
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Context-aware collaborative filtering (CACF) is an effective approach for adapting recommendations under users’ specific contextual situations and aims to improve predictive accuracy for Context-aware recommender systems (CARSs). Incorporating context in recommender systems (RSs) considering the equal importance to all contextual dimensions is not appropriate for seeking an intelligent and useful recommendation. In this paper, we propose a Real-coded Genetic Algorithm (RCGA) based CARS framework that exploits contextual pre-filtering and contextual modeling paradigms into CACF with appropriate context feature weights for enhancing accuracy as well as the diversity of the recommendation list. Further to alleviate the data sparsity, an effective missing value prediction (EMVP) algorithm is applied into proposed framework. The accuracy based on RCGA is compared with other two schemes: Support Vector Machine (SVM) and Particle Swarm Optimization (PSO), and RCGA has shown better results. Experimental results based on real-world datasets have clearly established the effectiveness of our proposed CARS schemes.
Introduction
At the time of exceptional growth in the importance of search technologies, many researchers and practitioners focus on how interactive systems can encourage and support the users’ behavior changing with encapsulated context. Context-aware recommender systems (CARSs) offer a new perspective of multi-dimensionality that makes the recommendation more relevant and intelligent (Adomavicius and Tuzhilin Citation2005).
CARSs differ from traditional RSs because they not only use ratings given by users for items but also exploit both the knowledge of the contextual situations under which the ratings were acquired and the target user asking for a recommendation. More specific definition of context can be as any circumstances or conditions which affect something or someone. The significance of contextual information has been identified in many disciplines including information retrieval, e-commerce personalization, ubiquitous and mobile context-aware systems, databases, data mining, marketing, and management (Adomavicius et al. Citation2011). However, the aggregation of multiple contexts gathers potentially useful information that would result in the increased predictive power of CARSs. An ideal CARS should be capable of labeling each user action with an appropriate context and effectively tailor the system output to the user in that given context.
Various approaches based on context-aware collaborative filtering (CACF) have been developed to utilize the strength of traditional collaborative filtering (CF) techniques to enhance recommendation ability of CARSs to pursue different tasks other than a product/item recommendation (Shi, Larson, and Hanjalic Citation2014; Verbert et al. Citation2012). In spite of that, the danger of sparsity arises if contextual information is applied too strictly. However, data sparsity usually complicates the process of item recommendation under neighborhood-based CF domain (Shams and Haratizadeh Citation2017). The performance of CF-based RSs is mostly evaluated through the predictive accuracy of the recommendations. Relying on the accuracy of recommendations alone may not be enough to find the most relevant items for a user and hence the diversity can be another important quality measure/criterion in the recommendation process (Adomavicius and Kwon Citation2008). Though the highly desirable feature of diversity is contrasting to accuracy, many researchers have compared several filtering techniques for CARSs in terms of accuracy and diversity (Panniello, Tuzhilin, and Gorgoglione Citation2014). The aim of our work is to identify an influential set of context features with appropriate weights effectively learned for each individual and handling sparse data that preserves both the accuracy and diversity.
The main contributions of this paper are summarized as follows:
We designed a context-aware recommendation scheme CACF, that is based on contextual pre-filtering and contextual modeling paradigms with a novel approach of context weighting using RCGA.
Our proposed scheme is compared with other well-Known schemes: Support Vector Machine (SVM) and Particle Swarm Optimization (PSO) for parameter optimization.
Further, an effective missing value prediction algorithm (EMVP) (Ma, King, and Lyu Citation2007) is incorporated into the proposed schemes to handle the sparsity problem.
Finally, we generated appropriate context feature weights using RCGA for the proposed CARS which would balance both accuracy and diversity of Top-N recommended list of items for each user.
The rest of the paper is organized as follows. Section 2 provides an overview of the state-of-the-art in the areas relevant for this research work. Section 3 presents the proposed RCGA-based CARS framework and demonstrates how the missing value prediction approach is assembled to alleviate the problem of sparsity and also presents for optimizing the tradeoff between accuracy and diversity. The experimental evaluation of aforementioned schemes is discussed in Section 4. Finally, Section 5 concludes with a discussion of the findings of our work and an outlook on future research needs and opportunities.
Related Work
With the increasing popularity of mobile apps, there is a need for CARS frameworks and models, appropriate for people who have a wide range of marketplaces where they can seek a lot of resources. A methodology is built for Context-aware mobile recommender systems, whereby users are asked to judge whether a contextual factor (e.g. Weather) influences the rating given under a certain contextual condition (e.g. The weather is cloudy) based on recommendation domain (e.g. Movie) (Campos et al. Citation2013). Furthermore, for providing location-based services like travel and tourism, various paradigms in Location-aware recommender system (LARS) have been proposed that use location-based ratings and real-world GPS datasets to produce personalized recommendation (Liu et al. Citation2013; Sarwat et al. Citation2014). Similarly, the long tail Context-aware music recommender systems (CAMRSs) can automatically play suitable music considering various users’ contextual information, such as weather, emotional state, running pace, location, time, social media activities, and low-level activities in real time that could save our time and effort (Wang et al. Citation2014).
The different application domains exhibited by different recommender algorithms show that recommendation process is not a one-size-fits-all problem. We need to have a deep understanding of choosing a recommender algorithm embedded with CARS that depends on specific domains. Most of the approaches are based on CF which strongly depends on the availability of meaningful user ratings on a large scale that leads to the problem of sparsity. Therefore, two models have been proposed: Differential Context Relaxation (DCR) and Differential Context Weighting (DCW) to deal with the problem of the sparsity of contexts (Zheng, Burke, and Mobasher Citation2013).
Techniques for Learning Context Feature Weights
In the following subsections, we briefly introduce some optimization techniques such as, SVM, PSO, and RCGA for learning context feature weights.
Support Vector Machine (SVM)
The Support Vector Machine (SVM) is a statistical learning theory, based on data mining method developed by Vapnik and the principle of Structural Risk Minimization is implemented by constructing an optimal separating hyperplane (Min and Han Citation2005; Min, Lee, and Han Citation2006). A linear SVM classifier is a hyperplane that separates all items into two classes, such as, like and dislike for each active user . Suppose
training samples have pairs
where
are a set of input context features, and
and
are corresponding outputs, 1 for like and −1 for dislike class. The task of linear SVM is to learn feature weights by mapping all pairs
into separating hyperplanes
, where
is the vector of context feature weights and
is the vector of input context features. The target is to maximize the distance of the hyperplanes to the nearest of the like and dislike classes. Maximizing the margin can be expressed as an optimization problem:
subject to
,
where
is the
training samples.
Particle Swarm Optimization (PSO)
Inspired by the collective behavior of birds and fishes, and the concept of evolutionary algorithm, Particle Swarm Optimization (PSO) algorithm was developed by Kennedy and Eberhart (Citation1995). It is an evolutionary computation technique based on swarm intelligence. For solving complex optimization problems, it is easy to implement and computationally less expensive in terms of both speed and memory requirements (Osuna-Enciso et al. Citation2016). PSO starts with a population of random solutions, and each individual solution is named as “particle” which represents a potential solution. Each particle is treated as a point in -dimensional space. The
particle is represented as
. The best previous position of any particle is recorded and represented as
. The index of globally best particle’s position is represented as
and the velocity (i.e. rate of change of a particle’s position) is represented as
. The updated velocity
and position
of the
particle at the
iteration are:
where and
are learning factors,
is inertia weight for balancing the global and local search,
and
are random values in the range between
and
.
Real-Coded Genetic Algorithm (RCGA)
Genetic Algorithm (GA) (Goldberg Citation1989) has received considerable attention toward handling any kind of objective function and any kind of constraints, i.e. linear or non-linear, defined on discrete, continuous or mixed search spaces. Most studies on feature weighting have used GA as the main heuristic method for determining weight vector (Noori Citation2015). The basic building blocks of binary GAs are genes and chromosomes. Chromosomes are evaluated by running GA for the respective parameter configuration and each GA uses a small-sized population of chromosomes to alleviate the problem of slow convergence, without losing potential solution (Wahde Citation2008). The conventional binary GA encodes the gene as a binary bit and chromosome as a string of binary bits. Whereas RCGA encodes the parameters in continuous domain representing genes as floating-point number and chromosome as a vector of floating-point numbers. In RCGA scheme, a chromosome length becomes much shorter than binary coding scheme (Blanco, Delgado, and Pegalaja Citation2001).
Proposed RCGA-based CARS Framework
The goal of the proposed framework is to enhance the capability of CARSs by improving the predictive accuracy. It combines a proposed novel aspect of context weighting using RCGA with features of state-of-the-art CARSs framework. The purpose of Context-Aware Collaborative Filtering (CACF) algorithm is to recommend a list of new items with current context for a particular active user based on his past experiences and like-minded users having experience in a similar context. The real coding approach seems particularly natural when tackling the problem of optimizing parameters with the variables in continuous domains (Herrera, Lozano, and Verdegay Citation1998). Therefore, we use RCGA to learn the individual user’s preferences for quality recommendations. The contextual pre-filtering and contextual modeling-based CACF algorithm is proposed for the CARS framework. Further to establish the superiority of our proposed RCGA, we have compared it with other two schemes, SVM and PSO.
The RCGA-based CARS framework exploits the idea of context weighting scheme into CACF algorithm, signifies the contribution of each context feature is weighted, where weighting vector consists of real values lies between
and the sum of weights equal to
. More specifically, there is a list of
users
, a list of
items
, and a list of
context features
. Each user u has a list of items experienced in certain contexts. We have given a target context
for an active user
, we need to assess how much to weight a rating
issued in some different context
, subject to a weighting vector
. Context weighting using RCGA can be considered as a novel approach for CARSs which requires an optimal set of context feature weights for each user.
Data Collection
To anticipate the relevance of an item for a user in a certain context, it needs to be filled with the value of each context feature through users’ past history which helps in providing personalized recommendations. The acquired contextual information is either static or dynamic in nature, but we picked up only the static nature of the context. Such information is explicitly captured, i.e. input given by users.
Neighbor Generation
One critical step of CACF is to compute the similarity between users interact with items in similar context features and identify the users with similar inclinations, which is useful for the generation of the relevant neighborhood set. The original CF-based recommendation scenario is most familiar, mature, and widely implemented to filter out the undesired list of users. The CACF follows the same scenario of CF which leverages the pervasive contextual information such that a user’s preference is not only predicted from opinions of similar users but also from feedback of other users in a context similar to that the user currently is in.
Similarity Computation of Context Features
The notion of context similarity computation is to give a higher importance to ratings of items when the computed context similarity is high. Selecting top neighbors of the active user
for target item
under context feature vector
satisfying threshold value
using weighted Jaccard metric
, we need to assess how much to weight a rating
issued in some different context vector
subject to a weighting vector
. The context similarity computation metric
and top neighbors
are defined as:
Computation of Users’ Similarity
The traditional similarity measure matrices gauge efficiently that how closely the opinions of a user’s pair match, taking into account only the ratings made by such pair. Although they rely only on computing the degree of agreement based on the set of items co-rated by the users, Pearson Correlation Coefficient (PCC) is the most popular among them (Chen Citation2005; Anand Citation2011). The modified CACF technique computed to measure users’ similarity using EquationEquations (5)(5)
(5) and (6) respectively.
where is second similarity threshold,
is the set of all collected items
, and pair of context feature vectors
and
is used for users
and
respectively, such that each has rated
in that context with
. We follow two stages in the recommendation process leading to two paradigms contextual pre-filtering and contextual modeling. Our assumption here, the given ratings of more similar contexts are more reliable for further predictions. However, there is a limit to this effect that context features with low similarity may add irrelevant ratings to the predictions. So, we use two similarity thresholds
and
to filter ratings for each stage.
Learning Context Feature Weights Using RCGA
The similarity is computed in terms of individual context feature similarity using weighted Jaccard measure and users’ similarity using modified PCC, treats all context features equally important, and considers all weights, i.e. are equal. This may not truly reflect the contribution of each context feature toward the similarity where users put different weights to different features (Agrawal and Bharadwaj Citation2013). To overcome such limitation, we adopt RCGA approach, which is one of the most effective and appropriate techniques for optimization problem.
Chromosome Representation
In our RCGA-based approach, each chromosome is represented as a set of weights , where each weight has two variables which indicate the maximum and minimum limits for weights in the range of valid values. Our approach shows how the weights defining users’ priorities can be evolved by the RCGA to learn the personal preferences of users and provide tailored suggestions. These weights are generated offline to every context feature for each user and determined in such a way that the sum of all weights is equal to
, i.e.
. Initially, we considered all weights are equally distributed, indicating that user
is giving equal priorities to all features. The potential to the problem of evolving context feature weights
for the active user
is represented as a set of weights
, where
is the weight is associated with each context feature
whose chromosome is a sequence of floating point numbers.
Crossover and Mutation Operators
Genetic operators are used in GA to maintain genetic diversity. In general, the gathered information resulting from GA is done by the selection mechanism is referred as exploitation, while exploration is searching for new regions within search space by Genetic operators. Although a number of crossover and mutation operators are suggested and applied for RCGA (Agrawal and Bharadwaj Citation2013). We employed the mostly used operators arithmetic crossover and uniform mutation for RCGA-based CARS. Crossover creates two new child chromosomes by allowing two parent chromosomes to exchange meaningful information, while mutation is used to maintain the genetic diversity of the population by introducing a completely new member into the parent chromosome. illustrates with an example of how RCGA operators work.
Figure 1. RCGA operators (a) Arithmetic crossover with a random value and (b) Uniform mutation with selected gene
replaces with
.

Fitness Function
Finding an appropriate fitness function is a challenging task for GA applications (Goldberg Citation1989). Each individual candidate solution in the population is assessed for its quality score known as the fitness score. A fitness function is an objective function that prescribes the optimality of a solution (chromosome) in a GA so that a particular chromosome may be ranked against all the other chromosomes. By applying GA operators, optimal chromosomes are allowed to breed and mix their datasets producing a new generation that will hopefully be better. An ideal fitness function correlates closely with the algorithm’s goal, and yet may be computed quickly. For each chromosome in the population, CACF is applied and Mean Absolute Error (MAE) is computed using EquationEquation (7)(7)
(7) as the average difference between actual rating and predicted rating for all users in the training set which is also used as a fitness score for that set of weights.
Each user contains
genes corresponding to weights for each context feature, which are evolved by an elitist approach. When the weight for any context feature is zero, that feature is ignored, which enables feature selection to be adaptive to each user’s preference. Such weights are used in EquationEquations (3-6)
(3)
(3) to generate neighborhood set on the basis of users’ similarity and context similarity. The chromosome search space for RCGA is defined in range
, i.e. initially we assume that each weight lies between
and
. Finally, the chromosome that gives the minimum MAE is chosen (such as minimization problem) which is suitable for our work.
Recommendation
To make recommendation accurate for an active user and a neighborhood set matching with a similar profile of the active user, it is necessary to find items experienced by users in the neighborhood set that the active user has not experienced before. After neighbors’ selection, the next step is to utilize similarity values for the computation of predicted ratings. The predicted rating
of an item
for an active user
is obtained by using EquationEquation (8)
(8)
(8) .
The main steps of the proposed RCGA-based CARS using a hybrid CACF algorithm to perform recommendation task are summarized as follows and also depicted in :
Figure 2. Schematic view of the RCGA-based CARS.
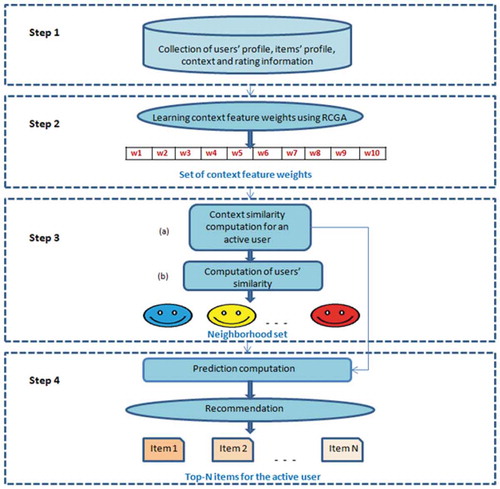
Step 1. Input data
In this step, users’ profiles, items’ profiles, and value of context features with ratings are collected in the form of , where
are context features.
Step 2. Learning context feature weights using RCGA
Context feature weights for each individual are learned by applying RCGA and finding the best fitness score using EquationEquation (7)(7)
(7) . Let
be the context feature weights for an active user.
Step 3. Neighborhood set generation
Compute the context similarity
for an active user with context feature weights using EquationEquation (3)
Compute the similarity
Step 4. Prediction computation and recommendation
Compute predicted rating based on adapted Resnick’s prediction formula by using EquationEquation (8)
(8)
(8) and finally recommend top-
list of items for
.
Alleviating the Problem of Sparsity
In this section, we consider the framework for the effective missing value prediction (EMVP) follows the basic outline suggested by Ma, King, and Lyu (Citation2007). It exploits both the ratings associated with context features and feature-based similarity among the similar breeds to predict the strength of users’ preferences according to the situation not yet provided. As illustrated in , the rating scale represents the users’ fondness of or preference toward the item within some contextual situation, and shaded blocks represent items rated for a given context feature vector in which rating is not available yet. Our approach utilizes the information linked up a user’s choices or preferences with the context in which the user rated an item to predict the shaded block (missing value) if possible. Otherwise, set it to zero, as seen in . The adapted EMVP algorithm consists of two components: Neighborhood set selection and Missing value prediction.
Figure 3. The (m x n) user-item subset matrix of movie dataset: (a) before missing value prediction. (b) after missing value prediction.
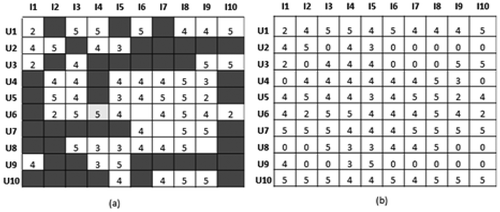
Neighborhood Set Selection
To predict missing value, both users’ similarity and items’ similarity are equally important. PCC is used to measure users’ similarity and items’ similarity. It involves context feature similarity using weighted Jaccard similarity measure which determines how relevant the ratings are under a given context for the active user when prediction occurs. For predicting every missing value , a set of similar users
toward user
can be generated according to:
Meanwhile, for predicting every missing value , a set of similar items
toward item
can be generated according to
where is a threshold parameter for users’ similarity and
is a threshold parameter for items’ similarity. If the value of similarity computed between chosen neighbor and target user computed by using EquationEquations (9)
(9)
(9) and (Equation10
(10)
(10) ) exceeds the threshold, then the neighbor is selected as a similar user or similar item, otherwise neglected.
Missing Value Prediction
The missing value prediction algorithm systematically combines contextual information into both user-based CF and item-based CF approaches to take advantage of both user correlations and item correlations in the matrix which make the prediction more accurate. It will predict the missing value only if it will bring positive influence for the recommendation of active users instead of predicting every missing value of the matrix. If
then the predicted missing value
is set to zero, whereas, in other cases, the missing values are predicted using EquationEquations (11
(11)
(11) –Equation13
(13)
(13) ).
If , the prediction of missing value
is defined as:
It needs to be considered those special cases when either do not get similar users’ set or similar items’ set, then it would fully utilize the information that makes predictions of missing values accurate as possible by follows.
If , the prediction of missing value
is defined as
If , the prediction of missing value
is defined as
Optimizing the Tradeoff between Accuracy and Diversity Using RCGA
The set of recommended item list should maintain a certain level of diversity with compromising certain level of accuracy, since the increasing diversity level can help commercial sites to promote long tail items sell. In order to suggest highly idiosyncratic and personalized products, one should consider offering not only accurate, but also diverse recommendations to fulfill users’ satisfaction. Our primary goal is to improve users’ satisfaction by maximizing the relevance of the suggested items to the target user. In this paper, we focus on aggregate diversity computation with measure dissimilarity between the pair of recommendation items on the basis of assigned weights to each context feature for users. For dissimilarity measure, we use the weighted Euclidean distance as given below.
The dissimilarity between pair of items
and
is calculated by the given value of context features
for item
and
for item
respectively with learned weights
assigned for active user
The following steps are used to compute aggregate diversity using S-TDE (Premchaiswadi et al. Citation2013) for top-
recommendations, the items must be ranked in descending order based on their predicted ratings before suggesting to active user
. For evaluation of such ranking, the number of actual relevant items
in the recommended list of a user is calculated. Where
and
are the target list of all items and predicted relevant items, respectively. Due to each item in a recommendation list can effect on the total diversity value of recommendations differently, Total diversity Effect (TDE) (Premchaiswadi et al. Citation2013) of items in top-
recommendations rely on the dissimilarities between each pair of items in the list. So, TDE is calculated with the help of EquationEquation (15)
(15)
(15) .
The total diversity of the recommendation list
is defined as the average distance between all possible pairs of items in the list is calculated using EquationEquation (16)
(16)
(16) .
Then, we measure recommendation diversity as the total number of distinct items that are being recommended across all users. We aggregate all diversity of the recommendation list for all users to get average diversity
.
Finally, we propose a set of context feature weights learned by RCGA for each individual applying in formula, which satisfy both accuracy and diversity in an optimum level. The
summarized both accuracy and diversity in terms of threshold
to establish a balanced relationship between the accuracy
and diversity
.
Experiments and Results
This section illustrates the results of the computational experiments performed to evaluate and analyze the effectiveness of the proposed RCGA-based CARS. The following subsections describe the set of experiments that we have conducted to examine the effectiveness of our new context weighting scheme. Particularly, we address the following three issues. First, we analyze the performance of the proposed CARS framework in terms of accuracy by considering two cases (a) CARS with equal context feature weights and (b) CARS with learned context feature weights. Second, in order to handle the sparsity problem we use learned context feature weights and employing EMVP algorithm. Finally, we analyze the tradeoff between accuracy and diversity of the CARS for the two real-world datasets discussed below.
Experimental Settings
To carry out experiments, we take two real-world datasets to evaluate our proposed model. In the area of movie, the movie dataset extracted from LDOS-CoMoDa dataset.Footnote1 The description of opted context features is presented in . The Restaurant-Customer dataset extracted from UCI Machine Learning RepositoryFootnote2 is also used for our experiments. Users added and rated new and existing restaurants filled with
opted context features described in . We performed experiments with gathering 10 random splits into training and active users. For each random split, three different sets of sample users (3, 5, and 10) were chosen randomly as active users, and remaining users were treated as training users for proposed RCGA-based CARS. Such random splits are intended for the execution of ten-fold cross-validation, where all experiments are repeated for
. The set of training users is used to find a set of neighbors for the active user, while the set of active users is used to test the performance of the system. To perform a context feature weights learning process for each dataset, we use different chromosome structures with
weights represented in and .
Table 1. Context features in Movie Dataset.
Table 2. Context features in Restaurant-Customer dataset.
Figure 4. The structure of chromosome in Movie dataset.

Figure 5. The structure of chromosome in Restaurant-Customer dataset.

In order to demonstrate relative performances of the following schemes:
Context-aware collaborative filtering with equal weights (CE).
Context-aware collaborative filtering with learned weights using SVM (CW-SVM).
Context-aware collaborative filtering with learned weights using PSO (CW-PSO).
Context-aware collaborative filtering with learned weights using RCGA (CW-RCGA).
Proposed RCGA-based CARS framework (CW-ERCGA).
The proposed framework is further enhanced using learned weights with
We have conducted three experiments:
Experiment 1: Variation of Context feature weights depending on user-to-user using SVM, PSO, and RCGA.
Experiment 2: Resolving the problem of sparsity using EMVP algorithm with the RCGA.
Experiment 3: Learned context feature weights using RCGA for controlling the tradeoff between accuracy and diversity.
Results and Discussion
In this section, we present the results of the experimental evaluation with two different real-world datasets to show a generic approach in RCGA-based CARS framework.
Variation of Context Feature Weights Depending on User-to-user Using SVM, PSO, and RCGA
In the first experiment, we calculated the weights of each context feature for each individual user by CACF scheme using some of the parameters optimizing techniques SVM, PSO, and RCGA. We took sample sets of active users to test the importance of context features for each user and compared with other traditional CE scheme. The CE scheme computes the MAE using equal weights for each context feature contributing in similarity computation for each user
and the other schemes CW-SVM uses SVM and CW-PSO uses PSO (see ) for learning context feature weights. The proposed scheme CW-RCGA uses an elitist GA for evolving the context feature weights for each user separately based on parameter values as shown in . RCGA process begins with roulette wheel selection for the next generation, followed by the real value assignment for each of the 10 genes in the range [0, 1] and the normalized weights are such that
.
Table 3. PSO parameter values used in Experiment.
Table 4. GA parameter values used in Experiment.
RCGA learns context feature weights using the actual ratings in the training set for the active user and computes the fitness score using EquationEquation (7)(7)
(7) . This process is repeated until the fitness score does not improve for
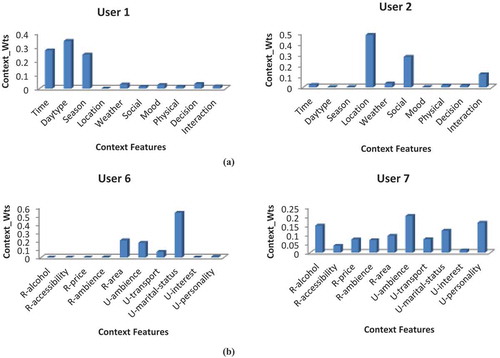
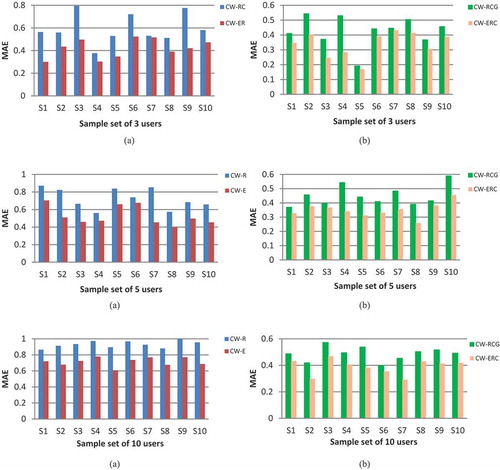
consecutive generations. Therefore, the number of generations will vary with the fitness score of weights for each user as depicted in . It is proved by that each user has a different proportion of affinity toward various context features and CW-RCGA outperforms other schemes CW-PSO, CW-SVM, and CE (see ).
Table 5. Comparison of MAE using various CARS approaches CE, CW-SVM, CW-PSO and CW-RCGA in terms of accuracy using two datasets.
Figure 6. Variations in number of generations with fitness value for (a) Movie dataset (b) Restaurant-Customer dataset.
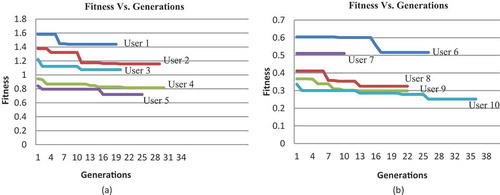
Figure 7. Comparison of evolved context feature weights for users in two datasets: (a) User 1 and User 2 in Movie dataset and (b) User 6 and User 7 in Restaurant-Customer dataset.
Resolving the Problem of Sparsity Using EMVP Algorithm with the RCGA
In the second experiment, we have tried to resolve the problem of high sparsity of contextual information in the rating matrix due to the fact that most users have not rated items under a similar context which is the main cause of low accuracy in the recommendation process. The EMVP algorithm works with the option of not to predict the missing value if it does not meet the predefined criteria, but it prevents from a bad prediction on missing value also. Our next idea is to propagate contextual information from one user to another in order to reduce the sparsity of contextual information.
Ideally, the configurable parameters should be set in a training set which indicate how we learned best suited CW-ERCGA’s parameters for desirable MAE. We assessed the impact of the various parameters on the predictive performance of CW-RCGA. For this purpose, we randomly choose different sets of parameters and picked the best one that gives a desirable MAE score over the testing set of active users. Naturally, the minimum MAE is attained for the best configuration of CW-ERCGA. It is evident from that the different parameters have a substantially different influence on the predictive performance of CW-ERCGA. The parameters and
determine how many missing values that need to be predicted. If it sets too high, most of the missing values cannot be predicted, and if it sets too low, every user/item will obtain too many neighbor users/items which would cause the inaccuracy as well as an increase in the computation cost. Accordingly, to simplify our model we set
, which balances the information from users and items and takes advantage of both types of CF (item-based CF and user-based CF). We plotted the results obtained by CW-RCGA against the results from CW-ERCGA over different sets of active users (see ). The results clearly demonstrate that CW-ERCGA outperforms CW-RCGA.
Figure 8. Comparison of evolved context feature weights for users in two datasets: (a) User 1 and User 2 in Movie dataset and (b) User 6 and User 7 in Restaurant-Customer dataset.
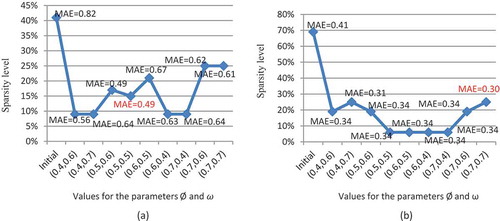
Figure 9. Comparison of MAEs between CW-RCGA and CW-ERCGA using two datasets: (a) Movie dataset (b) Restaurant-Customer dataset.
Learned Contextual Weights Using RCGA for Controlling the Tradeoff between Accuracy and Diversity
In the third experiment, we focus on the quality of top- recommendation of items in such order that the diversity is improved, while recommendation accuracy still mentioned. The effects of the top-
list on both diversity and accuracy are conversely changing direction, while the diversity tends to increase with the values of top-
increase (see ). We design the experiment to establish the balance between diversity and accuracy using the
approach and set the parameter value
according to the preference of users on various application domains, such as,
for Movie dataset and
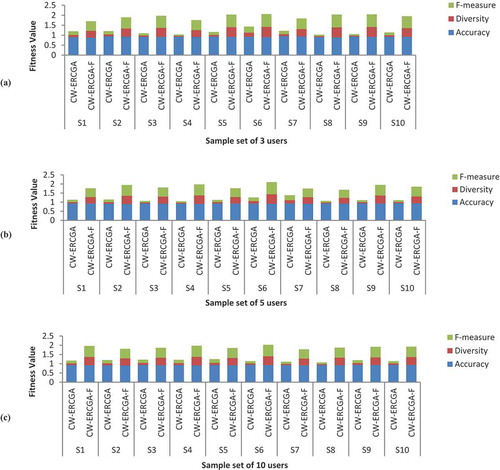
for the Restaurant-Customer dataset. Finally, we use RCGA for learning those weights to identify appropriate context features for each user that matches their criteria and give effective recommendation solutions. The results across all the evaluation triplets of accuracy, diversity, and
together with the learned context feature weights are depicted in .
Figure 10. Top-N item recommendations with diversity for five samples of active users in two different datasets: (a) Movie dataset and (b) Restaurant-Customer dataset.
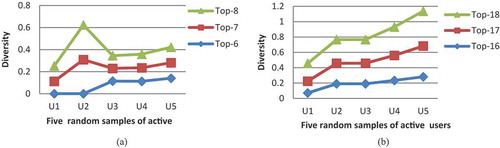
Figure 11. Effect of learned context feature weights on recommendation accuracy and diversity using RCGA in two CARS schemes CW-ERCGA and CW-ERCGA-F.
Conclusions and Future Directions
We have presented a real-coded genetic algorithm (RCGA) based CARS framework, where context features are weighted according to individual user’s preferences and choices. By using RCGA each user’s priority for each contextual feature is captured and that has significantly enhanced the performance in terms of both accuracy and diversity. The major issue in this approach is time complexity; however, this difficulty is resolved by performing offline learning of weights and the best set of weights are then stored on the user’s local machine, in a separate weight matrix which can be used for online recommendations (Al-Shamri and Bharadwaj Citation2008). Our work aims to address the sparsity problem in CARS by utilizing missing value prediction and optimize the tradeoff between accuracy and diversity using . We analyzed the effectiveness of different CARS schemes and compare their performance with the proposed scheme. Experimental results based on two real-world datasets show that the proposed context weighting scheme leads to a significant improvement as compared to other schemes.
One of the important directions in the future work would be toward enhancing the capability of the proposed CF-based CARS through hybridization with Reclusive method (Kant and Bharadwaj Citation2013). We would also consider the exploitation of spatio-temporal contextual information into mobile applications and incorporation of trust-distrust propagation mechanism to further enhance the recommendation accuracy of the proposed scheme (Anand and Bharadwaj Citation2013; Cao et al. Citation2008; Park, Park, and Cho Citation2015). As a further research, we would also like to extend the proposed framework of CARS considering multicriteria contextual information (Yi-Chung Citation2014) and the dynamic nature of context feature (Hee and Keith Citation2004) with different feature values for leveraging its recommendation capability to generate recommendations for both individual users as well as groups (Contreras, Maria, and Jordi Citation2015).
Notes
1. https://www.lucami.org/index.php/research/ldos-comoda-dataset/.
2. https://archive.ics.uci.edu/ml/datasets/.
References
- Adomavicius, G., and Y. Kwon. 2008. Overcoming accuracy-diversity tradeoff in recommender systems: A variance-based approach. Proceedings of the 18th Workshop on Information Technology and Systems. Paris, France.
- Adomavicius, G., B. Mobasher, F. Ricci, and A. Tuzhilin. 2011. Context-aware recommender systems. AI Magazine 32 (3):67–80. doi:10.1609/aimag.v32i3.2364.
- Adomavicius, G., and A. Tuzhilin. 2005. Toward the next generation of recommender systems: A survey of the state-of the-art and possible extensions. IEEE Transactions on Knowledge and Data Engineering 17 (6):734–49.
- Agrawal, V., and K. K. Bharadwaj. 2013. A collaborative filtering framework for friends recommendation in social networks based on interaction intensity and adaptive user similarity. Social Network Analysis and Mining 3 (3):359–79. doi:10.1007/s13278-012-0083-7.
- Al-Shamri, M. Y. H., and K. K. Bharadwaj. 2008. Fuzzy-genetic approach to recommender system based on a novel hybrid user model. Expert Systems with Applications 35 (3):1386–99. doi:10.1016/j.eswa.2007.08.016.
- Anand, D., and K. K. Bharadwaj. 2011. Utilizing various sparsity measures for enhancing accuracy of collaborative recommender systems based on local and global similarities. Expert System with Applications 38 (5):5101–09. doi:10.1016/j.eswa.2010.09.141.
- Anand, D., and K. K. Bharadwaj. 2013. Pruning trust-distrust network via reliability and risk estimates for quality recommendations. Social Network Analysis and Mining 3 (1):65–84. doi:10.1007/s13278-012-0049-9.
- Blanco, A., M. Delgado, and M. C. Pegalaja. 2001. A real-coded genetic algorithm for training recurrent neural networks. Neural Networks 14 (1):93–105. doi:10.1016/S0893-6080(00)00081-2.
- Campos, P. G., I. Fernandez-Tobias, I. Cantador, and F. Diez. 2013. Context-aware movie recommendations: An empirical comparison of pre-filtering, post-filtering and contextual modeling approaches. Proceedings of the 14th International Conference on E-commerce and Web Technologies, Lecture Notes in Bioinformatics, 137–49. Prague, Czech Republic.
- Cao, Y., R. Klamma, M. Hou, and M. Jarke. 2008. Follow me, follow you - spatiotemporal community context modeling and adaptation for mobile information systems. Proceedings of the 9th International Conference on Mobile Data Management, 108–15. Beijing, China: IEEE Computer Society.
- Chen, A. 2005. Context-aware collaborative filtering system: Predicting the user’s preference in the ubiquitous computing environment. Proceedings of the First International Conference on Location- and Context-Awareness, 244–53. Oberpfaffenhofen, Germany: Lecture Notes in Computer Science.
- Contreras, D., S. Maria, and P. Jordi. 2015. A web-based environment to support online and collaborative group recommendation scenarios. Applied Artificial Intelligence 29 (5):480–99. doi:10.1080/08839514.2015.1026661.
- Goldberg, D. 1989. Genetic algorithms in search, optimization, and machine learning. Boston, MA: Addison-Wesley.
- Hee, E. B., and C. Keith. 2004. Utilizing context history to provide dynamic adaptations. Applied Artificial Intelligence 18 (6):533–48. doi:10.1080/08839510490462894.
- Herrera, F., M. Lozano, and J. L. Verdegay. 1998. Tackling real- coded genetic algorithms: Operators and tools for behavioural analysis. Artificial Intelligence Review 12 (4):265–319. doi:10.1023/A:1006504901164.
- Kant, V., and K. K. Bharadwaj. 2013. Integrating collaborative and reclusive methods for effective recommendations: A fuzzy bayesian approach. International Journal of Intelligent Systems 28 (11):1099–123. doi:10.1002/int.21619.
- Kennedy, J., and R. C. Eberhart. 1995. Particle swarm optimization. Proceedings of the IEEE International Conference on Neural Networks, 1942–48. Perth, WA, Australia.
- Liu, Q., H. Ma, E. Chen, and H. Xiong. 2013. A survey of context-aware mobile recommendations. International Journal of Information Technology & Decision Making 12 (1):139–72. doi:10.1142/S0219622013500077.
- Ma, H., I. King, and M. R. Lyu. 2007. Effective missing data prediction for collaborative filtering. Proceedings of the 30th annual international ACM SIGIR Conference on Research and Development in Information Retrieval, 39–46. Amsterdam, Netherlands.
- Min, S. H., and I. Han. 2005. Recommender systems using support vector machines. Proceedings of the 5th International Conference on Web Engineering, pp.387–93. Sydney, Australia: Lecture notes in Computer Science.
- Min, S. H., J. Lee, and I. Han. 2006. Hybrid genetic algorithms and support vector machines for bankruptcy prediction. Expert Systems with Applications 31 (3):652–600. doi:10.1016/j.eswa.2005.09.070.
- Noori, B. 2015. Developing a CBR system for marketing mix planning and weighting method selection using fuzzy AHP. Applied Artificial Intelligence 29 (1):1–32. doi:10.1080/08839514.2014.962282.
- Osuna-Enciso, V., E. Cuevas, D. Oliva, H. Sossa, and M. Pérez-Cisneros. 2016. A bio-inspired evolutionary algorithm: Allostatic optimisation. International Journal of Bio-Inspired Computation 8 (3):154–69. doi:10.1504/IJBIC.2016.076633.
- Panniello, U., A. Tuzhilin, and M. Gorgoglione. 2014. Comparing context-aware recommender systems in terms of accuracy and diversity’. User Modeling and User-Adapted Interaction 24 (1–2):35–65. doi:10.1007/s11257-012-9135-y.
- Park, H. S., M. H. Park, and S. B. Cho. 2015. Mobile information recommendation using multi-criteria decision making with bayesian network. International Journal of Information Technology & Decision Making 14 (2):317–38. doi:10.1142/S0219622015500017.
- Premchaiswadi, W., P. Poompuang, N. Jongswat, and N. Premchaiswadi. 2013. Enhancing diversity-accuracy technique on user-based top-N recommendation algorithms. Proceedings of the IEEE 37th Annual Computer Software and Applications Conference Workshop, 403–08. Japan.
- Sarwat, M., J. J. Levandoski, A. Eldawy, and M. F. Mokbel. 2014. LARS*: An efficient and scalable Location-aware recommender system. IEEE Transaction on Knowledge and Data Engineering 26 (6):1384–99. doi:10.1109/TKDE.2013.29.
- Shams, B., and S. Haratizadeh. 2017. Graph-based collaborative ranking. Expert Systems With Applications 67:59–70. doi:10.1016/j.eswa.2016.09.013.
- Shi, Y., M. Larson, and A. Hanjalic. 2014. Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Computing Surveys (CSUR) 47 (1):3. doi:10.1145/2556270.
- Verbert, K., N. Manouselis, X. Ochoa, M. Wolpers, H. Drachsler, I. Bosnic, and E. Duval. 2012. Context-aware recommender systems for learning: A survey and future challenges. IEEE Transactions on Learning Technologies 5 (4):318–35. doi:10.1109/TLT.2012.11.
- Wahde, M. 2008. Biologically inspired optimization methods: An introduction. Sweden: WIT press.
- Wang, M., T. Kawamura, Y. Sei, H. Nakagawa, Y. Tahara, and A. Ohsuga.2014. Context-aware music recommendation with serendipity using semantic relations. Proceedings of 3rd Joint International Conference, 17–32. Seoul, South Korea: Lecture Notes in Computer Science.
- Yi-Chung, H. 2014. A multicriteria collaborative filtering approach using the indifference relation and its application to initiator recommendation for group-buying. Applied Artificial Intelligence 28 (10):992–1008. doi:10.1080/08839514.2014.962279.
- Zheng, Y., R. Burke, and B. Mobasher. 2013. Recommendation with differential context weighting. Proceedings of the 21st Conference on User Modeleling, Adaptation and Personalization, Lecture Notes in Computer Science, 7899, 152–64. Rome, Italy.