
ABSTRACT
In this study, a new Locally Linear Embedding (LLE) algorithm is proposed. Common LLE includes three steps. First, neighbors of each data point are determined. Second, each data point is linearly modeled using its neighbors and a similarity graph matrix is constructed. Third, embedded data are extracted using the graph matrix. In this study, for each data point mutual neighborhood conception and loading its covariance matrix diagonally are used to calculate the linear modeling coefficients. Two data points will be named mutual neighbors, if each of them is in the neighborhood of the other. Diagonal loading of the neighboring covariance matrix is applied to avoid its singularity and also to diminish the effect of noise in the reconstruction coefficients. Simulation results demonstrate the performance of applying mutual neighborhood conception and diagonal loading and their combination. Also, the results of applying the mutual neighborhood on Laplacian Eigenmap (LEM) demonstrate the good performance of the proposed neighbor selection method. Our proposed method improves recognition rate on Persian handwritten digits and face image databases.
Introduction
Many real data such as all types of images, speech signals and many other digital signals have high dimensionality to present. Investigation of these types of data is complicated and time-consuming. Therefore, dimensionality of these types of data needs to be reduced. Some applications of dimension reduction technique include data compression, decrease curse of dimensionality, de-noising and visualization.
In fact, most of data have an inherent dimensionality very lower than they are presented. It means data can be presented in a lower dimension space without losing major information. shows examples of three-dimensional data manifold that the inherent dimensionality of them is equal to two.
Figure 1. Examples of a three-dimensional manifold. Three-dimensional data (b) sampled from (a). (c) is two-dimensional data of sampled manifold (b).
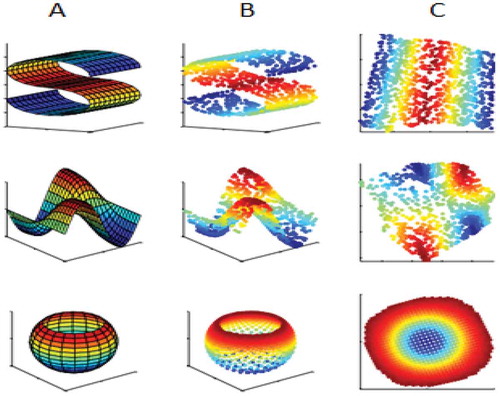
Dimension reduction is a mapping from high-dimension data into inherent low-dimension data in such a way that neighbors of each data and pair distance of them are preserved. Suppose a data set where
with
data points are represented in a space with dimensionality
. Dimension reduction methods attempt to extract the embedded low-dimensional data set Y =
where
and
.
Related works
Dimension reduction methods
Dimension reduction methods can be categorized as unsupervised and supervised algorithms.
Most supervised methods are applied to classification. Therefore, dimension reduction process of these methods is based on earning the maximum ratio of between classes scattering to the within class scattering using supervision information. The most famous of supervised dimension reduction methods is Linear Decomposition Analysis (LDA) (Fukunaga Citation1990). There are many methods such as Kernel LDA (KLDA) (Mika et al. Citation1999), Margin Maximizing Discriminant Analysis (MMDA) (Kocsor, Kovács, and Szepesvári Citation2004), Learning with Side Information (LSI) (Xing et al. Citation2002), Relevant Component Analysis (RCA) (Shental et al. Citation2002), Information Theoretic Metric Learning (ITML) (Davis et al. Citation2007), Neighborhood Component Analysis (NCA) (Goldberger et al. Citation2004) and Average Neighborhood Margin Maximization (ANMM) (Wang and Zhang Citation2007). All aforementioned methods can be categorized as linear/nonlinear and local/global methods.
On the other hand, in many dimension reduction methods i.e. manifold learning methods, there is not any supervision on data. Also, unsupervised dimension reduction methods can be divided into linear and nonlinear methods. Principle Component Analysis (PCA) is the most famous linear method (Jolliffe Citation2002).
Many manifold learning methods have been proposed based on the different algorithms and objective functions, such as Kernel PCA (KPCA) (Schölkopf and Smola Citation2002), Locally Linear Embedding (LLE) (Roweis and Saul Citation2000), Laplacian Eigenmaps (LEM) (Belkin Citation2001), Maximum Variance Unfolding (MVU) (Weinberger, Sha, and Saul Citation2004), multidimensional scaling (MDS) (Cox and Cox Citation2000), Isomap (Tenenbaum, De Silva, and Langford Citation2000), Hessian LLE (HLLE) (Donoho and Grimes Citation2003), Local Tangent Space Analysis (LTSA) (Zhang and Zha Citation2004), manifold charting (Brand Citation2002) and Locally Linear Coordination (LLC) (Teh Citation2002). All of these methods attempt to preserve local/global structure of data in the low-dimensional space as the same as in the input space. Some supervised version of the mentioned methods have been proposed such as Supervised Locally Linear Embedding Projection (SLLEP) (Li and Zhang Citation2011) and Discriminant Kernel Locally Linear Embedding (DKLLE) (Zhao and Zhang Citation2012). shows categorizations of all the aforementioned methods.
Table 1. List of dimension reduction methods and their categorization.
Dimension reduction would play a main role in many applications such as face recognition, action/behavior recognition, Optical Characteristic Recognition (OCR) etc. Since our main contribution is for OCR, we will give a short survey of researches conducted in this field.
OCR
In this study, we are interested in the offline Persian handwritten digits/characters recognition. OCR is a technique that converts the digital image and PDF format documents to searchable and editable documents. Machines enable to automatically recognize and separate check banks, bank statements, postal code, license plate etc. by OCR technique. OCR techniques are categorized into online and offline.
Many OCR methods have been proposed. In Sharma (Citation2012) a new OCR method based on using support vector machine and neural network was proposed. In Álvarez, Fernández, and Sánchez (Citation2012) and Ghaleb, George, and Mohammed (Citation2013), two stroke-based methods were proposed. In Pradeep, Srinivasan, and Himavathi (Citation2014), the performance of hybrid features for feed forward neural network-based English handwritten character recognition system was investigated. In Kacem, Aouïti, and Belaïd (Citation2012), handwritten Arabic personal names have been recognized by structural feature extraction such as loops, stems legs and diacritics. In Yu and Jiao (Citation2012), a new handwritten digit recognition method based on the distance kernel PCA was presented. In Singh and Lal (Citation2014), digits have been recognized using a single layer neural network with PCA. In this method, features have been extracted by PCA to reduce the computing complexity and time-consuming. The introduced handwritten Persian/Arabic character recognition in (Shayegan and Chan Citation2012) is based on a new approach of feature selection. In this method, features have been selected based on one- and two-dimensional spectrum diagrams of the standard deviation and the minimum to maximum distributions.
All the aforementioned OCR methods are based on the feature extraction and feature selection. Most of the feature extraction and selection methods are heuristic and their performances are limited to a special database. Therefore, existence of a reliable OCR method, which is independent of database, is necessary. Manifold learning-based OCR can satisfy these conditions.
Paper contributions
The main motivation of this study is introducing of a new nonlinear unsupervised dimension reduction method to extract the inherent low-dimensional data from the high-dimensional data with preserving the input data structure.
Most of the mentioned dimension reductions methods are based on the construction of a neighborhood graph matrix. In LLE, after determining of neighbors for each data points, a matrix is constructed by the linear reconstruction coefficients of each data point based on its neighbors. Then the embedded structure has been extracted by these coefficients. In LEM, the same as LLE, a graph matrix is constructed based on the Laplacian equation and then the achieved weight matrix is applied on the cost function of LEM method. In Locality Preserving Projection (LPP), which is a linear approximation of LEM, the same as LEM, a graph matrix is constructed. In MDS and Stochastic Neighbor Embedding (SNE), firstly a distance matrix is calculated based on the distance of data points from each other. Then the embedded data are extracted by this matrix.
The supremacy of all the aforementioned methods depends on their graph matrices which can determine their manifold structure. In this study, we propose a new neighbors selection method. Then, these new neighbors construct a new graph matrix that can characterize the manifold structure more efficiently. Our proposed neighbors’ selection method is based on the mutual neighborhood concept. Details of the proposed method will be described in section III.
Another innovation is related to the method of calculating the graph matrix in LLE technique. In LLE, reconstruction coefficients of each data point have been calculated based on a closed-form solution. Then these coefficients are used for constructing the graph matrix of LLE. In our proposed method, we apply the diagonal loading technique in calculating the reconstruction coefficients of each data point.
We would apply our proposed dimension reduction method on both ORL face image (Samaria and Harter Citation1994) and isolated Persian handwritten digit databases (Mozaffari et al. Citation2006; Ziaratban, Faez, and Faradji Citation2007). Simulation results demonstrate the performance of applying the mutual neighborhood conception and diagonal loading alone and together.
Rest of the paper is organized as follows. LLE is described in section II. Details of our proposed modifications on LLE are presented in section III. Experimental results are given section IV. Finally, section V concludes the paper.
LLE
LLE is a locally nonlinear manifold learning method. In this method, the structure of data manifold is preserved by extracting high dimensionality local structure of each data point and trying to transfer these local structures into the low dimensionality representation. In LLE, each data point is modeled by its linear reconstruction coefficients based on its neighbors. In fact, the global structure of data is preserved by the combination of these local structure features.
LLE method extracts the embedded low dimension data in three steps: (1) neighbors of each data point are detected, (2) each data point in high dimensionality space is approximated based on the linear combination of its neighbors, and (3) the low-dimensional embedded manifold is extracted using the obtained coefficients of the linear combinations. shows these three steps.
Figure 2. Three steps of LLE algorithm (Roweis and Saul Citation2000).
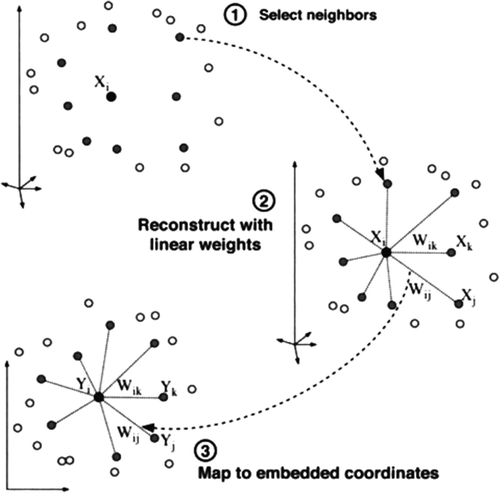
Finding neighbors
Neighborhood definition and neighbors’ selection are the main parts of manifold learning methods. Proper selection of neighbors helps to better modeling of the local structure of a data manifold. Usually, neighbors of each data point are determined by one of two methods: k-nearest neighbors (k-NN) and ε-ball methods. Euclidian distance is a traditional distance metric. Also, some modifications of Euclidian distance and the other distance metrics such as geodesic distance can be applied.
Calculation of linear reconstruction coefficients
After finding each data point’s neighbors, the data point is modeled linearly by its neighbors. The achieved coefficients matrix, W, from this model which characterizes the local structure of the data manifold in high dimensionality can be determined as follows:
where is the index set of the neighbors of
data point and
s show the linear reconstruction coefficients of data point
. These coefficients can be calculated in a closed form solution for each data point
as follows:
Therefore, is calculated by Eq. (2) as:
where is the covariance matrix of
’s neighbors, that they are centered to
, and
is a vector all of ones. If
is not a member of neighborhood of
,
has to be set zero. Also, condition of
is satisfied by dividing every
on
. After calculation of linear reconstruction coefficients of all data points, matrix
is produced.
This matrix represents the local structure features of the data manifold. These coefficients are invariant to scaling and rotation because of Euclidean form of the cost function (Roweis and Saul Citation2000). Also, the calculated coefficients are invariant to translation since. Therefore, these coefficients can properly extract and preserve the local features of data manifold. Consequently, establishment of all these local structures preserves the global structure of data manifold.
Finding coordinates of the embedded data manifold
After local structure explanation of high-dimensional data, low-dimensional representation of data is generated using the calculated linear constraint coefficients and minimization of the cost function of Eq. (3):
The aforementioned minimization problem can be solved as an Eigen problem (Roweis and Saul Citation2000). Therefore, the cost function can be rewritten as follows:
where
Finally, d eigenvectors corresponding to d smallest nonzero eigenvalues of are d-dimensional representation of data.
LLE is used in many applications. In Wu et al. (Citation2016), a voice conversion (VC) technique based on LLE was proposed. In this VC system spectral conversion part is based on the integration of LLE with a conventional exemplar-based spectral conversion. In Kang et al. (Citation2017), LLE was applied on assessing the state of a rolling bearing. In this application, after frequency and time domain feature extraction, the dimensionality of the extracted features was reduced by LLE. In Ziemann and Messinger (Citation2015), an adaptive LLE scheme was used for hyper spectral target detection. In this method, the target is separated from the background by graph theory modeling and then transferring by LLE into a low-dimensional coordinates. In Chen et al. (Citation2016), a manifold preserving edit propagation method was presented based on the k-NN and LLE technique where each pixel is represented by LLE in feature space.
Proposed method: mutual neighborhood with diagonal loading
In this study, two novelties are proposed to improve the performance of LLE. First, a new notion of neighborhood is defined. Second, diagonal loading technique is applied to calculate the linear reconstruction coefficients of each data point based on its neighbors.
Mutual neighborhood
In LLE technique and the most of the other methods of manifold learning, first neighbors of data points are determined and then the remaining steps are done based on these neighbors. In LLE, after finding neighbors, each data point is modeled by its neighbors (Eq. (1)). The obtained coefficients of the models characterize the local structural of data manifold and then the embedded data manifold is extracted based on preserving these local structures (Eq. (4)). Determining the true neighbors leads to model of each data point that can better characterize the local structure. Therefore, finding the real and true neighbors of each data point is very important and critical.
k-NN is a common method for finding neighbors. This method selects k nearest data points as neighbors based on Euclidian distance metric for each data point. Usually, distribution of data points in manifold is not uniform. Also, noise disturbs the data distribution. Therefore, notice to selection of exactly k data points as neighbors, some data may be selected as neighbors while their distances are farther and very different from the other selected neighbors’ distance. It means these farther data points are not in true neighborhood. We propose a new algorithm to find neighbors, called mutual neighborhood, as follows:
Mutual neighborhood algorithm
In the proposed neighborhood definition, initially K neighbors of each data point are determined (
, that
is the index set of the k-NN of
data point). Then K neighbors of each neighbors of
,
are detected. If
is a neighbor of
,
will be selected as a true neighbor. We called them mutual neighbors. Otherwise,
is removed from the list of the neighbors of
. Also, all data points have to be connected by at least one neighbor until LLE is performed correctly. Therefore, in our proposed algorithm if all neighbors of
are removed, the closest neighbor is selected as a true neighbor.
The proposed algorithm removes neighbors that are selected because of fixed number of neighbors and are not at a normal distance compared to the other neighbors. True selection of neighbors leads to have a better model from the local structure of data manifold and then it improves LLE performance. shows an example of our proposed neighborhood definition. Suppose we have 8 data points in two dimensions space and K of k-NN is 3. shows neighbors of each data point based on mutual neighborhood definition and common k-NN.
Table 2. Comparison between mutual neighborhood method and k-nearest neighbors’ algorithm for data points in .
Figure 3. An example of application of the proposed neighborhood definition for two-dimensional date points.
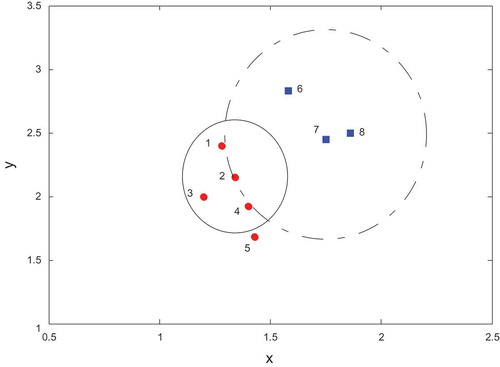
Based on the k-NN and mutual neighborhood conception, data points 1, 3 and 4 are selected as neighbors of data points 2. But selected neighbors for data point 7 are different. Based on the k-NN, data points 6, 8 and 2 are the three nearest neighbors of data points 7. But, based on mutual neighborhood conception, just data point 6 and 8 are selected as neighbors of data point 7, because data point 7 has not been selected as neighbors of data point 2.
Diagonal loading in LLE
In Ma and Goh (Citation2003), diagonal loading technique was proposed to improve the performance of adaptive beamforming for case of small sample. In LLE, the linear reconstruction coefficients are calculated as a closed solution for each data point (Eq. (2)) based on a covariance matrix scheme. Noise and small number of samples cause to not having an accurate estimation of covariance matrix. We applied the diagonal loading technique to calculate these linear reconstruction coefficients. Therefore, Eq. (2) is rewritten as follows:
where is identity matrix
and
is the value of diagonal loading. In this study, the value of
will be determined empirically.
Simulation results given in section IV demonstrate that mutual neighborhood conception, diagonal loading technique and their combination improve the performance of LLE based on the recognition rate of classification.
Formulation of our proposed method
Mutual neighborhood conception can be formulated as follows. After finding neighbors of each data point based on the k-NN’s algorithm, the cost function of the mutual neighbors LLE (MN-LLE) can be defined as follows:
Same as LLE, s are equal zero except
s that
s are members of
neighbors set. Also, calculation of the linear reconstruction coefficients of each data point is related to the reconstruction coefficients of its neighbors because of
. If
was equal to zero,
has to be removed from
neighbors set. Also,
is caused to each data point is at least connected to one neighbor. Therefore, mutual neighborhood conception is satisfied by this definition. Also, by definition of the mutual neighbors (MN) of
as
,MN-LEM cost function can be defined as:
Diagonal loading technique can be modeled as follows. Comparing Eqs. (2) and (5), Eq. (5) is the optimum solution of the below minimization problem:
Therefore, our proposed method can be formulated as follows:
In comparison with Eq. (6), Eq. (8) involves adding a penalty term to the minimization problem in Eq. (6) in order to keep the coefficients away from reaching large values. Consequently, mutual neighborhood conception induces a sparser neighborhood graph matrix than the common graph matrix. In fact, Matrix of is sparser than the common LLE method; i.e.
. Based on the definition of the mutual neighborhood conception, it is an obvious result.
Minimization problem given in Eq. (8) can be solved by the same way as LLE. First, mutual neighbors of each data point are determined and neighborhood graph matrix is constructed. Then matrix
is calculated. Finally, the embedded data are extracted by solving an Eigen problem, the same as LLE.
Simulation and results
Simulation results are based on three databases: ORL face image database (Samaria and Harter Citation1994), isolated Persian handwritten digits (IPHD) database (Ziaratban, Faez, and Faradji Citation2007) and IFHCDB Persian handwritten database (Mozaffari et al. Citation2006).
In our experiments, high-dimensional data manifold is constructed by rearrangement of pixel intensity levels of each object image with sizes m and n to a vector . Performance of our proposed method is investigated based on recognition rate of classification. Each database is randomly divided into three parts: training, validation and test sets. The value of diagonal loading parameter,
, is adjusted using validation set to provide the maximum recognition rate. Then the determined
is applied to calculate the recognition rate for the test set. k-NN-based classifier is used in this study. In applied KNN classifier, if there are multiple classes most common among its k-NN for a test data point, it is assigned to one of them with the minimum average of Euclidian distance. The value of k of KNN classifier is set to 3 in our simulations.
In this study, the effects of the combination of mutual neighborhood algorithm and diagonal loading technique (MN-DL-LLE) and also their separate (MN-LLE and DL-LLE) performance are investigated. For completing the investigation, the results are compared with another local manifold learning method, LEM. Also, mutual neighborhood conception is applied on LEM (MN-LEM). In MN-LEM, after determining the mutual neighbors of , the coefficients between
and its mutual neighbors are calculated as follows:
where t is the heat kernel parameter of Laplacian function. Then, the low-dimensional embedded data manifold () is extracted using the following equation:
where is a diagonal matrix with
. In our experiments,
is set to 1 if
is neighbor of
for LEM and MN-LEM.
ORL face image database
ORL image database includes 400 face images of size 112 × 92 at different time, lighting and facial expressions. There are 40 persons with 10 images for everyone. Some sample images are shown in .
Figure 4. The upper row shows face images of five different persons of ORL database and the lower row shows face images of one person with different lighting and facial expressions.

A set of different images for each person is randomly divided into three subsets, namely, four train images, three validation images and three test images. In this database, leave one out method is used for evaluating the performance of the proposed method. The experiments are done in different low dimensionalities () and the number of the neighbors is 7 (
). The results are given in .
Table 3. The recognition rates of LLE, MN-LLE, DL-LLE, MN-DL-LLE, LEM and MN-LEM for ORL database in different dimensionalities.
The results show that mutual neighborhood conception properly improves the performance of LLE and LEM methods. Also, diagonal loading technique affects LLE well. shows the values of the diagonal loading parameter of DL-LLE and MN-DL-LLE methods. These values are determined based on the train and validation datasets to provide the maximum recognition rate in different dimensionalities.
Table 4. The values of diagonal loading parameters of DL-LLE and MN-DL-LLE for ORL database in different dimensionalities.
IPHD
This database includes 2240 isolated Persian handwritten digit images from 1–9 except 2. There are 280 samples for each digit. shows some sample images of this database.
Figure 5. The upper row shows different shapes of number four in Persian handwritten and the lower row shows number 1–9 in Persian handwritten except number 2.

Samples of each class are randomly divided into three subsets, namely, 140 train images, 70 validation images and 70 test images. Validation images are used to determine the value of the diagonal loading parameter. The number of the neighbors is 10 and the recognition rates are calculated in the low dimensionalities of 6,9,12 and 15. shows the obtained results.
Table 5. The recognition rates of LLE, MN-LLE, DL-LLE, MN-DL-LLE, LEM and MN-LEM for IPHD database in different dimensionalities.
The results demonstrate the good performance of the proposed MN-DL-LLE and MN-LEM methods. Mutual neighborhood provides more effective local structure information and increases the performance of local manifold learning methods. The values of the diagonal loading parameter are given in . Again, diagonal loading enhances the results.
Table 6. The values of diagonal loading parameters of DL-LLE and MN-DL-LLE for IPHD database in different dimensionalities.
Isolated Farsi/Arabic handwritten character database (IFHCDB)
IFHCDB includes 52380 and 17740 isolated Persian handwritten characters and digits, respectively. The images are gray scale and 300 dpi. The number of samples in different classes is not the same. Some samples of IFHCDB digits are given in .
Figure 6. The upper row shows different shapes of number 5 and the lower row shows number 0–9 in Persian handwritten.

The digits are used to investigate the performance of our proposed method. In each class, the number of samples of train, validation and test are 150, 50 and 50, respectively. The samples are randomly selected. shows the results. Again the results demonstrate the good performance of the proposed method.
Table 7. The recognition rates of LLE, MN-LLE, DL-LLE, MN-DL-LLE, LEM and MN-LEM for the digits of IFHCDB database in different dimensionalities.
The values of the diagonal loading for IFHCDB database are given in .
Table 8. The values of diagonal loading parameters of DL-LLE and MN-DL-LLE for the digits of IFHCDB database in different dimensionalities.
Sparsity of the proposed representation
As we know, mutual neighborhood conception induces a sparser neighborhood graph matrix than the common graph matrix. The amounts of the sparsity of the neighborhood graph matrix in MN-DL-LLE and LLE are tabulated in for different number of neighbors. As shows, the proposed method leads to sparse representation of manifold structure. Also, the sparsity of the neighborhood graph matrices of MN-LLE and MN-LEM are the same as MN-DL-LLE.
Table 9. Comparison between nonzero elements of neighborhood graph matrices of LLE and MN-DL-LLE.
Conclusions
In local manifold learning methods, the construction of the neighborhood graph matrix is a main step that is related to the selection of the neighbors of each data point and the coefficients between each data point and its neighbors. In this paper, a new unsupervised nonlinear local manifold learning method was proposed. The proposed method is based on the mutual neighborhood conception and diagonal loading for linear reconstruction weight of each data point in LLE algorithm. The values of the diagonal loading parameter are determined by validation dataset corresponding to the best recognition rate. Also, the results of applying the mutual neighborhood conception on LEM demonstrate the proper performance of our proposed neighbor selection method. Simulations were carried out for ORL, IPHD and IFHCDB databases. The obtained results show the effectiveness of the proposed method. In all experiments, the proposed MN-DL-LLE algorithm has the best recognition rate. In all experiments for the ORL, IPHD and IFHCDB databases, recognition rates of MN-DL-LLE are approximately 8%, 3% and 10% better than LLE, respectively. Moreover, the neighborhood graph matrix based on the mutual neighborhood conception is very sparser than the neighborhood graph matrices of LLE or LEM. The results show that the proposed sparse neighborhood graph, which is constructed based on the mutual neighborhood conception and diagonal loading, can be better extracted the local information of the manifold. Therefore, in local manifold learning methods, the right choice of the neighbors and then a true definition of the connection coefficients between each data point and its neighbors can more effectively improve the performance.
References
- Álvarez, D., R. Fernández, and L. Sánchez. 2012. Stroke based handwritten character recognition. In International Conference on Hybrid Artificial Intelligence Systems, 343–51. Springer, Berlin, Heidelberg, March 28.
- Belkin, M., and P. Niyogi. 2001. Laplacian Eigenmaps and spectral techniques for embedding and clustering. Neural Information Proceeding Systems 14, 585–91, Vancouver, British Columbia, Canada, December.
- Brand, M. 2002. Charting a manifold. Advanced in Neural Information Proceeding Systems 16, 985–92, Vancouver, Canada, December.
- Chen, Y., B. An, J. Dong, and M. Zhao. 2016. A novel manifold preserving edit propagation based on K nearest neighbors and locally linear embedding. Optical and Quantum Electronics 48 (11):488. doi:10.1007/s11082-016-0756-y.
- Cox, T. F., and M. A. A. Cox. 2000. Multidimensional scaling. Boca Raton, FL: CRC press.
- Davis, J. V., B. Kulis, P. Jain, S. Sra, and I. S. Dhillon. 2007. Information-theoretic metric learning. In Proceedings of the 24th international conference on Machine learning, 209–16. ACM, Corvallis, OR, USA, June 20.
- Donoho, L. D., and C. Grimes. 2003. Hessian Eigenmaps: Locally linear embedding techniques for high-dimensional data. Proceedings of the National Academy of Sciences 100 (10):5591–96. Washington, DC 20001 USA, May 13. doi:10.1073/pnas.1031596100.
- Fukunaga, K. 1990. Statistical pattern recognition, 2nd ed., vol. 1, 990. San Diego, CA: Academic Press.
- Ghaleb, M. H., L. E. George, and F. G. Mohammed. 2013. Numeral handwritten Hindi/Arabic numeric recognition method. International Journal of Scientific & Engineering Research 4 (1).
- Goldberger, J., S. Roweis, G. Hinton, and R. Salakhutdinov. 2004. Neighbourhood components analysis. Neural Information Proceeding Systems 17, 513–20, Vancouver, Canada.
- Jolliffe, I. 2002. Principal component analysis. Springer Verlag, New York, Inc.
- Kacem, A., N. Aouïti, and A. Belaïd. 2012. Structural features extraction for handwritten Arabic personal names recognition. In Frontiers in Handwriting Recognition (ICFHR), 2012 International Conference on, 268–73. IEEE.
- Kang, S., D. Ma, Y. Wang, C. Lan, Q. Chen, and V. I. Mikulovich. 2017. Method of assessing the state of a rolling bearing based on the relative compensation distance of multiple-domain features and locally linear embedding. Mechanical Systems and Signal Processing 86:40–57. doi:10.1016/j.ymssp.2016.10.006.
- Kocsor, A., K. Kovács, and C. Szepesvári. 2004. Margin maximizing discriminant analysis. In European Conference on Machine Learning, 227–38. Springer Berlin Heidelberg.
- Li, B., and Y. Zhang. 2011. Supervised locally linear embedding projection (SLLEP) for machinery fault diagnosis. Mechanical Systems and Signal Processing 25 (8):3125–34. doi:10.1016/j.ymssp.2011.05.001.
- Ma, N., and J. T. Goh. 2003. Efficient method to determine diagonal loading value. In Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP’03). 2003 IEEE International Conference on, April 6, (5):341–44, Hong Kong, China.
- Mika, S., G. Ratsch, J. Weston, B. Scholkopf, and K. R. Mullers. 1999. Fisher discriminant analysis with kernels. In Neural Networks for Signal Processing IX, 1999. Proceedings of the 1999 IEEE Signal Processing Society Workshop, 41–48. Madison, WI, USA, August 25.
- Mozaffari, S., K. Faez, F. Faradji, M. Ziaratban, and S. M. Golzan. 2006. A comprehensive isolated Farsi/Arabic character database for handwritten OCR research. In Tenth International Workshop on Frontiers in Handwriting Recognition. Suvisoft, Finland, October 23.
- Pradeep, J., E. Srinivasan, and S. Himavathi. 2014. An investigation on the performance of hybrid features for feed forward neural network based English handwritten character recognition system. WSEAS Transactions on Signal Processing 10 (1):21–29.
- Roweis, S. T., and L. K. Saul. 2000. Nonlinear dimensionality reduction by locally linear embedding. Science 290 (5500):2323–26. doi:10.1126/science.290.5500.2323.
- Samaria, F. S., and A. C. Harter. 1994. Parameterisation of a stochastic model for human face identification. In Applications of Computer Vision, 1994., Proceedings of the Second IEEE Workshop on, 138–142. Sarasota, Florida, USA, December 5.
- Schölkopf, B., and A. J. Smola. 2002. Learning with kernels: Support vector machines, regularization, optimization, and beyond. Cambridge, Massachusetts, USA: MIT press.
- Sharma, A. 2012. Handwritten digit recognition using support vector machine. arXiv preprint arXiv:1203.3847.
- Shayegan, M. A., and C. S. Chan. 2012. A new approach to feature selection in handwritten Farsi/Arabic character recognition. In Advanced Computer Science Applications and Technologies (ACSAT), 2012 International Conference on, 506–11, Kuala Lumpur, Malaysia, November 26.
- Shental, N., T. Hertz, D. Weinshall, and M. Pavel. 2002. Adjustment learning and relevant component analysis. In European Conference on Computer Vision, 776–90. Springer Berlin Heidelberg.
- Singh, V., and S. P. Lal. 2014. Digit recognition using single layer neural network with principal component analysis. In Computer Science and Engineering (APWC on CSE), 2014 Asia-Pacific World Congress on, 1–7, Plantation Island Resort, Denarau Island, Fiji Islands, November 4.
- Teh, Y. W., and S. T. Roweis. 2002. Automatic alignment of hidden representations. Advances in Neural Information Processing Systems 15, 841–48, Cambridge, MA, USA: The MIT Press.
- Tenenbaum, J. B., V. De Silva, and J. C. Langford. 2000. A global geometric framework for nonlinear dimensionality reduction. Science 290 (5500):2319–23. doi:10.1126/science.290.5500.2319.
- Wang, F., and C. Zhang. 2007. Feature extraction by maximizing the average neighborhood margin. In Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 1–8, Minneapolis, MN, USA, June 17.
- Weinberger, K. Q., F. Sha, and L. K. Saul. 2004. Learning a kernel matrix for nonlinear dimensionality reduction. In Proceedings of the twenty-first international conference on Machine learning, 106. ACM, New York, NY, USA, July 4.
- Wu, Y. C., H. T. Hwang, C. C. Hsu, Y. Tsao, and H. M. Wang. 2016. Locally linear embedding for exemplar-based spectral conversion. In Proc. INTERSPEECH, 1652–56, San Francisco, California, USA, September.
- Xing, E. P., A. Y. Ng, M. I. Jordan, and S. Russell. 2002. Distance metric learning with application to clustering with side-information. Neural Information Proceeding Systems (15):505–12, Vancouver, British Columbia, Canada, December.
- Yu, N., and P. Jiao. 2012. Handwritten digits recognition approach research based on distance & Kernel PCA. In Advanced Computational Intelligence (ICACI), 2012 IEEE Fifth International Conference on, 689–93. Nanjing, China, October 18.
- Zhang, Z. Y., and H. Y. Zha. 2004. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. SIAM Journal of Scientific Computing 26 (1):131–338. doi:10.1137/S1064827502419154.
- Zhao, X., and S. Zhang. 2012. Facial expression recognition using local binary patterns and discriminant kernel locally linear embedding. EURASIP Journal on Advances in Signal Processing 2012 (1):20. doi:10.1186/1687-6180-2012-20.
- Ziaratban, M., K. Faez, and F. Faradji. 2007. Language-based feature extraction using template-matching in Farsi/Arabic handwritten numeral recognition. In Document Analysis and Recognition, 2007. ICDAR 2007. Ninth International Conference on, vol. 1, 297–301. Curitiba, Brazil, September 26.
- Ziemann, A. K., and D. W. Messinger. 2015. An adaptive locally linear embedding manifold learning approach for hyperspectral target detection. In Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXI, International Society for Optics and Photonics, Vol 9472, Baltimore, Maryland, United States, April.