Abstract
As geospatial data grows explosively, there is a great demand for the incorporation of data mining techniques into a geospatial context. Association rules mining is a core technique in data mining and is a solid candidate for the associative analysis of large geospatial databases. In this article, we propose a geospatial knowledge discovery framework for automating the detection of multivariate associations based on a given areal base map. We investigate a series of geospatial preprocessing steps involving data conversion and classification so that the traditional Boolean and quantitative association rules mining can be applied. Our framework has been integrated into GISs using a dynamic link library to allow the automation of both the preprocessing and data mining phases to provide greater ease of use for users. Experiments with real-crime datasets quickly reveal interesting frequent patterns and multivariate associations, which demonstrate the robustness and efficiency of our approach.
Intelligent crime analysis allows for a greater understanding of the dynamics of unlawful activities, providing possible answers to where, when, and why certain crimes are likely to happen. Geographic Information Systems (GISs) are used extensively in crime analysis as they allow us to model the real world along with many geographical layers (themes or coverages) represented by point, line, and area data types. In such multi-layered architecture, it is important to find associative relationships among layers for the discovery of thematically, geospatially, and temporally correlated events. Detected positive associative patterns are the key resource for geospatial decision-making, such as planning, precaution, prediction, and policy-making.
In many settings within GISs, we are often given an areal base map (layer, coverage, or theme) and asked to find multivariate associations based on the given areal base map. In particular, crime datasets are often recorded in areal-aggregated formats due to limited environmental circumstances, ethical issues, or topological/geometrical computational considerations. Environmentally, this is the case when the areal base map is of main interest (for instance, state division boundary map for state governments), or when only area aggregates are available to us (such as in voting data and census data). Ethically, this is when protecting privacy from geospatial analysis and geospatial data mining is of great importance. With geospatial crime data, crime incidents can be aggregated on an area basis to avoid delicate privacy and security issues; it is noted, however, that area aggregates at quite small geographical scales may remove privacy issues while still providing useful information (Bailey and Gatrell Citation1995). Computationally, it is when efficient and effective management of topological operations is necessary. Topological operations with areal objects have been identified as relatively easy and well established compared with other primitive data types (Bailey and Gatrell Citation1995). Geometrically, converting primitive data types to more complex data types is well supported by existing GISs through intersection, containment, and buffering operations, and is considered to be topologically restorable. However, transforming complex data types to primitive data types may cause loss of geometrical and topological information. The large areal aggregated geospatial-temporal crime datasets collected by the Queensland Police Service (QPS) in Australia need to be properly analyzed along with geospatial factors to reveal interesting patterns.
Despite the popularity of this areal base map-based multivariate association analysis, there are several impediments that hinder the development of this type of analysis. Geographic Information Systems are moving from data-poor to data-rich environments (Miller and Han Citation2001). Even if several geospatial statistics (χ2-test, nearest neighbor distances, the K-function, Moran's I, and Geary's c statistics) are available for detecting geospatial correlation structure (geospatial dependence, symmetric relations, or autocorrelation), these correlation statistics are computationally expensive and inefficient (also demanding a great degree of human involvement). In this highly competitive and fast-evolving society, we are often requested to make a prompt decision. Traditional data mining techniques (Han and Kamber Citation2000; Miller and Han Citation2001) are solid candidates to enhance the efficiency, however, they neglect the special characteristics of geoinformation and may miss geospatially interesting patterns (Estivill-Castro and Lee Citation2002). In addition, the heterogeneity of geospatial data types complicates the adoption of traditional data mining techniques to the geospatial context.
In this article, we propose a robust geospatial knowledge discovery framework that automates areal categorized multivariate association mining (ACMAM) and quickly reveals positive asymmetric associations among heterogeneous geographical layers in data-rich environments. We focus on exploratory data analysis assuming no prior knowledge is available. We utilize association rules mining and consider the characteristics of multi-layered GISs in order to reveal unbiased associations. The framework can be fully integrated into traditional GISs using a dynamic link library and scripting languages such as AVENUE for ArcView, Python for ArcGIS, or MapBasic for MapInfo. This allows for greater automation of both the preprocessing and data mining phases and thus provides greater ease of use for users. Experimental results with real complex crime datasets demonstrate the virtue of our framework. In our experiments, we have implemented the framework with a combination of a dynamic link library and scripting languages within ArcGIS families.
ASSOCIATION RULES MINING
Association rules mining (ARM) (Agrawal, Imielinski, and Swami Citation1993; Agrawal and Srikant Citation1994; Han and Kamber Citation2000; Hipp, Güntzer, and Gholamreza Citation2000) has been a powerful tool for discovering positive associations among a set ℐ = {I 1, I 2,…, I n } of items in a transactional database . Here, each transaction ∊ is a subset of ℐ. An association rule is an expression in the form of X ⇒ Y (c%), X ∊ ℐ, Y ∊ ℐ, and X ∩ Y = , where X is called antecedent and Y is called consequent. It is interpreted as “c% of transactions in that satisfy X also satisfy Y.” Typically, support and confidence are two measures of a rule's interestingness. Support ensuring statistical significance is the probability that X and Y exist in a transaction ∊ . Confidence indicating the rule's strength is the probability that Y exists in a transaction given that contains X. That is, support is an estimate for Prob(X ∪ Y) and confidence is an estimate for Prob(Y|X). Another measure of a rules interestingness is lift (Webb and Zhang Citation2002). The lift value is given by the ratio of confidence to expected confidence, where the expected confidence is the number of transactions that include the consequent divided by the total number of transactions. Lift indicates the increase in probability of X given Y. A set of items is referred to as an itemset. Two user-defined thresholds, minimum support and minimum confidence, are used for pruning rules to find only interesting rules. Item sets satisfying the required minimum support constraint are named frequent while rules satisfying the two thresholds are called strong.
Recently, (Mennis and Liu Citation2005) applied traditional ARM to socio-economic and land cover change analysis. It ignores spatial dimension, only considers areal types, and simply converts spatial database to relational tables to which traditional ARM can be applied. Typically, ARM has been applied to geospatial data in two different ways. This is parallel to the fact that there are two popular views of geographical space in a GIS: raster and vector. The vector view regards geographical space as a set of objects while the raster view sees it as a set of locations. Spatial association rules mining (SARM) (Koperski and Han Citation1995) is similar to the raster view in the sense that it tessellates a study region S into discrete groups based on spatial or aspatial predicates derived from concept hierarchies. For instance, a spatial predicate close_to(α, β) divides S into two groups, locations close to β and those not. So, close_to(α, β) can be either true or false depending on α's closeness to β. A spatial association rule is a rule that consists of a set of predicates in which at least one spatial predicate is involved. For instance, is_a(α, house) ∧ close_to(α, beach) ⇒ is_expensive(α). Although this approach efficiently mines complex geospatial datasets, it has several drawbacks. It is not directly applicable to datasets in which transactions can be infinite or indefinite, that is, situations where the traditional interesting measures cannot be directly measured. Also, a great degree of human involvement is required to find associative rules and patterns are not automatically generated. In this approach, the predefined concept hierarchy drives the human-oriented rule discovery which does not comply with exploratory data analysis and the principle to “let the data speak for themselves” (Gould Citation1981; Openshaw Citation1994).
Co-location rule mining (CLRM) (Shekhar and Huang Citation2001) discovers a subset of features given a set of point features frequently located together in a geographic space. It extends traditional ARM by providing a transaction-free approach using the concept of neighborhoods without having to define a reference feature. This avoids potential loss of proximity relationship information in partitioning continuous geographic space into transactions. Thus, this approach focuses on features similar to the vector approach. Here, transactions correspond to point locations and items correspond to features. Since features have different occurrences, the size of transactions vary with features. Thus, it is impossible to use the traditional interesting measures and this approach introduces two new interesting measures (prevalence and conditional probability) that can be used in a dynamic situation where transactions are not fixed to a constant. Prevalence indicates the minimum participation ratio of a feature in the antecedent and consequent of a rule. The conditional probability is the probability of finding the consequent in a neighborhood of antecedent. Huang, Shekhar, and Xiong (Citation2004) improve upon the event centric model and present a generalized algorithm to discover co-location patterns from point spatial datasets. It includes a multi-resolution filter that increases the performance of the algorithm when the features of the dataset are naturally clustered. One of the major problems with the co-location miner is that it cannot handle extended spatial data types such as line segments, polygons, and circles. Xiong et al. (Citation2004) propose the EXCOM algorithm which effectively solves this problem using the notion of zones around spatial objects called buffers. This algorithm integrates the best features of the event-centric model and applies a statistically consistent definition for the conditional probability measure. The authors suggest that the EXCOM algorithm could also be extended to mine co-incidence events, which extend the concept of co-location events.
AREAL CATEGORIZED MULTIVARIATE ASSOCIATION MINING
Framework of ACMAM
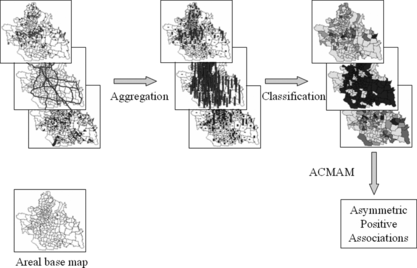
Our framework is a three-phase knowledge discovery process. It initially involves two preprocessing phases called aggregation and categorization (classification). Data mining is then applied to the processed datasets. Both of these steps are fully implemented within the GIS to allow greater automation of the process. In principle, it transforms all geospatial layers into areal aggregated data types based on a given areal base map. Areal aggregates are numerical values that will be further categorized into several groups. Geographic Information Systems provide a number of built-in categorization schemes and we use these functions in this article. Figure describes the overall framework involving data aggregation, categorization, and ARM. The discovery process is interactive and iterative. Each phase will be further discussed in the subsequent subsections.
FIGURE 1 The framework of areal categorized geospatial knowledge discovery.
Data Preprocessing and Aggregation
In geometrical and topological transformations, the intersection operation is a basis for other geospatial operations such as meet, overlap, cover, and contain (Worboys Citation1995). In addition, it has been used as a basis for qualitative spatial reasoning (Cohn, Bennett, Gooday, and Gotts Citation1997). Thus, intersection is a fundamental operation and is used as default for aggregation and conversion in this article.
Point-to-Area Aggregation
Point-to-area aggregation has been widely used in GISs. Containment or within function, so called point-in-polygon operation, can be used to aggregate point data. Aggregates are typically visualized through choropleth maps using graduated color to represent density. In this article, point-in-polygon operation is used in point data aggregation.
Line-to-Area Aggregation
Similar to point-to-area aggregation, we can use the intersection topological relationship in line-to-area conversion. Areal units that intersect with a target line object would represent the presence of the line object. Thus, those areal units imply proximity to the line object. This approach would work well when areal units are largely scaled to capture the details. One alternative is to use buffering. Buffering creates an enclosing polygon of a line object at a specified distance. Once transformed, we can apply area-to-area data aggregation that will be discussed in the next subsection. In this article, we adopt the former as default.
Area-to-Area Aggregation
Intersection operation is still a solid candidate for this transformation. We adopt an approach somewhat similar to the areal-stealing (or areal-weighting) interpolation technique (Gold Citation1991; Goodchild and Lam Citation1980) in order to aggregate heterogeneous areal datasets in our framework. Let B = {b 1, b 2,…, b n } be an areal base map with a set n of areal units. Let T = {t 1, t 2,…, t m } be an areal target map with a set m of areal units. Then, the target map is converted based on the following rules:
Formula 1 denotes the area of an areal unit in the base map is the sum of its intersection areas with target areal units. Formula 2 represents an aggregate value of the area in the base map is the sum of productions of stolen areas and corresponding values in the target map. This is explained in Figure . Figure (a) displays an areal base map, while Figure (b) shows a target areal map with different boundaries. Let us assume that an area highlighted in Figure (a), denoted by b
1, is of interest. It is labeled with the percentage of offenses against person over total offenses in the same study region. Our task is to aggregate the target layer based on the areal base map shown in Figure (a). Figure (c) depicts an overlay of b
1 and the target map labeled with area intersecting with areal units in the target map. According to Formula 1, the area of b
1 (16.34) is the sum of stolen areas (3.37, 4.98, 6.15, and 1.84) shown in Figure (c). The value of b
1 (b
1.value) can be computed as follows based on Formula 2: b
1.value = (3.37∗0.27 + . Thus, 40% of offences in b
1 are regarded as offences against person.
FIGURE 2 Area-to-area aggregation: (a) a base map; (b) a target map labeled with corresponding percentages of offenses against person over total offenses; (c) an overlay of the base map and the target map.

Categorization and Classification
Geographic Information Systems provide various built-in categorization schemes that can be used for highlighting dense areas including hot spots and local excesses. ArcGIS offers natural breaks, quantile, equal area, equal interval, and standard deviations. Natural breaks is the default categorization method in ArcGIS and this method identifies natural breakpoints between classes using a statistical formula called Jenk's optimization (Dent Citation1999). This method minimizes the sum of the variance within each of the classes. It is noted that natural breaks find groupings and patterns inherent in the data. Thus, it is chosen as default in our approach. However, other classification methods (or hot spot analysis techniques) can easily be integrated into our framework.
ACMAM
The apriori algorithm has been dominant in ARM since its first introduction in 1993 (Agrawal et al. Citation1993). Many apriori-like algorithms (Agrawal and Srikant Citation1994; Hipp et al. Citation2000) have been suggested using different indexing schemes or pruning techniques (Han and Kamber Citation2000). The apriori algorithm employs a candidate generation method that requires an iterative level-wise search where k-items are used to explore (k + 1)-items. It first finds frequent 1-itemsets that satisfy the minimum support constraint. These sets are then used to find frequent 2-itemsets which will be used to find frequent 3-itemsets. The downward closure property (all nonempty subsets of a frequent item must also be frequent) is used to improve the efficiency of the level-wise generation of frequent items. Once all frequent itemsets are generated, minimum confidence is then used to find only strong rules. Readers can refer to the original article (Agrawal et al. Citation1993; Agrawal and Srikant Citation1994) for details. Recently, FP-Tree (Han, Pei, Yin, and Mao Citation2004) approach without generating candidates has been proposed and shown to be more time efficient than the candidate generation approach while producing the same frequent patterns. We implement both algorithms in ACMAM and FP-Tree is used as default in our system.
In our approach, features correspond to items while areal units correspond to transactions. Feature sets denote sets of features. Areal categorized multivariate association mining is used to find frequent feature sets and strong geospatial rules based on a given areal base map. Association rules mining is used to compute all strong rules. Users can use must-contain constraints in ACMAM to tailor their search. Constraints can be placed on the antecedent and/or consequent. The former (a must-contain feature set → ∗) is used to explore possible associations of the feature set. For instance, a city council may want to explore the possible consequences of introducing a new casino into the area (casino → ∗). If a casino has a high correlation with many criminal activities, then the council may not want to introduce one into the region. The latter (∗ → a must-contain constraint) is used to explore possible stimuli of the feature set. In particular, this constraint is useful for crime data mining as it may reveal “possible lures” that attract a particular crime type.
EXPERIMENTAL RESULT: A CASE STUDYWITH CRIME DATASETS
Brisbane, the capital city of Queensland, Australia, is continuously experiencing steady population and crime growth (Murray and Shyy Citation2000; Murray, McGuffog, Western, and Mullins Citation2001). Understanding criminal activity in this region provides a valuable resource to city planners, policing agencies, and criminologists.
Description of Datasets
In this study region, the QPS records crime incidents as areal aggregates due to limited environmental circumstances and ethical issues. We utilize raw areal aggregate crime datasets recorded in the year of 1998 by the QPS around 217 central urban suburbs of Brisbane as our study region. We also utilize a number of geospatial feature datasets to investigate associative relations among crime incidents and geospatial features. The hierarchical nature of criminal types (in abbreviation) from Queensland is shown as a tree in Figure and their full types appear in Table . Obtained crime statistics have three main categories: personal safety (offenses against person), property security (offences against property), and other offenses. Each main category has subcategories that may be split into further types.
FIGURE 3 A crime taxonomy tree illustrating various crime types in Queensland.
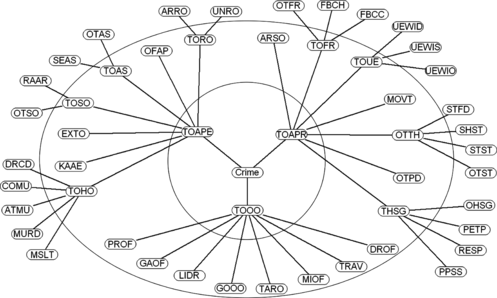
TABLE 1 Crime Type Abbreviation
The complex and hierarchical structure of the crime dataset is not the only concern for crime analysis. Various geospatial features must be studied to identify salient features that may lead to criminal activities. Table details the geospatial feature datasets that are considered in this experiment. All the feature datasets are aggregated onto an areal base map (217 suburbs) and categorized into several groupings using natural breaks. Most datasets are grouped into five categories. Some datasets, scarcely recorded or line data types, are grouped into two categories: absence and presence.
TABLE 2 Feature Datasets
Experimental Set-Up
Due to the hierarchical nature of crime data as shown in the crime tree in Figure , we examine different levels of the hierarchy in our experiments. We explore the top-level (TOAPE, TOAPR, and TOOO), the first-level and leaves of the crime tree (as depicted in Figure ) with the 15 geospatial feature datasets.
The default method of ArcGIS, natural breaks, has been used as the categorization method in our experiments. The number of categories plays a critical role, typically, 4–6 categories are recommended (Dent Citation1999). Too few categories may cause loss of detail while too many categories can cause confusion. In this article, we experiment with five groupings for quantitative associations and two groupings for Boolean hot spot associations. However, users can explore a given dataset with different categorization schemes with different numbers of classes in our framework. All the experiments are carried out using minimum support = 0.05% and minimum confidence = 0.7%. We select rules with a lift value greater than 1, which indicates that the antecedent and the consequent appear more often together than expected, meaning that the occurrence of the antecedent has a positive effect on the occurrence of the consequent. Areal categorized multivariate association mining finds frequent patterns and associations in all experiments within 1 second (varying from 0.047 to 0.547 second) using a 2.4 GHz Pentium IV workstation (Palo Alto, CA) with 1 GB main memory, which demonstrates the efficiency of our discovery framework.
We visualize a subset of the discovered association rules using the 3-D representation suggested by Wong, Whitney, and Thomas (Citation1999). The rows of the matrix floor represent items and the columns represent item associations. The green and red blocks of each column (rule) represent the antecedent and the consequent. Identities of the items are shown along the right side of the matrix. In the 3-D representation, the blue and the cyan represent the support and the confidence.
Boolean ACMAM
This analysis focuses on crime hot spots and densely featured areas, and reveals positive Boolean multivariate associations. Figures and show the Boolean associations that were discovered with ACMAM. Rules 1–7 are from the analysis of top-level crime types, rules 8–15 from first-level and rules 16–21 from leaf-level crime types.
FIGURE 4 Boolean ACMAM with support and confidence values.
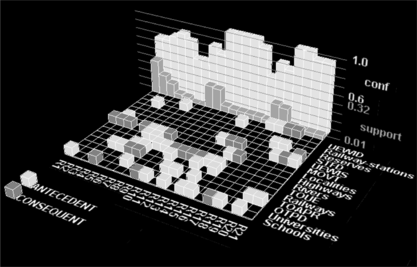
FIGURE 5 Boolean ACMAM with support and lift values.

Top-Level Association
This analysis considers the three top-level crime types with 15 geospatial features. Interestingly, Schools and Highways appear frequently with TOAPR. In particular, Schools or Highways can be found where TOAPR takes place with around 80% confidence. Highways seem to be frequently found with Schools, Railways, and Localities. In addition, this top-level analysis reveals some asymmetric associations among geospatial features. Schools, Localities, or Reserves seem to imply the existence of Highways with more than 74% of confidence. In addition, the constrained rule mining (∗ ⇒ TOAPR) reveals two combinations of features imply TOAPR with 60% of confidence level. Some other interesting frequent patterns and multivariate associations are shown in Figures and .
First-Level Association
Patterns and associations revealed in this analysis demonstrate which subcategories of TOAPR are particularly associated with Schools and Highways. The analysis reveals TOUE exhibits high co-existence with Highways, Schools, Railways. Also, it reveals that even though TOOO does not show high co-existence with Highways, one of its subcategories, TARO frequently exists with Highways with 14% of support. Multivariate associations with high confidence reveals OTPD and MOVT are “possible lures” of TOUE.
Leaf-Level Association
This analysis reveals associations with more detailed (low-level) crime types and concretes frequent patterns found in the first-level association analysis. Leaf-level frequent pattern mining reveals that UEWID is the main contributor to the high co-existence of TOUE with Highways/Schools. In addition, this analysis reveals co-existence of UEWIS with Highways. UEWID, UEWIS, or MOVT as consequent in the constrained mining (∗ ⇒ Leaf-level crimes) reveals several “possible lures” that attract these crime types. In particular, Schools attract UEWID and MOVT. This information could be used by residents nearby schools to better protect their properties.
Quantitative ACMAM
Quantitative ACMAM reveals associations with discretized intervals. As discussed, natural breaks with five classes (very dense, dense, medium, sparse, very sparse) has been used in this experiment. Figures and show the quantitative associations that were discovered with ACMAM. Rules 1–7 are from the analysis of top-level crime types, rules 8–13 from first-level and rules 14–18 from leaf-level crime types.
FIGURE 6 Quantitative ACMAM with support and confidence.

FIGURE 7 Quantitative ACMAM with support and lift.

Top-Level Association
Even though Schools and TOAPR are frequently located, Quantitative ACMAM reveals Schools are not associated with any particular naturally broken TOAPR groups. However, Highways frequently co-exist with one of TOAPR groups (TOAPR(sparse)). Interestingly, Highways co-exist with sparsely populated top-level crime types. The co-existence of Highways and densely populated top-level crime types is not highly supported. Some interesting frequent patterns and multivariate quantitative associations are shown in Figures and .
First-Level Association
Some minor crime types, not classified into major crime types but others, are found to be frequent in this analysis, in particular, MIOF(sparse), OTTH(sparse), and OTPD(sparse). Areal categorized multivariate association mining reveals these sparsely populated minor crime types imply Highways with more than 74% confidence.
Leaf-Level Association
Similarly, this association analysis concretes some high-level associations and detects new low-level crime associations. Highways seem to co-exist with OTST(sparse) which confirms the co-existence of OTTH(sparse) and Highways. On the other hand, the co-existence of Highways and RAAR(sparse) has been detected in this association test.
Complexity Analysis
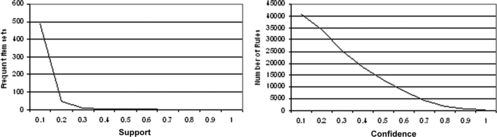
The number of frequent item sets generated and the number of association rules discovered are dependent on both the minimum support and minimum confidence parameters. Figure shows how varying these two parameters effects the number of frequent item sets and association rules as applied to Boolean ACMAM using leaf crime data. It can be seen that with even small changes to these parameters that the number of generated rules can become unworkable. Figure shows a similar effect when using quantitative ACMAM.
FIGURE 8 Number of generated frequent item sets and rules using Boolean ACMAM.
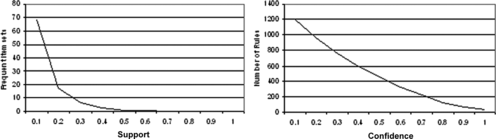
FIGURE 9 Number of generated frequent item sets and rules using quantitative ACMAM.
CONCLUSIONS
This article proposes a geospatial knowledge discovery framework that utilizes association rules mining based on a given areal base layer. This framework is well-suited for data-rich, multi-layered GISs and datasets. Experiments with real-crime datasets reveal interesting frequent patterns and multivariate associations that need further confirmatory data analysis to help prevent crime. It is an exploratory and data-oriented approach that automates the generation of interesting hypotheses.
This is part of a large project to investigate the analysis of criminal activities in relation to socio-economic, environmental, and demographic factors in the Brisbane area of Queensland. The overall aim is to propose a robust framework that will help users mine frequent causal patterns within multi-layered GIS environments. We use ArcGIS for our experiments and use its scripting languages and dynamic link libraries to implement this three-phase geospatial knowledge discovery framework. Future directions are twofold: first, the incorporation of more comprehensive feature datasets will reveal more interesting rules. However, this can also have the negative effect of producing far too many rules to be useful—a delicate balance must be found. Second, negative associations, in addition to positive associations, need to be mined so that “repulsive attributes” can be detected (such as police stations or frequent patrols). These associations will also help with crime prevention and control.
REFERENCES
- Xiong , H. , S. Shekhar , Y. Huang , V. Kumar , X. Ma , and J. S. Yoo . 2004 . A framework for discovering co-location patterns in data sets with extended spatial objects . In SIAM International Conference on Data Mining , Lake Buena Vista , FL . Proceedings of the ACM SIGMOD'93 International Conference on Management of Data , eds. P. Buneman and S. Jajodia , Washington , DC , 207 – 216 . New York : ACM Press .
- Agrawal , R. and R. Srikant . 1994 . Fast algorithms for mining association rules in large databases . In: Proceedings of the 20th International Conference on Very Large Data Bases , eds. J. B. Bocca , M. Jarke , and C. Zaniolo , Santiago de Chile , Chile , 487 – 499 . San Francisco: Morgan Kaufmann .
- Bailey , T. C. and A. C. Gatrell . 1995 . Interactive Spatial Analysis . Harlow , UK : Longman Scientific & Technical .
- Cohn , A. G. B. Bennett , J. Gooday N. M. Gotts . 1997 . Qualitative spatial representation and reasoning with the region connection calculus . GeoInformatica 1 ( 3 ): 275 – 316 .
- Dent , B. D. 1999 . Cartography: Thematic Map Design, , 5th ed . Boston : WCB McGraw Hill .
- Estivill-Castro , V. , and I. Lee . 2002 . Argument free clustering via boundary extraction for massive point-data sets . Computers, Environments and Urban Systems 26 ( 4 ): 315 – 334 .
- Gold , C. M. 1991 . Problems with handling spatial data - The Voronoi approach . Canadian Institute of Surveying and Mapping Journal 45 ( 1 ): 65 – 80 .
- Goodchild , M. F. N. S. N. Lam . 1980 . Areal interpolation: A variant of the traditional spatial problem . Geo-Processing 1 : 297 – 312 .
- Gould , P. 1981 . Letting the data speak for themselves . Annals of the Association of American Geographers 71 : 166 – 176 .
- Han , J. and M. Kamber . 2000 . Data Mining: Concepts and Techniques . San Francisco , CA : Morgan Kaufmann Publishers .
- Han , J. J. Pei , Y. Yin,, R. Mao . 2004 . Mining frequent patterns without candidate generation: A frequent-pattern tree approach . Data Mining and Knowledge Discovery 8 ( 1 ): 53 – 87 .
- Hipp , J. , U. Ganduuml;ntzer , and N. Gholamreza . 2000 . Algorithms for association rule mining – A general survey and comparison . SIGKDD Explorations 2 ( 1 ): 58 – 64 .
- Huang , Y. , S. Shekhar , and H. Xiong . 2004 . Discovering colocation patterns from spatial data sets: A general approach . IEEE Transactions on Knowledge and Data Engineering 16 ( 12 ): 1472 – 1485 .
- Koperski , K. and J. Han . 1995 . Discovery of spatial association rules in geographic information databases . In: Proceedings of the 4th International Symposium on Large Spatial Databases , eds. M. J. Egenhofer and J. R. Herring , Lecture Notes in Computer Science 951 , Portland , ME , 47 – 66 . Berlin : Springer .
- Mennis , J. , and J. Liu . 2005 . Mining association rules in spatio-temporal data: An analysis of urban socioeconomic and land cover change . Transactions in GIS 9 : 5 – 17 .
- Miller , H. J. and J. Han . 2001 . Geographic Data Mining and Knowledge Discovery: An Overview . Cambridge , UK : Cambridge University Press .
- Murray , A. T. I. McGuffog , J. , S. Western , and P. Mullins . 2001 . Exploratory spatial data analysis techniques for examining urban crime . British Journal of Criminology 41 : 309 – 329 .
- Murray , A. T. , and T. Shyy . 2000. Integrating attribute and space characteristics in choropleth display and spatial data mining. International Journal of Geographical Information Science 14:649–667.
- Openshaw , S. 1994 . Two exploratory space-time-attribute pattern analysers relevant to GIS . In: Spatial Analysis and GIS , eds. A. S. Fotheringham and P. A. Rogerson , 83 – 104 . London : Taylor & Francis .
- Shekhar , S. and Y. Huang . 2001 . Discovering spatial co-location patterns: A summary of results . In: Proceedings of the 7th International Symposium on the Advances in Spatial and Temporal Databases , eds. C. S. Jensen , M. Schneider , and V. J. Seeger , and B. Tsotras , Lecture Notes in Computer Science 2121 , Redondo Beach , CA , 236 – 256 . Berlin: Springer .
- Webb , G. I. and S. Zhang . 2002 . Removing trivial associations in association rule discovery . In: Proceedings of the First International NAISO Congress on Autonomous Intelligent Systems (ICAIS 2002) , Canada/The Netherlands : NAISO Academic Press .
- Wong , P. C. , P. Whitney , and J. Thomas . 1999 . Visualizing association rules for text mining . In: IEEE Symposium on Information Visualization , San Francisco , CA , 120 – 123 .
- Worboys , M. F. 1995 . GIS: A Computing Perspective . London : Taylor & Francis .
- Xiong , H. , S. Shekhar , Y. Huang , V. Kumar , X. Ma , and J. S. Yoo . 2004 . A framework for discovering co-location patterns in data sets with extended spatial objects . In: SIAM International Conference on Data Mining , Lake Buena Vista , FL .