
ABSTRACT
This paper presents a novel algorithm so-called VFC4.5 for building decision trees. It proposes an adaptation of the way C4.5 finds the threshold of a continuous attribute. Instead of finding the threshold that maximizes gain ratio, the paper proposes to simply reduce the number of candidate cut points by using arithmetic mean and median to improve a reported weakness of the C4.5 algorithm when it deals with continuous attributes. This paper will focus primarily on the theoretical aspects of the VFC4.5 algorithm. An empirical trials, using 49 datasets, show that, in most times, the VFC4.5 algorithm leads to smaller decision trees with better accuracy compared to the C4.5 algorithm. VFC4.5 gives excellent accuracy results as C4.5 and it is much faster than the VFDT algorithm.
Introduction
Decision trees are one of the most widely used classification techniques. Many variations of the decision tree algorithm were proposed in the literature (Saqib et al. Citation2015). They include Classification And Regression Tree (CART) (Breiman et al. Citation1984), Iterative Dichotomizer 3 (ID3) (Quinlan Citation1986), CHi-squared Automatic Interaction Detector (CHAID) (Kass Citation1980), and Conditional Inference Trees (Hothorn, Hornik, and Zeileis Citation2006). A decision tree is a classifier expressed as a recursive partition of the training instances. It is constructed in a top-down manner, in each iteration, the instance space is partitioned by choosing the best attribute to split them (Agrawal and Gupta, Citation2013; Patel and Singh Citation2015).
An attribute in a learning problem may be nominal (categorical), or it may be continuous (numerical). Numerical attributes with a very large, even infinite domain, become an important challenge in areas of pattern recognition, machine learning, and data mining. Mining data with numerical attributes require discretization before or throughout the process of model building (Garcia et al. Citation2013). A special kind of discretization is performed through the decision tree construction process. The decision tree algorithm uses binarization which splits the numerical values into two intervals (Yang and Chen Citation2016).
C4.5 is one of the best known and most widely used decision tree algorithms (Lu, Wu, and Bongard Citation2015). Its accuracy level is high enough, independently of the data volume to be processed. One of the latest studies that compares decision trees and other learning algorithms shows that C4.5 has a very good combination of error rate and speed (Hssina et al. Citation2014; Lim, Loh, and Shih Citation2000). Various studies identify the C4.5 algorithm as one of the top classifiers in data mining (Wu et al. Citation2008). The algorithm has the ability to handle an incomplete training dataset (Garca Laencina et al. Citation2015), and to prune the resulting decision tree in order to reduce its size and optimize the decision path. C4.5 also has the ability to deal with continuous attributes. It handles continuous attributes using the binarization process. Those attributes are replaced by the discrete ones using threshold values which separate data into two intervals (Behera and Mohapatra Citation2015; Kotsiantis Citation2013; Perner Citation2015).
Even for C4.5 and other algorithms that can directly deal with quantitative data, learning is often less efficient and less effective. Several researchers reported that the C4.5 algorithm contains some weakness in domains with continuous attributes. They offer evidence that it can be more benefited from continuous attributes by using a new discretization method, or by developing some process in the C4.5 binarization method (Chong et al. Citation2014; Quinlan Citation1996; Sumam, Sudheep, and Joseph Citation2013). In 2013, Sudheep, Sumam, and Joseph reported that the binarization process in C4.5 is computationally intensive (Sumam, Sudheep, and Joseph Citation2013). To perform binarization, the continuous attribute values are first sorted. This process is time consuming and it is not practical for large datasets. To sort the attribute values, the C4.5 algorithm uses the Quick Sort method with complexity . Despite this, several authors showed that the learning process may be dominated by sorting of continuous attribute values.
The generalization limit in domains with continuous attributes is the most important problem in the C4.5 algorithm. The selected threshold value can not reflect and judge the generalization capability of the continuous attribute. So, the C4.5 algorithm may use continuous attributes with a low generalization performance to split data. Deciding based on those attributes will increase the tree size and decrease the model accuracy. Liu and Setiono (Liu and Setiono Citation1995) reviewed and compared C4.5’s performance with Chi2 global discretization and concluded that Chi2 discretization is effective in improving performance. These authors found that Chi2 global discretization performed as well as C4.5 local discretization, and occasionally improved its accuracy (Liu and Setiono Citation1995). A recent research compares Multiple Scanning, and C4.5 discretization shows that using a cut point that reflects the data distribution can improve the decision tree performance. The authors proved that using Multiple Scanning discretized data yields more accurate and less complex decision trees in many cases (Grzymala- Busse and Mroczek, Citation2015). But, discretization as a preprocessing task neglects the correlation between the conditional attributes and the class attribute (Wang et al. Citation2015). Thus, the problem of dealing with continuous attributes could be addressed by choosing an appropriate threshold value that defines perfectly the interval borders. In this setting, we prose statistical mean and median as an alternative to threshold searching process in the C4.5 algorithm. In this paper, a new algorithm called Very Fast C4.5 (VFC4.5) is proposed.
The rest of the present paper is organized as follows: section 2 describes in details the C4.5 Binarization process. The new algorithm is denoted in section 3 with a mathematical formulation. Experimental investigations are drawn in section 5 and 6, where a set of tests are carried out to measure the efficiency of the VFC4.5 applied on different databases in comparison with the initial C4.5 algorithm, VFDT, and CART algorithms.
C4.5 algorithm
There have been many variations for decision tree algorithms. C4.5 is one of the well-known decision tree induction algorithms (Quinlan Citation2014). In 1993, Ross Quinlin proposed the C4.5 algorithm which extents the ID3 algorithm (Quinlan Citation1986). Using information gain ratio to select the best attribute, C4.5 avoids ID3’s bias toward features with many values that occurs (Ooi, Tan, and Cheah Citation2016; Zhu et al. Citation2014). C4.5 has the ability to handle continuous attributes by proposing two different tests in function of each attribute values type.
At the training stage, the C4.5 uses the top down strategy based on the divide and conquer approach to construct the decision tree (Liu and Gegov Citation2016). It maps the training set and uses the information gain ratio as a measurement to select splitting attributes and generates nodes from the root to the leaves. Every illustrating path from the root node to the leaf node forms a decision rule to determine which the class of a new instance is (Dai and Ji Citation2014). The root node contains the whole training set, with all training case weights equal to 1.0, to take into account unknown attribute values (Quinlan Citation2014). If all training cases of the current node belong to one single class, the algorithm terminates. Otherwise, if all training cases belong to more than one class, the algorithm calculates the information gain ratio for each attribute . The attribute with the highest information gain ratio is selected to split information at the node (Mu et al. Citation2017). For a discrete attribute
, the information gain ratio is computed by splitting training cases of the current node in function of each value of
(Ibarguren, Prez, and Muguerza Citation2015). If
is a continuous attribute, a threshold value must to be found for the splitting (Pandya and Pandya Citation2015).
Given a node with
instances, described by a matrix of continuous attributes
where each row
is an horizontal vector of
attribute values
pre-classified by a class
which is an element of the vertical class vector
. Consider a continuous attribute
, the C4.5 algorithm selects the optimal cut point
that maximizes information gain to divide samples in
into two subsets:
and
. As can be seen from algorithm 1, attribute values should be sorted with ascending order first, only distinct values are retained to select the candidate cut points. Then, the algorithm identifies the candidate cut points Eq. (1):
For each CCP, samples in are split into two intervals
and
to compute the information gain Eq. (2) for all condidate cut points:
where the information entropy measures the class impurity and the amount of information, and symbol
is the size of
. Then, the optimal cut point Eq. (3) is selected as a threshold value for attribute
:
Once threshold value is selected, the algorithm calculates the gain ratio to compare the discriminative ability of the candidate attributes and select the optimal one in order to split the current node Eq. (4).
where the split information is calculated as in Eq. (5)
The attribute that maximizes information gain ratio is selected as the best splitting feature, and the algorithm split the current node in function of the selected attribute. [!h]
Table
Very fast C4.5 algorithm
When analyzing real valued data and estimating subsets in data distribution, measures of central tendency can be used to identify and separate populations with different characteristics. The mean and median have been utilized as a binary cut-off to estimate threshold values and then to identify data outliers in geochemical data (Reimann, Filzmoser, and Garrett Citation2005). Also, median-based binarization is recently used to perform feature selection (Sugiyama and Borgwardt Citation2017). Combined with variance, mean is used as a threshold value in decision tree induction (Sumam, Sudheep, and Joseph Citation2013). Thus, measures of central tendency have been presented in several research studies to deal with real valued data. However, several practical questions arise when dealing with arithmetic mean and median as a threshold value. It is important to identify cases where such a simple measures can separate data into two pure subsets and cases where it might fail. Also, it is crucial to measure the efficiency of mean and median-split based on different data distributions to investigate their sensitivity and stability. To answer all these questions, we start by discussing theoretical characteristics of both the mean and median.
Mean or average is the representative value of the whole group of data. The arithmetic can take any value not observed in the original set of data, which can improve the generalization ability of a cut point (Lewis Citation2012). In this setting, using the mean as a threshold value will improve the classification of unseen cases. The median is also widely used as a measure of central tendency, and it is the central value in the set of data. It divides the data into two equal halves. This measure is affected by the number of values observed in the distribution (Rubin Citation2012). As shown in Eq. (6), the arithmetic mean involves both distribution values () and number of observations (
). That is why the mean is sensitive to the outlier values in a dataset, in such a case, the mean cannot deliver a relevant cut point. Whereas, as can be seen from Eq. (7), the median value is affected only by the number of observations (
), it is not sensitive to outlier values. The presence of outlier data values or the shape of frequency distribution has a dramatic impact on mean value (Sharma Citation2012), that is why, in such cases arithmetic mean could be replaced by the median (Reimann, Filzmoser, and Garrett Citation2005).
In order to answer the research questions related to the performances of mean and median as a splitting criterion, and which of those techniques yields most precise cut points, we simulate seven different continuous distributions:
Scenario 1: The Cauchy distribution with the location value
and the scale value
Scenario 2: The exponential distribution with the rate value
Scenario 3: The gamma distribution with the shape parameter
Scenario 4: The log-normal distribution with the mean value
Scenario 5: The logistic distribution with the location value
Scenario 6: The normal distribution with the mean value
Scenario 7: The Weibull distribution with the shape value
For each scenario 200 instances are simulated for two classes. Thus, for each scenario, according to the mean, median, and C4.5 threshold, three cut points are selected as can be seen from . The previous simulations are repeated 10 times in order to compute sensitivities and specificities.
Figure 1. Seven different distributional scenarios.
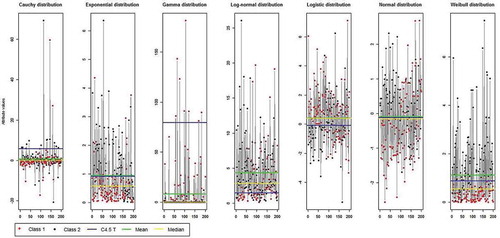
As can be seen from , the three measures are strongly dependent to the data distribution except when the examples are normal distributed. As shown in scenario 6 (Normal distribution), mean, median, and C4.5 threshold provide the same cut points. Consider which summarizes the accuracy rate for the three measures against the different scenarios, we can assume that in most cases C4.5 threshold results in better accuracies.
Table 1. Summary description of classification Datasets.
Table 2. Summary description of classification accuracy.
In accordance with and , the cut points provided by the mean is slightly higher than the median cut point which is explained by the presence of extreme values in both scenario 4 and 7. Thus, in those cases, median cut points are more accurate than the mean ones. On the other hand, the mean cut point shows a smallest increase in error rate when instances are strongly fluctuated (i.e., scenario 5). Otherwise, a closer inspection of the results in shows that in all scenarios there is at least one of the two cut points generated by mean and median that is slightly better or close to the C4.5 threshold cut point results. Thus, it is necessary to adopt both of mean and median as a candidate cut points and then to select the one that maximizes information gain. As shown in , the associated sensitivities and specificities found by mean and median method are usually slightly higher than those detected with the C4.5 threshold technique. As already shown in for the mean and median cut points, also for sensitivities and specificities from , using both the mean and median as cut points can yield to slightly higher or the same results as obtained using the C4.5 threshold technique.
Figure 2. Specificity and sensitivity results.
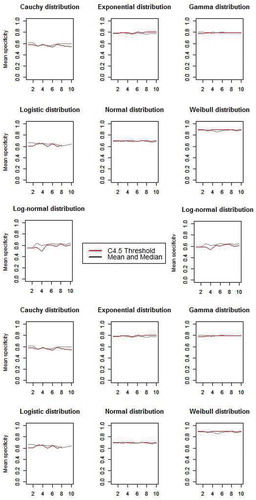
The mean and median can communicate important information about data distribution. To cope with extreme values, we propose the use of mean and median as candidate cut points. In fact, in a class imbalanced dataset, extreme values may represent a minor class ( (gamma distribution)). In this case, we suggest the mean as a threshold value. In other cases, median as it is not affected by extreme values can provide a more suitable threshold value ( (Weibull distribution)). In this case, we provide two potential cut points, and then we compute information gain for both of them. It is important to look the dispersion of a dataset when interpreting the measures of central tendency, which is why we will use the cut point that maximizes information gain as a threshold value.
Algorithm description
The proposed VFC4.5 algorithm uses three processes that are responsible for achieving the tree construction: attribute selection, attribute binarization, and dataset splitting. The first and the last ones are the same as in the C4.5 algorithm. We introduce the use of mean and median as a candidate cut points in the attribute binarization process. Let be a matrix of continuous attributes, with
instances and
attributes. Algorithm 2 provides the optimal attribute and cut point to split the
samples into two subsets. For each attribute, it calculates mean and median values. Once the splitting performances for both of mean and median is computed, the cut point that yields the highest value is set as a threshold value for the given attribute. Finally, algorithm 2 compares the splitting performances of all attributes and selects the optimal one.
Table
Analysis of time complexity
Suppose that there are cut points
for each attribute
. As described in algorithm 1, C4.5 starts with sorting the n examples for the m attributes which leads to a minimum complexity of
. In steps 5, the algorithm selects
cut points for each attribute
,
with a complexity of
. Then in steps 6 to 9, it calculates the split information for each cut point which leads to a complexity of
. Selecting the optimal cut point
leads to a complexity of
. Finally, the time complexity of algorithm 1 is
.
The main advantage of the proposed algorithm is that it avoids the sorting process with complexity of , also for each attribute, there are only two cut points to evaluate. In algorithm 2, we start by computing mean and median for each attribute with a complexity of
. In steps 6 to 9, the algorithm calculates the split information for each cut point which leads to a complexity of
. Selecting the optimal cut point in algorithm 2 leads to a complexity of
while there are only to cut points to evaluate. Thus, the time complexity of algorithm 2 is
.
Experimental setup
In this section, experimental comparisons are conducted on 49 (UCI) machine learning datasets. In order to investigate the VFC4.5’s performance, the results are compared to those of C4.5, VFDT, and CART algorithms. This section specifies all the properties and issues related to datasets, validation procedure, and the parameters of used algorithms. We carried out experiments on 49 datasets taken from the UCI repository (UCI, Citation2015). Datasets with and without continuous attributes were used to train the VFC4.5 algorithm. Also, small and large datasets were used in order to investigate VFC4.5’s performance. summarizes the main properties of the data. For each dataset, it includes the name, number of instances, number of numeric and nominal attributes, and number of classes. Ten-fold cross-validation was used to evaluate the performance of the algorithms. We used the J48 tree (the C4.5 decision tree implementation) of Weka software (Witten et al. Citation2016) to implement the new algorithm VFC4.5. summarizes the parameters of the used classifiers.
Table 3. Parameters of algorithms.
To demonstrate the usefulness and performance of our decision tree algorithm, we use accuracy, sensitivity and specificity as a performance measure to compare the generalization classification rate of VFC4.5 against C4.5, VFDT, and CART algorithms. Nevertheless, in decision tree, other measures are required to investigate the model complexity. We refer to the tree size, number of leaves, and time taken to build the model. Those performance measures will be adopted to measure the tree complexity. For all experiments, we have used the Wilcoxon test (Wilcoxon Citation1992) as a nonparametric statistical test. The Wilcoxon test is simple, safe, and robust test used for statistical comparisons of classifiers.
Analysis and empirical results
The collection of training sets, described previously, was applied to compare the performance of the algorithms. presents the algorithms performance in term of correctly classified instances over the 49 datasets. summarizes sensitivity and specificity. Similarly, summarizes the results associated with tree size and number of leaves for each classifier considered. We use the test accuracies from and run a Wilcoxon signed-rank test considering a level of significance equal to . shows the Wilcoxon test results of all used measures. We carried out all possible comparisons using the performance measures in . Finally, and contain all detailed results for training time.
Table 4. Comparisons of testing accuracy results of different DT algorithms.
Table 5. Comparisons of sensitivity and specificity results of different DT algorithms.
Table 6. Comparisons of tree complexity results of different DT algorithms.
Table 7. Comparisons of training time results of different DT algorithms.
Table 8. Wilcoxon’s signed rank tests of testing accuracies.
Table 9. Comparisons of testing accuracy results on artificial data.
Once the accuracy results are presented in the mentioned tables, we can point out that the algorithms that achieve the highest accuracy on different datasets are quite different. For about half of the datasets, the decision trees created by the proposed algorithm overcome the solutions of all other algorithms. Generally, VFC4.5 outperforms the other algorithms, it increase the average accuracy level compared to C4.5, CART, and VFDT by, respectively, 2.09%, 1.93%, and 4.78%. Notably, as the VFC4.5 algorithm generally yields the highest accuracy, it also produces the highest values for specificities, therefore, the smallest values for sensitivities as mentioned in . Investigating the impact of the type of attributes, we observe that VFC4.5 has higher accuracy when the datasets contain only continuous attributes (line 9, 22, 26, 30, 31, and 39 from ). In those cases, VFC4.5 outperforms all other algorithms. Besides, for mixed data, it is observed that VFC4.5 does not fail in all cases compared to C4.5, where results are quite similar. But clearly, CART has higher accuracy in those cases, independently of the number of classes (line 11, 16, 20, and 32 from ). Also, it is observed that VFC4.5 can perform best on binary-class datasets. It yields higher accuracy on 26 datasets compared to C4.5 results, it only fails to improve the performance on dataset . However, this statement does not hold for datasets with limited sample size, where VFDT outperforms the results of all other algorithms (line 15, 23, 25, 29 and 44 from ). in this setting, classes distribution has also an important impact on accuracy results. The proposed algorithm improves the C4.5 accuracy in class-imbalanced data with only few dominating classes (line 9, 22, 39 and 49 from ). However, in cases where there are many dominating classes, the CART algorithm yields the highest accuracy. To investigate the difference between the algorithms and validate the previous results, we ran a Paired Wilcoxon’s signed rank test. The results are reported in . It can be seen that there are no significant differences between C4.5, CART, and VFDT algorithms. However, all of them are statistically different from the VFC4.5 algorithm. Furthermore, to attest the effectiveness of the VFC4.5 algorithm we make a second Wilcoxon signed rank test, which gives significance even at
.
The VFC4.5 algorithm can also achieve reduction on the number of nodes, it outperforms the C4.5 results in 22 cases. In 20 datasets, the proposed algorithm improves both accuracy and tree size. But, the VFC4.5 creates more complex trees than CART and VFDT algorithms. This is explained by the higher accuracy achieved by the VFC4.5 algorithm.
and report the training time for real and artificial datasets. The results show that our algorithm performs faster than C4.5 in all cases. Compared to the VFDT results, the proposed algorithm fails to improve the training time in datasets with few examples. In contrast, for the datasets with high instances number (lines 4 and 5 from ) and features (lines 2, 17, and 33 from ), a significant time reduction has been achieved by using the VFC4.5 algorithm.
Conclusion
In this paper, we proposed a novel algorithm to speed up and improve the C4.5 algorithm performances. The results show that using mean and median as a threshold values can significantly speed up the process of binarization. But, also it improves the accuracy results. The results also show that for large number of training examples, VFC4.5 is faster than the VFDT algorithm and more accurate than C4.5. In contrast, experiments show that VFC4.5 fails in cases with few training examples and class imbalanced data with many dominating classes. For our future work, we plan to improve the VFC4.5 algorithm results on the two mentioned cases.
References
- Agrawal, G. L., and H. Gupta. 2013. Optimization of C4. 5 Decision Tree Algorithm for Data Mining Application. International Journal of Emerging Technology and Advanced Engineering 3 (3):341–45.
- Behera, H. S., and D. P. Mohapatra. Eds.., 2015. Computational Intelligence in Data Mining Volume 1: Proceedings of the International Conference on CIDM. 5-6 December 2015 Vol. 410. Springer.
- Breiman, L., J. Friedman, C. J. Stone, and R. A. Olshen. 1984. Classification and regression trees. CRC press.
- Chong, W. M., C. L. Goh, Y. T. Bau, and K. C. Lee. 2014. Advanced Applied Informatics (IIAIAAI), 2014 IIAI 3rd International Conference on, 930–35. IEEE.
- Dai, W., and W. Ji. 2014. A mapreduce implementation of C4. 5 Decision Tree Algorithm. International Journal of Database Theory and Application 7 (1):49–60.
- Garca Laencina, P. J., P. H. Abreu, M. H. Abreu, and N. Afonoso. 2015. Missing data imputation on the 5-year survival prediction of breast cancer patients with unknown discrete values. Computers in Biology and Medicine 59:125–33.
- Garcia, S., J. Luengo, J. A. Sez, V. Lopez, and F. Herrera. 2013. A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Transactions on Knowledge and Data Engineering 25 (4):734–50.
- Grzymala-Busse, J. W., and T. Mroczek 2015. A comparison of two approaches to discretization: Multiple scanning and C4. 5. In International Conference on Pattern Recognition and Machine Intelligence (pp. 44–53). Springer International Publishing.
- Hothorn, T., K. Hornik, and A. Zeileis. 2006. Unbiased recursive partitioning: A conditional inference framework. Journal of Computational and Graphical Statistics 15 (3):651–74.
- Hssina, B., A. Merbouha, H. Ezzikouri, and M. Erritali. 2014. A comparative study of decision tree ID3 and C4. 5. International Journal of Advanced Computer Science and Applications 4 (2).
- Ibarguren, I., J. M. Prez, and J. Muguerza 2015. CTCHAID: Extending the Application of the Consolidation Methodology. In Portuguese Conference on Artificial Intelligence (pp. 572–77). Springer International Publishing.
- Kass, G. V. 1980. An exploratory technique for investigating large quantities of categorical data. In Applied statistics, 119–27.
- Kotsiantis, S. B. 2013. Decision trees: A recent overview. Artificial Intelligence Review 39 (4):261–83.
- Lewis, M. 2012. Applied statistics for economists. Routledge.
- Lim, T. S., W. Y. Loh, and Y. S. Shih. 2000. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Machine Learning 40 (3):203–28.
- Liu, H., and A. Gegov. 2016. Induction of modular classification rules by information entropy based rule generation. In Innovative Issues in Intelligent Systems, 217–30. Springer International Publishing.
- Liu, H., and R. Setiono 1995. Chi2: Feature selection and discretization of numeric attributes. In Tools with artificial intelligence, proceedings., seventh international conference on (pp. 388–91). IEEE.
- Lu, Z., X. Wu, and J. C. Bongard. 2015. Active learning through adaptive heterogeneous ensembling. IEEE Transactions on Knowledge and Data Engineering 27 (2):368–81.
- Mu, Y., X. Liu, Z. Yang, and X. Liu. 2017. A parallel C4. 5 decision tree algorithm based on MapReduce. Concurrency and Computation. Practice and Experience 29:8.
- Ooi, S. Y., S. C. Tan, and W. P. Cheah. 2016. Temporal sampling forest: An ensemble temporal learner. In Soft Computing, 1–14.
- Pandya, R., and J. Pandya. 2015. C5.0 algorithm to improved decision tree with feature selection and reduced error pruning. International Journal of Computer Applications 117 (16).
- Patel, N., and D. Singh. 2015. An Algorithm to Construct Decision Tree for Machine Learning based on Similarity Factor. International Journal of Computer Applications 111:10.
- Perner, P. 2015. Decision tree induction methods and their application to big data. In Modeling and Processing for Next-Generation Big-Data Technologies (pp. 57–88). Springer International Publishing.
- Quinlan, J. R. 1986. Induction of decision trees. Machine Learning 1:81–106.
- Quinlan, J. R. 1996. Improved use of continuous attributes in C4. 5. Journal of Artificial Intelligence Research 4:77–90.
- Quinlan, J. R. 2014. C4. 5: Programs for machine learning. Elsevier.
- Reimann, C., P. Filzmoser, and R. G. Garrett. 2005. Background and threshold: Critical comparison of methods of determination. Science of the Total Environment 346 (1):1–16.
- Rubin, A. 2012. Statistics for evidence-based practice and evaluation. Cengage Learning.
- Saqib, F., A. Dutta, J. Plusquellic, P. Ortiz, and M. S. Pattichis. 2015. Pipelined decision tree classification accelerator implementation in FPGA (DT-CAIF). IEEE Transactions on Computers 64 (1):280–85.
- Sharma, J. K. 2012. Business statistics. Pearson Education India.
- Sugiyama, M., and K. M. Borgwardt. 2017. Significant Pattern Mining on Continuous Variables. arXiv preprint arXiv:1702.08694.
- Sumam, M. I., E. M. Sudheep, and A. Joseph. 2013. A Novel Decision Tree Algorithm for Numeric Datasets-C 4.5* Stat.
- UCI, UCI Machine Learning Repository, https://archive.ics.uci.edu/ml/datasets.html (2015).
- Wang, R., S. Kwong, X. Z. Wang, and Q. Jiang. 2015. Segment based decision tree induction with continuous valued attributes. IEEE Transactions on Cybernetics 45 (7):1262–75.
- Wilcoxon, F. 1992. Breakthroughs in Statistics. In Individual comparisons by ranking methods, 196–202. Springer New York.
- Witten, I. H., E. Frank, M. A. Hall, and C. J. Pal. 2016. Data Mining: Practical machine learning tools and techniques. Morgan Kaufmann.
- Wu, X., V. Kumar, J. R. Quinlan, J. Ghosh, Q. Yang, H. Motoda, … Z. H. Zhou. 2008. Top 10 algorithms in data mining. Knowledge and Information Systems 14 (1):1–37.
- Yang, Y., and W. Chen. 2016. Taiga: Performance optimization of the C4. 5 Decision Tree Construction Algorithm. Tsinghua Science and Technology 21 (4):415–25.
- Zhu, H., J. Zhai, S. Wang, and X. Wang. 2014. Monotonic decision tree for interval valued data. In International Conference on Machine Learning and Cybernetics, 231–40. Springer Berlin Heidelberg.