Abstract
Evolving game agents in a first-person shooter game is important to game developers and players. Choosing a proper set of parameters in a multiplayer game is not a straightforward process because consideration must be given to a large number of parameters, and therefore requires effort and thorough knowledge of the game. Thus, numerous artificial intelligence (AI) techniques are applied in the designing of game characters’ behaviors. This study applied a genetic algorithm to evolve a team in the mode of One Flag CTF in Quake III Arena to behave intelligently. The source code of the team AI is modified, and the progress of the game is represented as a finite state machine. A fitness function is used to evaluate the effect of a team's tactics in certain circumstances during the game. The team as a whole evolves intelligently, and consequently, effective strategies are discovered and applied in various situations. The experimental results have demonstrated that the proposed evolution method is capable of evolving a team's behaviors and optimizing the commands in a shooter game. The evolution strategy enhances the original game AI and assists game designers in tuning the parameters more effectively. In addition, this adaptive capability increases the variety of a game and makes gameplay more interesting and challenging.
INTRODUCTION
In recent years, video gaming has become a popular form of entertainment for all ages because of its interesting content and attractive multimedia aspects. People enjoy the plot of games and interactions with both human and virtual players. In addition, players relish being challenged by opponents whose responses vary unpredictably to the players’ actions.
Game designers realize that having game agents behave intelligently in a game is one of the key features to attract players. Thus, creating game characters that behave in a more humanlike manner and act unpredictably is important (Doherty and O'Riordan Citation2007). The main defect of most current games is that an agent may not be able to determine that a mistake has occurred. Games are no longer interesting if players are able to keep defeating them. In order to solve this problem, many game designers have focused on the improvement of artificial intelligence (AI) in game agents such that the best strategy will be adopted based on the situation in a game. An intelligent game agent is capable of thinking like a human, learning from experience, and choosing a proper strategy in various circumstances (Bourg and Seeman Citation2004; Fairclough et al. Citation2001; Nareyek Citation2004; Revello Citation2002). Thus, some AI techniques are applied to obtain an optimal solution in a complex gaming environment.
Various technical reports explored applying fuzzified automatons in the design of agent behavior (Alexander Citation2002a; Dybsand Citation2001; McCuskey Citation2000; Zarozinski Citation2001, Citation2002). Some game agents’ behaviors are designed based on the statistical data of players’ reactions in certain circumstances (Laramee Citation2002; Alexander Citation2002b; Mommersteeg Citation2002). Thus, a player's potential actions can be predicted and the corresponding counterstrategy applied. Some researchers use offline or online learning to discover effective tactics that can be utilized to beat static opponent strategies (Ponsen et al. Citation2007; Smith, Lee-Urban, and Mu˜noz-Avila Citation2007). The capability of these algorithms is limited because each individual bot behavior is fixed.
Particle swarm optimization (PSO) is an optimization approach widely used to solve continuous nonlinear functions (El-Abd and Kamel Citation2008). It is applied to evolve agents in games such as tic-tac-toe, checkers, and others (Messerschmidt and Engelbrecht Citation2004; Engelbrecht Citation2005, Citation2006; Duro and de Oliveira Citation2008; Tsai et al. Citation2011). PSO has the advantage of being able to converge fast; however, a local optimum is likely acquired instead of obtaining a global optimum.
In 1975, Holland introduced the genetic algorithm (GA), which is an evolutionary algorithm that imitates natural evolutionary processes such as inheritance, selection, crossover, mutation, and so forth, to search for solutions to optimization problems. Since then, genetic evolutionary computations, including genetic algorithms, and genetic programming, have been applied to solve nonlinear problems such as optimization, automatic programming, machine learning, economics, and so on (Sipper et al. Citation2007).
A good playing strategy is necessary in order to enjoy and win a first-person shooter (FPS) game. However, there are usually numerous parameters to be considered. Choosing a proper set of parameters in an FPS game is not a straightforward process. Changing a parameter to improve one aspect of an agent may be a drawback to other aspects of the agent. It usually takes time to obtain an acceptable set of parameters from a series of tests, which requires a great deal of effort from a game programmer. Cole et al. (Citation2004) used a GA to tune a set of parameters in Counter Strike: a bot's weapon preference, initial aggressiveness, path preference, and style of gameplay. Counter Strike, with parameterized rule-based AI, is a popular FPS game in which players can choose from a number of character models. According to their method, game programmers have to determine a range of values for each parameter. Bots tuned by this method can play as well as bots tuned by a human with good knowledge about the game.
Louis and Miles (Citation2005) applied a case-injected GA (CIGAR), which combines GAs with case-based reasoning, to learn to play a computer strategy game. GA does not guarantee to find an optimal solution to the current problem, and CIGAR improves the GA's performance by adding individuals who perform well into the population of the current game periodically. It solves the resource allocation problems in a real-time strategy game by using a parallel GA running on a ten-node cluster.
Genetic programming (GP; Koza Citation1992) is considered a subclass of GAs (Sipper et al. Citation2007). Instead of optimizing parameters, computer programs are optimized. GP often uses tree-based data structures to represent computer programs for adaption. It is flexible and allows programmers to develop more diverse solutions than those provided by GAs (Doherty and O'Riordan Citation2009).
Sipper et al. (2007) applied GP to find winning strategies for three games: backgammon, chess, and robocode. In these games, evolved game characters often win against human competitors. Doherty and O'Riordan (Citation2007, Citation2009) examined GP as a technique to automatically develop effective squad behaviors for shooter games. In the experiments, a team of five agents sharing perception among them play against an enemy agent. The team begins with the weakest weapon, whereas the enemy has five times the health of a team agent, and begins the game with the most powerful weapon. The teams that are evolved with perceptual communication perform better than evolved teams without perceptual communication.
Instead of dealing with perceptual communication among team members, in this study GA is used to evolve a team and focuses on improving the team's tactic in an FPS game, Quake III Arena. The source code of the team AI is modified, and the progress of the game is represented as a finite state machine (FSM). A fitness function is used to evaluate the effect of a team's tactics in certain situations during the game. The team evolves as a whole, and consequently, effective strategies are discovered and applied in various states.
In the One-Flag Capture the Flag (CTF) mode of Quake III Arena, we evolved a team and proceeded to compete against computer-controlled teams controlled by the original Team AI of the game. The evolved team adopts a strategy appropriate for the current situation in a game in order to obtain the team's best performance. The experimental results show that a team evolved according to the proposed method is superior to the computer-controlled teams. They also demonstrate that the performance of the evolved team is satisfactory and very stable.
QUAKE III ARENA–A FIRST-PERSON SHOOTER GAME
Quake is an FPS computer and video game that was released by id Software in 1996. It attracts players through its gorgeous scenes and exciting fighting modes with various NPC characters. The game includes a single-player mode and a multiplayer mode. In the single-player mode, a player encounters various monsters in mysterious arenas. In the multiplayer mode, players face opponents who can be other people on the network or the Internet. The most popular multiplayer mode is deathmatch, which includes free-for-all, one-on-one duels, or teamplay. The AI in the game is simple, as in earlier games. The second title in the Quake series is Quake II, which introduces many new weapons and enemies. The graphic engine is more advanced, and bots appear more intelligent than those in previous games. In 1999, the company released Quake III Arena, which focuses on multiplayer action. In order to increase the diversity of the game, the Quake III source code was released in 2005 for modification.
Quake III Arena
In Quake III Arena, a bot moves around to eliminate opponents and score points based on the objective of the game mode, which includes deathmatch, team deathmatch, capture the flag (CTF), and tournament. A series of maps consisting of combat against different characters is available in the game. The game ends when the time limit has been reached, or a player or team reaches a specified score.
In the mode of One-Flag CTF, one team must grab the flag, which is located in the center of an arena at the beginning of a game, before the other team and bring it to the enemy's base to score points. The team who has possession of the flag has to protect it from being robbed and also has to invade the enemy's base in order to score. Figure illustrates some in-game screenshots of Quake III Arena.
FIGURE 1 In-game screenshots of Quake III Arena. (Color figure available online.)

Victory in a One-Flag CTF game relies upon a team's tactics. The team leader, which is the Quakebot AI, should be able to deliberate and issue correct commands to its members based on different circumstances. In order to score points, various strategies may be applied according to the situation of the flag. The team leader is a commander and its followers are told to assault the enemy, seize the flag, defend the base, or lurk and strike the opponent, depending on the circumstances of a game. The role of a leader is critical and its strategic decision is the key to winning a game. There are many commands a leader may issue to its members. To simplify the problem, only critical commands, such as “attack,” “defend,” “camp,” “patrol,” “retrieve,” and “escort” are taken into account. Flexible strategies and mutual support are important in this type of game.
An agent who receives an “attack” command will attack its enemies and rob the white flag from the opposing team. The command “defend” is issued to an agent to return to its base to prevent the invasion of its enemies. A bot who receives a “camp” command will lurk and attack the enemy. The command “patrol” will instruct a bot to patrol an area, and to attack any enemy present there. The command “retrieve” is used to order agents to retrieve the flag from their enemy. An agent who receives an “escort” command will accompany and protect the team member who holds the flag. “Retrieve” and “escort” commands are never issued in the same circumstance; thus these two commands are taken as one in this research.
Behavior Control
Quake III is a rule-based system, and the perceptual system of its characters is similar to a human's perception. Its characters see and hear only objects located within a limited range without obstruction. The behaviors of an agent are composed of a few basic actions; for example, attacking an enemy consists of retreating, advancing, and shooting. The basic architecture of the bots’ AI in Quake III and the interface with the gene-evolution system, which is based on the proposed GA approach, are depicted in Figure . The interface dynamic link library (DLL) collects all the perceptual information and then transmits it to the Quakebot AI system through the socket I/O, as shown in Figure (a). Quakebot AI determines the most suitable response action on QuakeRule, which describes the rules of the game, and, via the socket I/O, sends it back to the interface DLL to present an action.
FIGURE 2 (a) The basic architecture of the bots’ AI in Quake III and (b) the interface with the gene-evolution system.
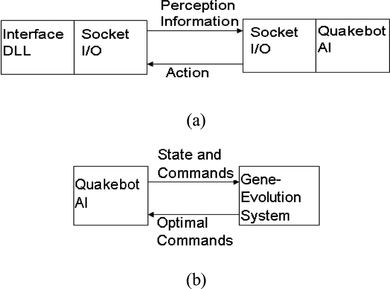
According to the progress of the game and a team's past commands obtained from Quakebot AI, the gene-evolution system, based on the proposed strategy, is able to evolve and obtain optimal commands for its team, as illustrated in Figure (b). The new set of commands is then transferred back to the Quakebot AI and the interface DLL through the socket I/O to change the team's behavior.
TEAM'S GA EVOLUTION METHOD
This research applies a GA-evolution method to evolve a team's behaviors in a multiplayer shooter game. The team evolved according to the proposed approach in Quake III Arena, henceforth called the Evolution team, is capable of evolving and using an effective tactic to win in the mode of One-Flag CTF. The Evolution team is directed by the GA-evolution system shown in Figure . In a multiplayer game, a single agent's capability is not as important; instead, success relies upon a team's tactics and the cooperation of all individuals. A set of suitable commands for a team's members in a circumstance may not fit at another. Thus, it is important to discover proper commands for various situations within a game.
Finite State Machine Representation
In a multiplayer shooter game, the changes are complicated and unpredictable because they are affected by multiple factors. To simplify the problem, the complex state transitions can be represented as a finite state machine.
The game starts with a flag at the center of the arena, which each team tries to acquire and bring to the opponent's base to score. A team without the flag will try to rob its opponent's flag as well as to take appropriate action to prevent the opponent team from scoring. Conversely, the team with the flag must secure the flag from being attacked and stolen. A round ends when a team scores, and a match may consist of a specified number of rounds or a set period of time. Although the gaming environment is complex, according to the situation of the flag in the game, it can be simplified as a finite state machine consisting of five states: Flag at the center (s 0), Flag captured by the Evolution team (s 1), Flag captured by the opponent (s 2), Flag dropped (s 3) and Scored (s 4), as shown in Figure . Each state switches to other states from different transitions. A game begins with the initial state, Flag at the center (s 0). It will change to the next state, Flag captured by the Evolution team (s 1), if the flag is retrieved by the Evolution team. It may also switch to a different state, Flag captured by the opponent (s 2), if the flag is retrieved by the opponent team. The state of Flag captured by the Evolution team (s 1) will change to the state of Flag dropped (s 3) if the team's flag retriever is killed, or it will transfer to the state of Scored (s 4) if the flag retriever touches down the flag on the enemy's base. Similarly, the state will change from Flag captured by the opponent (s 2) to Flag dropped (s 3) if the opponent's flag retriever is killed, or it may switch to Scored (s 4) if the flag retriever touches the flag on the base of the Evolution team. The next state of Flag dropped could be Flag captured by the Evolution team (s 1) or Flag captured by the opponent (s 2) if the Evolution team or the opponent takes the flag.
FIGURE 3 The state diagram is based on the situation of the flag in the game.
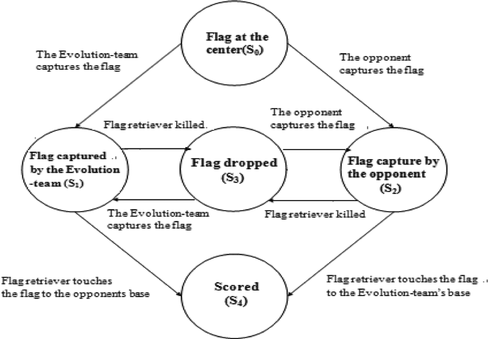
A game starts with the state of Flag at the center (s 0), and through various transitions (l), it reaches several transit states. It finally terminates in the state of Scored (s 4) when one team scores. A team wins the game if it has either scored more points than the opposing team in a certain period of time or has reached a determined score.
State Transitions and Weights
If a state transition is beneficial, then the less transition time a team takes toward scoring is better because more points can be won in a given period of time. Conversely, if a state transition is disadvantageous, then the more transition time a team takes, the less harmful it is for the team, because there are fewer points lost in a limited period. Thus, various state transitions are given different weights based on whether the change is beneficial or disadvantageous, as depicted in Table . The most critical beneficial transition is the change from Flag captured by the Evolution team (s 1) to Scored (s 4), and thus it has the highest weight. The least weight is for the change from Flag at the center (s 0) to Flag captured by the Evolution team (s 1) because it occurs at the beginning of the game. Conversely, the most disadvantageous transition is the change from Flag captured by the opponent (s 2) to Scored (s 4). The least disadvantageous transition is from Flag at the center (s 0) to Flag captured by the opponent (s 2). All the transition weights are shown in Table .
TABLE 1 State Transitions and Weights α l
The performance of a team is assessed based on the total number of flags captured over a period of time. Thus, if the transition in a game is desirable, the faster the movement to a better state, the greater the chance to win; in a disadvantageous circumstance, the longer the time the opponent is allowed to move to a worse state, the lesser the threat. The following fitness function F i is used to evaluate Evolution team i in a game.
Evolution in the Game
GA is applied to search for an optimal solution to win in Quake III Arena. The best team evolves from inheritance, selection, crossover, and mutation after generations. Initially, randomly selected individuals, which are possible solutions to the best strategy in a game, are created. Their performance is evaluated based on a preset fitness function after a generation. Teams with high fitness values can breed their offspring. The evolution process is repeated until an optimal solution is found or a preset maximum number of generations is reached. Thus, a variety of optimized strategies for different situations can be discovered.
To simplify the complex situations present within a game, the status of the game is represented as one of five states, according to the state diagram shown in Figure . The strategy of a team is the commands for their members during each state. Each team member may receive one of six commands, including “attack,” “camp,” “defend,” “patrol,” “retrieve,” and “escort” in each state except the state of “scored.” The command “retrieve” can be issued to an agent only when its team does not have the flag. Conversely, the command “escort” is given in the circumstances of the team holding the flag. Thus, “retrieve” and “escort” are recognized as the same command.
The commands “attack,” “camp ” “defend ” “patrol,” and “retrieve” for a team's members in all states are encoded as A, C, D, P, and R, respectively, in a character string. The tactics of a team include the commands for all its members in all states except the state of Scored. Thus, the gene of a team with m members is represented as an m × 4 characters string. The chromosome for team member j in team i in state S in generation k is, where j ∈ {1, 2, …, m}, S ∈ {s
0, s
1, s
2, s
3} = {Flag at the center, Flag captured by the Evolutionteam, Flag captured by the opponent, Flag dropped}, and
. Thus, the chromosomes, which are the commands used in a game, for team i in generation k are encoded as
In order to obtain an optimal strategy in the wide search space, the proposed method first generates n teams, in which chromosomes are given randomly. Each team then takes turns playing against a computer-controlled team, which is controlled by the Quake III AI. The performance of all teams is then evaluated according to Equation (Equation1). The chromosomes of u best-performing teams are stored in a gene pool. The chromosomes of v new teams are generated by selecting these chromosomes from the pool randomly, and proceeding to a crossover operation. A mutation is completed by changing t of the chromosomes generated from the crossover in each team. The v worst-performing teams in the generation are replaced by the new offspring teams. Thus, the teams of the next generation are bred by inheriting the best-performing teams’ chromosomes, as well as their crossover and mutation. The advantage of the mutation is to prevent premature convergence while maintaining the majority of good solutions in the searching space.
The details of the proposed method are described as follows.
| 1. | Randomly generate n teams, which are represented as | ||||||||||||||||
| 2. | Let each team take turns playing against an unevolved computer-controlled team. At the end of a match, record the results, strategies, and all state transition timet l . Evaluate the fitness value F i according to Equation (Equation1). | ||||||||||||||||
| 3. | Select the genes of the u best-performing teams ( | ||||||||||||||||
| 4. | For q = 1 to v,
| ||||||||||||||||
| 5. | k = k + 1. If the fitness value is convergent or k is greater than the predefined maximum generations, terminate and find the gene of the best Evolution team, otherwise go to Step 2. | ||||||||||||||||
EXPERIMENTAL RESULTS
The proposed strategy was examined in the mode of One-Flag CTF in Quake III Arena. The Quake III source code version is 1.32 and the presented gene-evolution system was coded in Visual Basic. In order to evaluate the performance of the proposed method, mpteam1, with the Central Plaza at the center of the map, was chosen because the map is identical on both sides. The arena is suitable for hiding and fighting, and is fair on both sides because of its symmetry. There are no traps in the map to prevent the execution of agent commands.
In the experiments, the population size is set at five, and each team includes five members. Initially, the strategies of the Evolution teams at each state are randomly selected. The performance of a team is assessed based on the fitness value obtained from Equation (Equation1). As is shown in Table , various state transitions are given different weights, based on how much the change is beneficial or harmful to the Evolution team. The most important beneficial transition is the change from Flag captured by the Evolution team to Scored. Conversely, the most disadvantageous change is from Flag captured by the opponent team to Scored.
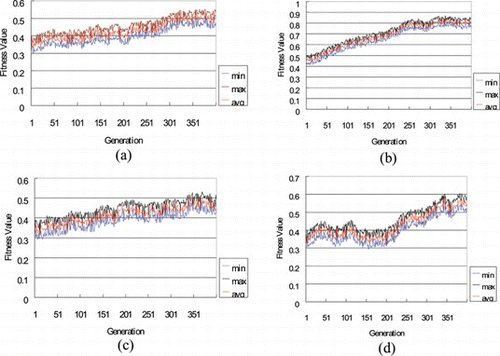
In the evolution phase, the match time is set as 30 minutes, which allows each Evolution team to play in turn against a computer-controlled team for 400 generations at the most. The probability of crossover and mutation are 0.4 and 0.1, respectively. The fitness values versus generations for various states in the evolution are illustrated in Figure . As is demonstrated in the figure, fitness values increase with the number of generations gradually in all states.
FIGURE 4 Fitness values vs. generation in the state of (a) flag at center; (b) flag captured by the evolution team; (c) flag captured by the opponent; (d) flag dropped. (Color figure available online.)
In order to evaluate the effects of evolvement, we first matched an unevolved team against a computer-controlled team for 20, 30, and 40 rounds. The results, shown in Figures (a), 6(a), and 7(a), demonstrate that the score of the unevolved team is compatible to that of the computer-controlled team. Next, the computer-controlled team is matched against the Evolution team; the two teams have the same number of agents and the same weapon settings. The results for the 20-match, 30-match, and 40-match games are indicated in Figures (b), 6(b), and 7(b). Compared to Figures (a), 6(a), and 7(a), the Evolution team clearly shows a satisfactory performance compared to the unevolved team. Comparisons of the results are also shown in Table , which suggests that the Evolution team has a better percentage of wins and a higher scoring percentage.
FIGURE 5 The scored points in 20 matches for (a) an unevolved team and a computer-controlled team, (b) a GA-evolution team and a computer-controlled team. (Color figure available online.)
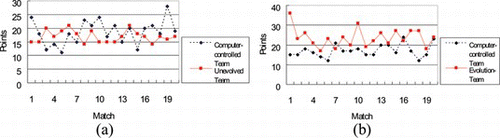
FIGURE 6 The scored points in 30 matches for (a) an unevolved team and a computer-controlled team, (b) a GA-evolution team and a computer-controlled team. (Color figure available online.)
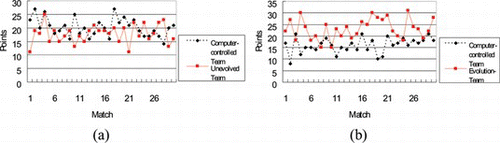
FIGURE 7 The scored points in 40 matches for (a) an unevolved team and a computer-controlled team, (b) a GA-evolution team and a computer-controlled team. (Color figure available online.)
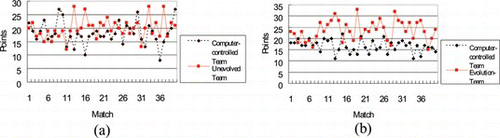
TABLE 2 Analysis of an Unevolved Team Playing Against a Computer-Controlled Team, and a Gene-Evolution Team Playing Against a Computer-Controlled Team
CONCLUSIONS
Training game agents in a multiplayer game is important to game developers and players. This study applied a GA to evolve a team in the mode of One Flag CTF in Quake III Arena to behave intelligently. The proposed approach is able to evolve a team's behavior and discover the appropriate strategy that will allow the team to win in a complex FPS gaming environment with a wide search space.
The proposed approach uses a finite-state machine to simplify the progress of a game, and evaluates the effect of tactics teams used in certain situations. The experimental results have demonstrated that the proposed evolution method is capable of evolving a team and optimizing the commands in a multiplayer shooter game. In terms of the percentage of wins and scoring percentage, the performance of evolved teams is better than that of unevolved teams. To reduce the search space, only six commands were used in this paper; performance is likely to be even better if more commands are considered. The evolution strategy enhances the original game AI and helps game designers to more effectively tune parameters.
REFERENCES
- Alexander , T. 2002a . An optimized fuzzy logic architecture for decision-making . In AI game programming wisdom , ed. S. Rabin , 367 – 374 . Hingham , MA : Charles River Media .
- Alexander , T. 2002b . GoCap: Game observation capture . In AI game programming wisdom , ed. S. Rabin , 579 – 585 . Hingham , MA : Charles River Media .
- Bourg , D. M. , and G. Seeman . 2004 . AI for game developers . Sebastopol , CA : O'Reilly Media, Inc .
- Cole , N. , S. J. Louis , and C. Miles . 2004 . Using a genetic algorithm to tune first-person shooter bots. In Proceedings of the IEEE congress on evolutionary computation, CEC ‘04: 1:139–145. San Diego, CA, June 19–23.
- Doherty , D. , and C. O'Riordan . 2007 . Evolving team behaviours in environments of varying difficulty. In Proceedings of the 18th Irish artificial intelligence and cognitive science conference, ed. S. J. Delany and M. Madden, 61–70. Dublin, Ireland.
- Doherty , D. , and C. O'Riordan . 2009 . Effects of shared perception on the evolution of squad behaviors . IEEE Transactions on Computational Intelligence and AI in Games 1 ( 1 ): 50 – 62 .
- Duro , J. A. , and J. V. de Oliveira . 2008 . Particle swarm optimization applied to the chess game. In Proceedings of the IEEE congress on evolutionary computation, 3702–3709. Hong Kong, China.
- Dybsand , E. 2001 . A generic fuzzy state machine in C++ . In Game programming gems 2 , DeLoura, M.A. ed., 337 – 341 . Hingham , MA : Charles River Media .
- El-Abd , M. , and M. S. Kamel . 2008 . A taxonomy of cooperative particle swarm optimizers . International Journal of Computational Intelligence Research 4 ( 2 ): 137 – 144 . Available at http://www.ripublication.com/ijcirv4/ijcirv4n2_7.pdf
- Engelbrecht , A. P. 2005 . Particle swarm optimization for learning game strategies. Available at http://cswww.essex.ac.uk/cig/2005/tutorials/pso.pdf
- Engelbrecht , A. P. 2006 . Fundamentals of computational swarm intelligence , 345 – 351 . Hoboken , NJ : Wiley .
- Fairclough , C. , M. Fagan , B. Mac Namee , and P. Cunningham . 2001 . Research directions for AI in computer games. In Proceedings of the twelfth Irish conference on artificial intelligence and cognitive science. Dublin, Ireland.
- Koza , J. R. 1992 . Genetic programming: On the programming of computers by means of natural selection . Cambridge , MA : MIT Press .
- Laramee , F. D. 2002 . Using n-gram statistical models to predict player behavior . In AI game programming wisdom , ed. S. Rabin , 596 – 601 . Hingham , MA : Charles River Media .
- Louis , S. J. and C. Miles . 2005 . Playing to learn: Case-injected genetic algorithms for learning to play computer games . IEEE Transactions on Evolutionary Computation 9 ( 6 ): 669 – 681 .
- McCuskey , M. 2000 . Fuzzy logic for video games . In Game programming gems , DeLoura, M.A. ed., 319 – 329 . Hingham , MA : Charles River Media .
- Messerschmidt , L. , and A. P. Engelbrecht . 2004 . Learning to play games using a PSO-based competitive learning approach . IEEE Transactions on Evolutionary Computation 8 ( 3 ): 280 – 288 .
- Mommersteeg , F. 2002 . Pattern recognition with sequential prediction . In AI game programming wisdom , ed. S. Rabin , 586 – 595 . Hingham , MA : Charles River Media .
- Nareyek , A. 2004 . AI in computer games . Game Development 1 ( 10 ): 58 – 65 .
- Ponsen , M. , P. Spronck , H. Mu˜noz-Avila , and D. W. Aha . 2007 . Knowledge acquisition for adaptive game AI . Science of Computer Programming 67 : 59 – 75 .
- Revello , T. E. 2002 . Generating war game strategies using a genetic algorithm. In Proceedings of IEEE evolutionary computation ‘02, 1086–1091. Honolulu, HI .
- Sipper , M. , Y. Azaria , A. Hauptman , and Y. Shichel . 2007 . Designing an evolutionary strategizing machine for game playing and beyond . IEEE Transactions on Systems, Man, and Cybernetics – Part C: Applications and Reviews 37 ( 4 ): 583 – 593 .
- Smith , M. , S. Lee-Urban , and H. Mu˜noz-Avila . 2007 . RETALIATE: Learning winning policies in first-person shooter games. Available at American Association for Artificial Intelligence http://www.aaai.org
- Tsai , C. T. , C. Liaw , H. C. Huang , and C. H. Ko . 2011 . An evolutionary strategy for a computer team game . Computational Intelligence 27 ( 2 ): 218 – 234 .
- Zarozinski , M. 2001 . Imploding combinatorial explosion in a fuzzy system . In Game programming gems 2 , DeLoura, M.A. ed., 342 – 350 . Hingham , MA : Charles River Media .
- Zarozinski , M. 2002 . An open source fuzzy logic library . In AI game programming wisdom , ed. S. Rabin , 90 – 101 . Hingham , MA : Charles River Media .