
ABSTRACT
This paper is a case study of visiting an external audit company to explore the usefulness of machine learning algorithms for improving the quality of an audit work. Annual data of 777 firms from 14 different sectors are collected. The Particle Swarm Optimization (PSO) algorithm is used as a feature selection method. Ten different state-of-the-art classification models are compared in terms of their accuracy, error rate, sensitivity, specificity, F measures, Mathew’s Correlation Coefficient (MCC), Type-I error, Type-II error, and Area Under the Curve (AUC) using Multi-Criteria Decision-Making methods like Simple Additive Weighting (SAW) and Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS). The results of Bayes Net and J48 demonstrate an accuracy of 93% for suspicious firm classification. With the appearance of tremendous growth of financial fraud cases, machine learning will play a big part in improving the quality of an audit field work in the future.
Introduction
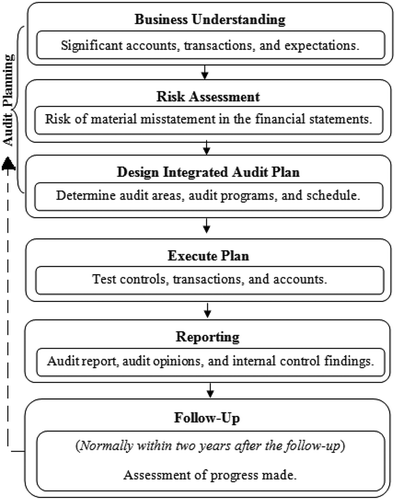
Fraud is a critical issue worldwide. Firms that resort to the unfair practices without the fear of legal repercussion have a grievous consequence on the economy and individuals in the society. Auditing practices are responsible for fraud detection. Audit is defined as the process of examining the financial records of any business to corroborate that their financial statements are in compliance with the standard accounting laws and principles (Cosserat Citation2009). It is a very exacting task to detect firms in spotting frauds, detecting errors, and disclosing employees guilty of abetting illegal transactions. Data analytics tools for an effective fraud management have become the need of the hour for an audit. The possibilities that how data analytics can improve the quality of the process is published in Emerging Assurance Technologies Task Force of the AICPA Assurance Services Executive Committee (ASEC) (Staff Citation2014). Generally, audits are classified into two categories as internal and external auditing (Cosserat Citation2009). Internal-audit, although is an independent department of an organization, but resides within the organization. These are company-employees who are accountable for performing audits of financial and nonfinancial statements as per their annual audit plan. External audit is a fair and independent regular audit authority, which is responsible for an annual statutory audit of financial records. The external audit company has a fiduciary duty and is critical to the proper conduct of business. For instance, their work is to audit the receipts, expenditures, accounts related to the trading, profit, contingency funds, balance sheets, public accounts, etc. kept in any government office. It is their duty to ensure that the funds allocated to any government department have been put to use as per law. On successful completion of an audit process, auditors deliver an audit and inspection summary report called audit paras to the company comprising of the details of all the findings from the audit. This may include discrepancies, noncompliance of accounting rules, leakage of revenue, inaccurate calculations, etc. The whole audit process flow is summarized in . In order to improve the advancement of data analytics tools for auditing, AICPA and Rutgers Business School in 2015 announced a research initiative on how data analytics can improve the quality of an audit (Tschakert Citation2016). Auditing Standards Board Task Force (ASBTF) is also working on developing an innovative Audit Data Analytics Guide in order to integrate the data analytics tools for the auditing tasks (Maria, Murphy and Tysiac Citation2015).
Figure 1. Audit work-flow.
Machine learning has got much attentiveness in the data analytics as it offers new computational as well as epistemological techniques to produce better results. Machine learning proposes several algorithms that are derived from the area of statistics and artificial intelligence. Many researchers have employed algorithms like artificial neural network, logistic regression, decision trees, and Bayesian belief networks for detecting management fraud in the financial statements (Fanning and Cogger Citation1998; Green and Choi Citation1997; Spathis Citation2002). The ensemble machine learning method is also applied successfully for improving the classification accuracies of the auditing task (Kotsiantis Citation2006). Machine learning algorithms like support vector machine, logistic regression, probabilistic neural network, genetic algorithm, etc. are also combined with feature selection methods in order to prove their usability in detecting fraud in the Chinese firms (Ravisankar Citation2011). In a review of data analytics tools like for fraud prediction, clustering, and outlier detection that are used for fraud management task, researchers listed algorithms like neural network, decision tree, Bayesian network, etc. as most commonly used methods (Sharma Citation2013).
The prime goal of an auditor during an audit-planning phase is to follow a proper analytical procedure to impartially and appropriately identify the firms that resort to high risk of unfair practices. Predictive analytics is also implemented using machine learning methods because it provides actionable insights for the audit companies. One of the most common applications of predictive analytics in audit is the classification of suspicious firm. Identifying fraudulent firms can be studied as a classification problem. The purpose of classifying the firms during the preliminary stage of an audit is to maximize the field-testing work of high-risk firms that warrant significant investigation. According to a research, data analytics has benefited internal auditing more as compared to advancements it has contributed for the external audits (Tysiac Citation2015). This research work is a case study of an external government audit company which is also an external auditor of government firms of India. During audit-planning, auditors examine business of different government offices but target to visit the offices with very-high likelihood and significance of misstatements. This is calculated by assessing the risk relevant to the financial reporting goals (Houston, Peters, and Pratt Citation1999). The three main objectives of the study are as follows:
To understand the audit risk analysis work-flow of the company by in-depth interview with the audit employees, and to propose a decision-making framework for risk assessment of firms during audit planning.
To examine the present and historical risk factors for determining the Risk Audit Score for 777 target firms, to implement the Particle Swarm Optimization (PSO) algorithm to rank examined risk factors, and evaluating the Risk Audit Class (Fraud and No-Fraud) of nominated firms.
To explore and test the applicability of 10 classification models in the prediction of a Risk class, and to check the collective performance of the models for the fraud prediction using Multi-Criteria Decision-Making (MCDM) methods like SAW, TOPSIS, etc.
Ten machine learning classifiers are explored, implemented, and tested by K-fold cross validation to check their applicability in the prediction of the high risk firms. The rationale is to build a classification model that can predict the fraudulent firm on the basis of the present and historical risk factors. Through the rigorous experiments, it has been found that Bayes Net and J48 classifiers outperform over the other machine learning methods in terms of their performance in predicting the risk-class (Fraud or No-Fraud) for an Audit Field Work Decision Support System. The rest of the paper is organized as follows: Section 2 presents the audit dataset, considered features, risk assessment procedure, and the complete methodology. Experiments, performance evaluation, and result-analysis are discussed in Section 3. Finally, the conclusion and future scope are discussed in Section 4.
Materials and methods
Data collection
Comptroller and Auditor General (CAG) of India is an independent constitutional body of India. It is an authority that audits receipts and expenditure of all the firms that are financed by the government of India. While maintaining the secrecy of the data, exhaustive one year nonconfidential data of firms is collected from the Auditor General Office (AGO) of CAG. There are total 777 firms from 46 different cities of a state that are listed by the auditors for targeting the next field-audit work. The target-offices are listed from 14 different sectors. The information about the sectors and their counts are summarized in .
Table 1. Target sectors.
Features
Many risk factors are examined from various areas like past records of audit office, audit-paras, environmental conditions reports, firm reputation summary, on-going issues report, profit-value records, loss-value records, follow-up reports etc. After an in-depth interview with the auditors, important risk factors are evaluated and their probability of existence is calculated from the present and past records. describes the various examined risk-factors that are involved in the case study. Various risk factors are categorized, but combined audit risk is expressed as one function called an Audit Risk Score (ARS) using an audit analytical procedure. At the end of risk assessment, the firms with high ARS scores are classified as “Fraud” firms, and low ARS score companies are classified as “No-Fraud” firms. Sample audit data of the corporate sector are shown in .
Table 2. Risk factors classification and other features in model.
Table 3. Sample data of the corporate sector unit.
Audit Risk Assessment (ARA)
Audit Risk Assessment (ARA) is a deliberate process of evaluating the likelihood of discrepancies or misstatements (event E) (Nikolovski et al. Citation2016). Risk is often measured as the expected value of any an unenviable outcome. During audit-planning, external auditors first quantitatively evaluate the risk of fraud in an organization in order to estimate the need for audit-field work. As Event E is a negative event, so historical data are also analyzed. For calculating the probability of discrepancies or misstatements (event E), formal methods are preferred. The associated formula for calculating the risk R is expressed as
where is the probability of discrepancy and
is the loss involved in the discrepancy. Due to different categories of risk, situations in an audit are sometimes more complex than the simple possibility case of one risk. In a situation with several possible risk types, the total risk is the sum of the different risk type and can be expressed as
where i is the total number of considered risk types.
When the audits are performed by any external audit company, the risk assessment plays a vital role in deciding the amount of field work that would be required before actually visiting the official firms. According to ISA315, an auditor should always obtain a clear understanding of the firm including all its internal environments, controls, entities, etc. for a complete risk assessment before actually visiting the firm (of Certified Public Accountants (AICPA) Citation2006). This process acts as initial evidence for performing an effective audit at client’s firm. As a formula, audit risk is the product of inherent risk (IR), control risk (CR), and detection risk (DR) (Srivastava and Shafer Citation1992). It can be calculated as
Inherent Risk (IR) is the risk present due to the discrepancies present in the transactions. For instance, transaction which involves settlement by checks has lower IR as compared to the transaction which involves exchange of cash. CR is the risk due to the discrepancies which are left undetected by an internal control system. For instance, CR risk is high when the separation of duties is not properly defined. DR is the risk of discrepancies present in the firm which are not even detected by the audit procedures. Human or sampling error, for instance. Considering all risk factors, a complete equation for evaluating an audit risk using Equation (2) and Equation (3) can be expressed as
where and
are the number of risk factors causing inherent risk and control risk, respectively. For this case study, the complete equation for the risk factors (risk factors categorized in ) can be expressed as
For calculating the audit risk of a firm, the probability of each risk factor is calculated using an analytical procedure and an audit risk score is calculated for each firm. In order to understand the complete step-by-step process, it is presented as a Risk Assessment Algorithm 1.
Proposed framework
The goal of the research is to design and develop a prediction model for the proposed audit field work decision support framework. The proposed framework which can also work as a Decision-Making System is presented in an abstract view in .
Figure 2. Proposed framework for an audit field work decision-making.
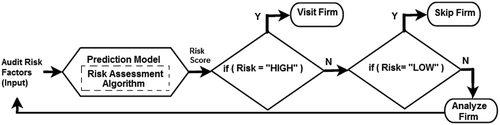
The selected features (as described in ) are used as candidates for the input vector of the model. The outcome of the proposed framework will be available in the form of a web-based application that helps an auditor to predict an audit risk class (Fraud or No Fraud). The complete flow of the prediction model for the proposed audit field work decision support framework is described in and discussed in this section.
Table
Figure 3. Prediction model.
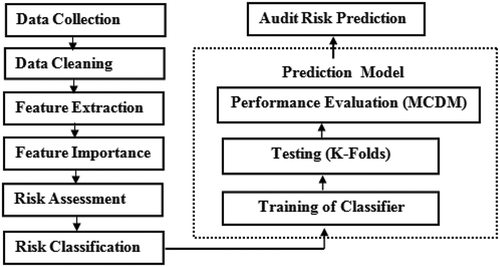
Data cleaning and feature extraction
In real applications, the learning algorithm is rarely such powerful and perfect. Data suffer from noise, missing values, errors, inconsistencies, class-imbalance problem etc. After cleaning and preparing the collected unstructured data from numerous files, different types of risk factors are explored. The data are organized in 777 rows and 9 important risk factors (columns).
Feature importance and selection
Proposed by Kennedy and Eberhart, Particle swarm optimization (PSO) is one of the simple and widely preferred optimization techniques (Kennedy Citation2011, Couceiro Citation2016). PSO is a heuristic global optimization technique and is successfully used as a feature importance and selection method in many physical problems (Kothari Citation2012, Couceiro Citation2016). gives the optimal weights to each risk factor according to Equation (6) using Particle Swarm Optimization (PSO) as described below:
Table 4. Risk factors weight assignment using Particle Swarm Optimization (PSO).
where is the total number of instances in training dataset,
is the Audit Risk Score (ARS) value of training dataset,
is the number of features,
is the feature, and
is the weight given to each feature defined in [0,1]. The weight of F3 is the lowest, so it can be eliminated.
The final formula used for all the machine learning models is given by
Classification models
Identifying a firm is fraudulent or not using an input vector (risk factors) can be considered as a binary classification problem. Ten state-of-the-art classification methods are employed in the case study are discussed in this section.
Decision Trees (DT): This model is an extension of the C4.5 classification algorithm. It is described by Quinlan and works by classifying samples by sorting them down the tree (Quinlan Citation1986).
AdaBoost (AB): It is a successful ensemble classifier by Schapire and Freund. It employs multiple learners to finally make a more powerful learning algorithm (Schapire Citation1999).
Random Forest (RF): It is an ensemble learning algorithm which builds a forest of decision trees using random inputs to improve the classification rate (Liaw and Wiener Citation2002).
Support Vector Machine (SVM): SVMs search for data points that are present at the edge of an area in a space (boundary between two classes) and refer them as support vectors. It is a preferred technique for classification (Keerthi and Gilbert Citation2002).
Probit Linear Models (PLM): The linear model is a traditional regression method for fitting the data. For binary classification, it is transformed using a logistic or probit function and offers similar results to the logistic regression (Chambers Citation1977; Finney Citation1992).
Neural Network (NN): It is inspired from biological neural networks and used to model complex relationships, and useful patterns in statistical data (Russell et al. Citation2003).
Decision Stump Model (DSM): It is a one-level decision tree. It is also used as a base learner in ensemble models (Iba and Langley Citation1992).
J48: It builds decision tree based on the theory of information entropy. J48 is an open source java implementation of the C4.5 algorithm (Quinlan Citation1996).
Naive Bayesian (NB): It computes the conditional a posterior probabilities of a categorical class variable of a given independent predictor variable using the Bayes Rule (Rish Citation2001).
Bayesian Network (BN): This model is based on probabilistic and directed acyclic graph theory. It builds a graphical model that represents a set of features and their conditional dependencies via a directed acyclic graph (Buntine Citation2016; Neapolitan et al. Citation2004).
Performance evaluation
To check the performance of 10 classifiers, K fold (K = 10) validation is implemented and 10 performance metrics namely Type-1 error, Type-2 error, accuracy, error rate, sensitivity, specificity, AUC, F1 score, MCC, and F2 score are evaluated using the results of the confusion matrix as described in . The confusion matrix commonly known as the Error Matrix in machine learning is a popular method to measure the performance of a binary classification model on a test dataset. The classifiers have been trained to distinguish between “Fraud” and “No-Fraud” firms, and the confusion matrix summarizes the results as described in for class Fraud. Here, X (true positive) is equivalent to the hits. X gives the number of actual fraudulent firms predicted correctly as fraudulent. Z (false negative) gives the number of fraudulent firms that are incorrectly marked as nonfraudulent firms. It is equivalent to the miss and commonly known as the Type-II error. Q (false positive) gives the count of nonfraudulent firms that are incorrectly labeled as fraudulent. It is known as the Type-I error. Y (true negative) indicates the number of nonfraudulent firms that are correctly classified as nonfraudulent. The accuracy and error rate are commonly used metric to test the performance of a classifier. The accuracy calculates the number of correct predictions from all predictions. Sensitivity is the true positive rate (TPR), measuring the hit rate of a classifier in predicting fraudulent firms. Specificity measures the true negative rate (TNR) of a model. The area under the curve (AUC) is equal to the probability that a classification model will rank a randomly chosen positive sample (fraud class sample) higher than a randomly chosen negative sample (nonfraud class sample). A graph is generated by plotting TPR against the FPR, depicting the relative trade-offs between true positive and false positives (Fawcett Citation2006). The accuracy is sometimes misleading and AUC (the area under the curve) is a more preferred approach as compared to accuracy (Bradley Citation1997). F measure (F1 score) is a balanced score of sensitivity and specificity. F2 score weights sensitivity value higher than specificity. Matthew’s correlation coefficient (MCC) is another balanced measure that focuses on true and false positives and negatives.
Table 5. Confusion matrix.
Table 6. Performance evaluation metrics.
Experiments and result analysis
Ten machine learning models are implemented for prediction of an audit risk class (fraud or no-fraud). To test the robustness of designed the framework, K fold cross validation method (K = 10) is implemented and performance of the models are compared using 10 different performance metrics. The results obtained from the 10 different metrics (discussed in the Section 2.4.4) are analyzed and collective performance scores of all the classifiers are calculated using two different multi-criteria decision-making methods TOPSIS and SAW are discussed here.
Experiment setting
The R “caret” package is used to implement the various classification models. The models are available in R open source software. R is licensed under GNU GPL. The brief implementation details of the models discussed in Section 2.4.3 are summarized in . One shot training and testing technique is adopted here. Training data i.e. 70 percent of the sample data are fed to enable the classifier. The model is trained on these training data and then tested on independent new samples (30 percent of the samples) of testing data. The purpose is to measure the prediction performance of the model when it is up and running and then predicting the risk-class of the new samples without the benefit of knowing the true risk-class of the samples.
Table 7. Machine learning classification methods.
Performance score and result analysis
The performance of the proposed framework is evaluated with 10 different performance parameters, and the results are summarized in . Researchers have proved that there is no classifier present that works perfectly for all the data problems (Ali and Smith Citation2006). Similarly, there are numerous measures to evaluate the performance of classifiers and there is no best metric for all the classification problems (Ali and Smith Citation2006; Smith-Miles Citation2009). Based on these two important considerations, this case study uses 10 performance metrics to compare 10 state-of-the-art classifiers. In an attempt to perform comprehensive performance evaluation, classifiers are evaluated against multiple criteria or metrics. For selecting the best classification algorithms against multiple criteria, selection problems can be modeled as the Multi-Criteria Decision-Making (MCDM) problem (Triantaphyllou Citation2013) . For unbiased ranking of 10 classifiers using MCDM methods, Simple Additive Weighting (SAW) and Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) methods are implemented. The reason for choosing these methods is their simplicity and involvement of subjective ranking of different performance criteria by experts.
Table 8. Average performance comparison of machine learning methods for the prediction of an audit risk on testing dataset.
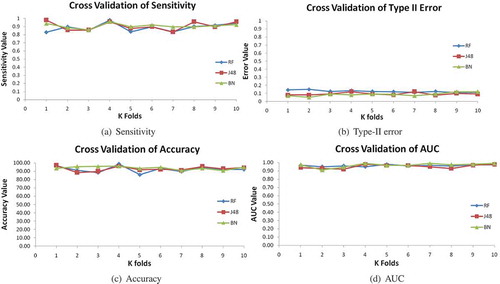
Different metrics are analyzed and their importance (weight of evaluation criteria) is judged for the prediction of an audit risk. It is observed that the proposed framework utilizes false positives routinely in order to predict firms that are under the risk of frauds. By examining historical and present information (summarized in ), the framework should have high sensitivity (the hit rate of predicting fraudulent firms). In the present scenario, the situation of not detecting the firm as fraud (low sensitivity) could be menacing for auditors whilst the low specificity (predicting honest firm as fraud) may only cause a further inspection. So, higher relative importance is given to sensitivity than the specificity. Similarly, the F score measure (balanced measure of sensitivity and specificity) is given lesser preference than the F2 score. Accuracy, error rate, and AUC are equally important but while analyzing the Type-I error (incorrect prediction of fraud firm) and Type-II error (failing to detect the fraud firm), the Type-II error is given more preference than the Type-I error. The collective score of SAW and TOPSIS are graphically represented in . It is reflected in the figure that J48 and Bayes Net outperform the other nine models in terms of the overall performance. Besides J48 and Bayes Net, Random Forest has also achieved a satisfactory performance on the audit dataset. Other models show considerably low performance on the data. To check the robustness of J48, Bayes Net and Random Forest further, the results of K-cross validation are graphically analyzed in . It is observed that the J48 and Bayes Net classifiers are quite robust in their performance, hence can be recommended as the prediction models for the Audit Field Work Decision Support System.
Figure 4. Performance score of SAW and TOPSIS MCDM methods.
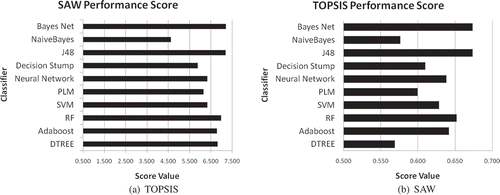
Figure 5. Ten-fold cross validation of Type-II error, sensitivity, accuracy, and AUC on the testing dataset in the audit risk prediction using Bayes Net, J48, and Random Forest.
Conclusion
This paper presents a case study of Comptroller and Auditor General (CAG) of India to check the applicability of machine learning methods to predict the fraudulent firms during audit planning. A complete Audit Field Work Decision Support framework is proposed to help an auditor to decide the amount of field work required for a particular firm and to skip visiting low risk firms. Fraudulent firm prediction is an important step at the preliminary stage of an audit planning as high-risk firms are targeted for the maximum audit investigation during field engagement.
After collecting the data of 777 firms from 14 different sectors, it is cleaned, transformed, and useful risk factors are examined with the help of an in-depth interview with the auditors. Different types of risks are explored and then calculated mathematically for the audit dataset using the audit risk formula. The Particle Swarm Optimization (PSO) algorithm is implemented for feature selection and feature importance. The Risk Assessment Algorithm is presented in the paper to clearly understand the complete risk assessment process. Ten state-of-the-art classifiers like SVM, NN, BN, RF, PLM, AB, DS, J48, etc. are implemented. For comprehensive assessment of all the classifiers, performance scores of 10 different evaluation criteria using subjective ranking of criteria by audit experts are considered. The results of two multi-criteria methods, TOPSIS and SAW, indicated that Bayes Net and J48 perform the best for this particular audit dataset. BayesNet and J48 also give stable results on K-fold validation testing, serving as a proof of eligibility of classifiers to perform an efficient risk assessment of the suspicious firms in the audit field work decision-making process.
For future works, we are targeting to improve the performance of the classifiers by the ensemble machine learning approach (using a hybrid of the best performing classifiers). In the next step, we offer the auditors to handle the last 10 years data of firms on the top of advance big data techniques like Hadoop, Spark, etc.
Acknowledgments
The authors wish to thank the auditors for their assistance, time, and continued support. The authors are also grateful for their helpful feedback and comments on the earlier version of this work.
Additional information
Funding
References
- Ali, S., and K. A. Smith. 2006. On learning algorithm selection for classification. Applied Soft Computing 6 (2):119–38. doi:10.1016/j.asoc.2004.12.002.
- Bose, I. et al. 2011. Detection of financial statement fraud and feature selection using data mining techniques. Decision Support Systems 50 (2):491–500. doi:10.1016/j.dss.2010.11.006.
- Bradley, A. P. 1997. The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognition 30 (7):1145–59. doi:10.1016/S0031-3203(96)00142-2.
- Buntine, W. 2016. Learning classification rules using bayes. Proceedings of the sixth international workshop on Machine learning, Sydney, Australia, ACM,94–98.
- Ramos, M. J. 2006. Wiley Practitioner’s Guide to GAAS 2006: Covering All SASs, SSAEs, SSARSs, and Interpretations. In Understanding the entity and its environment and assessing the risks of material misstatement 52–53. John Wiley & Sons.
- Chambers, J. M. 1977. Computational methods for data analysis. Technical report, New York.
- Cosserat, G. 2009. Accepting the engagement and planning the audit. In Modern auditing, ed. G. Cosserat and N. Rodda, 3rd ed., 734–36. John Wiley & Sons.
- Couceiro, M. 2016. Particle swarm optimization. In Fractional order darwinian particle swarm optimization: Applications and evaluation of an evolutionary algorithm, 1–10. Boston, MA: Springer.
- Fanning, K. M., and K. O. Cogger. 1998. Neural network detection of management fraud using published financial data. International Journal of Intelligent Systems in Accounting, Finance & Management 7 (1):21–41. doi:10.1002/(SICI)1099-1174(199803)7:1<21::AID-ISAF138>3.0.CO;2-K.
- Fawcett, T. 2006. An introduction to roc analysis. Pattern Recognition Letters 27 (8):861–74. doi:10.1016/j.patrec.2005.10.010.
- Finney, D. J. 1992. Miscellaneous problems. Probit Analysi 4:140–45. JSTOR.
- Freund, Y., R. Schapire,and N. Abe, 1999. A short introduction to boosting. Journal of Japanese Society For Artificial Intelligence 14:771–80.
- Green, B. P., and J. H. Choi. 1997. Assessing the risk of management fraud through neural network technology. Auditing 16 (1):14–16.
- Houston, R. W., M. F. Peters, and J. H. Pratt. 1999. The audit risk model, business risk and audit-planning decisions. The Accounting Review 74 (3):281–98. doi:10.2308/accr.1999.74.3.281.
- Iba, W., and P. Langley 1992. Induction of one-level decision trees. In Proceedings of the ninth international conference on machine learning, Moffett Field, California. 233–40.
- Keerthi, S. S., and E. G. Gilbert. 2002. Convergence of a generalized smo algorithm for svm classifier design. Machine Learning 46 (1–3):351–60. doi:10.1023/A:1012431217818.
- Kennedy, J. 2011. Particle Swarm Optimization. In Encyclopedia of Machine Learning, Boston, MA: Springer.
- Kothari, V. 2012. A survey on particle swarm optimization in feature selection, 192–201. Berlin, Heidelberg: Springer.
- Kotsiantis, S. 2006. Forecasting fraudulent financial statements using data mining. International Journal of Computational Intelligence 3 (2):104–10.
- Liaw, A., and M. Wiener. 2002. Classification and regression by randomforest. R News 2 (3):18–22.
- Maria, L., C. Murphy, and K. Tysiac. 2015. Data analytics helps auditors gain deep insight, 52–54, New York: Journal of Accountancy.
- Neapolitan, R. E., et al. 2004. Introduction to Bayesian Networks. In Learning Bayesian Networks, 40. Chicago: Pearson.
- Nikolovski, P., I. Zdravkoski, G. Menkinoski, S. Dicevska, and V. Karadjova. 2016. The concept of audit risk. International Journal of Sciences Basic and Applied Research (IJSBAR) 27 (3):22–31.
- Pearl, J. 1985. Bayesian networks: A model CF self-activated memory for evidential reasoning. In Proceedings of the 7th Conference of the Cognitive Science Society, Irvine, California, Pp. 329–334.
- Quinlan, J. R. 1986. Induction of decision trees. Machine Learning 1 (1):81–106. doi:10.1007/BF00116251.
- Quinlan, J. R. 1996. Improved use of continuous attributes in C4.5. Journal of Artificial Intelligence Research 4:77–90.
- Rish, I. 2001. An empirical study of the naive bayes classifier. In IJCAI workshop on empirical methods in artificial intelligence 3 (22):41–46. Seattle, Washington: IBM.
- Russell, S. J., P. Norvig, J. F. Canny, J. M. Malik, and D. D. Edwards. 2003. Artificial intelligence: A modern approach, Vol. 2, 65–71. Malaysia: Pearson Education Limited
- Sharma, A. 2013. A review of financial accounting fraud detection based on data mining techniques. International Journal of Computer Applications.
- Smith-Miles, K. A. 2009. Cross-disciplinary perspectives on meta-learning for algorithm selection. ACM Computing Surveys (CSUR) 41 (1):16–19.
- Spathis, C. T. 2002. Detecting false financial statements using published data: Some evidence from greece. Managerial Auditing Journal 17 (4):179–91. doi:10.1108/02686900210424321.
- Srivastava, R. P., and G. R. Shafer. 1992. Belief-function formulas for audit risk. Accounting Review 67 (2):249–83.
- Staff, A. 2014. Reimagining auditing in a wired world1. Technical report, University of Zurich, Department of Informatics. Zurich: Citeseer.
- Triantaphyllou, E. 2013. Multi-criteria decision making methods: A comparative study, Vol. 44. Boston, MA: Springer.
- Tschakert, N. 2016. The next frontier in data analytics. Journal of Accountancy. Accessed September 12, 2016. http://www.journalofaccountancy.com/issues/2016/aug/data-analytics-skills.html.
- Tysiac, K. 2015. Data analytics helps auditors gain deep insight. Journal of Accountancy. Accessed September 12, 2016. http://www.journalofaccountancy.com/issues/2015/apr/data-analytics-for-auditors.html.