Abstract
Question answering (QA) is a relatively new area of research. We took the approach of designing a question answering system that is based on question classification and document tagging. Question classification extracts useful information from the question about how to answer the question. Document tagging extracts useful information from the documents, which are used to find the answer to the question. We used different available systems to tag the documents. Our system classifies the questions using manually developed rules. An evaluation of the system is performed using Text REtrieval Conference (TREC) data.
There are many computer science innovations that make difficult tasks more manageable for people. Databases were developed to replace paper filing systems, which were difficult to manage. Faster processors are being developed for computers, so calculations that would take a day, take only seconds for a computer to complete. Question answering is one of the fields where a human task is being made easier.
The problem that question answering systems consider is given a set of documents and a question, find the answer to the question in that set of documents. This task would normally be performed by a human by indexing the collection of documents with an information retrieval system. Information retrieval systems, also known as search engines, are successful in retrieving documents, based on a query, from a collection of documents. Then when a question needs to be answered, a query will be created to retrieve documents relevant to the question. Finally, each document retrieved would be manually read until an answer to the question is found, or all the documents have been read. This method is time-consuming, and a correct answer could easily be missed by either an incorrect query, resulting in missing documents, or by careless reading. In addition the time needed for reading the documents might be wasted because the answer may not exist in any of the documents in the collection.
Question answering (QA) systems take in a natural language question, and return the answer from the set of documents if the answer can be found. Answer retrieval, rather than document retrieval, will be integral to the next generation of search engines. Currently, there is a website called AskJeeves,™Footnote 1 which attempts to retrieve documents to answer a question. This handles one of the problems a QA system has, but there is still the task of reading through the documents retrieved. Question answering systems will handle query creation and finding the exact entity that is the answer.
For example, if someone wants to know who shot Abraham Lincoln, without a QA system, she would first do a search on a relevant set of documents (i.e., the Internet) with a search engine. She would then formulate a query such as “Abraham Lincoln shot” to retrieve documents from the search engine. She would next read through the retrieved documents, then possibly change her search parameters, and try again if she was not happy with the retrieved documents. With a QA system she will just enter in the question, “Who shot Abraham Lincoln?”, and the system will retrieve the most probable answer.
Question answering systems employ information retrieval to retrieve documents relevant to the question, and then use information extraction techniques to extract the answer from those documents.
RELATED WORK
A QA system must analyze the question, extract answers from the set of documents, and then choose an answer to the question. Groups working on QA systems are trying new directions in QA research to see which methods provide the best results. The field of QA has been mainly driven by the TREC conferences, and most of the systems perform four steps: question analysis, passage retrieval, passage analysis, and answer ranking (Harabagiu, Maiorano, and Pasca, Citation2004). Usually research follow one of the following approaches: knowledge-based approach or statistical approach. Some QA systems use a knowledge base to compile information beforehand and using it later to answer questions (Kim, Kim, Lee, and Seo, Citation2001; Katz et al., Citation2003; Clifton and Teahan, Citation2004; Teahan, Citation2003). Some other systems attempt to form a logical representation of the question and the sentences that contain a possible answer. Then the answers could be found by matching the two representations looking for the missing information (Moldovan et al., Citation2002, Citation2004). Other systems use a multi-corpus to find the answers (Xu, Licuanan, May, Miller, and Weischedel, Citation2002; Lin, Fernandes, Katz, Marton, and Tellex, Citation2003; Wu et al., Citation2004; Chen, He, Wu, and Jiang, Citation2004). The most popular corpus that is used to try to improve answer finding is the Internet. There are many QA systems that are hybrid and use different methods of extracting and ranking answers: knowledge-based, pattern-based, and statistical-based (Echihabi et al., Citation2003; Jijkoun and de Rijke, Citation2004; Magnini, Negri, Prevete, and Tanev, Citation2002).
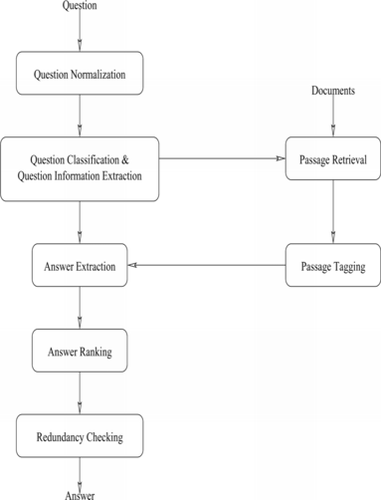
Compared to the previous works, we are considering improvements regarding the question classification and the documents tagging. Question classification can be performed in several ways. We chose the approach of analyzing a test bed of questions to manually infer extensive question categories and methods to classify questions. In order to aid in QA, document tagging involves extracting knowledge from the set of documents. This knowledge can be used with the knowledge from the question classification to answer questions. There are many ways to tag documents and many different systems out there that can be used to label the information in the documents. We are proposing to experiment with these different ways of tagging documents and how reliable they could be in extracting useful information for a QA system. The global architecture of our system is shown in Figure . Each of the modules in the system will be described later.
FIGURE 1 Model of our question answering system.
QUESTION NORMALIZATION
Before classifying the questions, our system changes some of the questions into a standard form that will be easier to classify. These changes are performed using regular expressions in Perl, but will be explained in algorithms to facilitate understanding the methods. We developed these normalizations because they will allow for more questions to be classified and handled similarly.
“s” Meaning “is”
Questions can be asked with 's after the question word meaning is. An example of this from the TREC corpus is:
Where's Montenegro' | |||||
The 's is changed to an is. The above example will be changed to “Where is Montenegro?”
“What” Factoid Normalization
There are many different ways to say the same thing. For example:
Name a film in which Jude Law acted. | |||||
Jude Law was in what movie? | |||||
Jude Law acted in which film? | |||||
What is a film starring Jude Law? | |||||
What film was Jude Law in? | |||||
What film has Jude Law appeared in? | |||||
These questions all require the same information, so they should all be treated the same. As well, they should all be classified as What questions, and more specifically, as What-Film questions. Question normalization is performed by changing the form of the question so that it gets classified into the correct category.
Our system will handle questions that involve the word which as a what question. This means, all questions that begin with Which, In which, and Of which are changed to What, In What, and Of what.
Questions, like the above examples, “Jude Law acted in which film?” and “Jude Law was in what movie?”, which do not start with a question word will be hard to classify later as a what question subcategory. For easier classification, these questions are changed to “What film was Jude Law acted in?” and “What movie was Jude Law in?”, which are not in proper English, but our system will answer this form better.
For this method, our system will first put a What at the beginning of the question, followed by the second half of the question, forming What movie in these examples. Then, was is added followed by the first half of the question, resulting in What movie was Jude Law acted in? The general rule is: the second half of the question followed by “was” followed by the first half of the question diminished by “was,” if it is there. Examples of questions this algorithm works on are:
Musician Ray Charles plays what instrument? to What instrument was Musician Ray Charles plays? | |||||
Ray Charles is best known for playing what instrument? to What instrument was Ray Charles is best known for playing? | |||||
The corpus callosum is in what part of the body? to What part of the body was the corpus callosum is in? | |||||
Boxing Day is celebrated on what date? to What date was Boxing Day is celebrated on? | |||||
Also, for any question starting with a preposition followed by the word what or which, the preposition is extracted. Another quick question reformulation is extracting the name of from questions that start with What was the name of or What is the name of. Examples of these are:
What is the name of the airport in Dallas Fort Worth? | |||||
What is the name of the chart that tells you the symbol for all chemical elements? | |||||
What is the name of Ling Ling's mate? | |||||
What is the name of the unmanned space craft sent to Mars by NASA? | |||||
What is the name of the Chief Justice of the Supreme Court? | |||||
“What” Definition Normalization
The definition questions could be stated in a standard form (“What is X?” or “Who is X?”), just by the target (“X”), or using formulation like why someone was famous, or what something was. We considered these questions to be definition questions for our system, and normalize all questions that wanted to know why someone was famous, or to define some target. The normalized form is “What is X?”, where X is the target, or “Who is X?”, where X is the target.
Examples of prenormalized who-definition questions are:
What is Francis Scott Key best known for? | |||||
What is Colin Powell best known for? | |||||
What is Betsy Ross famous for? | |||||
What is Giorgio Vasari famous for? | |||||
What is D.B. Cooper known for? | |||||
What is Archimedes famous for? | |||||
What is Jane Goodall famous for? | |||||
These questions will be changed to:
Who is Francis Scott Key? | |||||
Who is Colin Powell? | |||||
Who is Betsy Ross? | |||||
Who is Giorgio Vasari? | |||||
Who is D.B. Copper? | |||||
Who is Archimedes? | |||||
Who is Jane Goodall? | |||||
Examples of prenormalized what-definition questions are:
Define thalassemia. | |||||
What does ciao mean? | |||||
These are changed to:
What is thalessemia? | |||||
What is ciao? | |||||
“What” List Normalization
The list questions comprise the number of entities to be included in the list of answers. This is helpful in returning answers for these questions, so we extract the number, and reformat these questions to a similar format to other list questions. For each of these questions, the number is passed on to be used when the answer list is returned.
There were three patterns that the list questions were in:
List [NUMBER] | |||||
Name [NUMBER] | |||||
What are [NUMBER] | |||||
For these questions, these beginnings are taken out and are replaced with What. Examples of normalization of these questions are:
Name 10 autoimmune diseases. to What autoimmune diseases? | |||||
What are three currencies Brazil has used since 1980? to What currencies Brazil has used since 1980? | |||||
Name five diet sodas. to What diet sodas? | |||||
What are four United States national parks that permit snowmobiles? to What United States national parks that permit snowmobiles? | |||||
List 16 companies that manufacture tractors. to What companies that manufacture tractors? | |||||
QUESTION CLASSIFICATION
If we are to derive a method to extract information from questions, we first need a set of questions. The set of questions should be large enough for the classifications and categories to be meaningful. If we only use 10 questions to create classifications, our system will be less likely to classify as many questions than if we use a set of a million test questions.
The National Institute of Standards in Technology (NIST) has had a QA track in TREC from 1999 until now, and has included 2791 questions since then. We used these questions for the purpose of finding different categories and ways to classify questions, as well as ways for our system to go about answering them.
Our system puts questions into one of six categories:
When Questions | |||||
Who Questions | |||||
Where Questions | |||||
Why Questions | |||||
How Questions | |||||
What Questions | |||||
Notice that these do not include all the questions stems, since Which, Whom, and Name are not included in these categories. Any question that does not include one of the first five stems (Whom is considered as Who) is considered a what question. Questions are first classified into these categories by simple pattern-matching to see which question stem is applicable.
Once the questions are categorized, there are other rounds of classifications, but they are different for each stem. These rounds are detailed in Table , and the categories are more specific to the type of answer expected by the question. Classifying questions aids our system in finding the answer type of the question, as well as helping to create the query in which the documents will be retrieved from our information retrieval system.
TABLE 1 Question Categories
Our system classifies questions using rules that we derived through observation. Supervised machine-learning can also be used to classify questions, using methods similar to those outlined by Hermjakob (Citation2001) and Li and Roth (Citation2002). To do this, you start with a set of questions that have already been classified, then you use machine-learning to determine which patterns in the questions lead to certain classifications.
When using machine-learning, there needs to be a set of example data for the rules to be trained. This involves knowing which parts of the question are clues to how to classify them certain ways. When we manually classified the questions, we were able to discover these kinds of clues. Machine-learning may pick up on things it compiles as rules, but are not intuitively correct if looked at by a human. With the clues we learned from manually learning rules, we could more successfully train a system for classifying questions with machine-learning. Table outlines the categories that we built. Each category is accompanied with the pattern to recognize it, the type of the expected answer.
The what questions that are not easily classified by pattern-matching can be classified by discovering the focus of the question. The focus of the question is a clue about what type of entity the answer will be. In the question, “What country is the leading exporter of goats?”, the question focus is COUNTRY. The question focus is discovered by looking at chunked parts of speech-tagged questions. These focuses are then matched to a named entity, and that will be considered the answer type of the question. Table outlines all the focus that we discovered.
TABLE 2 Question Categories (continuation)
There is a subset of questions that have a focus which is unique and is not a named entity. For these questions, the hypernym set of WordNet is used to try and get a list of entities that are of the type of the focus.
PASSAGE RETRIEVAL
Question answering systems find the answer to a question in a collection of documents. In most cases, it is not feasible to process each document in a collection sequentially every time a new question is to be answered. An information retrieval (IR) system can be used to index the documents and allow a QA system to query the IR system, thus retrieving only the documents that are relevant to the question. We performed an indexing, using inverted files (Baeza-Yates and Ribeiro-Neto, Citation1999), on a paragraph basis by putting every paragraph in a separate document.
Once the documents are indexed, an information retrieval system allows you to retrieve documents relevant to a query. The two main ways to query the documents with an IR system are boolean and vector space.
Boolean queries will retrieve all documents from the indexed collection that fit the query. Boolean queries are made up of basic boolean operators: AND, OR, and NOT. In set notation, AND would be equivalent to the intersect of two sets, returning only elements that are common to both sets, OR would be equivalent to union, getting all items from both sets, and NOT would be elements from the first set that are not in the second set.
Vector space (Jurafsky and Martin, Citation2000) queries, also called vector-cosine, are a way of ranking documents based on a query. In this ranking method, the documents and query are represented as n dimensional vectors with each dimension representing a word in the query. The rank of the document for the query will be the cosine of the angle between the query vector and the document vector. The similarity between two vectors can be found as
When creating a query, a problem arises when the search is not specific enough, and the information retrieval system retrieves too many documents. For instance, for the question “How much money does the United States Supreme Court make?”, if United States is extracted, the query will retrieve 208,581 documents, which will contain too many unrelated terms of the same named entity as the answer type of the question. We consider 208,581 too many documents because, even if one-fourth of the documents contain the answer type of the question, that means there will be over 52,000 possible answers, with only a few of them related to the actual question.
There are three choices to solve this problem. One choice is to process all 208,581 passages. A second choice is to change the search from boolean to vector space, and to a certain number of documents. The third choice is to add words to the boolean query so fewer documents are returned. Processing all the documents is a poor alternative since there is a lower chance of finding the answer. If a vector space search is done, with topics such as United States, it will retrieve the documents with the most occurrences of United and States. This will eliminate documents based on the United States, instead of the question, so there is a chance that the documents eliminated will be question-related. The third choice is to find more words from the question to narrow the search. This will require development of a heuristic similar to Moldovan et al. (Citation1999) to discover which words will be more likely to be found in the document containing the answer. This method of going back and changing the query, based on the documents retrieved, is referred to as feedback loops and is discussed by Harabagiu et al. (Citation2001).
There are some sentences that do not contain proper nouns or dates, so other words should be considered to narrow down the documents retrieved. Moldovan et al. (Citation1999) discusses how verbs are unimportant to the query and should be left out. In WordNet 3.0, there are relations between verbs and nouns. This is useful when creating a query because you can expand a verb to include a noun representation of it, along with all the synonyms of it. In the question, “Who owns CNN?”, owns can be found to be derived from owner, proprietor, and possessor. This will be helpful if the answer is found in a sentence similar to “Ted Turner, owner of CNN, was at the White House today.”
Using other sets in WordNet, such as hypernym, hyponym, and synonym, the words from the question can be used to create a greater set of words that are associated with the question, and to retrieve documents relevant to the question. We query the documents using three methods:
Expanded Boolean Query | |||||
Important Word Boolean Query | |||||
Expanded Vector Space Query | |||||
In the expanded boolean query, we take all the nouns, verbs, and adjectives from the question that are not stop words, and find synonyms for each of them, using WordNet. We use these synonyms to form a query, where each word in the synonym set for a word is separated by OR, and each synonym set is separated by AND. Our system does not include the words contained in the question focus when creating the expanded query.
For example, if a question has two words that are extracted, say Word1 and Word2, and the synset for Word1 is S11 and S12 and the synset for Word2 is S21, S22, and S23, the boolean query will be: “(S11 OR S12) AND (S21 OR S22 OR S23).”
These queries are given to the collection we indexed with stemming and case folding such that all the forms of each word are used. This query ensures that all documents retrieved should be somehow related to the question. These queries are often too restrictive and retrieve no documents.
If the first method of querying retrieves no documents, then our system forms a boolean query with the proper nouns and dates from the question: important word boolean query. For instance, for the question which city hosted the 1988 Winter Olympics?, we perform the search using 1988 and Olympics. The query is done on the collection we indexed without stemming and case-folding because proper nouns and dates are normally not stemmed.
If there are no proper nouns or dates in the question, or the previous method retrieves too many documents (over 10,000), or no documents, then a vector space search is performed as previously explained.
DOCUMENT TAGGING
The document-tagging module of our system tags useful information from the passages retrieved by the information retrieval system. Our system uses information extraction techniques to extract useful information to help in QA. We utilized different outside systems to aid in tagging documents including:
WordNet (http://wordnet.princeton.edu) | |||||
OAK System (http://www.cs.nyu.edu/ | |||||
Lingpipe (http://www.alias-i.com/lingpipe) | |||||
Collins' Parser (http://people.csail.mit.edu/mcollins/code.html). | |||||
In this section, we present the following ways of tagging information in documents:
Tokenization and sentence splitting | |||||
Part of speech tagging | |||||
Chunked part of speech | |||||
Word sense tagging | |||||
Word dependency tagging | |||||
Named entity tagging | |||||
Co-reference resolution tagging. | |||||
Tokenization and Sentence Splitting
Before text is tokenized and split into sentences, it is just a string of characters. Tokenization is splitting a string of characters into lexical elements such as words and punctuation.
Sentence splitting separates the words and punctuations into their separate sentences. This involves a system probabilistically determining if certain punctuation, that can be used to finish a sentence, is in fact used to end the particular sentence. For example, a period can be used in an acronym and can also be used to end a sentence, or to be more complicated a sentence can end with an acronym with the last period performing both.
This is the first step before further processing can be done to the documents. Both the Lingpipe and Oak System use these techniques before further tagging documents.
Part of Speech Tagging
Each word in a sentence is classified as a part of speech (POS) that depends on the way the word is being used. For instance, the word fax can be used as a noun (Did you receive that fax I sent you?) or as a verb (Could you fax me that report?).
Systems use sets of universal tags for parts of speech. I am using the 48 tags of the Penn Treebank POS tag set (Marcus, Santorini, and Marcinkiewicz, Citation1994) because this Treebank was used to train the OAK system.
For POS tagging, our system is using the OAK system that uses a method similar to the Brill tagger (Brill, Citation1994), but has 13% fewer errors (Sekine, Citation2002). We used POS tags in patterns we developed for finding answers.
Chunked Part of Speech
A chunked part of speech is grouping words with certain parts of speech into noun phrases, prepositional phrases, and verb phrases. It is also referred to as a shallow parse since it is done with one pass.
OAK can perform a shallow parse of a document using chunked POS with a method similar to Ramshaw and Marcus (Citation1995). Its shallow parse forms noun and verb phrases with only one pass, using transformation-based rules similar to the Brill tagger. We used a chunked part of speech for the question classification and for tagging the documents.
Word Sense Tagging
Each word in WordNet has multiple senses for the different ways the word can be used. Word sense disambiguation is the process of determining in which sense a word is being used. Once the system knows the correct sense that the word is being used, WordNet can be used to determine synonyms. This is useful for seeing if a word from the question is associated with a word in the passage by being in the same synonym set.
We used a method similar to Chali and Kolla (Citation2004) to disambiguate the words. It creates a list of all the words in the document. Then it builds chains by comparing the WordNet entries for their glossary, synonym set, hyponym set, and hypernym set for any matches for each sense of each word. The sense that is more connected to the other words in the document is said to be the sense it is being used in.
By using this method, our system can tag each word that is contained in a lexical chain with the WordNet synset ID. The WordNet synset ID can be used to get a list of all the words belonging to that synset. This method of tagging will become useful in answer-ranking.
Word Dependencies Tagging
To discover word dependencies, a syntactic parse is used. Our method to tag word dependencies is by using the Collins (Citation1996) parser to get a statistical syntactic parse of the passages. These probabilities are found using supervised machine-learning. The probability is the chance that two words are dependent, given certain variables including part of speech and distance. The Collins parser requires all the sentences to be tagged with a part of speech before it tags the document with word dependencies. With the syntactic form you can see which words depend on other words. There should be a similarity between the words that are dependent in the question and the dependency between words of the passage containing the answer.
Named Entity Tagging
Our question classification module determines which type of entity the answer should be. The OAK system has 150 named entities that can be tagged. They are included in a hierarchy. They are found either by pattern-matching from a list of examples of entities or by regular expressions. For instance, CITY is best found with a list of cities, since that is almost the only way to tell if an entity is referring to a city. Another method of tagging certain named entities is by pattern-matching using regular expressions. For instance, where the named entity is a quantity (e.g., percentage), the pattern “NUMBER%” or “NUMBER percent” could be used to discover entities that are percentages.
As discussed previously, WordNet has sets for each word called hyponyms which are words that are examples of that word. This hyponym list can be loaded as a list of examples and our system tags these examples inside the document, in a similar way to how the OAK system tags NEs. To do this, our system has to know first what word's hyponym list is going to be used to tag the document. Knowing the NE, our system is looking to allow our system to tag only the entities relevant to the question. These entities are discovered with answer classifications. The hyponym list is then extracted and compared to the words of the document, and the entities that are in the list are tagged as possible answers.
Lingpipe can also tag three types of named entities which are: Person, Location, and Organization.
Our method of QA requires as many named entities to be tagged as possible. Thus, our system uses OAK, Wordnet, and Lingpipe to tag named entities.
Co-Reference Resolution Tagging
Knowing which terms are referring to the same entities is very helpful in QA (Ageno et al., Citation2004).
Our system resolves the references referring to the same entity and the pronouns. Lingpipe resolves references to the named entities: person, location, and organization. It gives each person, location, or organization in the document an ID number and each reference to that person, location, and organization will have the same ID number. Also, our system uses Lingpipe for pronoun resolution. Before documents are tagged by the OAK system, our system tags documents with Lingpipe and replace all pronouns with the entity they are representing.
WordNet can also be used to find different forms of a name. WordNet contains many different names of people, places, and organizations, and includes a synonym set and alternate forms for each of these entities. This feature of WordNet can be used to determine if a word is referring to an entity that appeared earlier in a passage.
Co-referencing will help in our system, when possible answers will be matched to patterns with entities from the question. It will also help for document retrieval because our system can retrieve documents for each term from the question that represents those terms.
Tagging documents allows for information from the words of the document to be labeled and used. Our system uses these tags to extract and rank possible answers.
ANSWER EXTRACTION AND RANKING
Since the answer types and question types are known from the question classifier, and the documents are tagged with both shallow parse and named entities, extracting the information from the documents uses patterns to extract the named entities associated with the answer type. The questions do not always have one named entity associated with their answer type, so the patterns need to reflect this as well. For some questions, the answer is not tagged and will be extracted with just patterns from the documents.
The answers for certain types of questions can also be extracted with patterns rather than our approach of extracting answers using the answer type. These patterns can be learned by using machine-learning techniques (Ravichandran and Hovy, Citation2002). Many groups have used a similar technique in their systems to discover patterns for finding answers (Roussinov, Ding, and Robles-Flores, Citation2004; Tanev, Kouylekov, and Magnini, Citation2004; Echihabi et al., Citation2003; Nyberg et al., Citation2003; Wu, Zheng, Duan, Liu, and Strzalkowski, Citation2003; Prager et al., Citation2003).
How many questions are answered using patterns and not named entities since these questions are looking for a count of a certain entity. We discovered that answers will appear frequently in the tagged documents in the pattern “[NP NUMBER ENTITY].”
There are two types of date questions—ones looking for a certain day that happens every year, and ones that are looking for a particular day. Some dates that are tagged by OAK do not fit into either of these categories and are considered relative dates. These include today, this year, this month, next week, and midnight. These dates are not helpful in answering questions, and are eliminated right away by specifying that the dates have to include a number. Also, answers to questions that are looking for a particular date should have a four-digit year in them.
OAK tags each quantity it sees as a quantity, but does not tag quantities together that are of the same measurement if the quantities are of different units. For instance, it will tag the measurement 4 foot 2 inches as 〈PHYSICAL_EXTENT 4 foot〉 〈PHYSICAL_EXTENT 2 inches〉. We can extract the full quantity if we use a pattern that extracts more than one quantity when two quantities of the same measurement are together.
For the rest of the questions, possible answers are obtained by extracting the named entities associated with the answer type of the question. This is done by pattern-matching with “ 〈NE X〉,” where X is a possible answer if NE is a named entity tag corresponding to the answer type of the question.
Fact-finding questions are handled differently because the process for finding a fact is more involved than finding certain entities. In fact-finding questions, there is always a topic that is being sought. If the question is “Who is X?” (X being a name of a person), there will be different methods for finding facts for it, compared to a nonperson entity that will be phrased as “What is a Y?” We have chosen to implement a method of pattern-finding to answer fact-based questions.
The patterns we are using for definition questions use shallow parsing, also called POS chunking. Gaizauskas, Greenwood, Hepple, Roberts, and Saggion (Citation2004) implemented a similar method of using shallow parsing to find patterns for fact-based questions. These fact-finding patterns were determined by manually examining definition-based questions from the TREC question test bed, which includes examples of facts for each question. We used the following four phases to determine the patterns our system uses to extract facts: manually finding facts, tag fact sentences, pattern creation, and error correction.
For a definition question, the answer sentences include facts about certain subjects. Our current definition patterns include with X representing facts and TARGET representing the subject of the fact:
[NP X TARGET] | |||||
[TARGET], X (, or. or ;) | |||||
[TARGET] (is or are) X (. or ;) | |||||
X called [TARGET] | |||||
[BEGINNING OF SENTENCE] [TARGET], X, is X | |||||
[TARGET] and other [NP X]. | |||||
Adding new patterns may lead to extracting some phrases that are not useful or not relevant at all. These phrases should be filtered out as generally as possible to keep both the applicable facts so the rule can apply to many situations. These patterns should be applied to different topics to confirm that the patterns will work with more than a single topic.
For instance, the pattern “[TARGET], X (, or. or;)” can end up extracting the next element from a list. Take “element 1, element 2, element 3,…and element n ” to represent any list in the set of retrieved documents. If the topic is element i , then element i+1 will be extracted with that extraction pattern. Our check for this is, if the extracted fact is just a name, then the fact is considered invalid.
All the incorrect facts might not be able to get filtered out. The hope is that they will get filtered out in the answer ranking module, which will rank the facts and only return relevant facts to the user.
After extracting the answers, we need to give a score to each possible answer, and return the ones with the highest score, or the answers with the highest scores if a list of answers is required. Our system's answer-ranking empirical formula for factoid and list questions uses the following variables:
-
w 1 denotes whether the answer is found in a pattern associated with the question type. The value will be 1 if it was found in such a pattern, and 0 if it was not.
-
w 2 denotes how many words from the question are represented in the passage with the answer, plus 3 more points for each word that is represented by a disambiguated word.
-
w 3 denotes if the answer appears in the WordNet glossary for important words from the question (value of 0 if it does not and 1 if it does).
-
w 4 denotes the distance between the important words from the question and the answer.
Each occurrence of an answer is given the following rank:
Each answer's final rank is the sum of the ranks of the occurrences of that answer. This means if a particular answer appears in 10 passages, then this formula is used for each passage and the scores are added together. This method of giving a higher score to answers that appear more than once is discussed in Clarke, Cormack, and Lynam (Citation2001).
This formula was derived using a test bed of 300 questions. These questions from TREC-1999 to TREC-2004 were chosen because our system extracts the answer to them. The average chance of our system, at random, picking a correct answer to a question in this test bed is about 9%. This means approximately 1 in 10 extracted answers are correct. With this ranking formula, our system is able to answer this test bed correctly 64% of the time. This shows that this method of ranking is improving the chance of picking a correct answer.
Answer redundancy is applicable to definition questions. As stated before, our system will sometimes extract facts that are invalid, and we consider that invalid facts will be eliminated because they will not be repeated, and thus will have a low rank. We rank answers to definition questions, giving them one point for repetition and four points if found in the WordNet gloss.
EVALUATION
The TREC question answering track provides a method to rank systems on how well they answer a set of questions. The National Institute of Standards in Technology only observes the answers a system gives to the specific set of questions and evaluates the correctness of those answers. This provides information about the overall accuracy of the participating systems, but provides little information about where the systems went wrong. Every question answering system is made up of modules, with each module handling different tasks in answering the question. Each module has the potential to create errors, and these errors can lead to a question being improperly answered. This section is an evaluation of the errors that occur in the modules of our system.
Our system has been trained on the TREC questions from 1999 to 2005. The National Institute of Standards in Technology provided the answers to the TREC question answering track questions. We used these answers to evaluate each of our modules for factoid, list, and other questions. For this evaluation, the questions should be unknown, so we performed this evaluation with only classifications and rules that we derived from the TREC questions from 1999 to 2003.
The overall evaluation shows that our current system is able to retrieve 149 out of the 484 answers to the list questions, 34 out of the 234 vital facts about the targets for the other questions, 66 out of 208 factoid questions. This means our system found 26.89% of the answers.
Knowing which module is the weakest link will help with knowing which modules should be improved to increase our system's overall accuracy. Moldovan et al. (Citation2004) performed a similar evaluation of their own modules to discover how much error is produced by the individual modules of their system. We are only considering the 208 factoid questions that include an answer in the AQUAINT data set. This will ensure that if a question is not answered, it is the fault of a module of our program. Out of the 208 questions, 38 of the queries failed to retrieve a document containing the answer. This is about an 18% error rate for the passage retrieval module. Out of the 170 questions that had documents successfully retrieved with the answer by the information retrieval system, only 88 of them had the correct answer extracted, giving an error rate of 48.3% for this module. Out of the 88 times the answer was successfully extracted, the correct answer was ranked the highest 66 times or 75% of the time.
Compared to other systems who entered the recent TREC competition, we discovered that our system performed with about 31% accuracy on a set of 208 test questions. The average accuracy from TREC question answering track was 21% for factoid questions, with only six groups submitting systems that were above 31%. These results show that we have a relatively good accuracy compared to the other systems that participated in the TREC (about 60 submitting systems).
CONCLUSIONS
Our approach to question answering extracts possible answers that fit the type of answer, dictated by the type of question, from the document set. Other methods use pattern-matching to extract possible answers, or a logical form to try to deduce an answer. Our method of QA creates queries; then the information retrieval system extracts the documents our system finds most relevant to the question. After the possible answers are extracted, our system uses an answer-ranking formula to choose the answer ranked most probable by our system.
In this approach, we had to use different methods of processing both the question and the documents. The most important part of our system is our question classifier, which uses rules we determined by manually observing a bank of sample questions. Our system classifies questions by question type, and the type of answer. A query is formed from the words of the question, to retrieve documents that pertain to the question.
The documents retrieved from the query are then tagged to enable our system to extract different information from the documents. Thus, the answers are extracted as labeled parts or by pattern-matching using the answer types. Then, our system ranks the answers according to various criteria that we determined gave our system the best accuracy on the test set of questions as compared to other formulas we tried. This ranking includes how frequently the possible answer appears in the documents retrieved, if it appears in an answer pattern associated with a question, and if words from the question are represented in the passage with the possible answer.
DECLARATION OF INTEREST
The author declares no conflict of interest.
Notes
http://www.askjeeves.com/
REFERENCES
- Ageno , A. , D. Ferres , E. Gonzalez , S. Kanaan , H. Rodriguez , M. Surdeanu , and J. Turmo . 2004 . Talp-qa system at trec-2004: Structural and hierarchical relaxation over semantic constraints . In: Proceedings of the 13th Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Baeza-Yates , R. and B. Ribeiro-Neto . 1999 . Modern Information Retreival , Chapter 8 . pp. 192 – 199 , London : Pearson Education Limited .
- Brill , E. 1994 . Some advances in transformation-based part of speech tagging . In: National Conference on Artificial Intelligence , pp. 722 – 727 , Seattle , WA .
- Chali , Y. and M. Kolla . 2004 . Summarization techniques at duc 2004 . In: Proceedings of the Document Understanding Conference . pp. 123 – 131 , Boston : National Institute of Standards in Technology (NIST) .
- Chen , J. , G. He , Y. Wu , and S. Jiang . 2004 . Unt at trec 2004: Question answering combining multiple evidences . In: Proceedings of the 13th Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Clarke , C. L. A. , G. V. Cormack , and T. R. Lynam . 2001 . Exploiting redundancy in question answering . In: Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval , pp. 358 – 365 , New Orleans , LA .
- Clifton , T. and W. Teahan . 2004 . Bangor at trec 2004: Question answering track . In: Proceedings of the Thirteenth Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Collins , M. ( 1996 ). A new statistical parser based on bigram lexical dependencies . In: Proceedings of ACL-96 , pp. 184 – 191 , Santa Cruz , CA .
- Echihabi , A. , U. Hermjakob , E. Hovy , D. Marcu , E. Melz , and D. Ravichandran . 2003 . Multiple-engine question answering in textmap . In: Proceedings of the Twelfth Text REtreival Conference (TREC 2003) , pp. 772 – 781 , Gaithersburg , MD .
- Gaizauskas , R. , M. A. Greenwood , M. Hepple , I. Roberts , and H. Saggion . 2004 . The university of Sheffield's trec 2004 q&a experiments . In: Proceedings of the 13th Text REtreival Conference (TREC 2004) , Gaithers-burg , MD .
- Harabagiu , S. , S. Maiorano , and M. Pasca . 2004 . Open-domain textual question answering techniques . Journal of Natural Language Engineering 9 ( 3 ): 3 – 44 .
- Harabagiu , S. , D. Moldovan , M. Pasca , R. Mihalcea , M. Surdeanu , R. Bunescu , R. Girju , V. Rus , and P. Morarescu . 2001 . The role of lexico-semantic feedback in open-domain textual question-answering . In: Proceedings of the 39th Annual Meeting of the Association of Computational Linguistics (ACL-2001) , pp. 274 – 281 , Toulouse , France .
- Hermjakob , U. 2001 . Parsing and question classification for question answering . In: Proceedings of the Association for Computational Linguistics 39th Annual Meeting and 10th Conference of the European Chapter Workshop on Open-Domain Question Answering , pp. 17 – 22 , Toulouse , France .
- Jijkoun , V. and M. de Rijke . 2004 . Answer selection in a multi-stream open domain question answering system . In: Proceedings 26th European Conference on Information Retrieval (ECIR'04) , pp. 99 – 11 , LNCS, 2997.
- Jurafsky , D. and J. H. Martin . 2000 . Speech and Language Processing . New York : Prentice Hall .
- Katz , B. , J. Lin , D. Loreto , W. Hildebrandt , M. Bilotti , S. Felshin , A. Fernandes , G. Marton , and F. Mora . 2003 . Integrating web-based and corpus-based techniques for question answering . In: Proceedings of the Twelfth Text REtreival Conference (TREC 2003) , pp. 426 – 435 , Gaithersburg , MD .
- Kim , H. , K. Kim , G. G. Lee , and J. Seo . 2001 . Maya: A fast question-answering system based on a predictive answer indexer . In: Proceedings of the Association for Computational Linguistics 39th Annual Meeting and 10th Conference of the European Chapter Workshop on Open-Domain Question Answering , pp. 9 – 16 , Toulouse , France .
- Li , X. and D. Roth . 2002 . Learning question classifiers . In: Proceedings of the 19th International Conference on Computational Linguistics (COLING-02) , Taipei , Taiwan .
- Lin , J. , A. Fernandes , B. Katz , G. Marton , and S. Tellex . 2003 . Extracting answers from the web using knowledge annotation and knowledge mining techniques . In: Proceedings of the Eleventh Text REtreival Conference (TREC 2002) , p. 447 , Gaithersburg , MD .
- Magnini , B. , M. Negri , R. Prevete , and H. Tanev . 2002 . Is it the right answer? exploiting web redundancy for answer validation . In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) , pp. 425 – 432 , Philadelphia , PA .
- Marcus , M. P. , B. Santorini , and M. A. Marcinkiewicz . 1994 . Building a large annotated corpus of english: The Penn treebank . Computational Linguistics 19 ( 2 ): 313 – 330 .
- Moldovan , D. , S. Harabagiu , C. Clark , M. Bowden , J. Lehmann , and J. Williams . 2004. Experiments and analysis of lcc's two qa systems over trec2004. In: Proceedings of the 13th Text REtrevial Conference (TREC 2004), Gaithersburg, MD.
- Moldovan , D. , S. Harabagiu , R. Girju , P. Morarescu , F. Lactusu , A. Novischi , A. Badulescu , and O. Bolohan . 2002 . Lcc tools for question answering . In: Proceedings of the Eleventh Text REtreival Conference (TREC 2002) , p. 388 , Gaithersburg , MD .
- Moldovan , D. , S. Harabagiu , M. Pasca , R. Mihalcea , R. Goodrum , R. Girju , and V. Rus . 1999 . Lasso: A toll for surfing the answer net . In: Proceedings of the 8th Text REtreival Conference (TREC 1999) , Gaithersburg , MD .
- Nyberg , E. , T. Mitaamura , J. Callan , J. Carbonell , R. Frederking , K. Collins-Thompson , L. Hiyakumoto , Y. Huang , C. Huttenhower , S. Judy , J. Ko , A. Kupsc , L. V. Lita , V. Pedro , D. Svoboda , and B. Van Durme . 2003 . The javelin question-answering system at trec 2003: A multi-strategy approach with dynamic planning . In: Proceedings of the Twelfth Text REtreival Conference (TREC 2003) , Gaithersburg , MD .
- Prager , J. , J. Chu-Carroll , K. Czuba , C. Wlty , A. Ittycheriah , and R. Mahin-dru . 2003 . Ibm's piquant in trec2003 . In: Proceedings of the Twelfth Text REtreival Conference (TREC 2003) , pp. 283 – 292 , Gaithersburg , MD .
- Ramshaw , L. and M. Marcus . 1995 . Text chunking using transformation-based learning . In: Proceedings of the Third Workshop on Very Large Corpora , D. Yarovsky and K. Church , eds. pp. 82 – 94 , Somerset , NJ : Association for Computational Linguistics .
- Ravichandran , D. and E. Hovy . ( 2002 ). Learning surface text patterns for a question answering system . In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL) , pp. 41 – 47 , Philadelphia , PA .
- Roussinov , D. , Y. Ding , and J. A. Robles-Flores . 2004 . Experiments with web qa system and trec2004 questions . In: Proceedings of the 13th Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Sekine , S. ( 2002 ). Proteus project oak system (English sentence analyzer), http://nlp.nyu.edu/oak. Last accessed Feb 29, 2004 .
- Tanev , H. , M. Kouylekov , and B. Magnini . 2004 . Combining linguistic processing and web mining for question answering: Itc-irst at trec-2004 . In: Proceedings of the Thirteenth Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Teahan , W. J. ( 2003 ). Knowing about knowledge: Towards a framework for knowledgable agents and knowledge grids. Artificial Intelligence and Intelligent Agents Tech Report AIIA 03.2, School of Informatics, University of Wales, Bangor .
- Wu , L. , X. Huang , L. You , Z. Zhang , X. Li , and Y. Zhou . ( 2004 ). Fduqa on trec2004 qa track . In: Proceedings of the 13th Text REtreival Conference (TREC 2004) , Gaithersburg , MD .
- Wu , M. , X. Zheng , M. Duan , T. Liu , and T. Strzalkowski . 2003 . Question answering by pattern-matching, web-proofing, semantic form proofing . In: Proceedings of the Twelfth Text REtreival Conference (TREC 2003) , pp. 578 – 585 , Gaithersburg , MD .
- Xu , J. , A. Licuanan , J. May , S. Miller , and R. Weischedel . 2002 . Trec2002 qa at bbn: Answer selection and confidence estimation . In: Proceedings of the Eleventh Text REtreival Conference (TREC 2002) , pp. 96 – 101 , Gaithersburg , MD .