
Abstract
Prediction of tourist decision-making processes, including tourist motive, attitude, behavior, and so on, is of great importance for the development of tourism marketing strategies. Recently, applying machine learning techniques to predict tourist decision-making processes has drawn much attention. However, many machine learning techniques applied in the tourist decision-making prediction task fail to address two practical yet important problems. One is the failure of constructing models that can generate accurate yet comprehensible predictions at the same time, and the other is the failure to accommodate the characteristics of data collected from tourists that is usually small yet noise prone. In this article, we address the two entangled problems using the twice-learning framework to predict tourist motive from tourist external and internal features data collected through on-site survey. The results indicate that, based on the two-phase learning process, we can predict tourist motive accurately as well as extract meaningful insights, which are useful for targeted marketing strategies development from the real-world data.
INTRODUCTION
With the tremendous increase in tourism demand in recent decades, tourism has become one of the world’s fastest growing industries. Prediction of tourist decision-making processes, including tourist motive, intention, behavior, and so forth, is widely regarded as a study of great importance for providing guidance for policy-making in the development of the industry (Hsu, Cai, and Li Citation2010; Lee Citation2009; Valle et al. Citation2012). Useful prediction models of the tourist decision-making process should not only generate accurate predictions but also explicitly explain why such predictions are made, in order to provide practitioners with meaningful insights (Song and Li Citation2008). The state-of-the-art prediction models used in tourism research include rough set models (Celotto, Ellero, and Ferretti Citation2012; Goh and Law Citation2003), structural equation models (Chi and Qu Citation2008; Gross and Brown Citation2008; Jalilvand et al. Citation2012) and so on. Although these models are comprehensible to some extent, they are somewhat more descriptive than predictive, and vulnerable to noise and model assumptions.
Since machine learning techniques were introduced to the tourism research in the late 1990s (Law and Au Citation1999; Pattie and Snyder Citation1996), the prediction performance in tourism research has been greatly improved. However, most of the machine learning techniques applied in tourism research are “black-box” in nature, such as neural network (Chen, Lai, and Yeh Citation2012; Law Citation2000; Palmer, Montaño, and Sesé Citation2006) and support vector regression (Chen Citation2011; Chen and Wang Citation2007; Hong et al. Citation2011). Little insight on the knowledge hidden beneath the data can be drawn from the model representation, which limits the application of machine learning in analyzing data in real-world tourist decision-making processes. To make machine learning suitable for tourist decision-making process prediction, a learner that is able to generalize well and comprehend the knowledge learned from data is highly demanded. To the best of our knowledge, no such models have ever been applied to tourist decision-making process prediction in empirical tourism research.
Moreover, another major obstacle for using machine learning to effectively predict the tourist decision-making process is that constraints in the data collection process and the data properties have never been given serious consideration during the learning process. The data related to tourists are usually taken from on-site surveys, and consequently have following inevitable flaws. (1) The amount of the dataset is limited. Questionnaires and interview surveys are the major ways to collect data from tourists. The data collection process is time and energy consuming, which inherently limits the amount of data that can be collected on site. Tourists might have no time or might be unwilling to complete the questionnaire surveys or be interviewed during their tour, which also accounts for the limited extent of the dataset. (2) The collected data are always noise-prone. Among those people who agree to be surveyed, some will not take it seriously and, therefore, will give the answers to the questions in a casual and unserious way. Also, if the questions are related to their privacy, they will be reluctant to provide answers. These situations lead to the fact that a large number of respondents will provide wrong answers or not answer the questions completely in the survey. Thus, the tourist decision-making process prediction tasks will usually end up with a small yet noisy dataset, which raises a big challenge to select an appropriate machine learning method for effective prediction. Unfortunately, up to now, most of the research related to tourist decision-making process prediction just applies existing machine learning methods in a straightforward way, without adapting any methods to the data properties in the tasks. Although some positive results might be achieved, the performances are still far from what could be done.
Therefore, to make effective predictions for the tourist decision-making process, a learner must have strong generalization ability and comprehension in order to process even small and noisy data. In this article, we address the problem with a twice-learning framework (Zhou and Jiang Citation2003), which is able to construct a comprehensible learner that generalizes well from essentially small and noisy datasets. In detail, a neural network ensemble is trained from the original dataset in the first learning phase, and then, in the second learning phase, virtual examples are generated from the trained neural network ensembles and used to train a set of decision rules. The empirical studies show that we can not only achieve more accurate predictions than the methods that are widely used in the empirical tourism research, but also discover useful rules that explicitly explain why such predictions are made. The discovered rules provides meaningful and effective insight into the development of the tourism industry.
The remainder of this article is organized as follows: the next section describes the twice-learning framework in detail; “Mining Practice” presents the mining practice to generate a comprehensible model, and then reports and analyzes the findings; “Related Work” presents the related work of the application of machine learning in empirical tourism research; the last section concludes this article and offers suggestions for future research.
TWICE-LEARNING FRAMEWORK
Because most of the traditional data mining approaches fail to produce models with strong generalization ability as well as high comprehensibility at the same time, Zhou and Jiang (Citation2003) proposed a twice-learning framework, which elaborates on combining these two abilities in a new way. This learning framework includes two phases of work, as shown in . In the first phase, a model with strong generalization ability is constructed using the original training data. This phase is aimed to preprocess the original dataset. In the second phase, another model with high comprehensibility is constructed from the preprocessed data in order to obtain the prediction that can be ultimately understood by human experts. Note that the noise contained in the original dataset would be “smoothed out” in the first phase, and the virtual examples are usually generated to augment the training data, which makes the learning process effective even if the training dataset is small. By employing the whole procedure, both strong generalization ability and high comprehensibility can be achieved at the same time. The algorithms of the framework used in each phase follow.
FIGURE 1 The twice-learning framework.
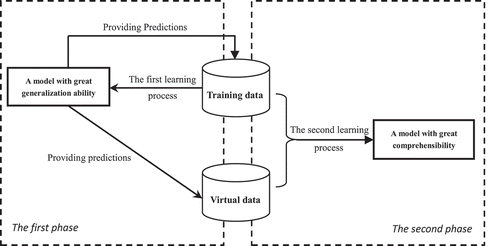
Let S= denote the training set. First, a model with strong generalization ability is employed to construct a predictive model N* from the training set S. And then N* is used to predict the concept label yi′ for each example xi (i = 1,2, …, n) in the training set. By replacing the true concept label yi of xi with yi′, a new dataset S′ is obtained. Note that yi′ may not be the same as yi. Because of the strong generalization ability of N*, it can usually provide more accurate prediction than other predictive models. By replacing the true label with the predicted label, the labeling noise contained in S would be smoothed out by the accurate prediction produced by N*, and hence, the S′ is less noisy than the original training set S, which is beneficial for the learning algorithm with strong comprehensive ability in the second phase.
In the second phase, a model with high comprehensibility is used to generate the predictions that can be clearly understood by human experts. Because a large training set is usually required in the learning process, the current training set S′ is enlarged by generating additional virtual examples. In detail, m random examples are generated and fed to N* for predictions, and then these predictions are used as their true labels. Let
denote the label of xj, and then a new dataset S″=
is obtained. Finally, the filtered training set S′ is combined with the newly generated virtual example set S″ to create a larger training set SR, and the enlarged training set is used for the model with high comprehensibility in the second phase.
One instantiation of the twice-learning framework employs neural network ensemble in the first phase and the C4.5 Rule in the second phase. Neural network ensemble (Hansen and Salamon Citation1990), which combines multiple neural networks for one target, has the strongest generalization ability. The C4.5 Rule (Quinlan Citation1993), which generates a set of decision rules in the form of “IF a AND b THEN c” can be essentially understood by the users. This instantiation, referred to as C4.5 Rule-PANE, has been successfully applied to computer-aided medical diagnoses (Zhou and Jiang Citation2003) and gene expression analysis (Jiang, Li, and Zhou Citation2006). The pseudocode of C4.5 Rule-PANE is shown in .
TABLE 1 The Pseudocode of C4.5 Rule-PANE Algorithm (Zhou and Jiang Citation2003)
Note that, to guarantee effectiveness, C4.5 Rule-PANE should satisfy the applicability condition proposed by Zhou and Jiang (Citation2004). The theoretical justification for the working mechanism is also provided in their work. The condition is summarized into an Application Theorem, which is listed as follows:
Application Condition (Zhou and Jiang Citation2004):
If the neural network ensemble in the first phase can achieve better performance in prediction than C4.5 Rule and if both are trained from the same dataset, C4.5 Rule-PANE can be applied to yield a model with strong generalization ability and comprehensibility.
MINING PRACTICE
In this study, we applied a twice-learning framework, C4.5 Rule-PANE, to mine tourist motive from tourist external and internal characteristics data collected through on-site survey. First, the process of data collection is introduced. Second, the effectiveness and superiority of C4.5 Rule-PANE on the collected data is verified. After that, the C4.5 Rule-PANE algorithm is used to construct the predictive model, and then the achieved findings are reported and discussed.
TABLE 2 The Detail Information of the Attributes
Data Collection
Data were collected through on-site surveys in Nanjing, China, from October to November 2012. The targeted respondents were tourists aged 18–65 years. Each respondent was required to complete a 15-item questionnaire referring to their personal characteristics (i.e., input attributes) and motive for tourism (i.e., target concept). Demographics and personal values are incorporated to represent tourists’ extrinsic and intrinsic characteristics, respectively. A five-point Likert-type scale is used, ranging from 1 (very unimportant) to 5 (very important), to evaluate the importance of each item of personal values perceived by the respondents in their daily life. The target concept refers to tourist motive to search for “relaxation and refreshment” (denoted by “physical”) versus “broaden knowledge and horizon” (denoted by “cultural”). The detail information of the attributes is tabulated in . Finally, 121 valid questionnaires were collected. Each valid questionnaire i(i = 1,2, … 121) is converted into a 14-dim vector of attributes xi = (xi1, xi2, …, xi14)T and a concept label yi, where xij indicated the answer to the jth question in questionnaire i, and .
Application Verification
In order to evaluate the applicability as well as the generalization performance of C4.5 Rule-PANE in this study, four widely used machine learning methods—naïve Bayes, neural network, neural network ensemble, and C4.5 Rule—are compared with C4.5 Rule-PANE before analyzing the current data. These four baseline methods have been generally considered as the powerful classification methods in empirical tourism research. All the methods are implemented using Waikato Environment for Knowledge Analysis (WEKA; Witten and Frank Citation2000), and the parameters of these methods are set as the default value in WEKA. Ten-fold cross validation is conducted to evaluate the performance of these methods.
TABLE 3 p-Values of the Pairwise t-Test between Any Two Compared Methods (Significance Level 95%)
shows the average error rates for all the compared methods in this study. Pairwise two-tailed t-test at 95% significance level is conducted over the results, and the corresponding p-values between each pair of algorithms are listed in , where the entries showing significance are boldfaced. and indicate the following:
Neural network ensemble performs significantly better than C4.5 Rule. This proves that the prerequisite of availability is satisfied.
FIGURE 2 Error rates of all the compared methods in analyzing the current dataset.
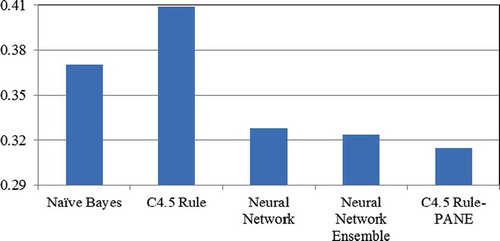
C4.5 Rule-PANE is a little better than neural network and neural network ensemble, but significantly better than C4.5 Rule and naïve Bayes, which suggests that the nonlinear mapping learned by C4.5 Rule-PANE is much closer to the ground truth mapping than the other compared methods.
Above all, C4.5 Rule-PANE is more suitable for predictive modeling in this study, compared with the state-of-the-art machine learning methods that have been widely used in empirical tourism research. Therefore, in the following section, we explore tourist motive by using C4.5 Rule-PANE.
Discovering Important Attributes
The whole original dataset with extrinsic and intrinsic attributes is used as the training dataset for C4.5 Rule-PANE. Through the gain ratio (Quinlan Citation1993) values produced by C4.5 Rule-PANE, the importance of the personal characteristics in predicting tourist motive is ranked. Gain ratio can be regarded as an importance measure of each individual attribute in predicting the target concept. It measures the ability to discriminate among the examples belonging to different concept classes, based on the value of this attribute. The higher the gain ratio value is, the greater the generalization ability of the attribute. The gain ratio of each individual attribute produced by C4.5 Rule-PANE in this study is presented in , and the importance of the personal characteristics in predicting what the tourist is mainly seeking during the tour is clearly indicated.
FIGURE 3 Gain ratios of the attributes obtained from C4.5 Rule-PANE.
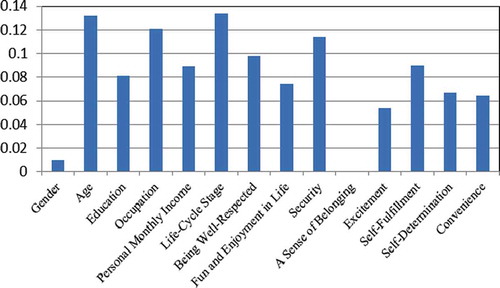
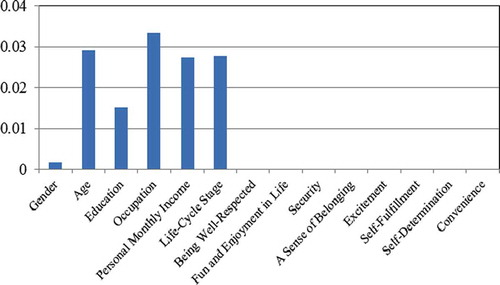
Surprisingly though, by comparing with , which represents the ranking of attributes provided by C4.5 Rule, different results are found. Without being preprocessed by neural network ensemble, the ranking list provided by C4.5 Rule shows that all of the personal attributes are of no importance in predicting tourist motive. Because the generalization ability of C4.5 Rule-PANE is much better than C4.5 Rule, the importance ordering of attributes disclosed by C4.5 Rule-PANE is much closer to the ground truth.
FIGURE 4 Gain ratios of the attributes obtained from C4.5 Rule.
Obtaining and Discussing Decision Rules
Because all the attributes may interact with each other to influence the final results, considering only the individual generalization ability would not lead to the accurate prediction for an individual. Thus, how these attributes interact with each other to produce the final predictions is further investigated, in order to find what personal characteristics account for a tourist motive.
TABLE 4 Decision Rules Learned from C4.5 Rule-PANE
Because of the high comprehensibility of C4.5 Rule-PANE, the multivariate relationship from the input attributes to the target concept is constructed by the learned decision rules, presented in . These rules characterize the typical groups of tourists who seek “relaxation and refreshment” or “broaden knowledge and horizon” during pleasure traveling in the form of “IF a AND b THEN c,” where a, b, c are logical expressions. From these rules, the underlying truth of tourist motive can be further disclosed and interpreted.
shows that, for the tourists who seek “relaxation and refreshment” (denoted by physical), three typical groups are found:
R1: The first group is middle-aged people holding jobs in white-collar fields, married with children. Because the dual pressures of working as well as raising children, people at this stage usually use tourism as a way to relieve themselves. Because “being well-respected” is not the major concern for them, this category of tourist would probably pay more attention to physical rather than spiritual needs during a tour. Therefore, the pursuit of relaxation and refreshment would probably be the driving force of their tourism.
R2: The second group is high-educated young people, married with no children. Most people in this group might have the ability to search for information on the Internet, such as the local culture and history of their destinations. In view of this, “broaden knowledge and horizon” might not be the major driving force in their tourism. Given their great concern for “security,” this group might probably view tourism as a way of pursuing ease and comfort.
R3: The third group is women with lower level of education. Choi et al. (Citation2008) indicated that uneducated female tourists usually have no interest in the local culture of their tourism destinations. Fun and relaxation would probably be their great concern during a trip. This argument is confirmed in this rule. As the rule presented, this group of tourists pay more attention to “convenience” and less attention to “excitement,” which indicates that the natural scenery sightseeing would be preferable to them, and relaxation and refreshment would probably be what they are seeking during a tour.
For the tourists who seek to “broaden knowledge and horizon” (denoted as cultural), three typical groups are found as well:
R4: The first group is high-educated and unmarried people. Given their great emphasis on “self-fulfillment” and “self-determination” presented in the rule, this group of people would use tourism as a way to enrich and improve themselves. Because they pay much attention to security, they would not use tourism to pursue excitement and adventure. Therefore, a safe cultural tour that might broaden their knowledge and horizon would probably be their reason for a trip.
R5: The second group is young students aged from 18 to 24. Most of these would be college students or graduate students. Because they attach much importance to self-fulfillment and less importance to fun and enjoyment in life, this group of tourists would probably pursue tourism as a way to enrich and improve themselves by means of increasing knowledge and experience at their destinations.
R6: The third group is male with high income. Because they attach much importance to self-fulfillment and little importance to excitement, this group of people would probably hope to have an easy and comfortable experience with intellectual enjoyment during the tour. To broaden their knowledge and horizon in order to gain a sense of self-fulfillment would probably be the driving force for them to travel.
RELATED WORK
Machine learning has been successfully applied to many disciplines, such as information science (Li, Li, and Zhou Citation2009; Zhou, Chen, and Dai Citation2006), medicine (Li and Zhou Citation2007), biology (Jiang, Li, and Zhou Citation2006), social science (Zhang and Zhang Citation2012, Citation2014), and other fields. The first application of machine learning techniques in tourism research was in the late 1990s, and its superiorities in model construction and prediction accuracy have made it an ideal data analysis tool in this field. Typical machine learning methods employed in tourism research include neural network, Bayesian method, and decision rule/tree.
The neural network method was first introduced to tourism research by Pattie and Snyder (Citation1996). Through the comparison of neural networks with several classical time series prediction methods, they indicated that neural network is a valid alternative to classical techniques in tourist prediction. Since then, the neural network method has been widely applied in tourism research, and its superiority of prediction accuracy over many classical prediction methods has been confirmed. For example, Law and Au (Citation1999) used neural network to predict Japanese travel demand for Hong Kong and found that neural network outperforms multiple regression, naïve, moving average, and exponent smoothing. Burger et al. (Citation2001) showed that the neural network method is the preferable prediction model over the naïve, decomposition, exponential smoothing, autoregressive integrated moving average, multiple regression, and genetic regression models. Kon and Turner (Citation2005) pointed out that neural network generally outperforms the classical time series and multiple regression models in tourism prediction research. However, due to its “black-box” nature, the neural network method cannot provide the explanation of the predictions from the model representation, therefore, the method has little practical significance from the economic perspective (Song and Li Citation2008). With the continual applications of neural network in tourism prediction, the limitation of it has been widely recognized by the tourism academics.
The Bayesian method has been widely used in predicting tourist attitudes and behaviors. Hsu, Tsai, and Wu (Citation2009) proposed a mechanism to combine a structural equation model (SEM) with a Bayesian network to predict tourist loyalty level and achieved effective predictions. Melián-González, Moreno-Gil, and Araña (Citation2011) used Bayesian model averaging (BMA) to investigate the relationship between the satisfaction of gay tourists and their perceptions of the condition in terms of the valuable resources. The analysis results would be beneficial to explain a destination’s competitiveness in the gay tourist segment. With the comparison of these predictions obtained by Bayesian methods with those obtained by other classical predictive models in these studies, the effectiveness of Bayesian network in predicting tourist attitudes and behaviors has been greatly confirmed. However, this paradigm highly relies on the choice of the Bayesian prior and model assumption and usually requires a large number of labeled training data for parameter estimation. So it might not achieve good performance when the prior knowledge of the problem to be solved is too insufficient to help select the Bayesian prior and determine the model assumption, and when the size of the training data is small. Besides, Bayesian inference is relatively slow, and, hence, it might not be of practical use in some applications that require quick prediction response.
Decision rule/tree has been used to characterize groups of tourists in the tourism market. Emel, Taskin, and Akat (Citation2007) learned decision rules to characterize various groups of outgoing tourists in the domestic tourism market. Li et al. (Citation2010) incorporated decision rule into a self-organizing, map-based segmentation process. With the obtained rules, several groups of outbound tourists in Hong Kong were profiled. Rong et al. (Citation2011) learned decision rules to characterize two groups of outbound tourists, viz., the online experience sharers and travel website browsers, based on their demographic and travel information attributes. A number of decision rules were obtained, which would be helpful for tourism managers in defining new target customers. Compared with decision rule, the use of decision tree has not appeared in tourism research until Kim, Timothy, and Hwang (Citation2011), who used decision tree to investigate the influential factors of Japanese tourists’ shopping preferences and intentions to revisit Korea. However, due to the limitation on the size of training data and the potential noise contained in the training data, the symbolic learning algorithm can achieve only reasonably good prediction accuracy, although its symbolic nature can help the user understand the discovered knowledge.
CONCLUSIONS
Prediction of tourist decision-making processes is of great importance in guiding the development of tourism marketing strategies. To make effective predictions of tourist decision-making processes, a learner with strong generalization ability and comprehensibility, as well as ability to accommodate the characteristics of data (such as the data is small and noisy prone), is required. To address the issue, this article introduces a twice-learning framework, C4.5 Rule-PANE, to generate a model that is accurate in prediction and essentially comprehensible to the data miners from a small yet noisy dataset. Mining practice on tourist motive prediction indicates that the twice-learning framework is effective, and the obtained comprehensible model discloses the importance of personal external and internal attributes in predicting tourist motive, as well as the relationship between a tourist’s personal attributes and his/her motive for pleasure traveling, which would be of great significance for tourism practitioners in developing targeted marketing and production strategies.
Note that, as well as demographic and personal-values attributes, more personal attributes such as tourist experience and self-concept would also be relevant to tourist motive and would be incorporated into the input attributes for prediction. Moreover, applying twice-learning methods, such as C4.5-Rule PANE, for predictive modeling in other empirical tourism research problems would be interesting future work.
FUNDING
The research is supported by the National Science Foundation of China under the Grant No. 41301145 and No. 41271149. The research is also supported by A Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.
Additional information
Funding
REFERENCES
- Burger, C. J. S. C., M. Dohnal, M. Kathrada, and R. Law. 2001. A practitioners guide to time-series methods for tourism demand forecasting–A case study of Durban, South Africa. Tourism Management 22(4):403–409.
- Celotto, E., A. Ellero, P. Ferretti. 2012. Short-medium term tourist services demand forecasting with rough set theory. Procedia Economics and Finance 3:62–67.
- Chen, C.-F., M.-C. Lai, and C.-C. Yeh. 2012. Forecasting tourism demand based on empirical mode decomposition and neural network. Knowledge-Based Systems 26:281–287.
- Chen, K.-T., and C.-H. Wang. 2007. Support vector regression with genetic algorithms in forecasting tourism demand. Tourism Management 28(1):215–226.
- Chen, K.-Y. 2011. Combining linear and nonlinear model in forecasting tourism demand. Expert Systems with Applications 38(8):10368–10376.
- Chi, C. G.-Q., and H. Qu. 2008. Examining the structural relationships of destination image, tourist satisfaction and destination loyalty: An integrated approach. Tourism Management 29(4):624–636.
- Choi, T.-M., S.-C. Liu, K.-M. Pang, and P.-S. Chow. 2008. Shopping behaviors of individual tourists from the Chinese mainland to Hong Kong. Tourism Management 29(4):811–820.
- Emel, G. G., C. Taskin, and Ö Akat. 2007. Profiling a domestic tourism market by means of association rule mining. Anatolia 18(2):334–342.
- Goh, C., and R. Law. 2003. Incorporating the rough sets theory into travel demand analysis. Tourism Management 24(5):511–517.
- Gross, M. J., and G. Brown. 2008. An empirical structural model of tourists and places: Progressing involvement and place attachment into tourism. Tourism Management 29(6):1141–1151.
- Hansen, L. K., and P. Salamon. 1990. Neural network ensembles. IEEE Transactions on Pattern Analysis and Machine Intelligence 12(10):993–1001.
- Hong, W.-C., Y. Dong, L.-Y. Chen, and S.-Y. Wei, 2011. SVR with hybrid chaotic genetic algorithms for tourism demand forecasting. Applied Soft Computing 11(2):1881–1890.
- Hsu, C. H. C., L. A. Cai, and M. Li. 2010. Expectation, motivation, and attitude: A tourist behavioral model. Journal of Travel Research 49(3):282–296.
- Hsu, T. K., Y.-F. Tsai, and H.-H. Wu. 2009. The preference analysis for tourist choice of destination: A case study of Taiwan. Tourism Management 30(2):288–297.
- Jalilvand, M. R., N. Samiei, B. Dini, and P. Y. Manzari. 2012. Examining the structural relationships of electronic word of mouth, destination image, tourist attitude toward destination and travel intention: An integrated approach. Journal of Destination Marketing and Management 1(1–2):134–143.
- Jiang, Y., M. Li, and Z.-H. Zhou. 2006. Generation of comprehensible hypotheses from gene expression data. In Proceedings of the International Workshop on Data Mining for Biomedical Application, Singapore, 116–123.
- Kim, S. S., D. J. Timothy, and J. Hwang. 2011. Erratum to: Understanding Japanese tourists’ shopping preferences using the decision tree analysis method. Tourism Management 32(3):544–554.
- Kon, S. C., and W. L. Turner. 2005. Neural network forecasting of tourism demand. Tourism Economics 11(3):301–328.
- Law, R. 2000. Back–propagation learning in improving the accuracy of neural network–based tourism demand predicting. Tourism Management 21(4):331–340.
- Law, R., and N. Au. 1999. A neural network model to forecast Japanese demand for travel to Hong Kong. Tourism Management 20(1):89–97.
- Lee, T. H. 2009. A structural model to examine how destination image, attitude, and motivation affect the future behavior of tourists. Leisure Science 31(3):215–236.
- Li, G., R. Law, J. Rong, and Q. Huy Vu. 2010. Incorporating both positive and negative association rules into the analysis of outbound tourism in Hong Kong. Journal of Travel & Tourism Marketing 27(8):812–828.
- Li, M., H. Li, and Z.-H. Zhou. 2009. Semi-supervised document retrieval. Information Processing & Management 45(3):341–355.
- Li, M., and Z.-H. Zhou. 2007. Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples. IEEE Transactions on Systems, Man and Cybernetics – Part A: Systems and Humans 37(6):1088–1098.
- Melián-González, A., S. Moreno-Gil, and J. E. Araña. 2011. Gay tourism in a sun and beach destination. Tourism Management 32(5):1027–1037.
- Palmer, A., J. J. Montaño, and A. Sesé. 2006. Designing an artificial neural network for forecasting tourism time series. Tourism Management 27(5):781–790.
- Pattie, D. C., and J. Snyder. 1996. Using a neural network to forecast visitor behavior. Annals of Tourism Research 23(1):151–164.
- Quinlan, J. R. 1993. C4.5: Programs for machine learning. San Mateo, CA: Morgan Kaufmann.
- Rong, J., H. Q. Vu, R. Law, and G. Li. 2011. A behavioral analysis of web sharers and browsers in Hong Kong using targeted association rule mining. Tourism Management 33(4):731–740.
- Song, H., and G. Li. 2008. Tourism demand modeling and forecasting–A review of recent research. Tourism Management 29(2):203–220.
- Valle, P. O., P. Pintassilgo, A. Matias, and F. André. 2012. Tourist attitudes towards an accommodation tax earmarked for environmental protection: A survey in the Algarve. Tourism Management 33(6):1408–1416.
- Witten, I. H., and E. Frank. 2000. Data mining: Practical machine learning tools and techniques with Java implementations. San Francisco, CA: Morgan Kaufmann.
- Zhang, C., and J. Zhang. 2012. Mining tourist preferences with twice-learning. Lecture Notes on Artificial Intelligence 7104:483–493.
- Zhang, C., and J. Zhang. 2014. Analyzing Chinese citizens’ intentions of outbound travel: A machine learning approach. Current Issues in Tourism 17(7):592–609.
- Zhou, Z.-H., K. J. Chen, and H. B. Dai. 2006. Enhancing relevance feedback in image retrieval using unlabeled data. ACM Transactions on Information Systems 24(2):219–244.
- Zhou, Z.-H., and Y. Jiang. 2003. Medical diagnosis with C4.5 rule preceded by artificial neural network ensemble. IEEE Transactions on Information Technology in Biomedicine 7(1):37–42.
- Zhou, Z.-H., and Y. Jiang. 2004. NeC4.5: Neural ensemble based C4.5. IEEE Transactions on Knowledge and Data Engineering 16(6):770–773.