Abstract
Given a set of collected evidence and a predefined knowledge base, some existing knowledge-based approaches have the capability of synthesizing plausible crime scenarios under restrictive conditions. However, significant challenges arise for problems where the degree of precision of available intelligence data can vary greatly, often involving vague and uncertain information. Also, the issue of identity disambiguation gives rise to another crucial barrier in crime investigation. That is, the generated crime scenarios may often refer to unknown referents (such as a person or certain objects), whereas these seemingly unrelated referents may actually be relevant to the common revealed. Inspired by such observation, this article presents a fuzzy compositional modeler to represent, reason, and propagate inexact information to support automated generation of crime scenarios. Further, the article offers a link-based approach to identifying potential duplicated referents within the generated scenarios. The applicability of this work is illustrated by means of an example for discovering unforseen crime scenarios.
INTRODUCTION
To resolve the puzzle of a given crime from a set of available evidence, investigators and forensic analysts aim to disclose the scenario that has actually taken place and to determine efficient strategies to proceed with the investigation (Shen et al., Citation2006). Hence, the effectiveness of this analytical process depends critically on investigators’ ability to articulate plausible scenarios and to identify course of actions needed for differentiating them.
Although the bottleneck of accomplishing such a task is the fact that humans are relatively inefficient at hypothetical reasoning, a decision-support system may assist investigators in generating plausible scenarios and analyzing them objectively. To this extent, compositional modeling (CM) (Keppens and Shen, Citation2001) has been successfully used to synthesize plausible crime scenarios from collected evidence (Keppens et al., Citation2005; Shen et al., Citation2006). This intelligent CM-based approach is brought forward to underpin the significant advantage of its ability to automatically construct many variations of an underlying crime scenario from a relatively small knowledge base. However, in such existing work it is assumed that the basic knowledge elements, termed scenario fragments (SF) as collected within the knowledge base, can all be expressed by precise and crisp information. Particularly, a set of probability distributions, possessed by each SF for representing the likelihood of its associated possible outcomes, are specified in numerical forms. In spite of this, especially in the case of crime detection and prevention, the degree of precision of available evidence and intelligence data can vary greatly, subject to different perception, judgement, and individuality of people. As such, an assessment of likelihood typically reflects the expertise and knowledge of experienced investigators is normally available in linguistic terms instead (Halliwell et al., Citation2003; Halliwell and Shen, Citation2009). The use of seemingly precise numeric descriptors suffers from an inadequate degree of accuracy.
Another crucial barrier for any investigation decision-support system is identity disambiguation problem that is commonly encountered in intelligence data analysis (Badia and Kantardzic, Citation2005; Pantel, Citation2006; Wang et al., Citation2005). In particular, a modest resolution used within the previous crime investigation systems (Keppens et al., Citation2005; Shen et al., Citation2006) is to assume that the identities of any involving instances (e.g., person, object, place, and organization) are globally unambiguous. However, this simple ignorance of possible identity aliases drastically reduces the degree of this approach's flexibility and actual utilization within the real world. Yet, another significant problem occurs whenever the scenario composition process has to refer to unknown identities. For instance, given the evidence of a man having been shot by a 9-mm gun, the abductive reasoner (Shen et al., Citation2006) can hypothesize the existence of a murderer owning such a weapon but requiring the possible matching of this unknown gun with weapon identities instantiated within the scenario space. Henceforth, complementing such abductive reasoning with the mechanism of identity resolution would enhance not only the quality and coverage of scenario acquired by associating sparse SFs through shared identities of involving participants but also the effectiveness of system management regarding duplicated fragments.
Recognizing the aforementioned shortcomings, we extend the initial model of fuzzy CM (Fu et al., Citation2007) in which the theory of fuzzy sets is applied to the conventional CM approach to provide a mechanism for representing, reasoning, and propagating vague and uncertain information. In addition, a link-based approach to identity resolution, which has proven effective for disclosing aliases in intelligence data (Boongoen and Shen, Citation2008; Boongoen et al., Citation), is exploited to identify duplicated identities within a collection of generated scenarios. This novel approach is not only able to refine the quality of scenarios but also to optimize the resource utilization.
The rest of this article is organized as follows. We next introduce knowledge representation of vague and uncertain information within CM by the use of fuzzy sets and then present an outline of the proposed approach. Then, we show how the plausible scenarios can be synthesized from available evidence and knowledge base under uncertainty. Next we describe how such generated scenarios can be refined to handle the identity problem by using link-based analysis. This is followed by an illustrative example showing the capability of the proposed approach to provide support in crime investigation. Finally, we conclude this article and point out future research.
REPRESENTING EVIDENCE AND CRIME SCENARIOS UNDER UNCERTAINTY
Knowledge Representation in CM
The conventional CM approach has been successfully applied to generate descriptions of crime scenarios from evidence (Keppens et al., Citation2005). In CM the knowledge base consists of a number of generic SFs, which represent generic relationships between domain objects and their states for certain types of partial scenario. An SF has two parts that encode domain knowledge: i) the relations between domain elements, which are often represented in a form that is similar to the style of conventional production rules but involving much more general contents, and ii) a set of rule instances that represent how likely it is that the corresponding relationships hold.
More formally, an SF is represented as follows:
| |||||
| |||||
p t is the consequent predicate, which describes the consequent when the conditions and presumed assumptions hold. It may represent a piece of new knowledge or relations which are derived from the hypothetical reasoning. | |||||
In the Distribution statement, the left-hand side of the “implication” sign in each rule instance is a combination of predicate-value pairs, involving antecedent and assumption predicates and their values, and the right-hand side indicates the likelihood of each alternative outcome if the fragment is instantiated. | |||||
Given a collection of such SFs and some collected pieces of evidence, CM applies an abductive reasoner to create plausible scenarios (see Shen et al., Citation2006; for details). However, for many problem domains, especially for crime detection and prevention, different kinds of inexact information may be involved which conventional CM cannot always handle, including
Vagueness: It occurs when the boundary of a piece of information cannot be determined precisely (e.g., Bob is tall). | |||||
Uncertainty: It captures the reliability or confidential weight of a given piece of information, usually represented by numerical values (e.g., If X is a bird, then it can fly, with certainty degree 0.95). | |||||
Both vagueness and uncertainty: Often, these two different kinds of inexactness may coexist (e.g., The amount of collected fiber is a lot, with certainty degree 0.7). | |||||
Both vagueness and uncertainty with the uncertainty also described in fuzzy terms: Instead of using numerical values, the uncertainty is represented as fuzzy numbers or linguistic terms (e.g., The amount of collected fiber is a lot, with certainty degree very likely). | |||||
The following subsections focus on the creation of a structured knowledge representation scheme, which is capable of storing and managing both vague and uncertain information. It involves two conceptually distinct aspects: i) fuzzification of SFs, including fuzzy parameters and fuzzy constraints, and ii) definition of fuzzy complex numbers, which facilitates the propagation of vagueness and uncertainty within the process of model composition.
Fuzzification of SFs
Fuzzy Parameters
Within the present work, vague and ill-defined concepts and quantities are defined as fuzzy variables whose values are fuzzy sets. For example, the police discovered the dead body of Smith in his bedroom. Bob, who is the next-door neighbor, witnessed somebody going into Smith's house; however, it is difficult for Bob to state an accurate height for that person (e.g., 180 cm). Intuitively, he might just describe the height of the person as short, average, or tall. In this case, height can be modeled as a fuzzy variable and can be described by using fuzzy sets short, average, or tall.
In implementation, fuzzy variables are indicated by means of the keyword fuzzyvariable. Defining such a variable involves specifying the following fields:
Name: A constant that uniquely identifies the fuzzy variable. | |||||
Universe of discourse: The domain of the fuzzy variable. | |||||
Unit: The variable's physical dimension. If a fuzzy variable has no unit, a default value of none is set. | |||||
Cardinality of partition: The number of fuzzy sets that jointly partition the universe of discourse. It is represented by a positive integer. | |||||
Quantity space: The membership functions of the fuzzy sets that jointly cover the partitioned domain. | |||||
Name of fuzzy sets: The symbolic label of each fuzzy set in the defined quantity space. | |||||
Unifiability: The declaration of a unifiable property of the variable, specified by a predicate. | |||||
The following example defines a fuzzy variable named Chance. The defined quantity space is shown in Figure .
FIGURE 1 The fuzzy quantity space of Chance.
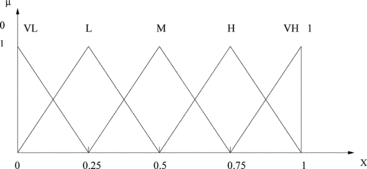
Fuzzy Constraints
In CM, knowledge is normally expressed as constraints or relations that must be obeyed by certain variables. Particularly, constraints used in the existing work require numerical values to quantify the probability of a consequence's occurrence. However, such subjective assessments are often the product of barely articulate intuitions. In fact, the seemingly numerically precise expressions may cause loss of efficiency, accuracy, and transparency (Cooman, Citation2005; Halliwell et al., Citation2003; Halliwell and Shen, Citation2009). Often, an expert may be unwilling or simply unable to suggest a numerical probability.
The work developed here models the vagueness of the probability distribution in terms of subjective certainty degree. Rather than using numerical value as in the literature, a fuzzy variable called Chance, which takes linguistic values from [0, 1], is introduced to capture subjective certainty degrees.
The following sample SF illustrates the concepts and applicability of fuzzy parameters and fuzzy constraints:
It describes a general relation between the heights of two people involved in a fight and the difficulty level for one to overpower the other. Here, the height is modeled as a fuzzy variable that takes values from a predefined quantity space of Q = {very short, short, average, tall, very tall}, and difficulty level is another fuzzy variable with possible values being easy, average, and difficult. In particular, this fragment covers two rule instances indicating that if suspect S is tall and victim V is short and S indeed attempted to kill V, then S stands a very high chance to overpower V easily. Conversely, if S is shorter than V and he indeed attempted to kill V, then there is only a very low chance for S to overpower V easily.
Note that it is not required that every possible combination of antecedent and assumption values has to be assigned a certainty degree because the number of combinations increases exponentially with the number of variables. Knowledge embedded in any reasoning system is always incomplete, and it is unlikely to obtain all such details but the most significant components. As with any practical knowledge-based approach, the default certainty degree for those unassigned combinations is set to 0.
Fuzzy Complex Numbers
Because generic SFs may involve both vague and uncertain information, when dynamically composing the potentially relevant ones into plausible scenario descriptions, such inexact information needs to be combined and propagated in the emerging scenarios. To achieve this, an innovative notion of fuzzy complex numbers (FCN), which extends real complex numbers, has recently been proposed (Fu and Shen, Citation2009) with the significant capability of representing two-dimensional uncertainties simultaneously. For completeness, a brief account of this novel concept is given below in the context of CM.
Definition 1
Inherit from the real complex numbers, an FCN, [ztilde], is defined in the form of:
In this work, to support CM both the real part and the imaginary part of an FCN are assigned with their embedded semantic meaning, and they will be propagated, respectively, in the model composition process. Specifically, the real part represents the certainty degree of a certain piece of information, whereas the imaginary part represents the fuzzy matching degree of a given evidence or derived piece of information using a particular rule instance of a certain SF. As such, FCNs offer an effective and efficient common scheme to represent the four types of inexact information as previously identified such that
Vagueness: In CM, the imaginary part only exists when fuzzy matching is performed between two pieces of information. In addition, given a piece of evidence, if there is no specific certainty degree assigned to it, then it is assumed to be certain by default. In this case the real part of the FCN in representing this piece of evidence is equal to 1. For example, given a fact, f 1: Bob is tall, this single piece of vague information is represented as [ztilde] = 1. However, when a piece of evidence, e 1: victim is tall, is collected, f 1 matches with e 1 with a fuzzy matching degree [btilde], such that if f 1 is activated, the FCN attached to f 1 is written as [ztilde] = 1 + i[btilde]. | |||||
Uncertainty: If a piece of information (e.g., a rule) only involves uncertainty, then the corresponding uncertainty measure can be represented as [ztilde] = ã, which can either be a real number or a fuzzy number. | |||||
Both vagueness and uncertainty coexist: The third and fourth types of inexactness can both be represented in the following generic form: [ztilde] = ã +i[btilde]. The only difference is that ã is a real number in the third type and is a fuzzy number in the fourth. | |||||
Note that the basic operations on FCNs form a straightforward extension of those on real complex numbers, and they are omitted here. Interested readers can refer to (Fu and Shen, Citation2009) for further details. However, it is worthy to point out that the modulus of FCNs is introduced to constrain the scenario descriptions; it will be used as a global measure to evaluate the overall confidence level of a piece of information. As such, the modulus of an FCN [ztilde] is defined as
OUTLINE OF THE APPROACH
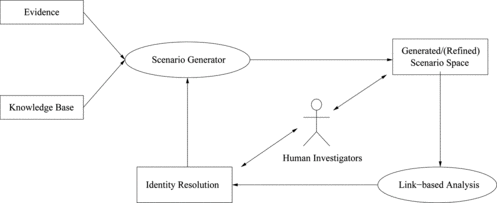
The outline of the proposed approach is shown in Figure . A new or ongoing investigation results in an initial set of evidence. Then, the Scenario Generator component generates a collection of plausible scenarios, called scenario space, by exploiting a given knowledge base. The scenario space describes how plausible states and events may be related to have caused the given evidence. Having obtained scenarios, the Link-based Analysis component is used to handle the identity problem. Consequently, a list of duplicate candidates is fed back to the Scenario Generator to produce an updated, more refined, scenario space.
FIGURE 2 Outline of the approach.
GENERATION OF PLAUSIBLE SCENARIOS
Given a set of collected evidence and a predefined knowledge base, plausible scenarios can be generated by a joint exploitation of two conventional inference techniques, named backward chaining and forward chaining. Note that because the precision degree of the underlying information can vary substantially, the collected evidence and the knowledge base in general cannot be matched precisely, and a partial matching may suffice. A fuzzy matching method is developed to perform such partial matching and hence SF instantiation (with respect to the given evidence). In addition, when composing an instantiated SF with an emerging plausible scenario, the attached certainty degree and fuzzy matching degree (which are concisely represented in terms of FCNs) need to be propagated from individual SFs to their related ones. Hence, an algorithm for propagating FCNs within the model composition process is also proposed herein.
Initialisation
Collected evidence and facts are used to form the initial elements contained within the emerging scenarios space (which is empty before this initialisation step). To allow instantiation of a fuzzy SF in accordance with a given piece of evidence, the system requires matching specific data items with broader and relatively subjective information. Such fuzzy matching is accomplished by the following procedure:
-
Find the so-called candidate SFs that involve any of the variables used to describe the collected evidence.
-
Identify the degree of match between evidence and each candidate SF. For simplicity, the match degree is obtained by calculating the maximum membership value over the overlapping area between the relevant fuzzy sets.
-
Return the matched SFs with the largest FCN modulus for instantiation.
Propagation of FCNs
After the initial instantiation, each added node in the emerging space has an FCN attached. Note that each rule instance in any generic SF also has an FCN attached that is called [ztilde] r , which indicates the certainty degree of its subjective causal propositions. In the generation of plausible scenarios, the attached FCNs are propagated to their related nodes via the FCN of the activated rule instance ([ztilde] r ).
For simplicity, the following rule instance in an SF:
Definition 2
If ⊕ is a conjunctive operator, the aggregated FCN of the antecedent is
Definition 3
If ⊕ is a disjunctive operator, the aggregated FCN of the antecedent is
The propagation process is then a combination process of the FCNs given to the variables (antecedents or consequent) with the FCN attached to the activated rule instances ([ztilde] r ). Because the rule instance in an SF only has the certainty degree attached, i.e., [ztilde] r = Re([ztilde] r ), the newly derived FCN attached to the consequent is computed using the following method:
Backward Chaining
This involves the abduction of domain variables and their states, which might have led to the available evidence. Plausible causes are created by instantiating the conditions and assumptions of the SFs, whose consequent match the given evidence with the largest FCN modulus. After that, the newly created instances of all plausible causes are recursively used in the same manner as with the original piece of evidence, instantiating all relevant fragments and adding the resulting instantiated variables, termed nodes to the emerging scenario space.
Due to the lack of inverse operators over fuzzy numbers, in backward chaining, given [ztilde] c and [ztilde] r , no general method exists to derive the exact value of [ztilde]antecedent in a closed form. Hence, specific fuzzy quantity spaces are built to approximately represent the possible values of the real and imagery parts of [ztilde]antecedent, assuming that they can only take values from such predefined quantity spaces. For computational simplicity, in this work it is further assumed that only fuzzy values from the same quantity space, Q FN = {V FN 1 ,…, V FN j ,…, V FN n }, are possibly taken by [ztilde] c and [ztilde] r .
In backward chaining, [ztilde] c and [ztilde] r are given. Algorithm 1 is constructed by ensuring the generality that each element in Q FN could be the possible value of [ztilde]antecedent. Thus, all such values are checked using Eq. (Equation6) as the constraint. The value that best satisfies this constraint when given [ztilde] c is selected to represent [ztilde]antecedent. Note that, the Re([ztilde] c ) and Im([ztilde] c ) are checked against the constraint separately.
Forward Chaining
All plausible causes of the collected evidence that the knowledge base entails may be introduced to the emerging scenario space during the backward chaining phase. Here, the forward chaining phase is responsible for extending the scenario space by adding all plausible consequences of the fragments whose conditions and assumptions match the instances created in the last phase. This produces further pieces of information that have not yet been identified otherwise but may be used to improve the plausible scenario description.
This procedure applies logical deduction to all the SFs in the knowledge base, whose conditions match the existing nodes in the emerging scenario space. Therefore the corresponding FCN propagation algorithm is straightforward, as described in Algorithm 2. In particular, [ztilde]antecedent and [ztilde] r are known, the [ztilde]new is computed by applying Eq. (Equation6), where [ztilde]new is the calculated FCN of the consequent variable. Given the fired Q FN in this work, once [ztilde]new is obtained it is used to match with the elements in Q FN , the element receives the highest fuzzy matching degree with [ztilde]new is returned to represent [ztilde] c .
FCN Updating
In the emerging scenario space, if an existing node resulted from instantiating another SF such that two instantiated SFs share a common variable, then the existing FCN of this node needs to be updated. Suppose that given the following two FCNs:
This is an intuitive appeal because, if is supported by the existing inference, then
is also supported.
Removal of Spurious Nodes
In the previous phases of scenario space generation, spurious nodes may have been added to the emerging scenario space. Such nodes are root nodes in the space graph that are neither facts nor instantiated assumptions nor the justifying nodes that support the instantiated assumptions. That is, they are irrelevant to the actual case under investigation and, hence, should be removed. The removal procedure recursively examines the root nodes in the emerging scenario space and deletes such nodes. It terminates when each root node in the emerging scenario space corresponds to either a fact or an assumption, guaranteeing all the spurious nodes are removed.
IDENTITY RESOLUTION
To achieve a decision support system that is truly effective to battle real crimes within highly deceptive environment, a verification mechanism is required to handle the identity problem, (Badia and Kantardzic, Citation2005; Pantel, Citation2006; Wang et al., Citation2005) thereby refining the quality of hypothesized scenarios. This analytical process is crucial as falsified identity has become the common denominator of all serious crime such as mafia trafficking, fraud, and money laundering. In particular to the September 11 terrorist attacks, tragic consequences could have been prevented to some extent if U.S. authorities had been able to discover the use of deceptive identity, e.g., multiple dates of birth and alias names. To such extent, many exiting verification systems (Branting, Citation2003; Wang et al., Citation2006) that rely on the inexact search of textual attributes would fail drastically to recognize the unconventional truth like that between Osama bin Laden and The Prince (Hsiung et al., Citation2005).
Link Analysis Approach
The aforementioned dilemma may be overcome through link analysis that seeks to discover information based on the relations hidden in data about people, places, objects, and events. Link analysis techniques have proven effective for identity problems (Boongoen and Shen, Citation2008; Hsiung et al., Citation2005; Pantel, Citation2006) by exploiting link information observed from legitimate activities such as making use of mobile phones and financial systems. Essentially, to justify the similarity between entities (e.g., names) within a link network, several well-known algorithms, such as SimRank, (Jeh and Widom, Citation2002) concentrate on the cardinality of joint neighbors to which they are linked (more details in Liben-Nowell and Kleinberg, Citation2007).
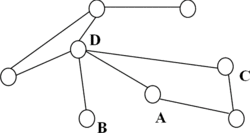
Analogously, the Connected-Triple method (Klink et al., Citation2006) evaluates the similarity of objects in accordance with their overlapping social context. This measurement is based on the social network G(V, E) in which objects of interest and their relations are represented by the set of vertices V and that of edges E, respectively. The similarity of any two objects can be estimated by counting the number of Connected-Triples of which they are a part. Formally, a Connected-Triple, Triple = {V Triple, E Triple}, is a subgraph of G containing three vertices V Triple = {v 1, v 2, v 3} ⊂ V and two edges E Triple = {e v 1 v 2 , e v 1 v 3 } ⊂ E, with e v 2 v 3 ∉ E. Figure presents an example of a social network in which object A and object B are justified similar because there exists a Connected-Triple link connecting them together, V Triple = {A, B, D} and E Triple = {e AD , e BD }, with e AB ∉ E.
FIGURE 3 A social network with Connected-Triple.
Application to Scenario Refinement
Within a scenario generated by the method of the previous section, associations among information entities (e.g., persons, objects, and locations) can be perceived through n-nary (n > 1) predicates p (i.e., a general notation for any p s , p a , and p t in If, Assuming, and Then statements, respectively), instantiated through user inputs or the underlying abductive and deductive reasoning processes. To identify entity pairs that are likely to constitute alias references, a link network G(V, E, W) (where V, E, and W represent a set of vertices, edges, and that of edge weights) is initially constructed from a given scenario S as follows:
Let O and | |||||
A link between objects o
i
, o
j
∊ O, which is denoted by an edge e
ij
∊ E between the corresponding vertices v
i
, v
j
∊ V, exists when they are part of q predicates (q ≥ 1). In particular, each edge e
ij
∊ E possesses | |||||
Then, the weight w ij ∊ W of an edge e ij ∊ E, where w ij ∊ {0, VL, L, M, H, VH, 1}, can be estimated as | |||||
Having obtained the link network, the similarity s(o i , o j ) of any two entities o i , o j ∊ O can be estimated from the number of their shared neighbors |N o i o j |, where N o i o j ⊂ O is the set of objects o x directly links to o i and o j , i.e., e ix , e jx ∊ E, e ij ∉ E. However, unlike the conventional Connected-Triple approach, the cardinality-based similarity measure s(o i , o j ) is adapted to weighted edges as
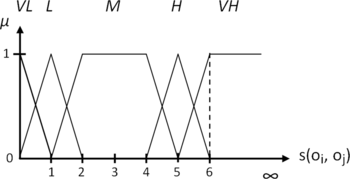
Fuzzy sets presented in Figure are used to generate a coherently interpretable linguistic description of any similarity degree s(o i , o j ): VL = VeryLow, L = Low, M = Moderate, H = High, and VH = VeryHigh. For instance, the similarity measure of 1.5 can be expressed as being L(0.5) and M(0.5), where membership degrees to corresponding fuzzy sets are given in brackets. Note that although the semantics of these descriptors are defined by domain experts in the current research, they can also be formulated from historical data using a machine learning technique. With this methodology, an investigator can efficiently differentiate and select the most likely case upon which the scenario is refined (see next section for an example).
FIGURE 4 Definition of fuzzy sets for describing a similarity measure.
ILLUSTRATIVE EXAMPLE
It is obvious that many explosive ingredients and liquids can be combined to create homemade liquid bombs. However, a lot of explosive chemicals can be concocted from some very common items, such as perfumes, drain cleaner, and batteries, and they are innocent in themselves. Also, the initial collected evidence may seem to be irrelevant with each other from the outset. This makes it very difficult for intelligence analysts to detect a plausible threat. This section shows how the proposed fuzzy compositional modeler and the link-based identity resolution can be used to generate and refine the plausible scenario space, given both vague and uncertain information in this application context.
Scenario Generation
Consider the following scenario: Assume that a suspect named Dave was trying to bring a bottle of coke on board on aircraft and a mobile phone is found on him. A few hours later the security control center found a small bag of hair dye in a suitcase under the name of Bob. Also, a light blue Nissan Micra was caught on the airport CCTV and Dave was alone in the car. With further investigation the police found out that this Nissan Micra belongs to Bob and the mobile phone is registered under the name of Bob as well. These pieces of evidence and some key SFs are listed in the Appendix. Note that because the evidence obtained from different sources may receive different certainty degrees, for example, the piece of evidence gathered by the CCTV camera record may receive a higher certainty degree than that described by a witness. To reflect this, the certainty degree (which may be initially assigned) of each piece of evidence is also provided.
Initial creation of the emerging scenario space is done by matching a given piece of evidence, say e 1, against the knowledge base. It is obvious that MF 1 is first instantiated. This piece of evidence only involves boolean proposition, such that the fuzzy matching degree of e 1 and MF 1 is either 1 or 0. By applying Algorithm 1 to MF 1, the results of Table are obtained.
TABLE 1 Results of Backward Chaining Due to e 1
As indicated previously, to avoid generating unnecessary explanations, the modeler produces only the current best or the most plausible explanations in the first instance. With regard to the use of the modulus of a derived FCN for plausibility evaluation, only r 1 in MF 1 is instantiated for further development. As a result the first node, “Seen with(Bob,Hair dyes,Airport)”, is added to the emerging scenario space with the FCN: H + i1. Given this and the instantiated MF 1, backward chaining is performed from the existing node. This leads to the instantiated antecedences and assumption in MF 1 being added to the scenario space. According to Table , [ztilde]antecedent r 1 = 1 + i1, it follows from Eq. (Equation4) that
It is obvious that
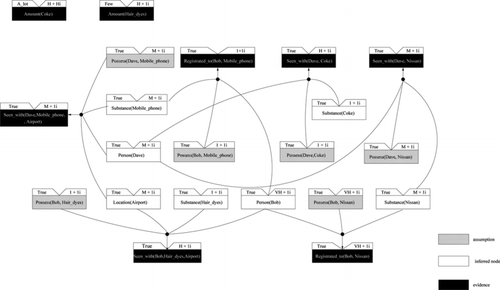
Similarly, the remaining pieces of evidence are used to match with the knowledge base sequentially. Note that, for those existing nodes in the emerging scenario space, their associated FCNs are updated by using Eq. (Equation8). As a result, after the backward-chaining and forward-chaining phase, the generated scenario space is depicted in Figure .
FIGURE 5 Generated scenario space.
Identity Resolution
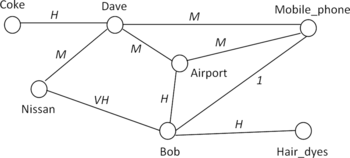
According to the scenario given in Figure , the link network (shown in Figure ) is achieved by following the method set out in the previous section. In particular, several entity pairs are identified with non-zero similarity values, thus forming a candidate list of duplicates. For instance,
s(Bob, Dave)=Low(0.5), Moderate(0.5) | |||||
s(Mobile phone, Nissan)=Low(0.67), Moderate(0.33) | |||||
s(Hair dyes, Nissan)=Very Low(0.33), Low(0.67) | |||||
s(Coke, Mobile phone)=Very Low(0.5), Low(0.5) | |||||
s(Coke, Nissan)=Very Low(0.5), Low(0.5) | |||||
FIGURE 6 A link network with fuzzy linguistic weights.
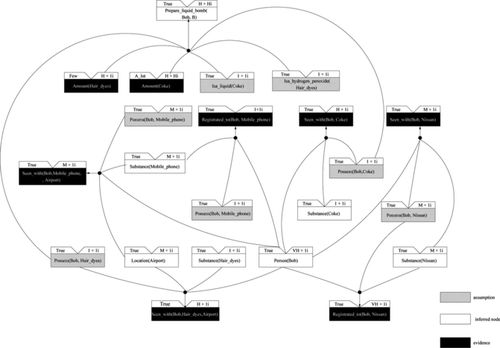
With fuzzy linguistic similarity descriptors, an investigator can conveniently perceive and differentiate among candidate pairs. The higher the similarity value, the greater the possibility of the entity pair being duplicates becomes. Intuitively, only the pair of (Bob, Dave) is applicable because others include incompatible entity types (e.g., Coke and Nissan), and they are justified with lower similarity degrees. Hence, Bob and Dave are accepted to be different references to the same person. This new finding is then used to refine the existing scenario space of Figure by activating MF 4. The forward chaining procedure is then performed and the results are listed in Table .
TABLE 2 Results of Forward-Chaining Propagation Within MF 4
According to the modulus of the FCN obtained for each matched proposition instance, the one associated with r 1 in MF 4 outperforms those associated with the rest. The revised scenario space is depicted in Figure . It is noteworthy that a new and interesting hypothesis of preparing a liquid bomb emerges as the result of this identity fusion. In addition to the capability to discover an unforseen scenario, the link-based approach is able to help the CM modeler scaling up to a large problem, in which instantiated instances can be efficiently managed.
FIGURE 7 Updated scenario space.
CONCLUSION
This article presents a novel approach to generate and refine plausible crime scenarios from available evidence. It has two significant advantages: i) the ability to represent and reason with information at varying degrees of precision and ii) the ability to enhance the quality of generated scenarios through the resolution of duplicated references. Initially, a knowledge representation formalism is introduced to represent both vague and uncertain information. In particular, FCN propagation algorithms are developed and integrated to the conventional abductive modeler (Shen et al., Citation2006) to generate plausible scenarios. Having obtained scenarios, a link-based method is used to identify potential duplicates (i.e., aliases), which are consequently exploited to refine the underlying scenarios.
To extend its applicability, an ontological methodology may be introduced such that the knowledge-based decision support system becomes compatible with a variety of information entities and their relations. Essentially, the similarity among entities, estimated from the ontology, can improve the effectiveness of both scenario generation (semantic matching) and identity resolution (filtering out candidates with dissimilar-typed entities). Also, a more general constraint satisfaction mechanism suitable for constraining variables modified by FCNs would help to improve the generality of the proposed approach. In particular, this may avoid the need to prefix just one common quantity space to which the real and imaginary parts of any FCN may belong.
This work is partly sponsored by the UK EPSRC grant no. EP/D057086. We are grateful to the members of the project team for their contribution and take full responsibility for the views expressed in this article.
REFERENCES
- Badia , A. , and M. M. Kantardzic . 2005 . Link analysis tools for intelligence and counterterrorism . In Proceedings of IEEE International Conference on Intelligence and Security Informatics , 49 – 59 . Atlanta , Georgia : Springer Berlin .
- Boongoen , T. , and Q. Shen . 2008 . Detecting false identity through behavioural patterns . In Proceedings of International Crime Science Conference , London , UK : Willan Publishing .
- Boongoen , T. , Q. Shen , and C. Price . Disclosing false identity through hybrid link analysis . AI and Law , In press (DOI: 10.1007/510506-010-9085-9)
- Branting , K. 2003 . A comparative evaluation of name matching algorithms . In Proceedings of International Conference on AI and Law , 224 – 232 . Edinburgh , Scotland : ACM .
- Cooman , G. D. 2005 . A behavioural model for vague probability assessments . Fuzzy Sets Syst. , 154 : 305 – 358 .
- Fu , X. , and Q. Shen . 2009. A novel framework of fuzzy complex numbers and its application to compositional modelling. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, 536–541. ICC , Jeju Island, Korea : IEEE.
- Fu , X. , Q. Shen , and R. Zhao . 2007 . Towards fuzzy compositional modelling . In Proceedings of the 16th International Conference on Fuzzy Systems , 1233 – 1238 . London , UK : IEEE .
- Halliwell , J. , and Q. Shen . 2009 . Linguistic probabilities: theory and application . Soft Computing , 13 : 169 – 183 .
- Halliwell , J. , J. Keppens , and Q. Shen . 2003 . Linguistic bayesian networks for reasoning with subjective probabilities in forensic statistics . In Proceedings of International Conference on Artificial Intelligence and Law , 42 – 50 . Edinburgh , Scotland : ACM .
- Hsiung , P. , A. Moore , D. Neill , and J. Schneider . 2005 . Alias detection in link data sets . In Proceedings of International Conference on Intelligence Analysis , McLean , VA : International Conference on Intelligence Analysis .
- Jeh , G. , and J. Widom . 2002 . Simrank: A measure of structural-context similarity . In Proceedings of International Conference on Knowledge Discovery and Data Mining , 538 – 543 . Edmonton , Alberta : ACM .
- Keppens , J. , and Q. Shen . 2001 . On compositional modelling . Knowledge Engineering Review , 16 : 157 – 200 .
- Keppens , J. , Q. Shen , and B. Schafer . 2005 . Probabilistic abductive computation of evidence collection strategies in crime investigation . In Proceedings of International Conference on Artificial Intelligence and Law , 215 – 224 . Bologna , Italy : ACM .
- Klink , S. , P. Reuther , A. Weber , B. Walter , and M. Ley . 2006 . Analysing social networks within bibliographical data . In Proceedings of the 17th International Conference on Database and Expert Systems Applications , 234 – 243 . Krakow , Poland : Springer Verlag .
- Liben-Nowell , D. , and J. Kleinberg . 2007 . The link-prediction problem for social networks . Journal of the American Society for Information Science and Technology , 58 : 1019 – 1031 .
- Pantel , P. 2006 . Alias detection in malicious environments . In Proceedings of AAAI Fall Symposium on Capturing and Using Patterns for Evidence Detection , Washington , DC , 14 – 20 .
- Shen , Q. , J. Keppens , C. Aitken , B. Schafer , and M. Lee . 2006 . A scenario-driven decision support system for serious crime investigation . Law, Probability and Risk , 5 : 87 – 117 .
- Wang , G. A. , H. Atabakhsh , T. Petersen , and H. Chen . 2005 . Discovering identity problems: A case study . In Proceedings of IEEE International Conference on Intelligence and Security Informatics , Atlanta , 368 – 373 .
- Wang , G. A. , H. Chen , J. J. Xu , and H. Atabakhsh . 2006 . Automatically detecting criminal identity deception: an adaptive detection algorithm . IEEE Transactions on Systems, Man and Cybernetics, Part A , 36 : 988 – 999 .
APPENDIX KEY SFs IN SAMPLE KNOWLEDGE BASE
-
Define fuzzyvariable
Name=Amount
Universe of discourse: [0,1]
Unit=none
Cardinality of partition=5
Quantity space:
Names of fuzzy sets={none, few, several, many, a lot}
Unifiability=Amount(X)}
-
If {Person(P),Substance(X), Location(L)}
Assuming {Possess(P,X)}
Then {Seen with(P,X,L)}
Distribution Seen with(P,X,L){
r1: true,true,true,true → true:H,
r2: true,true,true,true → false:VL} (MF 1)
-
If {Person(P), Substance(X)}
Assuming {Possess(P,X)}
Then {Seen with(P,X)}
Distribution Seen with(P,X){
r1: true,true,true → true:H,
r2: true,true,true → false:VL} (MF 2)
-
If {Person(P),Substance(X)}
Assuming {Possess(P,X)}
Then {Registered to(P,X)}
Distribution Registered to(P,X){
r1: true,true,true → true:VH,
r2: true,true,true → false:VL} (MF 3)
-
If {Amount(X), Amount(Y), Possess(P,X), Possess(P,Y)}
Assuming {Isa liquid(X), Isa hydrogen peroxide(Y)}
Then {Prepare liquid bomb(P,B)}
Distribution Prepare liquid bomb(P,B){
r1: many, few, true, true, true, true → true:VH,
r2: many, few, true, true, true, true → false:VL,
r3: few, many, true, true, true, true → true:VL,
r4: few, many, true, true, true, true → false:VH} (MF 4)
Collected Evidence
-
e 1: Seen with(Bob, hair dyes, airport)=true with certainty degree:H
e 2: Registered to(Bob, Nissan)=true with certainty degree:VH
e 3: Seen with(Dave, mobile phone, airport)=true with certainty degree:M
e 4: Registered to(Bob, mobile phone)=true with certainty degree:1
e 5: Seen with(Dave, coke)=true with certainty degree:H
e 6: Seen with(Dave, Nissan)=true with certainty degree:M
e 7: Amount(coke)=a lot with certainty degree:H
e 8: Amount(hair dyes)=few with certainty degree:H