Abstract
The effectiveness of some novel software tools used for clustering and classifying multivariate data is tested and used to evaluate mineral exploration criteria by examining a mineral deposit and major fault database. The database containing 364 diverse mineral deposits is divided into natural groups utilising a vector quantisation data-mining approach based on a self-organising map (SOM), and phenetic and cladistic analysis packages. The last two approaches are loosely based on biological principles of numerical taxonomy and evolutionary relationships, respectively. Based on the assumption of a common process of formation, the analyses are used to define the group (or class) of Archean orogenic-gold deposits, as distinct from gold deposit types such as turbidite-hosted orogenic gold, Carlin-type, and porphyry Cu – Au that should be excluded from this group. The main findings from this study are: (i) large, global-scale databases, representing the full range of commodity types, geographic locations, ages and variation in deposit characteristics, are required in order to classify new deposit examples using these techniques; (ii) traditional classifications are broadly correct but inadequately define deposit types; and (iii) SOM, and phenetic and cladistic analysis packages can aid in the identification of the characteristics (i.e. commodity, rock type, alteration, vein morphology, fluid composition) of the deposits that are mainly responsible for defining individual deposit groups. Applied to metallogenic terranes that host many different styles of mineralisation and deposit groups (such as Archean cratons), this approach can aid in identifying which deposits belong to a single coherent group. Analysis of the major fault database in this pilot study emphasises the need to obtain a significantly larger number of entries (total of 138 entries used, whereas ≫200 entries are required). It also highlights the impact of incomplete attribute data and the categorical nature of many of the datafields that describe faults. Nevertheless, preliminary results of several statistical analyses (Boolean, SOM, phenetic, cladistic) of the major fault database confirm the importance of empirically derived criteria for mineralisation, such as proximity to crustal-scale faults and anticlinal hinge zones, dilational jogs and fault roughness, strong rheological contrasts at lithological boundaries and metamorphic grade. Presence and concurrence of these parameters determine the extent of metallogenic endowment of a given fault system and segments within it.

Introduction
This study describes the compilation of a mineral deposit and major fault database, and the analysis of these data via the use of clustering and classification software packages to identify natural groupings and associations. The data were compiled as part of a larger ongoing investigation into craton- and regional-scale factors controlling orogenic-gold deposits that can be used for exploration targeting.
The motivation for identifying clusters and classifying mineral deposits is to support mineral prospectivity studies where it is critical that predictions are applied to a single class of mineral deposits. Further, attempts to understand ore-forming processes are only likely to be successful where the subject of the investigation is a single class of deposit. Thus, an effective means of classification is a prerequisite of such studies, and the computer-based methodologies offer an efficient and objective means of clustering and classification in databases. The goal in classifying major faults and shear zones is to distinguish mineralised from non-mineralised faults. If a group of characteristics of mineralised faults can be recognised, then these can be used to refine criteria for mineral exploration targeting.
In this study, a data-mining procedure based on the data-ordering and visualisation capabilities of the self-organising map (Kohonen Citation2001) and two methods from biological taxonomy concerned with the similarities and relationships between organisms have been applied. These techniques were used to: (i) investigate similarities and relationships between various mineral deposits and groups; (ii) identify characteristics that are critical to characterising these groups; (iii) investigate the usefulness of pattern-recognition software in identifying potentially prospective fault zones and mineral occurrences; and (iv) link the attributes of mineral deposits with those of faults to statistically assess the genetic role of faults in the generation of mineral deposits. Definition of these groups may enable the development of better ore genesis and exploration models with a view towards project generation in poorly known terranes (e.g. ‘what deposit types occur here and what are they like?’) and in well-known terranes (e.g. ‘what are the natural groups and controlling factors?’).
The first part of the study was the development of a mineral deposit database containing characteristics compiled from the literature and mine visits. The choice of which deposit characteristics to compile in the database has been guided by a mineral systems model (Wyborn et al. Citation1994, Citation1995). The mineral systems approach involves the definition of those parts of the system that are critical for the ore-forming process (see below) and the identification of measurable parameters that are considered critical and can act as quantifiable proxies (e.g. source rock, reactive minerals, structures for fluid infiltration) for each part of this process. The next step is the translation of these parameters into mapping criteria or attributes that may be extracted to form a regional-scale GIS database. The choice of method is important because it provides a framework in which to view the relationship between the components of the deposit-forming process and requires the kind of geological evidence that can be captured in a regional GIS. Mineral systems can be viewed in terms of the following six major components: (i) energy source to mobilise fluids and drive chemical reactions; (ii) sources of transporting ligands; (iii) sources of metals; (iv) transport pathway; (v) trap zone (and ore deposit location) with a chemical and/or physical cause for mineral precipitation at the trap site; and (vi) outflow zone (Wyborn et al. Citation1994). Factors associated with generation and transport of fluid(s) involved in this complex process are generally poorly constrained, and there are few factual data to quantify these aspects of a mineral system, especially across the range of mineral deposit types commonly considered. There is insufficient space in this paper to quote all primary references to particular deposit types or their tectonic settings. Hence, recent reviews that themselves contain exhaustive reference lists are quoted in the text. For comprehensive up-to-date descriptions of the deposit styles and their genesis, see Hedenquist et al. (Citation2005).
The second part of this study involved the compilation of a database of major faults, developed in order to identify geological, geophysical and geochemical parameters that are common to, and may differentiate, well-endowed, or mineralised, fault systems from non-mineralised fault systems. Existing public-domain information, output from GIS, and geophysical data were used in this compilation. In combination with independent datasets, analysis of the fault database can provide a useful approach for targeting and area selection in mineral exploration and help to improve understanding of the fundamental geometrical and kinematic characteristics of metallogenically endowed fault systems.
Mineral deposit database
The first step in the analysis was the development of a mineral deposit database containing over 150 variables that could describe obtainable features derived from the literature for 364 disparate, globally distributed, hydrothermal mineral deposits. In compiling this deposit database, the aim was to: (i) encompass a broad range of conventional deposit types such as volcanic-hosted massive sulfide deposits (VHMS), Mississippi-Valley-type deposits (MVT), porphyry Cu(±Au) deposits, and orogenic-gold deposits (Solomon & Groves Citation1994; Franklin et al. Citation2005; Frimmel et al. Citation2005; Goldfarb et al. Citation2005; Large et al. Citation2005; Leach et al. Citation2005; Sillitoe Citation2005); (ii) include several deposits cited in the classification scheme developed and applied by the US Geological Survey (Cox & Singer Citation1986); (iii) select several pairs of similar or closely related deposits to test whether the analyses grouped them together; conversely, anomalous deposits were also included to test for phylogenetic relationships (i.e. the relationship of deposits with conflict over their classification to well-known deposit types); and (iv) include both phenetic and genetic characteristics of the deposits (discussed in detail below). A criterion for selection of a deposit in the database is that there are comprehensive and reliable data available in the literature, typically at least two references in peer-reviewed journals.
An implicit assumption is that the deposit data in some way reflect the generation and transport of the ore-forming fluid(s), although relevant factors in the complex process of ore formation for most deposit types, such as tectonic setting and the generation and transport of a metal-bearing fluid from its source to site of deposition, are usually so poorly known and controversial as to be unsuitable for systematic analysis.
Deposit attributes
The selection of deposit attributes included in the database is based on the following criteria: (i) the attributes must include features which are generally included in deposit descriptions available in the literature; (ii) the attributes must cover a range of key features of various deposits and deposit classes; and (iii) the attributes must focus on describable features that are not, as far as possible, interpretations. As discussed above, a broad range of deposit styles were included in this study. Despite this goal of diversity, some similar and related deposits were included to test the classification tools. Most attributes were represented with the following values (using the example of commodity): 0 = absent, 1 = minor component or by-product, and 2 = major, abundant or extracted commercially. The absence of a documented lack of a characteristic was taken to mean unknown. All categorical data were converted to binary form (i.e. 0 = characteristic absent, 1 = present). Five groups of attributes were then selected to represent characteristics of deposits which may reflect the major processes involved in ore formation: fluid chemistry and ore-precipitation process, ore texture and geometry, host-rock, ore mineralogy and chemistry, and alteration mineralogy and chemistry. The specific attributes recorded in these groups are described below.
Fluid chemistry and ore-deposition process
Fluid chemistry and ore-deposition process together are taken as a proxy for the ore fluid, despite influences of the chemistry at the site of deposition and changes in physico-chemical conditions during ore deposition reactions. Fluid chemistry includes estimates of minimum and maximum temperature of ore deposition, salinity of the ore fluid, range of fO2 fCO2, fCH4 (recorded as a number corresponding to the negative log of the actual value), and whether the ore fluid was oxidised or reduced. The salinity, CO2, and CH4 contents of fluid inclusions are scored in a simplified form in which the maximum salinity (NaCl wt% equivalent) is recorded. The ore deposition process is accepted as described in the literature or, where such descriptions are lacking, inferred from ore textures; relevant characteristics are fluid – rock reaction, fluid mixing, fluid unmixing, fluid cooling, reduction, overpressuring, change in fO2 and change in pH. In complex systems, many factors may be interdependent, although, in many cases, particular processes dominate. Consequently, the scoring system (discussed in detail below) allows many factors to be equally important.
Ore structure, geometry and age of orebody
Ore structure here means a range of mesoscopic features with the following descriptors: massive sulfide, layered (along the bedding), infill, replacement, vein, breccia and recrystallised. Ore deposit geometry is the gross geometry and form of the deposit, and uses descriptors such as irregular breccia; stratabound; cleavage; fault/shear zone; pipe; multiple lenses; folded; vein; footwall stringer zone; mantos; other; minimum and maximum mineralisation age.
Host-rock
Host-rock is described in a simplified form in which a small range of rock types is used to encompass a broad spectrum of mineralogy, chemistry and chemical reactivity, with some structural components. The selected lithologies are: conglomerate, sandstone, shale-siltstone, limestone, dolomite, chert, iron-formation, volcanogenic sedimentary rocks, felsic volcanic, intermediate volcanic and mafic volcanic rocks, mafic intrusions, ultramafic rocks, porphyry, granite, metamorphic schist/gneiss, calc-silicate rocks and fault/breccia.
Ore mineralogy and chemistry
Ore mineralogy and chemistry comprise a non-exhaustive list of minerals that commonly occur in hydrothermal ore systems, such as quartz, muscovite, biotite, K-feldspar, chlorite, garnet, gold, oxides (e.g. magnetite) and sulfides (e.g. galena, sphalerite, chalcopyrite).
Alteration mineralogy and chemistry
The suite of alteration minerals described in the literature may to some extent duplicate the mineralogy as described above, where the alteration and ore are coincident. Alteration chemistry is assessed in terms of several major elements and oxides. Each element and oxide is ranked from 1 (strongly depleted elements) to 3 (conserved), and 5 (strongly enhanced elements).
Major fault database
Mineral exploration companies have long recognised the empirical relationship between ore deposits and major, potentially mantle-tapping structures and fault corridors (Groves et al. Citation1998; Sillitoe Citation2000; Haynes Citation2002; Grauch et al. Citation2003). Structures of this type are likely to provide pathways for fluids and play a major role in focusing mineralised fluids into the upper crust. Essentially, these zones represent trans-lithospheric columns of low strength and high permeability (Cox et al. Citation2001; Chernicoff et al. Citation2002). This recognition has been used as a guide in exploration and contributed towards the discovery of numerous deposits in modern and ancient terranes (e.g. Olympic Dam: Haynes Citation2002). On the other hand, not every major fault is metallogenically well-endowed, and many first-order faults appear to contain very little or no hydrothermal mineralisation (Bierlein et al. Citation2006 and references therein). The distinction between mineralised and unmineralised major faults is an issue of major importance to ore discovery. Consequently, the development of a set of critical parameters is likely to be a key step towards predictive mineral discovery. However, very little work has been aimed at understanding why certain lithospheric-scale fault systems and corridors are metallogenically well-endowed, whereas other seemingly identical faults are barren. Moreover, few attempts have been made to systematically classify, let alone prioritise, the fundamental criteria that distinguish metallogenically endowed from barren faults.
The geometry of many metallogenically well-endowed fault systems and corridors is highly non-linear (Blenkinsop & Bierlein Citation2004; Weinberg et al. Citation2004; Hodkiewicz et al. Citation2005), as these faults commonly record a complex kinematic history, including switching from compressional to transpressional convergence, and reversal of movement (Sibson Citation2001). Recurring themes include the presence of complex lithostratigraphic sequences with strong rheological contrasts which promote strain partitioning (Cox et al. Citation2001), proximity to ancient plate margins and suture zones (Robert & Poulsen Citation2001), the presence of mafic to intermediate igneous rocks (providing a possible link to asthenospheric input: Bierlein et al. Citation2001), extensive alteration resulting from the advective/convective throughput of large fluid volumes, and geometric aspects such as far-field orientation, fault misalignment and length, and the nature of displacement and relay zones between fault segments (Cowie & Scholz Citation1992; Peacock Citation2003). Many of the parameters listed above are empirical or are based on theoretical considerations and lack systematic testing, especially where the density of available datasets is low.
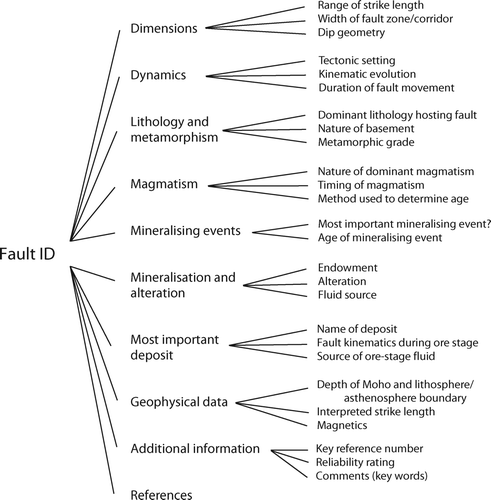
Based on these principles, a database was developed to identify geological, geophysical and geochemical parameters that are common to well-endowed fault systems. The database comprises major faults with a minimum strike length of 100 km from all continents and geological eras, independent of degree of endowment and associated ore commodity. The initial database structure was developed with a series of 11 Microsoft Excel spreadsheets that comprehensively characterise each individual entry (i.e. faults, fault corridors and mineralised trends: ) on the basis of 130 geological, geochemical and geophysical criteria. Each spreadsheet was designed to capture attributes that describe major faults in terms of, for example, fault dimensions, dynamics, lithology and metamorphism, magmatism, mineralisation and alteration. The spreadsheets contain up to 30 attribute columns which allow for the entry of both alpha-numerical and numerical information into cells via the selection of descriptive terms (e.g. phrases, nouns, adjectives or digits) selected from pull-down menus associated with each column. The spreadsheets also include data on ore deposits associated with each mineralised fault, and text-based fields that allow for the entry of geographical information, key references and additional comments. Conversion of the database from a spreadsheet- to an XMML-based structure enabled a broad range of users to create, retrieve and revise tectonic target information, while increasing the portability of the database via remote-login. A Java J2EE user interface with an Oracle database backend was used to collect data in the web-based online system. These data could then be downloaded into an Excel spreadsheet for editing. The Borland dbExpress database package was used with JBuilder to help map the spreadsheet data to the web pages. A suite of code generation and data analysis tools was developed in Visual Basic (by R. Woodcock & A Dent, CSIRO), to run within Excel. This suite made it easy to identify inconsistent data and export data so that later versions of the Excel spreadsheet could be uploaded into the online database. The final database application that was deployed allows for all the data to be viewed, edited and presented as overview lists in a similar format to the original Excel spreadsheet. The analysis tools enable simple queries to be formulated so that patterns in the data could be explored. Data can be retrieved on the basis of user-defined input parameters such as geographical location (e.g. Yilgarn Craton, Tasmanides, Mt Isa Inlier, South Andes) or commodity/deposit type (e.g. orogenic gold). Likewise, users can query the database for individual or combined geological, geophysical and geochemical criteria, compare and contrast the growing number of mineralised and barren fault systems contained in the database, and obtain information on specific fault systems, mineral deposit types and relevant references.
Figure 1 Schematic structure of the major fault database.
The fault database includes approximately 200 attributes with a mixture of data types [ordinal (e.g. ages); nominal (e.g. fault kinematics and tectonic settings); binary (yes/no)]. Invariant attributes, where only one class is represented, were removed (the attribute value unknown was not used) for the analyses herein. Earlier analyses indicated a strong bias towards age-related groups. As many attributes in the database include age data (e.g. age of fault, age of intrusion), these ages were removed from the subsequent analysis presented here except for one very broad and nominal age attribute: Archean, Proterozoic, Paleozoic, Mesozoic, Cenozoic. After validation and editing, the data that were analysed comprised 118 faults (including a blank) with 80 attributes, although some attributes were poorly populated. For the analysis, data were treated as follows: (i) ordinal data were not recoded, except age data which were removed for reasons explained above; (ii) nominal classes were recoded to numeric values for the phenetic analysis described below, although this presents a problem for the definition of group characteristics that cannot be coded in simple terms of 1, 2, 3, etc.; (iii) orientation data were coded into groups (e.g. 0 – 15° = 1); and (iv) binary data were coded as No = 0, Yes = 1. It is important to note that, because of the diverse types of data and their treatment, characteristics used to define and distinguish classes of faults derived from the analysis are not exhaustive, and other factors may be relevant.
At the end of 2005, the database contained a total of 138 major faults, of which 84 are mineralised (61% of total), and 54 are unmineralised faults (39%). Of the 84 mineralised faults in the database, 54 are associated with gold mineralisation. Of the 138 major faults, 30 faults are located in the Yilgarn Craton. The full version of both the fault and mineral deposit databases is available at <https://pmd-twiki.arrc.csiro.au/twiki/bin/view/Pmdcrc/ProjectA1>. Access to this site and the full reports (Lees Citation2004; Bierlein Citation2005) is currently restricted to stake holders of the Cooperative Centre for Predictive Mineral Discovery (pmd*CRC), but these are expected to be available in the public domain after the expiry of confidentiality agreements in 2008.
Data-analysis methods
Deposits were analysed, characterised and classified into natural groups using three software packages: CSOM (CSIRO's Self-Organising Maps: Sliwa et al. Citation2003; Fraser & Dickson Citation2005, Citation2006; Fraser et al. Citation2006); PATN (Pattern Analysis Software Package: Belbin Citation1995); and PAUP (Phylogenetic Analysis Using Parsimony: Swofford & Begle Citation1993). These techniques are described below.
CSIRO self-organising map (CSOM)
The following is a brief introduction to the self-organising map (SOM) approach, and the reader is referred to Kohonen (Citation2001) for more details. Self-organising map analysis procedures are widely used in fields such as finance, industrial control, speech analysis (Kaski Citation1997) and astronomy (Garcia-Berro et al. Citation2003), and the approach is increasingly accepted in the petroleum industry to assist in the calibration and interpretation of well-logs and seismic data (Briqueu et al. Citation2002; Strecker & Uden Citation2002). The CSIRO has developed its own implementation of the self-organising map (CSOM) data-mining approach, which is broadly based on the Matlab SOM Toolbox (Kohonen et al. Citation1996; Vesanto et al. Citation2000), but modified in terms of the algorithms and visualisations needed for Earth-science and spatial applications (Sliwa et al. Citation2003; Fraser & Dickson Citation2005). SOM is a data analysis, visualisation and interpretation tool that is based on the principles of vector quantisation and measures of vector similarity. While most SOM procedures can be considered exploratory, they can be used to perform broad categories of operations, including: (i) function fitting, prediction or estimation; (ii) clustering, pattern recognition or noise reduction; and (iii) classification.
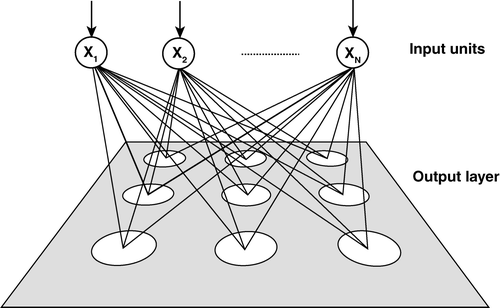
In SOM analysis, each sample is treated as an n-dimensional (nD) vector in a data space defined by its variables. This sample vector quantisation approach means that both continuous (e.g. geochemical assays, structural orientation data) and categorical variables (e.g. observed characteristics, rock types) can be used as inputs, making the SOM technique ideal for the analysis of complex and disparate geoscientific data. In addition, because SOM is unsupervised, no prior knowledge is required as to the nature or number of groupings within the dataset. These features are why the SOM technique has advantages over other more conventional analysis methods such as clustering (both hard and fuzzy), factor analysis, principal components and traditional neural networks (Kohonen et al. Citation1996; Brown et al. Citation2000; Vesanto et al. Citation2000; Fraser & Dickson Citation2005). The output of SOM analysis is typically a 2D rectilinear self-organised map that is composed of cells (nodes), each of which represents a node-vector in the data space defined by the variables (). These node vectors have been ‘trained’ to represent the original distribution of the samples in those data by the process described below. The nD data space defined by the input samples is seeded (typically randomly) by a defined number of seed-vectors. The number of seed-vectors is defined by the size of the required output map: for example, a 12 × 8 sized map produces 96 seed-vectors. In an iterative, two-step process that is applied to each input sample many times, these seed-vectors are subsequently trained to represent the structure and patterns of the input samples in the dataset. In the first step, which is referred to as the competitive step, a given input sample is compared with all seed vectors within a particular radius of the input sample, and ultimately a winning seed vector is determined as being the most similar. This process is based on a measure of vector similarity (e.g. dot-product, cosine, Euclidean distance, etc.). Once the seed-vector closest to the input vector (i.e. the winning or best-matching unit) is defined, its properties are modified by a percentage so that its characteristics more closely resemble those of that nearest input sample. In the second step, which is known as the cooperative step, all the seed-vectors within a given radius of the winning seed-vector are also modified, so that their properties are also changed by a percentage to more closely resemble the input sample in question. This procedure is then repeated for the next input sample. By reducing the radius of influence, and changing the percentage modification applied to the seed-vectors during each iteration through all input samples, the seed-vectors become trained to represent the structure of the original input data (node vectors). This may involve running hundreds or thousands of iterations of the above procedures on each input sample. Once the seed-vectors have been trained to represent the structure of the input data (called node-vectors or best-matching units, BMUs), all the original input samples closest to that node-vector are represented by that node on the 2D map. A regression is used to map from nD space to the 2D rectilinear representation on the map. A key feature of this mapping is that it preserves the relative relationships (topology) between the node-vectors: that is, node-vectors that are close in nD space remain close on the 2D map. The original input samples are now represented by particular nodes on the self-organised map, and these may well form a group or cluster. However, if that node is close to other nodes on the map, those nodes may be a subset of a larger group of similar samples formed by all the samples belonging to nearby nodes as well. The final product is an orderly 2D representation of a complex multi-parameter dataset that provides an ideal framework for visualisation and interpretation. On the self-organised map, it is common to show those nodes that represent original input samples in white, and to make their size proportional to the number of samples that each represents.
Figure 2 Architecture of a self-organising map neural network (modified from Kohonen Citation1982; Dowla & Rogers Citation1995). See text for explanation.
The unified distance matrix (U-matrix: Ultsch & Vetter Citation1994) representation of the map indicates the closeness between adjacent nodes on the map in terms of Euclidean distance. A colour – temperature scale is used so that cooler colours (blues) separate adjacent nodes that are closer (similarity), and hotter colours indicate larger Euclidean separations (difference). To assist in this display, alternate dummy nodes are added to the U-matrix, and these are coloured according to the distance between adjacent nodes, whereas the nodes that represent actual vectors are coloured according to the average of the distances to its neighbours. This representation gives rise to a topographic analogy in that there are valleys of blue nodes that are similar, separated by walls of brighter coloured nodes that represent class-boundaries or samples belonging to different groupings.
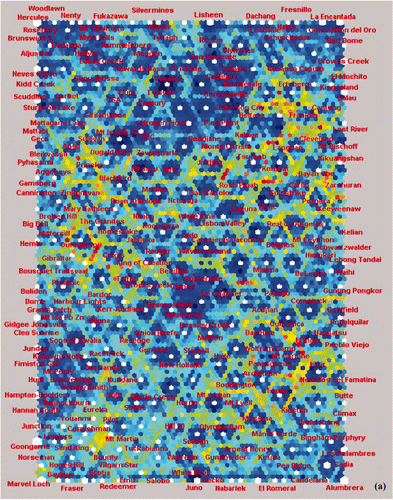
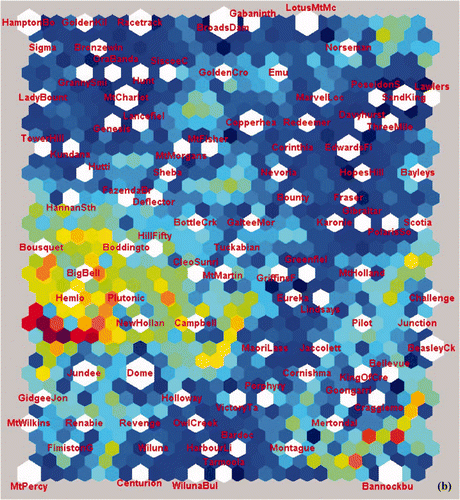
The mineral deposit data analysed using CSOM consisted of a subset of the overall database and contained 364 deposits. Each deposit was described using 156 attributes such as ore mineralogy, ore geochemistry, ore geometry and alteration mineralogy. The deposit name attribute was not used in the analysis, and no weighting of attributes was applied in the analysis. In order to test the effectiveness of this approach in clustering and classifying multivariate data in a hierarchical manner, a sub-set of Archean gold deposits from the global deposit database was analysed using CSOM. This database consisted of data from 112 mineral deposits each with 147 data fields. The mapped results with hit nodes in white, and represented in terms of size according to the number of hits per node, are shown in . Data fields in the major fault database were ascribed to 423 categorical fields during the SOM process. The final database consisted of 88 samples with some 89 fields after expansion of the categorical fields, and this database was input to the SOM.
Figure 3 (a) U-matrix output from the SOM analysis of the global mineral deposit database (364 deposits) showing groupings of deposits (uniform areas of cold colours) and boundaries between clusters (warm colours). (b) U-matrix output from the SOM analysis of a subset of 112 Archean gold deposits, mainly from the Yilgarn Craton in Western Australia and the Abitibi Belt in Ontario, Canada. Note: global is meant in the context of the data compilation including all commodity types, geographic locations and ages. Some deposit names are abbreviated due to a glitch in the software which allowed for nine letters per label only: e.g. Boddingto, Boddington; CleoSunri, Cleo-Sunrise; HamptonBo, Hampton-Boulder deposit; GrannySmi, Granny Smith; LadyBount, Lady Bountiful; NewHollan, New Holland (all Yilgarn Craton, WA).
Biological taxonomic approach to the analysis of databases
Two biological taxonomic approaches have been used to examine relationships within the databases: the phenetic and cladistic methods (Unda Citation2006). In both cases, computer algorithms are used to construct taxonomic trees. Several assumptions underlie the application of biological software to geological data. First, groups of hydrothermal mineral deposits formed from a common process; that is, they are part of a single, larger taxon or class of hydrothermal mineral deposits. This group involved the formation of a metal-bearing hydrothermal fluid and transport to a site of metal deposition, followed by the deposition of metals. Second, data (characteristics) are largely recordable features of mineral deposits that represent and reflect the processes of deposit formation, despite some post-mineralisation modification in some cases. Third, it is assumed that the data in the literature are reliable. If these assumptions are valid, then the data can be used to derive relationships between classes of deposits (cf. taxa) ranging from individual deposits (cf. genera) to larger groups, and these relationships can be displayed in a hierarchical system. It should be noted that, due to the different input formats required by the software packages, the data used in the three types of analysis (SOM, PATN and PAUP) differ slightly.
Phenetic method using PATN
The phenetic method (numerical taxonomy) is concerned with a measure of overall similarity between types of organisms (Belbin Citation1995). These similarities are determined using patterns of characteristics, generally morphological data or gene sequences, that can be expressed in numerical form. Measures of similarity are then used to identify clusters using an algorithm called UPGMA cluster analysis (Unweighted Pair Group Method, Arithmetic averaging: Sneath & Sokal Citation1973). The Pair Group Method uses a distance matrix in conjunction with the following algorithm to identify clusters (Carr Citation2006): (i) identify the minimum distance between any two taxa; (ii) combine these two taxa as a single pair; (iii) recalculate the average distance between this pair and all other taxa to form a new matrix; and (iv) identify the closest pair in the new matrix, and so on, until the last two clusters are joined. The clusters are represented as a type of phylogenetic tree called a phenogram or, more generally, a dendrogram (Belbin Citation1995). Note that the algorithm is a hierarchical procedure because it moves in a stepwise fashion to form an entire range of solutions, and it is a matter of subjective judgement as to how many groups to interpret from the results (Hair et al. Citation1998).
The algorithm described above is implemented in this study using the PATN program. This program is designed to test for similarities in morphological characteristics between species, without testing for relationships between the species, including genetics (Belbin Citation1995). Each mineral deposit was regarded as an individual species for this exercise. In principle, the characteristics should have some weighting according to their importance in formation of the deposit. Without other insights, it was assumed that characteristics were approximately equally weighted.
The mineral deposit database was analysed and a dendrogram produced, which was then simplified, interpreted and condensed into various groups which commonly correspond to the classic deposit styles (; ). The main division of deposits was into Pb – Zn deposits and Cu – Au – other metal deposits. Further subdivisions are shown in , which shows an interpreted output grid from the SOM analysis. The decision about how many clusters or groups to interpret from the hierarchical range presented in the dendrogram was made by comparing the similarity of the groups to well-known classes of deposit (Cox & Singer Citation1986; Solomon & Groves Citation1994; Franklin et al. Citation2005; Frimmel et al. Citation2005; Goldfarb et al. Citation2005; Large et al. Citation2005; Leach et al. Citation2005; Sillitoe Citation2005).
Figure 4 Simplified dendrogram of the major deposit types derived from the global mineral deposit database produced using the PATN phenetic analysis package (cf. ). The x-axis represents the degree of difference between related groups; the major division is between gold with other metals (upper nine groups) and deposit groups containing Pb and Zn (lower seven groups).
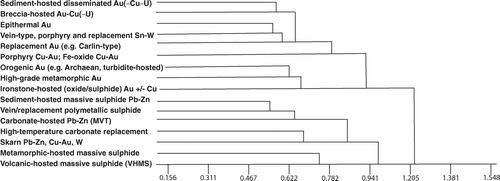
Figure 5 Simplified interpreted output grid from SOM analysis (cf. ), showing groupings corresponding to well-known classes of ore deposits. BHT, Broken Hill type; SHMS, sediment-hosted massive sulfide deposits; VHMS, volcanic-hosted massive sulfide deposits.
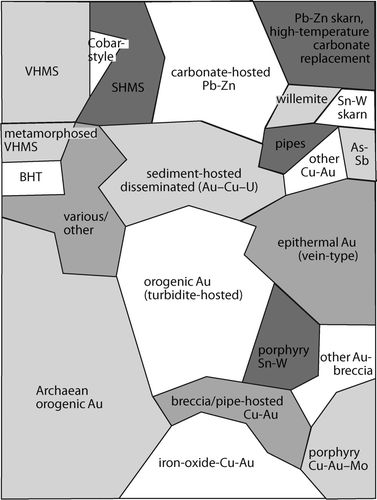
Table 1 Sixteen derived deposit groups with geological description and selected group characteristics that define those groups in terms of features and process.
Cladistic method: Phylogenetic analysis using parsimony (PAUP) using the example of orogenic-gold deposits
The cladistic method is concerned with the evolutionary relatedness: that is how closely related the groups are (Swofford & Begle, Citation1993). Central to this approach is the principle that organisms have evolved from a single common ancestor and that related organisms share common characteristics. The approach focuses on derived traits or characteristics that have evolved within the group under study rather than primitive traits that are present in the common ancestor and shared by all members of a group. Derived characteristics are more useful in explaining the evolutionary relationships, since characteristics that are not present in an ancestor of the whole group are most likely to have evolved from a more recent ancestor. Groups which have a common recent ancestor are most closely related. The PAUP software package was used to implement the cladistic method in this study (Swofford & Begle Citation1993). The algorithm uses the principle of maximum parsimony to construct a phylogenetic tree (). The algorithm compares different trees and selects the one that involves the least number of evolutionary changes to produce the current group from the common ancestor. These changes in characteristics are referred to as character changes where a character change is from a primitive state (character absent = 0) to a derived state (character present or abundant = 1 or 2). Parsimony is the criterion to find the phylogenetic tree or cladogram with simplest best-fit explanation. The geological rationale for using PAUP is that the mineral deposits of this single orogenic-gold class are genetically related, with the so-called parent or common denominator represented by (their derivation from) a regional-scale hydrothermal fluid (). Variation within the group is ascribed to variations in depositional mechanisms and conditions.
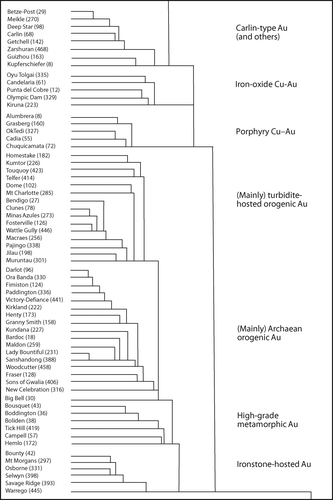
Figure 6 Excerpt from the dendrogram of the mineral deposit database produced using the PAUP cladistic analysis package. Figure illustrates the subdivision of 465 deposits into several gold-associated subclasses based on classifying attributes, and examples of deposits that are grouped into these subclasses. See text for discussion. Numbers after deposit names refer to the ID number in the database.
The mineral deposit database was analysed in PAUP. Several characteristics from the database had to be modified as the software only accepts integer data. In the interpretation of the cladistic analysis, it is important to remember that the data are entered as 0, 1, 2 referring to the abundance of a characteristic, for example, an ore or alteration mineral. A trend of 0 ⇒ 1 ⇒ 2 in a characteristic is interpreted as evolutionary. This is different to how geologists view the evolution of mineral systems. However, the approach highlights the characteristics which differentiate one group of deposits from another. This is logical in terms of the data, but requires separate analyses of major classes of deposits if the data are to be correctly interpreted in terms of mineral system evolution. Interpretation of these trees is difficult because they represent evolutionary changes of all of the characteristics for a large range of deposits. Thus, they will not be the same as phenetic trees, and some groups, clusters and individuals will appear out of place or geologically unreasonable. Nevertheless, the phylogenetic analysis shows some clear trends (). Lack of data appears to be a factor in some cases, causing what are geologically similar deposits to be characterised differently. Combinations of characteristics separate the main groups and subgroups of deposits. An example of the trends in the PAUP analysis is one of increasing metamorphic grade in groups of geologically similar mineral deposits. This seems to have a logical explanation in that increasing amounts of a new metamorphic mineral establish a 0 ⇒ 1 ⇒ 2 trend (e.g. a certain metamorphic mineral might be expected to be more abundant in higher grade deposits).
Results
Analysis of mineral deposit data
shows a U-matrix representation resulting from the CSOM analysis of the global mineral deposit database. An analysis of the distribution of deposit names on the nodes of the map into traditional mineral ore-type associations () shows that the SOM groupings, for the most part, correspond well to known classes of ore deposits (Cox & Singer Citation1986; Solomon & Groves Citation1994; Franklin et al. Citation2005; Frimmel et al. Citation2005; Goldfarb et al. Citation2005; Large et al. Citation2005; Leach et al. Citation2005; Sillitoe Citation2005). The major separation is between Pb – Zn (top) and Cu – Au (bottom) deposits (, ).
The corners of the map represent groupings that are significantly different from each other: these are massive Pb – Zn sulfides (top left ); Pb – Zn skarns (top right ); orogenic Au (lower left ; see also ); and porphyry Cu – Au (lower right ). Extending outward from the porphyry Cu – Au corner are other intrusion-related deposits, with a range of styles and commodities from Cu – Au along the lower margin, to epithermal deposits and skarns on the upper-right side. Smaller clusters commonly occur within the larger groups. Pb – Zn deposits include VHMS, the Cobar-style replacement deposits (Solomon & Groves Citation1994), sediment-hosted massive sulfides, and carbonate-hosted deposits comprising both MVT and Irish-type (Leach et al. Citation2005). Willemite deposits (Hitzman et al. Citation2003) form a small, but distinctive, group among other carbonate-hosted Pb – Zn deposits. Pipe-like and breccia-hosted Pb – Zn deposits also form small groups (Leach et al. Citation2005). Metamorphic rock-hosted Pb – Zn deposits form two small groups: a probable metamorphosed VHMS group adjacent to the likely VHMS parent, and Broken Hill-type deposits usually regarded as metamorphosed equivalents of sediment-hosted Pb – Zn deposits (Large et al. Citation2005) which are also shown in , . It is notable that high-temperature carbonate replacement deposits and Pb – Zn skarns, which are generally considered to represent the other end of the Pb – Zn spectrum (Large et al. Citation2005), are shown on on opposite sides of the SOM output grid. Between skarns and porphyry Cu – Au are several groupings comprising epithermal Au – Ag, breccia and replacement Au – Cu, and Au – As – Sb deposits. Porphyry Cu – Au ± Mo deposits (lower right of ), including other intrusion-related mainly Cu – Au styles such as iron oxide Cu – Au, pipe- and breccia-hosted Cu – Au and porphyry Sn – W deposits (Sillitoe Citation2005), are located close to one another in the output grid (, ).
Orogenic-gold deposits are dominated (at least in numbers in this analysis) by Archean gold deposits, but many smaller clusters are apparent. Another major group is the largely Paleozoic, turbidite-hosted, orogenic Au group of deposits (Goldfarb et al. Citation2005). In the centre of the interpreted map is the sediment-hosted disseminated Au ± Cu ± U cluster, which can be resolved into even smaller subgroups (not shown in ) of conglomerate Au – U, unconformity U, and Copper Belt Cu – Co styles (Frimmel et al. Citation2005). Other groups and various miscellaneous deposits contain a mixture of replacement deposits and unusual Au deposits; examples in this group include Crixas (Brazil), Outokumpu (Finland) and Mary Kathleen (Queensland, Australia). Although all characteristics play a part in determining the output clusters, it appears that limited groups of characteristics are principally responsible for separating deposits into the main mineral deposit groups. These include commodity, ore chemistry, ore texture and geometry (e.g. massive sulfide vs vein- or breccia-pipe-hosted).
In the context of the current study, the main point of the phenetic and genetic analyses is to define a coherent group, Archean orogenic gold, on which subsequent spatial analyses can be performed. In a global context, the group of orogenic-gold deposits (Groves et al. Citation1998; Goldfarb et al. Citation2005) form a distinct and coherent group, defined in the analysis by characteristics such as: (i) vein morphology; (ii) hosted by fault or breccia; (iii) quartz as the main gangue; (iv) gold as the main ore mineral; and (v) low fluid salinity. The lack of certain other characteristics such as massive sulfide or bedding-parallel helps to define the cluster as a coherent group. As these types of analyses are by their nature hierarchical, the orogenic-gold group of deposits comprises a number of subgroups down to the level of individual deposits (possibly equivalent to a species by analogy with biology). Nonetheless, the intermediate levels of subgroup retain coherent patterns which become increasingly relevant at the scale of Archean cratons.
Within the orogenic-gold group defined by the cladistic analysis using PAUP (), the turbidite-hosted orogenic-gold deposits, exemplified by those of the Paleozoic Lachlan Fold Belt, are distinct (Goldfarb et al. Citation2005). Several of the Archean gold deposits from the Yilgarn Craton in Western Australia also fall within this group, which is obviously dominated by the host-rock character and alteration assemblages related to the parent rock type. However, the majority of Archean orogenic-gold deposits fall within a large group that encompasses deposits from major Archean terranes such as the Yilgarn, Canadian and African cratons (). A small subgroup at this level (i.e. within the group of Archean orogenic-gold deposits: ) comprises an apparently intrusion-related category of deposits, including the porphyry-type Cu – Au – Mo Boddington in the southwest Yilgarn Craton (Roth et al. Citation1991), with distinguishing characteristics such as albitic and potassic alteration, tourmaline and intrusive host-rocks. Endowment of this group (as contained Au, a characteristic not included in the input data) is significantly above that of the average for Archean orogenic-gold deposits. Further subdivision of the orogenic-gold group shows the influence of other factors, such as iron-rich host-rocks and metamorphic grade ().
Analysis of major fault data
Simple database query using Boolean logic
A first-pass analysis of the data suggest that a conjunction of factors is common to the majority of mineralised faults. Many of these factors reflect conditions that are generally considered favourable for the formation of orogenic-gold deposits (). These include the presence of spatially associated mafic to intermediate intrusive rocks (in 73% of mineralised faults, compared with 50% of unmineralised faults), a high degree of fault non-linearity at the current level of erosion (86% vs 64%), and association with collisional orogenic (60% vs 39%) rather than intra-plate settings (11% vs 15%, respectively). Interestingly, 33% of mineralised faults extend to <10 km depth compared with 17% of unmineralised faults (based on geological and/or geophysical data from the literature). Conversely, 56% of mineralised faults extend for >10 km into the crust, compared with 63% of their unmineralised counterparts. The width of the fault corridor is <1 km for 54% of mineralised faults vs 44% of unmineralised faults. Mineralisation is associated with 26% of faults that can be defined as master structures, compared with 66% of spatially associated, semi-parallel structures. Likewise, 76% of mineralised faults have a geological extent of between 100 and 200 km (vs 37% of unmineralised faults). Perhaps not surprisingly, the rheology of 88% of mineralised faults is dominated by brittle/ductile conditions (vs 64% of unmineralised faults), and only 12% of mineralised faults occur in brittle-dominated settings (vs 29% of unmineralised faults).
Table 2 Example output generated by simple queries of the major fault database using Boolean logic.
The database provides a useful resource, and its interrogation serves to confirm the importance of parameters that are likely to influence the endowment of major faults, and spatially associated 2nd- and 3rd-order structures. On the other hand, the information contained in the present database remains insufficient to clearly identify new parameters, let alone rank potentially critical parameters. It is estimated that at least one order of magnitude more than the current number of fault entries would be required to achieve this objective. Interrogation and analysis of the existing data have also revealed several issues that limit the use of the database in developing and testing predictive targeting strategies. First, literature-based descriptive information entered into the database is largely interpretative and subjective, despite continuous efforts to filter and control the quality of the data. Second, the information is to a large extent non-spatial, which renders direct comparisons between both documented and unknown structures difficult, especially in terms of 3D assessments. Finally, many faults, especially major unmineralised structures, remain poorly defined and are poorly documented in the literature. In this regard, a too broadly defined database, even if well structured, is likely to remain inferior in a predictive sense when compared with a high-density dataset assessment of a small number of specific faults or fault pairs in an area of interest.
Phenetic and SOM analysis
As with the mineral deposit data, the filtered fault data were analysed using CSOM and phenetic (PATN) methods. Two phenetic analyses were performed. The first analysis divided faults into six groups (). On first inspection, these groups appear to correspond to broad ages (eras) of the faults, although as virtually all age data were removed, the groups must actually represent differences in fault morphology. The group of Precambrian faults is clearly subdivided into Archean and Proterozoic faults. However, this division is actually due to attributes such as fault geometry (length, width, depth), mineralisation factors (endowment, proximity of deposits to fault, fluid chemistry), metamorphic factors (retrograde or prograde, metamorphic grade, change in metamorphic grade across fault), and the presence of basement and ophiolites.
Figure 7 Summary of six fault groups. The clusters correspond roughly to the age of the faults despite the fact that only one of the eight database attributes contains age data. The distinction between the clusters is due to differences in fault morphology (dip, strike, linearity, etc.). Note that there are relatively large differences between the clusters as indicated by the high x-axis values (Euclidean distance between groups) at which the clusters join.

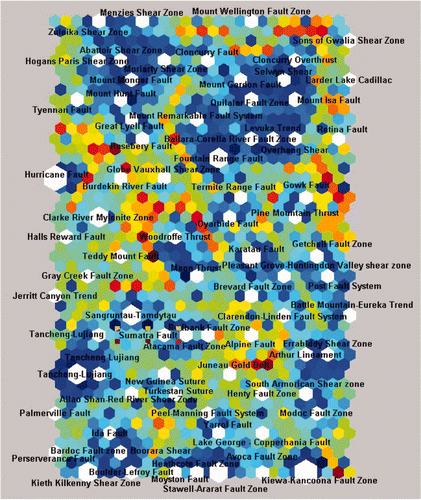
The second analysis into 11 groups separates Archean and Proterozoic faults (Appendix 1). At this level, the Gowk Fault in Iran is very different from the other faults in the database, not only because it occurs in unmetamorphosed rocks, but also because it has few other data for comparison. Some otherwise seemingly coherent groups are split, as can be expected in view of the relatively small and poorly populated dataset containing too many attributes. The main characteristics causing the split into groups (in both the six-group and 11-group analysis) are: mineralisation (yes/no), dip geometry, depth extent, width, whether the fault is tectonically active, presence of ophiolites, whether inversion or retrograde metamorphism has occurred, whether the mineralisation on the fault is related to the regionally Most Important Mineralising Event (MIME), and the endowment of mineral resources. The CSOM analysis of the fault database shows a similar and intriguing picture (). Although minimal age data are included in the analyses, faults are sorted into groups approximating general ages. Attributes apart from age, such as metamorphic grade, presence of basement, and fault geometry determine these broad groupings. Clearly, preliminary analysis of the fault database shows some promising results; however, the main constraints are an insufficient number of faults (as noted above, ≫200 entries are required), incomplete attribute data, and the fact that many of the data are categorical rather than spatial.
Figure 8 Output of the SOM analysis of a subset of 88 faults from the major fault database showing the U-matrix. Uniform areas of cold colours indicate groupings, and warm colours indicate the boundaries between clusters. In this representation of the output grid, additional cells are shown within each pair of the 24 × 14 output nodes to indicate the distance to the nearest neighbour in terms of similarity of the input pattern. The size of output units shown in white indicates the relative number of input patterns which correspond to that cluster.
Discussion and conclusions
The major classes of mineral deposits in the literature are commonly poorly defined, being based on various combinations of holotypes, commodity and genesis. However, consistent repeatable analysis of carefully collected data using well-defined characteristics can be used to determine the natural groupings of mineral deposits and determine which properties define and differentiate those groups. Groups defined by the analyses in this study generally agree with the major groups in the literature (e.g. VHMS, MVT, sediment-hosted Pb – Zn – Ag, orogenic gold), and subtle differences within and between groups reveal useful relationships across these, such as host-rock, ore chemistry, ore texture and geometry.
Statistical analyses are best undertaken on deposits of one genotype and with similar controls. To establish such groups, data analyses using self-organising map, phenetic and cladistic methods (SOM, PATN and PAUP) can be applied. These analyses show: (i) the importance of covering all commodity types, geographic locations and ages; (ii) that traditional classifications are broadly correct but inadequately define deposit types; and (iii) that the main attributes that define these groups can be determined. Applied to an area such as the Yilgarn Craton, such an approach can aid in defining deposits of a single coherent group, although itself comprising a number of subgroups which may be interesting to investigate further. The software methods used in this study have application to project generation in poorly known terranes. In light of these results, specific exploration models aimed at a given type of mineral deposit, or style of mineralisation, may need to be reviewed and revised. An example is the Archean gold deposits, where most deposits fit the traditional orogenic model, but some deposits and groups appear to be significantly different.
Interrogation of major fault and mineral deposit databases confirms the relative importance of empirically derived, critical and permissive parameters for mineralisation, such as proximity to crustal-scale faults and anticlinal hinge zones, dilational jogs and fault roughness, strong rheological contrasts, and metamorphic grade. The presence and concurrence of these parameters appear to determine the extent of metallogenic endowment of a given fault system and segments within it. Population of the major fault database is a prerequisite for reliable identification and ranking of factors that control fault endowment. Failure to obtain a statistically meaningful number of entries (≫200) has prevented more comprehensive and rigorous interrogation of the database, thus precluding the recognition and ranking of critical parameters. Nevertheless, using orogenic-gold mineralisation as an example, a first-pass multivariate analysis reveals a conjunction of factors that appears to be common to the majority of mineralised faults contained in the database. Factors considered favourable in the assessment of potentially mineralised faults include the presence of spatially associated mafic to intermediate intrusive rocks that can provide a potential source for the gold, an elevated degree of fault non-linearity, the presence of semi-parallel higher-order fault splays associated with long (100 – 200 km) and deep-seated master structures, pronounced rheological and/or metamorphic gradients across the fault, and fault location within collisional orogenic rather than intra-plate settings.
The pilot study presented herein illustrates the potential of computer-based methodologies for analysis of multivariate exploration datasets. In particular, applying these novel methods in combination has several advantages over approaches that use Boolean logic (i.e. prospective/non-prospective) in that they allow for the distinction between multiple degrees of prospectivity, or fertility. However, further work is needed to take the predominantly regional- to terrane-scale parameters considered here and apply them in project generation activities. In doing so, additional geological (e.g. fault parameters such as the role of intersections and dip directions), geochemical (e.g. camp-scale hydrothermal alteration patterns, fluid physio-chemistry) and geophysical datasets (e.g. aeromagnetics, edge-gradient amplitude variations) which impact at prospect scale (Bierlein et al. Citation2006) need to be investigated.
Acknowledgements
This study was conducted with the support of the predictive mineral discovery Cooperative Research Centre (pmd*CRC) and is published with the permission of the CEO, pmd*CRC. We are grateful to the following people for input into this study (in alphabetical order): A. Barnicoat, G. Begg, P. Betts, T. Blenkinsop, S. Cox, A. Dent, B. Dickson, B. Drummond, B. Goleby, G. Hall, S. Halley, B. Hobbs, J. Hronsky, C. Janka, R. Korsch, A. Morey, A. Ord, F. Robert, P. Roberts, R. Smith, C. Swaager, G. Tripp, I. Vos, J. Walshe and R. Woodcock. Juhani Ojala is thanked for constructive comments on an early version of this paper. The manuscript benefited greatly from a thorough review by David Groves.
References
- Belbin , L. 1995 . “ PATN Technical Reference; CSIRO Division of Wildlife and Ecology ” . Canberra : Report . (unpubl)
- Bierlein , F. P. 2005 . pmd*CRC Architecture A1 Project ‘What are the fundamental characteristics of mineralised (trans-lithospheric) fault systems?’ Cooperative Research Centre for Predictive Mineral Discovery Final Project Report , Melbourne : Monash University . pmd*CRC (unpubl.)
- Bierlein , F. P. , Hughes , M. , Dunphy , J. , McKnight , S. , Reynolds , P. R. and Waldron , H. M. 2001 . Trace element geochemistry, 40Ar/39Ar ages, Sm – Nd systematics and tectonic implications of mafic – intermediate dykes associated with orogenic lode gold mineralisation in central Victoria, Australia . Lithos , 58 : 1 – 31 .
- Bierlein , F. P. , Murphy , F. C. , Weinberg , R. F. and Lees , T. 2006 . Distribution of orogenic gold deposits in relation to fault zones and gravity gradients: targeting tools applied to the Eastern Goldfields, Yilgarn Craton, Western Australia . Mineralium Deposita , 41 : 107 – 126 .
- Blenkinsop , T. and Bierlein , F. P. Fault roughness and mineral endowment; a fractal approach . 4th international Conference on Fractals and Dynamic Systems in Geoscience, Technische Universität München . pp. 19 – 22 .
- Briqueu , L. , Gottlib-Zeh , S. , Ramadan , M. and Brulhet , J. 2002 . Traitement des disgraphies a l'aide d'un reseau de neurons du type ≪carte auto-organisatrice≫: application a l'étude lithogique de la couche silteuse de Marcoule (Gard France) . C.R. Geoscience , 334 : 31 – 337 . (2002)
- Brown , W. M. , Gedeon , D. , Groves , D. I. and Barnes , R. G. 2000 . Artificial neural networks: a new method for mineral prospectivity mapping . Australian Journal of Earth Sciences , 47 : 757 – 770 .
- Carr , S. M. 2006 . Course notes for Bio2900—Principles of Evolution and Systematics, Memorial University of Newfoundland, St John's . Online <http://www.mun.ca/biology/scarr/Bio2900.html>
- Chernicoff , C. J. , Richards , J. P. and Zappettini , E. O. 2002 . Crustal lineament control on magmatism and mineralization in northwestern Argentina: geological, geophysical, and remote sensing evidence . Ore Geology Reviews , 21 : 127 – 155 .
- Cowie , P. A. and Scholz , C. H. 1992 . Displacement-length scaling relationship for faults: data synthesis and discussion . Journal of Structural Geology , 14 : 1149 – 1156 .
- Cox D. P. & Singer D. A. eds. 1986. Mineral deposit models. US Geological Survey Bulletin 1693
- Cox , S. F. , Knackstedt , M. A. and Braun , J. 2001 . Principles of structural control on permeability and fluid flow in hydrothermal systems . Society of Economic Geologists Reviews , 14 : 1 – 24 .
- Dowla , F. U. and Rogers , L. L. 1995 . Solving Problems in Environmental Engineering and Geosciences with Artificial Neural Networks , Cambridge, MA : MIT Press .
- Franklin , J. M. , Gibson , H. L. , Jonasson , I. R. and Galley , A. G. 2005 . Volcanogenic massive sulfide deposits . Economic Geology 100th Anniversary Volume , : 523 – 560 .
- Fraser , S. J. and Dickson , B. L. Ordered vector quantization for the integrated analysis of geochemical and geoscientific data sets . From tropics to tundra: program & abstracts, 22nd International Geochemical Exploration Symposium, incorporating the 1st International Applied Geochemistry Symposium . September 19 – 23 2005 , Perth, Western Australia. pp. 52 – 53 . Canning Bridge, WA : Promaco Conventions . Association of Applied Geochemists
- Fraser , S. J. and Dickson , B. L. 2006 . “ Data mining geoscientific data sets using self organizing maps ” . In Mastering the Data Explosion in the Earth and Environmental Sciences, Extended Abstracts , 5 – 7 . Canberra : Australian Academy of Science .
- Fraser , S. J. , Mikula , P. A. , Lee , M. F. , Dickson , B. L. and Kinnersly , E. 2006 . “ Data mining mining data—ordered vector quantisation and examples of its application to mine geotechnical data sets ” . In Rising to the Challenge Edited by: Dominy , S. 259 – 268 . Australasian Institute of Mining and Metallurgy Publication Series No. 6/2006
- Frimmel , H. E. , Groves , D. I. , Kirk , J. , Ruiz , J. , Chesley , J. and Minter , W. E. L. 2005 . The formation and preservation of the Witwatersrand Goldfields, the world's largest gold province . Economic Geology 100th Anniversary Volume , : 769 – 797 .
- Garcia-Berro , E. , Santiago Torres , S. and Isern , J. 2003 . Using self-organizing maps to identify potential halo white dwarfs . Neural Networks , 16 : 405 – 410 .
- Goldfarb , R. J. , Baker , T. , Dubé , B. , Groves , D. I. , Hart , C. J. R. and Gosselin , P. Distribution, character and genesis of gold deposits in metamorphic terranes . Economic Geology 100th Anniversary Volume . pp. 407 – 450 .
- Grauch , V. J. S. , Rodriguez , B. D. and Bankley , V. 2003 . Evidence for a Battle Mountain – Eureka crustal fault zone, north-central Nevada, and its relation to Neoproterozoic – Early Paleozoic continental breakup . Journal of Geophysical Research , 108 ( B3 ) : 2140
- Groves , D. I. , Goldfarb , R. J. , Gebre-Mariam , M. , Hagemann , S. G. and Robert , F. 1998 . Orogenic gold deposits: a proposed classification in the context of their crustal distribution and relationship to other gold deposit types . Ore Geology Reviews , 13 : 7 – 27 .
- Hair , J. F. Jr , Anderson , R. F. , Tatham , R. L. and Balck , W. C. 1998 . Multivariate Analysis , Upper Saddle River, NJ : Prentice Hall .
- Haynes , D. W. 2002 . “ Giant iron oxide – copper – gold deposits: are they in distinctive geological settings? ” . In Giant Ore Deposits: Characteristics, Genesis and Exploration Edited by: Cooke , D. R. and Pongratz , J. 57 – 77 . University of Tasmania CODES Special Publication 4
- Hedenquist J. W. Thompson J. F. H. Goldfarb R. J. Richards J. P. 2005 Society of Economic Geologists Economic Geology 100th Anniversary Volume, 1905 – 2005
- Hitzman , M. W. , Reynolds , N. A. , Sangster , D. F. , Allen , C. R. and Carman , C. E. 2003 . Classification, genesis, and exploration guides for nonsulfide zinc deposits . Economic Geology , 98 : 685 – 714 .
- Hodkiewicz , P. F. , Weinberg , R. F. , Gardoll , S. J. and Groves , D. I. 2005 . Complexity gradients in the Yilgarn Craton: fundamental controls on crustal-scale fluid flow and the formation of world-class orogenic-gold deposits . Australian Journal of Earth Sciences , 52 : 831 – 842 .
- Kaski , S. 1997 . Data exploration using self-organizing maps . Acta Polytechnica Scandinavica, Mathematics, Computing and Management in Engineering, Series No. 82
- Kohonen , T. Clustering, taxonomy, and topological maps of patterns . Proceedings of the 6th International Conference on Pattern Recognition . pp. 114 – 128 . Los Alamitos, CA : IEEE Computer Society Press .
- Kohonen , T. 2001 . Self-Organizing Maps , (3rd extended edition) , Berlin : Springer . (Springer Series in Information Sciences Vol. 30)
- Kohonen , T. , Hynninen , J. , Kangas , J. and Laaksonen , J. 1996 . SOM_PAK: The self-organizing map program package . Helsinki University of Technology, Laboratory of Computer and Information Science, Report , A31 Online <http://www.cis.hut.fi/research/som_lvq_pak.shtml>
- Large , R. R. , Bull , S. W. , McGoldrick , P. J. , Walters , S. , Derrick , G. M. and Carr , G. R. Stratiform and strata-bound Zn – Pb – Ag deposits in Proterozoic sedimentary basins, northern Australia . Economic Geology 100th Anniversary Volume . pp. 931 – 964 .
- Leach , D. L. , Sangster , D. F. , Kelley , K. D. , Large , R. R. , Garwen , G. , Allen , C. R. , Gutzmer , J. and Walters , S. Sediment-hosted Pb – Zn deposits: a global perspective . Economic Geology 100th Anniversary Volume . pp. 561 – 608 .
- Lees , T. 2004 . “ Analysis of mineral deposit and faults databases ” . In Project A1 Progress Report, Cooperative Research Centre for Predictive Mineral Discovery. pmd*CRC , Melbourne : Monash University . (unpubl.)
- Peacock , D. C. P. 2003 . Propagation, interaction and linkage in normal fault systems . Earth-Science Reviews , 58 : 121 – 142 .
- Robert , F. and Poulsen , K. H. 2001 . Vein formation and deformation in greenstone gold deposits . Society of Economic Geologists Reviews , 14 : 111 – 155 .
- Roth , E. , Groves , D. , Anderson , G. , Daley , L. and Staley , R. 1991 . “ Primary mineralization at the Boddington gold mine, Western Australia: an Archean porphyry Cu – Au – Mo deposit ” . In Brazil Gold '91 , Edited by: Ladeira , E. A. 481 – 488 . Rotterdam : Balkema .
- Sibson , R. H. 2001 . Seismogenic framework for hydrothermal transport and ore deposition . Society of Economic Geologists Reviews , 14 : 25 – 50 .
- Sillitoe , R. H. 2000 . Gold-rich porphyry deposits: descriptive and genetic models and their role in exploration and discovery . Society of Economic Geologists Reviews , 13 : 315 – 345 .
- Sillitoe , R. H. 2005 . Supergene oxidised and enriched porphyry copper and related deposits . Economic Geology 100th Anniversary Volume , : 723 – 768 .
- Sliwa , R. , Fraser , S. J. and Dickson , B. L. Application of self-organising maps to the recognition of specific lithologies from borehole geophysics . Proceedings of the 35th Symposium on Advances in the Study of the Sydney Basin . Edited by: Hutton , A. C. , Jones , B. G. , Carr , P. F. , Ackerman , B. and Switzer , A. C. pp. 105 – 113 . Wollongong, NSW : University of Wollongong .
- Sneath , P. H. A. and Sokal , R. R. 1973 . Numerical Taxonomy. The Principles and Practice of Numerical Taxonomy , San Francisco : W. H. Freeman & Co .
- Solomon , M. and Groves , D. I. 1994 . The Geology and Origin of Australia's Mineral Deposits , Oxford : Oxford University Press . (Oxford Monographs in Geology and Geophysics 24)
- Strecker , U. and Uden , R. 2002 . Data mining of poststack seismic attribute volumes using Kohonen self-organizing maps . The Leading Edge , 21 ( 8 ) : 1032 – 1036 .
- Swofford , D. L. and Begle , D. P. 1993 . PAUP Phylogenetic Analysis Using Parsimony; Version 3.1 March 1993 User's Manual , Smithsonian Institute Laboratory for Molecular Systematics . Online <http://paup.csit.fsu.edu/about.html>
- Ultsch , A. and Vetter , C. 1994 . Self organizing feature maps versus statistical clustering: a benchmark . University of Marburg, Department of Mathematics and Computer Science Technical Report No. 9
- Unda , F. 2006 . Introduction to Phylogenetics Online <http://www.bioteach.ubc.ca/Biodiversity/Phylogenetics/index.htm>
- Vesanto , J. , Himberg , J. , Alhoniemi , E. and Parhankangas , J. 2000 . SOM toolbox for Matlab 5 . Helsinki University of Technology, Laboratory of Information and Computer Science Report , A57 Online <http://www.cis.hut.fi/projects/somtoolbox>
- Weinberg , R. F. , Hodkiewicz , P. F. and Groves , D. I. 2004 . What controls gold distribution in Archean terranes? . Geology , 32 : 545 – 548 .
- Wyborn , L. A. I. , Gallagher , R. and Raymond , O. Using GIS for mineral potential evaluation in areas with few known mineral occurrences . 2nd National Forum on GIS in the Geosciences Proceedings . pp. 199 – 211 . Australian Geological Survey Organisation Record 1995/46
- Wyborn , L. A. I. , Heinrich , C. A. and Jaques , A. L. Australian Proterozoic mineral systems: essential ingredients and mappable criteria . Australasian Institute of Mining and Metallurgy Annual Conference Proceedings . pp. 109 – 115 .
Appendix 1: Group membership of patn analysis of 118 faults divided into 11 distinct groups.