Abstract
AdaBoost.M1 has been successfully applied to improve the accuracy of a learning algorithm for multi-class classification problems. However, it may be hard to satisfy the required conditions in some practical cases. An improved algorithm called AdaBoost.MK is developed to solve this problem. Early proposed support vector machines (SVM)-based, multi-class classification algorithms work by splitting the original problem into a set of two-class subproblems. The amount of time and space required by these algorithms is very demanding. We develop a multi-class classification algorithm by incorporating one-class SVMs with a well-designed discriminant function. Finally, a hybrid method integrating AdaBoost.MK and one-class SVMs is proposed to solve multi-class classification problems. Experimental results on data sets from UCI and Statlog show that the proposed approach outperforms other multi-class algorithms, such as support vector data descriptions (SVDDs) and AdaBoost.M1 with one-class SVMs, and the improvement is found to be statistically significant.
In a multi-class classification problem, we are given ℓ-labeled training patterns S tr = {(x 1, y 1),…, (x ℓ, y ℓ)}, where x i ∈ R n , i = 1,…, ℓ, and y i ∈ {1,…, k}, meaning that x i belongs to class y i . A model is learned from these patterns and used to predict the class label of unseen data. Several solutions have been proposed for solving multi-class classification problems, and support vector machines (SVMs); is one of those with high performance (Goh, Chang, and Li, Citation2005; Hsu and Lin, Citation2002; Rifkin and Klautau, Citation2004). In addition, many studies have indicated that ensemble methods, such as boosting, can improve the accuracy of any given learning algorithm (Dietterich, Citation2000b; Freund and Schapire, Citation1997; Li, Wang, and Sung, Citation2005; Martínez-Muñoz and Suárez, Citation2007; Schapire and Singer, Citation1999; Sun, Todorovic, and Li, Citation2007). In this study, a hybrid method using an improved multi-class boosting algorithm and one-class SVMs with a well-designed discriminant function is proposed to solve a multi-class classification problem.
AdaBoost, the most popular boosting method, was proposed by Freund and Schapire (Citation1997). It requires the performance of each base classifier be better than random guessing. Many studies using naïve Bayes (Kim, Kim, and Ra, Citation2005; Nock and Sebban, Citation2001), decision trees (Dietterich, Citation2000a; Friedman, Hastie, and Tibshirani, Citation2000; Rodríguez and Maudes, Citation2007; Sun et al., Citation2007), artificial neural networks (ANN) (Rätsch, Onoda, and Müller, Citation2001; Schwenk and Benggio, Citation2000), or SVMs (Li et al., Citation2005) as the base classifiers for AdaBoost have been shown to obtain good performance due to the generalization ability of AdaBoost. Since conventional AdaBoost was designed for solving a two-class classification problem, various extensions have been proposed to solve the multi-class classification problem, e.g., AdaBoost.M1 (Freund and Schapire, Citation1997), AdaBoost.M2 (Freund and Schapire, Citation1997; Schapire Citation1997), AdaBoost.MH (Schapire and Singer, Citation1999), AdaBoost.ECC (Guruswami and Sahai, Citation1999; Li Citation2006), AdaBoost.MA (Eibl and Pfeiffer, Citation2005), SAMME (Zhu, Rosset, Zou, and Hastie, Citation2005), AdaBoost.SMO (Sun et al., Citation2007), AdaBoost.SECC (Sun et al., Citation2007), etc. Like its two-class counterpart, AdaBoost.M1 requires each base classifier have an accuracy higher than 1/2, but this may be hard to achieve for a multi-class problem in practice. In this study, we propose a new algorithm called AdaBoost.MK that only requires the performance of each base classifier to be better than a random guessing with an accuracy higher than (1/k).
Conventional SVMs (Cortes and Vapnik, Citation1995) were designed for binary classification and specific strategies were integrated into these SVMs for multi-class classification. These strategies split up the original problem into a set of two-class subproblems and then use discriminant functions to make a multi-class decision out of binary decisions. The proposed discriminant functions include One-Against-All (OVA) (Bottou et al., Citation1994), One-Against-One (OVO) (Friedman, Citation1996; Kreßel Citation1999), and Directed Acyclic Graph (DAG) (Platt, Cristianini, and Shawe-Taylor, Citation2000). In OVA, k binary SVMs are constructed for a k-class problem. A distinct SVM is trained with the patterns from the mth class against all the remaining patterns. Given a testing pattern x p , all the k SVMs are evaluated, and the pattern is assigned to the class having the largest value of the decision function (Cortes and Vapnik, Citation1995). The OVO approach constructs k (k − 1)/2 binary SVMs, one for each pair of different classes, for a k-class problem. By applying the voting method, the testing pattern x p is classified to the class with the largest count of votes (Friedman, Citation1996; Kreßel Citation1999). The DAG method does the same work as the OVO in the training period, while in the testing period it uses a “directed acyclic graph” architecture to make a decision instead of the voting method (Platt et al., Citation2000). Although OVA only constructs k binary SVMs in the training period, its demand for time and space is very large for large ℓ, because the learning of each binary SVM needs to consider all the ℓ training patterns. For example, if ℓ = 20000, a 20000 × 20000 kernel matrix must be constructed for each classifier. On the other hand, binary SVMs constructed by OVO or DAG use fewer training patterns taken from classes i and j where i, j ∈ {1,…, k}, and i ≠ j. But the number of binary classifiers is large when k is large. For example, if there are 20 classes, 190 classifiers must be trained.
Recently, KSVDD has been proposed for multi-class classification by constructing k support vector data descriptions (SVDDs) (Sun and Huang, Citation2003; Rifkin and Klautau Citation2004). A SVDD is optimized only for the training patterns of class m, where m ∈ {1,…, k}. Thus, the size of a kernel matrix and the training time of this method are less than those of OVA and OVO. In the testing period, it requires decisions based on k SVDD classifiers and a discriminant function. One-class SVMs have also been proposed for document classification (Manevitz and Yousef, Citation2001). Since the discriminant function used is simple, it may lead to poor performance. In this study, we propose a hybrid method integrating AdaBoost.MK and one-class SVMs to solve multi-class classification problems. AdaBoost.MK alleviates the strict error bound requirement imposed in AdaBoost.M1 and boosts the overall performance. Using one-class SVMs as base classifiers in AdaBoost.MK reduces the time and space complexities required by conventional SVMs. A well-designed discriminant function is used to improve the discrimination capability of one-class SVMs. Experimental results on data sets taken from The University of California Irvine Machine Learning Repository and Statlog show that the proposed method outperforms other multi-class classification algorithms with statistical significance.
RELATED WORK
Various AdaBoost algorithms have been proposed for solving multi-class classification problems. These algorithms can be split into two categories: (1) algorithms that extend the original AdaBoost algorithm to the multi-class classification problem without reducing it to a set of two-class subproblems, e.g., AdaBoost.M1 (Freund and Schapire, Citation1997), SAMME (Zhu et al., Citation2005), GAMBLE (Huang, Ertekin, Song, Zha, and Giles, Citation2007), etc., and (2) algorithms that reduce the multi-class classification problem to a set of two-class subproblems, e.g., AdaBoost.M2 (Freund and Schapire, Citation1997; Schapire Citation1997), AdaBoost.ECC (Guruswami and Sahai, Citation1999; Li Citation2006), AdaBoost.MH (Schapire and Singer, Citation1999), AdaBoost.MO (Allwein, Schapire, and Singer, Citation2000; Schapire and Singer, Citation1999), AdaBoost.SMO (Sun et al., Citation2007), AdaBoost.SECC (Sun et al., Citation2007), etc. In other words, the base classifiers in the first category output multi-class labels directly and base classifiers in the second category output two-class labels.
AdaBoost.M1 is the first attempt to extend AdaBoost to multi-class classification problems and is very popular. However, AdaBoost.M1 fails when the base classifiers misclassify more than half of the training patterns (err > 1/2) but perform better than a random guessing (err < (k − 1)/k). Zhu et al. (Citation2005) proposed a SAMME algorithm using a multi-class exponential loss function and a k-class response-encoding scheme to solve this problem. It has been shown that SAMME outperformed AdaBoost.M1. On the other hand, AdaBoost.M2 solves the multi-class classification problem by using a pairwise, one-against-one strategy. However, AdaBoost.M2 complicates the design of base classifiers due to a pseudo-loss measure. AdaBoost.MH adopts the one-against-all strategy. Other multi-class variants exist such as AdaBoost.ECC and AdaBoost.MO, which use the correcting output code to improve the performance.
The SVM-based technique was originally designed to handle two-class classification problems, but extensions have been developed to tackle multi-class problems. Tax and Duin (Citation1999), (Citation2004) and Ben-Hur, Horn, Siegelmann, and Vapnik (Citation2002) introduced a kernel-based method called SVDD or support vector clustering (SVC) to compute the smallest sphere in the feature space enclosing the image of the input data. This method can be adopted to solve the multi-class classification problem (Sachs, Thiel, and Schwenker, Citation2006; Sun and Huang, Citation2003). In order to determine the similarity between a testing pattern x p and the training patterns of class m, various discriminant functions have been proposed and are briefly described below.
| 1. | Lies-on or lies-inside the sphere (Sachs et al., Citation2006): The discriminant function is defined to be with | ||||
| 2. | Nearest-center (NC) (Sachs et al., Citation2006; Sun and Huang Citation2003): This discriminant function assigns a testing pattern x p to class m with the center a m being closest to x p . The discriminant function is defined as follows: | ||||
| 3. | Nearest-support-vector (NSV) (Sachs et al., Citation2006): In this approach, a testing pattern x p is assigned to class m which has the shortest distance between x p and its support vector set SV m . The discriminant function is defined as follows: | ||||
PROPOSED MULTI-CLASS CLASSIFIER (MOCSVMC)
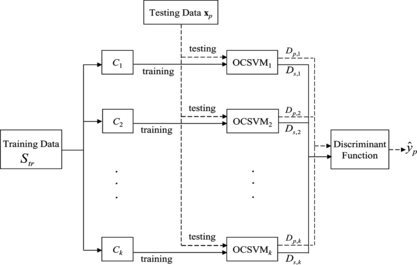
We propose a classifier, called multiple one-class-SVM classifier (MOCSVMC), for multi-class classification problems. For a training dataset with k classes, the MOCSVMC consists of k one-class SVMs (Schölkopf, Platt, Shawe-Taylor, Smola, and Williamson, Citation2001) together with a discriminant function, as shown in Figure . In this figure, solid lines indicate the processing flow of training and dotted lines indicate the processing flow of testing. Let S tr be the training set and C i , i = 1, …, k, contain the training samples of class i. In the training period, a one-class SVM OCSVM i is trained for each C i . Some desired parameter values associated with each OCSVM are also calculated. This training procedure for MOCSVMC is described in Algorithm 1. In the testing period, a testing pattern x p is first evaluated by the k OCSVMs and k projection values are obtained. Then, a discriminant function is applied to these values to make a final multi-class decision. This testing procedure for MOCSVMC is described in Algorithm 2. In this section, we first describe how an OCSVM is trained. Then we present the discriminant function used in the classifier.
FIGURE 1 The architecture of MOCSVMC.
Algorithm 1
MOCSVMC.Training ( S t r )
Input: The set of labeled training patterns S tr with k classes.
1: Set the parameter q for RBF kernel, and ν for the proportion of support vectors. | |||||
2: Split S tr into C 1, C 2, …, C k where C m contains the training patterns of class m. | |||||
3: for m = 1 to k do | |||||
4: Train the one-class SVM OCSVM m for the training subset C m , and obtain a set of coefficients (α j, m , ρ m ) from this model. | |||||
5: for s = 1 to |C m | do | |||||
6: | |||||
7: end for | |||||
8: | |||||
9: end for | |||||
Return: OCSVM m and associated parameter values, m = 1,…, k.
Algorithm 2
MOCSVMC.Testing ( x p )
Input: x p
1: for m = 1 to k do | |||||
2: | |||||
3: Ma p, m ← according to Eq. (Equation9). | |||||
4: end for | |||||
5: | |||||
Return: The predicted label .
FIGURE 2 The mth OCSVM, OCSVM m .
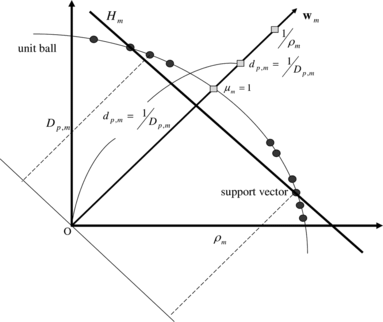
ONE-CLASS SUPPORT VECTOR MACHINE (OCSVM)
OCSVM is a kernel-based method for constructing a classifier using only a set of positive training patterns. For a set C m of training patterns, OCSVM m finds a hyperplane, H m , to separate these patterns from the origin O with maximum margin w m ·φ(x i ) = ρ m where x i lies on the hyperplane H m , as shown in Figure . The distance between the origin O and H m is ρ m /‖w m ‖. To allow for the possibility of outliers in the data set and to make the method more robust, the projection value from an image on w m need not be strictly larger than ρ m , but the small projection value should be penalized. Therefore, slack variables ξ i, m , i = 1, …, |C m |, are introduced to account for small projection values, and the objective function and constraints are as follows:
To solve the constrained optimization problem, a Lagrangian, as usual, is introduced. Also, to avoid working in the high-dimensional feature space, we pick a feature space where the dot product can be calculated directly, using a kernel function K in the input space, and the Wolfe dual form, which is a quadratic function in α i, m ′s, becomes
This constrained optimization problem can be solved using a standard QP solver. Three commonly used kernel functions are polynomial, sigmoid, and radial basis function (RBF). Throughout this article, the RBF kernel is adopted, that is,
Discriminant Function
A discriminant function is designed so that a testing pattern x p is assigned to the class m having the shortest distance between x p and μ m , which is the center of the mth OCSVM. This distance measure considers not only the reciprocal projection value difference between x p and μ m , but also the variance of the training subset C m . The discriminant function is defined as follows:
The proposed discriminant function has two advantages: (1) it considers the size and density of the training patterns for each class by the variance of the training subset C m ; (2) if the projection values (D p, 1,…, D p, k ) are very small and close to one another, it may get better discriminating power by using the reciprocal projection value. This discriminant function can be justified by an example. Firstly, we construct a MOCSVMC for the iris dataset which has three classes. Three OCSVMs are built. Then a sample x p is taken randomly from the dataset. The true class label, y p , of this sample is 3. Various parameter values associated with each OCSVM are computed and shown in Table . Apparently, the proposed distance measure classifies the pattern correctly, as shown in the last row of Table . Note that taking reciprocals of D p, m has the effect of increasing gaps between different projection values, and dividing each reciprocal by the variance is a normalization process to balance size variations among different classes.
TABLE 1 Example of p from Iris Dataset
AN IMPROVED MULTI-CLASS ADABOOST ALGORITHM (AdaBoost.MK)
AdaBoost.M1 is an extension of Adaboost to solve the multi-class classification problem. However, it tends to stop the iterative procedure prematurely due to its strict restriction on the performance of base classifiers. We improve this algorithm by introducing AdaBoost.MK which only requires a better performance than random guessing for base classifiers. The algorithm is shown in Algorithm 1 for a training set S tr with k classes. Note that the base classifier is MOCSVMC described in the previous section. Firstly, the number of iterations, T, to be done is set. Then the weight associated with each training pattern is initialized. In each iteration, ℓ patterns are drawn from S tr according to the weights of the patterns. Then a distinct MOCSVMC is built and the error induced by the built MOCSVMC is computed. Then the weights of the patterns are updated according to the value of the ensemble coefficient γ. The process is iterated until either the error induced by the MOCSVMC currently built is too big or the number of iterations exceeds the limit T.
Algorithm 3
AdaBoost.MK ( S t r )
Input: The labeled training patterns S tr = {(x 1, y 1),…, (x ℓ, y ℓ)}, x i ∈ R n , i = 1,…, ℓ, and y i ∈ {1,…, k}.
1: Set parameter T to be the number of maximum iterations. | |||||
2: Initialize the weight vectors: t = 1, and w i, t = 1/ℓ, for i = 1, 2,…, ℓ. | |||||
3: while t ≤ T do | |||||
4: Use w
i, t
to randomly draw ℓ training patterns with replacement from S
tr
, and put the drawn patterns in the set | |||||
5: Train the tth MOCSVMC, h
t
, by MOCSVMC.Training( | |||||
6: for i = 1 to ℓ do | |||||
7: Predict the class of x
i
with h
t
by MOCSVMC.Testing(x
i
), and let the predicted class be | |||||
8: end for | |||||
9: | |||||
10: if ε t ≥ (k − 1)/k then | |||||
11: T ← t − 1 and abort loop. | |||||
12: else if ε t = 0 then | |||||
13: γ t ← 10. | |||||
14: else if 0 < ε t < (k − 1)/k then | |||||
15: | |||||
16: end if | |||||
17: | |||||
18: | |||||
19: end while | |||||
Return: h t and γ t , for all built MOCSVMCs.
The major differences between AdaBoost.M1 and AdaBoost.MK are the statements of lines 10, 14, 15, and 17. In AdaBoost.M1, the error of each base classifier is required to be less than 1/2, i.e., ε
t
< 1/2. This requirement is too strict to satisfy for a multi-class problem. Instead, AdaBoost.MK requires ε
t
< (k − 1)/k. In AdaBoost.M1, the ensemble coefficient is set to be . The weights of the misclassified patterns are unchanged and the weights of correctly classified are decreased by the factor e
−γ
t
. In AdaBoost.MK, γ
t
has the value as shown on line 15, and the setting of this value will be derived later. Furthermore, the weights of misclassified patterns are increased by an exponential factor e
γ
t
/(k−1), while the weights of correctly classified patterns are decreased by another exponential factor e
−γ
t
, as shown on line 17. In this way, the chances of the misclassified patterns being selected in the next iteration are effectively increased.
The setting of the ensemble coefficient γ t is derived as follows. Similar to AdaBoost, AdaBoost.MK tries to minimize the following objective function of the whole combined boosting classifier:
When AdaBoost.MK stops, a number of MOCSVMCs are obtained. We can then use them to determine to which class a test pattern x
p
belongs. Let MOCSVMC1, …, MOCSVMC
N
be N base classifiers returned by AdaBoost.MK. By applying Algorithm 2, MOCSVMC.Testing(x
p
), on these base classifiers, we obtain predictions for t = 1,…, N. The class C that x
p
belongs to is then determined by
Note that γ t , t = 1,…, N, are ensemble coefficients of the base classifiers returned by AdaBoost.MK.
EXPERIMENTAL RESULTS
In order to test the performance of the proposed method, we have conducted several experiments using datasets from the UCI Repository and the Statlog collections.
Datasets
For the purpose of experiments, we choose the following multi-class datasets from the UCI Repository (Asuncion and Newman, Citation2007): iris, glass, and vowel, and the following datasets from the Statlog collection (Michie, Spiegelhalter, and Taylor, Citation1994): segment, satimage, and letter. The accuracy performance is recorded to compare the proposed method with other multi-class classification algorithms. Detailed information about the datasets is shown in Table . For each problem, we estimate the classification accuracy on a random subset using ν = 0.05 and different kernel parameters q from 2−3 to 25 with a stepping factor of 2 to determine the best parameter. In order to eliminate possible biases throughout this study, 10-fold cross validations were independently conducted 10 times for each dataset. However, for each 10-fold cross validation, all algorithms used the same random partition of a dataset.
TABLE 2 The Six Datasets for Experiments
Experiment I
Firstly, we compare the performance of the proposed MOCSVMC with other KSVDD-based methods. The results are summarized in Table . The MinD column stands for the method by MOCSVMC, the NC column means the method by KSVDD with the nearest-center measure, and the NSV column means the method by KSVDD with the nearest support vector measure. Each entry in the table represents the average of the accuracy values and standard deviations from 10 runs of 10-fold cross validations. The highest performance in each dataset is bold faced. One can see that MOCSVMC outperforms the other two KSVDD-based methods in all datasets, except for the vowel dataset.
TABLE 3 The Accuracy for Six Datasets from UCI and Statlog
The Fisher iris dataset contains 150 patterns belonging to three different classes. One of the classes is linearly separable from the other two which are not linearly separable. From Table we can see that MOCSVMC with the MinD measure has a higher accuracy (95.000%) than the other methods for this dataset. Moreover, MOCSVMC with the MinD measure (71.549%) is significantly better than the other two methods on the glass dataset. KSVDD with NSV (64.577%) is also significantly better than KSVDD with NC (49.394%). The inferior performance of KSVDD with NC indicates that simple discriminant functions may lead to poor performance. For the vowel dataset, MOCSVMC with the MinD measure performs slightly worse than KSVDD with NSV. MOCSVMC with MinD outperforms KSVDD with NC significantly for this case. For the other three datasets (segment, satimage, and letter), MOCSVMC with MinD outperforms the other two KSVDD-based methods significantly. We conclude from this experiment that MOCSVMC with the MinD measure outperforms the other two KSVDD-based methods, and the improvements are significant for most test datasets.
Experiment II
Secondly, we compare the performance of AdaBoost.MK with that of AdaBoost.M1. The three multi-class classifiers (MOCSVMC with MinD, KSVDD with NC, KSVDD with NSV) in Experiment I are used as the base classifiers in this study. Tables and list the experimental results for each combination of boosting algorithms (AdaBoostM1 and AdaBoost.MK) and base classifiers on UCI and Statlog datasets, respectively. Again, each entry represents the average accuracy and standard deviation from 10 runs of 10-fold cross validations. The highest performance in each column is bold faced. One can see that in almost all cases, except for the segment and satimage datasets with AdaBoost.M1, the combination of MOCSVMC with MinD and AdaBoost is the best performer. This shows that MOCSVMC with MinD works effectively when coupled with a meta-learner like AdaBoost.M1 or AdaBoost.MK.
FIGURE 3 Training/testing errors versus boosting rounds for AdaBoost.MK.
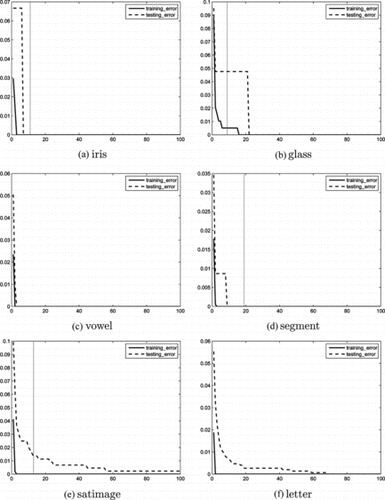
TABLE 4 The Accuracy of Multi-Class AdaBoost.M1 for Six Datasets from UCI and Statlog
TABLE 5 The Accuracy of Multi-Class AdaBoost.MK for Six Datasets from UCI and Statlog
Figure shows the plottings of errors, of training and testing, respectively, versus the number of boosting rounds for the six datasets. The solid lines indicate training errors and the dashed lines indicate testing errors. The base classifier we use is MOCSVMC with MinD which is a strong classifier. From this figure, we can see that errors decrease as the number of rounds increases. This shows that our AdaBoost.MK can improve classification accuracies even for strong base classifiers. For all datasets, except for vowel and letter, AdaBoost.MK terminates within 20 iterations when the condition ε t ≥ (k − 1)/k is satisfied, as indicated by vertical lines. Therefore, T is normally set to be 20 for the system.
By comparing Table with Tables and , we can see that for each dataset and each base classifier, the boosted classifier always has a higher performance than the corresponding nonboosted classifier. This shows that it pays to boost a base classifier in almost all cases. By looking at Tables and , we observe that for each dataset and for each base classifier, AdaBoost.MK outperforms AdaBoost.M1.
Experiment III
In this experiment, we compare AdaBoost.MK with AdaBoost. M1W (Eibl and Pfeiffer, Citation2002). Table shows the results obtained from AdaBoost.M1W for the six UCI and Statlog datasets with strong classifiers used in Experiment I. From Tables and , we can see that AdaBoost.MK performs comparably well as AdaBoost.M1W. However, due to a larger chance of selection given to misclassified patterns, AdaBoost.MK runs faster than AdaBoost.M1W, as shown in Table .
TABLE 6 The Accuracy of Multi-Class AdaBoost.M1W for Six Datasets from UCI and Statlog
TABLE 7 The Number of Average Iterations Run by AdaBoost.MK and AdaBoost.M1W
Finally, we test both AdaBoost.MK and AdaBoost.M1W with decision stump as the weak base classifier on the six datasets. The results are shown in Table . From this table, we can see that none of the two systems performs satisfactorily well. For some datasets, AdaBoost cannot offer any improvement at all. In both systems, the condition ε t ≥ (k − 1)/k is satisfied very quickly. Therefore, the systems stop before AdaBoost can provide any contributions.
TABLE 8 The Accuracy of AdaBoost.MK and AdaBoost.M1W with a Weak Base Classifier
CONCLUSION
We have presented a novel multi-class AdaBoost.MK algorithm with MOCSVMC and an improved discriminant function as the base classifiers to classify a k-class dataset. Experimental results allow us to make the following remarks regarding the proposed method:
MOCSVMC with the distance measure-based discriminant function is significantly better than KSVDD-based algorithms because of the exploitative power of the discriminant function. | |||||
The proposed AdaBoost.MK algorithm outperforms the AdaBoost.M1 algorithm because of the more relaxed condition and the increased boosting chance for the misclassified training patterns. | |||||
The proposed hybrid method outperforms other multi-class algorithms significantly for the datasets chosen from UCI and Statlog. | |||||
In this work we used RBF kernel functions in OCSVM. We will try different kernel functions coupled with the distance measure to examine the robustness of the discriminant function. We primarily used SVM-based classifiers as the base classifiers for AdaBoost, and found that AdaBoost.MK produced good boosting results. Another direction worthy to be examined further is the applicability of AdaBoost.MK to other types of base classifiers.
Acknowledgments
This work was supported by the National Science Council under grant NSC 95-2221-E-110-055-MY2.
The authors are grateful to the anonymous reviewer for the comments which were very helpful in improving the quality and presentation of this article.
REFERENCES
- Allwein , E. L. , R. E. Schapire , and Y. Singer . 2000 . Reducing multiclass to binary: A unifying approach for margin classifiers . Journal of Machine Learning Research 1 : 113 – 141 .
- Asuncion , A. and D. Newman . 2007 . UCI Machine Learning Repository. http://archive. ics.uci.edu/ml/ .
- Ben-Hur , A. , D. Horn , H. T. Siegelmann , and V. Vapnik . 2002 . Support vector clustering . Journal of Machine Learning Research 2 ( 2 ): 125 – 137 .
- Bottou , L. , C. Cortes , J. S. Denker , H. Drucker , I. Guyon , L. D. Jackel , Y. LeCun , U. A. Müller , E. Säckinger , P. Simard , and V. Vapnik . 1994 . Comparison of classifier methods: A case study in handwriting digit recognition . In: International Conference on Pattern Recognition ICPR94 , Vol. 2 , pp. 77 – 87 . Jerusalem , Israel : IEEE Computer. Society Press. Los Alamitos, CA, USA .
- Cortes , C. , and V. Vapnik . 1995 . Support-vector networks . Machine Learning 20 ( 3 ): 273 – 297 .
- Dietterich , T. G. 2000a . An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization . Machine Learning 40 ( 2 ): 139 – 157 .
- Dietterich , T. G. 2000b . Ensemble methods in machine learning . In: Multiple Classifier Systems , eds. J. Kittler and F. Roli , Vol. 1857 , pp. 1 – 15 . New York , NY , USA : Springer .
- Eibl , G. and K. Pfeiffer . 2005 . Multiclass boosting for weak classifiers . Journal of Machine Learning Research 6 : 189 – 210 .
- Eibl , G. and K. P. Pfeiffer . 2002 . How to make AdaBoost.M1 work for weak base classifiers by changing only one line of the code . In: Machine Learning: ECML 2002 , eds. T. Elomaa , H. Mannila , and H. Toivonen , Vol. 2430 , pp. 169 – 184 . New York , NY , USA : Springer .
- Freund , Y. and R. E. Schapire . 1997 . A decision-theoretic generalization of on-line learning and an application to boosting . Journal of Computer and System Sciences 55 ( 1 ): 119 – 139 .
- Friedman , J. H. 1996 . Another approach to polychotomous classification. Technical report, Department of Statistics, Stanford University. .
- Friedman , J. H. , T. Hastie , and R. Tibshirani . 2000 . Additive logistic regression: A statistical view of boosting . The Annals of Statistics 38 ( 2 ): 337 – 374 .
- Goh , K.-S. , E. Y. Chang , and B. Li . 2005 . Using one-class and two-class SVMs for multiclass image annotation . IEEE Transactions on Knowledge and Data Engineering 17 ( 10 ): 1333 – 1346 .
- Guruswami , V. and A. Sahai . 1999 . Multiclass learning, boosting, and error-correcting codes . In: Proceedings of the Twelfth Annual Conference on Computational Learning Theory , pp. 145 – 155 . New York , NY , USA : ACM Press .
- Hsu , C.-W. and C.-J. Lin . 2002 . A comparison of methods for multi-class support vector machines . IEEE Transactions on Neural Networks 13 ( 2 ): 415 – 425 .
- Huang , J. , S. Ertekin , Y. Song , H. Zha , and C. L. Giles . 2007 . Efficient multiclass boosting classification with active learning . In: The 7th SIAM International Conference on Data Mining (SDM 2007) .
- Kim , H.-J. , J.-U. Kim , and Y.-G. Ra . 2005 . Boosting Naïve Bayes text classification using uncertainty-based selective sampling . Neurocomputing 67 : 403 – 410 .
- Kreßel , U. H.-G. 1999. Pairwise Classification and Support Vector Machines. In: Kernel Methods: Support Vector Learning , pp. 255–268. Cambridge , MA : MIT Press.
- Li , L. 2006 . Multiclass boosting with repartitioning . In: Proceedings of the 23rd International Conference on Machine Learning (ICML2006) , eds. W. W. Cohen and A. Moore , pp. 569 – 576 . New York , NY , USA : ACM .
- Li , X. , L. Wang , and E. Sung . 2005 . A study of AdaBoost with SVM based weak learners . In: IEEE International Joint Conference on Neural Networks (IJCNN) , Vol. 1 , pp. 196 – 201 . Montreal , Canada .
- Manevitz , L. M. and M. Yousef . 2001 . One-class SVMs for document classification . Journal of Machine Learning Research 2 : 139 – 154 .
- Martínez-Muñoz , G. and A. Suárez . 2007 . Using boosting to prune bagging ensembles . Pattern Recognition Letters 28 ( 1 ): 156 – 165 .
- Michie , D. , D. J. Spiegelhalter , and C. C. Taylor . 1994 . Machine Learning, Neural and Statistical Classification . Englewood Cliffs , NJ : Prentice Hall .
- Nock , R. and M. Sebban . 2001 . A Bayesian boosting theorem . Pattern Recognition Letters 22 ( 3–4 ): 413 – 419 .
- Platt , J. C. , N. Cristianini , and J. Shawe-Taylor . 2000 . Large Margin DAGs for Multiclass Classification . In: Neural Information Processing Systems , Vol. 12 , pp. 547 – 553 . Cambridge : MIT Press .
- Rätsch , G. , T. Onoda , and K. R. Müller . 2001 . Soft margins for AdaBoost . Machine Learning 42 ( 3 ): 287 – 320 .
- Rifkin , R. and A. Klautau . 2004 . In defense of one-vs-all classification . Journal of Machine Learning Research 5 : 101 – 141 .
- Rodríguez , J. J. and J. Maudes . 2007 . Boosting recombined weak classifiers . Pattern Recognition Letters 29 ( 8 ): 1049 – 1059 .
- Sachs , A. , C. Thiel , and F. Schwenker . 2006 . One-class support-vector machines for the classification of bioacoustic time series . International Journal on Artificial Intelligence and Machine Learning 6 ( 4 ): 29 – 34 .
- Schapire , R. E. 1997 . Using output codes to boost multiclass learning problems . In: Proceedings of the Fourteenth International Conference on Machine Learning , pp. 313 – 321 . San Francisco , CA , USA : Morgan Kaufman .
- Schapire , R. E. and Y. Singer . 1999 . Improved boosting algorithms using confidence-rated predictions . Machine Learning 37 ( 3 ): 297 – 336 .
- Schölkopf , B. , J. C. Platt , J. , Shawe-Taylor , A. J. Smola , and R. C. Williamson . 2001 . Estimating the support of a high-dimensional distribution . Neural Computation 13 ( 7 ): 1443 – 1472 .
- Schwenk , H. and Y. Benggio . 2000 . Boosting neural networks . Neural Computation 12 ( 8 ): 1869 – 1887 .
- Sun , B.-Y. and D.-S. Huang . 2003 . Support vector clustering for multi-class classification problems . In: The Congress on Evolutionary Computation , pp. 1480 – 1485 . Canberra , Australia .
- Sun , Y. , S. Todorovic , and J. Li . 2007 . Unifying multi-class AdaBoost algorithms with binary base learners under the margin framework . Pattern Recognition Letters 28 ( 5 ): 631 – 643 .
- Tax , D. M. J. and R. P. W. Duin . 1999 . Support vector domain description . Pattern Recognition Letters 20 ( 11–13 ): 1191 – 1199 .
- Tax , D. M. J. and R. P. W. Duin . 2004 . Support vector data description . Machine Learning 54 ( 1 ): 45 – 66 .
- Zhu , J. , S. Rosset , H. Zou , and T. Hastie . 2005 . Multiclass AdaBoost. Technical Report 430, University of Michigan, Dearborn, MI, USA. .