Abstract
We explored the reliability of detecting learners' affect by monitoring their gross body language (body position and arousal) during interactions with an intelligent tutoring system called AutoTutor. Training and validation data on affective states were collected in a learning session with AutoTutor, after which the learners' affective states (i.e., emotions) were rated by the learner, a peer, and two trained judges. An automated body pressure measurement system was used to capture the pressure exerted by the learner on the seat and back of a chair during the tutoring session. We extracted two sets of features from the pressure maps. The first set focused on the average pressure exerted, along with the magnitude and direction of changes in the pressure during emotional experiences. The second set of features monitored the spatial and temporal properties of naturally occurring pockets of pressure. We constructed five data sets that temporally integrated the affective judgments with the two sets of pressure features. The first four datasets corresponded to judgments of the learner, a peer, and two trained judges, whereas the final data set integrated judgments of the two trained judges. Machine-learning experiments yielded affect detection accuracies of 73%, 72%, 70%, 83%, and 74%, respectively (chance = 50%) in detecting boredom, confusion, delight, flow, and frustration, from neutral. Accuracies involving discriminations between two, three, four, and five affective states (excluding neutral) were 71%, 55%, 46%, and 40% with chance rates being 50%, 33%, 25%, and 20%, respectively.
Verbal and nonverbal channels show a remarkable degree of sophisticated coordination in human–human communication. While the linguistic channel mainly conveys the content of the message, nonverbal behaviors play a fundamental role in expressing the affective states, attitudes, and social dynamics of the communicators. Although ubiquitous to human–human interactions, the information expressed through nonverbal communicative channels is largely ignored in human-computer interactions. Simply put, there seems to be a great divide between the highly expressive human and the perceptually deficit computer.
In an attempt to alleviate this shortcoming in human-computer interactions, the last decade has witnessed a surge of research activities that are aimed at narrowing the communicative bandwidth between the human and the computer. Notable among these endeavors is the rapidly growing area of affective computing. Affective computing is a subfield of human–computer interaction that focuses on the affective states (feelings, moods, emotions) of the user (Picard Citation1997). This emphasis of affect is quite critical because emotions are inextricably bound to cognition (Dweck Citation2002; Mandler Citation1984). Cognitive activities such as causal reasoning, deliberation, goal appraisal, and planning processes operate continually throughout the experience of emotion.
The primary practical goal of affective computing is to create technologies that can monitor and respond to the affective states of the user (Picard Citation1997). This is achieved by integrating the affective states of a user into the decision cycle of the interface in order to provide more effective, user-friendly, and naturalistic applications (Bianchi-Berthouze and Lisetti Citation2002; Conati Citation2002; de Rosis Citation2002; Lisetti and Gmytrasiewicz Citation2002; Prendinger and Ishizuka Citation2005; Whang, Lim, and Boucsein 2003). Progress in achieving the primary goal requires an interdisciplinary integration of computer science, psychology, artificial intelligence, and artifact design.
Although there are a number of obstacles that need to be overcome before functional affect-sensitive computer interfaces can be realized, the success of any affect-sensitive interface will ultimately depend upon the accuracy by which the user's affect can be detected. These interfaces are ultimately guided by the design goal of narrowing the communicative gap between the emotionally challenged computer and the emotionally rich human. Expectations are raised when humans recognize that a computer system is attempting to communicate at their level (i.e., with enhanced cognitive and emotional intelligence) far beyond traditional interaction paradigms (i.e., window, icon, menu, pointing device WIMP). When these expectations are not met, users often get discouraged, disappointed, or even frustrated (Norman Citation1994; Shneiderman and Plaisant Citation2005). Therefore, robust recognition of the users' emotions is a crucial challenge that is hindering major progress towards the larger goal of developing affect-sensitive interfaces that work.
Consequently, the last decade has been ripe with technologies that attempt to automatically detect the affective states of a user. Many of these technologies analyze physiological signals for emotion detection (Rani, Sarkar, and Smith Citation2003; Picard, Vyzas, and Healey Citation2001; Whang, et al. Citation2003). One potential pitfall to this approach is the reliance on obtrusive sensing technologies, such as skin conductance, heart rate monitoring, and measurement of brain activities. These obtrusive physiological sensors are acceptable in some applications and it is true that users habituate to the presence of these sensors, but they are not satisfactory in environments where the sensors distract users and interfere with the primary tasks. This has motivated designers of affect-sensitive technologies to focus on facial feature tracking and acoustic-prosodic vocal features—two technologies that are unobtrusive (see Pantic and Rothkrantz (Citation2003) for a comprehensive review and the proceedings of ACII 2007 edited by Paiva, Prada, and Picard (Citation2007) for recent updates).
State-of-the-art affect detection systems have overlooked posture as a serious contender when compared to facial expressions and acoustic-prosodic features, so an analysis of posture merits more close examination. Apparently there are some benefits to using posture as a means to diagnose the affective states of a user (Bull Citation1987; de Meijer Citation1989; Mehrabian Citation1972). Human bodies are relatively large and have multiple degrees of freedom, thereby providing them with the capability of assuming a myriad of unique configurations (Bernstein Citation1967). These static positions can be concurrently combined and temporally aligned with a multitude of movements, all of which make posture a potentially ideal affective communicative channel (Coulson Citation2004; Montepare, Koff, Zaitchik, and Albert Citation1999). Posture can offer information that is sometimes unavailable from the conventional nonverbal measures such as the face and paralinguistic features of speech. For example, the affective state of a person can be decoded over long distances with posture, whereas recognition at the same distance from facial features is difficult or unreliable (Walk and Walters Citation1988). Perhaps the greatest advantage to posture-based affect detection is that gross body motions are ordinarily unconscious, unintentional, and thereby not susceptible to social editing, at least compared to facial expressions, speech intonation, and some gestures. Ekman and Friesen (Citation1969), in their studies of deception, have coined the term nonverbal leakage to refer to the increased difficulty faced by liars, who attempt to disguise deceit through less-controlled channels such as the body when compared to facial expressions. Furthermore, although facial expressions were once considered to be the objective gold standard for emotional expression in humans, there is converging evidence that disputes the adequacy of the face in expressing affect (see Barrett (Citation2006) for a comprehensive review). At the very least, it is reasonable to operate on the assumption that some affective states are best conveyed through the face, while others are manifested through other nonverbal channels. This article adopts this position and aspires to investigate the potential of gross body movements as a viable channel to detect affect.
One option towards automated posture analysis is to use cameras and associated computer vision techniques to monitor body position and movement of a user. However, this approach is riddled with the problems that accompany nearly all computer vision-based applications, such as lighting, background conditions, camera angles, and other factors (Mota and Picard Citation2003). Fortunately, there is a relatively new sensor that circumvents these challenges. In 1997, Tekscan (South Boston, MA, USA) released the Body Pressure Measurement System (BPMS), which consists of a thin-film pressure pad (or mat) that can be mounted on a variety of surfaces. The system provides pressure maps in real time that can be analyzed for a variety of applications. For example, Tan and colleagues demonstrated that the BPMS system could be used to detect several static postures (leaning right, right leg crossed, etc.) quite reliably with an average recognition accuracy of 85% (Tan, Lu, and Pentland Citation1997).
Mota and Picard (Citation2003) reported the first substantial body of work that used automated posture analysis via the BPMS system to infer the affective states of a user in a learning environment. They analyzed temporal transitions of posture patterns to classify the interest level of children while they performed a learning task on a computer. A neural network provided real-time classification of nine static postures (leaning back, sitting upright, etc.) with an overall accuracy of 87.6%. Their system then recognized interest (high interest, low interest, and taking a break) by analyzing posture sequences over a 3-second interval, yielding an overall accuracy of 82.3%.
In this article, we explore the possibility of using posture to automatically detect the affective states of college students during a tutoring session with the AutoTutor learning environment (Graesser, Person, Harter, and Tutoring Research Group Citation2001; VanLehn, et al. Citation2007). We focus on Intelligent Tutoring Systems (ITSs) because they represent a domain that is on the forefront of affect-sensitive interface research (Conati Citation2002; D'Mello et al. Citation2005; Kort, Reilly, and Picard Citation2001; Litman and Forbes-Riley Citation2004). Affect-sensitive ITSs operate on the fundamental assumption that affect is inextricably linked to cognition. There is also some evidence that tracking and responding to human emotions on a computer increases students' persistence and learning (Aist, Kort, Reilly, Mostew, and Picard Citation2002; Kim Citation2005; Linnenbrink and Pintrich Citation2002). Hence, affect-sensitive ITSs attempt to incorporate the affective and cognitive states of a learner into their pedagogical strategies to increase engagement, reduce attrition, boost self-efficacy, and ultimately promote active learning.
The larger goal of the project is to re-engineer AutoTutor to enable it to adapt to the learner's affective states in addition to cognitive states. This adaptation would increase the bandwidth of communication and allow AutoTutor to respond at a more sophisticated metacognitive level. Quite clearly, robust affect recognition is an important requirement for the affect-sensitive AutoTutor because the system will never be able to respond to a learners' emotion if it cannot sense the emotion. Therefore, we explore the potential of affect-detection from body language as an incremental step towards this goal.
Our research differs from the previous research in automated affect detection from posture in four significant ways. First, much of the research in affect-detection has focused on the “basic” emotions (i.e., anger, fear, sadness, enjoyment, disgust, and surprise (Ekman and Friesen Citation1978)). While these basic emotions are ubiquitous in everyday experience, there is a growing body of evidence which suggests that they rarely play a significant role in deep learning of conceptual information (D'Mello, Craig, Sullins, and Graesser Citation2006; Graesser et al. Citation2006; Kort, Reilly et al. Citation2001). While it is conceivable that the more basic extreme emotions identified by Ekman are relevant to learning in some circumstances, as discussed later, the present study concentrated on emotions that we already know are relevant to learning with AutoTutor. Second, we monitored a larger set of affective states than Mota and Picard (Citation2003), specifically the affective states identified by Craig, Graessel, Sullins, and Gholson (Citation2004): boredom, flow, confusion, frustration, delight, and neutral. It is important to consider a larger set of affective states that encompass the entire gamut of learning (Conati Citation2002) because a person's reaction to the presented material can change as a function of their goals, preferences, expectations, and knowledge states. Third, some additional considerations arise because we monitored college students rather than children as in the Mota and Picard (Citation2003) work. Children are much more active than the college students, so the algorithms used to detect affective states may differ. The movements of college students are more subtle so it is important to pick up fleeting transitions in body pressure. We ultimately developed two different methods to infer affect from body movement. Both of these methods monitor gross body movements rather than explicit postures, and hence did not require an additional training phase for static posture detection, as in the Mota and Picard (Citation2003) work. The fourth difference between this research and other efforts is the method of establishing ground-truth categories of affect, which is a requirement for supervised learning methods. A number of researchers have relied on a single operational measure when inferring a learner's emotion, such as self-reports (De Vicente and Pain Citation2002; Klein, Moon, and Picard Citation2002; Matsubara and Nagamachi Citation1996) or ratings by independent judges (Liscombe, Riccardi, and Hakkani-Tür Citation2005; Litman and Forbes-Riley Citation2004; Mota and Picard Citation2003). In contrast, we propose the combination of several different measures of a learner's affect. Our measures of emotion incorporate judgments made by the learner, a peer, and two trained judges, as will be elaborated later.
The article is organized in four sections. First, we describe a study that collected data from the BPMS system and affect labels from multiple judges in order to train and validate the posture-based affect classifier. Second, we describe the BPMS system in some detail, as well as two sets of posture features used to develop the affect-detector. Third, the Results section begins with a description of a series of experimental simulations that attempt to measure affect recognition accuracy. We compare performance of affect classification from posture with classification accuracies obtained via a conversational sensor and facial feature tracking. And fourth, we present a summary of our major findings, limitations of our methodology, potential resolutions, and future work. Our ultimate goal is to explore how the learner's affective states may be integrated into AutoTutor's pedagogical strategies and thereby improve learning.
EMPIRICAL DATA COLLECTION: THE MULTIPLE JUDGE STUDY
Modeling affect involves determining what emotion a learner is experiencing at particular points in time. Emotion is a construct (i.e., an inferred conceptual entity), so one can only approximate its true value. Therefore, in contrast to a single operational measure to inferring a learner's emotion, we propose the combination of several different measures of a learner's affect. Our measures consist of emotion judgments made by the learner, a peer, and two trained judges. Employing multiple measures of affect is compatible with the standard criterion for establishing convergent validity (Campbell and Fiske Citation1959).
Participants
The participants were 28 college students from a southern university in the United States.
Materials
Sensors
Three streams of information were recorded during the participant's interaction with AutoTutor. A video of the participants face was captured using the IBM (San Francisco, CA, USA) blue-eyes camera (Morimoto et al. Citation1998). Posture patterns were captured by the Tekscan (South Boston, MA, USA) Body Pressure Measurement System (Tekscan Citation1997) which is described in some detail later. A screen-capturing software program called Camtasia Studio (developed by TechSmith Okemos, MI, USA) was used to capture the audio and video of the participant's entire tutoring session with AutoTutor. The captured audio included the speech generated by the AutoTutor animated conversational agent.
AutoTutor
AutoTutor is a fully automated computer tutor that simulates human tutors and holds conversations with students in natural language (Graesser et al. Citation2001; VanLehn et al. Citation2007). AutoTutor attempts to comprehend the students' natural language contributions and then responds to the students' typed input with adaptive dialogue moves similar to human tutors. AutoTutor helps students learn by presenting challenging problems (or questions) from a curriculum script (a set of questions, ideal answers, and expected misconceptions) and engaging in a mixed-initiative dialogue while the learner constructs an answer.
AutoTutor has different classes of dialogue moves that manage the interaction systematically. AutoTutor provides feedback on what the student types in (positive, neutral, or negative feedback), pumps the student for more information (“What else?”), prompts the student to fill in missing words, gives hints, fills in missing information with assertions, identifies and corrects misconceptions and erroneous ideas, answers the student's questions, and summarizes topics. A full answer to a question is eventually constructed during this dialogue, which normally takes between 30 and 100 turns between the student and tutor for one particular problem or main question.
The impact of AutoTutor in facilitating the learning of deep conceptual knowledge has been validated in over a dozen experiments on college students as learners for topics in introductory computer literacy (Graesser et al. Citation2004) and conceptual physics (VanLehn et al. Citation2007). Tests of AutoTutor have produced gains of .4 to 1.5 sigma (a mean of .8), depending on the learning measure, the comparison condition, the subject matter, and versions of AutoTutor. From the standpoint of the present study, we will take it as a given that AutoTutor helps learning, whereas our direct focus is on the emotions that occur in the learning process.
Procedure
Interacting with AutoTutor
The participants interacted with AutoTutor for 32 minutes on one of three randomly assigned topics in computer literacy: hardware, internet, or operating systems. During the interaction process, we recorded data from the three sensors previously listed. Participant completed a multiple choice pretest before interacting with AutoTutor and a multiple choice post-test after the tutoring session.
Judging Affective States
The affect judging process was conducted by synchronizing and displaying to the judges the video streams from the screen and the face. Judges were instructed to make judgments on what affective states were present at 20-second intervals; at each of these points, the video automatically paused (freeze-framed). Additionally, if participants were experiencing more than one affective state in a 20-second block, judges were instructed to mark each state and indicate which was most pronounced. However, in these situations only the more prominent affective state was considered in the current analyses. At the end of the study, participants were asked to identify any affective states they may have experienced that were not included in the specified list of seven emotions. However, a look at the data did not reveal any new affective states.
Four sets of emotion judgments were made for the observed affective states of each participant's AutoTutor session. First, for the self-judgments, the participant watched his or her own session with AutoTutor immediately after having interacted with the tutor. Second, for the peer judgments, participants returned approximately one week later to watch and judge another participant's session on the same topic in computer literacy. Finally, two additional judges (called trained judges) judged all of the sessions individually; these trained judges had been trained on how to detect facial action units according to Paul Ekman's Facial Action Coding System (FACS) (Ekman and Friesen Citation1978). The trained judges also had considerable experience interacting with AutoTutor. Hence, their emotion judgments were based on contextual dialogue information as well as the FACS system.
A list of the affective states and definitions was provided for all judges. The states were frustration, confusion, flow, delight, surprise, boredom, and neutral. Frustration was defined as dissatisfaction or annoyance. Confusion was defined as a noticeable lack of understanding, whereas flow was a state of interest that results from involvement in an activity. Delight was a high degree of satisfaction. Surprise was defined as wonder or amazement, especially from the unexpected. Boredom was defined as being weary or restless through lack of interest. Neutral was defined as no apparent emotion or feeling.
Proportions of Emotions Experienced
We examined the proportion of judgments that were made for each of the affect categories, averaging over the four judges. The most common affective state was neutral (.32), followed by confusion (.24), flow (.17), and boredom (.16). The frequency of occurrence of the remaining states of delight, frustration, and surprise were significantly lower, comprising .04, .06, and .02 of the observations, respectively. This distribution of affective states implies that most of the time learners are either in a neutral state or in a subtle affective state (boredom or flow). There is also a reasonable amount of confusion since the participants in this study were typically low-domain knowledge students as indicated by their low pretest scores.
Agreement Between Affect Judges
Interjudge reliability was computed using Cohen's kappa for all possible pairs of judges: self, peer, trained judge 1, and trained judge 2. Cohen's kappa measures the proportion of agreements between two judges with correction for base rate levels and random guessing (Cohen Citation1960). There were six possible pairs altogether. The kappas were reported in Graesser et al. (Citation2006): self-peer (.08), self-judge 1 (.14), self-judge 2 (.16), peer-judge 1 (.14), peer-judge 2 (.18), and judge 1–judge 2 (.36). While these kappas appear to be low, the kappas for the two trained judges are on par with data reported by other researchers who have assessed identification of emotions by humans (Ang, Dhillon, Krupski, Shriberg, and Stolcke Citation2002; Grimm, Mower, Kroschel, and Narayan Citation2006; Litman and Forbes-Riley Citation2004; Shafran, Riley, and Mohri Citation2003). For example, Litman and Forbes-Riley (Citation2004) reported kappa scores of .40 in distinguishing between positive, negative, negative, and neutral affect. Ang et al. (Citation2002) reported that human judges making a binary frustration-annoyance discrimination obtained a kappa score of .47. Shafran et al. achieved kappa scores ranging from .32–.42 in distinguishing among six emotions. In general, these results highlight the difficulty that humans experience in detecting affect.
ARCHITECTURE OF THE POSTURE-BASED AFFECT DETECTOR
The Body Pressure Measurement System (BPMS)
The BPMS system, developed by Tekscan (Citation1997), consists of a thin-film pressure pad (or mat) that can be mounted on a variety of surfaces. The pad is paper thin with a rectangular grid of sensing elements that is enclosed in a protective pouch. Each sensing element provides an 8-bit pressure output in mmHg. Our set-up had one sensing pad placed on the seat of a Steelcase (Grand Rapids, MI, USA) Leap Chair and another placed on the back of the chair (see Figure a).
FIGURE 1 Body pressure measurement system; (a) the two pressure pads placed on the chair; (b) pressure maps obtained from the pressure pads on the back and seat; (c) pressure maps divided into four triangular areas for spatial analyses.
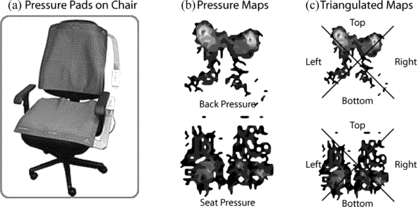
The output of the BPMS system consists of a 38 × 41 pressure matrix (rows × columns) for each pad. Each cell in the matrix monitors the amount of pressure exerted on a single sensing element (see Figure b). During the tutoring intervention, at each sampling instance (1/4 second for our study), matrices corresponding to the pressure exerted on the back and the seat of the chair were recorded for offline analyses.
High-Level Pressure Features
This feature set monitored the average pressure exerted on the back and seat of the chair along with the magnitude and direction of changes in pressure over a short time window. Several features were computed by analyzing the pressure maps of the 28 participants recorded in the study. We individually computed six pressure-related features and two features related to the pressure coverage for the back and the seat, yielding 16 features in all. Each of the features was computed by examining the pressure map at the time of an emotional episode (called the current frame or the frame at time t).
Perhaps the most significant pressure-related feature was the average pressure, which measured the mean pressure exerted in the current frame. This was computed by adding the pressure exerted on each sensing element and dividing the sum by the total number of elements. The average pressure is expressed in Equation (1) where R is the number of rows in the pressure matrix, C the number of columns, and p ij is the pressure of a sensing element in row i and column j. For the current study, R = 38 and C = 41.
We introduced another feature to detect the incidence of sharp forward versus backward leans, which ostensibly occurs when a learner is modulating his or her engagement levels. This feature measured the pressure exerted on the top of the back and seat pads. This was obtained by first dividing the pressure matrix into four triangular regions of equal area (see Figure c) and then computing the average pressure for the top triangular region. For the seat, this feature measured the force exerted on the frontal portion of the chair (sharp forward lean), while for the back it indicated whether the shoulder blades of the learner were on the back rest of the chair (heightened backward lean).
The next two features measured the direction of pressure change. These include the prior change and post change, which measured the difference between the average pressure in the current frame (t) and the frame J seconds earlier (t − J) and K seconds later (t + K), respectively (see Equations (2) and (3)). For the current analyses, J = K = 3 seconds. A positive prior change value is indicative of an increase in the pressure exerted, while a positive post change value reflects a reduction in pressure:
The reference change (see Equation (Equation4) measured the difference between the average pressure in the current frame (t) and the frame for the last-known affective rating (r). The motivation behind this measure was to calibrate the impact of the last emotional experience on the current affective state. It should be noted that unlike J and K, which were used to compute the prior and post changes, respectively, r is not a constant time difference. Instead, r varies in time across different affective experiences. For the current analyses, r was 20 seconds for a majority of the instances since affect judgments were elucidated every 20 seconds. However, since the affect judges voluntarily offered judgments between the 20-second time slots, in several cases, r < 20 seconds:
Finally, the average pressure change (a pressure ) measured the mean change in the average pressure across a predefined window of length N (see Equation Equation5). The window was typically 4 seconds, which spanned 2 seconds before and 2 seconds after an emotion judgment:
The two coverage features examined the proportion of nonzero sensing units (average coverage) on each pad along with the mean change of this feature across a 4-second window (average coverage change). The computations for average coverage can be depicted as follows. Consider x ij to be an indicator variable that determines whether the pressure (p ij ) on sensing element ij is nonzero. Then
The average coverage was the proportion of x ij values that were nonzero as indicated by Equation (Equation6). Analogous to Equation (Equation4), the average coverage change is expressed in Equation (Equation7) as
Spatial-Temporal Features
The second set of features used for the posture affect detector involved monitoring the spatial distribution of pressure contours and the magnitude by which they changed over time. Pressure contours were obtained by clustering the pressure maps for the back and seat of the chair using the Expectation-Maximization (EM) algorithm (Dempster, Laird, and Rubin Citation1977). The input to the EM algorithm were pressure values for each of the 1558 (38 × 41) pressure sensing elements from each sensor pad (i.e., back and seat). Each sensing element, along with the corresponding pressure exerted on it, was represented as a three-dimensional point. The first two dimensions represented the relative position of the sensing element (i.e., its X and Y coordinate) on the sensor map, while the third dimension was the pressure exerted on it. The EM algorithm was configured to output four clusters based on earlier findings by Mota and Picard (Citation2003) and preliminary experimental simulations in which the number of clusters was varied (k = 2, 3, 4, 5, 6). Fig. shows an example of the clustering data from the pressure maps with the EM algorithm.
FIGURE 2 Clustering pressure maps on the back and the seat with the EM algorithm. The left half of the image is the output from the back, while the right half is the output from the seat of the chair. The top quadrants (left and right) show the pressure maps on the back and seat. The eight plots on the bottom depict each individual clusters – four for the back (left) and four for the seat (right). Note that the clusters are based on position (X and Y co-ordinates of each sensing element) as well as intensity (pressure exerted on the sensing element).
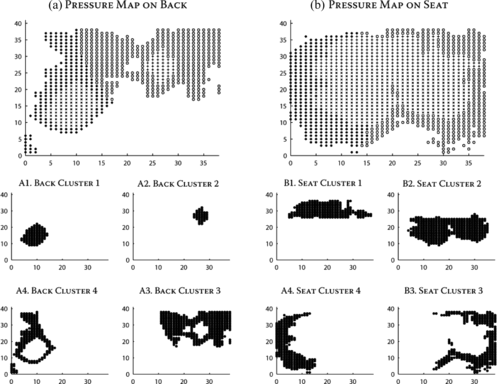
Since each data point was three-dimensional (i.e., X and Y position coordinates and pressure), each cluster was represented by a 3D mean, a 3D standard deviation, and a prior probability (i.e., proportion of the 1558 data points that are included in the cluster). Consequently, we extracted seven features from each cluster: three for the means, three for the standard deviations, and one for the prior probability. By tracking four clusters on each pad we obtained 28 features (4 × 7) in all. Additionally, since we were tracking both the back and the seat we obtained 28 × 2 = 56 features.
The aforementioned 56 features provide a snapshot of the spatial distribution of pressure exerted on the back and the seat of the chair while the learner interacts with AutoTutor. In order to obtain a measurement of arousal, we tracked the change in each pressure contour (cluster) over a short time window. In particular, the pressure contours across a 4-second window were monitored and the means and standard deviations of each of the 56 features were computed. Therefore, effective dimensionality was 112. In this manner, the features selected were spatial (distribution of pressure on pad) and temporal (changes in distribution over time).
Hierarchical Classification via an Associated Pandemonium
Perhaps the simplest method to develop an affect classifier is to experiment with several standard classifiers (neural networks, Naïve Bayes classifiers, etc.) and select the one that yields the highest performance in collectively discriminating between the affective states of boredom, confusion, delight, flow, frustration, and neutral (surprise was not included in the affect detector since its occurrence was quite rare). However, since affect detection is a very challenging pattern recognition problem, on par with automatic speech recognition, developing a six-way affect classifier that is sufficiently robust is quite challenging. An alternative approach is to divide the six-way classification problem into several smaller two or three-way classification problems.
One way to decompose the six-way classification problem into several smaller problems is to include a collection of affect-neutral classifiers which would first determine whether the incoming posture pattern resonated with any one or more of the emotions (versus a neutral state). If there is resonance with only one emotion, then that emotion would be declared as being experienced by the learner. If there is resonance with two or more emotions, then a conflict resolution module would be launched to decide between the alternatives. This would essentially be a second-level affect classifier. If three or more emotions are detected, then the second-level classifier would perform a three-way classification task. In situations where the emotion expression is very murky, four- or five-way distinctions might be required as well.
Figure depicts the manner in which the various classifiers are organized and interact. Central to the model lie five affect-neutral classifiers, each performing an emotion vs. neutral discrimination. To the left, we find 10 classifiers that specialize in making binary discriminations among the affective states. On the top there are 10 three-way emotion classifiers that are recruited when three or more affective states are detected by the affect-neutral classification layer. On the right, the various possibilities for four-way emotion classifiers are listed. Finally, the single five-way classifier lies at the bottom.
FIGURE 3 Hierarchical classification via an associated pandemonium.
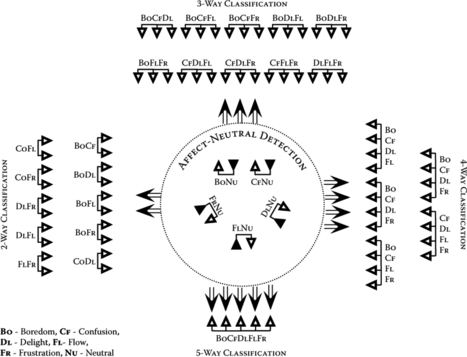
As an example, consider a situation where the affect-neutral classifiers output (Boredom, Neutral, Neutral, Neutral, Neutral). In this case, the Boredom-Neutral classifier has detect boredom, while the other four affect-neutral classifiers have detected neutral. In this situation, we would declare that the learner is experiencing the boredom emotion. If instead, the output of the affect-neutral level is (Boredom, Neutral, Neutral, Flow, Neutral), where the boredom-neutral classifier detects boredom, the flow-neutral classifier detects flow, and the other affect-neutral classifiers declare neutral, then the boredom-flow binary discriminator would be recruited to resolve the conflict (see Figure ).
Such a classification scheme is strongly motivated by the Pandemonium model (Selfridge Citation1959). It is expected that in most cases, the level 1 classifier (affect-neutral) or a two-way affect classifier would suffice. When more subtle distinctions are required from ambiguous input, a three-way or higher order classifier may also be necessary. However, four-way or five-way discriminations are expected to be much more rare, as discussed later.
MEASURING THE ACCURACY OF THE POSTURE-BASED AFFECT DETECTOR
In order to address the larger goal of extending AutoTutor into an affect-sensitive intelligent tutoring system, the need for real-time automatic affect detection becomes paramount. An emotion classifier need not be perfect but should possess some modicum of accuracy. The subsequent analyses include a series of classification experiments to evaluate the reliability of affect detection from gross body language.
Experimental Setup
Data Set Creation
The data used for the analyses was from the multiple judge study that was described earlier in which 28 participants interacted with AutoTutor on topics in computer literacy. Posture feature vectors for each method (high-level pressure features and spatial-temporal pressure contours) were extracted from the BPMS data stored offline. Each feature vector was then associated with an emotion category on the basis of each of the four human judges' affect ratings. More specifically, each emotion judgment was temporally bound to each posture-based feature vector. This data collection procedure yielded four ground truth models of the learner's affect (self, peer, two trained judges), so we were able to construct four labeled data sets. When aggregated across each 32-minute session for each of the 28 participants, we obtained 2967, 3012, 3816, and 3723 labeled data points for the self, peer, trained judge 1, and trained judge 2, respectively.
Affect judgment reliabilities between the human judges presented earlier revealed that the highest agreement was obtained between the trained judges (kappa = .36). However, it is still not firmly established whether the trained judges or the self-judgments are closer to ground truth. We addressed this issue by combining affect judgments from the trained judges in order to obtain a better approximation of the learner's emotion. In particular, an additional data set was constructed on the basis of judgments in which both trained judges agreed; this sample therefore focused on observations in which we had some confidence about the emotion. The frequencies of the emotions in each data set are listed in Table .
TABLE 1 Frequency of Affective States in Each Data Set
Classification Analyses
The Waikato Environment for Knowledge Analysis (WEKA) (Witten and Frank Citation2005) was used to comparatively evaluate the performance of various standard classification techniques (N = 17) in detecting affect from posture. The classification algorithms tested were selected from a list of categories including Bayesian classifiers (Naive Bayes and Naive Bayes Updatable), functions (logistic regression and support vector machines), instance based techniques (K-nearest neighbor with k = 1 and k = 3, K∗, locally weighted learning), meta classification schemes (AdaBoost, bagging predictors, additive logistic regression), trees (C4.5 decision trees, logistic model trees, REP tree), and rules (decision tables, nearest neighbor generalization, PART).
The classification analyses proceeded in two phases. In phase 1, the higher level pressure features (N = 16) were inputs to the classifiers. For phase 2, the spatial-temporal features (N = 112) were used to detect the affective states. Each phase was independent of the other since the primary goal here was to evaluate the accuracy of each method. Therefore, for each phase, we evaluated the accuracy of each of the 17 classifiers in discriminating the affective states grouped in the five categories of the hierarchy (see Figure ). There were 31 different classification experiments conducted for each feature set. These included five affect-neutral discriminations, 10 two-way discriminations, 10 three-way discriminations, five four-way discriminations, and a single five-way discrimination.
We established a uniform baseline for the different emotions by randomly sampling an equal number of observations from each affective state category. This sampling process was repeated for 10 iterations and all reported reliability statistics were averaged across these 10 iterations. For example, consider the task of detecting confusion from neutral with affect labels provided by the self. In this case, we would randomly select an equal number of confusion and neutral samples, thus creating a data set with equal prior probabilities of both these emotions. Each randomly sampled data set was evaluated on the 17 classification algorithms and reliability statistics were obtained using k-fold cross-validation (k = 10).
Trends in Classification Accuracy
A three-factor repeated measures analysis of variance (ANOVA) was performed in order to comparatively evaluate the performance of the classifiers in detecting affect from the posture features. The first factor (feature) was the feature set used as input into the classifier and had two levels: pressure and contours for the high-level pressure features and the spatial-temporal contours, respectively. The second factor involved the emotions classified and was composed of five levels: affect-neutral discriminations (chance = 50%), two-way affect discriminations (chance = 50%), three-way affect discriminations (chance = 33%), four-way affect discriminations (chance = 25%), and five-way affect discriminations (chance = 20%). The third factor was the judge that provided the affect judgments. This factor also had five levels: self, peer, trained judge 1, trained judge 2, and observations in which trained judges agree. The unit of analysis for the 2 × 5 × 5 ANOVA was the accuracy obtained by each of the 17 classifiers. The kappa score was utilized as the metric to evaluate performance of each classifier because this metric partials out random guessing.
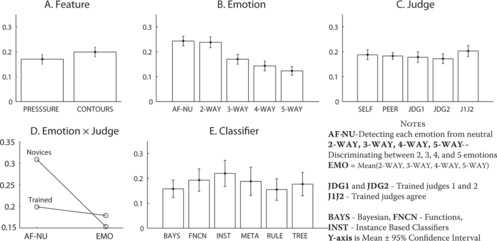
The ANOVA indicated that there were significant differences in kappa scores across all three factors, as well as for various interactions between the factors. On the basis of the ANOVA, we report comparisons between the various levels of our three factors (feature, emotion, and judge). Figure graphically depicts the mean kappa score obtained from the emotion classification for each level of each factor of the ANOVA.
FIGURE 4 Mean kappa across: (A) feature type; (B) emotions classified; (C) affect judge; (D) interaction between emotions classified and affect judge; (E) classification scheme.
Comparison Across Feature Sets
The results of the ANOVA indicated that there was a statistically significant difference in classification accuracy obtained from each feature set, F (1, 16) = 55, MSe = .003, p < .001 (partial η2 = .775). In particular, the classifiers based on the spatial-temporal contours (M CONTOUR = .20) outperformed those trained on the higher level pressure features (M PRESSURE = .17, see Figure a). However, the performance increments attributed to the spatial-temporal contours were marginal (an 18% increase in kappa over high-level pressure features). This marginal improvement may be indicative of problems commonly associated with high-dimensional feature spaces (N = 112 for spatial-temporal contours) due to multicollinearity among features.
Comparison Across Emotions
The ANOVA revealed statistically significant differences in kappa scores for the emotions classified, F (4, 64) = 269.14, MSe = .002, p < .001 (partial η2 = .944). Bonferroni post-hoc tests revealed that classification accuracy associated with discriminating each emotion from neutral (M AF-NU = .243) and two-way classifications (M 2-WAY = .238) were on par and quantitatively higher than classification accuracy associated with three-way (M 3-WAY = .177), four-way (M 4-WAY = .143), and five-way (M 5-WAY = .123) discriminations (see Figure b).
Discriminating a larger number of affective states is challenging, particularly when the states are collected in an ecologically valid setting (i.e., no actors were used to express emotions and no emotions were intentionally induced). As expected, there appears to be a linear relationship between the number of emotions simultaneously being discriminated and the associated classification accuracy score (R 2 = .91). It appears that each additional affective state included in the classification model is accompanied by a .04 (kappa) reduction in classification accuracy.
Comparison Across Affect Judges
The ANOVA revealed that there were statistically significant differences in kappa scores based on which judge provided the affect ratings used to train and validate the classifiers, F(4, 64) = 26.42, MSe = .001, p < .001 (partial η2 = .623). Bonferroni post-hoc tests revealed that classifiers based on affect ratings where the trained judges agreed (M J1J2 = .203, p < .01) yielded the best performance as depicted in Figure c. We recommend that this finding be interpreted with some caution since this data set probably consists of some of the more obvious cases, namely, since the trained judges were able to agree on an affective state.
Figure c indicates that overall classification performance between the self, peer, and two trained judges were on par with each other (M SELF = .188, M PEER = .183, M JDG1 = .178, and M JDG2 = .172). However, interesting patterns appear when one considers interactions between the affect judge and the emotions classified (see Figure d), which was statistically significant, F(16, 256) = 167.76, MSe = 0, p < .001 (partial η2 = .913). When one considers simple affect-neutral distinctions, it appears that classifiers trained on data sets in which affect judgments were provided by the novice judges (self and peer, M NOVICES = .309) were much higher than classifiers based on affect judgments from the trained judges (M TRAINED = .199). However, a reverse pattern was discovered for more complex discriminations between the various emotions (obtained by averaging accuracy scored for two-way, three-way, four-way, and five-way classifications). These classifiers were best for the trained judges (M TRAINED = .179) compared with the novices (M NOVICES = .153). This suggests that the novices were more adept at making affect-neutral distinctions, whereas the trained judges are more capable at performing complex emotional discriminations. Perhaps this phenomenon may be explained by the fact that the trained judges had considerable experience interacting with AutoTutor, and they make use of this contextual knowledge coupled with their facial expression training to discriminate between the affective states.
Comparisons Across Classifier Schemes
We performed an additional repeated measures ANOVA to determine whether there was any significant differences among the various classifier schemes previously described. This analysis had two factors: feature and classifier. Similar to the three-way ANOVA described earlier, the first factor (feature) was the feature set used as input to the classifier and had two levels: pressure and contours. The second factor of the ANOVA was the classification scheme (called classifier) divided across six levels for Bayesian classifiers, functions, instance-based learners, meta classifiers, rules, and trees. The unit of analysis for this 2 × 6 ANOVA was kappa scores associated with each of the affective models (affect-neutral, two, three-, four-, and five-way classifications).
As expected from the previous analyses, there was a statistically significant difference among the two feature sets used with the spatial-temporal contours feature set outperforming the high-level pressure feature set. There were also significant differences in the kappa scores across the various classifier schemes F(5, 20) = 34.81, MSe = .006, p < .001 (partial η2 = .807, see Figure e). Bonferroni post-hoc tests revealed that the kappa scores of the instance-based classifiers (M INST = .22) were significantly higher than the others. Performance of the function-based classifiers, meta classifiers, and trees (M FNCN = .193, M META = .188, M TREE = .155) were similar quantitatively and higher than Bayesian classifiers and rule-based learning schemes (M BAYS = .158, M RULE = .177).
It is informative to note that the results showed no statistically significant interactions between the feature set and the classification schemes (p = .113). This result indicates that the relative performance of the six classification schemes derived earlier is independent of the feature set (pressure or contours).
Maximum Classification Accuracy
The use of multiple assessments of the learner's affect (N = 5) and a large number of classifiers (N = 17) was useful in investigating the effect of different factors (feature set, affect judge, etc.) on affect detection accuracy. However, in order to achieve our goal of developing a real-time emotion classification system, we will shift our focus to the classifier that yielded the best performance. Table presents the maximum classification accuracies obtained across all 17 classifiers across the five data sets in discriminating the various combinations of affective states specified by the hierarchy (see Figure ).
TABLE 2 Maximum Classification Accuracy in Detecting Affect
The results revealed that the accuracy for affect-neutral discrimination and two-way emotion resolutions are reasonable (74% and 71%, respectively), but the accuracy drops when we attempt to resolve conflicts between three or more emotions (three-way = 55%, four-way = 46%, five-way = 39%). Therefore, it appears that the efficacy of the hierarchical classification scheme is inversely proportional to the probability of requiring the higher order emotion classification models to resolve discrepancies that arise during the affect-neutral discrimination phase. Simply put, the hierarchical method for affect detection would be feasible if we are able to get by with affect-neutral, two-way, and the occasional three-way classifications.
There is some evidence that suggests that human disagreements among the affective states usually occur at the affect-neutral stage or the two-way classification stage. An analysis on the source of classification errors made by the human judges (self, peer, judge 1, and judge 2) revealed that 63.5% of the time each emotion was confused with neutral (affect-neutral detection). The two-way conflicts occurred 30.4% of the time, while three-way conflicts were much rarer (5.5%). The four-way and five-way discriminations almost never occurred. Taken together, the ideal model for emotion classification would involve: (a) the detection of single emotions compared to neutral states, a resonance-based process that fits the Pandemonium model very well, and (b) the resolution of pairs of emotions that have some modicum of activation.
Comparison to Other Sensors
In addition to using posture as a diagnostic channel in inferring the affective states of the learner, the larger project of extending AutoTutor into an affect-sensitive intelligent tutoring system also relies on facial expressions and conversational cues (or dialogue features) that are obtained from AutoTutor's log files. We compared the affect detection accuracy scores associated with the two posture feature sets (pressure features and spatial-temporal contours) with previously established reliabilities from dialogue and facial features (D'Mello, Picard, and Graesser Citation2007). The comparisons were restricted to affect-neutral discriminations since the more complex affective models (two-way, three-way, etc.) have not yet been developed for the other sensors. It should also be noted that the data set used in the current study was also used to train and validate the dialogue and facial feature-based classifiers.
An initial analysis was performed by averaging across the accuracies associated with the five affect-neutral discriminations. It appears that the classification accuracy attributed to the posture sensor with the high-level pressure features was on par with the dialogue features (M PRESSURE = M DIALOGUE = 72%). Classification accuracies for the posture sensor with spatial-temporal contour features (M CONTOURS = 74%) rivaled accuracies obtained by monitoring facial features (M FACE = 75%). It should be noted, however, that the facial features used as predictors were manually annotated, as opposed to being automatically computed as in the case of the posture and dialogue features. This is a technological advantage of posture detection over the face as a channel for affect detection.
A finer-grained comparison of the accuracies of detecting each affective state from neutral revealed that the posture sensor (with spatial-temporal features) was the most effective for affective states that do not generate overly expressive facial expressions, such as boredom (74%) and flow (83%). On the other hand, the affective states of confusion (76%) and delight (90%), which are accompanied by significant arousal, were best detected by monitoring facial features. The negative affective state of frustration is typically disguised and therefore difficult to detect with the bodily measures of face and posture. Frustration was best detected by examining the dialogue features in the tutoring context (78%). Taken together, detection accuracies were 80% when particular emotions were aligned with the optimal sensor channels.
GENERAL DISCUSSION
This research was motivated by the belief that the affective states of learners are manifested through their gross body language via configurations of body position and modulations of arousal. We achieved several milestones which suggest that significant information can be obtained from body position and movement. Although the challenges of measuring emotions is beset with murky, noisy, and incomplete data, and is compounded with individual differences in experiencing and expressing emotions, we have found that the characteristics of the body posture are quite diagnostic of the affect states of learners. On the basis of two sets of body pressure features alone, our results showed that conventional classifiers are moderately successful in discriminating the affective states of boredom, confusion, delight, flow, and frustration from each other, as well as from the baseline state of neutral.
One may object to our use of the term moderate to characterize our classification results. However, it is imperative to note that an upper bound on automated classification accuracy of affect has yet to be established. While human classifications may be considered to be the ultimate upper bound on system performance, human performance is variable and not necessarily the best gold standard. As discussed earlier, our own results suggest that humans do not achieve a very high degree of concordance in judging emotions. Our findings with respect to low interrater reliability scores associated with emotion recognition independently replicate findings by a number of researchers (Ang et al. Citation2002; Grimm et al. Citation2006; Litman and Forbes-Riley Citation2004; Shafran et al. Citation2003).
Statisticians have sometimes claimed with hedges and qualifications that kappa scores ranging from 0.4–0.6 are typically considered to be fair, 0.6–0.75 are good, and scores greater than 0.75 are excellent (Robson Citation1993). On the basis of this categorization, the kappa scores obtained by our best classifiers would range from poor to fair. However, such claims of statisticians address the reliability of multiple judges or sensors when the researcher is asserting that the decisions are clear-cut and decidable. The present goal is very different. Instead, our goal is to use the kappa score as an unbiased metric of the reliability of making affect decisions, knowing full well that such judgments are fuzzy, ill-defined, and possibly indeterminate. A kappa score greater than 0.6 is expected when judges code some simple human behaviors, such as facial action units, basic gestures, and other visible behavior. However, in our case the human judges and computer algorithms are inferring a complex mental state. Moreover, it is the relative magnitude of these measures among judges, sensors, and conditions that matter, not the absolute magnitude of the scores. We argue that the lower kappa scores are meaningful and interpretable as dependent measures (as opposed to checks for reliability of coding), especially since it is unlikely that perfect agreement will ever be achieved and there is no objective gold standard.
In this article we introduced a two-step affect detection model where affect-neutral classifiers first determined whether the incoming pressure maps resonated with any one or more of the emotions (versus a neutral state). If there is resonance with only one emotion, then that emotion would be declared as being experienced by the learner. In situations where there is resonance with two or more emotions additional two, three, four or five-way conflict resolution modules are recruited. Comprehensive evaluations of this model were not presented in this article because the focus was primarily on exploring the potential of a posture-based affect detection. However, initial analyses with this model revealed that classification accuracy scores were notably lower for four- and five-way emotion classifications than for affect-neutral, two-way and three-way emotion discriminations.
Although the lower accuracy for the higher level classification models might seem problematic, it is important to note that it is not imperative for AutoTutor to detect and respond to all affective experiences of the learner. What is important, however, is that for a given turn, if AutoTutor decides to adapt its pedagogical strategy to incorporate the emotions of the learner, then it should be sufficiently confident that the correct emotion has been detected. Taking inappropriate action, like incorrectly acknowledging frustration, can have very negative effects on the learner's perception of AutoTutor's capabilities which are presumably linked to learning gains.
Therefore, one strategy for AutoTutor in situations that require four- or five-way classifications might be to simply ignore the affective element and choose its next action on the basis of the learner's cognitive state alone. Perhaps more attractive alternatives exist as well. For example, AutoTutor could bias the confidence of the tutor's actions as a function of the confidence of the emotion estimate. For example, if the system lacks confidence in its assessment of frustration, then an empathetic response may be preferred over AutoTutor's directly acknowledging the frustration and drastically altering its dialogue strategy. We are in the process of experimenting with these strategies to compensate for nonperfect affect recognition rates.
CONCLUDING REMARKS
This research provides an alternative to the long-standing notion that extoll the virtues of the face as the primary modality through which emotion is communicated. We hope to have established the foundation for the use of gross body language as a serious contender to traditional measures for emotion detection such as facial feature-tracking and monitoring the paralinguistic features of speech. When directly compared to other sensors, our results suggest that boredom and flow might best be detected from body language while the face plays a significant role in conveying confusion and delight. It is tempting to speculate from an evolutionary perspective that learners use their face as a social cue to indicate that they are confused, to potentially recruit resources to alleviate their perplexity. However, it appears that learners do not readily display frustration on the face, perhaps due to the negative connotations associated with this emotion. This finding is consistent with Ekman and Friesen's (Citation1969) theory of social display rules, in which social pressures may result in the disguising of negative emotions such as frustration. It is the contextual information obtained by mining AutoTutor's log files that best detects frustration.
Although the face might reign supreme in the communication of the basic emotions (i.e., anger fear, sadness, enjoyment, disgust, and surprise (Ekman and Friesen Citation1978)), our results clearly indicate that the face is not the most significant communicative channel for some of the learning-centered affective states such as boredom and flow. Instead, it is the body that best conveys these emotions. Furthermore, the face can be quite deceptive when learners' attempt to disguise negative emotions such as frustration. But bodily motions are ordinarily unconscious, unintentional, and thereby not susceptible to social editing. These factors make the body an ideal channel for nonintrusive affect monitoring.
We thank our research colleagues in the Emotive Computing Group and the Tutoring Research Group (TRG) at the University of Memphis (http://emotion.autotutor.org). Special thanks to Patrick Chipman, Scotty Craig, Barry Gholson, Bethany McDaniel, Jeremiah Sullins, and Amy Witherspoon for their valuable contributions to this study. We gratefully acknowledge our partners at the Affective Computing Research Group at MIT including Rosalind Picard, Rana el Kaliouby, and Barry Kort.
This research was supported by the National Science Foundation (REC 0106965 and ITR 0325428).
Notes
P – high-level pressure features; C – spatial-temporal pressure contours; BO – boredom; CF – confusion; DL – delight; FL – flow; FR – frustration; NU– neutral.
Related Research Data
REFERENCES
- Aist , G. , B. Kort , R. Reilly , R.W. Picard , and J. Mostow . 2002 . Experimentally augmenting an intelligent tutoring system with human supplied capabilities: Adding human-provided emotional scaffolding to an automated reading tutor that listens . In: Proceedings of the 6th International Conference on Intelligent Tutoring Systems (ITS2002) , Biarritz, France and San Sebastian, Spain, June 2–7, 2002 .
- Ang , J. , R. Dhillon , A. Krupski , E. Shriberg , and A. Stolcke . 2002. Prosody-based automatic detection of annoyance and frustration in human-computer dialog. In: Proceedings of the International Conference on Spoken Language Processing 2037–2039.
- Barrett , L. F. 2006 . Are emotions natural kinds? Perspectives on Psychological Science 1 : 28 – 58 .
- Bernstein , N. 1967 . The Co-Ordination and Regulation of Movement . London : Pergamon Press .
- Bianchi-Berthouze , N. and C. L. Lisetti . 2002 . Modeling multimodal expression of users affective subjective experience . User Modeling and User-Adapted Interaction 12 ( 1 ): 49 – 84 .
- Bianchi-Berthouze , N. , P. Cairns , A. Cox , C. Jennett , and W. Kim . 2006 . On posture as a modality for expressing and recognizing emotions . In: Emotion and HCI Workshop , British Computer Society HCI September 12, 2006, London .
- Bull , E. P. 1987 . Posture and Gesture . Pergamon Press : Oxford .
- Campbell , D. T. and D. W. Fiske . 1959 . Convergent And discriminant validation by the multitrait-multimethod matrix . Psychological Bulletin 56 : 81 – 105 .
- Cohen , J. 1960 . A coefficient of agreement for nominal scales . Educational and Psychological Measurement 20 : 37 – 46 .
- Conati , C. 2002 . Probabilistic assessment of user's emotions in educational games . Journal of Applied Artificial Intelligence 16 : 555 – 575 .
- Coulson , M. 2004 . Attributing emotion to static body postures: Recognition accuracy, confusions, and viewpoint dependence . Journal of Nonverbal Behavior 28 : 117 – 139 .
- Craig , S. D. , A. C. Graesser , J. Sullins , and B. Gholson . 2004 . Affect and learning: An exploratory look into the role of affect in learning . Journal of Educational Media 29 : 241 – 250 .
- de Meijer , M. 1989 . The contribution of general features of body movement to the attribution of emotions . Journal of Nonverbal Behavior 13 : 247 – 268 .
- Dempster , A. P. , N. M. Laird , and D. B. Rubin . 1977 . Maximum Likelihood from incomplete data via the EM algorithm . Journal of the Royal Statistical Society 39 : 1 – 38 .
- de Rosis , F. 2002 . Toward merging cognition and affect in HCI . Applied Artificial Intelligence 16 : 487 – 494 .
- De Vicente , A. and H. Pain . 2002 . Informing the detection of students' motivational state: An empirical study . In: Proceedings of the 6th International Conference on Intelligent Tutoring Systems (ITS2002) , Biarritz, France and San Sebastian, Spain, June 2–7, 2002 .
- D'Mello , S. K. , S. D. Craig , B. Gholson , S. Franklin , R. Picard , and A. C. Graesser . 2005 . Integrating affect sensors in an intelligent tutoring system. Affective interactions: The computer . In: The Affective Loop Workshop at the 2005 International Conference on Intelligent User Interfaces . New York : AMC Press .
- D'Mello , S. K. , S. D. Craig , J. Sullins , and A. C. Graesser . 2006 . Predicting affective states through an emote-aloud procedure from autotutor's mixed-initiative dialogue . International Journal of Artificial Intelligence in Education 16 : 3 – 28 .
- D'Mello , S. K. , R. Picard , and A. C. Graesser . 2007 . Towards an affect sensitive autotutor . IEEE Intelligent Systems 22 : 53 – 61 .
- Dweck , C. S. 2002 . Messages that motivate: How praise molds students' beliefs, motivation, and performance (in surprising ways) . In: Improving Academic Achievement: Impact of Psychological Factors on Education , ed. J. Aronson , pp. 61 – 87 . Orlando , FL : Academic Press .
- Ekman , P. and W. V. Friesen . 1969 . Nonverbal leakage and clues to deception . Psychiatry 32 : 88 – 105 .
- Ekman , P. and W. V. Friesen . 1978 . The Facial Action Coding System: A Technique for the Measurement of Facial Movement . Palo Alto , CA : Consulting Psychologists Press .
- Graesser , A. C. , S. Lu , G. T. Jackson , H. Mitchell , M. Ventura , A. Olney , and M. M. Louwerse . 2004 . AutoTutor: A tutor with dialogue in natural language . Behavioral Research Methods, Instruments, and Computers 36 : 180 – 193 .
- Graesser , A. C. , B. McDaniel , P. Chipman , A. Witherspoon , S. D'Mello , and B. Gholson . 2006 . Detection of emotions during learning with autotutor . In: Proceedings of the 28th Annual Conference of the Cognitive Science Society . Mahwah , NJ : Erlbaum .
- Graesser , A. C. , N. Person , D. Harter , and Tutoring Research Group . 2001 . Teaching tactics and dialogue in reply to: AutoTutor . International Journal of Artificial Intelligence in Education 12 : 257 – 279 .
- Grimm , M. , E. Mower , K. Kroschel , and S. Narayan . 2006. Combining categorical and primitives-based emotion recognition. In: 14th European Signal Processing Conference (EUSIPCO), September 4-8, 2008, Florence, Italy.
- Kim , Y. 2005 . Empathetic virtual peers enhanced learner interest and self-efficacy . In: Workshop on Motivation and Affect in Educational Software at the 12th International Conference on Artificial Intelligence in Education , July 18–22, 2005 , Amsterdam , the Netherlands .
- Klein , J. , Y. Moon , and R. Picard . 2002 . This computer responds to user frustration – Theory, design, and results . Interacting with Computers 14 : 19 – 140 .
- Kort , B. , R. Reilly , and R. Picard . 2001 . An affective model of interplay between emotions and learning: reengineering educational pedagogy building a learning companion . In: Proceedings IEEE International Conference on Advanced Learning Technology: Issues, Achievements and Challenges , Madison , WI , pp. 43 – 48 .
- Linnenbrink , E. A. and P. Pintrich . 2002 . The role of motivational beliefs in conceptual change . In: Reconsidering Conceptual Change: Issues in Theory and Practice , eds. M. Limon and L. Mason . Dordrecht , the Netherlands : Kluwer Academic Publishers .
- Liscombe , J. , G. Riccardi , and D. Hakkani-Tür . 2005 . Using context to improve emotion detection in Spoken dialog systems . In: EUROSPEECH'05, 9th European Conference on Speech Communication and Technology , Lisbon , Portugal .
- Lisetti , C. L. and P. Gmytrasiewicz . 2002 . Can a rational agent afford to be affectless? A formal approach . Applied Artificial Intelligence, An International Journal 16 : 577 – 609 .
- Litman , D. J. and K. Forbes-Riley . 2004 . Predicting student emotions in computer-human tutoring dialogues . In: Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics . East Stroudsburg , PA : Association for Computational Linguistics .
- Mandler , G. 1984 . Mind and Body: Psychology of Emotion and Stress . New York : Norton .
- Matsubara , Y. and M. Nagamachi . 1996 . Motivation systems and motivation models for intelligent tutoring . In: Proceedings of the Third International Conference in Intelligent Tutoring Systems , June 12–14, 1996 , Montreal , Canada .
- Mehrabian , A. 1972 . Nonverbal Communication . Chicago , IL : Aldine-Atherton .
- Montepare , J. , E. Koff , D. Zaitchik , and M. Albert . 1999 . The use of body movements and gestures as cues to emotions in younger and older adults . Journal of Nonverbal Behavior 23 : 133 – 152 .
- Morimoto , C. , D. Koons , A. Amir , and M. Flickner . 1998 . Pupil detection and tracking using multiple light sources . Technical Report , IBM, Almaden Research Center , San Francisco , CA , USA .
- Mota , S. and R. W. Picard . 2003 . Automated posture analysis for detecting learner's interest level . In: Workshop on Computer Vision and Pattern Recognition for Human-Computer Interaction (CVPR HCI), June 16–22, 2003, Madison, WI, USA .
- Norman , D. A. 1994 . How might people interact with agents? Communication of the ACM 37 : 68 – 71 .
- Paiva , A. , R. Prada , and R. W. Picard . (eds.). 2007 . Affective Computing and Intelligent Interaction . Springer .
- Pantic , M. and L. J. M. Rothkrantz . 2003 . Towards an affect-sensitive multimodal human-computer interaction . In: Proceedings of the IEEE, Special Issue on Multimodal Human-Computer Interaction (HCI) 91 ( 9 ): 1370 – 1390 .
- Picard , R. W. 1997 . Affective Computing . Boston , MA : MIT Press .
- Picard , R. W. , E. Vyzas , and J. Healey . 2001 . Toward machine emotional intelligence: Analysis of affective physiological state . IEEE Transactions Pattern Analysis and Machine Intelligence 23 : 1175 – 1191 .
- Prendinger , H. and M. Ishizuka . 2005 . The empathic companion: A character-based interface that addresses users' affective states . International Journal of Applied Artificial Intelligence 19 : 267 – 285 .
- Rani , P. , N. Sarkar , and C. A. Smith . 2003 . An affect-sensitive human-robot cooperation – Theory and experiments . In: Proceedings of the IEEE Conference on Robotics and Automation . Taipei , Taiwan : IEEE , pp. 2382 – 2387 .
- Robson , C. 1993 . Real Word Research: A Resource for Social Scientist and Practitioner Researchers . Oxford : Blackwell .
- Selfridge , O. G. 1959 . Pandemonium: A paradigm for learning . In: Symposium on the Mechanization of Thought Processes . London : Her Majesty's Stationary Office , pp. 511 – 531 .
- Shafran , I. , M. Riley , and M. Mohri . 2003 . Voice signatures . In: Proceedings IEEE Automatic Speech Recognition and Understanding Workshop , Piscataway , NJ : IEEE , pp. 31 – 36 .
- Shneiderman , B. and C. Plaisant . 2005. Designing the User Interface: Strategies for Effective Human-Computer Interaction. , 4th ed.Reading , MA : Addison-Wesley.
- Tan , H. Z. , I. Lu , and A. Pentland . 1997 . The chair as a novel haptic user interface . In: Proc. Workshop of Perceptual User Interface , pp. 56 – 57 .
- Tekscan . 1997 . Tekscan Body Pressure Measurement System User's Manual . South Boston , MA : Tekscan Inc .
- VanLehn , K. , A. C. Graesser , G. T. Jackson , P. Jordan , A. Olney , and C. P. Rose . 2007 . When are tutorial dialogues more effective than reading? Cognitive Science 31 : 3 – 62 .
- Walk , R. D. and K. L. Walters . 1988 . Perception of the smile and other emotions of the body and face at different distances . Bulletin of the Psychonomic Society 26 : 510 – 510 .
- Whang , M. C. , J. S. Lim , and W. Boucsein . 2003 . Preparing computers for affective communication: A psychophysiological concept and preliminary results . Human Factors 45 : 623 – 634 .
- Witten , I. H. and E. Frank . 2005 . Data Mining: Practical Machine Learning Tools and Techniques. , 2nd ed. San Francisco , CA : Morgan Kaufmann .