
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A novel technique for optimization of artificial neural network (ANN) weights which combines pruning and Genetic Algorithm (GA) has been proposed. The technique first defines “relevance” of initialized weights in a statistical sense by introducing a coefficient of dominance for each weight and subsequently employing the concept of complexity penalty. Based upon complexity penalty for each weight, candidate solutions are initialized to participate in the Genetic optimization. The GA stage employs mean square error as the fitness function which is evaluated once for all candidate solutions by running the forward pass of backpropagation. Subsequent reproduction cycles generate fitter individuals and the GA is terminated after a small number of cycles. It has been observed that ANNs trained with GA optimized weights exhibit higher convergence, lower execution time, and higher success rate in the test phase. Furthermore, the proposed technique yields substantial reduction in computational resources.
Introduction
Artificial Neural Networks (ANNs) and genetic algorithms (GA) are popular paradigms for learning and optimization, each with their own strengths and weaknesses. ANNs trained with backpropagation (BP) algorithm are highly popular due to their low complexity and ease of implementation. However, they are prone to getting stuck in local minima thereby yielding suboptimal solutions. GA, on the other hand, is good at global search and exhibits a robust performance. Applications of GA have been reported for defense in biological and chemical warfare (Haupt and Haupt Citation2011), design of combinational logic (Louis Citation2005), and wireless ad-hoc networks (Karthikeyan, Baskar, and Alphones Citation2012). Recent advancements in GA is based on a three-dimensional cellular GAs proposed by Asmaa, Erdogan, and Arslan (Citation2013) that provides better performance in terms of efficiency, and efficacy, for most of the problems. However, unguided mutation and variations in a host of parameters leads to extremely slow convergence of GA. With an aim to obtain complementary advantages from both GA and ANN, many researchers have reported a variety of neuro genetic techniques with varying success rates (Christiansen et al. Citation2012; Karlra and Prakash Citation2003; Srivastava, Shukla, and Srivastava Citation1998).
Design of ANN using GA has been under consideration for quite some time (Hunter and Chiu Citation2000). Kwon and Moon (Citation2007) have reported a neuro-genetic stock forecasting system where a recurrent neural network is trained for predicting the performance of a particular stock using a large pool of previous data. Similarly, Ramasubramanian and Kannan (Citation2006) have described a database intrusion prediction system based upon a hybrid neuro-genetic network. This hybrid approach to weight optimization is particularly useful when the ANN is trained with BP algorithm. In design of a hybrid neuro-genetic system, there is a scope to rope-in both improved GA and improved ANN training methodologies. Some authors have described a model which takes into account interdependence between individuals taking part in the reproduction process, thus building a more rational strategy for selection and fitness evaluation (Bull Citation2001). Hu et al. (Citation2015) have proposed a GA-optimized ANN to be used in ultrasonic flow meters. The GA is utilized to determine ANN architecture based on its efficient parallel advantage in global search. Using this approach, the initial weights and biases are also optimized, which makes the network capable to avoid getting stuck in local minima. A novel approach to improve the classification performance of a polynomial neural network has been proposed by Lin, Prasad, and Saxena (Citation2015). Libelli, Marsili, and Alba (Citation2000) described an adaptive mutation technique to enhance the mutation probability of less fit individuals. A novel “wavelet mutation operator” has been proposed by Ling and Leung (Citation2007a; and Citation2007b). Kumar, Gospodaric, and Bauer (Citation2007) report an improved GA based on biological evolution. The efficacy of GA as a pre-processing tool has been demonstrated on feature subset selection in Tan et al. (Citation2008). An ANN has been trained for bearing fault detection using input features selected by GA (Samanta, Al-Balushi, and Al-Araimi Citation2006). However, the task of optimizing weights of an ANN is a challenging one since the GA and ANN can no longer be treated as separate stages of a system. In this work, we report a neuro-genetic classifier trained with BP algorithm, in which an optimum set of weights is chosen using a novel GA-based technique.
BP works well on simple training problems but its performance falls off rapidly as the dimension or complexity (high correlation in the input samples) of input data increases. The problem of training a network using BP has two aspects. First is the task of finding the optimal number of hidden layer neurons. Second, the determination of weights and biases of the ANN. Specifying the weights of a neural net is mostly viewed as an optimization process, where an error goal needs to be achieved. However, optimization using BP imposes a great risk of getting stuck to a local minimum, since the error surface is high dimensional. GAs do not encounter such kind of performance issue as they keep the current best solution as the part of their population while they search for further better solutions. It is also clear that all the weights do not contribute equally to pattern classification. Thus, there are some set of weights which have less or no impact on the pattern separability. These types of weights are redundant and are referred to as excess weights (Haykin Citation2007). Therefore, the first issue addressed in this paper is elimination of redundant weights. This aspect has been addressed by many researchers in a plentitude of ways. A pruning strategy for Extreme Learning Machine has been proposed using the Successive Projections Algorithm (SPA) as an approach to automatically find the number of hidden nodes (Mesquita et al. Citation2015). Another pruning strategy has been proposed to find a compact structure of feedforward neural networks with high generalization ability in classification problems (Tong and Tanaka Citation2015). One of the novel aspects of this work is to amalgamate weight pruning and GA. This aspect has been discussed in the implementation section. A brief overview of the relevant prior work on GA-based weight pruning is now being presented in the next section.
Related Work
In the early stages of development of ANN training paradigms, Reed (Citation1993) presented a comprehensive review of network pruning algorithms. One of the earliest reported uses of GA for weight pruning can be traced in (Aleksander and Taylor Citation1992) which employed pruning of a trained network prior to presenting the test samples for improved generalization. This genetically pruned network was used for face recognition and sonar signal classification. Recently, Sabo and Yu (Citation2008) have proposed a simple pruning algorithm based upon cross validation and sensitivity analysis in order to get an optimal neural network topology which will result into a significantly lower computational complexity. Augasta and Kathirvalavakumar (Citation2015) have conducted a survey of existing pruning techniques that optimize the architecture of neural networks. They have also evaluated the effectiveness of various pruning techniques based on sensitivity analysis, mutual information, and significance on four real data sets. Apart from network and weight pruning approaches, researchers are also opting for statistical methods to prune the input features for simpler network architecture since the number of input layer neurons is equal to the input data dimension. Kingston, Maier, and Lambert (Citation2004) have employed statistical input pruning for environmental modeling. Christiansen et al. (Citation2012) have applied optimal brain surgeon (OBS) algorithm for automatically generating a topologically optimized ANN based upon the statistical properties of the input data set. GA-based search has been employed by Mantzaris, Anastassopoulos, and Adamopoulos (Citation2011) to eliminate excess weights from an ANN used to estimate Urinary Tract Infection from medical examination data. Workers have also reported novel evolutionary algorithms for pruning ANNs constructed for prediction applications (Yang and Chen Citation2012). However, an in-depth study of the prior work reveals the fact that researchers have by and large ignored the role of mutation operator in the GA flow in selecting the fittest weights for an ANN. Furthermore, the authors felt a need to incorporate some information about the statistical properties of individual weights converging on a particular neuron in the GA flow. The novel aspect of this work is the introduction of a mutation operator which performs thresholding of individual weights based upon their contribution to overall weight variance. Though the problem of weight optimization using GA has been attempted with varying degrees of success by previous researchers, it is for the first time to the best of our knowledge that the concept of weight pruning has been incorporated into the conventional GA, so that the weights having smaller effect on the network as compared to other weights be declared as excess weights and eventually be removed. It has also been proposed that weight pruning strategy will govern the population initialization operation of GA which will be described in section “Problem Formulation”.
Need of Improvement
Recently, Medeiros and Barreto (Citation2013) have proposed a novel weight pruning methodology for (Multilayer Perceptron) MLP classifiers. The proposed method is based on the observation that relevant synaptic weights tend to generate higher correlations between error signals associated with the neurons of a given layer and the error signals propagated back to the previous layer, whereas non-relevant (i.e. prunable) weights tend to generate smaller correlations. This observation has been termed as MAXCORE principle by the authors and has been introduced as the guiding principle behind the Cross Correlation Analysis of Back Propagated Errors (CAPE) methodology. CAPE has emerged as one of the most significant weight pruning strategy reported recently. In terms of computational complexity, CAPE has outperformed OBS and its variants.
However, this paper contests the claim of generality of the MAXCORE principle (Medeiros and Barreto Citation2013). Let us analyze a hypothetical ANN trained with BP algorithm whose backward pass is depicted in .
Figure 1. Backward pass of backpropagation.
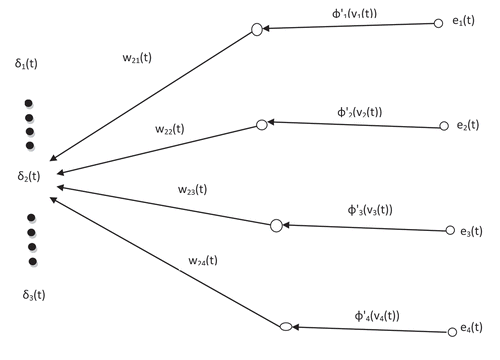
Let the errors generated by output neurons of the network presented with
training examples be represented in the form of an
matrix.
where each row of corresponds to the error generated by the output neurons for a given training pattern.
Similarly, backpropagated errors associated with hidden neurons of the same network can be represented in the form of an
matrix.
The correlation matrix can be evaluated as:
where is the entry in the correlation matrix corresponding to the scalar product of the kth column of
with the ith column of
.
Let us examine and
for the network shown in .
Let us assume . According to the MAXCORE principle,
is more relevant than
if
,
where
and
As evident from above equations, higher or lower values of depend not only upon
but also upon local gradients
of the output neurons connected to the hidden layer neuron i. Since, local gradient of the output neuron k is given by:
where is the induced local field and
is the differential of the activation function. Most of the time, a sigmoidal activation function is chosen which maps the synaptic weights
nonlinearly in the form of induced local field passed through
. Since, the contribution of
in the magnitude of correlation coefficient
depends upon
, which in turn are nonlinear functions of synaptic weights,
, a high value of
neither guarantees a high magnitude nor a high degree of relevance for
Furthermore, it is always better to define “relevance” of a synaptic weight either in a statistical sense or with respect to a performance metric. The standard practice of complexity regularization defines a risk function as:
where is the standard performance measure (e.g. MSE), and
is the complexity penalty term which depends upon the network model alone. As regularization parameter,
represents the relative importance of the complexity penalty term with respect to the MSE. Assuming
to have a moderate value somewhere between zero and infinity, the relative importance of complexity penalty term with respect to MSE is also moderate. Therefore, we can define “relevance” of individual synaptic weights both in terms of MSE and in terms of complexity penalty. However, to compute the relevance of weights in terms of
, we need to run BP algorithm first (at least forward pass). For the networks which have not yet undergone training, it would be better to first compute
in terms of complexity penalty. In the light of the above discussion, novel contributions of this work can be enlisted as follows:
This work seeks to define relevance of the weights in a statistical sense.
A coefficient of dominance has been proposed to identify nodes carrying higher information content and to determine complexity penalty for each weight.
Use of GA to optimize fittest weights in terms of MSE.
New schemes for initialization of population and mutation have been proposed.
Problem Formulation
The Proposed Methodology
The proposed methodology has been implemented in a sequence of several steps as illustrated in . As an illustration of the first stage of the methodology, let us consider an ANN with single hidden layer and three target classes subjected to IRIS data as input. The number of hidden layer neurons has been chosen to be three. As shown in , there are a total of 27 connections including 20 weights and 7 biases. All the connections have been initialized randomly. The connections would be evaluated as a part of weight pruning/modification scheme which is described in detail with analytical justifications in the next section. All the 27 connections have been encoded in the form of a chromosome string shown in . Many such chromosomes have been generated to initialize the mating pool. Each weight has been encoded using 10 bits. With this step, GA optimization of ANN weights commences. Subsequent steps follow the standard GA flow with crossover, mutation, and ranking of individuals which ultimately yields the “fittest” set of weights. The details of all individual stages of the methodology are described in the implementation section.
Figure 2. The proposed methodology.
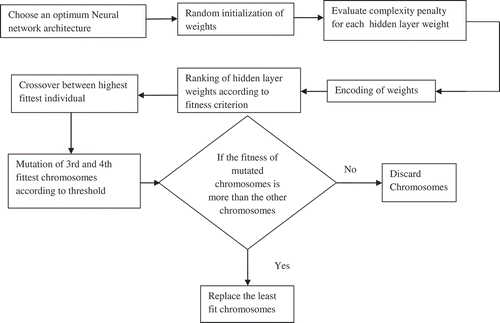
Figure 3. ANN architecture for IRIS data.
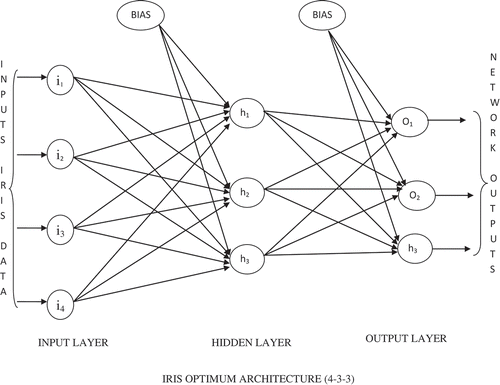
Figure 4. Weights and biases of represented as a chromosome.

Data Description
The simulations have been carried out on several benchmark data sets obtained from UCI machine learning repository. All the data sets chosen for this study represent pattern classification problems with varying number of samples, input dimensions, and target classes details of which is shown in . During the course of simulation, the number of training and test samples was kept equal in most of the cases except in the case of letter recognition where the results varied significantly when the number of test samples was changed.
Table 1. Data description.
Implementation
The Weight Pruning Scheme
The objective of pruning is to downsize the model to the level of least complexity that still provides the best generalization. In general, the capability of feedforward neural networks for data fitting increases as the number of connection weights increase, because an increase in the number of free parameters enables the network to finely capture subtle features. However, a model with too many parameters can pick up nonessential information in the sample data and cause the problem of overfitting. This leads to poor generalization. Therefore, application of appropriate pruning techniques can contribute to improvement in the generalization ability. Furthermore, a reduction in the network components is advantageous for hardware implementation of large-sized ANNs. The proposed idea seeks to incorporate weight pruning scheme into the conventional GA flow. The weights which are insensitive to the error changes can be discarded after each step of training. The pruned network is of smaller size and is likely to give higher accuracy than before its trimming. ANN use network pruning strategies which can be classified into two categories viz. weight decay and weight elimination. In both the strategies, a complexity penalty term is defined which appropriately quantifies the degree of redundancy in a weight. In weight decay procedure, if the initial weight vector is w, the complexity penalty term is defined as the squared norm of the weight vector w (i.e. all the free parameters) in the network and is expressed as:
where the set refers to all the synaptic weights in the network. However, in this scheme, some weights in the network have relatively larger values than others. This results in making smaller weights redundant since they have little influence on the training outcome. To overcome this limitation, the complexity penalty term is now redefined as follows:
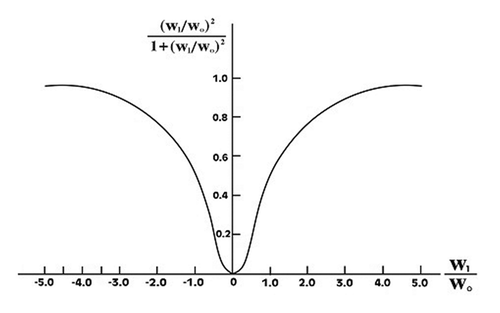
where wo is the preassigned weight change parameter defined according to the problem and wi refers to the ith weight in the network. It is proposed here that the optimality of a weight vector would be defined in the statistical sense. Higher the complexity penalty for a particular weight, more important is the weight for the learning process. If the weights converging on a particular hidden neuron have variance more than the variance of total weights in the network, then that hidden node will contribute more to the network. The real challenge in this case lies in selection of an appropriate . As can be inferred from , the choice of parameter
is crucial aspect of network pruning.
Figure 5. Variation of complexity penalty term with respect to (Haykin Citation2007).
In this study, a new pruning method has been proposed based on the weight variation information during the backpropagation training. Every node in the hidden layer is evaluated to determine the effective variance of weights. In order to compute the complexity penalty term as defined in Equation (9) for each weight, a coefficient of dominance called Dsi is calculated for each neuron and is expressed as:
where Dsi corresponds to wo of Equations. (9) and (10), is the variance of the weights of ith hidden node, and
is the effective variance of all the weights in the hidden layer.
In the similar way, all the remaining hidden layer neurons are evaluated to find the coefficient of dominance and a set is defined as:
The complexity penalty for each weight in the network is defined as:
The variance dependent weight pruning technique described above helps to increase the information content of the weight set convergent on a less dominant neuron. This can be explained in terms of a metric called Fisher information which is defined as a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X and can be stated as:
where log is the natural logarithm of the probability function.
The input to the hidden node is given by:
where is the ith input and
is the weight from ith input to jth hidden node. Also, the weights leading to a hidden node are regarded as zero mean random variables. Therefore, the mean of the input to the hidden node is given by:
Since, the weights are randomly chosen, they can be considered independent of the input feature. Thus, Equation (9) can be written as:
The variance of y is given by:
Using Equation (15) in (17), we get,
Since the different weights and input feature to a hidden node are independent, Equation (18) becomes
If the training samples are normalized to be in the interval [0:1], then
where is variance of random variable
. For a uniform random variable lying within [0:1],
Also, input to hidden layer weight is also regarded as a random variable with zero mean, uniformly distributed in the interval [–a, a]. Hence, the standard deviation of the input to a hidden layer weight is:
So, using Equations (13), (15), and (16))
where N denotes the number of weights converging on a particular node.
Equations (19) and (23) justify that input to a hidden layer neuron is also a random variable with zero mean and variance. The probability distribution function of the input to hidden layer node is given as:
where y corresponds to induced local field of jth hidden layer neuron and can also be defined as:
where xi is the data input and wji is the weight connecting from ith input node to jth hidden node .
According to Equations (23) and (24), the information content about the weight set in the hidden layer neuron which is the above-defined random variable can also be calculated as follows:
Using Equation (13), the fisher information is given as:
Using Equations (12), (15), and (17), we get:
Let the variance term be replaced by the coefficient of dominance (which is a simple ratio of the variances) and consider two different hidden nodes with and
as respective variances of weights convergent on them. Then, the fisher information for the two nodes is given by:
If Fisher information of node 1 will be more compared to that of node 2. This implies that a lower coefficient of dominance which makes the complexity penalty higher (and the weight more relevant) also enhances the information content of the convergent connections at a node.
The inclusion of variance in the complexity penalty term and the particular choice of coefficient of dominance are justified by the above explanation.
Genetic Optimization of Weights
Working of Genetic Algorithm
GAs are paradigms for optimization based loosely on several features of biological evolution. Initially, a pool of solutions (population) represented by chromosomes is created. Then, an encoding scheme is used to represent each individual. An evaluation/fitness function is required that provides ranking to each chromosome. The population undergoes reproduction until stopping criteria are met (Sivanandam and Deepa Citation2007).
The basic GA shown in the form of is explained as follows:
Figure 6. The Genetic Algorithm.
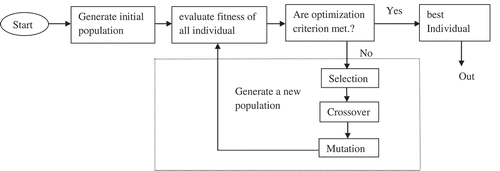
Generate random population of chromosomes, that is, suitable solutions for the problem.
Fitness of each chromosome in the population is evaluated.
The population undergoes reproduction followed by a number of iterations of the following three steps:
Parents are selected to reproduce according to their fitness.
Different operators are applied to the parents to form new offspring.
Place new offspring in the new population.
Use new generated population for a further run of the algorithm.
If the end criterion is satisfied, return the best solution to the current population.
Go to step 2.
Why Genetic Algorithm?
The proposed scheme not only prunes the weights according to the fitness function, it modifies them in accordance with the complexity penalty. The complexity penalty-based modification function yields an initial population of candidates which constitutes the solution space. GA is now used to evaluate the candidate’s fitness through crossover and mutation in successive generations. Actual pruning is accomplished only after the algorithms zeros in on the least fit weights. Weight pruning completely alters the architecture of an ANN. The altered architecture may be better than the original one in terms of convergence and error performance. However, we have no means of judging its optimality before the network is actually trained. From the point of view of custom hardware implementation, repeated alterations in the architecture of a network are highly undesirable and it leads to gross wastage of resources. The use of GA in the subsequent stage ensures efficient search of the solution space to identify one or more “good solutions” though not necessarily the best one. However, through successive generation cycles, it is not hard to identify the least fit (prunable) weight.
The Strategy
The strategy is depicted in the form of a flow chart in . As the first step initialization of population is done. Unlike the conventional method of random initialization we adopt a methodology which modifies the initial weights according to the complexity penalty to generate the mating pool in a controlled manner as described below.
Figure 7. Genetic optimization of ANN weights.
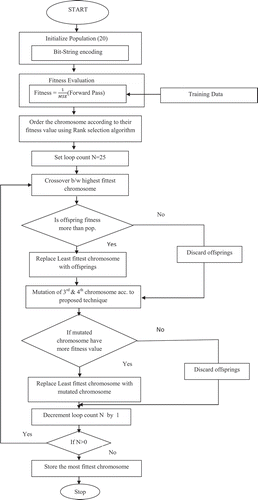
The initialized population of size is given by a set
Also,
where is a
vector of multipliers
if , then
lies in the range [0.9, 1.3].
If , then
is a
vector of random multipliers.
If , then
lies in the range [0.2, 0.5].
If , then
is pruned.
Multiplication of an initial weight by
generates
(in our case,
= 20) different weights which constitute the population after bit string encoding. It should be noted that weights with a higher complexity penalty (more relevance) generate a population with “high” complexity penalties (due to range of
). Similarly, non-relevant weights generate a population with “low” complexity penalties. By initializing the population in this manner, we are restricting the extremities of the search space to a specified range, thereby reducing the chances of the algorithm running a futile search and getting stuck in local minima. However, the necessity of randomness in initialization cannot be completely overlooked since it is essential to include largest possible number of potential solutions in the search space. To ensure this, we have generated random population from the weights having “moderate” complexity penalty.
The fitness function is defined as
Here, t and y represent the target and calculated outputs, respectively, and p signifies the number of training patterns. Fitness of each chromosome is evaluated by running the forward pass of BP algorithm. The chromosomes are ordered according to their fitness value using rank selection. Reproduction of new offspring is done by selecting fittest parents from the mating pool and subjecting them to two point restricted crossover.
Each generation cycle witnesses addition of the offspring to the mating pool if its fitness is more than that of one of its parents. In this case, the least fit chromosome is discarded and the offspring is ranked according to its fitness value. However, the offspring is discarded if it is not fitter than any of its parents. In both cases, third and fourth fittest chromosomes are mutated with a small mutation probability (0.06–0.09). If the mutated chromosomes are fitter than the original one, they are added to the mating pool and ranked accordingly and two least fit chromosomes are discarded. This heuristic step of mutating third and fourth rank chromosomes is like giving a “second chance” to some athlete taking part in Olympics and missing the bronze medal by a whisker. If mutation with a small probability increases the fitness then both original and mutated weights should be part of the mating pool in the next generation cycle. After 25 generation cycles, the average increase in fitness of weights was no longer significant employing the proposed scheme. The fitness values of the weights obtained using the proposed technique were compared with that obtained using conventional GA (random initialization) and it was verified that partially random initialization and mutation of third and fourth fitted chromosomes yielded fitter individuals in significantly less number of generation cycles.
Training the Pruned ANN
After 25 generation cycles of the GA, the pruned ANN is reinitialized with the stored weights. A single hidden layer neural network was trained using two different versions of BP algorithm for classifying five benchmark data sets. The number of hidden layer neurons was optimized experimentally and different architectures were found optimum for different data set. The network was first trained using traingdm function of Matlab. traingdm was chosen as the training function because it gives the highest degree of freedom for the investigator to fine tune the training parameters since both learning rate and momentum constant can be varied experimentally using this function. The network was also trained with Levenberg–Marquardt algorithm using trainlm function of MATLAB. Since, Levenberg–Marquardt algorithm is known to outperform simple gradient descent and other conjugate gradient methods in a plentitude of problems, it was necessary to examine whether the proposed technique is able to improve the performance of Levenberg–Marquardt algorithm. A 10-fold cross validation scheme was used to prevent over fitting. The training phase performance of the network in was evaluated with respect to four parameters viz. convergence success rate (% of time the simulation reaches error goal), mean epochs, execution time, and computational complexity. However, the generalization performance is the ultimate performance metric which gives the classification success rate. All the parameters have been evaluated both for unpruned and pruned networks.
Results and Discussions
Convergence and Generalization
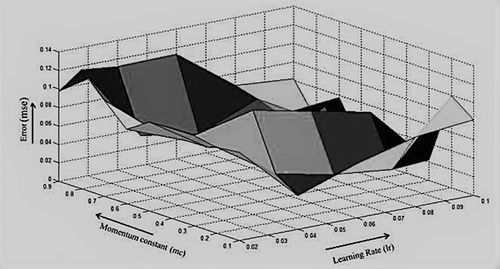
The training phase performances of the conventional ANN and GA-optimized ANN trained with traingdm are given in & , respectively. In , results are shown for the networks not subjected to GA-based weight optimization. It can be observed that the pruned architectures perform marginally better than their unpruned counterparts for all the three training parameters. A comparison of and reveals significant improvements in the performance of the ANN when the weights are optimized using GA. Furthermore, better performance of the pruned architectures can’t be ignored in this case also. The networks were then trained till convergence and subsequently presented with the test samples. and depict the error surface obtained using conventional BP and proposed algorithm, respectively. As evident from the plots, the error surface obtained using the proposed technique spans a larger area of the plot with multiple error minima. This indicates more consistent performance of the network initialized with GA-determined weights at almost all values of learning rate and momentum constant. The effect of the proposed techniques on Levenberg–Marquardt algorithm has been investigated. The pruned networks have again performed marginally but consistently better with trainlm as shown in . Although trainlm by default exhibits higher converge success and a lower epoch mean, GA-optimized weights have improved these parameters as can be observed in .
Table 2. Training phase performance of conventional ANN (traingdm).
Table 3. Training phase performance of GA-optimized ANN (traingdm).
Table 4. Training phase performance of conventional ANN (trainlm).
Table 5. Training phase performance of GA-optimized ANN (trainlm).
Figure 8. Surface plot for error obtained for the network trained using conventional backpropagation.
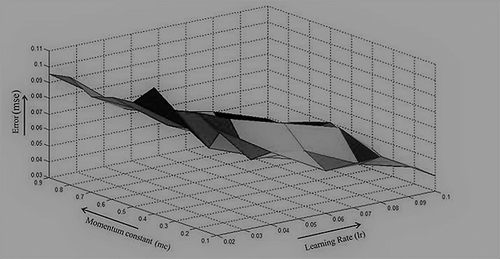
Figure 9. Surface plot for error obtained for the network trained using GA-optimized backpropagation.
The reflection of better convergence in the training phase on the generalization performance was as expected and the results are shown in and for traingdm and in and for trainlm, respectively. It is encouraging to note that magnitude of improvement in the performance matrices is more significant in complicated architectures e.g. “letter recognition-1 and 2”. Intuitively, more complex architectures have larger number of weights and hence more candidates in the mating pool leading to the fittest possible selection.
Table 6. Generalization performance of conventional ANN (traingdm).
Table 7. Generalization performance of GA Optimized ANN (traingdm).
Table 8. Generalization performance of conventional ANN (trainlm).
Table 9. Generalization performance of GA-optimized ANN (trainlm).
Computational Cost
The computational cost (complexity) is an important issue to be addressed during evaluation of algorithms. Sometimes, the algorithm’s effectiveness in providing a solution to a given problem requires the execution of complex computations and the use of excessive memory resources, which can create severe difficulties in real-time or low-cost applications. Let us analyze first the computational complexity of the weight pruning stage described in section “The weight pruning scheme.” Since we have developed the weight pruning scheme as an alternative to CAPE, we would now compare the computational cost for these two methodologies. and enlist the number of operations required by the proposed scheme and CAPE, respectively, as a function of number of input samples (N), input attributes (P), hidden neurons (Q), and output neurons (M). The number of operations required by the proposed methodology and CAPE was computed considering an MLP with N = 140 input samples, P = 2 input attributes, M = 1 output neuron, and the number of hidden neurons Q varying from 1 to 10. The same MLP was taken as reference by the inventors of CAPE (Medeiros and Barreto Citation2013).
Table 10. Computational operations required by the proposed method.
Table 11. Computational operations required by CAPE method (Medeiros and Barreto Citation2013).
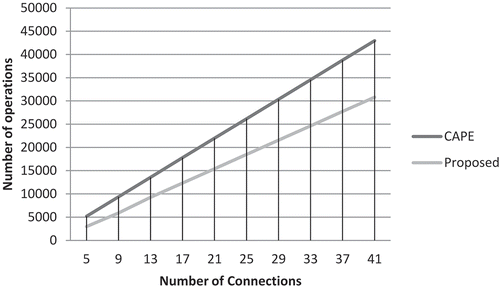
It can be easily observed from the tables that the proposed scheme requires lesser number of multiplication operations than CAPE. This is due to the fact that CAPE requires calculation of correlation coefficients to determine the relevance of weights, whereas we define relevance in terms of complexity penalty which involves fewer operations. Furthermore, unlike the proposed technique, CAPE involves running backward pass of BP which in turn involves computations through a nonlinear activation function incurring additional cost as shown in the last row of the tables. shows how the number of operations varies as a function of number of weights (connections). For the sake of simplicity, all the operations are considered to have same computational cost. From the graph, it is apparent that the proposed scheme demands lesser resources than the CAPE algorithm. It is also clear from that using proposed weight pruning stage, there is substantial reduction in the computational complexity and this reduction tends to become consistent with increasing number of connections.
Table 12. Percentage reduction in complexity by the proposed algorithm.
Figure 10. Estimated costs for CAPE and proposed scheme when pruning an MLP.
presents the stage-wise breakup of computations up to the commencement of GA. As we know, the computational complexity of GA is of the order , Where
,
, and
are number of generations, population size, and bit string length, respectively. In our case, this stage gives a complexity of
. In addition to it, evaluation of fitness for each weight requires running of forward pass of BP once per generation cycle which requires
operations. BP without GA requires
operations, where
is the number of epochs. This means savings in terms of mean epochs is going to decide which technique consumes lesser number of operations. It is evident from –,
for most of the architectures and even for Levenberg–Marquardt algorithm which takes much fewer epochs to converge.
Table 13. Stage wise break-up of computations.
Example: Pruned Network A: Trained with conventional trainlm (IRIS data). Epoch mean = 50.
Pruned Network B: Trained with GA optimized trainlm (IRIS data). Epoch mean = 30.
Computational complexity of network A = = O
=
Computational complexity of network B =
.
Thus, the savings in computations even for marginal improvement in epoch mean due to GA optimization is evident and this has been observed more prominently in complex architectures which take large number of epochs to converge.
Conclusion
The results presented in the previous section confirm the efficacy of the proposed technique in terms of convergence, execution time, and generalization performance. It is evident that both weight pruning and GA optimization stages play their respective parts and contribute significantly to improvement in performance of the BP-trained ANN. This improvement is reflected not only in ANN trained with traditional gradient descent with momentum term (traingdm) but also with a more advanced algorithm like Levenberg–Marquardt (trainlm). Reduction in the epochs required for convergence indicates that GA search about the weight space has yielded near optimal solutions. Initialization of population based upon complexity penalty as described in section “Implementation” seems to have paid dividend. Subsequently, the mutation of third- and fourth-ranked individuals (described as MAD algorithm) in the mating pool makes the whole process more competitive since the mutation operator seeks to increase the appropriateness of the weights in a statistical sense. Evaluation with the MSE-based fitness function also points toward a correlation between statistical “relevance” of weights and their fitness in terms of lower MSE. The computational complexity of the proposed weight pruning stage has been proven to be better than the existing weight pruning strategy CAPE. Also, the classification results obtained reveal the efficacy of the proposed technique. It can also be concluded that this approach can serve as an efficient and viable alternative to conventional neuro-genetic design of neural classifiers. Future work may be in the direction of further reducing the execution time of the proposed algorithm.
Disclosure Statement
The authors report no conflicts of interest. The authors alone are responsible for the content and writing of the paper. The Manuscript has not been published elsewhere and it has not been submitted simultaneously for publication elsewhere.
Additional information
Funding
References
- Aleksander, I., and J. Taylor. 1992. Pruning neural nets by genetic algorithm. Artificial neural networks 2. International Conference on Artificial Neural Networks (ICANN-92). Brighton, United Kingdom: Elsevier Science Publishers.
- Asmaa, A. N., A. T. Erdogan, and T. Arslan. 2013. Adaptive three-dimensional cellular genetic algorithm for balancing exploration and exploitation processes. Soft Computing 17:1145–57. doi:10.1007/s00500-013-0990-1.
- Augasta, M. G., and T. Kathirvalavakumar. 2015. Pruning algorithms of neural networks – a comparative study. Central European Journal of Computer Science 3 (3):105–15.
- Bull, L. 2001. On Co-evolutionary genetic algorithms. Soft Computing 5:201–07. doi:10.1007/s005000100082.
- Christiansen, N., J. Job, K. Klyver, and J. Hogsberg. 2012. Optimal brain surgeon on artificial neural networks in nonlinear structural dynamics. 25th Nordic seminar on computational mechanics. Lund, Sweden.
- Haupt, S. E., and R. L. Haupt. 2011. A mixed integer genetic algorithm used in biological and chemical defense applications. Soft Computation 15 (1):51–59. doi:10.1007/s00500-009-0516-z.
- Haykin, S. 2007. Neural network and learning machines. India: Prentice-HALL.
- Hu, L., L. Qin, K. Mao, and W. Chen. 2015. Optimization of neural network by genetic algorithm for flowrate determination in multipath ultrasonic gas flowmeter. IEEE Sensors Journal 16 (5):1158–67. doi:10.1109/JSEN.2015.2501427.
- Hunter, A., and K. S. Chiu. 2000. Genetic algorithm design of neural network and fuzzy logic controllers. Soft Computation 4:186–92. doi:10.1007/s005000000050.
- Karlra, P., and N. R. Prakash. 2003. A neuro-genetic algorithm approach for solving the inverse kinematics of robotic manipulators. IEEE Conference on Systems, Man and Cybernetics 2. Washington, USA: IEEE Publishers.
- Karthikeyan, P., S. Baskar, and A. Alphones. 2012. Improved genetic algorithm using different genetic operator combinations (GOCs) for multicast routing in ad hoc networks. Soft Computing 17 (9):1563–72. doi:10.1007/s00500-012-0976-4.
- Kingston, G., H. Maier, and M. Lambert. 2004. A statistical input pruning method for artificial neural networks used in environmental modeling. Biennial Meeting of the International Environmental Modelling and Software Society. Osnabruck, Germany: iEMSs Publisher.
- Kumar, P., D. Gospodaric, and P. Bauer. 2007. Improved genetic algorithm inspired by biological evolution. Soft Computation 11 (10):923–41. doi:10.1007/s00500-006-0143-x.
- Kwon, Y. K., and B. R. Moon. 2007. A hybrid neurogenetic approach for stock forecasting. IEEE Trans. Neural Network 18 (3):851–64. doi:10.1109/TNN.2007.891629.
- Libelli, S., Marsili, and P. Alba. 2000. Adaptive mutation in genetic algorithms. Soft Computation 4 (2):76–80. doi:10.1007/s005000000042.
- Lin, C. T., M. Prasad, and A. Saxena. 2015. An improved polynomial neural network classifier using real-coded genetic algorithm. IEEE transactions on systems. Man, and Cybernetics: Systems 45 (11):1389–401.
- Ling, S. H., and F. H. F. Leung. 2007a. An improved genetic algorithm with average-bound cross over and wavelet mutation operations. Soft Computation 11 (1):7–31. doi:10.1007/s00500-006-0049-7.
- Ling, S. H., F. H. F. Leung, and H. K. Lam. 2007b. Input-dependent neural network trained by real-coded genetic algorithm and its industrial applications. Soft Computation 11 (11):1033–52. doi:10.1007/s00500-007-0151-5.
- Louis, S. J. 2005. Genetic learning for combinational logic design. Soft Computation 9 (1):38–43. doi:10.1007/s00500-003-0332-9.
- Mantzaris, D., G. Anastassopoulos, and A. Adamopoulos. 2011. Genetic algorithm pruning of probabilistic neural networks in medical disease estimation. Neural Networks 24 (8):831–35. doi:10.1016/j.neunet.2011.06.003.
- Medeiros, C. M., and G. A. Barreto. 2013. A novel weight pruning method for MLP classifiers based on the MAXCORE principle. Neural Computing and Applications 22 (1):71–84. doi:10.1007/s00521-011-0748-6.
- Mesquita, D. P., J. Gomes, R. L. Rodrigues, and R. K. Galvao. 2015. Pruning extreme learning machines using the successive projections algorithm. IEEE Latin America Transactions 13 (12):3974–79. doi:10.1109/TLA.2015.7404935.
- Ramasubramanian, P., and A. Kannan. 2006. A genetic-algorithm based neural network short-term forecasting framework for database intrusion prediction system. Soft Computation 10 (8):699–714. doi:10.1007/s00500-005-0513-9.
- Reed, R. 1993. Pruning algorithms-A survey. IEEE Transactions on Neural Networks 4 (5):740–47. doi:10.1109/72.248452.
- Sabo, D., and X. Yu. 2008. A new pruning algorithm for neural network dimension analysis. IEEE World Congress on computational Intelligence Proc. Hong Kong, China.
- Samanta, B., K. R. Al-Balushi, and S. A. Al-Araimi. 2006. Artificial neural networks and genetic algorithm for bearing fault detection. Soft Computation 10 (3):264–71. doi:10.1007/s00500-005-0481-0.
- Sivanandam, S. N., and S. N. Deepa. 2007. Introduction to Genetic Algorithms. Berlin, Heidelberg: Springer Science & Business Media.
- Srivastava, A. K., K. K. Shukla, and S. K. Srivastava. 1998. Exploring neuro-genetic processing of electronic-noise data. Microelectronics Journal 29 (11):921–31. doi:10.1016/S0026-2692(98)00056-1.
- Tan, F., X. Fu, Y. Zhang, and A. G. Bourgeois. 2008. A genetic algorithm-based method for feature subset selection. Soft Computation 12 (2):111–20. doi:10.1007/s00500-007-0193-8.
- Tong, Z., and G. Tanaka. 2015. A pruning method based on weight variation information for feedforward neural networks. 4th IFAC Conference on Analysis and Control of Chaotic Systems 48(18): 221–226. Elsevier Science Publishers
- UCI machice learning repository http://archive.ics.uci.edu/ml/datasets
- Yang, S. H., and Y. P. Chen. 2012. An evolutionary constructive and pruning algorithm for artificial neural networks and its prediction applications. Neurocomputing 86 (1):140–49. doi:10.1016/j.neucom.2012.01.024.