
Abstract
This article introduces the Immigrant Population Search Algorithm (IPSA) inspired by the pattern of human population migration to find better habitats. The algorithm is viewed as a new optimization method for solving constrained optimization problems, and it belongs to the set of population-based algorithms that are proposed for combinatorial optimization. In this algorithm, the life environment is the solution space of the problem. Every point of this space is a solution for the problem, which may be feasible or infeasible, and the quality of life at that point is the value of fitness function for that solution. Each population group tries to investigate feasible and better habitats. In other words, it tries to optimize the problem. After the algorithm steps are described, the efficiency of the algorithm is compared to that of three other metaheuristic algorithms that are used to optimize some mathematic problems. The results show that the proposed algorithm performs better than the other three methods.
INTRODUCTION
Constrained optimization issues are used in several applications such as structural optimization, engineering designs, economy, allocation, and location matters. Usually, optimization should be done on complex or hard functions that are mostly multivariable and nonlinear with some constraints. Most of the time, an analytic solution does not exist, or an access to it is very difficult and time consuming. For example, NP-complete or NP-hard problems cannot be solved within a reasonable time when they are large. Using metaheuristic algorithms (Gogna and Tayal Citation2013) is a good way to find an optimal or a near-optimal solution to those problems. Some metaheuristic methods are based on a population of solutions. These methods, which are mostly inspired by natural phenomena, suggest solutions to problems by using swarm intelligence. They can be adjusted to solve constrained problems. Some metaheuristic algorithms that are based on the population of solutions are mentioned below as examples.
Genetic algorithm (GA) is based on the theory of Darwinian evolution and is inspired by genetic and natural evolution (D’Ambrosio et al. Citation2013). In this algorithm, solutions are shown as chromosomes, and the fitness function of the solution represents the quality of the chromosomes. The population of a solution evolves through genetic operators, and a new population is made. There are some methods designed to solve constrained problems by GA (Yeniay Citation2005).
Particle swarm optimization (PSO) is inspired by the social behavior of animals such as schools of fish or flocks of birds that live in groups and search for food together (Lazinica Citation2009; Neri, Mininno, and Iacca Citation2013). In this method, each animal (particle) tries to move in a direction toward where the best individual and group experiences have occurred. For this reason, the velocity of each particle is calculated based on its current position, its best position, and the best position of all the particles. Then, the new position of the particle is calculated. Some surveys were done to adjust PSO to solve constrained problems (Parsopoulos and Vrahatis Citation2002).
Differential evolution (DE) is a stochastic search that uses the distance and direction information of the current population for a search operation. This characteristic makes it different from other methods (Wang et al. Citation2013). Also, DE can solve constrained problems (Mezura-Montes, Velázquez-Reyes, and Coello Coello Citation2006).
Artificial bee colony (ABC) is inspired by the intelligent behavior of honey bees that search for flower nectar (Xiang and An Citation2013). In this method, each solution is a nectar source, and the amount of nectar in each source is the value of the fitness function for that solution. The honey bees search the problem space to find sources with more nectar (better solutions). Also, ABC is capable of adjusting to solve constrained problems (Karaboga and Basturk Citation2007; Stanarevic, Tuba, and Bacanin Citation2011).
Ant colony optimization (ACO) is inspired by the natural behavior of ants that search for food (Dorigo and Stützle Citation2010). In this method, the path of each ant is a solution to the problem. The method uses a factor that is named a pheromone after the natural chemical substances secreted by ants to communicate with each other. The amount of pheromone represents the abundance of selecting a path in previous solutions. This factor and the quality of a partial solution affect the selection of the partial solution. Constrained optimization problems can be solved by ACO, too (Afshar Citation2007).
Imperialist competitive algorithm (ICA) is inspired by the social behavior of imperialist countries that benefit from colony countries (Atashpaz-Gargari and Lucas Citation2007; Abdechiri, Faez, and Bahrami Citation2010). In this algorithm, every solution is a country, and the power of each country is related to its fitness function value. Powerful countries are imperialists, and weak ones are colonies. Each imperialist has some colonies, and the colonies move toward their imperialists and evolve. Also, imperialists compete to capture each other’s colonies, and the algorithm continues until only one imperialist remains. This method can be used for constrained optimization (Zhang, Wang, and Peng Citation2009).
Electromagnetism-like algorithm (EM) is inspired by the physical process of attraction and repulsion between charged particles (Jouzdani, Barzinpour, and Fathian Citation2012). In this algorithm, each solution is a particle, and its fitness function value relates to the amount of its charge. All the particles push one another, and the result of the pushing forces moves the particles. This process usually leads the particles to find better solutions. Also, EM is adjustable to solve constrained problems (Rocha and Fernandes Citation2008).
In this article, a new optimization algorithm inspired by the social behavior of human population groups that migrate to find better habitats is introduced, and the way of using it for constrained optimization is explained. The algorithm, which is based on the population of solutions, is referred to as an Immigrant Population Search Algorithm (IPSA). The structure of this article is as follows. The next section describes “Constrained Optimization” and is followed by an explanation of the “Conceptual Idea of the Proposed Algorithm.” In “Immigrant Population Search Algorithm,” the steps of the algorithm are described, and “Computational Results” compares the performance of the algorithm with three other algorithms. Finally, “Conclusions” presents the results.
CONSTRAINED OPTIMIZATION
A constrained optimization problem is usually written as an optimization problem in the form of Equation (1):
To solve constrained optimization problems, two functions are used: an objective function and a constraint violation function (CV). The value of the constraint violation function is calculated by Equations (3)–(5) (Rocha and Fernandes Citation2008). Considering Equation (1), Equation (3) calculates the constraint violation value for the inequality constraints. Its violation value is equal to zero if the constraint value is less than or equal to zero (i.e., it satisfies the condition), and it is equal to the constraint value (the violation value) if it is more than zero (i.e., it does not satisfy the condition). Also, considering Equation (2), Equation (4) calculates the constraint violation values for the equality constraints. Its violation value is equal to zero if the constraint value is near zero (i.e., it satisfies the condition), and it is equal to the constraint absolute value (the violation value) if its value is far enough from zero (i.e., it does not satisfy the condition). Finally, the sum of the violation values is calculated by Equation (3):
CONCEPTUAL IDEA OF THE PROPOSED ALGORITHM
The geographical area of a land has regions with different living conditions such as availability of water and food, temperature, wind intensity, amount of rainfall, sunshine intensity, fertility of the ground, availability of natural defense, and so forth. As observed in different land areas, some regions have a higher human population density than others. The higher the quality of the habitat is, the higher the human population density. The quality of a habitat is the result of all the living conditions in that place. But some conditions have more effect and some have less.
The focus of population groups in high-quality habitats is the result of settling, eliminating, and searching processes. When a new land is discovered, there is no information about the quality of its regions. So, when the first population groups want to settle in that land, they are randomly distributed on the land and inhabit there. But later, when a new population group wants to settle and inhabit the land, it observes the habitats of the current population groups and, after comparing their qualities, it chooses a place to inhabit in the neighborhood. The higher the relative quality of a habitat is, the higher the chance of selection by a new population group. This process is repeated for all newly arriving population groups.
Another factor that affects human population density is death. Some population groups are eliminated by the death process, and the quality of their habitats has an effect on it. The lower the relative quality of a habitat is, the higher the probability the population group will be eliminated. So, population groups that inhabit in higher quality habitats have a better chance of remaining.
Also, neighborhood searching affects human population density. Current population groups that have survived a death process search the neighborhood of their habitats to find better ones to inhabit. Neighborhood searching process promotes habitats to higher quality regions.
New coming populations are repeated, settled, and eliminated, and searching processes are done regularly. With an increase in the number of repetitions of this cycle, population groups concentrate around the best-quality residential areas of a given land.
IMMIGRANT POPULATION SEARCH ALGORITHM (IPSA)
In this algorithm, the land is the problem’s solution space, and the different living conditions (e.g., availability of water and food, temperature, etc.) are the dimensions of the land. The number of living conditions (dimensions) is represented by m, and the lower and upper limits of the kth dimension are shown as and
, respectively. Each population group lives in a habitat, and each habitat is a solution that has
dimensions. If the solution is shown as
, its elements (dimensions) are shown as
. Also, the life quality of each habitat is the value of the fitness function in that solution and is shown as
.
In each repetition of the algorithm, there are some population groups that currently live on the land and some other groups that come newly to settle there. The ith current population group lives in a habitat (solution) that is shown by , and its life quality (fitness function) is shown as
. Also, the ith new coming population group settles in a habitat (solution), which is shown by
, and its life quality (fitness function) is represented as
.
Overview
The proposed algorithm has the following parameters. The size of the current population, represented by nc, and the size of the new coming population, represented by cc. The total number of iterations is represented by MI, and MR is the modification rate. The number of local search iterations is LI; is equal to the final ratio of the local search domain; and Δ is a value for converting equality constraints to inequality constraints. In the algorithm stages, C is the loop counter, RN is the ratio of the neighborhood domain, RL is the ratio of the local search domain, XRL is the ratio coefficient of the local search domain,
is the current population,
is the new coming population,
is the fitness function of the current population, and
is the fitness function of the new coming population. The main stages of the proposed algorithm are shown in Algorithm 1. According to this algorithm, after initializing, the steps of migrating, eliminating, local searching, and updating are repeated MI times.
Table
In the progress of the proposed algorithm, it is necessary to compare two different solutions to determine the better one. Because the solutions can be feasible or infeasible, direct comparing of objective functions is not correct. So, Deb’s rules (Mezura-Montes, Velázquez-Reyes, and Coello Coello Citation2006) are used instead of that comparison. According to these rules,
any feasible solution is better than any infeasible solution;
among two feasible solutions, the one having a better objective function value is better;
among two infeasible solutions, the one having smaller constraint violation is better.
Initializing
In this stage, the first population groups are established on the vacant land. Thus, according to the lower and upper limits of the problem dimensions, the primary population is randomly created and distributed in the problem space and then RN, RL, and XRL ratios are initialized by Algorithm 2. In this algorithm, U(0,1) is a random real number between 0 and 1. According to the algorithm, XRL ratio is initialized such that, after MI times multiplying, the value of RL reaches the value of
.
Table
Migrating
Each newly arriving population group (
) that decides to settle on the land chooses one of the current population groups by the roulette wheel selection rule and then migrates to its neighborhood. If FXi is the fitness function and CVi is the constraint violation for solution
, then the value of Ki is calculated by Equation (6) for feasible solutions in minimizing problems, the value of Ki is calculated by Equation (7) for feasible solutions in maximizing problems, and the value of Ki is calculated by Equation (8) when the solution is infeasible (Stanarevic, Tuba, and Bacanin Citation2011). Then, using the value of Ki, the selection probability for the ith neighborhood (Pi) is calculated by Equation (9) and, according to this probability, the roulette wheel randomly selects a solution (
) within the population of current solution (
).
Algorithm 3 is used to establish a new population in the neighborhood of the current population. In this algorithm, after selecting a current solution () by the roulette wheel (line 1-1), the new solution (
) is equated to it, and then one of the dimensions (gth dimension) is selected randomly. The gth dimension of the new solution (
) is modified (lines 1-4 to 1-6) considering the neighborhood radius value (R) that is calculated according to the ratio of the neighborhood domain (RN). After this modification, if the value of
is out of the upper or lower limits of the problem dimensions, it will be equated to the limit (lines 1-7 and 1-8). The value of fitness function (FYi) is calculated then. This cycle is repeated for
times to create a new population.
Table
Eliminating
To prevent enlargement of the problem, the size of the population must be kept constant; some of the weak solutions, thus, must be eliminated. Accordingly, population is defined as the union of the two populations
(current population) and
(new coming population). So, population
has
members, and
is the fitness function of its ith member. To eliminate weak solutions,
members from population
are selected, and the remaining members are eliminated. The best solution of population
is always selected, but other nc-1 solutions whose selection probability is proportional to their quality (objective function value) are selected randomly.
In this part, the best solution in population is selected according to Deb’s rules and, after eliminating it from this population, it is added to empty population
. Then, for nc-1 times, by using the roulette wheel selection rule (as what is done in “Migrating”), a solution is selected from population
and, after eliminating it from this population, it is added to population
. Finally, the members of population
are replaced by the members of population
, and then population
is removed.
Local Searching
Local search can improve the solutions. In this part, the algorithm can take two policies. The first policy is that the local search be done in each iteration for all the current population solutions. The second policy is that the local search be done in each iteration only for the best solution of the current population. By the first policy, rather than the second one, better solutions are obtained, but more computing time is taken.
Local searching is the repetition of a process that includes finding a neighbor for the solution, comparing the neighbor with the solution, and replacing the solution with the neighbor if it is better. The steps of the local search are shown in Algorithm 4. In this algorithm, is the current solution that the local search is searching. At first, the neighbor solution (
) is equated to the current solution (
). Then, all of its dimensions are surveyed, and each dimension is selected with the probability MR to modify. The modification (lines 1-2-2-1 to 1-2-2-3) considers the neighborhood radius value (R) that is calculated according to the ratio of the local search domain (RL). The surveyed dimension of the neighbor solution (
) is then checked not to be out of the upper limit (Uk) or the lower limit (Lk) of that dimension. If it is, then it will be equated to that limit. After surveying all the dimensions, the fitness function is calculated for the neighbor solution. If the neighbor solution (
) is better (Deb’s rules) than the current solution (
), it will be replaced. Otherwise, it will be ignored. These steps are repeated LI times.
Table
Updating
To reach a convergence in the population of the solutions, the ratio of the neighborhood domain must be decreased. Also, the ratio of the local search domain must be decreased by the algorithm progress in order to focus on a solution region and to find a more accurate solution. The experimental computations show that when the ratio of the neighborhood domain decreases linearly and the ratio of the local search domain decreases geometrically, better solutions are obtained. So, according to Equations (10)–(11), the ratios are decreased. In the equation, C is the number of the algorithm iterations.
Convergence of the Algorithm
The proposed algorithm structure has three factors that create a scatter in the solution’s population, but the effects of these factors decrease with the algorithm’s progress, as described below.
Primary population: the primary population is scattered randomly in the solution space, but, with the progress of the algorithm, the new solutions are created nearby the better previous solutions, and they are finally pulled toward the best solution.
Finding neighbors: because the radius of the neighborhood is descending, it is expected that, with the algorithm’s progress, the neighbors will not scatter far from the solutions but rather focus around them.
Local search: the radius of finding neighbors in the local search is also descending. So, with the progress of the algorithm, the local search does not find the solutions far from their previous locations.
So, with the algorithm’s progress, it seems that the solutions are converged nearby the best solution of the population.
COMPUTATIONAL RESULTS
To show the performance of the proposed algorithm (IPSA) in solving constrained optimization problems, thirteen sample problems that have been surveyed by other researchers are given from Runarsson and Yao (Citation2000) and used. Each of these problems is a nonlinear programming problem that has some equality and inequality constraints with an objective function that should be maximized or minimized. These problems have been solved 30 times by the IPSA method. presents the results including the mean, best, worst, and standard deviation of the objective function’s values. In this table, the bold numbers are the values that reach the problem’s optimal value. As can be seen, the mean, best, and worst values reach the problem’s optimal value for five, six, and five times, respectively. Also, the solutions converge for problems g03, g04, g06, g08, g11, and g12 (the value of their standard deviation is near zero).
TABLE 1 Results of Solving Sample Problems by IPSA
The results are compared with the results of solving those problems 30 times by PSO (Muñoz Zavala, Aguirre, and Villa Diharce Citation2005), DE (Rocha and Fernandes Citation2008), and EM (Rocha and Fernandes Citation2008) methods shown in to . In each row of these tables, the bold numbers are the best values in that row.
TABLE 2 Mean Solutions Obtained by IPSA and Three Other Methods
As to suggest, some of the results are better than the problem’s optimal value. This difference is because of the error that results when equality constraints are converted to inequality constraints. In the IPSA, the local search is done for all the current population, and the parameters are determined by a trial-and-error method as follows: ,
,
,
,
,
, and the total iteration value emerges in such a way that the total number of objective function evaluations (240,000) is equal to that for other methods (350,000 times for PSO and 240,000 times for DE and EM). This is also in order for the methods to compete with one another in equal conditions.
shows the mean values of the solutions obtained by the IPSA method and compares them with those obtained by the three other methods. As can be seen, these values that are the results of PSO, DE, EM, and IPSA are the best values for eight, seven, four, and six times, respectively, whereas DE solutions are infeasible at least one time during 30 times of solving the g06 problem.
shows the best solutions obtained by PSO, DE, EM, and IPSA methods in 30 times of problem solving. As can be seen, these values are the best for seven, nine, six, and eight times, respectively.
TABLE 3 Best Solutions Obtained by IPSA and Three Other Methods
The worst solutions obtained by PSO, DE, EM, and IPSA methods in 30 times of problem solving are shown in . As can be seen, these values are the best for eight, seven, three, and seven times, respectively.
TABLE 4 Worst Solutions Obtained by IPSA and Three Other Methods
To compare the performance of IPSA with that of the three other mentioned methods, an error index is defined as Equation (12). In this equation, Y is the value of the solution that is obtained by a method, YB is the best value, and YW is the worst value among the values that result from the methods for the problem.
For example, for problem g01 in , the best value and the worst values are −14.800 and −14.555, respectively. So the value of the error index for the PSO method (the solution value of which is −14.710) is 0.3673.
shows the values of the error index for the mean of the solutions obtained by IPSA and the other three methods. This table results from . Because the DE algorithm could not obtain a feasible solution for problem g06, a penalty value 2 is assigned to its error index in .
TABLE 5 Error Index of the Mean Solutions Obtained by IPSA and the Other Three Methods
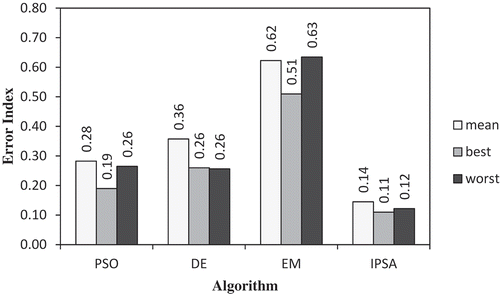
Calculating the error index is done also for the best of solutions (resulting from ) and the worst of solutions (resulting from ) as what is done for the mean of solutions. The average of the mean, best, and worst of the calculated error index values are shown and compared in . As shown, the IPSA method results in the lowest error index for all the three mean solutions, best solution, and worst solution.
FIGURE 1 Comparing the average of the error index values of IPSA and those of three other methods.
CONCLUSION
In this article, inspired by the migration model of human population groups, the use of an Immigrant Population Search Algorithm for constrained optimization problems is introduced for the first time. The steps of the algorithm include initializing, finding a neighborhood to establish a new population, eliminating weak solutions, replacing the remaining solutions as a current population, and a local search for improving the current solutions. In order to show the performance of this algorithm, thirteen sample problems were solved by the algorithm, and the results—including the mean, best, and worst of the solutions—are compared with the results obtained by solving those problems using PSO, DE, and EM optimization methods through defining an error index. The results show that the proposed method (IPSA) has the lowest error index for all the three means of the solutions, the best solution, and the worst solution.
REFERENCES
- Abdechiri, M., K. Faez, and H. Bahrami. 2010. Adaptive imperialist competitive algorithm (AICA). Paper presented at the 9th IEEE International Conference on Cognitive Informatics (ICCI), Beijing, China, July.
- Afshar, M. H. 2007. Partially constrained ant colony optimization algorithm for the solution of constrained optimization problems: Application to storm water network design. Advances in Water Resources 30(4):954–965.
- Atashpaz-Gargari, E., and C. Lucas. 2007. Imperialist competitive algorithm: An algorithm for optimization inspired by imperialistic competition. Paper presented at the IEEE Congress on Evolutionary Computation (CEC), Singapore, September.
- D’Ambrosio, D., W. Spataro, R. Rongo, and G. G. R. Iovine. 2013. Genetic algorithms, optimization, and evolutionary modeling. In Treatise on geomorphology. San Diego, CA, USA: Academic Press.
- Dorigo, M., and T. Stützle. 2010. Ant colony optimization: Overview and recent advances. In Handbook of metaheuristics, 227–263. New York, NY, USA: Springer.
- Gogna, A., and A. Tayal. 2013. Metaheuristics: Review and application. Journal of Experimental & Theoretical Artificial Intelligence 25(4): 503–526.
- Jouzdani, J., F. Barzinpour, and M. Fathian. 2012. An improved electromagnetism-like algorithm for global optimization. Paper presented at 42nd Conference on Computers and Industrial Engineering, Cape Town, South Africa, July.
- Karaboga, D., and B. Basturk. 2007. Artificial bee colony (ABC) optimization algorithm for solving constrained optimization problems. In Foundations of fuzzy logic and soft computing. Berlin, Heidelberg: Springer.
- Lazinica, A. 2009. Particle swarm optimization. InTech. Available at http://www.intechopen.com/books/particle_swarm_optimization.
- Mezura-Montes, E., J.Velázquez-Reyes, and C. A. Coello Coello. 2006. Modified differential evolution for constrained optimization. Paper presented at IEEE Congress on Evolutionary Computation (CEC), Vancouver, Canada, July.
- Muñoz Zavala, A. E., A. H. Aguirre, and E. R. Villa Diharce. 2005. Constrained optimization via particle evolutionary swarm optimization algorithm (PESO). Paper presented at Proceedings of the 2005 Conference on Genetic and Evolutionary Computation, Washington, DC, USA, June.
- Neri, F., E. Mininno, and G. Iacca. 2013. Compact particle swarm optimization. Information Sciences 239:96–121.
- Parsopoulos, K. E., and M. N. Vrahatis. 2002. Particle swarm optimization method for constrained optimization problems. Intelligent Technologies–Theory and Application: New Trends in Intelligent Technologies 76:214–220.
- Rocha, A. M. A. C., and E. M. G. P. Fernandes. 2008. Feasibility and dominance rules in the electromagnetism-like algorithm for constrained global optimization. In Computational science and its applications–ICCSA 2008, LNCS. Berlin, Heidelberg: Springer.
- Runarsson, T. P., and X. Yao. 2000. Stochastic ranking for constrained evolutionary optimization. IEEE Transactions on Evolutionary Computation 4(3):284–294.
- Stanarevic, N., M. Tuba, and N. Bacanin. 2011. Modified artificial bee colony algorithm for constrained problems optimization. International Journal of Mathematical Models and Methods in Applied Sciences 5(3):644–651.
- Wang, C.-X., C.-H. Li, H. Dong, and F. Zhang. 2013. An efficient differential evolution algorithm for function optimization. Information Technology Journal 12(3):444–448.
- Xiang, W.-L., and M.-Q. An. 2013. An efficient and robust artificial bee colony algorithm for numerical optimization. Computers & Operations Research 40(5):1256–1265.
- Yeniay, Ö. 2005. Penalty function methods for constrained optimization with genetic algorithms. Mathematical and Computational Applications 10(1):45–56.
- Zhang, Y., Y. Wang, and C. Peng. 2009. Improved imperialist competitive algorithm for constrained optimization. Paper presented at International Forum on Computer Science-Technology and Applications (IFCSTA), Chongqing, China, December.