
Abstract
Exploiting the opportunities provided by Web 2.0 technologies has led to the appearance of social web applications, which allow users to interact and collaborate with each other, thereby sharing experience in an online environment. Establishing a trust mechanism is vital in order to identify the trustful sources of information on the social web. Trust prediction can be a useful tool for identifying the potential trust relationships among users in an online community. Thereby, reliable participants can be recommended to users; this increases social interaction among users and makes the trust network denser. The main contribution of this study is to investigate the effectiveness of soft computing and neurofuzzy techniques within the context of trust prediction. Therefore, an adaptive neurofuzzy inference system (ANFIS) as a representative of neurofuzzy techniques is compared with the widely used classification techniques including C4.5 decision tree, artificial neural network (ANN), logistic regression, and Bayesian network. All methods are applied on a portion of data obtained from the Epinions network. The results of empirical experiments indicate that ANFIS achieves the best performance in terms of area under ROC (AUC) among all other methods. Furthermore, ANFIS follows closely a C4.5 algorithm concerning F-measure. Overall, the results of experiments indicate that AFNIS can be a suitable candidate for prediction of unknown trust relationships in an online community.
INTRODUCTION
Web 2.0 technology (O’Reilly Citation2009) provides tools and mechanisms that enable users to interact and collaborate with each other in a social media dialogue. Web 2.0 websites enable users to be both producer and consumer of content, simultaneously. As a result, the amount of user-generated content is increasing on the web. Social networking sites, blogs, wikis, folksonomies are examples of Web 2.0 (Jelassi and Enders Citation2008).
E-commerce also, as other areas, has exploited the opportunities offered by Web 2.0 technologies. For example, websites such as epinions.com provide a platform that allows users to exchange their opinions and ideas by posting reviews and comments about products and services. Consequently, the content generated by users (i.e., reviews) can be used by other users to make decisions about purchasing a specific product or service. In other words, customer reviews build trust and confidence in regard to a prospective product or service, which other users might intend to purchase. In addition, reviews written by users increase the knowledge of customers about the products or services. Positive reviews motivate other users to buy a certain firm offering. Furthermore, the firm itself can benefit from reviews written by users in order to better understand the customer needs and thereby improve product quality or marketing strategies.
As the amount of content generated by users increases, the problem of assessing the quality of that content becomes a challenging issue. Trust between users is an invaluable knowledge that can be utilized in search and recommendation (Massa and Avesani Citation2006). Establishing a trust mechanism is vital in order to identify the reliable sources of information in an online environment. Currently, some online community websites (for example, epinions.com) allow users to explicitly maintain a trust and distrust list, thereby developing a network of pair-wise trust relationships called a Web of Trust (WOT) (Kim and Phalak Citation2012). However, WOT is sparse because despite the many benefits of trust relationship in ecommerce, users are usually reluctant to express the trust relationship to other users (Ma et al. Citation2009). Trust prediction using trust propagation-based models (e.g., Golbeck and Hendler Citation2006) and trust prediction using classification techniques (e.g., Zolfaghar and Aghaie Citation2012; Ma et al. Citation2009) have been presented by researchers to estimate trust value.
Trust prediction can be used as a tool to identify potential trust relationships among users in an online community and to recommend trustworthy participants to users, thereby making the trust network denser and, thus, improving social interactions among users. In this study, we aim to investigate the effectiveness of soft computing and neurofuzzy techniques within the context of trust prediction. A review of previous research shows that data mining and machine learning techniques such as Support Vector Machines (SVM), decision tree, artificial neural network(ANN), and logistic regression (Zolfaghar and Aghaie Citation2012; Nguyen et al. Citation2009; Matsuo and Yamamoto Citation2009; Ma et al. Citation2009; Liu et al. Citation2008) have been utilized as trust prediction techniques. However, to the best of our knowledge, no research has used the neurofuzzy methods for trust prediction. Therefore, the main purpose of this study is to explore the effectiveness of neurofuzzy approaches within this context.
Soft computing and neurofuzzy techniques have been successfully applied in various applications for prediction purposes such as customer churn prediction (Abbasimehr, Setak, and Soroor Citation2013; Ghorbani, Taghiyareh, and Lucas Citation2009), intrusion detection systems (Toosi and Kahani Citation2007), time series prediction(Ma et al. Citation2009), tuning the parameters of a PID controller (Bishr, Yang, and Lee Citation2000), medical data retrieval (Sharma and Singh Citation2012), and so on. The main contribution of this study is the application of the adaptive neurofuzzy inference system (ANFIS; Ma et al. Citation2009; Jang, Sun, and Mizutani Citation1997; Jang Citation1993) for trust prediction. To accomplish this task, we use a dataset obtained from the EpinionsFootnote1 network. Because of computational limitations, not all obtained trust-network data can be processed. Therefore, sampling should be conducted in order to select a portion of a trust network. We utilize an efficient community detection algorithm in terms of computational cost for community detection. After selecting a cluster from the network, the required features are derived from both network structure and contextual data; User, Interaction, and Similarity features are derived for each user pair. Afterward, we enter the model-building phase, which consists of applying different modeling techniques on the prepared dataset. Finally, the resultant models are compared using evaluation metrics. The results of experiments indicate that the model built using ANFIS could be a suitable candidate for the trust prediction task.
The rest of this article is organized as follows. The next section describes some concepts and methods used throughout the article. “Overview of the Methodology” describes the methodology of the study, which consists of preprocessing, model building, evaluation, and analysis phases. “Empirical Study” reports the results of experiments and evaluates the performances of modeling techniques. The “Conclusion” ends the article.
CONCEPTS AND METHODS
In this section, we describe concepts and methods that are used in this article. First, a review of literature about trust prediction is presented, and then the ANFIS method is explained.
Trust Prediction
In Nguyen et al. (Citation2009), a quantitative trust model based on the Trust Antecedent (TA; Mayer, Davis, and Schoorman Citation1995) framework was built. According to the TA framework, the three key characteristics of a trustee that allow him/her to be trusted are ability, benevolence, and integrity. They evaluated the proposed method by applying SVM with linear kernel. The results of experiments indicated that the trust model based on the TA framework outperforms the MolTrust model (Massa and Avesani Citation2005), which was based on trust propagation.
In Ma et al. (Citation2009), authors demonstrated the usefulness of personalized and cluster-based trust prediction models. The result of experiments revealed that the personalized and cluster-based classifiers perform better than the global classifier, which was built in consideration of all of the users.
Trust has been studied in many fields; here, we consider only the research accomplished by the computer science community. In computer science literature, trust models are divided into three main types: trust evaluation, trust prediction, and trust propagation (Nguyen et al. Citation2009).
Using trust propagation to infer new trust relationships among users is the main approach of trust propagation research. Trust models based on trust propagation are not appropriate when the trust network is sparse (i.e., a small portion of users are linked; Nguyen et al. Citation2009).
Trust evaluation models have been employed to assign a global trust value to each user in a user community—for instance, in a P2P file-sharing network (Kamvar, Schlosser, and Garcia-Molina Citation2002).
In trust prediction researches, a trust problem is modeled as a binary classification. The aim of these researches is to build a classifier using different classification techniques in order to classify the relationship between two users as trust or distrust. SVM was used to build trust prediction models in Nguyen et al. (Citation2009), Matsuo and Yamamoto (Citation2009), and Liu et al. (Citation2008).
The well-known classification techniques such as C5.0 decision tree, logistic-regression, Bayesian network, and neural network were used in Zolfaghar and Aghaie (Citation2012). The results of their experiments indicated that the C5.0 algorithm outperforms all other methods.
There are two major approaches used to predict trust: global trust models and local trust models (Kim and Phalak Citation2012). Global trust models compute the trust score of a user by considering the information of the complete trust network. For example, in Kamvar, Schlosser, and Garcia-Molina (Citation2002), the authors presented a method for computing global reputation values in order to identify malicious peers in a peer-to-peer file sharing network. In the local trust model, the trust score of the user is calculated based on the user’s point of view (Massa and Avesani Citation2007). In Massa and Avesani (Citation2007), the global and local trust metrics were compared in the case of trust being conferred on controversial users (e.g., a user who is trusted by many and distrusted by many), the result of this study showed that the local trust metric leads to higher accuracy in comparison to the global one in predicting trust conferred on a controversial user (Massa and Avesani Citation2007).
Adaptive Neurofuzzy Inference System (ANFIS)
A fuzzy inference system consists mainly of fuzzy rules and membership functions and fuzzification and defuzzification operations (Jang Citation1993). There are two types of fuzzy inference systems that can be implemented: Mamdani type and Sugeno type (Sugeno Citation1985; Mamdani and Assilian Citation1975). Because the Sugeno system is more compact and computationally efficient than a Mamdani system, it is used in adaptive techniques for constructing the fuzzy models.
A fuzzy rule in a Sugeno fuzzy model has the form of, if x is A and y is B then z = f(x, y), where A and B are input fuzzy sets in the antecedent and, usually, z = f(x, y) is a zero or first-order polynomial function in the consequent.
An initially constructed fuzzy inference system (FIS) needs parameter tuning through a learning algorithm using sufficient input–output instances to improve its prediction ability. One of the widely used learning systems for adapting the linear and nonlinear parameters of an FIS, particularly the first-order Sugeno fuzzy model, is the ANFIS. ANFIS is a class of adaptive networks that are functionally equivalent to fuzzy inference systems (Jang Citation1993).
Suppose an FIS has two inputs x, y and one output z as the first-order Sugeno fuzzy model. The fuzzy rule set with two fuzzy if–then rules is as follows:
Where (p1,q1,r1) and (p2,q2, r2) are parameters of output functions. The ANFIS architecture to implement these two rules is demonstrated in , in which a circle indicates a fixed node, whereas a square indicates an adaptive node (Jang Citation1993). The architecture of ANFIS consists of five layers.
FIGURE 1 ANFIS Architecture (Jang Citation1993).
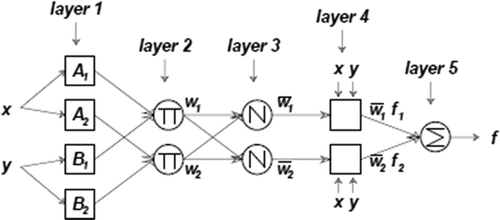
Both premise and consequent parameters of the ANFIS should be tuned using a learning algorithm to optimally model the relationship between input and output space. The basic approach of ANFIS is that it takes the initial fuzzy model and tunes it by means of a hybrid technique including gradient descent backpropagation and mean least squares optimization algorithms. There are two passes in the hybrid learning procedure for ANFIS. In the forward pass, ANFIS uses the least square estimate to identify the consequent. In the backward pass, the error rates, usually computed as the sum of the squared difference between predicted and actual output, propagate backward, and the premise parameters are updated by the gradient descent method (Jang Citation1993).
OVERVIEW OF THE METHODOLOGY
In this section, we describe the procedure used in this study. As shown in , first, we used trust-network data as input data for conducting our experiments. The detail of the dataset will be described in the next section. Second, a community detection algorithm was exploited to find clusters in the trust network so that we could select one of the clusters with which to conduct the experiments. Furthermore, the large community was selected, then, for each user pair in the selected community, some literature-referenced features related to trust factors were extracted and computed from the network. We considered each user pair as a data instance belonging to either the trust or the distrust class, and so, we obtained datasets of instances with which we built a trust prediction model employing a classification approach. Generally, a classification task involves two main steps: training a classifier and testing the resultant model (Han, Kamber, and Pei Citation2011) on a separate test set. In this study, we use the holdout splitting method (Han, Kamber, and Pei Citation2011) with proportion of 70/30. The training set is used by modeling techniques such as ANFIS to generate trust prediction models. Finally, the performances of models were evaluated using appropriate evaluation criteria.
FIGURE 2 Methodology of research.
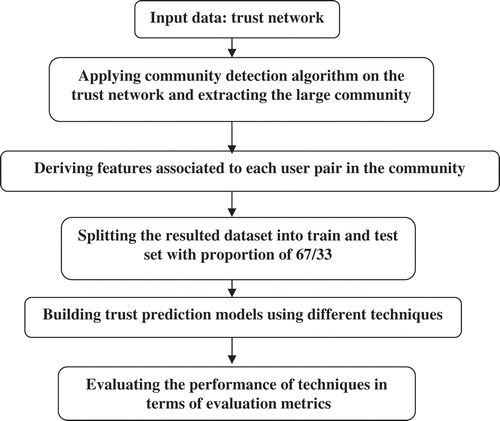
Preprocessing Phase
In this section, we provide more details with regard to the steps accomplished in the data preprocessing. In a data mining task, the preprocessing phase is an important step that improves the results of the mining task.
Clustering and Community Detection Algorithms
As a large network, the trust network is composed of smaller clusters. A cluster is defined as a set of vertices that are relatively more cohesive and connected densely (Hansen, Schneiderman, and Smith Citation2010). Many social network analysis tools can be utilized to identify these clusters or communities. To accomplish the community detection task, we need an efficient algorithm to find communities in a large network, quickly.
Community detection algorithms have been studied mainly in two fields: computer science and sociology, where each has developed different algorithms (Newman Citation2004a). The spectral bisectional algorithm(Fiedler Citation1973) and the Kernighan–Lin algorithm (Kernighan and Lin Citation1970) are the two principal algorithms from the computer science area. Algorithms developed in the sociology field are based on hierarchical clustering. The hierarchical clustering algorithm is fast, and there is no need to determine the number of clusters in advance. However, it does not specify at which number of groups the optimal division of a network can be yielded (Newman Citation2004a). To address the limitation of the aforementioned community detection algorithms, new algorithms have been developed that operate based on edge removal (Girvan and Newman Citation2002). In addition, in Newman (Citation2004b), a community structure detection method based on greedy optimization of the modularity index was presented, which seems to run well when applied on real-world networks (Clauset, Newman, and Moore Citation2004).
The community detection algorithm proposed in Clauset, Newman, and Moore (Citation2004) is a hierarchical agglomeration algorithm for finding communities fast. It works similarly to the algorithm proposed in Newman (Citation2004b), however, it utilizes a new data structure that makes it become faster. The running time of the algorithm on a network with n vertices and m edges is O(mdlogn), where d is the depth of the dendogram describing community structure (Clauset, Newman, and Moore Citation2004). In this study, because of its advantages with respect to computational time, we use the algorithm proposed in Clauset, Newman, and Moore (Citation2004) for extraction of the large community in the trust network.
Extracting Features
As mentioned, we formulate the trust prediction problem as a binary classification task that attempts to classify users’ pairs as trust or distrust relationships. For building trust prediction models, several types of features have been utilized in the previous researches. In Ma et al. (Citation2009) User and Interaction features were used for trust prediction. In this article, we describe each user pair using User, Interaction, and Similarity features. shows the User features (1–8), Interaction features (9–12), and Similarity feature (13).
TABLE 1 Utilized Features for Trust Prediction
A trust network can be formally represented by a directed graph G(V, E) where V denotes a set of users and E denotes direct trust relations among them.
User features contain both contextual and structural (network topology) information about users in the network. In the User feature category, the contextual features (1–3) are selected directly from the data. However, for extracting the structural features (4–8), we exploit the centrality concept. Centrality, which is a structural characteristic of nodes in a social network, is used to measure the importance of a node in a network. There are many centrality measures in the field of social network analysis (Aggarwal Citation2011). The most popular centrality metrics are degree centrality, PageRank, and eigenvector centrality. In this work, these centrality measures were employed to measure the importance of users in the trust network.
Degree centrality is the simplest and the most widely used metric for assessing the influence of a node in a social network (Aggarwal Citation2011). In-degree centrality of a user is calculated by counting the number of paths of length one that end at a user’s nodes. Out-degree centrality of users is computed by counting the number of paths of length one that originate from a user’s node (Aggarwal Citation2011).
Eigenvector centrality is based on the idea that a node in a network is more central if it is in relation with nodes that are central themselves (Ruhnau Citation2000). In contrast to the degree centrality, which assigns weights to each connection between two nodes equally, the eigenvector centrality assigns weights to connections in proportion to their centralities. Therefore, eigenvector centrality can be defined as a weighted sum of both direct and indirect connections of every length. Considering the eigenvector centrality, nodes that have many connections to the other nodes that are themselves central, have a high eigenvector centrality score (Bonacich Citation2007).
Let be the adjacency matrix of graph G (V, E),
if vertex
is connected to the vertex
,
, otherwise. The eigenvector centrality of vertex
is defined by Equation (1) (Ruhnau Citation2000):
In matrix notation, with , which is centrality of vertex
neighbors, this can be written by Equation (2) (Ruhnau Citation2000):
This type of equation can be solved using the eigenvalue and eigenvector of matrix A. By solving the equation, many different eigenvalues will be obtained. However, only the eigenvector of the maximal eigenvalue is an appropriate solution that can result in the desired centrality measure (Ruhnau Citation2000).
The PageRank algorithm (Page et al. Citation1999) is used in web search for rating web documents. The idea of the PageRank algorithm can be exploited to identify the most influential nodes in a social network (Aggarwal Citation2011). The PageRank of vertex ,
, is computed as follows (Equation (3))
The other structural feature is the reciprocated vertex pair ratio. In a directed graph, this is the number of neighbors of a vertex that have connections in both directions divided by the number of all neighbors. This feature shows to what extent the trustee mutually interacts with its neighbors.
Interaction features represent the information extracted from the interaction between each user pair. As demonstrated in , these features (9–12) are categorized as the contextual information in the network. The similarity feature (Jaccard coefficient) uses the network topology to measure the similarity between each user pair (trustor/trustee). The Jaccard coefficient (Han, Kamber, and Pei Citation2011) for user pair (i, j) is calculated by Equation (4):
Building Trust Prediction Models Using Different Techniques
In this study, C4.5, ANN, logistic regression, Bayesian network (Han, Kamber, and Pei Citation2011), and ANFIS are used to construct trust prediction models. In fact, our aim is to compare the performance of ANFIS with that of some well-known classification techniques.
Evaluation Metrics
As explained, we formulate the trust prediction problem as a binary classification problem. That is, we attempt to build a classifier with high performance. Therefore, it is essential to use appropriate evaluation criteria in order to assess the accuracy of the constructed models. In data mining and, in particular, the classification area, several metrics have been developed for evaluating the classification models. Accuracy is the prominent measure; however, in this study, the number of trust and distrust instances are not the same, in fact, the processed trust dataset suffers from the class imbalance problem. Therefore, we use the suitable metrics including AUC, Recall, Precision, and F-measure (Han, Kamber, and Pei Citation2011) for performance evaluation. The confusion matrix summarizes the four terms that are used to compute many evaluation metrics (Han, Kamber, and Pei Citation2011).
According to the confusion matrix (), Recall, Precision, and F-measure can be computed using Equations (5)–(7):
FIGURE 3 Confusion matrix (Han, Kamber, and Pei Citation2011).

ROC curves are used for comparing two classifiers (Han, Kamber, and Pei Citation2011). Indeed, for a given classification model, an ROC curve shows the trade-off between a true positive rate (TPR) and a false positive rate (FPR). The vertical axis of an ROC curve represents TPR, and the horizontal axis shows FPR. The main advantage of the ROC curve is that it considers various thresholds when computing the TPR and FPR (Han, Kamber, and Pei Citation2011).
The AUC is used for measuring the accuracy of a given model. The main point of AUC is that it considers all possible thresholds when comparing the predicted class of an instance with the real class of that instance (Han, Kamber, and Pei Citation2011; Tan, Steinbach, and Kumar Citation2005).
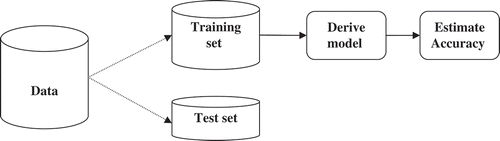
Holdout Method
The holdout method, based on randomly sampled subdivisions of the given data, is a common technique for evaluating the performance of classification models. In this method, as depicted by , the dataset is randomly divided into two separate sets, a training set and a test set. The training set is used to learn the model and the test set is used to assess the performance of the resulted model (Han, Kamber, and Pei Citation2011).
FIGURE 4 Schema of holdout method (Han, Kamber, and Pei Citation2011).
EMPIRICAL STUDY
Dataset Description
In this study, we selected the epinions.com network to conduct our experiments. Epinions is a large community network that enables users to interact about products and services. At epinions.com, users can write reviews of products and services. In addition, users can rate others’ reviews with a numerical rating (1–5). The generated reviews can help users make appropriate decisions in the process of purchasing a product or services. Each Epinions user can explicitly express trust or distrust relationships to other users. Therefore, a WOT is established through a set of trust relationships. An extended Epinions dataset was acquired from the TrustletFootnote2 website. The dataset was crawled by Paolo Massa (Massa and Avesani Citation2006) in 2003. The statistics of the extended Epinions dataset are summarized in .
TABLE 2 Statistics of the Employed Dataset
Extracting the Large Community from the Trust Network
In this study, we used the algorithm proposed in Clauset, Newman, and Moore (Citation2004) because of its advantages with regard to computational time. After running the algorithm on the trust network, we extracted the community with the highest number of nodes. The extracted community consists of 7240 nodes. Considering a directed network with n vertices, if the network is to be fully connected, then the number of its edges equals . We took into account only the trust relationship between pairs of users who were both trustor and trustee. Therefore, 115728 trust relationships were obtained. The set of 115728 trust statements is divided into a training set and a test set, exploiting the holdout method.
Deriving the Required Features from the Data
After extracting the large community from the data, we derived the features described in to build trust prediction models.
Model Building
In this study, C4.5, ANN, logistic regression, and Bayesian network were executed in WEKA data mining software (Witten and Frank Citation2005). In addition, ANFIS was implemented in MATLAB.
Results and Analysis
The main aim of this study was to investigate the effectiveness of a soft computing method within the context of trust prediction. ANFIS as a representative of soft computing techniques was compared with the well-known data mining algorithms C4.5 decision tree, logistic regression, artificial neural network, and Bayesian network. The resulting models were tested on the testing set. shows the performance of all techniques in terms of AUC, Precision, Recall, and F-measure. F-measure is a combined measure of recall and precision. It assigns equal weight to the precision and the recall (Han, Kamber, and Pei Citation2011). As a result, in the following, we will evaluate the resultant models using only AUC and F-measure.
TABLE 3 Performance Evaluation of Different Techniques
Concerning F-measure, the best result was obtained using C4.5 decision tree. However, except for the Bayesian network, all models lie in the interval 0.96–0.97. Therefore, ANFIS, ANN, and logistic regression do not perform significantly worse in terms of F-measure. That is, the ANFIS model follows closely the C4.5 model. In addition, compared with ANN, which is the most widely used algorithm for classification and prediction tasks, and logistic regression as well as Bayesian network, ANFIS performs slightly better with regard to F-measure (see and ).
FIGURE 5 Comparison of methods in terms of AUC and F-measure.
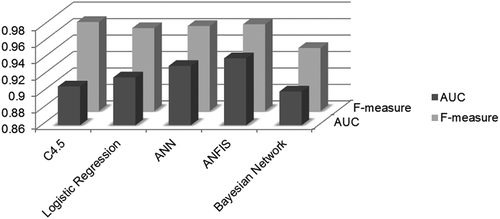
FIGURE 6 ROC curves for ANFIS and C4.5.
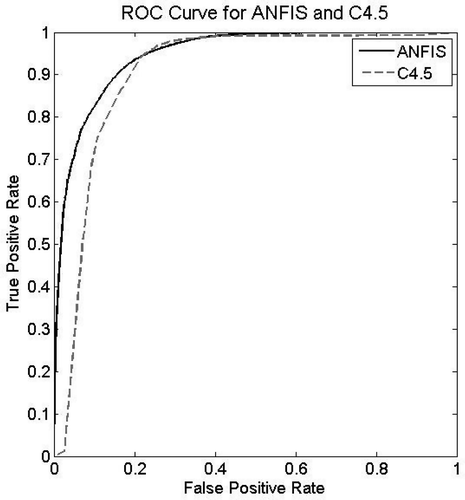
Assessing the resultant models in terms of AUC reveals that the model built using the ANFIS technique achieves the highest performance among all models. Looking more closely at the results provided in and , confirms that ANFIS performs relatively better than C4.5, logistic regression, and Bayesian network. Furthermore, ANN does not perform significantly worse compared to ANFIS. The model generated using the Bayesian network leads to the lowest AUC among all models. As pointed out previously, the main advantage of the AUC metric is that it evaluates a given classification model independent of any threshold. ROC curves are highly suitable tools for comparing classifiers in cases in which there is no information about misclassification cost.
FIGURE 7 ROC curves for ANFIS and ANN.
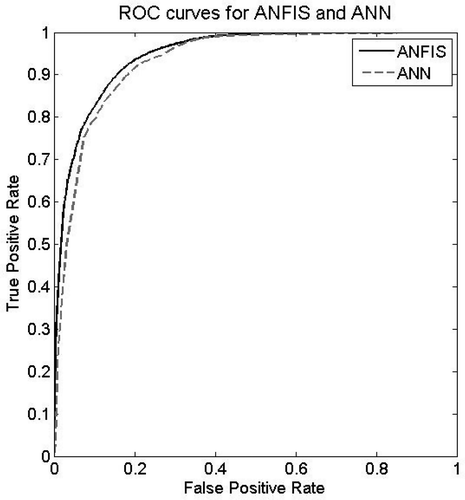
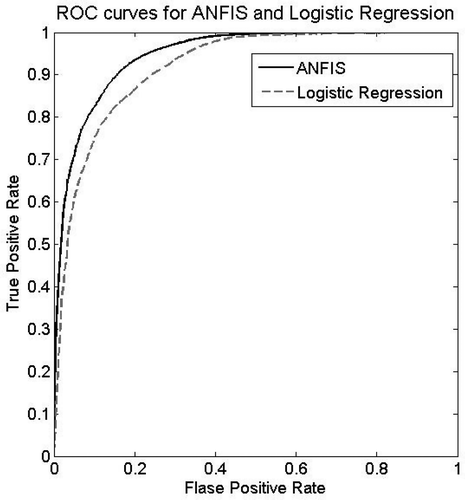
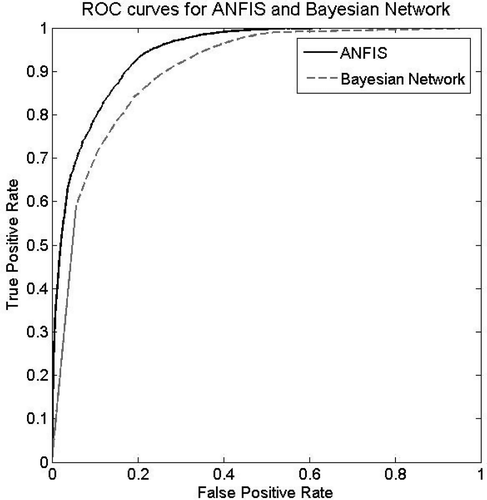
– illustrate the ROC curves of ANFIS and other methods. As revealed by those figures, ROC curves of ANFIS dominated the ROC curves of all other models. This dominance indicates the power of ANFIS in trust prediction. In other words, ANFIS appears to be a suitable modeling technique for the purpose of trust prediction.
FIGURE 8 ROC curves for ANFIS and logistic regression.
One of the significant characteristics of neurofuzzy and soft computing techniques is their ability to exploit human expertise for solving problems (Jang, Sun, and Mizutani Citation1997). In this regard, ANFIS allows the incorporation of expert knowledge in its structure. Moreover, ANFIS generates an interpretable model that is easy for humans to understand (Jang, Sun, and Mizutani Citation1997). This feature of ANFIS distinguishes it from some models, such as the ANN, which are black box models.
Although C4.5 decision tree performs slightly better than the ANFIS model, as can be seen from , carefully exploring the models that resulted from employing C4.5 and ANFIS indicated that the model obtained using ANFIS is more comprehensible and compact in comparison to the model generated from the C4.5 decision tree. The resultant ANFIS model in this study contains only ten rules, in contrast to the C4.5 decision tree, which generates 515 rules, thereby making it a less comprehensible model.
Overall, the results of experiments indicate that the ANFIS technique can be used for trust prediction because of its high performance, as confirmed in this study. In addition, one of the attractive features of ANFIS is that it allows knowledge of domain experts to be incorporated in its structure. This feature is useful when there is not available sufficient data to build a classifier. Additionally, the model learned using ANFIS is easy to understand.
FIGURE 9 ROC curves for ANFIS and Bayesian network.
CONCLUSION
Trust prediction can be a valuable approach for identifying the potential trust relationships among users in an online community and recommending truthful participants to users, thereby making the trust network denser and, thus, increasing social interactions among users. A trust prediction problem can be modeled as a binary classification task that attempts to classify users’ pairs as trust or distrust relationships. A number of classification techniques have been applied for predicting trust between a pair of users in an online community. In this article, we have described our investigation of the usefulness of neurofuzzy techniques in trust prediction. The adaptive neurofuzzy inference system (ANFIS) was selected as a neurofuzzy technique. To carry out the study, we compared ANFIS with the widely used classification methods including C4.5, ANN, Bayesian network, and logistic regression using trust network data that was gathered from the Epinions website, which is an online product-review sharing community. Because of the computational limitation, we first used an efficient community detection algorithm to select a sample from the network. Afterward, the important features indicating trust were extracted from the network and computed. The modeling techniques were applied on the dataset. The results were analyzed using more appropriate evaluation metrics, including AUC and F-measure. Analysis of the results indicated that in terms of AUC, ANFIS performs better than all other methods. This demonstrates the power of ANFIS in trust prediction. However, in terms of F-measure, ANFIS follows closely the C4.5 algorithm. In addition, ANFIS performs slightly better than ANN, logistic regression, and Bayesian network. Overall, ANFIS exhibits superior performance when applied in the trust prediction context. In addition, a deeper analysis of results revealed that, unlike the C4.5 decision tree algorithm, which generates a less comprehensible model, ANFIS produces a more compact and comprehensible model. Also, ANFIS allows the incorporation of expert knowledge into its structure, which makes this technique a suitable choice in cases when the available data is inadequate for building a high-quality classifier.
Notes
REFERENCES
- Abbasimehr, H., M. Setak, and J. Soroor. 2013. A framework for identification of high-value customers by including social network based variables for churn prediction using neurofuzzy techniques. International Journal of Production Research 51:1279–94. doi:10.1080/00207543.2012.707342.
- Aggarwal, C. C. 2011. Social network data analytics. New York, NY: Springer.
- Bishr, M., Y.-G. Yang, and G. Lee. 2000. Self-tuning pid control using an adaptive network-based fuzzy inference system. Intelligent Automation & Soft Computing 6:271–80. doi:10.1080/10798587.2000.10642795.
- Bonacich, P. 2007. Some unique properties of eigenvector centrality. Social Networks 29:555–64. doi:10.1016/j.socnet.2007.04.002.
- Clauset, A., M. E. J. Newman, and C. Moore. 2004. Finding community structure in very large networks. Physical Review E 70:066111. doi:10.1103/PhysRevE.70.066111.
- Fiedler, M. 1973. Algebraic connectivity of graphs. Czechoslovak Mathematical Journal 23:298–305.
- Ghorbani, A., F. Taghiyareh, and C. Lucas. 2009. The application of the locally linear model tree on customer churn prediction. Paper presented at International Conference of Soft Computing and Patter Recognition, December 4–7, 2009, Malacca, Malaysia.
- Girvan, M., and M. E. Newman. 2002. Community structure in social and biological networks. Proceedings of the National Academy of Sciences 99:7821–26. doi:10.1073/pnas.122653799.
- Golbeck, J., and J. Hendler. 2006. Inferring binary trust relationships in web-based social networks. ACM Transactions on Internet Technology 6:497–529. doi:10.1145/1183463.
- Han, J., M. Kamber, and J. Pei. 2011. Data mining: Concepts and techniques. San Francisco, CA: Elsevier Science.
- Hansen, D. L., B. Schneiderman, and M. A. Smith. 2010. Analyzing social media networks with NodeXL. San Francisco, CA: Elsevier, Morgan Kaufmann.
- Jang, J.-S. R. 1993. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics 23:665–85. doi:10.1109/21.256541.
- Jang, J. S. R., C. T. Sun, and E. Mizutani. 1997. Neuro-fuzzy and soft computing: A computational approach to learning and machine intelligence. Upper Saddle River, NJ: Prentice Hall.
- Jelassi, T., and A. Enders. 2008. Strategies for e-business: Creating value through electronic and mobile commerce: Concepts and cases. Harlow, England: FT Prentice Hall.
- Kamvar, S. D., M. T. Schlosser, and H. Garcia-Molina. 2002. The eigentrust algorithm for reputation management in p2p networks. Stanford, CA: Stanford InfoLab.
- Kernighan, B. W., and S. Lin. 1970. An efficient heuristic procedure for partitioning graphs. Bell System Technical Journal 49:291–307. doi:10.1002/bltj.1970.49.issue-2.
- Kim, Y. A., and R. Phalak. 2012. A trust prediction framework in rating-based experience sharing social networks without a web of trust. Information Sciences 191:128–45. doi:10.1016/j.ins.2011.12.021.
- Liu, H., E.-P. Lim, H. W. Lauw, M.-T. Le, A. Sun, J. Srivastava, and Y. A. Kim. 2008. Predicting trusts among users of online communities: An epinions case study. In Proceedings of the 9th ACM conference on Electronic commerce. Chicago, IL: ACM.
- Ma, N., E.-P. Lim, V.-A. Nguyen, A. Sun, and H. Liu. 2009. Trust relationship prediction using online product review data. In Proceedings of the 1st ACM international workshop on complex networks meet information & knowledge management. Hong Kong, China: ACM.
- Mamdani, E. H., and S. Assilian. 1975. An experiment in linguistic synthesis with a fuzzy logic controller. International Journal of Man-Machine Studies 7:1–13. doi:10.1016/S0020-7373(75)80002-2.
- Massa, P., and P. Avesani. 2005. Controversial users demand local trust metrics: An experimental study on epinions.com community. In Proceedings of the 20th national conference on artificial intelligence, vol.1. Pittsburgh, PA: AAAI Press.
- Massa, P., and P. Avesani. 2006. Trust-aware bootstrapping of recommender systems. Paper presented at ECAI 2006 Workshop on Recommender Systems August 28–29, Riva del Garda, Italy.
- Massa, P., and P. Avesani. 2007. Trust metrics on controversial users: Balancing between tyranny of the majority and echo chambers, International Journal on Semantic Web & Information Systems 3:39–64 doi:10.4018/jswis.2007010103.
- Matsuo, Y., and H. Yamamoto. 2009. Community gravity: Measuring bidirectional effects by trust and rating on online social networks. In Proceedings of the 18th international conference on world wide web. Madrid, Spain: ACM.
- Mayer, R. C., J. H. Davis, and F. D. Schoorman. 1995. An integrative model of organizational trust. The Academy of Management Review 20:709–34.
- Newman, M. E. J. 2004a. Detecting community structure in networks. The European Physical Journal B - Condensed Matter and Complex Systems 38:321–30. doi:10.1140/epjb/e2004-00124-y.
- Newman, M. E. J. 2004b. Fast algorithm for detecting community structure in networks. Physical Review E 69, 066133.
- Nguyen, V.-A., E.-P. Lim, J. Jiang, and A. Sun. 2009. To trust or not to trust? Predicting online trusts using trust antecedent framework. In Proceedings of the 2009 ninth IEEE international conference on data mining. Los Alamitos, CA: IEEE Computer Society.
- O’Reilly, T. 2009. What is web 2.0. Sebastopol, CA: O’Reilly Media.
- Page, L., S. Brin, R. Motwani, and T. Winograd. 1999. The pagerank citation ranking: Bringing order to the web. Stanford, CA: Stanford InfoLab.
- Ruhnau, B. 2000. Eigenvector-centrality—A node-centrality? Social Networks 22:357–65. doi:10.1016/S0378-8733(00)00031-9.
- Sharma, S., and P. Singh. 2012. A novel soft computing-based retrieval system for medical applications. Applied Artificial Intelligence 26:645–61. doi:10.1080/08839514.2012.701423.
- Sugeno, M. 1985. Industrial applications of fuzzy control. New York, NY: Elsevier Science Inc.
- Tan, P.-N., M. Steinbach, and V. Kumar. 2005. Introduction to data mining. San Francisco, CA: Pearson Education, Inc.
- Toosi, A. N., and M. Kahani. 2007. A novel soft computing model using adaptive neuro-fuzzy inference system for intrusion detection. Paper presented at IEEE International Conference on Networking, Sensing and Control, 2007, April 15–17, London, UK.
- Witten, I. H., and E. Frank. 2005. Data mining: Practical machine learning tools and techniques. San Francisco, CA: Morgan Kaufmann.
- Xu, G., Y. Zhang, and L. Li. 2010. Web mining and social networking: Techniques and applications. New York, NY: Springer-Verlag New York, Inc.
- Zolfaghar, K., and A. Aghaie. 2012. A syntactical approach for interpersonal trust prediction in social web applications: Combining contextual and structural data. Knowledge-Based Systems 26:93–102. doi:10.1016/j.knosys.2010.10.007.