Abstract
Cardiovascular disease is a chronic disease and an ongoing threat to human health. Clinical data, including chemistry analysis data and electrocardiogram (ECG) data for heartbeat behavior, are commonly used to classify the cardiovascular diseases in supporting medical diagnosis. This study proposes a new approach for enhancing rough set classifier which applied to diagnose cardiovascular disease. Two datasets were used in this empirical case study to illustrate the proposed approach. Due to its improved accuracy and fewer rules, the proposed approach is superior to listing methods.
Cardiovascular disease is one of many chronic diseases that seriously threatens human health. Cardiovascular disease is a general term encompassing several kinds of heart conditions including stroke, coronary, and hypertensive, inflammatory, and rheumatic. Primary factors attributed to cardiovascular disease include high blood pressure, tobacco use, high cholesterol, alcohol, and obesity. The clinical chemistry analysis data and heartbeat behavior from ECG data can help clinicians diagnose cardiovascular disease. A rough set is a predictive data mining tool that incorporates vagueness and uncertainty and can be applied in artificial intelligence and knowledge discovery in databases. A rough set has been successfully applied in many different fields, particularly the medical field, where it has been used since the late 1980s (Smith and Everhart, Citation1988). A rough set investigates structural relationships in data rather than probability distributions and produces decision tables rather than trees (Ziarko, Citation1991).
The discretization of continuous attributes is a problematic aspect of data mining, especially in rough set and classification problems. Rough set classifiers usually apply the concept of rough set to reduce the number of attributes in a decision table (Pawlak, Citation1991), and data discretization is used to find the cut points for attributes. By this method, the initial decision table is converted to one with less complex binary attributes without compromising key information. In healthcare, early detection of cardiovascular disease can reduce the medical costs. This study therefore focuses on improving methods of classifying cardiovascular disease. A new approach is proposed to enhance a rough set classifier for classifying problems. Two datasets are used in this empirical case study to illustrate the proposed approach: the arrhythmia dataset from the UCI repository of machine-learning and a practical collected dataset containing chemistry analysis data for 1068 patients.
RELATED WORKS
This section reviews related studies of cardiovascular disease, the rough set theory, the learning from examples module, version 2 (LEM2) rule extraction method, the filter rule method, and the modified minimize entropy principle approach.
Cardiovascular Disease
Cardiovascular disease, which is a common chronic disease that seriously threatens human health, is a general term encompassing several kinds of heart conditions, specifically, stroke, coronary, hypertensive, inflammatory, and rheumatic. The majority of fatalities are attributable to stroke and coronary heart disease (Mackay and Mensah, Citation2004). Primary risk factors for cardiovascular disease include high blood pressure, tobacco use, high cholesterol, alcohol, and obesity.
According to the World Health Organization (WHO) standards, high density lipoprotein (HDL) and low density lipoprotein (LDL) are the primary indicators of a dangerous condition, particularly LDL ≥130 mg/dL of HDL ≤35 mg/dL. Clinical chemistry analysis data can help clinicians classify diabetes and cardiovascular diseases (Ergun et al., Citation2004). However, biochemical testing has not included all items because of the cost and opinions of doctors (Nesto, Citation2004). Use of clinical data is important for classifying cardiovascular diseases to supporting medical diagnosis.
Rough Set
Rough set theory, first proposed by Pawlak (Citation1982), employs mathematical modeling to deal with data classification problems. Rough set addresses the continuing problem of vagueness by applying the concept of equivalence classes to partition training instances according to specified criteria. Two partitions are formed in the mining process. The members of the partition can be formally described by unary set-theoretic operators or by successor functions for upper and lower approximation spaces from which both possible rules and certain rules can be easily derived (Pawlak and Skowron, Citation2007).
Let B ⊆ A and X ⊆ U be an information system. The set X is approximated using information contained in B by constructing lower and upper approximation sets:
The elements in B ∗(X) can be classified as members of X by the knowledge in B. However, the elements in B∗(X) can be classified as possible members of X by the knowledge in B. The set BN B (x) = B∗(X) − B ∗(X) is called the B-boundary region of X and it consists of those objects that cannot be classified with certainty as members of X with the knowledge in B. The set X is called “rough” (or “roughly definable”) with respect to the knowledge in B if the boundary region is nonempty. Rough set theoretic classifiers usually apply the concept of rough set to reduce the number of attributes in a decision table (Pawlak, Citation1991) and to extract valid data from inconsistent decision tables. Rough set also accepts discretized (symbolic) input.
Rule Extraction and Filter
Rough set rule induction algorithms were implemented for the first time in a learning from examples (LERS) (Grzymala-Busse and Slowinski, Citation1992) system. A local covering is induced by exploring the search space of blocks of attribute-value pairs which are then converted into the rule set. The algorithm LEM2 (Grzymala-Busse, Citation1997) for rule induction is based on computing a single local covering for each concept from a decision table.
Rough set-mediated rule sets usually contain large numbers of distinct rules. The large number of rules limits the classification capabilities of the rule set as some rules are redundant or of “poor quality.” Some rule-filtering algorithms can be used to reduce the number of rules (Nguyen and Nguyen, Citation2003). For example, a rule filtering solution may be based on the computed quality indices of rules in a rule set. The quality index of each rule is computed using a specific rule quality function, which determines the strength of a rule based on the measure of support, consistency, and coverage (Agotnes, Citation1999). The upper approximation of minimal is determined by removing some rules from the input rule set ℜ. The heuristic is based on the assumption that the strongest rules are preferred to form the minimal coverage set. The heuristic algorithm proposed here does not seek the minimal solution for efficiency reasons. First, in the initialization step all rules are marked as “unused.” For each object, strongest rules that cover it are identified and marked to join the resulting set. The remaining rules that are not used in the covering process are filtered out.
Modified Minimum Entropy Principle Approach (MEPA)
A key goal of entropy minimization analysis is to determine the quantity of information in a given dataset. The entropy of a probability distribution is a measure of the uncertainty of the distribution (Yager and Filev, Citation1994). To subdivide the data into membership functions, the threshold between classes of data must be established. A threshold line can be determined with an entropy minimization screening method. The segmentation process starts with two classes. Thus, repeated partitioning with threshold value calculations allows further partition of the dataset into a number of fuzzy sets (Ross, Citation2004).
Assume that a threshold value is being sought for a sample ranging between x1 and x2. An entropy equation is written for the regions [x1, x] and [x, x2]; the first region is denoted p and the second region is denoted q. Entropy with each value of x are expressed as (Christensen, Citation1980):
The entropy estimates of p k (x) and q k (x), p(x) and q(x), are calculated as follows (Yager and Filev, Citation1994):
-
n k (x) = number of class k samples located in [x1, x1 +x]
-
n(x) = the total number of samples located in [x1, x1 +x]
-
N k (x) = number of class k samples located in [x1 +x, x2]
-
N(x) = the total number of samples located in [x1 +x, x2]
-
n =total number of samples in [x1, x2].
Figure illustrates the partitioning process. While moving x in the region [x1, x2], the values of entropy for each position of x are calculated. The value of x in the region holding the minimum entropy is called the primary threshold (PRI) value. By repeating this process, secondary threshold values denoted as SEC1 and SEC2 can be determined. Developing seven partitions requires tertiary threshold values denoted as TER1, TER2, TER3, and TER4 (Ross, Citation2004).
FIGURE 1 Partitioning process of minimize entropy principle approach.
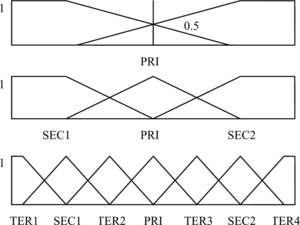
Chen and Cheng (Citation2008) modified the MEPA to improve the accuracy rate and reduce the number of rules in the decision tree. Unlike other methods, entropy-based discretization can reduce data size by using class information that makes it more likely. The interval boundary points are computed by MEPA to improve the accuracy of classification. Due to the excellent performance of the Chen and Cheng method, the current study applies their approach in a reinforced rough set classifier.
THE PROPOSED APPROACH
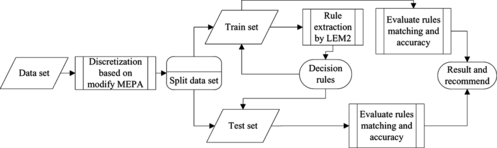
In this section, a new approach is proposed to reinforce the quality of a rough set classification system. Figure illustrates the research procedure.
FIGURE 2 Research procedure.
The Wisconsin Breast Cancer dataset (Newman et al., Citation1998) is analyzed to demonstrate the proposed approach. The dataset contains 699 instances that are characterized by the following attributes: (1) clump thickness, (2) uniformity of cell size, (3) uniformity of cell shape, (4) marginal adhesion, (5) single epithelial cell size, (6) bare nuclei, (7) bland chromatin, (8) normal nucleoli, and (9) mitoses. All attributes are assigned integer values. The dataset includes two classes—benign (458, 65.5%) and malignant (241, 34.5%)—and 16 missing values. Hence, all 16 instances are removed.
The proposed approach can be expressed as follows:
Algorithm 1 The proposed_approach procedure
TABLE 1 Thresholds of All Attributes in the Breast Cancer Dataset
-
Step 1: Partition continuous attributes by modified MEPA. From the number of general cut (Bazan et al., Citation2000), entropy values of each datum are computed using the entropy equation proposed by modified MEPA. By repeating this procedure to subdivide the data, the cut-off points can be obtained. As Table shows, if n(x) and N(x) equal zero, then stop the subdivision of the data in the range.
-
Step 2: Build membership function. Cut-off points (derived Step 1) are used as the midpoint of membership function. When the attribute value is lower than SEC1, then the membership degree equals 1. The same is true when the attribute value exceeds SEC2. Figure illustrates the membership function of the modified MEPA approach.
-
Step 3: Fuzzify the continuous data into the unique corresponding linguistic value. According to the membership function in Step 2, the maximal degree of membership for each datum is calculated to determine its linguistic value.
Algorithm 2 shows the discretization process in detail. This procedure returns a linguistic dataset by using modified MEPA to convert discretized continuous data into unique corresponding linguistic value.
-
Step 4: Extract rules by LEM2. Using Algorithm 3 (LEM2) and the linguistic values derived in Step 3, decision rules can be produced. Table shows partial rules.
-
Step 5: Improve rule quality by rule filtering. From the rule set extracted in Step 4, a filtering process is guided by Algorithm 4. The support threshold is used to eliminate the rules with low support. Table lists a performance comparison of the refined rules.
FIGURE 3 Membership function of Clump_Thickness.
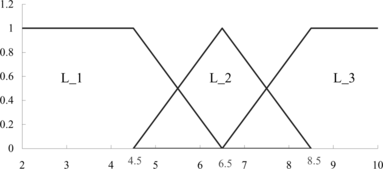
TABLE 2 Breast Cancer Dataset Result Rule Set Example Using LEM2
Algorithm 3 The LEM2 procedure
Algorithm 4 The FILTER procedure
TABLE 3 Result of Proposed Approach and Rough Set Approach
Algorithm 2 The discretization procedure
As Table (last column) indicates, the accuracy rate for the 27.7 refined rules is 98.3%. This outcome demonstrates the proposed approach outperforms listing methods.
EMPIRICAL CASE STUDY
For empirical analysis, two datasets were used to verify the proposed method: an UCI arrhythmia dataset and a practical collected dataset (cardiovascular disease dataset).
UCI Arrhythmia Dataset
The arrhythmia dataset was taken from the UCI repository of machine-learning (Newman, Hettich, Blake, and Merz, Citation1998). The task here was to distinguish normal from abnormal heartbeat behavior based on the ECG data described by 279 numeric and binary attributes. The data was slightly modified for ease of use. Attribute number 14 (“J”) was missing in most records, so this attribute was removed. The dataset included 452 instances and 32 missing values in different attributes. Therefore, those instances were removed, leaving 420 instances described with 278 attributes in 16 classes.
The dataset was split into two subdatasets: 66% of the dataset was used as a training set, and the other 34% was used as the testing set. The experiment of 66% and 34% random split was repeated three times. Table displays the accuracy rate of the rule filter with standard deviation, comparison of different methods applying to the same data.
TABLE 4 UCI Arrhythmia Dataset Experiment Result
Cardiovascular Disease Dataset
This dataset contained the following clinical chemistry analysis data for 1068 patients: (1) age; (2) gender; (3) triglyceride (TG); (4) HbA1c: glycated hemoglobin; (5) high density lipoprotein (HDL); (6) low density lipoprotein (LDL); (7) GLUAC: Fasting plasma glucose. All these attributes are integer values. The dataset included four classes: T1: Diabetes; T2: Cardiovascular Disease; T3: Hypertension; and T4: Hyperlipidemia. Ten instances were removed from the dataset due to missing values.
The dataset was split into two subdatasets: the 66% dataset was used as a training set, and the other 34% was used as a testing set. The experiment was repeated three times with the 66%/34% random split. Table presents the accuracy rate performed of the rule filter with standard deviation. The accuracy rate and number of rules demonstrate that the proposed approach outperforms the listing methods.
TABLE 5 Result of Cardiovascular Disease Dataset
CONCLUSIONS
A reinforced rough set theory based on modified MEPA for solving classification problems was proposed. The empirical results of three datasets indicate that the proposed approach outperforms the listing methods because of its accuracy and reduced number of rules. Specifically, the proposed method surpasses the listing method for three reasons:
-
The modified MEPA method discretizes attributes based on outcome class by using the entropy equations to determine thresholds and then subdividing the intervals by minimum entropy values. This method demonstrates good performance in rule-base classification (Chen and Cheng, Citation2008).
-
Although extracting rules based on rough set LEM2 are superior because they deduce rule sets directly from data with symbolic and numerical attributes, LEM2 requires prediscretized data. Therefore, modified MEPA can be incorporated into LEM2 to enhance rough set classification.
-
Algorithm 4 in the proposed method, which eliminates rules with low support, refines the extracted rules by reducing the number of rules without compromising accuracy.
The proposed approach can be used to classify cardiovascular diseases by analyzing clinical chemistry analysis data, which would improve accuracy of diagnosis and clinical treatment as well as reduce potential risks. Moreover, the results may be useful for system development and further research.
DECLARATION OF INTEREST
The authors declare no conflict of interest related to the content of this article.
Notes
Note: The NA denotes no given the answer in this method.
Note: The NA denotes no given the answer in this method.
Note: The NA denotes no given the answer in this method.
REFERENCES
- Agotnes , T. 1999 . Filtering large propositional rule sets while retaining classifier performance. Master's Thesis, Department of Computer and Information Science. Norwegian University of Science and Technology. .
- Bazan , J. , H. S. Nguyen , S. H. > Nguyen , P. Synak , J. Wróblewski , L. Polkowski , and T. Y. Lin . 2000 . Rough set algorithms in classification problem . In: Rough Set Methods and Applications . Heidelberg : Physica-Verlag .
- Bazan , J. and M. Szczuka . 2001 . RSES and RSESlib – A collection of tools for rough set . Lecture Notes in Computer Science 2005 : 106 – 113 .
- Chen , J. S. and C. H. Cheng . 2008 . Extracting classification rule of software diagnosis using modified MEPA . Expert Systems with Applications 34 : 411 – 418 .
- Christensen , R. 1980 . Entropy Minimax Sourcebook, General Description . Lincoln MA : Entropy Limited .
- Ergun , U. , S. Serhathoglu , F. Hardalaç , and I. Guler . 2004 . Classification of carotid artery stenosis of patients with diabetes by neural network and logistic regression . Computers in Biology and Medicine 34 : 389 – 405 .
- Grzymala-Busse , J. W. 1997 . A new version of the rule induction system LERS . Fundamenta Informaticae 31 : 27 – 39 .
- Grzymala-Busse , J. W. and R. Slowinski . 1992 . LERS – A system for learning from examples based on rough sets . In: Intelligent Decision Support: Handbook of Applications and Advances in Rough Set Theory . Dordrecht , Boston , London : Kluwer Academic Publishers .
- Mackay , J. and G. Mensah . 2004 . The Atlas of Heart Disease and Stroke , edited by World Health Organization, Geneva.
- Nesto , R. W. 2004 . Correlation between cardiovascular disease and diabetes mellitus: Current concepts . The American Journal of Medicine 116 : 11 – 22 .
- Newman , D. J. , S. Hettich , C. L. Blake , and C. J. Merz . 1998. UCI Repository of Machine Learning Databases. http://www.ics.uci.edu/~mlearn/. Last accessed July 25, 2007..
- Nguyen , H. S. and S. H. Nguyen . 2003 . Analysis of STULONG data by rough set exploration system (rses) . Proceedings of ECML/PKDD-2003 Discovery Challenge Workshop . Cavtat-Dubrovnik , Croatia .
- Pawlak , Z. 1982 . Rough sets . International Journal of Information and Computer Sciences 11 : 341 – 356 .
- Pawlak , Z. 1991 . Rough Sets, Theoretical Aspects of Reasoning about Data . Dordrecht , Netherlands : Kluwer Academic Publishers .
- Pawlak , Z. and A. Skowron . 2007 . Rudiments of rough sets . Information Sciences 177. .
- Platt , J. C. , B. Scholkopf , C. Burges , and A. J. Smola . 1999 . Fast training of support vector machines using sequential minimal optimization . In: Advances in Kernel Methods – Support Vector Learning . Cambridge , MA : MIT Press .
- Polat , K. , S. Sahan , and S. Günes . 2006 . A new method to medical diagnosis: Artificial immune recognition system (AIRS) with fuzzy weighted pre-processing and application to ECG arrhythmia . Expert Systems with Applications 31 : 264 – 269 .
- Ross , T. J. 2004 . Fuzzy Logic with Engineering Applications . New York : John Wiley & Sons, Ltd .
- Smith , J. W. and J. E. Everhart . 1988 . Using the ADAP learning algorithm to forecast the onset of diabetes mellitus . Proceedings of the Symposium on Computer Applications and Medical Care , Los Angeles , CA .
- Yager , R. and D. Filev . 1994 . Template-based fuzzy system modeling . Intelligent and Fuzzy System 2 : 39 – 54 .
- Ziarko , W. 1991 . The discovery, analysis, and representation of data dependencies in databases . In: Knowledge Discovery in Databases . Menlo Park , CA: AAAI Press , MIT Press .