Abstract
Software practitioners need ways to assess their software, and metrics can provide an automated way to do that, providing valuable feedback with little effort earlier than the testing phase. Semantic metrics were proposed to quantify aspects of software quality based on the meaning of software's task in the domain. Unlike traditional software metrics, semantic metrics do not rely on code syntax. Instead, semantic metrics are calculated from domain information, using the knowledge base of a program understanding system. Because semantic metrics do not rely on code syntax, they can be calculated before code is fully implemented. This article evaluates the semantic metrics theoretically and empirically. We find that the semantic metrics compare well to existing metrics and show promise as early indicators of software quality.
Process improvement demands the ability to measure what is currently being done. Metrics can provide a fast, automated way to measure aspects of software quality. Because this information is immediately available to the software development team, it can be used to pinpoint problematic classes. For example, metrics may indicate that a class is complex. Complex classes tend to be difficult to understand or test completely (Pressman 2001) and more error-prone (Khoshgoftaar and Munson 1990). Through metrics, this information is available before testing occurs, giving the development team valuable feedback as to error-prone classes earlier in the software development life cycle. From this early feedback, the project manager may decide to order code inspections or more extensive testing on the error-prone classes.
Traditional software metrics use code syntax to assess qualities such as the complexity, cohesion, coupling, and size of a class. In contrast, semantic metrics, created by Etzkorn and Delugach (2000), quantify the meaning of the code's task in its domain. As Etzkorn, Gholston, and Hughes pointed out (2002), programmer style or the programming language may distort traditional software metrics.
Also, some problems have been discovered with some well-known syntactic object-oriented metrics. For example, the Chidamber and Kemerer LCOM metric (1994) has been redefined multiple times due to problems with earlier definitions (Hitz and Montazeri 1996). Statistical studies have also been performed which indicate problems with this metric (Basili, Briand, and Melo Citation1996).
On the other hand, semantic metrics are concerned with the meaning of the task in the domain, not with the implementation. Semantic metrics extract domain-specific information from identifier names and comments. Differences in implementation caused by programmer style or programming language have no impact on semantic metrics.
Furthermore, since semantic metrics quantify meaning, not code syntax, code need not be fully implemented before semantic metrics are calculated. Semantic metrics consider only identifiers and comments, specifically class, attribute variable, and member function names and comments from the class header and function header blocks. This is done using the PATRicia system, a mature program understanding engine (Etzkorn, Bowen, and Davis Citation1999; Etzkorn and Davis 1997, 1994). Semantic metrics can be calculated as soon as this information is available, often late in the design phase or early in the implementation phase. Thus, semantic metrics are available earlier in the software development life cycle than many traditional metrics.
The PATRicia system examines informal tokens in the form of identifiers and comments from source code. It has occasionally been argued that in many real-world systems comments are poor or nonexistent, and identifier names may be inadequate. However, the PATRicia system has been extensively tested on real-world systems, and the results have been good or acceptable in most cases—very good or excellent in some cases (Etzkorn and Davis 1997; Etzkorn, Davis, and Bowen Citation2001; Etzkorn et al. Citation1999). It has been observed (Etzkorn et al. Citation1999) that in some cases where comments are lacking, the PATRicia system achieves its results through identifier analysis alone. However, in these cases the PATRicia system results were in most instances still good or acceptable.
Another such system that has been validated on informal tokens is the DESIRE program understanding system created by (Biggerstaff Citation1989; Biggerstaff, Mitbander, and Webster Citation1993, 1994). Therefore, the informal tokens approach to program understanding has been shown to be successful by multiple researchers. Thus, since the semantic metrics, as calculated in this research, use information produced by a heavily validated informal tokens program understanding engine, the information on which semantic metrics are based is useful and reasonably complete.
Two suites of semantic metrics—the Etzkorn and Delugach suite (2000) and the Stein et al. suite (2004a)—have been proposed. However, only the SCDE, SCDEa, and SCDEb metrics have been previously empirically validated (Etzkorn et al. Citation2002). None of the other semantic metrics has ever been empirically validated heretofore; several of them have also never been theoretically validated before. In this article, we provide empirical validation for the Etzkorn and Delugach suite of semantic metrics (2000) and for the Stein et al. suite of semantic metrics (2004a). We provide theoretical analyses for those metrics from either suite that have not been theoretically analyzed before. We also provide formal, mathematical definitions for the semantic metrics: for many of these metrics, a formal definition has not been published before.
In order to validate the metrics, it was necessary for us to design and develop a tool that collects metrics from a knowledge-based representation of previously understood source code. We call this tool semMet. Portions of semMet are based on a mature program understanding system called the PATRicia system (Etzkorn et al. Citation1999; Etzkorn and Davis 1997, 1994); however, the actual collection of semantic metrics from a knowledge-base has not been done prior to the development of semMet—Etzkorn's earlier work on the SCDE metrics was performed by hand on the raw output of the PATRicia system (Etzkorn et al. Citation2002). The operation of the semMet tool is described in this article.
METRIC DEFINITIONS AND THEORETICAL ANALYSIS
In this section, we first describe in general how semantic metrics are calculated. Then we provide descriptions of the Etzkorn and Delugach semantic metrics, followed by descriptions of the Stein et al. semantic metrics, describing the ideas behind the metrics, and in general how the metrics work. Finally, we provide a formal, mathematical definition of each of the metrics.
Semantic Metric Calculation
Etzkorn and Delugach (2000) created semantic metrics to avoid traditional metrics' distortions due to programmer style and language. We developed a tool called semMet to compute semantic metrics for object-oriented software. SemMet is based on parts of Etzkorn's Program Analysis Tool for Reuse (PATRicia) system, a mature program understanding engine (Etzkorn et al. Citation1999; Etzkorn and Davis 1997, 1994). The natural language processing approach and the knowledge-base structure used by semMet are the same as the PATRicia system. The knowledge-base format of semMet includes an interface layer consisting of keywords tagged with parts of speech and a conceptual graph layer.
Two main parts compose the semMet tool: the source code interface and the main processing module. The source code interface performs the following tasks on source code:
Determine the inheritance hierarchy and each class's members and their visibility (public, private, or protected). | |||||
Extract all comments. | |||||
Perform natural language processing to associate the appropriate parts of speech with each word in identifiers and comments (ex., readData becomes read: verb and data: noun). | |||||
The source code interface passes the resulting information to the main processing module, which performs the following tasks:
Compare each word with its part of speech to a knowledge base of concepts and keywords from the problem domain of the system. | |||||
Associate the concepts and keywords matched from the knowledge base with classes and members from the code. | |||||
Compute semantic metrics based on the concepts and keywords associated with each class and member, and generate a report. | |||||
Conceptual graphs are a knowledge representation technique (Sowa 1984) employed in natural language processing. Figure shows a sample conceptual graph. In the conceptual graph in Figure , we find that Betsy is eating soup for lunch. Several semantic metrics described in this article, particularly those proposed by Etzkorn and Delugach (2000), use conceptual graphs.
FIGURE 1 A conceptual graph example representing “Betsy eats lunch, part of which is soup.”
In the semMet knowledge base, weighted uplinks connect keywords in the interface layer to concepts in the conceptual graph layer, as shown in Figure . There are also weighted uplinks between concepts in the conceptual graph layer. A “keyword” is a node that occurs in the interface layer of the knowledge base, and is used to map to words extracted from comment sentences or identifiers. A “keyword” in the knowledge base interface layer is tagged with the part of speech, such as noun, verb, adjective, etc. A “concept” is a node that occurs in the conceptual graph layer in the knowledge base. It forms part of a conceptual graph. For example, the node “Breakfast” is a concept in Figure . The node “Toast, n.” is a keyword.
FIGURE 2 Example illustrating semMet's processing of a simple class.
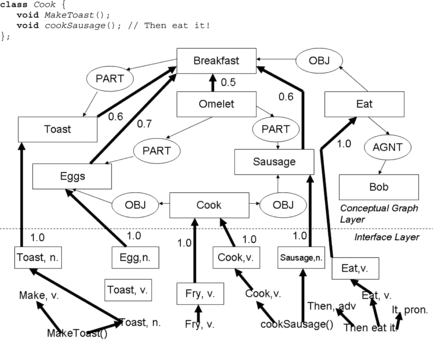
When a word from the source code is processed through the knowledge base, it is compared with the keywords and their parts of speech in the interface layer. For each keyword matched, the associated uplink(s) are fired. Each concept has a threshold, and if the weight of triggered uplinks to a concept is at least the threshold, then the concept is matched and its uplinks fire. This process is called inferencing. When inferencing has occurred for a class, the concepts and keywords matched are associated with that class. Similarly, the concepts and keywords matching each member function in the class are tracked. SemMet uses this information to calculate semantic metrics.
For example, Figure shows the processing performed for a simple class. The keywords and concepts shown in bold are those matched for the class. In Figure , the keyword layer of the knowledge base is shown and the conceptual graph layer of the knowledge base is shown. Concepts in the conceptual graph layer are identified by large rectangles; keywords in the interface layer have smaller rectangles. Links that form part of conceptual graphs are shown as thin arrows, whereas links that perform an inference function are shown as thick arrows. All thick arrows (inference links) have a weight associated with them (although not all the weights are shown in Figure so as to make it more readable).
In Figure , we find that a breakfast (which is being eaten by Bob) could consist of toast and eggs; alternately it could consist of toast and an omelet; alternately it could consist of eggs as well as an additional omelet. The omelet can contain both sausage and eggs. The sausage and eggs could be cooked.
Examining the code fragment shown in Figure , we find the identifiers “Cook,” “makeToast(),” and “cookSausage(),” and the comment sentence “Then eat it!” From the identifiers examined, “makeToast()” and “cookSausage(),” we find that Toast, a noun, has been recognized. Thus, “Toast, n.” the keyword in the interface layer that is serving as a noun, is fired. From the “cookSausage()” identifier, both the keyword “Cook, v.” and the keyword “Sausage, n.” in the interface layer are fired. These will (eventually) result in the corresponding concepts “Toast” and “Sausage” being fired in the conceptual graph layer.
From the comment sentence, “Then eat it,” three words are identified: “Then,” which is an adverb, “eat,” which is a verb, and “it,” which is a pronoun. The only corresponding keyword in the interface layer is “Eat, v.,” so that keyword is fired. This will (eventually) result in the concept “Eat” being fired in the conceptual graph layer. Further description of the operation of the PATRicia system (and thus of semMet) is provided in Etzkorn et al. (Citation1999) and Etzkorn and Davis (1997).
Etzkorn and Delugach Semantic Metrics Suite
Etzkorn and Delugach (2000) proposed the first semantic metrics for object-oriented software. They proposed these metrics to analyze software tasks within the problem domain, rather than merely analyzing code syntax.
Cohesion Metrics
Semantic metrics are well suited to measuring cohesion, which is difficult to assess based on program syntax alone, according to Briand, Daly, and Wust (Citation1998a). In this section, we define the semantic cohesion metrics proposed by Etzkorn and Delugach (2000).
Logical Relatedness of Methods (LORM)
Logical relatedness of methods measures the number of pairs of member functions linked by at least one conceptual relation, divided by the number of pairs of member functions in the class. For example, in Figure , if the concepts “Lunch”and “Eat” were identified as belonging to method f1 in Class A, while the concept “Betsy” was identified as belonging to method f2 in Class A, the pair f1, f2 would be counted in LORM. Method f1 is linked to method f2 by the conceptual relation “AGNT.”
LORM2
Logical relatedness of methods 2 is based on the number of concepts shared by member functions, regardless of the conceptual relations between those concepts. LORM2 measures the number of concepts shared by pairs of member functions, divided by the total number of possible shared concepts. For example, consider Figure . If Conceptual Graph #1 has been identified as belonging to method f1 of Class A, and Conceptual Graph #2 has been identified as belonging to method f2 of Class B, then the two member functions intersect on concepts “CAT” and “EAT.” Thus f1, f2 would be counted in LORM2, and the count for that pair would be 2. This definition works for knowledge bases with a conceptual graph structure. However, not all knowledge bases are based on conceptual graphs. Therefore, two variations on this metric emerged. LORM2a considers keywords only, not concepts; and LORM2b, proposed by Stein et al. (Citation2004a), considers concepts and keywords. These variations work the same as LORM2, except that the concepts and keywords are not assumed to be located within a conceptual graph structure.
FIGURE 3 Example used in text to illustrate some semantic metrics.
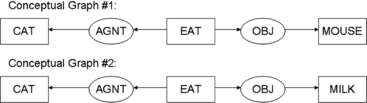
LORM3
The description of LORM3 was originally given as: “For two conceptual graphs, v1 and v2, given concepts ci (1 ≤ i ≤ n, where n is the number of concepts in v1) and concepts dj (1 ≤ j ≤ m, where m is the number of concepts in v2), such that the criteria for a compatible projection hold, for 1 ≤ q ≤ i, 1 ≤ r ≤ j:
Type(π1cq) ∩ Type(π2dr) > τ, where τ is the universal type. | |||||
The referents of π1cq and π2dr conform to Type(π1cq) ∩ Type(π2dr). | |||||
If referent(π1cq) is the individual marker s, then referent(π2 d r ) is either s or ∗.” (Etzkorn and Delugach 2000) | |||||
In this context, π is a mapping from the conceptual graph of a method to the intersection of the conceptual graphs of two methods.
This metric uses more complex features of conceptual graphs than the semMet knowledge-base format provides. Therefore, we propose a variation called LORM3′. LORM3′ measures the number of concepts and conceptual relations shared by pairs of member functions, divided by the total number of possible shared concepts and conceptual relations. For example, consider Figure . If Conceptual Graph #1 has been identified as belonging to method f1 of Class A, and Conceptual Graph #2 has been identified as belonging to method f2 of Class B, then the two member functions intersect on concepts “CAT” and “EAT,” as well as on the corresponding conceptual relations “AGNT” and “OBJ.” Thus f1, f2 would be counted in LORM3, and the count for that pair would be 4. This definition works for knowledge bases with a conceptual graph structure similar to that of the PATRicia system.
Complexity Metrics
Semantic metrics measure the complexity of a class's task in its domain. This contrasts with traditional syntactic metrics, which measure the complexity of an implementation.
Class Domain Complexity (CDC)
Class domain complexity counts the concepts and their associated conceptual relations, multiplied by a weighting factor for each concept. The suggested scale for concept weighting factors is 1.0 = complex, 0.50 = average, and 0.25 = simple (Etzkorn and Delugach 2000). For example, in Figure , if you consider Conceptual Graph #1 to be identified as belonging to Class A, further assume that all the concepts in Conceptual Graph #1 are complex, such that the weight is 1.0 for each concept. Then CDC = |CAT| + |[EAT + AGNT + OBJ]| + |MOUSE| = 1 + [1 + 2] + 1 = 5.
This definition relies on a knowledge base with a conceptual graph structure. Since some knowledge bases have a hybrid structure or no conceptual graphs, three variations on CDC emerged. CDCa considers concepts only; CDCb considers concepts, conceptual relations, and keywords; and CDC2 considers concepts, conceptual relations, inference relations, and keywords (Stein et al. Citation2004a).
Relative Class Domain Complexity (RCDC)
Relative class domain complexity estimates a class's comparative domain complexity relative to that of the other classes in the system. Relative class domain complexity is the CDC of the current class, divided by the maximum CDC that occurs for any class in the system. There is a version of RCDC for each version of CDC.
Key Class Identification (KCI)
Key class identification identifies key classes in the system. Key classes perform some essential or major functionality in a system. Key class identification is one if RCDC is > 0.75; it is zero otherwise. There is a version of KCI for each version of RCDC.
Semantic Class Definition Entropy (SCDE)
Semantic class definition entropy uses entropy (used in information theory to measure the quantity of information in a message) to quantify a program's psychological complexity. Semantic class definition entropy is based on the frequency of occurrence of a concept (and/or a keyword) within a class. Etzkorn et al. (Citation2002) proposed three versions: SCDE, based on concepts and keywords; SCDEa, based only on keywords; and SCDEb, based only on concepts (Etzkorn et al. Citation2002). All three versions consider the number of times a concept or keyword was inferenced in the knowledge base.
Relative Class Domain Entropy (RCDE)
Relative class domain entropy is based on RCDC (Etzkorn and Delugach 2000) and SCDE (Etzkorn et al. Citation2002). Relative class domain entropy is the SCDE of the current class, divided by the maximum SCDE that occurs for any class in the system. As with RCDC, there is a version of RCDE for each version of SCDE.
Entropy Key Class Identification (EKCI)
Entropy key class identification is based on KCI (Etzkorn and Delugach 2000) and SCDE (Etzkorn et al. Citation2002). Entropy key class identification is equal one if RCDE is > 0.75; it is zero otherwise. As with KCI, there is a version of EKCI for each version of SCDE, based on the corresponding version of RCDE.
Semantic Metrics Suite
Stein et al. proposed a second suite of semantic metrics (2004a). This suite uses similar concepts to those used by Etzkorn and Delugach (2000), but the Stein et al. metrics work with a broader range of knowledge bases. The suite of semantic metrics proposed by Etzkorn and Delugach requires a knowledge base with a conceptual graph structure. However, many knowledge bases do not contain any conceptual graphs, or they contain a hybrid structure such as that used by Etzkorn et al. (1997, 1999). The Etzkorn and Delugach metrics are inappropriate for such knowledge bases. Therefore, Stein et al. proposed their metrics to be independent of knowledge-base implementation. These metrics work with any knowledge base that associates concepts or keywords with classes and their members, whether the knowledge base uses conceptual graphs or not.
Cohesion Metrics
New semantic metrics were especially needed in the area of cohesion, since the Etzkorn and Delugach semantic cohesion metrics all require a knowledge base with conceptual graph structure. In this section, we define five cohesion metrics, including one variation on Etzkorn and Delugach's LORM2 (2000). In these definitions, the word “ideas” means concepts or keywords.
Logical Disparity of Members (LDM)
Logical disparity of members is the sum of the ideas (concepts or keywords) not shared by each pair of member functions, divided by the number of pairs of member functions. Logical disparity of members measures lack of cohesion (Stein et al. Citation2004a).
Percentage of Shared Ideas (PSI)
Percentage of shared ideas is the number of ideas associated with at least two of the class's member functions, divided by the number of ideas associated with any of the class's member functions (Stein et al. Citation2004a).
Percentage of Universal Ideas (PUI)
Percentage of universal ideas is the number of ideas associated with every member function of a class, divided by the number of ideas associated with any of the class's member functions (Stein et al. Citation2004a).
Logical Relatedness of Methods 2b
Logical relatedness of methods 2b performs the same calculation as LORM2, except that the concepts and keywords are not assumed to be located within a conceptual graph structure (Stein et al. Citation2004a).
Percentage of Related Ideas (PRI)
Percentage of related ideas is based on the cohesion of a member function (CMF) metric proposed by Stein (Citation2004); PRI is a class-level version of CMF. As such, PRI is the percentage of the class's ideas related to at least one other idea in the class by conceptual or inference relation.
Complexity Metrics
The complexity metrics in the Etzkorn and Delugach suite (2000) are adaptable to a nonconceptual graph approach. In this section, we define one metric from the Stein et al. suite, based on Etzkorn and Delugach's CDC (2000).
Class Domain Complexity (CDC2)
Class domain complexity 2 was introduced by Stein et al. (Citation2004a). Like CDC, CDC2 counts the ideas in a class with their relationships and multiplies those counts by a weighting factor for each idea. Unlike CDC, CDC2 includes inference relations as well as conceptual relations, so as not to rely on a conceptual graph-structured knowledge base.
Relative Class Domain Complexity (RCDC2)
As with the Etzkorn and Delugach (2000) versions of RCDC, RCDC2 considers the highest CDC2 value of any class in the system. Relative class domain complexity 2 is the CDC2 of the current class, divided by the maximum CDC2 that occurs for any class in the system (Stein et al. Citation2004a).
Key Class Factor (KCF)
Key class factor determines the proportion of the system's ideas contained in a class as an indication of the class's importance to the system. As with Etzkorn and Delugach's KCI (2000), this metric highlights the classes essential to a system (Stein et al. Citation2004a).
Key Class Indicator (KCI2)
As with the other versions of KCI, this version uses relative class domain complexity. If RCDC2 is > 0.75, KCI2a has a value of 1; its value is 0 otherwise (Stein et al. Citation2004a).
Mathematical Notation
To define the metrics presented in this article, some mathematical notation is necessary. Let {C1, C2,…, Cm} be the set of m classes in a system. For each class Ca, let Ka be the set of keywords in the knowledge base associated with class Ca and let Oa be the set of concepts in the knowledge base associated with Ca. Define Ia = Ka ∪ Oa; we will refer to this as the set of ideas associated with class Ca. Let Ra be the set of conceptual relations connected from any concept in Oa to any concept in the knowledge base.
Let Fa = {Fa1, Fa2,…, Fan} be the set of n member functions in class Ca. Then for each member function Fai, let Kai be the set of keywords associated with Fai, let Oai be the set of concepts associated with Fai, and let Iai = Kai ∪ Oai be the set of ideas associated with Fai. Let Rai be the set of conceptual relations connected from any concept in Oai to any other concept in the knowledge base. Let Aa = {Aa1, Aa2,…, Aat} be the set of t attribute variables in class Ca.
Let O be the set of all concepts in the knowledge base. Then define mapping % from set Ra to set O such that for any r in Ra and any x in O, r%x if and only if r forms a connection from concept x to any concept y in set O or r forms a connection from any concept z in set O to concept x.
Define qi to be the number of times keyword i in Ia was inferenced.
Let ∼ be a relation on set O such that if x and y are members of O, x ∼ y if there exists a conceptual relation in either direction between x and y, or there exists an inference relation in either direction between x and y. Let → be a relation between concepts p and q in set O such that p → q if and only if there exists a conceptual relation from p to q. Let # be a mapping from set Fa to set Aa such that Fai # Aaj if function Fai uses attribute Aaj in its implementation. Let ↣ be a mapping from set Fa to itself such that Fam ↣ Fan if function Fam calls function Fan. Let δ be a relation on set Fa such that Fas δ Fat if ∃ x ∊ Aa(Fas#x ∧ Fat#x) (the two functions share a common attribute variable). Bieman and Kang (1995) refer to this as a direct connection.
Table contains formal, mathematical definitions of all the semantic metrics referred to in this article. This is the first time the same notation has been employed to describe all the semantic metrics (and thus allow easy comparison between the metrics). Also, several of the metrics have never been formally, mathematically defined before in a published article.
TABLE 1 Formal, Mathematical Definitions of Semantic Metrics
THEORETICAL ANALYSIS OF METRICS
Kitchenham, Pfleeger, and Fenton (Citation1995) proposed a framework for assessing software metrics. In this framework, the authors assert that the entity, the attribute being measured, and the units of the measurement must be specified first. A valid measure must have the following properties (numbered for later reference):
-
Attribute validity: the entity involved has the attribute being studied.
-
Unit validity: the unit is appropriate for the attribute.
-
Instrumental validity: the instrument is calibrated correctly and the underlying model is valid.
-
Protocol validity: an acceptable protocol was used for the measurement (e.g., double-counting cannot occur under the protocol) (Kitchenham et al. Citation1995).
For valid direct measures, the following properties apply:
-
The attribute has different values for different entities.
-
The measure must make sense with the way the attribute relates with entities in real life (e.g., for a length measure, longer entities must have higher values).
-
Any of the attribute's units is acceptable.
-
Different entities can have the same value for the same attribute (Kitchenham et al. Citation1995).
Indirect measures are based on combinations of direct measures. Therefore, indirect measures must satisfy the following properties:
-
The measure uses a valid model of relations among attributes of entities.
-
The measure's model is dimensionally consistent.
-
The measure has no unexpected discontinuities, such as division by zero.
-
The measure makes proper use of units and data scales (Kitchenham et al. Citation1995).
Briand, Morasca, and Basili (Citation1996) listed criteria for complexity and four other attributes. The criteria for complexity, size, and cohesion follow (these are numbered for later reference); the others are not relevant to this article (Briand et al. 1996).
Complexity:
-
Non-negativity: the value is always at least zero.
-
Null value: the value is zero if there are no relations within a module.
-
Symmetry: complexity is independent of the direction of relations.
-
Module monotonicity: a system's complexity is at least the sum of the complexities of two modules with no relations in common.
-
Disjoint module additivity: given disjoint modules A and B and complexity measure u, u(A ∪ B) = u(A) + u(B) (Briand et al. 1996).
Size:
-
Non-negativity: any system's size is at least zero.
-
Null value: a system that contains no elements has a value of zero.
-
Module additivity: given disjoint modules A and B and size measure u, u(A ∪ B) = u(A) + u(B) (Briand et al. 1996).
Cohesion:
-
Non-negativity and normalization: the value falls in the range [0, max].
-
Null value: the value is zero if there are no relations within a module.
-
Monotonicity: adding relations within a module does not decrease the value.
-
Cohesive modules: given unrelated modules A and B and size measure u, u(A ∪ B) ≤ max(u(A), u(B)) (Briand et al. 1996).
Cohesion metrics
Some theoretical analysis of the Etzkorn and Delugach metrics was published in Etzkorn and Delugach (2000). They found that LORM meets all of the criteria of Briand et al. (1996) except the monotonicity property. However, LORM2 and LORM3′ were not evaluated theoretically. To evaluate the LORM2 metrics according to the criteria of Briand et al. (1996), consider a relation within a class to be a concept or keyword shared by a pair of member functions. All versions of LORM2 fulfill the property of non-negativity, although the original LORM2 has discontinuities where one function in a pair has no ideas associated with it and for any class with fewer than two functions. By reformulating the definition of LORM2 like the definition of LORM2a, this problem is avoided.
For the property of normalization, LORM2 and LORM2a fall in the range [0,2]. This is because the highest possible value for a pair of functions in xij in LORM2a (and the corresponding part of LORM2) is 2. To illustrate this point, let Fai and Faj be functions in class Ca such that |Kai| ≥ |Kaj|. For LORM2a, there are two cases here: |Kai| > |Kaj|, and |Kai| = |Kaj|. For the first case, the highest value occurs when Kai ∩ Kaj = Kaj (all keywords in Kaj are also in Kai). In this case, x ij = 2|Kaj|/|Kaj| = 2. Similarly in the second case, the highest value occurs when Kai = Kaj. In this case, xij = 2|Kai|/|Kai| = 2|Kaj|/|Kaj| = 2. Thus, the maximum value for each pair is two. The highest total value for the metric occurs when each pair has a value of two. If the class has p pairs of functions, then LORM2a for the class is 2p/p = 2. LORM2 fulfills this property in the same way as LORM2a.
Both LORM2 and LORM2a fulfill the properties of null value and monotonicity. For the property of cohesive modules, the proof is more complicated, but it can be shown that LORM2 and LORM2a fulfill this property.
In evaluating the LORM3′ metric under the criteria of Briand et al. (1996), consider a relation within a class to be a concept, keyword, or conceptual relation shared by a pair of member functions. LORM3′ fulfills the properties of non-negativity, normalization, null value, and monotonicity. LORM3′ fulfills the property of cohesive modules in the same way that the LORM2 metrics do.
For the Stein et al. metrics, some theoretical analysis was published in Stein et al. (Citation2004a). Stein et al. found that LDM, PSI, and PUI meet the criteria of Kitchenham et al. (Citation1995) and all of the criteria of Briand et al. (1996). However, LORM2b and PRI were not analyzed there. LORM2b falls in the range [0,1], fulfilling the properties of non-negativity and normalization. For the other properties, LORM2b has the same analysis as LORM2 and LORM2a. PRI fits in the framework of Kitchenham et al. (Citation1995) and meets all criteria set forth by Briand et al. (1996) for cohesion metrics in the same way CMF meets these criteria (see Stein Citation2004).
In summary, the semantic cohesion metrics meet all criteria set forth by Kitchenham et al. (Citation1995) and Briand et al. (1996), with one exception: LORM does not meet the monotonicity property.
Complexity Metrics
The theoretical analysis for CDC was given in Etzkorn and Delugach (2000). The theoretical analysis for CDC2 was given in Stein et al. (Citation2004a). Each version of RCDC has the same theoretical analysis, given in Stein et al. (Citation2004a). To summarize, all versions of CDC meet the criteria of Kitchenham et al. (Citation1995) and the following properties of Briand et al. (1996): non-negativity, symmetry, and monotonicity. In addition, CDCa fulfills the property of disjoint modules. All versions of CDC fail the null value property because they will have a non-zero value for any class that is associated with even one idea in the domain, even if there are no relationships within the class. The RCDC metrics are measures of relative complexity, not complexity, but they do fulfill the properties of non-negativity and nullvalue.
To analyze the SCDE series of metrics using the criteria of Briand et al. (1996), consider a relation to be an idea, keyword, or concept inferenced, respectively, for SCDE, SCDEa, and SCDEb. All three versions of SCDE fulfill the non-negativity, null value, and symmetry properties. However, all three versions fail the disjoint module additivity rule. To illustrate this, consider an example of SCDE where class Ck has four ideas inferenced 2, 2, 4, and 8 times, and class Cl has three ideas inferenced 4, 4, and 8 times. Then SCDE(Ck) = 1.75, SCDE(Cl) = 1.5, and SCDE(Ck ∪ C1) = 2.625 ≠ 1.75 + 1.5. Consider the case when the two classes in this example are the only classes in a system. Then all three versions of SCDE also fail the module monotonicity property, since 2.625 < 1.75 + 1.5. RCDE has the same theoretical analysis as RCDC.
Summary of Theoretical Analysis
The results of the theoretical analysis from the two previous sections are summarized in Table .
TABLE 2 Summary of Theoretical Analyses of Semantic Metrics
EMPIRICAL ANALYSIS OF METRICS
In the following experiments, statistical tests are performed to analyze the semantic metrics, as well as existing metrics. The goal is to determine whether the semantic complexity metrics are reasonable measures of complexity and the semantic cohesion metrics are reasonable measures of cohesion. However, there is no single, generally accepted definition of cohesion or complexity, so there is no objective standard with which to compare the metrics in order to test their appropriateness for measuring these attributes. Instead, the semantic metrics are compared with experts' ratings and with widely cited existing syntactic metrics to test for a relationship. Correlation was chosen as the statistical parameter in order to check for the existence and strength of such a relationship. For example, if CDC2, a semantic complexity metric, has a statistically significant, strong, positive correlation with WMC, a well-known syntactic complexity metric, that would indicate that it is reasonable to consider CDC2 to be measuring complexity. A very weak or insignificant correlation in this example could mean that CDC2 is not measuring complexity, or that CDC2 is measuring a different aspect or dimension of complexity than WMC is. On the other hand, a perfect correlation would indicate that CDC2 gives the same results as WMC. Consider the scale for correlation magnitude (absolute value) devised by Cohen (1998) and Hopkins (Citation2004) (note that this scale should be interpreted in a context set by the number of degrees of freedom in an experiment):
-
<0.1 trivial
-
0.1–0.3 minor
-
0.3–0.5 moderate
-
0.5–0.7 large
-
0.7–0.9 very large
-
0.9–1.0 almost perfect
For comparisons between semantic metrics and experts' ratings, the stronger the correlation is, the better the results. Here, a large correlation (a magnitude of 0.5 or higher) indicates that the metric agrees with the experts' assessment well enough to be a reasonable measure of complexity or cohesion. For comparisons between semantic metrics and established metrics, a large or very large correlation (0.5–0.9) would show a strong relationship between the semantic metric and the established metric, indicating that the semantic metric is a reasonable measure of complexity or cohesion. However, an almost perfect correlation (0.9–1.0) would indicate that the semantic metric measures complexity or cohesion very similarly to the way the existing metric measures it. Principle component analysis (PCA) is also performed for each set of metrics to indicate which metrics measure complexity or cohesion in a similar way.
For each experiment, the null and alternate hypotheses were:
-
H0: There is no correlation between the two variables (ρ = 0).
-
H1: There is a correlation between the two variables (ρ ≠ 0).
In these experiments, the desired result is to reject the null hypothesis, indicating a relationship between the metric being studied and the quantity to which it is compared. Such a relationship suggests that the metric in question measures cohesion or complexity similarly to an established measure of cohesion or complexity.
Since the metrics being studied are calculated at the class level (that is, each metric produces one value per class in an object-oriented software system), the experimental unit for each experiment is a class. Four experiments involve cohesion metrics and five experiments involve complexity metrics.
Data Collection
To analyze the semantic metrics statistically, their values were calculated using the semMet tool on the class definitions and function comment header blocks from three graphical user interface (GUI) systems written in C + + : Gina (Backer, Genau, and Sohlenkamp Citation2004), wxWindows (Smart, Citation2004), and Watson (Citation1993). The code inside the member functions was not examined by semMet.
Given the metric values, some basis for comparison is necessary in order to analyze the new semantic metrics for their potential as measures of complexity and cohesion. For this purpose, metrics are compared with assessments performed by two teams of experts for previous work by Etzkorn et al. (Citation2002). Both teams of experts examined source code from GUI packages, including class headers as well as member function code.
Expert Team 1 consisted of seven software developers, each with 5 to 15 years' experience in software development and at least 3 years' experience with C + + and GUI programming. Each expert had a BS in computer science or electrical engineering, and all but one had a master's degree. These experts analyzed a set of 17 classes from the Gina and wxWindows systems chosen to make a minimal windowing system (Etzkorn et al. Citation2002).
Expert Team 2 consisted of 15 students from a graduate-level software engineering course. Most of these experts had at least 1 year of experience in software development, and all had prior object-oriented programming experience, especially C + +. This team analyzed 13 classes taken from the wxWindows system (version 1.60) to make a minimal windowing system (Etzkorn et al. Citation2002). Each of the experts in the team analyzed all 13 classes.
The Etzkorn et al. (Citation2002) article was restricted to a study of the SCDE, SCDEa, and SCDEb semantic metrics. The experiment performed in that article separately compared these three metrics to each of the expert teams.
Expert team #2 examined a subset of the classes that were examined by Expert team #1. A smaller set of classes was used for the second experiment (with Expert team #2) because it was determined that the workload in the experiment using Expert team #1 was very difficult for the experts involved.
In addition to experts' assessments of classes from wxWindows and Gina, syntactic and semantic metrics were also calculated for these systems. The syntactic metrics used are given in Table . To calculate syntactic metrics WMC, DIT, and LCOM, Gen + + (Devanbu Citation1992) was used; to calculate syntactic metrics LCOM1, LCOM2, LCOM3, LCOM4, LCOM5, LCC, and TCC, HYSS (Chae, Kwon, and Bae Citation2000) was used. All of the semantic metrics were calculated using semMet. Since Gina has 303 classes and wxWindows has 112 classes, they were deemed sufficient for an initial analysis. However, the reader should note that GUI systems have different properties than software systems in general, so further analysis should be performed on systems from other domains.
TABLE 3 Syntactic Metric Definitions
Testing for Correlation
To test for correlation, Pearson's correlation coefficient was used in most experiments. However, Pearson's correlation coefficient assumes a normal distribution. The Kolmogorov-Smirnov test was used to check for a normal distribution for each data set. The check for a normal distribution was applied to all data sets, including the expert team data. If the data followed a distribution that was significantly different from normal, the data were ranked and Spearman's correlation coefficient was used.
One pitfall of performing so many correlation tests is the experiment-wide accumulation of type I (alpha) error. According to the Bonferroni Inequality, for k tests with the same alpha, overall alpha ≤ (k∗α). The formula 1 − (1 − α)k gives a tighter bound. Here, given 20 tests and α = 0.05, the overall alpha is 0.64. If the tests are not all independent, as is the case with the following experiments, the overall alpha is actually smaller than that (Stevens 2002).
To eliminate the concern about accumulating alpha error, the Bonferroni approach is to choose a very small alpha value such as α = 0.001 for each individual test. Then, even over many tests, the experiment-wide alpha value still stays below a reasonable level such as 0.05 or 0.10 (Stevens 2002). However, for this analysis, the experiment-wide results are of less interest than the individual results of each pairwise correlation. Requiring a very small alpha value for each pairwise comparison would eliminate all but the very strongest correlations, which tend to indicate redundant metrics rather than positive results. On the other hand, the worst likely result of falsely identifying a correlation between two metrics is mistakenly believing that a metric is a better measure of complexity or cohesion than it really is. If a user relies on a bad metric to analyze software, it may give meaningless results. However, this risk can be mitigated by calculating not just one, but multiple metrics when analyzing software.
Because requiring a very small alpha value for each pairwise comparison would eliminate all but the strongest correlations, which indicate redundant metrics rather than positive results, and because the consequence of falsely identifying a correlation between two metrics is easily mitigated, a higher experiment-wide alpha is an acceptable risk in exchange for a more powerful pairwise test. Therefore, for these experiments, a significance level of α = 0.05 is used for each pairwise correlation. Software metrics are not precise enough to be used for life-or-death applications, so a smaller significance level is not necessary.
Cohesion Metrics
For this section, four separate experiments were performed. In the first experiment, the semantic cohesion metrics were compared to expert cohesion ratings. In the second experiment, the semantic cohesion metrics were compared to more traditional syntactic object-oriented metrics. In the third experiment, semantic cohesion metrics were compared (pairwise) to other semantic metrics. Finally, in the fourth experiment, a PCA was performed to find the principal components that explain the variance in the cohesion data.
For the experiments involving cohesion, the experts used the following scale:
-
1.00 = Excellent
-
0.75 = Good
-
0.50 = Fair
-
0.25 = Poor
Experiment 1: Metrics Vs. Expert Cohesion Ratings
For this experiment, Expert Team 1 rated 17 classes from Gina and wxWindows for cohesion. These ratings were averaged and compared with the metric values to check for correlation, as shown in Table . Interrater reliability was 0.50. Only LORM, LCOM1, LCOM2, LCOM3, and LCOM4 had statistically significant correlations of any size with the ratings of this team.
TABLE 4 Metric Value Correlations with Experts' Cohesion Ratings. The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
Similarly, Expert Team 2 evaluated the cohesion of 13 classes from wxWindows, and their ratings were averaged and compared with the metric values. Interrater reliability was 0.89. For Expert Team 2, all but three semantic metrics had significant correlations, and of those, all had correlations of 0.5639 or higher.
The PUI had no correlation with the experts. We discovered that the definition of PUI is too optimistic: almost none of the classes in our systems had a value of PUI above zero. Once we discovered this, we considered developing a new metric based on ideas being shared by a majority of member functions, rather than all as in the definition of PUI, but we found that such a metric would also have nearly all zero values. For the systems we analyzed, few ideas were shared by more than three or four member functions in a class. We would be interested to see whether this is true of software in general, or whether the systems we analyzed were unusually lacking in cohesion.
The correlations are negative in Table because smaller values are good values for the various semantic cohesion metrics (large values are worse values), while the expert ratings have a larger number (1.0) for a good value, and a smaller number for a worse value.
Experiment 2: Semantic Metrics Vs. Syntactic Metrics
In this experiment, we checked for correlations between the semantic metrics and the syntactic metrics defined in Table . We used metric values from 277 classes from Gina (Backer et al. Citation2004) and wxWindows (Smart Citation2004). Our hypotheses were as follows:
-
H0: ρ = 0 (there is no correlation between the semantic metric and the syntactic metric).
-
H1: ρ ≠ 0 (there is a correlation between the semantic metric and the syntactic metric).
As shown in Table , there were statistically significant large correlations between LORM and LCOM4, between LORM2 and two versions of LCOM, between LORM3′ and three versions of LCOM, and between PSI and five versions of LCOM. There was also a statistically significant trivial correlation between PUI and all of the syntactic metrics, but the correlation value in these pairings is the same as if PUI were independent of all of the syntactic metrics. As mentioned in the previous section, this is because PUI yields too many zero values. If a p-value of 0.10 were acceptable, additional correlations between LORM and LCOM3, LORM2 and LCOM, LORM2a and LCOM, and LORM2b and LCOM would also be statistically significant.
TABLE 5 Semantic Cohesion Metric Correlations with Syntactic Metrics (p-Values in Parentheses). The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
These results led us to hypothesize that semantic metrics measure a different dimension of cohesion than syntactic metrics. We performed a principal component analysis to test this hypothesis.
Experiment 3: Semantic Metric Pairwise Correlations
In this experiment, we calculated semantic metric values for every class in the Gina (Backer Citation2004), wxWindows (Smart Citation2004), and Watson (Citation1993) systems, 417 classes in all. Then we computed correlations between each pair of semantic metrics. The hypotheses we used are as follows:
-
H0: ρ = 0 (there is no correlation between the two semantic metrics).
-
H1: ρ ≠ 0 (there is a correlation between the two semantic metrics).
As shown in Table , we found that most semantic cohesion metrics had statistically significant correlations of various strengths. As one would expect, the strongest correlations were between metrics whose definitions are similar, such as LORM2 and LORM2a.
TABLE 6 Pairwise Correlations of Semantic Metrics (p-Values in Parentheses). The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
Experiment 4: Principal Component Analysis
In this experiment, we performed a PCA to find the principal components that explain the variance in the cohesion data. For example, a study may include 50 different cohesion metrics, but they may only measure five dimensions of cohesion. In that case, some metrics are redundant, so most of the information could be gained by calculating fewer metrics. Principal component analysis helps identify which metrics measure the same dimension of an attribute (Briand, Wust, Daly, and Porter 2000).
In our principal component analysis, we found four principal components (PCs) explaining 75.8% of the variance in the data:
-
PC1 (33.0%): PSI, LORM, LORM2, LORM2b, LORM3
-
PC2 (20.2%): LCOM1, LCOM2, LCOM3, LCOM4
-
PC3 (15.6%): LCOM, LCC, TCC
-
PC4 (7.1%): LDM, PRI
In addition, LCOM5, PUI, and LORM2a did not load in any of these PCs.
These findings agree with previous studies (Briand, Daly, Porter, and Wust 1998a; Etzkorn et al. Citation2004) in their assignment of LCOM1-4 in one PC, LCC and TCC in another, and LCOM separate from LCOM1-5. The semantic metrics fall into different PCs than the syntactic metrics; this indicates that they measure different dimensions of cohesion. We feel this speaks well of the potential of semantic metrics.
Complexity Metrics
For this section, five separate experiments were performed. In the first experiment, the semantic complexity metrics were compared to expert complexity ratings. In the second experiment, the semantic complexity metrics were compared to expert size ratings. In the third experiment, the semantic complexity metrics are compared to more traditional syntactic object-oriented metrics. In the fourth experiment, semantic complexity metrics were compared (pairwise) to other semantic metrics. Finally, in the fifth experiment, a PCA was performed to find the principal components that explain the variance in the complexity data.
For experiments involving complexity, the experts used the following scale:
-
1.0: not complex
-
0.5: fairly complex
-
0.0: very complex.
This rating scale was chosen so that 100% (1.0) is “good” complexity (i.e., not complex), and 0 is “poor” complexity (i.e., very complex).
Experiment 1: Metrics Vs. Expert Complexity Ratings
The expert teams evaluated the same classes for this experiment as in the cohesion experiments. Interrater reliability was 0.9038 for Expert Team 1 and 0.4160 for Expert Team 2.
In this experiment, we included Depth of Inheritance Tree (DIT) among the complexity metrics. DIT as a complexity measure is not as obvious as metrics such as WMC. However, Kim (Citation1994) lists DIT as a measure of a specific type of complexity—complexity resulting from inheritance. Bluemke, Chang, Kusumoto, and Kikuno (2001) explains DIT as a complexity measure as follows: a class that is deeper in the inheritance hierarchy inherits more methods. This means that finding and testing all of a class's methods involves more classes and methods than otherwise. Both of these assessments match the viewpoints listed in Chidamber and Kemerer's analysis of DIT (1994). Also, Briand et al. (Citation1998a) found that a higher value for DIT is associated with greater fault proneness. Greater complexity is also associated with fault proneness, according to Khoshgoftaar and Munson (1990). These findings imply that DIT might be a good complexity measure.
Experiment 2: Metrics Vs. Expert Size Ratings
In this experiment, we assessed each complexity metric as a measure of size. Again, each expert team analyzed the same classes as in the previous experiments. This time the interrater reliability was 0.8972 for Expert Team 1 and 0.4399 for Expert Team 2. As shown in Table , nearly all of the metrics had statistically significant correlations with the experts' ratings. Most had moderate to large correlations.
TABLE 7 Metric Value Correlations with Experts' Complexity Ratings. The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
TABLE 8 Metric Value Correlations with Experts' Size Ratings. The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
Experiment 3: Semantic Metrics Vs. Syntactic Metrics
In this experiment, we checked for correlation between semantic complexity metrics and syntactic metrics for 277 classes from Gina (Backer et al. Citation2004) and wxWindows (Smart Citation2004). We used the same hypotheses used in the previous section.
As shown in Table , all semantic complexity metrics had statistically significant correlations with WMC. However, considerably fewer metrics had statistically significant correlations with DIT. Even the metrics with a significant correlation with DIT correlated better with WMC. We hypothesized that the semantic metrics measure a similar type of complexity to what WMC measures, but DIT measures another type. This led to the principal component analysis presented in the next section.
TABLE 9 Semantic Complexity Metric Correlations with Syntactic Metrics (p-Values in Parentheses). The Correlations in Bold Type are Statistically Significant (α = 0.05). The–Refers to Correlations with a Large p-Value (Not Close to Being Statistically Significant)
Also, all Etzkorn and Delugach semantic complexity metrics except the KCI series had large or very large correlations with WMC, whereas the Stein et al. semantic complexity metrics had only moderate correlations with WMC. The main difference between these sets of metrics is that the Stein et al. metrics consider inference relations in addition to concepts, keywords, and conceptual relations. These findings may indicate that inference relations between concepts and keywords do not contribute to the complexity of a task in the domain, or it may indicate that inference relations contribute to measuring a different type of complexity than was measured by WMC or the expert teams.
Experiment 4: Pairwise Correlations of Semantic Metrics
In this experiment, we calculated semantic metric values for every class in the Gina (Backer et al. Citation2004), wxWindows (Smart Citation2004), and Watson (Citation1993) systems, 417 classes in all, and compared the metrics to each other to see the correlation in each pair of metrics. Metrics with high correlation values often measure nearly the same thing, so it may be possible to calculate fewer metrics without losing much information. For this experiment, the hypotheses were as follows:
-
H0: ρ = 0 (there is no correlation between the two semantic metrics).
-
H1: ρ ≠ 0 (there is a correlation between the two semantic metrics).
All correlations in this experiment were statistically significant. Most of the correlations were in the moderate-to-very-large range. Of course, the highest correlations were among metrics whose calculations are interdependent (e.g., RCDC, KCI). The only surprising results were the almost perfect correlations between KCF and the various versions of CDC. The definition of KCF is different from and unrelated to the definition of CDC. However, these metrics appear to measure complexity similarly, despite the difference in their definitions.
Experiment 5: Principal Component Analysis
In this experiment, we performed a PCA to find the principal components that explain the variance in the complexity data. We found three PCs among the variables studied; these PCs explained 87.35% of the variance in the data.
PC1 (72.3%): CDC, CDCa, CDCb, CDC2, RCDC, RCDCa, RCDCb, RCDC2, KCIa, CDE, RCDE, EKCI, CDEb, RCDEb, EKCIb, KCF | |||||
PC2 (8.8%): DIT, CDEa, RCDEa | |||||
PC3 (6.3%): KCI, KCIb, KCI2, EKCIa, WMC | |||||
It is interesting that CDEa and RCDEa fall into a different principal component than the other versions of CDE and RCDE. These metrics are similarly defined: the only difference is that CDEa and RCDEa measure keywords only, whereas CDEb and RCDEb measure concepts only and CDE and RCDE measure both concepts and keywords. Similarly, it is interesting that KCI0 falls into PC1, whereas all other versions of KCI fall into PC3. KCIa measures concepts only; the others add conceptual relations, keywords, and inference relations.
CONCLUSIONS AND FUTURE WORK
In this article, we have performed theoretical and empirical analysis on two suites of semantic metrics. We found that many of the semantic metrics have a strong correlation with experts' assessments of software and with existing syntactic metrics, indicating that the semantic metrics are reasonable measures of cohesion and complexity. Since semantic metrics are not based on code syntax, they can be calculated before code is fully implemented, providing an early indication of a potentially fragile or fault-prone code. Such early warning can help software development teams evaluate and possibly redesign bad code before implementation is complete, potentially saving considerable time and money.
The following preliminary recommendations are provided for industrial software engineers who may consider using semantic metrics: First, the semantic cohesion metrics appear to have good results, especially LORM, LORM2, LORM2b, LORM3′, and PSI. The KCI metrics provide a new metric that has not been previously employed elsewhere, so they have good potential; also, the results with these metrics were also good. Of the semantic complexity metrics, the ones that appeared to have the best results were SCDEa, CDC, and CDCa.
Although this article presents some empirical validation of the semantic metrics, more such studies should be done. Studies involving non-GUI software would be particularly valuable, since Lorenz and Kidd observed that GUI software generally has different properties than other software (1994).
Also, semantic metrics can be computed before implementation from design or requirements specifications. Creating a system to do this and evaluating the results is the next logical step. Stein et al. (Citation2004b) began to address this issue but work remains to be done in this area. As a result of expanding semantic metrics' use to requirements and design specifications, semantic metrics could be calculated on the same system in all phases of the software development life cycle, providing a seamless set of metrics from requirements through maintenance.
TABLE 10 Pairwise Correlations of Semantic Complexity Metrics. All Correlations in This Table Had p-Values < 0.0020, So All Values in This Table are Statistically Significant
The research in this article was partially supported by NASA grants NAG5-12725 and NCC8-200.
REFERENCES
- Backer , A. , A. Genau , and M. Sohlenkamp . 2004 . The generic interactive application for C + + and OSF/MOTIF, version 2.0. Anonymous ftp at ftp.gmd.de, directory gmd/ginaplus. Last accessed 1/27/2004. .
- Basili , V. R. , L. Briand , and W. L. Melo . 1996 . A validation of object-oriented design metrics as quality indicators . IEEE Transactions on Software Engineering 22 : 751 – 761 .
- Bieman , J. and B.-K. Kang . 1995 . Cohesion and reuse in an object-oriented system . In: Proceedings of the Symposium on Software Reliability , pp. 259 – 262 , Seattle , Washington .
- Biggerstaff , T. J. 1989 . Design recovery for maintenance and reuse . IEEE Computer 22 : 36 – 49 .
- Biggerstaff , T. J. , B. G. Mitbander , and D. E. Webster . 1993 . The concept assignment problem in program understanding . In: Proceedings of the 15th International Conference on Software Engineering , pp. 482 – 498 , Baltimore , Maryland .
- Biggerstaff , T. J. , B. G. Mitbander , and D. E. Webster . 1994 . Program understanding and the concept assignment problem . Communications of the ACM , Vol. 37 , No. 5 , pp. 72 – 84 .
- Bluemke , I. 2001 . Object-oriented metrics useful in the prediction of class testing complexity . In: Proceedings of the 27th Euromicro Conference , pp. 130 – 136 , Warsaw , Poland .
- Briand , L. , J. Daly , V. Porter , and J. Wust . 1998a . A comprehensive empirical validation of design measures for object-oriented systems . In: Proceedings of the 5th International Software Metrics Symposium , pp. 246 – 257 , Bethesda , Maryland .
- Briand , L. , J. Daly , and J. Wust . 1998a . A unified framework for cohesion measurement in object-oriented systems . Empirical Software Engineering 3 : 65 – 115 .
- Briand , L. , S. Morasca , and V. Basili . 1996b . Property-based software engineering measurement . IEEE Transactions on Software Engineering 22 : 68 – 86 .
- Briand , L. , J. Wust , J. Daly , and V. Porter . 2000 . Exploring the relationships between design measures and software quality in object-oriented systems . Journal of Systems and Software 51 : 245 – 273 .
- Chae , H. , Y. Kwon , and D. Bae . 2000 . A cohesion measure for object-oriented classes . Software: Practice and Experience 30 : 1405 – 1431 .
- Chidamber , S. and C. Kemerer . 1994 . A metrics suite for object oriented design . IEEE Transactions on Software Engineering 20 : 476 – 493 .
- Chidamber , S. and C. Kemerer . 1991 . Towards a metrics suite for object oriented design . In: Proceedings of the Conference on Object-Oriented Programming Systems, Languages, and Applications , pp. 197 – 211 , Phoenix , Arizona .
- Cohen , J. 1998 . Statistical Power Analysis for the Behavioral Sciences. , 2nd ed. Mahwah , NJ : Lawrence Erlbaum Publishing Co .
- Devanbu , P. 1992 . A language and front-end independent source code analyzer . In: proceedings of the International Conference on Software Engineering . Melbourne , Australia .
- Etzkorn , L. , L. Bowen , and C. Davis . 1999 . An approach to program understanding by natural language understanding . Natural Language Engineering 5 : 1 – 18 .
- Etzkorn , L. and C. Davis . 1997 . Automatically identifying reusable OO legacy code . IEEE Computer 30 : 66 – 71 .
- Etzkorn , L. and C. Davis . 1994 . A documentation-related approach to object-oriented program understanding . In: Proceedings of the IEEE 3rd Workshop on Program Comprehension , pp. 39 – 45 , Washington , D.C.
- Etzkorn , L. , C. Davis , and L. Bowen . 2001 . The language of comments in computer software: A sublanguage of english . Journal of Pragmatics 33 : 1731 – 1756 .
- Etzkorn , L. and H. Delugach . 2000. Towards a semantic metrics suite for object-oriented design. In: Proceedings of the 34th International Conference on Technology of Object-Oriented Languages and Systems , pp. 71–80.
- Etzkorn , L. , S. Gholston , J. Fortune , C. Stein , D. Utley , P. Farrington , and G. Cox . 2004 . A comparison of metrics for object-oriented systems . Information and Software Technology 46 : 677 – 687 .
- Etzkorn , L. , S. Gholston , and W. Hughes . 2002 . A semantic entropy metric . Journal of Software Maintenance and Evolution 14 : 293 – 310 .
- Henderson-Sellers , B. 1996 . Software Metrics . Hemel Hempstaed , UK : Prentice-Hall .
- Hitz , M. and B. Montazeri . 1995 . Measuring coupling and cohesion in object-oriented systems . In: Proceedings of the International Symposium on Applied Corporate Computing . Monterey , Mexico .
- Hitz , M. and B. Montazeri . 1996 . Chidamber and Kemerer's metrics suite: A measurement theory perspective . IEEE Transactions on Software Engineering 22 : 267 – 271 .
- Hopkins , W. 2004 . A new view of statistics. http://www.sportsci.org/resource/stats. Last accessed 11/21/08. .
- Khoshgoftaar , T. and J. Munson . 1990 . Predicting software development errors using software complexity metrics . IEEE Journal on Selected Areas in Communications 8 : 253 – 261 .
- Kim , E. , O. Chang , S. Kusumoto , and T. Kikuno . 1994 . Analysis of metrics for object-oriented program complexity . In: Proceedings of the 18th Annual Computer Software and Applications Conference , pp. 201 – 207 , Taipei , Taiwan .
- Kitchenham , B. , S. Pfleeger , and N. Fenton . 1995 . Towards a framework for software measurement validation . IEEE Transactions on Software Engineering 21 : 929 – 944 .
- Li , W. and S. Henry . 1993 . Object-oriented metrics which predict maintainability . Journal of Systems and Software 23 : 111 – 122 .
- Lorenz , M. and J. Kidd . 1994 . Object-Oriented Software Metrics . Englewood Cliffs , NJ : Prentice Hall .
- Neal , R. 1997 . Modeling the object-oriented space through validated measures . In: Proceedings of the 1997 IEEE Aerospace Conference , pp. 315 – 327 , Aspen , Colorado .
- Pressman R. 2001 . Software Engineering: A Practitioner's Approach. , 5th ed. Boston : Mcgraw-Hill .
- Smart , J. 2004 . wxWindows. http://www.wxwindows.org. Last accessed 3/24/2004. .
- Sowa , J. 1984 . Conceptual Structures: Information Processing in Mind and Machine . Reading , MA : Addison-Wesley .
- Stein , C. 2004 . Fine-grained semantic metrics for object-oriented software . In: Proceedings of the International Conference on Software Engineering Research and Practice , Vol. 2 , pp. 525 – 531 , Las Vegas , NV .
- Stein , C. , L. Etzkorn , G. Cox , F. Farrington , S. Gholston , D. Utley , and J. Fortune . 2004a . A new suite of metrics for object-oriented software . In: Proceedings of the 1st International Workshop on Software Audit and Metrics , pp. 49 – 58 , Porto , Portugal .
- Stein , C. , L. Etzkorn , D. Utley , P. Farrington , G. Cox , J. Fortune , and S. Gholston . 2004b . Computing software metrics from design documents . In: Proceedings of the 42nd Annual ACM Southeast Conference , pp. 146 – 151 , Huntsville , AL .
- Stevens , J. 2002 . Applied Multivariate Statistics for the Social Sciences. , 4th ed. Mahwah , NJ : Lawrence Erlbaum Press .
- Watson , M. 1993 . Portable GUI Development with C + + . New York : Mcgraw-Hill .
- Weyuker , E. 1988 . Evaluating software complexity measures . IEEE Transactions on Software Engineering 14 : 1357 – 1365 .