Abstract
Multicriteria recommender systems typically gather the user preferences by asking a user to rate different aspects of an item on a sliding scale explicitly. However, this approach could possibly cause intrusiveness and conflict on user preferences. For example, an individual's preference on each aspect of an item may conflict with an overall preference. To overcome such limitations, we proposed the hybrid profiling framework to generate a set of useful implicit dataset to support multicriteria recommender systems. We also proposed two hybrid multicriteria recommendation approaches, namely the user-attribute-based (UAB) and the user-item matching (UIM) to improve recommendation accuracy. Finally, we conducted experiments to confirm the efficiency of the proposed approaches. The experiments show that the profiling framework and two hybrid recommendation approaches can alleviate the problem in an intrusive manner and decrease the degree of preference conflict without decreasing the accuracy of the recommendation. They also show that our proposed hybrid multicriteria recommendation approaches can significantly outperform both the traditional collaborative filtering and the simple multicriteria filtering approaches.
INTRODUCTION
Recommender systems have been developing over the last decade and have performed well in several applications, including those for recommending books, CDs, and news articles (Marlin Citation2003; Rosset et al. Citation2002), and some of these methods are used in the “industrial-strength” recommender systems, such as those deployed at Amazon (Linden, Smith, and York Citation2003) and MovieLens (Miller et al. Citation2003). Traditional recommender systems can be extended in a wide variety of ways. Utilizing multicriteria ratings is one of the ways that recommender systems are provided with a deeper understanding of users and items and also for final quality-improvement recommendations. However, the development and implementation of a multicriteria rating approach still have certain limitations.
Typically, multicriteria recommender systems gather multiple preference information of users explicitly by asking them to rate on several aspects of items. Many recommender systems require explicit feedback from the user and often at a significant level of user involvement. The extra information provided by multicriteria ratings can give rise to an important issue of intrusiveness. (Konston et al. Citation1997; Oard and Kim Citation1998; Middleton et al. Citation2004; Adomavicius and Kwon Citation2007). Users may be unwilling to provide various feedback if it requires a great deal of effort and extra time (Jung Citation2001; Kellar et al. Citation2004). In addition, users usually assign arbitrary ratings that do not reflect their honest opinions on the item (Lee and Park Citation2008; Palanivel and Sivakumar Citation2010). This situation causes some conflicts between overall and individual attribute ratings. Consequently, it has become a crucial obstacle in leveraging multicriteria information in recommender systems. If the users’ preferences are not completely obtained and well understood, the recommendation accuracy may be decreased, particularly in the systems that rely on ratings of other users as traditional collaborative filtering systems.
In this article, we proposed the hybrid profiling framework, which provides an implicit dataset to support multicriteria recommendation systems. We also proposed two hybrid multicriteria recommendation approaches, namely user-attribute-based (UAB) and user-item matching (UIM) to improve recommendation accuracy. The UAB approach incorporates knowledge regarding the global criteria of a user into user–user similarity calculation and then applies traditional user-based collaborative filtering to predict overall rating of an item. The UIM method is used to predict overall rating by matching the global criteria of the user with the strength level of aspects of an item to be recommended. The contribution of this work is how to reuse the data collected by the existing recommender system and extend the capability of the traditional single-criteria to a multicriteria system with less effort and time.
The remainder of the article is organized as follows. The next section reviews a number of basic principles and algorithms of recommender systems and related work. The section titled “Hybrid Profiling Framework” demonstrates the detailed operations of a hybrid profiling framework and proposes a variety of techniques for performing hybrid recommendations, respectively. The experimental setting and evaluation of our work and the results discussion are presented in the following section. The final section presents a conclusion and discusses some perspectives and ideas for future work.
BACKGROUND KNOWLEDGE
There are a number of theories concerning recommender systems, but this study discusses only a subset of them. The specific theories discussed have been chosen because they appear to be most applicable to the analysis and design of recommender systems.
Recommender Systems and Recommendation Approaches
Recommender systems have been shown to help users find items of interest from among a large pool of potentially interesting items. The general purpose of recommender systems is to predict how a particular user rates an item that he or she has not seen before. The process of recommender systems is mainly classified into two phases: prediction and recommendation (Burke Citation2002). In the prediction phase, the user's preference on the unknown item is typically estimated based on ratings of known items and possibly other input data (user profiles and/or item profiles). In the recommendation phase, such evaluated user's preferences obtained from the previous phase are utilized to support a user's decision-making by generating a recommendation list or a set of Top-N items (i.e., N items with highest-predicted rating) that maximize his/her preferences.
Recommender systems are typically classified into two fundamental approaches. First, content-based (CB)—the list of items is recommended to individual users based on the items that they have consumed in the past. Second, collaborative filtering (CF)—the list of items is recommended to individual users based on a similar user's preferences (Balabanovic and Shoham Citation1997). Apart from the mentioned two fundamental recommendation approaches, other approaches are also classified in the work done by Alexander (2005), Pazzani (Citation1999), and Burke (Citation2000). The demographic-based approach proposed by Pazzani can be viewed as a subcategory of CF because recommendations are generated based on the experience and the opinions of other users. However, the demographic-based approach considers only a user's demographic data rather than incorporating a user's rating behavior. The knowledge-based approach recommends items based on inferences about a user's needs and his/her preferences. It can be viewed as a subcategory of CB recommendations. It requires content description of items and well-structured profiles of users for recommending items to other users.
In fact, all discussed recommendation approaches have their strengths and weaknesses. Many researchers have developed the hybrid recommendation systems in order to capitalize on their respective strengths and thereby achieve good performance. There are various methods to design a hybrid approach. These methods are surveyed in literature (Burke Citation2002, Citation2007).
Similarity Calculation and Prediction for Recommender Systems
Similarity computation plays an important role in all recommender systems. There are many methods for calculating similarity between objects, between a user and another user or between an item and another item. The most popular methods are the Pearson Correlation Coefficient and the Cosine Vector Similarity. Suppose that in a movie recommender system we have five users and six movies. Let U = {u 1 , u 2 , …, u 5 } be a set of users and I = {i 1 , i 2 , …, i 6 } be a set of items. The similarity between a user x and y, sim(x, y) can be computed by using the Pearson Correlation Coefficient as in Equation (Equation1) (Shardanand and Maes Citation1995; Resnick et al. Citation1994) or by using the Cosine Vector Similarity as in Equation (Equation2) (Adomavicius, Manouselis, and Kwon Citation2011; Manouselis and Costopoulou Citation2007):
For item–item similarity between item i and j, sim(i, j), the Pearson Correlation Coefficient in Equation (Equation1) and the Cosine Vector Similarity in Equation (Equation2) are slightly changed as in Equation (Equation3) and Equation (Equation4).
Once similarities are obtained, they can be used as the weights of a user's ratings in predicting calculation. There are various methods to predict the rating of yet unknown items for a user, but the most popular and widely used is the weighted sum and the adjusted weighted sum as shown in Equation (Equation5) and Equation (Equation6), respectively:
Single-Criteria and Multicriteria Recommender Systems
Most recommender systems represented user's preference on a particular item by the overall rating of the item. This overall rating indicates how much the user prefers the item in total. Therefore, it can be considered as a single criterion of a user when making his or her decision on the item. Generally, ratings are represented by a numerical score limited to a certain range. The systems that utilize only overall rating information to represent the utility of an item and predict it for the user can be considered as single-criteria recommender systems.
Utilizing only the overall rating for prediction has been considered limited (Adomavicius and Tuzhilin Citation2005; Adomavicius and Kwon, Citation2007), because the utility of items for a particular user generally depends on several aspects of each item. The preferences of a user on several item's aspects are considered as multicriteria information, which the user takes into consideration whether the item is relevant or not. Because multicriteria information can affect the user's opinions, incorporating them in recommender systems may lead to more accurate recommendations (Lee, Liu, and Lu Citation2002; Adomavicius, Manouselis, and Kwon Citation2011). However, taking advantage of multicriteria information necessitates sophisticated techniques. The recommender system that leverages multicriteria information to represent complex preferences of users and support its recommendations can be considered a multicriteria recommender system.
Although there has been much work done on multicriteria recommendation, the traditional problem of multicriteria recommendation is not intended for an environment of personalized recommendation. It is used to find the items that are optimal in general (i.e., not optimal for an individual user). Currently, the multicriteria recommendation is considered to be one of the important issues for the next generation of recommender systems (Adomavicius and Tuzhilin Citation2005). A personalizing travel recommender system is developed by using the case-based reasoning technique, ranking and aggregating elementary items (locations, activities, services) based on the user's preferences and a repository of past travels (Ricci and Werthner Citation2002). This system, however, does not consider each elementary item as a multicriteria, it just performs optimization over a multidimensional solution space. Despite that, there are several projects that make a comparison of the items based on each attribute's weights ranking (Lee, Liu, and Lu Citation2002); the weight of each attribute is directly obtained from the individual user. The value of ranking for each attribute is the same for all users. The meta-recommender system (Schafer, Konstan, and Riedl Citation2001) allows users to specify their preference for each content attribute (e.g., movie genre, Motion Picture Association of America (MPAA) rating, or film length) and allows them to set an important condition for the recommender by rating the importance of these attributes to filter the recommendations toward what the users really want. This system, however, does not represent a multicriteria rating environment because the users specify only general filtering requirements for all movies, such as the preferred value and weights for the movie genre attribute. Research by Adomavicius and Tuzhilin (Citation2005) proposed to incorporate and leverage multicriteria ratings information in calculation of the similarity between two different objects within the same class, in other words, user–user similarity or item–item similarity. Two simple techniques are introduced. The first technique uses an aggregating similarity method. In this, the similarity between two users or two items is calculated based on each individual criterion by using some standard similarity metric such as cosine based and correlation based. Then, the overall similarity can be computed by aggregating the individual similarities in several ways such as averaging all individual similarities and the worst-case similarity. Another approach uses a multidimensional distance metrics method in which each rating can be represented as a point in the k + 1 dimension space, and distance between ratings or points is calculated by using standard multidimensional distance metrics, such as Manhattan distance, Euclidean distance, and so on. Finally, the distance metrics then are further transformed to similarity metrics and aggregated to overall similarity.
Obviously, in the environment of multicriteria recommender systems, users can specify their subjective ratings for various attributes components of an individual item. Although this information can be used for prediction and personalization purposes, the intrusiveness problem may occur during data gathering. Recently, some researchers (Palanivel and Sivakumar Citation2010) have suggested combining the multicriteria user-preference ratings with implicit relevance feedback to eliminate the intrusiveness problem and to improve the accuracy in recommendations. This work focuses on how to generate new user profiles, not how to generate new item profiles implicitly. Such work can only support multicriteria recommendation with a CF approach. Our work focuses on generating both new user and new item profiles to support multicriteria recommendations in terms of a hybrid approach to improve recommendation accuracy.
HYBRID PROFILING FRAMEWORK
Although the explicit preferences of users in traditional user profiles are usually provided for collaborative filtering, the attributes content of items in item profiles are provided for a CB recommendation approach. Typically, both data sources can be used to support implementation of single-criteria recommender systems. In this section, we describe how those data sources can be reused to support a multicriteria recommender system and improve recommendation accuracy throughout our proposed hybrid profiling framework and hybrid recommendation approaches.
The Figure shows the hybrid profiling framework and several data models, consisting of six matrices. The former two are called the user-item ratings (UIR) and the item-attribute binary values (IAB) matrices. The UIR contains an explicit preferences profile of users, and the IAB contains the attributes content profile of items in a given domain. Both matrices provide the initial data sources to construct various implicit data matrices in the hybrid profiling framework. In this article, we assume that data in UIR and IAB are already collected by the traditional recommender system. They can be used by traditional single-criteria CF approaches. The third matrix is called the user-item-attribute binary values and ratings (UIABR), which originated from the combination of data in the UIR and data in the IAB matrices. Data in the UIABR provide a data source to construct three other matrices, including the new user profiles, called the user-attribute weights (UAW), the user-item-attribute weights (UIAW), and the new item profiles called the item-attribute weights (IAW). These three data matrices provide implicit data as knowledge about users and items to support multicriteria recommendations. Such a hybrid profiling framework can be done in four steps as follows.
FIGURE 1 A hybrid profiling framework. (Color figure available online.)
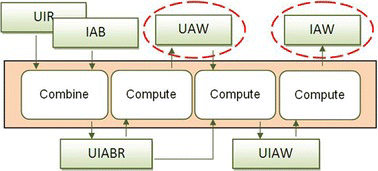
Step 1: Combine users’ preferences and items’ characteristics | |||||
Step 2: Compute global criteria weights of users (generate new user profiles) | |||||
Step 3: Compute users’ opinions on attributes of items | |||||
Step 4: Compute the strength of attributes of the items (generate new item profiles) | |||||
Step 1: Combine Users’ Preferences and Items’ Characteristics
In this step, we combine the traditional UIR and the IAB based on their common attributes. This combination then generates the UIABR data matrix.
Assume that in the context of the movie recommendation system, we have five users, U = {u1, u2, u3, u4, u5}, and six movie items, I = {m1, m2, m3, m4, m5, m6}. A user can express his or her preference feedbacks as an overall rating in numerical scales for each movie they have seen. All users’ feedbacks are stored in and represented as the UIR matrix, as shown in Table . Each row in the UIR contains the description of an individual user in terms of the movie rating patterns that the user has rated. Note that the Ø notation denotes an unrated item that has not been seen by the user. Although the data in UIR describes the rating behavior of users, the data in IAB describes items in terms of attributes associated with items. Assume that there are five potential genre attributes, A = {action, adventure, drama, horror, sci-fi, war}. In this movie recommendation context, each movie is described by a set of genres, because, in reality, each movie may consist of differences in numbers and types of genres. Therefore, we can consider each type of genre as an individual attribute of the movie. For example, movie m6 has two genres: adventure and drama. Typically, genre information is represented by a binary value as shown in Table . The 1 value denotes that the genre appeared in the content of the movie, and the 0 value is otherwise, because the UIR and the IAB are common in the movie identifier. Thus, we can combine these two matrices to get the UIABR table as shown in Table .
TABLE 1 Example Data of the Traditional User Profiles, User-Item Ratings (UIR)
TABLE 2 Example Data in Item-Attribute Binary Values (IAB)
TABLE 3 Example Data in the User-Item-Attribute Binary and Ratings (UIABR)
Step 2: Compute Global Criteria Weights of User
In this step, we analyze data in the UIABR to characterize the global criteria weights of a user based on genres of movies that the user has rated. The global criteria weights of a user are defined as general preferences of the user on genres for watching in the movie domain because, in general, many users usually repeatedly access items associated with attributes they prefer. Therefore, we can identify a user's degree of interest in attributes based on the number of times (frequencies) that the user has accessed those attributes. For example, let's consider the UIABR matrix, as shown in Table : the profile of user u2 shows that user u2 has interacted with three movies (m2, m4, and m6). The most frequently accessed genre by user u2 is the drama. From this observation, we can imply that user u2 reacted more positively to the drama genre than other genres in the movies domain.
In summary, global criteria weights of a user can be quantified in two steps. First, count the number of times that each type of genre appeared in the user's profile, and then normalize each number with maximum value of them as in Equation (Equation8):
For example, the global criteria weight of user u2 can be computed as follows:
Table shows the newly generated users’ profiles, which are represented by the UAW matrix. The data in each row are global criteria weights that express the general preferences of each user watching in the movie domain. For example, user u2 can be represented by the global criteria weight vector (g u2) as (0.333, 0.667, 1, 0, 0, 0.333). Then we can conclude that the type of genre that user u2 prefers is drama.
TABLE 4 Example Data in the User-Attribute Weights (UAW)
Step 3: Compute Users’ Opinions on Attributes of Items
In this step, we analyze data in the UAW and UIABR matrices to infer the opinions of a user on each genre attribute of a specific movie that the user has rated. In order to obtain rating opinions of a user on each genre attribute of a given movie, first we copy the UIABR to the new matrix. Then, for each user, we replace each (binary) value of the genre associated to items that the user has rated with the corresponding global criteria weight of the user. This process is achieved by multiplying each binary value, b i,a , of an item i with a corresponding global criteria weight, g x,a of a user x to extract only the genre attribute associated to a given item. Then, we transform each (global weights) replaced value of a user x to a specific weight, s x,i,a , on the genre attribute a of the item i, by dividing it with the maximum value of the replaced values of that item by Equation (Equation10), where A i is a set of attributes associated with the item i.
At this point, we can estimate how a particular user likes attributes of the movie by multiplying a specific weight of each attribute with the overall rating that the user rated to the item as the total preference by Equation (Equation11):
For example, the content of movie m6 is described by the two genres drama and adventure; we temporally replace the binary values of the movie m6 with the corresponding global weights of user u2 as stored in UAW. After that we transform these global weights to specific weights of the user on attributes of the movie and estimate the rating opinion of user u2 on each genre of movie m6 by using Equation (Equation11) as follows.
However, to make this information independent from any rating scale, we convert all rating opinions of the user that are in range 1–5 into weight opinions in range 0–1. This process can be done by two steps. First: transform an overall rating into an overall weight by dividing the overall rating with the maximum value of the rating scale—the possible highest rating that is used in a particular domain—as in Equation (Equation12). Second: multiplying each specific weight on attribute of the item, s x,i,a, , with the overall weight using Equation (Equation13):
For example, assume that the 1–5 rating scale is used in the movie recommender system. The weight opinion on an individual attribute of item m6 can be computed as:
Table shows the result data about the users’ weight opinions on attributes of items in range 0–1.
TABLE 5 Example Data in User-Item-Attribute Weights (UIAW)
Step 4: Compute the Strength of Attributes of the Items
Measuring the strength of each genre of movie as an interval scale is very challenging, because its value, in general, is subjective. There have been no instruments with which to measure. In the final step of the hybrid profiling, we quantify each genre (binary value) of a movie to each strength value based on the users’ opinions. The simplest way to achieve this process is to aggregate users’ opinion values of the movie's attribute as in Equation (Equation14). When this aggregation is applied to the whole data in table UIAW, the IAW table can be generated as shown in Table .
TABLE 6 Example Data in the Item-Attribute Weights (IAW)
Similarity Calculation on Dataset Generated From Hybrid Profiles Framework
Even though various similarities between entities in recommender systems can be computed by using a standard method, such as the Pearson correlation and cosine similarity, we found that the cosine method cannot work well when applied to the last three matrices generated in our proposed hybrid profiling framework. It is probably because some (object) row in the tables may be represented by the small size of a vector. There is much possibility that comparing two vectors that have a few elements using the cosine method will give the wrong result. For example, assume that we need to compare two entities, x and y, which are represented by two vectors as (3,3) and (3,3). With the cosine similarity method we get the similarity as 1. This is correct, but when we change values in these two vectors to (3,3) and (2,2), or (5,5) and (1,1), we get the same result, 1, as well.
Although the Pearson Correlation Coefficient can work well, it requires more effort when computing and using its results, because the result can be either a negative or a positive number. Therefore, to provide less effort in demonstrating performance of our proposed recommendation approaches based on generated data, we decided to apply the Tanimoto correlation method for all various similarity calculations. This method changes slightly based on what entities will be compared (i.e., Equation (Equation15) for user–user similarity or Equation (Equation16) for user–item similarity).
User-Attribute-Based (UAB)
In the traditional CF approach, similar tastes between two users are considered based on the shared items that both users have rated. Obviously, in the movie recommendation domain, the number of items that users can rate is larger than the number of users. It results in the sparsity problem. The system cannot compute the similarity between an active user and other users if an active user rated the items that no other user has rated or rated the item that only a few users have rated. Therefore, the system cannot recommend any items to the active user. To reduce this problem, We represent each user with his/her global criteria weights vector, which has a more compact and lower dimension than the vector of overall rating of items. To compute similarity between an active user and other users, we apply the Tanimoto similarity algorithm as shown in Equation (Equation16). Then we apply the average of adjusted weighted sum in the same way as traditional user-based CF to predict the overall rating that the user would assign to the items.
User-Item Matching (UIM)
Traditional CB filtering recommends an item that has content similar to those that an active user liked in the past. This approach requires extremely rich and complete descriptions of items. Typically, it has succeeded in the domain where content of items to be recommended are in the form of textual information that can be parsed automatically by the system, such as books and web pages. However, it is not suitable for the system in which an item is characterized by a few attributes and in the domain where the content of items being recommended is in nontextual format, such as music and movie or video. For the movie recommender system, in our case, the limitation of nontextual format of genre is not a limitation any longer because the item is described by the numerical score, instead of textual. We observed that the new user profile and the new item profile can be presented as the same structure. We can represent each user in the form of a global criteria weights vector, whereas we represent each item with a vector of strength value or weight of genres. Therefore, an active user and a particular item can be matched directly in order to compute the overall rating of the item for the user. That is what we call the user-item matching (UIM) approach. To achieve this approach, we slightly change and apply the Tanimoto correlation as shown in Equation (Equation16) to identify similarity between users x and items i, sim (x, i), and then compute a rating prediction of the item for the user using the adjusted weight formula, as shown in Equation (Equation17):
EXPERIMENTAL AND EVALUATION SETTING
In this research, we carried out experiments using the MovieLens dataset (Miller et al. Citation2003), provided by the GroupLens Research Project at the University of Minnesota. It contains 100,000 ratings, given by 943 users on 1682 movies. Each user has rated at least 20 movies. The ratings are integers between 0 and 5. In order to be more reliable for experimental results, the 5-fold cross-validation method is applied. The entire dataset is randomly divided into two disjoint subsets, 80% for training, and 20% for testing. The randomly dividing process is performed repeatedly five times to get five different pairs of 80% training and 20% testing dataset. The 80% training dataset then can be presented as the UIR matrix. At this point, we already have the first two matrices (i.e., the UIR matrix and the IAB values matrix. The data of these two matrices provide the initial data source that can be reused to generate other new data matrices by applying our proposed hybrid profiling framework. On completing the hybrid profiling processes, the two proposed hybrid recommendation techniques are implemented. Their performances are then compared to the traditional single-criteria user-based CF technique, as well as some multicriteria techniques, which are implemented by using the aggregation approach (Adomavicius and Tuzhilin Citation2005).
There are numerous evaluation techniques to evaluate the performance of recommendation algorithms. These include statistical or computational accuracy and decision-support or classification-accuracy metrics. The statistical accuracy measures, such as mean absolute error (MAE) and root-mean-square error (RMSE), are usually used to evaluate how well a recommendation algorithm is able to predict ratings of target users on given target items. Whereas the classification-accuracy metrics, such as the precision, recall, and F-measure, are generally used to evaluate how well a recommendation algorithm is able to correctly recommend or classify the items to users based on the user's interest. The precision is defined as the ratio of the number of relevant items to the number of selected items to recommend. The recall is defined as the ratio between the number of relevant selected items and the total number of relevant items. Precision and recall are inversely related. Also, the recall and the number of recommendations generated by the recommendation algorithm are related to each other. When the number of recommendations increases, they will also increase the probability of recall but decrease the probability of precision. The F-measure summarized both precision and recall in terms of harmonic means according to the relation between the precision and recall. In the evaluation phase, we used the MAE method to evaluate the effectiveness of our proposed techniques in term of prediction accuracy and used the precision to evaluate the recommendation classification accuracy. For the accuracy prediction evaluation, the MAE is applied to the raw predicted values, real-number range from 1–5. The lower MAE means better accuracy. For the recommendation classification accuracy, precision is applied to the two transformed values, relevant and nonrelevant. Because ratings in the MovieLens dataset are in the range from 1–5, we defined thresholds 3 and 4 for dividing these ratings into two categories, relevant and nonrelevant. If the predicted value is greater or equal to the threshold, this value is considered to be relevant, otherwise it is nonrelevant. The higher precision is the better precision, similarly in the case of recall and F-measure, the higher value is better than the lower value. However, in this work we are interested only in the precision.
Experimental Results and Discussion
To evaluate our two proposed recommendation approaches, we implemented both traditional single-user-based and item-based CF, referred to as the single-user-based CF (SUBCF) and the single-item-based CF (SIBCF), respectively. We also implemented multicriteria user-based and item-based by incorporating multicriteria data for similarity calculation using the attribute aggregating approach, referred to as the multi-attribute aggregation for user-based CF (MAUBCF) and the multi-attribute for item-based CF (MAIBCF), respectively. Our two proposed hybrid multicriteria recommendation approaches are the UAB and the UIM.
First, we consider the former five approaches, SUBCF, SIBCF, MAUBCF, MAIBCF, and UAB, through statistical accuracy MAE, focusing on value prediction on various neighbor sizes. The neighbor size, in the case of user-based CF is the number of users who have similar tastes with an active user. In the case of item-based CF, it means the number of items that have been rated by the set of similar users. We exclude the UIM from this evaluation because this approach predicts rating on an item for a given user by directly matching them to certain user and item characteristics. It does not need the neighbor size in the prediction process.
The line graph in Figure indicates that three multicriteria recommendation approaches, including MAUBCF, MAIBCF, and UAB outperform the two traditional single-criteria CF approaches, SUBCF and SIBCF. The UAB gives the best result when compare with others at various neighbor sizes ranging from 10–100. The performance of each approach is closer to the other when the neighbor size is increased. For all possible neighbor sizes, we found that the average MAE of each approach is almost the same. The MAIBCF approach gives slightly better results compared to the SIBCF, as shown in Table . From this experiment, we found that the performances of the UAB are quite more stable than other approaches, especially when the value of neighbor sizes are between 20 and 100. From this evidence we can summarize that the UAB approach is less affected by the neighbor sizes than other approaches.
FIGURE 2 The MAE of the SUBCF, MAUBCF, SIBCF, MAIBCF, and UAB. (Color figure available online.)
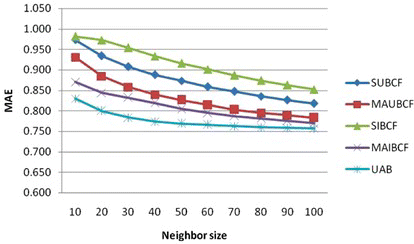
TABLE 7 Averages of MAE Evaluated from Whole Possible Neighbor
For evaluation of classification accuracy, the two different thresholds 3 and 4 are used for classification purposes, which classify recommendation items as relevant and nonrelevant items. If the prediction value is less than the defined threshold value, it is classified into the nonrelevant item and vice versa. We considered the neighbor size of 10 and the top most relevant N items (N = 1, 3, 5 and 7) for evaluating all five approaches because it is to the nature of real recommendation application. The results from SUBCF were used as a baseline in comparison with other approaches.
Table shows that the implicit dataset generated from our purposed hybrid profiling framework is useful to implement multicriteria recommendations. The results from the multicriteria recommendations approach are better than the results from the traditional single-criteria approaches in all cases. The scores of the MAIBCF show the best precision in the case of Top-1 and Top-3 for threshold 3 and also in the case of Top-1, 3, 5 and 7 for threshold 4, indicated by boldface. However, the results of the UAB give the precision value over the baseline at all levels, which are indicated by italic-boldface. The single-criteria item-based CF yields the worst results at all levels. Table shows the rate of improvement in the precision. The MAIBCF gives the best performance in classification accuracy followed by the UAB and MAUBCF.
TABLE 8 The Precision Scores in the Case of Top-1, 3, 5 and 7 at the Point of 10 Neighbor Sizes with Thresholds 3 and 4
TABLE 9 The Percentage of Precision Improvement from the Baseline of All Multicriteria Approaches
We also evaluate all five based on the neighbor size of 1. The precision scores are shown in Table . The results show that the UAB approach gives the best result, whereas the results of other approaches are lower than the baseline for all cases. The percentages of precision improvement were shown in Table .
TABLE 10 The Precision Scores in the Case of Top-1, 3, 5 and 7 at the Point of 1 Neighbor Sizes with Thresholds 3 and 4
TABLE 11 The Percentage of Precision Improvement from the Baseline of the UAB Approach
The UIM approach predicts and generates recommendations by directly comparing the user against each item. Therefore, we can compare it with the UAB based on neighbor size of 1. Table shows that the UAB approach gives the best result. However, in the case of Top-1, the UIM approach gives better precision results as shown in Table . The percentages of precision improvement are shown in Table .
TABLE 12 The Precision of UAB against UIM Method Based on 1 Neighbor Size with Threshold 3 and 4
TABLE 13 The Percentage of Precision Improvement from the UAB Approach of the UIM Approach
CONCLUSIONS
In the context of a multicriteria recommender system, obtaining a list of users’ preferences based on several aspects of items by explicitly asking users may cause some problems with regard to intrusiveness and conflicting data. In this article, we present the hybrid profiling framework, which combines user preferences and item profiles together to generate a useful implicit dataset and to provide data sources for multicriteria recommendation systems. We also propose two multicriteria recommendation approaches: the user-attribute-based (UAB) and the user-item matching (UIM) to take full advantage of those implicit data. The experimental results and performance evaluation show that the implicit data generated by the proposed hybrid profiling framework are useful for implementing multicriteria recommender systems. Moreover, the findings show that the proposed multicriteria recommendation approaches can improve the performance of recommendations as well, especially in the case of the one-neighbor size. The precision of the UAB approach is significantly higher than other CF approaches, whereas the UIM approach gives the best precision when compare with the UAB approach. The contributions of this work are able to extend capability and functionality, and upgrade the traditional single-criteria recommender system to the efficient multicriteria recommender system. Thus, the intrusiveness and data conflict between a user's opinions on several aspects and the overall rating of the item can be reduced by using the implicit dataset. In summary, the experimental results confirm that the proposed hyprid profiling and hybrid recommendations can significantly extend profiling capabilities, functionality, and quality of recommender systems. Also, leveraging implicit multicriteria information can be used to improve the quality of recommendations in real recommendation applications.
REFERENCES
- Adomavicius , G. , and Y. Kwon . 2007 . New recommendation techniques for multicriteria rating systems . IEEE Intelligent Systems 22 ( 3 ): 48 – 55 .
- Adomavicius , G. , N. Manouselis , and Y. Kwon . 2011 . Multi-criteria recommender systems . In Recommender systems handbook , ed. F. Ricci , L. Rokach , B. Shapira and P. B. Kantor , 769 – 803 . Springer
- Adomavicius , G. , and A. Tuzhilin . 2005 . Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions . IEEE Transactions on Knowledge and Data Engineering 17 ( 6 ): 734 – 749 .
- Balabanovic , M. , and Y. Shoham . 1997 . Fab: Content-based, collaborative recommendation. (Special Section: Recommender systems) . Communications of the ACM 66 ( March ): 1 – 7 .
- Burke , R. 2000 . Knowledge-based recommender systems . Encyclopedia of Library and Information Systems 69 ( Supplement 32 ): 175 – 186 .
- Burke , R. 2002 . Hybrid recommender systems: Survey and experiments . User Modeling and User Adapted Interaction 12 ( 4 ): 331 – 370 .
- Burke , R. 2007 . Hybrid recommender systems . In The adaptive web , ed. P. Brusilovsky , A. Kobsa and W. Nejdl , 377 – 408 . Berlin , Heidelberg : Springer .
- Deshpande , M. , and G. Karypis . 2004 . Item-based top-n recommendation algorithms . ACM Transactions on Information Systems 22 ( 1 ): 143 – 177 .
- Herlocker , J. L. , J. A. Konstan , A. Borchers , and J. Riedl . 1999 . An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval, 54:230–237 .
- Jung , K. Modeling web user interest with implicit indicators. Master thesis, Florida Institute of Technology , 2001 .
- Kellar , M. , C. Watters , J. Duffy , and M. Shepherd . 2004 . Effect of task on time spent reading as an implicit measure of interest. In Proceedings of the ASIS AM 04.
- Konstan , J. A. , B. N. Miller , D. Maltz , J. L. Herlocker , L. R. Gordon , and J. Riedl . 1997. GroupLens: Applying collaborative filtering to usenet news. Communications of the ACM 40 (3): 77–87.
- Lee , T. , and Y. Park . 2008 . A time-based approach to effective recommender systems using implicit feedback . Expert Systems with Applications 34 ( 4 ): 3055 – 3062 .
- Lee , W.-P. , C.-H. Liu , and C.-C. Lu . 2002 . Intelligent agent-based systems for personalized recommendations in Internet commerce . Expert Systems with Applications 22 ( 4 ): 275 – 284 .
- Linden , G. , B. Smith , and J. York . 2003 . Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing Jan.–Feb.
- Manouselis , N. , and C. Costopoulou . 2007 . Analysis and classification of multi-criteria recommender systems . World Wide Web Internet and Web Information Systems 10 ( 4 ): 415 – 441 .
- Manouselis , N. 2007 . Experimental analysis of design choices in multiattribute utility collaborative filtering . International Journal of Pattern Recognition and Artificial Intelligence 21 ( 2 ): 311 .
- Middleton , S. E. , N. R. Shadbolt , and D. C. De Roure . 2004 . Ontological user profiling in recommender systems . ACM Transactions on Information Systems 22 ( 1 ): 54 – 88 .
- Miller , B. N. , I. Albert , S. K. Lam , J. A. Konstan , and J. Riedl . 2003 . Movie Lens unplugged: Experiences with an occasionally connected recommender system. In Proceedings of the 8th international conference on intelligent user interfaces, 263–266. ACM.
- Marlin , B. 2003 . Modeling user rating profiles for collaborative filtering. In Proceedings of the 17th annual conference on neural information processing systems (NIPS'03).
- Oard , D. , and J. Kim . ( 1998 ). Implicit feedback for recommender systems. Proceedings of the AAAI workshop on recommender systems, 81–83 .
- O'Donovan , J. , and B. Smyth . 2005 . Trust in recommender systems . Proceedings of the 10th international conference on intelligent user interfaces IUI 05 15 ( June ): 167 .
- Palanivel , K. , and R. Sivakumar . 2010 . A study on implicit feedback in multicriteria e-commerce recommender system . Journal of Electronic Commerce Research 11 ( 2 ): 140 – 156 .
- Pazzani , M. J. 1999 . A framework for collaborative, content-based and demographic filtering . Artificial Intelligence Review 13 ( 5 ): 393 – 408 .
- Recker , M. M. , and A. Walker . 2003 . Supporting “word-of-mouth” social networks through collaborative information filtering . Journal of Interactive Learning Research 14 ( 1 ).
- Resnick , P. , N. Iacovou , M. Suchak , P. Bergstrom , and J. Riedl . 1994 . GroupLens: An open architecture for collaborative filtering of netnews. Proceedings of the 1994 ACM conference on computer supported cooperative work, 175–186.
- Ricci , F. , and H. Werthner . 2002 . Case base querying for travel planning recommendation . Tourism 3 ( 4 ): 215 – 226 .
- Rosset , S. , E. Neumann , U. Eick , N. Vatnik , and Y. Idan . 2002 . Customer lifetime value modeling and its use for customer retention planning. In Proceedings of the 8th ACM SIGKDD international conference on knowledge discovery and data mining (KDD-2002), July.
- Schafer , J. B. , D. Frankowski , J. Herlocker , and S. Sen . 2007 . Collaborative filtering recommender systems . International Journal of Electronic Business 2 ( 1 ): 77 .
- Schafer , J. B. , J. A. Konstan , and J. Riedl . 2001 . E-commerce recommendation applications . Data Mining and Knowledge Discovery 5 ( 1 ): 115 – 153 .
- Schafer , J. B. , J. Konstan , and J. Riedi . 1999 . Recommender systems in e-commerce. Proceedings of the 1st ACM conference on electronic commerce EC 99, 158–166.
- Shardanand , U. , and P. Maes . 1995 . Social information filtering: Algorithms for automating “word of mouth.” In Proceedings of the ACM conference on human factors in computing systems, 1:210–217.
- Takács , G. , I. Pilászy , B. Németh , and D. Tikk . 2008 . Matrix factorization and neighbor based algorithms for the netflix prize problem. In Proceedings of the 2008 ACM conference on recommender systems RecSys 08: 267.