
ABSTRACT
One the most important security issues is unauthorized access to Electronic Health Records (EHR). The number of leaked EHRs is drastically growing year by year. Medical records are processed and stored in systems with keyboard-based interfaces. Using these interfaces, intruders can break into a system and gain unauthorized access to protected data. We propose a novel solution based on a computer user profiling that prevents such an intrusion. In this approach, a computer user’s activity is constantly analyzed by performing real-time keyboard monitoring. This allows secure control of access to the computer systems dealing with EHRs. Introduced security systems are especially needed in medical environments where sensitive data are processed. To achieve the high performance of an intrusion detection system, we have constructed an ensemble of classifiers supported by machine learning methods. The obtained results show that the proposed method can be used in intrusion detection and monitoring systems.
Introduction
An Electronic Health Record (EHR) is an electronically stored digital version of medical data, where patient examination results, prescribed medications, as well as treatment history records are stored. These important patient private data are considered as especially sensitive, therefore, they should be extremely well protected (Fernández-Alemán et al. Citation2013; Gunter and Terry Citation2005). EHRs consist of real-time patient-centered records that make information available instantly to authorized users only. A system dealing with EHR is supposed to go beyond a standard clinical data collection system because EHRs are designed to share information between many different health-care providers and organizations; for example, medical specialists, pharmacies, laboratories, hospitals, medical centers, or even a school nurse’s office. As parts of such systems, the diagnosis support modules that automatically analyze patient EHRs are used (Wesołowski and Wrobel Citation2013).
The possible threats to health-care records could be categorized into risks associated with the following:
a human factor—employees or hackers,
natural disasters—earthquakes, fires, etc.
technical failures—system crashes.
The threats related to the human factor could be further divided into internal or external, intentional or accidental. Therefore, professionals dealing with health-care IT systems should have these particular threats in mind when developing methods to protect the health information of patients (Wager, Lee, and Glaser Citation2009).
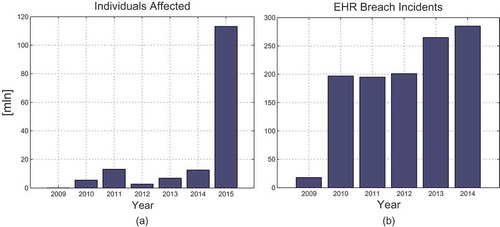
Protecting sensitive data such as EHRs is an important task, especially in an era when the ease of access to computers and networks has caused a drastic increase in cases of terrorism and cyber-terrorism. In the United States, it is required by the Health Information Technology for Economic and Clinical Health (HITECH) Act (section 13402(e)(4)) that the Secretary post a list of breaches of unsecured protected health information affecting 500 or more individuals. According to these reports (U.S. Department of Health and Human Services Citation2009) the number of breaches is growing by year, and the number of affected individuals reached a terrifying level of more than 113 million in 2015 (January to November). Those dependencies are depicted in .
Figure 1. Security breaches affecting 500 or more individuals (U.S. Secretary of HHS 2015).
The ubiquity of computers and mobile devices increases the risk of unauthorized access to EHR data. In most cases, an access to computer devices is protected by simple methods. The most popular methods for computer user authentication and verification usually require elements such as passwords or tokens. These elements are very vulnerable to loss or theft. The alternative is to use biometric methods because they use the individual characteristics of the person (Monaco et al. Citation2013; Palys, Doroz, and Porwik Citation2013; Porwik, Doroz, and Wrobel Citation2009). The forgery of biometric characteristics is possible, but it is much more difficult and requires specialized equipment (Porwik and Doroz Citation2014). Biometric methods used in computer systems security are mostly based on the analysis of a user’s activity connected to different manipulators (Alsultan and Warwick Citation2013; Banerjee and Woodard Citation2012; Teh, Teoh, and Yue Citation2013; Wesołowski, Palys, and Kudłacik 2015). The analysis of the way a keyboard is used involves detection of keyboard dynamics (Zhong, Deng, and Jain Citation2012). This allows building a profile of a user that can be applied in access authorization and verification methods.
Another major problem of information security is a one-time authorization performed usually when starting to work with a device or an IT system. This type of user authentication can result in a serious threat, especially in open type areas such as medical facilities, causing systems and EHR data to be vulnerable to an intruder attack. To ensure a high level of security, especially of medical data, information systems should be continuously monitored. Such monitoring is performed by the intrusion detection systems (IDS) that constantly monitor all user operations and then try to verify the identity of an individual.
The proposed approach concerns issues of EHR protection by means of computer user verification and intrusion detection based on user profiling. A profile of a user is built from information on time dependencies that occur between keystrokes. The user’s profile can be used in a host-based intrusion detection system (HIDS) which analyzes (preferably in real-time) the logs with the registered activity of a user and responds when an unauthorized access is detected. A verification of a user based on the analysis of his typing habits while using a keyboard can effectively prevent an unauthorized access to EHRs when a keyboard is overtaken by an intruder (in this situation a so-called masquerader) (Kudłacik, Porwik, and Wesołowski Citation2015; Raiyn et al. Citation2014; Salem, Hershkop, and Stolfo Citation2008). Such a situation can easily happen, for example, in hospitals, health-care or medical imaging centers when an authorized staff is busy with an emergency situation. This means that a legitimate user who is already logged into a system is not present and the system is open to any intruder. In this situation, a technical staff member, other unauthorized personnel, or even people from outside can take over control of a computer. It rightly shows that it is very important to protect different types of medical systems from an unauthorized access.
In the presented method, the process of collecting a user’s activity data is performed in the background, practically not involving the user. It also means that an intruder is not aware of being constantly monitored. The objective is to ensure the safety of patients’ sensitive EHRs. It is achieved through an immediate access lock when a takeover of a keyboard by an intruder takes place.
Related work
Today, different practical problems are solved by means of state-of-the-art artificial intelligence methods. In this domain, various classifiers are intensively developed (Foster, Koprowski, and Skufca Citation2014; Porwik and Doroz Citation2014; Trajdos and Kurzynski Citation2015; Wozniak and Krawczyk Citation2012).
There are a number of works related to computer-user profiling, authorization, and verification based on keystroke dynamics. Unfortunately, there are also a number of issues related to the datasets (benchmarks) used in research, which make it very difficult or even impossible to compare the works of different researchers. Most methods with regard to the dynamics of typing are limited to an examination of a user’s activity connected to entering a fixed phrase multiple times (Araujo et al. Citation2005; Killourhy and Maxion Citation2009; Zhong, Deng, and Jain Citation2012). Even if a number of researches are based on long text input, it is difficult to compare the results of individual studies due to differences in format of data, number of people participating in the study, period of time tested, as well as size of datasets. In most cases, the data used in the studies are not publicly available.
In Araujo et al. (Citation2005) an activity of users typing a fixed term has been studied, and the authors have come to interesting conclusions. It was noticed that an attempt to repeat (after spying) a style of typing of an authorized user by an intruder has increased the false acceptance rate (FAR) ratio.
The investigations described in Lopatka and Peetz (Citation2009) concern user identification only. In addition to capturing data related to a timestamp of a keystroke, the data from a sudden motion sensor (SMS) were recorded. The SMS is a part of some hard drives and it allows detection of sudden changes in movement or vibrations that occur, for example, when typing on a keyboard. A combined analysis of keystrokes and data retrieved from an SMS significantly improves the efficiency of the method. The problem is that such a sensor is becoming less frequently used, and in a desktop PC, readings from this sensor would not be related to the use of a keyboard.
The article by Pleva et al. (Citation2015) introduces a novel approach for person identification by using acoustical monitoring of typing the required word on the monitored keyboard. Best accuracy at the level of 97.03% was determined for tests with a cross-validation. The method is able to achieve accuracy even up to 99.33%, but, as the authors stated, such a high accuracy is reached if more sessions are used for training and if test recordings are randomly selected, which could be a problem in real-life application.
In the work (Alsultan and Warwick Citation2013), the authors highlighted, among other remarks, that a higher probability of intrusion occurs when a longer break in a legitimate user’s activity was detected. A longer break could indicate a legitimate user’s temporary absence. Therefore, the IDS should be focused on the analysis of short fragments of a user’s recorded activity logs immediately after a detected long break. It should be noted that some problems will occur when users work without breaks. In such a case, an IDS cannot work properly, because breaks at work will not be indicated. Therefore, the mentioned approach has some drawbacks and could be used as a supporting method only.
An interesting approach to a computer user authentication using dynamics of typing is described in Tappert, Villani, and Cha (Citation2010). Users had to type any text consisting of about 650 characters. Characters entered by the users were stored as plain text, without any encryption, and were divided into groups that were organized in a hierarchical structure. In this approach, some assumptions typical for the English language were used. Due to the proposed restriction, the method was intended only for texts written in English. The mentioned system is able to detect only 87.4% of intrusions in short-time analysis, whereas this result decreases to 83.3% when long-term analysis was introduced.
The method described in Wesołowski and Porwik (Citation2015) is based on the idea presented in Tappert, Villani, and Cha (Citation2010) but it is free of some of the limitations—it is language independent and is based on continuous free text typed by users during everyday activities. The approach presented in this article extends the idea described in Wesołowski and Porwik (Citation2015) by introducing a modification of the user-profiling method and intrusion detection method based on machine learning algorithms.
The proposed EHR protection system
The proposed intrusion detection model is divided into two submodels. With the first submodel, a legitimate user-profiling procedure is performed, whereas with the second submodel a verification process is carried out. To both submodels, machine learning algorithms were applied. The structure of the mentioned submodels is presented in .
Figure 2. General scheme of the EHR protection system.
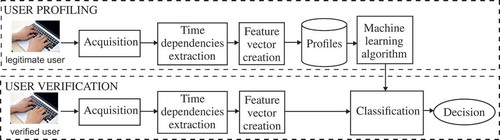
While performing a user-profiling procedure, a profile of a given user is built in the offline mode. In this phase, during data acquisition, the user’s activity in a computer system is recorded. After that, in a separate procedure, time dependencies representing the user’s behaviors when working with a keyboard are extracted. In the next step, feature vectors are created based on the extracted keystroke time dependencies. A subset of feature vectors of a given legitimate user with a user identifier uid constitutes this user’s profile. A profile of each user is stored in a database to be employed in the user verification process.
The beginning of a verification phase is similar to the user-profiling process, but in this case, the whole process is carried out in real time. In this phase, a user is treated as a potential intruder. An activity of a user is verified by the classification module that returns a decision if the activity is consistent with the previously registered profile. When a user is recognized as an intruder, a computer system will be blocked and access to the computer will be forbidden.
In the proposed intrusion-detection model, a distributed system creates a profile of each legitimate uid and stores it in a database on a server. In accordance to the law generally applicable in many countries, the profile does not contain any biometric or sensitive data stored in an open form. Such a solution allows a legitimate user to work on any of the computers in a protected medical center. After a successful login of a user to a computer system, a profile of this user is retrieved from a central database ().
Figure 3. In a distributed IDS, user profiles are stored in a central database on a server.
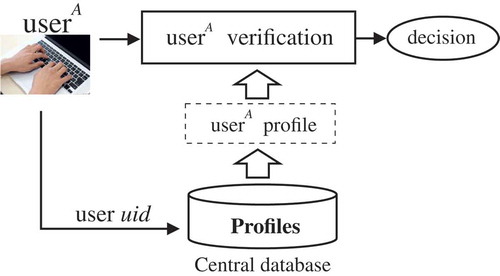
A distributed architecture allows the system to use the data of all profiled legitimate users in a machine learning process, but in the stage of user verification, the IDS checks for all potential intruders also outside the scope of those already profiled.
Analysis of a user’s activity
Recording user’s activity
For the purpose of this research, dedicated data-acquisition software was implemented. The software is designed to collect events generated by individuals (operators of computer systems) while they are using a keyboard. It is designed for Microsoft Windows operating systems and does not require any additional libraries. The proposed software works continuously in the background and records a user’s activity associated with the keyboard. The events are captured on the fly and saved in text files in a database. Because the program is dedicated to use within IT systems dealing with EHRs, information cannot be stored as open text. To ensure a high level of security, key identifiers are encoded, using the MD5 hash function. The consecutive lines of the data file contain a sequence of events related to a user’s activity. Each line starts with the prefix describing the type of event, followed by the timestamp of this event and an identifier of the key used. Possible values of the prefix are keyDown for a key-down event and keyUp for a key-up event. An example of input data is presented in .
Figure 4. Fragment of a given user’s dataset with activity records.

Input data preprocessing
Activity data analysis is carried out for each user uid separately. In the first stage of the data analysis, a preprocessing is performed in order to extract time dependencies of keystrokes generated while the user was working. Parameters of each jth keyboard event for a given user uid are stored in a vector ej:
where describes a type of jth event; tj is a timestamp of a given event; ωj is an identifier of a used key.
All vectors ej constitute the user’s activity dataset E. In practice, the number of vectors ej was restricted by the period of time when the user’s activity was recorded. Data in this form are difficult to interpret because they do not directly provide information on how a user interacts with a computer system. Therefore, it is necessary to extract time dependencies between keyboard events.
Time dependencies extraction
Time dependencies were designated on the basis of the set E, which comprises all vectors ej of a monitored user. Time dependencies between two keyboard events were calculated by means of the Algorithm 1. It should be noted that, during a data analysis, not only are single characters taken into account, but also pairs of keys (for example, when writing capital letters) are analyzed. Time dependencies for individual keys are represented by dwell times and for pairs of keys by a time between keystrokes.
Algorithm 1
Extraction of time dependencies from keyboard events data
1. input: E—keyboard events as a set of vectors ;
2. output: D—a set of time dependencies in a form of vectors ;
3. j: = 1; i: = 1;
4. repeat
5. read_input_data ;
6. if (typej = = keyDown), then
7. read_input_data
8. if ( and
) or (typej+1 = = keyDown), then
9.
10. D ← di
11. i: = i + 1; j: = j + 2;
12. end if
13. else
14. j: = j + 1;
15. end if
16. until end_of_data.
User profiling
As previously mentioned, a computer keyboard is the main input interface of a computer system. In our method, a keyboard has been divided into areas. All keys belonging to the same area were assigned to the same category in terms of functionality, and each key has been assigned an identifier ωj, as stated in the previous section. For a standard QWERTY layout, the principle of keys division is consistent with the scheme presented in .
Table 1. The principle of dividing the keys.
During user profiling, all vectors di ∈ D are divided into 113 groups. The groups are organized into two hierarchical data structures Tkeys and Tpairs (). Each group Gk(desc), k ∈ {1,…,113} has an assigned identifier. To facilitate an analysis, each group has a content descriptor (desc) giving information on which key types are assigned to this group. Groups constituting leaves of the tree Tkeys store time dependencies of 103 single keys—for these groups, a content descriptor corresponds to a key identifier desc = ωj. Groups higher in a hierarchy store time dependencies of all keystrokes assigned to all child groups. As a consequence of such a division, the root group G1(all keys) stores time dependencies of all single keystrokes. By analogy, groups in a structure Tpairs store time dependencies of keys that were used together as pairs. Groups constituting leaves represent pairs of two function keys (pairsFunction), two alphanumeric keys (pairsAlphanumeric), or one function and one alpha-numeric key (pairsMixed) pressed together.
Figure 5. Tree structures for organizing the groups of keys and key pairs.
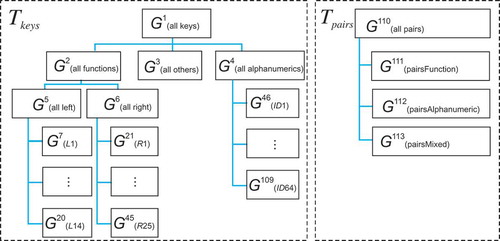
In , each box represents one group Gk(desc). During a user’s profiling process, the previously constructed vectors di ∈ D are assigned to the group Gk(desc), depending on the values of ωj and ωj +1.
If ωj = ωj +1, then a vector di is assigned to the group Gk(ωj) in the structure Tkeys. After enrollment, the same vector di is also added to all the groups higher in the hierarchy of the particular branch until reaching the root group G1(all keys). For example, if, for a vector di, the values ωj = ωj +1 = L1, then the mentioned vector di will be added to the groups G(L1)7, G5(all left), G5(all function), and finally, to the group G1(all keys). By analogy, if , then a vector di is added to the appropriate groups in the structure Tpairs.
If a number of vectors di added to a given group is equal to the value of guid, then the vector F of user features is created. The group that reached the number of elements equal to guid is cleared, and the process is continued until the required number of feature vectors F is reached.
Based on vectors stored in all previously formed groups , a feature vector F = [f1,f2,…, f113] is constructed as follows. The kth element fk of the vector F is calculated from time dependencies stored in a kth group
, according to the following formula:
where nk is the number of vectors in the group Gk and The frequency of creating feature vectors F is determined by the parameter guid. Lower values of guid cause more frequent creation of vectors F. This means that, from the same number of keyboard events, we can obtain more feature vectors F, but the single vector characterizes a shorter period of user activity. To the contrary, higher values of guid will decrease the number of feature vectors F. In this case, a user will have to perform more tasks in order to obtain the same number of feature vectors, and in turn, this can delay the intrusion detection. For all these reasons, the parameter guid is the key parameter of the profiling algorithm and using its nonoptimal value has a negative influence on the performance of the system, as shown in the experiments section. In our approach, the value of guid was optimized by means of the particle swarm optimization (PSO) algorithm (Lin, Chen, and Gaing Citation2010).
For a given uid, a profile describing this user’s activity is constituted. The value of the parameter r = 100 has been determined experimentally.
User verification
Literature sources indicate a high efficiency of classifiers and artificial intelligence algorithms for different purposes (Foster, Koprowski, and Skufca Citation2014; Szaleniec et al. Citation2013; Wozniak and Krawczyk Citation2012). In our approach for intrusion detection, we propose using an ensemble of classifiers. It allows us to obtain significantly better classification results compared to using individual classifiers. The proposed approach is based on three ensembles of classifiers ECa, a=1,…,3. Each of them consists of four heterogeneous classifiers: ,
,
, and
. The ensembles of classifiers ECa work simultaneously and are trained on three different training sets TSa. The three training sets TSa consist of feature vectors F randomly chosen from user profiles. The general structure of the proposed classification module is shown in .
Figure 6. The general scheme of the proposed classification module.
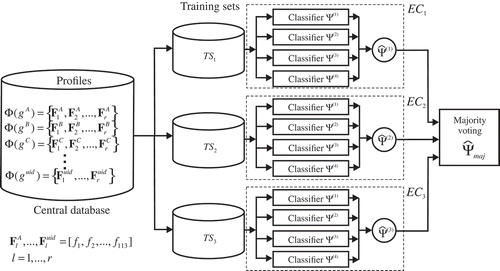
Classifier training phase is carried out using the different training sets TS1, TS2, and TS3 for each ensemble of classifiers ECa, a=1,…,3, (see ). The sets TSa are established by means of Algorithm 2.
Algorithm 2
Creating training datasets , a = 1,…,3
1: input: users profiles comprising feature vectors
2: output: training sets TS1, TS2, and TS3 of a uid;
3: randomly chosen vectors F from user’s profile
and
4: a: = 1 to 3 do
5: randomly chosen vectors F from another (randomly chosen) user’s profile, and
;
6:
7: train the ensemble ECa on set TSa;
8: end for
9: return TS1,TS2,TS3
User verification consists in assigning a user to one of two possible classes: legitimate user or intruder. A real-time activity of a given user is represented by a feature vector . For binary classification, a classifier
maps the vector F to a class label cj, where j ∈ {1,2}.
Many available classifiers return a probability of an object being assigned to a particular class. In the proposed approach, the classifiers return a probability
,
that a given object F belongs to a class
. At the input of the node
(), the following data matrix is introduced:
Each ensemble of classifiers , a=1,..,3 generates at the output a local decision
according to the formula
The class labels returned as a result of Equation (5) are converted to numerical values according to the formula
A constant value −1 means that a given ensemble indicates that an introduced vector F is derived from a legitimate user, whereas a constant value +1 indicates that a vector F represents an activity of an illegitimate user (intruder).
For such assumption, the final decision of the classification module is based on individual decisions of three separately working ensembles:
As a result of the classification, we obtain the values ± 1, which, similarly to Equation (6), indicate whether a tested vector F belongs to a legitimate or illegitimate user.
Experiments
The performance of our methods was tested experimentally using real data from the continuous activity of 15 computer users. The activity was recorded over one month in real working environments. During data acquisition, the activity was stored in log files - one per day of the users’ work. Because the users did not work every day, the input dataset consists of 281 activity logs in total. In the course of experiments for each of 15 legitimate users, the other 14 users constituted the group of potential intruders. During experiments, profiles of users were created and stored in a database. The profile should represent unambiguous typing habits of a single user. For each legitimate user, the training sets were created by means of Algorithm 2. Tests were performed using the 10-fold cross-validation method. In each experiment, three training sets TSa, described in the previous section, were used.
The accuracy measure was used to evaluate the effectiveness of the introduced intrusion detection method. The accuracy is the proportion of true results (both true positives and true negatives) among the total number of cases examined (Metz Citation1978). The content of each set TSa depends on the guid parameter. Hence, influence of this parameter on the accuracy of the system has been separately investigated. The PSO algorithm allows us to tune the value of the parameter guid. We optimize the value of parameter guid in order to maximize the accuracy. Two approaches for determining the value of the parameter guid were investigated: a single value of guid for all the users and a value of guid individually determined for each user. The analysis of the influence of parameter guid on the accuracy (shown in ) performed for each user separately shows that it is not possible to establish a global value of guid because optimal values of guid are different for each user.
Figure 7. Influence of guid parameter on accuracy level for exemplary userA, userB, userC and userD.
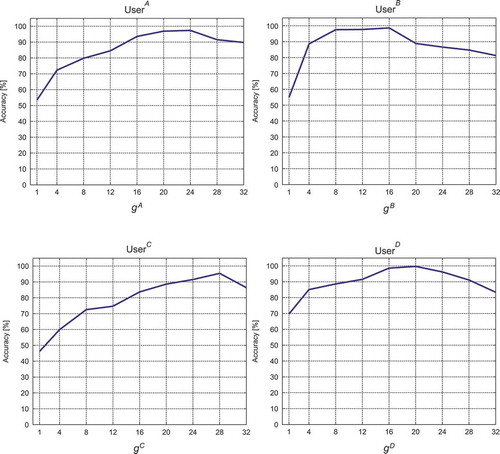
Therefore, an approach based on individually determined values of parameter guid should be applied. In our experiments, the optimal value of guid was determined for each user separately by means of the PSO algorithm.
After determining the individual values of guid, the effectiveness of various classification models was examined. At first, the classification module was based on single classifiers only. All classifiers work on the same input datasets.
It should be emphasized that not all datasets used in the study’s classification models return probability of a classified object belonging to the class. In this article, the classification model names were used. In practice, for the classification models that do not return a class membership probability, there are many techniques that produce probabilities of membership. Our studies have been carried out using the KNIME software and the WEKA package containing the classification models’ implementations that return values of probability. For example, for the classification model C4.5, the WEKA package implementation J48 was used. presents values of accuracy obtained for experiments with single classifiers.
Table 2. Single classifiers giving the highest accuracy.
The proposed architecture of our classification module assumes the use of four single classifiers in an ensemble. In the course of our experiments, we found that the following four classifiers give the highest accuracy of intrusion detection (see ):
The C4.5 algorithm is an extension of the ID3 algorithm and constructs a decision tree to maximize information gain (difference in entropy).
The Bayesian Network (BN) belongs to the family of probabilistic models. This classifier is used to represent knowledge about an uncertain domain. In particular, each node in this network represents a random variable, whereas the connections between network nodes represent probabilistic dependencies between corresponding random variables.
A Support Vector Machine (SVM) is a discriminative classifier formally defined by a separating hyperplane. In other words, given labeled training data (supervised learning), the algorithm outputs an optimal hyperplane that categorizes new examples.
A Random Forest (RF) consists of a collection or ensemble of simple tree predictors, each capable of producing a response when presented with a set of predictor values.
In the consecutive stage, instead of a single classifier, the one-layer ensemble with different members has been proposed as an alternative classification model. The one-layer ensemble of classifiers was built from classifiers chosen in the previous stage (). Next, the determined ensemble of classifiers was used to build the classification module having the structure shown in . Because the introduced system is using the majority voting to determine the final decision, the number of used ensembles has to be odd. The values of accuracy achieved for single ensemble (EC1) versus a classification module consisting of more than one ensemble of classifiers is depicted in .
Table 3. The accuracy results for proposed classification module.
Applying three ensembles of classifiers gives better results in comparison to a single ensemble of classifiers. Experiments show that further increasing the number of ensembles above three in the classification module did not improve the effectiveness of the proposed system (as seen in ).
Figure 8. Box-plot distributions of classification accuracy.
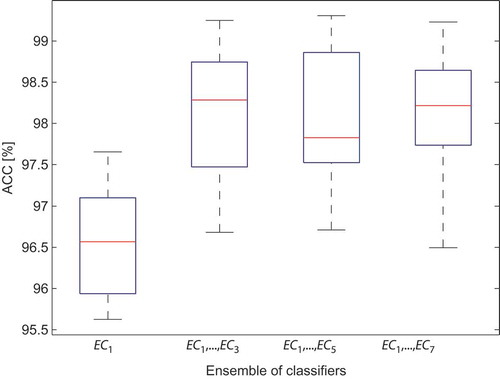
From , it follows that the difference between the classification modules based on single ensemble (EC1) versus the module based on three ensembles (EC1,…,EC3) is statistically significant. Instead of the box-plot approach, the popular Student’s t-test can be applied, in which the p-value can be calculated. Both solutions will produce the same conclusions.
The results of the proposed classification models were compared with other methods by which intruders are recognized. The comparative studies of this problem are presented in . There are a number of issues related to the datasets used in research on computer user profiling based on keystroke analysis. First of all, there are no standards for data collection and benchmarking as there are in some other fields of biometrics. For this reason, it is difficult to compare the works of different researchers based on the same dataset. More details on issues related to datasets can be found in the literature (Wesołowski and Porwik Citation2016). The classification quality of the methods was depicted by two popular accuracy measures and the equal error rate (EER) (Porwik, Doroz, and Orczyk Citation2014).
Table 4. A comparison of intrusion detection methods.
Conclusions
The aim of this study was to establish a classifier with the highest possible accuracy to detect intruders to computer systems. The novelty of our approach is a new concept of user profiling for which user activity is continuously recorded and tested, whereas in other applications, only constant profiling based on fixed text is analyzed. The investigated solution can be very useful in medical centers, hospitals, etc. where electronic health records data are processed in mass. Protection of medical data can be ensured by the approach described in this arfticle. We proposed to build a single user’s profile based on the keyboard as an input device of a computer system.
It should be noted that the solution proposed in this article is based on keystroke time dependencies and classification methods only, whereas in other researches key pressure also is analyzed. Today, pressure registration is only an experimental idea without practical applications, although some results are published (Quteishat et al. Citation2009). It should be emphasized that our proposition works on primary data and gives the comparable results, based on machine learning procedures only.
The new approach introduced in this article allows detecting intrusions based on computer users’ continuous activity. The value of accuracy achieved in this study equal 98.08%, which is better than the accuracy of other methods described in the literature. Competitive methods have a number of limitations. They work on an open text, use restrictions applicable only to a particular language, or they are based on the analysis of typing a short phrase (single word only). In other studies, users know that they are being tested so they can use this knowledge to influence the course of conducted experiments. Our approach is free from these limitations. First of all, a user’s profile is built in the background, it is not visible for an operator of a computer system, and the data acquisition process does not involve any additional tasks. The profiling method does not depend on the knowledge of the typed text. In competitive methods, during the profiling process, the text has to be processed in an open form. Storing and analyzing an open text that contains private (passwords, PINs) and sensitive (EHRs) data causes serious security issues. In the introduced method, users’ data are encoded so they can be used in systems dealing with sensitive data such as EHRs. The proposed solution in our study is language independent and can be used with users writing in various languages.
In the future, research could be performed for users who work in network environments where intruder detection and localization is more difficult. The future studies could also consider merging users’ activity data connected to the use of various manipulators and interfaces.
Funding
This work was supported by the Polish National Science Centre under the grant no. DEC-2013/09/B/ST6/02264.
Additional information
Funding
References
- Alsultan, A., and K. Warwick. 2013. Keystroke dynamics authentication: A survey of free-text methods. International Journal of Computer Science Issues 10 (4):1–10.
- Araujo, L. C. F., L. H. R. Sucupira, M. G. Lizarraga, L. L. Ling, and J. B. T. Yabu-Uti. 2005. User authentication through typing biometrics features. IEEE Transactions on Signal Processing 53 (2):851–855. doi:10.1109/TSP.2004.839903.
- Banerjee, S. P., and D. L. Woodard. 2012. Biometric authentication and identification using keystroke dynamics: A survey. Journal of Pattern Recognition Research 7 (1):116–139. doi:10.13176/11.427.
- Fernández-Alemán, J. L., I. C. Señor, P. Á. O. Lozoya, and A. Toval. 2013. Security and privacy in electronic health records: A systematic literature review. Journal of Biomedical Informatics 46 (3):541–562. doi:10.1016/j.jbi.2012.12.003.
- Foster, K. R., R. Koprowski, and J. D. Skufca. 2014. Machine learning, medical diagnosis, and biomedical engineering research - commentary. BioMedical Engineering OnLine 13 (1):1–9. doi:10.1186/1475-925X-13-94.
- Gunter, T. D., and N. P. Terry. 2005. The emergence of national electronic health record architectures in the United States and Australia: Models, costs, and questions. Journal of Medical Internet Research 7 (1):e3. doi:10.2196/jmir.7.1.e3.
- Killourhy, K. S., and R. A. Maxion. 2009. Comparing anomaly-detection algorithms for keystroke dynamics. In 2009 IEEE/IFIP international conference on dependable systems networks, 125–134. IEEE. doi:10.1109/DSN.2009.5270346.
- Kudłacik, P., P. Porwik, and T. Wesołowski. 2015. Fuzzy approach for intrusion detection based on user’s commands. Soft Computing 1–15. doi:10.1007/s00500-015-1669-6.
- Lin, C.-H., J.-L. Chen, and Z.-L. Gaing. 2010. Combining biometric fractal pattern and particle swarm optimization-based classifier for fingerprint recognition. Mathematical Problems in Engineering 2010 (4):1–14. doi:10.1155/2010/328676.
- Lopatka, M., and M. Peetz. 2009. Vibration sensitive keystroke analysis. Paper presented at Proceedings of the 18th Annual Belgian-Dutch Conference on Machine Learning, Tilburg, Netherlands, May 18–19, pp. 75–80.
- Metz, C. E. 1978. Basic principles of ROC analysis. In Seminars in nuclear medicine, vol. 8, 283–298. 4. Elsevier.
- Monaco, J. V., J. C. Stewart, S. H. Cha, and C. C. Tappert. 2013. Behavioral biometric verification of student identity in online course assessment and authentication of authors in literary works. In biometrics: Theory, applications and systems (BTAS), 2013 IEEE sixth international conference on, 1–8. IEEE.doi:10.1109/BTAS.2013.6712743.
- Palys, M., R. Doroz, and P. Porwik. 2013. On-line signature recognition based on an analysis of dynamic feature. In International conference on biometrics and kansei engineering (ICBAKE), 103–108. Washiungton, DC: IEEE Computer Society. doi:10.1109/ICBAKE.2013.20.
- Pleva, M., E. Kiktova, J. Juhar, and P. Bours. 2015. Acoustical user identification based on MFCC analysis of keystrokes. Advances in Electrical and Electronic Engineering 13 (4):309–313. doi:10.15598/aeee.v13i4.1466.
- Porwik, P., R. Doroz, and K. Wrobel. 2009. A new signature similarity measure. In nature & biologically inspired computing, 2009. NaBIC 2009. World Congress on, 1022–1027. IEEE. doi:10.1109/NABIC.2009.5393858.
- Porwik, P., and R. Doroz. 2014. Self-adaptive biometric classifier working on the reduced dataset. In Hybrid artificial intelligence systems, Lecture Notes in Computer Science 8480:377–388. Switzerland: Springer International. doi:10.1007/978-3-319-07617-1_34.
- Porwik, P., R. Doroz, and T. Orczyk. 2014. The k-NN classifier and self-adaptive Hotelling data reduction technique in handwritten signatures recognition. Pattern Analysis and Applications 18 (4):983–1001. doi:10.1007/s10044-014-0419-1.
- Quteishat, A., C. P. Lim, C. C. Loy, and W. K. Lai. 2009. Authenticating the identity of computer users with typing biometrics and the fuzzy min-max neural network(<Special Issue> Biometrics and its applications). Biomedical Fuzzy and Human Sciences: The Official Journal of the Biomedical Fuzzy Systems Association 14 (1):47–53.
- Raiyn, J., et al. 2014. A survey of cyber attack detection strategies. International Journal of Security and Its Applications 8 (1):247–256. doi:10.14257/ijsia.
- Salem, M. B., S. Hershkop, and S. J. Stolfo. 2008. A survey of insider attack detection research. In Advances in information security, ed. S. J. Stolfo, S. M. Bellovin, A. D. Keromytis, S. Hershkop, S. W. Smith, and S. Sinclair, vol. 39, 69–70. Boston, US: Springer.
- Szaleniec, J., M. Wiatr, M. Szaleniec, J. Skladzien, J. Tomik, K. Ole, and R. Tadeusiewicz. 2013. Artificial neural network modelling of the results of tympanoplasty in chronic suppurative otitis media patients. Computers in Biology and Medicine 43 (1):16–22. doi:10.1016/j.compbiomed.2012.10.003.
- Tappert, C. C., M. Villani, and S.-H. Cha. 2010. Keystroke biometric identification and authentication on long-text input. Behavioral Biometrics for Human Identification: Intelligent Applications 342–367. doi:10.4018/978-1-60566-725-6.ch016.
- Teh, P. S., A. B. Teoh, and S. Yue. 2013. A survey of keystroke dynamics biometrics. The Scientific World Journal 2013. doi:10.1155/2013/408280.
- Trajdos, P., and M. Kurzynski. 2015. An extension of multi-label binary relevance models based on randomized reference classifier and local fuzzy confusion matrix. In Intelligent Data Engineering and Automated Learning - IDEAL. Lecture Notes in Computer Science 9375: 69–76. Switzerland: Springer International. doi:10.1007/978-3-319-24834-9_9.
- U.S. Department of Health and Human Services. 2009. Breaches affecting 500 or more individuals. Technical Report. Office for Civil Rights. https://ocrportal.hhs.gov/ocr/breach/breach_report.jsf (accessed November 30, 2015).
- Wager, K. A., F. W. Lee, and J. P. Glaser. 2009. Health care information systems: A practical approach for health care management. John Wiley & Sons.
- Wesołowski, T., M. Palys, and P. Kudłacik. 2015. Computer user verification based on mouse activity analysis. In Studies in computational intelligence, D. Barbucha, T. N. Nguyen, and J. Batubara, vol. 598, 61–70. Springer International. 10.1007/978-3-319-16211-9_7
- Wesołowski, T., and K. Wrobel. 2013. A computational assessment of a blood vessel’s roughness. In Advances in intelligent systems and computing, R. Burduk, K. Jackowski, M. Kurzynski, and M. Wozniak, vol. 226, 227–236. Heidelberg, Switzerland: Springer International. 10.1007/978-3-319-00969-8_22
- Wesołowski, T. E., and P. Porwik. 2015. Keystroke data classification for computer user profiling and verification. In Computational collective intelligence, M. Núñez, T. N. Nguyen, D. Camacho, and B. Trawiński, 588–597, Lecture Notes in Artificial Intelligence 9330. Springer International. 10.1007/978-3-319-24306-1_57
- Wesołowski, T. E., and P. Porwik. 2016. Computer user profiling based on keystroke analysis. In Advances in intelligent systems and computing, R. Chaki, A. Cortesi, K. Saeed, and N. Chaki, vol. 395, 3–13. New Delhi, India: Springer. 10.1007/978-81-322-2650-5_1
- Wozniak, M., and B. Krawczyk. 2012. Combined classifier based on feature space partitioning. International Journal of Applied Mathematics and Computer Science 22 (4):855–866. doi:10.2478/v10006-012-0063-0.
- Zhong, Y., Y. Deng, and A. K. Jain. 2012. Keystroke dynamics for user authentication. In 2012 IEEE computer society conference on computer vision and pattern recognition workshops, 117–123. Washington, DC: IEEE Computer Society. doi:10.1109/CVPRW.2012.6239225.