
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Intelligent Environments and other Computer Science sub-fields based on the concepts of context and context-awareness are created with the explicit or implicit intention of providing services which are satisfying to the intended users of those environments. This article discusses the pragmatic importance of Preferences within the process of developing Intelligent Environments as a conceptual tool to achieve that system-user alignment and we also look at the practical challenges of implementing different aspects of the concept of Preferences. This study is not aimed at providing a definitive solution, rather to assess the advantages and disadvantages of different available options with the view to inform the next wave of developments in the area.
Introduction
New areas have recently emerged within Computer Science: first, Pervasive Computing and Communications (Percomm) and Ubiquitous Computing (Ubicomp) (Weiser Citation1991); then Internet of Things (IoT) (Atzori, Iera, and Morabito Citation2010), Ambient Intelligence (AmI) (Aarts and Roovers Citation2003), and Intelligent Environments (IE) (Augusto et al. Citation2013; Callaghan Citation2005). These areas follow more of a bottom-up approach, in the sense that systems in these areas are more service oriented and thus they look up for methods and tools which help realizing the target services, sometimes with a need to innovate on existing methods (see, for example, Cook, Augusto, and Jakkula (Citation2009)). Some examples of applications driving development in those areas are: domotics in Smart Homes, safety in Ambient Assisted Living, efficiency in Smart Offices, pedagogical support in Smart Classrooms, improved user experience and sales in Smart Shopping, improving the health of those in an Intensive Care Unit of a hospital, and so forth. Once the target services are identified, an infrastructure (sensors, actuators, network, interfaces, and intelligent software) is created which is capable of delivering those services. The system has to be reactive but also anticipatory and there are all sort of subtleties to consider which can affect user’s satisfaction of the system. A missed opportunity to help can be fatal in a healthcare environment, too much insistence or a reminder in the middle of an important meeting may not be welcomed. The more knowledge the system has about the user, the more effective the system can be. This knowledge includes a subtle understanding of the context as well, such as the do’s and don’ts associated with those different contexts. Clearly there are interesting tensions between obtaining knowledge about the user and privacy (Jones, Hara, and Augusto Citation2015) but that will not be the focus in this article. The focus will be instead on how to better align the system service delivery with the user’s expectations. From here onwards we will group all those areas mentioned at the beginning of this paragraph under the umbrella term “Intelligent Environments” (IE). Not that we think all those areas are the same. Nor do we suggest that Intelligent Environments is the best representative of the work conducted in all of them. Our choice is purely pragmatic to facilitate reference to those areas included here and also because they all share important common concepts like context-awareness and user focus, which are very relevant to this article.
One important driver in the design of Intelligent Environments is the notion of “context” and its associated “context-awareness”. A definition often cited is Dey’s (Dey Citation2001); however, that definition emphasizes too much the system and travels in the direction from the system to the user. We instead use a person-centric approach (Augusto et al. Citation2018) which goes from the user to the system so the user determines which the relevant contexts are, that is: “the information which is directly relevant to characterise a situation of interest to the stakeholders of a system”. Context-awareness is then defined as “the ability of a system to use contextual information in order to tailor its services so that they are more useful to the stakeholders because they directly relate to their preferences and needs”. As a result, we believe that user preferences is a dimension which plays an important role in linking users with contexts and hence contributing to these systems being better equipped to identify relevant contexts, to better decide how to act in those contexts, and finally on exhibiting behaviors which are more closely aligned with user’s expectations.
The concept of preferences has been the subject of analysis in various areas of science, including formal treatments in philosophy, logic and economics, among others (Hansson and Grüne-Yanoff Citation2018). These analyses had an impact in areas associated with Computer Science, like Artificial Intelligence. Our consideration of this topic is much more modest and is focused on the importance of preferences to facilitate better user-centered Intelligent Environment systems in the future (Augusto et al. Citation2013). We are not centered on an absolute notion of “betterness” but rather in the most pragmatic and subjective experience of daily life preferences by the users of a system, what they value and expect from such a system, and how it can be implemented more effectively. We suggest that a more thorough discussion on the effective management of preferences by the automated systems we face every day will contribute to a more satisfactory experience of the human-machine relationship being explored by humanity in the latest decades. In particular, we focus on a class of systems which are supposed to provide services supporting humans in daily life, and higher user’s satisfaction is expected when interacting with such Intelligent Environments as a smart home, a smart car, or a smart phone (Augusto Citation2014).
The rest of this work is as follows. Section 2 discusses some related works on the notion of preferences to provide a wider view and explain the relationship between those work and ours. Then, Section 3 emphasizes the aspects about the concept of preference which our experience in developing Intelligent Environments suggest are more important, discussing at the same time how they are covered in previous literature. Section 4 explores an example on how to represent some of the concepts under discussion. In this case, we use an ontology which we then discuss in terms of its pros and cons as well as the differences with some other relevant more theoretical work. Section 5 compares the advances made in this proposal with other works in the area and discusses some lines that may be considered in future works. Finally, Section 6 summarizes the conclusions drawn on the user preference management in IE.
Related Work
There have been formal approaches to the topic of preferences in general within Logic and Philosophy, especially modal-deontic varieties (Halldén Citation1957; von Wright Citation1963), and more recently these works have been revisited (Hansson Citation2001; Liu Citation2011). We try to keep our notation and presentation somehow aligned to the terminology in these works, although our approach focuses on different aspects of the concept. Whenever we think relevant we will point out at coincidences and departures from this classical body of literature.
There has been interesting work from a psychological point of view (Jawaheer, Weller, and Kostkova Citation2014; Lichtenstein and Slovic Citation2006) on the perception and use of preferences. Here we restrict ourselves to explicit and conscious preferences, in systems with a finite limited repertoire, which is available to a user and which the user can somehow access through an interface. Furthermore, we consider preferences which can be somehow ranked, for example, by means of the aggregation of data (Orwant Citation1994). We assume a simplified version where a simple interface allows the user to organize these preferences in layers of importance, with preferences not explicitly ranked assumed to remain in the lowest category.
The field of Artificial Intelligence (AI) has been long concerned with rational decision-making and rational choices by an artificial agent. This agent may either make decisions on its own or as part of a team in Multi-agent Systems (MAS) where preferences of the team can be combined in various sophisticated ways. Some examples of work describing systems where multi-agent systems can agree, disagree or agree to disagree are reported elsewhere (Chen et al. Citation2013; Oguego et al. Citation2018, Citation2017; Wooldridge Citation2009).
Other areas of computing have delved into this area, for example, Stefanidis, Koutrika, and Pitoura (Citation2011) explored preferences from the perspective of databases as a way to introduce soft constraints which can be used to increase system efficiency (e.g., when handling queries internally). A sophisticated identification and categorization of various aspects which can be considered to state preferences is identified. Our approach is different in the sense that it focuses on the users handling of preferences, therefore whilst we want to help users to identify how to prioritize services this has to be easy to use. We can of course envision future synergies between our work and more systematic explorations of preferences as outlined in some of the work above.
Recommender systems (Bobadilla et al. Citation2013) also address customer preferences, typically through storing the history of transactions from a consumer in a specific area of business. The analysis of these consumer preferences and user perceptions toward specific products can of course also be extended in different directions and eventually they can be related to the study we are conducting here. However, the gravitational center of those systems tends to be in a different area of emphasis. It usually centers about products and their qualities, and how the combination of features can be compared and ranked with other competing products. We focus on preferences at a higher level, as strategic concepts which humans use as guiding principles in their daily decision-making and which are usually product independent. Faced with practical daily life situations, humans use those preferences to make decisions, often these preferences are acquired unconsciously and also unconsciously applied. For example, humans of certain age may give more importance to health issues, to comfort, to finances, to safety, and so on. There may be age-related trends as well, for example, the preferences of teenagers may be different to those of adults and elderly people.
Preferences are also different from “habits” which can be collected from the user’s daily living choices and activities (Aztiria et al. Citation2013; Dimaggio et al. Citation2016). Habits can inform preferences, as well as relate to them, and are indicators of how a person interacts with a specific setting of an IE. However, habits are not a replacement for the higher level preferences we consider in this article. This bottom-up analysis on how from daily interactions with the environment some higher level lifestyle preferences can be inferred is out of the scope of this article.
Some of the most significant recent publications emanating from a philosophical and logical point of view have been produced by Hansson (Hansson Citation2001; Hansson and Grüne-Yanoff Citation2018). Actually, in the remaining of this article, we mostly focus on his work as a framework to compare our analysis of preferences for Intelligent Environments. Although we restrict ourselves to what can be implemented with current publicly available tools, we see several topics addressed by Hansson’s more general work as a good aspiration and as an inspiring roadmap.
Revisiting Preferences from an IE Perspective
Bearing in mind the type of real systems we want to help improving, we consider a smart home as a practical initial guide and inspiration. One assumption we make is that available services (a finite list of concepts) over which users can have preferences are already provided by developers and presented to users. Users can then choose and rank from those presented to them and they cannot modify this list they choose from. Users do not need to exhaustively rank all elements in the list of possible preferences. In this work, we also follow that “the user is Queen/King” (Augusto et al. Citation2013; Dertouzos Citation2002), hence what the user decides and prefers is not questioned by the system and should be used by that system to provide a context which is more of the user’s liking.
One other important assumption we do, which is aligned with those presented in Hansson and Grüne-Yanoff (Citation2018), is that preferences are subjective comparative evaluations. As preferences have a root on human experience we need to consider the humanistic side of things but we will look more deeply into what to represent and how to represent it from a computational point of view. Representation will intrinsically be linked to the way it is used (i.e., knowledge representation influences the possible computations and their cost) and the pragmatic effects this will have for both practical systems (e.g., how effectively a smart home can provide what a user wants) and other areas of CS (e.g., how affective computing can benefit of this to create a fuller bond human-system).
Here we revisit the initial discussion in preferences within IEs given in Augusto (Citation2014) to refine it and expand it based on recent practical experiences. In doing so we will make some simplifying assumptions, mostly from a CS point of view and with system implementation in mind. For example, we will consider a Boolean semantics; however, this should not be interpreted as a claim this is (or is not) the correct and final one. Other simplifications will be of a more generic nature: for example, we will consider that “needs” is a term to refer to preferences of the highest order.
In the IEs considered in this article, we assume users hold some concepts which allow them to label aspects of real life which are more or less dear to them as enablers of daily activities and as elements that allows them to obtain a more satisfactory experience of life. Examples of these could be: ‘health’, ‘comfort’, ‘finances’ and ‘information’. We call these preferences topics and assume they are a set , with
.
One can imagine each user may have constructed through life experience a complex network of inter-related preferences. Therefore, it is difficult to think preferences will be organized in an extreme fashion such as all being completely equal or a total order, even children prefer chocolate ice-cream to broccoli and also hesitate to make a choice standing at the ice cream shop and confronted with so many tasty flavors to choose from. We assume a graph-like structure with preferences in each node and a valuation attached to nodes stating which preferences are considered in higher regard to others. It still allows for the “horizontal all equals” or the total order cases although in practice it will be mostly used as a non-linear structure. We assume there are some relations which can be defined to discuss relative orders between preferences. We will adopt symbols to represent “is (strictly) preferred to” and
to mean “is equally preferred to” in a similar way to the corresponding Halldén’s “strict preference” and “indifference” (Halldén Citation1957). These binary relations can be combined in sets of them which define complex global orders over
. For example, say
are some preference concepts (e.g.,
meaning “health”,
meaning “comfort”,
meaning “finances”,
meaning “information”). Then, orders over human preferences on services can range from the extremes of a total order
to a completely neutral order
. However, we typically expect something intermediate, for example:
meaning for this user health-related issues are the most important, followed by those connected with comfort and finances, which in turn are more important than keeping herself/himself informed. In (Oguego et al. Citation2018) these binary relations are used in such a way that they represent a unidirectional graph where all
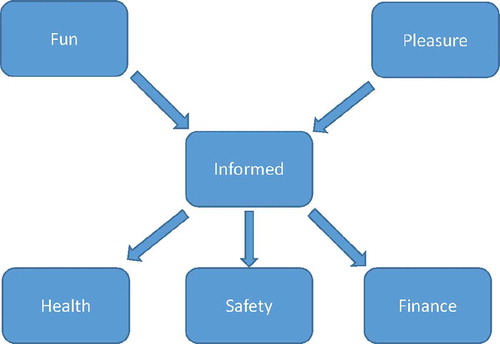
appear organized in layers or strata of importance with most important preference topics at the top. For example,
Finance) is interpreted graphically as shown in . The upper layer represents the most important preferences, then the next level in importance and then the least important. Other preferences which have not been ranked by the user are not included.
Figure 1. An example of preferences extracted from Oguego et al. (Citation2018).
Significant for us from the IE perspective is that we need to consider a set of services associated with the IE where the user is located, which we assume as a set , with
. These can be heating, lighting, music, turning the cooker on, delivering a reminder as a message to a phone, setting the favorite program channel on the smart TV or informing through a voice interface a booking has been done. These services should maximize the user experience. For some of these, however, the relation between IE services and user preferences can be complex. For example, lighting can be detrimental to finances, but in certain circumstances can increase the sense of security and safety or add to our well-being by providing the right amount of luminosity when we read. A greeting message may be perceived as a friendly system feature, sometimes it may be met with indifference, and other times, if the user is in bad mood or it is performed too frequently, it may be negatively perceived. So we assume relations between services and preference topics can contribute, detract, or be neutral to a preference topic. If
is a relationship between preference and service, for example (finances, light), we can consider a numerical measure of the effect of
on
. For example, light may be perceived to contribute to safety to the extent represented by three units of significance, be detrimental to a level of −1 to finances, and with 0 to fun. This mapping between preferences and services is complex. It may be provided by the engineers, or to some extent, it could be automated and acquired from the user. One challenge is how to acquire that mapping from the user in the least frustrating way, as too much effort required from the user on helping with the engineering of the system can offset its benefits.
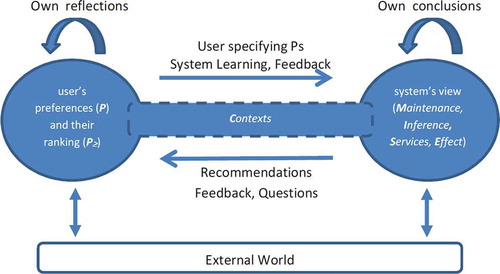
The considerations above refine the initial more generic theoretical model used in Augusto (Citation2014) and our new updated theoretical model reflecting our current focus on User Preferences consists of a structure where
represents the preferences system of one specific user
and
represents the World (the part of the preferences system external to the user). Then
and
can have their own structures specifying their inner components relevant to the handling of preferences:
where:
: a list of preference topics
, with
: a partial order relation over elements of P
: a maintenance module which can keep up to date
and
based on the input from the user and the world. It contains processes to compare preferences with existing ones and decide when they are genuinely new, when they are conflicting with others or when they are updates of existing ones. We are not prescribing here on any specific revision function.
: an inference system which can make inferences based on
and
. It is a mechanism capable to link preferences directly but also infer other general knowledge which may be relevant to support decision-making. We are not prescribing here on any deduction relationship.
where:
is a set of services
, with
is a set of contexts
, with
A context-dependent function such that
associates (preference, service) pairs to values indicating the effect of a given service on a preference in a given context
.
An Intelligent Environment can then be seen as a system that should try to optimize the function,
whereas an overall view of the system architecture under discussion is shown in .
Figure 2. Preferences System Architecture.
An interesting aspect which started to surface in the text above is how preferences can vary depending on various circumstances. This concept is important for the IE community and is usually related to context and context-awareness. For example, in summer, we may prefer ice cream to soup and in winter vice-versa. Lights up when we get up from bed at 3 am can be a positive personal safety service whilst in summer at 9 am perceived as an unnecessary waste of money. In fact, the influence of context on preferences and its relation to services is so important that we believe it deserves a separate analysis so that each context can potentially affect many or indeed all elements in . For example, the preferences and the services can be different, or at least organized in different ways for contexts for resting, e.g., home, and contexts related to obligations and performance, e.g., work. So whilst relaxing and eating may have precedence at home over writing, at work writing may have precedence over relaxing and eating. In both places we need all of them; however, the balance of emphasis and time spent on each of them at both contexts normally changes. Let us introduce two examples of contexts for John at home and at work and exercising the notation introduced above and which will help to clarify how changes in preferences can be reflected:
We can also further refine these contexts (), for example, dividing into day and night:
Preferences can be sometimes conflicting, for example, we may like specific food but may not be a healthy option. So on assessing food choices, we may have to decide between giving priority to our preference for enjoying a tastier meal and keeping our weight under control or our blood sugar levels within certain safety range. If in analyzing potential courses of action a system finds assessing more than one option, sometimes the presence of preference-related elements can help the system to select a course of action that, equal on other features (e.g., logical analysis), will provide higher user satisfaction, see, for example, Oguego et al. (Citation2018).
Figure 3. Contextualized Preferences.

Besides potential internal conflicts on daily life preferences within each user, we also find plenty of examples of conflict between preferences in a group of users. In order to cope with a multi-user scenario, the system needs to be escalated to be aware of various users , with
, with different preferences, sometimes conflicting (e.g., selecting TV programs in a family, setting air-conditioned temperature in an open office). Some examples of these scenarios are discussed elsewhere (Muñoz et al. Citation2011).
In these cases, categories of users (e.g., societal hierarchies) can help the system to take decisions. To this end, the IE could include a contextual function which gives a user priority value for a context
in a multi-user IE, for example, depending on who is in the room different individuals may be given priority in decision-making. Some instances of these situations could arise when an elderly member of the family is in the room, then her/his preferences should be given higher priority; likewise, if the CEO of the company is in a meeting that person can also be given priority in the use of shared resources. Another context which can influence a multi-user IE could be time. For example, before 9 pm children may be given priority selecting TV programs, whilst from 9 pm onwards adults may have final say on whether a program can be watched by children of certain age. A multi-user Intelligent Environment can then be seen as a system that should try to optimize,
It can also be discussed the relative merits of qualitative versus quantitative methods of representing and reasoning with preferences. Again, without making a definitive statement on this, we focus on providing users some effective way to indicate which their preferences are on system services. Ideally, it should be a method which can be then translated internally to a representation and used by the system in delivering an experience which is more likely to be better aligned with the user’s expectations. Both qualitative and quantitative methods can be useful and also co-exist in a system, depending on some of the system characteristics and level of complexity which can be afforded in the representation and processing of preferences. For example, following a qualitative approach, the user could indicate that the concept “Health” is preferred to the concept “Finance”. This approach can work well when there are few preferences to order. However, it may turn to be impractical when the number of preferences in the system is high. In this case, a quantitative approach where the user indicates, for example, a value between 0 and 100 for each preference without a direct comparison between them might be more useful. All this without ruling out that different contexts can be defined in the system where different relations or weights for the same set of preferences can be defined. Hansson considers qualitative approaches in Section 1.6 and quantitative ones in Section 2 of Hansson and Grüne-Yanoff (Citation2018), from a theoretical point of view. As an example of implementation in a real smart home system, Oguego et al. (Citation2018) adopt a pragmatic use of numbers to facilitate ranking and aggregation. These preference values and their ranking come from direct input from the user through a specially designed interface. Preferences then influence system behaviors encoded by engineers through rules, as a way to differentiate competing alternatives and select amongst them.
The changing dimension of preferences is addressed in Section 6 of Hansson and Grüne-Yanoff (Citation2018). This is an important practical feature of preferences, which can be addressed at various levels of complexity and sophistication. An initial approach in the context of real IEs could be taking as possible user preferences those related to the list of services offered by the environment. Initially, this list has to be offered somehow by the system engineers, for example, through a database where the preference system can be queried and results presented to users by means of an interface. There are two dimensions of change, one comes from the availability of these services (some may be added, some may be temporarily or permanently disabled), and then there is the users’ changing perception of the relative value of their preferences. Should there be any changes ideally the user has to be informed and the representation of preferences updated; however, for now we will assume changes on the options to choose from can only be made by engineers and changes to the preference order can only be made by the user, all through a suitable interface. That is, the system does not change any preference or services automatically, it only reflects the changes made by humans.
Selection of preferences and their justification are mentioned in Section 4 of Hansson and Grüne- Yanoff (Citation2018). These are addressed in Oguego et al. (Citation2018) through an argumentation system which handles preference-related conflicts. Rules are designed by the engineers, and preference specifications are assumed to be incomplete with those non-mentioned being not relevant or unknown. Both total and partial orders are allowed (in tie cases the system remains neutral and persistency of property values is assumed).
So far we guided our analysis based on the hypothesis that “the user is Queen/King” mentioned in the introduction. This axiom can be challenged and a case could be made that a system may have sometimes a case to persuade the user otherwise if the system believes is on the user’s best interest. This will imply the system having access to private user data which can genuinely support such disagreements. For example, to be able to argue that buying yet another chocolate cake this month is not in the best interest of someone with diabetes, the system needs to know the user has that condition. In general, to advice against something the user fears the system needs to know what the user’s fears are. Important issues of privacy and security take then increasing importance (Jones, Hara, and Augusto Citation2015).
Ontological Approach Exercise
This section offers a more specific way to revisit preferences from an IE perspective. This exercise considers existing technology, offering us an opportunity to show what can be done with it and also highlight features where it falls short of what it has been discussed in the wider discussion of Section 3.
Here we reuse OWL ontologies, a standard and well-known technology which has both a formal background and good tool support. With this choice we are not indicating that it is the only or the most adequate alternative; however, we believe that it is the one that allows us to consider a reasonable number of desirable features, and also can be contrasted with Hansson’s axioms, as it will be discussed further down.
From a CS point of view, and following the most accepted general definition, an ontology is a formal and explicit specification of a set of concepts in a particular domain (Gruber Citation1993). With this definition, two key aspects become relevant: on the one hand, an ontology is a formal representation, and therefore can be processed by a computer; on the other hand, the information explicit in an ontology allows to describe and shape any domain. The basic elements that conform an ontology are divided into concepts, also called classes, which represent an entity of interest (e.g., Preference, User); properties defined on a concept, both to indicate numerical type data, text strings (e.g., the name attribute), and so on, as well as to indicate relations with other concepts, for example, “hasPreference”; and instances, also called individuals, which represent concrete examples of concepts, as for example, Alice, which is a User instance. One of the main characteristics of ontologies is that the concepts are arranged in a hierarchical way, including property inheritance. In this way, individuals of a class also belong to its superclasses and inherit its properties. Another noteworthy characteristic is the possibility of building new concepts and properties through combinations of these elements. Thanks to the use of ontologies, a computer can distinguish the concepts of a domain, its properties and values, as well as perform inference operations such as discovering new knowledge about the domain or determining if the knowledge being modeled is consistent.
OWL (Web Ontology Language) (Bechhofer et al. Citation2004) is the most used language to express ontologies, after being adopted as a recommendation of the World Wide Web Consortium (W3C) in 2004. In fact, it is currently being used in a large number of both academic and commercial projects. OWL offers different degrees of expressiveness when creating ontologies, giving rise to various language versions. Each version has a certain level of complexity depending on its degree of expressiveness. This complexity refers to the computational cost in terms of time and memory required to perform the inference operations associated with the language. In general terms, the greater the expressiveness, the greater the complexity, even reaching a level of expressiveness in which the complexity is undecidable, i.e., the completion of the inference operations cannot be assured. There are currently four versions of OWL: OWL Full, OWL DL, OWL Lite and OWL 2. The first three are part of the so-called OWL 1.0 group published in 2004, while the latter has been developed as an extension of OWL DL since 2006, reaching a stable state at the end of 2009 (Hitzler et al. Citation2009) and the one usually adopted in current projects, as in our proposal.
Here, we discuss an OWL ontology named PrefOnto which we offer as a more tangible system around which to discuss the implementation challenges of some of the theoretical concepts discussed above. PrefOnto is composed of two main concepts, “User” and “Preference”. They are related through the object relationship “ hasPreference” from “User” to “Preference”. The different kinds of preferences are modeled as subclasses of the “Preference” concept. Thus, we are able to represent different types of preferences by means of concepts such as “Finance”, “Fun”, “Health”, “Safety”, etc., which are declared as disjoint subclasses of “Preference”.
As we are going to implement Hansson’s axioms here, we will follow its notation on the relationships among preferences, where the symbol ‘’ amounts to
in Halldén (equal in value to) and the symbol ‘
’ amounts to
(better or strict preference).
The “Preference” concept owns two self-referential relationships: “ isEquallyPreferredTo” and “ isPreferredThan”. The first one amounts to Hansson’s “”, where
and
are two preferences. This relationship is modeled as symmetric, transitive and reflexive according to Hansson (see comparison further down).
Regarding the “isPreferredThan”, it amounts to Hansson’s “” and again according to Hansson, it needs to be modeled as asymmetric, transitive and irreflexive. However, in this case, we can only define it as transitive due to the following OWL restriction (see this postFootnote1 for more information): any transitive property is classified as a non-simple property by an ontology reasoner, and this kind of property cannot be defined as asymmetric nor irreflexive. Observe that this restriction may suppose a problem since it is possible to obtain cyclic graphs if the asymmetric feature is not taken into account. For example, suppose we define the following transitive relationships among preferences
,
and
:
,
,
. As a result, a cycle is generated among these preferences as shown in , since we cannot define any of the relationship as asymmetric. In fact, if any of these relationships could have been defined as asymmetric, the reasoner would have detected an inconsistency in the model.
Figure 4. An example of cycle among preferences.
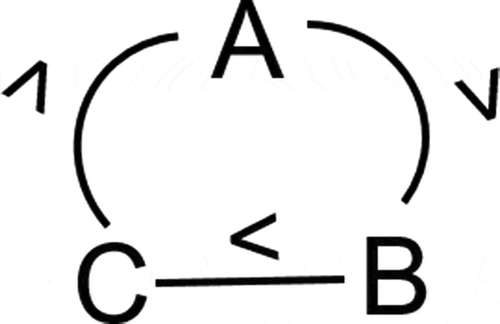
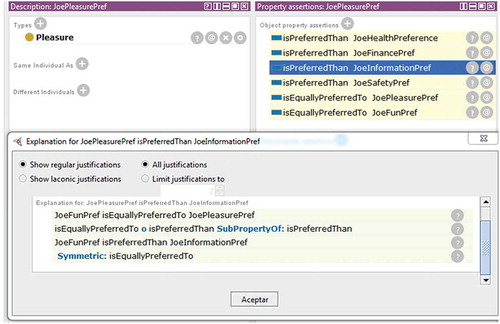
Figure 5. Protégé screenshot.
In order to solve this problem we have included in the ontology the following SWRL (Semantic Web Rule Language) rule that detects any cycle in the preference relationships:
Note that the head of the rule has been intentionally defined with no atoms. In this way the ontology reasoner is forced to raise an inconsistency whenever the atoms in the body hold according to the current state of affairs in the ontology. Thus, if we have and
as two instances of any preference concept and the facts
and
are stated in the ontology, an inconsistency is raised by the reasoner.
Finally, we have also defined the two mixed IP and PI transitivity properties defined in Hansson (Citation2001), page 324:
These two properties have been defined thanks to the property chain axiom (noted with ““) available in OWL 2. Thus, the IP-transitivity property has been defined as:
whereas the PI-transitivity property has been defined as:
Let see now an example of modeling preferences using PrefOnto. shows the ranking of Joes preferences. In the first place, he cares about pleasure and fun above everything else. In a second level, he also likes being informed. In the last place, he prefers being informed over health, safety and finance at the same level.
Firstly, we introduce the statements “Joe hasPreference ”, where
is an instance of each preference concept, e.g JoeFinancePref, JoeFunPref, etc. Then, we state the minimal set of relationship among Joes preferences, namely the smallest set of relationships satisfying the partial order representing Joes preferences:
Fun isEquallyPreferredTo Pleasure
Fun isPreferredTo Informed
Informed isPreferredTo Health
Health isEquallyPreferredTo Safety
Health isEquallyPreferredTo Finance
Now, by using an ontology reasoner such as Pellet Pellet Sirin et al. (Citation2007) and the property axioms defined above, it is possible to infer the following additional relationships:
Fun isPreferredTo Health
Fun isPreferredTo Finance
Fun isPreferredTo Safety
Pleasure isEquallyPreferredTo Fun
Pleasure isPreferredTo Informed
Pleasure isPreferredTo Health
Pleasure isPreferredTo Finance
Pleasure isPreferredTo Safety
Informed isPreferredTo Finance
Informed isPreferredTo Safety
Finance isEquallyPreferredTo Health
Finance isEquallyPreferredTo Safety
Safety isEquallyPreferredTo Health
Safety isEquallyPreferredTo Finance
shows a screenshot of Protégé with all the inferred statements related to Joe’s pleasure preference along with an explanation for “Pleasure isPreferredTo Informed”, which involves the IP-transitive axiom.
The expression of preferences through OWL as explained in this section allows us to compare this possible alternative to implement the concept in current systems against more theoretical and generic discussions of the concept like that one by Hansson’s described at the beginning of this article.
We first consider the initial assumptions and axioms from Sections 2.1 to 2.4 in Hansson (Citation2001). The following properties have been included in our PrefOnto ontology in a straightforward manner:
(symmetry of indifference)
(reflexivity of indifference)
(incompatibility of preference and indifference)
(transitivity of indifference)
(transitivity of strict preference)
(IP-transitivity)
(PI-transitivity)
Note that the two last properties are implemented in our ontology thanks to the use of the property chain axiom feature of the OWL 2 language.
Regarding the following property:
As stated in Section 4, it cannot be directly implemented due to OWL restrictions. However, we have managed to define an SWRL rule to detect this situation by raising an inconsistent state. So, although not prevented, it raises a warning when detected.
For the weak preference property:
To the best of our knowledge, it is not possible to define the union of properties in OWL. There is a manner to partially overcome this problem, by defining a property called and these pair of axioms:
Note that in this way, the part of the weak preference property holds in the ontology, but not the
part. That is, if we state in our ontology that
, then it is inferred that
. However, if we state that
, it is not inferred that
nor that
.
The transitivity of the weak preference:
can be defined straightforward for the property in the ontology, whereas the feature “antisymmetry of preference” (
) is defined by means of an SWRL rule.
Finally, regarding the completeness property, where Hansson proposes that it is ideal to have a complete order among preferences, it is important to bear in mind that OWL follows an open-world approach versus the traditional closed world. For example, suppose we add a new preference for Joe, e.g. “BeRelaxed”, but we do not express any relationship with the rest of the preferences already included. As a result, the reasoner will not infer anything additional about the relationships of this preference due to the open-world assumption. We think this is a sensible property of our system, as it must not assume that this new property is preferred or not to the rest.
Discussion
Works on preferences have been rather infrequent; however, we believe with the increased interest on technologies closer to humans daily life experience they will become more relevant. So what is the best option available? As we have shown options are quite dissimilar and complementary. We began considering earlier theoretical analysis from a logic and philosophical point of view, we continued with another theoretical analysis based on direct experiences building practical systems and then, in the previous section, we showed a possible way to express preferences through OWL.
In this section, we discuss how some of the most important features in preference management from an IE perspective are addressed by the works studied in the previous sections, including the alternatives proposed in this paper. In particular, we focus on how the features of preference representation, reasoning with preference, dealing with preference in multi-user scenarios and preference learning are managed by the works of Hansson (Hansson Citation2001; Hansson and Grüne-Yanoff Citation2018) and Oguego (Oguego et al. Citation2018) along with the IE-specific approach (Section 3) and the OWL ontology approach (Section 4) presented in this paper. In this way, we choose to offer a heterogeneous and balanced viewpoint among theoretical and practical approaches. A summary of this comparison is shown in . In this discussion, we will also include some other works that can be seen as further lines of research for each of the features being analyzed.
Table 1. Comparison of preference features management. The OWL ontology and IE approach have been introduced in this paper.
Preference Representation
Hansson & Grüe-Yanoff propose a formal language based on Halldén’s preference logic to define a complete preference system. Being it an all-purpose system, some definitions are more focused on economics. Thus, one important missing piece for IE in this system is the representation of context and services. Our IE preference system extends Hansson’s by including an explicit representation of these elements and a context-dependent function to associate preferences to services according to the context. In Oguego et al. a preference is an atomic concept with an associated numerical value, with Hansson’s “just noticeable difference” (JND) being 1. These values define a sort of partial order and comparison functions are based on comparison of added number values associated with the preferences. The OWL ontology option creates a preference hierarchy along with their comparing relationships of “better than” and “equal to”.
Other representation systems are worth of being studied in the future. The use of non-boolean semantics such a fuzzy system or a probability framework could be seen as an alternative to assign values to preferences (Aerts and Sozzo Citation2016; Bevilacqua, Bosi, and Zuanon Citation2017). Another interesting proposal is the use of a more sophisticated preference representation taxonomy as in Stefanidis, Koutrika, and Pitoura (Citation2011).
Reasoning with Preferences
Hansson’s proposal focuses on the classic comparative notions of “better than” and “equally valuable”. Following this model, we have implemented a practical reasoning system based on ontology axioms and SWRL rules (with the limitations explained in the second half of Section 4). A more sophisticated system may consider other value predicates used in ordinary language, such as “good”, “best”, “very bad” and others. On the other hand, preferences can be associated with values. Oguego’s work uses a simple scale where in n layers of preference, the top layer has a higher value than the other ones. Ideally, our IE approach is skeptical in choosing a specific reasoning process and may allow the combination of several reasoning systems to obtain a more informed decision. One example of an implementation is currently being used and based on a rule-based system as found in Augusto et al. (Citation2019).
Preferences in Multi-user Scenarios
Preferences in a multi-user IE require different alternative of making decisions by combining preferences. This research line has been explored in Oguego’s work and also in Muñoz, Bota, and Augusto (Citation2010). Basically, these works propose the definition of a “user hierarchy” to decide the most prevalent preference. In our IE approach, we extend this idea by combining the user hierarchy and context information as explained in Section 3. Other proposals such as negotiations and collaborative algorithms will be worth considering in the future for IE scenarios (Niemantsverdriet, Essen, and Eggen Citation2017; Xin, Lu, and Li Citation2015)
Preference Learning
Hansson’s proposal considers that is possible to infer unconscious or implicit preferences which are not explicitly indicated by the user but rather discovered by “user’s choices”. However, this proposal is only studied from a theoretical side. Our OWL ontology approach partially implements the idea of inferring implicit preferences relationships from the one explicitly stated as shown in Section 4. However, this inference cannot be considered a proper learning process. Oguego et al.’s approach does not provide learning itself however is embedded in an architecture which does provide complementary learning in various ways (see Augusto et al. (Citation2019)). In our more ideal IE approach, we have included a maintenance module that, apart from this type of inference, will allow updating existing preferences. Some ideas for this module may include aggregation of data from different sources, including sensors, choices, purchase history, etc., possibly weighted depending on those sources. However, this presents several additional challenges, as for example, it may make the user think that the system has been unknowingly altered according to an algorithm which the user may not know, understand, or agree with.
As a final remark to this discussion, we would like to highlight that it is not necessary for there to be a winner, since all proposals fall short in some sense, some are not fully implemented and what is implemented does not necessarily provide all that is needed. By means of this comparison, we expect to pave the way for the next step toward a complete preference system for IE that includes all the “good” experiences and outcomes of each proposal.
Conclusions
Technology has been evolving closer to humans daily life experience. Intelligent Environments is one of the various closely related Computer Science sub-fields trying to develop systems which can deliver support to users in specific situations based on context-awareness. For a system to be in a better position to deliver the services according to user expectations it helps if the system knows the user preferences related to those services.
This article discusses the pragmatic importance of preferences within the process of developing Intelligent Environments. We compared our more utilitarian take on preferences with the higher level analysis previously provided from philosophy and logic areas permeated through Artificial Intelligence. We provide an example of implementation using a currently available well-known technology of ontologies to highlight some of the associated shortcomings, facilitate comparison with other works and highlight potential directions for complementary progress.
We see this article only as the beginning of a long discussion on the most effective way to embed such a core concept of user preferences in the next wave of Intelligent Environments.
Author contributions
The context and context-awareness definitions were contributed by Prof. J. C. Augusto.
Additional information
Funding
Notes
References
- Aarts, E. H. L., and R. Roovers. 2003. IC design challenges for ambient intelligence. 2003 Design, Automation and Test in Europe Conference and Exposition (DATE 2003), Munich, Germany, March 3–7, pp. 10002–07.
- Aerts, D., and S. Sozzo. 2016. From ambiguity aversion to a generalized expected utility. modeling preferences in a quantum probabilistic framework. Journal of Mathematical Psychology 74:117–27. doi:10.1016/j.jmp.2016.02.007.
- Atzori, L., A. Iera, and G. Morabito. 2010. The internet of things: A survey. Computer Network 54 (15):2787–805. doi:10.1016/j.comnet.2010.05.010.
- Augusto, J. C. (2014). Reflections on ambient intelligence systems handling of user preferences and needs. In Proceedings of 10th International Conference on Intelligent Environments (IE’14), Shanghai, 29th of June to 4th of July. IEEE Press, pp. 369–71.
- Augusto, J. C., V. Callaghan, D. Cook, A. Kameas, and I. Satoh. 2013. Intelligent environments: A manifesto. Human-Centric Computing and Information Sciences, Springer Verlag, 3:12.
- Augusto, J. C., D. Kramer, U. A. Ibarra, A. Covaci, and A. Santokhee. 2018. The user-centred intelligent environments development process as a guide to co-create smart technology for people with special needs. Universal Access in the Information Society 17 (1):115–30. doi:10.1007/s10209-016-0514-8.
- Augusto, J. C., M. Quinde, J. G. G. Manuel, S. M. M. Ali, C. L. Oguego, and C. James-Reynolds (2019). The search smart environments architecture. In Proceedings of 15th International Conference on Intelligent Environments (IE’19), Rabat, Morocco, IEEE Press.
- Aztiria, A., J. C. Augusto, R. Basagoiti, A. Izaguirre, and D. Cook. 2013. Learning frequent behaviours of the user in intelligent environments. IEEE Transactions on Systems, Man, and Cybernetics: Systems 43 (6):1265–78. doi:10.1109/TSMC.2013.2252892.
- Bechhofer, S., F. van Harmelen, J. Hendler, I. Horrocks, D. McGuinness, P. Patel-Schneijder, and L. A. Stein. 2004. OWL Web Ontology Language reference. Recommendation, World Wide Web Consortium (W3C). http://www.w3.org/TR/owl-ref/
- Bevilacqua, P., G. Bosi, and M. Zuanon. 2017. Existence of order-preserving functions for nontotal fuzzy preference relations under decisiveness. Axioms 6 (4):29. doi:10.3390/axioms6040029.
- Bobadilla, J., F. Ortega, A. Hernando, and A. Gutirrez. 2013. Recommender systems survey. Knowledge-Based Systems 46:109–32. doi:10.1016/j.knosys.2013.03.012.
- Callaghan, V., Ed. 2005. International workshop on intelligent environments. Colchester, UK: IEE (Institution of Electrical Engineers).
- Chen, S., J. Liu, H. Wang, and J. Augusto. 2013. Ordering based decision making – a survey. Information Fusion 14:521–31. doi:10.1016/j.inffus.2012.10.005.
- Cook, D. J., J. C. Augusto, and V. R. Jakkula. 2009. Ambient intelligence: Technologies, applications, and opportunities. Pervasive and Mobile Computing 5 (4):277–98. doi:10.1016/j.pmcj.2009.04.001.
- Dertouzos, M. L. 2002. Human-centered systems. In The invisible future, ed. P. J. Denning, 181–91. New York, NY: McGraw-Hill, Inc.
- Dey, A. K. 2001. Understanding and Using Context.
- Dimaggio, M., F. Leotta, M. Mecella, and D. Sora (2016). Process-based habit mining: Experiments and techniques. In 2016 Intl IEEE Conferences on Ubiquitous Intelligence Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress, Toulouse, France, pp. 145–52.
- Gruber, T. R. 1993. A translation approach to portable ontology specifications. Knowledge Acquisition 5 (2):199–220. doi:10.1006/knac.1993.1008.
- Halldén, S. 1957. On the logic of better. Sweden: Library of Theoria.
- Hansson, S. O. 2001. Preference logic. In Gabbay D.M., Guenthner F. (eds.), Handbook of philosophical logic, vol. 4. Springer, Dordrecht.
- Hansson, S. O., and T. Grüne-Yanoff. 2018. Preferences. In The stanford encyclopedia of philosophy (Summer 2018), ed. E. N. Zalta. Metaphysics Research Lab, CSLI, Stanford University.
- Hitzler, P., M. Krötzsch, B. Parsia, P. F. Patel-Schneider, and S. Rudolph. 2009. Owl 2 web ontology language primer. W3C Recommendation 27 (1):123. http://www.w3.org/TR/owl2-overview/
- Jawaheer, G., P. Weller, and P. Kostkova. 2014. Modeling user preferences in recommender systems: A classification framework for explicit and implicit user feedback. ACM Transactions on Interactive Intelligent Systems 1–8:26. 4(2):8. doi:10.1145/2512208.
- Jones, S., S. Hara, and J. C. Augusto. 2015. efriend: An ethical framework for intelligent environments development. Ethics and Information Technology 17 (1):11–25. doi:10.1007/s10676-014-9358-1.
- Lichtenstein, S., and P. Slovic, Eds. 2006. The construction of preference. Cambridge Academic Press.
- Liu, F. 2011. A two-level perspective on preference. The Journal of Philosophical Logic 40:421–39.
- Muñoz, A., J. C. Augusto, A. Villa, and J. A. Bota. 2011. Design and evaluation of an ambient assisted living system based on an argumentative multi-agent system. Personal and Ubiquitous Computing 15 (4):377–87. doi:10.1007/s00779-010-0361-1.
- Muñoz, A., J. A. Bota, and J. C. Augusto. 2010. Intelligent decision-making for a smart home environment with multiple occupants. In Computational intelligence in Complex Decision Systems
- Niemantsverdriet, K., H. Essen, and B. Eggen. 2017. A perspective on multi-user interaction design based on an understanding of domestic lighting conflicts. Personal and Ubiquitous Computing 21 (2):371–89. doi:10.1007/s00779-016-0998-5.
- Oguego, C. L., J. C. Augusto, A. Muñoz, and M. Springett. 2018. Using argumentation to manage users’ preferences. Future Generation Computer Systems 81:235–43.
- Oguego, C. L., J. C. Augusto, A. Muñoz-Ortega, and M. Springett. 2017. A survey on managing users’ preferences in ambient intelligence. Universal Access in the Information Society 17: 97–114.
- Orwant, J. 1994. Heterogeneous learning in the doppelgänger user modeling system. User Model User-Adapted Interaction 4:107.
- Sirin, E., B. Parsia, B. C. Grau, A. Kalyanpur, and Y. Katz. 2007. Pellet: A practical owl-dl reasoner. Web Semantics: Science, Services and Agents on the World Wide Web 5 (2):51–53. doi:10.1016/j.websem.2007.03.004.
- Stefanidis, K., G. Koutrika, and E. Pitoura. 2011. A survey on representation, composition and application of preferences in database systems. ACM Transation Database System 36 (19):1–19. doi:10.1145/2000824.2000829.
- von Wright, G. H. 1963. The logic of preference. Philosophy 40 (151):78–79.
- Weiser, M. 1991. The computer for the 21st century. Scientific American 265 (3):94–104. doi:10.1038/scientificamerican0991-94.
- Wooldridge, M. 2009. An introduction to multiagent systems. New York City, USA: Wiley.
- Xin, M., M. Lu, and W. Li. 2015. An adaptive collaboration evaluation model and its algorithm oriented to multi-domain location-based services. Expert Systems with Applications 42 (5):2798–807. doi:10.1016/j.eswa.2014.10.014.