Abstract
Designing the proper agent behavior for a multiagent system is a complex task. Often it is not obvious which of the agents' actions, and the interactions among them and with their environment, can produce the intended macro-phenomenon. We assume that the modeler can benefit from using agent-learning techniques. There are several issues with which learning can help modeling; for example, by using self-adaptive agents for calibration. In this contribution we are dealing with another example: the usage of learning for supporting system analysis and model design.
A candidate-learning architecture is the combination of reinforcement learning and decision tree learning. The former generates a policy for agent behavior and the latter is used for abstraction and interpretation purposes. Here, we focus on the relation between policy-learning convergence and the quality of the abstracted model produced from that.
INTRODUCTION
Despite of its increasing popularity, agent-based simulation (ABS) still suffers from unsolved methodological problems. One of these problems concerns the proper design of the agent model for producing the intended macro-phenomenon. Ideally, the most simple, most comprehensible model that is valid on all relevant levels of aggregation has to be found. Finding such a design requires a high level of expertise from the developer in order to avoid a random trial-and-error development process. A general top-down approach guiding the development along organizational structures is not always advisable, especially if the system under examination exhibits emergent properties.
We propose to use agent-learning techniques to guide the discovery of the low-level agent behavior that produces the desired system-level behavior. The basic idea behind such a learning-driven design strategy (Junges and Klügl Citation2010b) consists in the delegation of the agent behavior design and test from the human modeler to the agents.
However, important questions need to be answered: What is the appropriate learning technique for a given class or domain of agent-based simulation models? How to actually apply the learning architecture in a given setting without being an expert on that particular technique? How to make the result of the learning accessible to the human modeler for evaluating the plausibility of the resulting agent design?
We have tested the suitability of a number of machine learning techniques for this task, ranging from learning classifier systems and neural networks (Junges and Klügl Citation2010a), via a combination of reinforcement learning and decision tree learning (Junges and Klügl Citation2010b) to genetic programming (Junges and Klügl Citation2011a,b). Although all tested architectures were able to fulfill the given tests, improvements must be made in order to support the interpretation aspects of the generated behavioral model. The optimality of the learnt system served in these tests only as one criterion among others, such as the accessibility and understandability of the resulting agent behavior model. However, it turned out that when using reinforcement learning techniques, the learning convergence is a critical issue not just for gaining more confidence in the result, but mainly for reducing ambiguity in the outcome produced.
In this article, we investigate the impact of the performance of the policy learning on the finally learnt behavior model. Assuming that the learning performance is a subject of both the scenario and the learning settings, we expect that changing the configuration of the learning algorithm has an impact on the production of a finally comprehensible model. We select for this task, as the agent learning architecture, a combination of reinforcement learning (Q-learning) and decision tree learning (C4.5). In this case, the model is generated by selecting the best learnt situation-action pairs in the online reinforcement-learning phase and applying them to a post-processing step, where an abstracted representation model is constructed.
In the next section we will outline existing approaches for learning agent architectures in simulation models. This is followed by a more detailed treatment of the learning-driven design approach and the learning architecture. Then we describe the used testbed, the experiments conducted with it, and discuss the results. The paper ends with a conclusion and an outlook to future work.
LEARNING AGENTS, MODELING, AND SIMULATION
Adaptive agents and learning has been one of the major focuses distributed artificial intelligence since its very beginning (Weiß Citation1996). Many different forms of learning have been shown to be successful when working with agents and multiagent systems. The following paragraphs offer a few general pointers on directly related work on agent learning for simulation model development. In general, our contribution is unique with respect to the general objective: not mere learning performance, but also its suitability for usage in a modeling support context.
Reinforcement learning (Sutton and Barto Citation1998), learning automata (Nowe, Verbeek, and Peeters Citation2006), evolutionary and neural forms of learning are recurrent examples of learning techniques applied in multiagent scenarios.
As an early example, Mahadevan and Connell (Citation1992) describe a general approach for automatically programming a behavior-based robot. Using the Q-learning algorithm, new behaviors are learnt by trial and error, based on a performance feedback function as reinforcement. In Lee and Kang (Citation2006), also using reinforcement learning, agents share their experiences, and most frequently simulated behaviors are adopted as a group behavior strategy. Neruda, Slusny, and Vidnerova (2008) compare reinforcement learning and neural networks as learning techniques in an exploration scenario for mobile robots. The authors conclude that reinforcement learning techniques make it possible to learn the individual behaviors—sometimes outperforming a hand-coded program—and behavior-based architectures accelerate reinforcement learning.
Techniques inspired by biological evolution have been applied for agents in the area of Artificial Life (Adami Citation1998; Grefenstette Citation1987), where evolutionary elements can be found together with multiagent approaches. An example of a simulation of a concrete scenario is given in Collins and Jefferson (Citation1991), in which simulated ant agents were controlled by a neural network that was designed by a genetic algorithm.
Denzinger and Kordt (2000) propose a technique for generating cooperative agent behavior using genetic algorithms. An experiment is developed for a multiagent scenario applied to a pursuit game, in which situation-action pairs guide the agents. The authors compare the proposed online approach with an offline approach for the same problem. The results show that the online learning phase improves the agents' performances in more complex variants of the scenario and when randomness is introduced, compared with the offline approach. In Denzinger and Schur (Citation2004), the authors present several case studies in which application-specific features were encoded into the fitness function. The conclusion is that there is not much difference in terms of performance by refining knowledge already available in the fitness function; however, adding new application knowledge improves the performance significantly. In general, some differences to our approach can be observed: in their case, although the results of the learning phase are used in an online way, the learning itself is offline, it does not take place in the “real” scenario where all agents are adapting at the same time; they focus on learning parts of the problem as the execution evolves, and not on learning a complete model of the agent for the problem, as in our case; they assume the agents have knowledge about the entire scenario, which can be unrealistic in certain scenarios. Because their focus is on cooperative behavior, a model of other agents is crucial for the success of the learning.
Although there is a wealth of publications dealing with the performance of particular learning techniques, especially reinforcement-learning approaches, there are not many works focusing on the resulting behavioral model dealing with usability. Abstraction and generalization capabilities are of fundamental importance to support the behavior interpretation, when considering our modeling objective. Cobo et al. (Citation2011) present a learning technique based on learning from demonstration, reinforcement learning, and state abstraction, which is called abstraction from demonstration (AfD). Essentially, AfD uses demonstrations from a human to create state abstractions and then applies reinforcement learning in the abstracted state-space to build a policy. In our approach, however, we configure the agents to explore the perceptions and actions set in the environment, and we expect to fully learn the agent behavior. The problem with using the abstracted space not for interpretation purposes, but for learning a policy or set of rules, is that an abstracted situation represents many more situations than the full-state representation, and potentially different best actions may be conflicting. In Whiteson and Stone (Citation2006), a function-approximation method is proposed to represent the state-action mapping for large or continuous state-spaces where reinforcement learning cannot be represented in a table format. The article presents an enhancement to an evolutionary function approximation that makes it more sample efficient: a combination of a neural network function approximation with Q-learning. Empirical results in a job-scheduling problem demonstrate that the new method can learn better policies than evolution or reinforcement learning methods alone. Although the method shows an example for dealing with the space-state dimensionality problem, in our modeling support case it constitutes a black-box system, for which it is even more difficult to extract human-readable information for the modeler. Complexity is added to the design strategy because of the need to use more sophisticated rule extraction techniques (Huysmans, Baesens, and Vanthienen Citation2006).
AGENT LEARNING FOR MODEL DESIGN
Our design strategy, based on learning-driven behavior construction, considers that a sufficiently elaborated decision-making process can be developed by setting up a simulation model of the agents and their environment. The idea is to transfer the initial agent behavior design from the human modeler to learning in a simulated environment.
We assume that learning parts or initial versions of the behavior model is beneficial for the human modeler, because it can serve as a source of inspiration to produce the final model. Moreover, we assume the following: even though the human modeler does not know exactly what behavior program the agents need to execute, it is possible to characterize what is a good performance of the agent in the environment using an objective function and that it is possible to set up a simulation model of the environment capturing all relevant features of the deployment environment.
Such a learning-supported analysis is especially useful when developing complex systems with emerging organization and indirect interaction. Then a direct determination of agent behavior may be cumbersome, even more so when experience for bridging the gap between (local) agent behavior and overall system outcome is missing.
We define a particular number of steps to be followed when implementing the proposed learning-driven strategy:
| 1. | Model the environment, from the identification of relevant aspects that compose the entities and dynamics; | ||||
| 2. | Determine the agent interfaces (sensors and actuators): the set of perceptions the agents can read from the environment as the input for their decision-making process; and the set of actions that can be triggered by reasoning upon these inputs; | ||||
| 3. | Decide on a learning architecture that is apt to connect perceptions and actions of the agent appropriately for actually producing the agent's behavior; | ||||
| 4. | Determine the objective function that evaluates the performance of the agents in the environment. Ideally it is derived from a description of the overall objective or intended aggregated behavior. It may contain a combination of evaluation on the group level and on the individual level; | ||||
| 5. | Simulate and test the overall outcome for analyzing whether the individual behavior description is plausible and for preventing artifacts that come from an improper environmental model, reward definition, or weak interfaces. | ||||
The resulting model generated by the simulation process ideally provides the agent program that fits the environmental model, interfaces, and objective function, producing the aggregated behavior intended. The learnt behavior model may also be used as an element in agent-oriented software engineering (AOSE) methodologies—for example, as the nominal behavior of the agents in an ADELFE process (Bernon et al. Citation2003).
LEARNING TECHNIQUES SUPPORTING AGENT DESIGN
Not all agent-learning techniques are equally apt for usage in the modeling support context. There are a number of properties that an appropriate learning technique may be able to exhibit for indicating a successful application.
Feasibility: The learning mechanism should be able to cope with the level of complexity that is required for a valid environmental model. Thus, it should not be necessary to simplify or even to reformulate the problem just to be able to apply the learning mechanism. That means the theoretical prerequisites for applying the learning technology must be known and fulfilled by the environmental model in combination with the reward function. The learning architecture must be able to find an adequate solution; | |||||
Interpretability and Model Accessibility: The mechanism should produce behavior models that can be understood by a human modeler. The architecture shall not be a black box with a behavior that the human modeler has to trust, but must be accessible for detailed analysis of the processes involved in the overall agent system; | |||||
Usability: The mechanism in the learning architecture should be well established and well understood. Its usage shoul not impose additional complexity to the modeler; for example, in setting a number of configuration parameters. How the learning process works should be explainable to and by the modeler. | |||||
There is a variety of possible agent learning techniques that may be suitable for the aim presented here and the requirements identified. After examining a number of possible agent learning techniques (Junges and Klügl Citation2010a), we selected Q-learning (Watkins and Dayan Citation1992) for further investigation. It is a well-known, simple reinforcement learning technique. It works by developing an action-value function that gives the expected utility of taking a specific action in a specific state. The agents keep track of all experienced situation-action pairs by managing the so-called Q-table, which consists of situation descriptions, actions taken in the respective situations and the corresponding expected reward predictions, called Q-values. Consequently, a Q-learning agent is able to compare the expected utility of the available actions without requiring a model of the environment. Nevertheless, the use of the Q-learning algorithm is restricted to a finite number of possible states and actions. It needs sufficient information about the current state of the agent in order to be able to assign discriminating rewards. The most important feature distinguishing reinforcement learning from other types of learning is that training information that evaluates the actions taken is used to instruct, rather than correct actions being given. This is what creates the need for active exploration, for an explicit trial-and-error search for good behavior. Although there are a number of extensions that improve the convergence speed of Q-learning, we include the standard Q-learning algorithm in our experiment due to its straightforward application to our design strategy.
We suppose that Q-learning meets the requirements for the application by providing both sufficient performance (if applicable) and interpretability of the result. The latter can be achieved by deriving some rule-like structure from a situation and the best action in this situation, together with a clear evaluation of those rules based on the Q-value of the situation-action pair.
The number of possible situation-action pairs can be overwhelming and thus can form a drawback in accessibility of the resulting agent model. If the situation is captured using n binary elements, the number of possible situation instances is 2 n , including a number of situations that the agent never encounters. In many situations only one piece of information is relevant. Therefore, we combine it with a post-processing step that aims at producing a compact and transparent representation of the behavior model. After examining a number of candidates in Junges and Klügl (Citation2010b), we selected the C4.5 decision tree learning algorithm (Quinlan Citation1993). As for the training instances of the algorithm, we select from the situation-action pairs: a string representation of the situations as the features set; and the action with the highest Q-value as the solution or class.
Clearly, there is no guarantee that there is a unique best action in our multiagent application of reinforcement learning. This lack of convergence makes it difficult to assign, from all relevant situations, a unique best action in a consistent way. Therefore, we focus on Q-learning and its setting for improving the learning quality and being able to derive a compact and transparent decision tree as agent behavior representation. We test and illustrate our approach using a simple testbed that poses sufficient challenges for the understanding of the learning process.
AGENT-BASED EVACUATION SIMULATION AS TESTBED
Pedestrian evacuation scenarios form a typical application domain for ABS. The objective of the agents is to learn a collision-free exiting behavior. Therefore, the reward and agent perceptions and action repertoire are shaped to support this goal.
Environment and Agents Basic Repertoire
The basic scenario consists of a room (20 m × 30 m) surrounded by walls, with one exit and 10 column-type obstacles (each with a diameter of 2 m). A number of pedestrians shall leave the room as fast as possible, avoiding collisions with other entities inside the room. We assume that each pedestrian agent is represented by a circle with a 50 cm diameter and that it moves with a speed of 1.5 m/sec. One time-step corresponds to 1 sec. Space is continuous, yet actions allow only discrete directions. We tested this scenario using one, two, five, and ten agents with homogenous speed. At the beginning, all agents are randomly located in the upper half of the room, the exit is in the middle of the bottom.
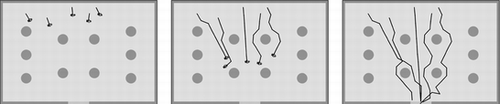
Figure presents an example configuration of the scenario with five agents, where, from left to right, we show the development of the routes taken by the agents.
FIGURE 1 Scenario and behavior example—five agents.
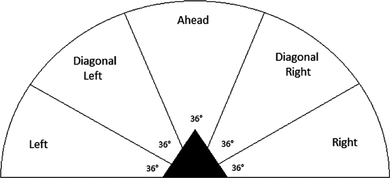
As interfaces between agents and environment, the perceived situation and the set of possible actions have to be defined. The perceptions of the agents, and their movement directions, are based on their basic orientation. The overall perceivable area is divided into five sectors with a defined field range of 2 m, as depicted in Figure . For every area, two binary perception categories were used: the first encoded whether the exit was perceivable in this area, and the second encoded whether an obstacle was present. An obstacle can be anything with which a collision should be avoided: walls, columns, or other pedestrians. Additionally, the agents hold a binary perception telling them whether the exit is to their left or right side, according to the X axis orientation.
FIGURE 2 Agent perception sectors.
The action set is shaped for supporting the collision-avoidance behavior. We assume that the agents are, per default, oriented toward the exit. The action set consists of A = {Move Left , Move DiagonalLeft , Move Straight , Move DiagonalRight , Move Right , Noop, Stepback}. For any of these actions, the agent turns by the given direction (e.g., + 36 degrees for Move DiagonalRight ), makes an atomic step, and orients itself toward the exit again. With this implicit representation of the orientation task in the actions, we allow the agents to focus on the tasks of collision avoidance and moving forward.
Reward was given to the agent a immediately after executing an action at time-step t. It was computed using Equation (1).
reward exit (a, t) = 1000, if agent a has reached the exit in time t, and 0 otherwise; | |||||
reward dist (a, t) = β × [(d t − 1(exit, a) − d t (exit, a)) + (y t (a) − y t − 1(a))] where β = 20 and d t (exit, a) represents the distance between the exit and agent a at time t, while y t (a) represents the Y coordinate of agent a at time t. We reward actions that reduce the distance to the exit; | |||||
feedback collision (a, t) was set to 100 if a collision-free actual movement had been made, to 0 if no movement happened, and to −1000 if a collision occurred. | |||||
Together, the different components of the feedback function stress goal-directed collision-free movements.
Basic Learning Setup
For dealing with the explore-exploit problem in reinforcement learning, we evaluate the learning using experiments composed of a series of trials, with 100 iteration steps each, representing the maximum number of steps that the agents may take to evacuate the room before a new trial begins. One step represents the execution of one action. There are two types of trials, which are executed alternately:
Explore trials: the agents randomly choose their actions and use the reward given by the environment to update their knowledge in the Q-table; | |||||
Exploit trials: the agents select the action with the highest Q-value given the current situation as described in the Q-table. | |||||
Every experiment took 10,000 explore-exploit cycles. The agents learn only during the explore phases, as a result of their exploration. Exploit phases test and show the behavior learnt throughout the simulation but have no effect on the Q-table.
We assume an initial Q-value of 0 for all untested state-action pairs. We set the learning rate to one and the discount factor to 0, which means that the agents' actions are selected based on recent experiences and not on the consideration of the future rewards. The discount factor value is an intentional simplification for the problem, as the agents do not need to maximize future rewards. They can focus on their local collision-avoidance problem. To increase this number would mean that the agents' actions would also be weighted by the subsequent actions, and this would require more exploration or more learning cycles, impacting otherwise on the convergence of the situation-action pairs. Each agent learns for itself, which means that they maintain their own individual Q-table.
At the end of the simulation, the Q-values are used to select the best situation-action pairs from the Q-table that will form the training set used to build the decision tree with the C4.5 algorithm. Additionally, we exclude the pairs that have not been tested sufficiently according to an experience threshold. In the post-processing case, the decision tree must be tested for correspondence to the original situation-action pairs that were used to produce it. Thus, the objective is to generate an abstracted view that fully resembles the behavior learnt.
Improved Parameters: Explore-Exploit Setup
We test a different configuration for improving learning convergence based on a more intelligent setting of the learning parameters. We set the learning rate to decrease from 1 to 0.2, according to a step function (in steps of 0.2 after 25% of the simulation time).
Whereas a decreasing learning rate is a common setting for supporting convergence, another change concerns improving the random-action selection in the explore trials. Analyzing previous tests, we noticed that the share of untested actions is high. Using the initial explore-exploit alternation, the selection of an action in the explore phase is now weighted by an experience parameter representing how often the action has been tested before. Thus, at the end of the simulation, the Q-table will contain more evenly tested actions in the situations frequently perceived by the agent.
Fixed Positions: Scenario Setup
One of the challenges for learning good situation-action pairs was the random positioning of the agents in every new trial. The question arises of whether to use fixed positions for learning individual agent behavior descriptions, but putting the experiences of all agents together in the post-processing step for generating a general agent model could provide a good solution to theoverall problem. Therefore we tested a scenario configuration where in the agents are placed at their same initial positions in all trials. This way, each agent has only its own route to learn, and therefore it needs to learn the situation-action pairs set with regard to the obstacles in that route.
Scenario Challenges
Despite its simplicity, the scenario poses some challenges to the behavior-learning task. From a simulation point of view, it can be coined as a shared-environment-actor model (Klügl, Citation2009). Agents indirectly coordinate their actions, which is done based on the learnt prediction of other agents' movements. There is no direct communication. In particular, an individual agent has to face the following challenges:
The truly parallel update has a consequence that the actions that an agent has selected might not work out as planned because the actions of different agents might interfere in an unforeseen way; | |||||
If there is more than one agent, the probability of encountering other agents is not static, but increases the nearer the agent comes to the exit. That means that whereas the agents in the beginning will encounter more obstacles, later they will interact more with other agents; | |||||
The enforced generalization—random positioning at the beginning of each trial—prevents the agents from fixing rules in their behavior that are too particular for the specific scenario. On the other side, this forms a challenge as some situation-action combinations may have different rewards with different starting positions; | |||||
The agents receive insufficient information for choosing an optimal action due to the locality of the perception as well as the missing discrimination between static obstacles and moving agents. | |||||
We should also emphasize that agents learn individually, based on their own particular perception and connecting this perception individually to one action. Individual learning is desirable because it is simpler to model and makes the approach more scalable as well, because heterogeneity—in terms of different agents and roles—can be introduced following the same design strategy.
Clearly, our testbed is not covering all critical aspects that challenge the development of a multiagent system. There are no organizational structures or normative elements, nor explicit communication to be learnt for a successful solution of the scenario. They do not need to fulfill more than one objective, thus they do not need to deliberate and select goals, nor do they have to explicitly plan. A rule-based architecture is sufficient for the problem addressed.
EXPERIMENTS AND RESULTS
In the following, we present experiments and discuss results with respect to learning performance of the Q-learning algorithm, properties of the learnt situation-action pairs, the performance of the C4.5 algorithm based on the different outcomes, and, finally, the usability of the resulting behavior model.
Performance Evaluation
The overall metric that can be used for measuring performance is the number of collisions. The time to reach the exit over all different setups does not vary significantly, because a collision is not directly imposing restrictions to the agents' movements, but indirectly through the rewards the agents receive.
Table presents the mean number of collisions for each scenario. The values are aggregated only after the first 50 explore-exploit cycles in order to avoid the inclusion of any warm-up data. The mean and deviation over the results of the different exploit cycles are given. Despite having the runs repeated, we did not give means and standard deviations over different runs, because the results are very similar. Clearly, the average number of collisions increases with the number of agents, because more agents share the same environment and have to learn to avoid not only obstacles, but also other pedestrians, which in their turn are also adapting. The configuration with fixed initial positions generally presents a lower number of collisions, given that the agents have to learn how to evacuate the room starting from the same position. However, as the number of agents increases, the difference between the averages decreases. This is because even with a better learning tuning, or favorable scenario configuration, when it comes closer to the exit, the pedestrian density increases and more collisions are expected.
TABLE 1 Mean Number of Collisions Per Run - Rows Represent the Number of Agents
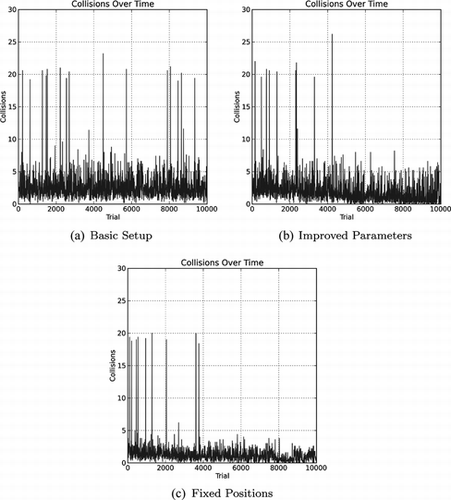
Figure illustrates the adaptation speed by depicting the number of collisions over time for an exemplary run with five agents for each configuration. We can see from this figure—as well as from Table —that in the basic setup, the agents hardly improve their performance (with regard to collisions) over time, and there is a slight improvement in the improved parameters and fixed initial positions cases. There are even some peaks in the plot, representing a higher number of collisions. This means that, even though the agents can learn how to avoid obstacles, they cannot predict all situations. For instance, the agents might learn that when there is an obstacle to the right they should move forward. However, this object to the right could be another pedestrian, that could eventually also move in the same direction and collide with it. The ability to discriminate between static obstacles and other pedestrians may improve the performance, but not in situations with a high density of pedestrians, all with dynamic behaviors.
FIGURE 3 Development of the number of collisions for an exemplary run with five agents.
To offer a better illustration of the learning process, we show in Figure the trajectories of the agents in exploit phases after (a) 100, (b) 1000, (c) 5000, and (d) 10,000 exploit cycles. In this figure, we consider the situation with two agents. We can see the progress of adaptation with collision-free and goal-directed movement. Experience hereby does not just mean positive reinforcement. Even if the agents do not know what is the best action, they know which one to avoid by checking the negative rewarded actions. Nevertheless, an important aspect about the developed behavior is that, even when approaching the final rounds of simulation, there is no consolidated best action for each situation. The agents are capable of learning their way out of the room, but for certain situations there are different actions that have similar Q-values, and with a constant learning rate, these actions are always changing to become the agent's preferred action. This means, for example that in one exploit round, Move Straight is the best action in a given situation, but in the next round, after the explore round, the agent has experienced a good reward for Move DiagonalLeft , and therefore, this one will bechosen. This lack of convergence has an impact on the interpretation of the final situation-action pairs (final Q-table). One can notice the improvement with decreasing and balanced learning rate. Moreover, the fixed positions case results in a clear best action in every situation.
FIGURE 4 Exemplary trajectories during exploit trials, for two agents.
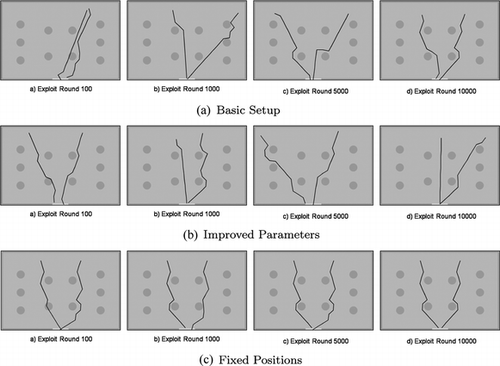
In the tests with the improved parameters, when the agents get to the exploit round 10000, they have learnt not only to avoid collisions, but also to minimize their route out of the scenario, according to the reward function. More interesting, the route chosen in that last round is the same chosen in every exploit round as the simulation approaches its end. It represents a better learning performance, because there are many fewer ambiguities in the Q-table interpretation that lead the agent to have multiple good routes. In the fixed initial positions case, this is more visible, but it is also valid for the random positions case.
Situation-Action Pairs Evaluation
In this section, we analyze the structure of the situation-action pairs taken from Q-learning. These pairs are extracted from the Q-table of the agents and represent their experienced situation and actions associated with an utility value. The selection of pairs is determined by taking for every situation the action with the highest Q-value, as it is done in the exploit phases. The experience of a pair is also regarded, as only those selected more frequently by the agents are considered.
The majority of the situation-action pairs have not been tested more than once, because they are a product of the exploration and represent situations that are visited only when adopting a complete random choosing behavior. Depending on the situation, there might be no action with a positive Q-value. There could be situations in which the agent has to go back to avoid severe harm but accepts a small negative reward. A Q-value of zero represents situation-action pairs that have not been tested at all: for instance, in the 1-agent case, the agent will never experience a situation where it has more than one object in its perception range, because the agent always faces only one column obstacle at a time. We call the resulting situation-action pairs set, after taking the best and most experienced pairs, the filtered pairs set.
Figures and show the distribution of the reward prediction (i.e., the Q-value), for the complete set for the one-agent case, and for a randomly selected exemplary agent from a simulation with five agents. In the one-agent case, the Q-value distribution points to a better exploration of the possible situations, as there are fewer situation-action pairs with Q-value of 0. In the 5-agents case, more situation-action pairs are left unexplored. Due to the interaction with other agents in the scenario, a larger variety of situations can be experienced.
FIGURE 5 Q-learning value distribution for an exemplary agent from a simulation with one agent.
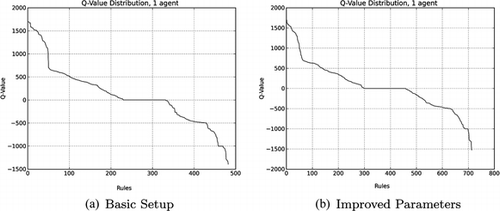
FIGURE 6 Q-learning value distribution for an exemplary agent from a simulation with five agents.
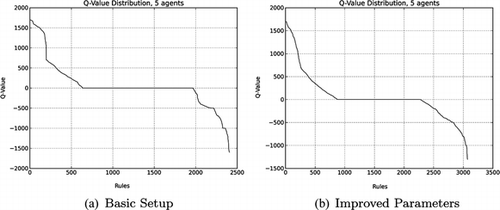
It is obvious that the Q-value alone cannot be a selection criterion for situation-action pairs forming a behavior model, because those with the highest Q-value naturally contain situations in which the agent directly perceives the exit. Another important aspect about the agents' experiences is that, when the agents are randomly positioned in the scenario at the beginning of each trial, the situation-action pairs are not biased by the fixed position, so the situation-action pairs set is more elaborated than it would be when they have to know only one best way to get to the exit.
Comparing the basic setup with the improved parameters, there is not much difference from the basic model in terms of Q-value. An exception is made for the better exploration promoted by the balanced exploration feature in the improved parameters case. This feature leads the agent to have an increase in the number of situation-action pairs as the consequence of facing more, different situations in the scenario.
Concerning the experience, Figure shows the experience distribution in the basic setup and the improved parameters cases, representing how many times the situation-action pairs have been tested for the case with five agents. Only a few of them have a higher experience number, as they reflect the situations that are most frequently visited during the simulation. This seems to be another good reason for having a balanced exploration of the actions as in the improved parameters setup; so as to make sure that the Q-values really reflect the best action.
FIGURE 7 Situation-action pairs experience distribution for an exemplary agent from a simulation with five agents.
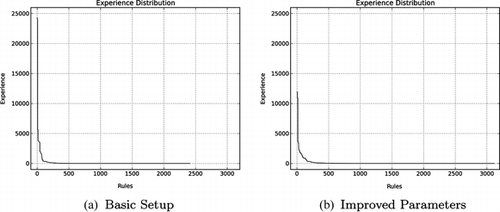
In contrast to these expectations, the number of situation-action pairs tested seems to be similar in the improved parameters setup. However, the situations were better explored in the sense that all the possible actions for a given situation have been equally tested. Instead of having situation-action pairs that have been tested much more often than others, the agents have a better knowledge about what to do in the most visited situations.
Another interesting analysis concerns the actual actions that were used in the situation-action pairs, as shown in Figure . The selected agent of the 5-agents case has in the basic setup case 21 filtered pairs, the agent from the 1-agent case has 20 filtered pairs. Figure shows the distribution of these final pairs over the possible actions. The majority of the pairs indicate the Move Straight action. This comes from the fact that the agent is reoriented toward the exit after the execution of any action. Unless the agent needs to avoid a collision, Move Straight is the best action to choose. The increased balanced experience in the improved parameters setup results in a slightly greater number of situation-action pairs, as fewer pairs are filtered out for missing experience: the agent from the 5-agents case has 30 filtered pairs and the agent from the 1-agent case has 25 filtered pairs. The distribution of actions is hardly different than in the basic case.
FIGURE 8 Situation-action pairs distribution over the actions for an exemplary agent from a simulation with five agents.

Classification Evaluation
In this section we test how well the filtered situation-action pairs set is suitable for applying the post-processing step. Metrics are the classification accuracy with the C4.5 decision tree algorithm, using: 10-fold cross validation in the training set, testing against all pairs in training set, and testing against another agent's pairs set.
Because the best pairs, selected by their higher Q-values and additionally filtered by the experience, represent the policy to be followed by the agents in exploit trials, we assume that they are the best candidates to generate an abstracted representation of the behavior. Using all situation-action pairs would not be ideal, as pairs with the same situation but slightly different valued actions would introduce ambiguities. This is essentially a matter of convergence in the learning, both for assuring the selection of the same action for a given situation—across different runs or different agents—and for assuring the coherence in the situation description for a particular action. For instance, two pairs determining the agent to Move Straight , cannot have conflicting perceptions in the situation description as Obstacle Ahead?. For these reasons, the objective of testing classification accuracy is twofold:
| 1. | Generalization–How the situation-action pairs generalize the behavior represented. That means, how coherent are the situation descriptions (as they form the input for the classification), in terms of producing the same output? This is basically a matter of learning convergence, which cannot be guaranteed in our multiagent scenario, with single-agent learning. We test generalization using cross-validation and testing against other agent's pairs set. | ||||
| 2. | Abstraction–how well the generated decision tree represents the training set, which in our case is exactly the set of best situation-action pairs. That means whether we can trust the abstracted decision tree model to be an accurate representation of the pairs selected to represent the best behavior. This is probably the most important aspect of the evaluation when it comes to our interpretation purposes. | ||||
Table summarizes the classification results, comparing the basic and the improved parameters setup.
TABLE 2 Classification Accuracy with C4.5 Decision Tree Algorithm, all Models
Although these are all well-learnt agent models, they cannot be generalized to other good solutions (other agents' experiences) in the basic setup. However, even in the basic model, we verify with the training set classification accuracy that the resulting decision tree model truly resembles the best-chosen situation-action pairs. This is an important validation of the design approach because we can provide the modeler with a much more compact representation of the behavior.
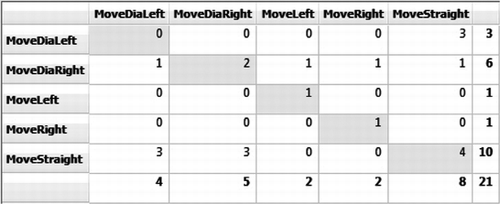
As a Complement, Figure shows the confusion matrix for the decision tree learnt from a basic setup simulation with five agents, testing with cross validation: rows represent the expected class (action) from the classification model, as presented in the Q-learning mapping, and columns represent the classification determined by the decision tree. We highlight the number of correctly classified instances. The majority of misclassified instances fall on cases where different actions could result in similar, good rewards. For instance, there is a common misclassification among the actions Move Straight , Move DiagonalRight and Move DiagonalLeft . This comes from the fact that when the agent is facing the exit, for instance, all three of these actions will maximize the reward (represented by reaching the exit).
FIGURE 9 Confusion matrix for the decision tree in the simulation with five agents, basic model. Rows represent the expected class (action) and columns represent the classification determined by the decision tree.
In Table , one can see the improvement in the classification rate promoted by the improved parameters setup. Not only can it be seen both in the collisions number (performance) and route choice, but it can be seen in terms of accuracy of the results. This has a special impact on the reliability of the model. Although it is possible to build a decision tree representation from the basic setup, the situation-action pairs generated by the improved parameters setup provide a better support to the modeler. However, the quality of the final results depends on the settings of the learning algorithm. By changing the exploration and the learning rate, we were able to improve the accuracy of the classification, which represents a better learning quality, compared with the basic setup. There is still room for improvements, as we understand that the environmental settings, such as number of agents and especially the reward function, also play an essential role in the convergence factor. With the perfect environment and learning settings, the learning would converge to a final solution for this collision-avoidance and evacuation task.
In the case of fixed initial positions, we take the agents from the 2-agents scenario, combine their situation-action pairs, and compare with the pairs learnt by one exemplary agent from the same scenario but with random initial positions. The classification accuracy is of 0.70 for the 10-fold cross validation, 0.91 for testing against the training set, and 0.86 when tested against the training set from the other agent, with random initial positions. The cross-validation result is lower because when combining the pairs from the two agents, we add ambiguity into the interpretation. For instance, when facing an obstacle, the agent on the left side has learnt that it should turn left, because this is where the exit is located. The same is not valid for the other agent (right side). More important is that we could have a good classification result when testing against all training sets and against the random agent. This represents an example of combined experienced in the construction of the behavior model.
Evaluation of the Resulting Decision Tree
The final question regards the finally produced decision tree with respect to its structure and content. For this analysis we consider the case with five agents, in all three different learning settings tested. The conclusions are equivalent for other numbers of agents.
In the basic setup case, the tree has an average of seven nodes and four leaves. For the cases with improved parameters and with fixed positions, the tree has an average of 7.4 nodes and 4.2 leaves. The size of the tree does not vary significantly from one case to another because the agents are learning essentially the same problem, determined by the reward given, the environmental settings, and consequently the situations experienced. This similarity implies that the agents will have to develop a set of situation-action pairs that is not so different in terms of their situation descriptions or agents' perceptions. What differs is how they learn to select the best action in each case, and this is dependent on the particular learning settings, whose consequences are verified both in the performance evaluation (collisions) and classification evaluation (abstraction).
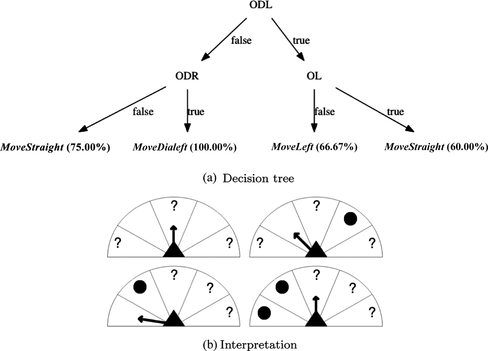
Figures , , and outline the trees generated from the experience of one exemplary agent in the case of the 5-agents case. In these figures, the codes represented in the nodes stand for different agent perceptions. “E” means Exit, “O” stands for Obstacle. The second letters represent the direction of the perception: “A” for Ahead, “DL” for textitDiagonally Left, “R” for Right, etc. “LS” (Left Side) is the perception used for determining on which side the exit is located, according to the agent's X-axis orientation. We also provide a different interpretation of the decision trees, by showing the situation and action chosen from the perception sectors point of view. In these cases, the action is represented by an arrow and an obstacle by a circle. Untested sectors are represented by a question mark.
FIGURE 10 Decision tree generated for an exemplary agent of the 5-agents case, basic model.
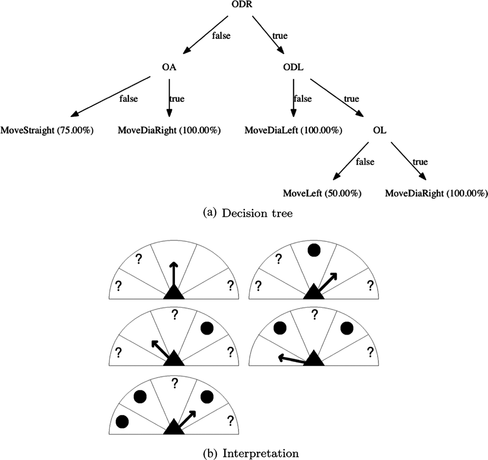
FIGURE 11 Decision tree generated for an exemplary agent of the 5-agents case, improved parameters model.
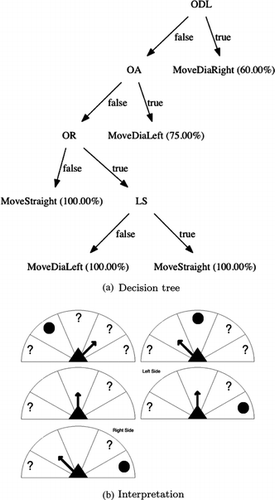
FIGURE 12 Decision tree generated for an exemplary agent of the 5-agents case, fixed initial positions model.
The tree learnt in the basic model configuration, depicted in Figure , shows the effect of the lower learning quality, as pointed in the performance evaluation section. Some movement actions, represented by the leaves of the tree, point to sectors of the perception range where previous obstacles have been perceived. This contradiction is basically a result of having similar situation-action pairs—in terms of situation description—pointing to different actions, and using them to create the abstracted model.
An interesting aspect of the behavior learnt in this particular scenario is shown in the decision tree for the improved parameters model, in Figure . We can see the effect of not having the ability to discriminate between columns and pedestrians when perceiving an obstacle. The agents have to learn to cope with the dynamic nature of this perception, as it may represent another moving pedestrian. As a consequence, the agents develop a wider collision-avoidance behavior by moving away from the obstacle instead of choosing sectors closer to the perceived object.
The decision tree learnt for the configuration with fixed initial positions shows, as expected, a natural bias toward the initial position defined. In Figure we show an example for an agent positioned in the top right corner of the room, having the exit to its right side. In this case, besides avoiding collisions, the agent tries to maximize the distance to the exit by selecting Move Straight , or movements to its left, as there is also a reward given by decreasing the Y-axis distance to the exit (Equation (1). Given that the agents are always oriented toward the exit, if the exit is to the agent's right side (the case in this example), moving to the left optimized the ΔY reward.
In principle, a structured set of rules producing a solution to the evacuation problem could be learnt—using a technique that results in something closer to human-readable rules. However, the classification results provided above demonstrate the need for improving the accuracy of the model in terms of generalization.
Although the trees may look similar in size and nodes content, they were generated from different situation-action pairs sets. These sets differ in the quality of their pairs, which may have a bigger impact in other, more complex, scenarios, where it is not so simple to see the intended overall behavior. These trees were created based on the experience of one exemplary agent from these simulations, and the numbers may still vary depending on the experience of that agent. We would get to the final model when we achieve the perfect environmental and learning settings, which would lead us to a final representation.
CONCLUSION AND FUTURE WORK
In this paper we investigated the aspects of learning convergence and interpretability in the context of a learning-driven modeling methodology. We proposed the use of agent learning to support the process of agent design in multiagent simulations. To be useful for the human modeler, the learnt model has to be easily readable and interpretable.
By using Q-learning as the learning technique, we concluded that the readability of the raw state-action mapping provided by this learning technique can be extended by using other machine learning techniques, such as decision trees. However, the quality of the learning plays an important role in this post-processing phase, in terms of abstraction. To improve the learning convergence, we investigated the configuration of the interface between the learning technique and the simulated scenario, and the impact of that in the interpretation of the results. Our tests were focused on the explore-exploit trade-off, how to set and balance the exploration, and the learning-rate configuration, that determines the influence of new rewards over time, during the simulation.
In a small evacuation scenario, we showed that the employed learning technique can produce plausible behavior in an agent-based simulation. However, the interface between the learning technique and the agent environment is by no means trivial. The environmental model, feedback function, perception, and action sets are critical. Comparing a basic model with standard Q-learning implementation and a setup with decreasing learning rate and balanced exploration, we derived a more accurate and thus useful model of the agent behavior.
Using a learning technique transfers the basic problem from direct behavior modeling to designing the agent interface and environment reward computation. To do so successfully, a general understanding of scenario difficulties and the available machine learning techniques is necessary. An example is the fundamental requirement of the Markov property in reinforcement-based approaches (Sutton and Barto Citation1998) in our case Q-learning. Provided perceptions need to contain sufficient information to be able to learn the expectation of immediate and future possible rewards accurately.
Nevertheless, there are improvements that need to be considered. First, we need to submit the abstracted models, the decision tree programs, to an evaluation inside the simulation loop. There is no guarantee that it will actually perform the same way as the reinforcement learning situation-action pairs. When creating the decision tree, original pairs from the reinforcement learning set were omitted: either because they were not tested enough or because they represented nonoptimal choices. Second, learning directly, the abstracted model may be interesting in an interactive development process, where the modeler can input his/her own beliefs. In this sense, we plan to continue investigating the approach with genetic programming (Junges and Klügl Citation2010b), and consider also function approximation techniques for reinforcement learning, in particular using decision trees (Adele et al. Citation1998). Finally, scalability has to be addressed. Real-world problems, or even more complex models, will increase the state-space representation, and the number of situation-action pairs from standard reinforcement learning. This will only make it more difficult to generate an abstracted model. In this sense, we also aim at experimenting with the current reinforcement learning technique, together with the proposed design strategy, in more complex scenarios. Complexity can be increased by: having more agents in the simulation broadening the perception range of the agents to include more perception variables adding more elements to the objective/fitness evaluation and also by including heterogeneous agents that are required to perform different roles and are subject to different objective/fitness functions. Moreover, organizational structures or normative elements, explicit communication, and explicit teamwork could be considered. Therefore, several challenges of practical multiagent systems are not taken into consideration in the current test case.
REFERENCES
- Adami , C. 1998 . Introduction to artificial life . New York , NY , USA : Springer-Verlag, Inc .
- Adele , L. P. , L. D. Pyeatt , A. E. Howe , and A. E. Howe . 1998 . Decision tree function approximation in reinforcement learning. Technical report, In Proceedings of the third international symposium on adaptive systems: evolutionary computation and probabilistic graphical models .
- Bernon , C. , M.-P. Gleizes , S. Peyruqueou , and G. Picard . 2003 . Adelfe: A methodology for adaptive multi-agent systems engineering . In Engineering societies in the agents world III Volume 2577 of Lecture Notes in Computer Science , eds. P. Petta , R. Tolksdorf , and F. Zambonelli , 70 – 81 . Berlin/Heidelberg : Springer .
- Cobo , L. C. , P. Zang , C. L. Isbell , and A. Thomaz . 2011 . Automatic state abstraction from demonstration. In Proceedings of the twenty-second international joint conference on artificial intelligence (IJCAI) .
- Collins , R. J. , and D. R. Jefferson . 1991 . Antfarm: Towards simulated evolution . In Artificial life II , 579 – 601 . Santa Fe , NM : Addison-Wesley .
- Denzinger , J. , and M. Kordt . 2000 . Evolutionary online learning of cooperative behavior with situation-action pairs. In Proceedings of the fourth international conference on multiagent systems, 2000. 103–110 .
- Denzinger , J. , and A. Schur . 2004 . On customizing evolutionary learning of agent behavior . In Advances in artificial intelligence, Vol. 3060 of Lecture notes in computer science , eds. A. Tawfik and S. Goodwin , 146 – 160 . Berlin/Heidelberg , Springer .
- Grefenstette , J. 1987 . The evolution of strategies for multi-agent environments . Adaptive Behavior 1 : 65 – 90 .
- Huysmans , J. , B. Baesens , and J. Vanthienen . 2006 . Using rule extraction to improve the comprehensibility of predictive models. Open access publications from katholieke universiteit leuven, Katholieke Universiteit Leuven .
- Junges , R. , and F. Klügl . 2010a . Evaluation of techniques for a learning-driven modeling methodology in multiagent simulation . In Multiagent system technologies, Vol. 6251 of Lecture notes in computer science , eds. J. Dix and C. Witteveen , 185 – 196 . Berlin/Heidelberg : Springer .
- Junges , R. , and F. Klügl . 2010b . Generating inspiration for multiagent simulation design by q-learning. In MAS&S Workshop at MALLOW 2010, Vol. 627 of CEUR Workshop Proceedings. Lyon, France: CEUR-WS.org .
- Junges , R. , and F. Klügl . 2011a . Evolution for modeling–A genetic programming framework for sesam. In Proceedings of ECoMASS@GECCO 2011. Evolutionary computation and multi-agent systems and simulation (ECoMASS) . New York , NY : ACM .
- Junges , R. , and F. Klügl . 2011b . Modeling agent behavior through online evolutionary and reinforcement learning. In MAS&S workshop at FedCSIS 2011, Szczecin, Poland .
- Klügl , F. 2009 . Agent-based simulation engineering. Habilitation Thesis, University of Würzburg .
- Lee , M. R. , and E.-K. Kang . 2006 . Learning enabled cooperative agent behavior in an evolutionary and competitive environment . Neural Computing & Applications 15 : 124 – 135 .
- Mahadevan , S. , and J. Connell . 1992 . Automatic programming of behavior-based robots using reinforcement learning . Artificial Intelligence 55 ( 2–3 ): 311 – 365 .
- Neruda , R. , S. Slusny , and P. Vidnerova . 2008 . Performance comparison of relational reinforcement learning and rbf neural networks for small mobile robots. In FGCNS '08: Proceedings of the 2008 second international conference on future generation communication and networking symposia, 29–32. Washington, DC, USA: IEEE Computer Society .
- Nowe , A. , K. Verbeeck , and M. Peeters . 2006 . Learning automata as a basis for multi agent reinforcement learning . In Learning and adaption in multi-agent systems, Vol. 3898 of lecture notes in computer science , eds. K. Tuyls , P. Hoen , K. Verbeeck , and S. Sen , 71 – 85 . Berlin : Springer .
- Quinlan , J. R. 1993 . C4.5: Programs for machine learning (morgan kaufmann series in machine learning) () , 1st ed. . San Francisco , CA : Morgan Kaufmann .
- Sutton , R. S. , and A. G. Barto . 1998. Reinforcement learning: An introduction . Cambridge , MA : MIT Press.
- Watkins , C. J. C. H. , and P. Dayan . 1992 . Q-learning . Machine Learning 8 ( 3 ): 279 – 292 .
- Weiß , G. 1996 . Adaptation and learning in multi-agent systems: Some remarks and a bibliography. In IJCAI ‘95: Proceedings of the workshop on adaption and learning in multi-agent systems, 1–21. London, UK: Springer-Verlag .
- Whiteson , S. , and P. Stone . 2006 . Sample-efficient evolutionary function approximation for reinforcement learning. In Proceedings of the twenty-first national conference on artificial intelligence. 518–23 . Boston , MA : AAAI Press .