Abstract
Spoken dialog systems have been a holy grail of computer science since Turing devised his test for intelligence, and an icon of science fiction from well before that. Although there are machines you can talk to – interactive voice response (IVR) systems which answer phones, voice command systems in cars, and the Furby toy come to mind – holding a conversation with a machine, spoken or typed, is still highly problematic. It seems there is something fundamental we don't understand about the way humans use language. One popular approach is to ignore our ignorance and assume that machines can figure it out for themselves using machine learning or some form of statistical modeling of a corpus of text. Corpus analysis, however, like archeology, attempts to understand human action by looking at what we leave behind. Instead we take a software agents approach and model the language production process. The SERA project is our latest effort looking at what other disciplines can tell us about language use in context. We find that, naturally, published work focuses on the interesting while the engineering challenge is to capture the essential but often mundane. This paper proposes a narrative approach based on Vygotsky's view of psychology that captures “the big picture”. The paper finishes with an outline for a tool that merges the functionality of more conventional annotation tools with that of existing scripting environments for conversational agents.
INTRODUCTION
From chatbots and Embodied Conversational Agents (ECA) on the Web, through synthetic characters in computer games, and virtual assistants on the desktop to computers that answer phones, the primary way to create an operational conversational system is for someone to use introspection over log files to decide what he or she would say, and thus what the machine should have said. These systems are far from perfect in an interesting way: they are rarely simply ineffective, they are usually down right annoying (De Angeli Citation2005). Why is that? What is it that we are missing about conversational agents, and is there a better way to move from raw data of a form we can collect to the design of better conversational interfaces?
Computer scientists have of course been interested in computers and language from the start, with some early successes. When the research community has looked at dialog systems in the wild however, results have been disappointing (Walker Citation2002; Wallis Citation2008). Indeed, much of the work in the area is aimed not at the dialog problem itself, but at ways of having Machine Learning solve the problem for us by using, for example, Partially Observable Markov Decision Processes (POMDPs) (Young Citation2007). The data sparsity issue, however, means that in practice these techniques are run over annotated training and test data. These annotation schemes abstract away from the raw data and arguably represent the theoretical content of field (Hovy Citation2010). This is discussed further below. Computer science, looking to the dialog problem itself, generally views language as a means of conveying information, but from Heidegger and Wittgenstein on, we know there is more to “language-in-use” than informing. The idea of language as action (Searle Citation1969) highlights its social aspects. If language is to humans what preening is to monkeys (Dunbar Citation1996), the very act of talking to someone is making and maintaining social relations. Making systems polite is not simply a matter of saying please and thank you, it involves knowing when something can be said, how to say it, and, if necessary, how to mitigate the damage. What is more, the effort put into the mitigation of an face threatening act (FTA) is part of the message (Brown and Levinson Citation1987). To a greater or lesser extent, conversational agents simulate human behaviour as a social animal and, rather than viewing dialog as primarily information state update (Traum et al. Citation1999) or as a conduit for information (Reddy Citation1993), we view conversational systems as interactive artifacts in our space.
THE SERA PROJECT
The EU funded SERA project was set up to collect real data on human-robot interaction. At the time, several high-profile projects were integrating established technology as spoken language technology demonstrators. We knew there would be severe limitations, and our initial aim was to put one of these demonstrators in someone's home and record what happened. We settled on using the Nabaztag “internet connected rabbit” [Violet Citation2010] as an avatar for a smart home. The intention was to have the rabbit sense people and their activities in the same way as a smart home would, but to have the rabbit as a focus for communication. Rather than having a disembodied voice for the “intelligence,” as in 2001: A Space Odyssey, or on the flight deck of the Enterprise in Star Trek, users get to talk to something and, more important, our results would apply to the way people would interact with a classic, mobile, autonomous robot that actually used on-board sensors.
The ostensive purpose of the SERA rabbits was to encourage exercise among the over 50 s. The setup (Figure ) is described in detail elsewhere (Creer et al. n.d.) but, briefly, it could detect when someone was there by using its motion detector and it was given an “exercise plan” that the subject was expecting to follow. If the subject picked up the house keys in a period when he/she was expected to go swimming, the rabbit would say “Are you going swimming? Have a good time.” When he/she returned it would say “Did you have a good time swimming?” If the subject responded, it would ask if he/she had stuck to the amount of exercise she had planned and would record the amount actually done in a diary. Figure shows the house keys being returned to the hook sensor, triggering the “welcome home” script.
FIGURE 1 One of the SERA rabbits on its stand as installed in subjects halls and kitchens.

The dialog manager for the SERA system was a classic state-based system with simple pattern-action rules to determine what to say next, what actions to do and possibly to transition to a new state. We used best practice to develop the scripting and employed a talented individual with no training to “use introspection over log files to decide what he or she would say, and thus what the machine should have said.”
Things went wrong, as we had thought they would (discussed below), but we also faced a major technical challenge with speech recognition in a domestic setting. For iteration 1 we had simple “yes/no” buttons, but for the second and third iterations we used “flash cards” that the rabbit could read in order to communicate. The problems with speech recognition and our attempted solutions are detailed elsewhere(Wallis Citation2011). Despite this admittedly major technical difficulty, all subjects talked to their rabbit some of the time—some much more than others—and all expressed emotion while interacting with it. We installed this setup in the homes of six subjects for 10 days at a time, over three iterations, and collected just over 300 videoed interactions.
Having collected the data, the challenge then was to translate the raw video data into information about the design of better conversational agents. In general, the project partners could not reach consensus on how to look at the data—although it is telling that we each had an opinion on how to improve the system. There were plenty of interesting things to look at in the video data and interviews and, having identified something interesting, we could design a quantitative experiment to collect evidence. Producing papers from the data was not a problem. What was missing was a means of getting the big picture—a means of deciding what really matters to the user. It is one thing to say that a particular conversational system needs to be more “human-like,” but some faults are insignificant, others are noticed but ignored, but another set of faults drives users to despair. Until we can build the perfect human-like system, distinguishing among the severity of the faults is key to designing interactive artifacts based on human behaviour.
As an example of the challenge of moving from data to design, in iteration 1 our talented script writer had the rabbit say “That's good!” whenever the subject had done more exercise than planned. This was greeted in the video recordings with “eye rolling,” the significance of which is obvious, as hopefully the rest of this paper will convince you. Our talented expert then attempted to make the rabbit less patronizing but she couldn't see how to do that. This makes sense given the observation by de Angeli et al. (Citation2001) that machines have very low social status. In the second iteration the rabbit scripts were changed to remove any notion of the rabbit being judgmental—all assessment was ascribed to some other person or institution such as the research team or the National Health Service. So the question remains, is it possible to create a persuasive machine? For iteration 3, the project consortium decided that our talented expert should try harder. Like so many things about language use, being more persuasive looks easy, but turning that into instructions for a plastic rabbit might (or might not) be impossible. A methodology for going from video data to a new design would certainly help clarify the issues involved.
METHODOLOGY
Looking at the data, there are many interesting things to study, but the interesting are not necessarily the critical when it comes to engineering conversational interfaces. What is more, we humans make conversation effortlessly and it is a real challenge to notice what is actually happening. Naively I might think that I am annoyed because the machine misheard me, but perhaps the annoyance comes from the way it was said rather that what was said (Wallis et al. Citation2001). Is there a better way to study interaction with conversational artifacts?
Human-Computer Interaction (HCI) is, of course, a well-established field, with approaches ranging from the strict reductionism often seen in psychology to the qualitative methods of the social sciences. When it comes to conversational agents, these approaches all have their uses (Wallis et al. Citation2001; Wallis Citation2008; Payr and Wallis Citation2011), but one cannot help but feel that the real issues are often lost in the detail. In an excellent book on interaction design, Sharp, Rogers and Preece (2007, p. 189) provide a list of reasons why an interface might elicit negative emotional responses. Many of the points are specific to the graphical nature of Graphical User Interface (GUIs) but three points are interesting in that they highlight the underlying assumption of HCI that the user is in control and the machine is a tool to be wielded. The job of the interface is thus to make clear the consequences of an action and Sharp et al. Citation2007 want a system that does what the user wants, does what they expect, and does not give vague or obtuse error messages. The HCI perspective assumes a passive system and the job of the interface is to make clear the capabilities and uses of that system. A human conversational partner, however, will have strategies that enable repair in the follow-up interaction. In conversation, vagueness might be the cost of speed, or it might enable things to be said that otherwise cannot. Vagueness is not a problem because the process is interactive and a human conversational partner can be expected to clarify as required. What is more, Humans are inherently proactive and can help out in a timely manner. If a system could recognise when a user is (about to become) frustrated and annoyed, then the system can proactively explain why it is not willing or able to do what the user wants; it can re-align user expectations, or provide more information. The point about conversational systems is that the relationship is an on-going interaction and the system nearly always gets a second chance. Whereas HCI focuses on making the artifact understandable, conversational agents can help out—and indeed are expected to.
HCI embraces many schools of thought but there is a strong tendency for the object of study to be passive, and the tools developed there reflect that. Perhaps what is needed is a methodology for looking at what people actually do with language—a methodology that is less tied to an existing model and is more focused on analysis. The classic debate in the pursuit of an objective science of human behavior is between qualitative and quantitative methods. Those with a psychology background will tend to use quantitative methods and report results with statistical significance. The methods include structured interviews and questionnaires, press bars and eye trackers. Formal methodologies that use statistical evidence rely on having a prior hypothesis (Shavelson Citation1988) and the formation of hypotheses is left to researcher insight and what are often called “fishing trips” over existing data. A positive result from formal quantitative experiments is certainly convincing, but the costs make such an approach difficult to use outside the lab. Qualitative researchers argue that there is another way that is equally convincing and is more suited to field work.
Two Approaches to Qualitative Analysis
In linguistics, Conversation Analysis (CA) (Sacks Citation1992) in its early days was driven by the notion of “unmotivated looking” and generally attempted to build theory from the bottom up. The result was surprisingly informative in that it highlighted the amazing detail of human-human interaction in conversation. As with more recent approaches, such as Grounded Theory (Urquhart et al., Citation2010) CA has a strong focus on embracing the subjective nature of scientific theory, but claims—quite rightly in my view—that a poor theory will fall very quickly if continually subject to the evidence of the data. Grounded Theory and several other qualitative methods talk about “working up” a theory by continually (re) looking at the data in light of the theory so far. The result is a hypothesis that can be tested using quantitative methods, but usually the researcher feels that the evidence is overwhelming. They may produce a quantitative analysis as well for reporting purposes of course, but the work has been done.
Another approach to studying human behavior is interesting in that it does not rely on having no theory, but avoids the subjectivity of the scientist by using the theoretical framework of the subjects. With such “ethnomethods,” the intention is to explain behavior, not from an outsider's view, but from the inside. In retrospect, some earlier work on dialog systems took exactly this approach and used Applied Cognitive Task Analysis (Militello and Hutton Citation1998) to find out what an expert language user (thought she) was doing in conversation. In what have become known as the KT experiments, Wizard of Oz experiments were run using the automated booking system scenario (Wallis et al. Citation2001). The wizard, KT, was then treated as the expert and was interviewed to elicit her language skills. The interviews roughly followed the Critical Decision Method (CDM) questions of O'Hare et al. (Citation1998), which are listed in the Appendix and discussed later in the paper. The idea is that the expert and the researcher go over recordings of the expert in action and discuss what plans, goals, and cues the expert was attending to and using at the time. The recording serves as a prompt so that things that have become second nature can be noticed. For example, a fireman may touch doors before opening them and, when the researcher asks why, it may become evident that the fireman had forgotten that he touches doors in that way. He is likely, however, to be able to account for his actions and explain that if a door is hot, there is probably fire behind it and special precautions must be taken.
The conclusion at the time was that KT needed to know far more about politeness and power relations than she did about time or cars. What is more, KT did not need to know about Face Threatening Acts (FTAs) (Brown and Levinson, Citation1987) or other scientific explanations; she just thought some things “wouldn't be polite.” To her, politeness is a primitive concept. Similarly, she did not think about power and distance relations, but did know about “her place” in the organisation and the roles and responsibilities it entailed.
The problem was that interviewing people about their everyday behavior is difficult because not only are things like politeness just common-sense to the subject, such things are perceived by the interviewee as just common-sense for the interviewer. The interviewee quickly becomes suspicious about why the interviewer is asking “dumb” questions.
In the modern version of CA this problem is circumvented in the case of an “expert language user” by acknowledging that communication only works when there is shared understanding. Communication requires a community of practice and its members, by definition, have direct access to the significance of a communicative act. Modeling the reasoning of a community member can be objective even if the reasoning being modelled is not. A community of bees can be (quantitatively) shown to communicate with each other, but a model of a bee communicating needs to capture the available behaviors, actions, and activities of the community of bees. Garfinkel's (Citation1967) observation (in different words) was that a bee would have direct access to the significance of communicative acts within the bee community. If a bee does something that is not recognizable, it is not a communicative act. If a bee fails to recognize a communicative act (that others would generally recognize) then that bee is not a member of the community of practice. The same of course applies to humans. As a member of the community of practice one has direct access to the significance of an act, but as a scientist one ought to be objective. Studying human interaction as a scientist, I need to be careful about my theories about how things work. As a mostly successful human communicator, I do not need to justify my understanding of the communicative acts of other humans. The first challenge is to keep the two types of theory separate. My scientific theory is outside, hopefully objective, and independent of my ability to hold a conversation. On the other hand, my folk theory of what is going on in a conversation is critical to making conversation. It is “inside” the process, and as long as it enables me to participate in communication-based activities, the objectivity of the theory is immaterial. In the case of the KT experiments, the researcher, as a member of KT's community of practice, can answer his own dumb questions.
The HCI community do emphasize the need for designers to understand users, but there is a strong tendency for the dominant view to be an “outsider's view.” Sharp, Rogers, and Preece (Citation2007), for example, provide a list of solidly academic cognitive models that are expected to shed light on how people will react to a given design, and that can be used to guide the design process. It is argued here that conversational interfaces ought to be designed with an insider's view of human agency. This perhaps explains why amateur developers are so good at scripting agents—there simply is no secret ingredient.
The proposal that we are pursuing is that, in order to simulate human conversational behavior, we need to capture a suitable insider understanding of events, and that understanding looks much like the essence of a play or novel.
CAPTURING OTHER PEOPLE'S FOLK THEORIES
The idea of folk psychology—the understanding of other people used by everyone, everyday—and its status as theory has been discussed at length by Dennett (Citation1987) and Garfinkel (Citation1967) has made explicit the challenges of collecting such data and championed techniques for studying one's own culture. In the 1970s, it came to light that similar ideas were being developed in Soviet psychology and Vygotsky, it seems, had worked through the notion that theatre and plays capture something essential about the nature of human action. The gist is that plays are interesting to us because they exercise our understanding of other people. Perhaps the way to look at human (understanding of human) action is in terms of actors, roles, scenes, backdrops, theatrical props, audiences, and so on. An examination of the computer interface from a Vygotskian perspective has been done before (Laurel Citation1993) but his legacy in HCI comes primarily through Leontiev and the idea of mediated action (Wertsch Citation1997). Human action is mediated by artifacts that have a highly socialized relevance to us; spoons are used in a particular way and multiplication tables are a conceptual tool that can be used to multiply large numbers. What roles can a computer play in socialized mediated action? The artifacts HCI study are props in scenes performed by actors with roles and Action Theory as it is known is an acknowledged part of the HCI repertoire (Sharp et al. Citation2007). This perspective, however, does not acknowledge the distinction between an inside and outside view, and critics can, quite rightly, question the objectivity of such an approach. Modeling human conversational behavior on such explicitly “folk” understandings is a different matter.
Narrative Descriptions
The folk reasoning of novels is fabulously about the inner workings of human mind and definitely subjective in nature. The fact that novels exist at all, however, suggests there is something shared. People's reporting of events can, famously, differ considerably, so why would we expect consistency in reporting of events unfolding in video data of human-machine interactions? The key is that our interest is in gross-level behavior. Conversational machines fail grossly rather than in detail. Rather than arguing the point however, an informal demonstration was set up in which some “folk” were presented with a video in which there is trouble with a rabbit. Figure is a still from a video recorded in Peter's office. The recording was not rehearsed, and indeed was not even planned, but was recorded spontaneously when someone pressed the video record button on the setup under development. In the spirit of CA, the reader is invited to use their own folk understanding of the data, and to this purpose, the recording has been made publicly available [PMRvideo Citation2011].
FIGURE 2 Mike and the rabbit talking with Peter.

Two narrators were asked to describe what happens in the recording. To set the scene and suggest a style of writing, they were given an opening paragraph:
Peter and Mike have been talking in Peter's office, where he has a robot rabbit that talks to you and that you can talk to using picture cards.
They were then asked to, independently, finish the story in around 200 words. The resulting stories appear in Figure .
FIGURE 3 Two narrative descriptions of the same event.

There are many differences, and many things were left out entirely. Neither narrator mentioned the rather interesting equipment in the background nor commented on the color of clothes the participants were wearing. There is no comment on accents or word usage; no comment on grammatical structure or grounding or forward and backward looking function. Whatever it is that the narrators attend to, it is different from the type of thing looked at by those using the popular annotation schemes. It does, however, seem to be shared, and so the events in Figure can be identified as common to both descriptions.
FIGURE 4 The third-party common ground.

Note that the observations of these events are not shared only by the narrators, they will also be “foregrounded” for the participants. That is, Peter and Mike will, to a large extent, observe the same things happening and, what is more, each will assume that his conversational partner, to a large extent, observes the same things. The hypothesis is that the shared background information is the context against which the conversation's utterances are produced. This is not to say that folk theory is objective theory, but if we want to simulate human reasoning and engineer better dialog systems, then the simulation needs to use the same reasoning as we do. The scientific challenge is to capture it, and to do that in a way that is convincing.
FROM DATA TO DESIGN
Narrative descriptions have been used as part of methodology before, but why it is useful or relevant is apparently not discussed. What is advocated above is that narrative descriptions are used to elicit an inside view of what is going on in dialog, and that the subjectivity of such descriptions is an asset rather than some necessary evil. The intention is to develop a theory (scientific) of other people's theory (folk) of other people's communicative acts. It turns out that formal descriptions of narratives have been done before, primarily as a means of looking at case studies in the study of business processes.
Abell's Model of Human Action
There is the adage that those who do not study history are bound to repeat it, but what does a proper study of history entail and how does it actually relate to future action? Schools of business studies tend to be split between those that look at case studies in detail and those that look for statistical co-variation. The scientific validity of causal inference from large N samples tends to go unquestioned, but how is one meant to draw conclusions from one or two historical examples and make informed decisions? Abell's theory of comparative narratives (Abell Citation2003; Citation2010) is a means of describing and comparing structures of sequential events in which human agency plays a part. What is more, it can be applied to single samples, and provides an explanation of why things happened as they did, and a mechanism for deciding future action. Abell's approach can be seen as a highly formal way of looking at the take-away message of a case-study. The mechanism is to look at the narrative structure, and our hypothesis is that the same mechanism provides the background to a jointly constructed conversation.
Abell's approach is to represent the world as being in a particular state, and human action moves the world to a new state. The human action is seen as partly intentional—that is, a human will act in a way to bring about preferred states of the world, based on beliefs—and partly normative; a human will do this time, what they did the last time the same situation occurred.
Abell's format for a narrative (Abell Citation2010) consists of:
A finite set of descriptive situations (states of the world), S. | |||||
The elements contained in set S are weakly ordered in time, providing a chronology of events in the sense that earlier states are transformed to later states. | |||||
A finite set of actors (individual or collective or an aggregate of actors), P. | |||||
A finite set of actions, A. | |||||
A mapping of P onto A giving pairs on PxA. | |||||
A mapping of elements of PxA onto SxS. | |||||
The structure of a narrative can be depicted as a multi-digraph N = (S:PxA). | |||||
The first observation from the two narrative descriptions above is that the narratives produced are internally consistent, but do not necessarily refer to the events in the same way. That is, it is not clear we can reassemble a narrative from the events that occur in both descriptions. It seems that the stories produced must be treated as whole units in any comparison rather than being disassembled.
A second observation is that, although the notion of states and transitions is, in a formal sense, complete, it seems that sequences of state/transitions are also first order objects and can form singular causes in an actor's reasoning. Mike's attempt to interact with the rabbit is motivated by his observation of the entire preceding interaction. Abell does talk at length about levels of description, but it seems our participants are switching levels as they go. The principle, however, remains sound and we need a way to present, formally, the notion of multiple-level descriptions.
Abell provides a theoretical framework for a model of causality that we can use to account for the action in our video data. These accounts are purely descriptive, but the observation is that they can be reused.
Plausible Accounts and Engineering
In order to make better conversational agents, the argument goes, we need to simulate the way humans make decisions in conversation. Ideally, we would have a good model of how people actually make decisions. The observation is that, when the aim is to engineer a virtual person, we can simulate the decision processes of fictional characters instead. The Vygotskian insight is that plays and novels exist because they provide plausible accounts of human behavior. Narrating video data as described, the accounting is, of course, produced by the annotator and is not actually in the original data. In effect, we are accessing the annotator's head, and the data is there to prompt the annotator to apply his/her knowledge to real (and often tricky) scenarios. Demonstrating internarrator agreement adds weight to the idea that we are capturing something true of the community of practice, but it is immaterial to the process of engineering better conversational agents.
Accounts of the action in the video data as written down by the narrators are of course descriptive in that they are written to “fit” past events. The claim is that they are also predictive. If Mike wants to use the system, then it would not be surprising if other people also want to try it. If failure to work causes disappointment in Mike, it is likely to also cause it in others. Having a predictive model of events, we are well on the way to having prescriptive rules that can be used to drive conversational behaviour.
What do these descriptive accounts look like? They are folk theory and, as such, will be in line with Dennett's (Citation1987) notion of an “intentional stance.” In detail they will fit with the idea that people do what they believe is in their interests—a fact too trivial to state for a human, but machines need to be told. Using Dennett's example, seeing two children tugging at a teddy bear, we perceive they both want it. In the video, Peter wants to show Mike how the system works; Mike believes the rabbit has finished talking. In implementation, a fleshed out account will look much like plans, goals, and cues in a Belief, Desire and Intention (BDI) agent architecture (Bratman et al. Citation1988). The challenge is to have the annotator fill in these details for their narrative and the proposal is to have a methodology and tools to help.
Figure provides a preliminary draft for the set of instructions to be given to our annotators. The aim is for the annotator to produce a narrative description of the video in order to capture the essential, while leaving out the detail. The narrative is then formalized as described by Abell to provide events and the links between them. The next step is to have the annotator flesh out those links by answering questions very similar to those used by O'Hare et al. Citation1998, (see the Appendix) in cognitive task analysis. The aim is to elicit the unstated and obvious and, in particular, the goals of the characters in the narrative, what information each character has that impinges on the action, and what choices were made. The result is an account of the action in the video that may or may not be a true description of reasoning by the participants but will be a plausible account that captures a causal description of events based on the annotator's folk understanding of actual events. Finally, having had the annotator work through his/her story in detail, he/she can be asked to expand on events in the video by exploring “what if” scenarios, producing script that agents might have said. Following the CDM approach mentioned above, the conditions under which an agent might say one thing rather than another can be explored and documented, providing a future conversational agent with our annotator's folk model of not only what to say but also when to say it.
FIGURE 5 A method for producing a plausible explanation of events and, from that, script for a conversational agent.

A (Partial) Walk Through
Figure provides a preliminary analysis of events and relations in Narrative 1, presented in XML mark-up. Note we are after plausible explanation here in order to do engineering, and any claim to having a true account of events in the video—as suggested by the commonality between annotators above—would need to be based on the notion of the “community of practice” and its view of events in the data.
FIGURE 6 A first pass at events in Narrative 1.

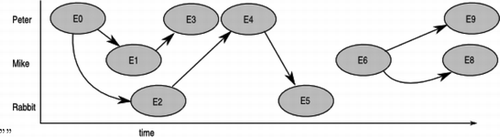
The choice of event to mark up is determined in part by the choice of words used in the initial description and in part by the need to put in the causal relations. One might want to have an alternate theory of why narratives hold together, but here we are embracing Abell's (Citation2003; Citation2010) theory. Figure provides the first part of that data graphically, putting in the agents on the vertical axis and time on the horizontal. Note that using this proposed annotation scheme, there is no fixed set of tags to be assigned to the narrative; it is, so far, an open coding scheme.
FIGURE 7 Events in Narrative 1, as a graph.
The next step is to explicitly state all the causal relations that may require the introduction of new information. The aim is for the annotator to flesh out the causal link for those relations in which B does not necessarily follow from A. To explain E0 and E6 requires, for instance, the introduction of motivations on behalf of the characters. Figure provides these causes as boxed labels at the top. The dashed arrow and the open state represent an expectation, expressed in the original narrative as “nothing happens.” In this step, the annotator is explicitly stating what he/she believes are the beliefs, goals, and intentions of the actors in the video using his/her folk psychological understanding of causality in narrative. Note that although the coding of events in the narrative is open, the linking is not. People do what they believe is in their interests according to the model, and the annotator's work bench can guide the annotator to provide the actor's doings (actions) the actor's beliefs, and the actor's interests or goals.
FIGURE 8 Narrative 1 with goals and expectations added.
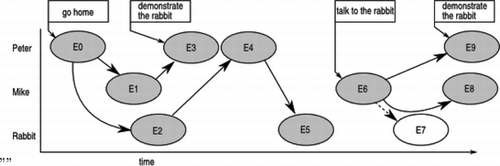
Given a set of goals, the annotator can be asked to account for the termination of paths. For instance, why does E3 not cause a new event. Because the rabbit interrupted; does this mean Peter failed to demonstrate the rabbit? No, Peter re-planned based on the rabbit's actions.
As described, the events have single causes and this is, of course, very unlikely of any human action. First, perhaps a better way to read the diagram is to interpret the large arrows as “triggers” rather than causes and to see the event at the foot of the arrow as a “cue to …” Similarly, the goals listed in the boxes are singular—which is very unlikely—but they are time critical and only there to explain events. It is perhaps in the nature of narrative that causality is linear, but of course there is nothing to stop us introducing explicit multiple causes should the annotator wish it.
The CDM probes explicitly ask the expert about his or her goals and cues, about strategies and plans, but they also ask about alternatives—about things that didn't happen in the recordings. In the video sample, Mike uses several strategies in his attempt to talk to the rabbit the cards, talking, yelling, and waving. What else might he have done? Ideally we could ask Mike, but instead we (or the annotator's work bench itself) can ask the annotator about possible alternative actions for the character in his/her narrative. Engineering a conversational agent, the annotator might be asked “what else might the agent say at this point?” And, as happens in the CDM probes, “Are there situations in which saying that would be more appropriate?”
In effect, the aim is to populate a model of human reasoning about language in use, and then use that model to drive a conversational agent. There are many such models of human reasoning ranging from micro-level scientific understanding of human behavior based on neurons to meta-level scientific understanding based on dialectics and control of the means of production. What is needed is “meso” level (Pàyr 2010) model of human behaviour based on everyday folk understanding. Such a model can be populated by anyone from the community of practice of human communicators because, by definition, that is what they are good at. A work bench that presents recordings of people interacting and asks that questions similar to the CDM probes may take us one step closer to being able to engineer conversational agents by simply “cranking the handle” without need for insight, as insight has, so far, failed to produce the goods.
CONCLUSION
From an engineering perspective, the issue is how to identify the critical behavior in human-machine conversation rather than the interesting behavior. The problem is to notice what is going on, and the SERA project set out to collect real human-robot interactions and look at them. The data collected is rich, but we did not reach consensus on the best way to study it. The engineering challenge is to move from raw, undifferentiated data to better design and, as argued above, one approach is to simulate folk reasoning about language in use. As was found in the KT experiments, looking at folk reasoning about language, one finds that much of the decision Vygotsky's point is that folk reason about other people's actions in terms of role, setting, characters, and in general the concepts of theatre making is based around social issues such as politeness and roles. The premise of this paper is that a simulation of a plausible virtual character is as good as a simulation of a real person for this purpose, and plausible accounts of the recorded actions of subjects can be provided by a narrator rather than the subjects themselves. Experience with suggests a way to take the narrator's understanding and turn it, systematically, into prescriptive rules that might provide more socially acceptable behaviour for a new generation of conversational interactive artifacts.
Acknowledgments
The research leading to these results has received funding from the European Community's Seventh Framework Programme [FP7/2007–2013] under grant agreement no. 231868.
Notes
If a door is warm, there is probably fire behind it, and special precautions must be taken.
REFERENCES
- Abell , P. 2003 . The role of rational choice and narrative action theories in sociological theory: The legacy of coleman's foundations . Revue française de sociologie 44 ( 2 ): 255 – 273 . http://www.jstor.org/stable/3323135
- Abell , P. 2010 . A case for cases: Comparative narratives in sociological explanation. http://www.lse.ac.uk/collections/MES/people/abell.htm
- Bratman , M. E. , D. J. Israel , and M. E. Pollack . 1988 . Plans and resource-bound practical reasoning . Computational Intelligence 4 : 349 – 355 .
- Brown , P. , and S. C. Levinson . 1987 . Politeness: Some universals in language usage . Cambridge : Cambridge University Press .
- Creer , S. , S. Cunningham , M. Hawley , and P. Wallis . 2011 . Describing the interactive domestic robot set-up for the SERA project . Applied Artificial Intelligence .
- de Angeli , A. 2005 . Stupid computer! abuse and social identity . In Abuse: The darker side of human-computer interaction (INTERACT ‘05) , ed. A. de Angeli , S. Brahnam , and P. Wallis Rome . http://www.agentabuse.org/
- de Angeli , A. , G. I. Johnson , and L. Coventry . 2001 . The unfriendly user: Exploring social reactions to chatterbots . In Proceedings of The International Conference on Affective Human Factors Design , ed. K. Helander , and Tham , London : Asean Academic Press .
- Dennett , D. C. 1987 . The Intentional Stance . Cambridge , Mass : The MIT Press .
- Dunbar , R. 1996 . Grooming, Gossip, and the Evolution of Language . Cambridge , Mass : Harvard University Press .
- Garfinkel , H. 1967 . Studies in Ethnomethodology . Prentice-Hall .
- Hovy , E. 2010 . Injecting linguistics into NLP by annotation. Invited talk, ACL Workshop 6, NLP and Linguistics: Finding the Common Ground.
- Laurel , B. 1993 . Computers as Theatre. Addison-Wesley Professional.
- Militello , L. G. , and R. J. Hutton . 1998 . Applied cognitive task analysis (ACTA): A practitioner's toolkit for understanding cognitive task demands . Ergonomics 41 ( 11 ): 1618 – 1641 .
- O'Hare , D. , M. Wiggins , A. Williams , and W. Wong . 1998 . Cognitive task analyses for decision centred design and training . Ergonomics 41 ( 11 ): 1698 – 1718 .
- Payr , S. 2010 . Personal communication.
- Payr , S. , and P. Wallis . 2011 . Socially situated affective systems . In Emotion–Oriented Systems: The Humane Handbook . ed. P. Petta , C. Pelachaud , and R. Cowie . Springer ISBN: 3642151833.
- PMRvideo 2011 . Peter and Mike have trouble with a rabbit. http://staffwww.dcs.shef.ac.uk/people/P.Wallis/PMRvideo.mov.
- Reddy , M. J. 1993 . The conduit metaphor: A case of frame conflict in our language about language . In Metaphor and thought , ed. A. Ortony . Cambridge University Press .
- Sacks , H. 1992 . Lectures on conversation . ed. G. Jefferson . Oxford : Blackwell .
- Searle , J. R. 1969 . Speech Acts, an essay in the philosophy of language . Cambridge University Press .
- Sharp , H. , Y. Rogers , and J. Preece . 2007 . Interaction Design: Beyond human-computer interaction () , 2nd ed. . Chichester , UK : John Wiley and Sons .
- Shavelson , R. J. 1988 . Statistical Reasoning for the Behavioral Sciences. , 2nd edition . Allyn and Bacon, Inc.
- Traum , D. , J. Bos , R. Cooper , S. Larson , I. Lewin , C. Matheson , and M. Poesio . 1999 . A model of dialogue moves and information state revision. Technical Report D2.1, Human Communication Research Centre, Edinbrough University.
- Urquhart , C. , H. Lehmann , and M. Myers . 2010 . Putting the theory back into grounded theory: Guidelines for grounded theory studies in information systems . Information Systems Journal 20 ( 4 ): 357 – 381 .
- Violet 2010 . Nabaztag. http://www.violet.net/_nabaztag-the-first-rabbit-connected-to-the-internet.html.
- Walker , M. , A. Rudnicky , J. Aberdeen , E. Bratt , J. Garofolo , H. Hastie , A. Le , B. Pellom , A. Potamianos , R. Passonneau , R. Prasad , S. Roukos , G. Sanders , S. Seneff , and D. Stallard . 2002. DARPA communicator evaluation: Progress from 2000 to 2001. In Proceedings of ICSLP 2002, Denver, USA.
- Wallis , P. 2008 . Revisiting the DARPA communicator data using Conversation Analysis . Interaction Studies 9 ( 3 ).
- Wallis , P. 2011 . ASR baseline implementation. http://staffwww.dcs.shef.ac.uk/people/P.Wallis/sera-D2.4-2-fin.pdf.
- Wallis , P. , H. Mitchard , D. O'Dea , and J. Das . 2001 . Dialogue modelling for a conversational agent. In AI2001: Advances etc. Intelligence, ed. M. Stumptner, D. Corbett, M. Brooks. Adelaide, Australia: Springer (LNAI 2256).
- Wertsch , J. V. 1997 . Mind as Action . Oxford University Press .
- Young , S. J. 2007 . Spoken dialogue management using partially observable Markov decision processes. EPSRC Reference: EP/F013930/1.