Abstract
Formal ontologies are difficult to read and understand for domain experts who do not have a background in formal logic. This severely restricts the ability of this user group to determine whether an ontology conforms to the requirements of the application domain or not. We argue that a formal ontology—in our case a description logic knowledge base—should be created in a linguistically motivated way so that domain experts can understand and query the ontology. We first show that this can be partially achieved with the help of a naming convention which is based on those linguistic expressions that occur in the application domain. We then go a step further and suggest the use of a controlled natural language for creating and querying formal ontologies that follows the syntactic structure of a well-defined subset of English.
INTRODUCTION
One of the biggest stumbling blocks to the use of formal languages in industry is their limited readability and understandability by domain experts (Zimmerman, Lundqvist, and Leveson, Citation2002)—ontologies are no exception in this respect (Rector et al., Citation2004). But ontologies have a rather special status among formal languages since their main purpose is to specify a vocabulary with which statements are created and exchanged not only between machines but also between humans and machines. In the ideal case, ontologies should be human-readable as well as machine-processable since they are agreements among all parties to commit to a common vocabulary in a specific application domain (see Gruber (Citation1993) for an introduction).
Recently, the use of computer-processable controlled natural languages has been suggested to create ontologies in a human-readable and machine-processable way (Schwitter and Tilbrook, Citation2004; Schwitter et al., Citation2008). These controlled natural languages look like natural language, but they are in fact formal languages “in disguise.” They have a formal syntax and semantics and can be translated unambiguously into an existing formal target language, for example, into a version of description logics or into first-order logic.
There exists an entire stream of research that investigates the usefulness of controlled natural languages for authoring and verbalizing description logic-based ontologies. For example, Schwitter and Tilbrook (Citation2004)Schwitter and Tilbrook (Citation2006) discuss the bi-directional mapping between the controlled natural language PENG and various subsets of the web ontology language OWL. This work built the foundation for Sydney OWL Syntax—a proposal of a controlled natural language syntax for OWL (Cregan, Schwitter, and Meyer, Citation2007). In Bernardi, Calvanese, and Thorne (Citation2007), a categorial grammar is introduced that translates the controlled natural language Lite Natural Language into the description logic DL-Lite, a tractable fragment of OWL. This fragment is expressive enough to deal with Unified Modeling Language (UML) diagrams and relational databases. In Hart, Dolbear, and Goodwin (Citation2007) the controlled natural language Rabbit is introduced which relies on a collaboration between a domain expert and a knowledge engineer to create an ontology. In this setting, the domain expert who owns the domain knowledge specifies Rabbit texts, and the knowledge engineer converts these texts into OWL. In Kaljurand (Citation2007), a bi-directional interface to OWL is discussed where a subset of the controlled natural language Attempto Controlled English is used for the purpose of authoring and verbalizing OWL ontologies. The three controlled natural languages Sydney OWL Syntax, Rabbit, and Attempto Controlled English are compared in Schwitter et al. (Citation2008) and a number of recommendations to an OWL-compatible controlled natural language have been put forward.
There exists another stream of research that studies the usefulness of controlled natural language and unrestricted natural language as ontology query languages. For example, in Bernstein, Kaufmann, and Fuchs (Citation2004), a controlled language-based query interface is presented which supports the construction of questions with the help of predictive interface techniques similar to Schwitter, Ljungberg, and Hood (Citation2003), and in Bernstein, Kaufmann, Göhring, and Kiefer (Citation2005), the authors show that the usability of controlled natural language as a query language outperforms the usability of a formal language such as Structured Query Language (SQL). There exist also a number of systems that support the use of unrestricted natural language for answering questions over description logic knowledge bases (Lopez, Motta, and Uren, Citation2006; Kaufmann, Bernstein, and Zumstein, Citation2006; Mithun, Kosseim, and Haarslev, Citation2007). These unrestricted approaches, however, have the same kind of problems as natural language interfaces to database systems (Copestake and Sparck-Jones, Citation1990; Androutsopoulos, Ritchie, and Thanisch, Citation1995; Popescu et al. Citation2004). Using unrestricted natural language is problematic because the end-users both over- and undershoot the system's capabilities: they do not know where the system's boundaries are and what kind of queries are supported. It is an ongoing debate whether restricted or unrestricted approaches are more convenient for end-users (Reichert, Linckels, Meinel, and Engel, Citation2005; Kaufmann, Bernstein, and Fischer, Citation2007), and it is not surprising that the performance of a natural language query interface depends highly on the quality and choice of the vocabulary in the knowledge base.
In this article, we will bring these two research streams closer together and argue that a description logic knowledge base should be created in a linguistically motivated way in order to support question answering in an optimal way. We will show that a controlled natural language can be used for making terminological and assertional statements and that the linguistic structure of these statements is related in a systematic way to the controlled natural language used for querying the knowledge base.
DESCRIPTION LOGICS (DLs)
Description logics are a family of knowledge representation languages that can be understood as decidable fragments of first-order logic (Baader et al., Citation2003; Baader, Citation2009). Description logics, such as the web ontology language OWL DL (Horrocks, Patel-Schneider, and van Harmelen, Citation2003), play an important role in the semantic web architecture because they are decidable and allow for a clear separation between the terminological and factual information.
A DL knowledge base usually consists of two components: a terminological component (i.e., TBox) and an assertional component (i.e., ABox). The TBox states general information about concepts (unary predicates) and roles (binary relations) through declarations, while the ABox asserts specific facts about individuals that occur in a particular application domain. For example, in the case of an ontology for a computer science department, the TBox might contain concept definitions like (1) and general inclusion axioms like (2):

And the ABox might contain concept assertions like (3) and role assertions like (4):
![]()
Note that we use the Knowledge Representation System Specification (KRSS) syntax here (Patel-Schneider and Swartout, Citation1993) in order to express these and all subsequent axioms in a compact way.
The expressivity of a DL depends on the set of constructors that can be used for defining concept terms starting from concept names and role names. Logical constructors include common constructors such as intersection, union, and complements, and more specific ones such as quantified role restriction in (5) and qualified number restriction in (6):
![]()
Other constructors are used to characterize roles and for enhanced reasoning with roles, for example: inverse, transitivity, and functionality. For instance, (7) defines a role with a specific domain and range restriction and provides a name for the inverse of the defined role:
![]()
In addition to these features, some DLs provide extensions that support algebraic reasoning over concrete domains and endorse statements such as
![]()
Here the age of an individual is specified with the help of a concrete domain predicate (=) and a concrete domain attribute (age) that takes a cardinal number (21) as filler.
LINGUISTIC STRUCTURES IN ONTOLOGIES
A DL ontology is essentially a logical theory that specifies a conceptualization of a specific part of the world—in our case of a computer science department. Since the aim of an ontology is to make domain assumptions explicit and to establish a common understanding of the structure of information in a particular domain, it is important that all parties are able to use the same vocabulary in order to make statements and ask queries in a way that is consistent with the logical theory. It should be possible for a domain expert to relate the terms used in the ontology in a direct way to the entities in the application domain without any additional decoding. That means the terminology should be easy to use and understood by humans so that humans and machines can cooperate in an optimal way. It has been shown in the domain of software engineering that proper naming conventions can make logical expressions easier to read and understand for humans (Zimmerman et al., Citation2002).
It seems intuitive to choose a naming convention for creating an ontology that is close to the linguistic expressions which naturally occur in a particular application domain. However, this is not always the case and a wide variety and fragmentation of naming schemes can be found in real-world ontologies (Schober et al., Citation2007). This is because knowledge engineers can in principle use any character sequence for naming entities and relations between these entities, and they often make cost/accuracy trade-offs when creating an ontology without thinking about the accessibility of these notations for domain experts who do not have expertise in formal methods. For a machine, it does not make any difference whether a concept or a role is labelled in a way that can be understood by a human or not. Here is an extreme example:

The labels that occur in this example make it difficult for a human reader to understand what the single concept and role names stand for, how they relate to each other, and how they refer to the entities in the application domain for which the ontology has been designed. It is much easier to understand what is going on if the terms in the ontology communicate the intended meaning using natural language-like expressions. For example:

Existing ontologies sometimes combine natural language expressions with nonlinguistic artifacts, but there is a clear tendency to use linguistic patterns in ontologies. (Mellish and Sun, Citation2005) collected 882 ontology files encoded in OWL and analyzed the linguistic structure of concept and role names. They found that 72% of concept names ended with an English noun, of concept names consisted entirely of noun sequences (various forms of compound nouns), and 14% contained no recognized word. The structure of role names showed a broader variety of patterns compared to concept names but still 65% of these patterns started with a verb.
Given these results, we suggest using those patterns that occur most frequently in existing ontologies in order to establish a linguistically motivated naming convention. In particular, we suggest using:
nouns and compound nouns as concept names (e.g., student and undergraduate_tudent); | |||||
transitive verbs and auxiliary verb-noun constructions as role names (e.g., take, consist_of, is_student_of, has_student); | |||||
normalized forms of proper nouns as identifiers for individuals (e.g., david_miller, comp101). | |||||
Following Schober et al. (Citation2007), we additionally make the following recommendations: (a) use an underscore (_) to delimit words in compound terms since this separator is closer to natural language than CamelCase; (b) replace homonyms by an alternative word form since homonyms create confusion; and (c) resolve abbreviations and acronyms in names and include them as synonyms in the ontology.
CONTROLLED NATURAL LANGUAGES (CNLs)
In the last section, we have argued that using a linguistically motivated naming convention can improve the readability and usability of an ontology for domain experts. But also knowledge engineers who have to maintain and extend an ontology for new business needs can benefit from naming conventions since well-chosen naming conventions can enhance clarity, avoid the introduction of mistakes, and make it easier for subsequent generations of analysts to understand what the ontology was designed for. A linguistically motivated naming convention can be applied directly when creating an ontology with an ontology editor although current ontology authoring tools do not actively enforce naming conventions.
Adopting a common naming convention is a good strategy to improve the quality of an ontology, but we can even go a step further towards natural language and express ABox and TBox statements of an ontology completely on the level of a CNL and then translate these statements automatically into the input language of a DL reasoner. That this can be done has been shown in previous work (Schwitter and Tilbrook, Citation2004; Kaljurand, Citation2007; Schwitter et al., Citation2008). Therefore, here we will provide only a brief overview in order to discuss the underlying design principles that shape the structure of CNL sentences before we focus on the structure of questions, the relationship between declarative sentences and questions, and their translation into a formal target language.
Terminological Statements in CNL
TBox statements express the intensional knowledge about a domain in the form of a terminology. This terminological information is static, and it is more likely that a knowledge engineer will write and modify such statements than a domain expert. Nevertheless, domain experts need to be able to read, understand, and validate this information with respect to a particular application domain. A CNL can help in this respect since it provides a high-level interface to a formal language that is potentially difficult to understand by a domain expert. For example, the previously introduced concept definition (1):
![]() can be expressed as a sentence in CNL that follows the structure of standard English:
can be expressed as a sentence in CNL that follows the structure of standard English:
![]()
Likewise, the general inclusion axiom (2):
![]() can be expressed as a sentences in CNL:
can be expressed as a sentences in CNL:
![]()
Note that the TBox statement in (11) uses the key phrase is defined as and makes it explicit that this statement is a definition that consists of a set of necessary and sufficient conditions. In contrast to (11), the TBox statement in (12) does not speak about a definition since it only states necessary conditions for a primitive concept.
The definition of primitive roles in CNL requires the use of meta-information in order to speak about the features of a role. The use of variables makes it possible to speak about these features in a very compact way in CNL. Note that variables are not a specific characteristic of a formal language; variables are also used in natural language texts, and you can find concrete examples in most introductory textbooks about logic. For example, the CNL rendering of the primitive role definition (7):
![]() requires two variables in order to mark the domain and range restrictions of the role:
requires two variables in order to mark the domain and range restrictions of the role:
![]()
This approach has the advantage that there is no need to use additional constructors (inverse, domain, and range) as in (7), since the CNL language processor can figure out the corresponding restrictions from the linguistic structure and the position of the variables. As long as only two variables are used as in (13), then these two variables can be replaced by two indefinite pronouns (somebody and something).
Assertional Statements in CNL
In contrast to TBox statements, ABox statements are much more dynamic in nature and more likely to be used by domain experts since they express facts that change over time and need to be updated more frequently. ABox statements rely on the vocabulary defined in the TBox. In the simplest case, ABox statements can be expressed via a linking verb or a transitive verb in CNL. For example, the previously introduced concept assertion (3):
![]() can be expressed via the simple CNL sentence (14) that links the individual to a concept name:
can be expressed via the simple CNL sentence (14) that links the individual to a concept name:
![]()
Likewise, the role assertion (4):
![]() can be expressed via the simple CNL sentence (15) that uses a transitive verb to relate two individuals:
can be expressed via the simple CNL sentence (15) that uses a transitive verb to relate two individuals:
![]()
The previously introduced quantified role restriction in (5) and the qualified number restriction in (6):
![]() can be rendered in a direct way in CNL as (16) and (17):
can be rendered in a direct way in CNL as (16) and (17):
![]()
The ABox statement introduced in (8) that uses a concrete domain attribute:
![]() can be rendered in CNL as (18):
can be rendered in CNL as (18):
![]()
In summary: all these ABox statements have the following functional structure:
![]()
Note that coordination is not allowed in subject position because this would introduce an ambiguity between a distributive or a collective reading (or a cumulative reading if we consider more than two elements in subject position). However, nominal expressions that occur in subject position can be modified in a number of ways, for example, with the help of a genitive construction as the example in (18) illustrates.
From Binary to N-ary Relations
Most DL languages only support binary relations and at first glance it looks like only very simple CNL statements can be captured by this logical framework. However, it is often necessary (and more natural) to describe relations among more than two individuals in one statement. For example, we would like to specify when and where a specific event occurs in a single sentence and write directly:
![]()
This ABox statement contains three prepositional phrases (on Monday, at 11 am, and in the Lincoln Building) that occur in the adjunct position of the sentence. This statement extends the functional structure introduced in the previous section:
![]()
On the CNL level, adjuncts are always optional in the sense that (20) is a syntactically complete sentence without the three prepositional phrases but not without the complement (COMP101) that depends on the verb.
The same outcome can be achieved on the DL level via reification of the verbal relation (Noy and Rector, Citation2006). The statement in (20) can be represented with the help of a concept assertion consisting of a new individual that stands for a reified relation and a set of role assertions that link this new individual to the other participating entities:

Here the new individual e1 stands for the reified relation and is an instance of the take concept. The roles (has_agent, has_theme, has_day, has_hour, and has_location) link this new individual to their corresponding individuals and values. The names of these roles are similar to those that are usually used to name thematic relations in frame semantics (Kipper, Korhonen, Ryant, and Palmer, Citation2008). Of course, this approach requires that the take concept is available in the TBox, for example, as a defined concept:
![]() and that all the relevant roles for this concept are also defined. For example, in our context, the declaration of the has_theme role looks as follows:
and that all the relevant roles for this concept are also defined. For example, in our context, the declaration of the has_theme role looks as follows:
![]()
This means that the concept term take occurs in this definition as a domain restriction and the concept term unit as a range restriction.
DL REASONERS
There exist a number of state-of-the-art DL reasoners for querying a DL knowledge base, for example: FaCT++ (Tsarkov and Horrocks, Citation2006), Pellet (Sirin et al., Citation2007), and RacerPro (Haarslev and Möller, Citation2003; Wessel and Möller, Citation2006). These reasoners usually implement a tableau-based decision procedure for general TBox reasoning (subsumption, satisfiability, and classification) and offer support for ABox reasoning (retrieval and conjunctive queries).
RacerPro and nRQL
RacerPro is a knowledge representation system (see Racer Systems (Citation2007) for an introduction) which implements the expressive description logic 𝒜ℒ𝒞𝒬ℋℐℛℛ + (𝒟−). This is the basic description logic 𝒜ℒ𝒞 augmented with qualifying number restrictions, role hierarchies, inverse roles, and transitive roles. In addition to these basic features, RacerPro also provides facilities for algebraic reasoning, including concrete domains and implements most of the functions specified in the KRSS specification (Patel-Schneider and Swartout, Citation1993).
The new RacerPro query language (nRQL) is a query language for RacerPro's concept language and supports—among other things—strong negation, negation as failure, and numeric constraints. RacerPro translates SPARQL (Prud'hommeaux and Seaborne, Citation2008) queries into nRQL queries. nRQL is a more expressive query language than SPARQL. In contrast to SPARQL, nRQL uses description logic reasoning and does not work on the syntactic level of triples but on the level of semantic models.
In the following, we will first show what the syntactic structure of nRQL queries looks like and then discuss the main types of queries that are supported by RacerPro and provide CNL renderings for these queries.
Queries in nRQL
An nRQL query consists of a query head and a query body. The query head specifies the format of the answer and the query body contains (unary or binary) query atoms that are used to specify retrieval conditions on the bindings of query variables. nRQL queries are either simple or complex. A simple nRQL query consists of a single query atom in the query body. For example, the following nRQL query (25):
![]() is a simple one and has a query variable (?1) as head and a binary query atom (?1 comp101 take) as body. This nRQL query can be expressed as a wh-question in CNL:
is a simple one and has a query variable (?1) as head and a binary query atom (?1 comp101 take) as body. This nRQL query can be expressed as a wh-question in CNL:
![]()
Note that the nRQL query in (25) cannot be answered over a DL knowledge base that contains reified relations as introduced in (22). In order to answer the CNL question (26) over a DL knowledge base that contains reified relations, the verbal relation of the question needs to be reified also and this results in a complex (conjunctive) nRQL query. A complex nRQL query consists of two or more query atoms in the query body and these query atoms are combined with the help of so-called query body constructors. For example, the nRQL query (27) represents the reified version of the wh-question (26):
![]()
Here the query body consists of a query body constructor (and) which takes an unary query atom ((?1 take)) and two binary query atoms ((?1 ?2 has_agent) and (?1 comp101 has_theme)) as arguments.
nRQL Queries in CNL
The query language nRQL distinguishes a number of different types of queries that can be answered over a DL knowledge base. In the following, we will discuss CNL renderings for the most important types of nRQL queries.
Queries about Concepts
In nRQL, queries about concepts can be used to retrieve all instances of a concept from an ABox. This type of query can be expressed in CNL via a wh-question (28) or via an imperative construction (29):
![]()
The nRQL query processing engine returns a set of tuples of the form (((?1 david_miller)) ((?1 eva_barth))) as answer to these two questions. Note that the CNL question (29) makes the expected answer set explicit using the universal quantifier all in contrast to (28). A partial answer such as ((?1 eva_barth)) would be an acceptable answer for question (28) but not for the imperative construction (29).
Queries about Roles
In nRQL, queries about roles can be used to retrieve role fillers from an ABox. Since these queries extract information from binary relations, there are in principle three different queries one can ask about the arguments of a binary relation. These queries correspond to the following three CNL questions:

In (30) we are asking for information about the subject as well as the object of a relation, in (31) we are only asking for information about the subject, and in (32) only for information about the object. Note that the linguistic structure of (32) is different from that of (30) and (31). In (32), the query word what has been moved from the object position to the front of the sentence and is used here together with a do-operator.
Boolean Queries
In nRQL, simple Boolean queries can be used to check whether or not at least one individual exists for a specific concept, whether or not a specific individual exists for a particular concept, and whether or not two specific individuals stand in a particular relation. Boolean queries return either true or false.
In CNL, we can express Boolean queries via yes/no-questions. The following two questions (33) and (34) are equivalent and interrogate whether or not at least one individual exists that is a student:
![]()
Note that these two CNL questions are constructed in a different way: question (33) uses the linking verb be in sentence-initial position and an existential there, and question (34) uses a do-operator and the intransitive verb exist.
The following CNL question checks whether or not a specific individual belongs to a specific concept:
![]() and finally, the subsequent CNL question (36) checks whether or not two individuals stand in a particular relation:
and finally, the subsequent CNL question (36) checks whether or not two individuals stand in a particular relation:
![]()
The answer to these questions is yes or no but in CNL one can also include the focus of the question in the answer, for example: Yes, Lisa Brown does.
Classical Negated Concepts and Roles
The nRQL query language allows for classical negated concepts and roles. For example, RacerPro can prove that somebody is not a student or that a student cannot teach a unit. Note that the negation of roles is only available in the nRQL query language but not in the concept language of RacerPro since this would affect the decidability of the language. Below are two CNL questions that use classical negation: in question (37), the noun (student) is negated and in question (38), the verb (teach) is negated:
![]()
The first question returns all instances that are not part of the concept and the second question returns all instances that are not a filler of a specific role with an existential restriction.
Implied Role Fillers
In nRQL, only explicitly modelled role fillers are retrieved by default. However, a DL knowledge base can have logically implied role fillers whose presence is enforced in the logical models of the knowledge base. Let us assume that we specified at some point that Every professor supervises a student and then asserted that Anna Grau is a professor. That means Anna Grau must supervise at least one student, but it might be the case that no instance of a student (who is supervised by Anna) is explicitly specified in the knowledge base. In CNL, we can identify individuals that have an implied role filler with an imperative construction that uses the specific keyword show for this purpose:
![]()
This imperative construction is translated into an nRQL query that uses a negation as failure (neg) operator together with a projection (project-to) operator:
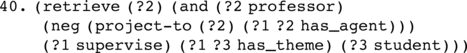
The part under the projection operator forms a subquery, after this subquery has been answered, the complement can be computed with the help of the neg operator. Note that the answer set of the imperative construction (39) is different from that of (41):
![]()
This imperative construction results in the subsequent nRQL query (42):
![]()
In summary, the answer to (39) returns only the implicit instances—for example, Anna Grau—while (41) returns all instances that are explicitly specified in the ABox of the knowledge base.
Concrete Domains
In nRQL, the concrete domain part of an ABox can be queried using concrete domain predicates. In CNL, we can use the following questions (43) and (44) for this purpose:
![]()
Note that these two questions return instances but not the values of the age attribute for these instances, although this could be achieved in nRQL with the help of a head projection operator. This could be expressed as follows in CNL: Whose age is at least 18 and display that age.
Synonyms
In nRQL, it is possible to check whether two instances are individual synonyms or not. In CNL, we can check this using the phrasal expression the same as, for example:
![]()
That means synonyms need not to be modelled in the linguistic lexicon. As we will see in the next section, only orthographic variants of content words are modelled in the linguistic lexicon but not synonyms.
Complex Queries
A complex nRQL query is constructed from unary and binary query atoms with the help of a number of query body constructors (e.g., and, union, neg). As soon as we work with a DL knowledge base that relies on reification of relations we will end up with complex queries in the translation. The following three CNL questions result in complex nRQL queries:
![]()
Note that the processing of the two questions (47) and (48) relies on a DL knowledge base that relies on reification, while (49) does not since the question is not looking for an individual previously introduced by a prepositional phrase. The translation of (47) and (48) results in a conjunctive query where the query atoms in the query body are connected by the query body constructor and, and the translation of (47) results in a complex query that additionally uses a negation as failure constructor.
THE CNL PROCESSOR
The task of the CNL processor is to translate ABox and TBox statements as well as questions written in controlled natural language into the input format of the DL reasoner, and to generate answers in CNL from the output of the reasoner.
The CNL processor uses a bi-directional unification-based grammar and a linguistic lexicon for this task that contains syntactic constraints and information that is relevant for the mapping between the linguistic expressions and the expressions used in the formal notation.
The kernel of the grammar is implemented as a definite clause grammar which can either run independently or be processed by a chart parser.
The CNL processor first translates the input sentences into Thousands of Problems for Theorem Provers (TPTP) notation (Sutcliffe and Suttner, Citation1998). TPTP is a widely used notation for representing problems for automated theorem proving in first-order logic. The use of TPTP as an intermediate representation language has the advantage that we can extend the grammar of the CNL processor later and interface the processor with other (first-order) reasoning services. TPTP gives us the required flexibility to translate statements and questions into a suitable target notation.
In our case, the CNL processor first translates ABox and TBox statements via TPTP notation into RacerPro's KRSS notation and adds the resulting formulas to the DL knowledge base. Likewise, CNL questions are first translated into TPTP notation but then transformed into nRQL syntax, and finally answered over the DL knowledge base using RacerPro's reasoning engine. The TPTP representation of a CNL question is stored by the language processor and then used as a starting point for answering questions. Since the syntactic structure of CNL questions and CNL statements is related in a systematic way, the same CNL grammar can be used as a processor and generator.
The CNL Lexicon
The lexicon of the CNL processor distinguishes between two main categories of words: content words and function words. Content words (nouns, proper nouns, verbs, and adjectives) are closely related to concept names, role names, and names for individuals; while function words (conjunction, disjunction, negation, quantifiers, cardinals, prepositions, and operators) are closely related to DL constructors. Note that function words are predefined in the lexicon and build the scaffolding for the CNL, while content words can be added by the user to the lexicon.
In order to detect ungrammatical sentences in CNL, the lexicon contains syntactic information that enforces, for example, number agreement between the subject and the verb of a CNL sentence like (50) and the subject and the do-operator of a question like (51):
![]()
The two lexical entries of the proper nouns David Miller and COMP101 below illustrate the structure of the lexical information:

These entries contain syntactic information, sortal information, and information that is required to generate the TPTP representation. The syntactic information deals with number agreement between the subject and the verb as previously explained. There is also information available in the lexicon that deals with orthographic variants of the input, for example: COMP-101 instead of COMP101, etc.
In order to resolve the ambiguity of prepositions on the surface level of the CNL, the lexicon includes sortal information for nouns, proper nouns, and prepositions. For example, the preposition on in (54) is ambiguous and its interpretation depends on the subsequent proper noun:
![]()
The sortal information for prepositions and proper nouns in the lexicon is used to disambiguate the two prepositional phrases on Monday and on South Campus and to generate the two distinct role names has_day and has_location in the DL representation as illustrated in (55) and (56):
![]()
Note that this sortal information is not required, if we do not allow for prepositional phrases in adjunct position—it is in theory possible to construct a reified version of sentence (54) that does not use prepositional phrases and that has the same expressivity as (54) as the following example (57) illustrates:

However, this solution introduces a meta-level (using explicit reification on the surface level of the CNL) and is clearly less readable and therefore less preferable than (54).
Let us assume that an ontology has already been constructed in a linguistically motivated way with the help of an ontology editor and that we are only interested in building an interface for querying the DL knowledge base. If this is the case, then we can automatically extract all concept names, role names, and names for individuals from the ontology using the following RacerPro functions:
 and populate the lexicon of the CNL processor semi-automatically.
and populate the lexicon of the CNL processor semi-automatically.
The CNL Grammar
The CNL grammar distinguishes three different types of sentences: sentences for asserting ABox statements, sentences for specifying TBox statements, and questions for querying the resulting knowledge base. The grammar rules for ABox and TBox statements are bi-directional (that means they can be used to analyze and generate statements) and a large number of these grammar rules can also be used to process questions since questions are derived from declarative sentences.
Processing Statements
Below is a (simplified) grammar rule in definite-clause grammar format that illustrates what kinds of feature structures are used to process CNL statements and to translate these statements during the parsing process into TPTP formulas:

This top-level grammar rule takes, for example, part in the translation of the following ABox statement:
![]()
The grammar rule breaks the sentence (62) into a noun phrase David Miller and into a verb phrase takes COMP101 on Monday and combines the logical form of the noun phrase with the logical form of the verb phrase in a compositional way. Each word form in this sentence is associated with a partial logical form in the lexicon; these partial logical forms are merged (via unification) during the parsing process into a complete TPTP formula. The grammar rule contains various feature structures that are used for syntactic, semantic, and pragmatic purposes; one of these feature structures (syn) guarantees, for example, that the noun phrase agrees in person and number with the verb phrase; other feature structures are used to deal with different processing modes (mode) of sentences, to handle the composition of the logical form (fol), to process discontinuous constituents in the input string (gap), to enable the construction of a paraphrase (para) that clarifies the interpretation of the input sentence, and to organize the collection of noun phrase antecedents (ant).
The CNL grammar produces the following TPTP formula for the input sentence (61) during the parsing process:

This logical formula is then further translated by the CNL processor into KRSS, the target language of RacerPro:

Note that the TPTP representation in (63) contains additional information (contemp(B,u)) about the time when the utterance occurred since the CNL processor can handle tense (e.g., present tense and past tense). This information does not appear in the KRSS representation since DL cannot deal with this kind of information and therefore all verb forms of the input sentences must be in present tense in a strict DL setting. However, the information about tense is potentially useful in other logical frameworks and application scenarios.
Processing Questions
The CNL processor distinguishes between wh-questions, yes/no-questions, and imperative constructions. It is well known that the structure of questions in natural language is related in a systematic way to the structure of declarative sentences. For example, the declarative sentence (62):
![]() has the following functional structure:
has the following functional structure:

In the case of wh-questions, the query word interrogates one of these functional elements but it does not necessarily occur in the same position as the interrogated element. For example, in:
![]() the query expression (on what day) occurs in sentence-initial position and acts as a filler for a gap in the adjunct position as (67) illustrates:
the query expression (on what day) occurs in sentence-initial position and acts as a filler for a gap in the adjunct position as (67) illustrates:
![]()
During the processing of (66), the query expression (i.e., filler) is moved back into the adjunct position (i.e., gap). Schematically, the result of this process looks as follows:

This process is supported by a special feature structure (gap) in the grammar that passes the query expression through and by a grammar rule that licenses an empty constituent at a specific position if the query expression is detected and can be inserted.
The TPTP representation for the question is constructed during the parsing process. That means at the same time as the syntactic movement of the query expression into the gap position takes place. As already explained in the previous section, each word form is related to a partial logical form in the linguistic lexicon. For example, the processing of the query expression on what day triggers the following partial logical form:
![]()
The processing of the entire question (66) results in the subsequent conjunctive TPTP query that contains the logical form (69) as a part:

The CNL processor takes this TPTP formula and transforms it into a corresponding conjunctive nRQL query:
![]()
Note that yes/no-questions are treated in a similar way as wh-questions. The CNL processor first generates a normalized TPTP representation that looks similar to the representation of a declarative sentence, and then translates this representation into a Boolean conjunctive query, for example, (72) into (73):

The TPTP representation of a question is stored by the CNL processor and can be used as a starting point to answer questions as we will see in the next section.
Generating Answers
The relationship between declarative sentences and questions can be used for generating answers to questions in CNL. Internally, all TPTP formulas are annotated with syntactic information during the parsing process. For example, the TPTP formula (70) contains additional annotations (#) for all predicates that have been derived from content words, for example:
![]()
At this point, we know that the verbal event in question (66) has been derived from an infinite verb (take - inf). Once the DL reasoner comes back with an answer for a question, the stored TPTP representation of a question is transformed into a TPTP representation for a declarative sentence and the relevant syntactic annotations are updated. In our case, this looks as follows:
![]()
That means the CNL processor can now take the transformed TPTP formula as input and generate the correct verbal form (takes - fin) for the answer string:
![]()
Since the DL reasoner deals with subsumption hierarchies and concept definitions, there is no need to encode this ontological information in the linguistic lexicon. We get this terminological information for “free” from the DL reasoner during the question answering process. For example, the following questions:
 return all the same answer, if we have information about students in the knowledge base, since the query word who is more general than the concept person and since the concept person subsumes the concept student.
return all the same answer, if we have information about students in the knowledge base, since the query word who is more general than the concept person and since the concept person subsumes the concept student.
WRITING IN CNL
The writing of DL statements and questions in controlled natural language can be supported with the help of a predictive text editor that guides the writing process in CNL (see Chintaphally et al., Citation2007; Schwitter et al., Citation2003; Thompson, Pazandak, and Tennant, Citation2005, for an introduction). We have implemented such editing techniques in the past (Kuhn and Schwitter, Citation2008; Schwitter et al., Citation2003), which have some similarities to editing techniques used in programming environments. The basic idea here is to process the grammar rules with the help of a chart parser (Gazdar and Mellish, Citation1989; Kay, Citation1980). The chart parser stores information about well-formed substrings as well as information about hypotheses of substrings in a chart and avoids repetition of work by looking up substrings in the chart instead of recomputing them. Complete and incomplete analyses are stored as so-called edges in the chart. Edges that correspond to partially recognized substrings are said to be active, while inactive edges represent completely recognized substrings. In our case, an active edge is a term of the form:
![]()
This term consists of the actual sentence number (Number), a start position (Pos1) and an end position (Pos2) of a substring, the category (Category1) on the left-hand side of the grammar rule, a list of categories that have been found (Found) on the right-hand side of the grammar rule, and a list of remaining categories to be found ([Category2|Categories]). Chart parsing allows us to look up the necessary information about those word forms which can follow the current input string in a table.
Let us assume that the user wants to query the DL knowledge base and plans to enter the following question into the predictive text editor:
![]()
At the beginning, the text editor will display the initial look-ahead information for questions. This information is grouped into three categories since the number of possible lexical entries for these categories is already large:
![]()
After clicking on the hypertext link for the wh-question, the editor will display the look-ahead information that falls under this category:
![]()
The user can type (or select) one of these query words—in our case where—that is then sent to the CNL processor. The chart parser of the CNL processor first initializes the chart, adds edges into the chart, and activates grammar rules in order to expand the chart. This results in a set of new hypothesis that can be harvested for new look-ahead information. In our case, the text editor will display the following function words:
![]()
After entering the word does, the editor will display the following look-ahead categories:
![]()
At this point, the user has to make a decision whether he or she wants to enter a determiner or a proper noun. After entering the proper noun David Miller (or selecting it from a list of available proper nouns), new look-ahead information is generated and displayed. This process continues until the structure of the question is complete.
Of course, an experienced user can switch off this look-ahead facility and rely on the error messages that the CNL processor generates if the user does not stick to the rules of the CNL. These predictive interface techniques guarantee that all statements and questions conform to the rules of the CNL and that only syntactically correct statements are added to the DL knowledge base.
CONCLUSIONS
We argued that a DL knowledge base should be constructed in a linguistically motivated way in order to support question answering in an optimal way. To achieve this, the naming conventions used for constructing the ontology should be based on a set of well-defined linguistic patterns and on a vocabulary that occurs naturally in the application domain.
We have seen that such a linguistically motivated naming convention makes it is also easier to create an ontology on the level of a computer-processable controlled natural language. The controlled natural language can be used to express ABox and TBox statements as well as a query and feedback language. The presented approach has a number of attractive advantages: the controlled natural language looks like English and is easy to understand by humans and easy to process by a machine; furthermore, the language is so precisely defined that it can be translated unambiguously into DL and thus is in fact a formal language. A logic-based grammar is used to process statements and questions, and the same grammar can run “backwards” taking logical formulas in TPTP notation as input and generate answers to questions in controlled natural language. The user does not need to learn and remember the rules of the controlled natural language since the writing process is supported with the help of predictive interface techniques.
It is important to note that not all parts of a DL knowledge base need to be constructed in controlled natural language. The aim of this article was to illustrate that this is possible and how this can be achieved with the help of logic programming and natural language processing techniques. However, it might be the case that a knowledge engineer feels more comfortable using an ontology editor such as Protégé (Horridge et al. Citation2004) to develop the terminological knowledge for an application domain. As long as the knowledge engineer develops the TBox of this knowledge base in a linguistically motivated way, then this terminological knowledge can be combined with assertional knowledge expressed in controlled natural language. For some applications, it might even be possible to extract this assertional knowledge from existing textual information and represent it in controlled natural language so that it can be checked easily and modified by a human author (and still be processed by a machine).
We are convinced that controlled natural languages are a promising approach for creating and querying DL knowledge bases and that many applications can benefit from such a high-level interface language. We are currently investigating how controlled natural languages can be used as an interface language to the semantic web, as a language for expressing business rules, and as a query and alert language in a decision-support system.
ACKNOWLEDGMENTS
I would like to thank Anne Cregan, Alfredo Gabaldon, and Kevin Lee of NICTA's Knowledge Representation and Reasoning program at the Kensington laboratory in Sydney – where I spent my sabbatical in 2008 – for many fruitful discussions related to this work.
Notes
This is an extended and improved version of an article entitled “Creating and Querying Linguistically Motivated Ontologies” in Proceedings of the Knowledge Representation Ontology Workshop (KROW 2008), CRPIT 90. Meyer, T. and Orgun, M.A., Eds., Australian Computer Society (ACS), pp. 71–80.
Related Research Data
REFERENCES
- Androutsopoulos , I. , G. Ritchie , and P. Thanisch . 1995 . Natural language interfaces to databases – An introduction . Journal of Language Engineering 1 ( 2 ): 29 – 81 .
- Baader , F. , D. Calvanese , D. McGuinness , D. Nardi , and P. F. Patel-Schneider . 2003 . The Description Logic Handbook. Cambridge , UK : Cambridge University Press .
- Baader , F. 2009 . Description logics. In: Reasoning Web: Semantic Technologies for Information Systems, 5th International Summer School 2009, LNCS 5689 , 1 – 39 . Berlin/Heidelberg , Germany : Springer Verlag .
- Bernardi , R. , D. Calvanese , and C. Thorne . 2007 . Lite natural language. In: Proceedings of the 7th International Workshop on Computational Semantics (IWCS-7) . Tilburg , The Netherlands .
- Bernstein , A. , E. Kaufmann , and N. E. Fuchs . 2004 . Talking to the semantic web – A controlled English query interface for ontologies. In: 14th Workshop on Information Technology and Systems , 212 – 217 . Washington , D.C. , USA .
- Bernstein , A. , E. Kaufmann , A. Göhring , and C. Kiefer . 2005 . Querying ontologies: A controlled English interface for end-users . In: Proceedings of the 4th International Semantic Web Conference , 112 – 126 . Galway , Ireland .
- Chintaphally , V. R. , K. Neumeier , J. McFarlane , J. Cothren , and C. W. Thompson . 2007 . Extending a natural language interface with geospatial queries . IEEE Internet Computing , pp. 82 – 85 .
- Copestake , A. , and K. Sparck-Jones . 1990 . Natural language interfaces to databases . Knowledge Engineering Review 5 : 225 – 249 .
- Cregan , A. , R. Schwitter , and T. Meyer . 2007 . Sydney OWL Syntax – towards a controlled natural language syntax for OWL 1.1. In: 3rd OWL Experiences and Directions Workshop (OWLED 2007) , eds. C. Golbreich , A. Kalyanpur , and B. Parsia , Vol. 258. CEUR Proceedings. Innsbruck, Australia .
- Gazdar , G. and C. Mellish . 1989. Natural Language Processing in Prolog. An Introduction to Computational Linguistics. Wokingham , England : Addison-Wesley.
- Gruber , T. 1993 . A translation approach to portable ontologies . Knowledge Acquisition 5 ( 2 ): 199 – 220 .
- Haarslev , V. and R. Möller . 2003 . Racer: A core inference engine for the semantic web. In: Proceedings of EON2003 , 27 – 36 .
- Hart , G. , C. Dolbear , and J. Goodwin . 2007 . Lege Feliciter: Using structured English to represent a topographic hydrology ontology . In: 3rd OWL Experiences and Directions Workshop (OWLED 2007) , eds. C. Golbreich , A. Kalyanpur , and B. Parsia , Vol. 258 . CEUR Proceedings .
- Horridge , M. , H. Knublauch , A. Rector , R. Stevens , and C. Wroe . 2004 . A Practical Guide To Building OWL Ontologies Using The Protégé-OWL Plugin and CO-ODE Tools. Edition 1.0. The University of Manchester, http://www.co-ode.org/resources/tutorials. Last accessed 16 December 2009 .
- Horrocks , I. , P. F. Patel-Schneider , and F. van Harmelen . 2003 . From 𝒮ℋℐ𝒬 and RDF to OWL: The making of a web ontology language . Journal of Web Semantics 1 ( 1 ): 7 – 26 .
- Kaljurand , K. 2007 . Attempto Controlled English as a Semantic Web Language, PhD thesis, Faculty of Mathematics and Computer Science, University of Tartu, Tartu, Estonia .
- Kaufmann , E. , A. Bernstein , and R. Zumstein . 2006 . Querix: A natural language interface to query ontologies based on clarification dialogs . In: Proceedings of the 5th International Semantic Web Conference (ISWC 2006) , 980 – 981 . Athens , GA .
- Kaufmann , E. , A. Bernstein , and L. Fischer . 2007 . NLP-Reduce: A “naïve” but domain-independent natural language interface for querying ontologies . In: 4th European Semantic Web Conference (ESWC 2007) , 1 – 2 . Innsbruck , Austria .
- Kipper , K. , A. Korhonen , N. Ryant , and M. Palmer . 2008 . A large-scale classification of english verbs . Language Resources and Evaluation 42 ( 1 ): 21 – 40 .
- Kay , M. 1980 . Algorithm schemata and data structures in syntactic processing. CSL-80-12, Xerox Park, Palo Alto, CA .
- Kuhn , T. and R. Schwitter . 2008 . Writing support for controlled natural languages . In: Proceedings of ALTA 2008 , eds. D. Powers and N. Stockes , December 8–10, 46–54. Tasmania, Australia .
- Lopez , V. , E. Motta , and V. Uren . 2006 . PowerAqua: Fishing the semantic web . In: The Semantic Web: Research and Applications, LNCS , pp. 393 – 410 .
- Mellish , C. and X. Sun . 2005 . The semantic web as a linguistic resource . In: 26th SGAI International Conference on Innovative Techniques and Applications of Artificial Intelligence , Peterhouse College , Cambridge , UK .
- Mithun , S. , L. Kosseim , and V. Haarslev . 2007 . Resolving quantifier and number restriction to question OWL ontologies . In: Proceedings of the 3rd International Conference on Semantic, Knowledge and Grid , IEEE Computer Society, 218–223. Xi'an, China .
- Noy , N. and A. Rector . 2006 . Defining N-ary relations on the semantic web, W3C Working Group Note 12 April 2006, http://www.w3.org/TR/swbp-n-aryRelations/. Last accessed 16 December 2009 .
- Patel-Schneider , P. F. and B. Swartout . 1993 . Description-logic knowledge representation system specification from the KRSS group of the ARPA knowledge sharing effort, 1 November .
- Popescu , A.-M. , A. Armanasu , O. Etzioni , D. Ko , and A. Yates . 2004 . Modern natural language interfaces to databases: Composing statistical parsing with semantic tractability . In: Proceedings of the 20th International Conference on Computational Linguistics (COLING) , Article No. 141. Geneva, Switzerland .
- Prud'hommeaux , E. and A. Seaborne . 2008 . SPARQL Query Language for RDF, W3C Recommendation, 15 January 2008, http://www.w3.org/TR/rdf-sparql-query/. Last accessed 16 December 2009 .
- Racer Systems . 2007 . RacerPro User's Guide, Version 1.9.2, Technical report, http://www.racer-systems.com. Last accessed 16 December 2009 .
- Rector , A. , N. Drummond , M. Horridge , J. Rogers , H. Knublauch , R. Stevens , H. Wang , and C. Wroe . 2004 . OWL Pizzas: Practical experience of teaching OWL-DL: Common errors & common patterns . In: Proceedings of the European Conference on Knowledge Acquistion , eds. E. Motta , et al. ., 63 – 81 . Northampton , UK , 2004, LNAI 3257, Springer-Verlag .
- Reichert , M. , S. Linckels , C. Meinel , and T. Engel . 2004 . Student's Perception of a semantic search engine . In: Proceedings of IEEE IADIS International Conference on Cognition and Exploratory Learning in Digital Age (CELDA) , 139 – 147 . Porto , Portugal .
- Schober , D. , W. Kusnierczyk , S. E. Lewis , J. Lomax , and Members of the MSI, PSI Ontology Working Groups, C. Mungall, P. Rocca-Serra, B. Smith, and S. A. Sansone. 2007. Towards naming conventions for use in controlled vocabulary and ontology engineering. In: Proceedings of Bio-Ontologies SIG Workshop. Vienna , Austria.
- Schwitter , R. , A. Ljungberg , and D. Hood . 2003 . ECOLE – A look-ahead editor for a controlled language . In: Proceedings of EAMT-CLAW03 , May 15–17, Dublin City University, Ireland, 141–150. Sydney, Australia .
- Schwitter , R. and M. Tilbrook . 2004 . Controlled natural language meets the semantic web . In: Australasian Language Technology Workshop , eds. S. Wan , A. Asudeh , C. , 55 – 62 . Sydney , Australia .
- Schwitter , R. and M. Tilbrook . 2006 . Let's talk in description logic via controlled natural language. In: Logic and Engineering of Natural Language Semantics, (LENLS2006), Tokyo, Japan, June 5–6 .
- Schwitter , R. , K. Kaljurand , A. Cregan , C. Dolbear , and G. Hart . 2008 . A comparison of three controlled natural languages for OWL 1.1. 4th OWL Experiences and Directions Workshop (OWLED 2008 DC), Washington DC, 1–2 April .
- Sirin , E. , B. Parsia , B. C. Grau , A. Kalyanpur , and Y. Katz . 2007 . Pellet: A practical OWL-DL reasoner . Journal of Web Semantics 5 ( 2 ): 51 – 53 .
- Sutcliffe , G. and C. B. Suttner . 1998 . The TPTP Problem Library: CNF Release v1.2.1 . Journal of Automated Reasoning 21 ( 2 ): 177 – 203 .
- Thompson , C. W. , P. Pazandak , and H. R. Tennant . 2005 . Talk to your semantic web . IEEE Internet Computing 9 ( 6 ): 75 – 79 .
- Tsarkov , D. and I. Horrocks . 2006 . FaCT++ description logic reasoner: System description . In: Proceedings of IJCAR 2006, LNAI 4130 , 292–297. Springer .
- Wessel , M. , and R. Möller . 2006 . A Flexible DL-based architecture for deductive information systems . In: Proceedings of the FLoC′06 Workshop on Empirically Successful Computerized Reasoning , Seattle , WA , August 22 , pp. 92 – 111 .
- Zimmerman , M. , K. Lundqvist , and N. Leveson . 2002 . Investigating the readability of state-based formal requirements specification languages . In: Proceedings of the International Conference on Software Engineering (ICSE′02) , 33–43 . Orlando , FL .
- This is an extended and improved version of an article entitled “Creating and Querying Linguistically Motivated Ontologies” in Proceedings of the Knowledge Representation Ontology Workshop (KROW 2008), CRPIT 90. Meyer, T. and Orgun, M.A., Eds., Australian Computer Society (ACS), pp. 71–80.