Abstract
This article presents a new unified approach to modeling grapheme-to-phoneme conversion for the PLATTOS Slovenian text-to-speech system. A cascaded structure consisting of several successive processing steps is proposed for the aim of grapheme-to-phoneme conversion. Processing foreign words and rules for the post-processing of phonetic transcriptions are also incorporated in the engine. The grapheme-to-phoneme conversion engine is flexible, efficient, and appropriate for multilingual text-to-speech systems. The grapheme-to-phoneme conversion process is described via finite-state machine formalism. The engine developed for Slovenian language can be integrated into various applications but can be even more efficiently integrated into architectures based on finite-state machine formalisms. Provided the necessary language resources are available, the presented approach can also be used for other languages.
INTRODUCTION
State-of-the-art telecommunication services in multilingual environments demand the development of multilingual text-to-speech (TTS) systems that use language-specific resources. In such systems an efficient and flexible mechanism must be developed for using these resources. The other problem is that input texts in native language for TTS systems can contain a lot of words, or even phrases, in other languages. These words have a significant impact on the final intelligibility of the synthesized speech when not processed correctly in the TTS system. Both problems are also closely connected with grapheme-to-phoneme conversion (G2P), the problem mainly discussed in this article. It is therefore necessary to develop language-independent G2P engines capable of acting on various phonetic lexicons. Switching to new language must be flexible, fast, and easy, without the need of explicitly knowing the language's specific phonetic regularities.
Grapheme-to-phoneme conversion is one of many steps needed in a TTS system. The traditional options for G2P conversion are the use of explicit rules or lexicon look-up, or a combination of the two. In this article, the latter option is followed. The phonetic transcriptions are obtained by lexicon look-up, if a phonetic lexicon is available. However, for some languages huge lexica are needed to account for linguistic exceptions. Efficient representation of such resources is also needed to meet real-time TTS constraints. The problem remains for the grapheme-to-phoneme conversion of unknown words, especially the nonnative ones found in many texts.
Obtaining the correct phoneme string from any written text of a given language in an efficient and flexible way is not a trivial task for many languages. Many studies have been performed on how to automatically extract the grapheme-to-phoneme conversion rules by using various machine learning techniques, based on HMMs, NN, or classification and regression trees (CART, Hain, Citation2000; Suontausta and Hakkinenen, Citation2000; Galescu and Allen, Citation2002; Gelfand et al., Citation1991; Pagel, Lenzo, and Black, Citation1998). CART trees help to obtain the phonetic knowledge existing in a phonetic lexicon automatically; that is, without the need for linguistic expertise. Classification trees have already proven themselves to be appropriate prediction models, where various features can also be used.
This article presents a new unified approach for grapheme-to-phoneme conversion. The G2P engine is based on the finite-state machine (FSM) formalism. Its cascaded structure consists of several processing steps. The modules inside a G2P engine can be used in different orders. The addition of new modules to any position inside a cascade is very flexible. Modules are proposed for processing foreign words and phonological post-processing rules. Separation of language-dependent resources from the language-independent G2P engine is also performed. CART models are used in the engine. CART models are also proposed for homograph disambiguation and syllabification, represented as weighted finite-state transducers (WFST). Language-specific processing steps can be efficiently considered during the construction of the G2P engine (e.g., stress prediction must be performed for the Slovenian language before grapheme-to-phoneme mapping). There is some work required to transform the training data into a format appropriate for training CART models. In this article we propose using heterogeneous relation graphs that can be used for the flexible construction of complex linguistic features.
The article is organized as follows. The second section presents the general TTS system architecture, where the language-independent core is separated from the language-dependent resources. Then a brief description is given of the FSM machines used in the unified grapheme-to-phoneme conversion process and the language independent approach of the proposed unified G2P conversion is presented in more detail. Then the implementation of the unified G2P is described for the Slovenian language. The article concludes with an analysis of the proposed unified G2P conversion approach's main benefits.
THE TTS SYSTEM ARCHITECTURE
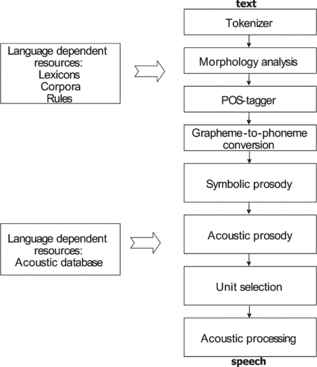
Figure presents the general architecture of the PLATTOS Slovenian TTS system, with separated language-dependent and language-independent parts of the TTS system. The language-dependent part represents external language resources such as lexicons, corpora, rules, and acoustic database. The language-independent engine consists of the following modules: tokenizer, morphology analyzer, POS tagger, grapheme-to-phoneme conversion module, symbolic and acoustic prosody modules, unit selection module, and acoustic module. All modules in the PLATTOS TTS system's architecture are based on finite-state machine formalism. Use of finite-state machines and classification and regression trees (CART) enables separation of language-dependent resources and trained models from the language-independent TTS engine (Rojc, Citation2003).
FIGURE 1 The architecture of the PLATTOS TTS system, with separated TTS engine and language-dependent resources.
FINITE-STATE MACHINES (FSM) FOR GRAPHEME-TO-PHONEME CONVERSION
The basic idea of handling linguistic analysis in TTS systems using WFSTs and Yarowsky's decision lists for homograph disambiguation implemented as WFSTs has been already discussed by Sproat and colleagues at Bell Labs (Sproat, Citation1998). They showed that FSMs are very appropriate formalisms for the representation of grapheme-to-phoneme conversion engines that can be efficient and flexible. Such engines can be even more efficiently integrated into FSM-based architectures (e.g., TTS systems and speech recognition systems).
Finite-state machines (FSM) represent an attractive solution as a unified framework for grapheme-to-phoneme conversion, since they have the following very interesting features (Emmanuel and Schabes, Citation1997):
Optimal speed: matching a string with a deterministic finite-state machine takes a time linearly proportional to the input size and is independent of the finite-state machine size; | |||||
Compactness; | |||||
Large-scale optimization: a lot of efficient algorithms exist; and | |||||
Modularity. | |||||
A finite-state automaton (FSA; Kuich and Salomaa, Citation1986; Hopcroft and Ullman, Citation1979; Daciuk, Citation1998; Mohri, Citation1995) can be seen simply as a directed graph with labels on each arc. A finite-state automaton A is a 5-tuple (Σ, Q, i, F, E) where Σ is a finite set called the alphabet, Q is a finite set of states, i ∊ Q is the initial state, F ⊆ Q is the set of final states, and E ⊆ Q × (Σ ∪ {ε}) × Q is the set of edges. FSAs are shown to be closed under union, Kleene star, concatenation, intersection, and complementation, thus allowing for natural and flexible descriptions. They are also very flexible due to their closure properties (Emmanuel and Schabes, Citation1997).
Finite-state transducers (FST; Mohri and Sproat, Citation1996; Mohri, Citation1994 Citation1997) can be interpreted as defining a class of graphs, a class of relations on strings, or a class of transductions on strings. In the first interpretation, an FST can be seen as an FSA, in which each arc is labeled by a pair of symbols rather than by a single symbol. A finite-state transducer T is a 6-tuple (Σ1, Σ2, Q, i, F, E), where Σ1 is a finite alphabet, namely the input alphabet; Σ2 is a finite alphabet, namely the output alphabet; Q is a finite set of states; i ∊ Q is the initial state; F ⊆ Q is the set of final states; and E ⊆ Q × Σ1∗ × Σ2∗ × Q is the set of edges. As with FSAs, FSTs are also powerful because of the various closure and algorithmic properties (Emmanuel and Schabes, Citation1997; Mohri, Citation1997). In this article, the following conventions when describing an FSM are used: final states are depicted by a bold circle; ε represents the empty string; and the initial state (labeled 0) is the leftmost state appearing in the figure.
UNIFIED APPROACH OF THE SLOVENIAN GRAPHEME-TO-PHONEME CONVERSION
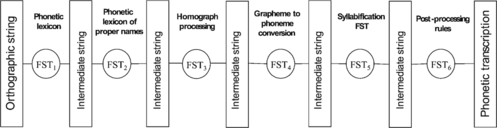
FSM properties are the main reason for the development of a unified Slovenian grapheme-to-phoneme conversion system based on FSM machines. Firstly, the proposed unified approach enables efficient integration of the Slovenian grapheme-to-phoneme conversion process into the PLATTOS TTS system and, secondly, it also provides a clean general purpose mechanism for storing and accessing linguistic knowledge. The processing steps that are included in the proposed approach to Slovenian grapheme-to-phoneme conversion process are depicted in Figure . Implementation of such a solution using FSMs represents a time and space efficient solution for grapheme-to-phoneme conversion, able to be used in multilingual and polyglot TTS systems. The speed of the grapheme-to-phoneme conversion process is independent of the number of entries in the lexicons and also of the rule context length (when using automatically obtained rules).
FIGURE 2 Processing steps proposed for Slovenian grapheme-to-phoneme conversion in the PLATTOS TTS system.
The proposed FSM based cascade module for the Slovenian grapheme-to-phoneme conversion approach in Figure consists of more processing steps. Phonetic lexicons, presented by finite-state machines, are used firstly for simple lexicon look-up. When the word is a homograph, its correct phonetic transcription must be determined using the context information already available and obtained in previous TTS processing steps during morphological analysis and part-of-speech (POS) tagging. Trained CART models containing automatically obtained weighted linguistic rules are used in the case of unknown words. They are represented as WFST machines due to the overall flexibility and efficiency of the G2P process. In many texts (e.g., newspaper, e-mails) there are also words in one or even more foreign languages. Such words, or even phrases, must be detected to be able to perform correct overall grapheme-to-phoneme conversion. In the final step, some linguistic postprocessing pronunciation rules are applied, to adapt the obtained phonetic transcriptions to the context of neighboring words and the pronunciation rules for the Slovenian language. The described grapheme-to-phoneme conversion engine is appropriate for integration into the architecture of the PLATTOS TTS system. The engine is flexible, efficient, and open to new languages. Some ideas about handling grapheme-to-phoneme conversion in TTS systems using WFSTs and Yarowsky's decision lists for homograph disambiguation implemented as WFSTs have already been discussed by Sproat and colleagues at Bell Labs (Sproat, Citation1998). Nevertheless, in this article, additional ideas are proposed for the grapheme-to-phoneme conversion of foreign words and proper names (also frequently found in many Slovenian texts), homograph disambiguation, syllabification, and FSM-based implementation of phonetic postprocessing rules. All these processing steps have an important influence on the final naturalness of synthesized speech. In the presented approach, time- and space-efficient incremental algorithms were used for the construction of finite-state transducers representing language specific resources (phonetic lexicons; Daciuk, Citation1998; Rojc, Citation2000). When usingFSM formalism, the language-specific order of the processing steps inside the unified G2P engine can be implemented in a flexible and efficient way (e.g., stress prediction must be done before the grapheme-to-phoneme conversion of unknown words for the Slovenian language). The FSM architecture of the G2P engine allows for arbitrary linking of G2P modules and changing their positions in the G2P engine; therefore, it is also open for other languages. In the following subsections all processing steps included in the unified G2P conversion will be described in more detail.
FIGURE 3 Proposed FSM based cascade module for grapheme-to-phoneme conversion.
Phonetic Lexicons
Common Words
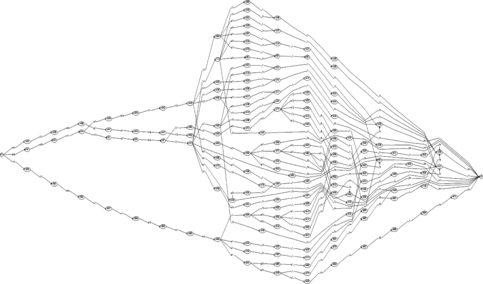
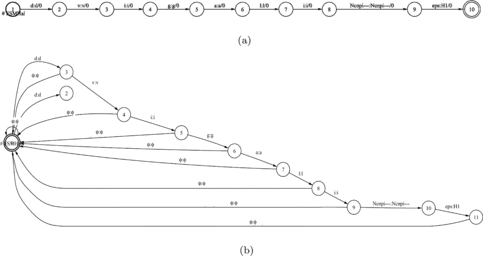
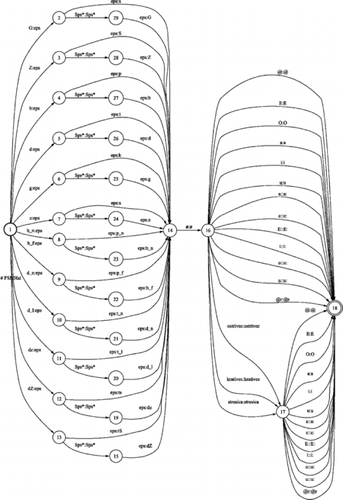
In any TTS system, external language resources (e.g., phonetic lexicons) represent a problem regarding memory usage and, especially, needed look-up time. The representation of phonetic lexicons using finite-state machines (FSM) is time and space efficient. The effect of using FSM for representation of external natural language resources is a considerable reduction in memory usage and optimal access time (look-up time), the latter is even independent from the sizes of the lexicons. In Figure the achieved compression of 100 lexicon entries, when using finite-state transducers, is illustrated in visual form. From the shape of the FST, it can be seen that prefixes and suffixes of the entries are especially well compressed (less states and transitions), whereas in the middle part of the FST the compression is not as efficient (more states and transitions remains after minimization).
FIGURE 4 Phonetic lexicon SIflex, represented as FST (100 entries).
Proper Names
Proper names are far more numerous than ordinary words according to the statistical results given in Liberman and Church (Citation1992). It is also well known that the pronunciation of proper names cannot typically be accounted for by using the same letter-to-sound (LTS) rules as for ordinary words. Phonetic lexicons of European proper names were developed during the Onomastica European project (Onomastica, Citation1995). The results of this project could lay the basis for a truly multilingual, lexicon-based proper names pronunciation system. Since these lexicons are huge, their representation must be time and space efficient to maintain the efficiency of the unified grapheme-to-phoneme conversion engine. Normally only Onomastica for a native language would be used (e.g., for the Slovenian language). Since there are a lot of foreign proper names found in native texts, other Onomastica lexica can also be used in the G2P engine as part of the external resources (in order to support the polyglot nature of the G2P engine). In this case their representation must be time and space efficient. Some long string entries are characteristic of Onomastica lexicons. Additional compression is, therefore, achievable, when some long entries are broken into constituent words before the lexicon compilation process is performed.
Disambiguation of Homographs
The written text can contain the so-called natural ambiguities and artifical ambiguities. Natural ambiguities consist of words that are polysemous. In the Slovenian language there are a lot of homographs that can be used in various contexts and cases. A nice example in the Slovenian language is the use of the homograph “gori” (top/mountain/burn):
Gori na gori gori (g∗O − rinag∗O − rigo − r/i :)(It burns on the top of the mountain).
The correct pronunciations for homographs can be mainly resolved by the context. Use of POS-tags can help to disambiguate a great number of them, but in some cases even the use of POS-tags is insufficient. Semantic information is also needed in such cases. POS-tags and word-context information in a homographic disambiguation process are used in the proposed G2P solution. In the proposed G2P engine we are able to use the Yarowsky's decision lists or CART homograph disambiguation model, which is proposed as an alternative approach in this article. Both models have to be trained on corpus-containing homographs.
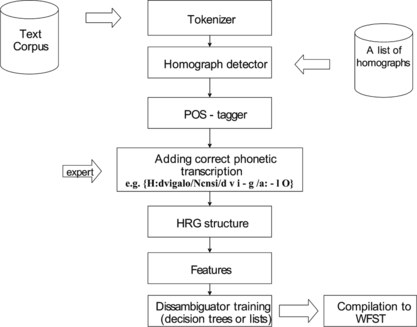
Figure presents the proposed approach for the homograph data preparation step needed in the process of homographic disambiguation model training. Firstly, the tokenizer defines the initial set of sentences to be included in the homograph corpus construction. The homograph detector then automatically tags each homograph in the input sentences and keeps only sentences containing homographs. The list of homographs can also be defined automatically, if such information exists in phonetic lexicons (e.g., as in the SIflex lexicon for the Slovenian language), or otherwise manually by a linguistic expert. Next follows the phase of automatic POS-tagging and the grapheme-to-phoneme conversion of the homographs in the corpus. In this step, homographs can have more than just one assigned phonetic transcription. In the next step, the linguistic expert has to manually choose the appropriate transcription by considering the context of the homograph. The processed sentences are then coded into heterogeneous relation graph (HRG) structures, flexible for an efficient feature vector construction process (Taylor et al., Citation2001). These features are used for the training of, e.g., CART model or a decision-list model, as will be shown in the implementation part of the article. Sproat stated that in the case of CART models, some work is necessary on the part of the user to transform the data into a format that can be used to train the models (Sproat, Citation2001). This problem is solved if the linguistic phonological knowledge is represented by HRG structure. These structures enable the definition of any type of linguistic features easily and flexibly.
FIGURE 5 The proposed approach for the construction of homograph training corpus for homograph disambiguation model.
Unknown Words
In many languages orthographic transcription has some relation to phonetic transcription. This can sometimes be fairly simple, complex or also quite complex. It is evident that people are able to pronounce unknown words fairly correctly. In TTS systems the main motivation for a grapheme-to-phoneme conversion module is to be able to automatically find this relation and determine phonetic transcriptions of unknown words (OOV; out of vocabulary words) correctly, if possible.
Phonetic Transcription Alignment
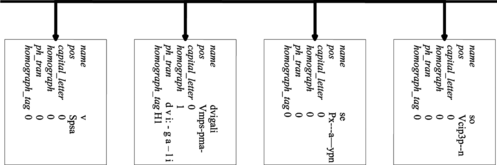
It is necessary to perform an alignment of orthographic and corresponding phonetic transcriptions between graphemes and phonemes before starting construction of the grapheme-to-phoneme conversion model for OOV words. The number of letters in a word and the number of phonemes in the corresponding transcription do not necessarily equate. In general, graphemes can be mapped to zero, one, two or even more phonemes. The same is true for phonemes. The alignment is not necessarily trivial even if the orthographic and phonetic transcriptions have the same number of letters and phonemes. When not all letters in the given context have the corresponding mapping into phonemes, the empty symbol ε is used as a filler symbol. Heterogeneous relation graphs (HRG), which are suitable structures for storing and representing linguistic knowledge about aligned entries in the phonetic lexicons, are used after the alignment process. Elements of the HRG structures are lists with attribute values, containing available linguistic information (grapheme-to-phoneme mapping, syllable positions, stress position, stress type, etc.). The HRG structure is very flexible when linking various phonological features for the construction of complex feature vectors to be used for training CART models. Feature vectors are defined simply by the list, with selected feature names (stress type, position in word, voiced consonant, vowel length, vowel height, vowel frontness, consonant type, consonant voicing, etc.). When using CART models, each feature vector can be composed from a number of different features (numerical or categorical) and, of course, the target value (e.g., stress type, syllable break, or phoneme). In Figure HRG representation of one aligned lexicon entry is presented for the SIflex Slovenian phonetic lexicon.
FIGURE 6 Heterogeneous relation graph (HRG) for one aligned lexicon entry, containing linguistic knowledge (e.g., from SIflex lexicon).
CART and WFST Models for Grapheme-to-Phoneme Conversion
CART trees can be used to obtain phonetic knowledge existing in the phonetic lexicon fully automatically, without the need for a linguistic expert. The advantage of CART trees over some other automatic training methods, such as NN and linear regression, is that their output is more readable and often more understandable to humans. This enables their manual modification if necessary. The constructed trees used in this article contain yes/no questions about features, and provide probability distribution, since they predict categorical values (CART tree). Feature vectors can be constructed by using phonetic lexicon. The vectors consist of a number of feature values, each containing the same number of fields. The first field always contains the value that should be predicted (target value). Additional description must also be defined, containing sets of all possible values for each feature name. Constructed feature vectors are usually separated into the training and testing feature sets. The ratio 9:1 is frequently used. Well-defined training techniques were developed to construct an optimal tree from a set of training data (Breiman et al., Citation1984).
Although CART trees are a size-efficient solution, it is hard to integrate them into a system whose architecture is based on FSMs. Fortunately, CART models can be compiled into the corresponding WFST models (Sproat and Riley, Citation1996) giving us time- and space-efficient representation of the CART models.
CART models can be fully described by a set of weighted rewrite rules. Kaplan and Kay (Citation1994) showed that the set of rewrite rules such as:
Final lists define how to rewrite special symbols in the input string, | |||||
Decisions in each node should be representable by regular expressions. | |||||
The whole tree is compiled in such a way that intersection of all obtained rules is computed. Each of the meta labels used in λ and ρ represents pairs of symbols (sets). Therefore, each tree represents a system of weighted rewrite rules. The rule for leaf L in the tree is defined by:
φ L represents the input symbol for the tree model, ψ L is the output expression defined in the leaf L, P L represents the path from the root to the leaf L, p is an individual branch on this path, and λ p and ρ p are left and right contexts for branch p for a corresponding question. Figure shows the procedure for compiling the trained decision tree models used in the unified grapheme-to-phoneme conversion into corresponding WFST models. In the first step all questions in the trees are described by regular expressions (using automatic procedure). Then the construction of rewrite rules for all tree leaves follows, including automatic definition of left and right contexts along the paths of the leaves. Rewrite rules are compiled into WFST machines and combined into the final WFST model using intersection operation.
FIGURE 7 Procedure for compiling decision tree models into corresponding WFST models.
Word Stress Prediction
The importance of information such as word stress is different among languages. In some languages (e.g., the Slovenian language) the correct prediction of stress is vital for correct mapping prediction in the subsequent grapheme-to-phoneme conversion procedure. In the English language the word stress can be interpreted differently, usually depending on the syntactic stress and, in some morphological derivations, it can even change position. Only vowels can be stressed in most languages. Prediction of word stress for each vowel cannot be accurate enough when only using the letter context. Often it is better to construct two separate models, one for predicting word stress and the other for grapheme-to-phoneme conversion. HRG structures can be used for storing and representing linguistic knowledge about phonetic lexicons' entries including stress type and position information. The construction of complex feature vectors is very flexible when linking various phonological features. Feature vectors can then be used for training CART word stress prediction models that can be compiled into WFST machine, as an optimised representation of the model.
Grapheme-to-Phoneme Conversion of Out-of-Vocabulary (OOV) Words
In an on-line unified grapheme-to-phoneme conversion model, in the G2P conversion step, the stress position and type should already be known or predicted. Therefore, stress information can be included as additional linguistic information into the HRG structures, containing linguistic knowledge about phonetic lexicons' entries. In the next step, HRG structures and the list with selected feature names are used for the construction of linguistic feature vectors. The compilation of the model into time and space-efficient representation as a WFST machine can follow after training the CART grapheme-to-phoneme conversion model.
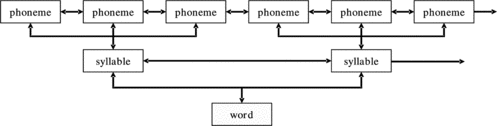
Syllabification
Information about syllable break positions is needed at higher levels of TTS processing. In many languages the pronunciation of phonemes is a function of corresponding syllable break positions. The phoneme's position in the syllable also has an important impact on phonemes' durations and represents important information for subsequent modules in the TTS system, predicting the speech segment duration. Syllabification can be performed using, e.g., declarative grammar for describing possible syllable break positions in polysyllabic words. A very simple example of such description can be that each word inside a sentence is composed of one or more syllables of structure C∗VC∗. Each syllable described in such a way can be composed from an obligatory nucleus of the syllable, marked with V. Any number of consonants, marked with C, can follow before and after the nucleus or both. Using rules, it is possible to define positions where the syllable break must be inserted in the input string. According to the defined syllable structure, there can exist more possible positions for each syllable break, but usually the first possible one is chosen. In finite-state machine formalism, this can be achieved by assigning higher weight to the last consonant of each syllable. Such an approach to syllabification is also called “the principle of maximal onset” (Sproat, Citation1998). Grammar can, for example, end each non-final syllable in a word with the corresponding symbol for marking syllable break positions. Later sections present two approaches for automatic syllabification. The first approach is based on a statistical analysis performed on some phonetic lexicon, containing syllable markers, and was proposed by Kiraz and Mobius (Citation1998). The other one, based on a trained CART model, is proposed in this article and is described in more detail later. In both approaches the syllabification models can be represented as WFST. Therefore, they are both appropriate for integration into the unified grapheme-to-phoneme conversion model and represent time- and space-efficient solutions.
Foreign Words
People who master more languages are very rare. They use their knowledge about language whenever it is necessary and are able to decide when to switch to another language. They are also capable of deciding when to perform total assimilation into the primary language or just perform assimilation of the prosody and use the corresponding foreign pronunciation.
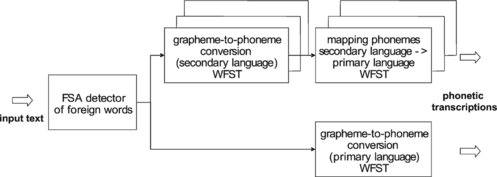
Therefore, one of the most important features for the TTS system would be the capability of synthesizing speech from sentences containing words and phrases in different languages. One possibility is to use different speech databases for the speech synthesis of such sentences. Such an approach is, however, unacceptable in many respects. The real polyglot TTS system is also expected to be capable of synthesizing speech using the same voice in sentences where words or word phrases are present in one, or even more, foreign languages. Newspaper texts are especially problematic, as there are a lot of phrases and proper names in non-primary languages. The main problem when discussing the polyglot approach is the common treatment of foreign language phrases inside one environment (use of different dictionaries), text analysis, language detection in the input text, and use of extensive polyglot pronunciation lexicons. The method proposed in this article consists basically of two main steps. In the first step, the detection of foreign words or phrases has to be performed. In this step, the detector can be built from a foreign words list. The list can be constructed from large text corpora available for a given language. Its representation as finite-state automaton can then represent a time and space efficient detector of foreign words in input sentences. After detection, the next step is a grapheme-to-phoneme conversion process as defined for the given language. Finally, in the last step, the mapping of foreign phonemes into the primary language phonemes has to be performed, as seen in Figure .
FIGURE 8 Proposed approach to foreign words' grapheme-to-phoneme conversion.
Grapheme-to-Phoneme Post-Processing
In continuous speech, the phonemes at word endings are often changed because they are influenced by the coarticulation effects that also spread to the next word. Lexicon items usually contain phonetic transcriptions as spoken in isolation (canonical form). Postprocessing rules are, therefore, important for any TTS system in order to achieve naturally sounding speech. Phonetic transcriptions must be adapted following the coarticulation and phonological rules of the language. Postprocessing rules represent, of course, a language-dependent step. They can be defined manually by linguistic experts or automatically, if a training corpus is available. In this article the grapheme-to-phoneme postprocessing method is described in the implementation part of the article, where postprocessing rules are defined by the expert and then represented as WFST machines. Such representation is efficient and suitable for integration into the architecture of any TTS.
In the previous sections, problems involving the grapheme-to-phoneme conversion process were exposed and the processing steps were described, which are used in the proposed grapheme-to-phoneme conversion engine. The G2P engine is composed of several FSM machines, each performing a specific task in the cascaded architecture. These tasks can be performed using different orders (the order of FSMs can be language dependent). An additional two FSMs are integrated into the engine. The first FSM for processing foreign words and the second for adaptation of canonical phonetic transcriptions found in specific word contexts (here, postprocessing phonological rules for a given language are used). In the engine, efficient incremental algorithms are used for lexica FSM representations. The use of CART models is proposed for homographic disambiguation problems and syllabification, represented as WFST machines. Implementation examples of the ideas presented in the first part of the article for the Slovenian language will be presented in the next sections. However, the engine can be efficiently and flexibly adapted for other languages and TTS systems, due to the FSM architecture, its features, and corresponding mathematical operations.
IMPLEMENTATION OF A UNIFIED GRAPHEME-TO-PHONEME CONVERSION ENGINE FOR THE SLOVENIAN LANGUAGE
This section presents the implementation of the proposed unified grapheme-to-phoneme conversion engine for the Slovenian language.
Efficient Representation of Phonetic Lexicons
Phonetic and morphology lexicons are the necessary prerequisites for any TTS system. Their efficient utilization is crucial, particularly in real-time applications. The use of FSM formalism is, therefore, especially attractive for efficient representation of lexicons. The following presents the lexicon compilation results of phonetic lexicons for the Slovenian language, when implemented with an FST machine. The SIflex phonetic lexicon is one of the SIlex lexicons and was developed in parallel with the SImlex morphology lexicon (Rojc and Kacic, Citation2000). In the FST construction 68,817 entries were used. The phonetic symbols used are SAMPA symbols (Speech Assessment Methods Phonetic Alphabet) for the Slovenian language. The compilation results using a proprietary FSMHal lexicon compiler (Rojc, Citation2003) are presented in . The final size of the FST is only 197 kB. Optimal access time (look-up time) is obtained using a determinization operation. In addition, a SIplex phonetic lexicon of proper names for the Slovenian language (237,657 entries) was presented as FST. Table presents the compilation results when using FST representation of the lexicon.
TABLE 1 SIflex Phonetic Lexicon Implemented as FST (68,817 entries)
TABLE 2 SIplex Phonetic Lexicon for the Slovenian Language, Presented as FST (23,657 entries)
Homograph Disambiguation
The Slovenian language is rich in homographs because of its lexical variations and stress patterns. Two approaches for an efficient homograph disambiguation process that can be used in the PLATTOS TTS system are presented in more detail.
Homograph Decision List Disambiguator
Yarowsky proposed the use of decision lists for homograph disambiguation (Yarowsky, Citation1997). Decision lists are actually a limited form of decision trees, and Yarowsky showed that the lists are also appropriate for typical homograph disambiguation. Table shows some context examples for the Slovenian noun/verb homograph “dvigali” (elevators/lift up) as found in the homograph training corpus. Table further illustrates word relations at different context positions relative to the ambiguous word “dvigali” (including±k word window), which are helpful for disambiguation. These were obtained during decision list training (Yarowsky, Citation1994). Figure shows the HRG structure containing all the needed linguistic information for a training homograph decision list. This structure includes linguistic knowledge about the homograph context found in the homograph corpus (POS tags) and was constructed as suggested in Figure .
TABLE 3 Context Examples for the Slovenian Homograph “dvigali” (elevators/lift up)
TABLE 4 Part of Constructed Decision List for Slovenian Homograph “dvigali” (elevators/lift up)
FIGURE 9 HRG structure (homograph level) for a sentence containing homograph “dvigali” (elevators/lift up).
The list in Table 1 shows part of the constructed decision list for the word “dvigali” (elevators/lift up). The first column of this table represents a particular piece of evidence for the possible phonetic transcriptions given in the second and third columns (p, previous word; n, next word). The list is ordered by log likelihood—the numbers given in the fourth column. The largest log likelihood values are associated with those pieces of contextual evidence that are most strongly biased toward one of the phonetic transcriptions. The cost values are also assigned according to these and given in the last column of the table. These are used in the WFST representation of the decision lists. Evidence given in Table can be represented by the following rewriting rules:
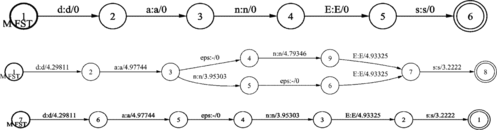
The word “dvigali” was assigned the phonetic transcription /dv/i:-ga-li/ if positioned in front of the POS tag Vmps-pma- and /dvi-g/a:-li/ when positioned in front of the POS tag Ncnpi. The problem is that a direct approach to decision list compilation is too complex, even if an unrealistically small alphabet is presumed. To solve this problem, the construction of a lexical transducer L (shown in Figure ) is first started, containing lexical analyses that are defined in Table for homograph “dvigali/lift up.” The lexical possibilities given by WFST (denoted with L), shown in Figure , are at first equally weighted, meaning that they are equally probable. The choice of appropriate form is totally dependent on the final WFST model used for disambiguation. In the next steps, the needed specific WFST models are constructed to be used for the final homograph disambiguation model. A WFST model for homograph disambiguation is composed from the following WFST machines: homograph tagger, environmental classifier (two transducers), disambiguator D, and filter F. All partial transducers are finally joined into one WFST homograph disambiguation model (Sproat, Citation1998).
TABLE 5 Possible Lexical Analysis for Homograph “divigali” (elevators/lift up), Described with Transducer L
FIGURE 10 Ambiguous lattice L with different possible lexical analyzes for homograph “dvigali” (elevators/lift up).

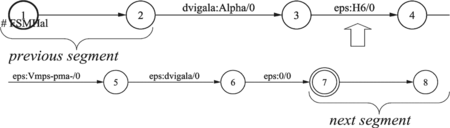
The homograph tagger must tag each appearance of the homograph in the input text (in this case “dvigali” (elevators/lift up)) using, e.g., labels H0, H1…, Hn for n different possible transcriptions. These labels mark which of n possible phonetic transcriptions correspond to a given lexical analysis. After instances of a particular homograph are found, WFST machines in Figure (a) and Figure (a) just insert homograph tags (H0 and H1). These machines only work locally. Being able to tag all instances of a particular homograph in a given sentence, they should be extended properly; in this article, the local extension algorithm is suggested for this purpose (Emmanuel and Schabes, Citation1997). The obtained WFST machines in Figure (b) and Figure (b) insert labels H0 after homograph “dvigali/Vmps-pma,” and H1 after “dvigali/Ncnpi—.”2. The local extension algorithm was also used for the construction of the homograph tagger, in order to operate globally on the input text.
FIGURE 11 Homograph tagger for “dvigali Vmps-pma-,” inserting H0 locally (a) and globally (b).
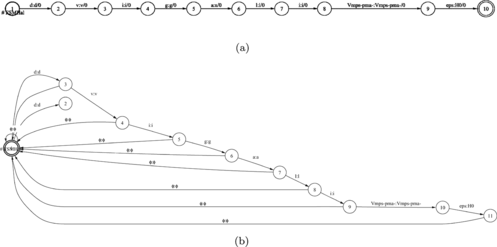
FIGURE 12 Homograph tagger for “dvigaliNcnpi—,” inserting HI, locally (a) and globally (b).
Composition of transducer L, shown in Figure , and constructed homograph taggers give the result as shown in Figure .
FIGURE 13 Composition result L○H 0○H 1.

The Context classifier is composed of two string-string FSTs. The first FST C 1 optionally rewrites any symbol except the label for the end of word and labels H0, H1, H2, H3 …, with the “blind” symbol Δ. The second FST C 2 is then used to recognize context evidence as defined in the decision list in agreement with its type and assigns the cost equal to the evidence position in the list (last column in Table ). Some mappings performed by the context classifier C 2 are shown in Table . Expressions in the third column contain tag for dummy symbol (Δ), tag for head verb (V), and tag marking the evidence in the decision list that occurs immediately to the left (L). The additional numbers 0, 1… are used to denote the pronunciation, so L0 will tag an element that, if it occurs immediately to the left, will trigger the first pronunciation of the target (H0 - dv/i:-ga-li).
TABLE 6 Mappings Performed by the Context Classifier C 2 for Homograph “dvigali” (Elevators/Lift up)
Composition of transducer shown in Figure and context classifiers C 1 and C 2 give the transducer shown in Figure .
FIGURE 14 Result of the composition between lexical analysis transducer, homograph tagger, and context classifier L○H 0○H 1○C 1○C 2.

The disambiguator D must perform a set of optional rewrite rules, as given in Table . The first column contains homograph tags (φ), the third column tags “ok” and the fifth column the left contexts of the rewrite rules (λ; the right context is not defined). As can be seen, the final two rules map in any context labels H0 and H1 with arbitrary high cost into label “ok” (e.g., 20 and 40).
TABLE 7 Rules for the Dissambiguator D
At the end, filter F is just used to remove all paths that still contain unconverted labels (when there is no defined corresponding rules for dissambiguator D) H0, H1, … This can be achieved by using filter of the form .
The correct analysis (strmo dvigali Vmps-pma-/steeply lift up Vmps-pma-)is calculated and shown as finite-state transducer in Figure and the path with minimal cost is finally determined (Figure ). The next step is to perform a left-projection operation on the obtained WFST (Figure ) and, finally, the intersection with transducer L can be performed. Finally the intersection:
FIGURE 15 Result of the composition L○H 0○H 1○C 1○C 2○D○F.

FIGURE 16 Result after the best path search algorithm Best Path[L○H 0○H 1○C 1○C 2○D○F].
FIGURE 17 Left projection π1[BestPath(L○H 0○H 1○C 1○C 2○D○F)].
Homograph CART Model Disambiguator
In this article we also propose the use of decision trees for homograph disambiguation. According to Taylor, decision trees can give better results, but they are bigger and less time and space efficient. Nevertheless, it is possible to compile the constructed trees into corresponding WFSTs and even combine them, thus obtaining efficient representation of a homograph disambiguation CART model. Such models can be efficiently integrated into the unified G2P conversion engine for the Slovenian language.
As an example, homograph “dvigala/lift up, elevators” can be chosen again, having two possible phonetic transcriptions, marked with tags H4 and H6. This homograph has two meanings and has the following features:
dvigala d v i - g / a: - l a → H4 Ncnpa,
dvigala d v /i: - g a - l a → H6 Vmps-pma-.
In the training corpus, the homograph “dvigala” appears once as a noun and once as a verb. The CART tree can model phonetic transcriptions for homograph “dvigala” in the various contexts found in the training material. Let's look at the sequence of questions in Figure , obtained when passing from root to leaf L of the CART tree. This sequence defines one rewrite rule that must be applied in a given context on the input string. The first question asks if the current word POS tag is a noun (Ncnpa) and the second question asks if the third word to the left is the word “ki/which.” The POS tags were coded according to Multext specifications (Multext, Citation1996). All questions can be represented by using regular expressions as seen in Table .3 Each question in the Figure can have left context, right context, both or none. When there are no left or right contexts, the regular expression only contains closure of the vocabulary Σ∗ (Sproat and Riley, Citation1996).
TABLE 8 Questions Presented by Regular Expressions
FIGURE 18 Sequence of questions from the root to leaf L.

Since regular expressions defining context λ and ρ for the rewrite rule are usually of different lengths, the context λ has to be left padded, and context ρ right padded using closure of the vocabulary Σ∗. The regular relations are, in general, not closed under the intersection, but the subset of the regular relations of equal length is closed. Since the intersections of all left and all right contexts have to be performed, the obtained regular relations must be of the same length. The whole rewrite rule for questions in Figure can then be written as:
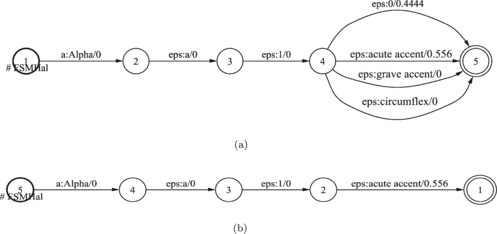
When the WFST shown in Figure , describing the input homograph word, is found in the following left and right contexts:
FIGURE 19 Input I for homograph disambiguator WFST_T_HGRAPH.

FIGURE 20 Result after homograph disambiguation BestPath(I○WFST_T_HGRAPH).
The proposed homograph disambiguator constructed by the CART tree and represented as WFST is interesting as it preserves the good classification results of the CART trees and, at the same time, presents a time- and space-efficient solution, which can efficiently be integrated into the whole G2P engine and the TTS system, based on WFSTs. The BestPath search algorithm finds the path with the most probable phonetic transcription tag for homograph in a given context, as would also be predicted by the tree model (shown in Figure for Slovenian homograph “dvigala/lift up”).
Unknown Words
Phonetic Transcription Alignment
The number of letters in the word and the number of phonemes in the corresponding transcription are, in general, unequal, although this is mainly true for the Slovenian language. In this approach the idea is to estimate the probabilities for one grapheme (G) to match with one phoneme (P). Then follows the use of a DTW algorithm for introducing epsilons at positions maximizing the probability of the words' alignment path. Once the dictionary is aligned, the associations' probabilities can be computed again, repeating the procedure until convergence is achieved. The used algorithm is shown in Figure (Pagel et al., Citation1998).
FIGURE 21 Alignment algorithm—automatic epsilon scattering method.

Word Stress
The following presents the construction of a Slovenian word-stress model. Since in the case of the Slovenian language, the type and position of the stress have an influence on grapheme-to-phoneme mappings, this model should be used in a G2P engine before a grapheme-to-phoneme mapping.
Feature vectors were constructed from HRG structures, containing linguistic knowledge from a phonetic lexicon (syllable position in the word, vowel length, vowel height, number of syllables from the end of the word, and part-of-speech tag [POS]). HRG structures were automatically constructed by using SIflex lexicon. The features were separated into training and test sets using the ratio 10:1. Table presents the confusion matrix in the case of the word stress model. It can be seen that the problem lies in the decisions as to when to use a stress marker on the vowel (great number of confusions). In Table , the first row represents actual (training) data and the first column represents the data as predicted by the trained model. For example, stress marker “/” was predicted 554 times in positions where no stress marker was present in the input training data and was unpredicted 381 times for those positions where it should be present. Table presents the results obtained on the test corpus, using CART model for the prediction of word stress for the Slovenian language.4 The majority of the errors occur during decisions about stress/non-stress positions in the input word. Quite often there is also confusion between stress types “/” and “∗.” On the other hand, the confusions between “\” and “∗” are quite rare.
TABLE 9 Confusion Matrix for Word Stress Module. “0” Marks no Stress, “/” Marks Long and Narrow Stressed vowels, “/” Marks Short and Wide Stressed Vowels, and “∗”Marks Long and Wide Stressed Vowels
TABLE 10 Prediction of Word Stress for Slovenian Languages
The CART tree, modeling the stress type prediction (e.g., Slovenian language), can be described with sequences of questions, as in Figure .5 This sequence from root node to leaf L defines the weighted rewrite rule that has to be applied in the specified context of any input string.
FIGURE 22 Sequence of questions from root to the leaf L.

All questions can be represented by using regular expressions, as seen in Table .
TABLE 11 Questions Represented by Regular Expressions (Generated Automatically)
Since regular expressions defining context λ and ρ for the rewrite rule are usually of different lengths, the context λ has to be left padded and the context ρ right padded, using the vocabulary Σ∗. The whole rewrite rule for defined questions from Figure can then be written as:
When the grapheme in the input word, described by the WFST in Figure , is found in the following left and right contexts:
FIGURE 23 Input I for word stress prediction model WFST_T_STRESS.
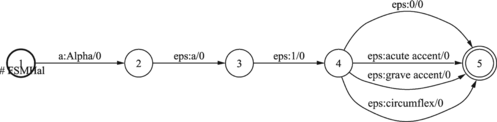
FIGURE 24 Result I○WFST_T_STRESS (a) and of BestPath(I○WFST_T_STRESS) (b).
Grapheme-to-Phoneme Conversion of Out-of-Vocabulary (OOV) Words
The next step is the construction of a Slovenian grapheme-to-phoneme conversion model for OOV words. The feature vectors were constructed from HRG structures, containing linguistic knowledge for the Slovenian language (syllable position in the word, vowels length, vowels height, number of syllables from the end of the word, and part-of-speech tag [POS]). HRG structures were automatically constructed by using SIflex lexicon. The features were separated into training and test sets using ratio 9:1. Table shows the obtained results of the G2P conversion on the test set. The training parameter defining the minimum number of examples that must be in a leaf of a decision tree was changed. The size of the prediction model increases when reducing this parameter. The final size of the model is defined by the number of questions and leaves of the trees in the constructed CART tree. It shows up that more accurately training data is always better, so when this parameter value is only 1, this still does not present an overtrained model. Therefore, the parameter value 1 was used.
TABLE 12 Grapheme-to-Phoneme Conversion (Letter-to-Phoneme) Results for the Solvenian Language
The next experiment illustrates the importance of correct stress type and position prediction for the Slovenian G2P conversion process. CART models for grapheme-to-phoneme conversion were first constructed using training-feature vectors without stress position and type information. In this case, the number of vowel confusions increased, as expected (Table ). According to the results in Table it can be said that additional information about stress type and position are necessary for better G2P conversion results.
TABLE 13 Vowel Confusion Matrix Results, When No Stress Type and Position Information Is Used
TABLE 14 Grapheme-to-Phoneme Conversion (Letter-to-Phoneme) Results for the Slovenian Language, When No Stress Type and Position Information Is Used
The CART tree modelling of the grapheme-to-phoneme conversion (e.g., Slovenian language) can also be described with WFST, following the procedure described previously, using analogy. After composition of the WFST model with the input grapheme, the BestPath search algorithm finds the most probable grapheme-to-phoneme mapping, as would be predicted by the CART model (e.g., in Figure ).
FIGURE 25 Grapheme-to-phoneme mapping found by BestPath search algorithm for the grapheme “a.” markers. Therefore, the approach is multilingual.
Syllabification Based on Lexicon Statistics
Two approaches for syllabification will be shown in the next two sections. Both are language independent and use weighted finite-state transducers (WFST), but they use different methods for the calculation of probabilities and defining syllable break insertion positions.
In the first approach the WFST is constructed from data obtained during syllable-structure analysis of the phonetic lexicon's entries. This approach was proposed by Kiraz (Kiraz and Mobius, Citation1998), but here the implementation results are presented for the Slovenian language. The SIflex phonetic lexicon (Rojc and Kacic, Citation2000) for the Slovenian language is used. In general, however, any phonetic lexicon can be used containing syllable markers. Therefore, the approach is multilingual.
Table presents the classes of Slovenian phonemes. The Slovenian language uses complex consonant clusters in the onset and coda parts of the syllables, as seen in Table . It uses up to four consonants in the onset and up to four consonants in the coda of the syllable.
TABLE 15 Classes of Slovenian Phonemes
TABLE 16 Examples of Consonant Clusters for the Slovenian Language
WFST Syllabification Transducer
A weighted finite-state transducer for syllabification, denoted as T
syll
, must contain, in the vocabulary, one additional symbol “-” for marking syllable break positions. The corresponding weight is assigned to each transition. The inverse form of T
syll
, marked as , can be used as desyllabifier. The construction of the syllabification transducer is as follows.
Firstly, a set of all syllables is obtained in the training database. The following example shows that four syllables are obtained for the Slovenian phonetic transcription of the word “pacientov/patient's” (p a - ts i - j ∗ E n - t o w). Secondly, separation of syllables into onsets, nuclei and coda is performed (this is done automatically). The onsets, nuclei, and coda obtained from the word “pacientov/patient's” are shown in Table .
TABLE 17 Syllable Structure for the Slovenian Word “Pacientov/Patient's
Weights for the T syll transitions are determined by inverting the frequencies of syllable codas, onsets, and nuclei, found in the SIflex phonetic lexicon. Table presents the set of Slovenian nuclei, found in the SIflex with corresponding frequencies. Onset, nucleus, and coda sets are compiled into weighted finite-state automaton (WFSA), by calculating the disjunctions of their elements. In this way three automata, A 0, A n , A c , are defined that are able to recognize the onsets, nuclei, and codas. The following three equations can be defined:
TABLE 18 A Set of Slovenian Nuclei Found in the SIflex Lexicon and the Corresponding Frequencies (f)
In the equations above, the values inside the brackets correspond to the weights assigned to the previous symbol in the expression. ξ denotes the set of onsets, ψ the set of nuclei, and ζ marks the set of codas.
The construction of all needed constituent syllable parts was performed in the previous step by the WFSAs: A 0, A n , and A c . Next, the syllable structure must be described. This usually represents a language-dependent step. For example, for English, German, and Slovenian the syllable structure can be defined by the following regular relation:
The automaton A syll recognizes one or more syllables found by automaton A syllstructure . After each but the last syllable there must be a syllable marker “ − .” Therefore, a WFST is needed that will insert syllable break markers after each but the last syllable. The conversion from A syll is very simple. It is performed by calculation of the identity transducer for automaton A syllstructure , where we replace the syllable break marker with the pair “ε: − .” The obtained WFST for syllabification can then be defined by the equation:
The operator Id generates the identity transducer of its argument. When using this operation each symbol of the transition a in the argument is replaced with the pair a:a. After the weighted T syll transducer is used on any Slovenian word, a BestPath search algorithm also has to be performed to find the path with the most probable syllable break insertion positions, as seen in Figure .
FIGURE 26 Syllabification performed on the Slovenian word “danes/today”: BestPath(Tentry○Tsyll).
Syllabification Using CART Model
The following presents an alternative solution to the syllabification model described above. The advantages of the CART trees are that training is easy and efficient, can produce relatively compact models, and they are readable by humans. In the following, the construction of a syllabification model for the Slovenian language is presented using CART trees. The presented approach can also be used for other languages. In the data preparation step, feature vectors are constructed using the linguistic knowledge obtained from the SIflex lexicon stored in HRG structures. Features like syllable position in the word, vowel's length, vowel's height, number of syllables from the end of the word, and part-of-speech tag (POS) are taken into account. The training of the syllabification CART model follows, where features are separated into training and testing sets using the ratio 9:1. Table presents the confusion matrix for the Slovenian syllabification WFST and CART models. Digit 1 states that a syllable break symbol must be inserted, and 0 states that there is no syllable break. It can be seen that there is more syllable/non-syllable break confusion in the case of the WFST syllabification model, based only on syllable structure statistics of the Slovenian language. Table shows the results obtained using WFST and CART models for syllable break prediction for the Slovenian language. The obtained results obviously favor the CART model with 98.06% against 81.45%.
TABLE 19 Confusion Matrix for a Syllabification Model. “0” Marks No Syllable Present and “1” Marks Syllable Is Present. (a) WFST Model and (b) CART Model
TABLE 20 Syllable Prediction for the Slovenian Language. (a) WFST Model and (b) Cart Model
Fortunately, the CART model can also be compiled into the WFST machine, keeping, at the same time, the achieved CART tree prediction accuracy. Namely, in CART tree modeling, syllabification (e.g., for the Slovenian language) can also be described with sequences of questions, as in Figure . This sequence from the root node to leaf L defines the weighted rewrite rule that has to be applied in the specified context, on any input string. All questions can be represented by using regular expressions. After performing the composition of the WFST tree model and the input grapheme, the BestPath search algorithm finds the most probable syllable break insertion positions, as would be predicted by the CART model (Figure ).
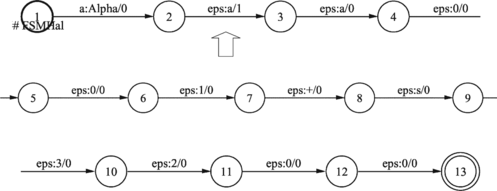
FIGURE 27 A sequence of questions from root to leaf L.
FIGURE 28 Information about syllable marker position for grapheme r in given context after performing BestPath search algorithm on syllabification WFST model.
Grapheme-to-Phoneme Approach to Foreign Words
This section proposes a new approach for dealing with words in a foreign language. The first step is shown in Figure , where the foreign words or phrases are detected by using an FSA detector, containing foreign language words. These detectors can be constructed by using large newspaper databases (e.g., SüddeutcheZeitung, Reuters corpus). In the second step, the unified grapheme-to-phoneme conversion process is followed for words of each detected language, and the last step performs the mapping of foreign phonemes into phonemes of primary language. Mappings can be defined by the linguistic expert or defined fully automatically, using some acoustic distance measures. Speech databases for other languages are needed in the latter case. The problem of words from a nonnative language is illustrated by the English phrase inside the Slovenian sentence, as was found in the newspaper text.
FIGURE 29 Proposed polyglot approach used in the scope of the grapheme-to-phoneme conversion.
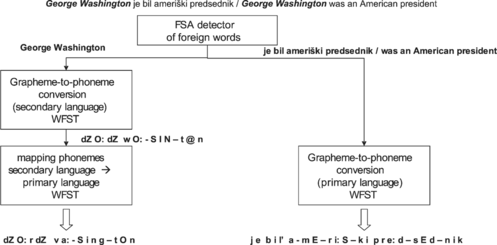
George Washington je bil ameriški predsednik. /
George Washington was an American president.
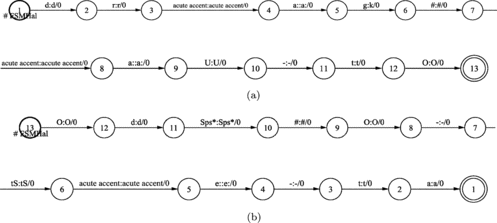
In the following figures only words in the English language are processed, due to the extent of the whole WFST and, consequently, due to its visualization problem. In Figure the English word phrase (George Washington) is first represented by the WFST. The next Figure shows the WFST obtained after composition with the English grapheme-to-phoneme conversion model. Here there are still English phonemes for corresponding graphemes. The final result is obtained after using a mapping transducer in Figure (map from English phonemes into Slovenian phonemes) and the composition operation defined on FSTs, as shown in Figure .
FIGURE 30 Input I - “George Washington.”
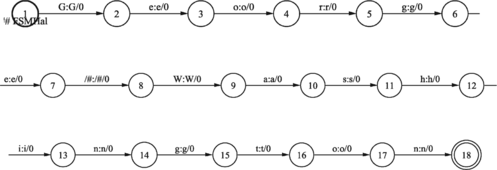
FIGURE 31 After performing English grapheme-to-phoneme conversion by phonetic lexicon transducer WFST_LEX_ANG.
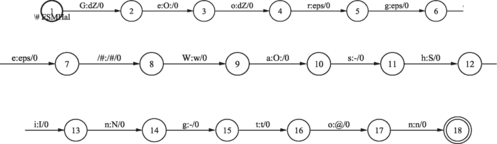
FIGURE 32 Mapping English phonemes into Slovenian phonemes by using the phoneme mapping transducer WFST_ANG2SLO, defined by the expert.
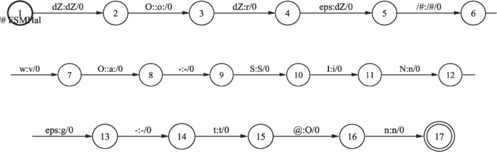
FIGURE 33 Final grapheme-to-phoneme conversion after composition of input transducer I, English grapheme-to-phoneme conversion transducer WFST_LEX_ANG and phoneme mapping transducer WFST_ANG2SLO: I ○ WFST_LEX_ANG ○ WFST_ANG2SLO.
Grapheme-to-Phoneme Postprocessing Rules
This article presents an approach for the postprocessing of phonetic transcriptions for the Slovenian language. The presented approach is, however, also applicable for other languages. It is possible to define a different number of postprocessing rules for each language. They must be used after a grapheme-to-phoneme conversion process in order to achieve better synthesized speech quality.
To be able to generate natural-sounding sentences for the Slovenian language, it is very important to be able to incorporate efficiently the following two phonological rules into the postprocessing module of the unified grapheme-to-phoneme conversion engine:
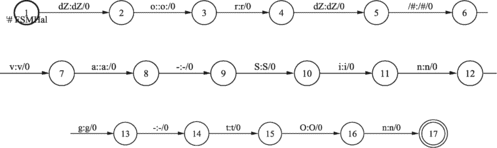
First rule:When the current word is before a word that begins with one of the vowels (a, /a :, \a…) and ends with a voiced consonant, this voiced consonant must be replaced with the corresponding unvoiced pair (Figure a). | |||||
Second rule:When the preposition (Sps∗ - POS tag according to Multext specifications) ends with a voiced consonant, this must not be changed when the next word starts with a vowel (Figure b). | |||||
FIGURE 34 Result obtained after using FST on input phonetic transcription “d r/a: g # /a: U - t O” (expensive # car) (a) and “O d/Sps∗ # O - tS /e: - t a” (from the # father) (b).
Both rules can be compiled into FST machines fully automatically, after being rewritten as rewrite rules using the regular expression syntax. The FST in Figure is obtained after composition. But FSTs, like the one constructed in Figure , only works locally, meaning that it is performed only once on the input text (phonetic transcription). A local extension algorithm in the second step has to be performed in order to work globally on any input text. In Figure the phonetic transcriptions for “d r /a: g # /a: U - t O” (expensive car) and “O d/Sps∗ # O - tS /e: - t a” (from the father) are then adapted into “d r /a: k # /a: U - t O” and “O d/Sps∗ # O - tS /e: - t a,” as defined by the phonological rules shown in Figure . In the second example there is no change, when applying the second phonological rule, since the next word starts with a vowel.
FIGURE 35 Finite-state transducer (FST) for rules 1 and 2: FST = ρε(min(det(rule_1 ∪ rule_2))).
In this section all the processing steps needed in the G2P conversion were defined in the form of WFST models. It is possible to join these models into one cascade that maps the input string (orthographic string) into the output string (phonetic transcription) using a composition operation, as defined on the WFSTs. It is also possible to insert additional models (transducers) when additional processing steps need to be performed in the unified cascade structure. These features define the unified grapheme-to-phoneme conversion engine that is modular, flexible, and efficient.
CONCLUSION
In this article, unified grapheme-to-phoneme conversion engine was proposed for the Slovenian TTS system PLATTOS. It is implemented using FSMs, since they can be efficiently used for linguistic processing and also for grapheme-to-phoneme conversion. Besides already known processing steps involved in the grapheme-to-phoneme conversion process, we focus on the integration of additional processing steps in the proposed unified G2P engine, such as the processing of foreign words and phonological postprocessing rules. The engine also follows the idea of separation of language-dependent resources from the engine itself, which can be flexibly performed because of the FSM architecture of the engine. The main motivation for representing CART models with WFSTs is because of their integration into the G2P engine and into the PLATTOS TTS system, both based on FSM formalism. The Slovenian language is very rich in homographs; therefore, a lot of attention was also paid to homograph disambiguation. In this area, a new approach was proposed using CART tree models for homograph resolution, represented by WFSTs, which can be efficiently integrated into the unified G2P engine as an additional processing step. In addition, an approach of semi-automatic construction for the homograph corpora needed for training model was proposed in this regard. Within the scope of syllabification processing steps, an alternative syllabification model was proposed, where the syllabification tree model, represented as WFST, can be flexibly added at the end of the grapheme-to-phoneme conversion process. In the unified G2P engine for the Slovenian TTS system there are some processing steps included (e.g., stress type and position-prediction) that are not necessarily needed in the cases of other languages. The architecture of the engine enables flexible removing of such processing steps or adding additional ones when constructed.
Notes
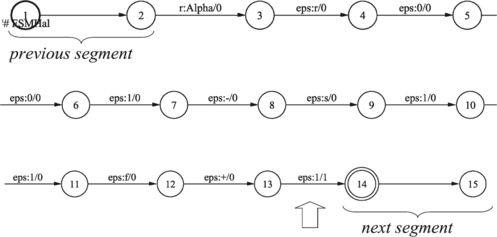
Vmps-pma- (verb, main, participle, past, plural, masculine, active), Ncnpi (noun, common, neuter, plural, instrumental), Spsi (adposition, preposition, simple, instrumental) and Rgp (adverb, general, positive) are codes as specified in the scope of the Multext project (Multext, Citation1996). p marks previous segment feature name and corresponding value. n marks next segment feature name and corresponding value.
Vmps-pma- (verb, main, participle, past, plural, masculine, active) and Ncnpi (noun, common, neuter, plural, instrumental) are codes as specified in the scope of the Multext project (Multext, Citation1996).
Meta symbol “Omega” is an abstract symbol used to mark the whole sequence of features for a given segment (Alpha, predicted homograph tag, POS, Word, Capital Letter) as shown in Figure . p marks previous segment feature name and corresponding value. N marks negative question. capletter is an abstract symbol used to mark the capital letters.
“/” marks acute accent, “\” marks grave accent, and “∗” marks circumflex.
“Omega” meta symbol is an abstract symbol, used to mark the whole sequence of features for given segment (Alpha, Grapheme, Stress, Stress type) as follows in Figure . p marks previous segment feature name and corresponding value. n next segment feature name and corresponding value. N marks negative question.
REFERENCES
- Breiman , L. , J. Freidman , R. Olshen , and C. Stone . 1984 . Classification and Regression Trees . New York : Chapman & Hall .
- Daciuk , J. 1998 . Incremental construction of finite-state automata and transducers and their use in the natural language processing. Ph.D. thesis , Technical University of Gdansk , Gdansk , Poland .
- Emmanuel , R. and Y. Schabes . 1997 . Finite State Language Processing . The Massachusetts Institute of Technology: MIT Press .
- Galescu , L. and J. F. Allen . 2002 . Pronunciation of proper names with a joint n-gram model for bi-directional grapheme-to-phoneme conversion . In Proceedings of the ICSLP , pp. 109–112, Denver , CO, USA .
- Gelfand , S. , C. Ravishankar , and E. Delp . 1991 . An iterative growing and pruning algorithm for classification tree design . IEEE Trans. PAMI 13 ( February ): 163 – 174 .
- Hain , H. U. 2000 . A hybrid approach for grapheme-to-phoneme conversion based on combination of partial string matching and a neural network . In Proceedings of the ICSLP , Vol. 3 , pp. 291 – 294 , Beijing , China .
- Hopcroft , J. E. and J. D. Ullman . 1979 . Introduction to Automata Theory, Languages, and Computation . Reading , Mass .: Addison Wesley .
- Kaplan , R. M. and M. Kay . 1994 . Regular models of phonological rule systems . Computational Linguistics 20 ( 3 ): 331 – 378 .
- Kiraz , G. A. and B. Mobius . 1998 . Multilingual syllabification using weighted finite-state transducers . Proceedings of the Third International Workshop on Speech Synthesis , Australia .
- Kuich , W. and A. Salomaa . 1986 . Semirings, automata, languages . In Monographs on Theoretical Computer Science . Berlin : Springer Verlag .
- Liberman , M. J. and K. W. Church . 1992 . Text analysis and word pronunciation in text-to-speech synthesis . In Advances in Speech Signal Processing . New York : Dekker .
- Mohri , M. 1994 . Minimization of sequential transducers . In Lecture Notes in Computer Science . pp. 151–163, Berlin: Springer Verlag .
- Mohri , M. 1995 . On some applications of finite-state automata theory to natural language processing . Natural Language Engineering 1 : 1 – 20 .
- Mohri , M. 1997 . Finite-state transducers in language and speech processing . Computational Linguistics 23 ( 2 ): 269 – 311 .
- Mohri , M. and R. Sproat . 1996 . An efficient compiler for weighted rewrite rules . In 34th Meeting of the Association for Computational Linguistics (ACL 96) . Santa Cruz , California .
- Multext . 1996 . http://www.lpl.univ-aix.fr/projects/multext
- Onomastica . 1995 . http://www.elda.fr/catalogue/speech/s0043.html
- Pagel , V. , K. Lenzo , and A. W. Black . 1998 . Letter to sound rules for accented lexicon compression . In Proceedings of the ICSLP , Sydney , Australia .
- Rojc , M. 2000 . Use of finite-state machines in automatic text-to-speech synthesis systems. M.Sc. thesis , Faculty of Electrical Engineering and Computer Science, University of Maribor , Maribor , Slovenia .
- Rojc , M. 2003 . Time and space optimal architecture of the multilingual and polyglot TTS system—architecture with finite-state machines. Ph.D. thesis , Faculty of Electrical Engineering and Computer Science, University of Maribor , Maribor , Slovenia .
- Rojc , M. and Z. Kacic . 2000 . A computational platform for development of morphologic and phonetic lexica . In LREC 2000 , Athens , Greece .
- Sproat , R. 1998 . Multilingual Text-to-Speech Synthesis . The Netherlands: Kluwer Academic Publishers .
- Sproat , R. 2001. Pmtools: A pronunciation modeling toolkit. In Fourth ISCA ITRW on Speech Synthesis , Blair Atholl , Scotland.
- Sproat , R. and M. Riley . 1996 . Compilation of weighted finite-state transducers from decision trees . In 34th Meeting of the Association for Computational Linguistics (ACL 96) , pp. 215 – 222 , Santa Cruz , California .
- Suontausta , J. and J. Hakkinenen . 2000 . Decision tree based text-to-phoneme mapping for speech recognition . In Proceedings of the ICSLP , pp. 199 – 202 , Beijing , China .
- Taylor , P. , A. W. Black , and R. Caley . 2001 . Heterogeneous relation graphs as a formalism for representing linguistic information . Speech Communication 33 ( 1–2 ): 153 – 174 .
- Yarowsky , D. 1994 . Decision lists for lexical ambiguity resolution . In Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics , pp. 88 – 95 .
- Yarowsky , D. 1997 . Homograph disambiguation in text-to-speech synthesis . In Progress in Speech Synthesis , eds. J. Olive , J. van Santen , R. Sproat , and J. Hirschberg , Springer , New York : Springer .