
Abstract
Feature selection in high-dimensional data is one of the active areas of research in pattern recognition. Most of the algorithms in this area try to select a subset of features in a way to maximize the accuracy of classification regardless of the number of selected features that affect classification time. In this article, a new method for feature selection algorithm in high-dimensional data is proposed that can control the trade-off between accuracy and classification time. This method is based on a greedy metaheuristic algorithm called greedy randomized adaptive search procedure (GRASP). It uses an extended version of a simulated annealing (SA) algorithm for local search. In this version of SA, new parameters are embedded that allow the algorithm to control the trade-off between accuracy and classification time. Experimental results show supremacy of the proposed method over previous versions of GRASP for feature selection. Also, they show how the trade-off between accuracy and classification time is controllable by the parameters introduced in the proposed method.
INTRODUCTION
In recent years, increasing growth of machine readable data (digital information) has led to new challenges for machine learning algorithms. Nowadays, many tasks in machine learning such as clustering, classification, and regression deal with huge datasets. In these tasks, a machine learning algorithm should analyze the related datasets entirely and fit them to a model. The huge size of most datasets generally leads to unacceptable process time or intractable complexity. The size of a dataset depends on the number of its instances and the dimensionality of feature space. Dimensionality of a dataset is the same as the number of features that describe each instance. Therefore, reduction of the number of dataset instances and features are two main problems to consider in reducing the size of datasets. Sampling methods can be used to reduce the number of instances.
Dimension reduction is the process of transforming a feature space to another one with lower dimensionality. Dimension reduction is divided into two main categories: transformation-based dimension reduction and selection-based dimension reduction. Principal component analysis (PCA) is an efficient and well-known transformation-based dimension reduction method. Feature selection is a type of dimension reduction in which the meaning of the features after reduction is similar to the original features. Benefits of feature selection include reducing data processing time, improving the accuracy of machine learning tasks such as classification and regression, and making the data available in a more compact and more understandable form. Usually, redundant and irrelevant features increase the complexity of the learning process. Knowledge discovery in a large dataset is more difficult and sometimes intractable.
In high-dimensional datasets, drawbacks of redundant and irrelevant features become even more critical. In this case, feature selection is almost unavoidable. In this study, a new feature selection method for high-dimensional data is proposed.
FEATURE SELECTION
Given a dataset with n features, there are 2n−1 nonempty feature subsets, each with the potential to become the optimal subset for representing that dataset within the specific problem area. Subset generator and subset evaluator are main components of a feature selection method. Hence, feature selection methods can be distinguished from each other according to these components.
Subset generator is equivalent to a searching method that determines the sequence of subset evaluations. By definition, the best subset generator reaches to optimal feature subset as fast as possible. There is no unique method with optimal performance for all problem areas.
Subset evaluator is the second component of a feature selection method. It determines the merit of each feature subset. Ideally, it should assign the best merit to the optimal feature subset, which contains the most relevant features to the target feature and excludes irrelevant and redundant features as much as possible. The overall procedure of feature selection is depicted in .
FIGURE 1 Overall procedure of feature selection.
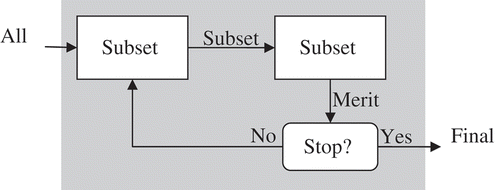
There are three types of feature selection methods: filters, wrappers, and hybrids (or embedded). Most filter methods use measures that usually have a background in statistics or information theory. Feature subsets are not directly scored by fitting a model on them and measuring accuracy or error rate of the model. Data variance, correlation coefficient, Fisher score (Chen and Li Citation2010; Chen and Lin Citation2006), and chi-squared (Hoel Citation1984) are statistical filter measures, and mutual information (Estévez et al. Citation2009; Novovičová et al. Citation2007), max-dependency, max-relevance, min-redundancy (Peng, Long, and Ding Citation2005), information gain (Liu and Yu Citation2005), and gain ratio (Duda, Hart, and Stork Citation2001) are some of the information-theory-based measures. Filter measures are not limited to these two categories, and some other kinds of measures exist such as class separability (Liu and Zheng Citation2006) and RELIEF measure (Dash and Liu Citation1997). Ratanamahatana and Gunopulos (Citation2003) proposed a simple method that uses a filter method implicitly. They trained a C4.5 decision tree on the training set and then trained a new classifier named selective Bayesian classifier (SBC) that uses features selected by the C4.5 decision tree. They claimed that SBC outperforms naïve Bayes and C4.5 classifiers.
Wrappers use predictors and fit models on data to evaluate feature subsets. They need to train a predictor (classifier or regression model) to evaluate each feature subset; therefore, they are more precise but slower than the filters. The main challenges in wrapper methods are selecting a proper predictor (Li et al. Citation2009; Maldonado and Weber Citation2009; Monirul Kabir, Monirul Islam, and Murase Citation2010; Sánchez-Maroño and Alonso-Betanzos Citation2011) and how to generate appropriate subsets (Macas et al. Citation2012; Tay and Cao Citation2001; Vignolo, Milone, and Scharcanski Citation2013). Finally, hybrid methods use both filter and wrapper evaluators simultaneously (Bermejo et al. Citation2012; Bermejo, Gámez, and Puerta Citation2011; Gheyas and Smith Citation2010; Ruiz et al. Citation2012). In the hybrid approaches, filter measures are usually used when a rough evaluation is acceptable, and the wrapper evaluator is utilized when more precise evaluation is needed. Hybrid approaches are meant to establish an intermediate solution by combining the advantages of filters and wrappers and managing a trade-off between speed and precision.
RELATED WORKS
In many real-world applications such as bioinformatics (Armananzas et al. Citation2011; García-Torres et al. Citation2013; Akand, Bain, and Temple Citation2010), medicine (da Silva et al. Citation2011), text mining (Azam and Yao Citation2012; Feng et al. Citation2012; Meng, Lin, and Yu Citation2011; Pinheiro et al. Citation2012; Uğuz Citation2011; Imani, Keyvanpour, and Azmi Citation2013), image processing (Jia et al. Citation2013; Rashedi, Nezamabadi-pour, and Saryazdi Citation2013; Vignolo, Milone, and Scharcanski Citation2013) remote sensing (Ghosh, Datta, and Ghosh et al. Citation2013; Guo et al. Citation2008; Li et al. Citation2011) and other domains (Pérez-Benitez and Padovese Citation2011; Wu et al. Citation2010; Zhang et al. Citation2011; Waad, Ghazi, and Mohamed Citation2013), the dimensionality of data are so high that they may lead to the breakdown of an ordinary feature selection algorithm. High dimensionality of the data asks for the development of more complicated methods to apply feature selection on a large number of features.
In addition, in many data analysis tasks, multiple interacting features are ignored assuming independency between features or considering only pair-wise features interaction (Zhanga, Chena, and Zhoub Citation2008). Zhang and Hancock (Citation2012) address the problem of considering multiple interacting features in high-dimensional datasets. Their work was inspired by studies on hypergraph clustering to evaluate feature subsets. They proposed a new evaluation measure based on information theory called multidimensional interaction information (MII) that determines significance of different conditional feature subsets with respect to the decision feature. In the case of datasets with a combination of nominal and numerical features, Michalak et al. (Citation2011) proposed a new feature similarity measure based on the probabilistic dependency between features.
A considerable number of the reported works concentrate on efficient search in feature subsets space. Each point in feature subsets space is a subset of features. Ahila, Sadasivam, and Manimala (Citation2012), proposed an evolutionary algorithm based on particle swarm optimization (PSO) to perform simultaneous feature and model selection. They used a probabilistic neural network as the classifier and PSO as the searching algorithm to explore feature subset space and model parameters. Bermejo, Gámez, and Puerta (Citation2011) proposed a new search method that reduces the number of wrapper evaluations by iteratively switching between filter and wrapper evaluations. Their method is based on the Greedy Randomized Adaptive Search Procedure (GRASP) metaheuristic algorithm. GRASP is a two-step iterative algorithm in which in each iteration a solution is initially constructed and is improved later. In this algorithm, in the construction step, evaluation is carried out using a lighter filter measure, while during the improvement step a more costly wrapper measure is utilized.
Bermejo, Gámez, and Puerta (Citation2011) proposed a new combinatorial method. Their algorithm iteratively switches between filter and wrapper evaluators. It uses a filter evaluator for constructing a ranked list of the features and considers the first block of the ranked features as selected candidates for inclusion in the wrapper evaluator’s selected features. The algorithm stops when there are no new feature candidates for inclusion in the wrapper evaluator’s feature selection.
GRASP FOR FEATURE SELECTION (FCGRASP)
Feature selection can be formulated as an optimization problem. In this case, feature selection is a search procedure for finding a subset of conditional features with the most relevancies to the target feature. This section is devoted to reviewing the application of GRASP for feature selection in high-dimensional data.
GRASP is a two-phase optimization algorithm introduced by Feo and Resende (Citation1989). Extensions of this algorithm and its applications can be found in their subsequent works (Feo and Resende Citation1995; Festa and Resende Citation2010; Resende and Ribeiro Citation2010). The two phases of the GRASP include
Construction phase: in this phase, a greedy randomized heuristic algorithm is used to construct a solution with which to begin. The process starts from an empty set and enlarges the set by selecting items from a randomly selected list of promising candidates.
Improvement phase: here, the algorithm improves the output of the construction phase using a local search algorithm. The constructed solution is fed to the local search algorithm as an initial point.
GRASP is an iterative algorithm. During each iteration, after the completion of these phases, both the constructed and the improved solutions are added to nondominated solutions. The nondominated solutions set is a set of solutions in which no item has a complete priority over any other one. This is because in GRASP we are dealing with a multiobjective optimization problem.
Bermejo, Gámez, and Puerta (Citation2011) introduced FCGRASP, a new search method for feature selection in high-dimensional data that reduces the number of wrapper evaluations by alternatively switching between filter and wrapper evaluations. Their proposed method is based on the GRASP metaheuristic algorithm. It is a two-step iterative algorithm in which, in each iteration, a solution is constructed and then improved. In this algorithm, evaluation process in the construction phase is performed using a lighter filter measure while improving the constructed solution is performed using a costly wrapper. This algorithm is depicted in .
FIGURE 2 GRASP algorithm for feature selection (FCGRASP).

The GRASP algorithm for feature selection has two input parameters: 1-Size: determines the number of features to be considered at each iteration, and 2- NumIter: determines how many iterations the algorithm needs. The only output variable of the algorithm is a set of nondominated solutions (NDS). A set of solutions is said to be nondominated if no member of the set is dominated by another in terms of length and precision simultaneously.
The first part of the algorithm is the initialization presented in lines 7–11 of the algorithm. At this stage, NDS is initialized to be empty and a probability is assigned to each feature. These probabilities are proportionate to predictability of a decision feature (class label or target feature) based on each conditional feature. In other words, each assigned probability is proportionate to the relevancy of the conditional feature and the decision feature. This relevancy can be evaluated by any filter or wrapper measure and stored in ProbSel array of variables.
After initialization, construction and improvement phases are performed iteratively (lines 13 to 29). Each iteration starts with the construction phase and ends after the improvement phase. The number of iterations is determined by NumIter parameter. In the construction phase (lines 15 to 24), a subset of features is randomly sampled from the set of all features. The chance of selecting feature Xi is proportionate to ProbSel[i]. The number of selected features is determined by the Size parameter and the subset is stored in the Subset variable. The Subset variables comprise an unsorted set; therefore, its features are sorted and stored in a new list R. The final step of the construction phase is to add features to the solution subset S incrementally. Initially, S contains only the best feature of R. Then, from the second features to the last, all features are checked, and if a feature improves the accuracy of classification, it is added to S.
The improvement phase is performed at the second part of the iteration. This phase is performed if and only if there are no solutions in NDS to dominate the last solution S constructed during the same iteration. Consequently, a new constructed solution is added to the NDS and the improvement phase begins. During the improvement phase, a local search algorithm is applied to the current solution S. There are several options, one of which is to search locally using methods such as hill climbing, simulated annealing (SA) and genetic algorithms (GA). In their reported work, Bermejo, Gámez, and Puerta (Citation2011) used a hill climbing algorithm for the improvement phase.
THE PROPOSED METHOD
There are some drawbacks in using hill climbing as the choice for the local search algorithm. In this section, a new method based on GRASP is proposed that uses an adopted version of SA for the improvement phase. The extended version of SA is presented in . Compared against the hill climbing algorithm, advantages of the proposed SA-based improvement phase include the following:
It is more likely to escape the local minimums in SA whereas there is no chance to escape in hill climbing.
FIGURE 3 An extended version of SA used in the improvement phase.

In each iteration, SA needs only one wrapper evaluation whereas hill climbing needs to evaluate all successor states. The number of all successors of each state is proportionate to the number of features in Xnds. Here, each successor state is constructed by adding a feature from Xnds to the current state or by removing a feature from the current state. It allows SA to have more steps than hill climbing and further exploration.
As the most important characteristic for this version of SA, it is made possible to implicitly control the trade-off between the length of the solution (number of finally selected features) and the precision of the results. In the proposed version of SA, there is a parameter to control the length of the solution.
The pseudocode of the proposed version of SA algorithm is shown in .
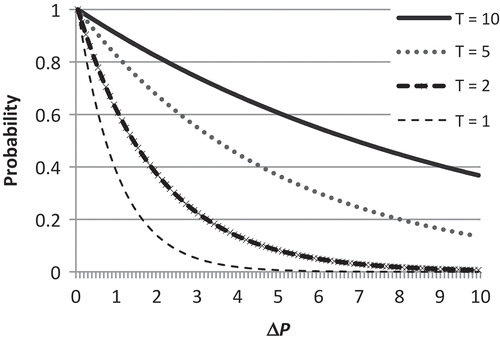
The algorithm starts with initialization at lines 9 and 10. In these lines, the current state of the algorithm Sol is initialized to specified input parameter S which determines the start of the search point, and then the merit of Sol calculates and stores in CurPrecision. Lines 11 to 25 represent the iterative part of the algorithm. The number of iterations is determined by NumIter parameter. Iteration consists of two steps: (1) constructing a successor state, and (2) acceptance or rejection of the constructed state. In the first step, the successor state is constructed by randomly adding one of features from Xnds that currently does not exist in the current state or by randomly removing a feature from the current state (lines 13 to 16). In the second step, the algorithm decides whether to accept or reject the new state. If the successor state S′ is better than the current state Sol, the current state is replaced with its successor, otherwise, replacement may occur with a probability proportionate to the current iteration of the algorithm and the difference between quality of these two states (CurPrecision-AuxPrecision or ΔP). The diagrams in show how acceptance probability changes against ΔP for different values of T. T is a variable that has maximum value k_temperature at the start of the algorithm and linearly decreases to 0 while algorithm approaches to the end. When T is high, it is more likely to accept worse states, and when it reaches to its minimum 0, there is no chance for worse states to be selected.
FIGURE 4 The acceptance probability against ΔP in the proposed SA.
Using this version of SA in the improvement phase of GRASP algorithms results in a new algorithm referred to as SAGRASP in what follows.
EXPERIMENTAL RESULTS
In this section, the results of comparing GRASP and SAGRASP are presented. The experiments reported are meant to compare the precision and speed of GRASP and SAGRASP, and also investigate the effect of SAGRASP parameters in implicitly controlling the size of the selected subset.
Experiment Setup and Datasets
Experiments are performed on 9 high-dimensional datasets (Feature Selection Datasets 2013Footnote1; UCI Machine Learning Repository 2013Footnote2) selected from different areas such as cancer prediction based on mass spectrometry, and text classification. Also, they are diverse enough in different aspects such as number of instances, number of features, and number of classes. Their characteristics are listed in .
TABLE 1 Characteristics of the Datasets
Algorithms are implemented in MATLAB 2010a on a PC with Intel Core2Due CPU 2.8 GHz and 2GB RAM. All wrapper evaluations are performed by embedded functions in MATLAB 2010a for training and testing decision trees. The output of each wrapper evaluation is the average accuracy obtained by 10 decision trees that trained independently.
TABLE 2 The Accuracy, Runtime, and Parameters Set for FSGRASP and SAGRASP
Experiment 1: FSGRASP vs. SAGRASP
shows the results of running FSGRASP and SAGRASP on 9 datasets introduced in . Columns 3 and 4 show average accuracy of these two algorithms in 10 runs over the specified datasets. Columns 5 and 6 show the average runtime in seconds. The last five columns show parameter values used in algorithms. While Size and NumIter are used in both, K_temp and P_add, SA_iter is used only in SAGRASP. These parameters were explained in previous sections (see algorithms in and ). Time complexity of both algorithms is proportionate to
As seen in , SAGRASP outperforms FSGRASP significantly on CB and TOX datasets and slightly on ARC dataset. Over other datasets, there is no preference between algorithms. With respect to runtime, FSGRASP outperforms SAGRASP in almost all cases, but it is not too important because as the number of features increases, the difference between runtime of algorithms decreases. For example, FSGRASP is 13.8 times faster than SAGRASP over the smallest dataset CB, but in datasets with a higher number of dimensions such as ORL, CLL, and GLI there is no significant difference between the two algorithms.
Experiment 2: Trade-Off Between Accuracy and Runtime
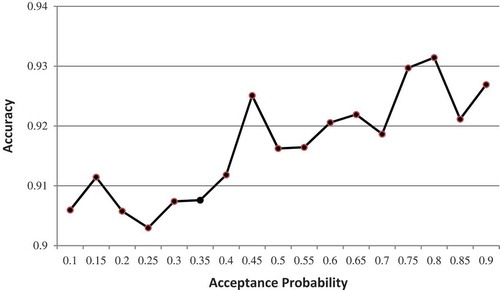
The results of the GRASP algorithm for feature selection in high-dimensional datasets show its superiority over a wide range of feature selection methods as presented in (Bermejo, Gámez, and Puerta Citation2011). The main superiority of SAGRASP over GRASP is not in accuracy improvement, but in its capability to explicitly control the trade-off between accuracy and runtime. This capability is related to P_add parameter of the proposed algorithm. shows the effect of P_add on accuracy over the ARC dataset. As depicted in , there is a high correlation between P_add and accuracy such that as P_add increases, the accuracy also increases.
FIGURE 5 The effect of acceptance probability on accuracy over the ARC dataset.
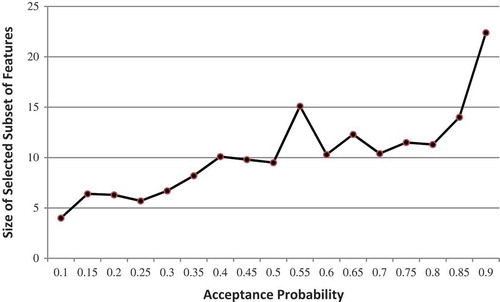
shows a similar relationship between P_add and the size of the selected subset of features.
FIGURE 6 The effect of acceptance probability on the size of the selected subset of features over the ARC dataset.
CONCLUSIONS AND FUTURE WORKS
In this article, a new feature selection algorithm for high-dimensional datasets, named SAGRASP, was proposed. It uses the GRASP algorithm as its basic framework and applies it with an extended version of SA as a local search algorithm. The proposed algorithm has two advantages over FSGRASP: better accuracy and controllability. SAGRASP outperforms FSGRASP significantly over two datasets. It has a P_add parameter to control the trade-off between accuracy and classification time.
Although the proposed method can implicitly control the trade-off between accuracy and classification time, it is still unable to control it explicitly. In other words, it is possible to increase or decrease the number of selected features by changing P_add parameter, but it is not clear how P_add must be set in order to obtain a specific number of features. An open line of research is to extend the proposed method in order to perform the control explicitly.
Notes
1 http://featureselection.asu.edu/datasets.php, retrieved September 21, 2013.
2 http://archive.ics.uci.edu/ml/datasets.html September 21, 2013.
REFERENCES
- Ahila, R., V. Sadasivam, and K. Manimala. 2012. Particle swarm optimization-based feature selection and parameter optimization for power system disturbances classification. Applied Artificial Intelligence 26(9):832–861.
- Akand, E., M. Bain, and M. Temple. 2010. Learning with gene ontology annotation using feature selection and construction. Applied Artificial Intelligence 24(1–2):5–38.
- Armananzas, R., Y. Saeys, I. Inza, M. Garcia-Torres, C. Bielza, Y. van de Peer, and P. Larranaga. 2011. Peakbin selection in mass spectrometry data using a consensus approach with estimation of distribution algorithms. IEEE/ACM Transactions on Computational Biology and Bioinformatics 8(3):760–774.
- Azam, N., and J. T. Yao. 2012. Comparison of term frequency and document frequency based feature selection metrics in text categorization. Expert Systems with Applications 39(5): 4760–4768.
- Bermejo, P., L. de la Ossa, J. A. Gámez, and J. M. Puerta. 2012. Fast wrapper feature subset selection in high-dimensional datasets by means of filter re-ranking. Knowledge-Based Systems 25(1):35–44.
- Bermejo, P., J. A. Gámez, and J. M. Puerta. 2011. A GRASP algorithm for fast hybrid filter-wrapper) feature subset selection in high–dimensional datasets. Pattern Recognition Letters 32(5):701–711.
- Chen, F.-L., and F.-C. Li. 2010. Combination of feature selection approaches with SVM in credit scoring. Expert Systems with Applications 37(7):4902–4909.
- Chen, Y.-W., and C.-J. Lin. 2006. Combining SVMs with various feature selection strategies (Vol. 207): Berlin, Heidelberg: Springer.
- da Silva, S. F., M. X. Ribeiro, J. E. S. Batista Neto, C. Traina Jr., and A. J. M. Traina. 2011. Improving the ranking quality of medical image retrieval using a genetic feature selection method. Decision Support Systems 51(4):810–820.
- Dash, M., and H. Liu. 1997. Feature selection for classification. Intelligent Data Analysis 1(1–4):131–156.
- Duda, R. O., P. E. Hart, and D. G. Stork. 2001. Pattern classification (2nd ed.). New York, NY: John Wiley and Sons.
- Estévez, P. A., M. Tesmer, C. A. Perez, and J. M. Zurada. 2009. Normalized mutual information feature selection. IEEE Transactions on Neural Networks 20(2):189–201.
- Feng, G., J. Guo, B.-Y. Jing, and L. Hao. 2012. A Bayesian feature selection paradigm for text classification. Information Processing & Management 48(2):283–302
- Feo, T. A., and M. G. C. Resende. 1989. A probabilistic heuristic for a computationally difficult set covering problem. Operations Research Letters 8(2):67–71.
- Feo, T. A., and M. G. C. Resende. 1995. Greedy randomized adaptive search procedures. Journal of Global Optimization 6(2):109–133.
- Festa, P., and M. G. C. Resende. 2010. Effective application of GRASP. In Wiley encyclopedia of operations research and management sciences 3:1609–1617. Wiley.
- García–Torres, M., R. Armañanzas, C. Bielza, and P. Larrañaga. 2013. Comparison of metaheuristic strategies for peakbin selection in proteomic mass spectrometry data. Information Sciences 222:229–246.
- Gheyas, I. A., and L. S. Smith. 2010. Feature subset selection in large dimensionality domains. Pattern Recognition 43(1):5–13.
- Ghosh, A., A. Datta, and S. Ghosh. 2013. Self-adaptive differential evolution for feature selection in hyperspectral image data. Applied Soft Computing 13(4):1969–1977.
- Guo, B., R. I. Damper, S. R. Gunn, and J. D. B. Nelson. 2008. A fast separability-based feature-selection method for high-dimensional remotely sensed image classification. Pattern Recognition 41(5):1653–1662.
- Hoel, P. G. 1984. Introduction to mathematical statistics (5th Ed.). New York, NY: John Wiley and Sons.
- Imani, M. B., M. R. Keyvanpour, and R. Azmi. 2013. A novel embedded feature selection method: A comparative study in the application of text categorization. Applied Artificial Intelligence 27(5):408–427.
- Jia, J., N. Yang, C. Zhang, A. Yue, J. Yang, and D. Zhu. 2013. Object-oriented feature selection of high spatial resolution images using an improved relief algorithm. Mathematical and Computer Modelling 58(3–4):619–626.
- Li, S., H. Wu, D. Wan, and J. Zhu. 2011. An effective feature selection method for hyperspectral image classification based on genetic algorithm and support vector machine. Knowledge-Based Systems 24(1):40–48.
- Li, Y., J. L. Wang, Z.-H. Tian, T.-B. Lu, and C. Young. 2009. Building lightweight intrusion detection system using wrapper-based feature selection mechanisms. Computers & Security 28(6):466–475.
- Liu, H., and L. Yu. 2005. Toward integrating feature selection algorithms for classification and clustering. IEEE Transactions on Knowledge and Data Engineering 17(4):491–502.
- Liu, Y., and Y. F. Zheng. 2006. FS_SFS: A novel feature selection method for support vector machines. Pattern Recognition 39(7):1333–1345.
- Macas, M., L. Lhotska, E. Bakstein, D. Novak, J. Wild, T. Sieger, … R. Jech. 2012. Wrapper feature selection for small sample size data driven by complete error estimates. Computer Methods and Programs in Biomedicine 108(1):138–150.
- Maldonado, S., and R. Weber. 2009. A wrapper method for feature selection using support vector machines. Information Sciences 179(13):2208–2217.
- Meng, J., H. Lin, and Y. Yu. 2011. A two-stage feature selection method for text categorization. Computers & Mathematics with Applications 62(7):2793–2800.
- Michalak, K., H. Kwasnicka, E. Watorek, and M. Klinger. 2011. Selection of numerical and nominal features based on probabilistic dependence between features. Applied Artificial Intelligence 25(8):746–767.
- Monirul Kabir, Md., Md. Monirul Islam, and K. Murase. 2010. A new wrapper feature selection approach using neural network. Neurocomputing 73(16–18):3273–3283.
- Novovičová, J., P. Somol, M. Haindl, and P. Pudil. 2007. Conditional mutual information based feature selection for classification task. Berlin, Heidelberg: Springer.
- Peng, H., F. Long, and C. Ding. 2005. Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(8):1226–1238.
- Pérez-Benitez, J. A., and L. R. Padovese. 2011. Feature selection and neural network for analysis of microstructural changes in magnetic materials. Expert Systems with Applications 38(8):10547–10553.
- Pinheiro, R. H. W., G. D. C. Cavalcanti, R. F. Correa, and T. I. Ren. 2012. A global-ranking local feature selection method for text categorization. Expert Systems with Applications 39(17):12851–12857.
- Rashedi, E., H. Nezamabadi–pour, and S. Saryazdi. 2013. A simultaneous feature adaptation and feature selection method for content-based image retrieval systems. Knowledge-Based Systems 39:85–94.
- Ratanamahatana, C. A., and D. Gunopulos. 2003. Feature selection for the naive Bayesian classifier using decision trees. Applied Artificial Intelligence 17(5–6):475–487.
- Resende, M. G. C., and C. C. Ribeiro. 2010. Greedy randomized adaptive search procedures: advances, hybridizations, and applications. In Handbook of metaheuristics, International Series in Operations Research & Management Science 146: 283–319. Berlin, Heidelberg: Springer.
- Ruiz, R., J. C. Riquelme, J. S. Aguilar-Ruiz, and M. García-Torres. 2012. Fast feature selection aimed at high-dimensional data via hybrid-sequential-ranked searches. Expert Systems with Applications 39(12):11094–11102.
- Sánchez-Maroño, N., and A. Alonso-Betanzos. 2011. Combining functional networks and sensitivity analysis as wrapper method for feature selection. Expert Systems with Applications 38(10):12930–12938.
- Tay, F. E. H., and L. Cao. 2001. A comparative study of saliency analysis and genetic algorithm for feature selection in support vector machines. Intelligent Data Analysis 5:191–209.
- Uğuz, H. 2011. A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowledge-Based Systems 24(7):1024–1032.
- Vignolo, L. D., D. H. Milone, and J. Scharcanski. 2013. Feature selection for face recognition based on multi-objective evolutionary wrappers. Expert Systems with Applications 40(13):5077–5084.
- Waad, B., B. M. Ghazi, and L. Mohamed. 2013. A three-stage feature selection using quadratic programming for credit scoring. Applied Artificial Intelligence 27(8):721–742.
- Wu, H., J. Zhu, S. Li, D. Wan, and L. Lin. 2010. A hybrid evolutionary approach to band selection for hyperspectral image classification. Berlin, Heidelberg: Springer.
- Zhang, K., Y. Li, P. Scarf, and A. Ball. 2011. Feature selection for high-dimensional machinery fault diagnosis data using multiple models and radial basis function networks. Neurocomputing 74(17):2941–2952.
- Zhang, Z., and E. R. Hancock. 2012. Hypergraph based information-theoretic feature selection. Pattern Recognition Letters 33(15):1991–1999.
- Zhanga, D., S. Chena, and Z.-H. Zhoub. 2008. Constraint score: A new filter method for feature selection with pairwise constraints. Pattern Recognition 41(5):1440–1451.