
ABSTRACT
In this research work, a fuzzy inference system (FIS) and an adaptive neuro-fuzzy inference system (ANFIS) were developed to classify apple total quality based on some fruit quality properties, i.e., fruit mass, flesh firmness, soluble solids content and skin color. The knowledge from experts was used to construct the FIS in order to be able to efficiently categorize the total quality. The historical data was used to construct an ANFIS model, which uses rules extracted from data to classify the apple total quality. The innovative points of this work are (i) a clear presentation of fruit quality after aggregating four quality parameters by developing a FIS, which is based on experts’ knowledge and next an ANFIS based on data, and (ii) the classification of apples based on the above quality parameters. The quality of apples was graded in five categories: excellent, good, medium, poor and very poor. The apples were also graded by agricultural experts. The FIS model was evaluated at the same orchard for data of three subsequent years (2005, 2006 and 2007) and it showed 83.54%, 92.73% and 96.36% respective average agreements with the results from the human expert, whereas the ANFIS provided a lower accuracy on prediction. The evaluation showed the superiority of the proposed expert-based approach using fuzzy sets and fuzzy logic.
Introduction
Apple (Malus x domestica Borkh.) is the fourth most important tree crop in Greece after olive, citrus and peach (Vasilakakis Citation2007). Apple quality is related to fruit maturity at harvest. Skin color, soluble solids content (SSC) and flesh firmness (FF) are the most important commonly used maturity indices for apple harvesting (Blankenship, Parker, and Unrath Citation1997; Marquina et al. Citation2004). Fruit quality is very important for the fruit market and is generally associated with climate (affected by the region and year) and soil conditions, tree characteristics and cultural practices and varies significantly due to all of the above (Kader Citation2002). High-quality fruits are sold at premium prices in the market offering better income to the farmer. Usually better quality with lower yield is better than the opposite in the handpicked fruits.
In this work, information/knowledge was collected for the most important quality parameters of apples at harvest time, namely fruit mass, FF, SSC and skin color. All these parameters are important for apple quality, and their combination gives a good estimation of the overall apple fruit quality. These four fruit quality parameters were studied in a commercial orchard for three consecutive years. It was decided to classify apples based on fruit mass, FF, SSC and skin color in five quality categories. The classification was performed using two intelligent methods, a fuzzy inference system (FIS), which is similar to expert systems, and a neuro-fuzzy inference system, which is a data-based system.
Rule-based expert systems were successfully applied for classification purposes in various application fields such as fault detection, biology and medicine (Huang et al. Citation2010). Fuzzy logic (FL) can improve such classifications and decision support systems by using fuzzy sets to define overlapping class definitions. Fuzzy set theory is an extension of conventional set theory that deals with the concept of partial truth (Zadeh Citation1975). FL aims to model the vagueness and ambiguity in complex systems (Zadeh Citation1976). Fuzzy set theory and FL provide powerful tools to represent and process human knowledge in the form of fuzzy IF-THEN rules. The application of fuzzy IF-THEN rules also improves the interpretability of the results and provides more insight into the classifier structure and decision-making process (Abraham Citation2005, Azeem Citation2012). The linguistic relationships are the main aspect in fuzzy systems for knowledge representation, thus they are usually applied to decision support systems (Turksen 2006).
FIS can provide insights into management behavior in complex systems as in agriculture. Imperfect information, uncertainty and other issues create conditions where expert knowledge is needed and which fuzzy systems can imitate (Papageorgiou et al. Citation2009). Fuzzy inference methods have found large applicability in agriculture in the recent years (Center and Verma Citation1998). Simonton (Citation1993) used FL to classify for plant structure analysis. Chen and Roger (Citation1994) evaluated cabbage seedling quality by FL, with good agreement between the results from fuzzy prediction and human experts. Shahin, Verma, and Tollner (Citation2000) developed a FL model for predicting peanut maturity. Fitz-Rodríguez and Giacomelli (Citation2009) used FL for growth mode characterization of greenhouse tomato plants. In the application area of quality grading, Lorestani et al. (Citation2006) and Kavdir and Guyer (Citation2003) used FL to grade apples with good results. In precision agriculture, there are applications of FL for site-specific application of inputs (Ambuel, Colvin, and Karlen Citation1994; Tremblay et al. Citation2010; Yang et al. Citation2000), quality prediction (Grelier et al. Citation2007) and grading (Mazloumzadeh, Shamsi, and Nezamabadi-Pour Citation2010 Papageorgiou et al. Citation2011a; Papageorgiou et al. Citation2011b; Papageorgiou et al. Citation2013).
The objective of this paper was to classify apples based on the four selected fruit quality parameters, fruit mass, FF, skin color and SSC using FL capabilities of handling inherent uncertainty. The above objective was investigated through the development of a FIS, which consists of simple and interpretable IF-THEN rules. In this research work, the proposed FIS was constructed by experts’ knowledge and then it was evaluated by a team of agricultural experts to show its prediction capabilities. Furthermore, we developed a new FIS constructed only by the available historical data using the adaptive neuro-fuzzy inference system (ANFIS). The proposed FIS was compared with the neuro-fuzzy method of ANFIS, which was constructed and formulated by the same data set.
For constructing a FIS from the available data, we selected the ANFIS method due to its efficiency in decision-making, classification and rule extraction. The ANFIS is a combination of adaptive neural networks and fuzzy systems that uses the learning capability of the neural network to derive the fuzzy IF-THEN rules with appropriate membership functions worked out from the training pairs, which in turn leads to the inference (Jang Citation1993b) and (Js R and Sun Citation1997). ANFIS has found great applicability in various agricultural studies. We report some recent studies of ANFIS application in agriculture. Akbarzadeh et al. (Citation2009) developed an ANFIS model for soil erosion estimation. Al-Gaadi, Aboukarima, and Sayedahmed (Citation2011) investigated the ANFIS exploitation on classifying the different combinations of sprayer boom height and nozzle flow rate and outputting the optimum combination that would deliver the best spray distribution uniformity. Naderloo et al. (Citation2012) applied the ANFIS methodology to predict crop yield based on different energy inputs, whereas at the same year, Krueger and his research team (2012) proposed an ANFIS model to characterize root distribution patterns under field conditions and an evaluation was accomplished. Recently, Khoshnevisan and his colleagues used ANFIS in two different applications on developing an intelligent system for predicting wheat grain yield on the basis of energy inputs (Khoshnevisan et al. Citation2014a) and on estimating the greenhouse strawberry yield (Khoshnevisan, Rafiee, and Mousazadeh Citation2014b).
For comparison purposes, the developed FIS and neuro-fuzzy (ANFIS) models were implemented in the same data sets of the three years. Both systems were evaluated for their effectiveness to classify apple quality by the same experts (which are different from the experts used for the initial FIS construction). Through the conducted experiments, the FIS constructed by experts is mainly efficient in the cases including uncertainty where small sets of data are available for decision-making. Usually the data-based approaches need large data sets to provide more accurate decisions even the uncertainty is present.
The remainder of this research is organized as follows. Section “Materials and methods” contains the description on materials and methods (FL, FIS and ANFIS). In section “Development of FIS for apple fruit total quality,” we present the development of FIS for apple fruit total quality, and in section “Development of ANFIS for grading apple quality,” we describe the development of ANFIS for grading apple quality. Experimental results of our analysis are given in section 5 “Results and discussion,” providing also a discussion on them. The results provided by the FIS regarding the quality of apples after defuzzification were evaluated by a team of experts and next were compared with the results produced by ANFIS model. Finally, we conclude the paper and discuss our future work in section “Conclusions.”
Materials and methods
Site description and measurements
The present study was carried out in central Greece, Agia area (22°35′ 33′′ E, 39° 40′ 28′′ N) in a 5 ha apple commercial orchard for the years 2005, 2006 and 2007. The following apple quality parameters were measured: fruit mass, FF, SSC and skin color (hue angle). Apple quality was measured in 55 locations of the field. The geographical position of these locations was recorded using a hand-held computer with GPS (Trimble Pathfinder) in order to create the quality maps. The methodology of data collection is presented in more detail in Aggelopoulou et al. (Citation2013).
These four quality parameters, i.e., fruit mass, skin color (hue angle), FF and SSC, were used as input variables in the developed FIS, described below. The output from this analysis, which represents the apple quality, was used to produce the total quality map in Surfer software.
The apples were graded first by a human expert and then by the constructed FIS and ANFIS. The expert was trained on the external quality criteria defined by the United States Department of Agriculture (USDA) standards (United States Standards for Grades of Apples Citation2002). The USDA standards for apple quality explicitly define the quality criteria so that it is quite straightforward for an expert to follow up and apply them.
Methods
Fuzzy logic
In recent years, the need for solutions to problems which are based on human perceptions and where there is not enough information to use traditional mathematical models, like in the area of precision agriculture, has forced the research to an alternative model using FL (Mazloumzadeh, Shamsi, and Nezamabadi-Pour Citation2010). FL, originally developed by Zadeh (Citation1965), has been proven to be a powerful tool to make decisions in complex systems because it introduces a different process of decision-making which is more human-like.
FL is a form of many-valued logic dealing with reasoning that is approximate rather than fixed and exact. Compared to traditional binary sets, FL variables may have a truth value that ranges in degree between 0 and 1. FL has been extended to handle the concept of partial truth, where the truth value may range between completely true and completely false. Furthermore, when linguistic variables are used, these degrees may be managed by specific functions (Jang et al. Citation1997, Azeem Citation2012).
FL has been commonly used for analyzing imprecise information in a non-probabilistic sense and allows integration of information from various parameters into the modeling process. More specific, FL can be used for mapping inputs to appropriate outputs. The main FL aspect is the concept of fuzzy sets describing imprecision or vagueness (Dubois and Prade Citation2000).
In FL theory, a subject can belong to one or more fuzzy set(s) with a gradation of membership. The degree of membership is defined by fuzzy membership functions. The mathematical definition of a fuzzy set F is a membership function μF(x) that associates any value x of the variable X to a membership grade between 0 and 1 (0 ≤ μF(x) ≤1). The membership function represents the degree, or weighting, that the specified value belongs to the set. Common membership functions are triangular, trapezoidal, Gaussian, sigmoid, and Bell’s generalized (Jang et al. Citation1997). These are chosen in such a way that a correct mapping between input and output spaces is achieved (Wang Citation1992).
The human experience and human decision-making behavior is modeled efficiently with the use of FL. The linguistic rules or relational expressions are used to express the input–output relationship, which is an important issue in modeling with FL.
Fuzzy inference system
The mapping from a given input to an output using FL is called fuzzy inference (Adriaenssens et al. Citation2004). Three important concepts comprise the fuzzy inference process: membership functions, fuzzy set operations and inference rules.
Unclear data and ambiguous efficiently are able to represent from the FIS (Azeem Citation2012; Jang, Sun, and Mizutani Citation1997; Kasabov Citation1998). It defines a nonlinear matching between one or more input variables and one output variable. Generally, it includes three stages: fuzzification, inference and defuzzification, which means the determination of a nonlinear matching between one or more input variables with one output variable.
As shown in , FIS basically consists of four important parts including a fuzzifier, a defuzzifier, an inference engine and a rule base. As in many fuzzy applications, the input data are usually crisp, so a fuzzification is necessary to convert the crisp input data into a suitable set of linguistic value, which is needed by the inference engine. In the rule base of FIS, a set of fuzzy rules, which characterize the dynamic behavior of the system, are defined. The inference engine is used to form inferences and draw conclusions from the fuzzy rules. The output of the inference engine is sent to the defuzzification unit. Defuzzification is a mapping from a space of fuzzy actions into a space of crisp actions.
Figure 1. General structure of a fuzzy inference system (Tagarakis et al. Citation2014).
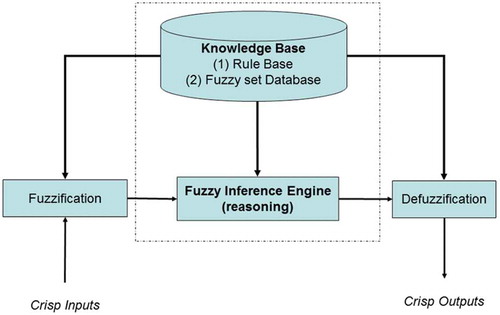
The fuzzifier transforms the “crisp” inputs into fuzzy inputs by membership functions that represent fuzzy sets of input vectors. The segment knowledge base contains the experts’ information in the form of linguistic fuzzy rules. The inference system (or else the inference engine) uses them together with the knowledge base for inference by a method of reasoning and the last segment is a defuzzifier, which transforms the fuzzy results of the inference into a crisp output using a defuzzification method (Heske and Heske Citation1996).
Inputs and output, in the fuzzification step, are determined as fuzzy sets and indicated with their membership functions. A fuzzy set is a set in which objects can belong to different degrees, called degrees of membership, which the confidence that the member belongs to the fuzzy set as a number is measured, ranging from 0 (completely false) to 1 (completely true). In other words, the fuzzy sets are extracted from the experts’ knowledge which these sets are distributed through the range of possible values that the variable can take (Dubois and Prade Citation2000).
Two parts comprise the knowledge base: the database, which defines the membership functions of the fuzzy sets used in the fuzzy rules, and the rule base, which consists of a collection of linguistic IF-THEN rules that are joined by a specific operator. Experts, in most cases, choose the membership functions and the fuzzy rules.
In FIS, the relation between the input variable(s) and the output variable(s) is represented by means of fuzzy IF-THEN rules of the following general form:
where A1, A2,…, Ak and B are fuzzy sets of the variables X1, X2,…, Xk and Y. This process is known as monotonic selection in which the right part of the rule (X1 is A1 and …) is called “antecedent proposition” and the left side (Y is B) is called “consequent proposition.”
An IF-THEN rule interpretation has the same meaning as in programming language that involves two steps: the evaluation of the “antecedent” (the membership degrees of the sets in the activated rules) through the use of a fuzzy operator is the first one, and the evaluation of the “consequent” as a result of the satisfaction degree of the antecedent is the second one. The basic composition operations for fuzzy sets are (Kasabov Citation1998) union, intersection, complement, Cartesian product and Cartesian co-product. These operations are used thanks to the application of some binary operator classified as T-norms (intersection operations) and S-norms (union operations).
The fuzzy output is determined by the degrees of fulfillment and the consequent parts of the rules. The output variable is “defuzzified” to produce quantifiable results (a numeric value) with no references to fuzzy sets theory (Dubois and Prade Citation2000; Prato Citation2005).
The satisfaction degrees and consequent parts of the fuzzy rules determine the output of the system. The variable output “defuzzified” produces measurable results (a numerical value), without references to fuzzy set theory (Dubois and Prade Citation2000; Prato Citation2005).
There are two ways to gather the IF-THEN rules: from experts’ knowledge through interviews and from a database of the input–output history using data mining and knowledge extraction techniques. In the first way, one or more experts are used to construct the FIS, where the experts determine the membership functions and fuzzy rules, and in the second way, data are to construct the FIS, which lighten the problem of knowledge elicitation.
The data are analyzed with the best possible accuracy using various techniques (Roubos Citation2003; Zurada and Lozowski Citation1996). Two neuro-fuzzy approaches like ANFIS, (Jang and Sun Citation1993) and NEFCLASS (Nauck and Kruse Citation1995) are the most common approaches for constructing a FIS based on available data, where a number of rules can be induced by data, and evolutionary algorithms that adapt the parameters of the membership functions during the learning process from input to output data for a priori rules (Kurgan and Musilek Citation2006). Nevertheless, in ANFIS and NEFCLASS approaches, there is a need for large data set for training to produce effective rules, thus making efficient decisions with small classification errors and usually they produce a relatively large set of IF-THEN rules that domain experts are finding difficult to manage them.
In this paper, the ANFIS technique was exploited to extract rules from data, thus constructing a FIS based on the available data. Due to small number of input and output variables, the ANFIS method is thought to be the most popular for fuzzy rule extraction because of its power on modeling complex nonlinear systems and its effectiveness (Naderloo et al. Citation2012).
ANFIS
Adaptive neural networks were handled by ANFIS system to develop a FIS (Jang and Sun Citation1993, Citation1995). This system is based on Sugeno-type system for the simulation and analysis of the mapping relationship between the input and output data through the back learning multiplication process. The learning process is used to determine the optimal distribution of membership function (Jang Citation1993b) based on the fuzzy “IF-THEN” rules from the Takagi and Sugeno (TS) type (Takagi and Sugeno Citation1985).
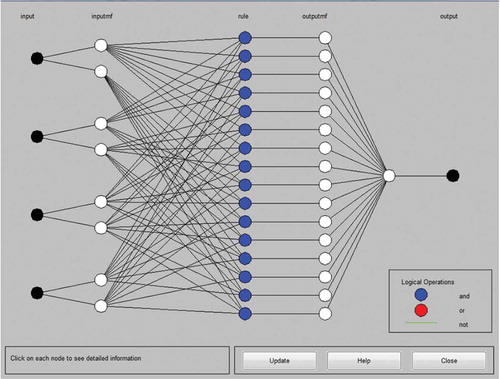
Five layers are included to construct a typical ANFIS system of the TS type, which can be seen in . These five network layers are used to perform the following fuzzy inference steps (Khoshnevisan, Rafiee, and Mousazadeh Citation2014b):
Figure 2. Adaptive neuro-fuzzy inference system structure (Khoshnevisan et al. Citation2014a).
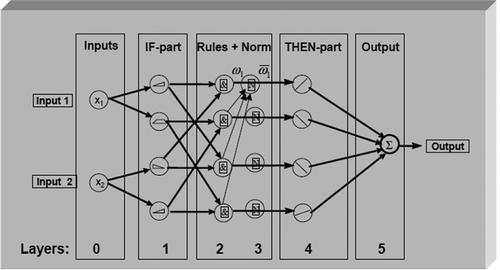
Layer 1: input fuzzification
Layer 2: fuzzy set database construction
Layer 3: fuzzy rule base construction
Layer 4: decision-making
Layer 5: output defuzzification
In layer 1, every node i is an adaptive node with a node function, given in Equation (1):
where x indicates the input to node i, Ai represents the linguistic label associated with this node function and O1i is the membership function of Ai that specifies the degree to which the given x satisfies Ai. As regards the input y, the node functions have exactly the same behavior with the function family as x, with the condition that they belong to the same layer. The most common MFs encompass triangular and bell-shaped. Bell-shaped membership function (MF) with a maximum equal to 1 and a minimum equal to 0 are calculated as follows:
In layer 2, every node is a fixed node and acts as a simple multiplier. The outputs of these nodes are given by Equation (3):
which are the so-called firing strengths of the rules.
Every node in layer 3 is an adaptive node indicated as N. The ith node calculates the ratio of the ith rule’s firing strength to the sum of all rules’ firing strengths. Equation (4) obtains the output of this layer:
Each node in layer 4 is an adaptive node with a function given by Equation (5):
where is the output of layer 3, and {pi, qi, ri} are referred to as consequent parameters.
The single node in layer 5 is a fixed node indicated as ∑ (sum), which computes the overall output as the sum of all incoming inputs, i.e., Equation (6):
Jang and Sun (Citation1997) explained the functions of these layers. The TS model defines the number of rules that come from a product of the number of membership functions in each input. In that layer, the output, after the handling by the node function, will provide the input data for the next layer (Khoshnevisan et al. Citation2014a).
Development of FIS for apple fruit total quality
The fuzzification is the first step in the construction process of FIS, and during this, the variables used to describe the decision process of apple fruit quality assessment are described and analyzed. Four inputs and one output were used to evaluate and classify apple fruit quality. The inputs were FF, fruit mass, SSC and skin color (hue angle) expressed at a number of quality levels, according to the experts’ suggestions. The four quality parameters were defined as fuzzy sets and membership functions were assigned to them (). shows the output total quality.
Figure 3 (a) Membership functions of “flesh firmness”; (b) membership functions of “fruit mass”; (c) membership functions of “SSC”; (d) membership functions of “hue angle.”
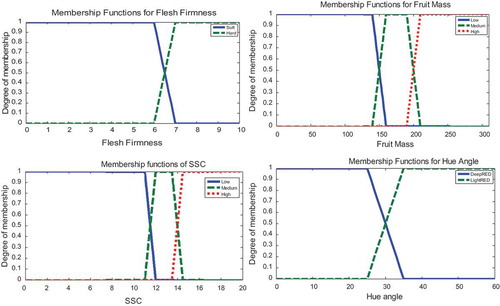
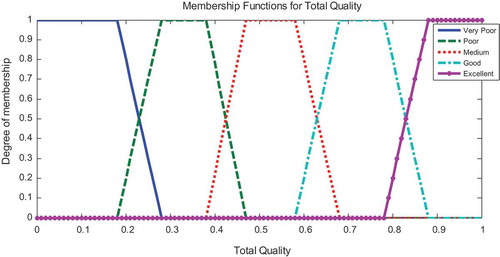
Figure 4. Membership functions of apple fruit total quality.
The knowledge base for apple variables contains both static and dynamic information. There are qualitative and quantitative variables, which must be fuzzified, inferred and defuzzified following the steps described in a previous section.
Variable description
The variables selected as inputs by experts as the most commonly used and measured for apple fruit quality were fruit mass, FF, SSC and the parameter hue for skin color. Fruit mass expresses the fruit size and, based on the European Union regulation (EU Regulation 543/2011 normalized for Red Delicious clones) and market requirements, three quality levels for fruit mass were used: low, medium and high (see ). These quality levels were determined from expert knowledge. SSC is related to organoleptic quality and, in particular for Red Delicious clones, to sweetness, as acidity is generally low. FF expresses the crispiness of the fruit flesh. Based on commercial studies with locally produced apples from Red Delicious clones (including Red Chief, the clone studied in this paper) and informal consumer acceptance tests, three quality levels for SSC (low, medium, high) and two quality levels for FF (soft and hard) were used (G.D. Nanos, unpublished data). The quality levels for SSC and FF are presented in . Finally, for the red apple cultivars like Red Chief, skin color is the most important external quality parameter for the market as consumers prefer apples with deep red skin color. The hue angle index represents clearly the red skin color intensity (McGuire Citation1992) and two quality levels were used in our study: light red and deep red ().
Table 1. Quality levels of input variables.
The variable defined as output is the apple fruit total quality. The experts were assigned five categories of total quality: very poor, poor, medium, good and excellent.
Determination of membership functions
There are two different ways to define fuzzy sets: the first one defines linguistic values based on variable behavior (through historical data where it is possible to determine the number and the shape of the sets); the second one defines linguistic values based on experts’ knowledge into a range between 0 and 1. It is worth mentioning that fuzzy membership functions of each class have an overlap with neighboring classes.
The shape of the membership function can have different forms, such as triangular, trapezoidal, Gaussian, sigmoid, etc. Triangular and trapezoidal functions were used for membership functions here as they are simple and commonly used (Heske and Heske Citation1996). In this section, the fuzzy sets for each variable of the model are defined with a brief interpretation of experts’ knowledge.
In , the classes “soft” FF (0–7) and “hard” FF (6–10) refer to soft and hard fruit, respectively. The classes “low” (0–160), “medium” (140–210) and “high” (>195) in fruit mass refer also to low, medium and high apple fruit mass, respectively (). The classes “low” (<11.5), “medium” (11.5–14) and “high” (>14) SSC refer to low, medium and high fruit SSC, respectively (). Finally, the classes “deep red” (<30) and “light red” (>30) refer to deep red and light red apple skin color, respectively ().
The boundaries of the membership functions for the output (fruit total quality) of the proposed FIS were chosen by trial and error and were determined at five quality levels: grade 1 (0–0.3), grade 2 (0.15–0.45), grade 3 (0.3–0.7), grade 4 (0.55–0.85) and grade 5 (0.7–1). These levels refer to very poor, poor, medium, good and excellent apple fruit total quality, respectively ().
In our case, we chose to describe the quality level of apples with a numerical continuous index (from 0 to 1) using fuzzy sets to define a relation between this numerical index and the expert linguistic terms.
Determination of fuzzy rule base
The knowledge from experts is used to determine the rule base of the proposed FIS. The experts were asked to summarize knowledge about the system in the form of IF-THEN rules. These rules are given in . The FIS used here had 36 rules based on the membership functions considered for inputs.
Table 2. Developed fuzzy rules.
An example of rule definition is: IF hue is “light red,” fruit mass is “medium,” SSC is “Low” and fruit firmness is “Soft,” THEN fruit total quality is “Q2 (low).”
The Sugeno and Mamdani types are the most known types of FISs and can be implemented in the Fuzzy Logic Toolbox of MATLAB. This toolbox is the most commonly used and was selected to construct FIS and next to evaluate and classify the data on apple to produce the apple total quality maps (ATQM).
The proposed FIS was initially constructed by experts’ knowledge and then it was evaluated by experts for the 3-year data set (Burhan Turken Citation2006; Grelier et al. Citation2007; Prato Citation2005). Next, ANFIS was implemented to extract fuzzy rules, producing a FIS from available data, which was evaluated for the same data set.
The information from experts is used to construct the FIS, whereas the rule-based knowledge extraction from data is used to develop a FIS, to assess the apple fruit total quality. Both FIS and ANFIS, which are expert- and data-based, respectively, evaluated for their effectiveness in classifying apple fruit quality.
Aggregation and defuzzification
In order to derive conclusions based on the fuzzy rules set and on the input data, the composition relation MAX–MIN was used. It means that each rule is evaluated with the MIN operator (the minimum membership value of the antecedent’s parts is chosen). Later, the outputs of each rule are mixed to obtain a single fuzzy set through the MAX operator (the resulting fuzzy sets of each activated rule are summed).
The defuzzification interface is a mapping from a space of fuzzy actions defined over an output universe of discourse into a space of non-fuzzy actions. The average and center of gravity (CoG) techniques are used to defuzzify, and their results are compared. CoG is computed from the following function:
where Nq is the number of quantization used to discretize membership function of the fuzzy output
. The fuzzy output is determined by the function
The CENTROID method of defuzzification was used to convert the fuzzy output set to a crisp number (Tagarakis et al. Citation2014). In this, the crisp value of the output variable is computed by finding the variable value of the CoG of the membership function for the fuzzy set. In FIS, we used the Mamdani-type rule base, with MIN implication method and MAX aggregation method, and with the CENTROID method of defuzzification (Kasabov Citation1998).
Model’s validation
The research experiment was conducted using MATLAB 2011 Fuzzy Logic Toolbox for the development of the FIS and ANFIS implemented for the 3-year data set. To experimentally analyze the proposed systems, data from three subsequent years 2005, 2006 and 2007, at the same orchard and same input variables, were used.
In order to evaluate the proposed FIS approach, a team of experts was used (which is different from the experts used for the initial FIS construction) and the agreement of evaluation was presented in the respective columns. Also the overall accuracy of agreement was calculated. Concerning the accuracy of the agreement, we mean how many cases were predicted correctly regarding the quality of yield as initially defined.
As the proposed approach is an expert-based, there is no reason to divide the data into training and testing sets as usually happens in machine learning algorithms where only numerical data are available for classification.
Furthermore, for comparison purposes, we explored a neuro-fuzzy approach, the ANFIS, which is a data-based rule extraction method. Through the literature there are many machine learning methods used for classification tasks; however, as the scope of our study is not devoted to investigate machine learning algorithms, we selected the most popular ones like decision trees, neural networks, Bayesian nets and decision rules.
Development of ANFIS for grading apple quality
According to Jang and Sun (Citation1995), Citation1997), the most well-known rule induction method is the ANFIS algorithm, which is used to extract rules from data for decision-making and prediction tasks. To the best of our knowledge, there is not any previous work for grading apple quality in precision agriculture that creates a FIS from experts’ knowledge and compare it with a FIS constructed from available data using this neuro-fuzzy approach.
ANFIS model has a main restriction that is related to the number of input variables. If the inputs of ANFIS increase more than five, then the IF-THEN rules numbers and the computational time will also increase and ANFIS will not be able to model output with respect to inputs. In this study, the number of yield quality inputs was four, including fruit firmness, fruit mass, SSC and hue.
The evaluation of some main ANFIS architectures is critical for the development of that model based on historical data for predicting the apple quality and for its development. For the ANFIS’s structure and formulation was used the same data set collected from the previous years in which the first two years were used for learning and the last year for testing (2007).
It is a crucial issue to find the most effective architecture of ANFIS model. To achieve this, we concentrate on the increment of the accuracy of the network and decrement of the errors using five necessary modifications. These settings include the number of membership functions, types of MFs (triangular, trapezoidal, bell-shaped, Gaussian and sigmoid), types of output MFs (constant or linear), optimization methods (hybrid or back propagation) and the number of epochs (Naderloo et al. Citation2012). MATLAB M-file environment version 7.14.0.739 (R2012a) was used to program ANFIS networks and develop ANFIS models.
Two important parts are useful to design the neuro-fuzzy model: the fuzzy input and output variables with their membership functions. The trial-and-error approach was used to the input variables to assign the number and type of the membership functions. MATLAB’s ANFIS editor offers different types of MFs including triangular, trapezoidal, generalized bell (Gbell), Gaussian curve, Gaussian combination, difference between two sigmoid functions and product of two sigmoid functions. represents the best results from all these MFs, which were evaluated and eventually Gbell MF. The hybrid learning method was applied because this algorithm uses back propagation for parameter associated with input MF and least-square estimation for parameters associated with output MF (MathWork Citation2012). Two hundred epochs were used to train the models.
Table 3. The characteristics of the best structure of ANFIS.
In , the results of the total number of parameters for different ANFIS are gathered. The total number of parameters for ANFIS 1 and 3 was 104, for ANFIS 2, 5 and 6 was 112, whereas for ANFIS 4 was 96, which show that the number of MFs for inputs was selected appropriately for ANFIS 1 and 3. It is also very important to choose the number of MFs for input variables that evaluate the total number of parameters in the model that should be greater than the number of training data pairs.
Table 4. ANFIS information for the different architectures.
It is observed that the best results are extracting from the combination of Gbell and linear MFs for input and output layers, respectively, rather than the application of other combinations. Because of the limitation of the total number of parameters that should not be kept greater than the number of training data pairs, the number of MFs was chosen based on the number of input parameters. As illustrated in , ANFIS models included four input parameters, the number of MFs was selected to be 2-2-2-2, with Gbell MFs and correspondingly the total number of parameters was computed as 104.
Figure 5. The topology of the ANFIS model to predict apple yield quality.
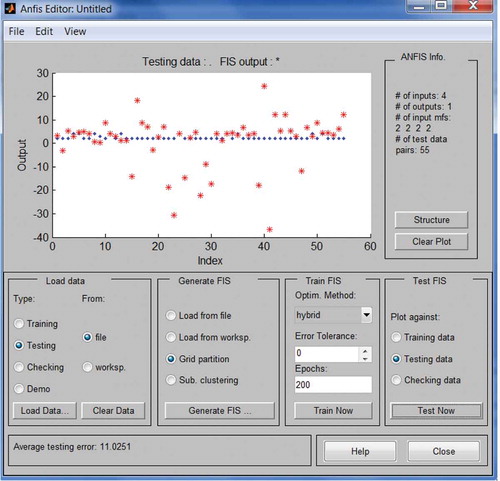
During the learning procedure, an acceptable ANFIS model, which means to produce better output closer to the target, must calculate the root mean square error (RMSE). In every step of the algorithm, a series of actions are achieved such as the calculation of the output value, then the comparison with the actual value. According to the obtained error (i.e., RMSE), the determination of the correction weights and bias network is achieved. After the phase of ANFIS development, the testing phase is accomplished considering the RMSE.
As can be seen in , the average testing error, which is the RMSE (Khoshnevisan et al. Citation2014a,b) for the selected best ANFIS configuration, for the year 2007 is 11.025. The average testing error was used as the performance measure of ANFIS implementation to estimate the average classification accuracy.
Figure 6. Snapshot of the testing data using ANFIS-Gbell MF.
Results and discussion
In , the descriptive statistics of the apple quality properties for the three years of the experiment are presented. An important part of FIS construction is to check that the obtained outputs match the experts’ knowledge. This means that the system must respond in an appropriate way to the different conditions that can be presented.
Table 5. Descriptive statistics of the apple quality properties for the three years of the experiment (from Aggelopoulou et al, Citation2013).
Evaluation of FIS model
The proposed FIS was exploited for grading apples using gathered data of three subsequent years (Prato Citation2005; Burhan Turken Citation2006; Grelier et al. Citation2007). The developed fuzzy expert system was evaluated for 3 years (Prato Citation2005; Burhan Turken Citation2006; Grelier et al. Citation2007) at the same orchard and same input variables. The fruit total quality in each orchard point was assessed by the expert trained on the external quality criteria for apple defined by the USDA standards (United States Standards for Grades of Apples Citation2002). Thus for each case, the total quality was used as gold standard for the system evaluation.
An evaluation analysis was conducted on the experts and the developed FIS for the three subsequent years. The evaluation results are depicted in – for every year. The average accuracy means the mean error of the initial values (the difference in the predicted and the initial values of fruit quality) produced by FIS is 83.64% for 2005, 92.73% for 2006 and 96.36% for 2007. The average accuracy for the three respective years is 90.91% (see ).
Table 6. Evaluation results of the FIS and apple experts for the 55 cells of the apple orchard in 2005; apple quality variables: fruit firmness (FF, kgf), soluble solid acidity (SSC, %), fruit mass (FM, g) and hue (HUE, °).
Table 7. Evaluation results of the FIS and apple experts for the 55 cells of the apple orchard in 2006; apple quality variables: fruit firmness (FF, kgf), soluble solid acidity (SSC, %), fruit mass (FM, g) and hue (HUE, °).
Table 8. Evaluation results of the FIS and apple experts for the 55 cells of the apple orchard in 2007; apple quality variables: fruit firmness (FF, kgf), soluble solid acidity (SSC, %), fruit mass (FM, g) and hue (HUE, °).
Table 9. Evaluation results of the FIS and experts.
Evaluation of ANFIS model
A number of experiments were conducting for selecting the best ANFIS architecture according to the less average testing error. As shown in , the best configuration find was Gbell membership functions for input nodes and a linear output. After 200 epochs, the model adapted the parameters of the membership functions by hybrid learning using the ANFIS function of the MATLAB Fuzzy Logic Toolbox, with a training error of 0.1924. MATLAB M-file environment version 7.14.0.739 (R2012a) was used to program ANFIS networks. The ANFIS implementation in our case study of continuous values showed that the average testing error was 11.02, which means that the provided accuracy is lower than that calculated from FIS. The average accuracy of ANFIS for prediction was estimated to be 88.98%.
Comparison between FIS and ANFIS models
The results of the proposed FIS were compared with the results produced by the data-based knowledge extraction method of ANFIS using the same data set. The performance of both methods was based on the average classification accuracy provided after testing for the year 2007. Making the comparison between the gained results from FIS and ANFIS models revealed that FIS model was able to forecast yield quality on the basis of four input yield quality measures with higher classification accuracy. The advantage of FIS is that it can use imprecise data as well as small data especially for agricultural systems providing efficient decision support. The evaluation shows the superiority of the proposed FIS approach, where the main advantages are its simplicity in structure and the interpretability of IF-THEN rules, as well as its efficiency when the data set is small, where the statistical, neural and neuro-fuzzy approaches have limitations. ANFIS is also not able to work efficiently in the case when the data set is small; this is also one of the main limitations in machine learning algorithms.
Moreover, ANFIS only supports Sugeno-type systems and these must have a number of properties reported in (MathWork Citation2012). The main restriction of the ANFIS model is related to the number of input variables. If ANFIS inputs exceed five, the computational time and rule numbers will increase, so ANFIS will not be able to model output with respect to inputs.
Comparison between FIS and other machine learning methods
Furthermore, the results of this study were compared with results of some popular machine learning methods investigated in the same prediction problem and at the same data set. Waikato Environment for Knowledge Analysis (WEKA) toolbox (WEKA, Citation2005) was used to test the available data set for prediction/classification of yield quality. The following algorithms implemented in WEKA have been used: decision trees, Bayesian Net, Naive Bayes algorithm, decision rules JRip, Decision Table, Ibk, multilayer perceptron and LibSVM.
Considering the decision trees, the J48 algorithm and the consolidated J48, an implementation of C4.5 release 8 (Quinlan, Citation1983) was used to extract rules from the available data set and test data categorizing quality into five categories. For the Bayesian networks, the Bayes Net and the Naive Bayes classifier were implemented to categorize the apple quality into five categories. The back-propagation algorithm for a multilayer perceptron was also used to categorize the yield data to five output nodes. The multilayer perceptron used in our case study has nine input nodes, one hidden layer and five output nodes (describe each decision). Moreover, the Rules JRip and the Decision Table were implemented in the same data set for categorizing apple quality (Witten & Frank, Citation2000).
The 10-fold cross-validation procedure was implemented in all examined approaches, thus the data set of the 56 entries is randomly divided into 10 subsets. The results are gathered in .
Table 10. Estimated classification accuracy of machine learning methods.
Machine learning algorithms usually need large data sets for training to provide accurate classification, and most of them do not produce accurate rules for prediction. These methods seem not to be able to perform efficiently due to the small data set provided for this case study. In this case, problems are difficult to collect more data to assess the quality of yield; thus the expert-based methods are preferred.
Moreover, it is difficult to accurately calculate the various standard statistical performance evaluation criteria (Mean square error (MSE), Mean absolute error (MAE), Mean absolute percentage error (MAPE)) for prediction tasks in the case of FIS due to FIS structure as a knowledge-based system and qualitative nature of predicted values. FIS is able to calculate a quantitative value in the range (0,1), which is translated to a fuzzy quality value to specify the quality of the yield. This fuzzy quality value is compared with the fuzzy value determined by the group of experts. It is not possible to provide a straightforward comparison between numerical values from FIS and experts.
In previous studies, apples were classified with recognition accuracies of 86.1% and 85.9% using Fisher’s linear classifier and Boltzmann’s perceptron network classifier, respectively, based on skin color features (Kavdir and Guyer Citation2003). The authors suggested that the low accuracy rate could be due to the variations in the visual properties of apples. In another study, Golden Delicious apple grading was succeeded in 90.8% (Lorestani et al. Citation2006), but the available data was not enough to confirm this result.
It is concluded based on the overall accuracy of each method that the FIS constructed by experts outperformed regarding the classification accuracy when compared with the FIS constructed by the available historical data. The proposed FIS is able to estimate yield with reasonably high overall accuracy, sufficient for this specific application area. After evaluation, the proposed FIS can be used as a knowledge-based tool in agriculture for grading apple quality.
Conclusions
In this work, a FIS was developed to classify apple total quality based on the four most important quality parameters of apples as defined by experts: fruit mass, FF, SSC and skin color. The innovative point of this work is the development of FIS by experts’ knowledge and its comparison with a FIS constructed from the available data (ANFIS) using knowledge extracted from data in the forms of rules expressed in FL. Based on the proposed FIS, apple quality was graded as excellent, good, medium, poor and very poor. The apples were also graded by an expert. The system was evaluated at the same orchard with 3-years data, and it showed 91% general agreement with the results from the human expert, indicating that it is a feasible method for classifying apples based on quality.
The proposed FIS, which is expert-based, can work with nonlinear functions of wide complexity, it is not attached to statistical presumptions about data features, it is easy to modify and it is highly flexible and tolerant to inaccuracies. It can work efficiently in the cases where qualitative knowledge and quantitative data are both available. It seems efficient especially in the cases where there is not enough information to use traditional mathematical models.
Furthermore, the ANFIS method was selected for fuzzy rule extraction as thought to be the most popular of the neuro-fuzzy systems for the knowledge extraction from data. The results provided show that the proposed FIS gives better results regarding the accuracy of the correctly predicted yield categories. Through the conducted experiments, the FIS constructed by experts is mainly efficient in the cases where expert knowledge and small sets of data are available for decision-making.
Future work is directed towards the construction of powerful FISs that will be able to enhance the knowledge base of rules extracted from data and cope with different types of knowledge efficiently.
Acknowledgments
We would like to express our gratitude to the experts G.D. Nanos, Professor of Pomology in the University of Thessaly, and I. Boutla, horticultural consultant in the cooperative of Zagora, for helping us to determine the rule base of the proposed FIS.
Additional information
Funding
References
- Abraham, A. 2005. Adaptation of Fuzzy Inference System Using Neural Learning. Studies Fuzziness 181:53–83.
- Adriaenssens, V., B. De Baets, P. L. M. Goethals, and N. De Pauw. 2004. Fuzzy rule-based models for decision support in ecosystem management. Science of the Total Environment 319:1–12. doi:10.1016/S0048-9697(03)00433-9.
- Aggelopooulou, K., A. Castrignanò, T. Gemtos, and D. De Benedetto. 2013. Delineation of Management zones in an apple orchard in Greece using a multivariate approach. Computers and Electronics in Agriculture 90:119–30. doi:10.1016/j.compag.2012.09.009.
- Akbarzadeh, A., R. T. Mehrjardi, H. Rouhipour, M. Gorji, and H. G. Rahimi. 2009. Estimating of soil erosion covered with rolled erosion control systems using rainfall simulator (neuro-fuzzy and artificial neural network approaches). Journal Applications Sc Researcher 5:505–14.
- Al-Gaadi, K. A., A. M. Aboukarima, and A. A. Sayedahmed. Employing an adaptive neuro-fuzzy inference system for optimum distribution of liquid pesticides. African Journal of Agricultural Research 6 (9): 2078–85. 4 May, 2011 Available online at http://www.academicjournals.org/AJAR.
- Ambuel, J. R., T. S. Colvin, and D. L. Karlen. 1994. A fuzzy logic yield simulator for prescription farming. Transactions of the ASAE 37 (6):1999–2009. doi:10.13031/2013.28293.
- Azeem, M. F. 2012. Fuzzy inference systems: Theory and practice. Croatia, European Union: InTech, Published: May 09, 2012 under CC BY 3.0 license, in subject Control Engineering. ISBN 978-953-51-0525-1 doi: 10.5772/2341.
- Blankenship, S. M., M. Parker, and C. R. Unrath. 1997. Use of maturity indices for predicting poststorage firmness of Fuji apples. HortScience : a Publication of the American Society for Horticultural Science 32:909–10.
- Burhan Turken, I. 2006. An ontological and epistemological perspective of Fuzzy set theory. The Netherlands: Elsevier.
- Center, B., and B. P. Verma. 1998. Fuzzy logic for biological and agricultural systems. Artificial Intelligence Review 12 (1/3):213–25. doi:10.1023/A:1006577431288.
- Chen, S., and E. G. Roger. 1994. Evaluation of cabbage seedling quality by fuzzy logic. ASAE Paper No. 943028, St. Joseph, MI.
- Dubois, D., and H. Prade. 2000. Fundamentals of Fuzzy Sets. the Netherlands: Kluwer Academic Publishers.
- Fitz-Rodríguez, E., and G. A. Giacomelli. 2009. Yield prediction and growth mode characterization of greenhouse tomatoes with neural networks and fuzzy logic. Transactions of the ASABE 52 (6):2115–28. doi:10.13031/2013.29200.
- Grelier, M., S. Guillaume, B. Tisseyre, and T. Scholasch. 2007. Precision viticulture data analysis using fuzzy inference systems. Journal International Sciences Vigne Vin 41 (1):19–31.
- Heske, T., and J. N. Heske. 1996. Fuzzy logic for real world design. San Diego, CA: Anna Books.
- Huang, Y., Y. Lan, S. J. Thomson, A. Fang, W. C. Hoffmann, and R. E. Lacey. 2010. Development of soft computing and applications in agricultural and biological engineering. In Computers and electronics in agriculture, Vol. 71, 107–27.
- Jang, J.-S. R. 1993b. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics 23 (3):665–85. doi:10.1109/21.256541.
- Jang, J. S. R., C. Sun, and E. Mizutani. 1997. Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence. Upper Saddle River, NJ, USA: Prentice-Hall International, Inc.
- Jang, J.-S. R., and T. Sun. 1993. Functional equivalence between radial basis function networks and fuzzy inference systems. IEEE Transactions on Neural Networks 4 (1):156–59. doi:10.1109/72.182710.
- Jang, J.-S. R., and T. Sun. 1995. Neuro-fuzzy modeling and control. Proceedings IEEE 83:378–406. doi:10.1109/5.364486.
- Js R, J., and T. Sun. 1997. Neuro-fuzzy and soft computing: a computational approach to learning and machine intelligence. USA: Prentice Hall.
- Kader, A. A. 2002. Postharvest technology of horticultural crops, 3rd ed., 49–54. USA: U.C. D.A.N.R. Publ. 3311.
- Kasabov, N. 1998. Foundations of neural networks, fuzzy systems and knowledge engineering. Cambridge, MA, USA: The MIT Press.
- Kavdir, I., and D. Guyer. 2003. Apple grading using fuzzy logic. Turkish Journal of Agriculture and Forestry 27:375–82.
- Khoshnevisan, B., S. Rafiee, and H. Mousazadeh. 2014b. Application of Multi-Layer Adaptive Neuro-Fuzzy Inference System for Estimation of Greenhouse Strawberry Yield Measurement 47:903–10.
- Khoshnevisan, B., S. Rafiee, M. Omid, and H. Mousazadeh. 2014a. Development of an intelligent system based on ANFIS for predicting wheat grain yield on the basis of energy inputs. Information Processing in Agriculture 1(1):14–22. doi:http://dx.doi.org/10.1016/j.inpa.2014.04.001 Issue.
- Kurgan, L. A., and P. Musilek. 2006. A survey of knowledge discovery and data mining process models. The Knowledge Engineering Review 21 (1):1–24. doi:10.1017/S0269888906000737.
- Lorestani, A. N., M. Omid, S. Bagheri Shooraki, A. M. Borhei, and A. Tabatabaeefar. 2006. Design and evaluation of a fuzzy logic based decision support system for grading of golden delicious apples. International Journal of Agriculture & Biology 8 (4):440–44.
- Marquina, P., M. E. Venturini, and R. Oria. 2004. Angel Ignacio Negueruela, Monitoring Colour Evolution During Maturity in Fuji Apples. Food Science and Technology International 10(5):315–321. doi: 10.1177/1082013204047903.
- MathWork. 2012. Fuzzy logic toolbox user’s guide, 137–79. Natick: Inc, 3, Apple Hill Drive.
- Mazloumzadeh, S. M., Ζ. M. Shamsi, and Ζ. H. Nezamabadi-Pour. 2010. Fuzzy logic to classify date palm trees based on some physical properties related to precision agriculture. Precision Agriculture 11 (3):258–73. doi:10.1007/s11119-009-9132-2.
- McGuire, R. G. 1992. Reporting of objective color measurements. HortScience : A Publication of the American Society for Horticultural Science 27:1254–55.
- Naderloo, L., R. Alimardani, M. Omid, F. Sarmadian, P. Javadikia, M. Y. Torabi, and F. Alimardani. 2012. Application of ANFIS to predict crop yield based on different energy inputs. Measurement 45:1406–13. doi:10.1016/j.measurement.2012.03.025.
- Nauck, D., and R. Kruse. 1995. NEFCLASS—A Neuro-Fuzzy approach for the classification of data. In Proceedings of the 1995 ACM symposium on applied computing, Eds. K. M. George, J. H. Carroll, E. D. Deaton, D. Oppenheim., and J. Hightower, 461–65. New York: ACM Press.
- Papageorgiou, E. I., K. Aggelopoulou, T. A. Gemtos, and G. D. Nanos. 2013. Yield prediction in apples using Fuzzy Cognitive Map learning approach. Computers and Electronics in Agriculture 91:19–29. doi:10.1016/j.compag.2012.11.008.
- Papageorgiou, E. I., A. Markinos, and T. A. Gemptos. 2009. Application of fuzzy cognitive maps for cotton yield management in precision farming. Expert Systems with Applications 36 (10):12399–413. doi:10.1016/j.eswa.2009.04.046.
- Papageorgiou, E. I., A. Markinos, and T. A. Gemtos. 2011a. Fuzzy Cognitive Map based approach for predicting yield in Cotton Crop Production as a basis for decision support system in precision agriculture application. Applied Soft Computing Journal. 11 (4):3643–57. doi:10.1016/j.asoc.2011.01.036.
- Papageorgiou, E. Ι., A. Markinos, and T. A. Gemtos. 2011b. Soft computing technique of Fuzzy Cognitive Maps to connect yield defining parameters with yield in cotton crop production in central Greece as a basis for a decision support system for precision agriculture application. In Fuzzy Cognitive Maps: Advances in Theory, Methodologies, Tools, Applications, edited by M. Glykas. Berlin: Springer Verlag.
- Prato, T. A. 2005. A fuzzy logic approach for evaluating ecosystem sustainability. Ecological Modelling 187 (2–3):361–68. doi:10.1016/j.ecolmodel.2005.01.035.
- Quinlan, J. R. 1983. Learning efficient classification procedures and their application to chess end games. In R. Michalski, J. Carbonell, and T. Mitchell, editors, Machine Learning — An Artificial Intelligence Approach, pp 463–482. Tioga, Palo Alto, CA.
- Roubos, A. R. 2003. Learning fuzzy classification rules from labeled data. Information Sciences 150:77–93. doi:10.1016/S0020-0255(02)00369-9.
- Shahin, M. A., B. P. Verma, and E. W. Tollner. 2000. Fuzzy logic model for predicting peanut maturity. Transactions of the ASAE 43 (2):483–90. doi:10.13031/2013.2729.
- Simonton, W. 1993. Bayesian and fuzzy logic classification for plant structure analysis. ASAE Paper No. 933603, St. Joseph, MI.
- Tagarakis, A., S. Koundouras, E. I. Papageorgiou, Z. Dikopoulou, S. Fountas, and T. Gemtos. 2014. A fuzzy inference system to model grape quality in vineyards. Precision Agriculture 15 (5): 555–78. doi:10.1007/s11119-014-9354-9. February 2014
- Takagi, T., M. Sugeno. 1983. Multidimensional fuzzy reasoning, Fuzzy Sets and Systems 9(1):313–325. doi: 10.1016/S0165-0114(83)80030-X
- Takagi, T., and M. Sugeno. 1985. Fuzzy identification of systems and its applications to modeling and control. IEEE Transactions on Systems, Man, and Cybernetics SMC-15:116–32. doi:10.1109/TSMC.1985.6313399.
- Tremblay, N., M. Y. Bouroubi, B. Panneton, S. Guillaume, P. Vigneault, and C. Bélec. 2010. Development and validation of fuzzy logic inference to determine optimum rates of N for corn on the basis of field and crop features. Precision Agriculture 11 (6):621–35. doi:10.1007/s11119-010-9188-z.
- Türkşen, I.B. 2006. An Ontological and Epistemological Perspective of Fuzzy Set Theory. New York: Elsevier B.V.
- United States Standards for Grades of Apples, 2002. Available at:http://www.ams.usda.gov/standards/apples.pdf.
- Vasilakakis, M. 2007. General and Specific Pomology, 275–312. Thessaloniki, Greece: Gartaganis Publ. in Greek.
- Wang, L., 1992. Fuzzy systems are universal approximators. Proceedings of International Conference on Fuzzy Systems.
- WEKA, 2005. https://www.cs.waikato.ac.nz/ml/publications/2005/weka_dmh.pdf
- Witten, I. H. and E. Frank. 2000. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations. Morgan Kaufmann, San Francisco.
- Yang, -C.-C., S. O. Prasher, J. A. Landry, J. Perret, and H. S. Ramaswamy. 2000. Recognition of weeds with image processing and their use with fuzzy logic for precision farming. Canadian Agricultural Engineering 42 (4):195–200.
- Zadeh, L. A. 1965. Fuzzy sets. Information and Control 8:338–53. doi:10.1016/S0019-9958(65)90241-X.
- Zadeh, L. A. 1975. Fuzzy logic and approximate reasoning. Synthese 30:407–428.
- Zadeh, L. A. 1976. The concept of a linguistic variable and its application to approximate reasoning, Information Sciences 9 (1976):43–80.
- Zurada, J. M., and A. Lozowski, “Generating linguistic rules from data using neuro-fuzzy framework”, Proc. of the fourth International Conference on Soft Computing (IIZUKA’96), Iizuka, Fukuoda, Japan, 1996, pp. 618–21.