Abstract
We propose a new activity-based event recognition system that is based on the construction of a novel Momentum Template combining the apparent moving areas and the velocity of the associated movement. Consideration is also given to movement that is not taking place in parallel to the projection plane of the camera. The construction of the momentum template is followed by the application of an angular transform. Linear discriminant analysis is applied to angular coefficients for dimensionality reduction. Recognition is performed by comparing Euclidean distances in the resulting subspace. Experimental evaluation in comparison to other recent methods shows the efficiency of the proposed method.
INTRODUCTION
The recognition of events is an emerging research area of rapidly increasing importance. Of particular significance is the need for recognition of events based on visual sensors. This need stems from current demand for the development of automatic surveillance applications as well as human–computer interfaces. In this domain, although some events are easy to detect (e.g., an explosion), events that are associated with human action and intention are generally challenging to detect and to interpret. A characteristic example has to do with human motion in a controlled area. Some types of motion (e.g., a person running), may have to be interpreted as abnormal and, therefore, should signal the occurrence of an event, whereas other types of motion will have to be interpreted as normal and should not trigger any system response. In this work, we propose a methodology that can facilitate the detection and interpretation of activities that can signify an abnormal event.
Human activity recognition (Aggarwal and Cai Citation1999; Gavrila Citation1999; Liang, Weiming, and Tan Citation2003) is a challenging task, because different people may perform the same activity in different ways. Although the earliest research in studying human movement was published many decades ago (Muybridge Citation1901), various new approaches on activity representation and recognition have been proposed in the past few years. One popular approach was presented in (Bobick and Davis Citation2001), aiming to describe activities in the form of a temporal template consisting of a binary motion-energy image (MEI) and a motion-history image (MHI). This temporal template has been widely used for the interpretation of human movement. The method in Weinland, Ronfard, and Boyer (Citation2006) extended the above temporal templates to three dimensions (3D) in order to achieve view-point independence.
A fast human activity recognition approach was proposed in Cherla et al. (Citation2008). This method used the average-template with a multiple feature vector. Dynamic time warping (DTW) was used to perform recognition. A motion-based approach was presented in Briassouli, Tsiminaki, and Kompatsiaris (Citation2009), which introduced a binary mask activity area (AA) in order to detect and segment multiple human activities. The activity history areas (AHAs), a temporally weighted version of AA, was used for activity recognition. In Turaga, Veeraraghavan, and Chellappa (Citation2009), activities were described as a cascade of dynamical systems in which similar actions were clustered together irrespective of the viewpoint and the rate of execution of the activity. In Qian et al. (Citation2010), Support Vector Machines were used for the recognition of multiple kinds of activities.
Other methods have recently reported improved performance. Space-time features within a bag-of-words model were used in Laptev et al. (Citation2008). In Yuan, Liu, and Wu (Citation2009), spatio-temporal invariant features were used for action detection, and a discriminative pattern matching approach was proposed for activity recognition. The method in Weiland, Ozuysal, and Fua (Citation2010) proposed a 3D histogram of oriented gradients (HOG) descriptor in order to provide robustness to both occlusions and viewpoint changes. In Gilbert, Illingworth, and Bowden (Citation2009), an overcomplete compound feature set was proposed based on very dense corner features, and a hierarchical classifier was used in order to achieve real time recognition. In Lin, Jiang, and Davis (Citation2009), a binary prototype tree was built via hierarchical K-means clustering of the set of training actions, whereas recognition was based on dynamic prototype sequence matching.
The improved efficiency of most current methods comes at the cost of increased computational complexity. This is because of sophisticated feature extraction, which may require the detection of feature points, or the deployment of complicated classifiers, to be used at the recognition stage. The approach proposed in the present paper constructs a new template based on the momentum of motion energy mass, which explicitly incorporates information about the amount of motion in a given activity. Angular coefficients are extracted from the momentum template using an angular transform, and dimensionality reduction is achieved using linear discriminant analysis (LDA). Experimental evaluation shows the improved discriminative power of the proposed approach, which is achieved at low computational complexity and with the additional potential benefit of easier discrimination between normal and suspicious activities.
The structure of the paper is as follows. The proposed feature extraction approach is described in the next section, which details the extraction of motion and angular features. Dimensionality reduction and classification are presented in the Subspace Projection and Activity Recognition section. The proposed method is experimentally evaluated in the Experimental Results section and, finally, conclusions are drawn in the last section.
FEATURE EXTRACTION FOR RECOGNITION
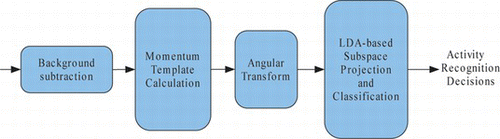
Our proposed feature extraction and recognition methodology is schematically outlined in Figure . As seen, a momentum template is constructed followed by the application of an angular transform and LDA for dimensionality reduction. The objective of this feature extraction process is to compact most useful information in an activity sequence into a short feature vector that will enable efficient recognition of activities and events. The operation of our system is detailed in the ensuing sections.
FIGURE 1 General block diagram of the recognition process. (Figure is provided in color online.)
Momentum of Motion Energy Mass
In our proposed system, we introduce a novel template as a first step in the feature extraction process. The advantage of the proposed template is that it is directly applicable not only to cases in which the subject is standing but also to cases in which there is translational motion. This is particularly useful for the detection of abnormal events because, in such cases, sudden intense translational activity can provide evidence of such events or disclose the intentions of the observed subject.
Let I(x, y, t), t = 1, 2, …, M, denote a sequence of scaled silhouettes depicting a subject conducting an activity. The image regions that exhibit motion are calculated using image-differencing, and a binary image indicating moving areas can be calculated as:
Let us assume that we divide Q(x, y, t) into R
disjoint regions (sets) , i = 1, 2, …, R. Region
is defined with reference to Q(x, y, t) as follows:
We define the motion energy mass of a spatial region of a difference image Q(x, y, t) as:
Using Equation (Equation2), Equation (Equation3) can be equivalently written as:
We also define the velocity of motion energy mass of frame region as:
Based on the motion energy mass and the velocity of the motion energy mass, we define the momentum of motion energy mass at time t as:
Using Equation (Equation5), the total momentum at time t, given by Equation (Equation6), can be equivalently written as:
Finally, the average momentum, calculated over the entire sequence (consisting of T difference images) is
Considering that significant translational movements will produce a significant shift of energy mass away from the center of the frame, we center and we obtain its centered version
for each t. Trivially,
Using Equation (Equation11), Equation (Equation8) can be rewritten as:
We define the horizontal and vertical momentum templates (MoT) as the two components ,
given by Equations (13) and (14), respectively. As seen, the coefficients of the MoT depend not only on the shape of the moving areas but also on the velocity with which these areas appear to be moving. This helps distinguish among activities with strong translational components. On the other hand, when the subject conducting an activity is standing, the shape information on the template dominates possible variations in execution speed and enables excellent discrimination.
The reliance of the method described above on image differences calculated as in Equation (Equation1) suggests that the method would be most suitable to be used in cases where stationary cameras are used. Further, in case sudden illumination changes or crowded environments are expected, appropriate mitigating strategies would need to be devised for a reliable background subtraction prior to the application of our method.
An interesting feature of our proposed template construction is that the calculation of momentum can be calculated on the fly by incorporating incremental contributions to the momentum template as the scene evolves. Although seeing the entire activity would help recognition, recognition based on partial availability of the activity is possible and, therefore, our method is appropriate for deployment in online/streamed recognition applications.
In the ensuing section, we propose a methodology for the practical calculation of the horizontal and vertical components of velocity of motion energy mass from binary silhouette sequences.
Calculation of Velocity of Motion Energy Mass
The momentum templates derived previously rely on the availability of the velocity of motion energy mass. Considering that our system is designed to work with binary silhouettes and binary difference images, no detailed optical flow can be calculated and used during the momentum template construction. However, the amount of translational motion in each region can be measured by observing the changes in the center of gravity in each of the regions of the binary difference image.
This calculation can take place separately for the horizontal and vertical components of velocity, by defining two sets of regions (horizontally and vertically oriented) on each difference image Q(x, y, t). At time t, the x-components of the centers of gravity can be calculated from the horizontally oriented region set, while the y-components
of the centers of gravity can be calculated separately for each region. Velocities are calculated based on the displacements of the centers of gravity for each region. This calculation is graphically shown in Figure .
FIGURE 2 Calculation of velocity of motion energy mass in (a) horizontal and (b) vertical directions. (Figure is provided in color online.)
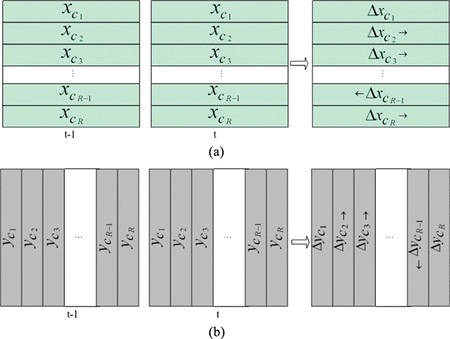
In case there is no motion energy in a region at time t, but motion energy appears in that region at time t + 1, the gravity center displacement (and the region velocity) cannot be defined. In such cases, we use the nearest nonzero neighboring velocity for that region.
Feature Extraction Using Angular MoT Representation
The information extracted based on the above template construction involves a large number of coefficients that could be difficult to use for recognition directly. A short feature vector based on the MoT template coefficients can be extracted using the angular transform originally introduced in Boulgouris, Plataniotis, and Hatzinakos (Citation2004). In order to apply the angular transform, a new coordinate system is defined, the origin of which is at the center of the MoT template. The calculation of the new coordinates is trivial and, henceforth, the coordinates (x, y) in the notation T(x, y) will be assumed to refer to the the momentum template (MoT) co-ordinates in the new coordinate system. The angular transform is calculated as:
FIGURE 3 Representation of the application of the angular transform on the MoT of the running activity.
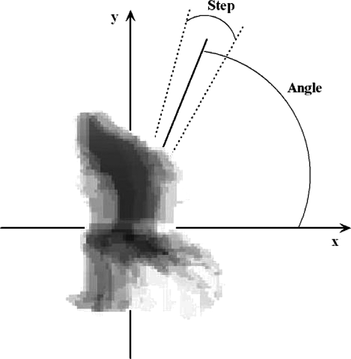
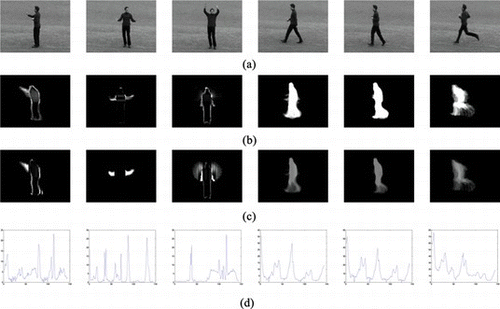
The angular transform is applied separately on the horizontal and vertical momentum templates, given by Equation (Equation13) and Equation (Equation14), respectively. An example using activities from the KTH human activity dataset is shown in Figure , which shows the MoT template and its respective angular transform representation. It must be noted that although some transforms look similar, their relative magnitudes may differ considerably, and this enables the disambiguation of the three activities involving significant translational motion. The angular transformation of the MoT, in combination with the momentum feature of the previous section, will be shown to result in excellent discrimination performance.
FIGURE 4 Template construction using activities from the KTH database. (a) Representative frames, (b) horizontal MoT templates, (c) vertical MoT templates, (d) angular representation of MoT templates in a combined feature vector. (Figure is provided in color online.)
Calculation Under Diagonal Motion
In the preceding discussion, it was implicitly assumed that the subject is standing or moving in a direction parallel to the camera projection plane. In practical situations, however, this may not actually be the case. In order to explore what would happen in such situations, we consider the example in Figure . In this case, the person is moving in a diagonal direction. This means that the direct calculation of momentum would be inaccurate as a result of the fact that the observed horizontal and vertical motion depends on the direction of motion.
FIGURE 5 Calculation of displacements in case of diagonal motion. The observed deviations from a straight path are due to actual vertical motion while the acting person is walking along the motion path.
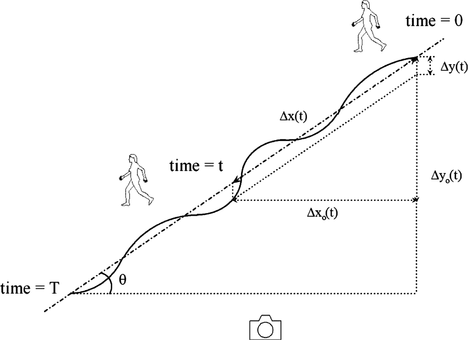
FIGURE 6 Six types of activities in the KTH database: (a) boxing, (b) claping, (c) waving, (d) walking, (e) jogging, (f) running.

Interestingly, as seen in Figure , the actual horizontal motion of the subject can be approximately calculated from the observed motion as:
From (16),
Similarly, from (17),
SUBSPACE PROJECTION AND ACTIVITY RECOGNITION
For the classification of an activity, we use the angular momentum coefficients, which are in a high-dimensional space (more than 100 coefficients). Therefore, our first task is the reduction of the dimensionality of the feature space. To this end, we use LDA in order to determine a low-dimensional feature space that is appropriate for recognition.
Let f denote the original angular feature vectors, b their mean, and b a the mean of each type of activity. The between-class scatter matrix S B and the within-class scatter matrix S W are calculated as:
The subspace projection yielding the optimal discrimination is determined from the maximization of the ratio of the determinant of the between and within class scatter matrix as:
Given a test sequence, activity recognition is achieved by comparing its feature vector to those of each of the training activities. The distances are expressed as:
The proposed system recognizes the performed activity based on the minimum distance among all results:
EXPERIMENTAL RESULTS
For the experimental evaluation of our method, we used the database in Schuldt, Laptev, and Caputo (Citation2004). This database includes six activities: walking, jogging, running, boxing, hand waving, and hand clapping, performed by 25 subjects in four different scenarios: outdoors, outdoors with scale variation, outdoors with different clothes, and indoors. In Figure 6, a number of such activities from the KTH human activity dataset are presented. Each sequence is divided into four segments as in Schuldt, Laptev, and Caputo (Citation2004), so the database contains 2391 sequences in total. All sequences were divided with respect to the subjects into a training set of eight subjects, a validation set of eight subjects, and a test set of nine subjects. For the application of our method, we calculated horizontal and vertical motion by partitioning each different image into horizontal and vertical stripes as shown in Figure. . The performance of our system is generally insensitive to stripe sizes between 10 and 20 rows/columns. For the results presented in this work, we used stripes of 10 rows or columns.
Initially, we evaluated the performance of our method, which uses Angular transform of momentum template (AMoT), on activities that do not involve significant translational motion. Specifically, we compared our method with the recently published method in Briassouli, Tsiminaki, and Kompatsiaris (Citation2009), in which recognition results were reported for the activities boxing, hand waving, and hand clapping. The results, tabulated in Table , demonstrate the efficiency of our approach for this subset of the KTH activities.
TABLE 1 Comparison with Activity History Areas for a Subset of Activities of the KTH Database
Subsequently, we tested our method using the full KTH database. Table presents a comparison between our AMoT method and the MoT template itself (without angular transform or LDA). It is seen that the angular transform and the application of LDA has a beneficial impact on the performance of our method. In case there is diagonal motion, we use the calculations presented earlier in order to mitigate the adverse effects of diagonal motion. The results of the comparison for this scenario are presented in Table and demonstrate the efficiency of our approach in case of diagonal motion.
TABLE 2 Performance Comparison Between the Momentum Template and the Angular Transformed Momentum Template with LDA
TABLE 3 Performance of Our Method With and Without Compensation for Diagonal Motion
Despite the fact that different instances of the same activity are performed at different speeds in the KTH database, the proposed method achieves very good performance in all cases because of the combination of the energy mass and velocity on the momentum template. This is a result of the fact that the reliance of our method on velocity is most important only when the observed activity includes strong translational motion. In cases where the observed subject is standing, the motion energy mass dominates during the classification process.
The recognition performance of our system in comparison to the recognition performance of several other approaches is shown in Table . As seen, despite its simplicity, our method achieves improved performance over the method in Qian et al. (Citation2010), and superior performance in comparison to the methods in Schuldt, Laptev, and Caputo (Citation2004); Meng and Pears (Citation2009); Niebles, Wang, and Li (Citation2008). In comparison to the state-of-the-art (Danafar, Giusti, and Schmidhuber Citation2010), our method exhibits lower performance, which was expected because of the significantly lower complexity of our system. The resultant confusion matrix is shown in Table . It should be noted that the separability between the activities that involve significant translational motion and those that do not is perfect, whereas the eventual misclassification rates are very low. This performance is achieved using a simple template that is efficient for both types of activities without requiring an initial pre classification into one of the two types. This constitutes very efficient activity recognition performance. Additional performance improvements could be achieved using a more refined methodology for the calculation of velocity of motion energy mass as well as the deployment of a more sophisticated classification approach. Performance improvements have also been shown (Laptev et al. 2008; Yuan, Liu, and Wu Citation2009; Weiland, Ozuysal, and Fua Citation2010; Gilbert, Illingworth, and Bowden Citation2009; Lin, Jiang, and Davis Citation2009). In these works, improved performance was achieved by means of complicated feature extraction and classification. Our method works with significantly lower complexity, at both the feature extraction and classification levels, and it achieves very satisfactory results.
TABLE 4 Comparison Between Different Approaches
TABLE 5 Confusion Matrix
CONCLUSIONS
We proposed a new activity-based event recognition system based on a novel momentum template combining the apparent moving areas and the velocity of the associated movement. The new template is applied in conjunction with an angular transform and LDA-based classification. Consideration was also given to movement that is not taking place in parallel to the projection plane of the camera. Experimental evaluation in comparison with other methods shows the efficiency of the proposed method.
REFERENCES
- Aggarwal , J. K. , and Q. Cai . 1999 . Human motion analysis: A review . Computer Vision and Image Understanding 73 ( 3 ): 428 – 440 .
- Bobick , A. F. , and J. W. Davis . 2001 . The recognition of human movement using temporal templates . IEEE Transactions on Pattern Analysis and Machine Intelligence 23 ( 3 ): 257 – 267 .
- Boulgouris , N. V. , K. Plataniotis , and D. Hatzinakos . 2004 . An angular transform of gait sequences for gait assisted recognition. In IEEE International Conference on Image Processing, Singapore, 857–860.
- Briassouli , A. , V. Tsiminaki , and I. Kompatsiaris . 2009 . Human motion analysis via statistical motion processing and sequential change detection . EURASIP Journal on Image and Video Processing 2009 , 16 .
- Cherla , S. , K. Kulkarni , A. Kale , and V. Ramasubramanian . 2008 . Towards fast, view-invariant human action recognition. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, June:1–8.
- Danafar , S. , A. Giusti , and J. Schmidhuber . 2010 . Novel kernel-based recognizers of human actions . EURASIP Journal on Advances in Signal Processing 2010, April .
- Gavrila , D. M. 1999 . The visual analysis of human movement: A survey . Computer Vision and Image Understanding 73 ( 1 ): 82 – 98 .
- Gilbert , A. , J. Illingworth , and R. Bowden . 2009 . Fast realistic multi-action recognition using mined dense spatio-temporal features. In International conference on computer vision, 925–931.
- Laptev , I. , M. Marszalek , C. Schuldt , and B. Rozenfeld . 2008 . Learning realistic human actions from movies . Computer Vision and Pattern Recognition , pp. 1 – 8 .
- Liang , W. , H. Weiming , and T. Tan . 2003 . Recent developments in human motion analysis . Pattern Recognition 36 ( 3 ): 585 – 601 .
- Lin , Z. , Z. Jiang , and L. S. Davis . 2009 . Recognizing actions by shape-motion prototype trees . IEEE 12th International Conf. on Computer Vision , pp. 444 – 451 .
- Meng , H. Y. , and N. Pears . 2009 . Descriptive temporal template features for visual motion recognition . Pattern Recognition Letters 30 : 1049 – 1058 .
- Muybridge , E. 1901 . The Human Figure in Motion . Dover Pulications .
- Niebles , J. , H. Wang , and F. Li . 2008 . Unsupervised learning of human action categories using spatial-temporal words . Internat J. Computer Vision 79 : 299 – 381 .
- Qian , H. M. , Y. B. Mao , W. B. Xiang , and Z. Q. Wang . 2010 . Recognition of human activities using svm multi-class classifier . Pattern Recognition Letters 31 : 100 – 111 .
- Schuldt , C. , I. Laptev , and B. Caputo . 2004. Recognizing human actions: A local svm approach. International Conference on Pattern Recognition 3:32–36.
- Turaga , P. , A. Veeraraghavan , and R. Chellappa . 2009 . Unsupervised view and rate invariant clustering of video sequences . Computer Vision and Image Understanding 103 : 353 – 371 .
- Weiland , D. , M. Ozuysal , and P. Fua . 2010 . Making action recognition robust to occlusions and viewpoint changes . Sept : 635 – 648 .
- Weinland , D. , R. Ronfard , and E. Boyer . 2006 . Free viewpoint action recognition using motion history volumes . Computer Vision and Image Understanding 104 ( 2–3 ): 249 – 257 .
- Yuan , J. , Z. Liu , and Y. Wu . 2009 . Discriminative subvolume search for efficient action detection . Computer Vision and Pattern Recognition 2442 – 2449 .