Abstract
This work is focused on defining and implementing a new similarity criterion for sequences of symbolic representations. The proposed algorithm returns a normalized index related to the degree of matching between sequences of qualitative labels. Performance of this method has been tested in the classification of voltage sags (transient reduction of voltage magnitude) gathered at 25 kV distribution substations. The objective is to assist monitoring systems in locating the origin of such disturbances in the transmission (HV) or distribution (MV) system. The promising classification accuracy achieved when this method was used with test data suggests that the presented algorithm could be applied satisfactorily and confirms its utility in classification approaches.
The motivation of this work is the interpretation of continuous signals involved in process monitoring as sequences of qualitative states. Expert System based monitoring applications have not been fully successful because of interface difficulties between measured process signals and expert knowledge bases (KB); that is, they lack of good human-like interpretation of signals. For this reason, it is necessary to develop new tools to deal with signals coming from process, allowing a more abstracted view of them and providing criteria and metrics to establish relations and comparisons among them. The goal is to deal with qualitative representations of signal behavior (tendencies, oscillation degrees, alarms, and degree of transient states …) instead of the numeric time series given by sensors and data acquisition systems. Then, it is possible to categorize the time series into a finite number of classes or patterns, enough to represent the system behaviors under study. Thus, the implementation of an intelligent monitoring system will consist in comparing the patterns of process variables with others registered in a case base and previously diagnosed. Unfortunately, time-series inherently contain inaccurate information since measurements are obtained and transferred with imperfect instruments. Some of the problems encountered when comparing time-series are noise, offset translation, amplitude scaling, and time misalignments among others. The problem of pattern matching in an efficient and precise way in series of data is a non-trivial problem and it is important in a wide variety of applications. Thus, we present a new algorithm, named Qualitative Similarity Sequence Index (QSSI) for the comparison of qualitative sequences. The algorithm returns a normalized similarity value when two qualitative sequences are compared. Based on the QSSI similarity principle, a methodology for classification of voltage sags (short duration voltage reductions) in the area of Power Quality Monitoring will be presented as an application example.
RELATED WORK
When tackling process monitoring based on qualitative representation of trends, there are two main aspects to deal with. The first one is how to get a consistent qualitative representation. It implies the alphabet definition (the set of meaningful symbols to be used in the representation) and the numeric to qualitative conversion (robust algorithms to convert numeric series into consistent sequences of symbols). The second aspect is related to the exploitation of these representations (sequences of qualitative symbols) to achieve monitoring goals. Although this problem has been addressed under different point of views, in general, it can be formulated as pattern matching problem and the main concern is focused on the definition of similarity criteria capable to deal with the complexity of qualitative sequences affected by the time component. Although independence between both, representation and reasoning, is desirable the majority of works are focused on specific applications and proposed formalisms addresses both aspects altogether. In the following paragraphs, the most representative paradigms have been reported.
The study of qualitative sequences has been often reported by researchers as Qualitative Trend Analysis (QTA) (Venkatasubramanian et al. Citation2003) or Qualitative Shape Analysis (Rengaswamy, Hagglund, and Venkatasubramanian Citation2001). The variation of a process variable with time is called the trend of that variable. The trend of a process variable is composed by simple shapes or symbols, also called primitives by some authors (Rengaswamy and Venkatasubramanian Citation1995). The trend analysis approach is based on monitoring the ordered set of shapes that abstract the trend of each process variable. The granularity of the shape information also plays a crucial role on variable description. Traditionally, the shape of a trend has been classified into constant, sharp decrease, linear increase, steps, etc. (Galati and Simaan Citation2006), and notated by an alphabet.
First-order trends are widely used since they are simpler and more robust to noise. (Sundarraman and Srinivasan Citation2003) describes a process variable as an ordered collection of enhanced atoms. An enhanced atom consists of a first-order shape, the time duration for which that shape is manifested, and the variable magnitudes at the beginning and end of the shape. This trend including quantitative information is called enhanced trend. Then, they defined a distance measure as the maximum value obtained from matching degree by shape, magnitude, and duration for two trends. Synchronization between real and theoretical trends is accomplished by a shape-matching degree table.
Motivated by the concept of episode, defined basically as the set [symbol, duration], some works have presented a formal language for trend representation where the episodes are characterized by seven basic primitives over which first and second derivatives do not change their sign (Cheung and Stephanopoulos Citation1990; Janusz and Venkatasubramanian Citation1991). Using these primitives, Dash, Rengaswamy, and Venkatasubramanian (Citation2001) proposed a novel approach to automate the identification of process trends based on an interval-halving procedure. The idea is to fit polynomials to the data and to identify the seven primitives. Later, in Dash, Rengaswamy, and Venkatasubramanian (Citation2003), the same identification method is employed and two similarity indices are defined based on the aligned qualitative sequences. The first one is just based on the similarity between primitives according to a similarity matrix, and the second one takes into account the time as a weighting factor. Finally, Maurya, Rengaswamy, and Venkatasubramanian (Citation2007) improves these similarity measures adding shape-based and magnitude-based similarities. In this way, they consider the normalized area under primitives and penalize the difference in the magnitude.
The same representation (Cheung and Stephanopoulos Citation1990) is used in Wong, McDonald, and Palazoglu (Citation2001) as a basis for classification of tendencies. First, signals are filtered by means of wavelets and next the triangular episodes are obtained. Next, fuzzy logic is used to convert the quantitative values of magnitude and duration in another symbolic representation including ‘small, medium, large’ symbols. As a result, a set of 57 shapes are obtained when the original 7 are combined. Sequences of symbols are modeled using HMM (Hidden Markov Models) to achieve classification goals based on probabilistic criteria.
Charbonnier and Gentil (2007) split the data into linear segments and classify the latest segments into seven shapes: Steady, Increasing, Decreasing, Positive or Negative Step, Increasing/Decreasing or Decreasing/Increasing Transient. After that, they transform the obtained shapes into three types of episodes defined as {[steady, increasing, decreasing], duration, extreme values}. The approach is used to recognize specific situations for Intensive Care Unit patient monitoring by means of simple rules.
In Meléndez and Colomer (Citation2001) an extension of the concept of episode expands the qualitative representation to both the qualitative and quantitative context considering any function of the signal as a basis for representation. This means that it is possible to build episodes, i.e., symbolic representations, according to any feature extracted from the variables (Gamero et al. Citation2006). According to this formalism, an episode is a set of numerical and qualitative features. The set includes the time duration that determines the temporal extension of episodes, the qualitative state obtained from the set of the extracted features, and other auxiliary characteristics useful for exploitation and explanation purposes such as classification, regression, or reasoning. This definition of episode has been used in this work to obtain a qualitative description of time series (voltage waveforms of disturbances affecting power quality) as a sequence of episodes.
An important problem encountered when comparing time-series is time misalignment, that is, the unmatching of two sequences due to a distortion (expansion or compression) in the time axis of one or both sequences. A method that tries to solve this inconvenience is Dynamic Time Warping (DTW) (Sakoe and Chiba Citation1978; Silverman and Morgan Citation1990) that uses dynamic programming to align time series with a given template so that total distance measure is minimised. Distance is calculated as an accumulation of local distances between corresponding elements in the time series being compared. Variations of the original algorithm have been proposed to cope with specific problems involving comparison of time sequences with distortion in the time domain. Thus, and adaption of DTW to deal with qualitative sequences is presented in (Colomer, Meléndez, and Gamero Citation2002). Another technique called segment-wise time warping (STW) is presented in Zhou and Wong (Citation2005). It combines a natural time scaling transformation through stretched segments and the DTW method. The time complexity of STW is quite high, therefore they need to use an index structure based on a lower bound function. Shou, Mamoulis, and Cheung (Citation2005) adopted a multi-step processing technique for similarity queries using DTW. They decompose each sequence into a small number of segments and then they use a version of the Segmented Dynamic Time Warping (SDTW) proposed in (Keogh and Pazzani Citation1999). Also the segmented sequences are used to derive lower bounds and finally they develop an index and a multi-step technique that uses the proposed bounds and performs two levels of filtering to efficiently process similarity queries.
Another symbolic representation method called SAX (Symbolic Aggregate approXimation) is presented in Lin et al. (Citation2003). First, the normalized time series are transformed into Piecewise Aggregate Approximation representation (PAA) (Keogh et al. Citation2000) and each PAA representation is symbolized into a discrete string. They define a distance measure based on looking up the distances between each pair of symbols and their Euclidean distance.
PAPER ORGANIZATION
This paper is structured as follows. First, the Qualitative Sequence Similarity Index (QSSI) is presented as a new similarity measure for qualitative sequences. Next, the proposed method will be applied to the classification of sags, originated in the HV and MV power systems. In the illustration example the concept of qualitative representation and episode is used to obtain a useful representation of sags, so the transformation of raw data into qualitative sequences is described too. Finally, main conclusions and some points about future work are given.
QUALITATIVE SEQUENCE SIMILARITY INDEX (QSSI)
The methods for computing similarity in the domain of strings over finite alphabets are the basis of the similarity index presented here. A way to represent time sequences is by means of an alphabet, which is often characteristic of the application. This conversion of time series into qualitative implies a discretization in both time (resampling) and magnitude (alphabet). Thus, each pattern is represented by a string of episodes identified by means of a pattern grammar. Then, the sequence comparison problem is reduced to quantifying the degree of similarity or, equivalently, the distance between qualitative sequences. To do this, however, the sequences to be compared must first be aligned.
An algorithm for sequence alignment will, in general, attempt to identify regions of high similarity by maximizing a certain score that quantifies the similarity between the sequences in an optimal (or suboptimal) alignment. Most of the alignment algorithms are based on the technique of dynamic programming (Gusfield Citation1997). These algorithms search optimal solutions for a given scoring or cost function. Usually, the scoring function is based on the definition of a set of operations, basically insertions, deletions, and substitutions, with a certain cost associated with each one. The algorithm searches the optimal alignment based on the application of these operations. Next, a criterion is needed to judge whether the two sequences share a sufficient degree of similarity. However, the majority of alignment algorithms lack normalization that would appropriately rate the obtained score with respect to the length of the sequences or will serve as a reference index for quantifying significance of the comparison. The proposed method, named Qualitative Sequence Similarity Index (QSSI), represents a normalized measure of the maximum similarity score between two qualitative sequences, the source S, and the target T. The analysis of similarity between two sequences has been defined in terms of traces (Sankoff and Kruskal Citation1983). A trace from S to T consists of a set of links between the elements that exist in both, S and T (Figure ). Each pair of elements connected by one of these links constitutes a match according to the terminology used for this author.
FIGURE 1 A possible trace for two sequences.
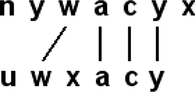
The QSSI algorithm is based on the Needleman–Wunsch algorithm for global sequence alignment (Needleman and Wunsch Citation1970). While only a sub-sequence of each of the sequences is aligned in the local alignment procedure, in a global sequence alignment the entire length of both sequences must be aligned. A global alignment is appropriate for comparing series that are expected to share similarity over the entire length. This is the case of monitoring applications focused on the assessment of transient states, as for example batch processes in the chemical and pharmaceutical industries, disturbance analysis in power quality monitoring or electrocardiogram (ECC) analysis in medical diagnosis. The idea behind the approach is to build up an optimal alignment and then to calculate the similarity using the total score of the aligned elements. The QSSI will be performed in three stages:
Obtaining matches (pairs of elements) using the Needleman–Wunsch algorithm. | |||||
Minimization of the temporal misalignment, that is, the selection of the optimal trace (with highest score). | |||||
Calculate the normalized similarity index. | |||||
The following subsections are devoted to explaining these steps in detail.
Obtaining Matches
Given two sequences S and T, with longitude m and n, respectively,
FIGURE 2 Contributors to the optimal alignment represented by a pathway W of length K = 4. W = [i k ,j k ]k=1–4 = [(2,3),(4,4),(5,5),(6,6)].
![FIGURE 2 Contributors to the optimal alignment represented by a pathway W of length K = 4. W = [i k ,j k ]k=1–4 = [(2,3),(4,4),(5,5),(6,6)].](/cms/asset/bb59c0dd-aef8-462e-b7f8-13d5e3b219e6/uaai_a_545213_o_f0002g.gif)
The pathway must to be monotonic. That is, i k+1 ≥ i k and j k+1 ≥ j k . An immediate consequence is that the lines from each pair of elements cannot cross other links. Figure shows an example in which three different analyses could be extracted from the previous sequences, but the third is the pathway for which the sum of the assigned cell values is largest. It is noteworthy that this last alignment is obtained through the path in Figure . FIGURE 3 A pair with three different alignments.  | |||||
Multiple connections are allowed. An element can have more than one trace (Figure ). FIGURE 4 Example of multiple connections. 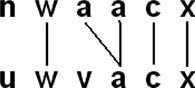 | |||||
An “N”-shaped configuration is not allowed. If a term has multiple lines, the terms at the other ends of these lines cannot have multiple connections (Figure ). This is also a common constraint in speech recognition (Sankoff and Kruskal Citation1983). FIGURE 5 The “N”-shaped constraint. 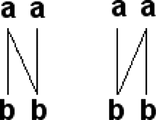 | |||||
Therefore, not all matches are suitable for comparing strings. The implementation of the Needleman–Wunsch algorithm returns only those candidates to traces that fulfil the constraints enumerated above. In this way, any relationship representing permutations is avoided, since this destroys the physical significance of a sequence. Also the alignment of the sequences allows a chain to overlap or enclose the other one, that is, for two sequences S and T with longitude m and n respectively and m > n, the possible traces can be aligned as shown in Figure . The next step will be to choose the optimal temporal alignment based on an accurate analysis of diagonals.
FIGURE 6 Possible alignments of two sequences.
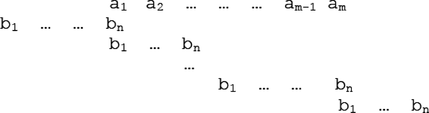
Minimization of the Temporal Misalignment
A diagonal dg in the alignment matrix is defined as the cells with a position (i,j) where j-i = dg. All the matches over a diagonal dg, are perfectly aligned in time, whereas matches out of the diagonal indicate the presence of a time misalignment. The goal in this step is to identify the diagonal, which minimizes the temporal misalignment between sequences S and T.
The time misalignment, represented by oblique lines in Figure , is produced by two basic effects: the existence of symbols without a correspondence in the other sequence and the different length of matched symbols. Due to their physical significance, these non-matched elements, and their durations cannot be ignored. Nevertheless, the importance of the duration depends on the application. In this way, the similarity obtained between symbols depends on the size (duration) and position of the intervals assigned to each symbol. For example, Figure displays from left to right the alignments related to diagonals ‘−1’, ‘0’ and ‘1’ corresponding to the example shown in Figure . The optimal diagonal is the one labeled as ‘0’, since this alignment minimizes the global temporal misalignment.
FIGURE 7 Alignments produced by diagonals −1, 0, and 1.
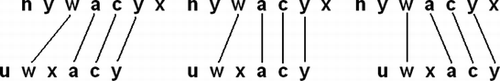
The optimal diagonal dg opt is obtained by calculating the distance of every match to the diagonal. The diagonal that has the minimum accumulated distance, f(dg), is the optimal one. Only the diagonals containing matches are considered in computing the accumulated distance:
Calculating the Similarity Index
Once the sequences are aligned in time, the algorithm calculates a normalized value representing similarity. The index of similarity for QSSI is defined as:
For the example in Figure , the QSSI of sequences are reported in the last row of Table . Obviously, the final matching should be the one with the maximum QSSI.
TABLE 1 Example Calculation of QSSI Values
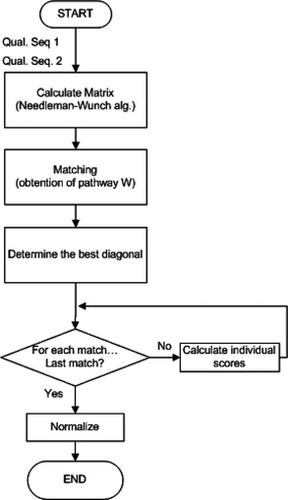
The function p(i k ,j k ) can be designed to deal with the different durations of qualitative symbols according to current requirements. For example, it can assign lower weight to further matching, which is measured from the optimal diagonal. The extreme case will happen when the time influence is not considered by defining p( i k ,j k ) = p 0 . The complete flow diagram of the QSSI algorithm is depicted in Figure .
FIGURE 8 Structure of the QSSI algorithm.
ILLUSTRATIVE EXAMPLE. RECOGNITION OF VOLTAGE SAGS
In this section, we show the application of the previously mentioned QSSI algorithm on a classification of voltage sags according to its origin in the power system, based on the similarity of qualitative sequences.
Motivation and Problem Overview
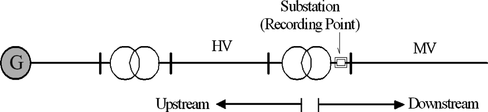
The current dependence of industry, commerce, and services on electricity has led to the regulation of power quality. The most common disturbances affecting power quality are voltage sags. Sags are defined as the time interval between the instant when the root mean square (RMS) voltage decreases down to 90% of its nominal value and the instant when it returns to its normal level (a three-phase unbalanced voltage sag is shown in Figure ). The origin of these alterations may be faults (shortcircuits) or the operation of heavy loads (motors, transformer energization, etc.), and the duration depends directly on the reaction time of the power system, including firing protective system in presence of faults. These disturbances propagate through the power system according to electrical laws (Bollen Citation2000); consequently once a disturbance is detected and registered in a monitoring point (typically in the secondary of distribution transformers) it is necessary to deduce its origin (up or downstream) (Figure ) for two main reasons: a rapid maintenance intervention (when required) and to assign responsibilities for damages suffered by customers (if any).
FIGURE 9 (a) Example of a three-phase unbalanced voltage sag; and (b) RMS voltage.
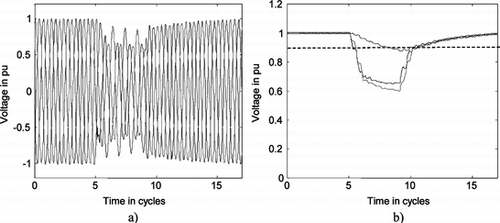
FIGURE 10 Situation of Power Quality Monitors in the secondary wiring of transformers in distribution substations.
With this aim, QSSI has been applied as a similarity measure to discriminate between voltage sags originated upstream (in the transmission network, HV) and downstream (in the distribution system, MV). Moreover, determining whether a sag has occurred in the distribution or transmission networks precedes the localization and mitigation stages (Hamzah, Mohamed, and Hussain Citation2004).
Qualitative Representation of Sags
Power quality monitors, installed in the secondary winding of nine 132/25 kV transformers (Figure ) in power distribution substations have been used in this work. These instruments have been configured to detect variations of voltage measured in delta configuration (phase to phase) and they register voltage and currents as time series during 39 of periods (1 period = 20 msec.), starting two periods before the disturbance is detected (128 samples per period).
Information contained in each sample is individually irrelevant; the significant information is given by the existence of specific primitives and their duration. So, previous to the classification, the voltage and current waveforms are transformed into a sequence of episodes, described by a set of ordered qualitative symbols and their duration. The pre-processing and discretization stages to obtain them are described below.
Sag Pre-Processing
Since voltage sags are characterized by the RMS waveform of voltages, simple pre-processing has to be applied to the instantaneous waveforms to obtain the RMS values. These values were obtained using a 1 cycle (20 msec, 128 samples) sliding window and applying the Short Fourier Transform (SFT) to estimate the magnitude of the fundamental frequency (50 Hz). This simple pre-processing is commonly used to identify basic characteristics of sags such as magnitude and duration (Bollen Citation2000). In this work the pre-processing has been applied before obtaining the qualitative description of waveforms in episodes as described in the next subsection. Using instantaneous values of waveforms, instead of RMS, to describe sags is only applicable when interest relies on phase shift, harmonic distortion or other transient characteristics (Djokic et al. Citation2005).
Discretization of Raw Data and Qualitative Representation
RMS series, describing voltage sags have been converted into sequences of episodes using the magnitude of waveforms and their first derivative. These parameters allow the signals to be represented in the same way a human expert would do it. The premise is that this human-based representation is sufficient to distinguish the different classes. Moreover, instead of considering the three phases in the conversion procedure, only the phase falling lowest during the sag was used. This is possible because the interest does not reside on the analysis of faulted phases but in the location up/downstream of the fault independently of which phase was affected. The results corroborate that this simplification is a valid way to obtain a useful representation for classification purposes. Then, the qualitative conversion procedure is performed following four basic steps:
Piecewise Aggregate Approximation (PAA) is used to reduce the length of RMS waveforms without losing information. PAA (Keogh et al. Citation2000) is a dimensionality reduction technique that approximates a time series by dividing it into M equal-length segments and using the average value of the samples in each segment as the data reduced representation. M must be selected to preserve the shape of the original time series. In this application, since the original waveforms contain 128 samples per cycle, a good choice for the segment length is 64 samples. Disturbances lasting less than half a cycle (64 samples) are not considered sags. Thus, dividing the original 4992 samples by 64 results in a sequence of length M = 78, where each sample represents the equivalent of a half cycle while the original shape and the minimal information required are preserved. | |||||
Low Pass Filtering: A 3-sample-length mean filter has been applied to the RMS waveform. The purpose of this filter is to smooth the dynamics of the signal to avoid spurious transitions between qualitative states. A similar effect would be obtained by defining a dead-band in the transitions between qualitative states. | |||||
Computing the first derivative. The derivative of the filtered sequence is calculated to identify transitions between qualitative states. | |||||
Qualitative representation. Finally, a qualitative representation is obtained from the evaluation of the magnitude and the derivative. A qualitative state is assigned to every sample according to the qualitative value of the derivative. According to the previous definition of episode, the consecutive samples with the same qualitative state constitute an episode and their length is defined by the number of them. The type of the episode, useful for classification purposes, is then obtained by adding the qualitative value of the magnitude. This gives information about the depth of the sag. In this way, episodes represent a constant behavior (derivative) between two time instants preserving the magnitude at these instants. | |||||
In the application, five categories (Steady State, Fall, Rapid Fall, Rise and Rapid Rise) have been defined for the derivative and six for the magnitude, resulting in an alphabet of 30 possible types of episodes (Table ). The six levels of magnitude have been defined according to the analysis of distribution of the depth of the sags. The histogram in Figure shows this distribution. Most of them (61%) have a minimum magnitude between 24 kV and 18 kV with a majority arriving between 20 kV and 22 kV. Thus, qualitative limits have been defined for each 2 kV around this majority class. Below 18 kV a reduced number of sags is given, resulting in a more disperse distribution. This band has been split into two categories with the threshold at 12 kV to have a similar representativity of the resulting categories. This categorization results in a minimum of 10% of available sags in each category.
FIGURE 11 Frequency chart of minimum voltage for sags.
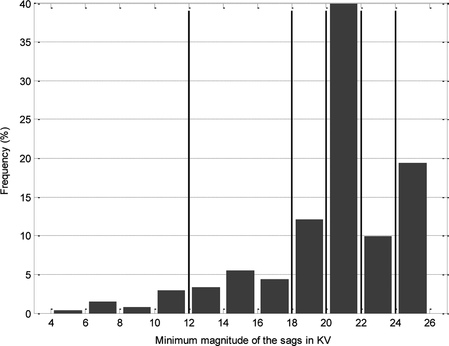
TABLE 2 Types of Episodes as ASCII Symbols (ASCII Code)
The application of this procedure results in a qualitative description of the waveforms of sags. This information can be represented by a string using the ASCII characters in Table followed by the duration expressed as the number of consecutive samples with the same qualitative state.
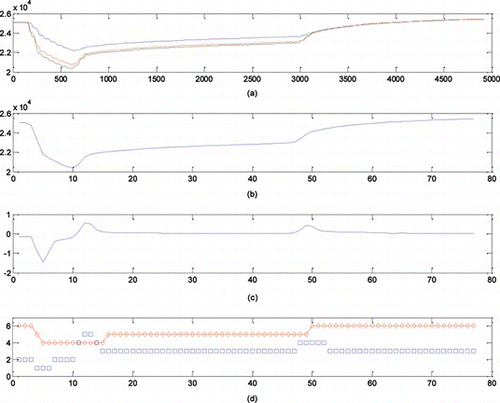
The whole procedure can be observed in Figure : (a) the three voltage phases are evaluated to select the deepest one; (b) the waveform is pre-filtered using PAA representation with ½ period (64 samples) length segments; (c) the first-derivative is calculated from the PAA waveform; and (d) the two waveforms (magnitude and derivative) are qualified (in the figure integer indexes are used for simplicity) before being converted into a discrete string. The evaluation of the first derivative is used to determine the duration of the episodes, since that establishes an interval with the same behavior. The qualified magnitude at the end of the episode is preserved in the definition of each episode as an auxiliary characteristic. Notice that the level at the beginning of the first episode is always the same, around 25 kV. Thus, the resulting string for the previous example is “v3a3b4d1e2d1m33x5w25”. According to Table , it is read as follows: during 3 samples (segments) the waveform falls and finishes at the highest level, during 3 more samples the signal presents a rapid fall and finishes at level 4, then it falls, slightly, during the following 4 samples remaining at the same level 4, and so on. This string containing the distinguished qualitative features will be used to compare this sag against others.
FIGURE 12 Basic procedure to obtain the qualitative representation of waveforms. (a) Selection of the phase with greater depth. (b) The waveform is pre-filtered using the PAA representation. (c) The first derivative is calculated from the PAA waveform. (d) The two waveforms are qualified according to breakpoints.
Classification of Voltage Sags
The whole set of data collected from nine substations was divided into two subsets. The first subset consists of a selection of representative registers to be used as a reference dictionary, and both subsets were used to test the performance of the QSSI algorithm. In the example, due to confidential restrictions on the use of real data, the names of the substations have been omitted and substituted with capital letters from A to I. The proposed method includes three main parts: first, preparation of the data as explained in Section 3.2. Next, each test case T is compared with the representative data set in the dictionary constructed previously. Finally, the test case is classified following a simple adaptive k-NN (k nearest neighbours) approach. These two last steps are described below.
Building the Dictionary
In the first stage, a subset of four representative substations (labeled as A, E, F, and I) were studied in order to build a dictionary of representative waveforms of sags. A total of 253 voltage sags classified as upstream/HV (transmission, 128 sags), or downstream/MV (distribution, 125 sags) according to the location of their origin in the power network was available from these substations. After transforming these waveforms into qualitative sequences a total of 94 representative patterns (40 labeled as HV and 54 labeled as HV) were retained to build the reference dictionary. Only the sags different enough from the others have been retained in the dictionary. Thus, a sag with a similarity greater than 2/3 with respect to another already in the dictionary is discarded. The dictionary size reveals that even though all substations are connected to a similar HV network, their behavior is not completely equal.
Test
The waveforms registered in the second subset of substations (B, C, D, G and H) were added to the first one, obtaining 528 voltage sags for testing. QSSI has been used to determine the similarity between these sags and those ones in the reference dictionary. The goal is to determine the class of new sags based on the similarity. The complete set of sags has been classified using a simple k-NN approach as it is explained in the next subsection.
Classification Method
Given a test case T, an adaptive k-nearest neighbour search algorithm (Ougiaroglou, Nanopoulos, and Papadopoulos Citation2007) returns the set of k most similar cases, C1, … ,C k . In this particular example a minimum of k = 3 nearest neighbours must be used to infer a class for the case T, and we have fixed k = 5 as the maximum. Thus, the number of nearest neighbour will vary between 3 ≤ k ≤ 5. Similarity is used to order the cases as they are retrieved allowing an early-break heuristic to interrupt the retrieval task once enough cases (a minimum of 3) of the same class have been retrieved. Here, two classes conforms the solution space based on the origin of the sag: upstream (HV) or downstream (MV). So the class corresponding to T could be determined according to the majority following a voting strategy.
RESULTS
Table shows classification results according to the majority rule for the whole set of substations. The last two columns indicate the assigned class, labeled as HV or MV. For example in the substation A there are 48 sags originated in HV and the approach classifies 47 as HV and 1 sag as MV. For those substations used to build the dictionary, an accurate classification would be expected, however, there are some misclassifications. An exhaustive analysis reveals that the main cause of misclassifications is because the majority rule is independent of the similarity degree of the retrieved cases (Table ). This suggests the need to improve the classification approach in future applications to take into account the closeness degree of similarity between the test and the retrieved cases.
TABLE 3 Classification Results
TABLE 4 Retrieved Cases for the Sag Originated in HV and Classified as MV in Substation A
On the other hand, a rare example is found in Substation I. Table shows the retrieved cases for this sag. Although a complete similitude was found to MV the majority belongs to HV, including a case with a similitude very close to 1. Figure shows the waveform of this sag and the waveform of the most similar one in HV. A revision of the information associated with these registers revealed that both corresponds to the same class and that the misclassification was due to a labelling mistake in the utility.
FIGURE 13 Two waveforms with a similar QSSI. (a) Classified as HV and (b) originally bad classified as MV in the dictionary.
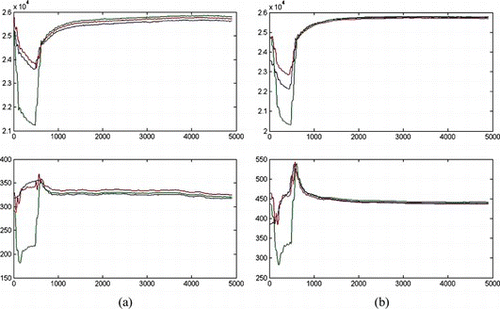
TABLE 5 Retrieved Cases for a Sag Wrongly Misclassified in Substation I
CONCLUSIONS
This work is focused on defining and implementing a similarity algorithm (QSSI) for the comparison of qualitative time series. Qualitative representations of signal trends can be used as representations of system behavior while they reduce the dimension of data and could provide a description in the same way a human expert would do it. First of all, a qualitative representation of waveforms is done. As a result, string chains with temporal extensions are obtained from time series (waveforms of sags in the application example). The QSSI algorithm returns a normalized index related to the degree of matching between sequences of qualitative labels. Performance of this method has been tested in the classification of voltage sags gathered at 25 kV distribution substations. The objective is to assist monitoring systems in locating their origin to MV or HV, i.e., upstream or downstream of the transformer. QSSI is used to return a similarity index between new and previously registered and labeled sags. Finally, an adaptive nearest neighbour criterion and a new decision variable are used to classify the new sag.
Therefore, the main contribution of the proposed methodology is the definition of the QSSI algorithm. QSSI is based on the Needleman–Wunsch algorithm for global sequence alignment. The idea behind the approach is to build up an optimal alignment between the two sequences and then calculate the similarity using the aligned elements.
Regarding the application example, the main advantage of using the proposed methodology to locate the origin of sags is that it allows sags gathered in different substations to be compared and similarities to be found, despite the existence of quantitative differences in the waveforms associated with the electrical characteristics (loads, network topology, transformers, etc.) of each substation.
The proposed methodology shows promising results for the whole set of substations thanks to QSSI, which is effectively used to obtain a similarity measure between two string chains. Those sags with similar index but wrongly classified exhibit a great analogy in their waveforms with sags previously labeled in a different class. A subsequent revision of the information associated with these registers revealed that there are some labelling mistakes in original data. An improved classification algorithm able to deal with similarity degree could achieve a success rate close to 100%.
The inclusion of a retaining mechanism once the origin of a sag was localised is expected to improve the performance of the system. The retrieved similarities for test data show that the QSSI algorithm has satisfactory usability and confirm that the method presented may prove to be a good tool in classification approaches. With additional research, the algorithm should be extended to deal complex sequences defined by multiple attributes instead just a string with time.
This work has been made possible by the interest and participation of ENDESA DISTRIBUCION and its Power Quality Department. It has also been supported by the research projects DPI2006-09370 and CTQ2008-06865-C02-02 funded by the Spanish Government. The eXiT research group is part of Automation Engineering and Distributed Systems (AEDS), awarded with a consolidated distinction (SGR-00296) for the 2005–2008 period in the Consolidated Research Group (SGR) project of the Generalitat de Catalunya.
REFERENCES
- Bollen , M. H. J. 2000 . Understanding power quality problems . New York : IEEE Press .
- Colomer , J. , J. Meléndez , and F. I. Gamero . 2002 . Pattern recognition based on episodes and DTW. Application to diagnosis of a level control system . In 16th International Workshop on Qualitative Reasoning , ed. N. Angell and J. A. Ortega , 37 – 43 . Sitges , Spain .
- Charbonnier , S. , and S. Gentil . 2007. A trend-based alarm system to improve patient monitoring in intensive care units. Control Eng. Practice 15:1039–1050.
- Cheung , J. T. , and G. Stephanopoulos . 1990 . Representation of Process Trends, Parts I and II . Computers & Chemical Engineering 14 : 495 – 540 .
- Dash , S. , R. Rengaswamy , and V. Venkatasubramanian . 2001 . A Novel Interval-Halving Algorithm for Process Trend Identification . In 4th IFAC Workshop on On-Line Fault Detection & Supervision in the CPI , ed. G. Stephanpolous , J. Romagnoli , and E. S. Yoon , 173 – 178 . Seoul , Korea , 2001 .
- Dash , S. , R. Rengaswamy , and V. Venkatasubramanian . 2003 . Fuzzy-logic based trend classification for fault diagnosis of chemical processes . Computers & Chemical Engineering 27 : 347 – 362 .
- Djokic , S. Z. , J. V. Milanovic , D. J. Chapman , and M. F. McGranaghan . 2005 . Shortfalls of existing methods for classification and presentation of voltage reduction events . IEEE Trans. on Power Delivery 20 ( 2 ): 1640 – 1649 .
- Galati , D. G. , and M. A. Simaan . 2006 . Automatic decomposition of time series into step, ramp, and impulse primitives . Pattern Recognition 39 ( 11 ): 2166 – 2174 .
- Gamero , F. I. , J. Colomer , J. Meléndez , and P. Warren , 2006 . Predicting aerodynamic instabilities in a blast furnace . Eng. Applications of Artificial Intelligence 19 ( 1 ): 101 – 111 .
- Gusfield , D. 1997 . Algorithms on strings, trees and sequences: Computer Science and Computational Biology . Cambridge , UK : Cambridge University Press .
- Hamzah , N. , A. Mohamed , and A. Hussain . 2004 . A new approach to locate the voltage sag source using real current component . J. Electric Power Systems Research 72 : 113 – 123 .
- Janusz , M. , and V. Venkatasubramanian . 1991 . Automatic generation of qualitative description of process trends for fault detection and diagnosis . Eng. Applications of Artificial Intelligence 4 : 329 – 339 .
- Keogh , E. , K. Chakrabarti , M. Pazzani , and S. Mehrotra . 2000 . Dimensionality reduction for fast similarity search in large time series databases . Knowledge and Information Systems J. 3 ( 3 ): 263 – 286 .
- Keogh , E. , and M. Pazzani . 1999 . Scaling up dynamic time warping to massive datasets . 3rd European Conference on Principles and Practice of Knowledge Discovery in Databases , 1 – 11 . London , UK : Springer–Verlag .
- Lin , J. , E. Keogh , S. Lonardi , and B. Chiu . ( 2003 ). A Symbolic Representation of Time Series, with Implications for Streaming Algorithms . In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery , 2 – 11 . San Diego, CA, June 13 . New York : ACM .
- Maurya , M. R. , R. Rengaswamy , and V. Venkatasubramanian . 2007 . Fault diagnosis using dynamic trend analysis: A review and recent developments . Eng. Applications of Artificial Intelligence 20 : 133 – 146 .
- Meléndez , J. , and J. Colomer . 2001 . Episodes representation for supervision. Application to diagnosis of a level control system . Workshop on Principles of Diagnosis DX'01 , 119 – 126 . Sansicario , Italy .
- Needleman , S. B. , and C. D. Wunsch . 1970 . A general method applicable to the search for similarities in the amino acid sequence of two proteins . J. Mol. Biol. 48 ( 3 ): 443 – 453 .
- Ougiaroglou , S. , A. Nanopoulos , A. N. Papadopoulos , Y. Manolopoulos , and T. Welzer-Druzovec . 2007 . Adaptive k-Nearest-neighbor classification using a dynamic number of nearest neighbors. In ADBIS 2007, 66–82. Berlin and Heidelberg : Springer–Verlag .
- Rengaswamy , R. , T. Hagglund , and V. Venkatasubramanian . 2001 . A qualitative shape analysis formalism for monitoring control loop performance . Eng. Applications of Artificial Intelligence 14 ( 1 ): 23 – 33 .
- Rengaswamy , R. , and V. Venkatasubramanian . 1995 . A syntactic pattern-recognition approach for process monitoring and fault diagnosis . Eng. Applications of Artificial Intelligence 8 ( 1 ): 35 – 51 .
- Sakoe , H. , and S. Chiba . 1978 . Dynamic programming algorithm optimization for spoken word recognition . IEEE Trans. Acoustics, Speech, and Signal Proc. ASSP-26 ( 1 ): 43 – 49 .
- Sankoff , D. , and J. Kruskal . 1983 . Time warps, string edits, and macromolecules: The theory and practice of sequence comparison . Reading , MA , USA : Addison Wesley .
- Shou , Y. , N. Mamoulis , and D. W. Cheung , ( 2005 ). Fast and exact warping of time series using adaptive segmental approximations . Machine Learning 58 ( 2–3 ): 231 – 267 .
- Silverman , H. F. , and D. P. Morgan . 1990 . The application of dynamic programming to connected speech recognition . IEEE Signal Processing Magazine 7 : 6 – 25 .
- Sundarraman , A. , and Srinivasan , R. (2003). Monitoring transitions in chemical plants using enhanced trend analysis. Computers & Chemical Engineering 27:1455–1472.
- Venkatasubramanian , V. , R. Rengaswamy , K. Yin , and S. H. Kavuri . 2003 . A review of process fault detection and diagnosis, Part III: Process history based methods . Computers & Chemical Engineering 27 : 327 – 346 .
- Wong , J. C. , K. A. McDonald , and A. Palazoglu . 2001 . Classification of abnormal operation using multiple process variable trends . Journal of process control 11 : 409 – 418 .
- Zhou , M. , and M. H. Wong . 2005 . A segment-wise time warping method for time scaling searching . Information Sciences 173 : 227 – 254 .