
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The availability of constant electricity supply is a crucial factor to the performance of any industry. Nevertheless, the unstable supply of electricity in Cameroon has led to countless periods of electricity load shedding, hence, making the management of the telecom industry to fall on backup power supply such as diesel generators. The fuel consumption of these generators remain a challenge due to some perturbations in the mechanical fuel level gauges and lack of maintenance at the base stations resulting to fuel pilferage. In order to overcome these effects, we detect anomalies in the recorded data by learning the patterns of the fuel consumption using four classification techniques namely; support vector machines (SVM), K-Nearest Neighbors (KNN), Logistic Regression (LR), and MultiLayer Perceptron (MLP) and then compare the performance of these classification techniques on a test data. In this paper, we show the use of supervised machine learning classification based techniques in detecting anomalies associated with the fuel consumed dataset from TeleInfra base stations using the generator as a source of power. Here, we perform the normal feature engineering, selection, and then fit the model classifiers to obtain results and finally, test the performance of these classifiers on a test data. The results of this study show that MLP has the best performance in the evaluation measurement recording a score of in the K-fold cross validation test. In addition, because of class imbalance in the observation, we use the precision-recall curve instead of the ROC curve and registered the probability of the Area Under Curve (AUC) as
.
Introduction
The expansion of mobile services of the telecommunication industries has resulted in the installation of cell towers to diverse parts of the world. In developing countries like Cameroon, the supply of the power grid is irregular and the network companies find it difficult to manage their base stations particularly, their data centers and other IT equipments. Due to this, the management of the base stations uses backup power supply such as diesel generators, solar panels, batteries and other secondary source of power to keep their systems in operation. However, these backup sources, particularly, the power generation plants have also created additional complications like external or internal seeps of oil, fuel or coolant, inaccuracies in the mechanical fuel level gauges and poor maintenance leading to fuel pilferage from the various base stations of the network operators. These anomalies directly increase the fuel consumption and affect the operations of the industry in the long run. Therefore, our goal in this work, is to adopt machine learning (ML) scheme, using TeleInfraFootnote1 as a case study to identify the anomaly in fuel consumption of their standby generators.
TeleInfra is a telecommunication company in Cameroon that uses backup generators when the main power grid goes down. The company provides services such as site maintenance and refueling of generators in the base stations. The dataset used in this paper is obtained from base stations under supervision of TeleInfra company. It contains attributes of fuel consumed by the generators and other information such as maintenance details.
Anomaly in a data is considered as an observation which does not conform to the expected standard in the data. Meanwhile, recent works in anomaly detection such as fraud detection analysis (Chouiekh and EL Hassane Citation2018; Zanin et al. Citation2018), thermal power plant (Banjanovic-Mehmedovic et al. Citation2017), medical image analysis (Taboada-Crispi et al. Citation2009), etc., have shown how well ML techniques can be used to address these challenges.
From the various anomaly detection researches, the algorithms used can outperform each other based on the type of data and the underlying assumptions employed. From the literature, most of the competitive ML techniques used in classification task like in our case, consist of SVMFootnote2, KNNFootnote3, LRFootnote4, and MLPFootnote5. In this study, we do a comparative analysis of the performance of these classifiers to determine the best classifier that can accurately detect the anomalies in the fuel consumption dataset. SVM aims at generating an optimal hyperplane (decision plane) that maximizes the margin between two classes, using support vectors. KNN stores the training data and predicts the test instance based on distance measure and the majority votes from the training sample. LR uses probabilities to predict the chance of a sample to belong in a certain class. MLP learns the complexity of the data and optimizes the weights to minimize classification error. A more detailed explanation of these classifiers is given in Section 3.
The rest of the paper is organized as follows: In Section 2 we perform exploratory data analysis to discover patterns in the data. Section 2.1 describes the dataset used for the study as well as preprocessing of the data. Section 2.2 presents a descriptive statistics of the data. We then provide a brief description of ML algorithms on SVM, MLP, KNN and LR classifiers in Section 3. Section 4 presents on the metrics to evaluate the performance of our models. Results and analysis on the performance of the classifiers are reported in Section 5. Section 6 provides the conclusion of the study.
Exploratory Data Analysis
Data Collection
In this study, a secondary source of data is gathered from TeleInfra. The data contains different power types used by the operator and we mainly focus on the base stations powered by the generator. Note that the information recorded here includes the working hours of the generator, the rate of consumption, fuel consumed, the quantity of fuel added in the generator, etc. gives a detailed report on the feature parameters used to depict the dataset. Furthermore, the data is defined in both numerical and categorical forms with missing valuesFootnote6 of . At the end, we used a sample size of
inputs of the fuel consumed by the generators within September
to September
.
Table 1. Variable description: variables associated with fuel consumption.
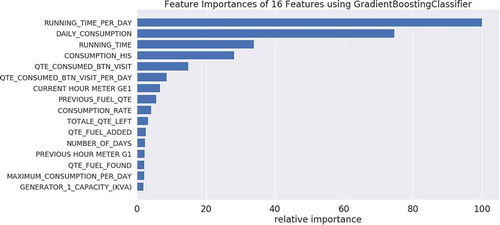
Meanwhile, in order to have a true predictive model of this research, we use the Gradient Boosting ClassifierFootnote7 to classify the strongest feature parameter associated with the recent residual. Thus, we calculate the basic regression coefficient of the residual on the selected feature and then sum it together with the current coefficient for that variable. shows the variable RUNNING_TIME_PER_DAY of the generator is the key important feature which has a great influence on the output. This is followed by the DAILY_CONSUMPTION and the least feature importance parameter is GENERAL_1_CAPACITY_(KVA).
Figure 1. Feature importance ranking fitted using Gradient Boosting classifier.
Descriptive Statistics
displays that the fuel consumed by the generator has a skew value of and a kurtosis (the measure of distribution curve) of
(refer to the left plot). The Gaussianity test in the right plot shows that there are some anomalies in the fuel consumed. This is clearly confirmed in left) where the generator working hours exceeded
hours in a day. All these features are highly captured with the Gradient Boosting Classifier. The plot also reported that the average fuel consumed in a day is
. In effect, out of an observation size of
,
is detected as an anomaly and this is clearly depicted in (right).
Figure 2. The distribution of fuel consumption. LEFT: A histogram showing the fuel consumed is slightly positively skewed. RIGHT: A probability plot showing that the fuel consumed is Gaussian.
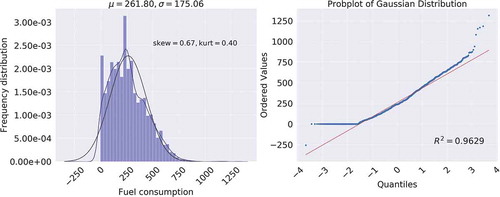
Figure 3. Graph of number of hours the generator function in 1 day (left) and pie chart of the target class labels (right).
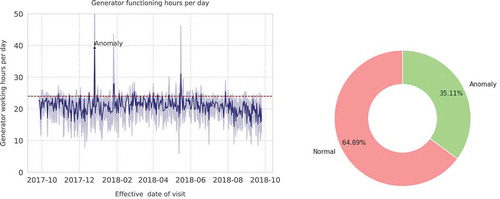
The pie chart in (right) shows that there is a class imbalance in the model data and this can affect the classification base task. This class imbalance is where the number of one class is significantly large compared to the other class. The effect of this would later be seen when we discuss about the performance measure in Section 5.
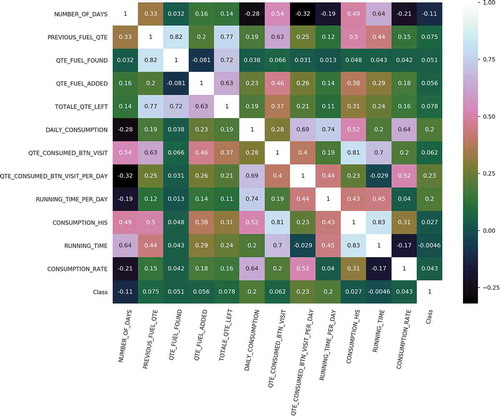
is a correlation matrix displaying the correlation coefficients between the feature parameters in . Correlation is a normalized covariance with its values ranging from to
. The matrix measures a linear relationship between variables with
indicating that the related variables have a strong negative relationship, that is, as one variable increases, the other one decreases and
indicates strong positive relation, that is, an increase in one variable results to increase in the other one. The diagonal values indicate the correlation of a variable with itself (known as auto-correlation). For instance, it can be seen from that the fuel consumed has a strong positive relation of
with the number of hours the generator is working. This means that as the generator continues to operate for long hours, the fuel consumption directly increases.
Figure 4. A Correlation matrix measuring the linear dependence between the feature parameters.
The anomalies (also known as outliers) detected in the data include hours the generator was working in 1 day, consumption exceeding what the fuel generator can consume in a day and the case where the fuel consumed and running time are zero. These outliers were used to generate the classification class. In our case, these selected samples are defined as anomaly and the others (refer to ) as normal.
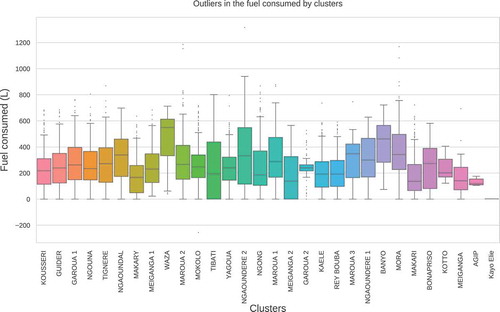
shows box plots of the fuel consumed by the clusters (also known as base stations). For the purpose of this study, the cluster is a group of sites where generators are located and therefore, the fuel consumed by a cluster is the total fuel consumed by different generators in the various sites. Note how most of the base stations have recorded outliers (thus, the dotted points on or below the whiskers) in the fuel consumption. In addition, Agip is the station that recorded the least of fuel consumption () in a day. On the average, most of the sites such as Kousseri, Guider, Ngaoundal, Waza, etc., consumed
of fuel per day.
Figure 5. Fuel consumed per cluster.
Methods
Support Vector Machine
Support vector classifier is a supervised machine learning technique used to separate two or more classes by finding a hyperplane which maximizes the margin between them. In the case of linearly separable classes, an ideal hyperplane (decision plane) called decision boundary is defined to separate two classes with the widest margin that ensures the distance between the boundary of the two or more classes is maximized (Hastie, Citation2005). Given a pair of input variables and corresponding class
such that
, the classifier find a function that correctly maps each input variable
to its corresponding class
. The decision boundary is defined as;
where is the weight vector and
the bias. The support vectors that is, the samples on the boundary of the margin determines the decision boundaries. If
in Equation 1 is greater than zero then the input variable belongs to class
, otherwise, it belongs to class
. To obtain an ideal hyperplane between the two classes, is the same as minimizing the norm of the weight vector (Hastie, 2005). For two-class classification, the input variable is either on the positive or negative side of the decision variable such that;
The margin can be maximized by minimizing the weight vector . In the case of non-separable, penalizing term is introduced to allow misclassification. The slack variable introduced in the case of non-separability measures how far the data deviate from the correct class (Kelleher, Namee, and D’arcy Citation2015).
When a sample is correctly classified then the slack variable corresponding to that input value is equal to zero. For non-linear classes, the kernel functions transform the input example to a more separable space. A non-linear kernel function transforms the inputs to a more separable space and defines a hyperplane that clearly separates the classes. Commonly used non-linear function includes the hyperbolic tangent, polynomial and radial basic kernel (Aggarwal Citation2014).
Multilayer Perceptron
MLP is a supervised machine learning neural network inspired by the human brain (Haykin Citation1994). The classifier consists of input layer, hidden layers, activation function and output layer. The input layer receives the vector and assigns a weight vector
. MLP is a forward feed, that is, weighted input table:Variables move from the input layer to the inner hidden layer (Aggarwal Citation2014). The hidden layers enhance the model capabilities by allowing the network to learn complex problem and give result in the output layer. A nonlinear activation function applied to the weighted linear summation of the input table:Variables to extract a relationship between the output and input variable.
where is the synaptic weight connecting neurons between the layers and
is the activation function which transforms the weighted sum of the input. The weight vector is unknown, therefore, weights in the input layer are randomly initialized based on the feature importance of the input variables. Hidden layers and activation function allow the model to learn non-linear function as a result, low weight value at the input layer allows the model to start as linear and due to increasing hidden layers, the model turns nonlinear with increased weights.
Commonly used nonlinear function is the sigmoid function. The weight adjustment is with respect to the error, that is, computed at each neuron to make sure error minimization. As a result of these connections, each node is penalized as every node contributes to the global error computed at the output layer. The aim is to minimize the error, therefore the error correction with respect to the weight (Haykin Citation1994) is done using the Gradient descent method and this is given as;
where is the learning rate and
is the error term. At the output node, the network error is computed. Noting that weights in the hidden layers are updated based on the error computed at the output node. Learning rate regulates the change of the adjusted weight in the direction of weight. A small value of
controls the step size toward convergence whereas high value will cause divergence. To ensure the error is minimized, weights are adjusted such that the new weight became;
The weight updates are done either in a batch, that is, using batch or the stochastic gradient descent methods.
K-Nearest Neighbors
KNN is a sluggish learning algorithm that depends on the knowledge gained from the training data to predict the test data. In general, the algorithm does not make any assumptions about the data but mainly bases its prediction on the neighboring terms. Therefore, if we consider to predict for unknown parameter, the KNN scheme will scan through the training data to obtain all the related instances that are close to the unknown points. For quantitative data, the Euclidean formula defined in Equation 8 is used to select the similarity points whilst for other data types like nominal or ordinal, Hamming distance can be applied.
Furthermore, in regression analysis, we measure the expectation of the predicted feature and for classification problems like in our case, the most dominant class is returned.
Since KNN depends on the number of neighbors during its testing phase and the algorithm uses distance measure to determine test class, the algorithm suffers from high computation cost. The choice of the value
influences the performance of the model. A small value of
can result in high accuracy but can results in over-fitting the model whereas for a large value of
, although the effect of noise is reduced, KNN is prompt to have lose boundary hence under-fitting the model.
Logistic Regression
LR makes use of conditional probability to map the input variable to a corresponding classification class. Given an input variable, the model predicts the probability of an input variable to belong to classification class. Suppose given an input variable such that
, and the corresponding class
where
represents the number of classes. LR uses non-linear activation, that is, the sigmoid function to give the relation between the input variables and the output class. In the case of binary classification where
is the probability of being in either class
or
is given by;
In this work, we aim to optimize the weighted parameters so that the classification error can be minimized. These parameters are either estimated by gradient ascent or stochastic gradient ascent methods (Pedregosa et al. Citation2011). The log-likelihood and Newton methods are commonly applied to glean optimal parameters (Qi and Sun Citation1993). In both gradient cases, the hyperparameters are adjusted until the model has a minimum error between the observed value and the predicted. Here, the stochastic gradient ascent updates the weight at every single point depending on the direction of the weight. This distinguishes the two gradient cases.
Performance Evaluation
To evaluate the predictive capabilities of the fitted models, we adopt methods such as train-test split and K-fold cross validation methods. In this work, we evaluate our predicted models discussed in Section 3 using cross tabulation presented in . Here, the table presents a binary classification confusion matrix. From , the following information about the classifiers’ performances can be obtained as follows:
Table 2. Performance metrics for classification.
True positive (TP): correct prediction of positive class
True negative (TN): predictions of negative class when the class is actually negative
False negative (FN): wrong prediction of positive class as negative.
False positive (FP): model predicts negative class predicted as positive.
Recall or sensitivity gives the classifier capability to correctly classify the positive class which is given as a ratio of TP and positive in the sample in the dataset. Other measures such as precision compare the true positive in the confusion matrix and the total number of positively predicted by the classifier. Specificity is also known as the true negative rate of the classifier, it is the ratio of true negative and negatives sample. F-measure the Harmonic mean of recall and precision. Equation 10 to 14 gives the formulae of the computation generated from the confusion matrix.
Cross validation is a technique used to check how the model will perform in general. We performed K-fold cross-validation with folds. The data are split into K folds, that is, for
folds,
folds are used to train the data and the
fold is used for testing. This process is repeated until all the folds are trained and tested. The accuracy of the classifier is obtained by taking the average of all accuracies gleaned in the test fold.
Due to the imbalanced nature of the normal and anomaly class in our dataset, ROCFootnote8 curves are used to measure how the classifier is performing in each class. As we saw earlier, the data is skewed and therefore, class distribution might affect classifier performance. The area under the curve (AUC) visualizes the classifier behavior on how often the model will classify positive class correctly and when the actual classification is negative, how often the model predicts positive. In this study, we want to maximize the true positive rate and minimize the false positive rate. The curve has TPR on the vertical axis and FPR on the horizontal axis. The plot ranges from with position (0,1) indicating a perfect classification model. The TPR and the FPR of the classifier is given by;
Results and Analysis
After accomplishing the normal feature engineering, selection, and as expected, fitting a classifier and obtaining some results in a form of a probability or a class, the next thing we need to do is to evaluate how efficient the classifier is on the metric performance using the validation dataset. In this work, the classification technique is done by splittingFootnote9 the model data into 80–20 ratio, to obtain the train and test sets, respectively.
and show the performance of the fitted models (SVM, MLP, KNN and LR) on the dataset. For instance, in , the TPs are (for SVM),
(for MLP),
(for KNN) and
(for LR). In the case of TNs, we have
(SVM),
(MLP),
(KNN) and
(LR). The lowest FP is recorded by MLP as
and the highest is captured by KNN as
. A summary probability of these performances are reported in . For example, the MLP classifier recorded the highest score of
on the test data. This is followed by the SVM classifier which gave an accuracy score of
on the validated data. Moreover, the proportion of the dataset that is classified as an anomaly and actually detected as an anomaly in the positive class [refer to Equation 12] is
(for LR),
(for SVM),
(for KNN) and
(for MLP). Note also that, the model classifier that recorded the highest specificity is the MLP with a percentage value of
.
Table 3. Classifier confusion matrix.
Table 4. Classifier evaluation performance.
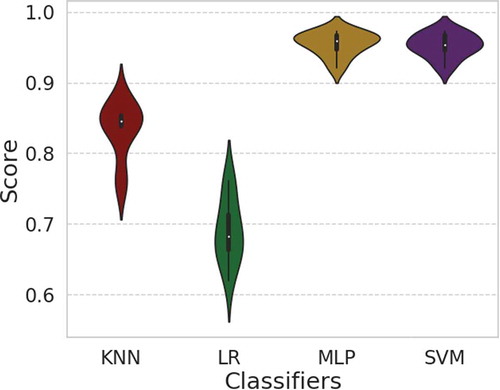
The Violin plots displayed in compare the 10-fold cross validation scores of the model classifiers. The white dot in the middle of the Violin plots denotes the median of each classifier. The thick gray bar in the center denotes the inter-quartile range whilst the thin gray line represents the confidence interval. The colored regions (red, green, yellow and magenta) on each side of the gray line is a kernel density estimation depicting the distribution shape of the model data. Note how the MLP and SVM classifiers have broader regions around their respective medians. This clearly means that, these classifiers (MLP and SVM) have a higher probability scores than the other two classifiers (LR and KNN).
Figure 6. Violin plots showing the 10-fold cross validation score for LR, KNN, MLP, and SVM.
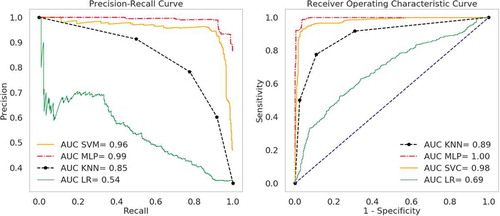
shows the ROC (right panel) and precision-recall (left panel) curves. Due to huge class imbalance in the dataset (refer to ) (right), the precision-recall curves is approximate for this study. Here, the MLP classifier registered an AUC of followed by the SVM with an AUC of
. These high values show that there is a trade-off between the true positive rate and the positive predictive value for these two classifiers, as relatively compared to KNN and LR. However, if we ignore the fact that there is a class imbalance in the dataset, then we measure the agreement between the true positive rate and false-positive rate for the predictive model. In this case, we consider the right panel curves. Note how the ROC curves overestimated the probabilities of the model classifiers. This is clearly due to the huge skewness in the distribution of the sample data. Hence, for the purpose of this study, we choose the left panel curves as appropriate.
Figure 7. Precision-Recall curves and ROC curves of classifiers.
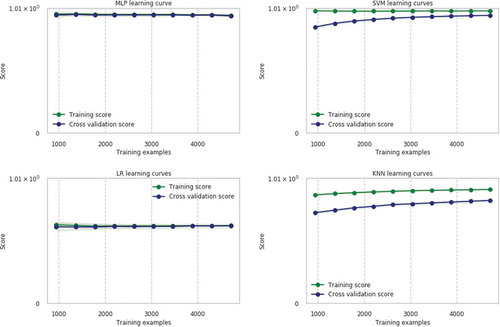
Using cross validation with 10 splits, we can observe the relationship between training score and cross validation score of different classifiers as presented in . The variation of cross validation curve results in high variance and that of the training score curve results in high bias. High variance is an indication that the model detects every noise in the data. High bias implies that the model data has less information. Regularization of bias and variance help the model to attain better predictive performance. The graphs presented in show that the cross validation curve tends to converge with increase in the training sample. In this work, the MLP and LR converge just after training samples whilst the other two classifiers slowly converge and may require more training samples that is
.
Figure 8. Training and cross validation score curve of MLP, KNN, SVM, and LR.
Conclusion
In this paper, we aimed at evaluating the classification algorithm by training the model to learn and identify the anomalies in the fuel consumption dataset obtained from a telecommunication base station. Four classification techniques were evaluated namely; SVM, LR, MLP, and KNN. MLP recorded the best performance generally with an accuracy score of on the test data. Although the SVM outperformed the other two classifiers (KNN and LR), using the K-fold cross validation technique, the MLP again slightly performed better than SVM with a score of
. Furthermore, from the performance measure table, the MLP registered the best predicting power of detecting the anomalies. The LR also performed better than the KNN in the precision score with respective values of
and
. The class imbalance in the dataset resulted in the work to choose the Precision-recall curve over the ROC curve to avoid overestimation. Again, the MLP recorded an AUC of
as the highest performance classifier. This is followed by SVM with an AUC of
. We therefore conclude that the MLP classifier gives the overall best performance over the other classifiers, that is, the classifier best fits the training examples compared to other classifiers in terms of anomaly detection and in evaluation performance such as K-fold cross validation as well as the use of the precision-recall curves.
Acknowledgements
The author would like to thank TeleInfra Company and Group One Holding Company for providing the dataset for this study. We wish to acknowledge Mr. OKALI DIMA Patrick from Group one holding for ensuring the data were available. Grateful for SciKit learn library as this work has been made possible from the use of their library packages. T. Ansah-Narh is very grateful to the Data Science Intensive (DSI) Program, organised by the African Institute for Mathematical Sciences (AIMS) South Africa, in conjunction with SA-DISCNet.
Notes
1. http://www.art.cm/en/node/3111.
2. Support Vector Machine.
3. K-Nearest neighbors.
4. Logistic Regression.
5. MultiLayer Perceptron.
6. Here, the NaN values are removed using the Pandas module dropna.
7. Using the Python module sklearn.ensemble.GradientBoostingClassifier, we can compute the feature import to choose the relevant feature parameters. Note, this classifier uses the forward stagewise algorithm.
8. Receiver Operating Characteristic.
9. Here, we separate the dataset into train and test sets using the Python SciKit module sklearn.model_selection.train_test_split.
References
- Aggarwal, C. C. 2014. Data classification: Algorithms and applications. Boca Raton, Florida, United States: CRC press.
- Banjanovic-Mehmedovic, L., A. Hajdarevic, M. Kantardzic, F. Mehmedovic, I. Dzananovic. 2017. Neural network-based data-driven modelling of anomaly detection in thermal power plant. Automatika. 58(1):69–79. doi:10.1080/00051144.2017.1343328.
- Chouiekh, A., and I. E. L. H. EL Hassane. 2018. Convnets for fraud detection analysis. Procedia Computer Science 127:133–38. doi:10.1016/j.procs.2018.01.107.
- Hastie, T., Tibshirani, R., Friedman, J., and Franklin, J. 2005. The elements of statistical learning: data mining, inference and prediction. The Mathematical Intelligencer 27(2):83-85. Springer. doi:10.1007/BF02985802.
- Haykin, S. 1994. Neural networks: A comprehensive foundation. Upper Saddle River, New Jersey, United States: Prentice Hall PTR.
- Kelleher, J. D., B. M. Namee, and A. D’arcy. 2015. Fundamentals of machine learning for predictive data analytics: Algorithms, worked examples, and case studies. Cambridge, Massachusetts, United States: MIT Press.
- Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12 Oct: 2825–30.
- Qi, L., and J. Sun. 1993. A nonsmooth version of Newton’s method. Mathematical Programming 58 (1–3):353–67. doi:10.1007/BF01581275.
- Taboada-Crispi, A., Sahli, H., Hernandez-Pacheco, D., Falcon-Ruiz, A. 2009. Anomaly detection in medical image analysis. In Handbook of research on advanced techniques in diagnostic imaging and biomedical applications, 426–46. Pennsylvania, United States: IGI Global.
- Zanin, M., M. Romance, S. Moral, R. Criado, et al. 2018. Credit card fraud detection through parenclitic network analysis. Complexity 2018. Hindawi. doi:10.1155/2018/5764370.