
ABSTRACT
Feature selection, an important combinatorial optimization problem in data mining, aims to find a reduced subset of features of high quality in a dataset. Different categories of importance measures can be used to estimate the quality of a feature subset. Since each measure provides a distinct perspective of data and of which are their important features, in this article we investigate the simultaneous optimization of importance measures from different categories using multi-objective genetic algorithms grounded in the Pareto theory. An extensive experimental evaluation of the proposed method is presented, including an analysis of the performance of predictive models built using the selected subsets of features. The results show the competitiveness of the method in comparison with six feature selection algorithms. As an additional contribution, we conducted a pioneer, rigorous, and replicable systematic review on related work. As a result, a summary of 93 related papers strengthens features of our method.
Introduction
Classification is a well-known data mining task, where one seeks to build models that extract patterns from a dataset, which can be afterwards used for predicting the label of new data (Han and Kamber Citation2011). In general, data for classification problems are labeled, containing one or more classes for each input instance. The objective is to obtain a model that relates the input features of the data points (instances) to their output labels. In this article, we deal with single-label classification problems, where each data point has a unique output label.
The presence of irrelevant and/or redundant features in a dataset, associated to the effects from the “curse of dimensionality,” can impair the performance of classification models built using such data. Furthermore, the computational cost in obtaining these models is usually higher and data with many features can also be considered more complex to understand (Guyon and Elisseeff Citation2003). Thus, removing non-important features from a dataset is a significant goal to achieve.
Feature Selection (FS) methods have been deeply studied in the literature to tackle these problems (Liu and Motoda Citation2007). FS can be viewed as a search for subsets of important features in a dataset and is usually considered as a pre-processing step in the data mining process. Each feature subset is a potential state in the search space, i.e., a possible solution for the search problem. The evaluation of the different states can usually be performed by using one or more importance measures, which estimate the quality of the feature subsets based on a specific purpose, such as for building better classification models.
Filter importance measures are based on information extracted from data only, addressing different aspects useful for data classification. On the other hand, importance measures applied according to the wrapper approach use a classification algorithm to estimate the quality of the feature subsets. Alternatively, the embedded approach selects features during classifier training. In contrast to wrapper and embedded FS, the filter approach is less biased toward a specific classification algorithm and usually can be performed at a lower computational cost. Moreover, the dataset is pre-processed only once and can be used as input to different classification algorithms. In this article we adopt the filter approach.
The search process related to FS can be solved by using heuristic methods such as Genetic Algorithms (GA) (Yang and Honavar Citation1998). In GA, feature subsets are often encoded as chromosomes, in which each gene represents the selection of a specific feature from the dataset, while importance measures are optimized as fitness functions. The standard Single-objective Genetic Algorithm (SOGA) focuses on one importance measure only, while Multi-objective Genetic Algorithms (MOGA) consider two or more importance measures simultaneously. MOGA provides support to the simultaneous optimization of potentially conflicting functions during the search for feature subsets. This fact is useful to accommodate relevant, but accidentally contradictory functions in data mining, such as classification accuracy and simplicity (Freitas Citation2004).
One of the most common approaches to dealing with such scenario is by using the Pareto dominance theory, as done by algorithms such as the usual Non-dominated Sorting Genetic Algorithm (NSGA-II) (Deb et al. Citation2000), where multiple objectives can be analyzed without any weighting.
The purpose of this study is to extend and integrate our previous pieces of work on the topic (Spolaôr, Lorena, and Lee Citation2011a, Citation2010b). Besides a more complete description of the developed MOGA and a uniform analysis of the most relevant experimental results, this article considers a wider range of datasets and importance measures than most of the related publications. It should be emphasized that, although the focused method currently supports the optimization of six feature importance measures and their combinations, we opted to present here a deeper evaluation of some combinations of pairs of simple measures, highlighted as most promising in our previous work and flexible enough to deal with both quantitative and qualitative features.
To gather evidence on related work, we conducted a Systematic Review (SR) to identify the use of MOGA for FS in the literature. According to the SR, few papers select features by using filter importance measures in MOGA. Moreover, many of these papers investigate a few labeled datasets, from specific domains, and study only two importance measures. This panorama from related work strengthens features of the method focused in this article, such as the flexibility to explore different filter measures in experimental evaluations with several datasets. The developed method can also be adapted to work on both labeled and unlabeled datasets, although we currently considered a supervised scenario only, for better uniformness.
This article is organized as follows: Section 2 describes basic concepts related to FS. Section 3 presents the MOGA method proposed for FS. Section 4 summarizes related work found by conducting the systematic literature review method (Kitchenham and Charters Citation2007). Section 5 describes the experimental setup, whose results are discussed in Section 6. Section 7 concludes this article.
Feature selection
Machine Learning (ML) techniques solve classification problems by extracting patterns from datasets with known instances, in an induction process. A dataset is composed of data points
, in which each
has
features describing properties and characteristics of the
data point. A usual representation of the data submitted to ML algorithms is the feature-value format. As exemplified at , in this format each column corresponds to a feature, with discrete (qualitative) or numeric (quantitative) values, and each row is an instance of the dataset. In classification problems, each data point
is also accompanied by a discrete label
, as presented at . The objective of the learning algorithm in such scenario is to obtain a model able to predict the labels of unknown instances.
Table 1. Data represented according to the feature-value format.
Feature selection provides support to identify a subset of important features in a dataset. As a result, a new and smaller dataset, composed of instances described by a lower number of features, is specified. Using the pre-processed dataset as input to an ML technique can lead to the obtainment of similar or better models than using all input features, with a reduced training cost. A better understanding of data is also achieved, by the identification of the most important characteristics of the data points. In high dimensional domains, such as gene expression analysis, another benefit is a reduction of effects associated to the curse of dimensionality.
Feature subset search
FS can be viewed as a search process for a high quality feature subset that maximizes or minimizes one or more importance measures. Given a dataset with features, each combination of
features is a possible solution or state in this search. As a result, the search space is composed of all possible combinations of the features, i.e., all feature subsets regarding the
features. Searching for the best subset of features involves moving through the states in this space according to four parameters: state evaluation criteria, search direction, search strategy and stop criterion.
Regarding the evaluation of the states, there are criteria for the individual or joint evaluation of the features in a subset. When considering the importance of each feature individually, a ranking of the features according to the score calculated by a measure is usually obtained. By using a threshold on the feature scores or on the number of features to be chosen, a subset of features can be selected. A disadvantage of feature ranking is that redundant features are usually ranked close to each other and tend to be jointly selected (Hall Citation2000). Therefore, redundant features can remain on the dataset. In this work, we used mainly feature importance measures that perform a joint evaluation of the features contained in a given subset. In such case, the features in the subset are evaluated regarding their joint importance.
The evaluation criteria for features subsets can also be categorized according to their interaction to an induction (classification) algorithm (Kohavi and John Citation1997). In the embedded approach the FS is performed internally by the induction algorithm during its training. The wrapper approach uses an induction algorithm as a black-box to evaluate candidate feature subsets in the search process. The filter approach, employed in this work, considers intrinsic properties of data, and does not involve any interaction with a particular induction algorithm.
The search directions define the sequence of states accessed during the search. The main search directions are forward, backward, and random (Liu and Motoda Citation1998). In forward direction, search begins from an empty feature subset and features are gradually added until a stop criterion is reached. Backward search does the opposite, beginning with all features and gradually discarding features from this set. In random direction there is no specific starting point. Genetic Algorithms fall into the last category, due to their stochastic nature and exploration of multiple solutions.
The search strategies can be complete, heuristic, or non-deterministic (Liu and Yu Citation2002). In complete search, all optimal states are identified. Although this search may be non exhaustive, as in Branch & Bound algorithms, it is usually costly to perform. Heuristic search is oriented by a specific knowledge of the problem to find potential good states at each step. This strategy is useful for FS in large datasets to save computational resources. Finally, non-deterministic search travels the search space randomly. GA use heuristic functions in a non-deterministic search.
The search process in FS can be stopped when a given number of features is selected or if no improvement can be achieved by adding or removing features from a subset. Another possible criterion is when a maximum number of iterations of the search is reached.
Categories of feature importance measures
A feature is relevant if its removal implies in the deterioration of the learning performance calculated when the feature was included in the data. Liu and Motoda describe a taxonomy of five categories of feature importance measures: consistency, dependency, distance, information, and precision (Liu and Motoda Citation1998). These categories can be briefly described as:
Consistency
Involves identifying a subset of features which allows to build a consistent hypothesis from data. For labeled data, consistency is related to the low occurrence of examples with similar values in the features, but distinct labels.
Dependency
They are also known as correlation or association measures. These measures consider, for example, the ability to predict the value of a feature from the value of another feature.
Distance
Also known as separability or discrimination measures. Important features according to these measures are those which allow a better discrimination of the concepts or classes present on data.
Information
Determine the information gain in using one or more features, that is, the difference between the a priori and the a posteriori uncertainty associated to the inclusion or elimination of features.
Precision
Considers the performance achieved by a classification model when using a particular subset of features. Therefore, this type of measure involves the interaction between FS and an induction algorithm.
Except from precision, all other categories provide measures that are based on different aspects from data. Since precision measures need to interact with an induction algorithm, they are not employed for filter FS and, as a consequence, they are not considered in this article. We chose measures from all the categories, except precision, to be combined in an MOGA. They are described in Section 3.1.
Feature selection via multi-objective genetic algorithm
As presented in Section 2, FS can be stated as a search for subsets of features optimizing some feature importance criterion. Genetic Algorithms (GA) are search and optimization techniques based on principles of Natural Evolution and Genetics frequently used in FS. They evolve a population of possible solutions to the problem by the application of a proper selection mechanism and of genetic operators to generate new solutions. Their usual application in FS consists in searching for a feature subset optimizing a given feature importance measure. The most commonly used representation for the individuals consists in a binary string with bits, one for each feature in the original dataset. A value of
in gene
indicates the selection of feature
, while a value of
implies that the feature is not selected. The importance measure is employed as a fitness function, i.e., in the evaluation of the feature subsets encoded in the individuals.
Nonetheless, it may be interesting to consider multiple aspects when evaluating the quality of a feature subset. Multi-objective Genetic Algorithms (MOGA) adapts the standard GA to the consideration of multiple objectives. Therefore, they can then be employed in the search for subsets of features which optimize multiple feature importance measures simultaneously (Zaharie et al. Citation2007).
As discussed in Section 2.2, there are different categories of importance measures that can be considered when evaluating a feature subset in FS. For each of the categories, there are also various measures that can be defined, looking at distinct aspects from data. In this work we use an MOGA to perform the search for subsets of features optimizing a combination of feature importance measures from different categories. The choice of measures from different categories is motivated by the possibility to explore eventual complementarities between them. We only consider measures that can be captured from the datasets, that is, feature importance measures that are representatives from the consistency, dependency, distance and information categories. Therefore, the method can be characterized as a filter approach for FS.
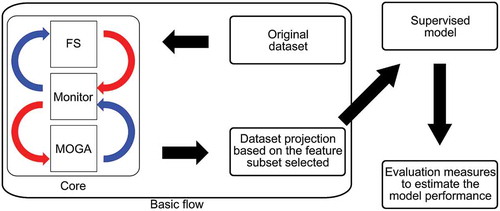
shows the modules that compose the core of the method implemented in this study. Both Monitor and Multi-objective Genetic Algorithm (MOGA) modules used are the same available in the Platform and Programming Language Independent Interface for Search Algorithms (PISA) framework (Bleuler et al. Citation2003). In particular, we chose the Non-dominated Sorting Genetic Algorithm (NSGA-II), which is a usual MOGA with concepts based on the Pareto theory for multi-objective optimization, in the MOGA module. By default, all objectives in PISA must be minimized. Moreover, the values of the objectives cannot be negative. Therefore, some feature importance measures had to be adapted accordingly. The Feature Selection (FS) module was adapted from a PISA module related to the Knapsack optimization problem.
Figure 1. Modules of the method developed in this work and their interactions. In particular, the monitor module manages the remaining components, which in turn perform feature selection and multi-objective optimization by a genetic algorithm.
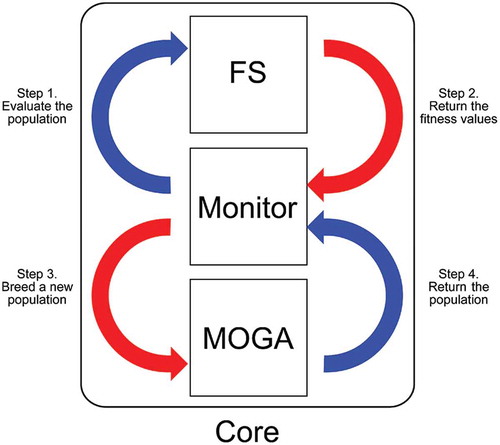
The modules interact in a systematic way during the optimization process. Given an initial population of the GA, composed of binary strings representing distinct features subsets, the Monitor module starts the FS module to evaluate the subsets of features encoded in the current population according to a given combination of importance measures. Afterwards, the Monitor manages a loop composed of two main procedures: (1) MOGA applies the selection and genetic operators, generating new individuals; (2) the FS module evaluates the current population using the importance measures being combined. The loop ends when a stop condition is reached, which was set to a maximum number of iterations of the MOGA in our experiments. The selection mechanism employed is the binary tournament and the genetic operators used were one-point crossover and bit-flip mutation. The remaining MOGA parameter values are described and justified in Section 5.2.
Given a dataset represented in a feature-value format as input, the output of the method is a reduced version of the dataset that is described by the features selected in the optimization process. NSGA-II gives several solutions, which represent different trade-offs in the optimization of the objectives, in accordance to the Pareto-based multi-objective optimization theory. We chose a unique feature subset using the Compromise Programming technique (Zeleny Citation1973). This simple technique consists of choosing the solution with the lowest distance to a reference point. For minimization, this point corresponds to a vector composed of the lowest values of the objective functions achieved within all MOGA solutions.
In what follows, the importance measures implemented in the FS module are described.
Importance measures considered
In order to explore distinct aspects from data, we chose importance measures from each one of the following categories: consistency, dependency, distance, and information.
For consistency evaluation, we used the Inconsistent Example Pairs (IP) (Arauzo-Azofra, Benitez, and Castro Citation2008) measure. This measure identifies the inconsistency rate of a dataset based on the number of inconsistent pairs of instances divided by the total number of pairs of instances. An inconsistent pair is characterized by presenting similar values for their features, while their class labels are different. Quantitative features must be discretized before calculating this rate. The higher the rate, the more inconsistent the feature subset is. In this work, the same discretization procedure considered in (Arauzo-Azofra, Benitez, and Castro Citation2008) is employed before applying IP.
Concerning dependency, the Attribute-class Correlation (AC) is used, as defined by Eq. (1). In this equation, will be
if the
feature is selected and
otherwise;
if the instances
and
have distinct labels or
otherwise;
represents the
feature value from
; and
denotes the module function. This measure highlights features that have more distinct values for instances of different classes. AC can also be used for qualitative features, by replacing the difference in the module (Eq. (1)) by the overlap function (Wilson and Martinez Citation1997), in which features with the same value show a difference of 1, while equal feature values have null difference.
Another dependency measure used was the Intra-Correlation (IC), defined by Eq. (2) (Wang and Huang Citation2009). It considers the Pearson correlation between the feature vectors in a subset (
corresponds to the column vector of the
feature). It normalizes the global correlation of a feature subset, using
as the number of 2-combinations of features, and
as the number of features of this subset.
The Inter-Class Distance measure—IE—(Zaharie et al. Citation2007) estimates the separability between classes in a dataset when using a given subset of features. Eq. (3) defines IE, where is the central instance (centroid) of the dataset,
denotes the Euclidean distance or the overlap function for qualitative features,
is the number of classes and
and
represent, respectively, the centroid and the number of instances in the class
.
The Laplacian Score—LS—(He, Cai, and Niyogi Citation2005) is also a distance based importance measure and takes into account the fact that instances related to the same concept tend to be close in the input space. In classification, for instance, this behavior can be observed among instances of the same label, highlighting the importance of modeling their local structure. LS builds a nearest neighbor graph, in which each node corresponds to a distinct instance and its nearest instances are connected to it. Eq. (4) defines the LS measure, with
and
. This formula includes the matrices
and
, where
, in which
extracts the diagonal matrix and
is the weight matrix of the graph edges, while
is called the Laplacian Graph.
In the information category, we considered the Representation Entropy—RE—(Mitra, Murthy, and Pal Citation2002) measure, defined by Eq. (5). The eigenvalues , calculated by the GNU Scientific Library, are extracted from a covariance matrix of the feature values of order
. If all eigenvalues are equal, the information is distributed uniformly in the data and there is low redundancy. On the other hand, if only an eigenvalue is different from
, then all information could be represented by a single feature.
All measures, except from LS, allow to evaluate a given subset of features jointly. For such, reduced versions of the dataset are built using the subset of features and the measures can then be calculated. On the other hand, LS evaluates each feature individually. We employed the average of the LS values of all features in a subset as a joint measure, such that all chosen measures perform joint feature evaluation.
Another important observation is that the PISA platform, used in the MOGA implementation, supports only the minimization of objective functions. This demanded a transformation of the maximization problems related to the AC, IE, and RE measures into equivalent minimization problems. To do so, for each measure, we subtract the corresponding objective values from the highest value reachable in the measure. In addition, the MOGA module assumes that all objectives have non-negative values, but the AC measure can reach negative values. Then, the AC original range of objective values was transformed into a range composed of positive values only, by summing the lowest value possible for AC.
gives an overview of the main characteristics of each of the importance measures mentioned in this article. This table shows the category of the measures and the feature type they are able to deal with (where QL stands for qualitative values and QT stands for quantitative values).
Table 2. Importance measures employed. These measures are associated with distinct categories and can deal with Quantitative (QT) and Qualitative (QL) feature values.
Related work found by the systematic review method
A Systematic Review (SR) was carried out to identify related work on the use of MOGA in FS (Spolaôr, Lorena, and Lee Citation2010a). The SR method is composed of three main steps: planning, conducting, and reporting (Kitchenham and Charters Citation2007). The planning step specifies the research questions that must be answered and creates a search protocol. The activities that integrate this protocol are carried out in the next step in order to identify a set of publications able to answer the research questions. The last step involves reporting the results in different ways, such as technical reports, PhD thesis, and papers.
The SR was performed by us in June 2010 (Spolaôr, Lorena, and Lee Citation2010a) and updated in January 2015 to answer research questions such as “What are the applications of MOGA in FS?”. A total of 93 publications on MOGA applications were found, from which 21 use the MOGA according to the filter approach. The 21 related studies are cited in the supplementary material available at https://db.tt/3iGgSTc5 and considered in what follows.
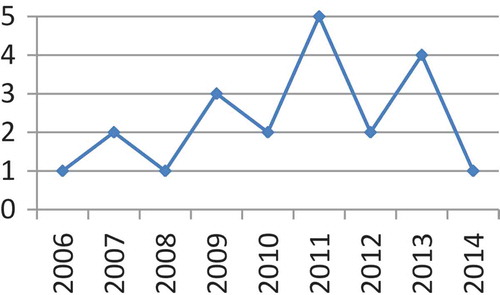
In this work, we address specific gaps of the literature, such as the use of filter importance measures from different categories and the application to different scenarios and data. shows how previous work on MOGA application for filter feature selection distribute along the years. This relatively recent research topic has been considered in publications at least once a year from 2006.
Figure 2. Frequency of related papers per year of publication.
Most of the related papers is devoted to FS applied to data from a specific domain, such as bioinformatics, medicine, economics, computer networks, signal, and image analysis. The exceptions are (Nahook and Eftekhari Citation2013; Santana, Silva, and Canuto Citation2009; Saroj Citation2014; Xue et al. Citation2013) and our previous work on the topic (Spolaôr, Lorena, and Lee Citation2011a, Citation2010b), which consider datasets from various domains.
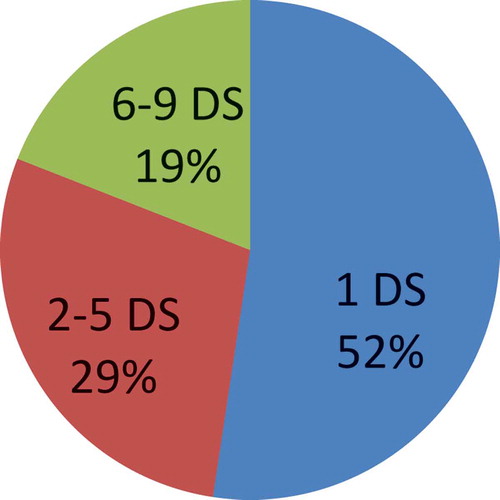
shows that most of the related papers () consider at most 5 datasets. It should be emphasized that this work uses more datasets than all MOGA applications for filter FS: 12—Section 5.1.
Figure 3. Percentage of related papers using specific numbers of datasets.
The NSGA-II Pareto-based MOGA is also the most used algorithm in related work, as exemplified in (Saroj Citation2014; Spolaôr, Lorena, and Lee Citation2011a; Xue et al. Citation2013; Zaharie et al. Citation2007). There are also papers employing a weighted sum of objectives in a standard GA. Nevertheless, in such approach one has to properly tune the weights given to each objective.
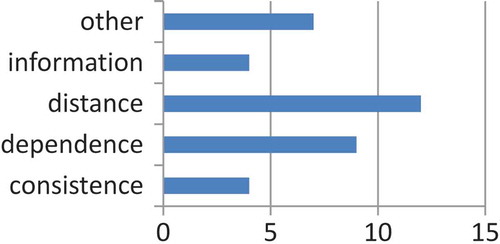
summarizes the categories of the feature importance measures by taking into account their frequency of use in related work on the filter approach. Although all categories are shown, only seven papers consider the combination of feature importance measures from distinct categories. A few pieces of work use importance measures which consider characteristics and properties of the application they deal with. Four of the related publications also consider the cardinality of the feature subset as an objective to be explicitly minimized.
Figure 4. Categories of feature importance measures used in related work.
Concerning our previous work, we compared 10 MOGA for filter FS in 5 labeled datasets in (Spolaôr, Lorena, and Lee Citation2010b). Only pairs of feature importance measures were considered, since previous experiments pointed disadvantages in the optimization of more measures. The main contribution was to highlight MOGA which optimize the simple inter-class distance measure (IE), motivating further investigations.
Four MOGA based on IE in combination to other measures were evaluated in nine labeled datasets in (Spolaôr, Lorena, and Lee Citation2011a). Two popular filter feature selection algorithms, named Correlation-based Feature Subset Selection (Hall Citation1999) (CFS) and Consistency Subset Evaluation Evaluation (Liu and Setiono Citation1996) (CSE), as well as five SOGA (Single-Objective Genetic Algorithms) based on each criterion individually were used for comparison. The best results were obtained with MOGA IE+AC, CFS, and CSE, which were competitive according to a statistical test at the significance level .
We employed the proposed MOGA in 12 labeled and 7 unlabeled datasets in (Spolaôr, Lorena, and Lee Citation2011b). The feature importance measures IE, AC, and IP were modified, aggregating the capability to address qualitative data. In addition, MOGA based on IC, RE and LS measures were used to perform FS in unlabeled data. The numerical results against models built using all features were promising, highlighting the MOGA IE+AC and IE+IP in data with both quantitative and qualitative features, respectively.
In this article, we extend such work by including a more extensive description of the MOGA proposed and a wider and more uniform experimental evaluation of the most relevant results, based on visual and numerical comparison procedures, as well as datasets with quantitative and qualitative features.
Experimental design
In order to evaluate the effectiveness of the feature subsets identified by the MOGA, we generated classification models from data described by the subsets and verified the performance achieved by them compared to the one achieved by models using all features. The same procedure was adopted for other FS techniques used as baseline. summarizes this experimental flow for FS. Starting from a dataset, FS is applied and the result is a reduced version of the input dataset, described by less features.
Figure 5. Experimental flow adopted in the evaluation of FS.
When inducing the classification models, four classification algorithms from different paradigms—the decision tree J48 (Witten and Frank Citation2011), Support Vector Machine (SVM) (Scholkopf and Smola Citation2001), Naive Bayes (NB) (Mccallum and Nigam Citation1998), and -Nearest Neighbor (NN) (Aha and Kibler Citation1991)—from the Weka tool (Witten and Frank Citation2011): data were applied, in order to reduce the influence of a specific algorithm on the results and to improve the experimental evaluation generality. Their parameters were kept with default values.
In addition, we also recorded the percentage of reduction in the number of features achieved by the FS algorithms. FS algorithms that are able to reduce more the number of features, while still maintaining the core patterns of the dataset can be considered better. The comparison of models built using the pre-processed and original datasets allow us to identify whether the main predictive characteristics of a dataset were maintained.
The datasets and algorithms used in the experiments are presented next.
Datasets
We chose 12 datasets from the UCI repository (Asuncion and Newman Citation2007; Bache and Lichman Citation2013), commonly employed in relate work (Spolaôr, Lorena, and Lee Citation2011a, Citation2010a): Australian (A), Crx (C), Dermatology (D), German (G), Ionosphere (I), Lung cancer (L), Promoter (P), Sonar (S), Soybean small (Y), Vehicle (V)—supported by the Turing Institute in Glasgow, Wisconsin Breast cancer (B), and Wine (W). summarizes the relevant information for each dataset, including their number of instances , total number of features
, number of quantitative features (QT), number of qualitative features (QL), number of classes
, and percentage of the Majority class Error (ME), which corresponds to the error rate obtained by classifying all data in the majority class.
Table 3. Summary of the datasets used in this study: Australian (A), Crx (C), Dermatology (D), German (G), Ionosphere (I), Lung cancer (L), Promoter (P), Sonar (S), Soybean small (Y), Vehicle (V), Wisconsin Breast cancer (B) and Wine (W).!
All datasets were divided according to the -fold stratified cross-validation strategy, resulting in
pairs of training and test sets which preserve the class distribution of the original dataset (Han and Kamber Citation2011). Training sets are used in FS and to build classification models, while test sets are used during the evaluation of such models.
Baseline algorithms
Three groups of algorithms were used for comparison against the MOGA. The first group consists of SOGA algorithms, each one optimizing an importance measure from Section 3.1 individually (single-objective) according to the filter approach.
Another group is composed of four SOGA algorithms following a wrapper approach, optimizing the error rate achieved by a particular classifier. We use four popular classification algorithms from different learning paradigms in such evaluation: (1) the decision tree J48, (2) support vector machine, (3) Naive Bayes, and (4) -Nearest Neighbor. In the last step of the experimental flow (), each feature subset produced by the wrappers was evaluated using the same classification algorithm employed during FS. Therefore, we expect that the results of these SOGA will be optimized and better for each of their respective classification algorithms.
All SOGA algorithms use the same encoding, selection mechanism, genetic operators, and stop condition as the MOGA. This was done to better analyze whether the multi-objective optimization of feature importance measures overcomes the optimization of each isolate measure. For MOGA we used the NSGA-II implementation available in the PISA with the following parameters: ,
,
,
,
,
. The parameters
,
, and
correspond, respectively, to the population size and the number of parents and children after reproduction. These parameter values were defined based on population sizes usually employed in the related work described in Section 4.
The last algorithm for comparison was an ensemble of feature ranking algorithms (EH) (Prati Citation2012), composed of three popular importance filter measures from literature: Information Gain (IG) (Liu and Shum Citation2003), Symmetrical Uncertainty (SU) (Press et al. Citation1992), and the measure inherent to the ReliefF algorithm (RF) (Robnik-Sikonja and Kononenko Citation2003). EH can also be regarded as an alternative to combine distinct importance measures. The aggregation was performed according to the Borda approach (Dwork et al. Citation2001), in which each feature has a general rank based on a weighted sum of the rankings assumed by this feature for each of the FS algorithms aggregated. We then select the best
features, i.e., 50% of the best features in the general ranking. This threshold was chosen due to its use in previous studies (Spolaôr, Lorena, and Lee Citation2011a) and its relevance in a supervised comparison procedure (Lee, Monard, and Wu Citation2006). For instance, we consider that the performance of a FS algorithm is very good if it is able to reduce 50% or more of the features, while maintaining or improving the accuracy value observed for all features. An advantage of EH over other ensemble methods is that it is flexible to work with different FS algorithms.
Evaluation procedures
As already discussed, the main comparison procedure adopted was to build classification models using the feature subsets identified by each FS algorithm.
In addition, we employed in this article a comparison model based on a trade-off between the reduction of the size of a feature subset and of the error rate (complement of accuracy for learning performance) achieved by the classifiers. It is important to emphasize this trade-off, as reaching good learning performance only is not the unique goal for some applications. In some cases, feature subset size reduction can be also important, for example, to build faster and less complex classifiers (Guyon and Elisseeff Citation2003). Decision trees (Witten and Frank Citation2011) are an example of learning algorithm that can yield simpler classifiers when some non-important features are discarded.
The comparison model, proposed in (Lee, Monard, and Wu Citation2006), plots the error rate achieved ( axis) by using a percentage of the features (
axis). Each classifier will originate one of such graph for a given dataset. shows an example of this trade-off graph.
Figure 6. Comparison procedure based on error rate (axis X) and size of feature subsets (axis Y) (Lee, Monard, and Wu Citation2006).
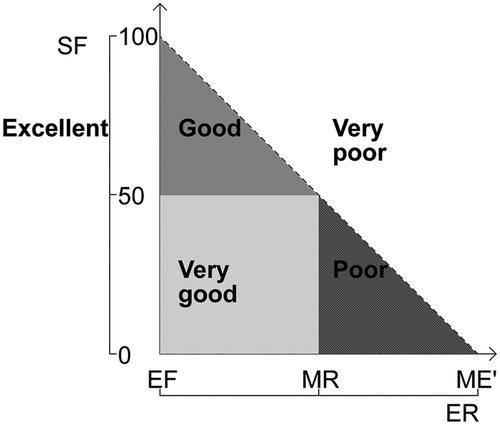
In this graph, EF stands for the Error without Feature selection, i.e., the error rate of the model built using all features. ME’ is equal to the majority class error (ME) if this value is lower than 0.5, or equal to 0.5 otherwise. MR is the average of EF and ME’. A good FS algorithm should reduce the datasets, while still building classification models of good performance. Therefore, some regions of quality are defined in , based on thresholds defined on both axes. If the error rate reduces and is lower than EF, the performance is considered excellent. A very good performance is verified when the classification error is acceptable, while a sharp reduction of 50% or more of the features is obtained. A good performance is achieved when the error rate is maintained acceptable, but more modest reductions in the number of features are verified. If the classification error is above the ME’ value, the performance is considered very poor, despite having reductions in the number of features. On the other hand, if the classification error approaches ME’ and more than 50% of the features were disregarded, the performance is poor, since this probably corresponds to the case where the most important features were those eliminated.
Each classifier built after using an FS algorithm is plotted in the graph as a point and categorized according to the region it falls within. This procedure was extended in this article to also include the result of a statistical test comparing each MOGA against the two related SOGA, i.e., the two SOGA optimizing the importance measures taken into account by the MOGA. This test considers the confidence interval based on the Student’s t distribution at the significance level .
For MOGA results that are statistically better than the SOGA ones, the correspondent point is a blue filled square, while the green hollow square was used to symbolize MOGA results statistically worse than the SOGA ones. A red triangle denotes the absence of statistical difference. Finally, the SOGA results are represented by blue hollow circles.
Experimental results
We show and analyze here the results of two combinations of measures representing different categories (Section 2.2): IE+AC and IE+IP. The choice to deepen the analysis on these MOGA is based on results from our previous work, which were summarized in Section 4, as well as the support provided by the corresponding measures to deal with both quantitative and qualitative features—. In particular, IE+AC was the best MOGA according to experimental evaluations conducted in datasets with quantitative features, whereas IE+IP presented the same behavior in analysis regarding datasets with qualitative features. It should be emphasized that the IP measure discretizes the data before evaluating quantitative features (Section 3.1), which could have hindered its experimental performance.
One can also note that these MOGA combine measures from different categories that use class information as an attempt to support feature evaluation. Finally, it is important to emphasize that optimizing three or more importance measures led to higher computational cost with small gains in classification performance, as pointed in (Spolaôr, Lorena, and Lee Citation2011a).
Due to the stochastic nature of genetic algorithms, they were executed five times for each training dataset. This strategy results in five feature subsets per algorithm and, consequently, five reduced versions of the dataset. Therefore, five classification models are also induced according to -fold stratified cross-validation, and the results for GA shown correspond to the average from 10 trainings sets*5 runs = 50 results.
Reduction in the number of features
shows the average and the corresponding standard deviation of the Percentage of Reduction (PR) in the number of features obtained by each FS algorithm, including the baselines. Cells with average PR greater than 50% are highlighted in bold. In this table, AC, IE, and IP rows correspond to the single optimization of these measures by SOGA. WJ, WS, WB, and WN are the wrapper algorithms employing the J48 (Decision Tree), SVM, Naive Bayes, and Nearest Neighbor classifiers, respectively. EH, which stands for the ensemble FS, always removes 50% of the features and is not shown.
Table 4. Percentage of Reduction (PR) in the number of features for each dataset. Cells with average PR greater than 50% are highlighted in bold.
Some baseline algorithms have lead to high reductions in PR, mainly the wrappers (although their standard deviation is higher). This was also verified for the SOGA IP and AC. IE was more conservative and maintained more features. This was also reflected in the results of the MOGA IE+AC and IE+IP, both related to IE, despite of AC and IP having lead to large reductions. Moreover, IE+AC was able to obtain reductions higher than 50% in various datasets. Therefore, one measure complemented each other regarding PR.
Predictive performance
and present the average accuracies of the predictive models built in this work. Specifically, shows the results of the J48 and SVM classifiers, while shows the results of the NB and NN classifiers. Those cells of FS algorithms which obtained PR () greater than 50% are highlighted by an asterisk. In addition, the cells in italics indicate models with accuracy worse or equal to the Majority Class Error. summarizes these results by taking into account the area of a polygon specific for each classification method and FS algorithm. Each polygon in turn is composed of 12 axes, in which each axis represents the average accuracy achieved by the correspondent classifier and FS strategy in a particular dataset.
Table 5. Performance of J48 and SVM models for each dataset. Cells regarding FS algorithms that obtained PR () greater than 50% are highlighted by an asterisk (*). Cells in italics indicate models with accuracy worse or equal to the Majority Class Error.
Table 6. Performance of NB and NN models for each dataset. Cells regarding FS algorithms that obtained PR () greater than 50% are highlighted by an asterisk (*). Cells in italics indicate models with accuracy worse or equal to the Majority Class Error.
Figure 7. Graphic summary of the predictive performance results. In particular, each bar consists in the area of a polygon in which each axis represents the average accuracy achieved by a specific classifier and FS algorithm.
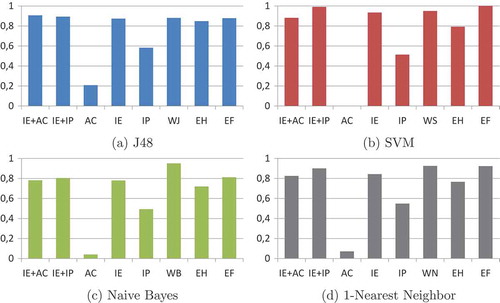
The results suggest a relative equilibrium in the predictive results of the MOGA IE+AC and the wrappers. These FS algorithms were able to generate several models with good predictive performance, while also reducing considerably the number of input features. Although suggests that IE+IP, IE and EF were also competitive, recall that EF used all features to learn from data and the remaining algorithms achieved low reducton in the number of features ().
Despite of the lower accuracies than those observed for the wrappers, the IE+AC algorithm has as benefits the independence of classifiers in the FS task. In addition, filter algorithms usually demand less running time than the wrapper approach (Liu and Motoda Citation2007), although we did not perform a running time analysis in this work.
One can find some possible relations between MOGA predictive results and data properties. For example, for three classification algorithms (J48, NB, and NN), IE+AC usually supports the building of better classifiers than the ones derived from IE+IP for datasets with less instances (n in ). This finding suggests that IE+AC can deal better with scenarios with limited number of training instances. Another example suggests that, for three classification algorithms (SVM, NB and NN), wrapper FS is the best choice for FS when the number of instances per feature, i.e., is higher. As
reduces, other algorithms highlight. This could suggest that the wrapper approach is not the best choice in harder scenarios, with less instances per feature (sparse datasets).
It is also useful to notice that, when AC is optimized in isolation, there are some severe reductions in the accuracy rates when compared to the use of all features. But, when combined to IE, which was conservative in feature reduction singly, the search was more controlled, able to reduce the number of features while still maintaining or in some cases improving the accuracy performances.
EH has also performed an effective combination of multiple ranking criteria for FS. Nonetheless, it does not have the support to automatically identify which number of features should be employed, as genetic algorithms solutions do. Another disadvantage is that EH is mainly designed for feature ranking algorithms, which in turn can rank redundant features similarly.
Trade-off PR vs accuracy
For better comparing the MOGA and SOGA filters, we investigate the trade-off graphs of Percentage of Reduction in the number of features vs the predictive performance achieved by the SVM classifier according to the comparison model described in Section 5.3. Results for the other classification models are summarized in and in the supplementary material available at https://db.tt/3iGgSTc5.
Figure 8. Total number of classifiers built using features selected by the MOGA and SOGA filters for each category related to the trade-off between percentage of reduction in the number of features and classification accuracy.
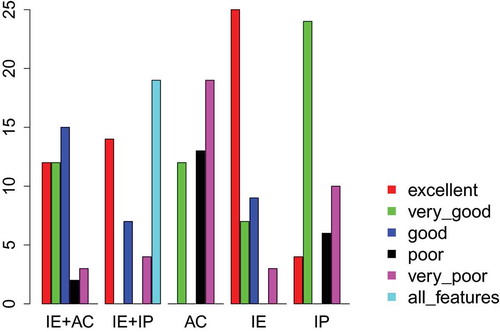
organizes the FS algorithms for each dataset according to the five categories assigned by the model—excellent (▴▴▴), very good (▴), good (▴), poor (), and very poor (▾), as well as a category named all features (—), which labels those cases where no feature reduction was achieved. In addition, shows the correspondent plots. Note that the model for the dataset L can not be plotted because the error of the SVM classifier built without feature selection (EF) is higher than 0.5 ().
Table 7. Comparison of SVM models built after FS. This comparison involves categorizing the models into six categories regarding the compromise between dimensionality reduction and prediction performance: excellent (▴▴▴), very good (▴▴), good (▴), poor (), very poor (▾) and all features (—).
Figure 9. Graphic comparison of SVM models built after FS with statistical test results.
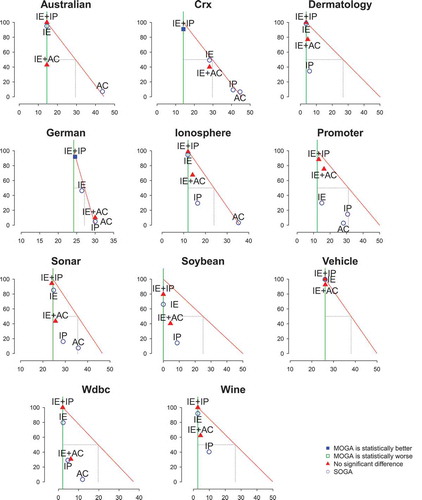
As illustrated in for SVM, no MOGA filter was significantly worse than its SOGA counterpart. Furthermore, the SVM classifiers correspondent to the MOGA were well categorized in most of the cases (), such that only one classifier was considered very poor (▾) for each filter. Nevertheless, as noted previously, IE+AC is better than IE+IP and reaches higher PR while maintaining a good accuracy performance.
SOGA IE also highlighted by supporting many classifiers with good trade-offs. However, as shown in , this filter often reaches smaller percentage of reduction in the number of features than IE+AC. This contributes to the obtainment of similar accuracy rates to those achieved by using all features.
While AC had several very poor results when optimized isolatedly, its combination with IE was very beneficial and improved the results achieved. This exemplifies the relevance of studying combinations of importance measures, even when one of the measures seems to be fruitless alone.
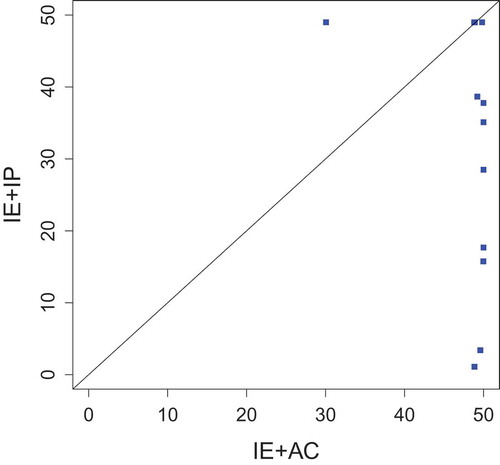
Non-dominated solutions
For comparing the multi-objective algorithms independently of the machine learning classification algorithms, we plotted graphs comparing the average number of non-dominated solutions obtained for each MOGA. The points in these graphs represent the 12 datasets studied, as exemplified in (Batista, Wang, and Keogh Citation2011) for another context. The coordinates of a point are the numbers of non-dominated solutions obtained by a given pair of MOGA. The MOGA with more non-dominated solutions can be considered the algorithm that addresses the most conflicting feature importance measures.
shows that IE+AC leads to more non-dominated solutions in the majority of the datasets, since the points are more concentrated toward its area (under the diagonal). Therefore, in addition to higher reductions in the number of features, IE+AC was also able to optimize more conflicting importance measures, an important characteristic concerning multi-objective optimization. This can also explain the good results obtained by this particular combination in FS.
Figure 10. Comparison between MOGA in terms of the number of non- dominated solutions.
Conclusion
This article presented a method for multi-objective optimization of multiple feature importance measures, by employing a multi-objective genetic algorithm grounded in the Pareto theory. Although the MOGA algorithm currently developed supports the optimization of six feature importance measures and their combinations, we performed in this article a deeper evaluation of two combinations of pairs of simple measures, highlighted as most promising in our previous work (Spolaôr, Lorena, and Lee Citation2011a, Citation2010b) and able to deal with both quantitative and qualitative features. In fact, the main differential of this work is a more complete description of the method and a uniform analysis of the most relevant experimental results, based on a wider range of datasets and importance measures than most of the 21 related papers found by a pioneer systematic review.
The experimental results show that some combinations of the measures in a filter feature selector can indeed capture some of the main patterns in a dataset, while reducing the number of features employed as input. As an appropriate trade-off between accuracy and reduction in the number of features is important for some classification applications, this can be considered a good result. In particular, the best combination was between a distance-based measure and a correlation-based measure. This behavior was verified for classification algorithms of different paradigms, which used the selected features as input to build predictive models. However, if the interest is to obtain the highest accuracy for a specific classification algorithm, the wrapper approach is more appropriate. Future work should include the comparison of some of the evaluated MOGA combinations with other meta-heuristics. Experimental evaluations with artificial and real datasets should also be performed. Finally, although a single solution from the Pareto front estimated by an MOGA is chosen in this work, a combination of the non-dominated solutions found could improve the results achieved.
Acknowledgments
We would also like to thank Aurora T. R. Pozo and Antonio R. S. Parmezan for their collaboration.
Additional information
Funding
References
- Aha, D., and D. Kibler. 1991. Instance-based learning algorithms. Machine Learning 6:37–66. doi:10.1007/BF00153759.
- Arauzo-Azofra, A., J. M. Benitez, and J. L. Castro. 2008. Consistency measures for feature selection. Journal of Intelligent Information Systems 30 (3):273–92. doi:10.1007/s10844-007-0037-0.
- Asuncion, A., and D. J. Newman. 2007. UCI machine learning repository. University of California, Irvine, School of Information and Computer Sciences. Accessed June 1, 2010. http://www.ics.uci.edu/˜mlearn/MLRepository.html.
- Bache, K., and M. Lichman. 2013. UCI machine learning repository. University of California, Irvine, School of Information and Computer Sciences. Accessed June 1, 2014. http://archive.ics.uci.edu/ml.
- Batista, G. E. A. P. A., X. Wang, and E. J. Keogh. 2011. A complexity-invariant distance measure for time series. In SIAM International Conference on Data Mining, 699–710. Mesa, United States: SIAM.
- Bleuler, S., M. Laumanns, L. Thiele, and E. Zitzler. 2003. PISA — A platform and programming language independent interface for search algorithms. In Evolutionary multi-criterion optimization, ed C. M. Fonseca, P. J. Fleming, E. Zitzler, L. Thiele, and K. Deb, 494–508. Berlin: Springer Berlin Heidelberg.
- Deb, K., S. Agrawal, A. Pratap, and T. Meyarivan. 2000. A fast elitist nondominated sorting genetic algorithm for multi-objective optimization: NSGA-II. In Parallel problem solving from nature, ed M. Schoenauer, K. Deb, G. Rudolph, X. Yao, E. Lutton, J. Merelo, and H. Schwefel, 849–58. Berlin: Springer Berlin Heidelberg.
- Dwork, C., R. Kumar, M. Naor, and D. Sivakumar. 2001. Rank aggregation methods for the Web. In International Conference on World Wide Web, 613–22. Hong Kong, China: ACM.
- Freitas, A. A. 2004. A critical review of multi-objective optimization in data mining: A position paper. SIGKDD Explorations Newsletter 6 (2):77–86. doi:10.1145/1046456.1046467.
- Guyon, I., and A. Elisseeff. 2003. An introduction to variable and feature selection. Journal of Machine Learning Research 3:1157–82.
- Hall, M. A. 1999. Correlation-based Feature Selection for Machine Learning. PhD Thesis, University of Waikato - New Zealand.
- Hall, M. A.–. 2000. Correlation-based feature selection for discrete and numeric class machine learning. In International Conference on Machine Learning, 359–66. Stanford: Morgan Kaufmann.
- Han, J., and M. Kamber. 2011. Data mining: Concepts and techniques, 3rd ed. San Francisco: Morgan Kaufmann.
- He, X., D. Cai, and P. Niyogi. 2005. Laplacian score for feature selection. In Advances in Neural Information Processing Systems, 507–14. Cambridge, United States: MIT Press.
- Kitchenham, B. A., and S. Charters. 2007. Guidelines for performing systematic literature reviews in software engineering. Technical report. Evidencebased Software Engineering - United Kingdom.
- Kohavi, R., and G. H. John. 1997. Wrappers for feature subset selection. Artificial Intelligence 97 (1–2):273–324. doi:10.1016/S0004-3702(97)00043-X.
- Lee, H. D., M. C. Monard, and F. C. Wu. 2006. A simple evaluation model for feature subset selection algorithms. Inteligência Artificial 10 (32):9–17.
- Liu, C., and H. Shum. 2003. Kullback-Leibler boosting. In Computer Vision and Pattern Recognition, 587–94. Madison, United States: IEEE.
- Liu, H., and H. Motoda. 1998. Feature selection for knowledge discovery and data mining. Norwell: Kluwer Academic Publishers.
- Liu, H., and H. Motoda. 2007. Computational methods of feature selection. Boca Raton: Chapman & Hall/CRC.
- Liu, H., and R. Setiono. 1996. A probabilistic approach to feature selection - a filter solution. In International Conference on Machine Learning, 319–27. Bari, Italy: Morgan Kaufmann.
- Liu, H., and L. Yu. 2002. Feature selection for data mining. Arizona State University, Ira A. Fulton Schools of Engineering. Accessed June 1, 2010. http://www.public.asu.edu/˜huanliu/sur-fs02.ps.
- Mccallum, A., and K. Nigam. 1998. A comparison of event models for naïve bayes text classification. In Workshop on Learning for Text Categorization, 41–48. Madison, United States: AAAI Press.
- Mitra, P., C. A. Murthy, and S. K. Pal. 2002. Unsupervised feature selection using feature similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence 24 (3):301–12. doi:10.1109/34.990133.
- Nahook, H. N., and M. Eftekhari. 2013. A feature selection method based on ∩ - fuzzy similarity measures using multi objective genetic algorithm. International Journal of Soft Computing and Engineering 3 (2):37–41.
- Prati, R. C. 2012. Combining feature ranking algorithms through rank aggregation. In International Joint Conference on Neural Networks, 1–8. Brisbane, Australia: IEEE.
- Press, W. H., S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery. 1992. Numerical recipes in C: The art of scientific computing. Cambridge: Cambridge University Press.
- Robnik-Sikonja, M., and I. Kononenko. 2003. Theoretical and empirical analysis of ReliefF and RReliefF. Machine Learning 53 (1–2):23–69. doi:10.1023/A:1025667309714.
- Santana, L. E. A., L. Silva, and A. M. P. Canuto. 2009. Feature selection in heterogeneous structure of ensembles: A genetic algorithm approach. In International Joint Conference on Neural Networks, 1491–98. Atlanta, United States: IEEE.
- Saroj, J. 2014. Multi-objective genetic algorithm approach to feature subset optimization. In IEEE International Advance Computing Conference, 544–48. Gurgaon, India: IEEE.
- Scholkopf, B., and A. J. Smola. 2001. Learning with Kernels: Support vector machines, regularization, optimization, and beyond. Cambridge, United States: MIT Press.
- Spolaôr, N., A. C. Lorena, and H. D. Lee. 2010a. A systematic review of applications of multiobjective metaheuristics in feature selection (in Portuguese). Technical report. NOTE: An English version of the technical report can be requested to the authors. Federal University of ABC - Brazil.
- Spolaôr, N., A. C. Lorena, and H. D. Lee. 2010b. Use of multiobjective genetic algorithms in feature selection. In IEEE Brazilian Symposium on Artificial Neural Network, 146–51. São Bernardo do Campo, Brazil: IEEE.
- Spolaôr, N., A. C. Lorena, and H. D. Lee. 2011a. Multi-objective genetic algorithm evaluation in feature selection. In Evolutionary multi-criterion optimization, ed R. Takahashi, K. Deb, E. Wanner, and S. Greco, 462–76. Berlin: Springer Berlin Heidelberg.
- Spolaôr, N., A. C. Lorena, and H. D. Lee. 2011b. Multiobjective genetic algorithms for feature selection (in Portuguese). In Encontro Nacional de Inteligência Artificial, 938–49. Natal, Brazil: Brazilian Computer Society.
- Wang, C., and Y. Huang. 2009. Evolutionary-based feature selection approaches with new criteria for data mining: A case study of credit approval data. Expert Systems with Applications 36 (3):5900–08. doi:10.1016/j.eswa.2008.07.026.
- Wilson, D. R., and T. R. Martinez. 1997. Improved heterogeneous distance functions. Journal of Artificial Intelligence Research 6:1–34.
- Witten, I. H., and E. Frank. 2011. Data mining: Practical machine learning tools and techniques, 3rd ed. San Francisco: Morgan Kaufmann.
- Xue, B., L. Cervante, L. Shang, W. N. Browne, and M. Zhang. 2013. Multi objective evolutionary algorithms for filter based feature selection in classification. International Journal on Artificial Intelligence Tools 22 (4):1350024–1–1350024–31. doi:10.1142/S0218213013500243.
- Yang, J., and V. Honavar. 1998. Feature subset selection using a genetic algorithm. IEEE Intelligent Systems and Their Applications 13 (2):44–49. doi:10.1109/5254.671091.
- Zaharie, D., S. Holban, D. Lungeanu, and D. Navolan. 2007. A computational intelligence approach for ranking risk factors in preterm birth. In International Symposium on Applied Computational Intelligence and Informatics, 135–40. Timisoara, Romania: IEEE.
- Zeleny, M. 1973. An introduction to multiobjetive optimization. In Multiple criteria decision making, ed. J. L. Cochrane, and M. Zeleny, 262–301. Columbia, United States: University of South Carolina Press.