
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Extreme learning machine for regression (ELR), though efficient, is not preferred in time-limited applications, due to the model selection time being large. To overcome this problem, we reformulate ELR to take a new regularization parameter nu (nu-ELR) which is inspired by Schölkopf et al. The regularization in terms of nu is bounded between 0 and 1, and is easier to interpret compared to C. In this paper, we propose using the active set algorithm to solve the quadratic programming optimization problem of nu-ELR. Experimental results on real regression problems show that nu-ELR performs better than ELM, ELR, and nu-SVR, and is computationally efficient compared to other iterative learning models. Additionally, the model selection time of nu-ELR can be significantly shortened.
Introduction
Recently, researchers in the area of artificial intelligence have given more attention to single hidden layer feedforward neural networks (SLFNs) due to their strong performance, such as RBF networks, SVM (considered as a special type of SLFNs), polynomial networks, Fourier series, wavelet, etc. (Bu et al. Citation2019; Cortes and Vapnik Citation1995; Park and Sandberg Citation1991; Shin and Ghosh Citation1995; Zhang and Benveniste Citation1992). Extreme Learning Machines (ELMs) are one of the most popular SLFNs, first introduced by Huang and his group in the mid-2000s (Huang, Chen, and Siew Citation2006; Huang et al. Citation2006; Huang, Zhu, and Siew Citation2006). Different from previous works, ELM provides theoretical foundations on feedforward neural networks with random hidden nodes. It can handle classification, regression, clustering, representational learning, and many other learning tasks (Ding, Zhang, and Zhang et al. Citation2017; He, Xin, and Du et al. Citation2014; Lauren, Qu, and Yang et al. Citation2018). In this paper, we focus on regression learning task.
The law of large numbers suggests an interesting characteristic of trained ELM, a minimum empirical error can ensure minimum testing error with high probability for large training samples. In theory, it happens with probability one for infinite training samples. However, due to limit samples in real world, ELM may learn a function that perfectly separates the training samples but that does not generalize to unseen data. To address this issue, an optimization extreme learning machine for binary classification (ELC) was proposed (Ding and Chang Citation2014; Huang, Ding, and Zhou Citation2010; Huang et al. Citation2012). ELC implements the bartlett’s theory (Bartlett Citation1998), for which the smaller the norm of the output weights is the better generalization performance the system tends to have. Compared to ELM, the minimization norm of output weights enables ELC to get the better generalization performance. Then, the optimization idea is generalized to solve multi-class classification and regression learning tasks. Empirical studies based on real benchmark problems have shown that compared with classical learning algorithms (such as SVR and ELM), optimization ELM for regression (ELR) tends to provide better generalization performance with low computational cost. From the model selection point of view, ELR builds the training model without frequently tuning the parameters.
It has been shown that there are two parameters of ELR needed to be tuned, kernel parameter L and penalty parameters. Several papers suggest that the ELM-style optimization model generally maintains good generalization ability with large parameter L (Frénay and Verleysen Citation2010; Huang, Ding, and Zhou Citation2010; Huang et al. Citation2012). In fact, one can set proper L (e.g. 103) before seeing the training samples. ELR uses parameters C and ϵ to apply a penalty to the optimization for samples which are not correctly predicted. However, C ranges from 0 to infinity and can be a bit hard to estimate the best value. In the case of SVM formulation, a new version of SVM for regression was developed where the epsilon penalty parameter was replaced by an alternative parameter nu (Chang and Lin Citation2002; Schölkopf et al. Citation2000). Parameter nu operates between 0 and 1 and represents the lower and upper bound on the number of samples that are support vectors and that lie on the wrong side of the hyperplane. It is the intuitive meaning that nu is more intuitive to tune than C or ϵ, and nu is successfully applied to ELC formulation (Ding et al. Citation2017).
In this paper, we extend ELR formulation to a new formula with such parameter nu, named nu-ELR, to address the problem mentioned above. In nu-ELR, the parameter ϵ is introduced into the new formula and it is estimated automatically for user. Compared to ELR, parameter nu lies in a smaller range than C (which goes from 0-infinity), which is tested on a linear scale.
This paper is organized as follows. In Section 2, the fundamental knowledge of ELR and ν-SVR is introduced. Section 3 presents the optimization problem of nu-ELR and derives its dual problem. In section 4, we propose an active set algorithm for solving the dual problem of nu-ELR. Section 5 compares ν-OELM with other state-of-the-art regressors for real benchmark datasets. Section 6 concludes the paper.
Related Works
In this section, the fundamentals of ELR and nu-SVR are reviewed.
ELR
Considering a regression problem with training samples, where
is the input pattern and
is the corresponding target. ELM is to minimize the training error as well as the norm of the output weights:
where is the vector of the output weights between the hidden layer of L nodes and the output node and
is the output (row) vector of the i-th hidden node with respect to the input
. The function
actually maps the training data
from the input space to the L-dimensional ELM feature space.
Note than the norm term can be replaced by one half the norm squared,
. Here, we use the
-insensitive loss function:
where is the width of the
-insensitive tube. Using the
-insensitive loss function, only the training points outside the
-tube contribute the loss, whereas the training points closest to the actual regression have zero loss. According to ELM learning theory (Huang, Chen, and Siew Citation2006), ELM can approximate any continuous target functions so that any set of distinct training points lies inside the tube. However, some testing points may lie outside the tube for noisy problems. In this case, potential violations are represented using positive slack variables
and
ELR attempts to strike a balance between minimization of training error and the penalization term.
The parameter C controls the trade-off between the norms of weights and the training error.
nu-SVR
The nu-SVR primal formulation problem, as given in (Chang and Lin Citation2002), is as follows:
where ξ. The regression hyperplane of nu-SVR is
if ξ
. Here ν is the user-specified parameter between 0 and 1, and training data
are mapped into a feature space by through a mapping
. The Wolfe dual formulations of this problem are
where Lagrange multipliers ,
is the implicit mapping kernel. Schölkopf et al. (Schölkopf et al. Citation2000) showed that ν is an upper bound on the fraction of margin errors, a lower bound on the fraction of support vectors, and both of these quantities approach ν asymptotically. Chang and Lin (Chang and Lin Citation2002) suggested that for any given
, at least one optimal solution of (6) satisfies the equation
, where
. Thus, the inequality constraint of (2) can be solved by an equality constraint
.
Optimization Problem of nu-ELR
The original ELM formulations for regression (ELR) used parameter C [0, inf] to apply a penalty to the optimization for points which were not correctly predicted. Parameter C is difficult to choose correctly and one has to resort to cross-validation or direct experimentation to find a suitable value. In this section, we will present a new formulation for nu-ELR, whose parameter C is replaced by parameter ν.
Optimization Formulation
Similar to ELR’s formulation, is used as the width of the
-insensitive tube, which is slacked by variables
. In the objective function,
is penalized by constant ν, and both variables
and
are traded off against model complexity via a constant parameter C. Thus, the optimization formulation of nu-ELR can be shown as
It should be noted that there are two major differences between nu-ELR and nu-SVR formulations:
The mapping mechanism of nu-SVR is inexplicit, in contrast to explicit mapping in nu-ELR. Thus,
in (5) is usually unknown and cannot be computed directly.
All kernel parameters in nu-SVR need to be tuned manually, whereas all parameters for ν-OELM are chosen randomly.
Considering many constraints of (7), we consider the Lagrangian:
where multipliers . This function has to be minimized with respect to variables
of the primal problem and maximized with respect to dual variables
. Setting the gradients of this Lagrangian with respect to
equal to 0 gives the following KKT optimality conditions:
Substituting three equations of (9) into leaves us with the following quadratic optimization problem:
where is ELM kernel. Similar to nu-SVR’s formulation, inequation constraint
can be converted to equation constraint
.
The resulting decision function can be shown as
From the dual formulation point of view, nu-SVR needs to satisfy one more optimization condition as compared to nu-ELR. In this case, nu-SVR tends to find a solution which is the sub-optimal to nu-ELR’s solution.
Karush-Kuhn-Tucker Conditions of nu-ELR
From the KKT optimality condition (Fletcher Citation1981), primal and dual optimal solutions satisfy the following slackness conditions.
Primal feasibility
Dual feasibility
Complementary slackness
By substituting (9) into (15), we have
From Equation (9) and (11), we have , where
is the predicted value of nu-ELR for the sample
. If
, from (16) we have
. By primal feasibility condition (12), we have
. If
, from (14) we have
. By primal feasibility condition (12) we further have
. If
, from (16) we have
. By complementary slackness condition (14) we have
, that is
. Likewise, KKT conditions of
can be concluded. In the light of the above, we have the following conditions:
Solving Algorithm of nu-ELR
It is well known that an active set algorithm is an effective method for solving quadratic programming problems with inequality constraints. As far as we know, it has been successfully applied to many ELM style quadratic programming optimization problems, such as ELM for classification, ELM for regression, SVM, etc. In the method, a subset of the variables is fixed at their bounds and the objective function is minimized with respect to the remaining variables. After a number of iterations, the correct active set is identified and the objective function converges to a stationary point.
The objective function of (10) can be rewritten as
Thus, formulation (10) can be equivalently written as
where
,
For simple computation, we set
as
, so the constraint
can be rewritten as
. We begin an active set algorithm with some notations. For a point
in the feasible region, we define
and
. Vectors
,
and
are defined according to these sets. The vector of elements in
whose indices belong to set
denotes
, and other elements in
denote
and
respectively. Likewise, we define
,
, and
, where
. Corresponding to the choice of indices set
,
, and
, we partition and rearrange matrix
as follows:
Thus, the objective function of (19) is equal to . At each iteration,
is fixed and the formulation (19) can be equivalently written as
Then, formulation (20) can be further rewritten as
where ,
,
, and
is the number of elements in vector
.
The Lagrangian for this problem (21) is
The partial derivatives of the Lagrangian are set to zero, which leads to the following simple linear system.
So, the optimal solution with the corresponding
can be solved by (22).
Based on the above derivation of quadratic formulations, the proposed active set algorithm can be summarized by two loops: The first loop iterates over all samples violating the KKT conditions (17), and the first step of iterative process beginning from samples that are not on bound. The iterator keeps alternating between passes over entire training samples and passes over the non-bound instances. If the optimality conditions are satisfied over all samples, the algorithm stops with the solution; otherwise, the second loop begins; The second loop is a series of iterative steps to solve the formulation (21). As is convex, the strict decrease of the objective function holds, and a global minimum of (21) can be obtained. The theoretical convergence proof of similar formulation was given in (Ding and Chang Citation2014).
Numerical Experiments and Comparison of Results
In this section, the performance of nu-ELR will be investigated by comparing it numerically not only with ELR but also with two other well-accepted learning models: ELM and nu-SVR. All the experiments have been conducted on a 4-core, i7-7700HQ CPU @ 2.8 GHz laptop with 8 GB RAM and a MATLAB implementation. We have evaluated four learning models on 26 famous real-world benchmark data sets on UCI Machine Learning Repository (Blake and Merz Citation2013) and Statlib (Mike Citation2005). All the inputs of the data sets have been normalized to the range [0,1], while the outputs are kept unchanged. To find the average performance, 50 trials are conducted for each dataset with every learning model. The training and testing samples of the corresponding data sets are reshuffled at each trial of simulation.
In these data sets, some features are in nominal format, which are used to identify the objects only, and they cannot be manipulated as numbers. Some steps should be performed to convert these features into numeric attributes, which are quantitative because, they are some measurable quantities, represented in integer or real values. For example, in ‘Abalone’ dataset, the ‘sex’ attribute has three states: M, F, and I, which are represented by 1, 2, and 3; In ‘Cloud’ dataset, the ‘season’ attribute has four states: AUTUMN, WINTER, SPRING, and SUMMER. We simply use ‘1, 0, 0, 0ʹ to represent AUTUMN, and ‘0, 1, 0, 0ʹ, ‘0, 0, 1, 0ʹ, ‘0, 0, 0, 1ʹ are used to represent other three states. After attribute preprocessing, the number of attributes in ‘Cloud’ dataset is increased from 6 to 9, and 7 to 36 for ‘Machine_cpu’ dataset, 4 to 19 for ‘Servo’ dataset.
Selection of Parameters
The popular Gaussian kernel functionis used in both nu-SVR. To train nu-ELR and ELR, the Sigmoid type of ELM kernel is used:
, where
. In addition, for the Sigmoid active function of ELM kernel, the input weights and biases are randomly generated from (−1, 1)N×(0, 1) based on the uniform probability distribution.
In order to achieve good generalization performance, we use grid search to determine the kernel parameter and ν for nu-SVR. Similar to Ghanty, Paul, and Pal (Citation2009), parameters ν and
of SVM are tuned on a grid of {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1}
{0.001, 0.01, 0.1, 0.2, 0.4, 0.8, 1, 2, 5, 10, 20, 50, 100, 1000, 10000}. According to the suggestion of (Ding and Chang Citation2014; Ding et al. Citation2017; Huang, Ding, and Zhou Citation2010; Huang et al. Citation2012), ELR tends to achieve better generalization performance when kernel parameter L is large enough. For ELR, L is set 1000, and parameter C is tuned on {0.001, 0.01, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 1000, 10000}. For nu-ELR, L is set 1000, parameters ν and C are tuned on a grid of {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1}
{0.001, 0.01, 0.05, 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 1000, 10000}. For ELM, there is only one parameter L (optimal number of hidden nodes) that needs to be determined. As the generalization performance of ELM is not sensitive to the number of hidden nodes L, parameter L is tuned on {5, 10, 20, 30, 50}.
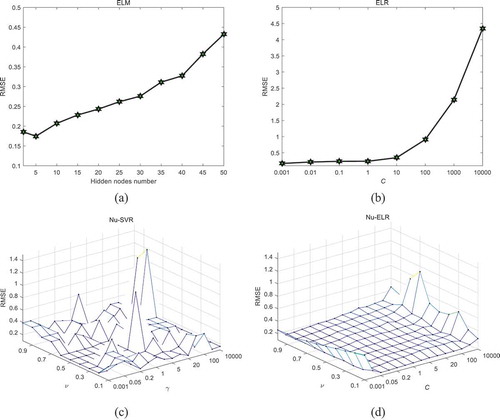
The generalization performance of four models (ELM, ELR, nu-SVR, and nu-ELR) on the ‘Sensory’ dataset for different combinations of model parameters (cf ) is presented. It is clear that the best generalization performance of nu-SVR depends heavily on the combinations (ν, ). The best generalization performance is usually achieved in a narrow range of such combinations. In contrast, the generalization performance of nu-ELR is less sensitive to combinations (ν, C), especially in a narrower range (0.1–1, 0.1–100).
Figure 1. Generalization performance of four learning models on sensory dataset for different combinations of parameters. (a) ELM, (b) ELR, (c) nu-SVR, (d) nu-ELR.
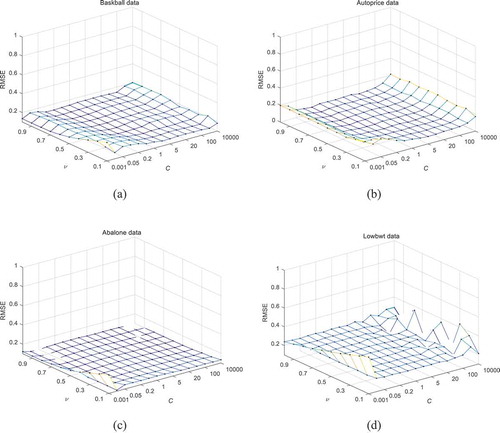
To analyze this phenomenon, four more data sets (Baskball, Autoprice, Abalone, and Lowbwt) are selected to run different combinations of parameters, as shown in . For both these data sets, we can confirm that nu-ELR performs smoother on local parameter combinations (ν, C) of (0.1–1, 0.1–100) than the whole combinations. For (d) of , if we fix the regularization parameter C at some value and vary the parameter ν in a large range, we found that generalization performance of nu-ELR is less sensitive to the variation of parameter ν.
Figure 2. Generalization performance of nu-ELR on four data sets. (a) Baskball, (b) Autoprice, (c) Abalone, (d) Lowbwt.
Statlib Data Sets
In this section, the performance of four learning models is tested through experiments of Statlib data sets, which contain 15 benchmark data sets, as listed in .
Table 1. Statlib data sets.
In our experiments, for each evaluated learning model, we use one training/testing partition to do parameter selection. Once the parameter selection process is completed, the selected model is used for other partitions. The selected parameter combination is then used for all independent trials, and the training and testing samples are randomly selected for each trial. First of all, we report model selection results for both four learning models, the selected combinations of parameters are listed in .
Table 2. Parameters setting on Statlib data sets.
For both 15 data sets, 50 trials have been conducted for each dataset. Experimental results include the root-mean-square error (RMSE) and the training time (s), as shown in and . For 11 out of 15 data sets, nu-ELR gives the best performance of RMSE. We also see that nu-ELR achieves the second-best performance for four other data sets when compared with three learning models. Clearly, nu-ELR performs better than ELR for all 15 data sets. Another observation is worth noting. It can be seen that for Balloon, Mbagrade, Space-ga data sets, compared to other learning models, nu-SVR performs significantly worse. A possible explanation is that the generalization performance of nu-SVR is very sensitive to the model parameters. After parameter selection, even nu-SVR performs well on one training/testing partition, it may perform very bad on other partitions.
Table 3. Performance comparison of four learning models (RMSE) on Statlib data sets.
Table 4. Training time comparison of four learning models (s) on Statlib data sets.
The training time experiment (see ) shows that the advantage of the ELM is quite obvious, as iteration is no need in the ELM training process. The training time of three learning models is similar to each other, except nu-SVR on some data sets (Balloon, Mbagrade, Space-ga). This phenomenon is originated from the fact that nu-SVR hardly finds the global solution within the limited iterations.
UCI Data Sets
In this section, the performance of four learning models is tested through experiments of UCI data sets, which contain 11 benchmark data sets, as listed in . shows the model selection results.
Table 5. UCI data sets.
Table 6. Parameters setting on UCI data sets.
From , out of 11 data sets, nu-ELR performs the best on 7 data sets, while nu-SVR performs the best on 4 other data sets. For Machine_cpu data set, we see that original nu-SVR is significantly better than other learning models when compared with RMSE. The most likely explanation for the superior performance of nu-SVR is that this data set is not sensitive to different training/testing partitions. For the Mpg dataset, it is worth noting that nu-SVR performs very badly compared to three other learning models, which has been discussed above. gives the training time comparison. An interesting point of comparison is with the Mpg data set. Although nu-SVR performs very badly, less training time is need compared to ELR and nu-ELR.
Table 7. Performance comparison of four learning models (RMSE) on UCI data sets.
Table 8. Training time comparison of four learning models (s) on UCI data sets.
A Performance Evaluation of Kernel Methods
Obviously, the kernel plays an important role in determining the characteristics of the nu-ELR learning model and choosing different kernels may result in different performances. In this section, another experiment was set up to see how the kernel affects the performance of different data sets for nu-ELR. Four commonly used kernel functions of ELM kernel
in literatures are adopted in this experiment:
Sigmoid function:
Sin function:
Hard-limit function:
Exponential function:
All the vectorsand variables
in these kernel functions are set the same, which are randomly generated from (−1, 1)N×(0, 1) based on the uniform probability distribution. The RMSE of regression performance on the test sets, across the Statlib data sets and UCI data sets, for the different nu-ELR kernels is shown in and .
Table 9. Comparison results of four kernel functions on Statlib data sets.
Table 10. Comparison results of four kernel functions on UCI data sets.
From both two tables, we see that the Sigmoid kernel shows the best performance over most of the data sets. The Sin and Hard kernels show similar performance over more than half of all data sets. Hard kernel is the second most accurate in our experiments, but is clearly less accurate than Sigmoid kernel. As the computational cost of each kernel is very similar, the comparison of training time is not shown in this experiment.
Conclusions
By a simple reformulation of ELR with parameter nu, a novel ELR formulation is proposed in this work as an inequality-constrained minimization problem with the key advantage being the new parameter nu is only searched within the range [0, 1]. It is further proposed to solve the minimization problem using the active set algorithm. Experimental results on two different data repositories, including 26 regression problems, demonstrate that nu-ELR achieves the best performance over most of the regression problems, compared with ELM, ELR, and nu-SVR learning models. In particular, it provides a fair comparison on the RMSE of the different kernels of nu-ELR. It is clear from these results that some kernels are better than others, and certain kernels are better suited to certain types of problems. In future works, the proposed approach will be extended for other kernel-based learning methods.
Additional information
Funding
References
- Bartlett, P. L. 1998. The sample complexity of pattern classification with neural networks: The size of the weights is more important than the size of the network. IEEE Transactions on Information Theory 44 (2):525–36. doi:10.1109/18.661502.
- Blake, C. K., and C. J. Merz. 2013. UCI repository of machine learning databases. http://archive.ics.uci.edu/ml/.
- Bu, Z., J. Li, C. Zhang, J. Cao, A. Li, and Y. Shi. 2019. Graph K-means based on leader identification, dynamic game, and opinion dynamics. IEEE Transactions on Knowledge and Data Engineering. doi:10.1109/TKDE.2019.2903712.
- Chang, C. C., and C. J. Lin. 2002. Training v-support vector regression: theory and algorithms. Neural Computation 14 (8):1959–77. doi:10.1162/089976602760128081.
- Cortes, C., and V. Vapnik. 1995. Support vector networks. Machine Learning 20:273–97. doi:10.1007/BF00994018.
- Ding, S., N. Zhang, J. Zhang, X. Xu, Z. Shi. 2017. Unsupervised extreme learning machine with representational features. International Journal of Machine Learning and Cybernetics. 8(2):587–95. doi:10.1007/s13042-015-0351-8.
- Ding, X., and B. Chang. 2014. Active set strategy of optimized extreme learning machine. Chinese Science Bulletin 59 (31):4152–60. doi:10.1007/s11434-014-0512-2.
- Ding, X. J., Y. Lan, Z. F. Zhang, and X. Xu. 2017. Optimization extreme learning machine with ν regularization. Neurocomputing 261:11–19. doi:10.1016/j.neucom.2016.05.114.
- Fletcher, R. 1981. Practical Methods of Optimization: Volume2 Constrained Optimization. New York: Wiley.
- Frénay, B., and M. Verleysen. 2010. Using SVMs with randomized feature spaces: An extreme learning approach, in: Proceedings of The 18th European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 28–30 April, 2010, 315–20.
- Ghanty, P., S. Paul, and N. R. Pal. 2009. NEUROSVM: An architecture to reduce the effect of the choice of kernel on the performance of svm. Journal of Machine Learning Research 10:591–622.
- He, Q., J. Xin, C. Y. Du, F. Zhuang, Z. Shi. 2014. Clustering in extreme learning machine feature space. Neurocomputing 128:88–95. doi:10.1016/j.neucom.2012.12.063.
- Huang, G.-B., L. Chen, and C.-K. Siew. 2006. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Transactions on Neural Networks 17 (4):879–92. doi:10.1109/TNN.2006.875977.
- Huang, G.-B., X. Ding, and H. Zhou. 2010. Optimization method based extreme learning machine for classification. Neurocomputing 74:155–63. doi:10.1016/j.neucom.2010.02.019.
- Huang, G.-B., H. Zhou, X. Ding, and R. Zhang. 2012. Extreme learning machine for regression and multiclass classification. IEEE Transaction on System, Man, and Cybernetics-Part B: Cybernetics 42 (2):513–29. doi:10.1109/TSMCB.2011.2168604.
- Huang, G.-B., Q.-Y. Zhu, K.-Z. Mao, C.-K. Siew, P. Saratchandran, and N. Sundararajan. 2006. Can threshold networks be trained directly? IEEE Transactions on Circuits and Systems-II: Express Briefs 53 (3):187–91. doi:10.1109/TCSII.2005.857540.
- Huang, G.-B., Q.-Y. Zhu, and C.-K. Siew. 2006. Extreme learning machine: Theory and applications. Neurocomputing 70:489–501. doi:10.1016/j.neucom.2005.12.126.
- Lauren, P., G. Qu, J. Yang, P. Watta, G-B. Huang, A. Lendasse. 2018. Generating word embeddings from an extreme learning machine for sentiment analysis and sequence labeling tasks. Cognitive Computation 10(4):625–38. doi:10.1007/s12559-018-9548-y.
- Mike, M. 2005. Statistical datasets. http://lib.stat.cmu.edu/datasets/.
- Park, J., and I. W. Sandberg. 1991. Universal approximation using radial basis-function networks. Neural Computation 3:246–57. doi:10.1162/neco.1991.3.2.246.
- Schölkopf, B., A. Smola, R. C. Williamson, and P. L. Bartlett. 2000. New support vector algorithms. Neural Computation 12:1207–45. doi:10.1162/089976600300015565.
- Shin, Y., and J. Ghosh. 1995. Ridge polynomial networks. IEEE Transactions on Neural Networks 6 (3):610–22. doi:10.1109/72.377967.
- Zhang, Q., and A. Benveniste. 1992. Wavelet networks. IEEE Transactions on Neural Networks 3 (6):889–98. doi:10.1109/72.165591.