Abstract
This article addresses business news analysis by using artificial intelligence. An interdisciplinary method combining financial textual data mining and ontology-based reasoning is proposed and evaluated. The experiments are performed using a well-known Cyc ontology and textual material from the financial domain. Our experiments show that using semantic technologies for business news analysis helps to provide the user with more relevant answers to his/her queries.
INTRODUCTION
Business news analysis is an important part of many businesses strategies. We propose, using artificial intelligence, to support the user in business news analysis tasks. In particular, this study explores the process of business news analysis by the ontology population with entities, facts, and events extracted from news text and reasoning based on the obtained ontology. The motivation for the performed work comes from the idea that business news aggregate enormous amount of interesting business, financial, organizational, and personal information, which can be discovered, combined, and used in reasoning and question answering by some reasoning tool-kits.
Gruber (1993) defined ontology as an explicit specification of a conceptualization. According to Gruber (Citation1993), ontologies consist of the following main components: concepts, relations, functions, axioms, and instances. Ontologies allow performing different tasks such as web page annotation and information retrieval (Heflin and Hendler Citation2000), question answering (Bradesko et al. 2010; Curtis, Matthews, and Baxter Citation2005), and word sense disambiguation (Curtis, Cabral, and Baxter Citation2006). Moreover, ontologies are used for domain knowledge representation, knowledge re-use, and knowledge sharing (Chandrasekaran, Josephson, and Benjamins Citation1999).
Because ontologies are dynamic by their nature, while populating the ontologies with new instances, it is necessary every time to identify their equivalent instances already present in the ontology. It is also important to find the correct location and context for the instances we insert into the ontology.
In this article, we present a pipeline for business news analysis, which utilizes an entity, event, and fact extraction service such as OpenCalais (OpenCalais 2011) and OntoPlus (Novalija, Mladenić, and Bradeško 2011) methodology, which facilitates time-consuming and expensive manual population of a large ontology, such as the Cyc Knowledge Base (Cyc KB; Cycorp 2011) and exploits Cyc for reasoning and question answering.
The pipeline for business news analysis relies on semantic technology, which proved to be useful for textual data analysis. For instance, in question answering based on textual sources (Bradesko et al. 2010) such as the news articles from the financial domain, using semantic information enables providing better answers, especially if the semantic information matches the content of the articles. Using ontologies allows to search not only within the terms occurring in the query, but also within their semantically related concepts. Given the query “Which companies issued shares in the last month?” the ontology-based system that performs a search on the financial articles would provide the user with an answer including the companies that performed IPO, bonus share issuance, etc. Therefore, the available ontology information about IPO as a subclass of IssuingASecurity leads to more efficient textual data analysis.
The Cyc KB is a common-sense ontology, which has been in development for more than 20 years (more than 900 human years of effort) and is used as a knowledge source in the Cyc Artificial Intelligence system. It aggregates already more than 15,000 predicates, 300,000 concepts and 3,500,000 assertions (Cycorp 2011). However, the annotation experiments in the financial domain, conducted on a randomly selected subset of business news, have shown that the representation of the financial knowledge in Cyc can be improved (Novalija and Mladenic Citation2008).
Manual building of large ontologies, such as the Cyc KB, demands a substantial amount of human effort, which is the reason that all domains are not covered yet in all details. Further extension or population of such a large ontology is challenging as well because of its complexity and interconnectivity. In our research in the process of ontology population, we have used OntoPlus (Novalija, Mladenić, and Bradeško 2011) methodology, which facilitates knowledge intensive, time-consuming, and expensive manual development of a large ontology such as the Cyc KB. OntoPlus methodology for text-driven semiautomatic ontology extension uses ontology content, ontology structure information, and co-occurrence data between existing and candidate ontology concepts. The OntoPlus methodology describes how business and financial subdomains can be obtained from the Cyc KB using a financial glossary and a set of user-defined keywords.
Ontology content of a particular concept is defined as the available textual representation of the referred concept. The ontology content includes a natural language concept denotation (lexical entries for a particular concept) and textual comments about the concept. Ontology structure of a particular concept is defined as the neighborhood concepts involved in the hierarchical and nonhierarchical relations with the referred concept.
For instance, an example Cyc concept CommonStock has the associated content “Share; Ordinary share; The collection of Stock whose instances represent owners (stockholders) who have only a residual claim on an Organization's assets after all debts and claims generated by PreferredStocks have been met…” and the associated structure “Equities; shares; stocks; issues; class B stocks; class A stocks…,” etc.
Co-occurrence information is represented by the occurrence of two or more concepts within a defined textual block. The available textual information is used to find the co-occurrences between existing ontology concepts and new domain concepts suggested for ontology extension.
OntoPlus methodology defines ontology extension as a process of adding new concepts to the existing ontology or, augmentation of the existing textual representation of the relevant concepts present in the ontology with new available textual information—extension of the concept comments, changing or adding concept denotation. By ontology population we consider adding new instances of concept (e.g., LehmanBrothers as Business, MingchunSun as Person) or relation instances (e.g., positionOfPersonInOrganization MingchunSun LehmanBrothers Economist) into the ontology.
One more aspect of the suggested pipeline for news analysis is the usage of ontological reasoning for question answering. The reasoning systems operate based on the logically formulated knowledge. As Panton and colleagues (Citation2006) state, in order to mimic human reasoning, Cyc uses background knowledge regarding science, society and culture, climate and weather, money and financial systems, health care, history, politics, and many other domains of human experience. What is obvious or natural for a human mind should be “explained ” to the machine using formalized knowledge representation and logical rules.
For example, a word palm is a sequence of characters assumingly carrying the same meaning regardless its context unless we explicitly provide additional information to a computer:
The coconut palm is typically found along sandy shorelines → (PALM is a plant. | |||||
The doctor was holding pills on his palm → (PALM is part of hand. | |||||
Cyc's representation language is known as CycL. It is essentially an augmented version of first-order predicate calculus (FOPC). Using CycL, it is possible to correctly encode the above statements so that the machine explicitly understands them and uses them for question answering. The knowledge base in Cyc is divided into various microtheories (Mt) (Contexts in Cyc 2011), which contain a set of facts valid in a particular context. Cyc microtheories are used to represent thematic subsets of the ontology. Cyc contains a number of business and finance related microtheories, such as FinancialTransactionMt, BusinessGMt, BusinessMoneyMt, AccountingMt, ProductGMt, and others.
These microtheories define and describe money, general (capitalist) business practices, accounting concepts and principles, the major business-related organizations and activities, formal products, and so forth. In addition, a number of business and financial concepts are defined in UniversalVocabularyMt—the microtheory that contains the “definitional” assertions about everything in Cyc's universe of discourse.
Because of the efficiency of usage and business domain coverage, we have selected OpenCalais (OpenCalais 2011) fact extraction service for our news analysis problem. OpenCalais is a Thomson-Reuters free Web service, which recognizes named entities and obtains relationships and events from text. OpenCalais uses a set of natural language processing approaches and machine learning techniques for named entity and fact extraction. OpenCalais supports a rich set of semantic metadata, including entities (39 types of entities), events, and facts (76 different events and facts; OpenCalais – English Semantic Metadata 2011). The examples of OpenCalais entities include Company, Person, Country, Product, ProgrammingLanguage, and so forth. Typical OpenCalais events and facts are CompanyFounded, CompanyLocation, Merger, Arrest, MovieRelease and others. In addition, OpenCalais also provides GenericRelation type, which basically contains a triple subject-predicate-object.
The main hypothesis in this research is that the entity, event, and fact extraction from business news, ontology population with extracted formalized business knowledge, and use of the obtained populated ontology for reasoning and question answering provide the user with a possibility to automatically analyze textual financial and business information, to detect important information, and to save temporal and personal efforts.
For the experiments we have used a collection of the financial news from the Yahoo! Finance website (Yahoo! Finance 2011). We have crawled 3400 news stories, extracted entities, facts, and events with OpenCalais service and applied OntoPlus methodology to map the extracted knowledge into the Cyc KB. Following that, we have selected a number of questions and asked them using the Cyc reasoning interface.
This article is structured as follows: “Related Work” presents the overview of existing approaches to news analysis and ontology population; problem definition is given in “Problem Definition (Hypothesis)”; the pipeline for business news analysis is discussed in “System Pipeline”; “Evaluation” describes the experiments and results; “Conclusion” is the final section.
RELATED WORK
Automatic News Analysis
The analysis of news sources represents an important research challenge of our times. News not only reflects the different processes happening in the world, but also influences the economic, political, and social situation. Moreover, news sources contain a large amount of information, which can be compiled and analyzed through reasoning and question answering.
The study of business news is interdisciplinary, combining both artificial intelligence techniques and financial data analysis.
The discoveries and developments in the 21st century artificial intelligence (AI) have changed the ambitions of scientists in different research areas. As Duong (Citation2008) stated in an article about the industrial application of AI and its effect on foreign direct investment in the Third World, “AI has transformed our way of thinking and solving problems, has changed consumer behaviors, and has improved quality of life”. AI became the motivational force in the “New Economy” or “Knowledge Economy.” Duong suggested that higher forms of AI would be able to increase the productivity of the economy.
The information technology community have developed and implemented a number of systems, applying various AI approaches for economic purposes and business news analysis. The information technology artifacts for business and financial tasks include, for instance, such tools as ATRANS (Lytinen and Gershman Citation1986). Developed in 1986, ATRANS was created to operate in the domain of international banking telexes. This historically important system automatically extracted the information required to complete the transfer (the various banks mentioned in the telex, their roles in the money transfer, payment amounts, dates, security keys, etc.) and formatted it for entry into the bank's automated transaction processing system. For text analysis, the ATRANS developers utilized case frame analysis and conceptual dependency formalism.
The AI techniques, methods, and tools constitute a central part of our research. The use of the Cyc ontology and the Cyc reasoning interface allows us to effectively analyze queries based on the data obtained from the news.
Recently, a number of systems dealing with news analysis have been developed (Andersen et al. Citation1992; Losch and Nikitina Citation2009; Iacobelli, Birnbaum, and Hammond Citation2010). JASPER (Andersen et al. Citation1992) is a fact extraction system developed and deployed by the Carnegie Group for Reuters Ltd., which uses a template-driven approach, partial understanding techniques, and heuristic procedures to extract certain key pieces of information from text. JASPER combines frame-based knowledge representation with object-oriented processing, pattern matching, and heuristics, which allows it to efficiently and quickly analyze textual sources.
The newsEvents Ontology developed by Losch and Nikitina (Citation2009) allows modeling of business events, the affected entities and relations between them. Losch and Nikitina (Citation2009) use a pattern-based approach with a defined and specified EventRole pattern for ontology design.
Iacobelli, Birnbaum, and Hammond (2010) have presented a system called Tell Me More, which mines the Web for news stories based on the seed news story and selects snippets of text from those stories, which offer new information beyond the seed story. The obtained new content is classified as supplying additional quotes, additional actors, additional figures, and additional information depending on the criteria used to select it.
Knowledge Extraction
Several interesting approaches, which can be applied to news analysis, deal with data mining and knowledge extraction from the Web. In Chang and colleagues (Citation2006) the authors compare the existing Web data extraction approaches.
Carlson and colleagues (2010) implemented a system for coupled semisupervised learning for information extraction. A number of categories (e.g., academic fields, athletes) and relations (e.g., PlaysSport(athlete, sport)) are extracted from web pages, starting with a handful of labeled training examples of each category or relation, plus hundreds of millions of unlabeled web documents. Carlson and coauthors (Citation2010) state that much greater accuracy can be achieved by further constraining the learning task, by coupling the semisupervised training of many extractors for different categories and relations.
Ghani and colleagues (2000) demonstrated the possibility of discovering interesting regularities about companies by extracting and then mining information on the Web. Etzioni and colleagues (Citation2008) presented an Open Information Extraction from the Web wherein the identities of the relations to be extracted are unknown and the billions of documents found on the Web necessitate highly scalable processing.
Ontology Extension and Population
The automatic and semiautomatic ontology extension and population processes usually include a number of typical ontology development steps, such as definition of relevant information sources, preprocessing of the input material, ontology augmentation according to the chosen methodology, ontology evaluation, and ontology revision.
According to Reinberger and Spyns (Citation2005), the majority of methods for ontology learning from text contain collecting, selecting, and preprocessing of an appropriate corpus; discovering sets of equivalent words and expressions; establishing concepts with the help of the domain experts; discovering sets of semantic relations and extending the sets of equivalent words and expressions; validating the relations and extended concept definition with help of the domain experts; and creating a formal representation. As Grobelnik and Mladenic (Citation2006) state, ontology learning from text is closely connected to domain understanding, data understanding; and task definition and is followed by ontology evaluation and ontology refinement.
Ontology development can be performed by the means of natural language processing (Burkhardt et al. Citation2008; Sabrina, Rosni, and Enyakong Citation2001). The Web is considered a source of text suitable for ontology extension in Agirre and coauthors (Citation2000), where the English lexical ontology WordNet (2011) is extended based on clustering word senses.
SOFIE (Suchanek, Sozio, and Weikum Citation2009) is a system for automated ontology extension, which can parse natural language documents, extract ontological facts from them, and link the facts into ontology. SOFIE uses logical reasoning on the existing knowledge and on the new knowledge in order to disambiguate words to their most probable meaning, to reason on the meaning of text patterns, and to take into account world knowledge axioms.
Other ontology extension and population methods, which use lexico-syntactic patterns for ontology learning, include Text2Onto (Cimiano and Völker Citation2005) and SPRAT (Maynard, Funk, and Peters Citation2009).
An interesting system for topic ontology construction was suggested by Fortuna, Grobelnik, and Mladenić (Citation2007). OntoGen (Fortuna, Grobelnik, and Mladenić Citation2007) uses the vector-space model for document representation and operates based on a cosine similarity between textual documents. Machine learning and text mining techniques are combined with user-friendly interface.
Several methods of automatic ontology development operate with the enlarging of the Cyc KB. As was stated by Lenat (Citation1995), “one can think of Cyc as an expert system with a domain that spans all everyday objects and actions”. The automated population of Cyc with named entities involves the Web and a framework for validating candidate facts (Shah et al. Citation2006). The semiautomatic approach for Cyc KB development by Witbrock and colleagues (Citation2003) presents the user-interactive dialogue system for knowledge acquisition, in which the user is engaged in a natural-language mixed-initiative dialogue. Medelyan and Legg (Citation2008) proposed the methodology, which operates with Cyc and Wikipedia, in which the concepts from Cyc are mapped onto Wikipedia articles describing correspondent concepts. Sarjant and colleagues (Citation2009) base their method of Cyc augmentation, using pattern matching and link analysis, on the approach by Medelyan and Legg (Citation2008).
Taylor et al. (2007) have conducted a research on Cyc microtheories. In their work, they considered the problem of how to automatically determine where to place new knowledge into an existing ontology.
An appealing approach of extending and using Cyc for answering clinical researchers’ ad hoc queries is described in (Lenat et al. Citation2010). Even long and complex queries are parsed into CycL fragments, which often can be united only in a single way after applying various constraints. The semantic research assistant (SRA) performs a set of database calls and then combines their results into answers to a specified query.
Question Answering
Because part of our research includes utilization of large common-sense ontologies for reasoning and question answering, in this subsection we present a number of different question answering systems. The discussed question answering systems are mainly based on large knowledge bases or ontologies (Tunstall-Pedoe Citation2010; Grunning et al. Citation2010; Bradeško et al. Citation2010).
Soderland and colleagues (2010) conducted research on the adaptation of the Open information extraction to domain-specific relations. The key ideas of this approach include domain specific class recognition with minimum manual effort, learning rules for relation extraction based on limited training data, and active learning over learned rules to increase precision and recall. In Tunstall-Pedoe (Citation2010) a system called True Knowledge is described. True Knowledge is a commercial, open-domain question-answering platform. True Knowledge aggregates a large knowledge base of common sense, factual and lexical knowledge, natural language translation system, and inference system. An interesting approach was taken by the IBM team (Ferrucci et al. Citation2010), which created a system to play in the quiz show Jeopardy. In order to develop Watson (Ferrucci et al. Citation2010), researchers used a number of machine learning techniques and developed DeepQA architecture. DeepQA is a massively parallel probabilistic evidence-based architecture. The overarching principles in DeepQA are massive parallelism, many experts, pervasive confidence estimation, and integration of shallow and deep knowledge. The Halo project (Grunning et al. Citation2010) was updated to include design and evaluation of a tool called AURA, which enables domain experts in physics, chemistry, and biology to author a knowledge base and then allows a different set of users to ask novel questions against that knowledge base.
Bradeško and coauthors (2010) have presented a system that enables contextualized question answering and provides document overview functionalities. Based on ontologies and domain-specific document collections, the system is able to obtain a high number of relevant answers. The system employs AnswerArt (Dali et al. Citation2009) technology for question answering and Cyc ontology for providing semantic context to the document collection from a particular domain of interest.
In order to contextualize question answering, Bradeško and colleagues (Citation2010) have selected ASFA abstracts for a document collection and extended Cyc (2011) by using WordNet (2011) and ASFA ontology (2010). The approach consists of the data preparation phase, where the relevant part of Cyc ontology is extracted and extended with other relevant general or domain-specific ontologies. In particular, each part of the triplet was extended by a set of synonyms and direct generalizations were obtained from the ontology.
In general, the technology allows missing any single or any two elements from the triple. It is also possible to have all three defined and the question actually checks whether the question is true— or more accurately— if such a claim is found in the document repository.
The technology provided by Bradeško and colleagues (Citation2010) successfully illustrates how the extended ontology can contribute to question answering. Interestingly enough, in our research, the same resources (such as Cyc ontology) are used in different types of question answering.
Related Work Comparison
If we compare our techniques to the existing methods of news analysis, we can notice that similarly to Losch and Nikitina (Citation2009), we utilize semantic information from the ontology. As in Iacobelli, Birnbaum, and Hammond (Citation2010), we extract facts from a set of news stories. However, our approach for news analysis is further semantically driven, because we also use ontology to reason based on the facts obtained from business news and common-sense facts existing in the ontology.
As in Soderland and colleagues (Citation2010), we populate ontology with new information. Analogically to Lenat and colleagues (Citation2010) and Tunstall-Pedoe (Citation2010), we use large common-sense ontology for reasoning and for question answering. We use news as a primary source of data as other approaches (Andersen et al. Citation1992; Losch and Nikitina Citation2009; Iacobelli, Birnbaum, and Hammond Citation2010) do.
As in Bradeško and coauthors (Citation2010), we use Cyc ontology in our experiments. However, our question-answering experiments are based on the population of Cyc ontology and reasoning in consideration of the extended and populated ontology. In their question answering experiments Bradeško and colleagues (Citation2010) use only synonymic and hierarchically related terms; however, Cyc has an implemented reasoning system, which goes far beyond “hierarchical” and “synonymic” question answering.
The work by Suchanek, Sozio, and Weikum (Citation2009) resembles our approach of ontology extension applied to Cyc ontology augmentation. Cyc extension as well involves interaction with logical constraints from the knowledge base.
However, the pipeline of news analysis presented in this article constitutes a whole strategy of business news analysis and question answering based on the ontology reasoning and information from the news. In our research, we combine different tools—fact extraction system and common-sense knowledge base with inference system, which allows us to automatically extract facts from textual sources, populate the ontology, and reason based on the populated ontology.
PROBLEM DEFINITION (HYPOTHESIS)
As stated in the Introduction, in this research we aim to show that the entity, event, and fact extraction from business news, followed by ontology population with the extracted formalized business knowledge and use of the obtained populated ontology for reasoning and question answering, supports the user in business information analysis. The ontology population with facts obtained from business news helps to provide the user with more relevant answers to his/her queries.
In this section, we describe the formal background for the proposed problem. In order to formalize the ontology population in more details, we adapt the Maedche and Staab (Citation2001) ontology definition.
L represents lexical entries for concepts, instances, and relations; | |||||
C is a set of concepts; | |||||
H c is a taxonomy of concepts; | |||||
R is a set of nontaxonomic relations; | |||||
H r is a set of taxonomic relations; | |||||
I is a set of instances; | |||||
F, G , and K are the relations connecting concepts, relations, and instances with lexical entries from L ; | |||||
A is a set of relation axioms. | |||||
Following the ontology definition and the problem of ontology extension described in Novalija, Mladenić, and Bradeško(2011), the ontology population problem can be defined in the following way (Fortuna, Grobelnik, and Mladenić Citation2007):
O represents an existing ontology, which we are extending; | |||||
T is a domain glossary—atextual source of information we use for ontology extension; | |||||
O P is a populated ontology. | |||||
The pipeline for business news analysis and adaptation of OntoPlus methodology enables population of the existing ontology by adding (a) a new instance and (b) a new fact.
(a) The following formula corresponds to adding a new instance to the existing ontology:
| |||||||||||||||||||||||||||||
(b) Adding a new fact or event to the existing ontology O is presented in the following way:
| |||||||||||||||||||||||||||||
SYSTEM PIPELINE
In order to analyze news, we should characterize the nature of the information presented. Namely, business news usually contains specific domain information (including business-related terms, economic terms, financial terms), common-sense information, different named entities (e.g., names of people, locations, organizations, etc.) and information from other domains.
With OntoPlus methodology presented in Novalija, Mladenić, and Bradeško (2011), we can effectively handle the extension of large ontology with specific domain information. At the same time, the ontology used for news analysis already contains common-sense knowledge, which allows operating with common-sense information extracted from news.
The ontology population with named entities extracted from news can be done with the assistance of different entity, event, and fact extraction services, such as OpenCalais (2011).
In Figure we have defined a pipeline for business news analysis using OpenCalais for entity, event, and fact extraction; OntoPlus for Cyc ontology population; and Cyc reasoning tolls for reasoning based on the extended and populated ontology.
FIGURE 1 System pipeline (analyzing business news using OpenCalais, OntoPlus and Cyc). (Color figure available online.)
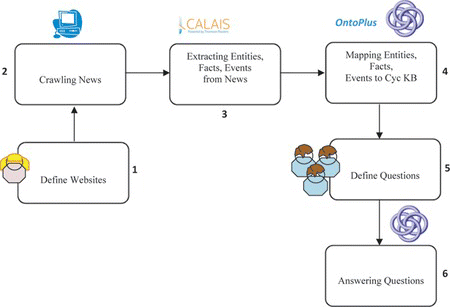
In detail, the proposed pipeline for news analysis accounts for the following steps:
| 1. | News websites definition. In the first phase of the pipeline for news analysis, a list of websites, which contain business news, is defined. | ||||
| 2. | News crawling. The news is automatically crawled from the RSS feeds of the provided websites, and afterward, news cleaning is performed. Every news item represents a separate textual file. | ||||
| 3. | Entities, events, facts extraction from news. With a fact extraction service, such as OpenCalais, we are able to extract the information about entities, events, and facts present in our news collection. | ||||
| 4. | Entities, events, facts mapping to Cyc KB. In this phase, ontology population is performed. For ontology population we have created a set of mappings between OpenCalais entities, events, and facts types and Cyc concepts—collections and predicates. We also apply OntoPlus methodology for concept disambiguation in the ontology population process. | ||||
| 5. | Questions definition. For question definition, a set of questions involving reasoning aspects is composed. For the business news analysis we have composed business-related questions. | ||||
| 6. | Questions answering. The questions are asked using the Cyc reasoning interface, and Cyc proofs are analyzed. | ||||
The Cyc KB and the OpenCalais tool provide the user with a base for news analysis. Extraction of entities, events, and facts with the fact extraction service and mapping them to Cyc using OntoPlus methodology provides a simple and effective way of Cyc KB population with information from the news.
In order to perform the ontology population, we have created a set of mappings between OpenCalais types and Cyc concepts and relations. The examples of mapping support operations are given in Figure .
FIGURE 2 Mapping support.
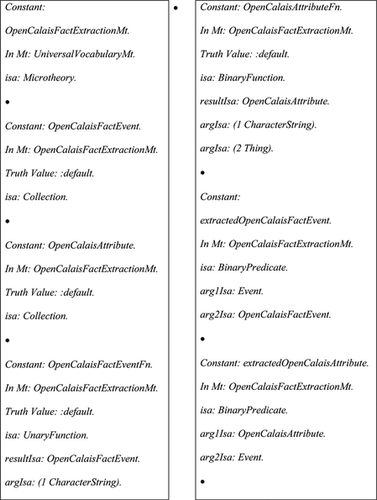
The support operations include creating Cyc microtheory OpenCalaisFactExtractionMt—the contextual space, where all information about the entities, events, and facts extracted with OpenCalais are added. In addition, we create Cyc functions (OpenCalaisFactEventFn,OpenCalaisAttributeFn), Cyc collections (OpenCalaisFactEvent, OpenCalaisAttribute), and Cyc predicates (extractedOpenCalaisAttribute, extractedOpenCalaisFactEvent), which are used in the mapping process.
Figure presents an example of mapping an OpenCalais Fact/Event type of Merger into Cyc KB.
FIGURE 3 Mapping OpenCalais fact/event merger to Cyc fact/event merger.

It is noticeable that the support elements described in Figure are present in the mappings in Figure .
Here, the extracted “company” entities of the OpenCalais relation called “Merger” are mapped to Cyc collections Business and LegalCorporation. The “Merger” relation is presented in Cyc with a predicated “mergees,” which represents the organizations merged in the OrganizationMerger event. The OntoPlus methodology is used in mapping for named entity disambiguation.
Although other events and facts extracted by OpenCalais are predefined and usually pertain to a specific domain (e.g., Merger and Acquisition for the Business domain, MovieRelease for Entertainment news), Generic Relations attempt to recognize all Subject-Predicate-Object relationships without predefining their types. We illustrate the typical generic relations extracted from news data in Figure .
FIGURE 4 Generic relations.

This triplet-based relation extraction allows identifying a number of non-predefined events and mapping them to the Cyc KB using OntoPlus methodology. In our research, we have extracted the named entities from the subject and object of the triplet, then we mapped the predicate of the triplet to the most relevant event (Event) from Cyc and presented the correspondent named entities as actors in this event.
The OntoPlus methodology is used in mapping for named entity disambiguation. Figure presents the procedure of mapping OpenCalais Generic Relation type to the Cyc KB.
FIGURE 5 Algorithm of mapping OpenCalais generic relations to Cyc KB.

Procedure mapGenericRelationToOntology as an input takes the ontology O and the generic relation GR, consisting of subject, predicate, and object. As an output, we retrieve the modified ontology, populated with named entities from the generic relation and the information connected to the event present in text. The function findNamedEntities provides a list of all named entities present in text, for example, in the subject or object of the generic relation. For each discovered named entity, we find a relevant instance from the ontology using function mapNamedEntityToOntology. This similarity-based function obtains from the ontology all possibly relevant instances. By applying OntoPlus methodology, we are able to identify the most similar instance for the defined named entity. If no relevant instances are obtained, the ontology is populated with a correspondent named entity. With function findOntologyEvents, we are able to find a set of events in the ontology. With function mapPredicateToOntologyEvent, which also uses OntoPlus methodology, we obtain the most relevant event type for the predicate from the generic relation. Finally, we assert the information about named entities as “actors” in the correspondent event.
Following the mapping of extracted entities, facts, and events into the Cyc KB, Cyc can be used for reasoning based on the obtained new knowledge and existing ontological rules.
The pipeline of news analysis presented in this article constitutes an entire strategy of business news analysis and question answering based on the ontology reasoning and information from the news. In our research, we combine different tools—a fact extraction system and a common-sense knowledge base with inference system, which allows us to automatically extract facts from textual sources, populate the ontology, and reason based on the populated ontology.
EVALUATION
Data Description
As described above, the business and financial domain has been selected as a primary domain of interest. The business and financial domain is characterized by a dynamic and concentrated information flow. The business and financial domain represents the notion of business organizations—organizations that provide goods and services—and available information about them. The area of finance includes knowledge about money, investments, markets, and risks.
Figure shows the example concepts from the business and financial domain (Harvey Citation2003).
FIGURE 6 Business and financial domain concepts.

Figure presents three typical examples of instances found in business news.
FIGURE 7 Business and Financial Domain Instances.

The data obtained from business and financial information sources is nonstructured and continuously changing. There exist a large number of documents displaying different types of business and financial data; they often contain numerical values, date and time stamps, and references to various named entities, such as people, organizations, and locations.
For our experiments we have used the RSS feeds data Yahoo! Finance website (2011). The news collection used in the current experiment accounts for 3400 Yahoo! Finance news from 2008.
Experimental Settings
In order to evaluate the proposed methodology, we have conducted a series of experiments on the financial data sources. For the proposed methodology evaluation, we have used manual evaluation by human experts (Dellschaft and Staab Citation2008).
Question-answering experiments demonstrate the capacity of Cyc to answer business news-related questions after populating the Cyc KB with business and financial instances.
Following that, a number of queries, as given in Table , were tested using Cyc reasoning tools. We have evaluated the obtained results with the precision of question answering.
TABLE 1 Experimental Queries
In addition, in order to evaluate how efficiently the ontology population is performed, we have selected 50 business news items and calculated the precision of the suggested new ontology instances population.
Results
In our question-answering experiment, we performed news analysis extracting all entities, events, and facts from news collection using OpenCalais fact extraction service and inserting them into the Cyc KB using OntoPlus methodology. Following that, a number of queries (Table ) were tested using Cyc reasoning tools.
From the collection of 3400 news items, a fact extraction service managed to extract 55,607 entities and 33,294 facts and events, out of which 16,335 are generic relations. The number of extracted entities by OpenCalais type is shown in Table .
TABLE 2 Extracted Entities by OpenCalais
It is noticeable that the most popular entity types that occur in business news are Industry terms (13537), Companies (8322), People (8300), Positions (8218), and Organizations (8207).
The number of extracted facts and events by OpenCalais type is shown in Table .
TABLE 3 Extracted Facts/Events by OpenCalais
According to the extracted events and facts, business news contains a substantial amount of information about personal careers (5870), communication between business-related people (254), company tickers (757), location of companies (795), and so forth.
What rarely occurred in our business news collection or did not occur at all, is the information about patents (patent filing (0), patent issuance (0)) and changes of some company properties (company accounting change (0), company listing change (4), company name change (2), company restatement (0), etc.).
Table illustrates the precision of ontology population for selected entity, event, and fact types from 50 selected business news items. The precision of ontology population displays both the quality of the entity, event, and fact extraction using the fact extraction service and the quality of entity, event, and fact mapping to Cyc.
TABLE 4 Precision of Ontology Population
It is noticeable that the precision is high for companies, countries, continents, market indices, products, URLs, and others.
An example of the typical Merger event extracted by the OpenCalais fact extraction service and mapped to Cyc is provided in Figure . This figure displays the merger of two companies (US Airways and United Airlines). Using OpenCalais → Cyc mappings, we are able to populate Cyc KB with new company instances: UnitedAirlines, UsAirways ; a new event instance: MergerKnownUnitedAirlinesUsAirways; new predicate instances: (merges MergerKnownUnitedAirlinesUsAirways UnitedAirlines), (merges MergerKnownUnitedAirlinesUsAirways UsAirways), and so on.
FIGURE 8 Extracted merger event.

An example of Generic Relation mapping to Cyc is displayed in Figure . Here, a generic relation BushConsiderNewEconomicMeasures (see Figure ) is identified as an instance of Thinking. The correspondent for the subject is Cyc individual GeorgeHWBush, who is defined as an actor in this generic relation.
FIGURE 9 Extracted generic relation.

We have conducted a question-answering experiment using queries presented in experimental settings and Cyc reasoning tools. The precision of question answering is provided in Table .
TABLE 5 Evaluation of News-Based Question Answering
The result values provided in Table state that ontology population with information from business news in combination with the ontology-based reasoning can contribute to effective query processing. For different types of queries and different queries a different precision is given as a result, however, for most of the selected queries, the precision of question answering exceeds 90%. For instance, the worst results have been obtained for query # 5. The errors might come from misleading in OpenCalais → Cyc mappings, as well as from the wrong entities, events, and facts extracted by OpenCalais.
Illustrative results of question answering using Cyc are given in Figure , Figure and Figure . Figure shows the Cyc reasoning tools proof for query:
FIGURE 10 Economists in companies from financial sector: Mingchun Sun.

FIGURE 11 Companies involved in layoff activity from Georgia-State (USA): Delta AirLines.

FIGURE 12 Companies involved in buying activities: Dasa.

Are there any economists working in companies from the financial sector?
The proof in Figure says that Lehman Brothers (LehmanBrothers) is a company from the financial sector (Financials-SectorSP) and MingchunSun is a person who works in the position (positionOfPersonInOrganization) of economist (Economist) in Lehman Brothers (LehmanBrothers) company.
Figure demonstrates how Cyc reasoning tools find an answer for the following query:
Are there any companies from the State of Georgia in USA involved in layoff activities?
From the proof in Figure , we can notice that Atlanta (CityOfAtlantaGA) is a capital city (capitalCityOfState) of the state of Georgia, USA (Georgia-State). Delta Air Lines (DeltaAirLines) is a company, which has residence (residenceOfOrganization) in Atlanta (CityOfAtlantaGA). It is possible to see that the state geographically incorporates (geographicallySubsumes) the capital city. Also, the proof says that Delta Air Lines (DeltaAirLines) participated in an event connected to the layoffs (CompanylayoffsAnnouncedDeltaAirLines).
Figure shows the proofs for the following query:
Are there any companies involved in buying activities?
In Figure the user can see that Dasa is a company (Business), as well as being an actor in the event DasaBuyManyCompanies, which is an instance of Buying.
The following scenario illustrates how business news analysis can be implemented in practice, assuming we have a particular statement from a particular person in the news (Figure ).
FIGURE 13 Business analysis according to system pipeline.

Using OpenCalais, we can extract the available information about this person—the name of the person, his/her position, the relevant company. A set of OpenCalais(Cyc mappings and OntoPlus methodology allows effective mapping of new instances into the Cyc KB.
The new information gives the user a possibility to get answers to queries such as, “Find corporate officers in Bache Commodities Limited.” The proof presented in Figure states that ChristopherBellew is a SeniorVicePresident-CorporateOfficer in BacheCommoditiesLimited and that eventually, SeniorVicePresident-CorporateOfficer is a subclass of CorporateOfficer.
In summary, population of the Cyc KB with entities, events, and facts extracted from business news allows users to perform better question answering based on the populated ontology.
CONCLUSION
This article explores the process of business news analysis by the ontology population with entities, facts, and events extracted from text and reasoning based on the obtained ontology. Acknowledging the fact that business news contains a large amount of interesting business, financial, organizational, and personal information that can be discovered, combined, and used in reasoning and question answering, we have proposed a pipeline for business news analysis using the OpenCalais fact extraction service, OntoPlus methodology, and the Cyc KB.
The task of news analysis, as presented in our research, is challenging because of the nature of the news. News reflects the different processes happening in the world. News influences the economic, political, and social situations. Moreover, news sources contain a large amount of information.
We have used 3400 news stories, extracted entities, facts, and events with the OpenCalais service and applied OntoPlus methodology to map the extracted knowledge into the Cyc KB. Following that, we have selected a number of questions and tested them using the Cyc reasoning interface. Using Web and news sources, we have manually detected the number of correct answers obtained and calculated the precision of question answering. For the ontology population evaluation, we have calculated the precision of the ontology population with entities, events, and facts extracted from 50 business news items.
The pipeline of news analysis presented in this article constitutes a whole strategy of business news analysis and question answering based on the ontology reasoning and information from the news. In our research, we combine different tools—a fact extraction system and a common-sense knowledge base with inference system, which allows to automatically extract facts from textual sources, populate the ontology, and reason based on the populated ontology. The use of the Cyc ontology and the Cyc reasoning interface allows us to effectively analyze queries based on the data obtained from the news.
The pipeline for business news analysis presented in this thesis is based on the wide specter of business entities, events, and facts, ontologically represented. We do not perform open information extraction, as other researchers do (Etzioni et al. Citation2008; Soderland et al. Citation2010). However, at the same time, while ontologically representing subject-predicate-object textual triplets, we automatically find the most related event from the ontology for the predicate.
As in Soderland and coauthors (Citation2010), we populate ontology with new information. Analogically to Lenat and colleagues (Citation2010) and Tunstall-Pedoe (Citation2010), we use large common-sense ontology for reasoning and question answering. News is the primary source of our data as in Andersen and colleagues (Citation1992); Losch and Nikitina (Citation2009); and Iacobelli, Birnbaum, and Hammond (Citation2010) approaches.
As in Bradeško and colleagues (Citation2010), we use Cyc ontology in our experiments. However, our question-answering experiments are based on the population of Cyc ontology and reasoning based on the extended and populated ontology. In their question-answering experiments, Bradeško and colleagues (Citation2010) use only synonymic and hierarchically related terms, whereas Cyc has an implemented reasoning system, which goes far beyond “hierarchical” and “synonymic” question answering.
Comparing our techniques of ontology-based news analysis with other existing approaches, we can say that using large common-sense ontologies, such as the Cyc KB, and reasoning based on the information existing in these ontologies can provide users with a wider spectrum of results than using specific, separate ontologies for news events or other pattern-based systems.
The results of the experiments justify the suitability of the pipeline for business news for analysis of financial information, and the applicability of large lexical ontologies such as the Cyc KB to analysis of textual sources, in particular business news. The future work should include the improvements in instance mapping, disambiguation, and better generic relation resolution. In addition, the tests on the news sources from other domains should be performed.
Acknowledgments
This work was supported by the Slovenian Research Agency and the IST Programme of the EC under PASCAL2 (IST-NoE-216886) and ACTIVE (IST-2007-215040).
REFERENCES
- Agirre , E. , O. Ansa , E. Hovy , and D. Martínez . 2000 . Enriching very large ontologies using the www. In Proceedings of ECAI 2000 workshop on ontology learning, August 5, Berlin, Germany.
- Andersen , P. M. , P. J. Hayes , A. K. Huettner , I. B. Nirenburg , L. M. Schmandt , and S. P. Weinstein . 1992 . Automatic extraction of facts from press releases to generate news stories. In Proceedings of applied natural language processing , 170 – 177 . Trento , Italy .
- ASFA thesaurus, http://www4.fao.org/asfa/asfa.htm (accessed June 2010).
- Bradeško , L. , L. Dali , B. Fortuna , M. Grobelnik , D. Mladenić , I. Novalija , and B. Pajntar . 2010 . Contextualized question answering. In Proceedings of 32nd information technology interfaces 2010, June 21–24, Cavtat/Dubrovnik , 73 – 78 .
- Burkhardt , F. , J. A. Gulla , J. Liu , C. Weiss , and J. Zhou . 2008 . Semi automatic ontology engineering in business applications. In Proceedings of GI Jahrestagung 2008, 688–693.
- Carlson , A. , J. Betteridge , R. C. Wang , E. R. Hruschka Jr. , and T. M. Mitchell . 2010 . Coupled semi-supervised learning for information extraction. In Proceedings of the third ACM international conference on web search and data mining , February 3–6, New York, 101 – 110 .
- Chandrasekaran , B. , J. R. Josephson , and R. V. Benjamins . 1999. What are ontologies and why do we need them? IEEE Intelligent Systems and Their Applications 14:20–26.
- Chang , C. H. , M. Kayed , M. R. Girgis , and K. Shaalan . 2006 . Survey of web information extraction systems . Journal of IEEE Transactions on Knowledge and Data Engineering 18 ( 10 ): 1411 – 1428 .
- Cimiano , P. , and J. Völker . 2005 . Text2Onto A framework for ontology learning and data-driven change discovery. In Natural language processing and information system: 10th International Conference on Applications of Natural Language to Information System, June 15–17, Alicante, Spain, 227–238
- Contexts in Cyc, http://www.cyc.com/cycdoc/course/contexts-basic-module.html (accessed June 2011).
- Curtis , J. , J. Cabral , and D. Baxter . 2006 . On the application of the Cyc ontology to word sense disambiguation. In Proceedings of the nineteenth international FLAIRS conference, Melbourne Beach, FL, 652–657.
- Curtis , J. , G. Matthews , and D. Baxter . 2005 . On the effective use of Cyc in a question answering system. In Proceedings of the international joint conference on artificial intelligence workshop on knowledge and reasoning for answering questions (KRAQ'05) Edinburgh, Scotland, 61–70.
- Cycorp, Inc., http://www.cyc.com (accessed June 2011).
- Dali , L. , D. Rusu , B. Fortuna , D. Mladenić , and M. Grobelnik . 2009 . Question answering based on semantic graphs. In Proceedings of the WWW-2009 workshop on semantic search (SemSearch2009), Madrid, Spain.
- Dellschaft , K. , and S. Staab . 2008 . Strategies for the evaluation of ontology learning. In Book Frontiers in Artifical Intelligence and Applications, Volume 167: Ontology Learning and Population: Bridging the Gap between Text and Knowledge, 253–272.
- Duong , W. N. 2008 . Ghetto'ing third world workers with hi-tech : Industrial application of artificial intelligence and its effect on foreign direct investment in the third world -- Exploring regulatory solutions through an emblematic case for the new economy . Temple International and Comparative Law Journal 22 ( 1 ).
- Etzioni , O. , M. Banko , S. Soderland , and D. S. Weld . 2008 . Open information extraction from the web . Communications of the ACM 51 ( 12 ), 68 – 74 .
- Ferrucci , D. , E. Brown , J. Chu-Carroll , J. Fan , D. Gondek , A. A. Kalyanpur , A. Lally , J. W. Murdock , E. Nyberg , J. Prager , N. Schlaefer , and C. Welty . 2010 . Building Watson: An overview of the deepqa project . AI Magazine 31 ( 3 ), 59 – 79 .
- Fortuna , B. , M. Grobelnik , and D. Mladenić . 2007 . OntoGen: Semi-automatic ontology editor. In Proceedings of the 2007 conference on human interface: Part II (HCI) 9:309–318.
- Ghani , R. , R. Jones , D. Mladenić , K. Nigam , and S. Slattery . 2000 . Data mining on symbolic knowledge extracted from the web. In: Proceedings of the sixth international conference on knowledge discovery and data mining, KDD-2000, August 20–23, Boston, MA.
- Grobelnik , M. , and D. Mladenić . 2006 . Knowledge discovery for ontology construction . In Semantic Web Technologies: Trends and Research in Ontology-Based Systems , ed. J. Davies , R. Studer , and P. Warren , John Wiley & Sons .
- Gruber , T. R. 1993 . A translation approach to portable ontologies . Knowledge Acquisition 5 ( 2 ): 199 – 220 .
- Grunning , D. , V. K. Chaudhri , P. Clark , K. Barker , S. Y. Chaw , M. Greaves , B. Grosof , A. Leung , D. McDonald , S. Mishra , J. Pacheco , B. Porter , A. Spaulding , D. Tecuci , and J. Tien . 2010 . Project halo update - Progress toward digital Aristotle . AI Magazine 31 , 33 – 58 .
- Harvey , C. R. 2003 . Yahoo financial glossary. Fuqua School of Business, Duke University,.
- Heflin , J. , and J. Hendler . 2000 . Dynamic ontologies on the web. In: Proceedings of the seventeenth national conference on artificial intelligence, Menlo Park, CA, 443–449.
- Iacobelli , F. , L. Birnbaum , and K. J. Hammond . 2010 . Tell me more, not just “more of the same.” In: Proceedings of the 15th international conference on intelligent user interfaces, 81–90. New York, NY: ACM.
- Lenat , D. B. 1995 . Cyc: A large-scale investment in knowledge infrastructure . Communications of the ACM 38 ( 11 ).
- Lenat , D. , M. Witbrock , D. Baxter , E. Blackstone , C. Deaton , D. Schneider , J. Scott , and B. Shepard . 2010 . Harnessing CYC to answer clinical researchers’ ad hoc queries . AI Magazine 31 ( 3 ), 13 – 32 .
- Losch , U. , and N. Nikitina . 2009 . The news events ontology? An ontology for describing business events. In: Proceedings of the workshop on ontology design patterns, ISWC October 25, Washington, DC.
- Lytinen , S. L. , and A. Gershman . 1986 . ATRANS: Automatic processing of money transfer messages. In Proceedings of the fifth national conference on artificial intelligence, AAAI, 1089–1095. Trento, Italy.
- Maedche , A. , and S. Staab . 2001. Ontology learning for the semantic web. IEEE Intelligent Systems 16 (2): 72–79.
- Maynard , D. , A. Funk , and W. Peters . 2009 . SPRAT: A tool for automatic semantic pattern-based ontology population. In Proceedings of the international conference for digital libraries and the semantic web, Trento, Italy.
- Medelyan , O. , and C. Legg . 2008 . Integrating Cyc and wikipedia: Folksonomy meets rigorously defined common-sense. In Proceedings of wiki-AI workshop at the AAAI'08 conference, July 14, Chicago, U.S.
- Novalija , I. , and D. Mladenić . 2008 . Extending ontologies for annotating business news. In Proceedings of siKDD 2008. Ljubljana, Slovenia.
- Novalija , I. , D. Mladenić , and L. Bradeško . nd. OntoPlus: Text-driven ontology extension using ontology content, structure and co-occurrence information. Knowledge-Based Systems 24 (8): 1261–1276.
- OpenCalais, http://www.opencalais.com (accessed June 2011).
- OpenCalais - English semantic metadata: Entity/fact/event definitions and descriptions, http://www.opencalais.com/documentation/calais-web-service-api/api-metadata/entity-index-and-definitions (accessed June 2011).
- Panton , K. , C. Matuszek , D. Lenat , D. Schneider , M. Witbrock , N. Siegel , and B. Shepard . 2006 . Common sense reasoning – From Cyc to intelligent assistant . In Ambient intelligence in everyday life , 1 – 31 . Lecture Notes in Artificial Intelligence, vol. 3864 , ed. Y. Cai and J. Abascal . New York , NY : Springer .
- Reinberger , M.-L. , and P. Spyns . 2005 . Unsupervised text mining for the learning of DOGMA-inspired ontologies . In Ontology learning from text: methods, evaluation and applications , ed. P. Buitelaar , S. Handschuh , and B. Magnini . Amsterdam , The Netherlands : IOS Press .
- Sabrina , T. , A. Rosni , and T. Enyakong . 2001 . Extending ontology tree using NLP technique. In Proceedings of the national conference on research & development in computer science REDECS 2001, Selangon, Malaysia.
- Sarjant , S. , C. Legg , M. Robinson , and O. Medelyan . 2009 . “All you can eat” ontology-building: Feeding wikipedia to Cyc. In Proceedings of the 2009 IEEE/WIC/ACM international conference on web intelligence, WI'09,. Milan, Italy, 341–348.
- Shah , P. , D. Schneider , C. Matuszek , R. C. Kahlert , B. Aldag , D. Baxter , J. Cabral , M. Witbrock , and J. Curtis . 2006 . Automated population of Cyc: Extracting information about named-entities from the web. In Proceedings of the nineteenth international FLAIRS conference, Melbourne Beach, FL, 153–158.
- Soderland , S. , B. Roof , B. Qin , S. Xu , Mausam , and O. Etzioni . 2010 . Adaptation information extraction to domain-specific relations . AI Magazine 31 ( 3 ): 93 – 102 .
- Suchanek , F. M. , M. Sozio , and G. Weikum . 2009 . SOFIE: A self-organizing framework for information extraction. In: Proceedings of the 18th world wide web conference, www2009. Madrid, Spain, 631–640.
- Taylor , M. E. , C. Matuszek , B. Klimt , and M. Witbrock . 2007 . Autonomous classification of knowledge into an ontology. In: Proceedings of the twentieth international FLAIRS conference. Key West, FL, 140–145.
- Tunstall-Pedoe , W. 2010 . True knowledge: Open-domain question answering using structured knowledge and inference . AI Magazine 31 ( 3 ): 80 – 92 .
- Witbrock , M. , D. Baxter , J. Curtis , D. Schneider , R. Kahlert , P. Miraglia , P. Wagner , K. Panton , G. Matthews , and A. Vizedom . 2003 . An interactive dialogue system for knowledge acquisition in Cyc. In Proceedings of the eighteenth international joint conference on artificial intelligence, Acapulco, Mexico.
- WordNet – Princeton University Cognitive Science Laboratory, http://wordnet.princeton.edu (accessed June 2011).
- Yahoo! Finance, http://finance.yahoo.com (accessed June 2011).