74.83%) and senior (78.00%) endoscopists.
Conclusions
The DL model combined with the attention mechanism module in this paper demonstrated outstanding classification performance based on the Hill grading and has great potential for improving the accuracy of the Hill classification by endoscopists.
KEY MESSAGES
A new attention mechanism module has been proposed and integrated into the DL model.
According to our knowledge, this is the first study to establish a four-category DL model based on the Hill grading.
The DL model demonstrated outstanding classification performance based on the Hill grading and has great potential for improving the accuracy of the Hill classification by endoscopists.
1. Introduction
The worldwide prevalence of gastroesophageal reflux disease (GERD) ranges from 8% to 33%. It is a common and complex digestive system disease. Current studies suggest that the mechanism of esophageal mucosal injury is related to the anatomical or physiological defects of the esophagogastric junction (EGJ) [Citation1]. Among them, the gastroesophageal flap valve (GEFV) is an important part of the EGJ and plays a crucial role in the anti-reflux barrier [Citation2]. GEFV was first proposed by Tocornal et al. [Citation3] in 1968. In 1987, Thor and Hill et al. [Citation4] confirmed the existence of GEFV in the EGJ through autopsy. In 1996, Hill et al. [Citation5] proposed a Hill grading system based on the endoscopic manifestations of GEFV, which considered Hill grades I-II as normal GEFV and III-IV grades as abnormal GEFV. According to studies, abnormal GEFV is closely related to diseases such as GERD, Barrett’s esophagus, hiatal hernia, laryngopharyngeal reflux disease, dyspepsia, and esophageal variceal bleeding [Citation6–10]. Hill classification is also an important reference index for preoperative and postoperative evaluation of surgical or endoscopic treatment of GERD [Citation11, Citation12]. It is evident that GEFV is closely related to various diseases. The Hill classification can provide an important reference for clinicians to judge the patient’s condition. The Hill classification under endoscopy requires careful consideration. Scholars also called for the inclusion of Hill classification in routine endoscopy reports and GERD assessment examinations [Citation6,Citation13].
The advancement of science and technology has led to the increasing utilization of artificial intelligence (AI) in medical image classification research [Citation14–16]. As early as 1995, some researchers began applying convolutional neural networks (CNN) to analyze medical images [Citation17]. Recently, scholars have turned their attention to utilizing deep learning (DL) in digestive endoscopy to classify gastroesophageal reflux disease (GERD) according to the Los Angeles grading standard. In 2021, researchers proposed a 3-category DL model employing CNN, achieving high accuracy in GERD classification [Citation18]. Subsequently, in 2022, another team enhanced the model’s performance by incorporating DL and machine learning technologies [Citation19]. Building upon these advancements, our team, in 2023, introduced DL and explainable AI to create a 5-category DL model for GERD based on the Los Angeles classification standard, achieving an impressive classification accuracy of 87.6% [Citation20]. This highlights the substantial potential of DL models in GERD classification research.
In our study, we curated a dataset comprising high-resolution GEFV endoscopic images. To improve the DL model, we introduced a novel attention mechanism module. The dataset consisted of RGB visible light images, each comprising three channels denoting red (R), green (G), and blue (B) light information. These channels represent the intensity or brightness of each pixel in the RGB image. We integrated the early dynamic attention (EDA) mechanism to enhance the RGB channels before feeding them into the feature extraction backbone network. Following this, we incorporated the compressed and expanded attention module SE-Attention [Citation21] to filter and enhance spatial domain features. Four distinct feature backbone networks were selected for further evaluation, comparing their accuracy, learning rate, model size, Area Under the Curve (AUC) value, and interpretability. Our study aimed to explore the clinical relevance of DL models and their potential to enhance the efficiency and accuracy of endoscopists using the Hill classification system. We compared the classification accuracy of DL models with that of endoscopists of varying experience levels. Notably, this research represents a pioneering effort in establishing a four-category DL model based on the Hill grading system.
2. Methods
2.1. Preparation of the datasets
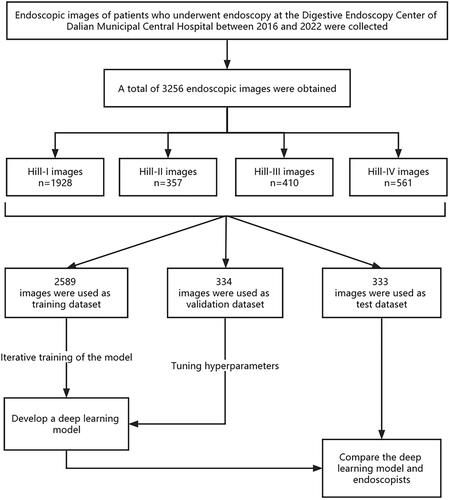
We strictly followed the inclusion and exclusion criteria to collect GEFV endoscopic images of patients who underwent endoscopy at the Endoscopy Center of Dalian Municipal Central Hospital (Dalian, China) from 2016 to 2022. The collected images were quality-controlled and Hill graded by an expert endoscopist and an experienced endoscopist. In our endoscopy center, all endoscopy examinations are performed by professional endoscopists who have undergone systematic training and qualification. These endoscopists have also participated in completing a minimum of 200 endoscopy cases. At the same time, the time to complete the gastroscopy is at least 7 min, and a minimum of 38 clear images of all parts of the upper gastrointestinal tract should be obtained. We collected a total of 3256 GEFV endoscopic images (1928 images of Hill-I, 357 images of Hill-II, 410 images of Hill-III, and 561 images of Hill-IV). The detailed data are presented in . We use an Olympus endoscope (GIF-HQ290, GIF-Q260J, GIF-H260Z, GIF-Q260, and GIF-H260; Olympus Medical Systems, Co., Ltd., Tokyo, Japan) and an Olympus endoscopic video system (EVIS LUCERA ELITE CV-290/CLV-290SL and EVIS LUCERA CV-260SL/CLV-260SL). After obtaining the dataset, we carried out data enhancement methods, including endoscopic image flipping, image folding, brightness adjustment, image fitting, reorganization, etc., to expand the dataset and enhance the model’s generalization ability.
Table 1. Detailed introduction of datasets and division of training dataset, test dataset, and validation dataset.
The Ethics Committee of Dalian Municipal Central Hospital has approved this study (Approval No. YN2016-065-01). Patient consent was waived due to the non-interventional retrospective design of the study.
2.1.1. Collect images of GEFV
2.1.1.1. Inclusion criteria
Collect GEFV endoscopic images of patients who underwent endoscopy at the Endoscopy Center of Dalian Municipal Central Hospital from 2016 to 2022. These images were required to provide a clear view of the GEFV structure and allow for Hill grading analysis.
2.1.1.2. Exclusion criteria
Images with subpar quality, including issues like ghosting, astigmatism, blurriness, the presence of mucus, foreign objects, or blood, which might compromise the image quality, were excluded from the analysis.
2.1.1.3. The Hill classification criteria [Citation5]
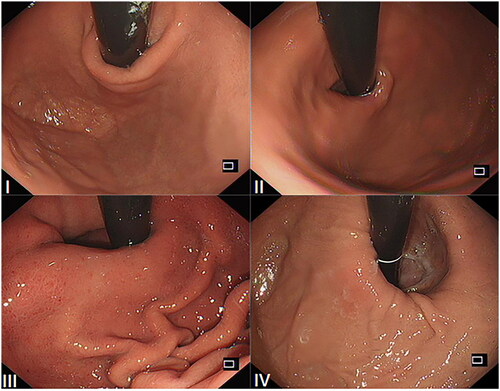
Grade I: The edge of the tissue ridge is obvious, tightly wrapping the endoscope along the lesser curvature; Grade II: The ridge is not as obvious as Grade I, but it occasionally opens with respiration and closes promptly; Grade III: The ridge is barely present and cannot tightly wrap the endoscope; Grade IV: There is no ridge at all. The gastroesophageal area is open, and the esophageal squamous epithelium is readily visible. The sample images of the Hill classification standard are shown in .
Figure 1. The sample images of the Hill classification standard: (I) Hill-I; (II) Hill-II; (III) Hill-III; (IV) Hill-IV.
2.1.2. The levels of endoscopists participating in the experiment
A total of three levels of endoscopists participated in this research. Expert endoscopists: have more than 20 years of experience in digestive endoscopy; Senior endoscopists: have 5–10 years of experience in digestive endoscopy; Junior endoscopists: have 1–3 years of experience in digestive endoscopy.
2.2. Research design
As shown in , our experimental process is as follows: In strict accordance with the inclusion and exclusion criteria, a total of 3256 GEFV endoscopic images of patients undergoing endoscopy examination at the Digestive Endoscopy Center of Dalian Municipal Central Hospital between 2016 and 2022 were obtained. The collected GEFV endoscopic images were classified into four categories based on the Hill-grading standard by an expert endoscopist and a senior endoscopist. 2589 classified GEFV endoscopic images were utilized as a training dataset to train the DL model to automatically identify endoscopic image features at different Hill grades. 323 classified GEFV endoscopic images were used as a validation dataset to verify the accuracy of the DL model and tune its hyperparameters. 344 classified GEFV endoscopic images were utilized as the test dataset, and the test dataset was used to test the accuracy of the DL model and manual recognition. Through the test, the classification accuracy of the model for each type of image under different backbone networks is obtained, and then the classification ability of the model is demonstrated through visualization methods such as the confusion matrix and receiver operating characteristic (ROC) curve. Then conduct interpretability experiments for the DL model, as well as the comparison experiment of the backbone network model and the ablation experiment of the attention module. Finally, the images of the test dataset were submitted to 5 junior endoscopists and 4 senior endoscopists in the form of questionnaires for classification, and then the classification accuracy of the DL model was compared with that of doctors at all levels.
Figure 2. Flow chart of the experiment design.
2.3. Development of the DL model
This study adopts the feature extraction strategy of transfer learning to develop an attention-based deep convolutional neural network classification model. The introduction to the model is as follows:
The model of this paper is shown in . During the model training process, after inputting an image, a certain data enhancement is performed through random cropping and horizontal flipping (this operation is not performed during the test process) and then enters the first part of the model, EDA. The module’s function is to separate the three RGB channels of the image and then operate on each channel. Typically, each channel in an RGB image uses 8 bits (or more) to represent color intensity, which means that each channel can contain 256 different intensity levels, ranging from 0 (darkest) to 255 (brightest). In image processing and computer vision, each color channel of an image is treated as an independent channel or image, and feature processing and enhancement of a single channel can be achieved. This allows us to perform feature processing and enhancement on individual channels. Considering the R channel as an example, copy the R channel three times to make it the same number and size as the original image channel, and then send the 3 R features into the pretraining model to obtain the feature encoding tensor while simultaneously performing the same operation on the 3 G and 3B features. Finally, combine the three copied channels to achieve feature fusion, and then perform feature fusion with the original input RGB features. Fusion is used to obtain a feature matrix weighted by dynamic feature attention, followed by feature extraction from the backbone network. After training and testing 12 different backbone networks (Attention-56 [Citation22], DenseNet-121 [Citation23], GoogLeNet [Citation24], MobileNet V2 [Citation25], NASNet [Citation26], ResNet-50 [Citation27], ResNext-50 [Citation28], SE-ResNet50 [Citation21], ShuffleNet V2 [Citation29], VGG-16 [Citation30], VGG-19 [Citation30], and Xception [Citation31]), we selected four backbone networks (ResNet-50, VGG-16, VGG-19, and Xception) with better performance, and after obtaining the feature matrix (C_H_W) through the backbone network, we entered the next part of the model and pooled the feature map globally, so that the feature map of C_H_W became C_1_1, and then through a fully connected layer, we reduced the number of channels to C/R (to extract the useful features in the channel). After the activation function, the features of C_1_1 are obtained through a fully connected layer (the purpose is to facilitate the operations on the original feature matrix). Then multiply the most original feature matrix with the features of this C_1_1 to get the final feature matrix, which is adjusted by the attention mechanism. The final output is then obtained according to the feature matrix. The output is a four-bit vector (0001, 0010, 0100, and 1000) representing each of the four categories.
Figure 3. Network framework diagram. Use the attention module EDA to enhance the feature information of the RGB three primary colors channel domains; use the compressed and expanded attention module SE-Attention to realize feature filtering and enhancement in the spatial domain.
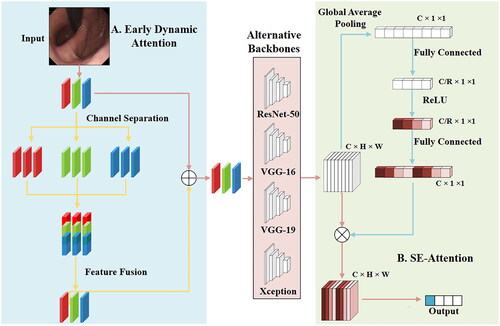
2.3.1. EDA
The EDA module achieves dynamic weighted aggregation of image channel domains through RGB channel feature separation, enhancement, and fusion. After obtaining the feature matrix of weighted aggregation, it is added to the original image, and then a feature map of RGB channel domain activation is obtained.
2.3.1.1. Channel separation
After obtaining the image’s feature map, the image is separated into its three channels, R, G, and B, using channel separation. Simultaneously, in order to keep the original size of the feature map, the separated feature maps are copied and combined. In this way, the expansion of the number of channels is achieved, from three channels of R, G, and B to nine-channel feature maps of R*3, G*3, and B*3.
2.3.1.2. Feature fusion
After enhancing the features of the RGB channels, the features need to be fused to ensure that the enhanced features are consistent with the original features, and the feature maps of the nine channels in the first part are passed through the normalization layer to obtain the same size as the original image. Equalize feature maps, and then the attention-weighting operation of feature maps can be realized.
2.3.2. SE-Attention
The SE-Attention module focuses on the channel dimension and employs a new structural unit, the squeeze-and-excitation unit, to model the dependence of the channel dimension and realize the adaptive adjustment of the characteristic response value of each channel.
2.3.2.1. Squeeze
The global space feature of each channel serves as its representation. This step carries out the transformation from the feature vector of C*H*W to the channel feature of C*1*1, activated in a new dimension spacing operation.
2.3.2.2. Excitation
After obtaining the channel vector of C*1*1, learn the degree of dependence on each channel through the network model, adjust the feature map based on the degree of dependence, and ultimately obtain the corresponding output.
2.4. Evaluation of the DL model
The following indicators will be used to evaluate our model:
Accuracy: The proportion of correctly classified samples to all samples.
Precision: The number of correctly classified positive samples accounts for the proportion of all predicted positive samples by the classifier.
Recall: The ratio of the number of correctly classified positive samples to the actual number of positive samples.
F1-Score: The F1-Score indicator combines the output results of precision and recall. The F1-Score value ranges from 0 to 1, where 1 represents the best output of the model and 0 represents the worst output of the model.
True positive (TP) stands for true case, which refers to the number of positive signals accurately detected; False positive (FP) stands for false positives, which refers to the number of false positive signals detected by mistake; True negative (TN) stands for true negative case, which refers to the number of accurately detected negative signals; False negative (FN) stands for false negative cases, which refers to the number of falsely detected counterexample signals.
Confusion Matrix: The visualization of the algorithm’s performance is presented in the form of a specific matrix.
ROC Curve: The ROC curve is a graphical representation that plots the hit probability (P(y/SN)) on the ordinate axis against the false report probability (P(y/N)) on the abscissa axis, obtained by the subject under different judgment standards in specific stimulus conditions. Each point on the curve represents a specific threshold, and the curve is drawn by connecting these points. It is a curve obtained by dividing the classification results of the model into multiple cut-off points, with each cut-off point’s specificity as the ordinate and 1-specificity as the abscissa. Mainly used for threshold selection and model comparison.
2.5. Statistical analysis
This study used SPSS 26.0 software (IBM Corp., Armonk, NY, USA) for statistical analysis. Classification accuracy is expressed as a percentage. Classification accuracy of the DL model and endoscopists was compared using the Chi-square test. p < 0.05 was considered statistically significant.
3. Result
3.1. Model prediction
All experiments are conducted on the NVIDIA GeForce RTX 3090 GPU with 24GB of memory using the PyTorch framework. During the training process, the Adam optimizer is used for model training. The fixed learning rate and batch size of each GPU vary slightly depending on the backbone network. Generally speaking, the learning rate is 0.001 and the batch size is 8.
demonstrates the experimental results of each classification model in the test data set when combined with EDA and SE-Attention attention modules, including model accuracy, learning rate (Lr), capacity, and other parameters. According to , accuracy is used to evaluate the classification and prediction performance of the model, and the four network models with better performance are ResNet-50, VGG-16, VGG-19, and Xception. Among them, the ResNet-50 and Xception backbone networks performed best after combining the attention module, achieving 93.39% and 92.49%, respectively; VGG-19 also performed well, achieving an accuracy of 91.89%; and VGG-16 achieved an accuracy of 89.49%.
Table 2. Accuracy, Lr (learning rate), Batch_size, capacity (#Params), and epochs of different models in the test dataset.
3.2. Evaluation indicators
We test the classification effect of each category in combination with the attention module (EDA + SE-Attention) using the four high-performing backbone networks of ResNet-50, VGG-16, VGG-19, and Xception. As shown in , four of the models have good results on the recognition of the first category, and their F1-Scores are all above 0.98. Due to the relatively small number of data training samples, the recognition of the third category by the four models’ effect is the worst (both accuracy and recall are poor), indicating that the recognition of the two adjacent classes of 2–3 and 3–4 is prone to errors. In the resulting test, ResNet-50 performed the best (accuracy reached 93.39%, AUC reached 0.989), followed by the Xception model (accuracy reached 92.49%, AUC reached 0.986), and VGG-16 performed relatively poorly (accuracy reached 89.49%, and the AUC reached 0.964).
Table 3. The result of the classification of each category (Precision, Recall, F1-score, AUC).
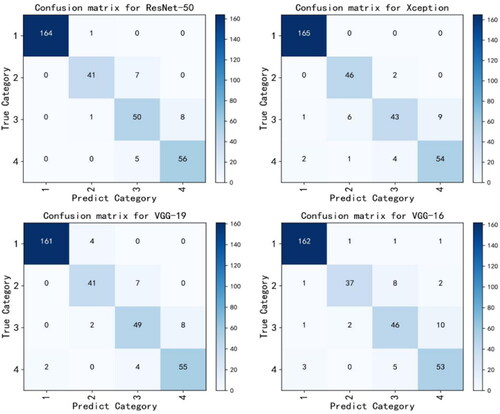
3.3. Confusion matrix
The confusion matrix can be used to observe the model’s performance in each category and to calculate the model’s accuracy and recall rate for each category. In addition, through the confusion matrix, it can be observed which categories are difficult to distinguish, which is convenient for better-targeted features designed to make categories more distinguishable. depicts the confusion matrix that the four backbone networks in the test dataset predicted, making the classification effect of the model on these four categories more obvious. Among them, Xception reached 100% in the recognition of the first category, whereas ResNet-50 performs better overall, with the majority of its discrimination errors concentrated in categories 2 and 3. The performance of VGG-16 is average, and the predictions of categories 2 and 3 contain more errors.
Figure 4. The confusion matrix of prediction in the test dataset for the four models.
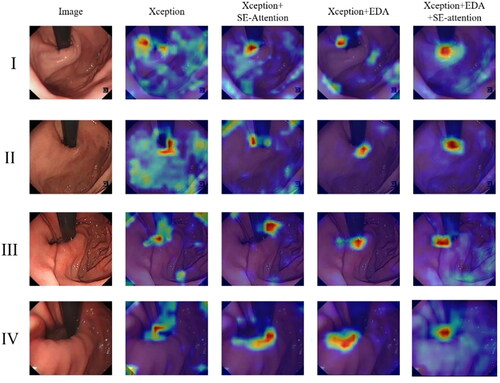
3.4. ROC curve
The ROC curve can easily detect the impact of any model classification threshold value on the model’s classification ability. The closer the ROC curve is to the upper left corner, the higher the accuracy of the model classification. .displays the ROC curves predicted by the four backbone networks in the test dataset. AUC introduces the threshold of the prediction probability, which can be analyzed comprehensively. The higher the AUC, the clearer the classification boundary and the better the classification effect of the model. The four models that integrate the attention mechanism module have outstanding overall effects on the recognition of the four categories, as their AUC scores are all above 0.96. Among them, the four models have better recognition effects in the first and fourth categories, and the AUC scores are all higher than 0.97, indicating that most of the model’s recognition errors occur in the second and third categories.
Figure 5. The ROC space of the prediction in the test dataset for the four models.
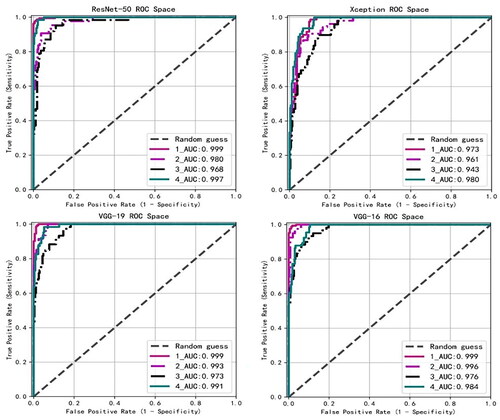
3.5. Visual interpretation of model classification results
The DL models have a ‘black box’ nature [Citation32], i.e. the network has high accuracy, but its inner working mechanism is hard to explain. In this study, the gradient-weighted class activation mapping (Grad-CAM) algorithm [Citation33] was employed to characterize the model of each point in the output layer by obtaining the value of the feature matrix of the GEFV endoscopic image in the model output layer. The significance of decision-making is to establish a class activation heat map. The class activation heatmap is then overlaid on the original GEFV endoscopic image, enabling visual interpretation of the model classification results. In this regard, we conducted comparative experiments with four backbone network models and ablation experiments to determine the effectiveness of the attention mechanism.
3.5.1. Comparative experiment of backbone network model
The evaluation results of four different backbone networks combined with attention modules are summarized in . The results indicate that the four models have achieved good performance after combining the attention module. The highlighted part (red area) in the figure is the area with a higher weight adopted by the model when classifying GEFV endoscopic images. The model determines that it should classify and evaluate according to this part. In contrast, the remaining light-colored parts (blue parts) are the areas with lower weights adopted. Consequently, the attention weight distribution of the model in classifying GEFV endoscopic images can be understood by observing the distribution of different colors in the heat map generated by Grad-CAM, providing a visual interpretation of the model classification results. After combining the ResNet-50 and Xception network models with the attention mechanism, the areas with higher weights are concentrated on the tissue ridges and around the endoscope, with almost no deviation. However, there are slight deviations in the highlight region of the VGG-16 and VGG-19 models.
Figure 6. Visualization of samples by Grad-CAM for the four models (including EDA + SE-Attention module).
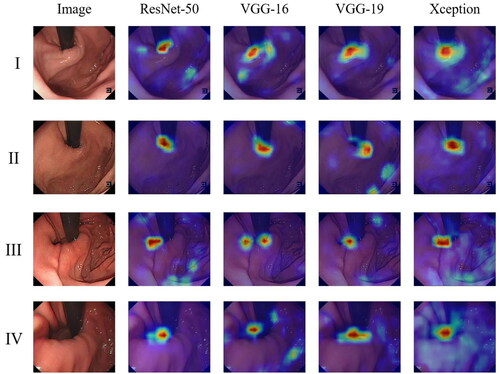
3.5.2. Ablation experiment of the attention module
A series of experiments were conducted to verify our hypothesis and investigate the effectiveness of the attention module described in this paper. Ablation experiments are a common scientific experimental design used to determine whether a certain factor has a significant impact on the experimental results. By systematically removing or changing one or more factors, we can identify which factors are the key ones that have an impact on model discrimination. We conducted ablation experiments for the EDA module and SE-Attention module in this article. The ablation experiments of the Xception and attention modules are shown in . Experiments revealed that the attention module can adjust and strengthen the attention area of GEFV endoscopic image discrimination. Both attention modules can enhance the weight of the tissue ridge and the area surrounding the endoscope. Under the comprehensive effect of the two attention modules, the weight distribution effect of the model is the best and most significant. This result is more helpful for us to comprehend the role of the attention module and the mechanism of the model for GEFV endoscopic image discrimination.
Figure 7. Visualization of samples by Grad-CAM for the models (Xception, Xception + EDA, Xception + SE-Attention, Xception + EDA + SE-Attention).
3.6. Human-AI comparison
The Hill grading test was conducted on a group of 9 endoscopists, consisting of 5 junior and 4 senior endoscopists. .compares the classification accuracy of the best-performing DL model, ResNet-50, with that of endoscopists with different levels of experience in the test dataset. As shown in , the classification accuracy of senior endoscopists and endoscopists as a whole is similar to that of ResNet-50 in the Hill-II grade, with no statistically significant difference (p > 0.05). In the Hill-I, Hill-III, Hill-IV, and overall, ResNet-50 had substantially higher classification accuracy than endoscopists in all levels (p < 0.01). After comparing junior endoscopists with ResNet-50, we discovered that the classification accuracy of the DL model in Hill grades I-IV and overall was higher than that of junior endoscopists (p < 0.05). Overall, the classification accuracy of ResNet-50 (93.39%) was higher than that of both junior (74.83%) and senior (78.00%) endoscopists.
Table 4. Comparison of the accuracy between the ResNet-50 and endoscopists with different levels of experience in the test dataset (Chi-square test).
3.7. Summary of results
After testing 12 kinds of backbone networks combined with attention modules, we selected four models with better performance (ResNet-50, VGG-16, VGG-19, and Xception) for more detailed testing. Among them, ResNet-50 combined with the attention module produced the best results, with an accuracy of 93.39% and an AUC of 0.989. Xception also performed well, with an accuracy of 92.49% and an AUC of 0.986. In the model classification discrimination experiment for each category, we discovered that the classification errors of the model are mainly concentrated on the discrimination of Hill-II and Hill-III, which may be caused by the imbalance of categories. Then we performed the visual interpretation of the model. We conducted a comparison of four backbone network models and an ablation experiment for the attention module. These results clarified how the model discriminates GEFV endoscopic images, and the experiments also verified the effectiveness of the attention module. Through the human-computer comparison experiment, we can demonstrate that ResNet-50 has great potential to improve the accuracy of endoscopists, particularly junior endoscopists, in the Hill classification.
4. Discussion
With the development of computer science and technology, AI has been increasingly applied in medicine, particularly in the field of digestive endoscopy, which has achieved unprecedented progress [Citation34]. By assisting with digestive endoscopy, AI can improve the diagnosis rate of young endoscopists, reduce misdiagnosis and missed diagnoses, and simultaneously enable patients to receive high-quality medical services [Citation35]. In recent years, research on the classification and diagnosis of GERD by AI-assisted endoscopy has begun to attract the attention of scholars [Citation18–20]. Current investigations imply that the mechanism of esophageal mucosal injury is related to the anatomical or physiological defects of the EGJ [Citation1]. As an important part of EGJ, GEFV plays an important role in the anti-reflux barrier [Citation2], and the Hill grading under endoscopy can well predict GERD [Citation36,Citation37]. In a survey conducted in South Korea [Citation38], the incidence of abnormal GEFV was significantly higher in Russians (44.2%) than in native Koreans (28.5%), and erosive esophagitis (61%) was also significantly higher than in normal people (32%). In a Vietnamese study [Citation10], the abnormal rate of GEFV was substantially correlated with a high GERDQ score, indicating that patients with severe GERD symptoms had a higher abnormal rate of GEFV. A systematic review and meta-analysis have also reported that abnormal GEFV is more likely to have GERD symptoms and more likely to develop erosive esophagitis than normal GEFV [Citation6], and the correlation is enhanced with the increase in GEFV grade [Citation39]. Guo et al. [Citation13] discovered that the percentage of acid exposure time was positively correlated with Hill grade, whereas the post-reflux swallow-induced peristaltic wave index and the mean nocturnal baseline impedance were negatively correlated. It is suggested that the Hill grading can be used as supporting evidence for the diagnosis of GERD.
The Hill grading system can not only predict GERD but also provide an important reference index for preoperative and postoperative evaluations of the surgical or endoscopic treatment of GERD. Studies have demonstrated that after endoscopic anti-reflux mucosal resection (ARMS) in patients with GERD, the Hill grade of patients after surgery is lower than that before surgery [Citation40,Citation41]. Another study [Citation12] compared ARMS and Stretta radiofrequency ablation in the treatment of GERD. Through the 6-month follow-up observation, it was determined that the clinical curative effect of the two surgical methods for Hill grades II and III was equivalent, while ARMS should be preferred for patients with Hill grades IV. Li et al. [Citation42] revealed that endoscopic tightening of the cardia mucosa was effective for all levels of Hill-grade GERD patients, especially for Hill-III. In addition, the Hill grade decreased at 12 and 36 months after laparoscopic antireflux surgery compared to preoperatively [Citation11], suggesting that the Hill grade can be used as one of the important indicators for evaluating the curative effect after surgery. In 2022, the American Foregut Society (AFS) proposed a new endoscopic classification method to assess the esophagogastric junction, which expanded on the basis of the Hill classification to make it more comprehensive [Citation43]. In the future, we will explore the use of AI-assisted AFS endoscopic classification, compare it with the Hill classification, and improve the comprehensiveness of GEFV functional evaluation.
Our research proposed an attention mechanism module, tested the attention module with 12 backbone networks, and selected 4 excellent DL models, among which the accuracy of ResNet-50 reached 93.39%. To explore the interpretability of the DL model classification and the function of our attention mechanism module, we designed an ablation experiment of the attention mechanism module, which proved the role of this attention mechanism module in the model’s GEFV image discrimination. In order to verify the performance of the model and obtain a comparison between endoscopists with different seniorities and the model test, 3 levels of endoscopists are taken into consideration. This multi-level evaluation method helps to better cope with complex medical image classification tasks, make full use of physician resources, and improve the level of medical care for patients. The classification accuracy of ResNet-50 (93.39%) was significantly higher than that of junior (74.83%) and senior (78.00%) endoscopists, as determined by human-AI comparison. It is evident that the DL model can assist digestive endoscopy in Hill grading and improve the classification accuracy of endoscopists. To the best of our knowledge, this study is the first four-category study in the field of DL model-assisted digestive endoscopy to perform the Hill classification, which may help endoscopists incorporate the Hill classification into routine endoscopy reports and GERD assessment examinations, thereby promoting the clinical application of the Hill classification. We also believe that in the future, with the assistance of AI, the accuracy of the Hill classification will be further improved.
This study has its limitations. Firstly, the Hill classification could be influenced by various factors, such as inflation extent and respiratory cycles, potentially leading to errors when the DL model encounters these confounding elements. Additionally, this research is based on a retrospective study conducted in a single center, with all images captured using Olympus equipment. Expanding the sample size is necessary. Furthermore, the study involved a limited number of participating endoscopists, and the experiment relied solely on image data, disregarding temporal variations and gastroscope grading variability. To address these limitations, future research will refine the methodology, validate it across different endoscopic systems, involve more endoscopists, incorporate video data into the experiments, conduct prospective studies across multiple centers, and actively work towards promoting clinical applications.
5. Conclusions
The DL model, combined with the attention mechanism described in this paper, demonstrates excellent classification performance based on the Hill classification, has great potential for improving the accuracy of endoscopists in the Hill classification, and has broad clinical application prospects.
Ethical approval and consent to participate
This research was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of Dalian Municipal Central Hospital (Approval No. YN2021-065-01). Patient consent was waived due to the non-interventional retrospective design of the study.
Authors’ contributions
Zhijun Duan, Xin Yang, and Jiuyang Chang designed the study; Zhenyang Ge and Youjiang Fang drafted the manuscript; Zhenyang Ge analyzed the data; Youjiang Fang and Yu Qiao provided technical support; Zhijun Duan and Xin Yang revised the manuscript; Jiuyang Chang, Yu Qiao, Zequn Yu, and Jing Zhang contributed to the interpretation of the data. All authors have read and agreed to the published version of the manuscript.
Acknowledgments
We appreciate all coworkers from the Digestive Endoscopy Center of Dalian Municipal Central Hospital and Dalian Central Laboratory of Integrative Neuro-gastrointestinal Dynamics and Metabolism Related Diseases Prevention and Treatment for their assistance.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data presented in this study are available on request from the corresponding author.
Additional information
Funding
References
- Gyawali CP, Kahrilas PJ, Savarino E, et al. Modern diagnosis of GERD: the lyon consensus. Gut. 2018;67(7):1–14. doi: 10.1136/gutjnl-2017-314722.
- Xie C, Li Y, Zhang N, et al. Gastroesophageal flap valve reflected EGJ morphology and correlated to acid reflux. BMC Gastroenterol. 2017;17(1):118. doi: 10.1186/s12876-017-0693-7.
- Tocornal JA, Snow HD, Fonkalsrud EW. A mucosol flap valve mechanism to prevent gastroesophageal reflux and esophagitis. Surgery. 1968;64(2):519–523.
- Thor KB, Hill LD, Mercer DD, et al. Reappraisal of the flap valve mechanism in the gastroesophageal junction. A study of a new valvuloplasty procedure in cadavers. Acta Chir Scand. 1987;153(1):25–28.
- Hill LD, Kozarek RA, Kraemer SJ, et al. The gastroesophageal flap valve: in vitro and in vivo observations. Gastrointest Endosc. 1996;44(5):541–547. doi: 10.1016/s0016-5107(96)70006-8.
- Osman A, Albashir MM, Nandipati K, et al. Esophagogastric junction morphology on Hill’s classification predicts gastroesophagealreflux with good accuracy and consistency. Dig Dis Sci. 2021;66(1):151–159. doi: 10.1007/s10620-020-06146-0.
- Fujiwara Y, Higuchi K, Shiba M, et al. Association between gastroesophageal flap valve, reflux esophagitis, Barrett’s epithelium, and atrophic gastritis assessed by endoscopy in Japanese patients. J Gastroenterol. 2003;38(6):533–539. doi: 10.1007/s00535-002-1100-9.
- Koya Y, Shibata M, Watanabe T, et al. Influence of gastroesophageal flap valve on esophageal variceal bleeding in patients with liver cirrhosis. Dig Endosc. 2021;33(1):100–109. doi: 10.1111/den.13685.
- Wu W, Li L, Qu C, et al. Reflux finding score is associated with gastroesophageal flap valve status in patients with laryngopharyngeal reflux disease: a retrospective study. Sci Rep. 2019;9(1):15744. doi: 10.1038/s41598-019-52349-5.
- Quach DT, Nguyen TT, Hiyama T. Abnormal gastroesophageal flap valve is associated with high gastresophageal reflux disease questionnaire score and the severity of gastroesophageal reflux disease in vietnamese patients with upper gastrointestinal symptoms. J Neurogastroenterol Motil. 2018;24(2):226–232. doi: 10.5056/jnm17088.
- Håkanson BS, Lundell L, Bylund A, et al. Comparison of laparoscopic 270° posterior partial fundoplication vs total fundoplication for the treatment of gastroesophageal reflux disease: a randomized clinical trial. JAMA Surg. 2019;154(6):479–486. doi: 10.1001/jamasurg.2019.0047.
- Sui X, Gao X, Zhang L, et al. Clinical efficacy of endoscopic antireflux mucosectomy vs. Stretta radiofrequency in the treatment of gastroesophageal reflux disease: a retrospective, single-center cohort study. Ann Transl Med. 2022;10(12):660–660. doi: 10.21037/atm-22-2071.
- Guo Z, Wu Y, Zhan Y, et al. Correlation between gastroesophageal flap valve abnormality and novel parameters in patients with gastroesophageal reflux disease symptoms by the lyon consensus. Sci Rep. 2021;11(1):15076. doi: 10.1038/s41598-021-94149-w.
- Jeyaraj PR, Samuel Nadar ER. Computer-assisted medical image classification for early diagnosis of oral cancer employing deep learning algorithm. J Cancer Res Clin Oncol. 2019;145(4):829–837. doi: 10.1007/s00432-018-02834-7.
- Guan Q, Wang Y, Du J, et al. Deep learning based classification of ultrasound images for thyroid nodules: a large scale of pilot study. Ann Transl Med. 2019;7(7):137–137. doi: 10.21037/atm.2019.04.34.
- Chen X, Wang X, Zhang K, et al. Recent advances and clinical applications of deep learning in medical image analysis. Med Image Anal. 2022;79:102444. doi: 10.1016/j.media.2022.102444.
- Lo SB, Lou SA, Lin JS, et al. Artificial convolution neural network techniques and applications for lung nodule detection. IEEE Trans Med Imaging. 1995;14(4):711–718. doi: 10.1109/42.476112.
- Wang CC, Chiu YC, Chen WL, et al. A deep learning model for classification of endoscopic gastroesophageal reflux disease. Int J Environ Res Public Health. 2021;18(5):2428. doi: 10.3390/ijerph18052428.
- Yen HH, Tsai HY, Wang CC, et al. An improved endoscopic automatic classification model for gastroesophageal reflux disease using deep learning integrated machine learning. Diagnostics. 2022;12(11):2827. doi: 10.3390/diagnostics12112827.
- Ge Z, Wang B, Chang J, et al. Using deep learning and explainable artificial intelligence to assess the severity of gastroesophageal reflux disease according to the Los Angeles classification system. Scand J Gastroenterol. 2023;58(6):596–604. doi: 10.1080/00365521.2022.2163185.
- Hu J, Shen L, Albanie S, et al. Squeeze-and-excitation networks. IEEE Trans Pattern Anal Mach Intell. 2020;42(8):2011–2023. doi: 10.1109/TPAMI.2019.2913372.
- Wang F, Jiang M, Qian C, et al. 2017). Residual attention network for image classification. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 6450–6458. doi: 10.1109/CVPR.2017.683.
- Huang G, Liu Z, Weinberger KQ. 2016). Densely connected convolutional networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2261–2269.
- Szegedy C, Liu W, Jia Y, et al. 2014). Going deeper with convolutions. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1–9.
- Sandler M, Howard AG, Zhu M, et al. 2018). MobileNetV2: inverted residuals and linear bottlenecks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4510–4520.
- Zoph B, Vasudevan V, Shlens J, et al. 2017). Learning transferable architectures for scalable image recognition. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8697–8710.
- He K, Zhang X, Ren S, et al. 2015). Deep residual learning forimage recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778.
- Xie S, Girshick RB, Dollár P, et al. 2016). Aggregated residual transformations for deep neural networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5987–5995.
- Ma N, Zhang X, Zheng H, et al. 2018). ShuffleNet V2: practical guidelines for efficient CNN architecture design. ArXiv, abs/1807.11164
- Simonyan K, Zisserman A. 2014). Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556
- Chollet F. 2016). Xception: Deep learning with depthwise separable convolutions. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1800–1807.
- Das A, Rad P. 2020). Opportunities and challenges in explainable artificial intelligence (XAI): a survey. ArXiv, abs/2006.11371
- Selvaraju RR, Das A, Vedantam R, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. Int J Comput Vis. 2020;128(2):336–359. doi: 10.1007/s11263-019-01228-7.
- Xu Y, Tan Y, Wang Y, et al. A gratifying step forward for the application of artificial intelligence in the field of endoscopy: a narrative review. Surg Laparosc Endosc Percutan Tech. 2020;31(2):254–263. doi: 10.1097/SLE.0000000000000881.
- Song YQ, Mao XL, Zhou XB, et al. Use of artificial intelligence to improve the quality control of gastrointestinal endoscopy. Front Med. 2021;8:709347. doi: 10.3389/fmed.2021.709347.
- Kim GH, Song GA, Kim TO, et al. Endoscopic grading of gastroesophageal flap valve and atrophic gastritis is helpful to predict gastroesophageal reflux. J Gastroenterol Hepatol. 2008;23(2):208–214. doi: 10.1111/j.1440-1746.2007.05038.x.
- Kim GH, Kang DH, Song GA, et al. Gastroesophageal flap valve is associated with gastroesophageal and gastropharyngeal reflux. J Gastroenterol. 2006;41(7):654–661. doi: 10.1007/s00535-006-1819-9.
- Ko SH, Baeg MK, Jung HS, et al. Russian Caucasians have a higher risk of erosive reflux disease compared with East Asians: a direct endoscopic comparison. Neurogastroenterol Motil. 2017;29(5):. doi: 10.1111/nmo.13002.
- Bao Y, Chen X, Xu Y, et al. Association between gastroesophageal flap valve and endoscopically diagnosed gastroesophageal reflux disease according to lyon consensus: a meta-analysis of Asian studies. J Clin Gastroenterol. 2022;56(5):393–400. doi: 10.1097/MCG.0000000000001552.
- Inoue H, Ito H, Ikeda H, et al. Anti-reflux mucosectomy for gastroesophageal reflux disease in the absence of hiatus hernia: a pilot study. Ann Gastroenterol. 2014;27(4):346–351.
- Yoo IK, Ko WJ, Kim HS, et al. Anti-reflux mucosectomy using a cap-assisted endoscopic mucosal resection method for refractory gastroesophageal disease: a prospective feasibility study. Surg Endosc. 2020;34(3):1124–1131. doi: 10.1007/s00464-019-06859-y.
- Li Z, Li Y, Wu Y, et al. Endoscopic tightening of the cardia mucosa in gastroesophageal reflux disease: a case series of 120 patients up to 1-year follow-up. J clinical transl res. 2022;8(2):147–151.
- Nguyen NT, Thosani NC, Canto MI, et al. The American Foregut society white paper on the endoscopic classification of esophagogastric junction integrity. Foregut: the Journal of the American Foregut Society. 2022;2(4):339–348. doi: 10.1177/26345161221126961.