
ABSTRACT
This article proposes an algorithm for script identification by textural analysis of the image corresponding to the script types. In the first phase, each letter is modeled by the equivalent script type, which is determined by its position in the baseline area. Then, feature extraction is carried out. It is based on the script type cooccurrence pattern analysis. The obtained features of the script are stored for further analysis. The difference in script characteristics contributes to the diversity of the extracted features, which simplify the feature classification obtained by an extension of a state-of-the-art classification tool called Genetic Algorithms Image Clustering for Document Analysis. Accordingly, it represents the key element in the decision-making process of script identification. The proposed method is tested on an example of German printed documents, which contain Latin and Fraktur scripts. The experiment shows correct results, which is promising.
Introduction
Recognition of the script is a very important step in document image analysis (Ghosh, Dube, and Shivaprasad 2010). Up to now, a large number of methods has been developed to recognize script. They are classified as global and local methods.
Global methods consider large parts of document images. They are subjected to the statistical and frequency-domain analysis (Joshi, Garg, and Sivaswamy Citation2007). However, document image parts or blocks have to be normalized and free of noise in order to receive correct results of the analysis (Busch, Boles, and Sridharan Citation2005).
Local methods separate text into small pieces. They can be made of characters, words, or lines, which represent connected components. Furthermore, the analysis of different features such as the black pixel runs, etc., is carried out (Pal and Chaudhury Citation2002). Local methods are characterized as computer-time intensive. However, they are suitable for low-quality document images, which include noise.
Our method unifies the local and global approaches. It extracts the characters in text as in the local approach. Then, it maps each character according to its script type. In this way, the modeling of the document is performed by coding (Brodic et al. Citation2013). Furthermore, the obtained coded text is subjected to cooccurrence analysis (Haralick, Shanmugam, and Dinstein Citation1973), similar to a global approach. In addition, the first and second order descriptors are extracted from the gray-level cooccurrence matrix (GLCM) (Haralick, Shanmugam, and Dinstein Citation1973; Clausi Citation2002). The decision-making script identification is established using an extension of the automatic classifier Genetic Algorithms Image Clustering (GA-IC) (Amelio and Pizzuti Citation2014).
The proposed approach incorporates the texture-like analysis. It is suitable for extracting similarities and dissimilarities between images by classifying their texture features. In our case, the image is replaced with text, which is given by a 1D matrix (vector) instead of a 2D matrix. Furthermore, the number of variables is considerably reduced during the coding process, resulting in an algorithm that is computationally nonintensive. However, the algorithm extends from those given in Brodic et al. (Citation2013, Citation2014) by adding the first-order statistic descriptors. This way, the feature vector consists of 12 descriptors. Because the number of relevant texture features is extended, this leads to improved results of script identification.
The proposed method is applied to German text scripted by Latin and Fraktur. The Fraktur type was created by Johann Schonsperger in Augsburg by the order of Kaiser Maximilian in 1513 (Haralambous Citation1991). When the reformation movement spread across Germany, some distinction in printed church books was mandatory. Hence, Protestant books were printed using Fraktur, and Catholic books were printed in Latin. Accordingly, the algorithm for characterization and identification of these two different scripts has importance in the field of cultural heritage.
This article is organized as follows. “Methods” describes the proposed algorithm. “Experiment” illustrates the experiment. The section following gives the results and discussion, and “Conclusions” draws conclusions and points out further research direction.
Methods
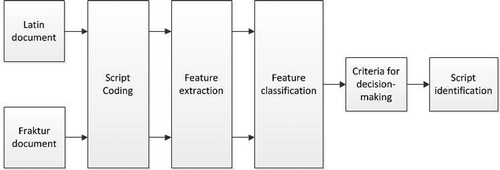
The proposed algorithm is a multistage method for script characterization, classification, and identification. It includes script coding, script-type occurrence, first- and second-order texture statistics, classification of descriptor values, and, accordingly, the decision-making script identification. illustrates the multistage method.
Figure 1. The flow of the multistage script discrimination method.
Script Coding
The algorithm introduces script coding, which is based on the position of the letter in the text line, i.e., on its height. Each text line in a document includes three vertical zones (Zramdini and Ingold Citation1998; Chaudhuri, Pal, and Mitra Citation2002):
upper zone,
middle zone, and
lower zone.
Hence, each letter can be mapped according to the aforementioned zones. illustrates the script-type determination.
Figure 2. Script-type definition: (a) Latin script, (b) Fraktur script.
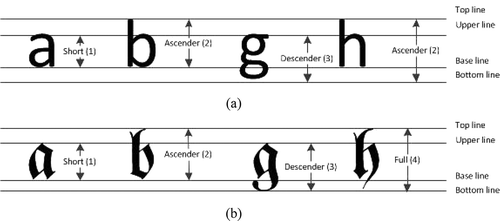
The following script types exist (Zramdini and Ingold Citation1998; Chaudhuri, Pal, and Mitra Citation2002):
short letter (B),
ascender letter (A),
descender letter (D),
full letter (F), and
space letter (S).
This way, the number of variables is considerably reduced. To organize data for further statistical analysis, the following mapping is made:
Space can be mapped to 0. Because the space is in the same position in such type of digraphia, it can be excluded from further consideration.
Starting from images, a set of multidimensional data extracts of German texts is compiled. It can be expressed in a Latin or in a Fraktur fashion. As mentioned, all letters can be classified into four sets.
shows German letters as well as their coding according to and .
Table 1. Coding of German alphabets.
Table 2. Coding of German diacritics.
The application of the proposed concept of German text written in Latin and Fraktur script is illustrated in .
Figure 3. German text: (a) Latin script, (b) Latin text coding, (c) Latin coded text, (d) Fraktur script, (e) Fraktur text coding, (f) Fraktur coded text.

Script-Type Distributions
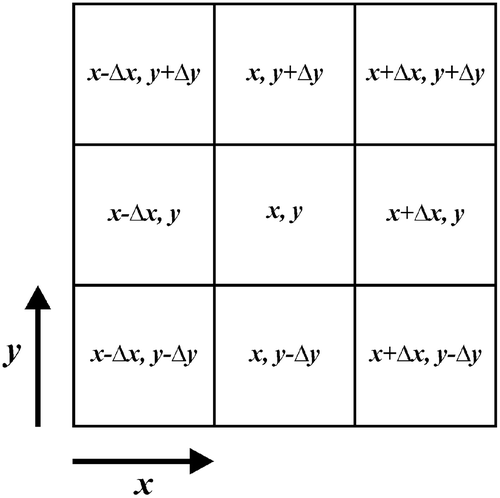
In the proposed algorithm, all letters of the script have been substituted with equivalent script types. This way, the text is mapped into the coded text. Then, the coded text is subjected to the cooccurrence analysis (Haralick, Shanmugam, and Dinstein Citation1973). It generates texture features of an image by calculating cooccurrence probabilities. They are conditional joint probabilities of all pairwise combinations of gray levels in the window of interest (WOI). WOI is determined by the interpixel distance ∆x and ∆y in x and y directions (typically ∆x = ± 1 and ∆y = ± 1) (Clausi Citation2002). shows the WOI.
Figure 4. WOI for the calculation of texture features.
The method starts from the top-left corner. It counts the occurrence of each reference-pixel-to-neighbor-pixel relationship. Each element (i, j) of Gray Level Co-occurrence Matrix (GLCM) represents the sum of the number of times the pixel with the intensity i is located at ∆x and ∆y from the pixel of intensity j. At the end of this process, the element (i, j) gives the number of how many times the gray levels i and j appear as a sequence of two pixels located at ∆x and ∆y. GLCM P for an image I with M rows and N columns is given as (Haralick, Shanmugam, and Dinstein Citation1973; Clausi Citation2002; Eleyan and Demirel Citation2011):
The normalized version of the matrix P is given as a matrix C:
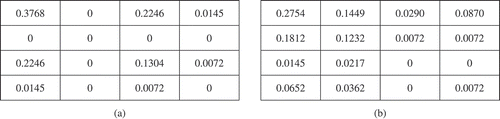
In our case, the coded text represents a 1D image (see ). Hence, the following is valid: ∆x = ± 1, ∆y = 0. Furthermore, the number of gray levels G is 4. To note the differences between scripts, the different texts from are subjected to the cooccurrence analysis. shows the obtained GLCM.
Figure 5. Statistical analysis of the text: (a) normalized GLCM for Latin script, (b) normalized GLCM for Fraktur script.
The statistical features extracted from the image texture can be divided into the first-order and second-order statistics. In this article, we use the following first-order descriptors: mean μx and μy, and standard deviation σx and σy. Mean value μx is given as
Furthermore, mean value μy is calculated as
Standard deviation σx is given as
Whereas standard deviation σy is calculated as
Second-order statistics include 14 descriptors proposed by Haralick (Haralick, Shanmugam, and Dinstein Citation1973). We explore the eight commonly used texture descriptors, which are extracted from GLCM. They are energy, entropy, maximum, dissimilarity, contrast, inverse difference moment (invdmoment), homogeneity, and correlation.
Energy measures the image uniformity. It is defined as:
It receives high values when the image has very good uniformity, i.e., when the pixels are very similar.
Entropy measures the randomness of gray-level distribution, i.e., the spatial disorder in the image. Entropy is calculated as follows:
It receives the highest values when all entries are equal, or very similar. In contrast, it receives low values when the image is characterized by spatial disorder.
Maximum determines the most predominant pixel pairs in the image. It is defined as
Dissimilarity measures the variation of gray-level pairs in the image. It is calculated as follows:
Dissimilarity receives values from [0,1].
Contrast measures the gray-level variation in GLCM. It is calculated as follows:
If the neighboring pixels have similar gray-level values, then the contrast of the image is poor (low). Typically, high contrast characterizes the heavy textures, whereas low contrast appears for soft textures.
Invdmoment measures the image smoothness. It is calculated as
It receives high values when local gray level is uniform.
Homogeneity measures image uniformity of the nonzero elements in GLCM. It is calculated as
Homogeneity has high values for diagonally oriented GLCM. This means that if there are many pixels with the same or similar gray-level values, then homogeneity receives high value.
Correlation measures the linear dependency of gray levels of neighboring pixels. It is calculated as
where μx, μy are means and σx, σy represent standard deviations.
shows the first-order texture descriptors for both scripts (extracted from the text in ).
Table 3. Comparison of the first-order texture descriptors between Latin and Fraktur scripts.
shows the second-order texture descriptors for both scripts (extracted from the text in ).
Table 4. Comparison of the second-order texture descriptors between Latin and Fraktur scripts.
Classification and Script Identification
The method adopted for classifying document images in Fraktur and Latin scripts is an extension of the GA-IC method (Amelio and Pizzuti Citation2014) and it is called Genetic Algorithms Image Clustering for Document Analysis (GA-ICDA). To prove the advantage of this classification tool, the classification is performed with k-means, self-organizing map (SOM), Support Vector Machine (SVM), and Naïve-Bayes classifiers, as well.
GA-IC is an evolutionary-based procedure for clustering an image database, represented as a weighted graph. A node represents an image. An edge connects two nodes only if they are within an h-neighborhood to each other. The h value of the nearest neighborhood is related to the number of neighbors of the nodes in the image graph G. Given a node i of G, the h-neighbors of i are those nodes whose distance from i is in the first h-lowest distance values. This means that the corresponding images are sufficiently similar to each other in terms of a given distance measure. The weight on the edges linking the nodes is the strength of such a similarity among them. Generally, this graph exhibits stronger components with dense intraconnections, representing groups of images very similar to each other. These components are linked to each other by a small number of interconnections. A genetic algorithm is then applied on this graph in order to find clusters of nodes corresponding to classes of images.
GA-ICDA presents two substantial differences from the traditional image classifier GA-IC in the construction of the image graph. The first consists in the feature representation of the images. The second consists in introducing an ordering between the nodes of the graph. Consequently, an edge is allowed between two nodes not only if their corresponding images are similar, but also if they are not far to each other with respect to this ordering.
Specifically, each node of the graph is a document image, represented as a feature vector. Each vector is composed of the 12 GLCM-derived features of interest, obtained from the previously considered statistical analysis. They are four first-order texture descriptors (μx, μy, σx, σy) and eight second-order texture descriptors (energy, entropy, maximum, dissimilarity, contrast, invdmoment, homogeneity, and correlation).
When the graph is realized by document images, it is more likely that a high h-neighborhood of the nodes causes the introduction of “noisy” edges. They are edges connecting nodes whose corresponding images are not very similar to each other. However, choosing an extremely low number of h-neighbors determines the loss of the document graph components. In order to overcome this problem, we introduce a strategy, derived from the concept of Matrix Bandwidth (Marti et al. Citation2001), to break “noisy” edges linking nodes that are spatially too distant from each other. In particular, consider the node ordering induced by the graph adjacency matrix. It is a one-to-one function mapping the nodes of the graph to integers f: V → {1,2,…n}. Let f(v) be the label of the node v ∈ V, where each node has been assigned to a different label. For each node v ∈ V, we calculate the difference between f(v) and the labels F of its adjacent nodes corresponding to its h-neighborhood. Then, for each node v, we choose to eliminate those edges between v and its adjacent nodes whose corresponding label difference is greater than a threshold value T.
Experiment
The algorithm is subject to experiment in order to investigate its efficiency and correctness. To perform the experiment, a custom-oriented database is created. It includes training and test sets. The training set consists of 102 German documents—excerpts from the Internet to the poems written by J. W. von Goethe. All documents are written in Latin and Fraktur scripts. The smallest document contains roughly 200 characters, whereas the largest one counts around 1,000 characters. Furthermore, the test set includes 18 German documents written in Latin and Fraktur scripts. Typically, documents contain approximately 500 characters. The result of the experiment gives the percentage of the correct script recognition.
Results and Discussion
It is very important to use only the measures with distinct difference in values for the different scripts. Establishing the ratio between these measures for different scripts gives their relation, which can be utilized as a part of the identification criteria.
The first experiment is linked with the examination of the first-order texture descriptors obtained from the training set of the database written in Latin and Fraktur scripts. shows the results.The results of first-order descriptors are illustrated graphically in .
Table 5. Comparison of the first-order texture descriptors between Latin and Fraktur scripts extracted from training part of the database.
Figure 6. First order texture descriptors obtained from Latin and Fraktur scripts extracted from training part of database: (a) mean μx, (b) mean μy, (c) standard deviation σx, and (d) standard deviation σy.
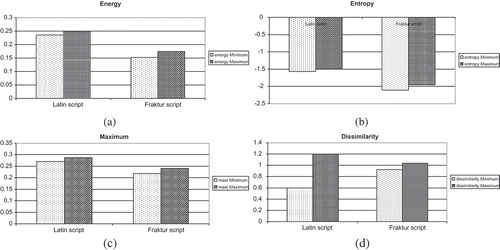
The results of the first-order descriptors show that mean μx and μy can be almost separated between different scripts. Furthermore, standard deviation σx and σy slightly overlap each other.
The second-order texture descriptors obtained from the training part of the database written in Latin and Fraktur scripts as shown in .
Table 6. The second--order texture descriptors obtained from the training part of the database written in Latin and Fraktur scripts.
The results of second-order descriptors are illustrated graphically in .
Figure 7. Second-order texture descriptors obtained from Latin and Fraktur scripts extracted from training part of the database: (a) energy, (b) entropy, (c) maximum, (d) dissimilarity, (e) contrast, (f) inverse difference moment, (g) homogeneity, and (h) correlation.
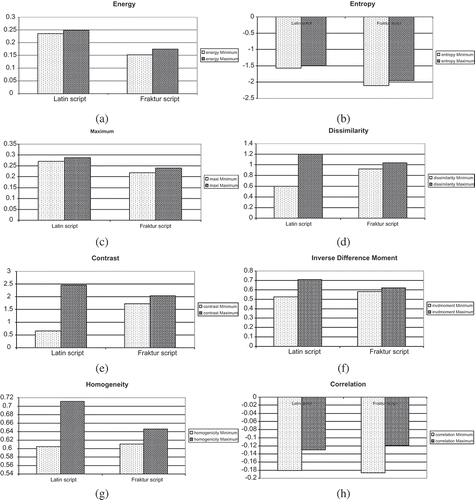
The significant differences between scripts are shown in energy, entropy, and maximum. Hence, these descriptors can be used for script dissemination. The text written in Fraktur is characterized by a smaller dispersion of values. It is valid for dissimilarity, contrast, inverse difference moment, and homogeneity. Still, the value of correlation is similar.
Furthermore, the experiment is conducted on the test set of the database. The first-order texture descriptors obtained from the test part of the database written in Latin and Fraktur scripts are shown in .
Table 7. Comparison of the first-order texture descriptors between Latin and Fraktur scripts extracted from the test part of the database.
The results from the test set show similar values as those obtained from the training set. These results do not slightly overlap as in the training set. Currently, they are completely separated.
The second-order texture descriptors obtained from the test part of the database documents written in Latin and Fraktur scripts are shown in .
Table 8. The second-order texture descriptors obtained from the test part of the database written in Latin and Fraktur scripts.
The results from the test set show similar values as those obtained from the training set.
Furthermore, the experiment has been performed by using the GA-ICDA classifier for the automatic dissemination of the documents in Latin and Fraktur scripts. The advantage of the GA-ICDA classifier is tested by exploring classification with k-means, SOM, SVM, and Naïve-Bayes methods, when the same 12 GLCM features are adopted for document representation.
In particular, the training set of 102 German documents (51 in Latin and 51 in Fraktur scripts) has been adopted for learning the parameters of GA-ICDA: the h value of the nearest neighborhood and the threshold value T for eliminating “noisy” edges. Then, the performances of GA-ICDA in correctly classifying Fraktur and Latin scripts have been evaluated on the test set of 18 German documents (8 in Latin and 10 in Fraktur scripts).
gives the comparison of GA-ICDA with two other unsupervised classifiers (k-means and SOM) on the training set (102 samples).
Table 9. Comparison of GA-ICDA on the training set (102 samples) with two other unsupervised classifiers (k-means and SOM).
The training set is used in GA-ICDA for tuning the parameters in order to obtain the best possible results on this dataset. After that, the test set is classified based on these obtained parameters. The training set is used in the other classifiers for training. After that, the test set is classified. depicts the comparison of GA-ICDA with two other supervised classifiers (SVM and Naïve-Bayes) on the test set (18 samples).
Table 10. Comparison of GA-ICDA on the test set (18 samples) with two other supervised classifiers.
Normalized Mutual Information (NMI; Strehl and Ghosh Citation2003), precision, recall, and f-measure are the metrics adopted for evaluating the results obtained from GA-ICDA. Evaluation has been performed 50 times on both the training and test sets and the average values and standard deviation of NMI, precision, recall, and f-measure have been computed on the 50 runs.
Running GA-ICDA on the training set obtains the best results of average Normalized Mutual Information (NMI), precision, recall, and f-measure values of 1 and standard deviation 0, for an h-value equal to 15 and a T parameter equal to 25.
The same values of these parameters have been used for evaluating the performances of GA-ICDA on the test set. Results of average precision, recall, and f-measure are equal to 1 with a standard deviation of 0. It indicates that GA-ICDA is quite accurate in classifying different kinds of scripts, when 12 first- and second-order statistical descriptors are adopted for document representation.
At the end, the speed testing of the proposed method shows that it is computationally nonintensive. It is valid, because the processing time is as low as 0.1 s per text that includes 2 K characters.
Conclusions
This manuscript proposes an algorithm for script characterization, identification, and recognition on an example of German printed documents written in Latin and Fraktur scripts. The algorithm includes the comprehensive statistical analysis of the coded document, which is obtained by mapping the initial text document according to the script types of each character. Because the characteristics of both scripts are different, the statistical analysis shows significant diversity between them. Hence, the successful script identification is conducted by an extension of the state-of-the-art GA-IC classification tool. The proposed technique is tested on a custom-oriented database. The experiments gave encouraging results. The concept presented in this manuscript can be used in processing steps of optical character recognition.
Nomenclature
| A: | = | ascending letter |
| B: | = | short letter |
| C: | = | probability cooccurrence matrix |
| D: | = | descending letter |
| F: | = | full letter |
| G: | = | number of gray levels |
| GA-IC: | = | Genetic Algorithms Image Clustering |
| GA-ICDA: | = | Genetic Algorithms Image Clustering for Document Analysis |
| GLCM: | = | Gray Level Cooccurrence Matrix |
| I: | = | image |
| NMI: | = | Normalized Mutual Information |
| P: | = | cooccurrence matrix |
| SOM: | = | Self-Organizing Map |
| SVM: | = | Support Vector Machine |
| WOI: | = | Window of Interest |
Funding
This work was partially supported by the Grant of the Ministry of Education, Science and Technological Development of the Republic Serbia, as a part of the project TR33037.
Additional information
Funding
References
- Amelio, A., and C. Pizzuti. 2014. A new evolutionary-based clustering framework for image databases. In Image and signal processing (ICISP 2014), ed. A. Elmoataz, O. Lezoray, F. Nouboud, and D. Mammass, LNCS 8509, 322–31. Cherbourg, France: Springer.
- Brodić, D., Z. N. Milivojević, and Č. A. Maluckov. 2014. Script characterization in the old Slavic documents. In Image and signal processing (ICISP 2014), eds. A. Elmoataz, O. Lezoray, F. Nouboud, and D. Mammass, LNCS 8509, 230–38. Cherbourg, France: Springer.
- Brodić, D., Z. N. Milivojević, and Č. A. Maluckov. (2013). Recognition of the script in Serbian documents using frequency occurrence and co-occurrence analysis. The Scientific World Journal 2013 (896328):1–14. doi:10.1155/2013/896328.
- Busch, A., W. W. Boles, and S. Sridharan. 2005. Texture for script identification. IEEE Transactions on Pattern Analysis and Machine Intelligence 27 (11):1720–32. doi:10.1109/TPAMI.2005.227.
- Chaudhuri, B. B., U. Pal, and M. Mitra. 2002. Automatic recognition of printed Oriya script. Sadhana 27 (1):23–34. doi:10.1007/BF02703310.
- Clausi, D. A. 2002. An analysis of co-occurrence texture statistics as a function of grey level quantization. Canadian Journal of Remote Sensing 28 (1):45–62. doi:10.5589/m02-004.
- Eleyan, A., and H. Demirel. 2011. Co-occurrence matrix and its statistical features as a new approach for face recognition. Turkish Journal of Electrical Engineering and Computer Science 19 (1):98–107.
- Haralambous, Y. 1991. Typesetting old German: Fraktur, Schwabacher, Gotisch and initials. In Proceedings of Tex 90, Cork, Ireland, 1990, 129–38.
- Haralambous, Y. 1991. Typesetting old German: Fraktur, Schwabacher, Gotisch and initials. TUGboat 129–38.
- Haralick, R., K. Shanmugam, and I. Dinstein. 1973. Textural features for image classification. IEEE Transactions on Systems, Man, and Cybernetics 3 (6):610–21. doi:10.1109/TSMC.1973.4309314.
- Joshi, G. D., S. Garg, and J. Sivaswamy. 2007. A generalised framework for script identification. International Journal of Document Analysis and Recognition (IJDAR) 10 (2):55–68. doi:10.1007/s10032-007-0043-3.
- Marti, R., V. Campos, M. Laguna, and F. Glover. 2001. Reducing the bandwidth of a sparse matrix with tabu search. European Journal of Operational Research 135 (2):450–59. doi:10.1016/S0377-2217(00)00325-8.
- Pal, U., and B. B. Chaudhury. 2002. Identification of different script lines from multi-script documents. Image and Vision Computing 20 (13–14):945–54. doi:10.1016/S0262-8856(02)00101-4.
- Strehl, A., and J. Ghosh. 2003. Cluster ensembles a knowledge reuse framework for combining multiple partitions. Journal of Machine Learning Research 3 (2003):583–617.
- Zramdini, A. W., and R. Ingold. 1998. Optical font recognition using typographical features. IEEE Transactions on Pattern Analysis and Machine Intelligence 20 (8):877–82. doi:10.1109/34.709616.