Abstract
The aim of this study is to develop a new hybrid model by combining a linear and nonlinear model for forecasting time-series data. The proposed model (GRANN_ARIMA) integrates nonlinear grey relational artificial neural network (GRANN) and a linear autoregressive integrated moving average (ARIMA) model by combining new features and grey relational analysis to select the appropriate inputs and hybridization succession. To validate the performance of the proposed model, small and large scale data sets are used. The forecasting performance is compared with several models, and these include: individual models (ARIMA, multiple regression, GRANN), several hybrid models (MARMA, MR_ANN, ARIMA_ANN), and an artificial neural network (ANN) trained using a Levenberg Marquardt algorithm. The experiments have shown that the proposed model has outperformed other models with 99.5% forecasting accuracy for small-scale data and 99.84% for large-scale data. The obtained empirical results have proven that the GRANN_ARIMA model can provide a better alternative for time-series forecasting due to its promising performance and capability in handling time-series data for both small- and large-scale data.
Time-series forecasting is an important area of forecasting. It involves analyzing the collected past observations of the same variables to examine the underlying relationship and to develop an appropriate model to represent it. This modeling approach is recommended only when little knowledge is available or when there is no satisfactory explanatory model that relates the prediction variable to other explanatory variables (Zou, Xia, Yang, and Wang, Citation2007).
Time-series forecasting has been applied widely in many different fields such as economics, sociology, and science. Forecasting methods can be broadly divided into two categories: statistical and artificial intelligence (AI)-based techniques. Box-Jenkins or autoregressive integrated moving average (ARIMA), multiple regressions, and exponential smoothing are the examples of statistical methods, while AI paradigms include fuzzy inference systems, genetic algorithm, neural networks, machine-learning, and etc. (Zhang, Patuwo, and Hu Citation2001). Statistical methods are usually associated with linear data, while neural networks are usually associated with nonlinear data. Statistical methods have been used successfully in time-series forecasting for several decades. As well as being simple and easy to interpret, statistical methods also have several limitations. One of the major limitations of statistical methods is that it is merely depicted as a linear model, also known as a model driven approach. Thus, they have to fit the data with the available data, and a prior knowledge about the relationships between inputs and outputs prior to modeling is highly desired.
With the aim to improve the forecasting performance of nonlinear systems, nonlinear statistical time series models such as bilinear model, threshold autoregressive model (TAR), smoothing transition autoregressive model (STAR), autoregressive conditional heteroscedastic model (ARCH), and generalized autoregressive conditional heteroscedastic model (GARCH) have been proposed. These models are known as the second generation of time-series models. However, limited success or gain has been found during the last two decades using nonlinear models since most of them are developed specifically for particular problems without broad-spectrum applicability for other situations. In addition, the formulations of these models are more complex and difficult to develop compared to linear models.
Hence, a different approach has been proposed and engaged successfully in time-series forecasting. An artificial neural network (ANN) has been applied in solving numerous time-series forecasting problems such as stock, electricity prices, breast cancer, rainfall-runoff (Abraham and Nath Citation2001; Delen, Waller, and Kadam Citation2005; Ganeta, Romeo, and Gill Citation2006; Hamid and Iqbal Citation2004; Srinivasulu and Jain Citation2006), and others. One of the main reasons that ANN performs better than statistical methods is due to its influential feature in handling nonlinear time series data. In addition, ANN has also been shown to be effective in modeling and forecasting nonlinear time-series with or without noise (Zhang et al. Citation2001). Artificial neural networks also do not require any knowledge nor prior information about systems of interest. Previous researchers (Ma and Khorasani Citation2004; Hippert, Pedreira, and Souza Citation2001; Zhang Citation2004) have claimed that forecasting is a major application area of ANN.
Zhang, Patuwo, and Hu (Citation1998) have compiled substantial results achieved by the previous researchers. Even though most published researches indicate the superiority of the ANN model in comparison to simpler linear models, quite a few studies give disparity comments on ANN performance. Gorr, Nagin, and Szcypula (Citation1994) and Denton (Citation1995) showed that ANN performed about the same as the linear model. Several other researchers (Brace, Schmidt, and Hadlin Citation1991; Caire, Hatabian, and Muller Citation1992; Heravi, Osborn, and Birchenhallc Citation2004; Taskaya-Termizel and Ahmad Citation2005) also reported the pessimistic findings about ANN in forecasting daily electric load for one step ahead forecast. In their study, they showed that ANN was not as effective as the linear time-series model in forecasting performance even if the data is nonlinear. However, Kang (Citation1991) had shown that ANN always performs well compared to ARIMA and even better when the forecasting horizon is increased.
Some researchers (Box and Jenkins Citation1982; Makridakis et al. 1982; Chatfield Citation2001; Zhang et al. Citation2001) have reported that there is no such single forecasting method that gives an appropriate result in all situations. This is due to the characteristics of the model itself, in which the statistical model is usually a linear model, and ANN is a nonlinear model. Each of them will perform well in linear and nonlinear data, respectively. Therefore, it is hard for us to determine whether the time-series problems under study are linear or nonlinear, particularly when we are dealing with real-world, time-series data.
Frequently, the real-world, time-series problems are not absolutely linear or nonlinear; they often contain both linear and nonlinear patterns. Furthermore, real time-series problems are often affected by irregular and infrequent events that cause time-series forecasting to become more difficult and complicated. Thus, a single model is not the best way for forecasting. Although both ANN and ARIMA models have succeeded in their linear and nonlinear domains, neither ANN nor ARIMA can adequately model and predict time-series. The linear model is unable to deal with nonlinear relationships while the ANN model alone is not able to handle linear and nonlinear patterns equally well.
With the intention to improve the forecasting accuracy, the combination of forecasting approaches has been proposed by many researchers (Bates and Granger Citation1969; Newbold and Granger Citation1974; Besseler and Brandt Citation1981; Chi Citation1998). From their studies, they indicate that the integrated forecasting techniques surpass the individual forecasts.
RELATED STUDIES ON HYBRID MODELS
Hybrid models have been introduced by Reid (Citation1968) and Bates and Granger (Citation1969) to overcome the deficiency of using individual models such as statistical methods and AI. Hybrid models merge two or more different methods to improve the prediction accuracy. These models can also be referred to as combined models or ensemble models. Combining the models is thought to improve the forecasting accuracy since the essential forecasting methods represent different information to produce their forecasting results. The methods that are based on the same information or suffering from the same biases usually gain slight improvements in forecasting accuracy compared to the methods that are based on different information (Nikolopoulos, Goodwin, Patelis, and Assimakopoulos Citation2007). Hybrid methods can be implemented in three different ways: linear models, nonlinear models, and both linear and nonlinear models.
In linear hybridization, two or more linear models are combined using the same dataset or a different dataset to gain ultimate forecasting value. Shamsuddin and Arshad (Citation1990) had used a multivariate autoregressive moving average (MARMA) model to predict natural rubber prices for the Malaysian domestic market. Their work differs from Shamsuddin (Citation1992) in terms of techniques, which is implemented using different models based on different data sets. Authors combined autoregressive moving average (ARMA) and econometric model (multiple regression), where an ARMA model is used to explain the residual yield from a multiple regression model. The findings show that the forecasting errors produced by a MARMA model is reduced by 4.5% compared to the individual econometric models. This result indicates that the hybrid model has the potential to improve forecasting accuracy.
Hybrid forecasting has also been implemented using a nonlinear model by hybridizing ANN with a genetic algorithm (GA), fuzzy logic (FL), and rough sets (RS) (Dorganis, Alexandidi, Patrinos, and Sarinevers Citation2006; Hou, Lian, Yao, and Yuan Citation2006; Yang, Ye, Wang, Khan, and Hu Citation2006; Abraham and Nath Citation2001). Authors found that by hybridizing ANN with these methods it could improve the forecasting accuracy. For example, (Citation2007) have hybrid ANN and rough set for short-term load forecasting. In their works, they used rough set to reduce the number of attributes prior to ANN learning. In other words, rough set is employed as a feature selection tool. Outcome from this study showed that the time taken for training ANN decreased and the forecasting accuracy improved. combined ANN and rough set to predict air-conditioning load. They used both univariate and multivariate time-series data. Their findings illustrated that the empirical results are better compared to the results given by the ANN model alone. The result also indicates that if more relevant data are used in the study, the forecasting accuracy could be better. In this hybridization, GA, RS, or FL are embedded in ANN as preprocessing tools to improve the ANN forecasting performance by extracting important and significant features in time-series data.
However, most of the hybridization methods, which have been proposed in the previous literature (Chi Citation1998; Shamsuddin and Arshad Citation1990; Dorganis et al. Citation2006), have major drawbacks. Most of them are designed to combine similar methods—linear model with linear model and nonlinear model with nonlinear model. In reality, time-series data typically contain both linear and nonlinear patterns. Therefore, neither linear nor nonlinear models can be sufficient in modeling time-series data since linear models cannot deal with nonlinear relationships. Additionally, nonlinear models cannot handle both linear and nonlinear patterns equally well.
To overcome this shortcoming, Zhang (Citation2003) has suggested combining linear models and nonlinear models since combining different relevant methods could improve the forecasting accuracy. The merging of this structure can help the researchers in modeling complex autocorrelation structures in time-series data more efficiently. Furthermore, by using different models or models that contradict each other significantly, lower generalization variances or errors could be generated Zhang (Citation2003). In addition, Goodwin (2000) has shown that the forecasting accuracy of combination models which involves a simple average is dependent on the correlation of the forecasted error of the constituent methods; the lower the correlation, the higher the expected accuracy will be.
Encouraging results gained from Zhang (Citation2003) which combined linear models and nonlinear models has become a favorite topic to improve the forecasting accuracy recently. Several studies have been conducted and their results clearly suggest that the hybrid model is able to outperform each component model used in isolation. For example, Pai and Lim (Citation2005) used a hybrid model to forecast daily stock by using a support vector machine and an ARIMA model. Lu, Niu, and Jia (Citation2004) used the hybrid model to forecast daily load data. Tseng and Tzeng (Citation2002) combined a seasonal autoregressive integrated moving average (SARIMA) and a backpropagation model to forecast seasonal time-series data. Their results showed that the hybrid model produced better forecasting results compared to the SARIMA model or to ANN model alone. Meanwhile, Jain and Kumar (Citation2007) found that more accurate results could be obtained by hybridizing ARIMA models and ANN in forecasting hydrologic time-series. Recently, Díaz-Robles et al. (Citation2008), combined an ARIMA model and ANN for predicting particulate matters in urban areas or specifically in Temuco, Chile. Their findings showed that the performance of a hybrid model (ARIMA and ANN) is better than the performance of the individual model.
However, several researchers have argued that predictive performance improves when using hybrid models (Armstrong Citation2001; Taskaya-Termizel and Ahmad Citation2005; Taskaya-Termizel and Casey Citation2005; Zou et al. Citation2007). For example, Taskaya-Termizel and Casey (Citation2005) showed that the individual model outperformed five of the nine used datasets. Recently, Zou et al. (Citation2007) have investigated the performance of individual ANN, individual ARIMA, and hybrid ARIMA_ANN in forecasting the Chinese food grain prices. Their results showed that the individual ANN outperformed the hybrid ARIMA_ANN and individual ARIMA. These inconsistent results indicate the need for further research on how to obtain a good forecasting result from hybrid linear and nonlinear models. It is observed that there are three weaknesses in the previous studies, and these include type of data used, redundancy factors, and the implementation of hybridization sequence. Each of these weaknesses is described as follows.
-
Most of the studies on time-series forecasting used univariate time-series data. Most of them are solely based on one historical data such as previous sales and previous income. However, Hou et al. (Citation2006) showed that by considering more significant input can improve the forecasting accuracy. Furthermore, previous studies have also illustrated that the accuracy of time-series methods can be improved by incorporating multivariate information that will affect the future behavior of the series; hence the prediction can be improved (Makridakis et al. 1982; Makridakis and Wheelwright 1989).
-
Second, most of the works utilizing ANN for prediction did not look at the possibility of input redundancy. For an ordinary user, ANN appears like a black box processor whcih does not have any capabilities to recognize insignificant inputs. Improper selection and redundancy of inputs can lead to instability that will affect the accuracy of prediction (Li, Li, Li, Wei, and Qin Citation2003). Several methods have been introduced to eliminate the redundancy inputs such as grey relational analysis (Zhang and He Citation2005), the Markov blanket model, decision trees (Chebrolu, Abraham, and Thomas Citation2005), genetic programming (Abraham, Grosan, and Martin-Vide Citation2007), and adaptive genetic algorithm (Chaivivatrakul and Somhom Citation2004).
-
Third, the hybrid sequence in conventional hybrids is normally started with a linear model and followed by a nonlinear model to model the residual. This is due to the ANN's capability to deal with linear data that tend to be usually overfitting. But Heravi et al. (Citation2004) had shown that the linear ARIMA model outperformed ANN in forecasting nonlinear stock data. This result indicated that the overfitting problem essentially occurred in both the linear and nonlinear model. Nevertheless, the issue is to choose the one that will suffer from an overfitting problem acutely.
Hence, this study proposes a new hybrid approach for combining a nonlinear model and a linear model to overcome the drawbacks of previous studies by including more additional features; these include multivariate time-series, feature selection in removing and selecting significant input data, and altering the sequence of combination execution. In this study, grey relational analysis (GRA) is integrated with ANN (GRANN) to remove redundancy inputs. Grey relational analysis is employed due to its adaptability in dealing with small or large data sets (Zhang and He Citation2005; Sallehuddin, Shamsuddin, and Yusof 2008a).
THE PROPOSED METHOD
The aim of this study is to combine a nonlinear model and a linear model with various features enhancement. In practice, multiple regression (MR) is usually used in modeling multivariate time-series data due to its simplicity (Chu and Zhang Citation2003; Mentzer and Bienstock Citation1998; Uysal and Roubi Citation1999). In this study, we propose GRANN instead of MR. Two experiments are conducted to validate the effectiveness of the proposed methods.
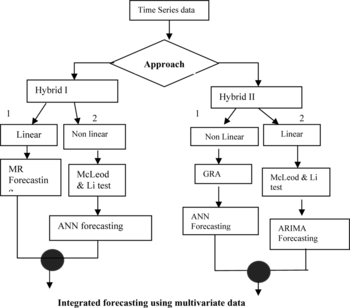
The first experiment compares the performance between a multiple regression model (MR) and a GRANN in handling multivariate time-series analysis, and the second experiment examines the accuracy of the combination between linear and nonlinear time-series forecasting models in predicting multivariate time-series analysis. Although several studies have shown that the combinations of a linear and a nonlinear model could improve the accuracy, most of the studies employed univariate time-series data (Lu et al. Citation2004; Pai and Lim 2005; Voort, Dougherty, and Watson Citation2005). Therefore, in this study, the experiments are conducted to see whether the same result will be formed whenever multivariate time-series data are employed. Furthermore, to investigate the effects of changing a hybrid sequence, two types of hybrid models (Hybrid I and Hybrid II) are developed. Hybrid I consists of MR and ANN using a conventional hybrid sequence, and Hybrid II integrates GRANN and ARIMA with an altered hybrid sequence. Hybrid I is used as a comparative model in order to evaluate the performance of the proposed hybrid model. As a benchmark, a conventional hybrid method as proposed in a previous study (ARIMA_ANN) for handling univariate time-series data is also developed. To find out whether GRANN_ARIMA is the best model for forecasting multivariate time-series data, several comparisons are conducted, and this will be given in the next section.
A Framework of the Proposed Hybrid Methods
Figures and illustrate the framework of the conventional hybrid model (Lu et al. Citation2004; Voort et al. Citation2005; Zhang Citation2003)—Hybrid I and the proposed Hybrid II. The conventional hybrid model and Hybrid I use the same sequence of hybridization in which a linear model is applied primarily to find the linear relationship in the data. Subsequently, ANN is utilized to model the residual derived from the linear model. In this case, we assume that the linear components have been fully identified by the linear model.
FIGURE 1 A conventional hybrid model.
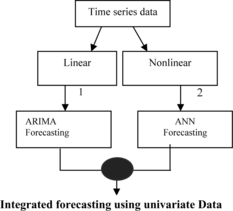
FIGURE 2 A proposed hybrid model.
Consequently, the residual left in the data presents the nonlinear component. To confirm that the assumption is true, McLeod and Li test are used to verify the nonlinearity of residual data, before the modeling process using ANN is carried out by Hybrid I.
Meanwhile, proposed Hybrid II model and conventional hybrid model are reversed from each other in terms of the model used and the sequence of hybridization. In Hybrid II, GRANN is initially applied, and followed by linear model, ARIMA. In this model, GRA is used to select the significant inputs before the forecasting is implemented using ANN. McLeod and Li's test is conducted to verify the linearity of the residual data; both of these steps are not included in conventional methods.
Table summarizes the similarities and differences of each model. Hybrid I is a hybrid model using a conventional approach with multivariate time-series data. Meanwhile Hybrid II (GRANN_ARIMA) is the proposed approach for forecasting multivariate time-series data. Grey relational analysis is used as feature selection tools to extract the significant factors that have an effect on China crop yield and daily Kuala Lumpur Stock Exchange (KLSE) close price.
TABLE 1 Similarities and Differences Between a Conventional Model and a Proposed Hybrid Model
The following section describes on the experimental data set-up and these includes data source, data features, and data is splitting.
Experimental Data Set-up
To assist the analysis for benchmarking of the proposed hybrid model, two different datasets are used. The first sample contains 13 observations and represents a small scale data. These data are obtained from (Zhang and He Citation2005) and they had specified annual China gross grain crop yields with their affecting factors. In a previous study, two methods are combined: a neural network and a rough set to predict the national gross grain crop yield from 1990 to Citation2003.
Table shows yearly data for gross grain crop yields and its affecting factors in China from 1990 til Citation2003. There are 10 factors that affect the production of gross grain crop in China, and these include (a) total power of agricultural, (b) electricity consumed in rural areas, (c) irrigation area, (e) consumption of chemical fertilizer, (f) areas affected by natural disaster, (g) budgetary expenditure for agriculture, (h) sown area of grain crops, (l) consumption of pesticide, (m) consumption of agricultural film, and (n) agriculture laborers. The total production of grain crop yield is denoted by (d).
TABLE 2 Grain Crop Yield and Its Affecting Factors
Kuala Lumpur Stock Exchange data contains 200 observations of daily KLSE close price from 4 January 2005 til 21 October 2005, and it represents large-scale data. Table illustrates the fraction of the stock market dataset that was used in this research. They are daily close prices for KLSE (Close_KLSE), consumer index (CI), construction index (CoI), gold index (GI), finance index (FI), product index (PI), Mesdaq index (MI), mining index (MinI), plantation index (PlI), property index (Pr oI) (ProI), Syarian index (SI), technology index (TI), trading/service index (TSI), composite index (CptI), and industrial index (II).
TABLE 3 Fraction of Daily KLSE Closing Price with 14 Affecting Factors
Essentially, each dataset is divided into two parts: in-of-sample and out-of-sample data. In-of-sample data refers to the training dataset and is used exclusively for model development, while out-of-sample refers to the test data and is used for evaluation of the unseen data. In other words, test data is used for an independent measure of how the model might be expected to perform on untrained data. The test data should not be used in the model estimation or model selection process to ensure that the real forecasting performance is evaluated.
In ANN, however, training data usually are divided further into a training and validation set, where a validation set is used to monitor network performance during training with the intention that early stopping criteria will be met if the network attempts to overfit the training data. There is no specific rule governing the splitting of the data in the literature. It is generally agreed, however, that more data should be allocated for model building and selection. Most of previous studies are based on the ratio of splitting for training and testing such as 70%: 30%, 80%: 20%, or 90%: 10%. In this study, the split data is based on 90%: 10%.
Grey Relational Analysis (GRA)
Grey relational analysis is a method of analysis that has been proposed in the grey system theory and was founded by Professor Deng (Citation1982, Citation1989). Grey relational analysis is suitable for solving complicated interrelationships between multiple factors and variables and has been successfully applied on cluster analysis, robot path planning, project selection, prediction analysis, performance evaluation, and factor-effect evaluation and multiple criteria decisions. The mathematics of GRA is derived from space theory (Deng Citation1989). The purpose of GRA is to measure the relative influence of a compared series in the reference series. In other words, the calculation of GRA reveals the relationship between two discrete series in a grey space. According to the definition of grey theory, the grey relational grade (GRG) must satisfy four axioms including norm interval, duality symmetric, wholeness, and approachability (Deng Citation1989; Lin, Lu, and Lewis 2007). The four axioms are described as below.
Let X be the grey relational set, x 0 ∊ X represent the reference series, and x i ∊ X the compared series; x 0 (k) and x i (k) are the values at time k:
-
Norm interval
-
Duality symmetric
-
Wholeness
-
Approachability with the decrease of
will increase.
The basic idea of GRA is to judge the relational degree of sequences according to similarity between their geometric shapes of the curves of the sequences. Therefore, in this study, GRA calculations compare the geometric relationships between time-series data in the relational space by evaluating the grey relational grade—GRG. In other words, the GRG represents the relative variations between one major factor and all other factors in a given system. If the relative variations between two factors are basically consistent during their development process, then GRG is large or vice versa. The GRG is used to show the whole relationship for the system (Lin et al. 2007; Deng Citation1982).
Basic Algorithm of GRA
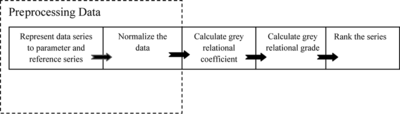
There are three (3) main steps in GRA (Figure ). The first step is data preprocessing. There are two processes involved in this step: data representative and data normalization. Initially, (X) represent the original data series, (x 0) as reference and (x i ) parameter series, followed by data normalization. Data normalization is commonly required since the range and unit in one data sequence may differ from others. Therefore, these data must be normalized, scaled, and polarized into a comparable sequence before proceeding to other steps. This process is called the generation of grey relation or standard processing. There are few equations for data preprocessing in grey relational analysis, (Equations (Equation1a)–(Equation1c)).
FIGURE 3 Basic steps in GRA.
If the expectancy is the higher-the-better, then it can be expressed by
The second step is to locate the grey relational coefficient by using Equation (Equation2), (Tosun Citation2005):
ζ is known as an identification coefficient with ζ ∊ [0,1]. Normally ζ = 0.5 is used because it offers a moderate distinguishing effect and stability (Lin et al. 2007; Sallehuddin et al. 2008b). Furthermore, based on mathematical proof, the value change of ζ will only change the magnitude of the relational co-efficient; it would not change the rank of the GRG (Chiang, Tsai, and Wang 2000).
Finally, to obtain the GRG, the average value of a grey relational coefficient is computed and is defined as (Tosun Citation2005):
The GRG γ i represents the level of correlation between the reference sequence and the comparability sequence. Based on the calculated value of GRG, the grey relational order based on the size of γ i is constructed. Each γ i is ordered to the increasing grey relational coefficient. This derived order then gives the priority list in choosing the series that is closely related to the reference series x o . For example, if γ (x 0, x i ) > γ (x 0, x j ), then the element x i is closer to the reference element x 0 than the element x j . Generally, γ i > 0.9 indicates a marked influence, γ i > 0.8 a relatively marked influence, γ i > 0.7 a noticeable influence, and γ i < 0.6 a negligible influence (Fu, Zheng, Zhao, and Xu Citation2001).
Application of GRA
To illustrate, the KLSE closing price dataset is chosen. First, represent the original data series as a reference and comparative series. For example, in data set 2, only one sequence of x 0 (KLSE close price), is employed as the reference series and all other sequences serve as a comparison or parameter series, x i ; and it is called a “local grey relation” measurement. Sometimes, a reference series is also called an objective series.
Since the comparative series and reference series differ in terms of units and different amounts, the grey relational coefficient cannot be computed directly from the original data. First, the original data need to be normalized using Equation (Equation1a). Then compute the grey relational coefficient for each data. After that, calculate the GRG for each affecting factor towards the particular selected output. Then rank each affecting factor based on these GRG values in descending order. The higher GRG values imply the more important the affecting factors. Figure simplified the processes involved in GRA for finding the relationship among KLSE closing price and its affecting factors.
FIGURE 4 Best input feature selected by GRA.
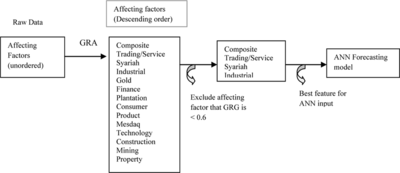
From the Figure , it shows that the raw data which contains the unordered affecting factors for KLSE, are analyzed by GRA to produce a ranking scheme for KLSE affecting factors. This ranking scheme in descending order based on the GRG values. The highest GRG value is ranked as the first order (composite index) followed by the smaller GRG values. The smallest GRG value is the least important affecting factor, in this case the property index. Based on the recommendation of previous research (Fu et al. Citation2001), the affecting factors that have less than 0.6 GRG is deleted from the ranking scheme. Figure illustrates that four affecting factors (composite, trading/service, Syariah, and Industrial) or (SI, TSI, CmpI, and II) are sufficient for predicting the next day KLSE closing price.
Consequently, Tables and illustrate the affecting factors that are yielded by applying GRA, which have the greatest influence on annual grain crop yield and daily close price for KLSE. Based on the calculated value of GRG, only six factors; a,b,c,e,h, and l are selected as inputs to ANN to predict the grain crop yield. This result is similar to the previous study by Zhang and He (Citation2005).
TABLE 4 Affecting Factors for Grain Crop Yield Selected by GRA
TABLE 5 Affecting Factors for KLSE Close Price Selected by GRA
While for KLSE daily close price, out of 14 affecting factors being observed, only four factors were identified as the most influential factors: SI, TSI, CmpI, and II. Therefore, these four factors are used as inputs to ANN to predict the next day close price for KLSE. The application of GRA has reduced the number of input need to be trained in the ANN learning phase. By using few input nodes, the complexity of the ANN structure can be reduced, hence, speed-up the ANN convergence rates.
On the other hand, in multiple regression analysis, the goodness fit test is used to recognize the proper inputs. The significant inputs are identified based on t-values and p-values. If t-values are less than 1 and p-values are above some accepted level, such as 0.05, then this variable is excluded from the list.
Nonlinearity Test: McLeod and Li Test
The nonlinearity test is implemented to examine the degree of linearity of time-series data in our study. The McLeod and Li test (Citation2004) is based on the autocorrelations of the squared residuals produced by the ARIMA model using n observations as shown below:
Performance Measurement
To evaluate the performance of the proposed hybrid model—GRANN-ARIMA—four statistical tests are carried out. These tests are root mean square error (RMSE), mean square error (MSE), mean absolute percentage error (MAPE), and mean absolute deviation (MAD):
Different statistical tests are used in this study since each method measured the error in different angles. For instance, MSE is the simplest methods to implement but it is scale-dependent and is not appropriate for comparison between series (De Gooijer and Hyndman Citation2006). The MAD is a frequently used and intuitive measure of forecast accuracy which measures the magnitude of the deviation between the observed values of a given time-series (Jones et al. Citation2008; Bowermann and O'Connel Citation1993). The RMSE is usually used for absolute performance measure (Zhang and Qi Citation2005). In addition, MAPE is favored and has gained popularity in the forecasting literature because it is not prone to change in the magnitude of time-series data (Young Citation1993). These measurements are employed as performance indicators and calculated based on the out-of-sample data. GRANN-ARIMA is the best alternative model for forecasting multivariate time-series data if it gives the lowest values for RMSE, MSE, MAD, and MAPE.
The forecasting precision performance is better when the value is smaller or approaching to zero. If the results are not consistent with these four criterions, we choose MAPE as a benchmark (Makridakis 1993).
PROPOSED HYBRID METHOD
Most of the real world problems consist of linear and nonlinear patterns. Even though, there are a lot of methods that can be applied to solve time-series forecasting problems, none of them can handle both patterns simultaneously. To tackle these two patterns uniformly well, hybridizing the linear and nonlinear model is proposed in order to improve the forecasting accuracy.
Conventional Hybrid Method for Univariate Time-Series Data
There are several works related to hybrid nonlinear and linear models (ARIMA model as linear model and ANN as nonlinear model) to forecast univariate time-series data (Zhang Citation2003; Lu et al. Citation2004; Shouyang, Lean, and Lai Citation2005; Voort et al. Citation2005). These authors applied an ARIMA model initially to the data and followed with ANN for data residual. This hybrid model (Y t ) is illustrated as
Hybrid Model for Multivariate Time Series Data Using Conventional Approach
In this hybridization, MR replaces ARIMA as the linear model, L
tm
and ANN represents the nonlinear model, N
tm
in handling multivariate time-series data. The proposed Hybrid I model is given as
Let is the forecast value of the MR model at time t, and
represents the residual at time t as obtained from MR model; then
Hence, the hybridized forecast given by Hybrid I model is,
The Hybrid I model can be determined by two steps. First, the MR model is used to analyze the linear part of the multivariate time-series problem, and second, the ANN model is built to model the residuals produced by the linear model, MR.
Hybrid Model for Multivariate Time-Series Data Using the Proposed Hybrid Model (Hybrid II)
In the proposed method, ARIMA is used as the linear model, L tm and GRANN is used as the nonlinear model, N tm . Both models are hybridized as shown by Equation (Equation14):
Therefore, the hybridized forecast obtained from Hybrid II, model can be written as
Similar to the Hybrid I model, the Hybrid II model can be determined through two steps. But both hybrid models are different in terms of hybridization execution, where in the Hybrid II model, the nonlinear model is implemented first than followed by the linear model.
VARIABLES SELECTION AND MODEL CONSTRUCTION
Each dataset was partitioned into two sets: 90% training and 10% for validation data, based on the ANN model requirements for training. This part will give some explanation about the design and development of each model used in this study.
Experimental Design of MR Model
The MR methodology is a strategy for identifying the relationship between several independent or predictor variables and dependent variables. It is used to analyze the affecting factors for forecasting both the China crop yield and the daily KLSE closing price. The MR methodology consists of five iterative phases:
-
data collection and preparation
-
reduction of explanatory and predictor variables
-
model refinement and selection
-
model validation
-
forecast future outcomes based on the known data.
The multiple regression methodology was utilized over the training data set to estimate the significant regression coefficients b 0, b 1, b 2,…, b q of linear regression:
Development of ARIMA Model
Since its introduction in the 1970's, the Box-Jenkins approach has become one of the most popular methods for time-series forecasting. In an ARIMA model, the future value of a variable is supposed to be a linear combination of past values and past errors. The ARIMA model can be represented as follows:
The AR part of the model indicates that the future value of Y t are weighted averages of current and past realizations, while the MA part of the model shows how current and past random shocks will affect the future values of Y t . However, the ARIMA model is usually referred to as using ARIMA(p,d,q), where p and q represent AR and MA polynomials, respectively, and d represents the number of differences.
Based on the proposed procedure of Box and Jenkins (Citation1982), the ARIMA model involves the following steps:
-
stationary test of time-series
-
identification of the ARIMA (p,d,q) structure
-
estimation of the unknown parameters
-
goodness of fit tests on the estimated residual
-
forecast future outcomes based on the known data.
This five-step model building process is repeated several times until a satisfactory model is finally selected. The final model can then be used for forecasting purposes. Forecasting with the estimated model is based on the assumption that the estimated model will be held in the horizon for which the forecasting is made. The ARIMA model is basically a model-oriented approach where the model is fitted to available data.
Development of ANN Model
In this study, we use multilayered feedforward with backpropagation (BP) learning. A BP algorithm is an effective and the most popular supervised learning algorithm used in time-series forecasting. Back propogation networks are well known for their capability to learn complex relationships between sets of variables. Most often, however, the phenomenon we are trying to model is very complex. There is no prior knowledge involved; hence it can be used to select the input variables which are relevant to modeling input-output relationships. Basically, there are eight steps involved in designing ANN structure as presented in Table (Sallehuddin et al. 2008a).
TABLE 6 Eight Steps in Developing ANN Model
To determine the best ANN structure for each dataset, we use the common practice of cross-validation in ANN modeling. This data is divided into two portions: training and testing. The training sample is then further divided into a training and validation sample. The ANN model with BP learning was trained using C programming language, while ANN with a LVM algorithm was built using MATLAB.
Design and Development of Hybrid Model: Hybrid ARIMA_ANN Model
The combination of the ARIMA and ANN model was performed to use each model capability to capture the different patterns in time-series data. The methodology consists of two steps: (1) the first step involves the development of an ARIMA model to forecast time-series data, for example, KLSE closing price; and (2) the second step involves the development of an ANN model to describe the obtained residuals from the ARIMA model. In this study, MLP architectures with a BP algorithm with a sigmoid activation function are used and the learning parameters are setting with various values with a different number of hidden nodes.
Design of Hybrid MR and ARIMA (MARIMA)
The combination of the MR and ARIMA model was performed to complement each other's limitations in order to capture different patterns in time-series data. The methodology consists of two steps: (1) the development of an MR model to forecast time-series data, for example, KLSE closing price; and (2) the development of an ARIMA model to describe the residuals obtained from the MR model.
Development of GRANN_ARIMA
The combination of the GRANN and ARIMA model was performed to detain different patterns in time-series data. Here, GRA was employed earlier to find the significant input factors before hybrid GRANN_ARIMA is developed. These significant inputs will be fed into an ANN model to forecast time-series data. The cooperation of GRA and ANN is called GRANN. Subsequently, the ARIMA model was developed to describe the residuals obtained from the GRANN model. In this study, MLP architecture with a BP algorithm using the sigmoid activation function are used and various values of learning parameters and a different number of hidden nodes were employed to obtain better structures.
Design of MR and ANN
The combination of the MR and ANN model was performed in two different steps. In the first step, an MR model was developed using STATISTICA software to forecast time-series data, and in the second step, an ANN model was developed to describe the residuals obtained from the MR model.
EXPERIMENTAL RESULTS
This section will explain the results of the study. Part 1 describes the results produced by Experiment I, and Part 2 discusses the results from Experiment II.
Results from Experiment I
As we mentioned earlier, the aim of this experiment was to investigate the capability of the GRANN model in analyzing multivariate time-series in searching the relationships between the independent and dependent variables. Before the modeling process is complete using ANN, GRA is employed to obtain the significant affecting factors which affect the production of crop yield in China and the KLSE close price.
Table depicts the structure and learning parameter used in the developing GRANN and the error produced in the training and testing phase for both data samples. For example, based on the calculated value of GRG, only six factors—a, b, c, e, h, and l—are selected as the inputs to GRANN to predict the grain crop yield. Thus, a three-layer feedforward neural network with a single output unit, 12 hidden units, and 6 input units are used in this study with the learning rate (α) and momentum (β) are (0.5, 0.9), respectively. The network structures and learning parameters are determined by trial-and-error. In this study, we only consider the situation of one-step-ahead forecasting. Therefore, only one output node is employed. The RMSE for the best GRANN model are 232 for the training phase and 417 for the testing phase.
TABLE 7 GRANN Structure
Ten independent variables are used to build a multiregressions model for grain crop yield. Several models are built and evaluated based on statistical goodness fit. However, the final model only used four independent variables: a, c, h and n.
The equation for grain crop yield is given as
For KLSE close price, 14 variables are used initially; but only three variables are used finally: finance index (FI), trading/service index (TSI), and composite index (CptI). The equation for KLSE close price is as follows:
Various statistical tests can be used to validate the models. In this study, R 2, adjusted R 2, standard error, S e , F-test, and p-value are used to validate the model. R 2 and adjusted R 2 are the square of the correlation between the observed values of the response variable and the fitted values from the regression equation. Therefore, they are used to indicate the robustness of the model in explaining the actual consumption of the data. Both models are tolerable since R 2 and adjusted R 2 have high values with a small standard error, S e (refer to Table ). In the interim, F-test and p-values are used to determine the importance of the model. From Table , the F-test is considered significant since p-value is approaching to zero. Therefore, Equations (Equation20) and (Equation21) are considered reasonable enough for predicting grain crop yield.
TABLE 8 Statistical Test for Grain Crop and KLSE Close Price
By comparing the input parameter used by GRANN and MR in forecasting crop yield, it is found that three variables selected by both models are equal. This indicates the significance of these variables {a, c, and h}. The result shows that the total power of agricultural (a), irrigation area (c), and the sown area of grain crops (h) are the most affecting factors to grain crop yield in China since they are preferred by both MR and GRANN, while the composite index (CptI) and trading/service index (TSI) are the most influential factors that affect the movement of KLSE close price.
Comparison Between GRANN Model and MR Model
In order to examine the performance of GRANN in forecasting multivariate time-series, the result from MR models and GRANN models are compared. RMSE, MSE, MAD, and MAPE are used to observe the forecasting performance between GRANN and MR models. Table gives the performance measure of GRANN models and MR models, and the prediction outputs of each model are shown in Figures and . Table shows the predicted error values of crop grain yield for the next 2 years (2002 and Citation2003) given by the GRANN model and MR. The application of the GRANN model gives the smallest error (RMSE, MAPE, MSE, MAD) compared to the MR model.
TABLE 9 Forecasting Values of GRANN Versus MR
Figure shows an increasing production of grain crop in Citation2003. Output from the GRANN model shows that there is a slight increment (0.1%) for grain crop yield in 2003. However, the MR model predicts the production of grain crop is going to be decreased by about 4.8% in 2003. The actual values show about 0.9% increment in 2003 for crop grain yield. Hence, we can conclude that GRANN forecasting result is more reliable than MR.
FIGURE 5 Forecasting values for each model (crop yield).
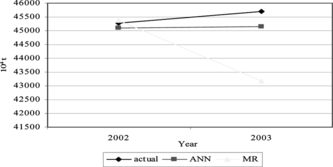
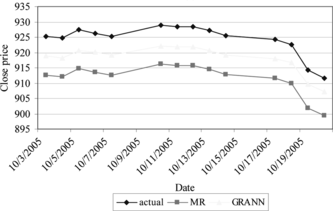
Table depicts the forecasting error generated by GRANN and MR in forecasting KLSE daily close price for the next 14 days. The values of RMSE, MAPE, MSE, MAD given by GRANN is smaller than MR. The forecasting values given by GRANN is closer to the actual value as illustrated in Figure . This indicates that the forecasting results yield from GRANN are more accurate compared to MR.
FIGURE 6 Forecasting values for each model (KLSE close price).
From the study, we found that GRANN performs better than MR, because ANN provides more superior methodology than multivariate analytical (Parzen and Winkler Citation1982; Rao and Ali Citation2002; Ali and Al-Mahmeed Citation2002). This conforms with the results of the previous study that ANN is suitable for multivariate data analysis (Prerez, Ortega, Gonzalez, and Boger Citation2004). This result also strengthened our justification of implementing ANN as a multivariate model in our study.
Results of Experiment II
The second experiment is conducted with two main objectives. The first objective is to compare the performance of an individual and proposed hybrid model in forecasting time-series. In order to achieve this objective, the proposed hybrid model which consists of a nonlinear and linear model, is developed. Shamsuddin (Citation1992) proposed a hybrid linear model known as MARMA to predict natural rubber price. In their study, they applied MR and ARMA methods to model the residual. However, in our study, we developed two hybrid models—Hybrid I and Hybrid II. Both methods pooled linear and nonlinear models using multivariate time-series data. In Hybrid I, MR is used as a multivariate tool in conjunction with ANN to model the residual; in Hybrid II, GRANN is a employed as a multivariate tool in cooperation with ARIMA to model the residual. The MR and GRANN models are used as a yardsticks to measure the performance of the proposed hybrid models, respectively.
The second objective is to investigate the stream of implementation that can affect the performance of the proposed model in forecasting multivariate time-series data. Previous studies by Zhang (Citation2003), Lu et al. (Citation2004), Shouyang et al. (Citation2005), and Voort et al. (Citation2005) have employed linear models originally to the data, and followed by a nonlinear model (ANN) to predict the residual. In this study, the sequence is changing, i.e., the nonlinear model primarily, and followed by a linear model for residual. Time-series forecasting can be obtained by integrating the values from linear and nonlinear models.
Experimental Results for the Hybrid I Model (MR_ANN)
Results obtained from this test verify that the data are nonlinear and ANN is suitable in modelling the residual. Table shows the predicted residual value from the ANN model. The network structure for crop yield is 2-4-2; two inputs unit, four hidden units, and two output units, respectively. The 5-11-4 is the network structure used for the KLSE close price. The learning and momentum rates are set between [0.5, 0.9].
TABLE 10 Results for the Hybrid I Model
The predicted value from the MR model (from Experiment I) is integrated with predicted value from the ANN model to get the ultimate forecasting value for China total grain crop yield in the years 2002 and 2003, and 14 days ahead for the KLSE close price. Table shows that the RMSE, MSE, MAPE, and MAD for the Hybrid I model, which combine MR and ANN models, have the lowest value compared to the MR model alone.
Based on RMSE, the prediction accuracy in the Hybrid I model increases about 28% and 30% for crop yield and KLSE close price. As a result, the combination of two different models that have dissimilar characteristics (linear and nonlinear) can improve the forecasting accuracy in multivariate time-series analysis.
Result from the Proposed Hybrid II
In this experiment, we alter the sequence order of implementation proposed by previous researchers, in which a nonlinear model is employed initially and followed by a linear model for the residual. However, in this study, GRANN is used as the nonlinear model and ARIMA as the linear model. The McLeod and Li test is employed to check the nonlinearity degree of the data. The results from this test verify that the residuals data are linear; hence, ARIMA is suitable in modelling the residual. ARIMA (1, 0, 1) is used to model the residual and the predicted residual for 2 years prior and ARIMA (0, 1, 3) is used to model the residual daily KLSE close price (Table ).
TABLE 11 Results for the Proposed Hybrid II
The predicted value from the GRANN model (from Experiment I) is integrated with a predicted value from the ARIMA model to get the final forecasting value for both samples. Table shows the result for the proposed Hybrid II models, which gives a smaller prediction error (GRANN_ARIMA). This result indicates that the forecasting ability of the multivariate time-series data is improved even further if the GRANN_ARIMA model is adopted. The forecasting accuracy of GRANN_ ARIMA in both samples is increased by about 33% and 73% compared to the prediction given by the GRANN model.
The results of these experiments have proven that the performance of the proposed model is better compared to the individual model in analyzing and forecasting multivariate time-series data thus conforming to the previous results obtained from Hybrid I.
A Comparison of Hybrid I, Hybrid II, and Conventional Hybrid Models
Experimental results yielded from this study reveal that both the blend methods of Hybrid I and Hybrid II can improve the forecasting accuracy. Nonetheless, the arising issue is to choose which one is better—Hybrid I or Hybrid II. Consequently, a comparison of forecasting performance for both hybrid models (Hybrid I and Hybrid II) is given in this section to examine the effect of forecasting performance by varying the order of implementation on multivariate time-series data.
As depicted in Table , RMSE, MSE, MAPE, and MAD given by both Hybrid II models is lower than Hybrid I with the forecasting accuracy increasing 78% and 86% in each sample data, respectively. These results show that the best method for combining models is Hybrid II. At the same time, this result indicates that altering the sequence of hybridization will affect the accuracy. For an illustration, the error given by the proposed approach, GRANN_ARIMA is better compared to MR_ANN with the conventional hybridization approach.
TABLE 12 Comparison Performance of Hybrid I, Hybrid II, and the Conventional Hybrid Model
To further evaluate the performance of the GRANN_ARIMA model, a comparison with the conventional hybrid model (ARIMA_ANN) which was proposed by previous studies, is carried out. The ARIMA_ANN model cannot be developed for crop yield data since the sample size is too small and insufficient for developing the ARIMA model. From the experiment, we found that the forecasting performance improves better if Hybrid II is used instead of using the conventional hybrid. This shows that the type of data being used will also influence the forecasting performance. The more relevant data being considered in the experiment, the better the performance of the forecasting model; GRANN_ARIMA used multivariate time-series instead of the univariate time-series used in ARIMA_ANN.
Figures and summarize the results of examining the affect of altering the sequence of hybridization. It is clear that the GRANN_ARIMA performs better than the other two hybrid models. As shown in Figures and , the forecasting value from hybrid GRANN_ARIMA is more accurate compared to MR_ANN and ARIMA_ANN, since the values are approaching the actual value. The value of R2, adjusted R2 in MR, and the value of the Ljung-box test in ARIMA are high since these values are based on in-sample data. Therefore, there is no guarantee that the model can also give a high performance for out-sample data.
FIGURE 7 Comparison of Hybrid I and Hybrid II (crop yield).
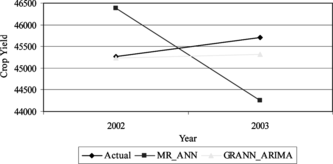
FIGURE 8 Comparison of Hybrid I and Hybrid II (KLSE close price).
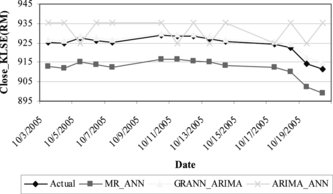
Table showed that the RMSE, MAD, MAPE, and MSE, which are calculated based on out-of-sample data for MR_ANN or ARIMA_ANN, is worse compared GRANN_ARIMA in both sample data used. The Varying performance between in-sample and out-sample indicates that overfitting exists. For example, overfitting occurs when determining the appropriate parameters to be included in the MR model.
The goodness fit test, which is used to check the adequacy of the MR model, has probably excluded the significant factors that should be considered. According to Zhang (Citation2003), we need to apply a linear model first to avoid overfitting in ANN. However, the result from this study shows that over-fitting also occurred in a linear model. This result supports the findings given by Heravi et al. (Citation2004). Therefore, we conclude that overfitting can also occur in linear models. Based on the MR and ARIMA performance, the probability of overfitting arising in a linear model is higher compared to a nonlinear model. This result supports our claims to change the sequence of hybridization for better forecasting.
To obtain more accurate forecasting results, Hybrid II methods using a GRANN_ ARIMA model is suggested because it can work well in sample data that represents both small-scale and large-scale data. This result may be explained by the fact that: (1) ANN is capable of dealing equally well with linear and nonlinear data; (2) ANN is accepted as a universal approximator; (3) Past studies have shown that over-fitting problems in ANN can be avoided by using cross-validation and optimal learning parameters (Lachtermacher and Fuller 1995).
Comparison of the GRANN_ARIMA (Hybrid II) Model with the Benchmark Model
From the previous experiment, we found that GRANN_ARIMA is the best model for forecasting multivariate time-series data. To further validate our findings, an assessment performance with a benchmark model for univariate and multivariate models is conducted. In this study, MARMA and ARIMA models are selected because they are linear statistical models. Furthermore, ARIMA, also known as a Box-Jenkins model, has dominated time-series forecasting for more than half a century. Additionally, ARIMA modeling has been used in a univariate framework as a sophisticated benchmark for evaluating alternative proposals (Abraham and Nath Citation2001; Taylor Citation2003; Zhang Citation2003). MARMA is used in this study because it has been used as a statistical modeling technique for a hybrid model in a previous study (Shamsuddin and Arshad Citation1990; Shamsuddin Citation1992). Table shows the performance of each model. We found that the accuracy of GRANN_ARIMA is always better than both the MARMA and ARIMA models. This result is not surprising because ARIMA is a linear model and the MARMA model is a combination of two linear models. Because of this reason, it cannot handle nonlinear data as well as a nonlinear model.
TABLE 13 Comparison of GRANN_ARIMA with MARMA and ARIMA
Table show that the comparison with individual linear ARIMA cannot be implemented for crop yield data. Due to the small sample dataset being used and the nonstationary time-series data, the ARIMA model cannot be developed. Theoretically, the minimum amount of data that needs to apply the ARIMA model is about 40 to 50 observations of data. This model needs more data for tracking the pattern or component in time-series data prior to the modeling process. Before a model estimation can be done, time-series data must be in a stationary form. Otherwise, the differencing process needs to be implemented and it will reduce the size of the data. In this study, the data is annual data with approximately 11 periods, and nonstationary. These data need to be transformed into a stationary form. From the results, it shows that the proposed GRANN_ARIMA model can also perform well in nonstationary and small sizes of time-series data.
Comparison of the GRANN_ARIMA Model with ANN Using Second-Order Error (Lavemberg Marquet)
Table demonstrates the results given by the GRANN_ARIMA and ANN models using a second-order error—Lavemberg Marquet (LVM). Table shows the results of the experiments. For the first dataset (crop yield-small-scale data), the performance of LVM is slightly better than GRANN_ARIMA with a 5% growth. On the other hand, GRANN_ARIMA performs much better than LVM in the second dataset (KLSE close price that represents large-scale data) with more than 80% growth.
TABLE 14 Comparison of GRANN_ARIMA with Lavenberg Marquet (LVM)
From the experimental results it is shown that the proposed hybrid models always give better results compared to the individual model regardless of the sequence of the proposed hybrid model. For instance, an error produced by an individual model is greater than an error produced by the proposed hybrid model (MR and MR _ANN; GRANN and GRANN_ARIMA), except for an ANN trained with a second-order error (LVM) for the crop yield (refer to Table ). However, the difference of RMSE, MSE, MAPE, and MAD produced from the proposed Hybrid II model, which comprises, GRANN, ARIMA, and LVM, are small, where the difference of accuracy percentage is 0.02—almost approaching zero. As a consequence, we can conclude that both of them are comparable.
Significant Test of the Proposed Model (GRANN_ARIMA)
From the experimental results, it is shown that the proposed hybrid model—GRANN_ARIMA—outperformed the individual and hybrid model in terms of forecasting accuracy. But this result cannot assure that the proposed hybrid model—GRANN_ARIMA—is significant compared to the comparative models. Therefore, a significant test of GRANN_ARIMA is conducted between the proposed hybrid model and the comparative models. These include the individual model (ANN, ARIMA, and MR) and the hybrid model that was proposed by Zhang (Citation2003)—ARIMA_ANN. Further testing is carried out between the actual data and the GRANN_ARIMA to verify the significance of the proposed hybrid model. As a result, two different hypothesis tests are carried out—one sample t-test and a paired t-test.
One Sample t-Test
The basic idea of this test is to compare the mean of the forecasted value obtained from GRANN_ARIMA and the mean of the actual value. The question posed here is whether the proposed hybrid model can represent the underlying relationship in the actual time-series and then be employed as a forecasting model to predict the KLSE closing price and China crop yield. If so, we expect that there is no difference between the mean of the actual data and the forecasted values. Therefore, the following hypotheses are proposed:
-
H 01: There is no difference between the mean of the actual data and GRANN_ARIMA.
-
H 02: There is a difference between the mean of the actual data and GRANN_ARIMA.
The experiments are running using SPSS 10. In this case, the mean of the actual data is assumed to be a test value. The test value for crop yield is 45484 and for the KLSE closing price is 924. The forecasted mean value is compared to the specified test values to investigate whether the GRANN_ARIMA can represent the real situation of the underlying pattern in the crop yield and the KLSE closing price. If the mean obtained from GRANN_ARIMA is less than the test value, it indicates that the model underfit the real situation; otherwise it overfit the real situations. If the value is equal to the test value, it indicates that the model is appropriately used as a forecasting model since it represents the real situation.
For the crop yield, the mean difference between the actual data and the forecasted values are −211.75 (refer to Table ). The p value is greater than 0.05 (refer to Sig. (2-tailed)); therefore, we accept the null hypothesis of H 01. The 95% confidence interval ranges from −739.2431 to 315.7531 (include zero). Therefore, the two means are not significantly different from each other. Consequently, an assumption can be made that the GRANN_ARIMA can be used to forecast the crop yield since it can represent the underlying pattern in the actual data.
TABLE 15 One Sample Test for Crop Yield
Table shows that the mean difference between the actual data and the forecasted values is 1.8250. The 95% interval is range between the positive and negative values (−0.7373 and 4.3873) where the zero value is included. The p value is also greater than 0.05 (P = 0.148), so H 01 is accepted. Hence, the two means are not significantly different from each other. Therefore, an assumption can be made that the GRANN_ARIMA can be used to forecast the KLSE closing price since the underlying pattern in the actual data is well presented.
TABLE 16 One Sample Test for the KLSE Closing Price
Paired t-Test
Since data used for a prediction in both models are similar, the paired t-test (two samples for mean) is carried out on prediction accuracy to test the hypotheses. The aim of this test is to check whether the means of predicted values obtained from the GRANN_ARIMA models are different from the other models that were employed in this study. Therefore, the following hypotheses are proposed:
-
H 01: There is no difference between the mean of the other model and GRANN_ARIMA (μ1 = μ2).
-
H 02: There is a difference between the mean of the other model and GRANN_ARIMA (μ1 > μ2) or (μ1 < μ2).
Here, the other model is referred to as ARIMA, ANN, MR, and ARIMA_ANN.
Table shows the statistics and correlations of the crop yield, and Table illustrates the results of a paired t-test. From Table , it is clearly shown that the mean of GRANN_ARIMA is higher than the other models. Even though the standard error of the ANN model is the lowest and the GRANN_ARIMA is the second lowest, the mean of GRANN_ARIMA is higher and closer to the mean of the actual data. Both models are also highly correlated. However, GRANN_ARIMA are negatively correlated to the MR model and the standard error produced by the MR model which is the highest.
TABLE 17 Statistics and Correlations for Crop Yield
TABLE 18 Paired t-Test for Crop Yield
The results of a paired t-test for the crop yield are shown in Table . The results show that between the actual model and the other model with GRANN_ARIMA, we found that the P > 0.05 (0.447, 0.059, 0.543). These results indicate that H 01 need to be accepted, since the difference between the upper and lower value for the 95% interval range between negative and positive values where a zero value is included. This implies that there is no statistical difference between the mean of actual data or the other model to the mean obtained from a predicted value of GRANN. However, if we compared it to other models, the mean of GRANN_ARIMA is higher. Therefore, the assumption can be made that the GRANN_ARIMA is capable of giving a better prediction than other models.
Table depicts the statistics and correlations obtained from the KLSE closing price. It can be clearly seen that all the models are positively correlated with GRANN_ARIMA except for ARIMA_ANN and ARIMA.
TABLE 19 Statistics and Correlations for KLSE Closing Price
Accordingly, both models showed that they are not correlated and negatively weakly correlated with GRANN_ARIMA. The ARIMA model gives the smallest standard error compared to the others.
Table describes the paired t-test gained from the KLSE closing price. Since P < 0.05 for Pair 1, Pair 2, Pair 3, and Pair 4 (refer to Sig. (2-tailed)), H 01 is rejected. This indicates that there is a significant difference between the mean produced by other models and the mean produced by GRANN_ARIMA.
TABLE 20 Paired t-Test for the KLSE Closing Price
There are however, two different scenarios: First, when the 95% confidence is bounded in negatives values, this implies that the μ1 − μ2 < 0 or μ1 < μ2. In this case, the mean of GRANN_ARIMA is higher than the actual data, MR and ANN. Therefore, the assumption can be made that the predicted capability of GRANN_ARIMA is better than MR and ANN. The underlying pattern in the actual data is also well presented by GRANN_ARIMA. Second, when the 95% confidence range is in positives values or μ1 − μ2 > 0 or μ1 > μ2 (refer to Pair 4, ARIMA_ANN vs. GRANN-ARIMA), the result is not acceptable since both models are weakly correlated.
While for Pair 5, P > 0.05 and therefore H 01 is accepted. The 95% confidence interval is bounded between negatives and positives. This indicates that there is no difference between the mean produced by ARIMA and GRANN_ARIMA. But this result is not meaningful and not acceptable since both models are negatively weakly correlated. Based on the results from both tables, a conclusion can be drawn that GRANN_ARIMA has given a better prediction than other models.
CONCLUSION
In this study, GRANN_ARIMA is proposed as a new approach for hybridizing linear and nonlinear models. Unlike conventional hybrid models, the proposed model has few integrated features such as those engaged with multivariate time-series data, GRA as a feature selection to remove irrelevant input data, and subsequently, altering the sequence of hybridization. To verify the effectiveness of the proposed hybrid model, several comparisons have been conducted through a few experiments on two different types of time-series data with different scales of data. As a summary, our research findings demonstrate several advantages compared to the previous hybrid model and the well-accepted benchmark individual models, and these can be summarized below:
-
GRANN can perform better than multiple regressions in handling multivariate time-series data due to ANN's effectiveness in modeling and forecasting nonlinear time-series with or without noise (Chi, Citation1998; Uysal and Roubi Citation1999; Prerez et al. Citation2004). Hence, ANN is used as a multivariate modeller in our proposed model.
-
The forecasting accuracy of the proposed hybrid model, GRANN_ARIMA, is better compared to the individual model—GRANN, ARIMA, MR, and second-order error, LVM. This result conforms to the outcome from previous studies due to the hybridizing of two dissimilar models that will reduce the forecasting error (Zhang, Citation2003; Zhang and He Citation2005).
-
Altering the sequence of hybrid models will improve the forecasting accuracy. A hybrid model with a changing sequence of hybridization (Hybrid II) is outperformed by the Hybrid I and a conventional hybrid.
-
Altering the sequence of hybrid models will decrease the probability of overfitting problems occurring in the conventional hybrid model, ARIMA_ANN.
-
The forecasting value of GRANN_ARIMA is more accurate compared to the hybrid linear MARIMA model since it can handle both linear and nonlinear patterns equally well in time-series data.
-
The forecasting error produced by GRANN_ARIMA is the smallest compared to other models that are tested in this study.
-
Overall, GRANN_ARIMA outperformed the individual and conventional hybrid model in both small-scale data and large-scale data. Therefore, it could be assumed that GRANN_ARIMA is more robust.
-
GRANN_ARIMA can also predict the behavior of the data better than MR, MARMA, LVM, and the Hybrid I model.
In this study, complex time-series data is explored; it can however, be extended to simple and seasonal time-series data. Although this method proves to be effective for practical application by the case study in agricultural data and finance data, we believe that its procedure and mechanism has a universal significance and can be extended to other application problems such as in science, engineering, and social fields. In the meantime, in contrast to individual models, the hybrid modeling process is somewhat complicated and time-consuming. However, this limitation does not seem to be insignificant due to the rapid improvement of computer technologies. In conclusion, the proposed approach for hybridizing linear and nonlinear models, GRANN_ARIMA can be used as an alternative tool for forecasting time-series data for better forecasting accuracy.
This work is supported by Universiti Teknologi Malaysia, Johor Bahru Malaysia. Authors would like to thank Soft Computing Research Group (SCRG), for their continuous support and devotion in making this study a success. Many thanks go to the reviewers for their insightful comments and for suggesting many helpful ways to improve this article.
Notes
na, not applicable; model cannot be developed.
Legend: GRANN_AR: GRANN_ARIMA.
Related Research Data
REFERENCES
- Abraham , A. 2002 . Intelligent systems: Architectures and perspectives, recent advances in intelligent paradigms and applications . A. Abraham , L. Jain , and J. Kacprzyk . eds., Studies in Fuzziness and Soft Computing , pp. 1 – 35 . Germany : Springer Verlag .
- Abraham , A. , C. Grosan , and C. Martin-Vide . 2007 . Evolutionary design of intrusion detection programs . International Journal of Network Security 4 ( 3 ): 328 – 339 .
- Abraham , A. and B. Nath . 2001 . A neourofuzzy approach for modeling electricity demand in victoria . Applied Soft Computing Journal 1 : 127 – 138 .
- Ali , J. and M. Al-Mahmeed . 2002 . Neural networks: predicting kuwaiti KD currency exchange rates versus U.S dollar . Arab Journal of Administrative Sciences . 6 : 17 – 35 . Rao , C. P. and A. Jafar . Neural network model for database marketing in the new global economy . Marketing Intelligence & Planning 20 ( 1 ): 35 – 43 .
- Armstrong , J. S. 2001 . Long Range Forecasting: From Crystal Ball to Computer. (2nd ed.) . New York : Wiley .
- Bates , J. M. and C. W. J. Granger . 1969 . The combination of forecasts . Operational Research Quarterly 20 : 451 – 468 .
- Besseler , D. A. and J. A. Brandt . 1981 . Forecasting livestocks prices with individual and composite methods . Applied Economics 13 : 513 – 522 .
- Bowermann , B. L. and R. T. O'Connel . 1993 . Forecasting and Time Series: An Applied Approach . Duxbury Pacific Grove , CA , Boston , Duxbury Press .
- Box , G. E. P. and G. Jenkins . 1982 . Some practical aspects of forecasting in organization . Journal of Forecasting I pp. 3 – 21 .
- Brace , M. C. , J. Schmidt , and M. Hadlin . 1991. Comparison of the forecasting accuracy of neural networks with other established techniques. In: Proceedings of the First Forum on Application of Neural Network to Power Systems . pp. 31–35. Seattle , WA,
- Caire , P. , G. Hatabian , and C. Muller . 1992 . Progress in forecasting by neural networks . In: Proceedings of the International Joint Conference on Neural Networks 2 : 540 – 545 .
- Chaivivatrakul , S. and S. Somhom . 2004 . Vegetable product forecasting system by adaptive genetic algorithm . TENCON 2004. 2004 IEEE Region 10 Conference , Vol. B , pp. 211 – 214 .
- Chatfield , C. 2001 . Time Series Forecasting . Boca-raton , FL : Chapman & Hall/CRC Press .
- Chebrolu , S. , A. Abraham , and J. Thomas . 2005 . Feature deduction and ensemble design of intrusion detection systems. Computers and Security . Elsevier Science 24 ( 4 ): 295 – 307 .
- Chi , F.-L. 1998 . Forecasting tourism: A combined approach . Tourism Management 19 ( 6 ): 515 – 520 .
- Chiang , B.-C. , S.-L. Tsai , and C.-C. Wang . 2000 . Machine Vision-Based gray relational theory applied to IC marking inspection . IEEE Transactions on Semiconductor Manufacturing 15 ( 4 ).
- Chu , C. W. and G. P. Zhang . 2003 . A comparative study of linear and nonlinear models for aggregates retail sales forecasting . International Journal of Production Economics 86 ( 3 ): 217 – 231 .
- De Gooijer , J. G. and R. J. Hyndman . 2006 . 25 Years of time series forecasting . International Journal of Forecasting 22 : 443 – 473 .
- Delen , D. , G. Waller , and A. Kadam . 2005 . Predicting breast cancer survivability: A comparison of three data mining methods . Artificial Intelligence in Medicine 34 : 113 – 127 .
- Deng , J. L. 1989 . Introduction to grey system theory . The Journal of Grey System 1 : 1 – 24 .
- Deng , J. L. 1982 . Control problems of grey systems . Systems and Control Letters 5 : 288 – 294 .
- Denton , J. W. 1995 . How good are neural networks for causal forecasting? The Journal of Business Forecasting 14 ( 2 ): 17 – 20 .
- Díaz-Robles , L. A. , J. C. Ortega , J. S. Fu , G. D. Reed , J. C. Chow , J. G. Watson , and J. A. Moncada-Herrera . 2008 . A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas . The Case of Temuco, Chile, Atmospheric Environment 42 ( 35 ): 8331 – 8340 .
- Dorganis , P. , A. Alexandidi , P. Patrinos , and H. Sarinevers . 2006 . Time series sales forecasting for short shelf-life food products based on artificial neural networks and evolutionary computing . Journal of Food Engineering 75 : 196 – 204 .
- Fu , C. , J. Zheng , J. Zhao , and W. Xu . 2001 . Application of grey relational analysis for corrosion failure of oil tubes . Corrosion Science 43 : 881 – 888 .
- Ganeta , R. , L. M. Romeo , and A. Gill . 2006 . Forecasting of Electricity prices with neural networks . Energy Conversion and Management 47 : 1770 – 1778 .
- Goodwin , P. 2000 . Correct or combine: Mechanically integrating judgmental forecasts with statistical methods . International Journal of Forecasting 16 : 261 – 275 .
- Gorr , W. L. , D. Nagin , and J. Szcypula . 1994 . Comparative study of artificial neural network and statistical models for predicting student grade point averages . International Journal of Forecasting 10 : 17 – 34 .
- Granger , C. W. J. 1993 . Strategies for modeling nonlinear time series relationships . The Economic Record 69 ( 206 ): 233 – 238 .
- Hamid , S. A. and Z. Iqbal . 2004 . Using neural networks for forecasting volatility of S& P 500 index futures prices . Journal of Business Research 57 ( 10 ): 1116 – 1123 .
- Heravi , S. , D. R. Osborn , and R. Birchenhallc . 2004 . Linear versus neural network forecasting for European industrial production series . International Journal of Forecasting 20 : 435 – 446 .
- Hippert , H. S. , C. E. Pedreira , and R. C. Souza . 2001 . Neural networks for short-term load forecasting: A review and evaluation . IEEE Transactions on Power Systems 16 ( 1 ): 44 – 45 .
- Hou , Z. , Z. Lian , Y. Yao , and X. Yuan . 2006 . Cooling-load prediction by the combination of rough set theory & artificial neural network based on data fusion technique . Applied Energy 83 : 1033 – 1046 .
- Jain , A. and A. M. Kumar . 2007 . Hybrid neural network models for hydrologic time series forecasting . Applied Soft Computing 7 ( 2 ): 585 – 592 .
- Jones , S. S. , R. S. Evans , J. L. Allen , A. Thomas , P. J. Haung , S. J. Welch , and G. L. Snow . 2008 . A Multivariate time series approach to modeling and forecasting demand in emergency department . Journal of Biomedical Informatics 4 ( 1 ): 103 – 139 .
- Kang , S. 1991 . An investigation of the used of feedforward neural networks for forecasting . PhD thesis . Ohio : Kent State University , Kent, OH .
- Lachtermacher , G. and J. D. Fuller . 1995 . Backpropagation in time series forecasting . Journal of Forecasting 14 : 381 – 393 .
- Li , Y. , A. Li , R. Li , L. Wei , and S. Qin . 2003. Study on characteristics of biomass pyrolysis gas in view of grey relation analysis and BP neural network. ACTA Energies Solaris Sinica 24(6):776–780.
- Lin , S. J. , I. J. Lu , and C. Lewis . 2007 . Grey relation performance correlations among economics, energy use and carbon dioxide emission in Taiwan . Energy Policy 35 : 1948 – 1955 .
- Lu , J.-C. , D.-X. Niu , and Z.-L. Jia . 2004 . A study of short term load forecasting based on ARIMA-ANN. Proceedings of the Third International Conference on Machine Learning and Cybernetics. August, pp. 26–29. Shanghai. .
- Ma , L. and K. Khorasani . 2004 . New training strategies for constructive neural networks with application to regression problem . Neural Network 17 : 589 – 609 .
- Makridakis , S. and S. C. Wheelwright . 1989 . Forecasting Methods for Management. , 5th ed. , New York : John Wiley and Sons .
- Makridakis , S. 1993 . Accuracy measures: Theoretical and practical concerns . International Journal of Forecasting 9 : 527 – 529 .
- Makridakis , S. , A. Anderson , R. Carbone , R. Fildes , M. Hibdon , R. Lewandowski , J. Newton , E. Parzen , and R. Winkler . 1982 . The accuracy of extrapolation (time series) methods: Results of a forecasting competition . Journal of Forecasting 1 : 111 – 153 .
- McLeod , A. I. and W. K. Li . ( 2004 ). Diagnostic checking ARMA time series model using squared residual autocorrelations . Journal of Time Series Analysis 4 : 269 – 273 . In: S. Heravi, D.-R. Osborn, and C. R. Birchenhall, eds. Linear versus neural network forecasts for European industrial production series. International Journal of Forecasting 20:435–446.
- Mentzer , J. T. and C. C. Bienstock . 1998 . Sales Forecasting Management . Thousand Oaks , CA : Sage Publications .
- Newbold , P. and C. W. J. Granger . 1974 . Experience with forecasting univariate time series and combination of forecast . Journal of the Royal Statistical Society Series A 137 : 131 – 149 .
- Nikolopoulos , K. , P. Goodwin , A. Patelis , and V. Assimakopoulos . 2007 . Forecasting with cue information: A comparison of multiple regression with alternative forecasting approaches . European Journal of Operational Research 180 : 354 – 368 .
- Pai , P. F. and C.-S. Lim . 2005 . A hybrid ARIMA and support vector machines model in stock price forecasting . Omega 33 : 497 – 505 .
- Parzen , E. and R. Winkler . 1982 . The accuracy of extrapolation (time series) methods: Results of a forecasting competition . Journal of Forecasting 1 : 111 – 153 .
- Prerez , S. M. , M. H. Ortega , M. L. Gonzalez , and Z. Boger . 2004 . Comparative study of artificial neural network and multivariate methods to classify spanish do rose wines . Talanta 62 : 983 – 990 .
- Rao , C. P. and J. Ali . 2002 . Neural network model for database marketing in the new global economy . Marketing Intelligence & Planning 20 ( 1 ): 35 – 43 .
- Reid , D. J. 1968 . Combining three estimates of gross domestic product . Economica 35 : 431 – 444 .
- Sallehuddin , R. , M. Shamsuddin , and N. M-Yusof . 2008a . Artificial neural network time series modeling for revenue forecasting . Chiang Mai Journal of Science 35 ( 1 ): 1 – 16 .
- Sallehuddin , R. , S. M. Shamsuddin , and S. Z. M. Hashim . 2008b . Application of grey relational analysis for multivariate time series . Eight International Conference on Int. System Design and Application pp. 432–437. .
- Shamsuddin , M. N. 1992 . A short note on forecasting natural rubber prices using a MARMA . The Malaysian Journal of Agricultural Economic 9 : 59 – 68 .
- Shamsuddin , M. N. and F. M. Arshad . 1990 . Composite model for short term forecasting for natural rubber prices . Pertanika 12 ( 2 ): 283 – 288 .
- Shouyang , W. , W. Y. Lean , and K. K. Lai . 2005 . Crude oil price forecasting with TEI@Imethodology . Journal of Systems Science and Complexity 18 ( 2 ): 145 – 166 .
- Srinivasulu , S. and A. Jain . 2006 . A comparative analysis of training methods for ANN rainfall-runoff models . Applied Soft Computing 6 : 295 – 306 .
- Taskaya-Termizel , T. and M. C. Casey . 2005 . A comparative study of autoregressive neural network hybrids . Neural Networks 18 ( 5–6 ): 781 – 789 .
- Taskaya-Termizel , T. and K. Ahmad 2005 . Are ARIMA neural network hybrids better than single models? . In: Proceeding of International Joint Conference On NNs (IJCN 2005) . Montreal , Canada .
- Taylor , J. W. 2003 . Short term electricity demand forecasting using double seasonal exponential smoothing . Journal of The Operational Research Society 54 : 799 – 805 .
- Tosun , N. 2005 . Determination of optimum parameters for multi-performance characteristics in drilling by using grey relational analysis . International Journal of Advance Manufacturing Technology 28 ( 5–6 ): 400 – 455 .
- Tseng , F.-M. , H.-C. Yu , and G.-H. Tzeng . 2002. Combining neural network model with seasonal time series ARIMA model. Technological Forecasting and Social Change 69:71–87.
- Uysal , M. and M. Roubi . 1999 . Artificial neural network versus multiple regression in tourism demand analysis . Journal of Travel Research 38 : 111 – 118 .
- Voort , V. D. , M. Dougherty , and M. Watson . 2005 . Combining Kohonen maps with ARIMA time series models to forecast traffic flow . Transp. Resc. Circ. (Emerge Techno) (1996) 4C(5):307–308; 8:18–21, August, 4764–4769. .
- Xiao , Z. , S.-J. Ye , B. Zhang , and C.-S. Sun . 2007 . BP neural network with rough set for short term load forecasting . Expert Systems with Applications 36 ( 1 ): 273 – 279 .
- Yang , H. Y. , H. Ye , G. Wang , J. Khan , and T. Hu . 2006 . Fuzzy neural very short term load forecasting based on chaotic dynamics reconstruction . Chaos, Solitons & Fractals 29 : 462 – 469 .
- Young , P. 1993 . Technological growth curves – A comparison of forecasting model . Technological Forecasting and Social Change 44 : 375 – 389 .
- Zhang , G. P. 2003 . Time series forecasting using a hybrid ARIMA and neural network model . Neurocomputing 50 : 159 – 175 .
- Zhang , G. P. and M. Qi . 2005 . Neural network forecasting for seasonal and trend time series . European Journal of Operation Research 160 : 501 – 504 .
- Zhang , G. P. 2004 . Neural Networks in Business Forecasting . London , UK , Idea Group Publishing Press .
- Zhang , G. P. , B. E. Patuwo , and M. Y. Hu . 1998 . Forecasting with artificial neural networks. The state of the art . International Journal of Forecasting 14 ( 1 ): 35 – 62 .
- Zhang , G. P. , B. E. Patuwo , and M. Y. Hu . 2001 . A simulation study of artificial neural networks for nonlinear time-series forecasting . Computers & Operations Research 28 : 381 – 396 .
- Zhang , Y. and Y. He . 2005 . Study of prediction model on grey relational BP neural network based on rough set . In: Proceedings of The Fourth International Conference on Machine Learning and Cybernetics . Guangzhou , China , pp. 4764 – 4769 .
- Zou , H. F. , G. P. Xia , F. T. Yang , and H. Y. Wang . 2007 . An investigation and comparison of artificial neural network and time series models for Chinese food grain price forecasting . Neurocomputing , 70 ( 16–18 ): 2913 – 2923 . doi:10.1016/j.neucom.2007.01.009. .