
Abstract
Mining with multilabel data is a popular topic in data mining. When performing classification on multilabel data, existing methods using traditional classifiers, such as support vector machines (SVMs), k-nearest neighbor (k-NN), and decision trees, have relatively poor accuracy and efficiency. Motivated by this, we present a new algorithm adaptation method, namely, a decision tree–based method for multilabel classification in domains with large-scale data sets called decision tree for multi-label classification (DTML). We build an incremental decision tree to reduce the learning time and divide the training data and adopt the k-NN classifier at leaves to improve the classification accuracy. Extensive studies show that our algorithm can efficiently learn from multilabel data while maintaining good performance on example-based evaluation metrics compared to nine state-of-the-art multilabel classification methods. Thus, we draw a conclusion that we provide an efficient and effective incremental algorithm adaptation method for multilabel classification especially in domains with large-scale multilabel data.
INTRODUCTION
Multilabel classification is a challenging and popular topic in many applications, such as text categorization and gene function classification. For example, we can classify a newspaper article concerning David Beckham into two categories of entertainment and sports, at least. It is hence a challenge for the traditional single-label classification, because it always assumes that predefined data categories are mutually exclusive and each data point can belong to exactly one category.
To handle the multilabel classification issue, an intuitive approach is problem transformation (PT; Tsoumakas, Katakis, and Vlahavas Citation2010), in which a multilabel problem is transformed into one or more single-label problems. The advantage of this method is that a multilabel classifier can be readily built using many state-of-the-art binary classifiers off the shelf. However, the computational complexity of PT methods is in direct proportion to the total number of class labels (denoted as ), and the expressive power of such a system can be weak; for example, the systems of RAKEL (a random k-label sets algorithm; Tsoumakas and Vlahavas Citation2007; Tsoumakas, Katakis, and Vlahavas Citation2011) and EPS (Read, Pfahringer, and Holmes Citation2008; an efficient ensemble of pruned sets method). Contrary to the PT approach, many algorithm adaptation (AA) methods extended from specific learning algorithms have been designed to handle multilabel data directly, such as multilabel support vector machines (SVMs; J. H. Xu Citation2012), multilabel decision trees (Clare and King Citation2001), and multilabel lazy learning algorithms (M. L. Zhang and Zhou Citation2007; Cheng and Hüllermeier Citation2009). However, the computational complexity of AA methods is in direct proportion to
and N (the size of training data) or their quadratic function. They will present a low efficiency when meeting large-scale multilabel data. In addition, because the selected single-label classifiers are meta-algorithms, the capabilities of these methods are also inferior in their efficiency. For example, the SVM classifier requires additional time overhead when handling nonlinear multilabel data with discrete attributes.
Motivated by this, we propose an efficient and effective algorithm adaptation method based on an incremental decision tree with the k-nearest neighbor (k-NN) classifier for multilabel classification, called decision tree for multi-label classification (DTML). Our contributions are as follows:
We incrementally build a decision tree learning from multilabel data. It is conducive to improve the training efficiency compared to the existing methods using traditional classification models.
We introduce the k-NN classifier at leaves using only subsets of training data. It is beneficial to improve the test efficiency while maintaining the classification accuracy in the classification.
Extensive studies demonstrate that our algorithm can achieve better performance on the evaluation metrics and train much faster than several well-known PT methods and AA methods especially in domains with large-scale data sets.
The rest of this article is organized as follows. Section “Related Work” reviews the related work. Our DTML algorithm is described in detail in section “Our DTML Algorithm.” Section “Experiments” provides the experimental study and section “Conclusions” is the summary.
RELATED WORK
To handle the multilabel classification issue, existing efforts mainly come from two thoughts, namely, PT and AA. Details are as follows.
PT Methods
In this subsection, we review three PT methods. First, the most well-known PT method is the binary relevance (BR) method (Tsoumakas, Katakis, and Vlahavas Citation2010). It is a “one-vs.-rest” paradigm, which treats every label independent of all other labels. The representative works include a BR-based k-NN algorithm (called BRkNN; Spyromitros, Tsoumakas, and Vlahavas Citation2008) and an efficient BR-based chaining method called an ensemble framework for classifier chains (ECC; (Read et al. Citation2009). These BR-based methods can reduce the complexity in the learning space, but they cannot perform very well on the evaluation metrics.
The second paradigm is the label powerset (LP) method. It considers each unique set of labels that exits in a multilabel training set as one of the classes. The representative works include a RAKEL algorithm (Tsoumakas and Vlahavas Citation2007; Tsoumakas, Katakis, and Vlahavas Citation2011) and an EPS (Read, Pfahringer, and Holmes Citation2008). However, these methods suffer when many label combinations are associated with very few examples. In addition, because the computational cost of LP methods is relevant to O(K2) and the complexity of metaclassifiers, it will be too high if the magnitude of class labels is large.
The third paradigm is the pair-wise classification. It is a “one-vs.-one” paradigm where one classifier is associated with each pair of labels. A famous work is an extended algorithm of label ranking (Füurnkranz et al. Citation2008) called multi-label classification via calibrated label ranking (MLCLR). It incorporates the calibrated scenario and substantially extends the expressive power of existing approaches to label ranking. However, this approach will also face the challenge of complexity when the number of labels is large.
In addition, we should mention the efficient random decision tree ensembling algorithms based on PT methods (BR-RDT and LP-RDT, collectively called multi-label classification based on random decision tree ([MLRDT]; X. T. Zhang et al. Citation2010) for multilabel classification. The main difference between random decision trees (RDTs) and other classical decision tree methods, such as C4.5, is that RDT constructs decision tree randomly and need not using any information of labels. That nature makes RDT fast and the computational cost independent of labels.
Algorithm Adaptation Methods
We summarize the algorithm adaptation method corresponding to the basic classifiers as follows.
Methods using decision trees and boosting: The AA method using decision trees (Clare and King Citation2001) was first proposed in 2001. Authors modified the expression for entropy of C4.5 to allow a tree to predict a label vector. The first system, BoosTexter, for multilabel classification and ranking (Schapire and Singer Citation2000) was proposed in 2000. It supplies AdaBoost.MH and AdaBoost.MR, both of which belong to a multilabel adaptation of the well-known AdaBoost paradigm. However, this family of methods has been recognized as having high computational complexity (Petrovskiy Citation2006).
Methods using SVMs: Representative works include rank-SVM (Elisseeff and Weston Citation2002) using the kernel SVM as a ranking function, an extended algorithm called calibrated rank-SVM (A. Jiang, Wang, and Zhu Citation2008), and a zero-label based rank-SVM method (J. H. Xu Citation2012). However, because the computational complexity of rank-SVM is in direct proportion to
, it will be too high if the magnitude of a data set is large.
Methods using k-NN: A state-of-the-art lazy multilabel method MLkNN (M. L. Zhang and Zhou Citation2007) was proposed in 2007. It adapts the k-NN algorithm for multilabel classification using Bayesian relevance. It has been noted that MLkNN outperforms rank-SVM (Elisseeff and Weston Citation2002), AdaBoost.MH (Comité, Gilleron, and Tommasi Citation2003), and BoosTexter (Schapire and Singer Citation2000). In 2009, an extended work on lazy classification called instance-based learning and logistic regression for multi-label data (IBLR) (Cheng and Hüllermeier Citation2009) was introduced. It combines both instance-based learning and logistic regression to classify multilabel data. In 2012, a fuzzy similarity measure and k-NN-based method was proposed for multilabel text classification (J.-Y. Jiang, Tsai, and Lee Citation2012). These new extended algorithms enable improving the classification performance while maintaining the time efficiency compared to MLlNN. However, because the computational complexity of k-NN is in direct proportion to O(kN2), it also will be too high if the magnitude of a data set is large.
Methods using neural networks: In 2006, a neural network adaptation algorithm for multilabel data called back-propogation for multi-label learning ([BP-MLL]; M. L. Zhang and Zhou Citation2006) was proposed. It adapts the error function of a back-propagation algorithm to account for multiple labels in the learning process. In 2009, adaptive resonance theory neural networks (Sapozhnikova Citation2009) were developed to handle multilabel classification. In 2012, a competitive neural network–based algorithm called multi-label hierarchical classification using a competitive neural network ([MHC-CNN]; Borges and Nievola Citation2012) was proposed for multilabel hierarchical classification. This family of methods performs better on the classification performance but presents a higher computational complexity due to the complexity of metamodels.
Other: A novel algorithm for effective and efficient multilabel classification in domains with many labels, called hierarchy of multi-label classifiers ([HOMER]; Tsoumakas, Katakis, and Vlahavas Citation2008), was proposed in 2008. It constructs a hierarchy of multilabel classifiers, each dealing with a much smaller set of labels and a more balanced example distribution. This leads to improved predictive performance along with linear training and logarithmic testing complexities with respect to
OUR DTML ALGORITHM
We first formalize the problem of multilabel classification in this section. Let E denote the domain of an instance space and denote the set of labels. Suppose a multilabel training data set
, whose instances are drawn identically and independently from an unknown distribution. Each instance,
is associated with a label set
. The goal of multilabel classification is to train a classifier
that maps a feature vector to a set of labels, while optimizing some specific evaluation metrics. Our DTML algorithm presented in this section aims to handle this problem efficiently and effectively. Algorithm 1 shows the processing flow of DTML. First, it employs a “divide and conquer” strategy by recursively partitioning the training set and generates an incremental decision tree to reduce the learning time in Steps 1–18. Second, it implements the test using the kNN classifier at leaves in Steps 19–22. Details of techniques are as follows.
Construction of a Decision Tree
Our DTML algorithm is built on an incremental decision tree, which follows the strategy of split-feature selection that discrete attributes should not be chosen again, whereas numerical ones can be chosen multiple times in a decision path. In DTML, a training instance-e first traverses the decision tree from the root to an available growing node, evaluating the appropriate attribute at each node and following the branch corresponding to the attribute’s value in e. In addition, relevant statistics are stored at the current node (Step 3). Contrary to the split test using all training instances in traditional decision trees, it is evaluated only using instances accumulated at the current node in DTML (Steps 4–5). To deal with multilabel decision trees, we adopt the same estimation method of information gain for multilabel data in Clare and King (Citation2001). Suppose
is the estimator function of information gain (IG), then, correspondingly, the IG of a discrete attribute ai could be expressed in Eq. (1). It specifies the difference between the entropy of training instances S accumulated at the node and the weighted sum of the entropy of the subsets sv caused by partitioning on the value v of that attribute ai, where the size of S is
.
subject to
Algorithm 1 DTML
Input: Training set: D; Test set: TE; Label set: L; Minimum count of split instances: ; Check period: CP; Memory size: MS; Maximum height of tree: maxH; Attribute set: A.
Output: Vector of predicted class labels;
Generate the root of a decision tree T;
for each training instance e in the training data set D do
Sort the training instance e into an available node and store the information;
if the count of instances at the current node of
Install the split test for a split attribute
if the selected split feature is the cut-point of a numerical attribute ai then
Generate two children nodes;
end if
if it is a discrete attribute ai then
Generate children nodes by the number of attribute values in ai;
end if
if the count of training instances observed in the current tree T % CP = = 0 then
if the memory consumption in the current tree T > MS then
Install the pruning in the current decision tree T;
end if
end if
end if
end for
for each test instance e in the test data set TE do
Traverse the tree from the root to leaves;
Predict the label set Y(e) of instance e in the k-nearest neighbor algorithm;
end for
where indicates the number of different attribute values for ai, and
and
specify the probability of the ith class label in S and sv, respectively. Regarding the solution to cut-points of numerical attributes, our estimation method is given as follows. Suppose ai is a numerical attribute at the current growing node. In our algorithm, sequential attribute values of ai will be discretized into min(10,
) intervals. Hence, the IG of the xth cut-point in ai (denoted as
) could be estimated in Eq. (2).
subject to
where refers to the ratio of the number of instances whose attribute values of ai are lower than
divided be the total number of instances at the current node, and
specifies the information expectation of values of
. This is similar to the definition on
and
, respectively. According to the values of IG, we select a candidate split attribute or cut-point with the highest IG as the final split feature. The current growing node is correspondingly replaced with the decision node and children nodes regarding the attribute type (Steps 6–11).
Pruning
In the growing of a decision tree mentioned above, we take two measures in DTML to avoid the space overflow below. First, a threshold is specified to limit the maximum height of the decision tree (namely, maxH) as shown in Step 4. That is, if the depth of a decision path in the current tree is up to maxH, this path will not grow continuously. Second, a pruning mechanism is adopted. As shown in Steps 12–16, if the checking threshold CP and the memory limit MS are met, the pruning is installed from bottom to top. First, stop all undergoing splits of growing nodes and change them into leaves and then remove the storage space of information in the nodes corresponding to the evaluation metric of accuracy. Second, cut off several subtrees from bottom to top with the roots whose values of accuracy are lower than 50%.
Prediction in k-NN
In our algorithm, we utilize the k-NN classifier to implement the prediction on the test data set. More precisely, each test instance e first traverses from the root to an available leaf corresponding to the attribute values. Second, we select k-nearest neighbors of e by the Euclidean distanceFootnote1 and count the label distributions in k-nearest neighbors, denoted as , namely, the number of instances with the
label
. Last, we use the majority voting with a threshold r (0 < r < 1) to label the test instance e. That is, if the value of
is no less than the value of r multiplying k neighboring instances at the current leaf, we will assign the class label
to e. Thus, we can obtain a label set of Ye for e.
TABLE 1 Fourteen objects from emotions
Illustration
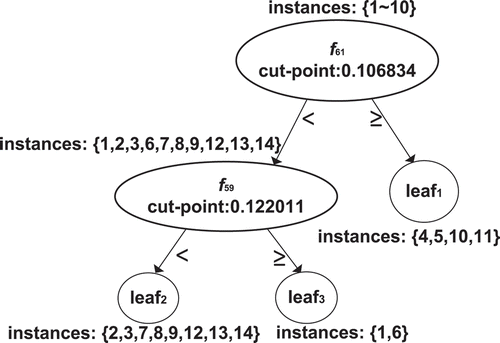
Let us consider the following example to show the process of our algorithm. As shown in , we randomly select 14 objects from the Emotions database, which contains 72 continuous dimensions of attributes and six class labels. Due to the space limit, we only list two attributes involved in the split test here. According to Algorithm 1, each example arrives one by one at the root of the current decision tree. When the statistical count of instances at the root is up to (e.g., 10), we install the split test and we can get the IG of all cut points using Eq. (2). We specify the attribute value of attribute f61 with the maximum IG as the split point. Correspondingly, we generate two child nodes regarding the cut point. In addition, we divide the previous 10 instances collected at the current node into child nodes regarding the split point. In a similar way, the decision tree grows up continuously until all training instances arrive. illustrates the final decision tree generated over 14 instances in .
FIGURE 1 A decision tree grows over 14 instances.
Classification Risk Analysis of DTML
In this subsection, we will analyze the performance of DTML at a leaf. More specifically, suppose that the decision tree generated in DTML is a complete binary tree and the height of this tree is l. In addition, suppose that there are m instances arrived at the current tree and the probability that each training instance reaches a leaf is equal. Thus, the mean number of instances at a leaf amounts to , denoted as
. We select k-nearest neighbors from the data set
according to the Euclidean distance. Therefore, we can formalize these selected instances whose label set contains
as follows:
Further, we could define the classification risk (denoted as PE) in DTML for any test instance arrived at the current leaf in Eq. (4).Footnote2
where indicates the probability that ex is predicted correctly in DTML and
indicates the probability that the label
belongs to Yx. According to the aforementioned description, we can get the value of
in Eq. (5).
where indicates the probability that there is at least an instance containing the label
in the k-nearest neighbors of
from the data set of
. Suppose that the probability that each instance has a label belonging to the label set L is equal; thus, we can get the infimum value of
in Eq. (6).
In the above analysis, we can rewrite Eq. (4) in Eq. (7):
where the value of k is relevant to the value of ln, denoted as . According to Eq. (7), if we aim to reduce the classification risk in DTML, it is better to reduce the value of ln. However, we know that the higher the height of the decision tree, the lower the value of ln. Thus, we conclude that a higher height of the decision tree is conducive to improve the classification performance in DTML. This conclusion is built on the training data when there are no irrelevant or noisy variables, but as complexity increases the model is bound to overfit and the test performance will start degrading (Hastie, Tibshirani, and Friedman Citation2008). In our algorithm, it occurs when the height of the decision tree is larger than half the dimension count of the database. It is also validated in the experimental results in section “Relationship between the Height of the Decision Tree and Classification Performance.” Thus, to avoid overfitting in our algorithm, we limit the value of maxH no more than half of the attribute dimensions of databases.
Computation Complexity Analysis
The computational cost of DTML consists of the training cost and the testing cost as discussed next.
Training Complexity
Training complexity mainly comes from the construction cost of a decision tree in DTML, which is in direct proportion to O(VdNlog2(N)), where V is the maximum number of values per attribute, d is the number of attribute dimensions, and N is the size of training data. Regarding the computational cost of MLRDT (X. T. Zhang et al. Citation2010), the least complexity is in direct proportion to O(mNlog2(N)), where m is the number of random decision trees. Due to , our algorithm is slower than MLRDT. This is because the time cost of the split test in our algorithm is directly proportional to O(Vd), whereas there is no time cost in the split test in MLRDT. However, comparing the computational cost of a traditional decision tree used in the aforementioned multilabel classification methods (denoted as C4.5new), it is the same as that of C4.5, which is in direct proportion to
. In a common case, due to
, the training complexity in DTML is hence much lower than that of C4.5new.
Test Complexity
The test computation complexity on a test instance in DTML is directly proportional to , where
specifies the average number of instances at leaves. Compared to other methods using simple label distribution statistics, such as the MLRDT method (X. T. Zhang et al. Citation2010), it is in direct proportion to O(mq), where q refers to the average depth of the branches that the test instance belongs to. As
in general, the time complexity of our algorithm is hence higher. However, compared to other k-NN-based algorithms, such as BRkNN and MLkNN (denoted as k-NNnew), it is directly proportional to O(kN2). Apparently, we could conclude that the test computation complexity in DTML is less that in k-NNnew because of
. The above conclusions will be validated in the experiments.
EXPERIMENTS
This section is devoted to validating the performance of our DTML algorithm with regard to effectiveness and efficiency. Before presenting the experimental results, we first give some information about data sets and baseline algorithms included in the study, as well as the criteria used for evaluation in sections “Data Sets and Baseline Algorithms” and “Evaluation Measures,” respectively. Further, we discuss the relationship between the height of the decision tree and the performance in section “Relationship between the Height of the Decision Tree and the Classification Performance.” Finally, we analyze the performance of DTML compared to nine state-of-the-art PT methods and algorithm adaptation methods on both of effectiveness and efficiency.
Data Sets and Baseline Algorithms
In our experiments, we select seven benchmark multilabel databases containing numerical or discrete attributes only from different applications domains and a simulated database containing numerical and discrete attributes.Footnote3 Details of these data sets are listed in , where label cardinality is the average number of labels in a database and label density is the average number of labels in a database divided by .
TABLE 2 Descriptions of data sets
Regarding the baseline algorithms, we select several popular PT methods using the original base classifiers and the decision trees (the WEKA implementation of J48 in its default setting) as the base classifier respectively. In addition, we select several multidata classification methods using k-NN and three efficient multilabel classification algorithms—HOMER(Tsoumakas, Katakis, and Vlahavas Citation2008), MLRDT(X. T. Zhang et al. Citation2010), and M3L(Hariharan, Vishwanathan, and Varma Citation2012))Footnote4—as the baseline methods. summarizes the details of all baseline methods. All parameters involved in these algorithms follow the optimal values defined in the original references; for example, the optimal value of k is 10 for MLkNN. However, regarding the parameters of CP, MS, and in the training of DTML, they are specified by users. In this article, we specify these parameters below, namely,
(every 100 k training instances), MS = 1.4 G (the value is limited by the memory configuration of used computers),
, k = 100, and ratio = 0.5. All experiments are conducted on a P4, 3.00-GHz PC with 2 G main memory, running Windows XP Professional.
TABLE 3 Description of baseline algorithms
Evaluation Measures
In this subsection, we give several popular example-based evaluation metrics (Tsoumakas, Katakis, and Vlahavas Citation2010) used in our experiments. For the definitions of these measures, let D be a multilabel evaluation data set, consisting of N multilabel instances , where
is the set of true labels and
is the set of all labels. Given an instance ei, the set of labels predicted by a multilabel classification method is denoted as
, where f is a multilabel classifier. Example-based measuresFootnote5 including hamLoss, accuracy, precision, and recall are as follows:
where Δ corresponds to the XOR operation in boolean logic. According to these definitions, we know that the smaller value of hamLoss and the greater values of accuracy, precision, and recall indicate better performance. In addition, we formulate a general evaluation measure regarding all example-based measures, called .
This definition shows that a smaller value of indicates the better overall performance on example-based measures. In this definition, the smoothing value of Δ is added to avoid dividing zero. Δ is set to a very small value; for example,
.
Relationship between the Height of the Decision Tree and the Classification Performance
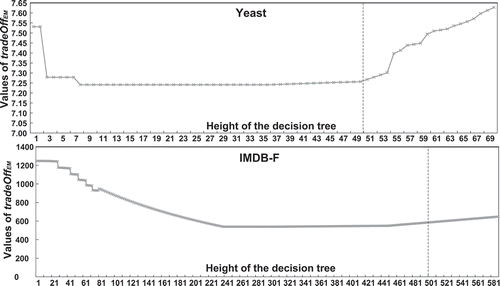
shows the relationship between the height of the decision tree and the classification performance in our algorithm. We only report the trade-off values on the example-based measures varying with the height of the decision tree. A similar conclusion was obtained from experimental results on different data sets. Thus, to avoid redundancy, we only give experimental studies conducted on two representative databases, namely, Yeast with numerical attributes and IMDB-F with discrete attributes. In the observation, we can see that as the height of the decision tree increases, the overall performance of becomes better until it reaches half of the attribute dimensions (marked in the dotted line). This validates the conclusion mentioned in section “Classification Risk Analysis of DTML” that as the height of the decision tree increases, the classification performance will be improved, and then it will begin overfitting and start degrading. Therefore, in our algorithm, the value of maxH is specified by half of the attribute dimensions.
FIGURE 2 Prediction results varying with the height of the decision tree.
Performance Evaluation
In this subsection, we evaluate our algorithm against nine state-of-the-art algorithms with regard to effectiveness and efficiency. In our experiments, if algorithms cannot accomplish the calculation in 24 h on a data set, their experimental results are marked with “—” (In this case, we think that these algorithms are not comparable to our algorithm). If there is an exception in the running (i.e., out of memory), the experimental results are marked with “/”.
reports the effectiveness between DTML and nine baseline algorithms conducted on five small-sized data sets and three large-scale data sets with a larger number of labels or a large number of instances.
Considering the performance on five small-sized data sets, firstly, DTML performs best on hamLoss. This is because DTML adopts the threshold constraint in the k-NN classifier, which avoids labeling blindly. Secondly, considering the evaluation measures of accuracy, precision, and recall, DTML sometimes performs worse than the PT methods based on k-NN (such as BRkNN), sequential minimal optimization (SMO) (such as RAKEL and EPS), and perceptron (such as MLCLR) and the AA methods based on SMO (such as HOMER), k-NN (such as MLkNN), and logistic regression (such as IBLR). The reasons are respectively analyzed below. The classifiers of SMO, perceptron, k-NN, and logistic regression are more suitable for handling numerical attributes compared to the decision tree with informed split tests in our algorithm. Thus, in general, these classifier-based methods are superior to our algorithm on the data sets of Emotions, Yeast, and Scene with pure numerical attributes, whereas they are inferior to our algorithm on SLASHDOT-F and SimulatedData with discrete attributes. However, considering the decision tree–based PT methods, our algorithm performs better than EPS, RAKEL, and MLCLR on most data sets except MLRDT. This is because, compared to RAKEL and MLCLR based on the decision tree, our algorithm introduces the k-NN classifier at leaves of the decision tree instead of a single decision tree used in these methods. Compared to the MLRDT algorithm, our algorithm does not present advantages on the evaluation measures of accuracy, precision, and recall. This is because MLRDT is an ensemble model of random decision trees and the ensemble model usually
TABLE 4 Estimations on all data sets
outperforms the single model. However, regarding the overall performance on tradeoff, DTML wins three times and MLRDT wins twice, and they can beat other baseline algorithms.
Considering the performance on three large-sized data sets, we can observe the obvious advantages of our DTML algorithm. DTML beats all baseline algorithms considering the overall performance on tradeoff. The
TABLE 5 Overheads of training and test time on all data sets
reason is that the baseline algorithms are batch learning algorithms, and they cannot handle the large-scale data sets as well as our incremental algorithm due to the heavier space overheads.
On the other hand, we consider the time overheads in DTML compared to nine baseline algorithms. From the experimental results as shown in , we found the following. DTML does not always perform better on the test time overhead compared to the decision tree–based PT methods (such as RAKEL, EPS, and MLCLR), because our algorithm uses the k-NN classifier to classify the test instance after it traverses the decision tree from the root to a leaf. It probably requires more time compared to the majority class method used in RAKEL and MLCLR based on the decision tree. However, it is clearly superior in the training time overhead. Thus, our algorithm still has an advantage for the total time overhead.
In addition, this advantage is very obvious compared to RAKEL and MLCLR based on the classifiers of SMO and linear perceptrons. This is because our decision tree model built incrementally leads to a light time overhead compared to those models built in batch.
DTML is always inferior to the k-NN-based PT method (BRkNN) in the training time overhead but it is still superior in the total time overhead. This is because the training time complexity in BRkNN is O(1), whereas the test time complexity is , which is much more than DTML. In a similar way, DTML performs more efficiently compared to the k-NN-based AA method (MLkNN) and the IBLR method based on the instance-based learning and logistic regression, because the number of instances at a leaf
is much lower than the value of N.
Compared to other efficient multilabel classification methods, DTML performs faster than HOMER and M3L. This is because the basic classifiers in HOMER and M3L need to learn in batch, whereas our model can learn incrementally. However, DTML performs a little slower than MLRDT; this is because MLRDT adopts a random selection strategy in the split tests instead of the informed split tests in DTML. This is beneficial in reducing the computation overhead.
In sum, our DTML algorithm is the second fastest algorithm compared to all baseline algorithms. It preforms a little slower than MLRDT but it is more suitable for handling large-scale data sets due to the lighter space overheads. In addition, DTML performs best regarding the overall performance on the example-based measures, which wins six times on the value of from eight data sets. Therefore, we conclude that our DTML algorithm is an efficient and effective algorithm, especially in domains with large-scale data sets.
CONCLUSIONS
In this article, we have proposed a new algorithm adaptation method for multilabel classification, called DTML. It utilizes an incremental decision tree to reduce the training time and adopts the k-NN classifier at leaves to maintain the effectiveness. Experiments show that our algorithm is more effective on the example-based evaluation measures compared to nine state-of-the-art algorithms for multilabel classification. In addition, it is a fast algorithm and is more suitable for handling large-scale data sets. In future work, we will focus on how to handle sparse multilabel data and multilabel data streams with concept drifts.
Notes
1 It is also suitable for data sets with discrete attributes, because the selected data sets with discrete attributes have binary values; that is, 0 and 1.
2 To simplify the problem, our model is built on the assumption that class labels are independent of each other.
3 The simulated database simply connects a database with numerical attributes only and the other one with discrete attributes only in parallel. Both databases are generated in the multilabeled data generators from MOA (Bifet et al. Citation2010).
4 We only give experimental results of hamLoss and OneError and the time overhead for M3L to compare our algorithm. This is because the source code of M3L (Hariharan, Vishwanathan, and Varma Citation2012) does not provide results on other estimation metrics.
5 We do not give the evaluation measure F1 here, because it can be estimated in precision and recall.
References
- Bifet, A., G. Holmes, R. Kirkby, and B. Pfahringer. 2010. MOA: Massive online analysis. Machine Learning Research 11:1601–604.
- Borges, H. B., and J. C. Nievola. 2012. Multi-label hierarchical classification using a competitive neural network for protein function prediction. Paper presented at International Joint Conference on Neural Networks, Brisbane, Australia, June 10–15.
- Cheng, W., and E. Hüllermeier. 2009. Combining instance-based learning and logistic regression for multilabel classification. Machine Learning 76:211–25.
- Clare, A., and R. D. King. 2001. Knowledge discovery in multi-label phenotype data. Paper presented at Fifth European Conference on Principles of Data Mining and Knowledge Discovery, Freiburg, Germany, September 3–7.
- Comité, F. D., R. Gilleron, and M. Tommasi. 2003. Learning multi-label altenating decision tree from texts and data. Paper presented at Machine Learning and Data Mining in Pattern Recognition, Leipzig, Germany, July 5–7.
- Elisseeff, A., and J. Weston. 2002. A kernel method for multi-labelled classification. In Advances in Neural Information Processing Systems, ed. T. G. Dietterich, S. Becker, and Z. Ghahramani, 681–87. Cambridge, MA: MIT Press.
- Füurnkranz, J., E. Hüllermeier, M. E. Loza, and K. Brinker. 2008. Multilabel classification via calibrated label ranking. Machine Learning 73:133–53. doi:10.1007/s10994-008-5064-8.
- Hariharan, B., L. Z. Manor, S. V. N. Vishwanathan, and M. Varma. 2010. Large scale max-margin multi-label classification with priors. Paper presented at International Conference on Machine Learning, Haifa, Israel, June 21–24.
- Hariharan, B., S. V. N. Vishwanathan, and M. Varma. 2012. Efficient max-margin multi-label classification with applications to zero-shot learning. Machine Learning 88:127–55. doi:10.1007/s10994-012-5291-x.
- Hastie, T., R. Tibshirani, and J. Friedman. 2008. The elements of statistical learning: Data mining, inference, and prediction. New York, NY: Springer-Verlag.
- Jiang, A., C. Wang, and Y. Zhu. 2008. Calibrated rank-SVM for multi-label image categorization. Paper presented at International Joint Conference on Neural Networks, Hong Kong, China, June 1–6.
- Jiang, J.-Y., S.-C. Tsai, and S.-J. Lee. 2012. FSkNN: Multi-label text categorization based on fuzzy similarity and k nearest neighbors. Expert Systems with Applications 39:2813–21. doi:10.1016/j.eswa.2011.08.141.
- Petrovskiy, M. 2006. Paired comparisons method for solving multi-label learning problem. Paper presented at International Conference on Hybrid Intelligent Systems, Auckland, New Zealand, December 13–15.
- Read, J., B. Pfahringer, and G. Holmes. 2008. Multi-label classification using ensembles of pruned sets. Paper presented at IEEE International Conference on Data Mining, Pisa, Italy, December 15–19.
- Read, J., B. Pfahringer, G. Holmes, and E. Frank. 2009. Classifier chains for multi-label classification. Paper presented at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Bled, Slovenia, September 7–11.
- Sapozhnikova, E. P. 2009. Multi-label classification with art neural networks Paper presented at Second International Workshop on Knowledge Discovery and Data Mining, Moscow, Russia, January 23–25.
- Schapire, R. E., and Y. Singer. 2000. Boostexter: A boosting-based system for text categorization. Machine Learning 39:135–68. doi:10.1023/A:1007649029923.
- Spyromitros, E., G. Tsoumakas, and I. Vlahavas. 2008. An empirical study of lazy multilabel classification algorithms. Paper presented at Fifth Hellenic Conference on AI, Syros, Greece, October 2–4.
- Tsoumakas, G., I. Katakis, and I. Vlahavas. 2008. Effective and efficient multilabel classification in domains with large number of labels. Paper presented at ECML/PKDD Workshop on Mining Multidimensional Data, Antwerp, Belgium, September 15–19.
- Tsoumakas, G., I. Katakis, and I. Vlahavas. 2010. Mining multi-label data. In Data mining and knowledge discovery handbook, ed. O. Maimon, and L. Rokach, 667–85. New York, NY: Springer.
- Tsoumakas, G., I. Katakis, and I. Vlahavas. 2011. Random k-label sets for multi-label classification. IEEE Transactions on Knowledge and Data Engineering 23:1079–89. doi:10.1109/TKDE.2010.164.
- Tsoumakas, G., and I. Vlahavas. 2007. Random k-label sets: An ensemble method for multilabel classification. Paper presented at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Warsaw, Poland, September 17–21.
- Xu, J. H. 2012. An efficient multi-label support vector machine with a zero label. Expert Systems and Applications 39:4796–804.
- Xu, M., Y. Li, and Z. Zhou. 2013. Multi-label learning with pro loss. Paper presented at Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, Washington, July 14–18.
- Zhang, M. L., and Z. H. Zhou. 2006. Multi-label neural networks with applications to functional genomics and text categorization. IEEE Transactions on Knowledge and Data Engineering 18:1338–51.
- Zhang, M. L., and Z. H. Zhou. 2007. ML-kNN: A lazy learning approach to multi-label learning. Pattern Recognition 40:2038–48.
- Zhang, X. T., Q. Yuan, S. W. Zhao, W. Fan, W. T. Zheng, and Z. Wang. 2010. Multi-label classification without the multi-label cost. Paper presented at SIAM Conference on Data Mining, Columbus, Ohio, April 29–May 1.