
Abstract
A method to identify feasible minimal network coding configurations between a source and a set of receivers without altering or modifying the established network infrastructure is proposed. The approach minimizes the resources used for multicast coding while achieving the desired throughput in the multicast scenario. Because the problem of identifying minimal configurations of a graph is known to be NP-hard, our method first identifies candidate minimal configurations and then searches for the optimal ones using a genetic algorithm (GA). Because the optimization process considers the number of coding nodes, the mean number of coding node input links and the sharing of resources by sinks, the problem is thus a multiobjective problem. Two multiobjective algorithms, MOGA and VEGA, are chosen to solve the problem because they are simple enough not to place heavy demands on source nodes when the minimal configuration is sought. The optimization process is investigated by the simulation of a range of randomly generated networks of varying sizes. Performance differences between the multiple-objective GAs are observed, which seem to arise from the difference in their methods of searching. Nevertheless, both methods perform well in terms of identifying feasible minimal configurations with optimized coding resources. The performance is assessed by comparing the optimized solutions with randomly chosen starting configurations. There are always reductions in the number of coding nodes used, typically 50%, and resource sharing is multiplied by several times. Typical mean in-link savings are 10% but may range from zero to close to 30%. We thus show that relatively simple multiple-objective GAs can deliver optimized minimal coding configurations for the network coding multicast problem. Moreover, the approach here offers an improvement over solutions in the literature because our method remains feasible for relatively large networks and its implementation at the source simplifies the functions that must be employed at intermediate nodes.
INTRODUCTION
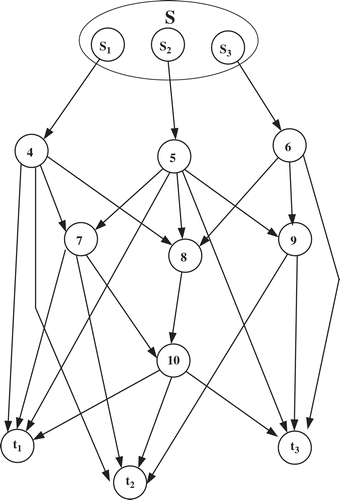
Network multicast refers to the simultaneous transmission of the same information to multiple receivers in a network. Multicast transmission has historically been a demanding task that consumed considerable network resources such as channel bandwidth and network power. To minimize network resource usage, network coding (NC; Fragouli and Soljanin Citation2007) allows nodes to combine two or more independent bit streams via binary addition as well as perform their traditional functions of packet routing and duplication. In the multicast NC problem, a source, S, needs to deliver h packets to N sinks over an underlying communication network G. Recently, considerable efforts have been made to minimize the coding resources in the multicast scenario (Fragouli and Soljanin Citation2007; Kim et al. Citation2006) and in this article, a feasible engineering solution is proposed for this challenge. To illustrate the issues, the network shown in is considered with respect to a particular example scenario. Source S wishes to transmit a number of data packets, say 3, from s1, s2, and s3, simultaneously to sinks t1, t2, and t3. S intends to identify a minimal configuration between itself and the sinks for its multicast traffic delivery.
FIGURE 1 Example network used to illustrate the proposed method.
In their seminal research, Ahlswede et al. (Citation2000) illustrated that if NC is permitted at the nodes of a network, the communication rate can be improved over that obtainable by routing alone. (Li, Cai, and Yeung Citation2003) showed that linear coding (in which each packet sent over the network is a linear combination of the original packets) is sufficient for multicast network coding problems. Koetter and Médard (Citation2003) introduced an algebraic framework for the study of network coding and gave a condition for valid codes. This framework was used by Ho et al. (Citation2003) to show that linear network codes can be efficiently constructed by employing a randomized algorithm. Jaggi et al. (Citation2005) proposed a deterministic polynomial-time algorithm to find feasible network codes for multicast networks. The identification of the minimal configuration with a minimum number of coding points is NP-hard (Fragouli and Soljanin Citation2007). Here, our solution based on a genetic algorithm (GA) deals with this by developing candidate solution paths and identifying the best one rather than tackling the NP-hard problem. The remainder of the article presents the problem formulation and related work before introducing the proposed solution method and its simulation, followed by the results and conclusions.
PROBLEM FORMULATION
We consider a communications network represented by a directed acyclic graph with unit capacity edges and in which the value of the min-cut between the source node and each of the receivers is h. There is a set of h unit rate information sources
and a set of N receivers
. We assume each receiver has at least one set of h linear disjoint paths (h-LDPs). We denote by
a set of h-LDPs from the source to the receiver node
and the choice of paths is not necessarily unique. Our objective of interest is the minimal configuration
with optimum coding resources, consisting of fewer than hN paths. We assume that source
simultaneously emits
, which is an element of some finite field
. In linear NC, each node of
receives an element of
from each input edge, and then forwards a linear combination of its inputs to each output edge.
There is detailed discussion concerning the linear NC resources required for multicasting in Fragouli and Soljanin (Citation2007). Therein, the major complexity components are described as Set-up complexity and Operational complexity. The former denotes the complexity of designing the network coding scheme, which includes selecting the paths through the information flows and determining the operations that the nodes of the network perform. The latter encompasses the running cost of using NC; that is, the amount of computational and network resources required per information unit successfully delivered. Moreover, this complexity is strongly correlated with the NC scheme employed. To recover the source elements σi which have been linearly combined over by the coding nodes, each receiver needs to solve a system of h2 linear equations, requiring
operations over
if Gaussian elimination is used. The linear combination of h information streams requires
finite field operations. The complexity is further affected by the size of the finite field over which we operate. The cost of finite field arithmetic grows with the field size. For example, typical algorithms for multiplication or inversions over a field of size
require O(n2) binary operations (Fragouli and Soljanin Citation2007). Also, the field size affects the required storage capabilities at intermediate network nodes. Moreover, the complexity is affected by the number of network coding points, which are generally more expensive because of the need to equip them with encoding capabilities. In addition, coding points incur delay and increase the overall complexity of the network (Langberg, Sprintson, and Bruck Citation2006). The computational complexity at each coding point of
is considerably increased by the number of in-links per coding point, which exhausts the coding resources via increasing the operational complexity of the network (Fragouli and Soljanin Citation2007). Therefore, we are interested in optimizing the number of coding points and the number of in-links per coding point while identifying the minimal configuration
.
RELATED WORK
This problem is somewhat similar to that of the “Traveling Salesman” (Cormen et al. Citation2001) and in both cases GAs may be employed to search for the suitable geometrical properties (e.g., shortest paths, minimal configuration). Determining a minimal set of nodes wherein coding is required is known to be difficult (Kim et al. Citation2006). The problem of deciding whether a given multicast rate is achievable without coding, that is, whether the minimum number of required coding nodes is zero, reduces to a multiple Steiner subgraph problem, which is NP-hard (Richey and Parker Citation1986). Hence, the optimization problem to find the minimal number of required coding nodes is NP-hard. Even approximating the minimal number of coding nodes within any multiplicative factor or within an additive factor of |V |1-ξ is NP-hard (Langberg, Sprintson, and Bruck Citation2009).
As a first attempt at an evolutionary approach to the NC problem, Kim et al. (Citation2006) considered coding resource minimization while achieving the desired throughput in a multicast scenario by inspection of the outgoing links of all of the nodes. In this NP-hard problem, they employed the structure of the standard GA, which was introduced by Holland (Citation1975), operating on a set of candidate solutions, which it improved sequentially via mechanisms inspired by biological evolution (recombination and mutation of genes plus survival of the fittest). The algorithm proposed in Kim et al. (Citation2006) reduces the number of coding links/nodes relative to prior approaches in Fragouli and Soljanin (Citation2007) and Langberg, Sprintson, and Bruck (Citation2006) and applies to a variety of generalized scenarios.
Here, our solution overcomes two major drawbacks of the approach in Kim et al. (Citation2006). First, a node where coding is required cannot be decided independently, which implies that whether coding is required at a node depends on whether coding is performed at other nodes; the verification procedure cannot thus be applied separately to each node. Hence, when the number of involved nodes is augmented, the complexity grows rapidly. Second, the GA operations must run in each node on an individual basis, meaning that costly functional integration (hardware and software upgrade) is essential at each node. These operations increase transmission complexity and exhaust network node resources.
PROPOSED SOLUTION WITH EVOLUTIONARY APPROACH
Here, the proposed solution runs at the source where the processing and memory capacity are sufficient to execute these algorithms. All intermediate nodes are required to perform only their core operations (forwarding, duplicating, and coding). shows a block diagram of the optimization process, which comprises two fundamental elements: the preliminary process (which creates a search space) and the multiobjective GA process (which creates and identifies feasible minimal configurations); these will now be considered in turn.
FIGURE 2 Block diagram of the operation of the proposed solution.

Preliminary Process
The preliminary process provides unevaluated individuals to the search space and then the two generic algorithms (path augmentation and linear disjoint path) contribute to create the search space.
Path Augmentation Algorithm
This implementation is new but derives from the breadth first search (BFS) algorithm (Mehlhorn and Sanders Citation2008). The algorithm identifies all available paths from each subsource to each receiver
. shows all available paths identified for receiver {t1}. The algorithm’s time complexity can be calculated as
, where |V| is the number of nodes in G(V, E).
FIGURE 3 (a) All available paths from each subsource {S1, S2, S3} to receiver {t1}; (b) and (c), two different sets of linear disjoint paths for receiver {t1}.
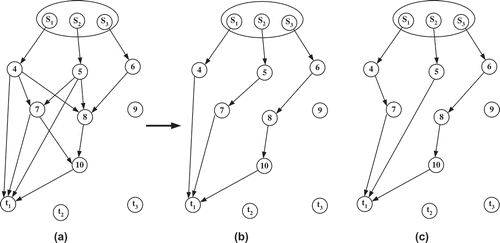
Linear Disjoint Path Algorithm
The set of h paths between the source and receiver is defined as a set of linear disjoint paths when none of the paths overlap. The algorithm hierarchically examines all available paths from each sub source to each receiver
to form different sets of h-linear disjoint paths (LDPs). and 3(c) show two different sets of LDPs identified for receiver {t1}. The two paths are compared to form a set of LDPs with time complexity
. Here, the set of LDPs is classified based on sink IDs with the denomination
where
for the qth path to the sink. For example, sink {t1} has three sets of 3-linear disjoint paths:
,
and
.
This algorithm contributes to the satisfaction of the multicast demand (min-cut, max-flow) theorem and the formation of the minimal configuration. It is an enhancement to the approach in Fragouli and Soljanin (Citation2007) for identifying the minimal configuration that considered edge disjoint paths only. Here, the LDP algorithm allows us to overcome this restriction so that overlapped paths are also accepted to form the minimal configuration. For example, in the minimal configuration of there are two different data streams {S3} and {S2} at link (8,10).
FIGURE 4 The random shuffle process creates an unevaluated individual to form the search space.
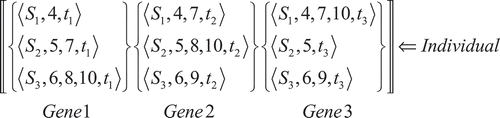
Search Space
A random shuffle process picks from each sink column
and creates a row. A row is defined as an individual and its elements
are defined as genes. The random shuffle process is terminated when the search space size (Z) reaches a predefined number. This is a significant stage of the proposed solution because it is the commencement of the mapping of the NC problem into a GA framework. The minimal configuration is created by the sets of LDPs. During this creation, either the same or different data streams overlap at some links. A tail node of an overlapped link becomes a coding node, and other intermediate nodes become forwarding nodes. The vital point is that data streams are either coded or not; all sinks are able to simultaneously receive multicast data via LDPs. Moreover, the source can assign linearly independent coding vectors for coding nodes, therefore all sinks are able to form full-rank-decoding matrices. Thus, the minimal configuration is either feasible or unfeasible; it is not necessary to evaluate for a full rank state in contrast to the approach in Kim et al. (Citation2006), which can be unmanageable as a result of the evaluation.
Brief Introduction to GAs
The operation of GAs is on a set of candidate solutions, referred to as a population. Each solution is typically represented by bit strings, trees, graphs, or any data structure adjusted to the problem being solved and known as a chromosome. Each of these is assigned a fitness value that measures how well it solves the problem at hand, compared with other chromosomes in the population. Typically, a new population is generated from the current one using three genetic operators: selection, crossover, and mutation. Chromosomes for the new population are selected randomly (with replacement) in such a way that fitter ones are selected with higher probability. For crossover, the surviving chromosomes are randomly paired, and an exchange of bit string subsets takes place in each pair to create two offspring. Chromosomes are then subject to mutation, which refers to random flips of the bits applied individually to each of the new chromosomes. The process of evaluation, selection, crossover, and mutation forms one generation in the execution of a GA. The above process is iterated with the newly generated population successively replacing the current one. The GA terminates when a certain stopping criterion is reached, for example, after a predefined number of generations. GAs have been applied to a large number of scientific and engineering problems, including many combinatorial optimization problems in networks (Arabas and Kozdrowski Citation2001; Vidyarthi, Ngom, and Stojmenovic Citation2005; Kavian et al. Citation2007).
Potential of GAs to Solve this Problem
There are several aspects of this problem suggesting that GA-based methods might be promising candidates. Such approaches have worked well if the space to be searched is large but not known to be perfectly smooth or unimodal. Moreover, they will operate even if the space is not well understood (Mitchell Citation1996), which makes traditional optimization methods difficult to apply. Here, the search space of our problem is not smooth or unimodal (two objective constraints are unknown) with respect to the number of sets of linear disjoint paths, because each sink has different combination sets of the linear disjoint paths. The search space in this work consists of a large number of feasible or infeasible individuals, which are created by the different combination sets of linear disjoint paths. An NP-hard problem results in which the individuals are not well understood. It should also be noted that, although it is difficult to characterize the structure of the search space, once provided with a solution, we can verify its feasibility (count the number of coding nodes, an average number of in-links per coding point, and average resources shared per coding node) in polynomial time. Thus, if the use of genetic operations can suitably limit the size of the space to be actually searched, a solution could be obtained relatively efficiently using the established procedures of GAs (Mitchell Citation1996).
Multiobjective GAs
Multiobjective formulations are realistic models for many complex engineering optimization problems, such as minimizing cost, maximizing performance, maximizing reliability, and so on. The multiple objectives are generally conflicting, preventing their simultaneous optimization. The GA is a popular metaheuristic approach that is particularly well suited for this class of problem. Therefore, traditional GAs are customized to accommodate multiobjective problems by using specialized fitness functions. Konak, Coit, and Smith (Citation2006) present a comprehensive overview of multiple-objective optimization methods using GAs. Here, we are interested in schemes with relatively simple implementations because the search space and fitness evaluation method of the proposed solution are complex. Moreover, the proposed solution is implemented at the source node and complex search methods would place unfeasible demands on source nodes. Thus, based on Konak, Coit, and Smith (Citation2006) we select two multiobjective methods, multiobjective GA (MOGA) and vector-evaluated GA (VEGA), and investigate how these methods perform on the problem formulated above.
Multiobjective GA (MOGA)
The well-established, single-objective GA described earlier is modified to find a set of multiple nondominated solutions in a single run. The potential of the GA to simultaneously search different regions of a solution space means that a MOGA is a promising candidate for finding a diverse set of solutions for difficult problems such as those that are nonconvex. The crossover operator of the GA may exploit structures of good solutions with respect to different objectives in order to create new nondominated solutions in unexplored parts of a Pareto front. Therefore, GAs have been the most popular heuristic approach to multiobjective design-and-optimization problems.
Vector-Evaluated Genetic Algorithm (VEGA)
In this method, the selection operator of the GA is modified so that at each generation a number of subpopulations are generated by performing proportional selection according to each objective function in turn. Thus, for a population size K and number of objectives q, each subpopulation’s size is K/q. These subpopulations are then shuffled together to obtain a new population of size K; each new generation is created by the usual GA operations of crossover and mutation.
GA Operations and Individual Evaluation
An initial population (P1) is obtained by randomly selecting the individuals in the search space at t = 1. The GA operations form a new generation (P2) from P1 (generally ). The population size (K) is constantly maintained at the size of P1 throughout the GA. P1 is evaluated, and the highest fitness individuals are recombined by crossover to form an offspring population (Qt).
Crossover
The number of genes in each individual depends on the number of sinks (N) that requested multicast data from the source. In this work, single point crossover is employed with a crossover point , where
represents the nearest integer to u. A value of 0.7 for
was found to give good results after experimentation. shows the crossover operation with
with the illustrative assumption that the Pareto optimal solution is f(2,2,3). The parents are selected based on their fitness and both are close to the Pareto optimum in . The recombination forms the offspring in , which exhibit higher fitness values and are thus are added to the offspring population Qt. In this implementation, each generation results in the recombination of sets of parents to form sets of offspring. By iteratively applying the crossover operator, genes of “good” individuals are expected to appear more frequently in the population, eventually leading to convergence to an overall “good” solution.
FIGURE 5 Crossover operation showing (a) the parents and (b) the offspring.

Mutation
The mutation operator introduces random changes in the characteristics of chromosomes. It is generally applied at the gene level. In typical GA implementations, the mutation rate (probability of changing the properties of a gene) is very small and depends on the length of the chromosome. Therefore, the new chromosome produced by mutation should not be that different from the original one. Mutation plays a critical role in GA. The crossover operator leads to population convergence by making the chromosomes in the population comparable. Mutation reintroduces genetic diversity back into the population and assists the search escape from local optima. In this implementation, the length of the chromosome depends on a number of sinks. If a gene is randomly substituted by mutation, the original chromosome diverges significantly because the mutation rate (1/N) is extremely high. This issue is eliminated by substituting a single path in a randomly selected gene and inserting a random path without perturbing a linear disjoint feature of the gene, producing factor of h a reduction in the mutation rate. shows the mutation operation on one of the offspring in . Gene 2 is randomly selected and its path is randomly substituted by another path while keeping the linear disjoint feature of the gene.
FIGURE 6 Mutation operation.
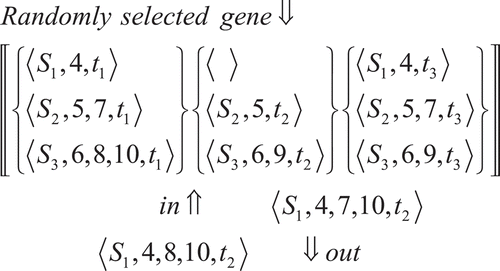
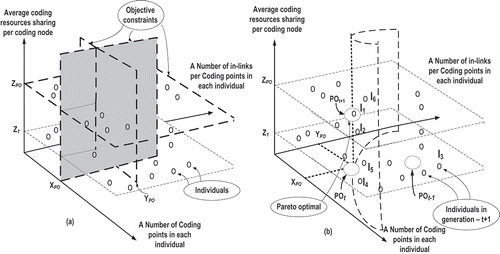
FIGURE 7 Pareto optimization process for the problem considered; (a) objective constraints, (b) Pareto optimal front.
Selection
A selector operator plays a vital role in this work because it could pull the search to a narrow area of search space. The selector operator selects K of the offspring in the offspring population Qt based on their fitness, and they are copied into the generation Pt+1, where K is the population size.
The selector operator performs differently in MOGA and VEGA. The GA operators of crossover and mutation work on a mating pool to form the offspring population Qt. The selector operator creates two different mating pools for MOGA and VEGA. The generation Pt are assigned their fitness using the objective functions, and they are evaluated using the Pareto optimal . The selector operator in MOGA concerns closer individuals to the Pareto optimal
, and the MOGA mating pool is filled by them. For example, the individuals I1 and I2 and are in (b), but the selector operator in VEGA is concerned with closer individuals to each objective of the Pareto optimal
, and the VEGA mating pool is filled by them. For example, the individuals from I1, I2, I4, and I5 are closer to
(X), the individuals I1, I2, I4, and I5 are closer to
(y), and individuals I1, I2 and I6 are closer to
(Z), and the VEGA mating pool is filled by them. Moreover, the offspring population Qt is evaluated using the Pareto optimal
, and the selector operator performs on Qt in the same way as the selector operator on MOGA.
Termination Criterion
If the source is able to identify w feasible multicast structures (individuals) then the search is terminated and the current population is returned, else the process repeats from crossover and t becomes t+1. Moreover, if the termination condition is not met during g generations, the entire population is removed and the process is randomly reinitiated.
Evaluation of Individuals
The fitness evolution process proposed concentrates on optimizing the network coding resources in the multicast scenario by identifying the minimal configurations between sources and sinks, and contributes to coding resource optimization in them. Three objective functions are employed to assign fitness values to individuals in the initial population or the mating pool:
Optimize the number of coding nodes in individuals-
;
Achieve a desired throughput rate (constraining a number of in-links at each coding point)-
Optimally share coding resources in individuals-
The first two objectives optimize the network coding resources; the first and third optimize network resources. An optimum number of coding nodes are in multicast routes of the minimal configuration when it consumes the optimum coding resources when selected by the source for its multicast transmission. The use of coding nodes in multicast transmission automatically implies that a number of channels simultaneously convey more than one packet, contributing to efficient channel capacity use and network resource savings. The second objective allows the source to maintain a desired throughput rate during its multicast transmission. This can be achieved by constraining the number of input links at each coding point. Moreover, it allows the saving of coding resources (storage capacity and computation) at the coding nodes. The third objective allows the sharing of the optimum coding resources with all sinks and can be enacted by considering the average coding resources sharing per coding node, defined as the sum of the number of receivers connected to each coding node divided by the number of coding nodes. In addition, it also improves the usage of the coding resources that are discovered via the first two objectives.
The problem is thus one of multiobjective optimization, and such cases generally exhibit conflicting objectives, preventing their simultaneous optimization. In this case, the first and third objectives are in direct conflict because when the number of coding points is optimized, they are unlikely to be evenly spread. Here, the standard GA is customized to accommodate multiobjective problems by using specialized fitness functions and introducing methods to promote solution diversity. The approach is to determine an entire Pareto optimal solution set rather than a single fitness calculation in traditional GA. It is a most suitable solution because neither the first nor third objectives have preidentified constraints. Therefore, the Pareto optimal solution is updated at each generation by comparing it with the one obtained in the previous generation.
It is assumed that the source intends to identify the w minimal configurations for termination. Minimal configuration I may be viewed as a point in the solution space . The points (XOP, YOP, ZOP) are objective constraints and the feasible set of them forms a Pareto optimal front. shows the objective constraints and shows a surface that is Pareto optimal on ZOP. The Pareto optimal surface is updated at each generation, with the first arising from the randomly selected initial population. The value of YOP is maintained to be ≥ 2, but XOP and ZOP are updated at each generation with the minimum value being preferred for XOP and the maximum value for ZOP. For example, shows Pareto optimal (OPt-1, OPt, and OPt+1) for generation-
consecutively, and they are updated at each generation. Pareto optimal set (OPt-1) is:
and set OPt is:
. The comparison of (OPt-1) and OPt is:
Therefore, the Pareto optimal (OPt) is moved to the position (OPt+1) on surface Z1.
The mutual comparison between individuals is extremely challenging in multiobjective optimization, and the proposed method can avoid the difficulty of comparison. At each selection operation, the individuals are assigned their fitness using objective functions. Then each individual is compared with the Pareto optimal (XPO, YPO, ZPO), using
. If any individual is far away from the Pareto optimal, it can be defined as a weakly fit or infeasible individual. With reference to , the individual I3 on surface Z1 is in this position but individual I1 is a fitter individual, which should be selected in preference.
As shown in and , individuals are in a path-based format, which is hard to analyze at the fitness-assignment process stage. Therefore, each individual is converted to a sparse matrix, as shown in , where {7, 8, and 10} can be identified as coding nodes because {7} is connected to {4} and {5}, which are in turn connected to sources {S1} and {S2}. Moreover, {8} is connected to {S2} and {S3} via {5} and {6}. Node {10} is connected to coding nodes {7} and {8}. Then, objective function can thus be calculated as 3. The “1”entries of all coding nodes are counted via their respective rows, and in there are six “1” entries in total, or an average of two per coding point (i.e.,
).
FIGURE 8 (a) An individual in a path format; (b) related sparse matrix.

The objective function calculation process is to count when a sink column contains a “1” entry in a row representing a coding node. This means that the coding node contributes to the path to the sink in question. For example, in , sink {t1} has an entry “1” at row 7, meaning that the coding node 7 contributes to the route to {t1}. However, when the first coding node identified is connected to a second coding node, then this also adds to the number of nodes shared by the route. For example, in , coding node 10 contributes to paths to {t1, t2, t3} in its own right, but because it is connected to coding nodes 7 and 8, these also contribute to routing to {t1, t2, t3}. In total, the example has one contribution from {7} directly, three from {10} directly, and three each from {7} and {8}, indirectly. Because there are three sinks, objective function
can be calculated for as (1 + 3 + 3 + 3)/3 = 10/3, and the overall individual’s fitness is f(3,2,10/3).
SIMULATION
The methods described were tested using a software environment developed in MATLAB R2009a and the computer system was: Windows VistaTM Home Basic with service pack 2 (32 bit) running on an Acer Aspire 5735, Intel® Pentium® Dual CPU T3400 2.16GHz processor with 3GB RAM. Fifty different randomly generated topologies were used in the simulations. Each of these consisted of a single source with three data streams, and a different number of nodes, links, and sinks. provides the topological parameters that were used to create random networks. The tests proceeded as four projects, each of which consisted of a different number of runs. In each run, an equal size topology was employed but it was randomly generated at the beginning. The parameters for the GA processes were: population size , crossover probability
, mutation probability
, and termination criterion (w). They are represented as a parameter set
. The mutation probability was decreased with an increasing number of sinks. Each simulation continued until either termination or a predefined generation number (g – here taken as 10 for all projects) had passed, in which case the GA is with a new initial population and is marked as a failed search.
TABLE 1 Topological Details and Parameter Sets for Projects 1–4
RESULTS AND DISCUSSION
These simulations do not attempt to deliver the actual multicast traffic levels, rather, they identify the minimal source to sink configurations, which is NP-hard. The performance of the proposed solution is considered in two parts, the preliminary process and the evolutionary process.
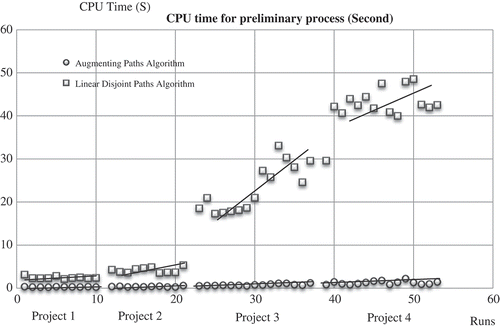
shows the performance of the two preliminary algorithms as a function of increasing scale (project) for the simulations in the all projects. The path augmentation is largely independent of network size in contrast to the linear disjoint path algorithm, which has a more difficult task to perform as the network gets larger. Moreover, there is an inefficiency entering the discovery of disjoint paths because the algorithm obtains all available sets of linear disjoint paths but not all of these are needed in the discovery of the feasible minimal configuration.
FIGURE 9 The performance of the two preliminary algorithms.
With respect to the evolutionary process, the search performance of the two multiobjective GA techniques, MOGA and VEGA, differed as the network size varied. shows the CPU time for MOGA and VEGA at each run of projects 1 to 4. In each run, an initial population was randomly selected and then used by both algorithms. An extremely high searching time (here, 1000 seconds of CPU time) was taken as an indication of search failure as indicated in . There is one subtle point to note in that the figure indicates that the two algorithms failed in runs 19, 22, 24, 32, 38, 39, and 41. However, on examination of their randomly generated topologies, it was apparent that insufficient coding nodes had arisen from the stochastic nature of the generation process for the algorithm to ever find a solution. These runs were thus impossible from the outset and so were not taken into account when the simulation results were analyzed.
FIGURE 10 The performance evaluation of the GA processes based on CPU time.
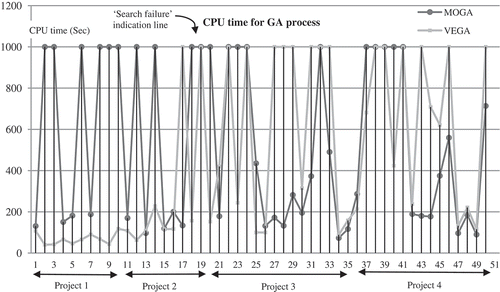
Runs 1 to 10 were small-scale networks, and shows that VEGA was able to find feasible solutions for all runs in less than 100 seconds. MOGA succeeded in runs 1, 4, 5, and 7 with CPU times slightly below 200 seconds. The next set of ten runs considered slightly larger networks than the first ten. VEGA showed a slight degradation in its performance for these runs, with 7 out of 9 runs able to find a feasible solution in less than 200 seconds. MOGA showed a slight improvement in that it was able to return 5 out of 9 successful runs in less than 200 seconds. Runs 21–35 increased the network size further over runs 11–20 and VEGA’s performance deteriorated further because it delivered only 4 out of 12 successful runs that took less than 200 seconds to complete. In contrast, MOGA showed a remarkable improvement, with 7 out of 12 runs succeeding in less than 200 seconds. Finally, runs 36–50 again used a network size that was larger than in runs 21–35. These tests took both algorithms closer to the limits of their operation, with VEGA delivering just 2 successes out of 12 runs in less than 200 seconds and MOGA’s corresponding success being reduced to 6 out of 12 runs.
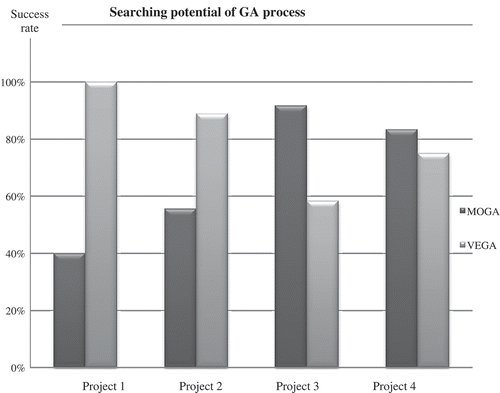
The searching potential of MOGA or VEGA depends not only on their performances but also on the availability of minimal configurations and coding nodes in the randomly generated networks (as was dramatically apparent in the apparent failures discussed above). The impact of this factor is shown in , where the percentage success rates for MOGA and VEGA in the four projects are illustrated. In the first two smaller projects, VEGA outperforms MOGA, but this trend reverses as the network size grows in the second two projects. This is most likely explained by the fact that VEGA is a simple scheme and MOGA makes use of fitness sharing, which promotes the exploration of new areas of the Pareto front by artificially reducing fitness of solutions in regions containing many solutions (Konak, Coit, and Smith Citation2006). When the network is small, the number of solutions is reduced, meaning that there is little to be contributed by the fitness sharing process. However, the increase in possible solutions with network size gives MOGA an advantage through its enhanced searching capabilities. The increasing number of nodes relative to sinks (and, hence, the increasing average node degree) coupled with the greater number of sinks as the projects progress greatly increases the routing possibilities, permitting MOGA to gain an advantage from its greater sophistication.
FIGURE 11 The performance evaluation of the GA processes based on searching potential.
shows comparisons of fitness of the most feasible individual (minimal configuration) identified at the end of randomly selected runs with fitness of the most infeasible individual in an initial population of its run. The comparisons prove how the most feasible individual is more advanced than the most infeasible individual in terms of network coding resources usage, if the source selects the most feasible minimal configuration for its multicast transmission. The savings in the number of coding nodes (Xi) and the mean number of in-links (Yj) are given as percentages relative to the starting point. The resource sharing (Zk) improvement is left as a ratio because all percentages would be extremely high and it is, thus, more useful to look at how the sharing has multiplied during the optimization. From , it can be observed that there are always savings in the number of coding nodes and these are generally 50% or more. Resource sharing is several times higher and may be improved by an order of magnitude. Mean in-link savings are more variable, approaching nearly 30% at best but sometimes being at or near zero.
TABLE 2 A Most Feasible Individual (Minimal Configuration) of Each Run Compares with a Most Infeasible Individual of its Initial Population Based on Their Fitness. Randomly Selected Runs of Each Project are Shown
CONCLUSIONS
There are many situations where multicast is required and it has historically presented a demanding challenge in terms of network resources such as channel bandwidth and network power. The introduction of network coding offers the prospect of substantial reductions in resource requirements. The solution presented in this work comprises a preliminary process and a GA optimization stage. The former deals with the aspects of path augmentation and linear disjoint path determination and produces a set of possible minimal configurations with optimized coding resources to deliver multicast traffic from the source to multiple sinks. These consist of three features (objectives) that contribute to optimize the network coding resources during multicast transmissions. Searching for the optimum choices of minimal configurations is NP-hard, so heuristic methods are needed. The search space and fitness evaluation processes are extremely complex in this problem, placing restrictions on the complexity of the optimization algorithms that may run within the network. Therefore, two of the classic multiobjective GAs, viz., MOGA and VEGA, were chosen because their searching and implementation complexities are relatively low. The solution philosophy was to identify minimal configurations and choose the best from these, thus sidestepping the difficult task of a full search of the complete solution space.
The performances of the algorithms proposed were investigated by simulating a range of networks of varying sizes. Specifically, for the preliminary processes, path augmentation was undemanding in terms of CPU time, and its operation was largely independent of network size. In contrast, the linear disjoint path algorithm placed greater demands on the CPU as the network size increased, reflecting that its task is more difficult as the network gets larger. Regarding the evolutionary optimization, VEGA (the simpler of the two algorithms) exhibited better performance both in terms of CPU time and searching potential than MOGA for small networks, but this position reversed as the network size grew. We believe this to be a result of the fitness sharing scheme present in MOGA that would not be of great utility for smaller search spaces. Nevertheless, both techniques exhibited good potential for identifying feasible minimal configurations with optimized coding resources. In most cases, there were considerable improvements in fitness by optimization in comparison with randomly chosen starting configurations. All optimized cases delivered savings in the number of coding nodes, typically 50%, and resource sharing was multiplied by several times in addition. Mean in-link savings of typically 10% usually resulted, but the benefits ranged from zero to almost 30%.
Nevertheless, we have shown that relatively simple multiple-objective GAs can deliver optimized minimal coding configurations for the network coding multicast problem. Moreover, the approach here offers an improvement over solutions in the literature because our method remains feasible for relatively large networks, and its implementation at the source simplifies the functions that must be employed at intermediate nodes. The approach taken has shown itself to be of great utility in minimizing complexity and resource demands, laying the foundations for efficient multicast network schemes for future traffic delivery.
FUNDING
This work was supported by EPSRC Grant EP/F033591/1, Network Coding via Evolutionary Algorithms.
REFERENCES
- Ahlswede, R., N. Cai, S.-Y. R. Li, and R. W. Yeung. 2000. Network information flow. IEEE Transactions on Information Theory 46 (4 ):1204 –1216.
- Arabas, J., and S. Kozdrowski. 2001. Applying an evolutionary algorithm to telecommunication network design. IEEE Transactions on Evolutionary Computation 5 (4 ):309 –323.
- Cormen, T. H., C. E. Leiserson, R. L. Rivest, and C. Stein. 2001. Introduction to algorithms. Cambridge, MA: The MIT Press.
- Fragouli, C., and E. Soljanin. 2007. Network coding fundamentals. Foundations and Trends in Networking 2 (1 ):1 –133.
- Ho, T., R. Koetter, M. Médard, D. Karger, and M. Effros. 2003. The benefits of coding over routing in a randomized setting. Paper presented at Proceedings of the IEEE International Symposium on Information Theory, 442. Yokohama, Japan, Jun/July.
- Holland, H. 1975. Adaptation in Natural and Artificial Systems. Ann Arbor, MI: University of Michigan Press.
- Jaggi, S., P. Sanders, P. A. Chou, M. Effros, S. Egner, K. Jain, and L. Tolhuizen. 2005. Polynomial time algorithms for multicast network code construction. IEEE Transactions on Information Theory 51 (6 ):1973 –1982.
- Kavian, Y. S., H. F. Rashvand, W. Ren, M. S. Leeson, E. L. Hines, and M. Naderi. 2007. RWA problem for designing DWDM networks – delay against capacity optimization. Electronics Letters 43 (16 ):892 –893.
- Kim, M., C. W. Ahn, M. Médard, and M. Effros. 2006. On minimizing network coding resources: An evolutionary approach. Network Coding Workshop (NetCod).
- Koetter, R., and M. Médard. 2003. An algebraic approach to network coding. IEEE/ACM Transactions on Networking 11 (5 ):782 –795.
- Konak, A., D. W. Coit, and A. E. Smith. 2006. Multiobjective optimization using genetic algorithms: A tutorial. Reliability Engineering and System Safety 91 (9 ):996 –1007.
- Langberg, M., A. Sprintson, and J. Bruck. 2006. The encoding complexity of network coding. IEEE Transactions on Information Theory 52 (6 ):2386 –2397.
- Langberg, M., A. Sprintson, and J. Bruck. 2009. Network coding: A computational perspective. IEEE Transactions on Information Theory 55 (1 ):147 –157.
- Li, S.-Y. R., N. Cai, and R. W. Yeung. 2003. Linear network coding. IEEE Transactions on Information Theory 49 (4 ):371 –381.
- Mehlhorn, K., and P. Sanders. 2008. Algorithms and data structures. Heidelberg: Springer-Verlag.
- Mitchell, M. 1996. An introduction to genetic algorithms. Cambridge, MA: The MIT Press.
- Richey, M. B., and R. G. Parker. 1986. On multiple Steiner subgraph problems. Networks 16 (4 ):423 –438.
- Vidyarthi, G., A. Ngom, and I. Stojmenovic. 2005. A hybrid channel assignment approach using an efficient evolutionary strategy in wireless mobile networks. IEEE Transactions on Vehicular Technology 54 (5 ):1887 –1895.