Abstract
Automatic discrimination of speech and music is an important tool in many multimedia applications. This article presents an evolutionary, fuzzy, rules-based speech/music discrimination approach for intelligent audio coding, which exploits only one simple feature, called Warped LPC-based Spectral Centroid (WLPC-SC). Comparison between WLPC-SC and the classical features proposed in the literature for audio classification is performed, aiming to assess the good discriminatory power of the proposed feature. The length of the vector for describing the proposed psychoacoustic-based feature is reduced to a few statistical values (mean, variance, and skewness), which are then transformed to a new feature space, applying linear discriminant analysis (LDA), with the aim of increasing the classification accuracy percentage. The classification task is performed applying a support vector machine (SVM) to the features in the transformed space. The final decision is made by a fuzzy expert system, which improves the accuracy rate provided by the SVM, taking into account the audio labels assigned by this classifier to past audio frames. The accuracy rate improvement due to the fuzzy expert system is also reported. Experimental results reveal that our speech/music discriminator is robust and fast, making it suitable for intelligent audio coding.
Automatic discrimination between speech and music has become a research topic of interest in the last few years. Several approaches have been described in the recent literature for different applications (Saunders Citation1996; Scheirer and Slaney Citation1997; El-Maleh, Klein, Petrucci, and Kabal, Citation2000; Harb and Chen Citation2003; Wang, Gao, and Ying Citation2003). Each of these uses different features and pattern classification techniques and describes results on different material.
Saunders (Citation1996) proposed a real-time speech/music discriminator, which was used to automatically monitor the audio content of FM audio channels. Four statistical features on the zero-crossing rate and one energy-related feature were extracted; a multivariate-Gaussian classifier was applied, which resulted in high classification accuracy.
In automatic speech recognition (ASR) of broadcast news, it is desirable to disable the input to the speech recognizer during the nonspeech portion of the audio stream. Scheirer and Slaney (Citation1997) developed a speech/music discrimination system for ASR of audio sound tracks. Thirteen features to characterize distinct properties of speech and music, and three classification schemes (MAP Gaussian, GMM, and k-NN classifiers) were exploited, resulting in an accuracy of over 90%.
Automatic discrimination of speech and music is an important tool in many multimedia applications. El-Maleh et al. (2000) combined the line spectral frequencies and zero-crossings-based features for frame-level narrowband speech/music discrimination. The classification system operates using only a frame delay of 20 ms, making it suitable for real-time multimedia applications. An emerging multimedia application is content-based indexing and retrieval of audiovisual data. Audio content analysis is an important task for such an application (Zhang and Kuo, Citation2001). Minami, Akutsu, Hamada, and Tonomura (Citation1998) proposed an audio-based approach to video indexing, where a speech/music detector is used to help users browse a video database.
A comparative view of the value of different types of features in speech music discrimination is provided in Carey, Parris, and Lloyd-Thomas (Citation1999), where four types of features (amplitudes, cepstra, pitch, and zero-crossings) are compared for discriminating speech and music signals. Experimental results showed cepstra and delta cepstra bring the best performance. Mel frequencies spectral coefficients (MFSC) or mel frequencies cepstral coefficients (MFCC) are very often features used for audio classification tasks, providing quite good results. In Harb and Chen (Citation2003), mel frequencies spectral coefficients first-order statistics are combined with neural networks to form a speech music classifier that is able to generalize from a little amount of learning data. Mel frequencies cepstral coefficients are a compact representation of the spectrum of an audio signal taking into account the nonlinear human perception of pitch, as described by the Mel scale. They are one of the most used features in speech recognition and have recently been proposed in musical genre classification of audio signals (Tzanetakis and Cook, Citation2002; Burred and Lerch Citation2004).
Another application that can benefit from distinguishing speech from music is low bit-rate audio coding. Designing a universal coder to reproduce well, both speech and music are the best approaches. However, it is not a trivial problem. An alternative approach is to design a multi-mode coder that can accommodate different signals. The appropriate module is selected using the output of a speech-music classifier (ISO-IEC Citation1999; Tancerel, Ragot, Ruoppila, and Lefebvre, Citation2000; Qiao Citation1997).
In this article, we present our contribution to the design of a robust and real-time implemented speech/music discriminator, which can be integrated into an intelligent audio coder with application to internet audio streaming. For such a goal, we define a simple but effective feature, called warped Linear Predictive Coding (LPC)-based spectral centroid (WLPC-SC), which will be used as the only feature in the analysis stage. Other speech/music discrimination approaches based on only one type of feature are presented in Karneback (Citation2001) and Wang et al. (2003), which result in fast and robust classification systems. The approach in Karneback (Citation2001) takes psychoacoustic knowledge into account in that it uses the low-frequency modulation amplitudes over 20 critical bands to form a good discriminator for the task, while the approach in Wang et al. (2003) exploits a new energy-related feature, called modified low energy ratio, which improves the results obtained with the classical low energy ratio.
The length of the vector for describing our psychoacoustic-based feature is reduced to a few statistical values (mean, variance, and skewness), which are then transformed to a new feature space applying linear discriminant analysis (LDA). Linear discriminant analysis intends to provide a significant improvement in the classification accuracy percentage. The classification task is performed applying support vector machines (SVM) to the features in the transformed space. The final decision will be made by a quite simple fuzzy expert system, which is designed to improve the accuracy rate provided by the SVM classifier. The classification results for different types of music and speech signals show the good discriminating power of the proposed approach.
SPEECH/MUSIC DISCRIMINATION FOR INTELLIGENT AUDIO CODING
Speech/music discrimination involves a suitable processing for two main tasks: audio feature extraction and classification of the extracted parameters. In this work, contributions in both directions are done. The resulting speech/music discriminator can be integrated into an intelligent multi-mode audio coder. First, this system must perform an intelligent segmentation of audio signals, so that they are composed of audio frames labelled as speech or music, according to the decisions of the speech/music discriminator. Once the audio frames have been labelled, they are applied to coders adapted to the characteristics of each frame (i.e., a Harmonic Vector eXitation Coding, or HVXC, coder could be used for speech frames and an Advanced Audio, or AAC, coder for music frames). The underlying speech/music discriminator will assign a different cost to the two error possibilities, the cost being much higher of classifying a music frame as speech than the opposite. It aims to achieve high quality, low bit rate audio coding for all types of audio signals, and must be applicable to last generation mobile phone systems and internet audio streaming.
New Warped LPC-Based Feature
We propose the use of the centroid frequency analysis window to discriminate between speech and music excerpts. Usually, speech signals have a low centroid frequency, which varies sharply at a voiced-unvoiced boundary. Instead, music signals show quite a varying behavior. There is no specific pattern for such signals. We compute the centroid frequency by a one-pole lpc-filter. Geometrically, the lpc-filter minimizes the area between the frequency response of the filter and the energy spectrum of the signal. The one-pole frequency tells us where the lpc-filter is frequency-centered. Therefore, somehow, the one-pole frequency informs us where most of the signal energy is frequency-localized.
However, the human auditory system is nonuniform in relation to the frequency. According to this statement, the Mel, the Bark, and the equivalent rectangular bandwidth (ERB) scales (Harma et al. 2000) are defined for audio processing. A close scale to the before mentioned is the logarithmic scale, which has a long tradition of use in audio technology. For speech/music discrimination, it would be desirable to use a feature that works directly on some of these auditory scales, resulting in frequency-warped audio processing.
The transformation from frequency to Bark scale is a well studied problem (Harma et al. 2000; Smith and Abel Citation1999). Generally, the Bark scale is performed via the all-pass transformation defined by the substitution in the z domain
We propose the use of a one-pole, warped-lpc filter based on this bilinear transformation to compute the WLPC-SC feature of each analysis window. The implementation of these filters can be downloaded from http://www.acoustics.hut.fi/software/warp (Harma et al. 2000).
As can be seen in Figure , the WLPC-SC feature shows clear differences between voiced and unvoiced phonemes due to the frequency-warped processing. Besides, these differences are bigger than in a drum-based music signal. The results in Figure suggest that WLPC-SC could be a profitable low complexity feature to design a robust music/speech discriminator.
FIGURE 1 Example illustrating the values that LPC-SC and WLPC-SC takes for both speech and music signals.
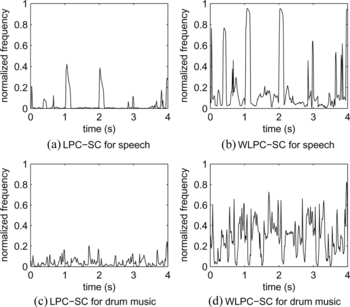
In our system, an analysis frame of 23 ms (1024 samples at 44100 Hz sampling rate), a long texture frame of 1 s (43 analysis windows), and a short texture frame of 250 ms are defined. Overlapping with a hop size of 512 samples is performed. Hence, the vector for describing the proposed feature, when using long texture frames, consists of 85 values, which are updated each 23 ms-length analysis frame. This large dimensional feature vector is difficult to handle for classification tasks, giving rise to two main drawbacks: 1) too much computational cost, 2) possibly too high misclassification rate. Therefore, reducing the feature space to a few statistical values each 1 s-length texture window is required. Mean, variance, and skewness of the feature vector are computed here. Skewness has been probed to be a good statistical feature for classification purposes. However, better classification results can be achieved if the statistical feature data are transformed or projected into a new feature space in which the classes are easier to be distinguished and a more robust decision rule can be found.
Linear Discriminant Analysis
There are two major techniques for transforming data from a feature space to another where separation between classes can be easier and more accurately done: Principal component analysis (PCA) and LDA. We have evaluated both techniques and the results reveal that LDAs outperform PCAs for speech/music discrimination. Principal component analysis often fails in classification problems, since the principal axes do not necessarily entail discriminatory features. Nevertheless, LDA achieves significant improvement in class separation, since it separates the class means while attempting to sphere the data classes.
Linear discriminant analysis is a technique for transforming raw data into a new feature space in which classification can be carried out more robustly. Let us assume that a set of N samples {f 1, f 2,…, f N } ∊ ℝ n is given. Each sample belongs to one of M classes {C 1, C 2,…, C M }. The within-class scatter matrix S w is defined as
The between-class scatter matrix S b is also defined:
Linear discriminant analysis maximizes the between-class scatter to within-class scatter ratio, which involves maximizing the separation between classes while the variance within a class is minimized. The solution to this optimization problem is obtained by a singular value decomposition (SVD) of . If the columns of a matrix W are the eigenvectors of
, LDA maps the original data set into a new feature space as
In general, the dimensionality of the transformed feature set is lower than the number of training classes, which can be further reduced by incorporating in W only those eigenvectors corresponding to the largest singular values determined in the scatter SVD.
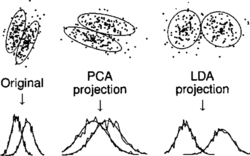
An example of PCA and LDA transformations, taken from Goodwin and Laroche (Citation2003), is shown in Figure . The original data consists of two classes, and the task is to find a projection onto one dimension that separates the classes.
FIGURE 2 A two-class example of PCA and LDA transformations.
Classification by SVM
For classification purposes, a number of standard statistical pattern recognition (SPR) classifiers (Duda, Hart, and Stork, Citation2000) were evaluated. The basic idea behind SPR is to estimate the probability density function (pdf) for the feature vectors of each class. In supervised learning, a labelled training set is used to estimate the pdf of each class. In the simple Gaussian (GS) classifier, each pdf is assumed to be a multidimensional Gaussian distribution, whose parameters are estimated using the training set. In the Gaussian mixture model (GMM) classifier, each class pdf is assumed to consist of a mixture of a specific number K of multidimensional Gaussian distributions. Unlike the k-NN classifier, which needs to store all the training feature vectors in order to compute the distances to the input feature vector, the GMM classifier only needs to store the set of estimated parameters for each class. The iterative EM algorithm can be used to estimate the parameters of each Gaussian component and the mixture weights.
In the test we have performed, the GMM classifier showed the best results among the classical SPR classifiers. However, SVM (Vapnik, Citation1998) have shown superb performance at binary classification tasks and handle large dimensional feature vectors better than other classification methods. Basically, a SVM aims at searching for a hyperplane that separates data points belonging to different classes with maximum margins.
Let's suppose a given training data set {(f 1, y 1), (f 2, y 2),…, (f N , y N )}, f i ∊ ℝ n , y i ∊ (+ 1, − 1), for i = 1,…, N, with the aim of discriminating two classes (speech and music). If y i = +1, the data is music; otherwise, the data is speech. The SVM tries to determine an estimating function that allows to accurately classify a given data f ∊ ℝ n . The generic SVM estimating function is defined as
The bias b ∊ ℝ in (Equation6) is obtained as
Finally, the function Φ that appears in (Equation6) and (Equation7) is known as kernel function. Among all the possibilities of kernel functions, we have chosen in this work radial basis functions (RBF), which are defined as
Other modern classification techniques, such as neural networks (NN), expert systems and dynamic programming, could also be used. We have decided to use SVM, because it is one of the modern classification techniques that is achieving better results for classification purposes.
Fuzzy Rules-Based Expert System
We are interested in discriminating between speech and music for intelligent audio coding. A suitable coder must be selected each 23 ms-length analysis frame according to the decision of the speech/music discriminator (i.e., a HVXC coder can be applied to speech frames and an ACC coder to music frames). If coder selection is only based on current analysis frame data, the SVM classifier we will obtain low accuracy rate. It is very important to assure a robust performance of the speech/music discriminator for intelligent audio coding. Hence, we propose the use of a fuzzy rules-based expert system for selecting the suitable coder each 23 ms-length analysis frame, which takes into account information not only of the current frame but also of past frames. The classification stage will consist of two components: the SVM and the fuzzy expert system. It seems likely that the inclusion of the expert system within the classification stage implies an improvement of the classification accuracy rate obtained by the SVM classifier.
The fuzzy expert system takes the final decision from four input parameters. The input parameters (P 0, P 1, P 2, and P 3) represent the probabilities obtained by the SVM for four consecutive 250 ms-length short texture frames. The last of them includes, just at the end, the current 23 ms-length analysis frame.
Using these probabilities and a knowledge base, the fuzzy rules-based expert system selects the suitable coder (a coder adapted to music or a coder adapted to speech) for intelligent audio coding. The fuzzy rules-based expert system structure appears in Figure .
FIGURE 3 Expert system general structure.
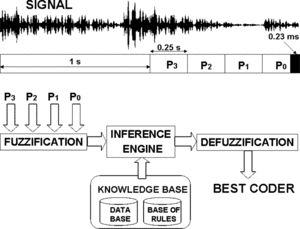
All inputs have been calculated applying to the SVM the statistical feature data (mean, variance, and skewness), projected into a new feature space by LDA, corresponding to the vector associated to each 250 ms-length short texture frame. These vectors consist of the WLPC-SC feature values corresponding to the 23 ms-length analysis frames that constitute each 250 ms-length short texture frame. All probabilities are [0,1] normalized. Input membership functions are represented in Figure .
FIGURE 4 Membership functions for input variables.
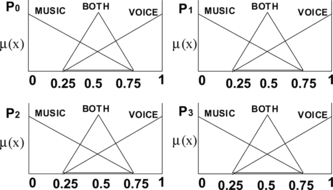
There is only one output variable, called “Coder”, which is [0,1] normalized. If the output value is higher than 0.5, a speech coder is selected. Otherwise, a music coder is selected. Membership functions for the output variable are shown in Figure .
FIGURE 5 Membership functions for the output variable.
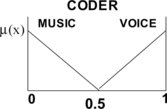
Next, we briefly outline the performance of the expert system and the methodology for building a new knowledge base.
-
1) Fuzzy rules-based expert system: The fuzzificator transforms the input values for the inference engine process. The inference engine obtains an output fuzzy set using inputs and relationships defined in a fuzzy rules base.
-
The expert system takes the decision about the suitable coder for processing the audio signal from the input probabilities, a data base (input and output membership functions information), and a fuzzy rules base.
-
Finally, the defuzzificator transforms the output fuzzy set in a value that allows the selection of the suitable audio coder each 23 ms-length analysis frame.
-
Building knowledge base. The new rules added to the expert system knowledge base have been calculated using evolutionary computation. This methodology has been successfully used in other research works (Cordon, Herrera, Hoffmann, and Magdalena, Citation2001; Galan, Bago, Aguilera, Velasco, and Magdalena, Citation2005). The algorithm for knowledge acquisition is based on random rules generation and later insertion of new rules into the knowledge base whether an improvement in the classification accuracy rate is achieved or not. In order to assess this improvement, it is required to compare the performance of the evaluated system (in our case, the intelligent audio coder) with and without each new rule.
-
The fuzzy expert system takes a decision every 23 ms. Two types of errors can happen: an audio frame is labelled as speech when it is a music frame and the opposite. The first one (Music as Speech Error [MSE]) is considered more serious than the second one (Speech as Music Error [SME]), since it gives rise to a significant loss of audio quality. The Speech as Music Error is less critical, because it implies an increase in the bandwidth necessary to transmit the signal, but no loss of audio quality is produced.
-
In order to design and evaluate the fuzzy expert system, a fitness function that considers both types of error is used:
Parameters in expression (Equation11) have been experimentally determined. It is not possible to compute them mathematically because perceptual information from expert listeners must be taken into account. For designing and testing the system, different audio files composed of 23 ms-length analysis frames labelled as speech or music are available. The system uses these files to train and build the knowledge base, which includes all learning rules that allow the improvement of the intelligent audio coder performance.
EXPERIMENT EVALUATION
First of all, the audio test database is carefully prepared. The speech data come from news programs of radio and TV stations, as well as dialogs in movies. The languages involve English, Spanish, French, and German with different levels of noise, especially in news programs. The speakers involve males and females at different ages. The length of the whole speech data is about 1 hour. The music consists of songs and instrumental music. The songs cover as many styles as possible, such as rock, pop, folk, and funk, and they are sung by males and females in English and Spanish. The instrumental music we have chosen covers different instruments (piano, violin, cello, pipe, clarinet) and styles (symphonic music, chamber music, jazz, electronic music). Some movie soundtracks are also included, which are played by various different instruments. The length of the whole music data is also about 1 hour.
Next, we intend to assess the speech/music discrimination ability of the proposed feature. To achieve such a goal, comparison with the timbral features proposed in Tzanetakis and Cook (Citation2002) is performed. The WLPC-SC feature is compared separately to all timbral texture features proposed in Tzanetakis and Cook (Citation2002). The vector for describing our psychoacoustic-based feature consists of the mean, the variance, and the skewness over each texture window. WLPC-SC is based on the analysis window.
The following specific features are used in Tzanetakis and Cook (Citation2002) to represent timbral texture: spectral centroid (SC), spectral roll-off (SR), spectral flux (SF), time domain zero crossings (ZC), MFCC, and low energy (LE) features. The last one (LE) is the only feature that is based on the texture window rather than the analysis window. Table shows the classification accuracy percentage results when WLPC-SC is compared to the timbral features.
TABLE 1 Classification Accuracy Percentage. WLPC-SC vs. Timbral Features
The results in Table are obtained by using a RFB-based SVM as classifier, which is properly trained and adjusted. At the sight of the results in Table , we can say that the proposed feature performs better than most of the timbral features in Tzanetakis and Cook (Citation2002) for speech/music discrimination. The SC performs as well as the WLPC-SC, while MFCCs give slightly better accuracy percentages. The good discrimination ability provided by the SC and MFCC features is achieved at the cost of a complexity increase regarding the WLPC-SC feature, which is much higher in the case of the MFCC feature. Note that the WLPC-SC feature does not require a Discrete Fourier Transform (DFT) computation, while both SC and MFCC features need this computation. As shown in Table , the proposed feature achieves high accuracy percentages while maintaining the complexity at a reduced degree.
Now, we are interested in comparing MFCC with all timbral features and all timbral features plus WLPC-SC. We intend to know if the proposed feature improves the classification accuracy percentage when it is added to all timbral features for speech/music discrimination. Table shows how the inclusion of the WLPC-SC feature, within the feature set used for speech/music discrimination, entails a discrimination capability improvement. The classification accuracy percentage goes up about 2% to reach the value of 93%. However, it must be noted that no improvement is accomplished when all timbral texture features are used for speech/music discrimination regarding the case of using only the MFCC feature.
TABLE 2 Discrimination Capability Improvement when the WLPC-SC Feature is Included within the Feature Set
Regarding the proposed feature, we are also interested in knowing how much warping transformation influences in speech/music discrimination. Table compares the classification accuracy results for both the proposed feature (WLPC-SC) and the same feature without warping transformation (LPC-SC).
TABLE 3 Classification Accuracy Percentage. WLPC-SC vs. LPC-SC
From the results in Table , it can be said that warping transformation is a very important operation for the good performance of the feature proposed in this article, because it entails taking psychoacoustic information into account. Table shows an improvement in the speech/music discrimination capability higher than 10% regarding the case of not using the warping transformation.
Once we have assessed the speech/music discrimination capability of the proposed feature, we are interested in knowing the improvement in the classification accuracy percentage due to PCA and LDA transformations. Table shows the results obtained by the proposed approach (WLPC-SC + SVM) in three different cases: a) No transformation, b) PCA, and c) LDA.
TABLE 4 Classification Accuracy Percentage Results When Using: a) No Transformation, b) PCA, and c) LDA
From the results in Table , it can be said that feature space transformation is an important operation for decreasing the misclassification rate. The best accuracy corresponds to LDA, because it achieves a significant improvement in class separation.
Next, we would like to assess the performance of a SVM-based classifier for speech/music discrimination when compared to the classical GMM classifier. Here, a three-component GMM classifier with diagonal covariance matrices is used for comparison, because it showed a slightly better performance than other SPR classifiers. The performance of the system does not improve when using a higher number of components in the GMM classifier. The GMM classifier is initialized using the K-means algorithm with multiple random starting points. Table shows the results obtained when a RBF-based SVM and a three-component GMM with diagonal covariance matrices are used as classifiers for speech/music discrimination. In both cases, LDA has been used.
TABLE 5 Comparing RBF-SVM and 3-GMM for Speech/music Discrimination When LDA is used
As expected, the best results are obtained when the SVM-based classifier is used for speech/music discrimination. Our experiments show that the differences between SVM and GMM are shortened when LDA is not performed. It seems that LDA achieves only a slight improvement in the performance of the GMM classifier.
Finally, Table shows the improvement in the classification accuracy rate due to the inclusion into the classification stage of the fuzzy expert system regarding the case of using only the SVM. Results in Table are accomplished by evaluating only one feature (the proposed WLPC-SC feature). Remember that the fuzzy system receives every 23 ms the decisions of the SVM corresponding to the last four 250 ms-length short texture frames. The fuzzy system takes the final decision according to these decisions provided by this classifier and a set a properly defined fuzzy rules.
TABLE 6 Classification Accuracy Percentage. SVM vs. SVM + Fuzzy System
We can see from Table that the fuzzy rules-based expert system implies a better performance of the speech/music discriminator. The global accuracy percentage grows about 6%. Besides, the fuzzy expert system gives rise to an important decrease in the MSE errors (about 10%), which improves the audio coder performance, since this type of error is considered critical for audio coding purposes. Because of its simplicity and robustness, the resulting speech/music discriminator can be integrated into a real-time intelligent audio coder with different applications (i.e., internet audio streaming).
CONCLUSIONS
This article presents a simple but robust approach to discriminate speech and music. The method exploits only one feature in the analysis stage, called WLPC-SC, and a SVM improved by a fuzzy rules-based expert system in the classification stage. The experimental evaluation compares the proposed feature to other commonly used features in audio classification tasks, and also tries to assess the improvement due to the warping transformation. An improvement of about 10% in the discrimination capability is achieved regarding the case of not using warping transformation. The approach proposed in this article implements LDA transformation in order to achieve a reduction in the misclassification ratio. Comparison with PCA and no feature space transformation is reported. The classification stage consists of a SVM-based classifier and a fuzzy rules-based expert system, which takes the final decision from the probabilities provided by the SVM and the fuzzy system knowledge base. The fuzzy system achieves an improvement of about 6% regarding the case of using only the SVM-based classifier. The classification accuracy percentage of the proposed approach is above 98% for a wide range of audio styles. The experimental results demonstrate the robustness of the system, making it suitable for a wide range of multimedia applications.
This work was supported by FEDER, the Spanish Ministry of Education and Science under Project TEC2006-13883-C04-03, and the Andalusian Council under project P07-TIC-02713.
REFERENCES
- Burred , J. J. and A. Lerch . 2004 . Hierarchical automatic audio signal classification . Journal of the Audio Eng. Soc. 52 : 724 – 739 .
- Carey , M. J. , E. S. Parris , and H. Lloyd-Thomas . 1999 . A comparison of features for speech, music discrimination. Proc. IEEE ICASSP'99, Phoenix, AZ, pp. 1432–1435 .
- Cordon , O. , F. Herrera , F. Hoffmann , and L. Magdalena . 2001 . Genetic fuzzy systems. Evolutionary tuning and learning of fuzzy knowledge bases . Advances in Fuzzy Systems. Applications and Theory 19 .
- Duda , R. , P. Hart , and D. Stork . 2000 . Pattern Classification . New York : Wiley .
- El-Maleh , K. , M. Klein , G. Petrucci , and P. Kabal . 2000 . Speech/music discrimination for multimedia applications . Proc. IEEE ICASSP 2000 6 : 2445 – 2448 .
- Galan , S. G. , J. C. Bago , J. Aguilera , J. R. Velasco , and L. Magdalena . 2005 . Genetic fuzzy systems in stand-alone photovoltaic systems . I International Workshop in Genetic Fuzzy Systems , Granada .
- Goodwin , M. M. , and J. Laroche . 2003 . Audio segmentation by feature-space clustering using linear discriminant analysis and dynamic programming . In Proc. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics . New York , pp. 131 – 134 .
- Harb , H. and L. Chen . 2003 . Robust speech music discrimination using spectrum's first order statistics and neural networks . Proc. IEEE Int. Symp. on Signal Processing and Its Applications 2 : 125 – 128 .
- Härmä , A. , M. Karjalainen , L. Savioja , V. Välimäki , U. K. Laine , and J. Huopaniemi . 2000 . Frequency-warped signal processing for audio applications . Journal of the Audio Engineering Society 48 : 1011 – 1031 .
- ISO-IEC . 1999 . MPEG-4 Overview (ISO/IEC JTC1/SC29/WG11 N2995 Document .
- Karneback , S. 2001 . Discrimination between speech and music based on a low frequency modulation feature. European Conf. on Speech Comm. and Technology , Alborg , Denmark , pp. 1891 – 1894 .
- Minami , K. , A. Akutsu , H. Hamada , and Y. Tonomura . 1998 . Video handling with music and speech detection . IEEE Multimedia 5 : 17 – 25 .
- Qiao , R. Y. 1997 . Mixed wideband speech and music coding using a speech/music discriminator . In Proc. IEEE Annual Conference on Speech and Image Technologies for Computing and Telecommunications , pp. 605 – 608 .
- Saunders , J. 1996 . Real-time discrimination of broacast speech/music . In Proc. IEEE ICASSP '96 , Atlanta , GA , pp. 993 – 996 .
- Scheirer , E. and M. Slaney . 1997 . Construction and evaluation of a robust multifeature speech/music discriminator . Proc. IEEE ICASSP′97 , Munich , Germany , pp. 1331 – 1334 .
- Smith III , J. O. and J. S. Abel . 1999 . Bark and ERB bilinear transforms . IEEE Trans. Speech and Audio Processing 7 : 697 – 708 .
- Tancerel , L. , S. Ragot , V. T. Ruoppila , and R. Lefebvre . 2000 . Combined speech and audio coding by discrimination . Proc. IEEE Workshop on Speech Coding , pp. 17 – 20 .
- Tzanetakis , G. and P. Cook . 2002 . Musical genre classification of audio signals . IEEE Trans. on Speech and Audio Processing 10 ( 5 ): 293 – 302 .
- Vapnik , V. N. 1998 . Statistical Learning Theory . New York : Wiley .
- Wang , W. Q. , W. Gao , and D. W. Ying . 2003 . A fast and robust speech/music discrimination approach . Proc. 4th Pacific Rim Conference on Multimedia 3 : 1325 – 1329 .
- Zhang , T. and J. Kuo . 2001 . Audio content analysis for online audiovisual data segmentation and classification . IEEE Trans. on Speech and Audio Processing 9 ( 4 ): 441 – 457 .